Embed Size (px)
Citation preview

Estd. 1934
AC EQ C&U N I EE BR UG DE II F D LDEK NON C LOW
FEROZEPUR
DSCW
COMPUTATIONAL SCIENCE & TECHNOLOGY
Sept. 2017
JOURNAL OF
Ferozepur | Punjab | India
College For WomenDev Samaj
Vol. - IIssue - I
RNI No. : PUNENG/2017/73125
ISSN 2457 - 0982
A Unique Prestigious Post Graduate Institution of Northern India Affiliated to Panjab University, Chandigarh
Highest ranked college in India with 3.75 CGPA out of 4Re-accredited by NAAC Bangalore (2013-14)
Star Science Department, College with Potential for Excellence and College of Excellence Status by U.G.C., New Delhi.

Chief Coordinator Er. Prateek Prashar
Dean College DevelopmentDev Samaj College for Women,
Ferozepur,152002.
Editor in ChiefDr. (Mrs.) Madhu Prashar
Principal,State & National Awardee,
Dev Samaj College for Women,Ferozepur,152002.
CHIEF PATRONShriman Nirmal Singh
Hon'ble Secretary, Dev Samaj and Chairman, DSCW
JOURNAL OF COMPUTATIONAL SCIENCE & TECHNOLOGY
ADVISORY COMMITTEE
Dr. Ravinder Kumar Singla Professor,Deptt. of Computer Science & Applications
Punjab University, Chandigarh.E-mail : [email protected]
Dr. Gurpreet Singh Lehal, Professor Department of Computer Science &
Director, Advanced Center for TechnicalDev. of Punjabi Language, Literature &
Culture, Punjabi University, Patiala.E-mail : [email protected]
Dr. T.D. NarangProfessor, Department of Mathematics, Guru Nanak Dev University, Amritsar.
E-mail : [email protected]
Dr. Vikram, Professor, Head of Computer Science Department,
Chaudhary Devi Lal Univ. Sirsa, Haryana.E-mail : [email protected]
Dr. Gurvinder SinghProfessor and Head of Comp. Sc. Deptt. Guru Nanak Dev University, Amritsar.E-mail : [email protected]
Dr. Indu ChabbraProfessor, Deptt. of Comp. Science & Applications, Pb. Univ. Chandigarh.
E-mail : [email protected],
Dr. Kulbhushan AgnihotriAssociate Professor
Deptt. of Applied Sciences and Humanities, Shaheed Bhagat Singh State
Technical Campus, FerozepurE-mail : [email protected]
Dr. S.K. SrivastvaAssociate Professor, Department of
Mathematics, Beant College of Engineering and Technology, Gurdaspur
E-mail : [email protected]
Dr. Sonal ChawlaProfessor, Chairperson
Deptt. of Comp. Science & Applications, Panjab University, Chandigarh
E-mail : [email protected]
Dr. Krishan Kumar SalujaAssociate Professor
Department of Computer Science, Shaheed Bhagat Singh State Tech. Campus
FerozepurE-mail : [email protected]
I

Dr. Satish KumarAssociate Professor
Computer Science & Application,Swami Sarvanand Giri, Regional Center,
Hoshiarpur, Panjab University, Chandigarh.E-mail : [email protected]
Mr. Sanjay GuptaAsstt. Professor, Deptt. of Mathematics
E-mail : [email protected]
Ms. NishaAsstt. Professor, Deptt. of Comp. Science
E-mail : [email protected]
Ms. Amandeep KaurAsstt. Professor, Deptt. of Comp. Science
E-mail : [email protected]
Mr. Shivam KumarAsstt. Professor, Deptt. of Comp. Sc.E-mail : [email protected]
Dr. Manish JindalAsso. Professor, Muktsar Regional Centre,
Panjab University, Chandigarh.E-mail : [email protected]
Ms. ShabinaAsstt. Professor, Deptt. of Comp. Science
E-mail : [email protected]
Mr. RajeshAsstt. Professor, Deptt. of Comp. ScienceE-mail : rajesh. [email protected]
Mrs. Shilpa NandaAsstt. Professor, Deptt. of MathematicsE-mail : [email protected]
Dr. VinodAsstt. Professor, Deptt. of Comp. ScienceE-mail : [email protected]
Ms. Aditi PrasharAsstt. Professor, Deptt. of Mathematics
E-mail : [email protected]
Er. Anand NayyarProfessor cum Head-Research and Entrepreneurship Cell,
Department of Computer Application & IT,KCL College of Management and Technology
E-mail : [email protected]
EditorMr. Sanjeev Kumar
Assistant Professor and HeadPost Graduate Department of Computer Science.
E-mail : [email protected]
Editorial Board
Printed & Published byDr. Madhu Prashar on behalf of Dev Samaj College for Women
and Printed at Ashu Graphics (Ferozepur Printing Press), Near Thana Sadar, Ferozepur City (Punjab)
and published at Circular Road, Near Bansi Gate, Dev Samaj College for Women, Ferozepur City (Punjab)
Editor Mr. Sanjeev KumarAsstt. Prof. & Head, Post Graduate Deptt. of Computer Science,
Dev Samaj College for Women, Ferozepur City (Punjab)
II

MESSAGE
It gives me an ecstatic feeling of pride and delight to learn that Dev Samaj
College for Women, is bringing out an annual journal titled "JOURNAL OF
COMPUTATIONAL SCIENCE & TECHNOLOGY" to promote research and
explore creative talents in different disciplines through various research papers
of the esteemed scholars from across the nation. We always believe in strong
efforts of individuals to set a new benchmark in the field of authentic research. I
hope this effort will make an immense contribution to the field of research which
has become the dire need of the times.
As there is the Paradigm shift in the education system of our country. There is a
great need of research oriented scholars and the faculty. Thus DSCW has taken
many strong initiatives to promote quality research in different disciplines by
encouraging the faculty to excavate the deeper recesses of knowledge.
Adhering to our mission, we, at Dev Samaj, believe in excellence and education,
in exuberance of virtues, sharing of cultures and diminishing of boundaries. I
am of the opinion that our journal would stand in conformity to the same and it
would help us come out of our cocoons by becoming comfortably more sensitive
to the greater realities of life. It would help us delve deep into the fathomless sea,
that we call the sea of knowledge. On this occasion, I extend my warm wishes
and felicitation to all those associated with this journal and wish them all
success.
Dr. (Mrs.) Madhu PrasharEditor-in-Chief
III

ABOUT THE JOURNAL
"JOURNAL OF COMPUTATIONAL SCIENCE & TECHNOLOGY" is a national
and refereed journal, publishes only original research-papers, articles, book reviews,
communications cases that focus on problems and issues relevant to area of Computer
Science and Mathematics. It provides a forum for authors to present research findings
and, where applicable, their practical applications and significance; analysis of policies,
practices, issues, and trends. The journal publishes articles from areas such as
architecture, software, artificial intelligence, theoretical computer science, networks and
communication, information systems, multimedia and graphics, information security,
Modeling and Simulations, Image processing and Matlab, Transformation Techniques
(Laplace, Fourier, Z-transform etc.),Probability and Statistics ,Fuzzy Technologies and
systems, Numerical Analysis, Number theory, Operational Research, Optimization & its
applications, Differential equations, Mathematical Biology, Coding theory,
Computational Elasticity, Complex Analysis, Functional Analysis etc..
Authors are responsible for making sure that they have not duplicated an article
already published or accepted. Authors should certify on the cover page of the manuscript
that the material is not published, copyrighted, accepted or under review elsewhere.
Journal neither charges any processing fee nor pays any honorarium to authors. Before
submission please make sure that your paper is original work. Acceptance or rejection
notification will be sent to all authors within 15 days.
Cover Page. This shows the title of the paper, name(s) of the author(s),
designation, official address, telephone/fax number and e-mail address for the contact
author. Include acknowledgements, if desired.
Abstract. All manuscripts should include an abstract of about 200 words,
summarizing the paper's main points, results/conclusions and significance. Abstracts are
not required for book reviews and case studies.
Keywords. All manuscripts should include keywords to identify the main topics
of the article. Like the title, they are used for indexing and referencing the article. Avoid
using words that appear in the title. Alphabetize keywords.
Text. The body of the paper should be about 10-15 pages long. Define all technical
terms. Capitalization should be kept to the minimum and should be consistent.
Manuscripts should normally be around (3000-5000 words, 1.5 spaced, Times New
Roman font, 12 font size).
IV

Reference List. Place the reference at the end of the manuscript. The list should mention only
those sources actually cited in the text or notes. References should be in APA Referencing
style.
Table and Figures. Use figures and tables to summarize lengthy material.
Appendix. Place technical material in an appendix. This includes detailed descriptions of
research methodology and analysis.
Copyright Transfer. Prior to publication, authors must sign a form affirming their work is
original and is not a violation of an existing copyright. Authors will receive a complimentary
copy of the issue in which his/her paper.
Call for Paper
You will have to submit your manuscript together with the Copyright Form to
Editor
Journal of Computational Science and Technology
Dev Samaj College for Women
Ferozepur- 152002
Punjab
Contact No. 01632-222145
Mob. No. 8427752125,9872427821
V
S.
No.
Title
Page
no.
1
Investigation of two atomic number for some
engineering
materials
Kulwinder Singh Mann, Asha Rani, Manmohan
Singh,
Harmandeep
Kaur
2
Machine Transliteration :A
Survey
Kanwaljit Kaur,Dr. Gurpreet Singh
Lehal
3
Review And Analysis On Routing Protocol For
Manet
Anjali, Rohit Kumar, Sargam Sharma
4
Speech Recognition: A
Survey
Kirandeep Singh, Dr. Gurpreet Singh
Lehal
5
Enhance the security in cloud computing using
Diffi-HellmanMr. Kanwarjeet Singh, Ms. Amandeep Kaur
6 Optimization and its Applications
Ms. Manju Dhand
7 A REVIEW ON SENSOR SCHEDULING METHODS USINGTHE CONCEPT OF PAIRED-SENSORS Amit Grover, Ginish
8 An Enhanced Ant Colony Algorithm to Conserve Energy
in
Clustered Ad Hoc
Network
Rajdeep Singh Chauhan, Mandeep Handa, Manpreet
Singh
9
A Review: Recovery in Distributed Operating
System Mr. Bohar Singh, Malkeet
Singh
10
Image watermarking Techniques: A Survey Amrinder
Singh,
Sukhjeet Kaur
Ranade
11
NEW FORMS OF MATHEMATICAL
ACTIVITY
Mr. Ajaydeep, Ms.
Tamanna
12
TRENDS IN
MATHEMATICS
Dr. Rajwinder Kaur , Ms.
Rajni
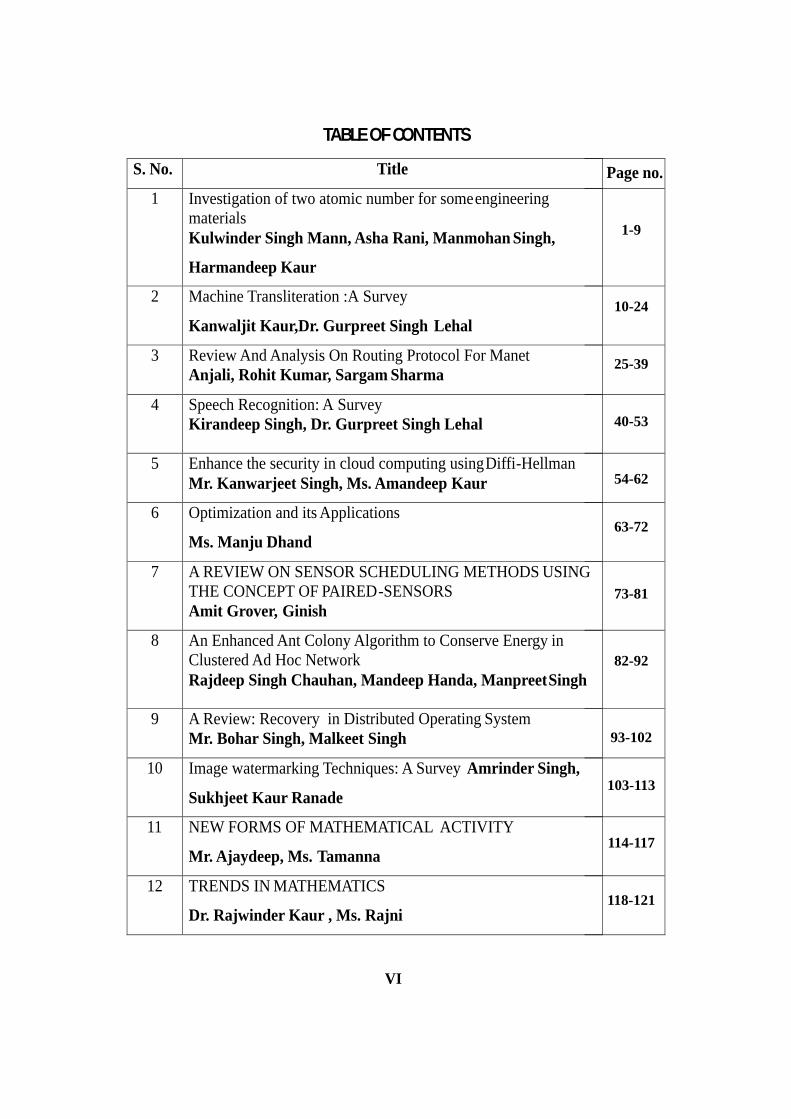
TABLE OF CONTENTS
VI
1-9
10-24
25-39
40-53
54-62
63-72
73-81
82-92
93-102
103-113
114-117
118-121

INVESTIGATION OF TWO ATOMIC NUMBERSFOR SOME ENGINEERING MATERIALS
Kulwinder Singh Mann Department of Applied Sciences,
Inder Kumar Gujral Punjab Technical University, Jalandhar-Kapurthala Highway, Kapurthala -144601, India
Department of Physics, D.A.V. College, Bathinda - 151001, Punjab, India
Asha Rani
Department of Applied Sciences
Ferozepur College of Engineering & Technology, Ferozeshah, Ferozepur, Punjab
Manmohan Singh
Department of Physics
KMV Jalandhar - 144001 Punjab (India)
Harmandeep Kaur
Department of Physics, DAV College, Bathinda - 151001, Punjab, India
ABSTRACT
The important parameters (mass attenuation coefficients, mass energy absorption
coefficients and corresponding effective atomic numbers) are useful in the estimation of
gamma-ray shielding behaviours of any material. For six engineering materials (Soils,
Dolomite, Gypsum, Igneous rock and Lime Stone), these parameters have been
computed and compared in the wide energy range 0.001-10 MeV. The dramatic variation
in the parameters is due to the dominance of various interaction and absorption processes
at different energies of gamma-photons. Compton scattering is dominant at the
intermediate energy range 0.05-1 MeV thus small values of the effective atomic numbers
are found in that range. A computer program (Z -toolkit) has been designed in MS-eff
excel for various computations required in this study. Graphical comparison between
photon interaction and energy absorption phenomena has been presented by using
corresponding parameters in the chosen energy range. For chosen samples, it has been
found that the difference between two effective atomic numbers (Z for photon eff,PI
interaction and Z for energy absorption) is insignificant (< 1%) at photon energies eff,En
below 0.002 MeV and above 0.300 MeV. In energy range 0.002-0.3 MeV, the values of
both these effective atomic numbers differs considerably thus information about these
parameters is useful in shielding behaviour analysis of building materials.
1

KEYWORDS: Effective atomic number; effective electron density; mass attenuation
coefficient; radiation shielding; Z -toolkiteff
INTRODUCTION
The applications of the gamma rays are increasing rapidly in several fields, such as;
nuclear and radiation physics, industry, medicine, energy production, radiation
dosimetry, biology and agriculture. Various researchers suggested that exposure to
gamma radiations poses a great risk to human health and electronic devices [1-3].
Gamma-rays are hazardous for living tissues, thus in shielding of these radiations the use
of appropriate engineering material must be used for safety measures. Gamma-rays are
continuous emitted from radioactive sources, nuclear wastes, nuclear weapons and
nuclear reactors.Conventionally, Lead has been used as shielding material for these
radiations. Lead is inconvenient to use on large scale for shielding purpose due its heavy
weight, scarce and expenditure involved. For homeland safety and security, the use of
engineering materials with the best gamma-ray shielding behaviour must be encouraged.
So a detailed investigation of gamma-ray interaction and energy absorption parameters
for commonly used engineering materials is required. It is necessary to find the cost
effective and safe building materials. The computed data and conclusions will be of prime
importance for researchers working in this field.
Motivation And Objectives
Bricks are used in the construction of buildings and have been used since ancient times for
making of walls of the residential and non-residential buildings. The shielding properties
of a brick depend on the properties of the raw materials used for its making. The mixtures
of clay and sand moulded in various ways, dried and burnt to make a common brick. [4].
Some of the innovative and commonly manufactured eco-friendly building materials
utilizing flyash are; clay flyash bricks, flyash bricks, road construction material and
cellular light weight concrete [5]. The innovative bricks using the residual flyash are
considered high quality building materials by the manufacturers that will potentially
decrease some of the negative environmental impact of coal-fired power generation
while meeting increasing demands for greener building materials in India [6]. Shielding
effectiveness of a material is its ability to stop (absorb) the radiations exposed on it. The
material which has high value of mass attenuation coefficient has high value of shielding
effectiveness and vice-versa. Mann et al., [7] has designed computer program GRIC2-
toolkit useful in theoretical evaluation of shielding parameters of any material. Taylor et
al., [8] have energy range 0.01-1000 MeV. Han et al., [9] suggested that the knowledge of
the mass attenuation coefficient, mass energy
2
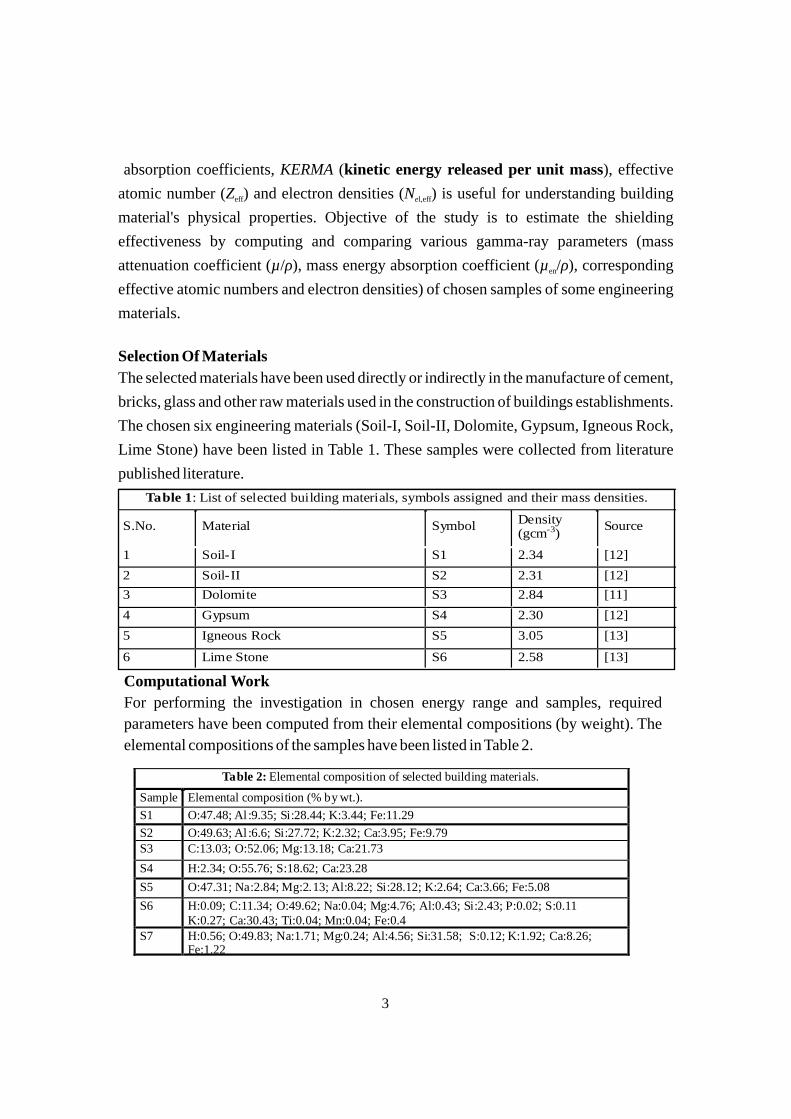
absorption coefficients, KERMA (kinetic energy released per unit mass), effective
atomic number (Z ) and electron densities (N ) is useful for understanding building eff el,eff
material's physical properties. Objective of the study is to estimate the shielding
effectiveness by computing and comparing various gamma-ray parameters (mass
attenuation coefficient (µ/ρ), mass energy absorption coefficient (µ /ρ), corresponding en
effective atomic numbers and electron densities) of chosen samples of some engineering
materials.
Selection Of Materials
The selected materials have been used directly or indirectly in the manufacture of cement,
bricks, glass and other raw materials used in the construction of buildings establishments.
The chosen six engineering materials (Soil-I, Soil-II, Dolomite, Gypsum, Igneous Rock,
Lime Stone) have been listed in Table 1. These samples were collected from literature
published literature.
S.No.
Material
Symbol
Density (gcm-3)
Source
Table 1: List of selected building materials, symbols assigned and their mass densities.
1 Soil-I
S1
2.34
[12]
2 Soil-II
S2
2.31
[12]
3 Dolomite
S3
2.84
[11]
4 Gypsum
S4
2.30
[12]
5 Igneous Rock
S5
3.05
[13]
6 Lime
Stone
S6
2.58
[13]
Computational Work
For performing the investigation in chosen energy range and samples, required
parameters have been computed from their elemental compositions (by weight). The
elemental compositions of the samples have been listed in Table 2.
Table 2: Elemental composition of selected building
materials.
Sample
Elemental composition (%
by
wt.).
S1
O:47.48; Al :9.35; Si:28.44; K:3.44;
Fe:11.29
S2
O:49.63; Al :6.6; Si:27.72; K:2.32;
Ca:3.95;
Fe:9.79
S3
C:13.03;
O:52.06; Mg:13.18;
Ca:21.73
S4
H:2.34; O:55.76;
S:18.62;
Ca:23.28
S5
O:47.31; Na:2.84;
Mg:2.13; Al:8.22; Si:28.12; K:2.64; Ca:3.66;
Fe:5.08
S6
H:0.09; C:11.34;
O:49.62; Na:0.04;
Mg:4.76;
Al:0.43;
Si:2.43;
P:0.02;
S:0.11
K:0.27; Ca:30.43;
Ti:0.04; Mn:0.04;
Fe:0.4
S7
H:0.56; O:49.83;
Na:1.71;
Mg:0.24;
Al:4.56;
Si:31.58;
S:0.12;
K:1.92; Ca:8.26;
Fe:1.22
3

[a). Zeff-toolkit for computations
A computer program has been designed in MS-excel-2007 for required computations.
This program has been named as (Z -toolkit) and is a modified form of GRIC2-toolkit eff
[7]. It is capable to compute µ/ρ, µ /ρ, Z (Effective atomic number for photon interaction) en eff,PI
and Z (Effective atomic number for energy absorption) values at desired energy for any eff,En
material (compound or mixture) from its chemical composition. The working of the toolkit is
based on the database that consists of the available values of µ/ρ, µ /ρ and σ for all the en
periodic table elements of arranged in matrixes for the chosen energy range obtained from
tabulated data [14-16]. This matrix database is required for the execution of the Z -toolkit. eff
The effective atomic number for photon interaction, Z is denoted as Z . eff,PI eff
b). Computation of effective atomic number
The effective atomic number (Z )of a material consisting of different elements is based on eff
the determination of total attenuation cross section for gamma ray interaction and it can be
obtained by the following relation [8]:
(1)
A literature survey shows that Eq. (1) has been frequently used for calculating Zeff. The total
atomic cross section (σa) can obtained as follows [17]:
(2)
where, µ/ρ is total mass attenuation coefficient, NA is the Avogadro's number, Ai and wi are
atomic weights (in gram) and fractional weights of the constituents of the sample
respectively. The total electric cross section σe can be obtained by the following formula [9]:
(3)
where, fi is ratio of the number of atoms of ith element to the total number of atoms of all
elements in the chosen material, Zi is the atomic number of the ith elements in the material, and
(µ/ρ)i is the total mass attenuation coefficients of the ith element in it. Manohara et al., [18] has
gone one step further and obtained the value of effective atomic number:
(4)
where, ni is the number of atoms of the ith constituent element in the material. The above
formula can be used for calculating the effective atomic number of both compounds and
4

mixtures. Damla et al., [19] have proposed and verified experimentally the calculations of
effective atomic number using the following interpolation formula for any sample.
(5)
where, σ1 and σ2 are the elemental cross section (b/atom) in between which the atomic cross
section σa of the sample lies and Z1 and Z2 are the atomic numbers of the elements
corresponding to the cross sections σ1 and σ2, respectively. The three different methods
produce somewhat different values of effective atomic numbers for the same material. The
average value of all the three effective atomic numbers considered as the true value of the
effective atomic number of the sample material
(6)
c). Photon energy-absorption effective atomic number, Z eff,En
The photon-energy absorption effective atomic number, Z obtained from mass energy-effEn
absorption coefficient ( /). It is a convenient parameter in dosimetry for representing the en
photon-energy-absorption (absorbed dose) in a material. The values of Z , for chosen effEn
material has been computed by replacing / with / in Eqs.(1-6). The / values of the en en
chosen material have been computed using the additivity law.
where, (?en/?)i is the mass energy-absorption coefficient of the ith constituent element present
in the material. The values of (?en/?)i for the elements were taken from the compilation of
Hubbell and Seltzer [14].
5

Standardization of the Z -toolkiteff
The computed values of different parameters by present method are verified by
comparing them with the experimental values obtained from literature. As this toolkit is
modified from GRIC2-toolkit which has already been standardized for the accurate
computation of mass attenuation coefficient (µ/ρ) values in the wide energy range 0.015-
15 MeV. Figs.1 shows that for building materials, the results obtained by Z -toolkit are in eff
good agreement with experimental values of effective atomic numbers (Z ) [19]. eff
Thereby, it is verified that for chosen samples the toolkit can compute accurately the
values of Z .eff
RESULTS AND DISCUSSION
The following points are evident from these figs.:
(i) There are three energy ranges, approximately E < 0.01 MeV, 0.03 < E < 3 MeV and E
> 400 MeV, where photoelectric absorption, Compton scattering and pair
production, respectively, are the dominating attenuation processes, and
(ii) There are sharp variations in the values of total mass attenuation and energy
absorption coefficients for incident photon energies at 2.00 keV and 4.99 keV, due to
the K-absorption edge for Silicon and Calcium respectively. At the K-absorption
edge for Silicon and Calcium the value of total mass attenuation coefficient is in +2 2between (1.51 - 2.26) 10 cm /g.
It can be seen that variation of / and / with elemental composition is large below 100 keV, en
negligible between 0.110 MeV and further there is again significant variation in / and / en
up to photon energy of 100 MeV. For all the samples values of / are more than that of / in en
energy range 0.215 MeV. These variations are interpreted as being due to photoelectric 45absorption, which varies as Z , and less but significantly due to coherent scattering,
23which varies as Z . The present theoretical results are similar to the observations of
Zavelskii [20], who proposed a direct relation of / with atomic number of heavy metals in
rock salt at low energy. In the intermediate energy region, where incoherent scattering is
the most dominant process, the mass attenuation coefficient is found to be almost constant
due to the linear Z-dependence of incoherent scattering, and trivial role played by pair
production. In the high-energy region, the significant variation in mass attenuation 2
coefficient is due to the Z -dependence of pair production.
6

a). The effective atomic numbers for photon energy-absorption and for photon
interaction
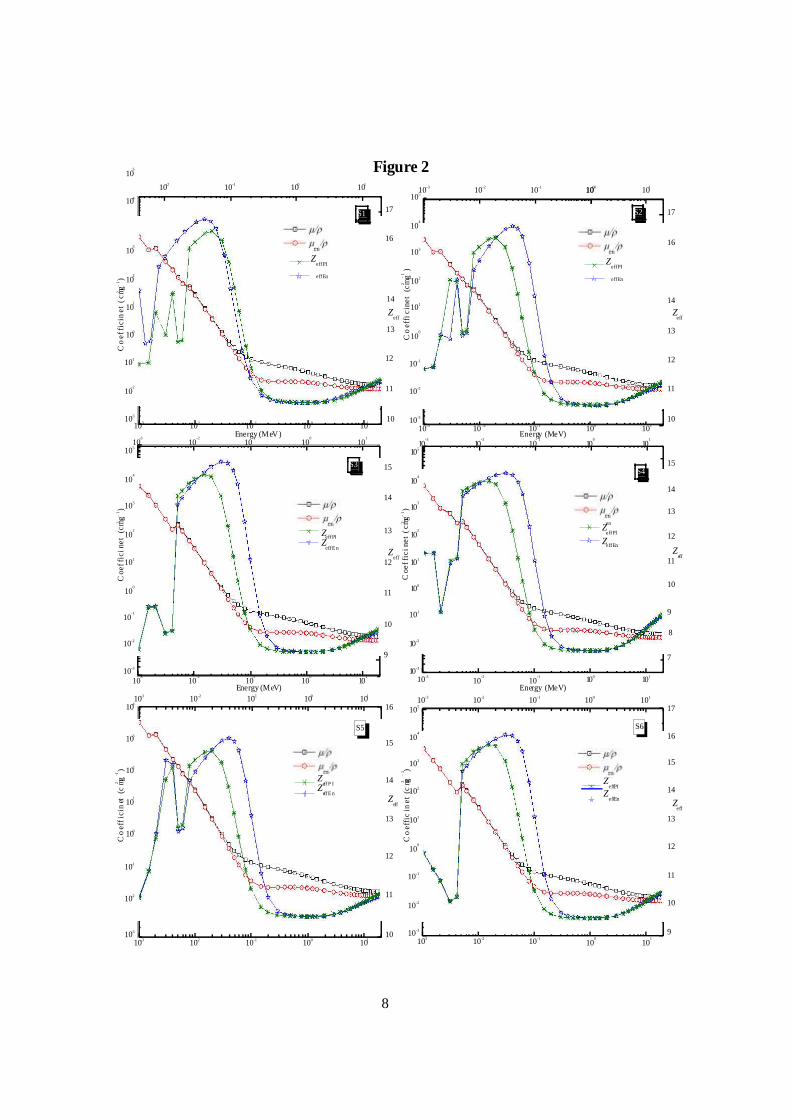
Fig.2 shows the combined variations of values of Z , Z , / , and / in wide energy eff,PI eff,En en
range. For all chosen samples, it is evident that values of both Z and Z agreed very eff,PI eff,En
well at energies below about 2 keV and above about 300 keV.
b). The energy dependence of Z and Z eff,En eff,PI
The results on effective atomic numbers for photon energy-absorption (Z ) and for effEn
photon interaction (Z ) have been calculated and analyzed. Calculations have been effPI
carried out in the photon-energy region from 1 keV to 20 MeV and the variation of Z effEn
and Z values with energy and composition of the samples have been explained effPI
graphically in fig2. Due to the significant difference between the two types of effective
atomic numbers, Z have been used in the absorbed dose calculations for radiation effEn
therapy and in medical radiation dosimetry (2-300 keV). But, Z can be used instead of eff,PI
Z in radiotherapy, where gamma-photons in the MeV range are used.eff,En
CONCLUSION
It is concluded that the computer program, Z -toolkit is dependable for theoretical study eff
of shielding behaviour of any material in chosen energy range 0.001-20 MeV. At
particular energy, the effective atomic number and effective electron density will be
useful for deciding the gamma-rays shielding behaviour of material.
The minimum values of Z are found at intermediate energies, typically 0.05 MeV < E < 5 eff
MeV, where Compton scattering is dominant. It has been shown that the difference
between Z and Z for the samples is insignificant (less than 1%) at photon energies effEn effPI
below about 2 keV and above about 300 keV. The use of Z is important, however, when effEn
dealing with the absorbed dose due to photons in the 2–300 keV energy range. But, Z effPI
can be used instead of Z in radiotherapy, where photons in the MeV range are used. 3). effEn
The maximum values of Zeff and Nel,eff are found in the low-energy range, where
photoelectric absorption is the main interaction process. Significant differences up to
39% between Z and Z occur in the 2–300 keV range. The reason for these effEn effPI
differences is that the transition from photoelectric absorption to Compton scattering as
the dominating absorption process is shifted to higher energy for the mass energy-
absorption coefficient as compared with the mass attenuation coefficient.
This investigation indicated that instead of attenuation coefficients the effective atomic
numbers provide better information about gamma-ray shielding behaviour of chosen
material at particular energy.
7
S1
S2
S3
S4
2-1
2-
12
-1
Co
eff
icin
et(c
mg
)C
oe
ffic
ine
t(c
mg
)C
oe
ffi
cin
et
(cm
g)
2-
12
-1
2-
1
Co
effi
cin
et
(cmg
)C
oe
ffic
ine
t(
cm
g)
Co
effi
cin
et(c
mg
)
9
105
104
10
-2
10-1
101
Figure 2
10-3
10-2
10-1
100
101
105
17
17
104
16
1610
3
102
103
102
101
100
14
Z
eff
13
101
100
14
Z
eff
13
10-1
12
10-1
12
10-2
11
10
-2
11
10-3
10 10
-3
10-2
10-1
100
101
Energy (M
eV
) 10
-3
10
-2
10
-1
10
0
10
1
105
15
104
14
10-3
10 10
-3
10-2
10-1
100
101
Energy
(M
eV
) 10
-3
10
-2
10
- 1
10
0
10
1
105
15
104
14
103
10
2
101
Z effPI
Z effE n
13
Z eff
12
103
10
2
101
en Z
effPI Z effEn
13
12
Z eff 11
100
100
10
11
-1
10-1
10
10-2
9
10-3
10-3
10-2
10-1
100
101
10
10
-2
10-3
10-3
10
-2
10
-1
10
0
8
7
10
1
Energy (M eV)
10-3
10-2
10-1
100
101
104 16
S5
103
15
Energy (M eV )
10-3
10-2
10-1
100
101
105 17
S6
104
16
10
3
15102
10
1
10
0
10-1
10-2
effP I
Z effE n
14
Z eff
13
12
11
102
10
1
10
0
10
-1
10
-2
en
Z
effPI
Z effEn
14
Z eff
13
12
11
10
10-3
10-3
10-2
10-1
100
101
10
10
-3
10-3
10-2
10-1
100
9
101
100
Z
effPI
effEn
100
Z
effPI
effEn
Z
8

