Embed Size (px)
Citation preview

CIS429/529 Cache Basics 1
Caches
° Why is caching needed?• Technological development and Moore’s Law
° Why are caches successful?• Principle of locality
° Three basic models and how they work (in detail)• Direct mapped, fully associative, set associative
° How they interact with the pipeline
° Performance analysis of caches• Average Memory Access Time (AMAT)
° Enhancements to caches
CIS429/529 Cache Basics 2
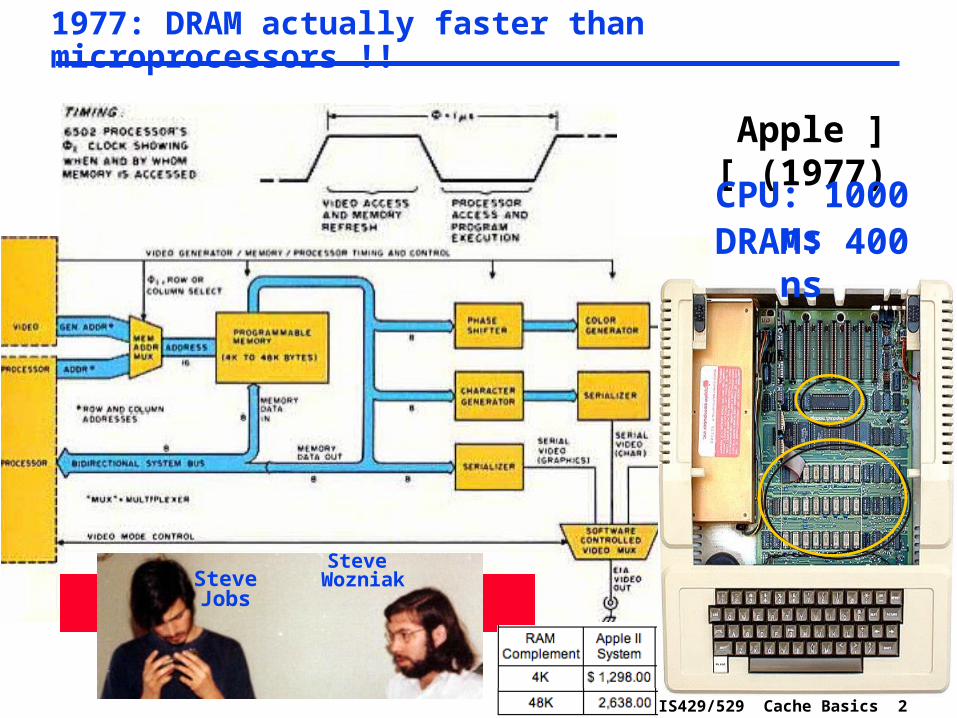
