Embed Size (px)
Citation preview

S
High Availability in GCE
By Allan and Carmen Mason

Who We Are
S Allan Mason
Advance Auto Parts
“The largest retailer of automotive replacement parts and accessories in the United States.”

Who We Are
S Carmen Mason
VitalSource Technologies
"VitalSource is a global leader in building, enhancing, and delivering e-learning content.”

Agenda
S Current Infrastructure and Failover solution.
S HA requirements
S Something to manage our traffic
S Topology Managers
S Execution
S Final Infrastructure and Failover solution.

S
Infrastructure & Failover Solution
Current Data Center (LaVerne)

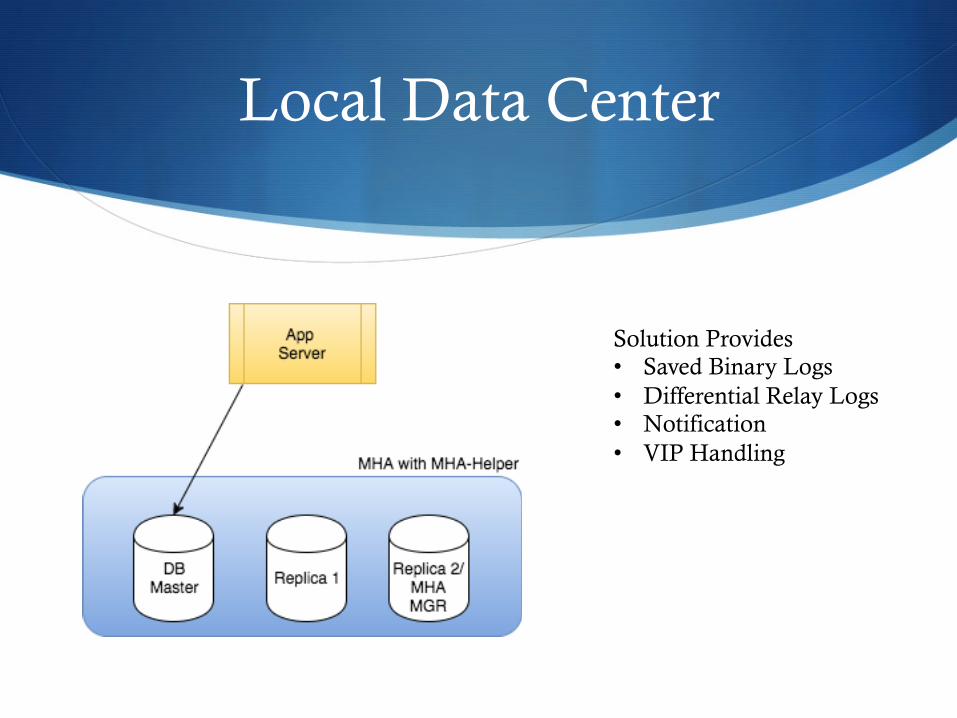
Local Data Center
Solution Provides • Saved Binary Logs • Differential Relay Logs • Notification • VIP Handling

What a Failover looks like
S 7 to 11 seconds
S Automatically assigns most up to date replica as new master
S Automatically updates VIP.
S Replicas are slaved to the new master.
S A CHANGE MASTER statement is logged to bring the old master in line once it’s fixed.
S Alerts by email, with the decisions that were made during the failover.
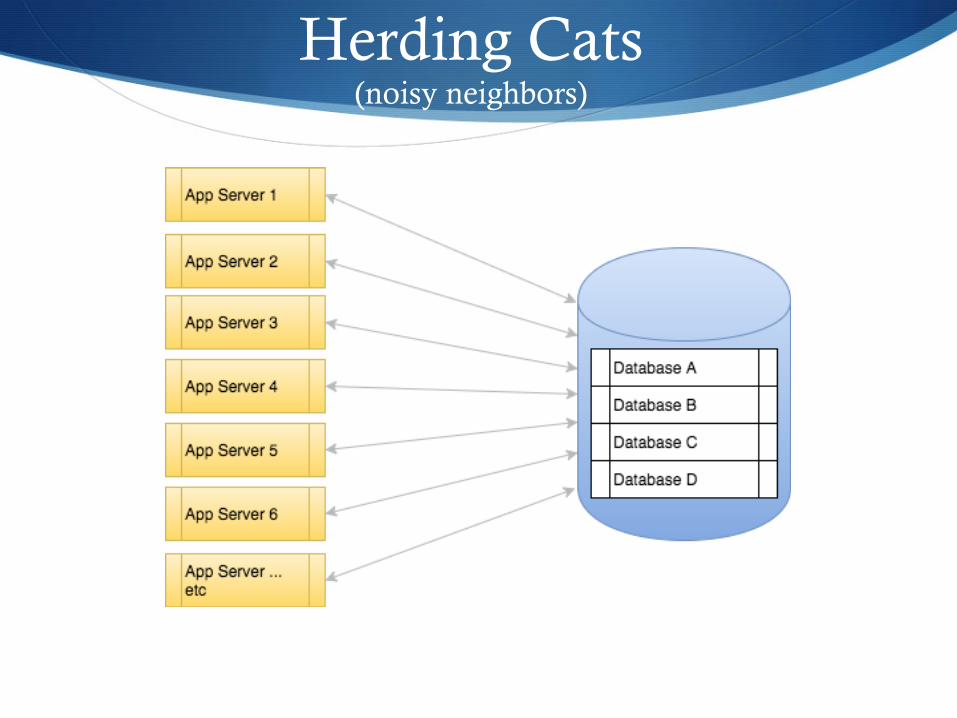
Herding Cats (noisy neighbors)

