Embed Size (px)
Citation preview

EECS750: Advanced Operating Systems
2/24/2014
Heechul Yun
1

Administrative
• Project – Feedback of your proposal will be sent by Wednesday – Midterm report due on Apr. 2
• 3 pages: include intro, related work, progress, and plan
• Summary assignment – Email subject line: [EECS750] Summary: Paper title – Deadline: 11:59 p.m., a day before the class.
• Class presentation
– Email subject line: [EECS750] Presentation: Paper title – Deadline: 5:00 p.m., a day before the class. – Don’t need to write a summary for the paper you present
2

Operating System Level Shared Memory Management in the
Multicore Era.
University of Kansas
Heechul Yun

Multicore for Embedded Systems
• Benefits of multicore processors – Reduce #of computers & cost – Save space, weight, power (SWaP) – w/o performance loss
• But performance isolation is difficult
4
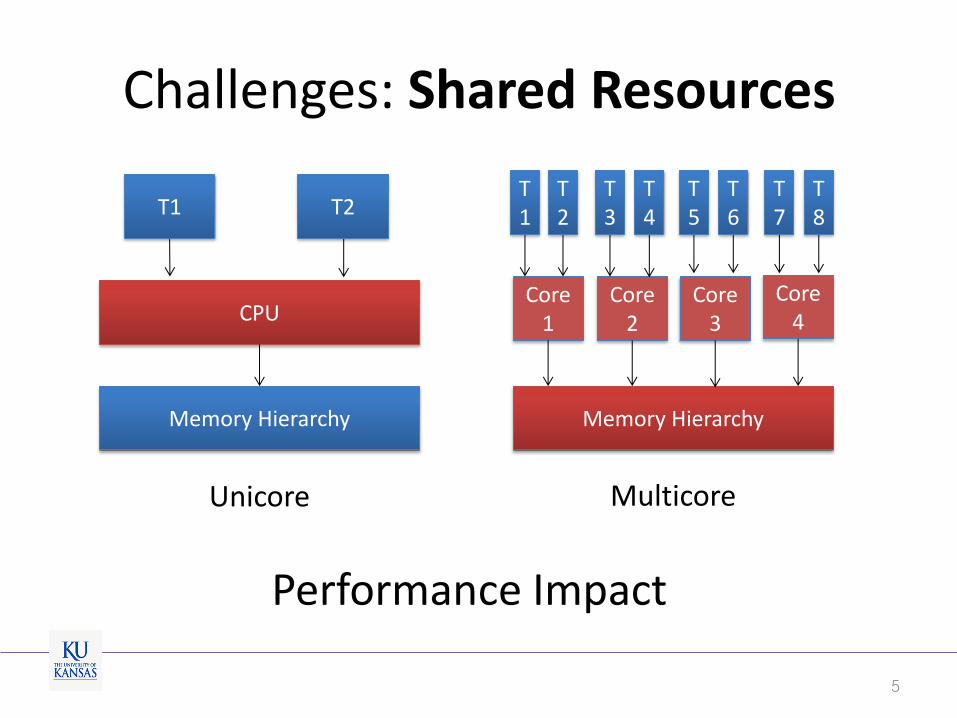
Challenges: Shared Resources
5
CPU
Memory Hierarchy
Unicore
T1 T2
Core1
Memory Hierarchy
Core2
Core3
Core4
Multicore
T1
T2
T3
T4
T5
T6
T7
T8
Performance Impact
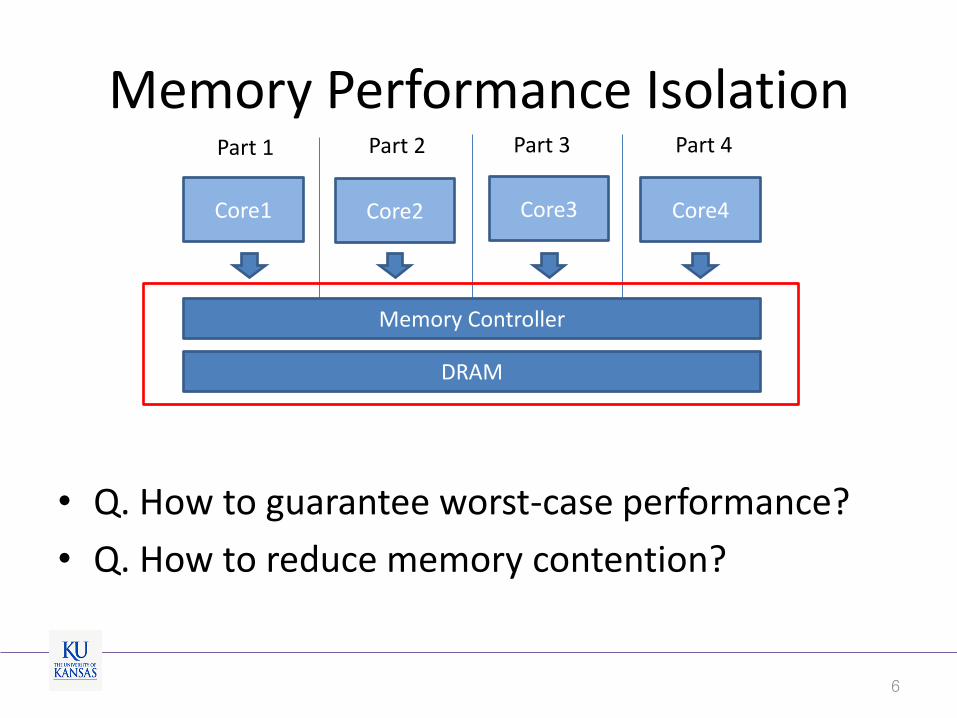
Memory Performance Isolation
• Q. How to guarantee worst-case performance?
• Q. How to reduce memory contention?
Part 1 Part 2 Part 3 Part 4
6
Core1 Core2 Core3 Core4
DRAM
Memory Controller
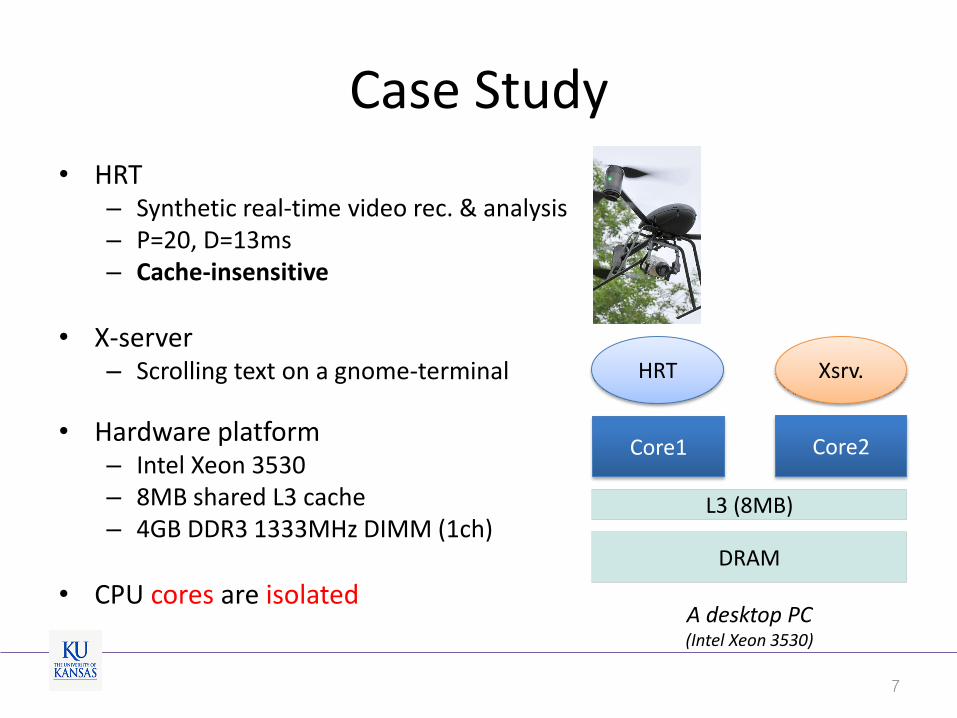
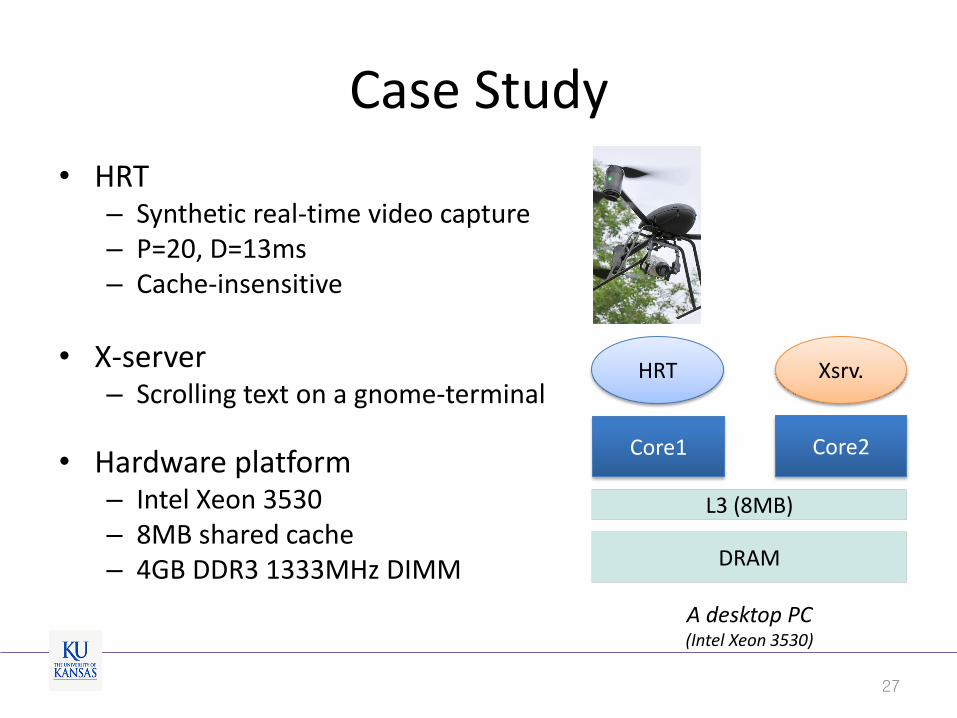
Case Study
• HRT – Synthetic real-time video rec. & analysis – P=20, D=13ms – Cache-insensitive
• X-server – Scrolling text on a gnome-terminal
• Hardware platform – Intel Xeon 3530 – 8MB shared L3 cache – 4GB DDR3 1333MHz DIMM (1ch)
• CPU cores are isolated
7
A desktop PC (Intel Xeon 3530)
DRAM
L3 (8MB)
Core1 Core2
HRT Xsrv.
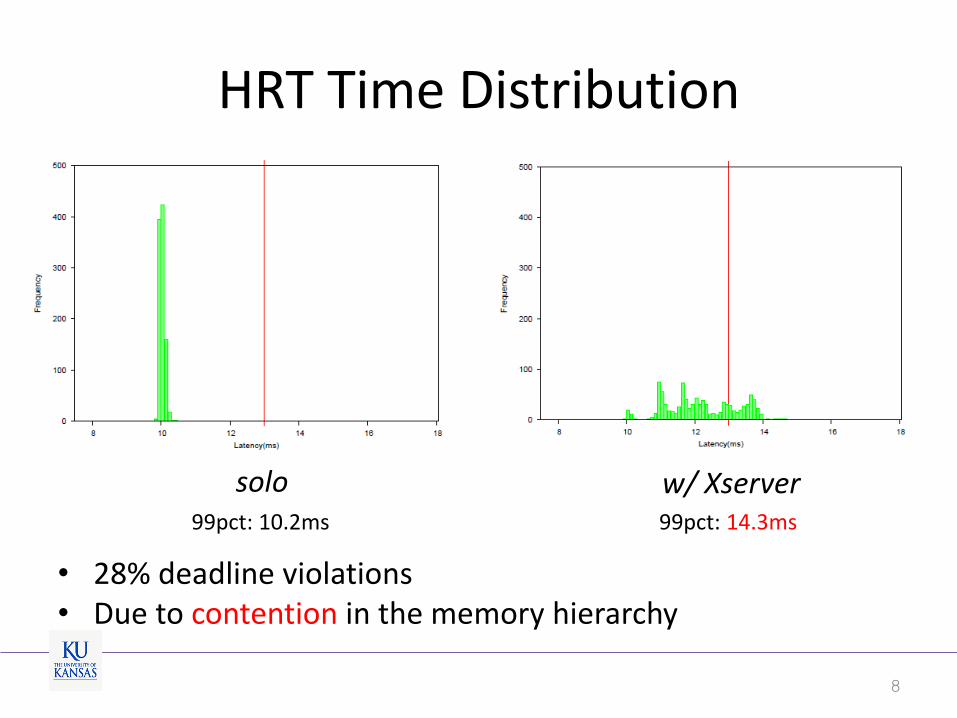
HRT Time Distribution
• 28% deadline violations • Due to contention in the memory hierarchy
8
solo 99pct: 10.2ms
w/ Xserver 99pct: 14.3ms
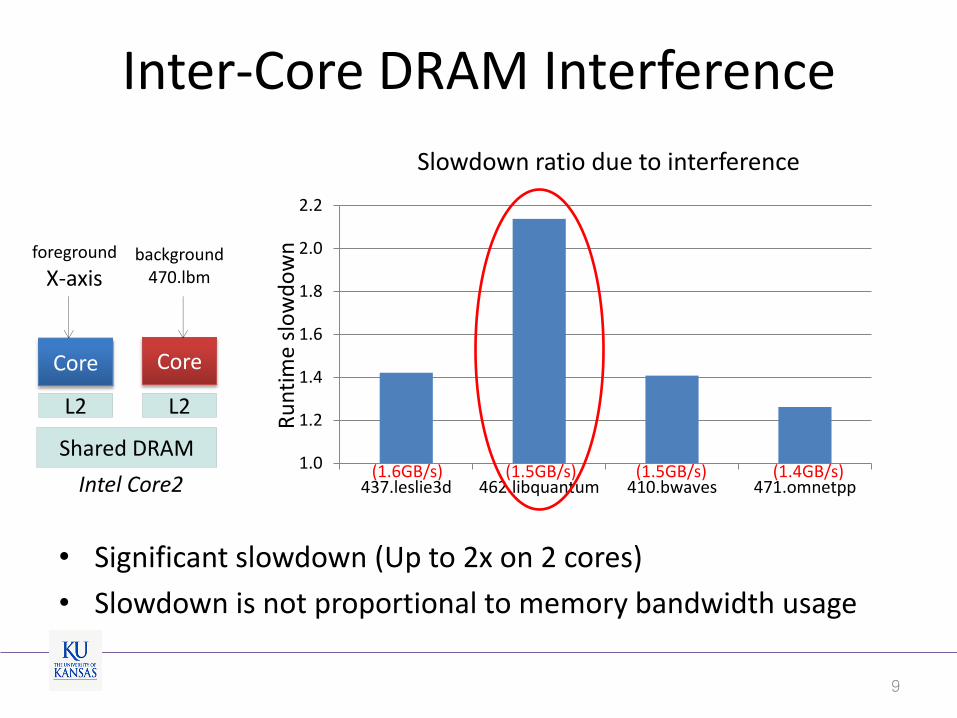
Inter-Core DRAM Interference
• Significant slowdown (Up to 2x on 2 cores)
• Slowdown is not proportional to memory bandwidth usage
9
Core
Shared DRAM
foreground
X-axis
Intel Core2
L2 L2
1.0
1.2
1.4
1.6
1.8
2.0
2.2
437.leslie3d 462.libquantum 410.bwaves 471.omnetpp
Slowdown ratio due to interference
(1.6GB/s) (1.5GB/s) (1.5GB/s) (1.4GB/s)
Core
background 470.lbm
Ru
nti
me
slo
wd
ow
n
Core

