Embed Size (px)
Citation preview

Heterogeneous Datacenters: Options and Opportunities Jason Cong1, Muhuan Huang1,2, Di Wu1,2, Cody Hao Yu1 1 Computer Science Department, UCLA 2 Falcon Computing Solutions, Inc.

2
Data Center Energy Consumption is a Big Deal
In 2013, U.S. data centers consumed an estimated 91 billion kilowatt-hours of electricity, projected to increase to roughly 140 billion kilowatt-hours annually by 2020 • 50 large power plants (500-megawatt coal-fired) • $13 billion annually • 100 million metric tons of carbon pollution per year.
https://www.nrdc.org/resources/americas-data-centers-consuming-and-wasting-growing-amounts-energy)

3
◆ Understand the scale-out workloads § ISCA’10, ASPLOS’12 § Mismatch between workloads and processor designs; § Modern processors are over-provisioning
◆ Trade-off of big-core vs. small-core § ISCA’10: Web-search on small-core with better energy-efficiency § Baidu taps Mavell for ARM storage server SoC
Extensive Efforts on Improving Datacenter Energy Efficiency
4
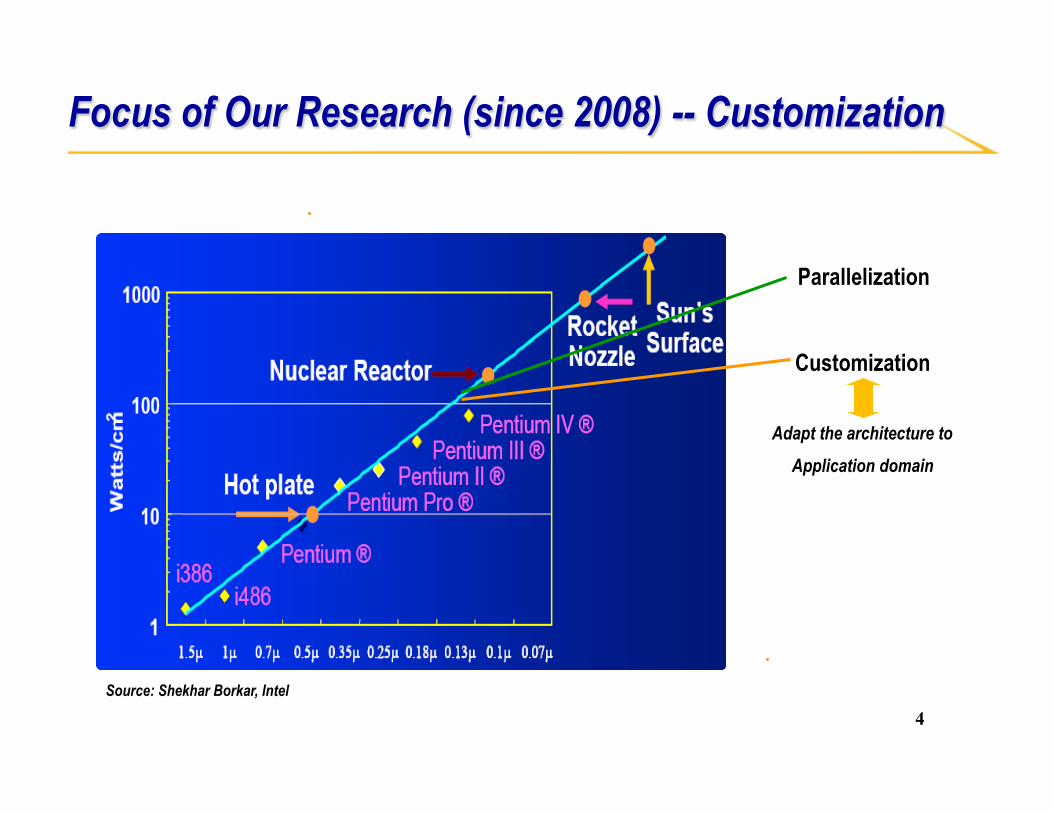
Focus of Our Research (since 2008) -- Customization
Parallelization
Source: Shekhar Borkar, Intel
Customization
Adapt the architecture to Application domain

5

6
◆ FPGA gaining popular among tech giants § Microsoft, IBM, Baidu, etc.
◆ Intel’s acquisition of Altera
§ Intel prediction: 30% datacenter nodes with FPGA by 2020
Computing Industry is Looking at Customization Seriously
Microsoft Catapult Intel HARP

7
◆ Evaluation of different integration options of heterogeneous technologies in datacenters
◆ Efficient programming support for heterogeneous datacenters
Contributions of This Paper

8
Small-core on Compute-intensive Workloads
10.97
5.26 7.8
3.13
8X ARM 8X ATOM
NORM
ALIZ
ED
EXEC
UTIO
N TI
ME
LR KM
6.86
5.21
4.88
3.1
8X ARM 8X ATOM
NORM
ALIZ
ED
ENER
GY
◆ Data set § MNIST 700K Samples § 784 Features, 10 Labels
◆ Results § Normalized to reference
Xeon performance
◆ Baselines § Xeon: Intel E5 2620
12 Core CPU 2.40GHz § Atom: Intel D2500 1.8GHz § ARM: A9 in Zynq 800MHz
◆ Power consumption (averaged) § Xeon: 175W/node § Atom: 30W/node § ARM: 10W/node