1977: DRAM actually faster than microprocessors !!
Apple ][ (1977)
Steve WozniakSteve
Jobs
CPU: 1000 ns DRAM: 400 ns
CIS429/529 Cache Basics 3
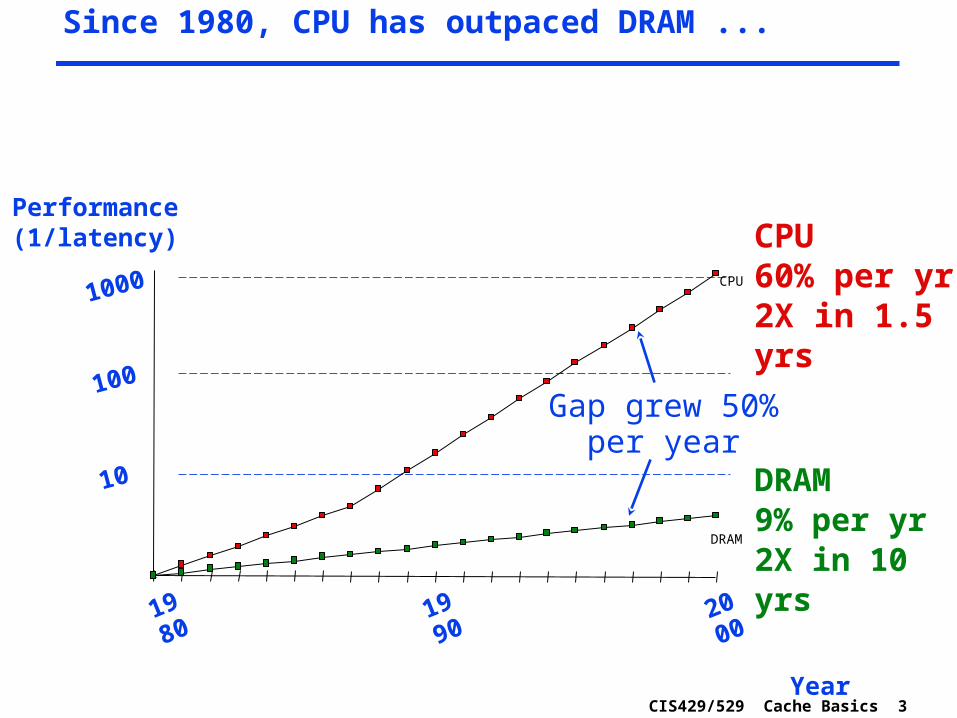
Since 1980, CPU has outpaced DRAM ...
CPU60% per yr2X in 1.5 yrs
DRAM9% per yr2X in 10 yrs
10
DRAM
CPU
Performance(1/latency)
100
1000
1980
2000
1990
Year
Gap grew 50% per year
CIS429/529 Cache Basics 4
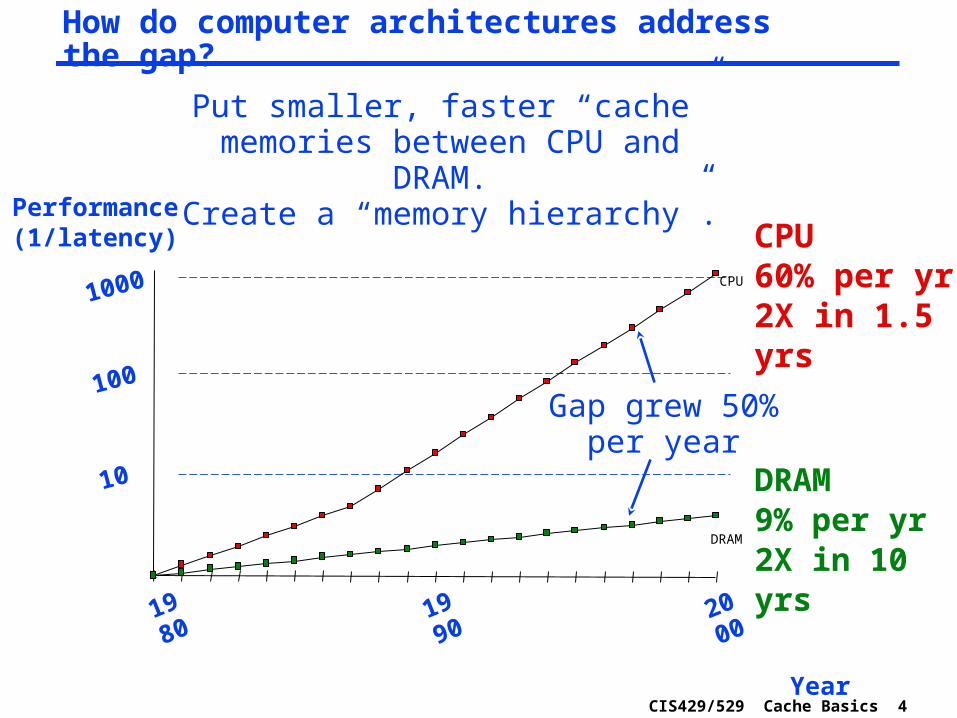
How do computer architectures address the gap?