Outline
• Motivation
• Background & Problems
• DRAM Bandwidth Mgmt. (Time)
• DRAM Bank Allocation Mgmt. (Space)
• Conclusion
10
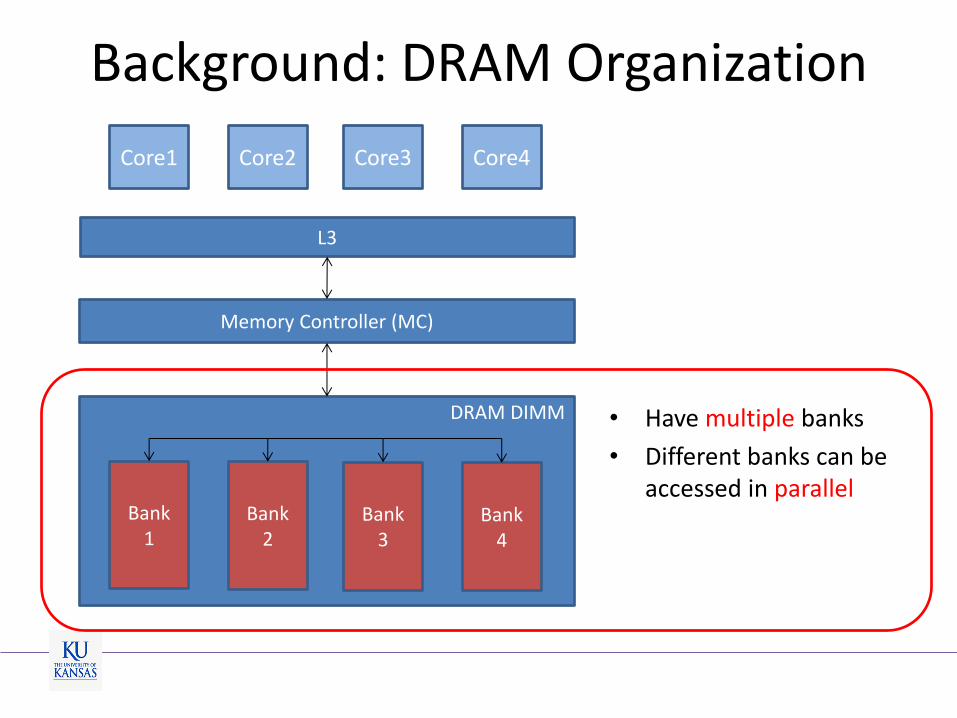
Background: DRAM Organization
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
• Have multiple banks
• Different banks can be accessed in parallel
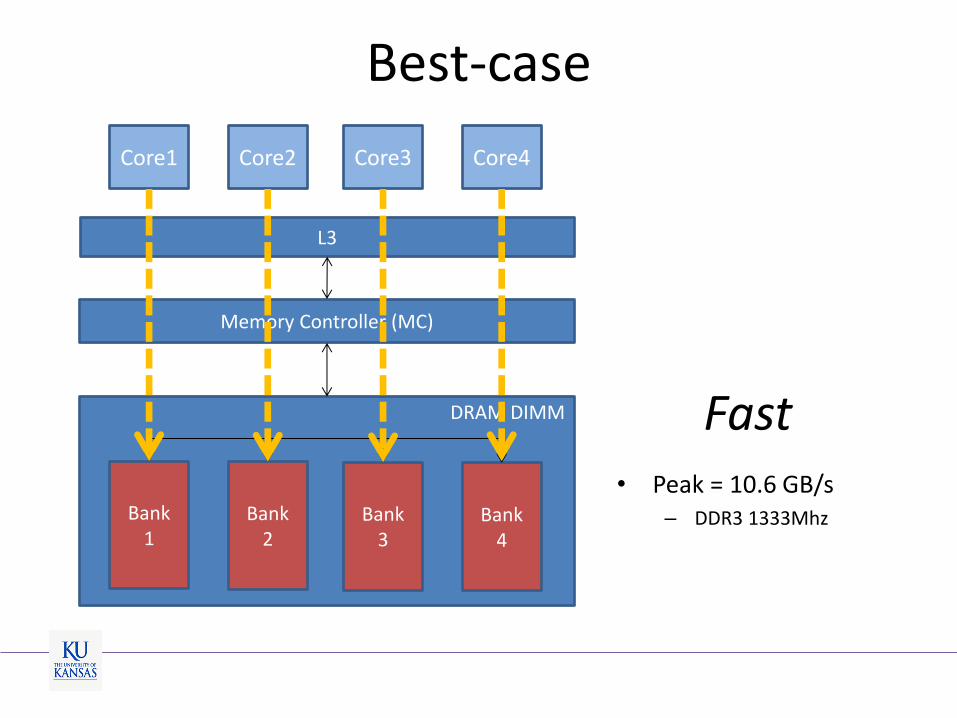
Best-case
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
Fast
• Peak = 10.6 GB/s – DDR3 1333Mhz
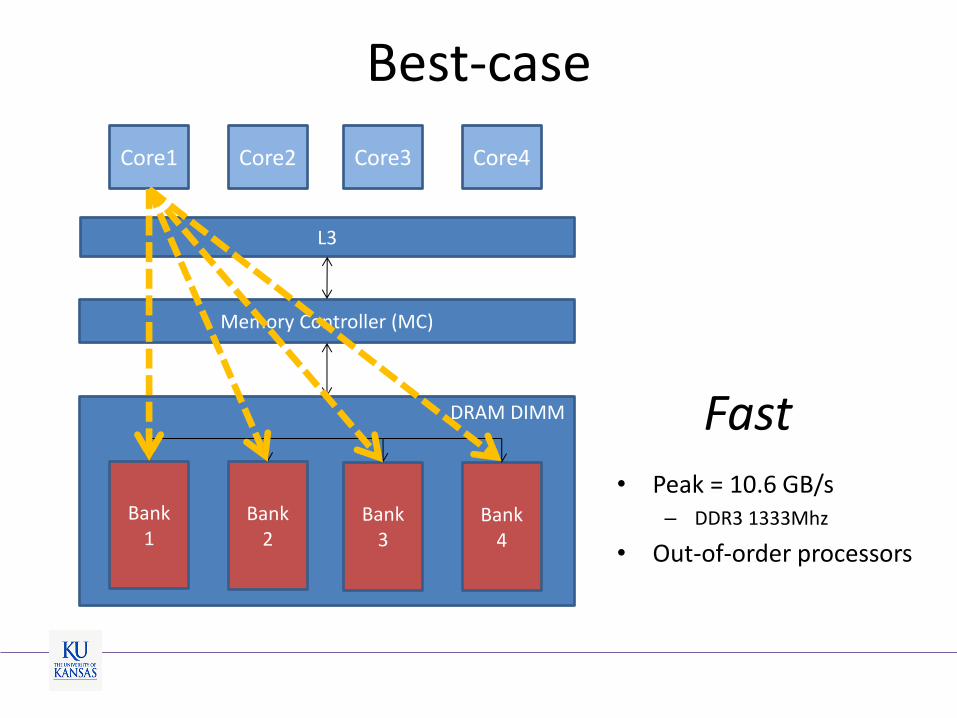
Best-case
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
• Peak = 10.6 GB/s – DDR3 1333Mhz
• Out-of-order processors
Fast
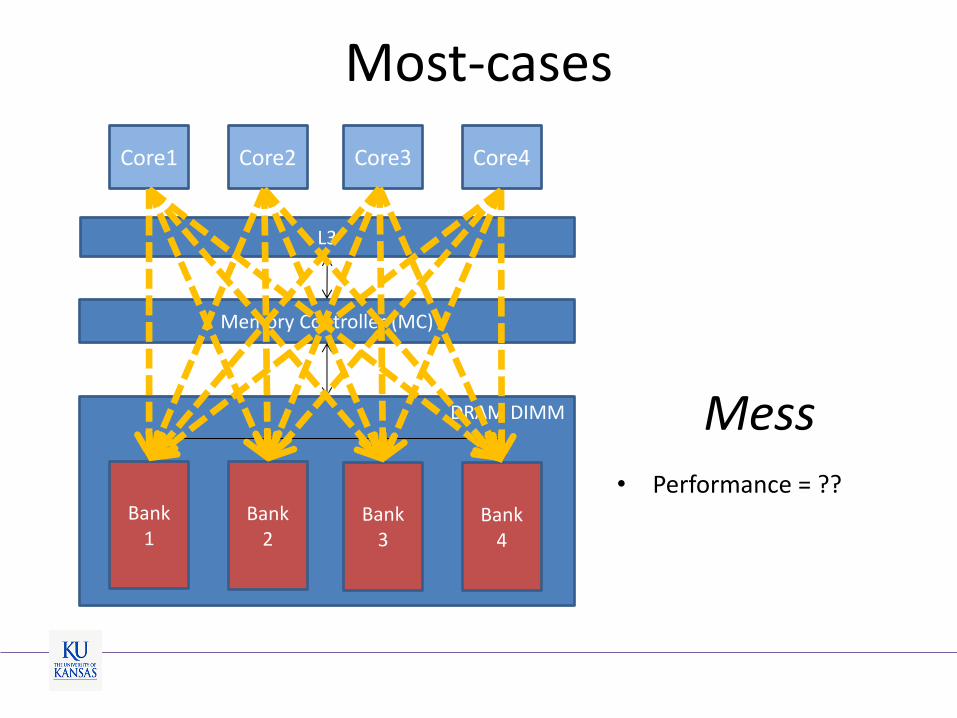
Most-cases
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
Mess
• Performance = ??
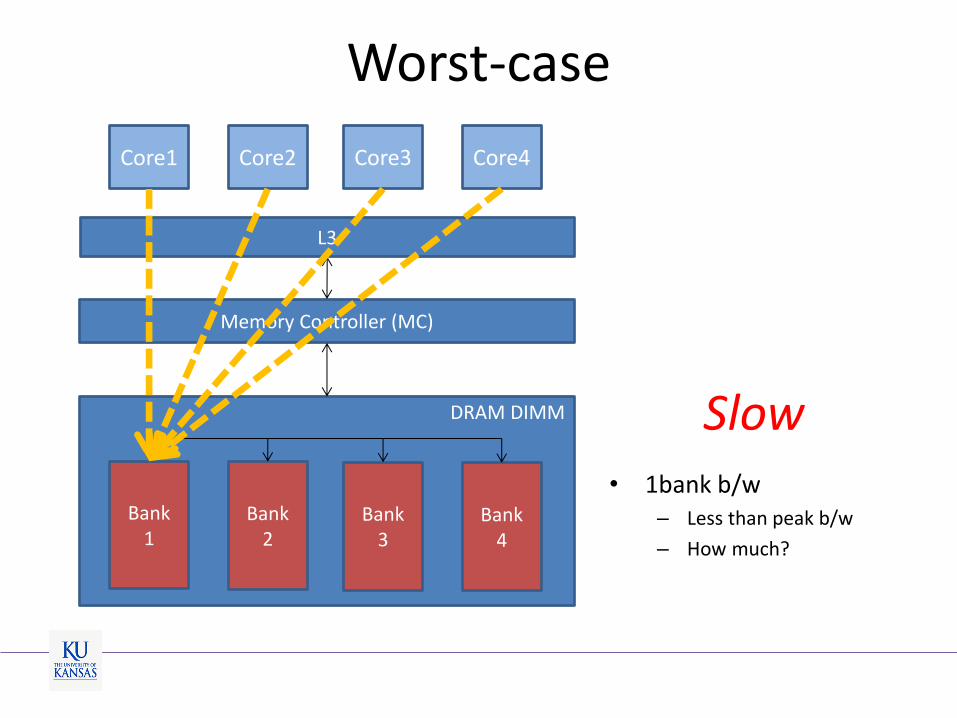
Worst-case
• 1bank b/w – Less than peak b/w
– How much?
Slow
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