9
Small Cores Alone Are Not Efficient!

10
Small Core + ACC: FARM
- 8 Xilinx ZC706 boards - 24-port Ethernet switch - ~100W power
◆ Boost Small-core Performance with FPGA
11
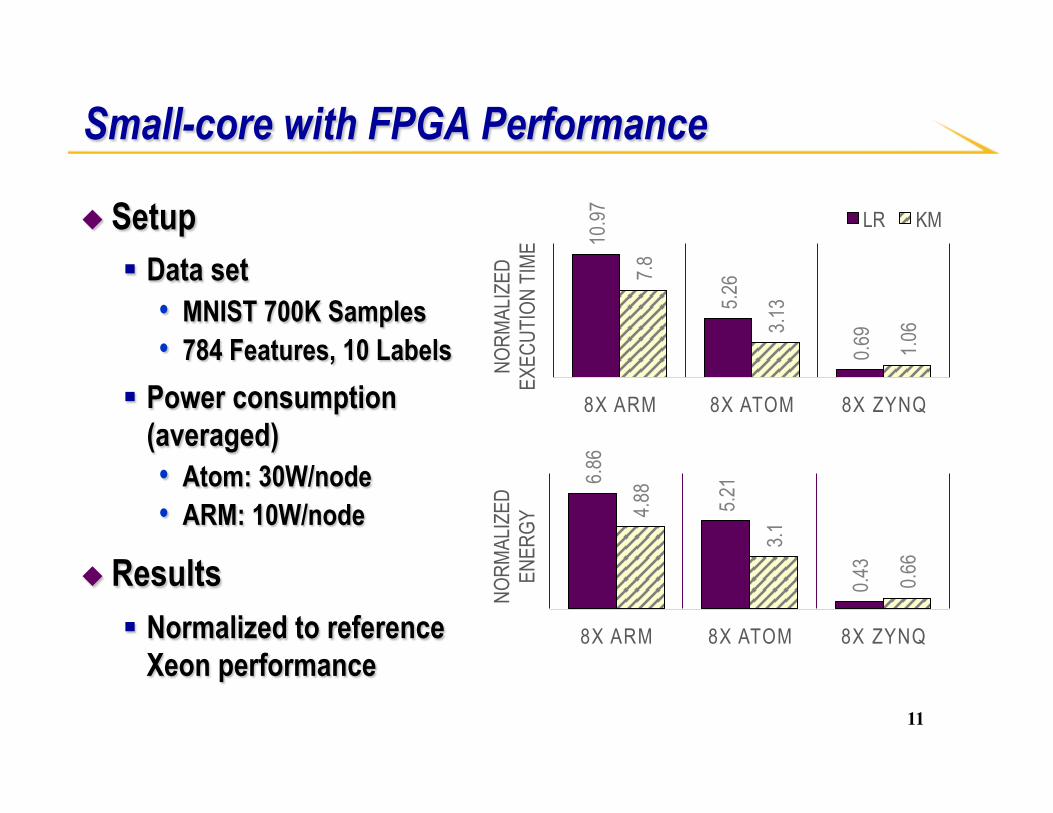
Small-core with FPGA Performance
10.97
5.26
0.69
7.8
3.13
1.06
8X ARM 8X ATOM 8X ZYNQ
NORM
ALIZ
ED
EXEC
UTIO
N TI
ME
LR KM
6.86
5.21
0.43
4.88
3.1
0.66
8X ARM 8X ATOM 8X ZYNQ
NORM
ALIZ
ED
ENER
GY
◆ Setup § Data set
• MNIST 700K Samples • 784 Features, 10 Labels
§ Power consumption (averaged) • Atom: 30W/node • ARM: 10W/node
◆ Results § Normalized to reference
Xeon performance

12
Small Cores + FPGAs Are More Interesting!

13
◆ Slower core and memory clock § Task scheduling is slow § JVM-to-FPGA data transfer is slow
◆ Limited DRAM size and Ethernet bandwidth § Slow data shuffling between nodes
◆ Another option: Big-core + FPGA
Inefficiencies in Small-core

