Embed Size (px)
Citation preview

1
Curbing Delays in Datacenters:Need Time to Save Time?
Mohammad Alizadeh
Sachin Katti, Balaji Prabhakar
Insieme Networks Stanford University

2
Window-based rate control schemes (e.g., TCP) do not work at near zero round-trip latency

3
Datacenter Networks
1000s of server ports
Message latency is King need very high throughput, very low latency
web app db map-reduce HPC monitoringcache
10-40Gbps links
1-5μs latency

4
Transport in Datacenters
• TCP widely used, but has poor performance– Buffer hungry: adds significant queuing latency
TCP~1–10ms
DCTCP ~100μs
~Zero Latency
How do we get here?
Que
uing
Lat
ency
Baseline fabric latency: 1-5μs

5
(KBy
tes)
Experiment: 2 flows (Win 7 stack), Broadcom 1Gbps Switch
Reducing Queuing: DCTCP vs TCP
S1
Sn
ECN Marking Thresh = 30KB

Towards Zero Queuing
S1
Sn
ECN@90%
S1
Sn
ECN@90%
S1
Sn
ECN@90%

0 5 10 15 20 25 30 35 40 45 500
5
10
15
20
25
30
35
40
45
50Queueing Latency
Total Latency
Round-Trip Propagation Time (μs)
Late
ncy
(μs)
Towards Zero Queuing
ns2 sim: 10 DCTCP flows, 10Gbps switch, ECN at 9Gbps (90% util)
0 5 10 15 20 25 30 35 40 45 507
7.5
8
8.5
9
9.5
10
Round-Trip Propagation Time (us)
Thro
ughp
ut (G
bps)
Target Throughput
Floor ≈ 23μs
S1
Sn
ECN@90%
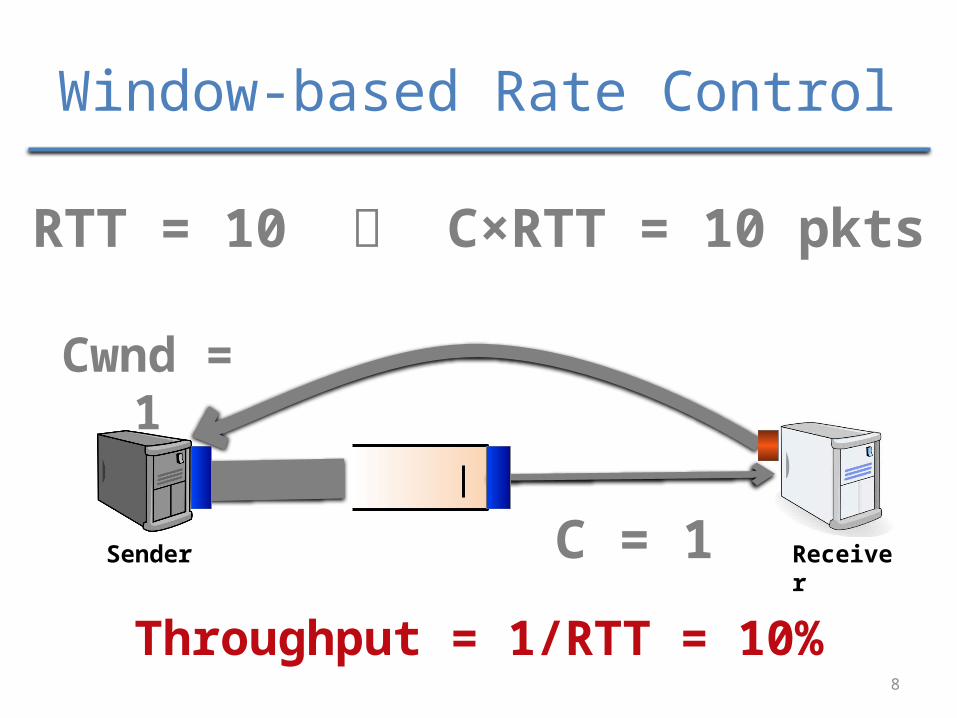
8
ReceiverSender
RTT = 10 C×RTT = 10 pkts
Cwnd = 1
Throughput = 1/RTT = 10%
Window-based Rate Control
C = 1