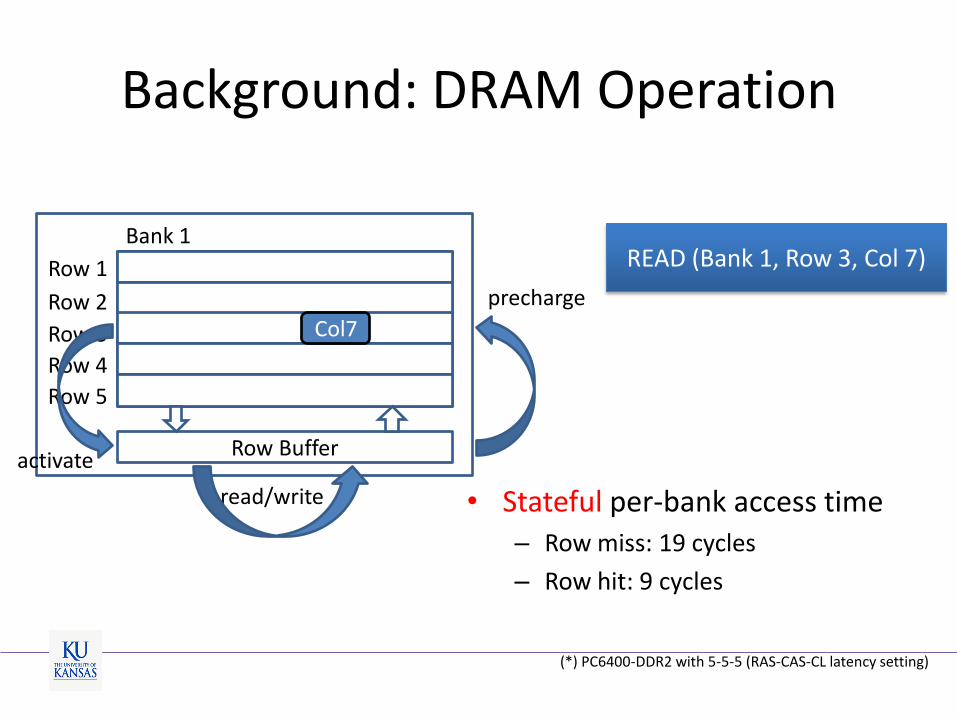
Background: DRAM Operation
• Stateful per-bank access time – Row miss: 19 cycles
– Row hit: 9 cycles
(*) PC6400-DDR2 with 5-5-5 (RAS-CAS-CL latency setting)
Row 1
Row 2
Row 3
Row 4
Row 5
Bank 1
Row Buffer activate
precharge
read/write
Col7
READ (Bank 1, Row 3, Col 7)
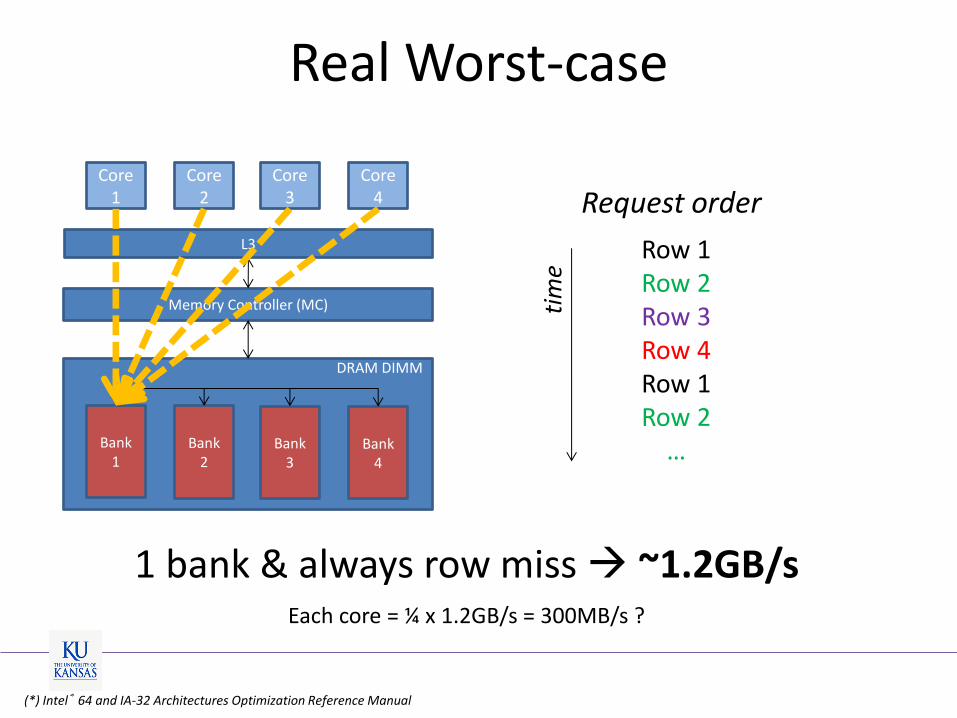
Real Worst-case
(*) Intel® 64 and IA-32 Architectures Optimization Reference Manual
1 bank & always row miss ~1.2GB/s
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1
Core2
Core3
Core4
Row 1 Row 2 Row 3 Row 4 Row 1 Row 2
…
Request order
tim
e
Each core = ¼ x 1.2GB/s = 300MB/s ?
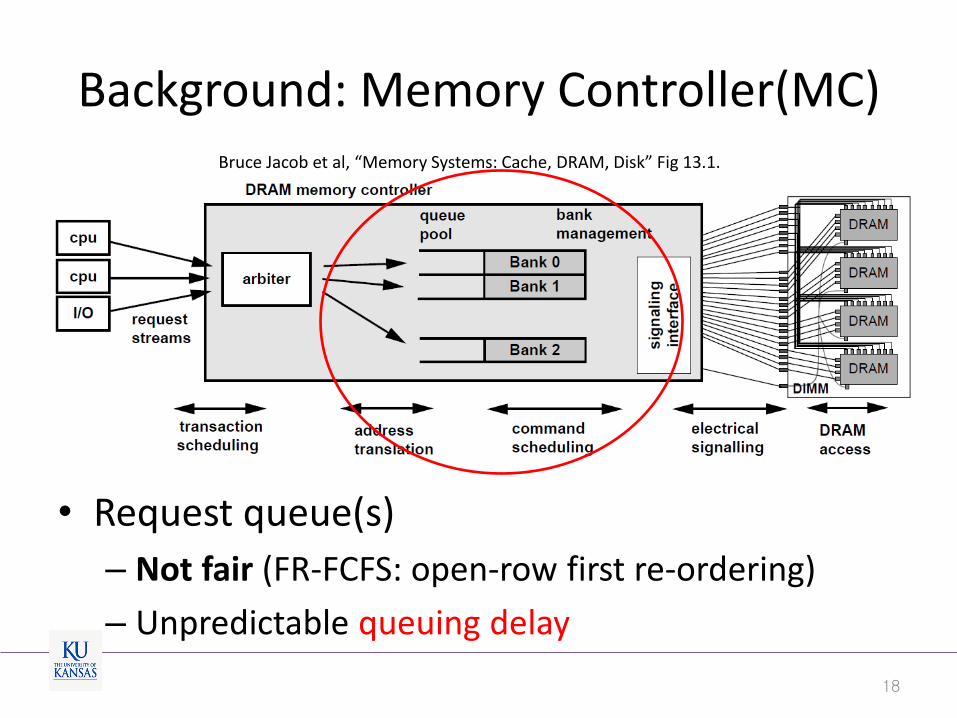
Background: Memory Controller(MC)
• Request queue(s)
– Not fair (FR-FCFS: open-row first re-ordering)
– Unpredictable queuing delay
18
Bruce Jacob et al, “Memory Systems: Cache, DRAM, Disk” Fig 13.1.