CPU60% per yr2X in 1.5 yrs
DRAM9% per yr2X in 10 yrs
10
DRAM
CPU
Performance(1/latency)
100
1000
1980
2000
1990
Year
Gap grew 50% per year
Put smaller, faster “cache” memories between CPU and
DRAM. Create a “memory hierarchy”.

CIS429/529 Cache Basics 5
The Goal: illusion of large, fast, cheap memory
° Fact: Large memories are slow, fast memories are small
° How do we create a memory that is large, cheap and fast (most of the time)?
• Hierarchy
• Parallelism
Let programs address a memory space that scales to the disk size, at a speed that is usually as fast as register access
CIS429/529 Cache Basics 6
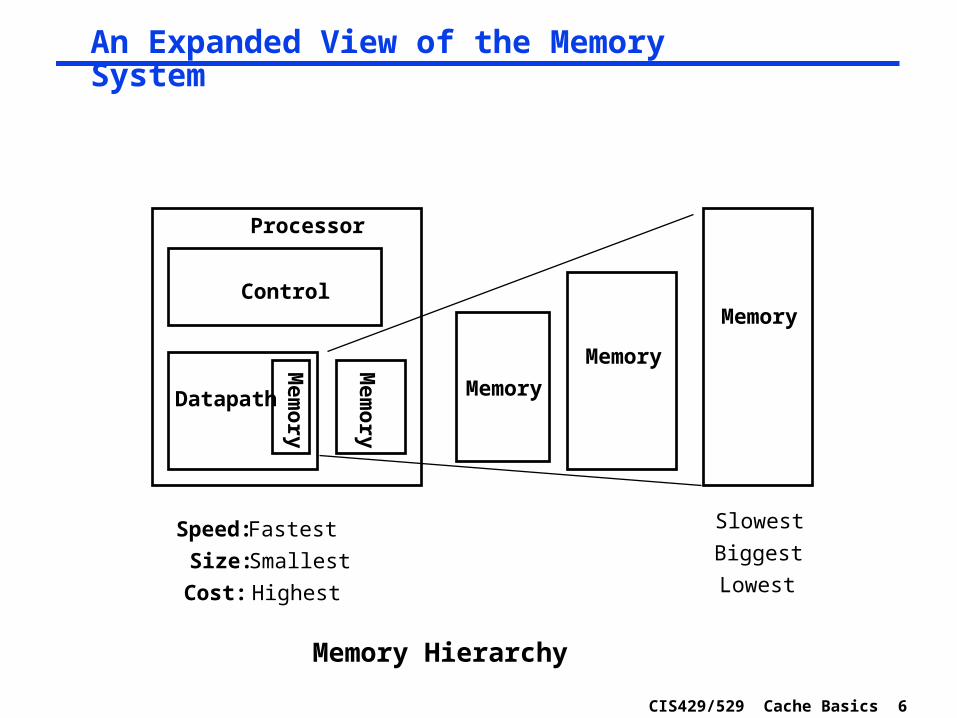
An Expanded View of the Memory System
Control
Datapath
Memory
Processor
Mem
ory
Memory
Memory
Mem
ory
Fastest Slowest
Smallest Biggest
Highest Lowest
Speed:
Size:
Cost:
Memory Hierarchy