14
22 workers
1 master / driver
Each node: 1. Two Xeon processors 2. One FPGA PCIe card
(Alpha Data) 3. 64 GB RAM 4. 10GBE NIC
Alpha Data board: 1. Virtex-7 FPGA 2. 16GB on-board
RAM
1 file server
1 10GbE switch
◆ A 24-node cluster with FPGA-based accelerators § Run on top of Spark and Hadoop (HDFS)
Big-Core + ACC: CDSC FPGA-Enabled Cluster
15
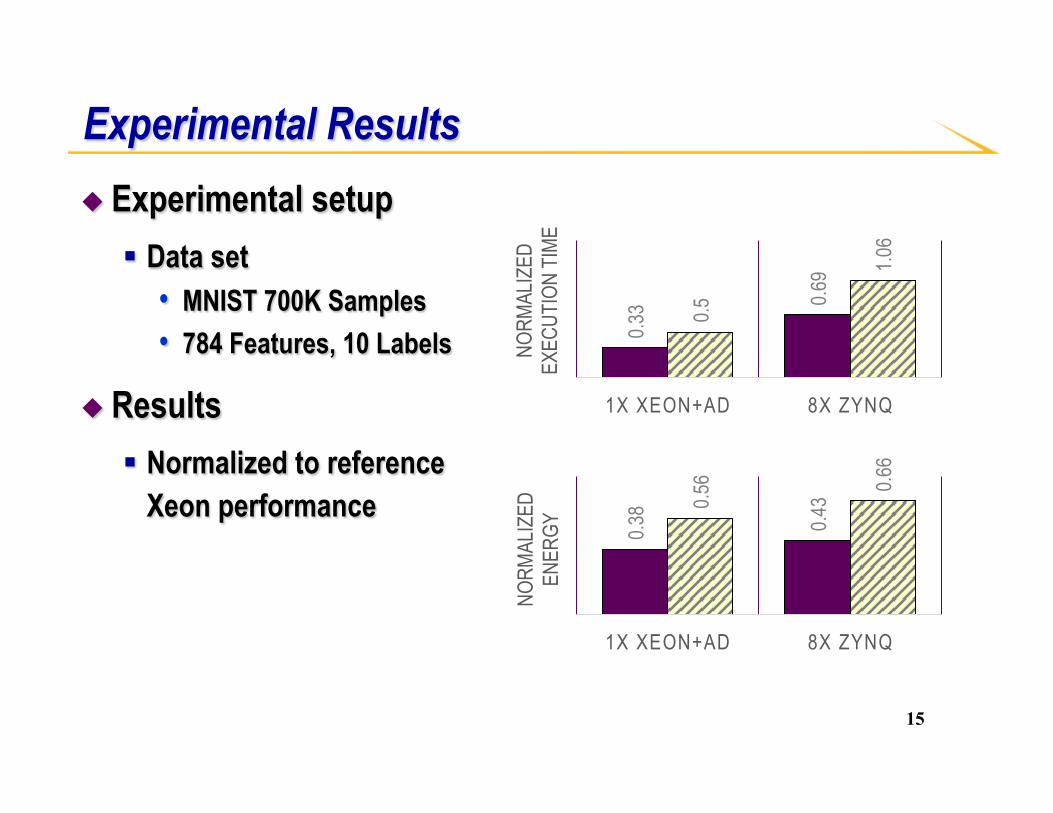
◆ Experimental setup § Data set
• MNIST 700K Samples • 784 Features, 10 Labels
◆ Results § Normalized to reference
Xeon performance
Experimental Results
0.33 0.6
9
0.5
1.06
1X XEON+AD 8X ZYNQ
NORM
ALIZ
ED
EXEC
UTIO
N TI
ME
0.38
0.43 0.5
6 0.66
1X XEON+AD 8X ZYNQ
NORM
ALIZ
ED
ENER
GY

16
◆ Based on two machine learning workloads § Normalized performance (speedup), and energy efficiency
(performance/W) relative to big-core solutions
Overall Evaluation Results
Performance Energy-Efficiency
Big-Core+FPGA Best | 2.5 Best | 2.6 Small-Core+FPGA Better | 1.2 Best | 1.9
Big-Core Good | 1.0 Good | 1.0 Small-Core Bad | 0.25 Bad | 0.24