• Multiple parallel resources (banks)
• Stateful bank access latency
• Unpredictable queuing delay
• Unpredictable memory performance
Challenges for Performance Isolation
19

Related Work
• Hardware approaches – Predictable DRAM controllers
• Hard: [Paolieri ’09], [Akesson ‘08], [Reineke ‘11], [Goossen ’13], [Zheng’13]
• Soft: [Mutlu ’08, ‘07], [Ebrahimi ’10]
– Cons: can’t apply to commodity systems
• Software approaches – Contention-aware scheduling
• Try to find minimally interfering task->core mapping • [Fedorova’07], [Merkel’10]; Survey paper:[Zhuravlev’12]
– Cons: still unpredictable, no guarantees
20

Outline
• Motivation
• Background & Problems
• DRAM Bandwidth Mgmt. (Time)
– MemGuard [RTAS’13]
• DRAM Bank Allocation Mgmt. (Space)
• Conclusion
21
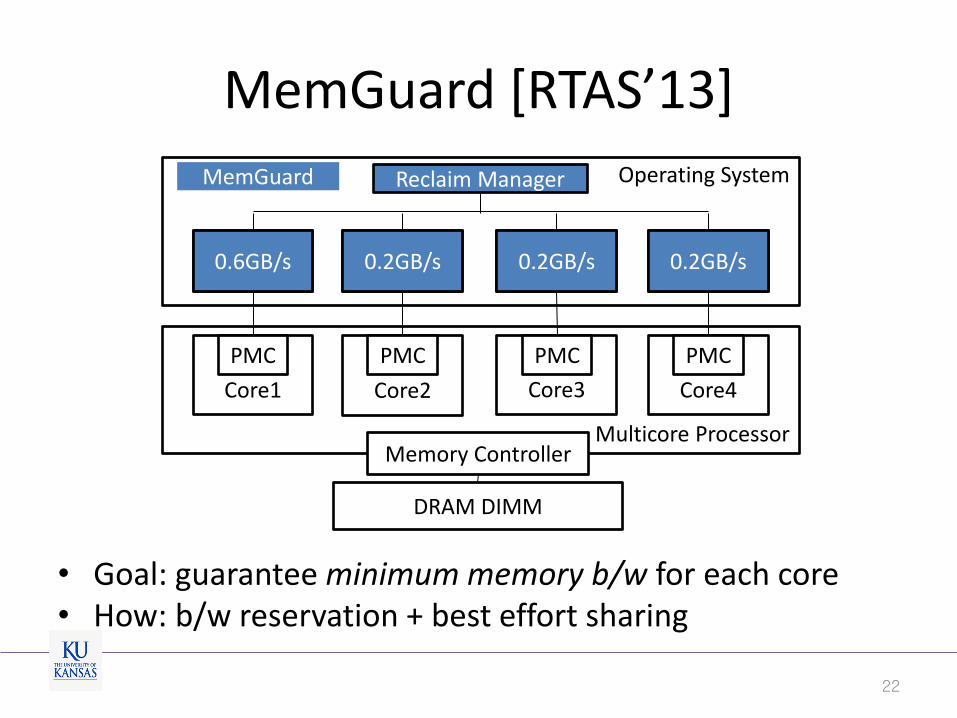
MemGuard [RTAS’13]
22
• Goal: guarantee minimum memory b/w for each core • How: b/w reservation + best effort sharing
Operating System
Core1
Core2
Core3
Core4
PMC PMC PMC PMC
DRAM DIMM
MemGuard
Multicore Processor Memory Controller
BW Regulator
BW Regulator
BW Regulator
BW Regulator
0.6GB/s 0.2GB/s 0.2GB/s 0.2GB/s
Reclaim Manager
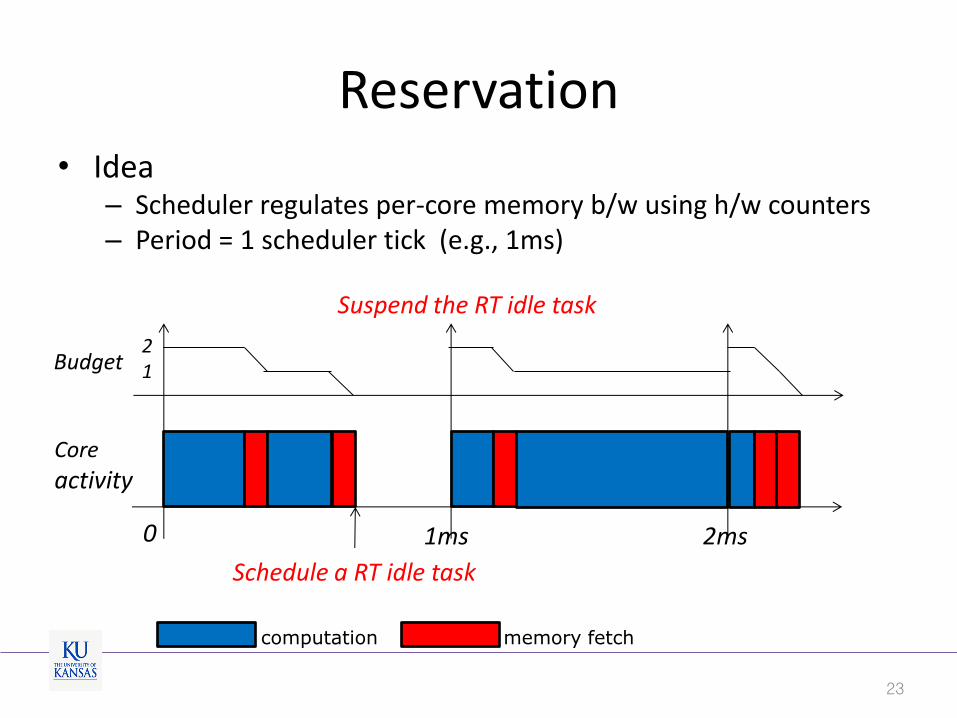
Reservation • Idea
– Scheduler regulates per-core memory b/w using h/w counters – Period = 1 scheduler tick (e.g., 1ms)
23
1ms 2ms 0
Schedule a RT idle task
Suspend the RT idle task
Budget
Core
activity
2 1
computation memory fetch
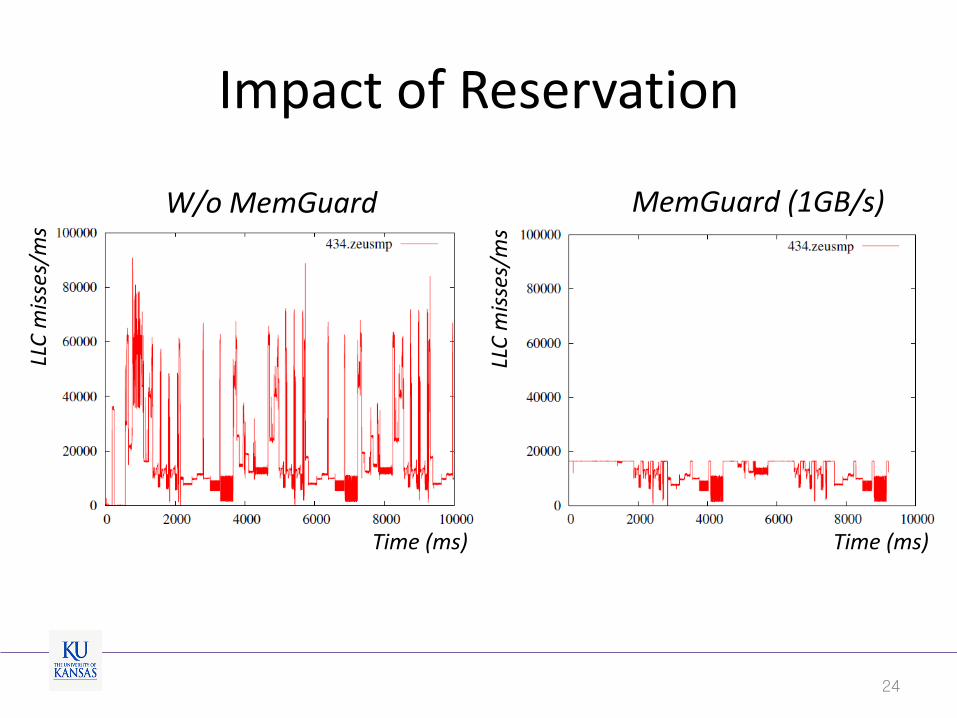
Impact of Reservation
24
LLC
mis
ses/
ms
Time (ms) Time (ms)
W/o MemGuard MemGuard (1GB/s)
LLC
mis
ses/
ms