REFERENCES [1] G.S. Sidhu, P. S. Singh, G. S. Mudahar, Radiat. Prot. Dosim. Vol., 86 (3) (1999), 207–216.
[2] I. C. P. Salinas, C. C. Conti, R. T. Lopes, Appl. Radiat. Isot. 64 (2006) 13–18.
[3] T. Singh, P. Kaur, P. S. Singh, Asian J. Chem., 21 (2009) 225–228.
4] T. Faith, A. Umit,. Centre for Applied Energy research, University of Kentuchy, (2001) 31-32.
[5] C. F. Christy, D. Tensin. Greener building material with flyash. Asian journal of civil
engineering (building and housing), 12(1) (2011), 87-105.
[6] Building Materials in India( 50 Years – A Commemorative Volume, 1998. Building Materials
& Technology Promotion Council, New Delhi, India.
[7] K. S. Mann, M. S. Heer, A. Rani, Nucl. Instrum. Methods A, 797 (2015) 19-28.
[8] M.L. Taylor, R. L. Smith, F. Dossing, R. D. Franich, Medical Physics 39 (2012) 1769-1778.
[9] I. Han, L. Demir, M. Sahin, Ann. Nucl. Energy, 37 (2010) 910–914.
[10] Report ANSI/ANS–6.4.3, Gamma-ray attenuation coefficients and buildup factors for
engineering materials, American Nuclear Society, La Grange Park, Illinois, 1991.
[11] J. H. Hubbell, Phys. Med. Biol., 44 (1999) R1R? 22.
12] K. S. Mann, J. Singla, V. Kumar, G. S. Sidhu, Ann. Nucl. Energy, 43 (2012) 1571?66.
[13] K. S. Mann, G. S. Sidhu, Ann. Nucl. Energy, 40(2012) 241-252.
[14] J. H. Hubbell, S. M. Seltzer, Tables of X-ray mass attenuation coefficients and mass energy-
absorption coefficients 1 keV-20 MeV for elements Z = 1 to 92 and 48 additional substances of
dosimetric interest, NISTIR 5632, 1995.
[15] L. Gerward, N. Guilbert, K. B. Jensen, H. Levring, Radiat. Phys. Chem., 60 (2001) 23–24.
[16] L. Gerward, N. Guilbert, K. B. Jensen, H. Levring, Radiat. Phys. Chem., 71 (2004) 653–654.
[17] S. Guru Prasad, K. Parthasaradhi, W. D. Bloomer, Rad. Phys. Chem., 53 (1998) 449-453.
[18] S. R. Manohara, S. M. Hanagodimath, L. Gerward, Phy. Med. Biol., 53(2008)377-386.
[19] N. Damla, H. Baltas, A. Celik, E. Kiris, U. Cevik, Radiat. Prot. Dosim., (2011) 1-9.
doi(10.1093/rpd/ncr432 [20] F. S. Zavelskii, At. Energy, 16 (1964) 319–322.
9

MACHINE TRANSLITERATION: A SURVEY
Kanwaljit Kaur
MPhil Research Scholar
Department of Computer Science Punjabi University, Patiala, Punjab
Dr. Gurpreet Singh Lehal
Professor Department of Computer Science,
Punjabi University, Patiala,Punjab
ABSTRACT
Machine transliteration is an emerging research area which converts words from one
language to another without losing its phonological characteristics. Transliteration is a
supporting tool for machine translation and Cross language information retrieval.
Transliteration is mainly used for handling named entities and out of vocabulary words in
a machine translation system. It preserves the phonetic structure of the words. This paper
discusses the various challenges, approaches and existing systems in transliteration. The
major challenges in developing a transliteration system are missing sounds, zero or
multiple character mappings, differences between scripts etc. The approaches for the
transliteration system can be phoneme based, grapheme based or combination of both.
Few researches that have taken place in the field of transliteration are listed in this paper,
although the list may not be exhaustive.
Index Terms—Transliteration, Machine translation, Cross Language Information
Retrieval, Named Entities.
INTRODUCTION
TRANSLITERATION converts the text from one script to another. Systematic
transliteration refers to the conversion of a word in source script to a word in target script
such that the target language word is:
Transliteration [1] can be seen as two level processes: first segmenting the source
language word into transliteration units and then aligning and mapping these units to
target language units.
10

Transliteration may define complex conventions and tries to be more perfect to enable the
reader to recalculate the spellings of the original words. Thus, transliteration should
preserve the syllable sounds in the words. Transliteration can be of two types namely
forward and backward transliteration. Transliteration of a word from its native script to
foreign script is called forward transliteration. Restoring previously transliterated word to
its native script is called backward transliteration.
Machine translation decodes the meaning of the source text and re-encode the meaning in
target language using various approaches as dictionary translation and statistical or
example based translation. But when many crucial issues like out of vocabulary words,
Proper nouns and other technical terms needs to be handled, transliteration approaches
are taken to solve these issues. Thus machine transliteration usually supports machine
translation and helps preventing translation errors when translations of proper names and
technical terms do not exist in translation dictionary. The general transliteration model
consists of two stages: Training running on a bilingual corpus and Transliteration.
Training stage comprises of aligning the source-target words at character or sound level
and rule generation. The transliteration stage segments the new (test) source word and
generates appropriate transliteration. In this survey paper, we are discussing about some
of the challenges that a transliteration system may face including script differences,
missing sounds, language of origin etc. The section 3 lists the various approaches and
existing translitera- tion systems.
COMMON CHALLENGES IN TRANSLITERATION
A. Script Differentiation
The main hurdle transliteration system needs to tackle is the difference between source
and target language script. A script represents text using set of useful symbols. Script
represents one or more writing systems. For example Devnagri is the script for over 120
languages including Hindi, Nepali, Sindhi; Maithili etc. Thus one script can be used for
multiple languages. On the other hand, one language can be written in multiple scripts as
Japanese can be written in Hiragana, Katakana and kanji ideographs. Another important
issue is the direction in which a script is written. The language like Persian, Arabic are
written from Right To Left (RTL) whereas the English and other languages are written
form Left to Right (LTR).
11

B. Missing Sounds
All the languages have their own phonetic structure, and symbols. If there is a missing
phonetic in the letters of a language, then those phonetic are represented using digraphs
and tri-graphs. Transliteration systems needs to take care of the convention of writing the
missing phonetics in each of the languages involved in transliteration.
C. Multiple Transliterations
Based on the opinion of different humans, a source term can have multiple valid
transliterations .Different dialects in the same language can also lead to transliteration
variants. Multiple transliterations certainly affect the accuracy of a system as gathering all
possible variants of a word in a corpus is not feasible.
D. Language Of Origin
Named entities can have multiple transliterations and each transliteration is correct
according to the context under consideration. So, these words can be sometimes
transliterated by considering local context and sometimes considering global context.
One challenge would be which letters to choose to represent the origin of the word. The
name Razaq has the Arabic origin while it is written as Razak in Indian origin [2].
E. Transliterate Or Not
Whether a word should be translate or transliterate, deciding this phenomena is a big
challenge. Place names and organization names are the most common cases where both
translation and transliteration are necessary. For example, the word ”Kashmir Valley”
needs both translation and transliteration.
MACHINE TRANSLITERATION APPROACHES
I. Many different transliteration methods have been proposed in literature leading to the
variations in methodologies and language supported. Due to many different variations
categorization of transliteration approaches is not very straightforward. One
categorization possible is based on information sources used in the process. The
categorization is as follows:
• Grapheme based approaches that consider transliteration as orthographic process and
use spellings.
• Phoneme based approaches consider the task as purely phonetical process and use
phonetics.
• Hybrid approach that mixes up the above two approaches.
12

A. Grapheme Based Models
Grapheme based transliteration[1] is a process of mapping a grapheme sequence from a
source language to a target language ignoring the phoneme level processes. In this ap-
proach characters from source language are directly mapped to characters of target
language. So, they are also called direct methods. This approach mainly relies upon
statistical information that can be obtained from characters. Grapheme based models are
classified into the Statistical Machine Transliteration (SMT) based model, Rule based
models, Hidden Markov Model , Finite State Transducer (FST) based model.
1) Rule Based Approach: In Rule based approach, set of rules are specified by human
experts in order to map a source sentence segment to representation in target language
sentence. Rules are generally based on the morphological, syntactic and semantic
information of the source and target languages. Rules are very important for various
stages of translation such as syntactic processing, semantic interpretation and contextual
processing of the language. Transliteration in rule based system is done by pattern
matching of the rules. The success lies in avoiding the pattern matching of unfruitful
rules. General world knowledge is required for solving interpretation problems such as
disambiguation.
Ali and Ijaz(2010) have developed "English to Urdu transliteration system which is based
on rule based approach. Kak et al. (2010) have developed a rule based converter for
Kashmiri language for Persio-Arabic script to Devnagari script.
2) SMT Approach: Statistical approach [3] tends to be easier than generating handcrafted
rules. In this approach, translations are based on mathematical model whose parameters
are derived from the analysis of bilingual text corpora. Every sentence in the target
language is the translation of the source language sentence with some probability. The
sentence having highest probability is the required translation. This approach finds the
most probable English sentence given a foreign language sentence and automatically
aligns the words within sentences in the parallel corpus, then probabilities are determined
automatically by training statistical model using parallel corpus. So, sentences get
transliterated based on the probabilities. The SMT approach is more advantageous than
rule based approach as it efficiently uses human and data resources. There are many
parallel and monolingual corpora available in machine readable format. Generally SMT
systems are not tailored to any specific pair of languages. Moreover rule based systems
require rules to be made manually which is very costly and time consuming. Lee and
13

Chang(2003) have developed an English Chinese transliteration system based on
Statistical Model. Malik(2013) has developed a system for transliterating Urdu to Hindi
based on statistical approach.
3) FST approach: Finite State Transducers [3] are being used in different areas of pattern
recognition and computational linguistics. A finite state transducer is a finite state
machine having an input and output tape and has an intrinsic power of transducing or
transliterating. When transducer shifts from one state to another, it will print a word as an
output. So transducer can accept the word in one language and can produce transliteration
in another language. So, transducer can be seen as a bilingual generator. It is a network of
states which are labeled with input and output symbols and transition between them.
Starting from initial state and walking through the end state, FST can transform an input
string by matching it with input labels and produce a corresponding output string using
output labels. Knight and Graehl(1998) have developed a phoneme based back
transliteration model from Japanese to English using Finite State Transducer.
4) HMM (Hidden Markov Model) Approach: Hidden Markov Model is a statistical model
in which the system is assumed to have hidden states. The model has a set of states each
having a probability distribution. Transitions between the states are controlled by set of
probabilities called transition probabilities. In HMM, the state is not visible but output
dependent upon the state is visible. The translation is achieved according to the associted
probability at a particular state.
B. Phoneme Based Model
Phonemes are the smallest significant units of sound. In phoneme based approach, the
written word of source language is mapped to written word of target language via the
spoken form associated with the word. Phoneme based method [1] [3] is also known as
Pivot method. The reason for using this approach is that phonetical representation makes
it possible to use it as an intermediate form between source and target languages (Similar
to Interlingua MT). The other reason for the interest in phonetic based transliteration is its
ability to capture the pronunciation of the words. This model there- fore usually needs two
steps: 1) produce source language phonemes from source language graphemes and 2)
produce target language graphemes from source phonemes. Phonetic- based methods
identify phonemes in the source word W, produce source language phonemes (P) and then
map the phonetical representation of those phonemes (P) to character representations in
14

the target language to generate the target word(s) T. In phoneme based approaches, the
transliteration key is the pronunciation of the source phoneme rather than spelling or the
source grapheme. The phoneme based approach has also received remarkable attention in
various works. Based on phonology, the source text can be transliterated to target text in
terms of pronunciation similarities between them. The syllables are mapped to phonemes,
based on some transcription rules [4]. The mapping templates between phonemes of
source and target language are the transliteration rules.
C. Hybrid and Correspondence based Models
The Correspondence and hybrid[1] transliteration model makes use of both source
language graphemes and source language phonemes when producing target language
transliterations. Both models can be combination of two or more transliteration
approaches. These can be combination of grapheme and phoneme based models or
combination of two grapheme models for e.g. Rule based and statistical. The
correspondence based model makes use of the correspondence between a source
grapheme and a source phoneme when it produces target language graphemes; the hybrid
model simply combines grapheme and phoneme through linear interpolation. Some
examples of Hybrid models are:
• Grapheme Based + Phoneme Based
• Rule Based + SMT
LITERATURE SURVEY
Arbabi et al. developed an Arabic-English transliteration system [2] using knowledge-
based systems and neural networks. The first step in this system was to enter the names
into the database which was obtained from telephone dictionary. As in Arabic script, short
vowels are generally not written, a knowledge-based system is used to vowelized these
names to add missing short vowels. The KBS system accepts all unvowelized names and
generates all possible vowelizations conforming to Arabic name. The words which
cannot be properly vowelized by KBS are then eliminated using artificial neural network.
The network is trained using cascade correlation method, a supervised, feed forward
neural processing algorithm. Thus the reliability of the names in terms of Arabic
syllabification is determined through neural networks. The output of the network is in
binary terms. If the node fires with a threshold of 0.5, then the word is given to KBS for
vowelization otherwise set aside to be vowelized in some other way. The artificial neural
network is trained on 2800 Arabic words and tested on 1350 words. After this, the
vowelized names are converted into phonetic roman representation using a parser and
15

broken down into groups of syllables. Finally the syllabified phonetics is used to produce
various spellings in English. KBS vowelize almost 80% of the names but with higher
percentage of extra vowelizations while ANN vowelizes over 45% of the names with very
low rate of errors.
Wan and Verspoor have proposed an "Automatic English- Chinese name Transliteration?
[4] system. The system transliterated on the basis of pronunciation. That is, the written
English word was mapped to written Chinese character via spoken form associated with
the word. The system worked by mapping an English word to a phonemic representation
and then mapping each phoneme to a corresponding Chinese character. Since the
phoneme-to-grapheme process is considered the most problematic and least accurate
step, they limited their model to place names only. The transliteration process consisted of
five stages: Semantic Abstraction, Syllabification, Sub-syllable divisions, Mapping to
Pinyin and Mapping to Han characters.
Semantic abstraction was a preprocessing step that performed dictionary look-ups to
determine which parts of the word should be translated or which should be transliterated.
As Chinese characters are monosyllabic so each word to be transliterated was divided into
syllables. The outcome of the syllabification process was a list of syllables each with at
least one vowel part. A sub-syllabification step further divided the syllables into sub
syllables to make them pronounceable within the Chinese phonemic set. The phonetic
representation of each sub syllable was transformed to Pinyin, which is the most common
standard Mandarin Romanization system. Another fixed set of rules transforms Pinyin to
Han (Chinese script). Therefore, the transliteration models were divided into a grapheme-
to-phoneme step and a phoneme-to-grapheme transformation which was based on a fixed
set of rules.
Kang et. al. presented an English-to-Korean automatic transliteration and back
transliteration system [5] based on decision tree learning. The proposed methodology is
fully bidirectional. They have developed very efficient character alignment algorithm
that phonetically aligns the English words and Korean transliteration pairs. The
alignment reduces the number of decision trees to be learned to 26 for English-to- Korean
transliteration and to 46 for Korean-to-English back transliteration. After learning, the
transliteration and back transliteration using decision tree is straightforward.
Oh et. al. have developed an "English to Korean Transliteration System based on
correspondence model [6] ? by using both phonetic information and Orthography. This
16

system first performs alignment and then transliteration. The proposed system is
composed of two main parts: data preparation and machine transliteration. The data
preparation step creates training data by devising an EPK alignment algorithm. The EPK
alignment algorithm recognizes the correspondence among the English grapheme",
Phoneme" and the Korean grapheme". The machine transliteration part is com-posed of
"generating pronunciation" step and "generating transliteration" step. The generating
pronunciation step generates most probable correspondence between an English
pronunciation unit and a phoneme. Based on the pronunciation of the English word, a
Korean word is generated in "generating transliteration" step. This word and character
accuracy reported for the system is 90.82% and 56% respectively.
Lee et. al. has developed an English Chinese language transliteration system [7]
based on statistical approach . In the proposed model the back transliteration problem is
solved by finding the most probable word E, given transliteration C. The back-
transliteration probability of a word E is written as P(E—C) as stated by Bayes' rule. In the
preprocessing phase a sentence alignment procedure is applied to align parallel text at the
sentence level in order to find the corresponding transliteration for a given source word in
a parallel corpus. Then tagging is done to identify proper nouns in the source text. In the
second step, the model is applied to isolate the transliteration in the target text. The
transliteration model is further augmented with linguistic processing, to remove
superfluous tailing characters in the target word in the post processing phase.
Malik A. had explained a simple rule based transliteration system for Shahmukhi to
Gurmukhi script [8]. For transliteration of Shahmukhi to Gurmukhi, the PMT system uses
transliteration rules. It preserves both the phonetics as well as the meaning of transliterated
word. PMT is a system in which each word is transliterated across two different writing
systems being used for same language. Two scripts are discussed and compared. For the
analysis and comparison, both scripts are subdivided into different groups on the basis of
types of characters e.g. consonants, vowels, diacritical marks, etc. Transliteration rules are
then developed for character mappings between Shahmukhi and Gurmukhi. The system was
tested for both classical and modern literature. The classical literature comprises of hayms of
Baba Nanak, Heer by Waris Shah, Hayms by Khawaja Farid and Saif-ul-Malooq by Mian
Muhammad Bakhsh. The modern
transliteration and back transliteration using decision tree is straightforward. Oh et. al.
literature is collected from poetry and short stories of
different poets and writers. The system has reported 98% accuracy on classical literature
and 99% accuracy on modern literature.
Harshit Surana and Anil Kumar Singh in 2008, proposed a transliteration system
on two Indian languages Hindi and Telugu [9]. In their experiment, a word was first
classified as Indian or foreign using character based n - grams. The probability about
word's origin was computed based on symmetric cross entropy.
17

Based on this probability measure, transliteration was performed using different
techniques for different classes (Indian or foreign). For transliteration of foreign words,
the system first used a lookup dictionary or directly map from English phoneme to IL
letters. For transliteration of Indian word, the system first segmented the word based on
possible vowels and consonant combinations and then mapped these segments to their
nearest letter combinations using some rules. The above steps generate transliteration
candidates which were then filtered and ranked using fuzzy string matching in which the
transliteration candidates were matched with the words in the target language corpus to
generate target word. The out of vocabulary words are not handled by this system. Hong
et al. have developed a Hybrid Approach to English-Korean Name Transliteration system
[10]. The base system is built on "MOSES" with enabled factored translation features.
The process of transliteration begins by mapping the units of source words to units of
target words. The base system is expanded by combining various transliteration methods
viz. web based n-best re ranking, a dictionary based method, and a rule- based method.
The pronouncing dictionary is created from an English-Korean dictionary containing
130,000 words and CMU pronouncing dictionary containing over 125,000 words and
their transcriptions. For a given English word, if the word exists in the pronouncing
dictionary, then its pronunciations are translated to Korean graphemes by a mapping
table. Also 150 rules have created to map English alphabet into one or more several
Korean graphemes. The system achieved 45.1 and 78.5, respectively, in top-1 accuracy.
P.J. et. all. proposed English to Kannada transliteration system[11] using Support Vector
Machine. The proposed system uses sequence labeling approach for transliteration which
is a two step approach. The first step performs segmentation of source string into
transliteration units and the second step performs comparisons of source and target
transliteration units. It also resolves different combination of alignments and unit
mappings. The whole process is divided into three phases: preprocessing, training using
SVM and transliteration. The preprocessing phase converts the training file into a format
required by SVM. The authors are using database of 40,000 Indian place names for the
training of SVM. In this phase, English names are romanized and then segmented based
on vowels, consonants, digraph and trigraphs. Alignment is performed at the end of the
preprocessing phase. During training phase, aligned source language names are used as
input and target language names are used as label sequence and given to SVM. The
training phase generates a transliteration model which produces top N probable Kannada
transliteration during transliteration phase. The system is tested on 1000 out of corpus
18

place names. The system is also compared with Google Indic system and reported higher
accuracy while transliterating Indian names and places. The overall accuracy of the
system is 87.28%.
Kak et al. have developed A rule based converter for Kashmiri language [12] from Persio-
Arabic to Devanagari script. As Devanagari letters do not have one to one corre-
spondence with Persio-Arabic characters. So character position and the combination of
the characters were also taken into consideration while developing the rules. The
converter was tested on 10000 words and more than 90% accuracy was found.
Deep and Goyal have developed a Rule based Punjabi to English transliteration system
for common names [13]. The proposed system works by employing a set of character
sequence mapping rules between the languages involved. To improve accuracy, the rules
are developed with specific con- straints. This system was trained using 1013 preson's
names and tested using different person names, city names, river names etc. The system
has reported the overall accuracy of 93.22%.
Jasleen and Josan have proposed a statistical model for En- glish to Punjabi machine
transliteration of out-of-vocabulary words using MOSES, a statistical machine
translation tool [14]. Letter to letter mapping is used as a baseline method in the proposed
system. The problems of baseline method like multiple mappings of a character in target
language or a char- acter having no mapping in the target script are handled using
statistical machine transliteration approach. The system was tested on 1000 entries. The
baseline model produce 73.13% accuracy rate. The statistical method shows the
improvements in performance by producing 87.72% accuracy rate.
Dhore et al. proposed Hindi to English transliteration of Named entities using
Conditional random Fields [15]. Indian places names are taken as input in Hindi language
using Devanagari script by the system and transliterated into English. The input is
provided in the form of syllabification in order to apply the n-gram techniques. This
syllabification retains the phonemic features of the source language Hindi into translit-
erated form of English. The aim is to generate transliteration of a named entity given in
Hindi into English using CRF as a statistical probability tool and n-gram as a feature set.
The proposed system was tested using bilingual corpus of 7251 named entities created
from web resources and books. The commonly used performance evaluation parameter
19

was "word accuracy". The system has received very good accuracy of 85.79% for the bi-
grams of source language Hindi.
Lehal and Saini presented an Urdu to Hindi transliteration system [16]. The system uses
various rules and lexical resources such as n-gram language models to handle challenges
like multiple/zero character mappings, missing diacritic marks in Urdu, multiple Hindi
words mapped to an Urdu word etc. The proposed system is divided into Pre-Processing,
Processing and Post-processing stage. The preprocessing stage normalizes and joins the
broken Urdu words in order to prepare them for transliteration. In the processing phase
corresponding to an Urdu word, Number of possible Hindi words is generated using a
hybrid system based on rule based character mapping table between Urdu and Hindi
characters and a trigram character Language Model. The post-processing stage joins the
broken words in Hindi and chooses the best alternative, where ever multiple alternatives
for Hindi words exist. The system has been tested on 18403 Urdu words and accuracy
reported was 97.74%.
Rathod et al. have proposed the named entity transliteration for Hindi to English and
Marathi to English language pairs using Support Vector Machine (SVM)[17]. The overall
architecture of proposed system is divided into three phases viz. Preprocessing, Training
and testing. In the preprocessing phase the source named entity is segmented into
transliteration units through the process of syllabification and segmented units are
phonetically mapped to target language transliteration units using some rules. During
training phase, the parallel data obtained during syllabification is arranged in required
format and n-gram features are used to train this data. The classification is done by using
the polynomial kernel function of Support Vector Machine (SVM). The system was tested
for person names, historical place name, city names of Indian origin. The overall accuracy
of the system recorded to be 86.52%.
Malik et al. have developed a system for transliterating Urdu words to Hindi based on
statistical approach [18]The proposed system solves the problem of Urdu-Hindi
transliteration through Statistical Machine Translation (SMT) using a parallel lexicon.
From the parallel Urdu - Hindi entries, two types of alignments viz. character and cluster
alignments are produced. Based on the alignments 8 types of Urdu-Hindi transliteration
models are developed. Two types of target language models have developed i.e. Word
language model and Sen- tence language model scoring the well-formedness of different
20

translation solutions produced by the translation model. By combining transliteration
models based on the alignments and language models based on monolingual Urdu and
Hindi corpus total 24 Statistical Transliteration (ST) systems are developed. The system
has achieved the maximum word-level accuracy of 71.5%. The maximum word-level
accuracy is 77.8% when the input Urdu text contains all necessary diacritical .At
character- level; transliteration accuracy is more than 90%.
Sanjanashree and Anand Kumar presented a framework for bilingual machine
transliteration for English and Tamil based on deep learning [19]. The system uses Deep
belief Network (DBN) which is a generative graphical model. The transliteration process
consists of three steps viz. Preprocessing, Training using DBN and testing. The
preprocessing phase does the Romanization of Tamil words. The data in both languages is
converted to sparse binary matrices. Character padding is done at the end of every word to
maintain the length of the words constant while encoding as sparse binary matrices. Deep
Belief Network is a generative graphical model made up of multiple layers of Restricted
Boltzmann Machine, a kind of Random Markov Field and Boltzmann Machine. The
system uses two layers RBM on source and target side called as source and target
encoders. The sparse binary matrices act as input for source and target encoders which are
trained separately. Two layers RBM on the right side is the encoders for source language
and the left side is the target language encoders. The joint layer concatenates the outputs
of the source and target encoders. It is the transliteration layer as at this layer
transliteration takes place. DBN layers are trained using un- supervised learning
algorithm called Contrastive Divergence (CD). The rate of learning for English and Tamil
is 0.6 and 0.4. Back propagation is performed at the end to fine-tune the weights. A source
language word is passed to source encoder to joint layer and goes through target encoders
giving final output as transliterated word. For evaluation purpose, 3900 proper nouns
including person names and place names in Tamil and equivalent transliterated word in
English are used. 900 words are used for evaluation and rest 3000 words are used for
training. The accuracy achieved is about 79%. Lehal and Saini have also developed
"Sangam: A Perso- Arabic to Indic Script Machine Transliteration Model" [20]. Sangam
is a hybrid system which combines rules as well as word and character level language
models to transliterate the words. The system has been successfully tested on Punjabi,
Urdu and Sindhi languages and can be easily extended for other languages like Kashmiri
and Konkani. The transliteration accuracy for the three scripts ranges from 91.68% to
97.75%, which is the best accuracy reported so far in literature for script pairs in Perso-
21

Arabic and Indic scripts. Mathur and Saxena have developed a system for English- Hindi
named entity transliteration [21] using hybrid approach. The system first processes
English words to extract phonemes using rules. After that statistical approach converts
the English phoneme to equivalent Hindi phoneme. The authors have used Stanford's
NER for name entity extraction and extracted 42,371 name entities. Rules were applied to
these entities and phonemes were extracted. These English phonemes were transliterated
to Hindi and a knowledgebase of English-Hindi phonemes was created. The probabilities
are generated on the knowledgebase using ngram probability model. Once all the English
phonemes have been transliterated, Hindi phonemes are combined to form a Hindi word.
The system was tested on 1000 sentences containing 9234 name entities. The accuracy of
the system was compared with human translator transliterating these name entities
manually. The system attained accuracy of 83.40% as it can transliterate Person,
Location, Date and Time but most of the entities of type organization are not transliterated
accurately.
Sunitha and Jaya proposed a phoneme based model for English to Malayalam
transliteration [22]. The system is based on pronunciation and uses a pronunciation
dictionary. The proposed system takes a text as an input and split it into words. These
English words are transformed into English phonemes. 39 general phonemes have been
identified based on CMU dictionary to convert English graphemes into phonemes. Pro-
nunciation dictionary stores the pronunciation of each English word so corresponding
pronunciation of each English words is taken from this dictionary. The pronunciations
obtained from dictionary are searched in a mapping table to obtain Malayalam graphemes
using handcrafted rules. Malayalam graphemes are grouped to form Malayalam word.
The pro- posed system suffers with Out of vocabulary words. For such cases, this system
does grapheme based transliteration and directly transliterates the English graphemes to
Malayalam graphemes.
CONCLUSION
In this paper work, we have presented a survey on challenges, different approaches and
evaluation metrics used for different machine transliteration systems. We have also listed
some of the existing transliteration systems. From the survey we have found that almost
all existing language machine transliteration systems.
22

REFERENCES
[1] S. Karimi, F. Scholer, and A. Turpin, “Machine transliteration survey,” ACM Comput. Surv.,vol. 43, no. 3, pp. 17:1–17:46, Apr. 2011. [Online]. Available: http://doi.acm.org/10.1145/1922649.1922654
[2] M. Arbabi, S. M. Fischthal, V. C. Cheng, and E. Bart, “Algorithms for arabic name transliteration,” IBM Journal of research and Development, vol. 38, no. 2, pp. 183–194, 1994.
[3] K. Kaur and P. Singh, “Article: Review of machine transliteration techniques,” International Journal of Computer Applications, vol. 107, no. 20, pp. 13–16, December 2014, full text available.
[4] S. Wan and C. M. Verspoor, “Automatic english-chinese name transliteration for development of multilingual resources,” in Proceedings of the 17th International Conference on Computational Linguistics - Volume 2, ser. COLING ? 98. Stroudsburg, PA, USA: Association for Computational Linguistics, 1998, pp. 1352–1356. [Online]. Available: http://dx.doi.org/10.3115/980432.980789
[5] B.-J. Kang and K.-S. Choi, “Automatic transliteration and back- transliteration by decision tree learning.” in LREC. Citeseer, 2000.
[6] J.-H. Oh and K.-S. Choi, “An english-korean transliteration model using pronunciation and contextual rules,” in Proceedings of the 19th interna- tional conference on Computational linguistics-Volume 1. Association for Computational Linguistics, 2002, pp. 1–7.
[7] C.-J. Lee and J. S. Chang, “Acquisition of english-chinese transliterated word pairs from parallel-aligned texts using a statistical machine translit- eration model,” in Proceedings of the HLT-NAACL 2003 Workshop on Building and using parallel texts: data driven machine translation and beyond-Volume 3. Association for Computational Linguistics, 2003, pp. 96–103.
[8] M. G. Malik, “Punjabi machine transliteration,” in Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2006, pp. 1137–1144.
[9] H. Surana and A. K. Singh, “A more discerning and adaptable mul- tilingual transliteration mechanism for indian languages.” in IJCNLP. Citeseer, 2008, pp. 64–71.
[10] G. Hong, M.-J. Kim, D.-G. Lee, and H.-C. Rim, “A hybrid approach to english-korean name transliteration,” in Proceedings of the 2009 Named Entities Workshop: Shared Task on Transliteration. Association for Computational Linguistics, 2009, pp. 108–111.
[11] P. Antony, V. Ajith, and K. Soman, “Kernel method for english to kannada transliteration,” in Recent Trends in Information, Telecommuni- cation and Computing (ITC), 2010 International Conference on. IEEE, 2010, pp. 336–338.
[12] A. A. Kak, N. Mehdi, and A. A. Lawaye, “Building a cross script kashmiri converter: Issues and solutions,” Proceedings of Oriental COCOSDA (The International Committee for the Co-ordination and Standardization of Speech Databases and Assessment Techniques), 2010.
[13] K. Deep and V. Goyal, “Development of a punjabi to english transliter- ation system,” International Journal of Computer Science and Commu- nication, vol. 2, no. 2, pp. 521–526, 2011.
[14] J. Kaur and G. S. Josan, “Statistical approach to transliteration from english to punjabi,” International Journal on Computer Science and Engineering, vol. 3, no. 4, pp. 1518–1527, 2011.
[15] M. L. Dhore, S. K. Dixit, and T. D. Sonwalkar, “Hindi to english machine transliteration of named entities using conditional random fields,” International Journal of Computer Applications, vol. 48, no. 23, pp. 31–37,2012.
23