17
◆ Evaluation of different integration options of heterogeneous technologies in datacenters
◆ Efficient programming support for heterogeneous datacenters § Heterogeneity makes programming hard!
Contributions of This Paper
18
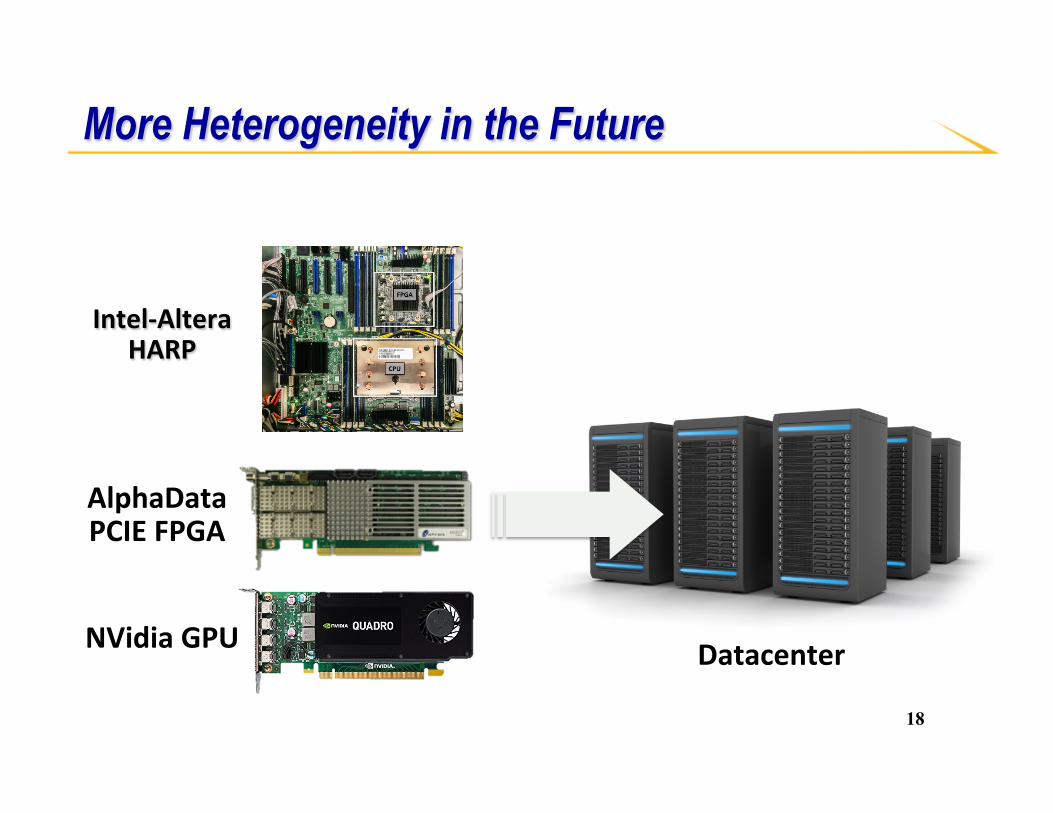
More Heterogeneity in the Future
Intel-AlteraHARP
AlphaDataPCIEFPGA
NVidiaGPU Datacenter
19
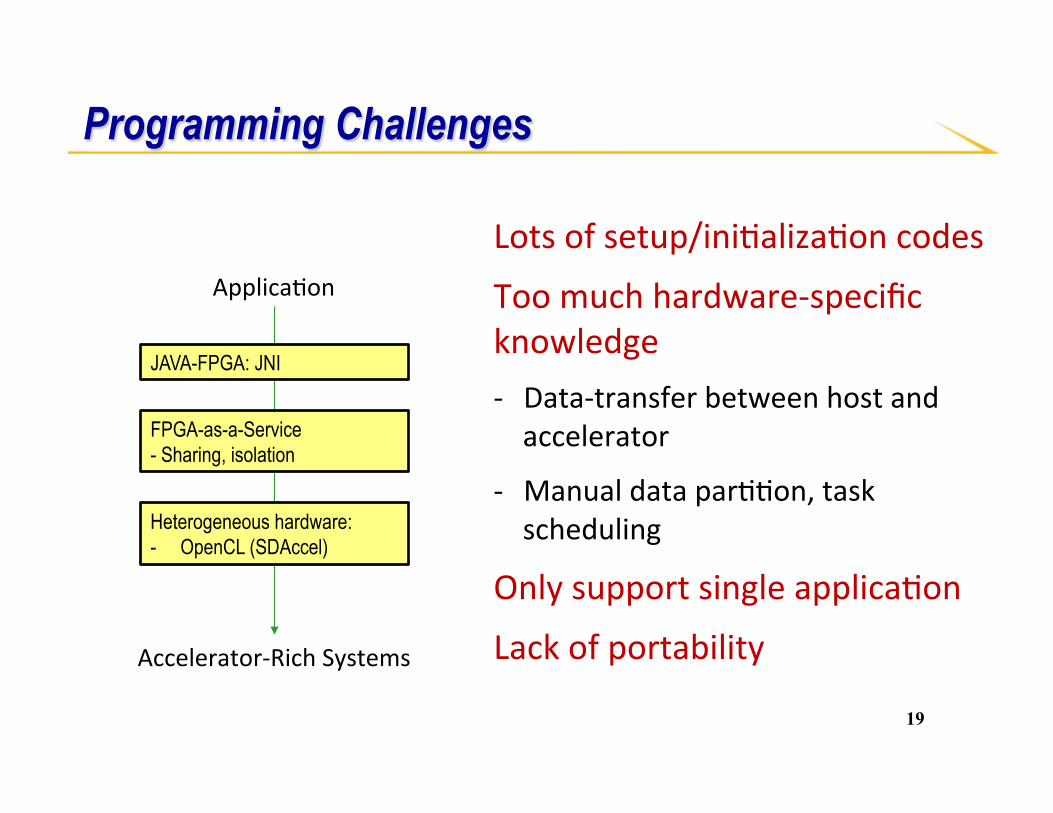
Programming Challenges
Lotsofsetup/ini-aliza-oncodes
Toomuchhardware-specificknowledge- Data-transferbetweenhostandaccelerator