Reservation
• Key insight
– Worst-case bandwidth can be guaranteed.
– Total reserved bandwidth < worst-case DRAM bandwidth (𝑟𝑚𝑖𝑛)
• System-wide reservation rule
– 𝐵𝑖𝑚𝑖=0 ≤ 𝑟𝑚𝑖𝑛
• m: #of cores
• Bi: Core i’s b/w reservation
25

Best-Effort Sharing
• Spare Sharing [RTAS’13]
• Proportional Sharing [Under submission to TC]
26
Core0
900MB/s ti
me(
ms)
Core1
300MB/s 0
guaranteed b/w
best-effort b/w
throttled
reschedule
1
2
Case Study
• HRT – Synthetic real-time video capture – P=20, D=13ms – Cache-insensitive
• X-server – Scrolling text on a gnome-terminal
• Hardware platform – Intel Xeon 3530 – 8MB shared cache – 4GB DDR3 1333MHz DIMM
27
A desktop PC (Intel Xeon 3530)
DRAM
L3 (8MB)
Core1 Core2
HRT Xsrv.
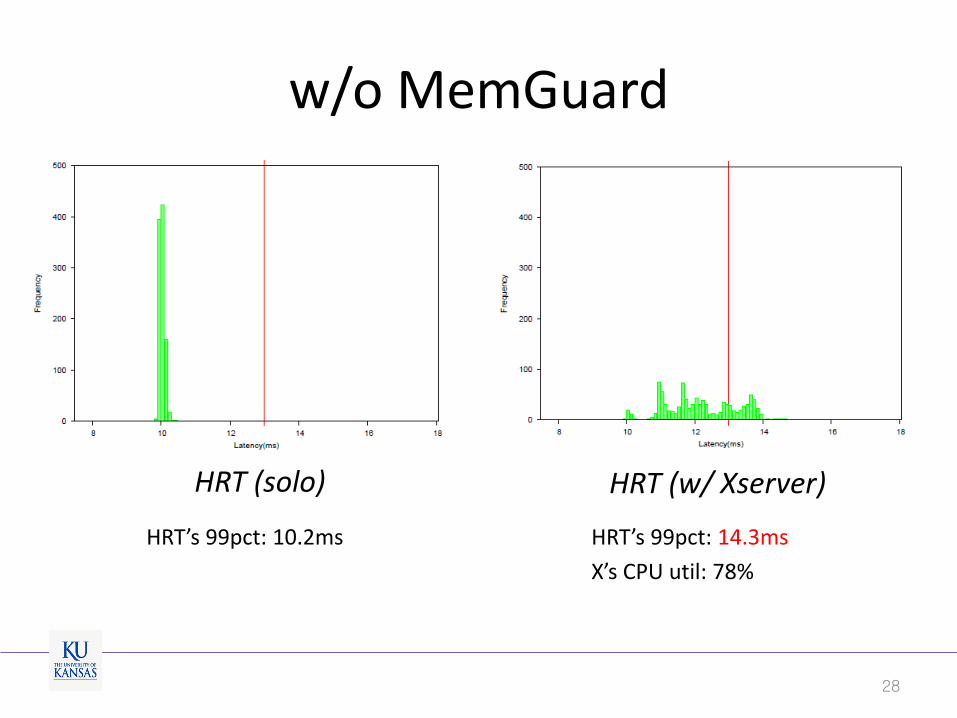
w/o MemGuard
HRT’s 99pct: 10.2ms
28
HRT (solo) HRT (w/ Xserver)
HRT’s 99pct: 14.3ms
X’s CPU util: 78%
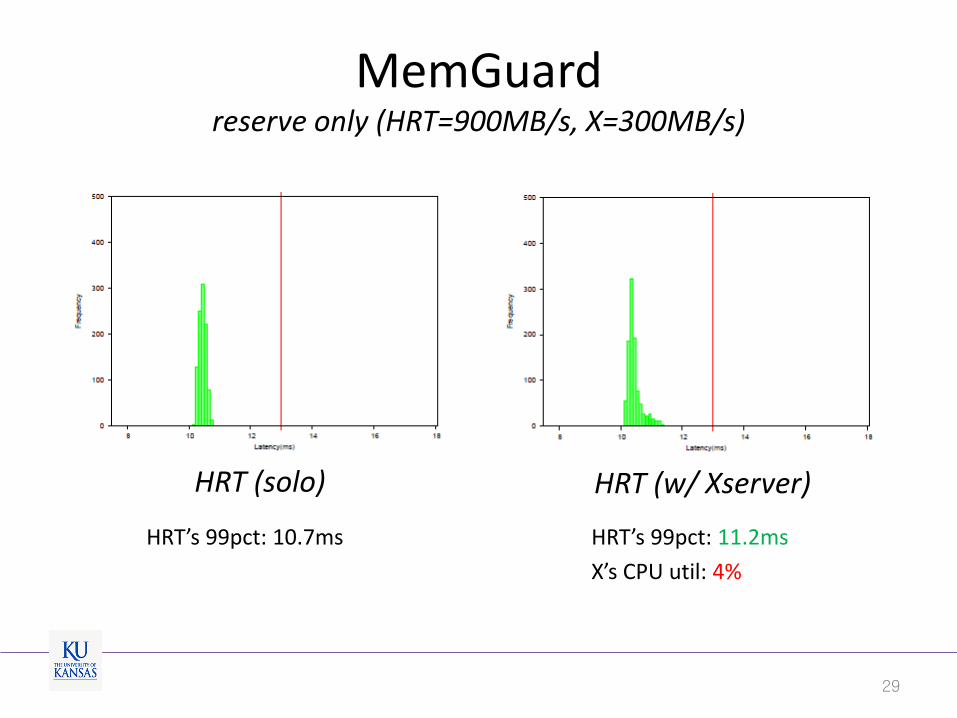
MemGuard reserve only (HRT=900MB/s, X=300MB/s)
29
HRT (solo) HRT (w/ Xserver)
HRT’s 99pct: 10.7ms HRT’s 99pct: 11.2ms
X’s CPU util: 4%
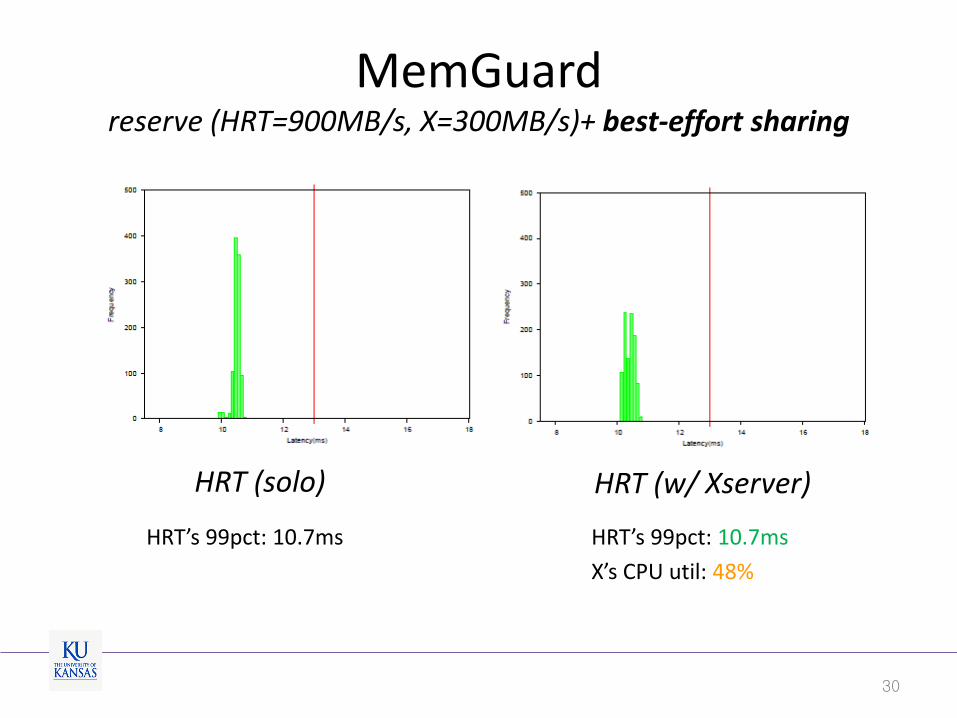
MemGuard reserve (HRT=900MB/s, X=300MB/s)+ best-effort sharing
30
HRT (solo) HRT (w/ Xserver)
HRT’s 99pct: 10.7ms HRT’s 99pct: 10.7ms
X’s CPU util: 48%
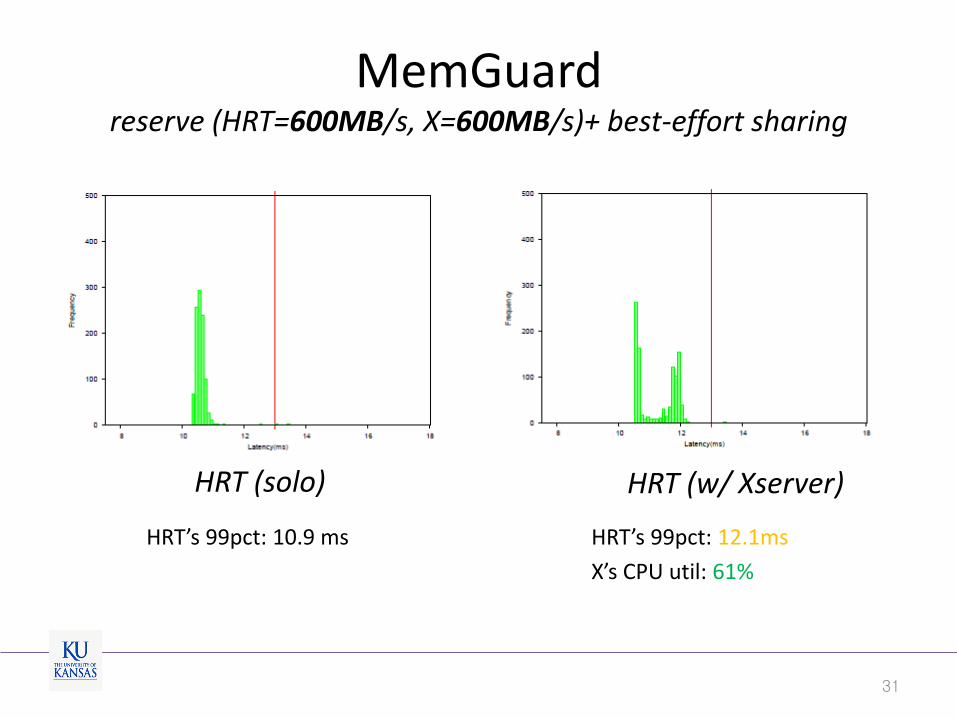
MemGuard reserve (HRT=600MB/s, X=600MB/s)+ best-effort sharing
31
HRT (solo) HRT (w/ Xserver)
HRT’s 99pct: 10.9 ms HRT’s 99pct: 12.1ms
X’s CPU util: 61%