[16] G. S. Lehal and T. S. Saini, “Development of a complete urdu-hindi
transliteration system.” in COLING (Posters), 2012, pp. 643–652.
[17] P. Rathod, M. Dhore, and R. Dhore, “Hindi and marathi to english machine
transl i teration using svm,” International Journal on Natural Language
Computing, vol. 2, no. 4, pp. 55–71, 2013.
[18] M. A. Malik, C. Boitet, L. Besacier, and P. Bhattcharyya, “Urdu hindi machine
transliteration using smt,” WSSANLP-2013, p. 43, 2013.
[19] P. Sanjanaashree and M. Anand Kumar, “Joint layer based deep learning
framework for bilingual machine transliteration,” in Advances in Com- puting,
Communications and Informatics (ICACCI, 2014 International Conference on. IEEE, 2014,
pp. 1737–1743.
[20] G. S. Lehal and T. S. Saini, “Sangam: A perso-arabic to indic script machine
transliteration model.”
[21] S. Mathur and V. P. Saxena, “Hybrid appraoch to english-hindi name entity transliteration,” in
Electrical, Electronics and Computer Science (SCEECS), 2014 IEEE Students' Conference on.
IEEE, 2014, pp. 1–5.
[22] C. Sunitha and A. Jaya, “A phoneme based model for english to malayalam transliteration,” in Innovation Information in Computing Technologies (ICIICT), 2015 International Conference on. IEEE, 2015, pp. 1–4.
24

REVIEW AND ANALYSIS ON ROUTING PROTOCOL FOR MANET
AnjaliResearch Scholar, Panjab University,Chandigarh 160014, India.
n.
Rohit Kumar
Assistant Professor,
Department of Computer Science & Engineering Chandigarh University, Gharruna
Sargam Sharma
Assistant Professor, Department of Computer Science,
Dev Samaj College for Women, Ferozepur.
ABSTRACT
In this period of wireless devices, Mobile Ad-hoc Network (MANET) has become an
important part for communication for mobile devices. Mobile Ad-Hoc Networks are
those networks which don't have any fixed infrastructure. A network consist of
dynamic, self-configured and self-organized set of nodes, having no centralized
hierarchy is known as MANETs, where nodes itself behave as routers. A number of
routing protocols has been proposed in past years for the use of Mobile Ad Hoc
Networks in various application areas such as military, govt. etc. In this paper we
provide an overview of a wide range of the existing routing protocols with a particular
focus on their functionality and their pros and cons. Also, the contrast is provided based
on the information and routing methodologies used to make routing decisions.
Key Words: MANET, Comparison in Different Protocols, Routing Protocol.
INTRODUCTION
The recent survey and research paper shows that demand of wireless portable devices
such as mobile phones, PDAs and laptops is increasing in everyday life. It leads to the
possibility of spontaneous or ad hoc wireless communication. Ad hoc networks are
autonomous, self configuring, adaptive which make them applicable in various areas [2].
Wireless network comes up with two variations of - first is network with existing
25

infrastructure and network with Infrastructure less or Ad Hoc wireless network.[3].
Network with existing infrastructure: In this number of mobile nodes are wirelessly
connected to a non-mobile Access Point (AP). They communicate to access points to send
& receive packets from other nodes [3].Network with Infrastructure less or Ad Hoc
wireless network: An ad hoc network is a network composed only of nodes, with no
Access Point. Communications possible even between two nodes that are not in direct
range with each other, packets are exchanged between the two nodes are forwarded by
intermediate nodes, using a routing algorithm. In this network each and every node does
participate voluntarily in transit packet from one node to another node [3].
MANET:
A MANET is a self-organizing collection of wireless mobile nodes that form a temporary
network without the help of a fixed networking infrastructure(access point). In it each
node can move freely and by node moving topology keeps on changing. Constrained
bandwidth and variable capacity links. Limited Physical Security & Frequent routing
updates. Reduce infrastructure cost and ease of establishment and fault tolerance as
routing is performed individually by nodes using intermediate nodes to forward packets
to destination [6]. Nodes may join and leave the network at any time it means it follow
dynamic topology.
This paper reviews the key studies of Mobile ad hoc routing protocols introduced
by various authors. Firstly, we discuss the application of MANET. Secondly, we
introduce classification of routing protocols based on the route discovery and routing
information update mechanisms, then we discuss the comparison between them. Further
on, we discuss the protocols under the three main routing protocols and their comparison
and advantages and disadvantages also the between the routing protocols so that their
behavior and performance can be captured under different conditions.
APPLICATIONS:
In the early time, MANET applications and deployments was only in military oriented. In
some of the past years, with rapid advances in mobile ad-hoc networking research, ad-hoc
networks have attracted considerable attention and commercialize in almost all fields of
life. Few applications of MANET are described below:
1) Tactical Networks? [16]
a) Military communication, operations. [9]
b) Automated Battlefields
26

2) Emergency Services:a) Disaster recovery [9]
b) Search and rescue operations. c)Supporting doctors and nurses in hospitals.3) Commercial Environments (business) :?[17]
a) Used in business dynamic access to customer files stored in a central location on the fly b) Provide consistent databases for all agents4) Entertainment:a) Multi-user games
b) Outdoor Internet access
5) Civil Applications or Education:?17]
a) Setup virtual classrooms or conference rooms
b) Setup ad hoc communication during conferences, meetings, or lectures.
6) Sensor Networks:
a) Home applications: smart sensor nodes and actuators can be buried in Appliances to allow end users to manage home devices locally and remotely. b) Tracking data highly correlated in time and space, e.g., remote sensors for weather, earth activities
7) Location Aware Services :
a) Automatic Call forwarding, advertise location specific services, Location–dependent travel guide [18]
8) Commercial Environments (Vehicular Services)��
a) Transmission of news, road condition, weather, music
b) Local ad hoc network with nearby vehicles for road/accident guidance
4. CLASSIFICATION OF PROTOCOLS:
A routing Protocol is used to transmit a packet from source to destination via number of nodes
and for this there is numerous routing protocols have been devised for such kind of activities.
Such protocols must handle the limited resources available with these networks, which
include high power consumption, low bandwidth and high mobility. Routing protocols tells
the way how a message is sent from one node to another.
27

Fig 2: Different type of Routing Protocols
A) Proactive Protocols: Proactive protocols is also known as distance vector and table
driven protocols .In this information is stored in the form of tables in every node and
when any type of change occur in network topology then need to update these tables also.
Proactive protocols continuously learn the topology of the network by exchanging
topological information among the network nodes. Thus, when there is a requirement for
a route to a destination, such route information is available immediately. Periodic route
updates are exchanged in order to synchronize the tables. Some examples of table driven
ad hoc routing protocols are Dynamic Destination Sequenced Distance-Vector Routing
Protocol (DSDV), Optimized Link State Routing Protocol (OLSR) and Wireless
Routing Protocol (WRP). These protocols differ in the number of routing related tables
adhoc changes are broadcasted in the network structure [12]. In this, Slow reaction on
restructuring and failures.
B) Reactive Protocols: Reactive protocol is also known as source initiated on
demand protocols. In this the route is Discover when needed. The main aim is to
minimize the network traffic overhead. These routing protocols are based on some
type of "query-reply" dialog. They do not attempt to continuously maintain the up-to-
date topology of the network. Rather, when the need arises,[4] a reactive protocol
invokes a procedure to find a route to the destination; such a procedure involves some
sort of flooding the network with the route query. The source node emits a request
message, requesting a route to the destination node. This message is flooded, i.e.
relayed by all nodes in the network, until it reaches the destination. The path followed
28

by the request message is recorded in the message, and returned to the sender by the
destination, or by intermediate nodes with sufficient topological information, in a
reply message. Thus multiple reply messages may result, yielding multiple paths - of
which the shortest is to be used. Some examples of source initiated ad hoc routing
protocols include the Dynamic Source Routing Protocol (DSR) , Ad Hoc On-Demand
Distance Vector Routing Protocol (AODV) , and Temporally-Ordered Routing
Algorithm (TORA). No periodic updates are required for these protocols but routing
information is only available when needed [12]. High latency time in route finding and
also Excessive flooding can lead to network clogging.
C) Hybrid Protocols: A hybrid protocol is consolidation of both protocols proactive
protocols and reactive protocols. It reducing the control traffic overhead from
proactive systems and decrease the latency caused by route discovery delays of reactive
systems, by maintaining some form of routing table Hybrid protocols (Royer, 1999) are
designed [10]. Some Hybrid Routing Protocols include CEDAR, ZRP and SRP. The
difficulty of all hybrid routing protocols is how to organize the network according to
network parameters. The common disadvantage of hybrid routing protocols is that the
nodes that have high level topological information maintains more routing information,
which leads to more memory and power consumption.
Fig 3: Comparison Table of Three Routing Protocols
29

4.1 PROACTIVE PROTOCOL:
4.1.1) DSDV (Destination-Sequenced Distance-Vector):
DSDV is proposed by Perkins and Bhagwat [11]. It is a table-driven routing scheme for
ad hoc mobile networks based on the Bellman–Ford algorithm improvement like loop-
free. It's one of the earliest protocols. In this nodes keep on informing the neighbor nodes
about the topology changes of network. Each device maintains a routing table
containing entries for all the devices in the network. In order to keep the routing table
completely updated at all the time each device periodically broadcasts routing
message to its neighbor devices. When a neighbor device receives the broadcasted
routing message and knows the current link cost to the device, it compares this value
and the corresponding value stored in its routing table. If changes were found, it updates
the value and re-computes the distance of the route which includes this link in the
routing table [10]. Less delay is required in the path set up process. All available wired
network protocol can be useful to adhoc wireless networks with less modification
attery power and a small amount of bandwidth even used when the network is idle for
regular updating its routing table. DSDV is not suitable for highly dynamic or large
scale networks.
4.1.2) OLSR (Optimized Link State Routing Protocol ) :
OLSR is proposed by Clausen and Jacquet [11]. A proactive protocol OLSR is inherited
from link state routing and claims to perform better in dense and large net-works In this
protocol design each node chooses a group of nodes from its neighbor which act as
multipoint relay (MPR) through this less flooding occur. It optimizes the pure link state
routing protocol. Optimizations are done in two ways: by reducing the size of the
control packets and by reducing the number of links used for forwarding the link state
packets. OLSR is based on the following three mechanisms: neighbor sensing, efficient
flooding and computation of an optimal route using the shortest-path algorithm. Route
immediately available in OLSR but Bigger overhead and need more power.
4.1.3) WRP (Wireless Routing Protocol):
Wireless Routing Protocol proposed by Murthy and Garcia-Luna-Aceves [11],
DSDV that inherits the properties of Bellman-Ford Algorithm. It keeps each route
information of whole network all the time. Wireless routing protocols (WRP) is a loop
free routing protocol. The main goal is maintaining the shortest distance to every
.
B
30
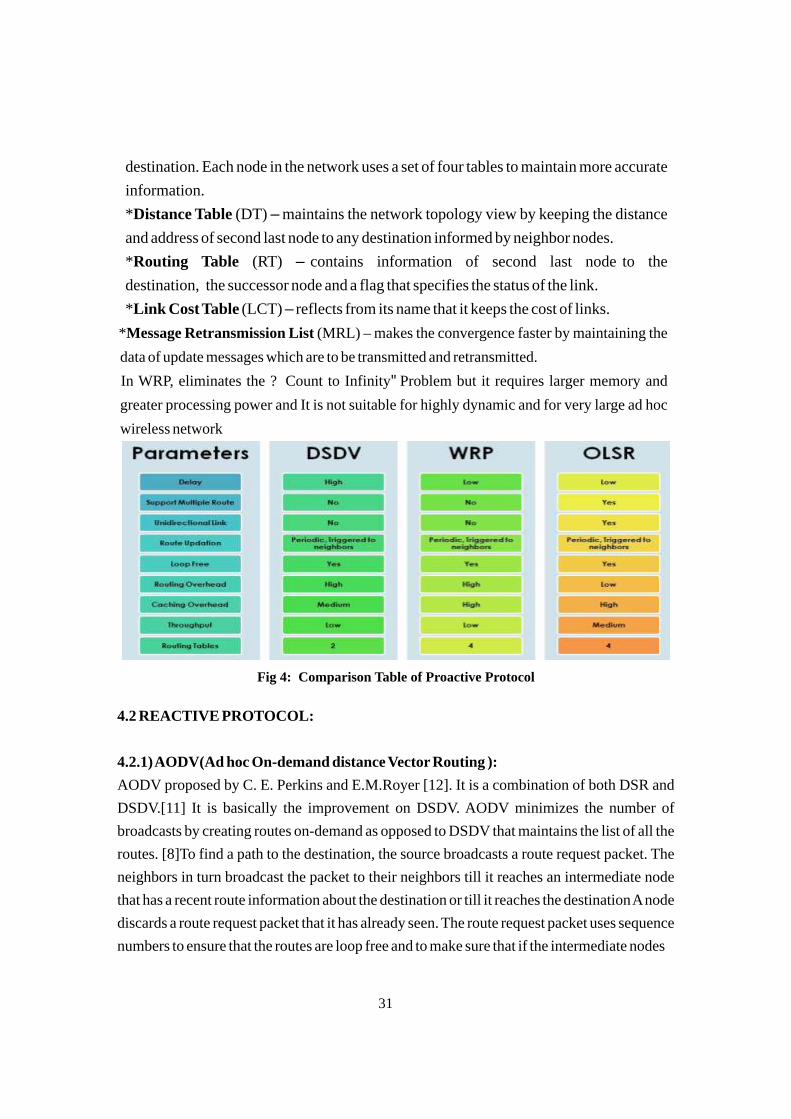
destination. Each node in the network uses a set of four tables to maintain more accurate
information.
*Distance Table (DT) – maintains the network topology view by keeping the distance
and address of second last node to any destination informed by neighbor nodes.
*Routing Table (RT) – contains information of second last node to the
destination, the successor node and a flag that specifies the status of the link.
*Link Cost Table (LCT) – reflects from its name that it keeps the cost of links.
*Message Retransmission List (MRL) – makes the convergence faster by maintaining the
data of update messages which are to be transmitted and retransmitted.
In WRP, eliminates the ? Count to Infinity" Problem but it requires larger memory and
greater processing power and It is not suitable for highly dynamic and for very large ad hoc
wireless network
Fig 4: Comparison Table of Proactive Protocol
4.2 REACTIVE PROTOCOL:
4.2.1) AODV(Ad hoc On-demand distance Vector Routing ):
AODV proposed by C. E. Perkins and E.M.Royer [12]. It is a combination of both DSR and
DSDV.[11] It is basically the improvement on DSDV. AODV minimizes the number of
broadcasts by creating routes on-demand as opposed to DSDV that maintains the list of all the
routes. [8]To find a path to the destination, the source broadcasts a route request packet. The
neighbors in turn broadcast the packet to their neighbors till it reaches an intermediate node
that has a recent route information about the destination or till it reaches the destination A node
discards a route request packet that it has already seen. The route request packet uses sequence
numbers to ensure that the routes are loop free and to make sure that if the intermediate nodes
31

reply to route requests, they reply with the latest information only. [6] When a node forwards a
route request packet to its neighbors, it also records in its tables the node from which the first
copy of the request came. This information is used to construct the reverse path for the route
reply packet. AODV uses only symmetric links because the route reply packet follows the
reverse path of route request packet. As the route reply packet traverses back to the source , the
nodes along the path enter the forward route into their tables. If the source moves then it can
reinitiate route discovery to the destination. If one of the intermediate nodes move then the
moved nodes neighbor realizes the link failure and sends a link failure notification to its
upstream neighbors and so on till it reaches the source upon which the source can reinitiate
route.
Discovery if needed [11]. In this, the connection setup delay is lower [1] but the intermediate
nodes can lead to inconsistent routes if the source sequence number is very old and the
intermediate nodes have a higher but not the latest destination sequence number, thereby
having stale entries. Also, multiple Route Reply packets in response to a single Route Request
packet can lead to heavy control overhead and unnecessary bandwidth consumption due to
periodic beaconing [10].
4.2.2) DSR (Dynamic Source Routing):
DSR Proposed by D. B.Johnson, Maltz and Broch [12] to restrict the bandwidth consumed by
control packets in ad hoc wireless networks by eliminating the periodic table update messages
required in the proactive routing protocols. It is similar to AODV in that it forms a route on-
demand when a transmitting node requests one. However, it uses source routing (also called
path addressing, allows a sender of a Packet to partially or completely specify the Route the
packet takes through the network) instead of relying on the routing table at each intermediate
device. A node maintains route caches containing the source routes that it is aware of. The
node updates entries in the route cache as and whenever it has a packet to transmit. DSR
performs the process of data transmission in two fragments: Route discovery and Route
maintenance
1) Route discovery: When the source node wants to send a packet to a destination, it looks up
its route cache to determine if it already contains a route that is unexpired to the destination.,
then it uses this route to send the packet. But if the node does not have such a route, then it
initiates the route discovery process by broadcasting a route request packet. The route request
packet contains the address of the source and the destination, and a unique identification
32

number. Each intermediate node checks whether it knows of a route to the destination. If it
does not, it appends its address to the route record of the packet and forwards the packet to its
neighbors. A route reply is generated when either the destination or an intermediate node with
current information about the destination accepts the route request packet [Johnson96]. If the
node generating the route reply is an intermediate node then it adjoins its cached route to
destination to the route record of route entreaty the packet and puts that into the route respond
the packet. To send the route reply packet, the responding node must have a route to the
source. The alteration of route record can be used if symmetric links are supported [10].
2) Route maintenance: which is done by keeping the information of each node, in the cache
for a specific period of time for future use.[10] It uses two types of packets for route
maintenance:- Route Error packet and Acknowledgements. When a node confronts a fatal
transmission problem at its data link layer, it generates a Route Error packet. When a node
accepts a route error packet, it removes the hop in error from it's route cache. All routes that
contain the hop in error are removed at that point. Acknowledgment packets are used to verify
the correct operation of the route links. In DSR, the intermediate nodes also utilize the route
cache information efficiently to reduce the control overhead but Even though the protocol
presents well in static and low-mobility environments, the performance degrades rapidly with
increasing mobility. As well, considerable routing overhead is involved due to the source-
routing mechanism employed in DSR. This routing overhead is instantly proportional to the
path length.
4.2.3) TORA (Temporally Ordered Routing Algorithm):
TORA Proposed by Park and Corson. Temporarily ordered routing algorithm (TORA) is
highly adaptive, loop-free, distributed routing algorithm follows the concept of link reversal
[11]. In order to achieve this, the TORA does not use a shortest path solution. TORA builds
and maintains a Directed Acyclic Graph (DAG) rooted at a destination [20]. The main quality
of TORA is to control messages, are localized to a very small set of nodes near the occurrence
of a topological change. .Information may flow from nodes with higher heights to nodes with
lower heights. Information can therefore be thought of as a fluid that may only flow downhill
[5]. To accomplish this, nodes need to stabilized the routing information about adjoining (one
hop) nodes. The protocol performs three basic functions: 1) Route Creation: Route Creation
is done by QRY and UPD packets. The route creation algorithm begins with the height
(propagation ordering parameter in the quintuple) of destination set to 0 and all specific node's
33

height set to NULL (i.e. undefined). The source broadcasts a QRY packet with the destination
node's id in it. A node with a non-NULL height reacts with a UPD packet that has its height in
it. A node having a UPD packet sets its height to one more than that of the node that generated
the UPD. A node with higher height is marked upstream and a node with lower height
downstream. In this way a directed acyclic graph is constructed from source to the destination
2) Route maintenance: When a node moves the DAG route is broken, and route maintenance
is required to reestablish a DAG for the same destination. When the last downstream link of a
node fails, it generates a fresh reference level. This results in the propagation of that reference
level by neighboring nodes as shown in figure 7. Links are opposite to reflect the change in
adapting to the new reference level. This has the same effect as reversing the direction of one
or more links when a node has no downstream links.
3)Route erasure: TORA floods a broadcast clear packet (CLR) throughout the network to
erase invalid routes.
TORA provides the supports of link status sensing and neighbor delivery, definitive, in-order
control packet delivery and security authentication[20].
4.3 HYBRID PROTOCOL: 4.3.1) ZRP (Zone Routing Protocol): ZRP [19] aims to
address excess bandwidth and long route request delay of proactive and reactive routing
protocols. ZRP divides the entire network into zones of variable size. Every node in the
network has a zone associated to it. The size of a zone is not determined by geographical
measurement but is given by a radius of length ρ, where ρ is the number of hops to the
perimeter of the zone[7]. ZRP uses proactive approach for routing inside the zone i.e. intra-
zone routing protocol (IARP) and reactive approach for routing outside the zone i.e. inter zone
routing protocol (IERP).
Fig 5: Comparison Table of Reactive Protocol
34

IARP is used by a node to communicate with in the nodes of its zone and is limited by the zone
radius ρ. It maintains routes in zone, each node continuously needs to update the routing
information in order to determine the peripheral nodes as well as maintain a map of which
nodes can be reached locally[19]. IERP is used to communicate between nodes of different
zones. The IERP take help from the IARP. Route discovery is done through a process called
Bordercasting that uses a Bordercast Routing Protocol (BRP) to only transmit route requests
to peripheral nodes. BRP is used to direct the route requests initiated by the IERP to the
peripheral nodes and also utilizes the topology information provided by IARP to construct a
bordercast tree. For route requests away from areas of network, a query control mechanism is
employed by BRP.
ZRP uses query control mechanisms by query detection, early termination and random query
processing delay to solve this problem. In query detection mechanism, it is possible to detect
queries relayed by other nodes in the same zone to prevent them from reappearing in the
covered zone. Also, a node can prevent route request from entering already covered regions
by using
early termination. A random query processing delay can be employed to reduce the
probability of receiving the same request from several nodes.[19] ZRP is best for large
networks spanning diverse mobility patterns by providing the benefits of both reactive and
pro-active routing but the decision on the zone radius has a significant impact on the
performance of the protocol.
4.3.2) ZHLS (Zone Based Hierarchal Link State Routing):
ZHLS based on hierarchical structure in which the network is divided into non-overlapping
zones[11]. According to Joa and Lu , each node is designated a zone ID one unique node ID
and, which are calculated using geographical information. Therefore the network follows a
two-level topology structure: node level and zone level. Respectively, there are two types of
link state updates: node level LSP (Link State Packet) and the zone level LSP. A node level
LSP contains the node IDs of its neighbors in the same zone and zone level LSP contains the
zone IDs of all other zones. A node periodically broadcasts the node level LSP to all other
nodes in the same zone. Therefore, through periodic node level LSP exchanges, each and
every nodes in a zone keep similar node level link state information. Before transmission, the
source node first checks its intra-zone routing table. If the destination occurs in its zone, the
routing information is already present. Otherwise, the source sends a location request to every
other zones through gateway nodes, which in turn replies with a location response containing
35

the zone ID of the desired destination. ZHLS has a low routing overhead as compared to
AODV and DSR. Also the routing path is adapted to the dynamic topology as only node ID
and zone ID are required for routing [7]. The zone level topology is robust and resilient to path
breaks due to mobility of nodes but the Additional overhead incurred in the creation of the
zone level topology [7].
4.3.3) DDR (Distributed Dynamic Routing): DDR proposed by Nikaein et al. based on tree-
based routing protocol without the need of a root node [11]. The main idea of our proposed
distributed dynamic routing (DDR) algorithm is to construct a forest from a network topology
(i.e. graph G). Each tree of the constructed forest forms a zone . Then, the network is
partitioned into a set of non-overlapping dynamic zones, Z1; Z2; :::; Zn. Each zone Zi contains
p mobile nodes, N1; N2; :::; Np [13]. Then, each node calculates its zone ID independently.
Each zone is connected via the nodes that are not in the same tree but they are in the direct
transmission range of each other. So, the whole network can be seen as a set of connected
zones. Thus, each node Nu from zone Zi can communicate with another node Nv from zone Zj[
13]. In this strategy tree are constructed using periodic beaconing messages, which are
exchanged by neighboring nodes only. These trees within the network form a forest with the
created gateway nodes acting as links between the trees in the forest. These gateway nodes are
regular nodes belonging to separate trees but within transmission range of each other. A zone
naming algorithm is used to assign a specific zone ID to each tree within the network. Hence,
the overall network now comprises of a number of overlapping zones The DDR algorithm
comprise of the following six phases:
(i) preferred neighbor election;
(ii) intra-tree clustering;
(iii) inter-tree clustering;
(iv) forest construction;
(v) zone naming;
(vi) zone partitioning.
Each of these phases are executed based on information received in the beacon messages.
During the initialization phase, each node starts in the preferred neighbour election phase. The
preferred neighbour of a node is a node that has the most number of neighbours. After this, a
forest is constructed by connecting each node to their preferred neighbour. Next, the intra-tree
clustering algorithm is initiated to determine the structure of the zone (or the tree) and to build
up the intra-zone routing table. This is then followed by the execution of the inter-tree
algorithm to determine the connectivity with the neighboring zones. Each zone is then
36

assigned a name by running the zone naming algorithm and the network is partitioned into a
number of non-overlapping zones [14]. DDR does not rely on a static zone map to perform
routing but In this networks with high traffic, this may also result in significant reduction in
throughput, due to packets being dropped when buffers become full.[14]
4.3.4) DST (Distributed Spanning Tree Based Routing ): In DST the nodes in the network
are grouped into a number of trees. Each tree has two types of nodes; route node, and internal
node [11]. The root controls the structure of the tree and whether the tree can merge with
another tree, and the rest of the nodes within each tree are the regular nodes. Each node can be
in one three different states; router, merge and configure depending on the type of task that it
trying to perform. To determine a route DST proposes two different routing strategies; hybrid
tree-flooding (HFT) and distributed spanning tree shuttling (DST). In hybrid tree-flooding,
control packets are sent to all the neighbours and adjoining bridges in the spanning tree, where
each packet is held for a period of time called holding time. The idea behind the holding time is
that as connectivity increases, and the network becomes more stable, it might be useful to
buffer and route packets when the network connectivity is increased over time [15] .In
distributed spanning tree shuttling, the control packets are disseminated from the source are
rebroadcasted along the tree edges. When a control reaches down to a leaf node, it is sent up
the tree until it reaches a certain height referred to as the shuttling level. When the shuttling
level is reached, the control packet can be sent down the tree or to the adjoining bridges.
DDR have Reduced transmission but the holding time used to buffer the packets may
introduce extra delays in to the network. It relies on a root node to configure the tree, which
creates a single point of failure.
Fig 6: Comparison Table of Hybrid Protocol
37

CONCLUSION
Wireless mobile ad-hoc network has very enterprising applications in today's world. we
emphasis on a comprehensive analysis about the Mobile Ad Hoc Network (MANET).we
define their applications that are used in emergency operations such as search and rescue,
policing and firefighting as well as military environments, civil environments, etc. We have
focused to describe and review some of routing proto-cols for MANETS. The protocols are
divided into three main categories: (i) Source-initiated (reactive or on-demand), (ii) Table-
driven (pro-active), (iii) Hybrid protocols. Due to mobility and high diversity of ad-hoc
networks, this is quite difficult task to accomplish all the challenges with a single protocol
suite. That is why many algorithms and mechanisms are designed for different scenarios.
Each routing protocol has unique features. Based on network environments, we have to select
the suitable routing protocol. The main differentiating factor between the protocols is the
procedure of finding and maintaining the routes between source destination pairs. DSR,
AODV and OLSR are preferable for tiny networks while TORA and ZRP are suitable for large
networks. This article will help the fresh researchers to get their domain of interest and to
identify the areas in which existing protocols are lacking.
REFERENCES
[1] Gurpreet Singh, 1 Atinderpal Singh, Performance Evaluation of Aodv and Dsr Routing Protocols
for Vbr Traffic for 150 Nodes in Manets, International Journal Of Computational Engineering Research
(ijceronline.com),Vol. 2 Issue. 5-2012.
[2] Anit Kumar, Pardeep Mittal, A Comparative Study of AODV & DSR Routing Protocols in Mobile
Ad-Hoc Networks, Volume 3, Issue 5, May 2013,
[3] Amit Shrivastava, Aravinth Raj Shanmogavel, Nitin Chander, Overview of Routing Protocols in
MANET?s and Enhancements in Reactive Protocols.
[4] Gurpinder Singh, Jaswinder Singh, MAnet: issues and behavior analysis of Routing Protocols,
Volume 2, issue 4, april 2012, ISSN:227128X
[5] Rutvij H. Jhaveri,Ashish D. Patel, Jatin D. Parmar, Bhavin I. Shah, MANET Routing Protocols
and Wormhole Attack against AODV, IJCSNS International Journal of Computer Science and Network
Security, VOL.10 No.4, April 2010
[6] Alex Hinds, Michael Ngulube, Shaoying Zhu, and Hussain Al-Aqrabi, A Review of Routing
Protocols for Mobile Ad-Hoc NETworks (MANET), International Journal of Information and Education
Technology, Vol. 3, No. 1, February 2013
[7] Vivek Sharma, Bashir Alam, Unicaste Routing Protocols in Mobile Ad Hoc Networks: A Survey,
International Journal of Computer Applications (0975 – 8887),Volume 51– No.14, August 2012
38

[8] Chintan N. Patel, Prof. Milind S. Shah, Prof. Vyomal N. Pandya, Comparison Of Reactive Routing
Protocols For MANET, International Journal of Engineering Research & Technology (IJERT),Vol. 2 Issue
3, March - 2013,ISSN: 2278-0181,www.ijert
[9] Ms. Aastha kohli , Mr. Sukhbir, A Review paper on Routing Protocol Comparison, , (I J R A S E T),
Vol. 1 Issue II, September2013, ISSN: 2321-9653
[10] Laraib Abbas1, Muddesar Iqbal, Muhammad Shafiq1, Saqib Rasool , Azeem Irshad,A
COMPREHENSIVE REVIEW OF SOME WELL KNOWN ROUTING PROTOCOLS FOR
MANETS,ijater,ISSN No: 2250-3536 Volume 3, Issue 6, Nov. 2013.
[11] Anuj K. Gupta, Harsh Sadawarti, and Anil K. Verma, Review of Various Routing Protocols for
MANETs, International Journal of Information and Electronics Engineering, Vol. 1, No. 3, November 2011.
[12] Anuj K. Gupta, Harsh Sadawarti, and Anil K. Verma,A Review of Routing Protocols for Mobile Ad
Hoc Networks, ISSN: 1109-2742, Issue 11, Volume 10, November 2011 [13]Navid Nikaein, Houda Labiod
and Christian Bonnet, DDR-Distributed Dynamic Routing Algorithm for Mobile Ad hoc Networks
[14] Mehran Abolhasan,Tadeusz Wysocki, Eryk Dutkiewicz, A review of routing protocols for mobile ad
hoc networks,University of Wollongong Research Online, 2004.
[15] Sunil Pathak1, Dr. Sonal Jain2, A Survey: On Unicast Routing Protocols for Mobile Ad Hoc
Network, International Journal of Emerging Technology and Advanced Engineering, ISSN 2250-2459, ISO
9001:2008 Certified Journal, Volume 3, Issue 1, January 2013.
[16] Imrich Chlamtac a, Marco Conti b, Jennifer J.-N. Liu, Mobile ad hoc networking: imperatives and
challenges, elesvier, 2003
[17] Pravin Ghosekar, Girish Katkar, Dr. Pradip Ghorpade, Mobile Ad Hoc Networking: Imperatives
and Challenges ,IJCA Special Issue on "Mobile Ad-hoc Networks" MANETs, 2010
[18] Jeroen Hoebeke, Ingrid Moerman, Bart Dhoedt and Piet Demeester, An Overview of Mobile Ad
Hoc Networks: Applications and Challenges
[19] Sweety Goyal, ZONE ROUTING PROTOCOL (ZRP) IN AD-HOC NETWORKS, IJREAS Volume
3, Issue 3 (March 2013) ISSN: 2249-3905.
[20] Tamilarasan-Santhamurthy, A Quantitative Study and Comparison of AODV, OLSR and TORA
Routing Protocols in MANET, IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 1,
No 1, January 2012.
39