“Firemen just ran into our datacenter with a hose.”
- Bossman

S
Requirements & Issues

S

Why Google Cloud?
S Amazon is our competition. S Our biggest reason.
S Amazon seems to cost more? S It is hard to be sure.
S Reserved Instances S Lost interest and capital opportunity cost though
S Lost flexibility
S Probably fine if you need a lot of instances, with a stable load.

Project Requirements
S Move our existing applications and databases to GCE.
S Infrastructure (INF) team CANNOT be the bottleneck.
S The initial request was to move to GCE in one year.
S Given 1 month to test and decide on MHA w/ MHA Helper wrapper replacement.

Boss’s Mandate
S “Do things the right way.”

Second Generation High Availability with CloudSQL!
Misconceptions
S CloudSQL high availability is only if the entire zone fails, not the instance. S This failover could take 5 minutes to even begin to trigger.
S Server options are MySQL and PostgreSQL (beta) S No Percona Server?

Why Not ‘Lift and Ship’
S MHA with MHA Helper wrapper was not a viable option at the time. S GCE instances are CentOS 7, which MHA Helper didn’t
support.
S No VIP support in Google Cloud.

Our Requirements & ‘nice to have’s
S Try to at least reach our current uptime with a hands free automatic failover. S Availability: Min 99.9% (<8.76 hours/yr application uptime).
S Prefer 99.999% (<31sec. downtime/yr). Doesn’t everybody?
S VIP handling or traffic control to direct the apps to the database.
S All slaves are brought up to date with differential relay logs.
S Slaves still reachable are issued CHANGE MASTER statements.
S Old master is fenced off until we can get to it.

Traffic Control & Topology
S Two problems… S Traffic control : How do the applications find the Master?
S Topology: Who’s the new Master, after current Master fails?

S
Traffic Control

The Players: Traffic Control
S MaxScale S https://mariadb.com/products/mariadb-maxscale
S HAProxy S http://www.haproxy.org/
S ProxySQL S http://www.proxysql.com/

Why Not MaxScale?
S MaxScale S New License: BSL
S Research showed that it does not scale above 6 threads as well as ProxySQL.

Why Not HAProxy?
S HAProxy S Although a viable solution, we wanted something written
specifically for MySQL, that provides additional functionality.

Why ProxySQL?
S ProxySQL S Written specifically for MySQL. S Monitors topology and quickly recognizes changes, forwarding
queries accordingly. S Provides functionality that we liked, such as:
S Rewriting queries on the fly – bad developers! S Query routing – read / write splitting
S Load balancing – balance reads between replicas S Query throttling – If you won’t throttle the API…

ProxySQL Install
S Can be found in the Percona repo
S Each app is in it’s own Google Container Engine (GKE) cluster. S Every app gets it’s own container cluster.
S ProxySQL is in each of those containers ( aka tiled ) S No network latency
S No single point of failure

ProxySQL Config
S Do not run with the default config as is. Change the default admin_credentials in /etc/proxysql.cnf S admin_credentials = "admin:admin”
S “SETEC ASTRONOMY” (Google it!) S Mount the config file as a Kubernetes Secret

ProxySQL Config
S We use the remaining defaults in the configuration file for now, with the following exceptions: S mysql-monitor_ping_interval = 5000 # default = 60000 (ms)
S connect_retries_on_failure = 5 # default = 10