Real-Time Performance Improvement
• Using MemGuard, we can achieve – No deadline miss for HRT – Good X-server performance
32
HRT X-server
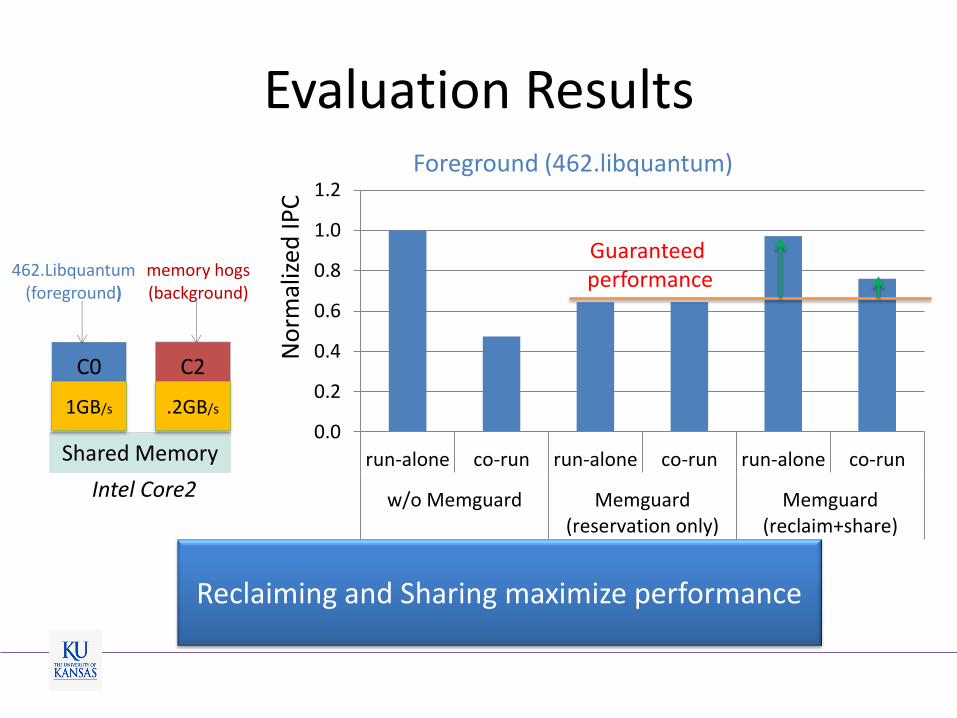
Evaluation Results
C0
Shared Memory
C2
Intel Core2
L2 L2
462.Libquantum (foreground)
0.0
0.2
0.4
0.6
0.8
1.0
1.2
run-alone co-run run-alone co-run run-alone co-run
w/o Memguard Memguard(reservation only)
Memguard(reclaim+share)
No
rmal
ized
IPC
Foreground (462.libquantum)
1GB/s
memory hogs (background)
C2
.2GB/s
Reclaiming and Sharing maximize performance
Guaranteed performance

Summary of MemGuard
• Unpredictable memory performance – multiple resources(banks), per-bank state, queueing delay
• MemGuard – Guarantee minimum memory bandwidth for each core – b/w reservation (guaranteed part) + best-effort sharing
• Case-study – On Intel Xeon multicore platform, using HRT + X-server – MemGuard can improve real-time performance efficiently
• Limitations – Coarse grain (a OS tick) enforcement – Small guaranteed b/w due to potential bank conflict DRAM bank partitioning (next part)
34
https://github.com/heechul/memguard

Outline
• Motivation
• Background & Problems
• DRAM Bandwidth Mgmt. (Time)
• DRAM Bank Allocation Mgmt. (Space)
– PALLOC [RTAS’14]
• Conclusion & Future Work
35
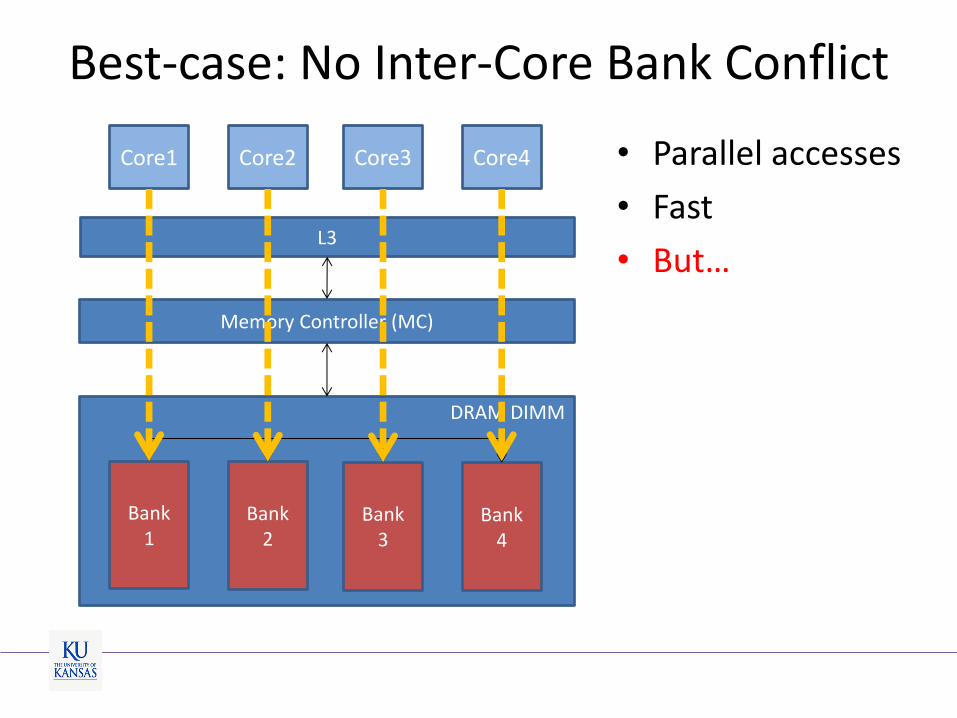
Best-case: No Inter-Core Bank Conflict
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
• Parallel accesses
• Fast
• But…
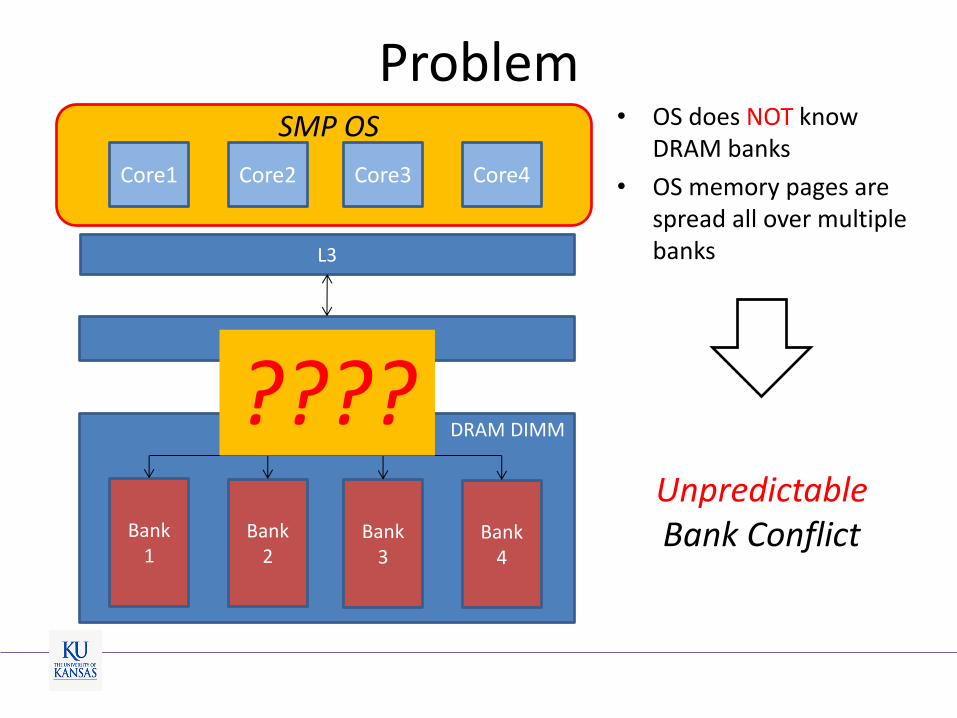
Problem
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
• OS does NOT know DRAM banks
• OS memory pages are spread all over multiple banks
???? Unpredictable Bank Conflict
SMP OS
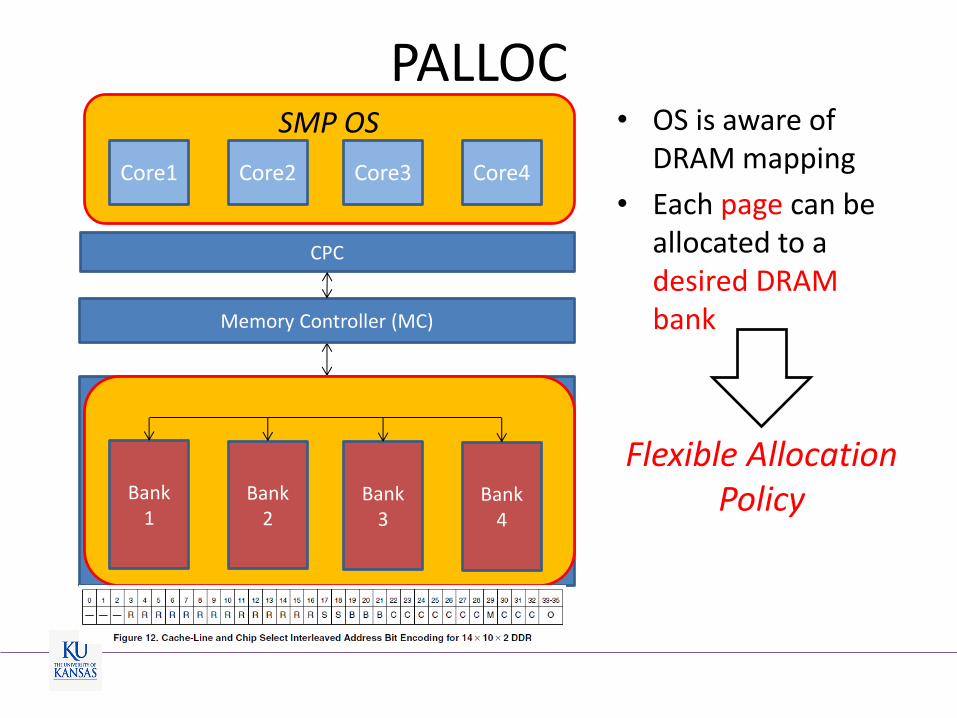
DRAM DIMM
PALLOC
CPC
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
• OS is aware of DRAM mapping
• Each page can be allocated to a desired DRAM bank
Flexible Allocation Policy
SMP OS
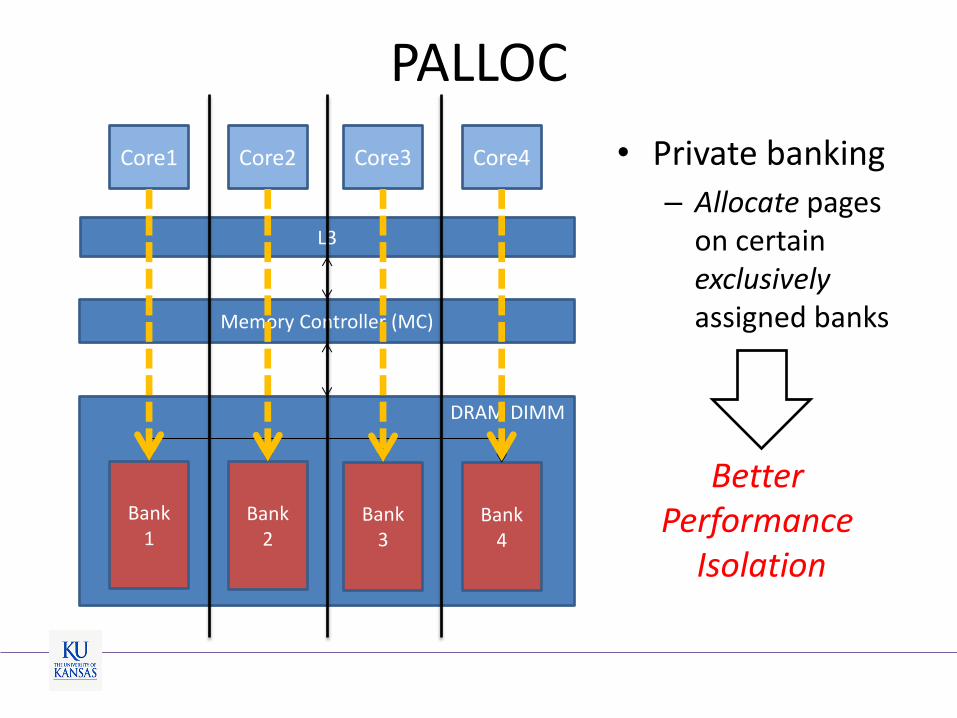
PALLOC
L3
DRAM DIMM
Memory Controller (MC)
Bank 4
Bank 3
Bank 2
Bank 1
Core1 Core2 Core3 Core4
• Private banking
– Allocate pages on certain exclusively assigned banks
Better Performance
Isolation