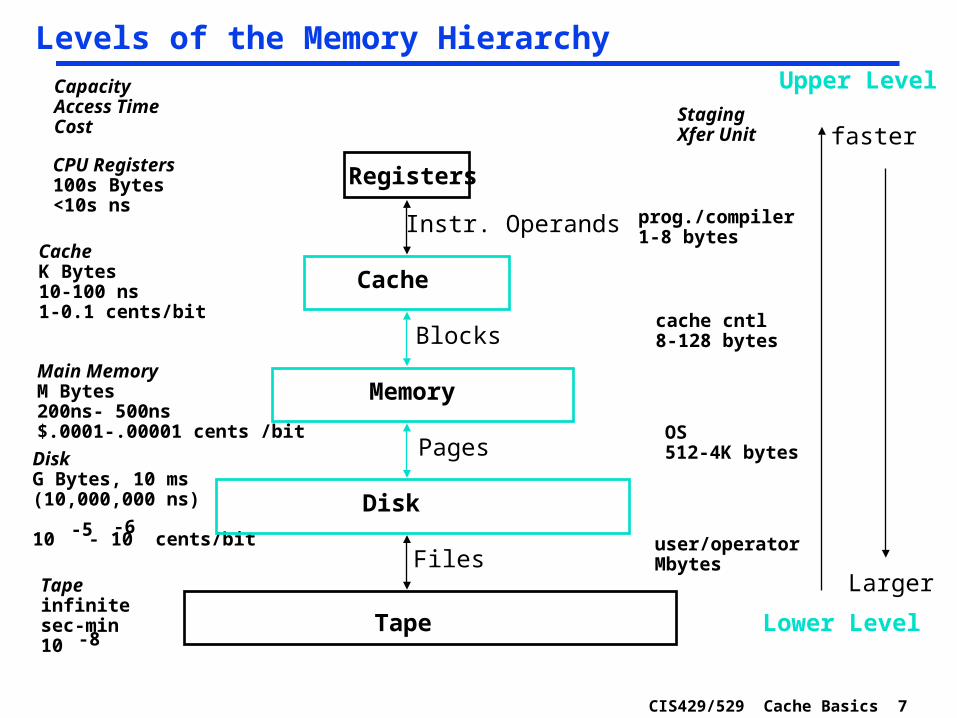
CIS429/529 Cache Basics 7
Levels of the Memory Hierarchy
CPU Registers100s Bytes<10s ns
CacheK Bytes10-100 ns1-0.1 cents/bit
Main MemoryM Bytes200ns- 500ns$.0001-.00001 cents /bit
DiskG Bytes, 10 ms (10,000,000 ns)
10 - 10 cents/bit-5 -6
CapacityAccess TimeCost
Tapeinfinitesec-min10 -8
Registers
Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
StagingXfer Unit
prog./compiler1-8 bytes
cache cntl8-128 bytes
OS512-4K bytes
user/operatorMbytes
Upper Level
Lower Level
faster
Larger
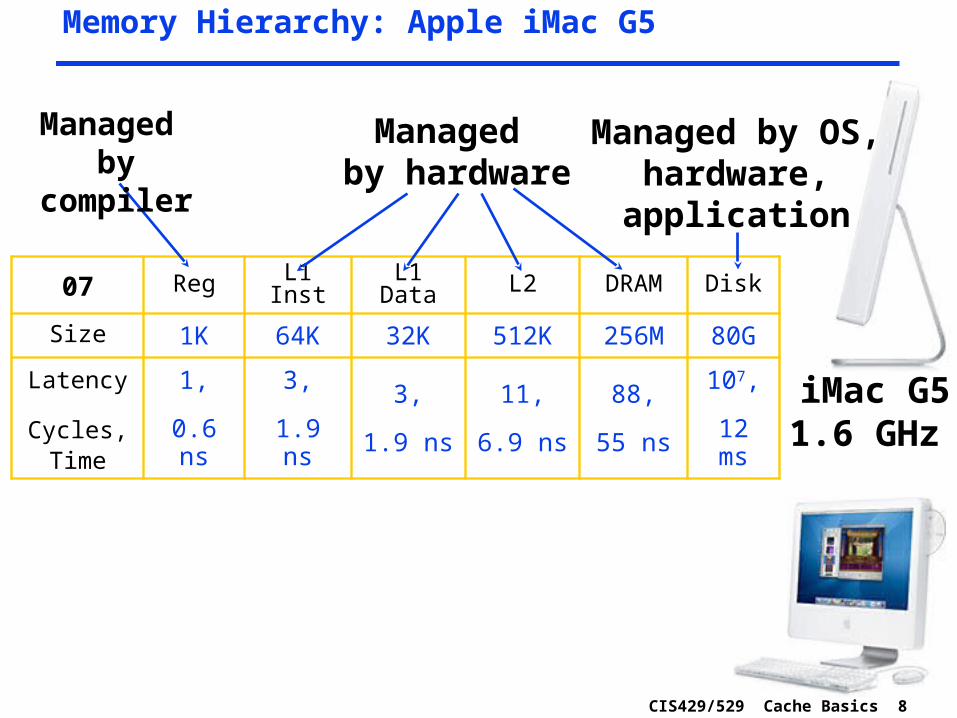
CIS429/529 Cache Basics 8
Memory Hierarchy: Apple iMac G5
iMac G51.6 GHz
07 Reg L1 Inst L1 Data L2 DRAM Disk
Size 1K 64K 32K 512K 256M 80G
Latency
Cycles, Time
1,
0.6 ns
3,
1.9 ns
3,
1.9 ns
11,
6.9 ns
88,
55 ns
107,
12 ms
Managed by compiler
Managed by hardware
Managed by OS,hardware,
application