SPEECH RECOGNITION: A SURVEY
Kirandeep Singh
MPhil, Research Scholar
Department of Computer Science, Punjabi University, Patiala
Dr. Gurpreet Singh Lehal
Professor, Department of Computer Science, Punjabi University,
Patiala.
ABSTRACT
Speech recognition is the progressive area of Natural Language Processing. Speech
recognition is a technique in which a human speaks to computer in his/her comfortable
language and computer is such an intelligent to understand his spoken word and respond
accordingly. Speech recognition technology helps to convert recognized and spoken language
into text by computers and other computerized devices such as Smart Technologies and
robotics. Peoples those don't understand English language they can interact with computers in
their native languages using speech recognition technology. At the present time, a lot of
researches are going on for the development of much robust speech recognition systems for
different languages. There are many exciting tools like KALDI, HTK, CMU SPHINX and
others are used to develop speech recognition systems. A great work for English, European
and East Asian languages has been done.ASR for regional languages are also under
processing. This paper discusses the various challenges, approaches and existing systems in
speech recognition. The major challenges in developing a speech recognition system are
noisy environment, disfluences sounds, speaking speed, gender, speech accents, word
boundaries etc. Typically, Speech recognition has two phases first is training phase and
second is testing phase. First step in speech recognition is to convert incoming human sound
that is in analog signal, into digital signal. Digitized sampled signal is complex for direct
processing by a system, so it needs to extract speech features from it. There available many
options for feature extraction, such as, Mel-Frequency Cepstrum Coefficients (MFCC),
Linear Prediction Coding (LPC), and others. After feature extraction from a speech signal
next step in recognition is to compare these computed features with trained patterns in
database, to find a spoken word, this phase is known as testing phase. Different techniques
exist for recognition step such as DTW, HMM, Neural Network, vector quantization and
40

others. In final step, if computer can correctly recognize spoken word then it would be use for
any event stirring or print recognized text on screen, as per user requirement. Few researches
that have taken place in the field of speech recognition are listed in this paper, although the list
may not be exhaustive.
INDEX TERMS—Speech Recognition, Acoustic Vector, Mel- Frequency Cepstrum
Coefficients, Hidden Markov Model.
INTRODUCTION
SPEECH is the most natural and efficient way of com- munication among human beings.
People would like to interact with computer in speech as they are very comfortable with it.
Speech recognition is a way by which a speech signal is converted into sequence of words by
a computer program. The attempts to devise ASR were started in 1960s. Researchers started
to exploit fundamentals ideas in acoustic phonetics. Major shift in ASR came during 1980
when researchers shifted from template based approach to more rigorous statistical modeling
framework[1]. The statistical or HMM is robust in the sense that it provides many efficient
algorithms for training, speaker adaptation and recognition. However when the system is
migrated from laboratory to real world, it encounters many problems because of ambient
noise, speaker variations, channel distortions etc. How to overcome these problems and/or
improve performance of ASR in real life conditions is being extensively studied by the
researchers. Based on the advances in statistical modeling, speech recogni- tion finds
widespread applications in automatic call processing in telephone network, query based
information system, stock price quotations, voice dictation, weather reports etc.
Fig. 1. Basic components of speech recognition. Features are extracted in order to distinguish
between dif- ferent linguistic units. Features are also robust against noise and other factors
that are irrelevant for recognition process. The number of feature extracted is usually much
lower than the number of samples in a speech signal, thus reducing the amount of data.
Extracted features are compared with stored reference patterns called acoustic model which
is usually Hidden Markov Model. The pronunciation dictionary gives the combination of
phonemes making valid words and can contain information about different variants of a
single word. The language model predicts the likelihood of occurrence of one word after
another in a certain language. In other words the probability of the occurrence of kth word
following (k-1) previous words is defined as P(wk—wk-1,wk-2.w1).
41

COMMON CHALLENGES IN SPEECH RECOGNITION
A. Human comprehension of speech compared to ASR
Speech recognition systems can be developed for the gram- matical structure and some
statistical model can be used to improve word predication, but still there is a problem that how
much world knowledge of speaking and encyclopedia can be modeled. Of course, we cannot
model the world knowledge. so we cannot measure computer system up to human
comprehensive.
B. Body language
Humans communicate not only through speech but body signals are also used such as hand
waving, eye moment and others. Consequently in any ASR system such information is
completely missed.
C. Noise
Any unwanted information in any sound signal is a noise. While speaking in any
environment, a radio playing some- where down the corridor,a clock ticking, another human
speaker in the background are all examples of noise. ASR should as much intelligent to detect
such noise and filter it out from the speech signal.
D. Spoken language And Written language Are Different
Written language and spoken language are essentially dif- ferent in nature. Written language
is one way communication while spoken language is dialog oriented. In spoken language we
give feed back to the sound that we understand. In last few years it has been observed that
spoken language is grammat- ically less complex whereas in written language grammatical
possibilities should always be kept in mind. Normally speech contains repetitions, slips of the
tongue, changes of subject in the middle of phrase,hesitations etc. Such disfluences are
communally ignored by human listener. In ASR, such kind of behavior should be represented
by the machine and these differences should be identified and addressed carefully.
E. Continue Speech
Communication does not have natural pause between words of a spoken sentence, usually
pauses come at the beginning and end of a speech.ASR should be capable to convert a sound
wave into a sequence of spoken words.
SPEECH RECOGNITION APPROACHES
A. Template Based Approach
In template based approach[2], a collection of prototypical speech patterns is stored as a
reference pattern. Whenever an unknown spoken utterance comes, it is matched with the each
42

stored reference pattern and the pattern having best match is selected. The unknown speech
pattern is compared against each reference pattern and measure of similarity (distance)
between test pattern and reference pattern is computed. The approach has the advantage in its
simplicity and uses perfectly accurate word models. Normally templates for entire words are
constructed so errors due to segmentation and classifications can be avoided[1]. The system
is insensitive to sound class so the basic techniques developed for one sound class can be
easily applied to another sound class with little or no modification. The disadvantage is that
the prerecorded templates are fixed so for speech variations, we have to store many templates
per word. The speaking environment and characteristics of the transmission medium can
affect the efficiency of reference patterns.
B. Artificial Intelligence approach (Knowledge Based approach)
The Artificial Intelligence approach[3] is a hybrid of the acoustic phonetic approach and
pattern recognition approach. It exploits the ideas and concepts of Acoustic phonetic and
pattern recognition methods. Knowledge based approach uses the information on the subject
of linguistic, phonetic and spectrogram. Knowledge engineering design consists of the direct
and indirect incorporation of expert's speech knowledge into a recognition system. This
knowledge is generally derived from suspicious study of spectrograms and is incorporated
using rules or procedures. The problem in this approach is due to the difficulty in quantifying
expert knowledge. Another difficult problem is the incorporation of many levels of human
knowledge phonetics, phonotactics, lexical access, syntax, semantics and pragmatics. In
more indirect forms, knowledge has also been used to design the models and algorithms of
template matching and stochastic modeling techniques.
C. Vector Quantization (VQ)
ASR frequently uses Vector Quantization (VQ)[4]. It is valuable for speech coders, i.e.,
efficient data reduction. While transmission rate is not a major issue for ASR, so that
usefulness of VQ lies in the efficiency of using compact codebooks for reference models and
codebook searcher in place of more costly evaluation methods. In isolated word recognition,
each different vocabulary word has its own code- book that is trained by multiple repetitions
of that specific word. During the testing of an incoming word, all codebooks are evaluated
and ASR system chooses the codebook that raises the lowest distance measure. Basically VQ
does not have any time related information (e.g., the temporal order of phonetic segments in
each word and their relative durations are ignored), as codebook entries are not ordered and
can come from any part of the training words. Codebook entries are selected to minimize
average distance across all training frames, and frames, corresponding to longer acoustic
43

segments ( e.g., vowels) are more frequent in the training data.
D. Neural Network
The artificial intelligence approach ( [5], Lesser et al. 1975; Lippmann 1987) is the way to
automate the recognition procedure likewise a person applies his intelligence in visualizing,
analyzing, and characterizing speech based on a set of measured acoustic features. This
approach[6] has not been extensively used in commercial systems. The spotlight in this
approach has been mostly in the representation of knowledge and integration of knowledge
sources. Connectionist models significantly depend on the good learning or training
strategies. In connectionist models, knowledge or constraints is scattered across many simple
computing units as an alternative to en coded them in individual units. Nature of computing
units are simple, and knowledge is not programmed into any individual unit Function; rather,
it lies in the connections and interactions between linked processing elements.
E. Stochastic Approach
Stochastic modeling[7] is based on probabilistic modeling that deals with uncertain and
incomplete information. In speech recognition, uncertainty and incompleteness takes place
from many sources; for example, confusable sounds, speaker variability's, contextual effects,
and homophones words. The most popular stochastic approach is hidden Markov modeling.
Thus, stochastic approach is predominantly appropriate approach to speech recognition. A
hidden Markov model is characterized by a finite state markov model and a set of output
distributions. HMMs facilitate easy integration of knowledge sources into a compiled
architecture. A negative side effect of this is that it does not afford much insight on the
recognition process. Therefore, it is often complicated to analyze the errors of an HMM
system in an attempt to improve its performance.
F. Support Vector Machine (SVM)
SVM[8] is a tool for pattern recognition that uses a discriminative approach. SVMs use linear
and nonlinear separating hyper-planes for data classification. This approach cannot be
willingly applied to task that involves variable length data classification as it can only classify
fixed length data vectors. Before SVMs can be used, variable length data should be
transformed into fixed length vectors.
LITERATURE SURVEY
The earliest attempts in speech recognition were made during 1950 and 1960s. In 1952, at
Bell Laboratories, Davis, Biddulph, and Balashek built an isolated digit recognition
44

system[9] for a single speaker using the formant frequencies measured/estimated during
vowel regions of each digit. In 1956 at RCA Laboratories, Olson and Belar tried to recognize
10 distinct syllables of a single speaker, as embodied in 10 monosyllabic words 10].
In 1959, at University College in England, Fry and Denes tried to build a phoneme
recognizer[10] to recognize four vowels and nine consonants. They used spectrum analyzer
and pattern matcher for the recognition. By incorporating statistical information, they
increased the overall phoneme recognition accuracy for words consisting of two or more
phonemes. Their work marked the first use of statistical syntax in automatic speech
recognition.
In 1960s, Martin and his colleagues at RCA Laboratories developed a set of
elementary time-normalization methods [11] To detect speech starts and ends that
significantly reduced the variability of the recognition scores. At the same time, in the Soviet
Union, Vintsyuk proposed the use of dynamic program- ming methods generally called
dynamic time warping for time aligning a pair of speech utterances including algorithms for
connected word recognition.
In 1970, the area of isolated word or discrete utterances became a viable and usable
technology based on the studies in Russia and Japan. The Itakura of Bell laboratories[10]
introduced that through the use of an appropriate distance measure based on LPC spectral
parameters, linear predictive coding (LPC) could be used in speech recognition. Also
researchers here, started experiments aiming at making speaker independent systems. A wide
range of clustering algorithms was used to achieve this goal. In 1973, Hearsay I system by
CMU was able to use semantic information to significantly reduce the number of alternatives
considered by the recognizer. CMU's Harpy system was able to recognize speech using
vocabulary of 1011 words with reasonable accuracy. These projects were funded by DARPA
(Defense Advanced Research Projects Agency).
In 1980, there was a shift in methodology from template based to more rigorous
statistical modeling framework. One of the key technologies was Hidden Markov Model
(HMM) although the technique became widely applied in mid-1980s. Furui proposed the use
of cepstral coefficients as spectral features in speech recognition. The n-gram model defining
the probability of occurrence of an ordered sequence of n words was introduced by IBM for
large vocabulary speech recognition systems. The primary focus was the development of a
language model which describes how likely a sequence of language symbols appear in a
speech signal [12].
45

In 1990's DARPA program was continued. The emphasis was on the different speech
understanding application areas such as transcriptions of broadcast news and conversational
speech. The BN transcription technology was integrated with information extraction and
retrieval technology, and many Application systems, such as automatic voice document in-
dexing and retrieval systems, were developed[10]. Various other techniques were developed
viz. the maximum likelihood linear regression (MLLR) , the model decomposition, parallel
model composition (PMC) , and the structural maximum a posteriori (SMAP) method to
reduce the mismatch caused by background noise , microphones , voice individuality etc.
Rebiner and Sambur have proposed "A Statistical Decision Approach to the Recognition of
Connected Digits"[13]. Each utterance which was a string of three digits was first analyzed to
find end points and a voiced-unvoiced-silence part of the utterance was obtained. The digit
string was then segmented into individual digit based on the voiced-unvoiced-silence
information. The voicing region in each segmented digit is analyzed using linear predictive
coefficients (LPC). The LPC coefficients are converted to parcor or reflection coefficients
and linearly warped to compute average digit length. The recognition of each digit within the
string is done using a distance measure based on minimal residual error. The measure also
takes into account the effect of co articulation and multiple repetitions. The system can be
used for both speaker independent and speaker-dependent situations. The recognition system
has been tested on six speakers in the speaker-dependent mode. The accuracy achieved is 99
percent. In speaker-independent mode, the system was tested with 10 new speakers and
reported accuracy was 95%.
Rebiner and Wilpon proposed "simplified, robust, training procedure for speaker trained,
Isolated word recognition systems"[14]. The method has been proposed in order to overcome
the extensive burden of training required in statistical analysis. The method gives a training
procedure which has advantages of both averaging and clustering techniques. The proposed
method is more reliable and robust than casual training. The word spoken by the user is
measured and saved for the first time. When user speaks the word second time, DTW distance
is computed between new pattern and previously stored pattern. If the distance comes out to
be below a threshold, a reference pattern is created ad training for that word is completed;
otherwise third or subsequent passes are executed to save word reference pattern again. This
procedure continues until all words are completed or until a maximum word repetition count
is met. For testing the effectiveness of the training procedure, an experiment was performed
46

taking nine talkers (five males, four females). Word reference template was created for 39-
word vocabulary consisting of alphabets, the digits 0-9 and three command words. The
experiment showed that the for 95.2% of all words, a single reference pattern is obtained from
the first four replications of that word by a given talker.
Lee and Hon presented a "Large Vocabulary Speaker Independent Speech Recognition
System Using HMM"[15]. In their paper, they described about SPHINX which is a HMM
based speaker independent large vocabulary recognizer. The system uses two types of HMM
models: context-independent phone models and function-word-dependent phone models.
Each word in SPHINX is represented by pronunciation net- work of phones and set of
sentences accepted by grammar is represented by network of words. In order to add
knowledge to HMM, three set of parameters viz. instantaneous LPC cepstrum coefficients,
differenced LPC cepstrum coefficients and power and differenced power are computed. The
speech is sampled at 16-khz and 12 LPC cepstrul coefficients are computed which are then
transformed to melscale using bilinear transform and vector quantized into three codebooks
which improves recognition accuracy and reduces VQ distortion. SPHINX is a phone-based
HMM recognizer. A total of 153 HMM are created using a set of 105 HMM to model phones
in 42 selected function words. The 153 HMM are trained through the use of a forward-
backward algorithm which runs on 4160 sentence database. For recognition of speech, a
time-synchronous Viterbi beam search technique is used. A threshold is determined and at a
particular time, all states which are worse than the best state by more than the threshold are
pruned. The system can recognize speech for no language model, a word pair language model
and a bigram language model. The system has been tested for the 997 words and accuracy for
bigram, word pair and no language model comes out to be 93%, 87.9% and 53.4%.
Kita et. al. proposed "HMM Continuous Speech Recognition Using Stochastic Language
Models"[16]. Their system uses HMM-LR method which is an integration of Hidden Markov
Models and LR parsing. First, the LR parser predicts the phoneme candidates and then these
candidates are verified using HMM phoneme models. During the process of verification, all
possible partial parses are constructed and the HMM verifier updates an array containing end
point candidates and their probabilities. This partial parse is pruned whenever the highest
probability in the array is lower than a threshold value. To improve recognition accuracy,
word bigram/trigram model has been applied to Japanese syllables as they have special
stochastic structure. The LR parser in the system is a stochastic shift reduces parser as it is
closely related to stochastic context free grammar.
47

Suzuki et. al. proposed a speech recognition system based on acoustic models by considering
variations in voice characteristics[17]. This system works by constructing voice-
characteristic dependent acoustic model by using tree based clustering technique. The
phonetic context is judged from linguistic phonetic knowledge using triphone models. To
con- struct the voice-characteristic-dependent acoustic models, each speaker's voice is
labeled according to the result of listening test. Since the context-dependent triphones can be
very large, so these are grouped into number of clusters. So a tree based clustering technique
is applied to speaker's voice characteristics. The simultaneous clustering of voice
characteristics along with phonetic context allows the construction of voice- characteristic-
dependent acoustic models. For recognition of speech, each leaf node having same phonetic
context but different voice characteristics is integrated as a mixture distribution. Either the
Yes or No node regarding phonetic context and both Yes and No nodes regarding voice
characteristics are chosen and process is repeated for root to leaf nodes. At the end we get set
of leaf that differs only in voice characteristics. The system has been trained using 20000
sentences spoken by 130 speakers of each gender and tested using total of 100 sentences
spoken by 23 speakers of each gender. For the evaluation, the speech data is down-sampled to
16 kHz and parameterized to 12 melcepstral coefficients. Three states left to right HMMs
were used to model 43 Japanese phonemes, 146 phonological context questions and 20 voice
characteristic questions. Embedded training has been applied before and after integrating
voice-characteristic dependent acoustic model. The result shows that proposed method
performs better than conventional 4-mixture model in case of males and in case of females the
proposed method performed well than conventional 8-mixture models.
Revathi and Venkatramani developed Speaker Independent Continuous Speech and Isolated
Digit Recognition using VQ and HMM[18] which is based on perceptual features of speech.
The system uses combination of Vector Quantization and HMM for speech recognition. The
perceptual features are extracted by first computing the power spectrum of windowed speech
and the grouping is done to 21 critical bands in bark scale. In order to simulate power law of
hearing, loudness equalization and cube root compression is performed. After performing
IFFT and LP analysis, the LP coefficients are converted into cepstral coefficients. Speech
recognition using VQ consists of extracting features from training and testing data and
building VQ codebooks for all 0-9 digit and continuous speeches. The codebooks are
generated from training data using K-means clustering algorithm. Further hmm models are
developed with state transition probability, observation symbol probability distribution and
48

initial probability distribution to optimize the likelihood of the training set observation
vectors. For discrete HMM, models are initialized with 256 observation sequences and 8
states. Code books indices are used as input to train the models. Observation sequences from
feature vectors of all test speeches are given to HMM models and probability density values
are calculated. After that all probabilities are compared and speech is selected whose
likelihood is the maximum. Average accuracy of the system for speaker independent isolated
digit using VQ+HMM is 93% and for speaker independent continuous speech is 100%.
Dua et.al. has developed Punjabi Automatic Speech Recognition System using HTK based on
Hidden Markov Model[19]. The GUI of the system has been developed using JAVA platform
in Linux environment. The system architecture consists of four phase's viz. Training data
preparation, Acoustic Analysis, Acoustic model generation and GUI based decoder. The first
phase deals with the recording and labeling of speech signal. The system is trained using 115
distinct Punjabi words which are recorded using a unidirectional microphone. The data is
sampled at 16 khz . 8 speakers recorded the data and each word is spoken 3 times by each
speaker. The 2nd phase is the feature extraction phase in which original recorded waveform is
converted into series of acoustical vectors. The features are extracted using MFCC(Mel
frequency cepstral coefficient) technique. For this signal is segmented in a series of frames,
each having length between 20 to 40 ms. Each frame is multiplied by a windowing function
and after that a vector of acoustical coefficients is extracted from each windowed frame. In
acoustic model generation phase, comparisons are made to recognize unknown utterances.
First HMM is initialized by generating some prototype for each word. For generating
prototype, some topology is used which consists of 4 observation functions and two non
emitting states. After that optimal values for HMM parameters are estimated using Hrest tool.
In order to recognize speech, the test signal is converted to series of acoustic vectors. This data
along with HMM definition, Punjabi word dictionary, task network and generated HMM list
is given to htk tool Hvite which compares it against recognizer's markov models and
recognized word is displayed in text form. The performance of the system is tested in different
environments using total of 6 distinct speakers each uttering 35-50 words. The average
performance comes out to lie in the range of 94 to 96%. Kumar et.al. Proposed a system
named Continuous Hindi Speech Recognition using Gaussian Mixture HMM[20]. In this, the
performance of the system is compared against differ- ent number of Gaussian mixture. The
aim is to find the optimal number of Gaussian mixture that exhibits maximum accuracy.
System uses the database of 51 words which are recorded at the sampling rate of 16 khz.
49

Features are extracted through MFCC technique. 39 MFCC are used in the experiment. In
HMM training of continuous Hindi speech recognition system 5 states left right with no skips
is used as a prototype model and 40 prototypes HMM model for all Hindi mono- phones are
created. The mono-phone model further extends to triphone model to increase recognition
accuracy. Different types of experiments have been conducted in order to test the
performance of the system. Experiments with different vocabulary size showed that system
has higher performance with small vocabulary. Experiments were performed five times with
different number of Gaussian mixture. Tri-phone based continuous speech recognition
system reported high accuracy with 4 mixtures GMM. Another experiment showed that tri-
phone based system which is a context dependent system has better performance than mono-
phone based system which is context independent. The authors are able to achieve 97.04%
accuracy with 51 word vocabulary size.
Baby et.al. have proposed the enhancement of automatic speech recognition system based on
deep neural network using exemplar based technique[21]. The system used coupled
dictionaries as a pre-processing stage. The noisy speech is first decomposed as a weighted
sum of atoms in an input dictionary having exemplars sampled from a domain of choice. In
order to directly obtain the estimations of speech and noise, the resulted weights are applied to
a coupled output dictionary having exemplar sampled in short time Fourier transform
(STFT). The system has been evaluated using three different input exemplar spaces namely
Mel, magnitude STFT and MS spaces. Three types of settings have been used as DFT-DFT
setting, Mel-Mel and Mel-DFT settings and MS-DFT settings. In DFT-DFT setting DFT
exemplar space is chosen as the input
exemplar. In order to create the input dictionary using DFT exemplars, a random segment of
acoustic data spanning T frames is taken and its full resolution magnitude STFT of size F*T is
considered. In Mel-Mel and Mel-DFT, NMF based decomposition is done using Mel
dictionary having Mel ex- emplars. In order to obtain Mel exemplar, magnitude STFT of size
F*T is pre-multiplied with STFT-to-Mel matrix. MS-DFT setting makes use of MS
exemplars to obtain compositional model using NMF. MS-exemplars are obtained by
considering T frames of acoustic data and filtered using a filter bank having B channels. The
resulting B band-limited signals are half-wave rectified to model non negative nerve firings
and low pass filtered at a 3 db cut-off frequency. The system has been trained and tested using
AURORA-4 database with both clean and multi-condition training. Average word error rates
are used to evaluate and compare the performance of various settings. The system yielded
average overall WERs of 26.8% and 11.9% with clean and retrained DNN respectively.
50

Nguyen et. al. have improved the English ASR system using two approaches of Deep Neural
Network Hybrid and bottleneck[22] features based on denoising en-coders. Deep Neural
Network architecture for Hybrid HMM/GMM consists of large number of fully connected
hidden layers followed by final classification layer. Architecture for bottleneck feature
extraction is similar to hybrid HMM/GMM but it has a small bottleneck layer. For training the
acoustic model, the authors have used TED talk lectures consisting of 22 hours of audio
distributed among 920 talks. The non spoken sounds have been filtered out using
segmentation and the remaining audio used for training was around 175 hours of speech. One
eighth of the Giga corpus filtered according to the Moore- Lewis approach has been used for
language modeling. During supervised training, the neural network predicts context de-
pendent HMM states. The auto-encoders are pre-trained using gradient descent method with
learning rate of 0.01%. The input vectors are corrupted by masking noise. Bottleneck
consisting 39 units is then added to the remaining layers. The authors have evaluated the
system using 2012 development set and 2013 test set. The word error rate in baseline system
is 30% on dev2012 and 36.1% on test2013. The hybrid DNN/HMM combination
outperforms the baseline setup showing the error rates of 18.7% and 22.7%. Lee et. al.
proposed a multistage enhancement technique for Automatic Speech Recognition[23]. In
first stage the multi-channel speech enhancement method works on spatial information of
speech signal for improvements. The second stage enhances the performance of the system at
server side by employing a data driven approach based single channel speech enhancement
method. The single channel speech enhancement method uses a priori and posteriori SNR to
train the noise reduction gain function. The performance of the proposed method is evaluated
by recording the 1200 spoken sentences by 12 Korean persons (5 females, 7 males). The
speech samples are recorded in various noisy environments such as car, street, caf etc. The
word recognition rate in proposed method is 77.9% which is higher than conventional method
(65.7%).
Mohan and Babu have implemented a speech recogni tion system in MATLAB environment
using MFCC (Mel- Frequency Cepstral Coefficients) and DTW (Dynamic Time
Warping)[24]. The system employs two phases: Feature Ex- traction and Feature Matching.
Before extracting features using MFCC, the voice signal is converted from Analog to Digital
by following Pre-Emphasis and filtering. For Pre- emphasis FIR filter is used which increase
the higher frequency magnitude with respect to lower frequencies. Voice sample is framed
within ranges of 20 to 30ms. Each frame is then multiplied by a hamming window. After that
Fast Fourier Transform is taken for each frame to transform the signal into frequency domain.
Each resultant frame is then multiplied by Triangular MEL filter bank. Logarithm and
Discrete Cosine Transform. The resulting values are MFCC. After feature extraction, DTW
51

algorithm is used for feature matching by calculating least distance between features of
spoken word and reference templates. Among the calculated scores, the reference template
with least value is selected as detected word.
CONCLUSION In this paper work, we have presented a survey on challenges, different
approaches and evaluation metrics used for different speech recognition systems. We have
also listed some of the existing speech recognition systems. From the survey we have found
that almost all existing language speech recognition systems are based on HMM and pattern
based approaches. We have tried to list down the works of few different scholars and
institutions but there might exist some more groups and organizations that are involved in the
development of speech recognition systems.
REFERENCES
[1] Barbara Resch. Automatic speech recognition with htk. Signal Processing and Speech
Communication Laboratory. Inffeldgase. Austria. Disponible en Internet: http://www. igi. tugraz.
at/lehre/CI, 2003.
[2] Mathias De Wachter, Mike Matton, Kris Demuynck, Patrick Wambacq, Ronald Cools, and Dirk
Van Compernolle. Template-based continuous speech recognition. Audio, Speech, and Language
Processing, IEEE Transactions on, 15(4):1377–1390, 2007.
[3] Victor W Zue and Lori F Lamel. An expert spectrogram reader: A knowledge-based approach to
speech recognition. In Acoustics, Speech, and Signal Processing, IEEE International Conference on
ICASSP?86., volume 11, pages 1197–1200. IEEE, 1986.
[4] HB Kekre, Archana A Athawale, and GJ Sharma. Speech recognition using vector quantization. In
Proceedings of the International Confer- ence & Workshop on Emerging Trends in Technology, pages
400–403. ACM, 2011.
[5] Roger K Moore. Twenty things we still dont know about speech. In Proc. CRIM/FORWISS
Workshop on Progress and Prospects of speech Research an Technology, 1994.
[6] Joe Tebelskis. Speech recognition using neural networks. PhD thesis, Siemens AG, 1995.
[7] Ananth Sankar and Chin-Hui Lee. A maximum-likelihood approach to stochastic matching for
robust speech recognition. Speech and Audio Processing, IEEE Transactions on, 4(3):190–202, 1996.
[8] Yixiong Pan, Peipei Shen, and Liping Shen. Speech emotion recognition using support vector
machine. International Journal of Smart Home, 6(2):101–108, 2012.
[9] Sadaoki Furui. History and development of speech recognition. In Speech Technology, pages
1–18. Springer, 2010.
[10] Sadaoki Furui. 50 years of progress in speech and speaker recognition. SPECOM 2005, Patras,
pages 1–9, 2005.
52

[11] Taabish Gulzar, Anand Singh, Dinesh Kumar Rajoriya, and Najma Farooq. A systematic analysis
of automatic speech recognition: an overview. Int. J. Curr. Eng. Technol, 4(3):1664–1675, 2014.
[12] Sadaoki Furui. Cepstral analysis technique for automatic speaker ver- ification. Acoustics,
Speech and Signal Processing, IEEE Transactions on, 29(2):254–272, 1981.
[13] Marvin R Sambur and Lawrence R Rabiner. Statistical decision approach to the recognition of
connected digits. The Journal of the Acoustical Society of America, 60(S1):S12–S12, 1976.
[14] LR Rabiner and JG Wilpon. A simplified, robust training procedure for speaker trained, isolated
word recognition systems. The Journal of the Acoustical Society of America, 68(5):1271–1276, 1980.
[15] Kai-Fu Lee and Hsiao-Wuen Hon. Large-vocabulary speaker- independent continuous speech
recognition using hmm. In Acoustics, Speech, and Signal Processing, 1988. ICASSP-88., 1988
International Conference on, pages 123–126. IEEE, 1988.
[16] Kenji Kita, T Kawabaa, and Toshiyuki Hanazawa. Hmm continuous speech recognition using
stochastic language models. In Acoustics, Speech, and Signal Processing, 1990. ICASSP-90., 1990
International Conference on, pages 581–584. IEEE, 1990.
[17] Hiroyuki Suzuki, Heiga Zen, Yoshihiko Nankaku, Chiyomi Miyajima, Keiichi Tokuda, and
Takamitsu Kitamura. Speech recognition using voice-characteristic-dependent acoustic models. In
Acoustics, Speech, and Signal Processing, 2003. Proceedings.(ICASSP?03). 2003 IEEE International
Conference on, volume 1, pages I–740. IEEE, 2003.
[18] A Revathi and Y Venkataramani. Speaker independent continuous speech and isolated digit
recognition using vq and hmm. In Communi- cations and Signal Processing (ICCSP), 2011 International
Conference on, pages 198–202. IEEE, 2011.
[19] Mohit Dua, RK Aggarwal, Virender Kadyan, and Shelza Dua. Punjabi automatic speech
recognition using htk. IJCSI International Journal of Computer Science Issues, 9(4):1694–0814, 2012.
[20] Ankit Kuamr, Mohit Dua, and Tripti Choudhary. Continuous hindi speech recognition using
gaussian mixture hmm. In Electrical, Electron- ics and Computer Science (SCEECS), 2014 IEEE Students?
Conference on, pages 1–5. IEEE, 2014.
[21] Deepak Baby, Jort F Gemmeke, Tuomas Virtanen, et al. Exemplar-based speech enhancement for
deep neural network based automatic speech recognition. In Acoustics, Speech and Signal Processing
(ICASSP), 2015 IEEE International Conference on, pages 4485–4489. IEEE, 2015.
[22] Quoc Bao Nguyen, Tat Thang Vu, and Chi Mai Luong. Improving acoustic model for english asr
system using deep neural network. In Computing & Communication Technologies-Research, Innovation,
and Vision for the Future (RIVF), 2015 IEEE RIVF International Conference on, pages 25–29. IEEE, 2015.
[23] S. Lee, Y. Lee, and N. Cho. Multi-stage speech enhancement for automatic speech recognition. In
2016 IEEE International Conference on Consumer Electronics (ICCE), pages 383–384, Jan 2016.
[24] Bhadragiri Jagan Mohan and NR Babu. Speech recognition using mfcc and dtw. In Advances in
Electrical Engineering (ICAEE), 2014 International Conference on, pages 1–4. IEEE, 2014.
53