PALLOC
• Modified Linux kernel’s buddy allocator
– Lowest level allocator, mother of all allocations
• Can specify <banks> for each CGROUP
40
# echo 4-7 > /sys/fs/cgroup/corun/palloc.dram_bank allow bank 4 or 5 or 6 or 7 for ‘corun’ cgroup

Simplified Pseudocode
41
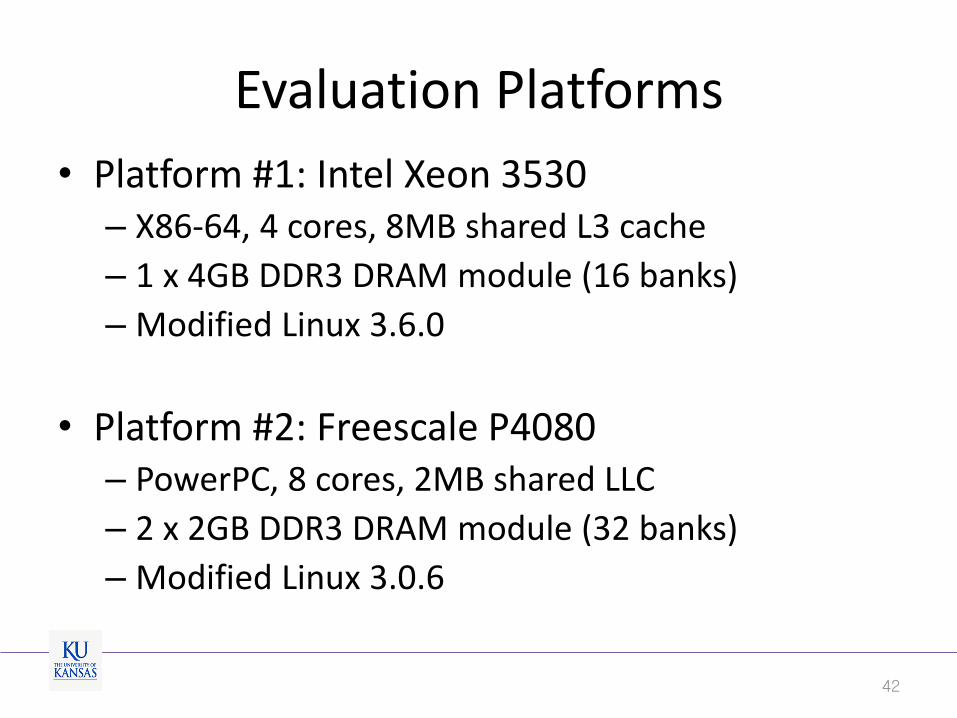
Evaluation Platforms
• Platform #1: Intel Xeon 3530 – X86-64, 4 cores, 8MB shared L3 cache
– 1 x 4GB DDR3 DRAM module (16 banks)
– Modified Linux 3.6.0
• Platform #2: Freescale P4080 – PowerPC, 8 cores, 2MB shared LLC
– 2 x 2GB DDR3 DRAM module (32 banks)
– Modified Linux 3.0.6
42
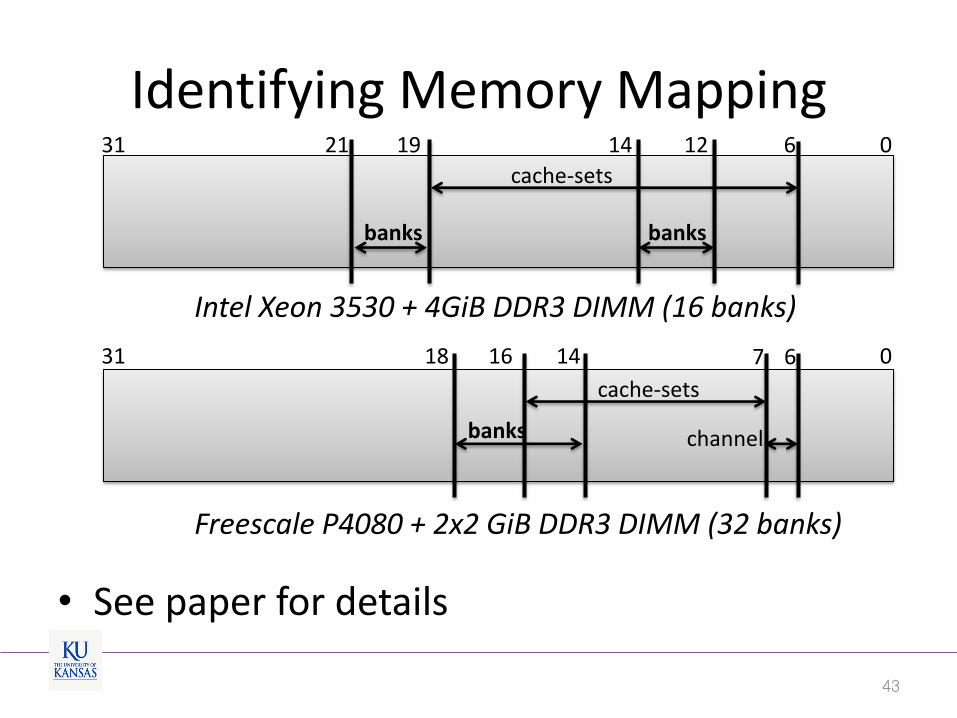
Identifying Memory Mapping
• See paper for details
43
12 14 19 21
banks banks
cache-sets
31 0 6
14 18
banks
31 0 6 7
channel
cache-sets
16
Intel Xeon 3530 + 4GiB DDR3 DIMM (16 banks)
Freescale P4080 + 2x2 GiB DDR3 DIMM (32 banks)
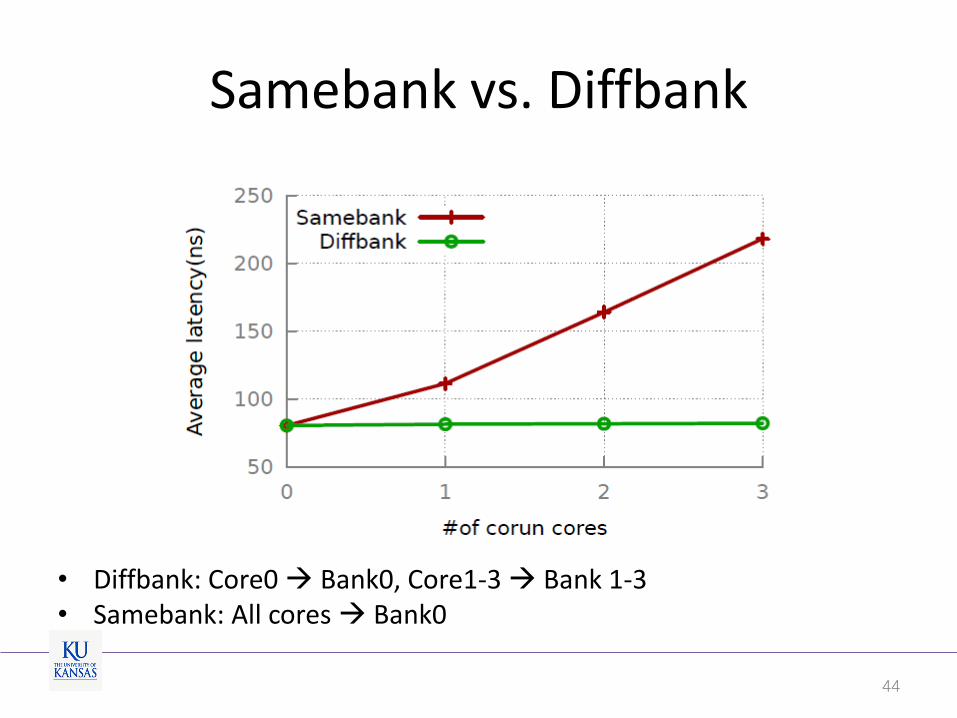
Samebank vs. Diffbank
• Diffbank: Core0 Bank0, Core1-3 Bank 1-3 • Samebank: All cores Bank0
44
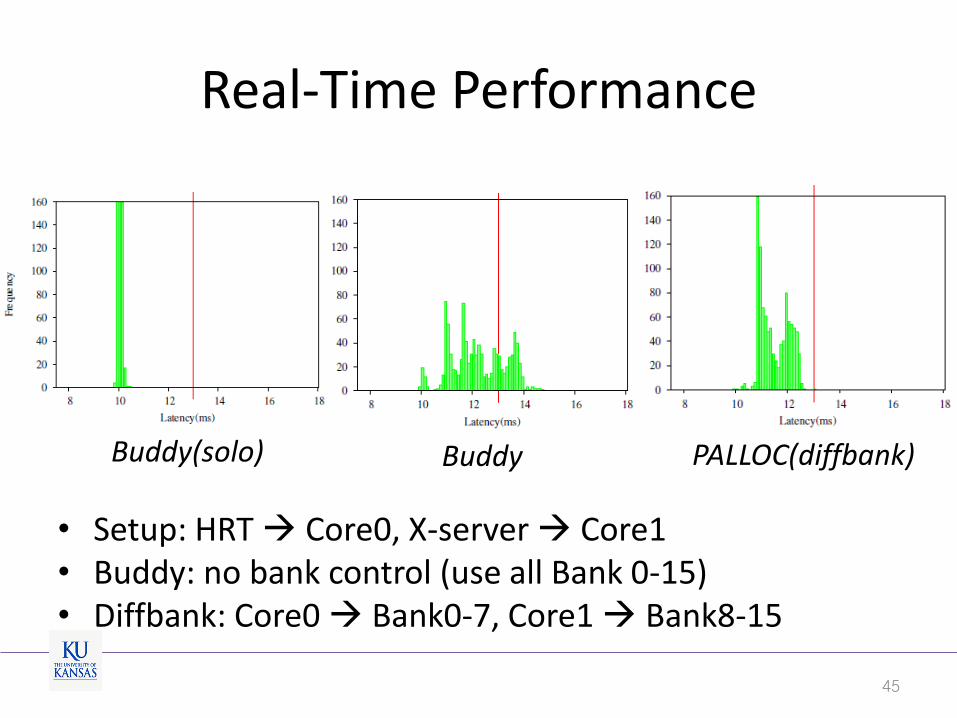
Real-Time Performance
• Setup: HRT Core0, X-server Core1 • Buddy: no bank control (use all Bank 0-15) • Diffbank: Core0 Bank0-7, Core1 Bank8-15
45
Buddy(solo) PALLOC(diffbank) Buddy
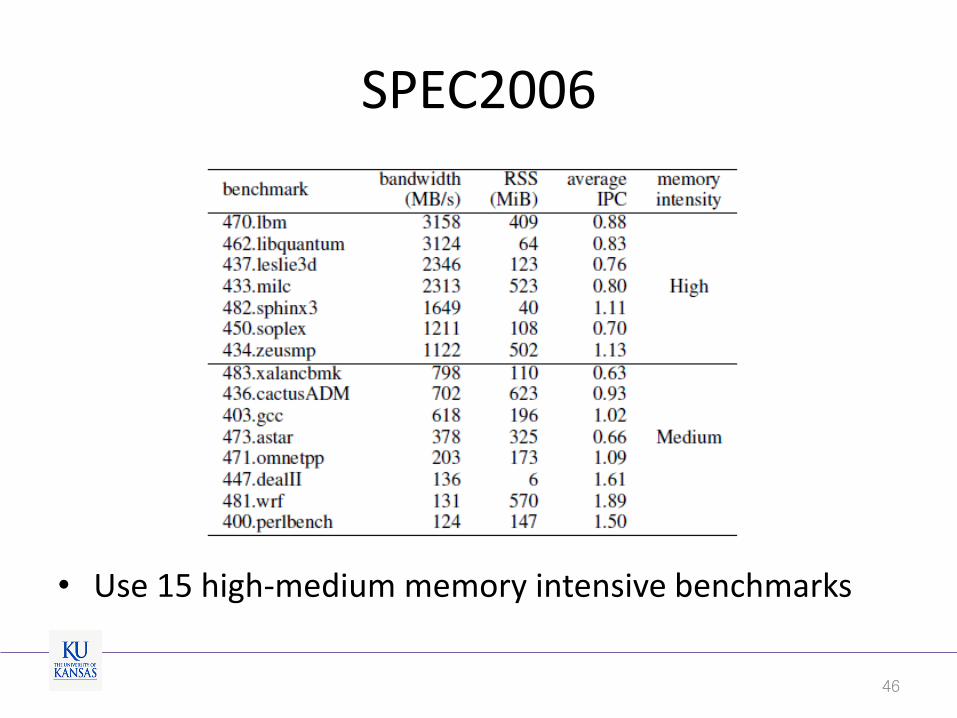
SPEC2006
• Use 15 high-medium memory intensive benchmarks
46
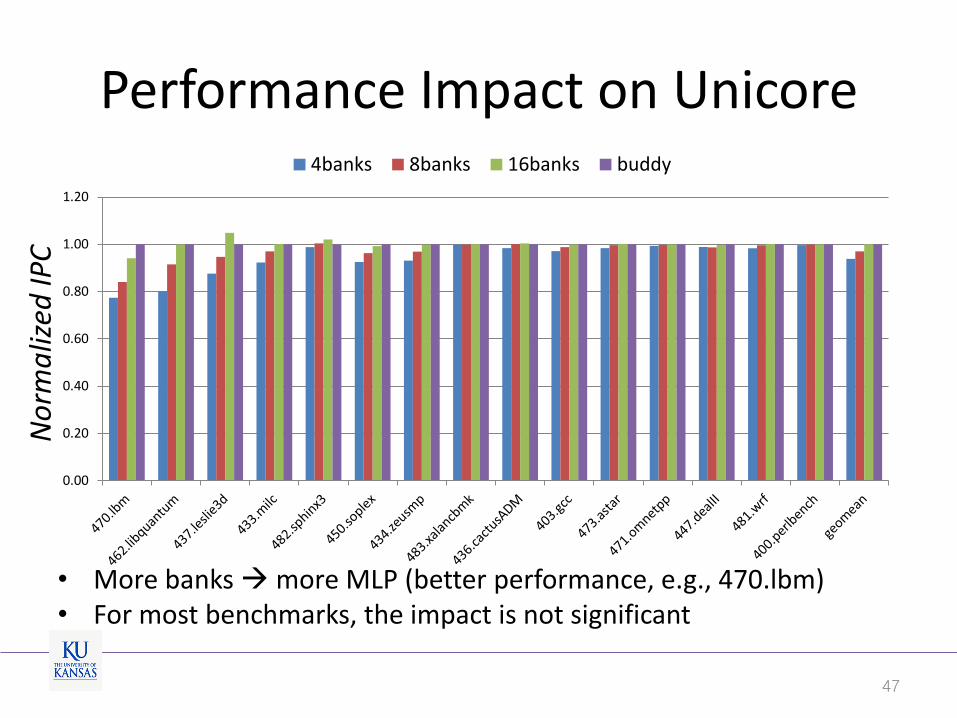
Performance Impact on Unicore
• More banks more MLP (better performance, e.g., 470.lbm) • For most benchmarks, the impact is not significant
47
0.00
0.20
0.40
0.60
0.80
1.00
1.20
4banks 8banks 16banks buddy
No
rma
lized
IPC