- Manualdatapar--on,taskscheduling
Onlysupportsingleapplica-on
Lackofportability
Applica-on
Accelerator-RichSystems
JAVA-FPGA: JNI
FPGA-as-a-Service - Sharing, isolation
Heterogeneous hardware: - OpenCL (SDAccel)
20
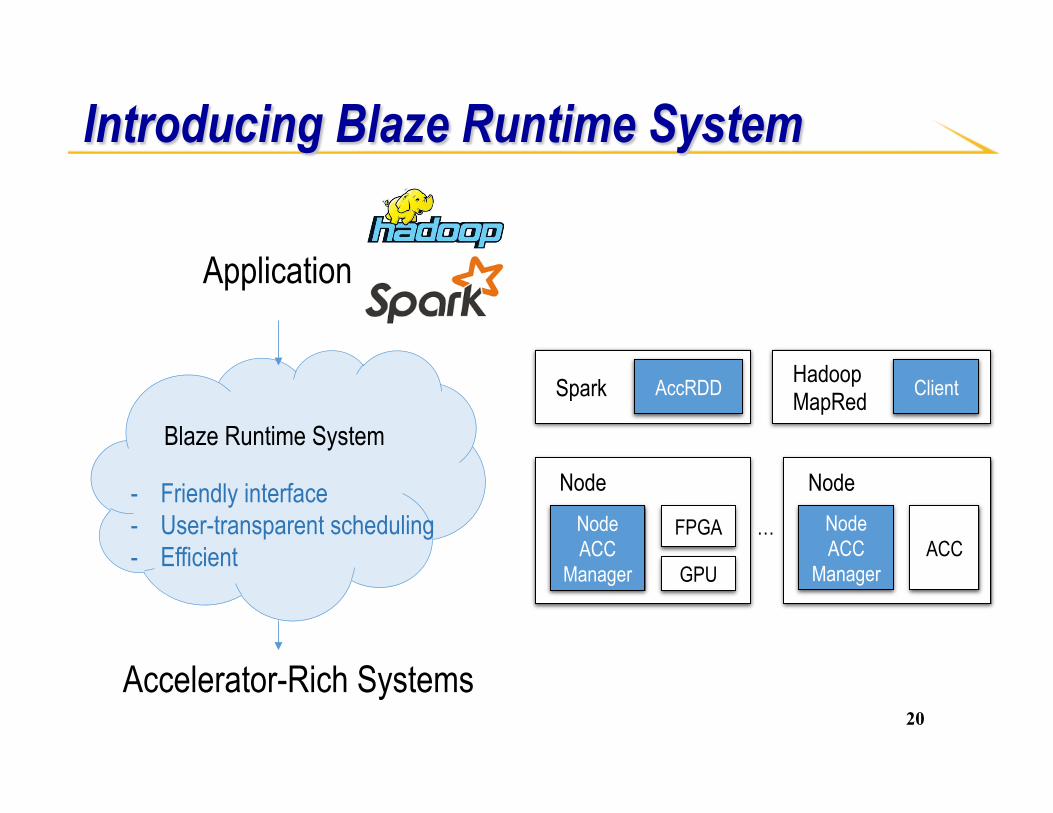
Introducing Blaze Runtime System
Node ACC
Manager
FPGA
Node Node ACC
Manager ACC
Node
Spark AccRDD Hadoop MapRed Client
…
GPU
Application
Accelerator-Rich Systems
Blaze Runtime System - Friendly interface
- User-transparent scheduling - Efficient