Enhance the security mechanism in Cloud Computing using Diffie-Hellman Algorithm
Mr. Kanwarjeet Singh Research Scholar,
Department of Information Technology & Engineering, CQ University, 0278845,Australia [email protected]
Ms. Amandeep Kaur Assistant Professor, Department of Computer Science,
Dev samaj College for Women, Ferozepur, Punjab. [email protected]
ABSTRACT
Cloud security is the main issue over the wide area network. Cloud computing provide
various types of services like software, platform and application as a service. These services
are accessed through internet. Cloud provide services on demand, user can pay according to
access. That's why today organizations prefer cloud services. Cloud computing provide
various services but security is the main issue in cloud. In this paper security enhanced on user
end by image pattern and further enhance security on data using diffie-hellman algorithm.
This approach prevents threats and enhance the security.
Keywords: Cloud Computing, Pattern based security, Diffie-Hellman algorithm.
INTRODUCTION
Cloud computing is a new emerging technology. Cloud is a broad solution that delivers
information technology as a service. [1] Cloud computing ropes the data and applications that
are used on the remote servers. It allows the users to access the personal files with the help of
internet. Cloud computing support services like: SAAS, IAAS, PAAS. To offer these
services, the service providers are used. The provider helps to deliver the storage and
computing services by the use of internet access. To store the data in cloud computing, it
makes ubiquitous data access possible. They can execute their applications using cloud
computing platforms with software deployed in the cloud which reduces the upheaval task
regarding full software installation and continual up gradation on their local devices.
Components of Cloud Computing: Cloud computing consists of three main components.
Each component in cloud computing plays a role that is specifically assigned to it.
54

Fig 1: Cloud Computing
Clients: The first component is clients or we can say users. In the cloud computing, the
information is managed by end users. They interact with the clients to manage information
related to clouds. The clients are further classify into three categories [2]:
a. Mobile Client: The clients can be mobile in nature. It includes windows mobile smart
phone, like a Blackberry or I Phone.
b. Thin: These clients do not do computation work. They only used to display information.
These clients don't have the internal memory; the servers do all the work for the clients.
c. Thick: These clients use different browsers to connect the internet cloud. These browsers
includes internet explorer, Mozilla Firefox or Google Chrome to connect to the Internet
cloud.
Datacenter: The second component is datacenter. It is a collection of servers. These servers
host the various applications. End users interact with datacenter to access various
applications.
Now days, the concept called virtualization is used to install a software that allow multiple
users to use applications virtually. Distributed Servers: Distributed servers are one of the
important components of cloud computing. These servers are present throughout the Internet.
These server hosts the various applications.
Aspects of cloud management systems:
The cloud management system is a combination of software and technologies, these
technologies are designed to manage many cloud environments. The cloud management
system is able to manage a pool of heterogeneous compute resources. It provides the access to
55

end users and it also helps to monitor security and manage resource allocation. The cloud
management system covers frameworks for workflow structure mapping and management.
The cloud management system has characteristics like, it has the ability to manage multiple
platforms from a single point of reference. [3] It is able to deal with system failures
automatically with abilities such as self tracking and monitoring, an explicit notification
mechanism.
Introduction of Diffie-Hellman algorithm: The Diffie-Hellman algorithm depends for its
effectiveness on the difficulty of computing discrete logarithms. We can define the discrete
logarithm in the following way. First, we define a primitive root of a prime number p as one
whose powers modulo p generate all the integers from 1 to p 1. That is, if a is a primitive root
of the prime number p, then the numbers are distinct and consist of the integers from 1 through
p 1 in some permutation.
For any integer b and a primitive root a of prime number p, we can find a unique exponent I
such that
The exponent i is referred to as the discrete logarithm of b for the base a, mod p.
LITERATURE SURVEY
Sumit Goyal,(2013): In which author discuss about cloud computing types. These types are
public cloud, private cloud, hybrid cloud and community cloud. Cloud computing is a
distributed and virtualized system; it provides a large range of users with distributed access to
scalable and virtualized infrastructure over the internet. Cloud computing provides various
types of services like hardware services and software services over the internet.
Cong Wang, et.al, (2010): In this paper, author discuss about the security in cloud
computing. Cloud Computing consists the architecture of IT enterprise. The cloud computing
has the many advantages in the information technology field: on demand self service,
ubiquitous network access, location independent resource pooling, rapid resource elasticity,
usage-based pricing and transference of risk. [4] Cloud computing brings the new and
challenging security threats towards users outsourced data. For this purpose, cloud service
providers are used. These are the separate administrative entities. The data correctness is the
big issue in cloud computing. For the cloud computing, third party auditor is used. It uses the
56

two main requirements as: the third party auditor should be able to efficiently audit the cloud
data storage without demanding the local copy of data and the auditing process should bring
in no new vulnerabilities towards user data privacy. Here author describes the public key
based homomorphism authenticator. For this the random masking is used. It helps to achieve
the privacy preserving public cloud data auditing system, which meets all requirements.
Sonal Guleria, Dr. Sonia Vatta, (2013): describes that the Cloud computing is emerging
field because of its performance, high availability, least cost and many others. In cloud
computing, the data will be stored in storage provided by service providers. Cloud computing
provides a computer user access to Information Technology (IT) services which contains
applications, servers, data storage, without requiring an understanding of the technology. An
analogy to an electricity computing grid is to be useful for cloud computing. To enabling
convenient and on-demand network access to a shared pool of configurable computing
resources are used for as a model of cloud computing.[5] Cloud computing can be expressed
as a combination of Software-as-a-Service which refers to a service delivery model to
enabling used for business services of software interface and can be combined creating new
business services delivered via flexible networks and Platform as a Service in which Cloud
systems offering an additional abstraction level which supplying a virtualized infrastructure
that can provide the software platform where systems should be run on and Infrastructure as a
Service which Providers manage a large set of computing resources which is used for storing
and processing capacity. But still many business companies are not willing to adopt cloud
computing technology due to lack of proper security control policy and weakness in
safeguard which lead to many vulnerability in cloud computing. This paper has been written
to focus on the problem of data security. To ensure the security of users' data in the cloud, we
propose an effective and flexible scheme with two different algorithms .A user can access
cloud services as a utility service and begin to use them almost instantly. These features that
make cloud computing so flexible with the fact that services are accessible anywhere any time
lead to several potential risks. The key intent of this research work is to investigate the
existing security schemes and to ensure data confidentiality, integrity and authentication.
Shuai Han, et.al, (2011): In this paper, author uses a third party auditor scheme. Cloud
computing technology acts as next generation architecture of IT solution. It enables the users
to move their data and application software to the network which is different from traditional
solutions. [6] Cloud computing provides the various IT services, due to which it contains
57

many security challenges. The data storage security is the big issue in cloud computing. In
this paper, author purpose a new scheme called third party auditor. It helps in providing the
trustful authentication to user.
Tejinder Sharma, et.al, (2013): in this paper author discuss about the cloud computing. As,
the computer networks are still in their infancy, but they grow up and become sophisticated.
Cloud computing is emerging as a new paradigm of large scale distributed computing. It has
moved computing and data away from desktop and portable PCs, into large data centers. It
has the capability to harness the power of Internet and wide area network to use resources that
are available remotely.[7] There are many security issues in the cloud computing. In this
paper, author discuss about the various scheduling problems. One of the challenging
scheduling problems in Cloud datacenters is to take the allocation and migration of
reconfigurable virtual machines into consideration as well as the integrated features of
hosting physical machines. In order to select the virtual nodes for executing the task, Load
balancing is a methodology to distribute workload across multiple computers. The main
objective of this paper to propose efficient and enhanced scheduling algorithm that can
maintain the load balancing and provides better improved strategies through efficient job
scheduling and modified resource allocation techniques.
Pradeep Bhosale etal, (2012): discuss that today's world relies on cloud computing to store
their public as well as some personal information which is needed by the user itself or some
other persons. Cloud service is any service offered to its users by cloud. As cloud computing
comes in service there are some drawbacks such as privacy of user's data, security of user data
is very important aspects. In this paper author discuss about the enhancement of data security.
Not only this makes researchers to make some modifications in the existing cloud structure,
invent new model cloud computing and much more but also there are some extensible
features of cloud computing that make him a super power.[8] To enhance the data security in
cloud computing used the 3 dimensional framework and digital signature with RSA
Encryption algorithm. In 3 Dimensional frameworks, at client side user select the parameters
reactively between CIA (Confidentiality, Integrity & Availability) and before actual storing
the data in cloud a digital signature is created using MD 5 Algorithm and then RSA
Encryption algorithm is applied then it stored on cloud.
Jasmin James, et.al, (2012): discuss about the security in cloud computing. Cloud
computing is fast growing area in computing research. With the advancement of the Cloud,
many new possibilities are coming into picture, like how applications can be built and how
different services can be offered to the end user through Virtualization. There are the cloud
58

services providers who provide large scaled computing infrastructure defined on usage, and
provide the infrastructure services in a very flexible manner. The virtualization forms the
foundation of cloud technology where [9] Virtualization is an emerging IT paradigm that
separates computing functions and technology implementations from physical hardware. By
using virtualization, users can access servers without knowing specific server details. The
virtualization layer will execute user request for computing resources by accessing
appropriate resources. In this paper, author firstly analyses the different Virtual Machine
(VM) load balancing algorithms. Secondly, a new VM load balancing algorithm has been
proposed and implemented for an IaaS framework in simulated cloud computing
environment.
Jen-Sheng Wang, et.al,(2011): in this paper, author about the various methods and
techniques which helps in managing the security of cloud computing. The information
security is critical
issue in the age of Internet. [10] The information is valuable and important. The cloud
computing has made information security managing a most significant and critical issue. The
information security in cloud computing requires many factors. In this paper, the Key Success
Factors are used. These factors include many aspects as: external dimension, internal
dimension, technology dimension, and execution dimension. These factors are used to
purpose a new scheme, which is used to overcome the various problems in cloud computing
that are related to the security.
PURPOSED WORK Diffie-Hellman algorithm is used with the AES. The AES is very
complexity and its size is very large. To reduce the system complexity we use Diffie-Hellman
algorithm. It helps to make the cloud computer more efficient than the existing one. The
Diffie-Hellman algorithm is used to provide the security to the system and it also helps in the
management of the information. All we know that security is a major issue in cloud
computing because data is stored of some far location from user so number of attacks is
possible on cloud computing like:
�H Denial of Service (DoS) attacks
�H Cloud Malware Injection Attack
�H Authentication Attacks
�H Man In The Middle Cryptographic Attacks
So here to prevent these attacks we are going to propose a new schema which is based on
diffie Hellman. It works like in initial stage it will shows us a simple authentication with user
name and password. After that Diffie-Hellman is used to encrypt data. All the proposed
architecture is shown as following:
59

Fig 2: User Authentication Here user enters user name and password and click on login Diffie Hellman Algorithm
�H Alice and Bob agree to use a prime number p = 23 and base g = 5.
�H Alice chooses a secret integer a = 6, then sends Bob
A = ga mod p A = 56 mod 23 A = 15,625 mod 23 A = 8
�H Bob chooses a secret integer b = 15, then sends Alice
B = gb mod p B = 515 mod 23 B = 30,517,578,125 mod 23 B = 19
�H Alice computes s = Ba mod p
s = 196 mod 23 s = 47,045,881 mod 23 s = 2
�H Bob computes s = Ab mod p
s = 815 mod 23 s = 35,184,372,088,832 mod 23 s = 2
RESULTS AND DISCUSSIONS
The new technology to enhance security is based on the Diffie-Hellman algorithm. As we
know that the data is stored on far location in the cloud computing so we need high security
and processing speed to make it confidential. Here the graph shows the performance of our
proposed scenario. Bars in the graph are representing time taken by algorithm to do
encryption. Different experimental results are shown in the graph which is done on the basis
of different experiments.
60
Fig 3: Comparison evaluation Now this graph contains the response time graph for previous
scenario. At its y axes there are number of characters and the bars are showing time taken for
encryption.
Table 1: results comparison
Number of
characters
Time taken
by Proposed
scenario
Time taken
by previous
scenario
5 1.25 sec 5 sec
4 1 sec 4 sec
7 1.75 sec 7 sec
3
6
0.67 s
15 sec
ec
3 sec
6 sec
In our proposed schema the complexity of algorithm is not too much so it can provides much
security in very less time as compare to base paper but the algorithms used in base paper are
highly complex so they takes lots of steps and also time for encryption.
CONCLUSION AND FUTURE SCOPE
Conclusion The schema is proposed to enhancement of security and performance of cloud computing
during network attacks. Cloud needs a high performance as well as security because the data
on cloud is stored at some far place. A new come up is built by the integration of authentication
and Diffie-Hellman algorithm. Experiment is done in NetBeans using cloud-sim simulator
and results are shown in above section.
Future work
As the security is growing day by day attackers are also being more cognizant. Each security
schema has some weak points i.e. if attacker knew them then he can bypass security. So to
make system more secure we can work on the weakness of algorithm and can further enhance
the security.
REFERENCES
[1] Cloud computing principles, systems and applications NICK Antonopoulos
http://mgitech.wordpress.com.
61

[2] Anthony T.Velte, Toby J.Velte, Robert Elsenpeter, Cloud Computing A Practical Approach, TATA
McGRAW-HILL Edition 2010.
[3] H T T P : / / W W W. H O W S T U F F W O R K S . C O M / C L O U D - C O M P U T I N G / C L O U D -
COMPUTING1.HTM
[4] Sonal Guleria1, Dr. Sonia Vatta2, to enhance multimedia security in cloud computing environment
using crossbreed algorithm, Web Site: www.ijaiem.org Email: [email protected],
[email protected], Volume 2, Issue 6, June 2013 [5] Cong Wang, Qian Wang, and Kui Ren,
Wenjing Lou, Privacy-Preserving Public Auditing for Data Storage Security in Cloud Computing,
978-1-4244-5837-0/10/$26.00 ©2010 IEEE [6] Shuai Han, Jianchuan Xing, ensuring data
storage security through a novel third party auditor scheme in cloud computing, roceedings of
IEEE CCIS2011
[7] Tejinder Sharma, Vijay Kumar Banga. Efficient and Enhanced Algorithm in Cloud Computing,
International Journal of Soft Computing and Engineering (IJSCE) ISSN: 2231-2307, Volume-3,
Issue-1, March 2013
[8] Pradeep Bhosale Priyanka Deshmukh Girish Dimbar Ashwini Deshpande , Enhancing Data
Security in Cloud Computing Using 3D Framework & Digital Signature with Encryption,
International Journal of Engineering Research & Technology (IJERT) Vol. 1 Issue 8, October –
2012
[9] Jasmin James, Dr. Bhupendra Verma, efficient VM load balancing algorithm for a cloud
computing environment, Jasmin James et al. International Journal on Computer Science and
Engineering (IJCSE)
[10] Jen-Sheng Wang, Che-Hung Liu, Grace TR Lin, How to Manage Information Security in Cloud
Computing.
62

OPTIMIZATION AND ITS APPLICATIONS
Manju Dhand
Assistant Professor in Mathematics,
D.M. College, Moga
ABSTRACT
Optimization is a buzzword in the industry today. Optimization means 'to make an
optimum utilisation of resources'. In the present era of global and cut-throat competition,
only those business enterprises can survive and grow which follow the policy of
optimization. The organisations are investing heavily in their infrastructures, in order to
manage their business effectively. Every economy has scarce natural resources. In order
to strengthen the pace of economic development, optimum utilisation of these resources
becomes all the more vital. Taking the field of finance, the concept of optimum capital
structure is all the more essential. It is only after having an optimal capital structure that a
business can make efficient utilisation of its funds. A business enterprise has to face
various problems like assignment of people on jobs, transportation of goods,
replacements of articles, minimisation of costs, maximisations of profits, network
analysis, queuing problem and many more. All these problems can be solved
quantitatively by following the concept of optimization which includes various
mathematical techniques for different kinds of problems under the subject of 'Operations
Research'. This paper throws light on various applications of optimization theory in
mathematics, engineering design, computer science, finance, business and health care.
The inns and outs of these techniques will be discussed to help the organisations to do the
best in their respective areas.
INTRODUCTION
Optimization is being used by all of us, although we are not aware of the term. One has to
take certain decisions for himself and for others. A student has to decide which course he
should choose for study. A person seeking employment has to decide which job he should
choose for service. Therefore, one has to develop his talents in such a way that he is in a
position to take a correct decision at a proper time. An effective decision depends on many
factors, which may be economic, social and political. For example starting of a new
factory at a place would depend on economic, factors such as construction costs, labour
63

costs, availability of raw materials, transportation costs, taxes, energy, pollution control
costs etc. On the other hand, starting of a new Management Institute in a state would
depend on the number of students available for further studies and also on state and local
politics. Decision making in business and industry is very difficult since it affects many
people. In business, the decision-maker is not only faced with a large number if interacting
variables but has to take into account the actions of the other competitions, over which he
has no control. Both the quantitative and qualitative (i.e. intuition, experience, common
sense, facts, figures and data) analyses are required to make most economical decision.
Undoubtedly, we can say, we always try to make best of the deal. Here comes the need of
the concept of optimization. The science and art of optimization is termed as 'Operations
Research'. Operations research has gained significance in applications like lean
production, world-class manufacturing system (WCM), Benchmarking, Just-in Time
(JIT) inventory techniques. It is an approach to problems of how to co-ordinate and
control the operations within an organisation. Following is an example to understand the
concept clearly. In order to run an organisation effectively as a whole the problem arises
frequently is of co-ordination among the conflicting goals of its various functional
departments. Consider the problem of stocks of finished goods. The various departments
of the organisation may like to handle this problem differently. To the marketing
department, stock of large variety of products is a means of supplying the company's
customers with what they want and where they want it. Clearly the fully stocked ware-
house is of prime importance to the company. The production department argues for long
production runs preferably on a smaller product range, particularly if there is a significant
time loss when production is switched from one variety to another. On the other hand, the
finance department sees stocks kept as capital tied up unproductively and argues strongly
for their reduction. Finally the personnel department sees great advantage in labour
relations if there is a steady levels of production leading to steady employment. To
optimise the whole system, the decision maker must decide the best policy keeping in
view the relative importance of objectives an validity of conflicting claims of various
departments from the perspective of whole organisation. In simple words, optimization
means making the best of anything, whether it is physical resources or human resource,
Optimization is to make perfect, effective or functionally viable use of resources.
ORIGIN AND HISTORY
During World War II, Britain was having very limited military resources, an urgent need was
64

felt to allocate the scarce resources in an effective manner to the various military operations
and to the activities within each operation. Therefore the British and the American
militarymanagement invited large number of scientists to apply a scientific approach to many
strategic and tactical problems. Their efforts were instrumental in winning the Air Battle of
Britain', 'Battle of North Atlantic' and the Island Campaign' in the Pacific. The name
? Operations Research (O.R.) came directly from the context in which it was used and
developed viz. 'Research on Military Operations'. At the end of World War II, the scientists of
this group moved to different sections. eg., transportation, health, education etc. with a
conviction that the operations under the control of management can be analysed scientifically
and the optimum method for carrying out operations can be investigated. In India, OR got its
formal recognition with the formation of O.R. society in 1957. The society became the
member of the International Freedom of O.R. scientists in 1959. The publication of the journal
OPSEARCH by ORSI in 1964 further added to the growth of O.R. activities in India. In recent
years, Operations Research has had an increasingly great impact on the management of
organisation. Both the number and variety of its applications continue to grow rapidly. The
subject is also being used widely in other types of organisations, including business and
industry. Many industries including aircraft and missile, automobile, communication,
computer, electronics, mining, paper, petroleum and transportation made wide spread use of
O.R. in determining their strategical decisions scientifically. In addition to it, the subject has
been used by industries, the financial institutions, government agencies and hospitals also.
? According to D.W. Miller and M.W. Starr ,"O.R. is applied design theory. It uses any
scientific, mathematical or logical means to attempt to cope with the problems that confront
the execute when he tries to achieve a thoroughgoing rationality in dealing with his decision
problems.'
hgoing rationality in dealing with his decision problems.'
THE OPERATIONS RESEARCH APPROACH
O.R. represents an integrated framework to help make decision. To have clear understanding
of this framework the following sequential steps are to be kept in mind:
1. Orientation 2. Problem definition
3. Data collection 4. Model formulation
5. Solution 6. Model validation and Output analysis
7. Implementation and Monitoring
65
A brief summary of steps, process activities and process output is presented below.
Process Steps
Process Activities
Process output
Step
I
Observe
the problem environment
Visits
Conferences
Observations Research
Sufficient information
and
support to proceed
and nature of
solution requested
Model that works under stated
environmental constraints
Sufficient inputs to operate and test model
Solution that supports current organisational objectives
Improved working and
Management support for long
Step
II
problemDefine and analyse the
Define objectivesDefine limitations
Step
III
Develop a Model
Define
interrelationships
Formulate equations
Use known O.R. model
Search alternate model
Step IV Select Appropriate data input
Analyze internal-external data Analyse fact Collect opinions Use
computer data banks,
Step
V &
VI
Provide
a
solution Qualified
the model
Test the
model
Final limitations Update the
model
Step
VII
Implement the Solution
Resolve behavioural issues
Sell
the idea
and
give explanations
Get Management involved
run operations of model.
?
following key elements of any optimization problem.
?? Decision variables, which are numerical representations of the available actions
or choices.
Examples include production levels, price settings, and capital or
human resources allocations.
An objective that is the goal of the optimization, something to be achieved. This
goal must be measureable. Examples include maximising profit, minimising
distance travelled and minimising unused raw materials.
? Constraints specifying requirements or rules, placing limits on how the objective
can be purchased by limiting the permissible values of the decision variables.
Some examples are machine processing capacity per hour, customer demand by
sales territory, raw materials availability and bill of material in manufacturing or
assembly and budgetary restrictions.
The process of optimization usually flows like: Raw data-> Standard Reports -> Adhoc
Reports and OLAP -> Descriptive Modelling -> Productive Modelling -> Optimisation
Modelling. Each stage forms the foundation upon which the next stage is built. And
each stage adds value to the data and information received from the preceding stages.
A well defined approach to optimization begins with a rigorous description of the
66

MAJOR TECHNIQUES OF OPTIMIZATION
Some of the most commonly used techniques by a progressive management in
decision-making process are:
1. Linear programming- Allocation of Resources, Asset management
2. Decision Theory - How to make decisions in deterministic probabilistic
environments
3. Network Theory- Use of CPM and PERT for the purpose of planning,
analysing, scheduling and controlling the progress.
4. Inventory Control- Controlling the inventory, how much to produce, finding
lead time, recorder level etc. How to minimize the sum of three conflicting
inventory costs. Carrying cost, Storage costs and Ordering costs.
5. Queuing Theory- How to reduce waiting time of customers, when to establish
new counter for facility
6. Sequencing: To determine a sequence of performing given jobs if the
objective is to minimize the total efforts.
7. Game theory: For assessing the impact of a decision on one's competitors.
8. Simulation: It is a process of designing an experiment which will duplicate or
present nearly as possible the real situation and then watching it what does
happen.
9. Transportation Problem: For transporting goods from one place to another.
APPLICATIONS OF OPTIMIZATION:
Whenever there is a problem of optimization there is a scope of application of techniques
of O.R.
1. In Industry: In the field of industrial management, there is a chain of problems
starting from the purchase of raw materials to the dispatch of finished goods. The
management is interested in having an overall view of the method of optimizing profits.
The various operations or processes are:
* What is to be manufactured?
* What amount of raw material will be available for production?
* What, how and when to purchase it at the minimum procurement cost?
* What amount of raw material will be used for the production? And how it is to be
allocated or optimum allocation of limited resources such as men, machines,
materials, time and money.
* What amount is to prepared, keeping the constraints of resources and costs in mind?
Above questions come under the category of Asset allocation, where the techniques of
linear programming can be used.
67

* Who will prepare the product? (Assigning right job to right person). (Assignment
model)
* Where the finished goods will be stored? (Transportation model)
Project scheduling: By what time the project will he completed, and finding out the
critical activities, the activities which the organization, cannot afford to he delayed.
(PERT-CPM) Selection of advertising media. Demand forecast and stock levels. To
decide best time launch a particular product Inventory management: How much to
prepare and when identifying the safety stock, reorder level. (Inventory Model)
Location and size of warehouse or new plant distribution centers and retail outlets. .
Manpower planning, wage salary administration. Determining optimal number of
persons for each service centre.
So in the nut shell, the organization uses the techniques of optimization in all the four
major departments of organization viz. purchasing, procurement, exploration, in
production management, project planning. Marketing management and personnel
management.
2. Engineering design: Optimization theory provides a formal basis for decision
making in a Variety of applications in engineering design Engineering Optimization
aims to serve all disciplines within the engineering community. The major areas of
concern in this are: planning, design, construction and operation. Find out the
optimal design of the product to be manufactured. Making efficient usage of the
resources for that particular machine and product. Steel industry in India is using the
techniques of Operation research in finding product mix, inventory management, and
optimizations of designs, allocation and transportation of goods.
3. Health Care: Health care industry is also using the techniques of operations research
for its operations, some of the operations are the same as that of any of the business
organization, like buying raw materials like bandages etc., allocation of right person to
the right job. But the health care sector is implementing these OR techniques to
simultaneously reduce cost and improve quality of care, contradicting the notion that
improving quality and cost of health care has to involve trade-offs. The various
operations in health sector, where optimization is required are: 1. Assignment of right
doctor to the patient. 2. Assignment of Rooms to the patients. 3. How to reduce wailing
time of the patients? 4. Finding out the location for the health centre. 5. Designing the
medicine depending on the material used and its cost. The Institute for Healthcare
68

increases in many fold and it becomes unable to provide remedial action for the same.
The Preventive Health Care Facility Location (PHCFL) problem is to identify optimal
locations for preventive health care facilities so as to maximize f participation. People
should have more flexibility to select service locations Preventive health care programs
aim to save lives and contribute to a better quality of life by diagnosing serious mcdical
conditions early and reducing the likelihood of life-threatening disease. Evidence shows
that successful treatment of some health problems is more likely if an illness is
diagnosed at an early stage. Facility location decisions, are a critical element in strategic
planning in preventive health care programs.
4. Computer Science- The field of computer science is using the optimization for
hardware as well as software optimization. In hardware, it deals with processor, memory
and other hardware resources, whereas in case of software optimization, we deal with
designing software which will run by utilizing the system resources to maximum
optimal level possible. Compiler optimization is the process of tuning the output of a
compilor to minimize or maximize some attributes of an executable computer program.
The most common requirement is to minimize the time taken to execute a program, a less
common one is to minimize the amount of memory occupied. The growth of portable
computers has created a market for minimizing the power consumed by a program.
Compilor optimization is generally implemented using a sequence or optimizing
transformations, algorithms which take a program and transform it to produce an output
program that uses resources. Routing problems in case of networking arc also using the
concepts of finding shortest distance from source to destination, finding flow of data
through a particular channel
Program optimization or Software optimization is the process of modifying a software
system to make some aspect of it work more efficiently or use fewer resources. In
general, a computer program may be optimized so that it executes more rapidly, is
capable of operating with less memory storage or other resources, or draw less power.
Here the concept of code Optimization which is the process of transforming a piece of
code to make more efficient (either in terms of time or space) without changing its
output or sideffects. The only difference visible to the code's user should be that runs
faster and consumes less memory.
Computational tasks can be performed in several different ways with varying efficiency.
For example, consider the following C code whose intention is to obtain the sum of all
integers from 1 to n:
69

int i, sum = 0; for i=1;i,=n;i++) t=4*i; sum=i+t; printf("sum:%d\n",sum); in the above
code t is calculated n number of times, which will lead to wastage of processing time. This
code can be rewritten int, sum=0; t=4*i; for(i=1;i,<=n;i++) sum=i+t;
printf("sum:%d\n",sum); Search engine optimization (SEO) is the process of improving
visibility of a website or a web page in search engine. In general the site listed first will
attract the more visitors. Optimizing a website may involve editing its content and
associated coding of both increase its relevance to specific keywords and to remove
barriers in between. Promoting a site to increase the number of clicks. The acronym
"SEO" can refer to "search engin optimizers." a term adopted by an industry of
consultants to carry out optimization projects on behalf of clients, and by employees who
perform SEO services in-house. Search engine optimizers may offer SEO as a stand-
alone service or as a part of a broader marketing campaign. Resource optimization: The
techniques of OR can be applied for allocation of resources (like the job done by
operating system, operating system perform job of resource allocation to various
processes (here, resource may be Input/output device, memory, processor time).
5. Agriculture: With population explosion and subsequent shortage of food every
country is facing the problem of optimum allocation of land to various crops in
accordance with climatic conditions and available facilities. The problem of optimal
distribution of water from various water resources is faced by each developing country
and a good amount of research can be done in this direction.
ROLE OF COMPUTERS
Use of a digital computer has become an integral part of the O.R. approach to decision-
making. The computer may be required due to the complexity of the model, volume of
data required or the computations to be made. In other words, computer in today's
scenario has become an indispensable tool for solving Operations Research problems.
Many O.R. techniques are available today in the form of 'canned' programmes.
The O.R. problems are time consuming and involve tedious computations. Even a simple
problem with few variables take a long time to solve manually and even by a hand
calculator. For a highly complex, real life business problem, the task of performing
computations, even with a hand calculator, is simply out of question. For this reason
many of the techniques were not widely used until 60's. The advent of computers
accelerated the wide use of O.R. techniques for solving complex business problems faced
70

by managers and administrators in business and government. Computers provide the
much needed computational support for many of these techniques. The automation of
computational algorithm allows decision- makers to concentrate on problem's formulation
and the interpretation of the solutions. Major computer manufacturer and vendor have
developed software packages for the various computer systems providing computational
support for problems to be solved V the application of O.R. techniques. Further, commercial
software houses and academic departments in universities have also produced software
packages for solving the various Operations Research problems. Computer manufacturers
like IBM, CDC, Honeywell, UNIVAC, ICL, etc. have invested substantial amounts in
developing software programs for solving the optimizing, scheduling, inventory, simulation
and other Operations Research problems. The role of computers in solving current as well as
future problems can be explained with the help of following example :
Most of linear programming models (of even a small-scale industry) involve 200 to 300
decision variables with 10 to 200 constraints. It is believed that most of the business problems
particularly the blending problems of oil refineries will result an LP model with 4,000 to
5,000 variables and 3,000 to 3,500 constraints. The problem of such a magnitude is virtually
impossible to solve through manual computations. Such type of a problem may be solved by
application of sophisticated software packages, e.g., IFP/OPTIMUM, developed' by
EXECUCOM Systems Corporation, Austin in Texas. The aforesaid package may be used to
solve a linear programming, integer programming and non-linear programming problem
with large number of variables and constraints. In addition to finding optimal solution, IFPS
(Iteractive Financial Planning System) OPTIMUM package can be directed to perform post-
solution analysis in two parts, viz., DECISION ANALYSIS and CONSTRAINT
ANALYSIS.
GROWTH OF OPERATIONS RESEARCH IN DIFFERNET SECTORS
The sciencere efforts were made by National productivity council, National Industrial
Development corporation, Administrative Staff College Hyderabad, and Indian Institutes of
Management etc. in the direction of accepting O.R. methods. Organised industries in India
are becoming conscious of the role of O.R. and a good number of them have well-trained
O.R. teams. Some of these organisations are 'Indian Airlines', Railways, Defence
organisation, Fertiliser Corporation of India, Hindustan Steel Ltd., Tata Iron and Steel Co.,
TELCO, DCM, CSIR, STC, BHEL, SAIL, ONGC, etc. Assignment models have been used
71

by Kirloskar company for allocation of their salesmen to different areas so as to maximize the
profit. Linear programming models have been used to assemble various diesel engines at the
lowest possible cost. D.C.M, Calico and Binny's have been using LP models for cotton
blending. A number of organisations are utilising OR techniques for solving problems related
to staffing, production planning, blending, product mix, maintenance, inspection,
advertising, capital budgeting, investment and the like.
CONCLUSION
To survive in the wide-spread global competition and dynamic market scenarios, there is a
high pressure on the management to make economic decision. One of the essential
managerial skills is ability to allocate and utilise resources appropriately in the efforts of
achieving the optimal performance efficiently. Decision-makers have to consider a large
number of factors and large
amount of data while taking the decision. Operations research techniques can be very helpful
in such situations and the success stories of implementation of OR techniques in India and
abroad has proved this thing that these techniques can be a boon for the industry. Also the
availability of software packages have increased the benefits of OR to many fold. The future
of OR is very promising and its proper implementation and usage will prove to a harbinger of
success for every organisation in any sector.
REFERENCES
[1] Budnick F.S. Meleavy Dennis, Mojena Richard, Principles of Operation Research for
Management, Second Edition; 1999
2] B. Erkan, M.C. Jothishankar, T. Ekrem, W. Teresa, „Evolution of operations management: past,
present and future?, Management Research News.
[3] Chawla K.K., Gupta Vijay, Sharma B.K., „Operations Research?, Kalyani Publishers, Fourteenth
Edition, 2009
[4] Kapoor, V.K. „Operations Reserach?, Sultan Chand & Sons, Seventh Edition, 2001
[5] Mahadevan, B, „Operations Management: Theory and practice?, Pearson Education, Third
Edition 2008
[6] Sharma, J.K., „Quantities techniques: Theory and applications?, Macmillan, Third Edition.
[7] Sharma, S.D., „Operation Research, Kdear Nath Ram Nath and Co. World Wide Web
www.google.com
72