ProxySQL Config
S Sample MYSQL_SERVERS: S { address = "instancename_1" , port = 3306 , hostgroup = 0 }, S { address = "instancename_2" , port = 3306 , hostgroup = 1 }
S Sample MYSQL_USERS: S { username = "username_1" , password = "<password hash
from mysql.user>" , default_hostgroup = 0 , active = 1 }, S { username = "username_2" , password = "<password hash
from mysql.user>" , default_hostgroup = 0 , active = 1 }

ProxySQL Failover
S Create the monitor user in MySQL. S GRANT REPLICATION CLIENT ON *.* TO 'monitor'@'%'
IDENTIFIED BY 'password';
S ProxySQL monitors the read_only flag on the server to determine hostgroup. In our configuration, if a server is in hostgroup 0 it is writable. If it is in hostgroup 1 it is read-only. S hostgroup = 0 (writers) S hostgroup = 1 (readers)

S
Replication Topology

The Players: Topology
S Master High Availability Manager with tools for MySQL (MHA) S https://github.com/yoshinorim/mha4mysql-manager/wiki
S Orchestrator S https://github.com/github/orchestrator

Wooo Shiny! Put a pin in it…
S Orchestrator S Does not apply differential relay log events.
S Lack of extensive in-house experience with it.
S Set up in test environment to consider for near-term use.

What is Known
S Why MHA? S Easy to automate the configuration and installation
S Easy to use.
S Very fast failovers: 7 to 11 seconds of downtime, proven several times in production.
S Brings replication servers current using the logs from the most up to date slave, or the master (if accessible).

Setup MHA

Setup MHA
S One manager node, three MHA nodes.
S Install a few perl dependencies.
S Install MHA node on all DB servers. S Including on the manager node.
S Install MHA Manager.
S MHA assumes it runs as root.
S Create /etc/sudoers.d/mha_sudo Cmnd_Alias VIP_MGMT = /sbin/ip, /sbin/arping Defaults:mha !requiretty mha ALL=(root) NOPASSWD: VIP_MGMT

MHA Requirements
S SSH with passphraseless authentication.
S Set databases as read_only (all but Master).
S log_bin must be enabled on candidate masters.
S Replication filtering rules must be the same on all MySQL servers.
S Preserve relay logs: relay_log_purge = OFF;

MHA Sanity Check
S MHA Manager has built in Sanity Checks. S If it is all good? It just listens...
[info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..

MHA Failover
[warning] Got error on MySQL select ping: 2006 (MySQL server has gone away)
S If the MHA Manager can ssh to the Master, it will save the binlogs to the MHA Manager’s directory. S Otherwise it copies the Relay Log from the most up to date slave.
S Polls 4 more times to see if the Master is really really not there.
S Polls the servers. Who’s dead? Who’s alive?
S Begins Phase 1: Configuration Check
S Phase 2: Dead Master Shutdown
S Phase 3: Master Recovery Phase

S
Execution of Our Solution


“I have this TERRIBLE idea…”
DB Slave in Datacenter
Server in Old DR site
GCE DR instance
Desperately trying to upload Terabytes of data
And then replicate it from the datacenter!

Moving the BIG guys
S Tried to use the VPN from the datacenter to GCE. S Too unstable.
S Tried direct to GCE. S Too slow
S Aspera to the rescue! S http://www.asperasoft.com/

Xtrabackup
S On Source Server S innobackupex
S --compress --compress-threads
S --stream=xbstream --parallel
S --slave-info
S On Destination Instance S Install xbstream and qpress
S xbstream -x
S innobackupex --decompress


Trickle
S Trickle to throttle, and not kill our delicate network. S -s run as a one-off vs trickled service
S -u set the upload rate (KB/s)
S GSUtil S -m Parallel copy (multithreaded and multiprocessing) S gs:// Google Storage bucket.
S trickle -s -u 75000 gsutil -m cp 2017mmddDB.xbstream gs://mybucket/

Aspera
S Aspera
S -Q fair (not trickle) transfer policy
S -T Max throughput, no encryption
S -v Verbose
S -m 400M minimum transfer rate
S -l 800M target transfer rate
S -i key file
S ascp -Q -T -v -m 400M -l 800M -i /home/ascp/.ssh/id_rsa /path/to/bkup/2017mmddDB.xbstream [email protected]:/target/dir