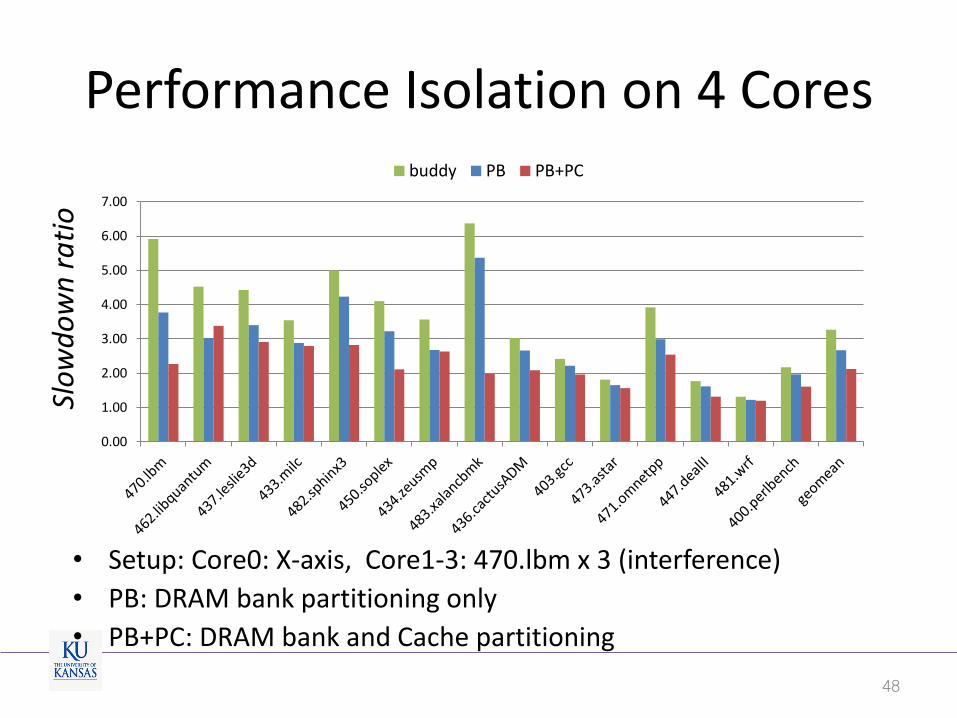
Performance Isolation on 4 Cores
• Setup: Core0: X-axis, Core1-3: 470.lbm x 3 (interference)
• PB: DRAM bank partitioning only
• PB+PC: DRAM bank and Cache partitioning
48
Slo
wd
ow
n r
ati
o
0.00
1.00
2.00
3.00
4.00
5.00
6.00
7.00
buddy PB PB+PC

Summary of PALLOC
• PALLOC – DRAM bank aware kernel level memory allocator
– Can eliminate inter-core bank conflicts
• Evaluation – Private banking policy improves performance isolation
• without significant single-thread performance reduction
– But, far from ideal isolation because memory bus is still a bottleneck need for b/w control (MemGuard)
49
https://github.com/heechul/palloc (TBA)

Outline
• Motivation
• Background & Problems
• DRAM Bandwidth Mgmt. (Time)
• DRAM Bank Allocation Mgmt. (Space)
• Conclusion & Future Work
50

Conclusion
• Problems – The shared memory hierarchy in multicore – Today’s OSes do not manage it. – Resulting in high performance variations and poor QoS guarantees
• Proposed solutions – MemGuard: DRAM bandwidth (time) control – PALLOC: DRAM bank (space) control Improved performance isolation
• Funding agencies
51

Future Work
• T1: Better integration of MemGuard and PALLOC – Bank assignments affect reservable memory bandwidth
(i.e., PALLOC MemGuard)
• T2: Smarter policies – Optimal assignments for known workloads – Dynamic adaptation schemes for unknown workloads
• T3: Fine-grained QoS guarantees in the Cloud – Improve QoS guarantees in public cloud systems – A vision for real-time cloud systems (NSF CNS/CSR
Highlights)
52





