A REVIEW ON SENSOR SCHEDULING METHODS USING THE CONCEPT OF PAIRED-SENSORS
Amit Grover
SBSSTC, Ferozepur city.
amitgrover_321@rediffmail.
Ginish
SBSSTC, Ferozepur city.
ABSTRACT:
The wireless sensor networks are utilized in a lot much application now days. The
wireless sensor network have made their place in the healthcare monitoring, military
applications, environment analytical studies, weather prediction, pollution level
analysis, etc like fields in the recent years. The popularity of the wireless sensors is
rising with the new concept of smart cities. To convert the cities in smart cities it
becomes very important to get the more and more data from the city in order to create
the perfect cities. The sensor networks are the most adaptable solutions for such
applications. The main problem lies with the lifetime of the sensor networks which
must be increased up to the significant level to reduce the overall sensor network
deployment costs. The researchers have already worked on energy efficient routing,
data aggregation, clustering and other schemes. In this paper, we are going to propose
the new-age sensor scheduling algorithm which schedules the sensors according to
time after creating the sensor pairs. The paired sensors nodes will be scheduled to
work one after one with the significant time slot computed with the optimal
parameters. The variety of experiments would be conducted to evaluate the overall
performance of the sensor network with time-scheduling of the paired sensors.
KEYWORDS: Wireless sensor network, energy efficient WSN, paired sensor
scheduling, time- based scheduling.
INTRODUCTION
Wireless sensor network (WSN) refers to a bunch of spatially distributed and dedicated
sensors for observation and recording the physical conditions of the atmosphere and
transmitting the collected information to a central location. WSNs evaluate
environmental conditions like sound, temperature, pollution levels, wind speed,
humidity and direction, pressure, etc. WSN were initially designed to facilitate military
operations however its application has since been extended to health, traffic, and many
73

of different consumer and industrial areas. A WSN consists of anyplace from a couple of
a whole lot to thousands of sensing element nodes. The sensing element instrumentality
includes a radio transceiver alongside Associate in Nursing antenna, a microcontroller,
Associate in nursing interfacing electronic circuit, Associate in nursing an energy
supply, sometimes a battery. The scale of the sensing element nodes can even vary from
the scale of a shoe box to as tiny because the size of a grain of mud. As such, their costs
additionally vary from a couple of pennies to many bucks counting on the practicality
parameters of a sensing element like energy consumption, procedure speed rate,
bandwidth, and memory. A sensing element node, additionally referred to as a atom,
may be a node during a wireless sensing element network that's capable of acting some
process, gathering sensory info and human action with alternative connected nodes
within the network. An atom may be a node however a node isn't continually an atom.
Motivated by this, there are varied studies examining strategies that effectively
manage energy consumption whereas minimizing adverse effects on different quality
of service necessities like property, coverage, and packet delay. for instance, [2], [3],
and [4] change routes and power rates over time to cut back overall transmission power
and balance energy consumption among the network nodes. Reference [5] aggregates
information to cut back spare traffic and conserve energy by reducing the overall
employment within the system. Reference [6] makes the observation that once
operational in impromptu mode, a node consumes nearly the maximum amount energy
once idle because it will once sending or receiving, as a result of it should still maintain
the routing structure. Consequently, several studies have examined the likelihood of
protective energy by turning nodes on and off sporadically, a way usually stated as duty
cycling. Of explicit note, GAF [7] makes use of geographic location info provided for
instance by GPS; ASCENT [8] programs the nodes to self-configure to certain a routing
backbone; Span [9] may be a distributed algorithmic rule that includes native
coordinators; and PEAS [10] is specifically meant for nodes with strained computing
resources that operate in harsh or hostile environments. Whereas the salient options of
those studies square measure quite completely different, the analytical approach is
analogous. For the foremost half, they discuss the qualitative options of the algorithmic
rule, so perform numerical experiments to hit Associate in nursing energy
savings share over some baseline system. during this paper, we tend to additionally
think about a wireless sensing element network whose nodes sleep periodically; but,
instead of evaluating the system with a given sleep management policy, we tend to
impose a price structure Associate in Nursing rummage around for an best policy
amongst a category of policies. So as to approach the matter during this manner, we'd
like to think about a so much less complicated system than those utilized in the same
studies. Thus, we tend to think about solely one sensing element node and target the
74

tradeoffs between energy consumption and packet delay. As such, we tend to don't think
about different quality of service measures like property or coverage. The only node into
account in our model has the choice of turning its transmitter and receiver off for
fastened durations of your time so as to conserve energy. Doing thus clearly leads to
further packet delay. We tend to conceive to determine the style within which the best (to
be outlined within the following section) sleep schedule varies with the length of the
sleep amount, the statistics of incoming packets, and also the charges assessed for
packet delay and energy consumption.
LITERATURE REVIEW
The existing model is based on the sleep and awake scheduling of the wireless sensors in
the wireless sensor networks connected with the mobile cloud computing platforms.
The existing model proposes the collaborative location-based sleep scheduling, which
offers the sleep and awaken interval assignment to the nodes in the pairs or paired
groups. The existing model is capable of enhancing the lifetime of the sensor networks
by offering the scheduling model but lacks in the various points. The existing model is
not capable enough to provide the second layer (Data link layer) connectivity to utilize
the maximized connectivity among the awaken sensors.
The existing model is also not capable of scheduling the nodes in the complete sleep
mode, because it offers the level-two collaborative location-based sleep scheduling,
which causes the forceful awakening of the sensor nodes due to connectivity loss. The
existing scheme is also not capable of handling the heterogeneity among the wireless
sensor nodes working upon the different types of data in order to deliver the data
efficiently from every group.
Zhu, Chunsheng et. al. [1] has planned the cooperative location-based sleep programming
for wireless sensing element networks integrated with mobile cloud computing. During
this paper, actuated by these 2 observations, 2 novels cooperative location-based sleep
programming (CLSS) schemes area unit planned for WSNs integrated with MCC.
Supported the locations of mobile users, CLSS dynamically determines the awake or
asleep standing of every sensing element node to cut back energy consumption of the
integrated WSN. Notably, CLSS1 focuses on maximizing the energy consumption saving
of the integrated WSN whereas CLSS2 considers conjointly the quantifiability and
hardiness of the integrated WSN. H. T. Dinh et. al. [2] has conducted the survey on mobile
cloud computing: design, applications, and approaches. Along with AN explosive growth
of the mobile applications and rising of cloud computing thought, mobile cloud
computing (MCC) has been introduced to be a possible technology for mobile services.
75

MCC integrates the cloud computing into the mobile surroundings and overcomes
obstacles associated with the performance (e.g., battery life, storage, and bandwidth),
surroundings (e.g., heterogeneousness, quantifiability, and availability), and security
(e.g., dependableness and privacy) mentioned in mobile computing. This paper offers a
survey of MCC that helps general readers have a summary of the MCC together with the
definition, design, and applications. S. Wang et. al. [3] has worked on reconciling mobile
cloud computing to modify made mobile multimedia system applications. In spite of
advances within the capabilities of mobile devices, a niche can still exist, and should even
widen, with the wants of made multimedia system applications. Mobile cloud computing
will facilitate bridge this gap, providing mobile applications the capabilities of cloud
servers and storage along with the advantages of mobile devices and mobile property,
probably sanctionative a brand new generation of really omnipresent multimedia system
applications on mobile devices: Cloud Mobile Media (CMM) applications. R. Buyya et.
al. [4] has worked on the cloud computing and rising it platforms for his or her Vision,
hype, and reality for delivering computing because the fifth utility. During this paper, the
authors have conferred some representative Cloud platforms, particularly those
developed in industries, together with our current work towards realizing market-
oriented resource allocation of Clouds as accomplished in Aneka enterprise Cloud
technology. What is more, they need highlighted the distinction between High
Performance Computing (HPC) employment and Internet-based services employment.
The authors conjointly represented a meta-negotiation infrastructure to ascertain
international Cloud exchanges and markets, and illustrate a case study of harnessing
=Storage Clouds' for top performance content delivery. C. Zhu et. al. [5] has conducted
the survey on communication and knowledge management problems in mobile sensing
element networks. A lot of and a lot of application eventualities need the sensors in WSNs
to be mobile instead of static thus on build ancient applications in WSNs become smarter
and modify some new applications. All this induce the mobile wireless sensing element
networks (MWSNs) which may greatly promote the event and application of WSNs.
However, to the most effective of our data, there's not a comprehensive survey regarding
the communication and knowledge management problems in MWSNs. during this paper,
specializing in researching the communication problems and knowledge of management
problems in MWSNs, the authors have discussed different research methods regarding
communication and data management in MWSNs and propose some further open
research areas in MWSNs .
76

SCOPE OF THE STUDY
The sleep scheduling among the wireless sensors connected with the mobile cloud
computing (MCC) is the process to maximize the lifetime of the sensor nodes. The sleep
scheduling is the process to schedule the nodes in the sleeping and awaken intervals
divided on the basis of time and placed according to the position of the nodes. The ideal
sleep scheduling process must be capable of enhancing the energy efficiency as well as
requires the high order connectivity in order to deliver the collected data to the mobile
cloud computing platform. The main purpose of the sleep scheduling algorithm is to
maintain the energy and connectivity balance between the sleeping and awaken groups.
The earlier model is based upon the lifetime enhancement of the sensor networks by
offering the sleep-awake scheduling method. The earlier model constructs the pairs of
the sensor nodes in order to practice the sleep awake scheduling. This model also
emphasizes the optimal interval calculation for the maximization of the sensor network.
The proposed has been designed to overcome the shortcomings of the earlier solution by
utilizing the data link layer level scheduling solution to maximize the connectivity of the
awaken sensors. The forceful awakening of the nodes is prevented in order to maximize
the lifetime of the sensor network by using the proposed sensor sleep-awake scheduling.
Figure 1
Figure 2
77
Figure 3
Figure 4
Existing model Figure 1(pairing of existing nodes), Figure 2 (Sleep nodes are shown as
dark), Figure 3(path movements of awake nodes), Figure 4 (Showing existing technique)
Figure 5 Figure 6
78

Figure 7
Figure 8
Proposed Model : Fig 1(pairing of existing nodes), Fig2 (Sleep nodes are shown as
dark), Fig 3(path movements of awake nodes), Fig4 (Showing proposed Technique)
METHODOLOGY
At very first step, the literature on the routing algorithms in wireless sensor networks
would be studied in detail in order to understand their working, advantages and demerits.
Then the algorithm flow would be reviewed and the possible solution in order refine their
performance would be evaluated. Afterwards, the algorithm would be programmed in
MATLAB. The experiment results would be thoroughly analyzed and compared with the
existing algorithm results. This is also very important to get the information about the
parameters used for collecting the routing algorithm results in wireless sensor network
simulations. This proposed model under the research project would be implemented in
the MATLAB simulator. A thorough performance and feature testing model would be
79

formed and utilized to analyze the performance of the simulated clustering protocol, to
detect the flaws and to recover them. Afterwards, the experiment results would be
thoroughly analyzed and compared with the existing routing algorithms to examine the
performance of the new sleep scheduling algorithm for WSNs.
CONCLUSION
The existing model is based on the sleep and awake scheduling of the wireless sensors in
the wireless sensor networks connected with the mobile cloud computing platforms. The
existing model proposes the collaborative location-based sleep scheduling, which offers
the sleep and awaken interval assignment to the nodes in the pairs or paired groups. The
existing model is capable of enhancing the lifetime of the sensor networks by offering the
scheduling model but lacks in the various points. The existing model is not capable
enough to provide the second layer (Data link layer) connectivity to utilize the maximized
connectivity among the awaken sensors. The existing model is also not capable of
scheduling the nodes in the complete sleep mode, because it offers the level-two
collaborative location-based sleep scheduling, which causes the forceful awakening of
the sensor nodes due to connectivity loss. The existing scheme is also not capable of
handling the heterogeneity among the wireless sensor nodes working upon the different
types of data in order to deliver the data efficiently from every group.
REFERENCES [1] Zhu, Chunsheng, Victor Leung, Laurence T. Yang, and Lei Shu. "Collaborative location-based
sleep scheduling for wireless sensor networks integrated with mobile cloud computing." (2014).
[2] H. T. Dinh, C. Lee, D. Niyato, and P. Wang, "A survey of mobile cloud computing: Architecture,
applications, and approaches," Wireless Commun. Mobile Comput., vol. 13, no. 18, pp.
1587–1611, Dec. 2013.
[3] S. Wang and S. Dey, "Adaptive mobile cloud computing to enable rich mobile multimedia
applications," IEEE Trans. Multimedia, vol. 15, no. 4, pp. 870–883, Jun. 2013.
[4] R. Buyya, C. S. Yeo, S. Venugopal, J. Broberg, and I. Brandic, "Cloud computing and emerging it
platforms: Vision, hype, and reality for delivering computing as the 5th utility," Future Generation
Comput. Syst., vol. 25, no. 6, pp. 599–616, Jun. 2009.
[5] C. Zhu, L. Shu, T. Hara, L. Wang, S. Nishio, and L. T. Yang, "A survey on communication and
data management issues in mobile sensor networks," Wirel. Commun. Mob. Comput., vol. 14,
no. 1, pp. 19–36, Jan. 2014.
[6] M. Li and Y. Liu, "Underground coal mine monitoring with wireless sensor networks," ACM
Trans. Sens. Netw, vol. 5, no. 2, Mar. 2009.
80

[7] M. Yuriyama and T. Kushida, "Sensor-cloud infrastructure - physical sensor management with
virtualized sensors on cloud computing," in Proc. 13th Int. Conf. Netw.-Based Inf. Sys. (NBiS),
2010, pp. 1–8.
[8] G. Fortino, M. Pathan, and G. D. Fatta, "Bodycloud: Integration of cloud computing and body
sensor networks," in Proc. IEEE 4th Int. Conf. Cloud Comput. Technol. Sci. (CloudCom), 2012, pp.
851–856.
[9] R. Hummen, M. Henze, D. Catrein, and K. Wehrle, "A cloud design for user-controlled storage and
processing of sensor data," in Proc. IEEE 4th Int. Conf. Cloud Comput. Technol. Sci. (CloudCom),
2012, pp. 232–240.
[10] Y. Takabe, K. Matsumoto, M. Yamagiwa, and M. Uehara, "Proposed sensor network for living
environments using cloud computing," in Proc. 15th Int. Conf. Netw.-Based Inf. Sys. (NBiS), 2012,
pp. 838–843.
81

AN ENHANCED ANT COLONY ALGORITHM TO CONSERVE
ENERGY IN CLUSTERED AD HOC NETWORK
Rajdeep Singh Chauhan
Assistant Professor, LLRIET Moga
Mandeep Handa
Assistant Professor, LLRIET Moga
Manpreet Singh
Assistant Professor, LLRIET Moga
ABSTRACT
Energy Conservation is a phenomenon used for the different nodes of the network to save
the energy of those nodes which are participating in the network, for extending the
working time of the ad-hoc nodes. The ad-hoc nodes are the nodes which have the
wireless property i.e. they work for the network without any physical connection between
the node and the source of the energy. The ad-hoc nodes has to be charged from an energy
source and after that the node is unplugged from the source of energy, the node starts
consuming the energy as the time passes away and the battery which stores the energy for
the node gets flat soon i.e. looses all its energy which causes the node to turn off and the
network gets down. Ant colony algorithm is one of the best approaches to get the shortest
path of the neighborhood nodes. The shortest path is get by using flooding technique in
ant algorithm but there is a problem, when there is a change in the topology of the
network, for each & every change, the node has to perform flooding to get the shortest
path which give rise to the problem of congestion & decreases the throughput. Such
problems i.e. energy consumption and flooding results in the decrease of efficiency of the
network. This motivates the need of some novel technique to handle such problems. The
present work describes that the whole network nodes are divided into clusters. So rather
then using the flooding technique for all the neighbor nodes, the flooding is used only
among the clusters which reduces the network congestion and results in the increase of
throughput and also describes an energy conservation technique by introducing a new
mode i.e. idle mode.
KEYWORDS:- Flooding, Ant, Clusters, Energy Conservation.
82

INTRODUCTION
A. Wireless Ad-hoc network
A wireless Ad-hoc network is a wireless network having no particular centralized node.
The name ad-hoc in referred because the realization of the network is not dependent upon
the previous infrastructure. In this network each node gives its contribution in the
transmission of data by forwarding the data to the other nodes and getting the data from
the other nodes. All the nodes in this kind of network have same priority which means all
the nodes have to follow the same set of rules for transmitting the data. The nodes in ad-
hoc network are dynamic nodes i.e. these nodes changes their position by the time. So to
determine the optimized route for transmitting the data among the nodes of the ad-hoc
network is a great challenge because of the dynamic changes in the topology which occur
very frequently [1]. Wireless ad-hoc network is an autonomous system of mobile nodes
connected by wireless links; each node operates as an end system and a router for all other
nodes in the network. Nodes in mobile ad-hoc network are free to move and organize
themselves in an arbitrary fashion. Each node is free to roam while communicating with
others. The path between each pair of the nodes may have multiple links and the radio
between them can be heterogeneous. This allows an association of various links to be a
part of the same network [2].
B. Energy Consumption
Energy consumption is the process of consuming energy by the node. The nodes which
participate in the network are wireless nodes that mean the nodes have to get charged from
the source of energy and save energy in the battery. After the node is not in physical
connection with the energy source the node starts consuming energy from the battery and
gets discharge. The rate of energy consumption depends upon the usage of node, i.e. of the
usage is much frequent the energy consumption is high else it is proportional to the usage.
C. Flooding
Flooding is a phenomenon which is used by the nodes of ad-hoc network to get the routing
information about the neighborhood nodes in the network. Flooding starts with the one
node which sends the flooding packet to the other neighbor nodes to get the routing
information about them. The flooding packet received by the neighbor nodes again send
the same type of packet to their neighbor nodes and also reply their status to the previous
node. This process keeps on repeated by all the nodes till the routing tables are not
83

completed for each node. These routing tables further help the nodes to get the
information about the factors which are used in networking for e.g. routing distance,
routing path etc.
D. Ant's Colony Algorithm
The frequent changes in the topology of the ad-hoc network make it difficult to find the
shortest path between the sender and the receiver because the location of the nodes keeps
on changing. So to find the shortest path between the nodes of the network to transfer the
data is a big challenge, which inspires to use some efficient algorithm in the dynamic
environment. However Ant's algorithm overcomes this problem by using the ant's
phenomena to find the shortest path. When an ant moves on the path to search for food it
follows the chemical known as pheromone which is secreted by the other ant on the way
of food and when it reaches at a point where there are more the one ways to the food then
the ant take the decision to follow the path based upon the intensity of the pheromone
secreted by the other ants. It follows the path having more intensity of pheromone.
[3]This leads all the ants to find the shortest path between their nests and
`the food as the time passes away. The pheromone on the branches of the shortest path to
the food grows faster than pheromone on other branches. If the obstacle is being put on the
way of ant's nest & the food having two branches of the path to the food, one is shorter
than the other. The ants deposit pheromone while moving. The ant which has chosen the
shorter path will reach first to the food, pick up and then return back to the nest. It will
repeat the same phenomena again and again. When other ants reach the food, they will
also follow shortest path since this path has more pheromone [4].
LITERATURE SURVEY
Gabber E. et. al (2004) [5] discussed a new intra-domain IP routing algorithm called
TRAIL BLAZER (TB) that alleviates network congestion by local decisions based on
latency measurements collected by scout packets. TB is a member of a class of traffic-
aware routing algorithms based on the behavior of ants. TB maintains in every router a
probability table that controls the selection of outgoing links for a given destination. This
table is modified by passing scout packets. Some scout packets follow existing high
probability paths, and other scout packets explore new pathsby making random
? mistakes in order to find detours around congested areas of the network. Scout packets
do not have global knowledge of the network topology. Rather, they are influenced by
84

probability trails left by previous scout packets, and leave a trail of updated probability
information. Even though TB may cause packet reordering which may affect the
congesting control mechanisms of TCP, TCP traffic sent over TB has a similar bandwidth
to shortest-path routing.
Chen G., et al. (2006) [6] discussed that the routing in wireless sensor networks is very
challenging due to their inherent characteristics of large scale, no global identification,
dynamic topology and very limited power, memory and computational capacities for
each sensor. Recent researches on WSNs routing protocol has proved that data centric
technologies are needed for performing in network aggregation of date to yield energy-
efficient dissemination. Optimization (ACO) algorithms have been introduced to design
the data centric routing protocol & have got many achievements, but still have some
shortcomings blocking their further applications in the large scale WSN's to overcome the
flaws of conventional ant based data centric routing algorithm, they proposed an improve
protocol by adding a new type of ant, search ant, to supply prior information to the
following ants.
Shen Z. W., et. al [7] (2008) proposed a routing algorithm that was referred to Energy
Prediction and Ant Colony Optimization Routing (EPACOR). In this algorithm when a
node needs to deliver data to the sink, ant colony systems are used to establish the route
with optimal or sub-optimal power consumption and side by side learning mechanism
was embedded to predict the energy consumption of neighboring nodes when the nodes
chooses a neighboring node added to the route. They also compared EPACOR with MST
(Minimal Spanning Tree) followed the Prim algorithm and (LET) Least Energy Tree
followed by Dijkstra algorithm. The numeric experiment shows that the EPACOR has the
best network lifetime among the other two.
LI B., et al. (2009) [8] discussed new dynamic spectrum environment in cognitive radio
networks necessities novel routing protocols which should be spectrum-aware, self-
configured, high-adaptive and robust to match the dynamic nature of Cognitive Radio
Network (CRN) and exploit the available spectrum efficiently. In this paper, the author
presents ASAR, which is a biologically inspired routing solution for CRN. In the routing
algorithm, paths are discovered, observed and learned by guided ants communicating in
an indirect way. F-ants are used to exploit spectrum feasible paths to the destinations and
B-ants are used to collect information about the network and update routing table in the
nodes.
85

Bandyopadhyay M., et al. (2010) [9] elaborates Ant colony optimization (ACO) is a
stochastic approach for solving combinatorial optimization problems like routing in
computer networks. Zone based routing algorithms is build on the concept of individual
node's position for routing of packets in mobile ad-hoc networks. Here in this paper they
have used Zone based ANT colony using Clustering which assures to find shortest route
using the DIR principle together with minimum overhead for route discovery and
mobility management. Unlike other Zone based approach, in clustering it is not required
to consider zone related information of each node while finding shortest path. Here, it is
being proposed a new routing algorithm for mobile ad hoc network by combining the
concept of Ant Colony approach and Zone based routing approach using clustering to get
shortest path with small number of control messages to minimize the overhead.
Simulations show that Zone Based ant colony routing algorithm has relatively short route
establishment overhead than other zone based ant colony algorithms in highly mobile
scenarios.
Magyare E.A., et al. (2010) [10] discussed a novel routing algorithm called Bees Ants
algorithm. This algorithm is a combination of Ant colony based Routing Algorithm
(ARA) and Bee Hive based Routing Algorithm. The proposed routing algorithm depends
on splitting the network into two parts; one is a fixed network and the other is a mobile ad
hoc network (MANET), then applying the Ant colony based Routing Algorithm on the
mobile part and the Bee Hive based Routing Algorithm on the fixed one. After comparing
the proposed algorithm with the ARA algorithm, it shows promising results in terms of
propagation delay, queue delay, and number of hops.
PROBLEM FORMULATION
The problem with Energy Consumption Flooding Technique and are described as
follows: The ad-hoc node losses energy when working in the network which results in the
dysfunction of the node and the network. Most of the time when the node is not
performing any sufficient task it consumes energy which is worthless. This leads to find
some technique by using which the energy of the node can be conserved when it is not in
working. The ant colony algorithm is used to find the shortest path between the nodes of
network but when this algorithm is used on wireless adhoc network it makes the
algorithm to work much frequently because of the dynamic changes in the location of the
nodes. So when there is a change in topology of the network each time the flooding
86

technique is to be used to find the shortest path, which consumes most of the bandwidth of
the network and result in decreased in throughput.
OBJECTIVES
The energy conservation and clustering technique is used to reduce the effect of energy
consumption and flooding to achieve the following objectives:-
1. To achieve improved Throughput.
2. To conserve the energy.
PRESENT WORK
Energy Conservation: The problem of energy consumption leads to develop energy
conservation technique. In this present work a new mode i.e. third mode of a node is
introduced known as idle node, rather than having just two modes (Active and Passive) in
traditional algorithm. The idle mode is a mode in which the node consumes minimal
energy but working. When the node is not in working, rather than remaining in active
mode it goes into idle mode and remain in same mode till the node is not activated by
some data transfer request by the other nodes. This leads to conserve the energy.
Figure: 1 Flow Chart describing the steps for the Energy Conservation in Ant Colony Algorithm.
87

Clustering:
The dynamic change in topology leads to network traffic as discussed earlier. This
problem can be optimized by dividing the network into clusters. All the nodes of wireless
Ad-hoc network are divided according to the cluster i.e. C1, C2, C3…Cn. Each cluster is
having a cluster address. So at the time of the changes in the topology, the flooding is done
among the clusters having a specific cluster address instead of all nodes, which reduces
the traffic over the network.In the present work the scenario consist of 50 nodes in the
network which is divided into 5 clusters according to the geographical area. Whenever a
node goes from one cluster to another cluster the cluster information is updated. Each
cluster of multiple nodes having unique address which represents that particular cluster,
whenever there is a need to send the data to any node the data is sent to the cluster address.
The optimized algorithm is divided into various steps. The algorithm starts with the
collection of the status of all the nodes which are contained in the network. After that the
whole network is divided into the clusters based on their geographical area. Each cluster
is given an address, so that whenever there is need to send the data, it is sent to the cluster
address and the required node for which the data is sent receives the data. In algorithm, it
is continuously checked that weather the topology is changed in the network or not.
Whenever there is any change in the topology, the flooding technique is performed but
rather then in the old algorithm, in which the flooding was performed between all the
nodes, in this optimized algorithm the flooding is performed in the clusters only.
88

Clusters of the node in Ant Colony Algorithm were sent in earlier algorithm to just 5
clusters instead of 50 nodes in old algorithm. According to the flooding packets sent
and received by the various nodes of the clusters the routing table of the cluster is
updated and data transmission is performed according to the routing table.
5. SIMULATION RESULTS
a). SIMULATION ENVIROMENT The simulation experiment is carried out in
LINUX (REDHAT version 5). The detailed simulation model is based on network
simulator-2 (ver-2.34), is used in the evaluation. The NS instructions can be used to define
the topology structure of the network and the motion mode of the nodes, to configure the
service source and the receiver, to create the statistical data track file and so on.
C. Simulation Parameter
Table 1: Simulation parameters
b).Traffic Model The continue bit rate (CBR) is used in the simulator. The source nodes
as well as the destination nodes were spread over the region of network randomly. The
scenario of 50 nodes which are divided into 5 clusters initially is developed. The
following figure.3 and figure 4 shows the scenario based on old algorithm as well as new
optimized algorithm.
Parameters
Environment Size
Packet Size
Traffic Type
Bandwidth
MAC Protocol
Antema Type
Value
500x500
512 Byte
CBR
40 MHZ
IEEE 802.11
Omni Directional
Figure 3 Old Ant Colony Algorithm without clustering
89
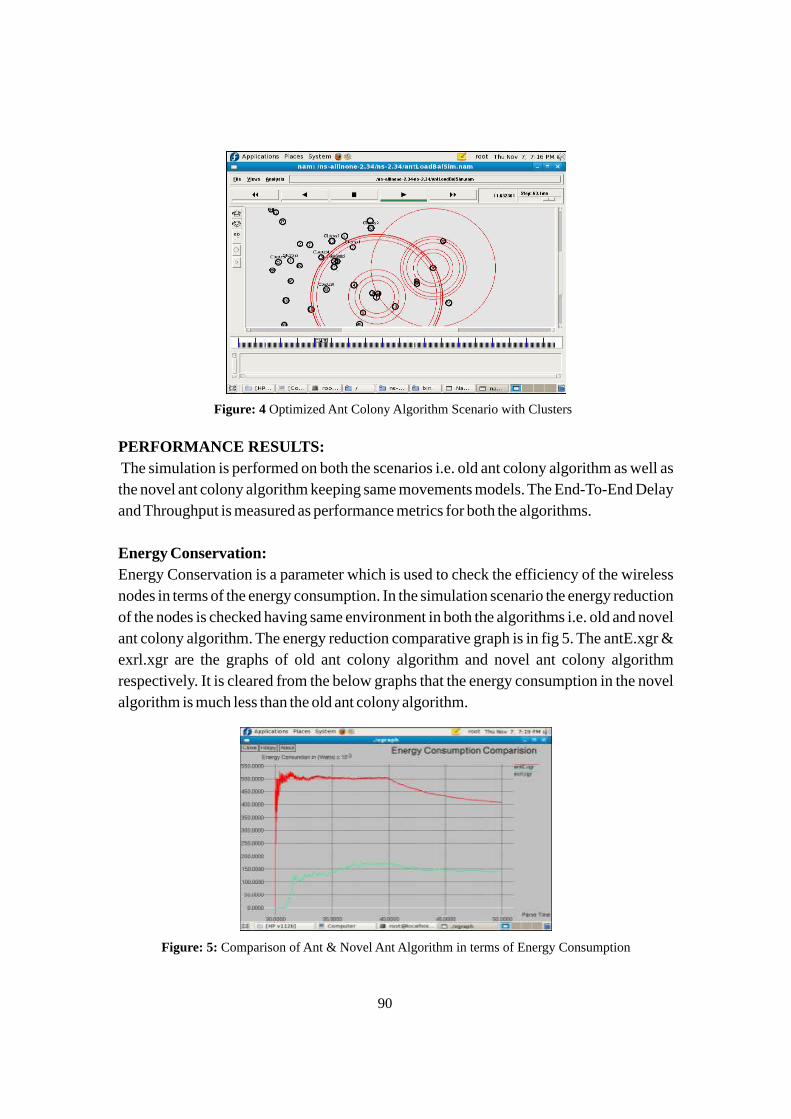
Figure: 4 Optimized Ant Colony Algorithm Scenario with Clusters
PERFORMANCE RESULTS:
The simulation is performed on both the scenarios i.e. old ant colony algorithm as well as
the novel ant colony algorithm keeping same movements models. The End-To-End Delay
and Throughput is measured as performance metrics for both the algorithms.
Energy Conservation:
Energy Conservation is a parameter which is used to check the efficiency of the wireless
nodes in terms of the energy consumption. In the simulation scenario the energy reduction
of the nodes is checked having same environment in both the algorithms i.e. old and novel
ant colony algorithm. The energy reduction comparative graph is in fig 5. The antE.xgr &
exrl.xgr are the graphs of old ant colony algorithm and novel ant colony algorithm
respectively. It is cleared from the below graphs that the energy consumption in the novel
algorithm is much less than the old ant colony algorithm.
Figure: 5: Comparison of Ant & Novel Ant Algorithm in terms of Energy Consumption
90
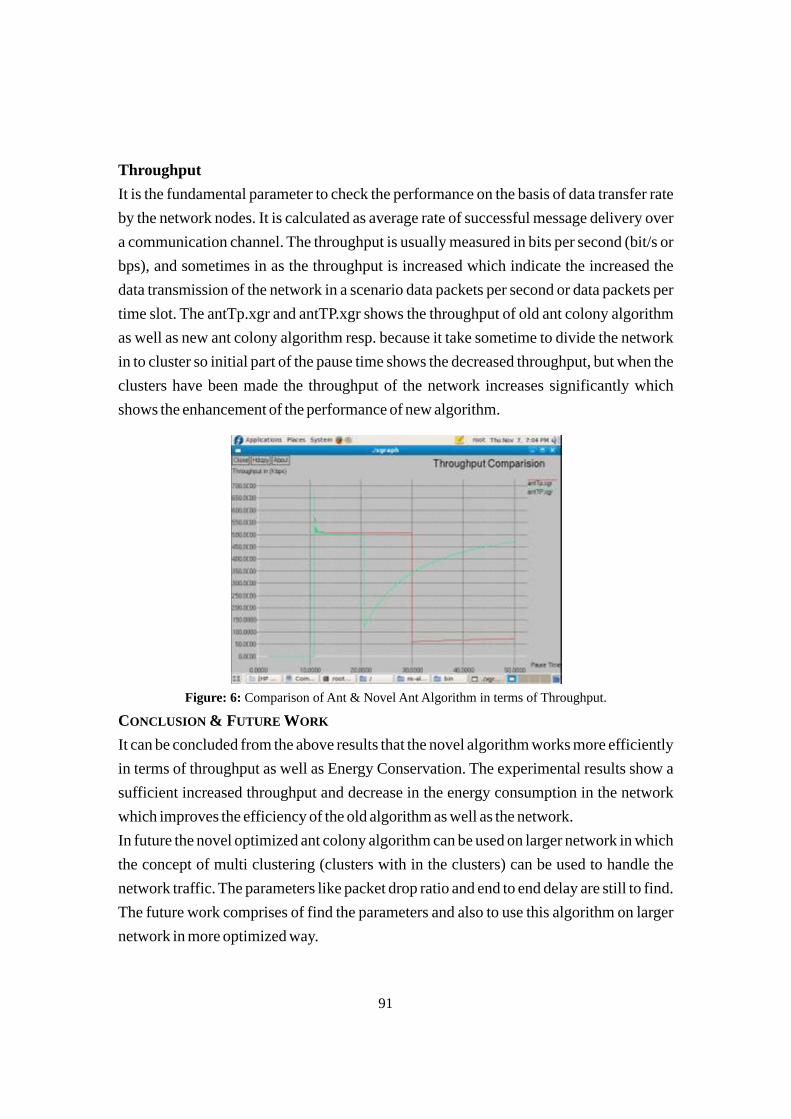
Throughput
It is the fundamental parameter to check the performance on the basis of data transfer rate
by the network nodes. It is calculated as average rate of successful message delivery over
a communication channel. The throughput is usually measured in bits per second (bit/s or
bps), and sometimes in as the throughput is increased which indicate the increased the
data transmission of the network in a scenario data packets per second or data packets per
time slot. The antTp.xgr and antTP.xgr shows the throughput of old ant colony algorithm
as well as new ant colony algorithm resp. because it take sometime to divide the network
in to cluster so initial part of the pause time shows the decreased throughput, but when the
clusters have been made the throughput of the network increases significantly which
shows the enhancement of the performance of new algorithm.
Figure: 6: Comparison of Ant & Novel Ant Algorithm in terms of Throughput.
CONCLUSION & FUTURE WORK
It can be concluded from the above results that the novel algorithm works more efficiently
in terms of throughput as well as Energy Conservation. The experimental results show a
sufficient increased throughput and decrease in the energy consumption in the network
which improves the efficiency of the old algorithm as well as the network.
In future the novel optimized ant colony algorithm can be used on larger network in which
the concept of multi clustering (clusters with in the clusters) can be used to handle the
network traffic. The parameters like packet drop ratio and end to end delay are still to find.
The future work comprises of find the parameters and also to use this algorithm on larger
network in more optimized way.
91