Pt-heartbeat
CREATE DATABASE dbatools; CREATE TABLE `heartbeat` ( `ts` varchar(26) NOT NULL, `server_id` int(10) unsigned NOT NULL, `file` varchar(255) DEFAULT NULL, `position` bigint(20) unsigned DEFAULT NULL, `relay_master_log_file` varchar(255) DEFAULT NULL, `exec_master_log_pos` bigint(20) unsigned DEFAULT NULL, PRIMARY KEY (`server_id`) pt-heartbeat -D recovery --update -h localhost --daemonize pt-heartbeat -D recovery --monitor h=masterIP --master-server-id masterID -u dbatools -p Password

Failing Prod over to GCE
S Database slave in GCE production environment.
S Run parallel builds, where possible, to test against.
S Cut over in our time, during a maintenance window.

Switch to GCE Master
S Stop writes to current master: S screen S FLUSH TABLES WITH READ LOCK;
S SET GLOBAL READ_ONLY = 1; S Keep this window open.
S Stop slave on new master: S SHOW SLAVE STATUS\G to check that the slave is waiting for the master to
send another event. (Not currently updating)
S STOP SLAVE; S RESET SLAVE ALL;
S Stop service on current master: S service mysql stop S DNS changes are made here in both Google and our local DNS servers.
S Start MHA manager now that we are no longer replicating back to DC

S
Final Infrastructure &
Failover solution Google Cloud
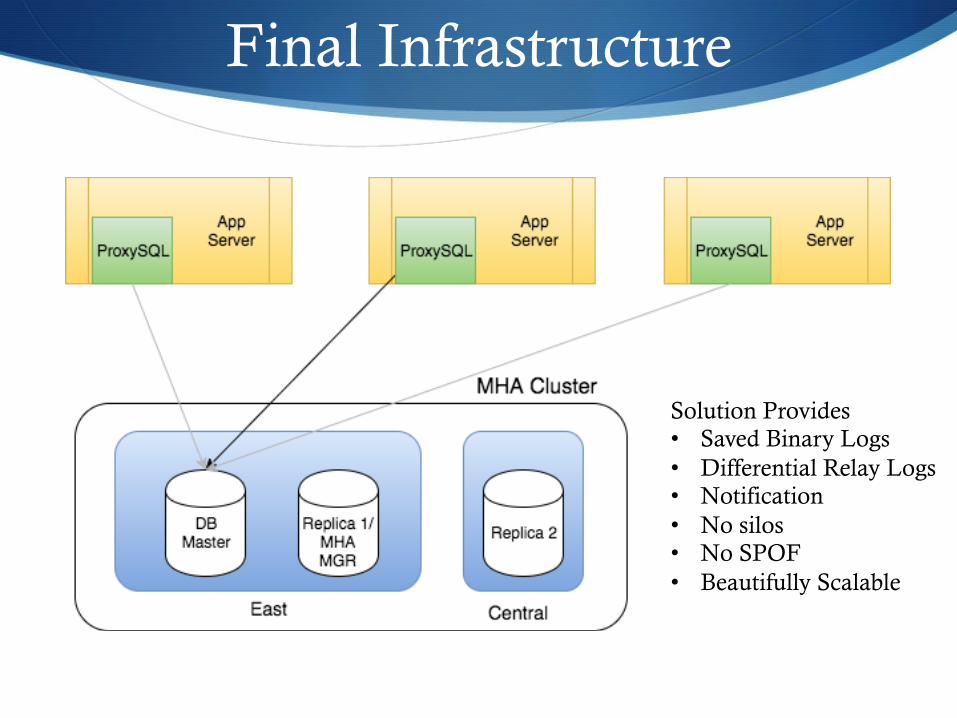
Final Infrastructure
Solution Provides • Saved Binary Logs • Differential Relay Logs • Notification • No silos • No SPOF • Beautifully Scalable

What a Failover Looks Like
S 10-20 seconds
S Automatically assigns most up to date replica as new master
S ProxySQL directs traffic to master.
S Replicas are slaved to the new master.
S A CHANGE MASTER statement is logged to bring the old master in line once it’s fixed.
S Alerts by email and notifications in HipChat, with the decisions that were made during the failover.

New Issues
S ~10ms lag between regions, which means… S All database instances are in the same region as the application
GKE clusters.
S Avoid allowing Central instance to be master to prevent lag, as all GKE clusters are in an East region. S no_master

Contact Info
S Allan Mason
S Carmen Mason
S http://www.vitalsource.com
S @CarmenMasonCIC

S
Thanks! go away





