21
Overview of Deployment Flow
User Application
Node ACC Manager
FPGA
GPU
ACC
ACC Requests Input data
Accelerator Designer: ACC register
Acc Look-up Table
Output data
Application Designer:

22
Programming Interface for Application valpoints=sc.textfile().cache()for(i<-1toITERATIONS){valgradient=points.map(p=>(1/(1+exp(-p.y*(wdotp.x)))-1)*p.y*p.x).reduce(_+_)w-=gradient}
valpoints=blaze.wrap(sc.textfile())for(i<-1toITERATIONS){valgradient=points.map(newLogisticGrad(w)).reduce(_+_)w-=gradient}
classLogisticGrad(..)extendsAccelerator[T,U]{
valid:String=“Logistic”defcall(in:T):U={p=>(1/(1+exp(-p.y*(wdotp.x)))-1)*p.y*p.x}}
Spark.mllib Integration • No user code changes or
recompilation

23
Under the Hood: Getting data to FPGA
Solutions - Data caching - Pipelining
Spark Task NAM FPGA device
Inter-process memcpy
PCIE memcpy
17.99%
17.99%
32.13%
28.06%
3.84%
Receivedata
Datapreprocessing
Datatransfer
FPGAcomputa-on
Other

24
Programming Interface for Accelerator classLogisticACC:publicTask//extendthebasicTaskinterface{LogisticACC():Task(2){;}//specify#ofinputs//overwritethecomputefunctionvirtualvoidcompute(){//getinput/outputusingprovidedAPIsintnum_sample=getInputNumItems(0);intdata_length=getInputLength(0)/num_sample;intweight_size=getInputLength(1);double*data=(double*)getInput(0);double*weights=(double*)getInput(1);double*grad=(double*)getOutput(0,weight_size,sizeof(double));double*loss=(double*)getOutput(1,1,sizeof(double));//performcomputationRuntimeClientruntimeClient;LogisticApptheApp(out,in,data_length*sizeof(double),&runtimeClient);theApp.run();}};