REFERENCES
[1]. Bandyopadhyay M., Baumik P (2010) "Zone Based Ant Colony Routing In Mobile Ad-hoc Network"
Copyright Clearance Centre (CCC) 978-1-4244-5489-1/10(IEEE 2010).
[2]. Chen G., Guo T., Wang W., Zhao T. (2006), "An Improved Ant-Based Routing Protocol In Wireless
Sensor Networks"1-4244-0429-0-/06(IEEE 2006).
[3]. D. Kim, J. Garcia and K. Obraczka, "Routing Mechanisms for Mobile Ad Hoc Networks based on the
Energy Drain Rate", IEEE Transactions on Mobile Computing. Vol 2, no 2, 2003, pp.161-173.
[4]. Gabber E., Smith M. A. (2004) "Trail Blazer: A Routing Algorithm Inspired By Ants", IEEE
International Conference on Network Protocols (ICNP?04).
[5]. Hussein O., Saadawi T. "Ant Routing Algorithm for Mobile Ad-hoc Networks (ARAMA)*". LI B., LI
D., LI H. (2009), "ASAR: Ant-Based Spectrum Aware Routing For Congnitive Radio Networks" 978-
1-4244-5668-0/9(IEEE 2009).
[6]. Maghayreh E.A., Al-Haija S.A., Alkhateeb F., Alijawarneh A. (2010) "Bees_Ant Based Routing
Algorithm"978-0-7695-3973-7/10(IEEE 2010).
[7]. Shen, H. and Jin, X.Y. (2008) "AMR system adopting routing algorithm of wireless sensor networks",
IEEE, pp. 1-4.
[8]. Wenjing Guo, Wei Zhang, Gang Lu "A Comprehensive Routing Protocol in Wireless Sensor Network
Based on Ant Colony Algorithm" 2010 Second International Conference on Networks Security,
Wireless Communications and Trusted Computing , 2010 Second International Conference on
Networks Security, Wireless Comunications and Trusted Computing, PP 41-44
[9]. Yanhua Li, Zhi-Li Zhang, and Daniel Boley "From Shortest-path to All-path: The Routing Continuum
Theory and its applications" IEEE Transaction on Parallel and Distributed systems, VOL. X, NO. X,
JANUARY 2010, PP 1-11.
92

A REVIEW: RECOVERY IN DISTRIBUTED OPERATING SYSTEM
Bohar Singh Asstt. Professor,CSE DEPTT SBSSTC,FEROZEPUR.
Malkeet Singh Asst Professor,CSE DEPTT SBSSTC,FEROZEPUR.
ABSTRACT
In modern world of computer science large-scale date centres, such as those used for
cloud computing service provision, are becoming ever-larger as the operators of those
data centres seek to maximize the benefits from economies of scale. With these increases
in size becomes a growth in system complexity, which is usually problematic. There is an
increased desire for automated "self-star" configuration, management, and failure-
recovery of the data-centre infrastructure, but many traditional techniques scale much
worse than linearly as the number of nodes to be managed increases. As the number of
nodes in a median-sized data-centre looks set to increase by two or three orders of
magnitude in coming decades, it seems reasonable to attempt to explore and understand
the scaling properties of the data-centre middleware before such data-centres are
constructed.
KEYWORD: Recovery, Rollback, Checkpoint
INTRODUCTION
With these increases in size comes a growth in system complexity, which is usually
problematic. The growth in complexity manifests itself in two ways. The first is that many
conventional management techniques (such as those required for resource-allocation and
load-balancing) that work well when controlling a relatively small number of data-centre
[1] nodes (a few hundred, say) scale much worse than linearly and hence become
impracticable and unworkable when the number of nodes under control are increased by
two or three orders of magnitude. The second is that the very large number of individual
independent hardware components in modern data centres means that, even with very
reliable components, at any one time it is reasonable to expect there always to be one or
more significant
93

component failures (so-called ? normal failure? ): guaranteed levels of performance
and dependability must be maintained despite this normal failure; and the constancy of
normal failure in any one data-centre soon leads to situations where the data-centre has a
heterogeneous composition (because exact replacements for failed components cannot
always be found) and where that heterogeneous composition is itself constantly
changing.
Checkpoints and rollback-recovery are well-known techniques that allow processes to
make progress in spite of failures. The failures under consideration are transient problems
such as hardware errors and transaction aborts, i.e., those that are unlikely to recur when a
process restarts. With this scheme, a process takes a checkpoint from time to time by
saving its state on stable storage .When a failure occurs, the process rolls back to its most
recent checkpoint [3],assumes the state saved in that checkpoint, and resumes execution.
We first identify consistency problems that arise in applying this technique to a
distributed system. We then propose a checkpoint algorithm and a rollback-recovery
algorithm to restart the system from a consistent state when failures occur.
Failure in Distributed Systems
A distributed system [6] consists of two kinds of components: sites, which process
information, and communication links, which transmit information from site to site. A
distributed system is commonly depicted as a graph where nodes are sites and undirected
edges are bidirectional communication links. We assume that this graph is connected,
meaning that there is a path from every site to every other. Thus, every two sites can
communicate either directly via a link joining them, or indirectly via a chain of links. The
combination of hardware and software that is responsible for moving messages between
sites is called a computer network.
94

We won't worry about how to route messages from one site to another, since routing is a
computer network service normally available to the distributed database system.
Site Failures
When a site experiences a system failure, processing stops abruptly and the contents of
volatile storage are destroyed. In this case, we'll say the site has failed. When the site
recovers from a failure it first executes a recovery procedure, which brings the site to a
consistent state so it can resume normal processing. In this model of failure, a site is
always either working correctly (is operational) or not working at all (is down). It never
performs incorrect actions. This type of behaviour is called fail-stop, because sites fail
only by stopping. Surely this is an idealization of a site's possible faulty behaviour.
Computers can occasionally act incorrectly due to software or hardware bugs. By using
extensive testing during implementation and manufacturing, and built-in redundancy in
hardware and software, one can build systems that approximate fail-stop behaviour. We'll
simply assume that sites are fail-stop.
Communication Failures
Communication links are also subject to failures. Such failures may prevent processes at
different sites from communicating. A variety of communication failures are possible: A
message may be corrupted due to noise in a link; a link may malfunction temporarily,
causing a message to be completely lost; or a link may be broken for a while, causing all
messages sent through it to be lost. Message corruption can be effectively handled by
using error detecting codes, and by retransmitting a message in which the receiver detects
an error. Loss of messages due to transient link failures can be handled by retransmitting
lost messages. Also, the probability of losing messages due to broken links can be reduced
by rerouting. If a message is sent from site A to site B, but the network is unable to deliver
the message due to a broken link, it may attempt to find another path from A to B whose
intermediate links and sites are functioning properly. Error correcting codes, message
retransmission, and rerouting are usually provided by computer network protocols. We'll
take them for granted. Unfortunately, even with automatic rerouting, a combination of
site and link failures can disable the communication between sites. This will happen if all
paths between two sites A and B contain a failed site or a broken link. This phenomenon is
called a network partition. In general, a network partition divides up the operation a sites
into two or more components, where every two sites within a component can
95

communicate with each other, but sites in different components cannot. Figure 1.2 shows
a partition of the system. The partition consists of two components, (B, C}and {D, E}, and
is caused by the failure of site A and links (C, D) and (C, E). As sites recover and broken
links are repaired, communication is re-established between sites that could not
previously exchange messages, thereby merging components. For example, in Fig. 1.2, if
site A recovers or if either link (C, D) or (C, E) is repaired, the two components merge and
every pair of operational sites can communicate.
Fig 1.2: A Network Partition (Components shown in dotted lines are faulty).
We can reduce the probability of a network partition by designing a highly
connected network, that is, a network where the failure of a few sites and links will not
disrupt all paths between any pair of sites. However, making a network highly connected
requires the use of more components and therefore entails more expense. Moreover, the
network's topology is often constrained by other factors, such as geography or the
communication medium. Thus, our ability to avoid partitions is limited.
Undeliverable Messages
Site and communication failures require us to deal with undeliverable messages. A
message may be undeliverable because its recipient is down when the message arrives, or
because its sender and recipient are in different components of a network partition. There
are two options:
1. The message persists. The computer network stores the message, and delivers it to its
destination when that becomes possible. 2. The message is dropped. The computer
network makes no further attempt to deliver it. Some computer networks that adopt
option (2) attempt to notify the sender of an undeliverable message that the message was
dropped. But this is inherently unreliable. If a site fails to acknowledge the receipt of a
message, the network cannot tell whether the site did not receive the message or it
received the message but failed before acknowledging it.
96
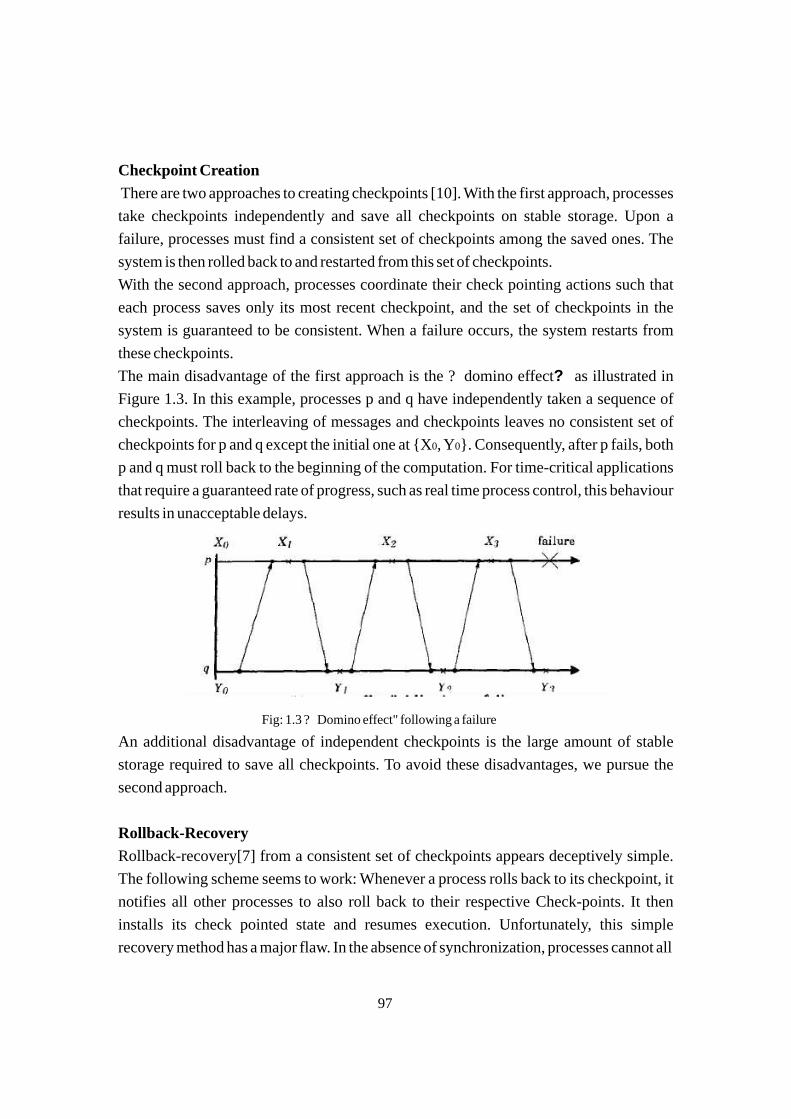
Checkpoint Creation
There are two approaches to creating checkpoints [10]. With the first approach, processes
take checkpoints independently and save all checkpoints on stable storage. Upon a
failure, processes must find a consistent set of checkpoints among the saved ones. The
system is then rolled back to and restarted from this set of checkpoints.
With the second approach, processes coordinate their check pointing actions such that
each process saves only its most recent checkpoint, and the set of checkpoints in the
system is guaranteed to be consistent. When a failure occurs, the system restarts from
these checkpoints.
The main disadvantage of the first approach is the ? domino effect? as illustrated in
Figure 1.3. In this example, processes p and q have independently taken a sequence of
checkpoints. The interleaving of messages and checkpoints leaves no consistent set of
checkpoints for p and q except the initial one at {X0, Y0}. Consequently, after p fails, both
p and q must roll back to the beginning of the computation. For time-critical applications
that require a guaranteed rate of progress, such as real time process control, this behaviour
results in unacceptable delays.
Fig: 1.3 ? Domino effect" following a failure
An additional disadvantage of independent checkpoints is the large amount of stable
storage required to save all checkpoints. To avoid these disadvantages, we pursue the
second approach.
Rollback-Recovery
Rollback-recovery[7] from a consistent set of checkpoints appears deceptively simple.
The following scheme seems to work: Whenever a process rolls back to its checkpoint, it
notifies all other processes to also roll back to their respective Check-points. It then
installs its check pointed state and resumes execution. Unfortunately, this simple
recovery method has a major flaw. In the absence of synchronization, processes cannot all
97

recover (from their respective checkpoints) simultaneously. Recovering processes
asynchronously can introduce live locks as shown below.
Figure 1.4 illustrates the histories of two processes, p and q, up to p's failure. Process p
fails before receiving the message n1, rolls back to its checkpoint, and notifies q. Then p
recovers, sends m2, and receives n1. After p's recovery, p has no record of sending m1,
while q has a record of its receipt. Therefore the global state is inconsistent. To restore
consistency, q must also roll back (to ? forget" the receipt of m1) and notify p. However,
after q rolls back, q has no record of sending rtr while p has a record of its receipt. Hence,
the global state is inconsistent again, and upon notification of q's rollback, p must roll
back a second time. After q recovers, q sends n2 and receives m2. Suppose p rolls back
before receiving) n2 as shown in Figure 1.5 .
Fig. 1.4: history of p and q upto p's failure
With the second rollback of p, the sending of m2 is ? forgotten? . To restore consistency,
q must roll back a second time. After p recovers it receives n2, and upon notification of q's
rollback, it must roll back a third time. It is now clear that p and q can be forced to roll back
forever, even though no additional failures occur. Our rollback-recovery algorithm [4]
solves this live lock problem. It tolerates failures that occur during its execution, and
forces a minimal number of processes to roll back after a failure. However, in Tamir17, a
single failure forces the system to roll back as a whole. Furthermore, the system crashes
(and does not recover) if a failure occurs while it is rolling back.
Fig.1.5: history of p and q upto p's 2nd rollback
98

Classes of CheckpointsOur algorithm saves two kinds of checkpoints on stable storage:
* Permanent. * Tentative.
A permanent checkpoint cannot be undone. It guarantees that the computation needed
to reach the check pointed state will not be repeated. A tentative checkpoint, however,
can be undone or changed to be a permanent checkpoint. When the context is clear, we
call permanent checkpoints "checkpoints". Checkpoint Algorithm We assume the
algorithm is invoked by a single process that wants to take a permanent checkpoint.
We also assume that no failures occur in the system.
Naive Algorithms
It is obvious that if every process takes a checkpoint after every sending of a message, and
these two actions are done atomically, the set of the most recent checkpoints is always
consistent. But creating a checkpoint after every send is expensive. We may naively
reduce the cost of the above method with a strategy such as ? every process takes a
checkpoint after every k sends, k >l" or 'every process takes a checkpoint on the hour".
However, the former can be shown to suffer domino effects by a construction similar to
the one in Figure 13.1, while the latter is meaningless for a system that lacks perfectly
synchronized clocks.
Motivation
The algorithm is patterned on two phase- commit protocols. In the first phase, the initiator
q takes a tentative checkpoint and requests all processes to take tentative checkpoints. If q
learns that all processes have taken tentative checkpoints, q decides all tentative
checkpoints should be made permanent; otherwise, q decides tentative checkpoints
should be discarded. In the second phase, q's decision is propagated and carried out by all
processes. Since all or none of the processes take permanent checkpoints, the most recent
set of checkpoints is always consistent. However, our goal is to force a minimal number of
processes to take checkpoints. The above algorithm is modified as follows: a process p
takes a tentative checkpoint after it receives a request from q only if q's tentative
checkpoint records the receipt of a message from p, and p's latest permanent checkpoint
does not record the sending of that message. Process p determines whether this condition
is true using the label appended to q's request. This labelling scheme is described below.
Messages that are not sent by the checkpoint or rollback-recovery algorithms are system
messages. Every system message m contains a label m.l. Each process appends outgoing
99

system messages with monotonically increasing labels. We define ┴ and ┬ to be the
smallest and largest labels, respectively. For any processes q and p, let m be the last
message that q received from p after q took its last permanent or tentative checkpoint.
Define:
last_rmsg (p) = { m.l if m exists,┴ otherwiseq
Also, let m be the first message that q sent to process p after q took its last permanent or tentative checkpoint.
Define:First_smsg (q) = { m.1 if m exists, ┴ otherwisep
When q requests p to take a tentative checkpoint, it appends last_rmsg (p) to its request; p q
takes the checkpoint only if last_m msg (p) >first_smsg (q) > ┴.q p
Rollback-Recovery
We assume that the algorithm is invoked by a single process that wants to roll back and
recover (henceforth denoted restart). We also assume that the checkpoint algorithm and
the rollback-recovery algorithm are not invoked concurrently.
Motivation
The rollback-recovery algorithm is patterned on two phase- commit protocols. In the first
phase, the initiator q requests all processes to restart from their checkpoints. Process q
decides to restart all the processes if and only if they are all willing to restart. In the second
phase, q's decision is propagated and carried out by all processes. Since all processes
follow the initiator's decision, the global state is consistent when the rollback-recovery
algorithm terminates. However, our goal is to force a minimal number of processes to roll
back. If a process p rolls back to a state saved before an event e occurred, we say that e is
undone by p. The above algorithm is modified as follows: the rollback of a process q
forces another process p to roll back only if q's rollback undoes the sending of a message
to p. Process p determines if it must restart using the label appended to q's ? prepare to
roll back request.
Interference
In this section, we consider concurrent invocations of the checkpoint and rollback-
recovery algorithms. An execution of these algorithms by process p is interfered with if
any of the following events occur: (1) Process p receives a rollback request from another
process q while executing the checkpoint algorithm. (2) Process p receives a checkpoint
request from q while executing the rollback-recovery algorithm. (3) Process p, while
executing the checkpoint algorithm for initiator i, receives a checkpoint request from q,
100

but q's request originates from a different initiator than i. (4) Process p, while executing
the rollback-recovery algorithm for initiator i, receives a rollback request from q, but q's
request originates from a different initiator than i. One single rule handles the four cases
of interference: once p starts the execution of a checkpoint [rollback] algorithm, p is
unwilling to take a tentative checkpoint [rollback] for another initiator or to roll back
[take a tentative checkpoint]. As a result, in all four cases, p replies ? no" to q. This rule
can, however, be modified to permit more concurrency in the system. The modification is
that in case (l), instead of sending ? no to q, p can begin executing the rollback-recovery
algorithm after it finishes the checkpoint algorithm.
Cluster System
The need for high availability (HA) and disaster recovery (DR) in IT environment is more
stringent than most of the other sectors of enterprises. Many businesses require the
availability of business-critical applications 24 hours a day, seven days a week, and can
afford no data loss in the event of a disaster. It is vital that the IT infrastructure is resilient
with regard to disruption, even site failures, and that business operations can continue
without significant impact. As a result, DR has gained great importance in IT. Clustering
of multiple industries standard servers together to allow workload sharing and fail-over
capabilities is a low cost approach. In this paper, we present the availability model
through Semi-Markov Process (SMP) and also analyze the difference in downtime of the
SMP model and the approximate Continuous Time Markov Chain (CTMC) model. To
acquire system availability, we perform numerical analysis and SHARPE tool evaluation.
High availability clusters (also known as HA Clusters or failover Clusters) are computer
clusters implemented to provide high availability of services. They operate by having
redundant computers or nodes which are used to provide service when a system
component fails.
A cluster is a collection of computer nodes -- independent, self-contained computer
systems working together – to provide a more reliable and powerful system than a single
node alone. Clustering has proven to be a very effective method for scaling to larger
systems for added performance, as well as providing higher levels of availability and
lower management costs. For this reason, software packages such as IBM's RS/6000
Cluster Technology (i.e., Phoenix) and Microsoft's Cluster Services i.e. Wolf pack are
being used to build high availability systems.
CONCLUSION
We have presented a checkpoint algorithm and a rollback-recovery algorithm to solve the
problem of bringing a distributed system to a consistent state after transient failures. In
101

contrast to previous algorithms, they tolerate failures that occur during their executions.
Furthermore, when a process takes a checkpoint, a minimal number of additional
processes are forced to take checkpoints. Similarly, a minimal number of additional
processes are forced to restart when a process restarts after a failure. We also show that the
stable storage requirement of our algorithms is minimal. As per the requirements and area
of computer nodes there are so many databases recovery techniques to overcome the
transaction failure. Recovery in a single system is quite easy then in a network model.
REFERENCES
[1] Ilango Sriram & Dave Cliff, "Effects of component-subscription network topology on large-scale
data centre performance scaling", Department of Computer Science University of Bristol ,
Bristol, UK, 2004.
[2] Yun Wei, Chuanyi Ji, "Non-Stationary Random Process for Large-Scale Failure and Recovery of
Power Distributions", Georgia Institute of Technology, Atlanta, GA, 2004.
[3] Emil Vassev, Que Thu Dung Nguyen and Heng Kuang, " Fault-Tolerance through Message-
logging and Check-pointing", Concordia University, 2006.
[4] T.T.Lwin and T.Thein, "High Availability Cluster System for Local Disaster Recovery with Markov
Modelling Approach", University of Computer Studies Yangon, Myanmar, 2009.
[5] Johnson, David B., and Willy Zwaenepoel. "Recovery in distributed systems using asynchronous
message logging and checkpointing." In Proceedings of the seventh annual ACM Symposium on
Principles of distributed computing, pp. 171-181. ACM, 1988.
[6] Chow, Randy, and Yuen-Chien Chow. Distributed operating systems and algorithms. Addison-
Wesley Longman Publishing Co., Inc., 1997.
[7] Koo, Richard, and Sam Toueg. "Checkpointing and rollback-recovery for distributed systems."
Software Engineering, IEEE Transactions on 1 (1987): 23-31.
[8] Koo, Richard, and Sam Toueg. "Checkpointing and rollback-recovery for distributed systems."
Software Engineering, IEEE Transactions on 1 (1987): 23-31.
[9] Bhargava, Bharat, and Shy-Renn Lian. "Independent checkpointing and concurrent rollback for
recovery in distributed systems-an optimistic approach." In Reliable Distributed Systems, 1988.
Proceedings., Seventh Symposium on, pp. 3-12. IEEE, 1988.
[10] Lin, Luke, and Mustaque Ahamad. "Checkpointing and rollback-recovery in distributed object
based systems." In Fault-Tolerant Computing, 1990. FTCS-20. Digest of Papers., 20th
International Symposium, pp. 97-104. IEEE, 1990.
102

Image Watermarking Techniques: A Survey
Amrinder Singh M.phil,Research scholar,
Department of Computer Science, Punjabi University,Patiala,Punjab,India
Sukhjeet Kaur Department of Computer Science,
Punjabi University,Patiala,Punjab,India
ABSTRACT Image watermarking is the process of embedding secret information without degrading the quality original image. The main objective of watermarking is to provide copyright protection, content authentication, ownership identification and data integrity. In this paper we classify the robust and fragile watermarking techniques based on different
domains in which data is embedded. Detailed literature survey of various applications
and existing watermarking techniques is done.
Index Terms- DCT,DWT,DFT,robust watermarking and fragile watermarking.
INTRODUCTION
ATERMARKING is the process of hiding digital infor-mation in a carrier signal to
protect the digital multime-dia data [1].Digital multimedia like photographs, digital
music, or digital video. Watermarks are embedded in the multimedia objects (digital
content) for several reasons like copyright pro- tection, content authentication, tamper detection etc. Various types of watermarks have been developed for different types of applications. One is visible watermarks and other is invisible watermarks. Visible watermarks are easily detected by the observer but invisible watermarks are imperceptible. There are three essential factors those are generally used to determine quality of watermarking scheme [2].
A. Robustness to attacks It means that the Watermark should be difficult to remove or destroy. Robust is a measure of resistance of watermark against various types of attacks to image like compression,
filtering, rotation, scaling, collision attacks, resizing, cropping etc.
B. Imperceptibility
It means that the quality of host image should not be degraded by presence of watermark
and it is very difficult to perceive by the viewers. In order to achieve good visual imper-
ceptibility, digital watermarking scheme takes the advantage of the human visual system
(HVS) models.
103

C. Capacity
The maximum amount of watermark information is embed- ded into the host image
without degradation of image.
GENERAL PROCEDURE The general process of watermarking consists of watermark generation, watermark embedding and watermark detection. The watermark can be pseudo random numbers, binary image, logo or gray scale image which is embedded into the original image. Once the watermark is embedded to the original image it suffers from various unintentional
attacks (like compression) and intentionally attacks (like cropping). Watermark should be
robust against these types of attacks. Watermark detec- tor is used to check the existence
of the watermark either by comparing it with the original image and find out the
watermark(known as non-blind watermarking) or by using correlation measure is used to
detect the strength of the extracted watermark(blind watermarking)[3].
Fig. 1. Watermarking Process. A. Classification of watermarking
The digital watermarks are classified into various categories.
1) Robust, Fragile and semi Fragile Watermarking: Ac- cording to the specific
application requirements, watermarking can be categorised into robust, fragile and semi
fragile. Robust watermark is embedded in the digital image and resist against various
transformations like geometric transformation (such as rotation, scaling) and
compression. Robust watermarking is used in various types of application like owner
identification, proof of ownership and copy right protection. In the fragile watermarking
the watermarks are sensitive against malicious or non malicious attacks. Various
applications like image authentication and content integrity verification use the fragile
watermarking. If any slightest amount of modification is done the watermarks are
expected to be completely destroyed. And in semi fragile watermarking minor
transformations are allowed such as lossy compression but major changes are not
allowed.
2) Spatial and frequency domain: In spatial domain the watermark is embedded into the
digital image by directly modifying the intensity of the pixels. Mostly modifications are
104

done in the least significant bits of original contents. In frequency domain watermarks are
inserted into the digital contents by modifying the transform coefficients of an image and
inverse transform is applied to obtain the watermarked image. Various transform such as
discrete Fourier transform, discrete cosines transform and discrete wavelets transforms
are existed.
3) Visible and invisible: Visible watermarking is associated with the perception of the
human eye. A visible watermark is a visible semi-transparent text or image overlaid on the
original image such as owner logo or copyright sign. A watermarking technique in which
watermark is embedded in the digital image in such a way that it cannot be perceived with
human's eyes and only detected by using the watermark detecting techniques is called the
invisible watermarking.
4) Blind and informed watermarking: Both blind and in- formed detectors are available
to detect the watermark in the digital images. The detector which is used to detect the
watermark without the knowledge of the original image or embedded watermark is
known as the blind detector. The detector which requires some information about the host
watermark signal for extraction is known as informed detector.
APPLICATION AREAS OF WATERMARKING
There are various applications of digital watermarking. Some broad application areas in
which digital watermarking can be classified are broadcast monitoring, owner identifica-
tion, authentication, proof of ownership, transaction tracking, copy control, device
control, and legacy enhancements [1].
A. Broadcast Monitoring
Watermarking is an alternative method for active monitoring to ensure that the
commercials are broadcast at the times and locations of their agreement with
broadcasters. Broadcast monitoring is becoming trendy because it is used for the
prevention of illegal distribution of digital data, to ensure that accurate royalty payments
are given to musician and actors and ensuring the advertisers that they received correct air
time purchased from broadcasting firms. In broadcast monitoring we can add a unique
watermark in each video or sound clip before broadcast and automated monitoring
stations can then receive broadcasts and look for these watermarks, identifying when and
where the content appears. Numerous companies provide watermark-based broadcast
monitoring services. For example, Teletrax offers a service that is based on video
watermarking technology from Philips.
105