9
ReceiverSender
Cwnd = 1
Throughput = 1/RTT = 50%
Window-based Rate Control
RTT = 2 C×RTT = 2 pkts
C = 1

10
ReceiverSender
Cwnd = 1
Throughput = 1/RTT = 99%
Window-based Rate Control
RTT = 1.01 C×RTT = 1.01 pkts
C = 1

11
Receiver
Sender 1
Cwnd = 1
Sender 2 Cwnd = 1
As propagation time 0: Queue buildup is unavoidable
Window-based Rate Control
RTT = 1.01 C×RTT = 1.01 pkts

12
So What?
Window-based RC needs lag in the loop
Near-zero latency transport must:
1. Use timer-based rate control / pacing
2. Use small packet size
Or… Change the Problem!
Both increase CPU overhead (not practical in software)
Possible in hardware, but complex (e.g., HULL NSDI’12)

13
Changing the Problem…
Priority queue
Switch Port
FIFO queue
Switch Port
7 1
9 435
Queue buildup costly need precise rate control
Queue buildup irrelevant coarse rate control OK

14
pFABRIC

15
H1 H2 H3 H4 H5 H6 H7 H8 H9
DC Fabric: Just a Giant Switch

16
H1
H2
H3
H4
H5
H6
H7
H8
H9
H1
H2
H3
H4
H5
H6
H7
H8
H9
H1
H2
H3
H4
H5
H6
H7
H8
H9
TX RX
DC Fabric: Just a Giant Switch

17
H1
H2
H3
H4
H5
H6
H7
H8
H9
H1
H2
H3
H4
H5
H6
H7
H8
H9
TX RX
DC Fabric: Just a Giant Switch

18
H1
H2
H3
H4
H5
H6
H7
H8
H9
H1
H2
H3
H4
H5
H6
H7
H8
H9
Objective? Minimize avg FCT
DC transport = Flow scheduling on giant switch
ingress & egress capacity constraints
TX RX

19
“Ideal” Flow Scheduling
Problem is NP-hard [Bar-Noy et al.]– Simple greedy algorithm: 2-approximation
1
2
3
1
2
3

20
pFabric in 1 Slide
Packets carry a single priority #• e.g., prio = remaining flow size
pFabric Switches • Very small buffers (~10-20 pkts for 10Gbps fabric)• Send highest priority / drop lowest priority pkts
pFabric Hosts• Send/retransmit aggressively• Minimal rate control: just prevent congestion collapse

21
Key Idea
Decouple flow scheduling from rate control
H1 H2 H3 H4 H5 H6 H7 H8 H9
Switches implement flow scheduling via local mechanisms
Hosts use simple window-based rate control (≈TCP) to avoid high packet loss
Queue buildup does not hurt performance
Window-based rate control OK

22
Switch Port
7 1
9 43
Priority Scheduling send highest priority packet first
Priority Dropping drop lowest priority packets first
5
small “bag” of packets per-port prio = remaining flow size
H1
H2
H3
H4
H5
H6
H7
H8
H9
pFabric Switch

23
pFabric Switch Complexity
• Buffers are very small (~2×BDP per-port)– e.g., C=10Gbps, RTT=15µs → Buffer ~ 30KB– Today’s switch buffers are 10-30x larger
Priority Scheduling/Dropping• Worst-case: Minimum size packets (64B)– 51.2ns to find min/max of ~600 numbers– Binary comparator tree: 10 clock cycles– Current ASICs: clock ~ 1ns

24
Why does this work?
Invariant for ideal scheduling: At any instant, have the highest priority packet (according to ideal algorithm) available at the switch.
• Priority scheduling High priority packets traverse fabric as quickly as possible
• What about dropped packets? Lowest priority → not needed till all other packets depart Buffer > BDP → enough time (> RTT) to retransmit

25
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80123456789
10
Ideal pFabric PDQDCTCP TCP-DropTail
Load
FCT
(nor
mal
ized
to o
ptim
al in
idle
fabr
ic)
Evaluation (144-port fabric; Search traffic pattern)
Recall: “Ideal” is REALLY idealized!
• Centralized with full view of flows• No rate-control dynamics• No buffering• No pkt drops• No load-balancing inefficiency

26
Mice FCT (<100KB)
Average 99th Percentile
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80123456789
10
Ideal pFabric PDQ DCTCP TCP-DropTail
Load
Nor
mal
ized
FCT
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80123456789
10
Load
Nor
mal
ized
FCT

27
Conclusion
• Window-based rate control does not work at near-zero round-trip latency
• pFabric: simple, yet near-optimal– Decouples flow scheduling from rate control– Allows use of coarse window-base rate control
• pFabric is within 10-15% of “ideal” for realistic DC workloads (SIGCOMM’13)

28
Thank You!

29





