Compile to ACC_Task (*.so)
25
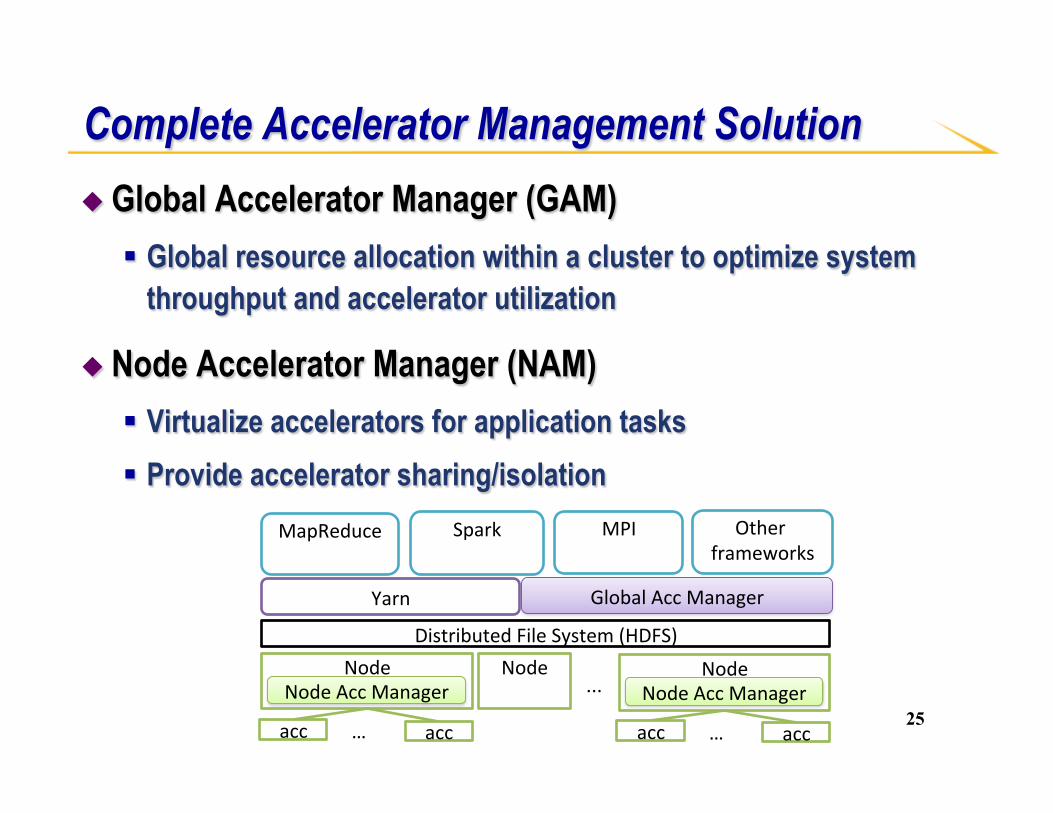
◆ Global Accelerator Manager (GAM) § Global resource allocation within a cluster to optimize system
throughput and accelerator utilization
◆ Node Accelerator Manager (NAM) § Virtualize accelerators for application tasks § Provide accelerator sharing/isolation
Complete Accelerator Management Solution
MapReduce Spark MPI
Node...
Yarn GlobalAccManager
NodeAccManager
…
DistributedFileSystem(HDFS)
acc acc
NodeNodeAccManager
…acc acc
Node
Otherframeworks
26
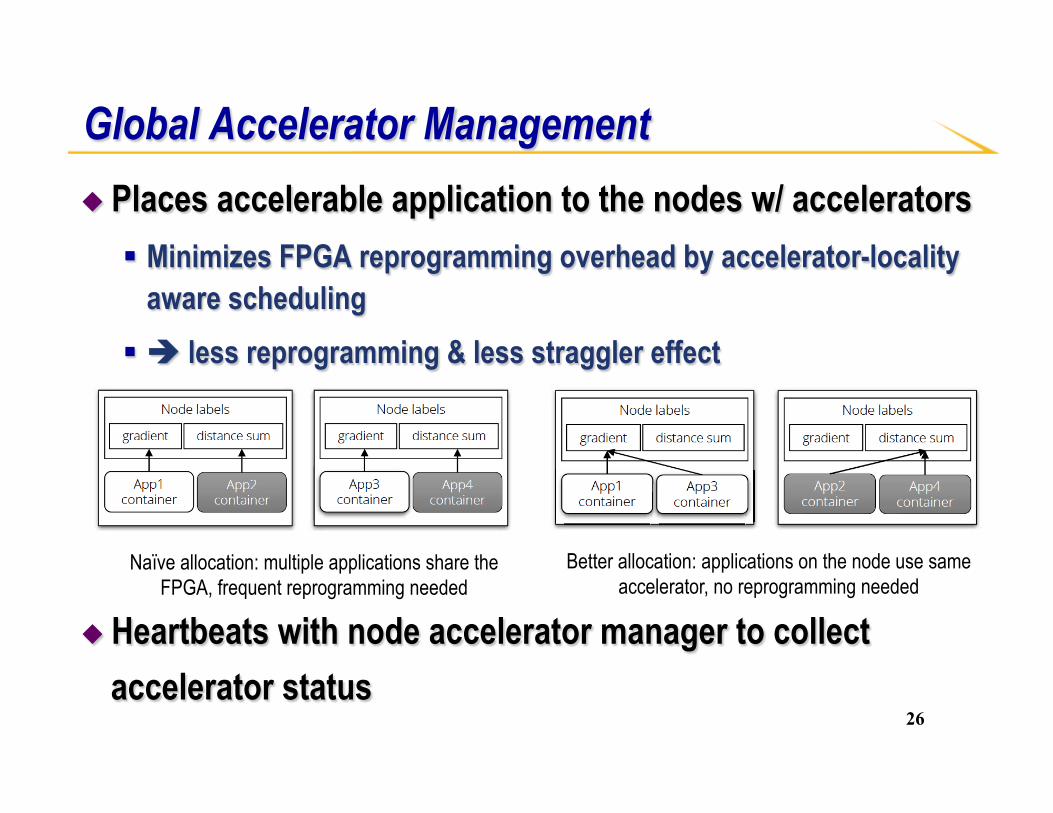
◆ Places accelerable application to the nodes w/ accelerators § Minimizes FPGA reprogramming overhead by accelerator-locality
aware scheduling § è less reprogramming & less straggler effect
◆ Heartbeats with node accelerator manager to collect accelerator status
Global Accelerator Management
Naïve allocation: multiple applications share the FPGA, frequent reprogramming needed
Better allocation: applications on the node use same accelerator, no reprogramming needed
27
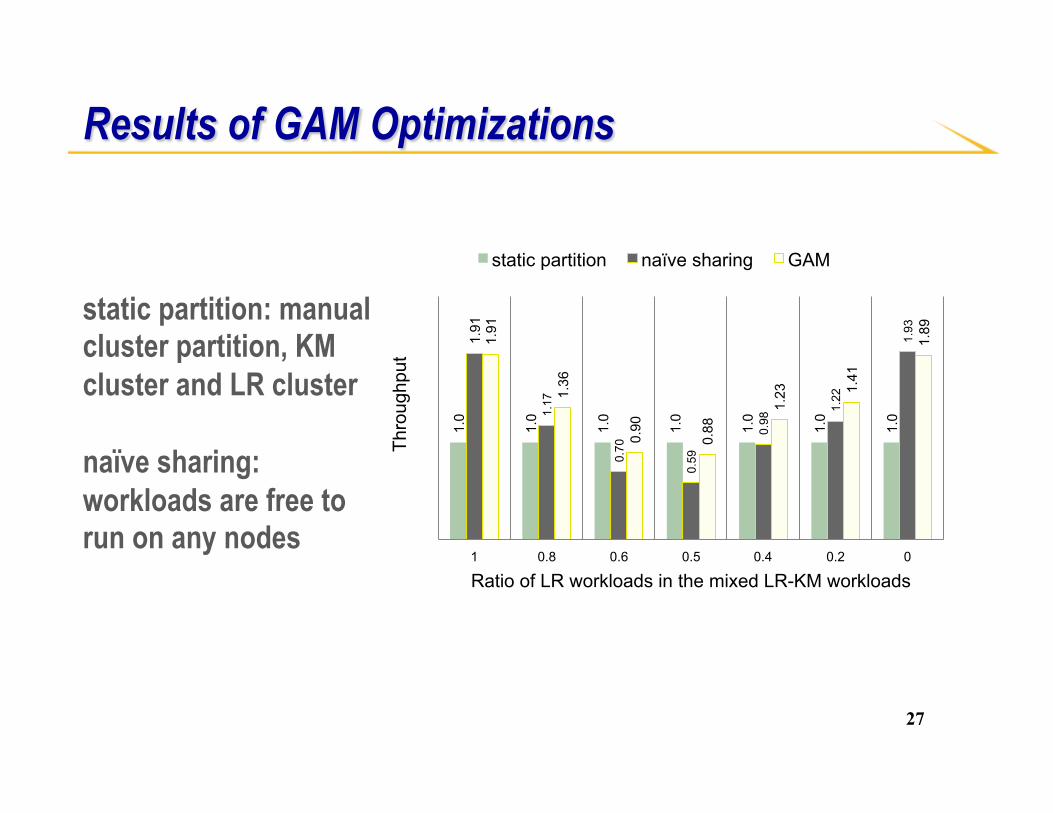
Results of GAM Optimizations
static partition: manual cluster partition, KM cluster and LR cluster naïve sharing: workloads are free to run on any nodes
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.91
1.17
0.70
0.59
0.98
1.22
1.93