B. Owner identification
Text copyright notice is no longer essential to give assurance of copyrights but still
recommended. The main limitation of such a copyright is that it is very easy to remove.
Digital watermarking provides the security of copyrights through owner identification.
Robust watermarking is used to insert the information about the original owner of the
digital data because it stays alive after intentional or unintentional attacks to remove
watermark. A robust watermark cannot be removed without affecting the quality of
watermarked digital data. A watermark is the integral part of digital content so no extra
space is required to store it.
C. Content Authentication
The content of digital data can easily be altered such that it is very complicated to detect
what has been changed. Digital contents related to medical images, identity proofs,
commer- cials transactions, paintings, photographs for court evidence, it is extremely
important to make sure that the contents from a specific source are authentic. Fragile
watermark is embedded to the digital data at the source that can authenticate the integrity
of digital contents if there is minor change in digital contents watermark is not detected. In
some cases we need a watermark which survive after minor transformations, such as
lossy compression, but are invalidated by major changes is called semi fragile
watermarks. Temper detection and content authentication are closely related. If content is
detected to be tempered, this means that it is not authenticate, but in temper detection
techniques are based on the concept of localisation to discover the particular regions
where the modification is done.
D. Proof of Ownership
Watermarking is not only used to identify copyright owner- ship but to actually prove
ownership. This cannot be done with the textual notice because it can be so easily forged.
Let's take an example two person claims to own copyright of a digital image. In such a
case it is very hard to find the rightful owner. To solve this problem in order to directly
prove the image ownership, it is easy to prove ownership of the watermarked message
inserted in it. Embedding a watermark in the digital images is constructive to prove the
ownership.
E. Transaction Tracking
In transaction tracking each recipient is provided with the customized copy of the
electronic data to prevent the illegal distribution. Unique label is embed in the digital
content is known as fingerprint. If later unauthorised copies of the contents are found,
with the help of fingerprints the origin of the piracy can be located. The transaction
tracking system was implemented by DiVX Corporation. Each DiVX-enabled player
106

inserts a unique watermark into every video that it played. If illegal copies of movies are
found, then DiVX track the source of piracy by using watermarks.
F. Copy control
To prevent the illegal copying of the digital data water- marking plays an effective role.
Watermarks are embedded in the digital content itself, indicating the number of copies
that are permitted. Only numbers of permission able copies are accepted and
implemented with a special kind of detector that controls the watermark after each copy is
created.
G. Legacy Enhancement
Sometimes a system needs an upgrade to enhance the functionality but this upgrade may
be incompatible with the existing system. For example most of the countries in the world
are currently transitioning from analog to digital tele- vision. This process is a costly and
time-consuming. During this transition, the legacy analog system must continue to
function until
totally new digital broadcasting equipment must be introduced and consumers must
purchase digital television receivers. Digital watermarking can be used to improve the
functionality of legacy system. One example is Tektronix's digital watermark encoder for
synchronizing audio and video signals [4]. When the video and audio channels of a
television signal are processed separately problem of lip-sync occurs. In which the
motion of the lips is either ahead or behind the speech. The Tektronix product inserts a
highly compressed version of the audio signal within the video signal, before any digital
signal processing. After signal processing the real-time audio signal is compared with the
embedded signal to adjust the time delays before broadcasting.
ROBUST WATERMARKING
A. Robust Watermarking Techniques In Spatial Domain
Nikolaidis and Pitas [5] In this paper spatial domain copy- right protection method is
purposed in which watermark is embedded by slightly modifying the intensity of
randomly selected pixels of image. Blind watermarking is used in the detection process
i.e. original image is not required at the time of watermark detection and the process is
carried out by comparing the mean intensity value of marked pixels against that of the
unmarked pixels. Watermark is resistant to JPEG compression and lowpass filtering.
Kampan et al.[6] in this paper spatial domain watermarking for digital image is purposed.
The watermark which is binary image embedded into the original image. First the host
image is divided into several blocks of different sizes and then brightness of pixels in each
block is adjusted. Quality of watermarked image is least affected and robust against
107

various types of degradation. Nasir et al.[7] have purposed a new robust watermarking
technique based on a block probability in spatial domain for colour images. A binary
watermark image is embedded four times in different positions. Non blind watermarking
scheme is used i.e. original image is required at the time of watermark extraction.
Watermark is robust against various image processing operations such as filtering,
compression, scaling, cropping, rotation, randomly removal of some rows and columns
lines, self similarity and salt and pepper noise.
B. Robust Watermarking Techniques In Frequency Domain
1) DCT Domain Techniques: Cox et al. [8] introduces a technique for robust
watermarking, the watermark is based on the 1000 random samples which are added into
the 1000 largest DCT coefficients of the original image except the DC term located in
(0,0) of the DCT matrix and inverse DCT is performed to retrieve the watermarked image.
Watermark extraction was based on presence of original image and exact frequency
locations of the watermark. Lin et al. [9] have purposed a new approach to image
watermarking based on the DCT. By the concept of mathematical reminder we adjust the
DCT low frequency coefficients to safeguard the visual quality of the watermarked
image. Watermark is embedded into the low frequency components of the covered image
in DCT fre- quency domain. This technique is more suitable for robustness of watermark
against highly JPEG compressed image. Gupta et al.[10] have purposed efficient
algorithm which is useful for protecting the distribution rights of digital images.
Watermark bits are pseudo random numbers generated by Linear Feedback Shift Register
(LFSR). Watermark is embedded into the DCT coefficients of the host image. Robustness
against major image processing attacks is achieved.
2) DFT Domain Techniques: Solachidis and Pitas [11] have purposed a method for
digital image watermarking in which they embed a circularly symmetric watermark in the
magnitude of the DFT domain. Since the watermark is circular in shape with its center at
image center it is robust against geometric rotation attacks. Watermarking detection is
done by the correlation and original image is not required in the process. The technique is
computationally not expensive to recover from rotation. Robustness against cropping,
scaling, JPEG compression, filtering, noise addition and histogram equalization is
demonstrated. Poljicak et al.[12] have devel- oped a method to minimizes the degradation
of an image due to the implementation of a watermark in the frequency domain of the
image. Embedding process of watermark is done in the magnitudes of the DFT. Quality of
degradation is measure by using the PSNR ratio. The obtained results were used to
develop a watermarking strategy that chooses the optimal radius of the implementation to
minimize quality degradation. The proposed method showed excellent robustness to the
attacks from the StirMark benchmark, halftoning, print-scan process and print-cam
process.
108

3) DWT Domain Techniques: Barni et al.[13] have pur- posed a novel blind
watermarking algorithm, which embeds the watermark in the DWT domain by exploiting
the char- acteristics of the HVS, is presented. In contrast to previous methods in the DWT
domain, masking is accomplished pixel by pixel by taking into account the texture and the
lumi- nance content of all the image sub bands. The watermark is adaptively embedded to
the largest detail bands which consist of a pseudorandom sequence. For detection
procedure compute the correlation between the watermarked coefficients and the
watermarking code. The value of the correlation is compared to a threshold to decide
whether the watermark is present or not. Robustness is checked under the JPEG and
wavelet-based compression, median filtering, Gaussian noise addition, multiple
marking, cropping plus zero padding, and morphing. Keyvanpour and Merrikh-Bayat
[14] In this paper robust watermarking scheme in DWT domain is purposed. For selecting
the positions of the embedding watermark bits dynamic blocking scheme is used instead
of static one. The change to the blocks with strong edge strength is less visible to human
eyes. Then according to binary algorithm watermark is embedded into the significant
wavelet coefficients of dynamic blocks with strong edge. The watermark detection
process is based on the correlation method. Wang et al.[15] introduces a new digital image
watermarking algorithm in DWT domain based on texture block and edge detection. By
using the masking property of human visual system, texture blocks are extracted after the
edge detection using canny operator of the original image. Watermark is embedded into
both low frequency and high frequency sub bands in discrete wavelet domain. Watermark
is capable of maintaining the effective balance between invisibility and robustness.
FRAGILE WATERMARKING
A. Fragile Watermarking Techniques In Spatial Domain
Walton [16] developed a technique to implement a fragile watermark to prevent the
unauthorized tampering. Watermark is directly embedded in the spatial domain. It
adopted the concept of checksum to verify the completeness of the image. Checksum
array is constructed from the most significant bits of each pixel of image and embedded in
the least significant bits of the pixel. Various limitations are found in this scheme. First the
attacker can modify image content while keeping the least significant bit same. Second,
they cannot determine the exact regions of modification in verification process. They
only tell us weather image has been modified or not. Yeung and Mintzer [17] have
109

proposed a fragile watermarking scheme in which all the bits are used for watermark
embedding and extraction. This algorithm uses the secret key to generate a unique
mapping that randomly assigns a binary value to gray levels of the image. Image integrity
is checked by the comparison between decoded binary image and the inserted watermark.
This algorithm has high localization accuracy because each pixel is individually
watermarked. The technique offers fast image verification to detect and localize
unauthorized image alterations but it does not detect changes in image size due to scaling
or cropping. Zong et al. [18] have purposed a new fragile watermarking technique which
is used for image authentication. A logo is embedded as the watermark for the integrity
authentication and tamper detection. In this method a image feature is selected and hashed
to generate the chaotic key, which adds uncertainty to each watermark bits. The extracted
images feature varies for different images, the water- mark bits encrypted by this chaotic
sequence are different, and thus collage attack fails. This scheme is especially fit for the
application in digital camera. Suthaharan [19] purposed new fragile watermarking
algorithm for image authentication and tamper detection. To achieve superior
localization with greater security against many attacks including vector quantization
attack it uses a gradient image and its structure. The proposed scheme is a block-wise
independent scheme like the Wong's scheme but it uses distinct input keys for each image
block based on a gradient image and user supplied master key and a session key. Zang and
Wang[20] have purposed a novel fragile watermarking scheme capable of perfectly
recovering the original image from its tampered version. The watermark data is derived
from the entire original content and embedded into the host using a reversible data-hiding
technique. Although a malicious modification may destroy part of the embedded
watermark, the tampered areas can still be located and the watermark data extracted from
the reserved regions can be used to restore the host image without any error. Rinaldi
Munir [21] has purposed a fragile watermarking method based on the chaos map for
image authentication. Before embedding watermark is encrypted by XOR-ing with a
chaotic image which by using logistic map. And then encrypted watermark is embedded
using LSB of pixels. For authentication extraction of watermark is done from
watermarked image and compared with the original watermark. To check the
performance typ- ical attacks like histogram equalization, text addition, image flipping,
copy-paste attack in the same image, and copy-paste attack into another watermarked
image. This method is able to detect the tempering at pixel level.
110

B. Fragile Watermarking Techniques In Frequency Domain
1) DCT Domain Techniques: Wu and Liu [22] have pro- posed a frequency domain
technique for image authentication. The watermark is inserted by changing the quantized
DCT coefficients before entropy coding. Special lookup table of binary values is used to
partition the space of all possible DCT coefficient values into two sets. The two sets are
then used to modify the image coefficients to encode a bi-level image (such as a logo). To
reduce the blocking effects of altering coefficients the DC coefficient and other lower
energy coefficients are not marked. This scheme is to be able to determine whether an
image has been altered or not and able to locate any alteration made on the image. Chen et
al.[23] in this paper a new digital image authentication and recovery method is described.
The original image is divided into smaller blocks. Blocks of image are DCT transformed
and then encoded with different patterns. To find the best pattern for each block an
optimal selection is adopted which results in better image quality. This method is able to
identify and localize the tempered regions.
2) DWT Domain Techniques: HongJie et al.[24] have pur- posed a wavelet-based fragile
watermarking scheme for secure image authentication. By using the discrete wavelet
transform (DWT) embedded watermark is generated and then the im- proved security
watermark scrambled by scrambling encryp- tion is embedded into the LSB of the image
data. The proposed algorithm possesses excellent tamper localization properties,
enhances the security against VQ attack and transplantation attack and also evaluate
whether the modification made to the image is on the contents or the embedded
watermark. Rajawat and Tomar [25] have proposed a new algorithm for digital
watermarking and tampering detection technique. In which the RGB component of the
input original image is taken and 2-level DWT is applied, which divides the image into
low frequency and high frequency components. The same process is done for the
watermark which is embedded into the original image. New watermarked image is
obtained by multiply the scaling factor with separated components of the input original
image and the watermark. The experimental results gave good PSNR value which is
reached up to 55 percentage.
CONCLUSION
Various applications of watermarking like broadcast mon- itoring, owner identification,
authentication, proof of owner- ship, transaction tracking, copy control, device control,
and legacy enhancements are discussed. We classify the robust and fragile watermarking
111

techniques based on different domains in which watermark is embedded. Watermark is
embedded into the image in such a way that it is very difficult to find and the quality of the
image is not degraded. Robust watermark are resistant against various image processing
transformations where as the fragile watermarks are very sensitive to malicious and non
malicious attacks.
REFERENCES
[1] I.J. Cox, M. L. Miller, J. Bloom, T. Kalker, and J. Fridrich, Digital watermarking and
steganography. Morgan Kaufmann, 2008.
[2] R. Wolfgang, C. Podilchuk, and E. Delp, ? Perceptual watermarks for digital images and
video," Proceedings of the IEEE, vol. 87, no. 7, pp. 1108–1126, Jul 1999.
[3] V. M. Potdar, S. Han, and E. Chang, ? A survey of digital image watermarking techniques, in
Industrial Informatics, 2005. INDIN?05. 2005 3rd IEEE International Conference on. IEEE,
2005, pp. 709– 716.
[4] I. J. Cox, M. L. Miller, and J. A. Bloom, ? Watermarking applications and their properties," in
itcc. IEEE, 2000, p. 6.
[5] N. Nikolaidis and I. Pitas, ? Robust image watermarking in the spatial domain, Signal
processing, vol. 66, no. 3, pp. 385–403, 1998.
[6] S. Kimpan, A. Lasakul, and S. Chitwong, ? Variable block size based adaptive watermarking in
spatial domain, in Communications and In- formation Technology, 2004. ISCIT 2004. IEEE
International Symposium on, vol. 1. IEEE, 2004, pp. 374–377.
[7] I. Nasir, Y. Weng, and J. Jiang, ? A new robust watermarking scheme for color image in spatial
domain, in Signal-Image Technologies and Internet-Based System, 2007. SITIS?07. Third
International IEEE Con- ference on. IEEE, 2007, pp. 942–947.
[8] I. J. Cox, J. Kilian, F. T. Leighton, and T. Shamoon, ? Secure spread spectrum watermarking for
multimedia,? Image Processing, IEEE Trans- actions on, vol. 6, no. 12, pp. 1673–1687, 1997.
[9] S. D. Lin, S.-C. Shie, and J. Y. Guo, ? Improving the robustness of dct-based image watermarking
against jpeg compression,? Computer Standards & Interfaces, vol. 32, no. 1, pp. 54–60, 2010.
[10] G. Gupta, A. M. Joshi, and K. Sharma, ? An efficient dct based image watermarking scheme for
protecting distribution rights,? in Contempo- rary Computing (IC3), 2015 Eighth International
Conference on. IEEE, 2015, pp. 70–75.
[11] V. Solachidis and I. Pitas, ? Circularly symmetric watermark embedding in 2-d dft domain,Image
Processing, IEEE Transactions on, vol. 10, no. 11, pp. 1741–1753, 2001.
[12] A. Poljicak, L. Mandic, and D. Agic, ? Discrete fourier transform–based watermarking method
with an optimal implementation radius, Journal of Electronic Imaging, vol. 20, no. 3, pp. 033
008–033 008, 2011.
112

[13] M. Barni, F. Bartolini, and A. Piva, ? Improved wavelet-based watermark- ing through pixel-wise
masking, Image Processing, IEEE Transactions on, vol. 10, no. 5, pp. 783–791, 2001.
[14] M.-R. Keyvanpour and F. Merrikh-Bayat, ? Robust dynamic block-based image watermarking in
dwt domain, Procedia Computer Science, vol. 3, pp. 238–242, 2011.
[15] Y. Wang, X. Bai, and S. Yan, ? Digital image watermarking based on texture block and edge
detection in the discrete wavelet domain, in Sensor Network Security Technology and Privacy
Communication System (SNS & PCS), 2013 International Conference on. IEEE, 2013, pp.
170–174.
[16] S. Walton, ? Information authentication for a slippery new age, Dr. Doobs J, vol. 20(4), pp.
18–26, 1995.
[17] M. M. Yeun and F. Mintzer, ? An invisible watermarking technique for image verification,? in
Image Processing, 1997. Proceedings., Interna- tional Conference on, vol. 2. IEEE, 1997, pp.
680–683.
[18] H. Zhong, F. Liu, and L.-C. Jiao, ? A new fragile watermarking technique for image
authentication," in Signal Processing, 2002 6th International Conference on, vol. 1. IEEE, 2002,
pp. 792–795.
[19] S. Suthaharan, ? Fragile image watermarking using a gradient image for improved localization
and security, Pattern Recognition Letters, vol. 25, no. 16, pp. 1893–1903, 2004.
[20] X. Zhang and S. Wang, ? Fragile watermarking with error-free restoration capability,
Multimedia, IEEE Transactions on, vol. 10, no. 8, pp. 1490– 1499, 2008.
[21] R. Munir, ? A chaos-based fragile watermarking method in spatial domain for image
authentication,? in Intelligent Technology and Its Applications (ISITIA), 2015 International
Seminar on. IEEE, 2015, pp. 227–232.
[22] M. Wu and B. Liu, ? Watermarking for image authentication. in ICIP (2), 1998, pp. 437–441.
[23] C.-H. Chen, Y.-L. Tang, and W.-S. Hsieh, ? An image authentication and recovery method using
optimal selection of block types, in Multimedia (ISM), 2014 IEEE International Symposium on.
IEEE, 2014, pp. 151– 154.
[24] H. He, J. Zhang, and H.-M. Tai, ? A wavelet-based fragile watermarking scheme for secure image
authentication, in IWDW. Springer, 2006, pp. 422–432.
[25] M. Rajawat and D. Tomar, ? A secure watermarking and tampering detection technique on rgb
image using 2 level dwt,? in Communication Systems and Network Technologies (CSNT), 2015
Fifth International Conference on. IEEE, 2015, pp. 638–642.
113

NEW FORMS OF MATHEMATICAL ACTIVITY Mr. Ajaydeep
Assistant Professor,
Dev Samaj College of Education for Women Ferozepur City
Ms. Tamanna
Assistant Professor,
Dev Samaj College of Education for Women Ferozepur City
ABSTRACT
Mathematics is the study of numbers, quantity, space, structure, and change.
Mathematical activity includes research, applications, education and exposition. These
mathematical activities have changed a lot in the recent years. Many new forms of
mathematical activity are gaining significance: algorithms and programming, modeling,
mathematical experiments, conjecturing, expository writing and lecturing. Which of
these non-traditional mathematical activities could and should be taught to students?
INTRODUCTION
Mathematical activity (research, applications, education, and exposition) has changed a
lot in the years. Some of these changes, like the use of computers, are very visible and are
being implemented in mathematical education quite extensively. Many new forms of
mathematical activity are gaining significance: algorithms and programming, modeling,
conjecturing, expository writing and lecturing. It is absolutely obvious that education
can, and should, lead to a successful life, so defined. Moreover, mathematical education is
a particularly significant component of such an education. This is true for two reasons. On
the one hand, I would state dogmatically that mathematics is one of the human activities,
like art, literature, music, or the making of good shoes, which is intrinsically worthwhile.
On the other hand, mathematics is a key element in science and technology and thus vital
to the understanding, control and development of the resources of the world around us.
These two aspects of mathematics often referred to as pure mathematics and applied
mathematics, should both be present in a well-balanced, successful mathematics
education.
NEW FORMS OF MATHEMATICAL ACTIVITY Algorithms and programming
The traditional thousand year old paradigm of mathematical research is defining notions,
114

stating theorems and proving them. Perhaps less recognized, but almost this old, is
algorithm design. While different, these two ways of doing mathematics are strongly
interconnected. It is also obvious that computers have increased the visibility and
respectability of algorithm design substantially. Algorithmic mathematics is not the
antithesis of the theorem against the proof type classical mathematics, which we call here
structural. Rather, it enriches several classical branches of mathematics with new insight,
new kinds of problems, and new approaches to solve these. Mathematical education must
follow the mathematical research; this is especially so in those (rare) cases when research
results fundamentally change the whole framework of the subject. So set theory had to
enter mathematical education. However, the range of the penetration of an algorithmic
perspective in classical mathematics is not yet clear at all, and varies very much from
subject to subject. Graph theory and optimization, for example, have been thoroughly re-
worked from a computational complexity point of view; number theory and parts of
algebra are studied from such an aspect, but many basic questions are unresolved; in
analysis and differential equations, such an approach may or may not be a great success;
set theory does not appear to have much to do with algorithms at all. Our experience with
\New Math" warn us that drastic changes may be disastrous even if the new framework is
well established in research and college mathematics. Some algorithms and their analysis
could be taught about the same time when theorems and their proofs first occur, perhaps
around the age of 14. Of course, certain algorithms (for multiplication and division etc.)
occur quite early in the curriculum. But these are more recipes than algorithms; no
correctness proofs are given (naturally), and the efficiency is not analyzed. The route
from the mathematical idea of an algorithm to a computer program is long. It takes the
careful design of the algorithm; analysis and improvements of running time and space
requirements; selection of data structures; and programming. In college, to follow this
route is very instructive for the students. But even in secondary school mathematics, at
least the mathematics and implementation of an algorithm should be distinguished. An
important task for mathematics educators of the near future is to develop a smooth and
unified style of describing and analyzing algorithms. A style that shows the mathematical
ideas behind the design; that facilitates analysis; that is concise and elegant would also be
of great help in overcoming the contempt against algorithms that is still often felt both on
the side of the teacher and of the student.
Problems and conjectures
In a small community, everybody knows what the main problems are. But in a community
115

of 100,000 people, problems have to be identified and stated in a precise way. Poorly
stated problems lead to boring, irrelevant results. This elevates the formulation of
conjectures to the rank of research results. Of course, it is difficult to formulate what
makes a good conjecture. It is easy to agree that if a conjecture is good, one expects that its
resolution should advance our knowledge substantially. Many mathematicians feel that
this is the 0case when we can clearly see the place of the conjecture, and its probable
solution, in the building of mathematics; but there are conjectures so surprising, so utterly
inaccessible by current methods that their resolution must bring something new we just
don't know where. In the teaching style of mathematics which emphasizes discovery
(which I personally and the best), good teachers always challenged their students to
formulate conjectures leading up to a theorem or to the steps of a proof. This is time-
consuming, and there is a danger that this activity too is eroding under the time pressure
discussed above. I feel that it must be preserved and encouraged.
Mathematical experiments
In some respects, computers allow us to turn mathematics into an experimental subject.
Ideally, mathematics is a deductive science, but in quite a few situations, experimentation
is warranted: (a) Testing an algorithm for efficiency, when the resource requirements
(time, space) depend on the input in a too complicated way to make good predictions. (b)
Cryptographic and other computer security issues often depend on classical questions
about the distribution of primes and similar problems in number theory, and the answers
to these questions often depend on notoriously difficult problems in number theory, like
the Riemann Hypothesis and its extensions. Needless to say that in such practically
crucial questions, experiments, must be made even if deductive answers would be ideal.
(c) Experimental mathematics is a good source of conjectures; a classical example is
Gauss' discovery (not proof) of the Prime Number Theorem. Among the contemporary
examples of this, let me mention the most systematic one: the graph-theoretic conjecture-
generating program GRAFFITI. A simple example: a student can develop a real feeling
for the notion of convergence and convergence rate by comparing the computation of the
convergent sums. Mathematical experimentation has indeed been used quite extensively
in the teaching of analysis, number theory, geometry, and many other topics. The success
seems to be controversial; my feeling is that, similarly as in the teaching of algorithms, the
development of large well-tested sets of experimental tasks takes time, and is the most
crucial element of the success of these teaching methods. I do not include here
verification of the correctness of a program, which is not a mathematical issue, but rather
software engineering.
116

Modeling
To construct good models is the most important first step in almost every successful
application of mathematics. The role of modeling in education is well recognized, but its
weight relative to other material, and the ways of teaching it, are quite controversial.
Modeling is a typical interactive process, where the mathematician must work together
with engineers, biologist, economists, and many other professionals seeking help from
mathematics. A possible approach here is to combine teaching of mathematical modeling
with education in team work and professional interaction. A good example is the course
Discrete Mathematical Modeling at the University of Washington. The main feature of
this course is that the students, in groups of 2 or 3, must and a real-life problem in their
environment. They have to develop a model, gather data, and code the algorithms that
answer the original question, and give a presentation of the results. The real-life problems
raised are quite broad in scope, from problems on favorite games to attempts to help
family or friends in their business, and some of the answers obtained turn out quite useful.
Exposition and popularization
The role of this activity is growing very fast in the mathematical research community.
Besides the traditional way of writing a good monograph (which is of course still highly
re- graded), there is more and more demand for expositions, surveys, mini courses,
handbooks and encyclopedias. Many conferences (and often the most successful ones)
are mostly or exclusively devoted to expository and survey-type talks; publishers much
prefer volumes of survey articles to volumes of research papers. While full recognition of
expository work is still lacking, the importance of it is more and more accepted. On the
other hand, mathematics education does little to prepare students for this.
CONCLUSION
Mathematics is a notoriously difficult subject to talk about to outsiders. Much more effort
is needed to teach students at all levels how to give presentations, or write about
mathematics they learned. An important task for mathematics educators of the near future
is to develop a smooth and unified style of describing and analyzing algorithms and
modeling.
REFERENCES
[1]. Fajtlowicz, S. (1988). On conjectures of Graffiti. Discrete Math.
[2]. Lovasz, L. (1988). Algorithmic mathematics: an old aspect with a new emphasis, in: Proc. 6th
ICME, Budapest, J. Bolyai Math. .
[3]. Peters, A.K. (2004). Experimentation in Mathematics: Computational Paths to Discovery.
117

TRENDS IN MATHEMATICS
Dr. Rajwinder Kaur
Assistant Professors
Dev Samaj College of Education for women Ferozepur City
Ms. Rajni
Assistant Professors
Dev Samaj College of Education for women Ferozepur City
ABSTRACT
Mathematical activity (research, applications, education, and exposition) has changed a
lot in the recent years. Some of these changes, like the use of computers, are very visible
and are being implemented in mathematical education quite extensively. There are other,
more subtle trends that may not be so obvious. These trends are like the size of the
community and of mathematical research activity, new areas of application and their
increasing significance, new tools: computers and information technology and new forms
of mathematical activity. In this article we discuss some of these trends and how they
could, or should, influence the future of mathematical education.
INTRODUCTION
My intention in this talk is to study, grosso modo, the dominant trends in present-day
mathematics, and to draw from this study principles that should govern the choice of
content and style in the teaching of mathematics at the secondary and elementary levels.
Some of these principles will be time-independent, in the sense that they should always
have been applied to the teaching of mathematics; others will be of special application to
the needs of today's, and tomorrows, students and will be, in that sense, new education.
However, before embarking on a talk intended as a contribution to the discussion of how
to achieve a successful mathematical education, it would be as well to make plain what
are our criteria of success. Indeed, it would be as well to be clear what we understand by
successful education, since we would then be able to derive the indicated criteria by
specialization. Moreover, mathematical education is a particularly significant component
of such an education.
TRENDS IN MATHEMATICS
The size of the community and of mathematical research activity: The number of
118

mathematical publications (along with publications in other sciences) has increased
exponentially in the last 50 years. Mathematics has outgrown the small and close-knit
community of nerds that it used to be; with increasing size, the profession is becoming
more diverse, more structured and more complex. Mathematicians sometimes pretend
that mathematical research is as it used to be: that we find all the information that might be
relevant by browsing through the new periodicals in the library, and that if we publish a
paper in an established journal, then it will reach all the people whose research might
utilize our results. But of course 3/4 of the relevant periodicals are not on the library table,
and even if one had access to all these journals, and had the time to read all of them, one
would only be familiar with the results of a small corner of mathematics. A larger
structure is never just a scaled-up version of the smaller. In larger and more complex
animals an increasingly large fraction of the body is devoted to ? overhead? : the
transportation of material and the coordination of the function of various parts. In larger
and more complex societies an increasingly large fraction of the resources is devoted to
non-productive activities like transportation information processing, education or
recreation. We have to realize and accept that a larger and larger part of our mathematical
activity will be devoted to communication. This is easy to observe: the number of
professional visits, conferences, workshops, research institutes is increasing fast, e-mail
is used more and more. The percentage of papers with multiple authors has jumped. But
probably we will reach the point soon where mutual personal contact does not provide
sufficient information flow.
New areas of application, and their increasing significance
The traditional areas of application of mathematics are physics and engineering. The
branch of mathematics used in these applications is analysis, primarily differential
equations. But in the boom of scientific research in the last 50 years, many other sciences
have come to the point where they need serious mathematical tools, and quite often the
traditional tools of analysis are not adequate. For example, biology studies the genetic
code, which is discrete: simple basic questions like finding matching patterns, or tracing
consequences of flipping over substrings, sound more familiar to the combinatorialist
than to the researcher of differential equations. A question about the information content,
redundancy, or stability of the code may sound too vague to a classical mathematician but
a theoretical computer scientist will immediately see at least some tools to formalize it
(even if to find the answer may be too difficult at the moment). Even physics has its
encounters with unusual discrete mathematical structures: elementary particles, quarks
and the like are very combinatorial; understanding basic models in statistical mechanics
119

requires graph theory and probability. Economics is a heavy user of mathematics—and
much of its need is not part of the traditional applied mathematics toolbox. The success of
linear programming in economics and operations research depends on conditions of
convexity and unlimited divisibility; taking indivisibilities into account (for example,
logical decisions, or individuals) leads to integer programming and other combinatorial
optimization models, which are much more difficult to handle. Finally, there is a
completely new area of applied mathematics: computer science. The development of
electronic computation provides a vast array of well-formulated, difficult, and important
mathematical problems, raised by the study of algorithms, data bases formal languages,
cryptography and computer security, VLSI layout, and much more. Most of these have to
do with discrete mathematics, formal logic, and probability.
New tools: computers and information technology
Computers, of course, are not only sources of interesting and novel mathematical
problems. They also provide new tools for doing and organizing our research. We use
them for e-mail and word processing, for experimentation, and for getting information
through the web, from the MathSciNet database, Wikipedia, the Arxives, electronic
journals and from home pages of fellow mathematicians. Are these uses of computers just
toys or at best matters of convenience? I think not, and that each of these is going to have a
profound impact on our science. It is easiest to see this about experimentation with Maple,
Mathematica, Math lab, or your own programs. These programs open for us a range of
observations and experiments which had been inaccessible before the computer age, and
which provide new data and reveal new phenomena. Electronic journals and databases,
home pages of people, companies and institutions, Wikipedia, and e-mail provide new
ways of dissemination of results and ideas. In a sense, they reinforce the increase in the
volume of research: not only are there increasingly more people doing research, but an
increasingly large fraction of this information are available at our fingertips (and often
increasingly loudly and aggressively: the etiquette of e-mail is far from solid). But we can
also use them as ways of coping with the information explosion. Electronic publication is
gradually transforming the way we write papers. At first sight, word processing looks like
just a convenient way of writing; but slowly many features of electronic versions become
available that are superior to the usual printed papers: hyperlinks, colored figures and
illustrations, animations and the like.
120

CONCLUSION
However, before embarking on a talk intended as a contribution to the discussion of how
to achieve a successful mathematical education, it would be as well to make plain what
are our criteria of success. Indeed, it would be as well to be clear what we understand by
successful education, since we would then be able to derive the indicated criteria by
specialization.
REFERENCES
[1]. Fajtlowicz, S. Postscript to Fully Automated Fragments of Graph Theory (n.d). Retrieved from
http: //math.uh.edu/~siemion/postscript.pdf
[2]. Halmos, P. R. (1981). Applied mathematics is bad mathematics, in Mathematics Tomorrow (ed. L.
A. Steen).
[3]. Laszlo (2008). Trends in Mathematics: How they could Change Education? Retrieved from
http://www.cs.elte.hu/~lovasz/lisbon.pdf
121

ASHU GRAPHICS (FEROZEPUR PRINTING PRESS)Mall Road, Ferozepur City (Punjab) - 152 002





