1.91
1.36
0.90
0.88
1.23
1.41
1.89
1 0.8 0.6 0.5 0.4 0.2 0
Thro
ughp
ut
Ratio of LR workloads in the mixed LR-KM workloads
static partition naïve sharing GAM
28
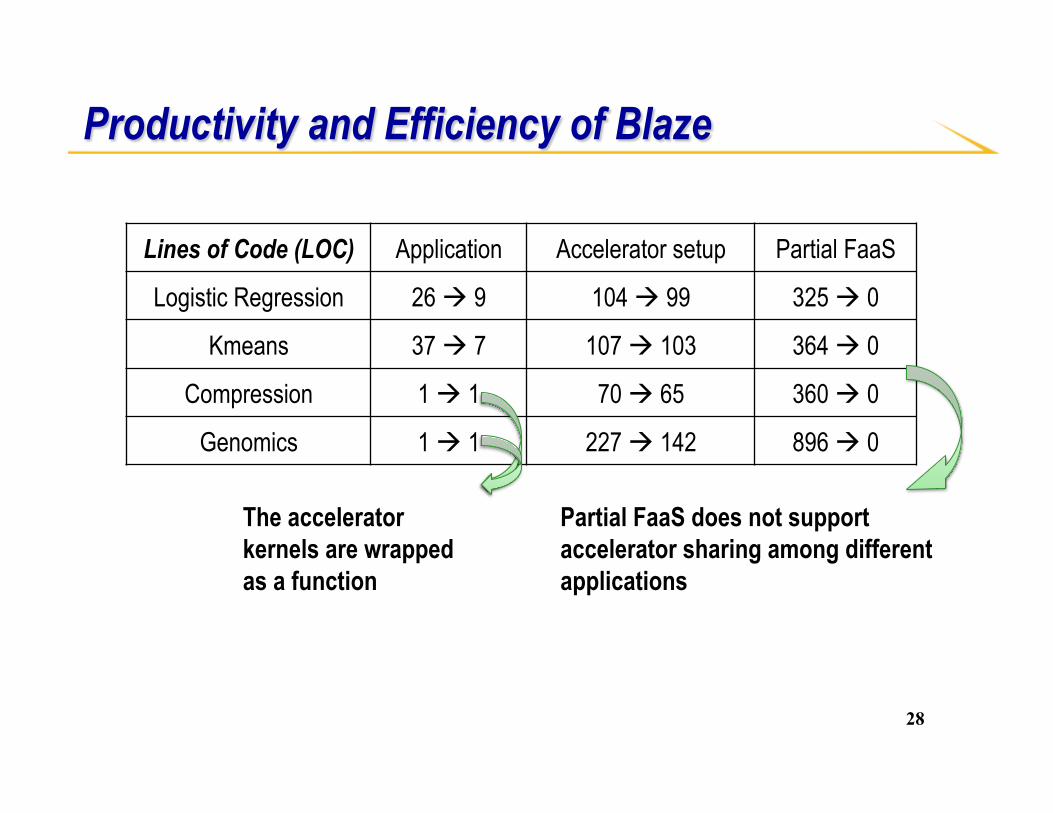
Productivity and Efficiency of Blaze
Lines of Code (LOC) Application Accelerator setup Partial FaaS
Logistic Regression 26 à 9 104 à 99 325 à 0
Kmeans 37 à 7 107 à 103 364 à 0
Compression 1 à 1 70 à 65 360 à 0
Genomics 1 à 1 227 à 142 896 à 0
The accelerator kernels are wrapped as a function
Partial FaaS does not support accelerator sharing among different applications

29
◆ Blaze has overhead compared to manual design
◆ With multiple threads the overheads can be efficiently mitigated
Blaze Overhead Analysis
0
0.2
0.4
0.6
0.8
1
1.2
1 thread 12 threads
Nor
mal
ized
Thr
ough
put
to M
anua
l Des
ign
Software
Manual
Blaze
0
20
40
60
80
100
120
140
160
180
200
Manual Blaze
Exec
utio
n Ti
me
(ms)
JVM-to-native
Native-to-FPGA
FPGA-kernel
Native-private-to-share

30
♦ Center for Domain-Specific Computing (CDSC) under the NSF Expeditions in Computing Program
♦ C-FAR Center under the STARnet Program
Acknowledgements – CDSC and C-FAR
Bingjun Xiao (UCLA)
Hui Huang (UCLA)
Muhuan Huang (UCLA)
Di Wu (UCLA)
Yuting Chen (UCLA)
Cody Hao Yu (UCLA)












![[@IndeedEng] Redundant Array of Inexpensive Datacenters](https://img.pdfslide.us/doc/110x75/5562d65ad8b42aac778b4a48/indeedeng-redundant-array-of-inexpensive-datacenters.jpg)
