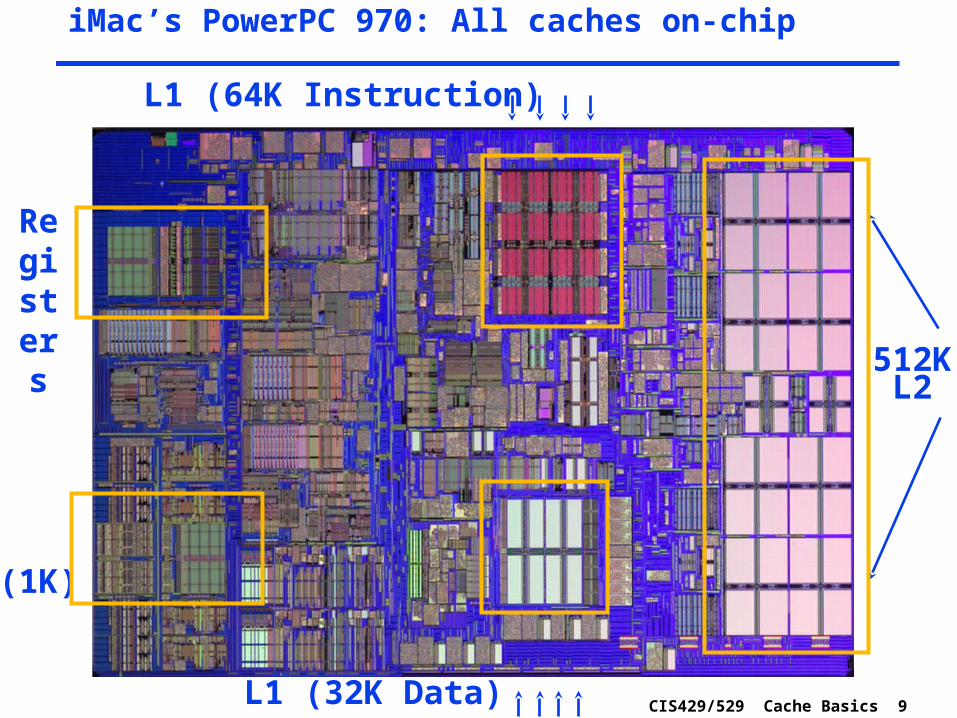
CIS429/529 Cache Basics 9
iMac’s PowerPC 970: All caches on-chip
(1K)
Registers
512KL2
L1 (64K Instruction)
L1 (32K Data)

CIS429/529 Cache Basics 10
The Principle of Locality
° The Principle of Locality:• Program access a relatively small portion of the address space at any instant
of time.
° Two Different Types of Locality:• Temporal Locality (Locality in Time): If an item is referenced, it will tend to be
referenced again soon (e.g., loops, reuse)• Spatial Locality (Locality in Space): If an item is referenced, items whose
addresses are close by tend to be referenced soon (e.g., straightline code, array access)
° Last 15 years, HW relied heavily on locality for speed
Locality is a universal property of programs which is exploited in many aspects
of HW and SW design.

CIS429/529 Cache Basics 11
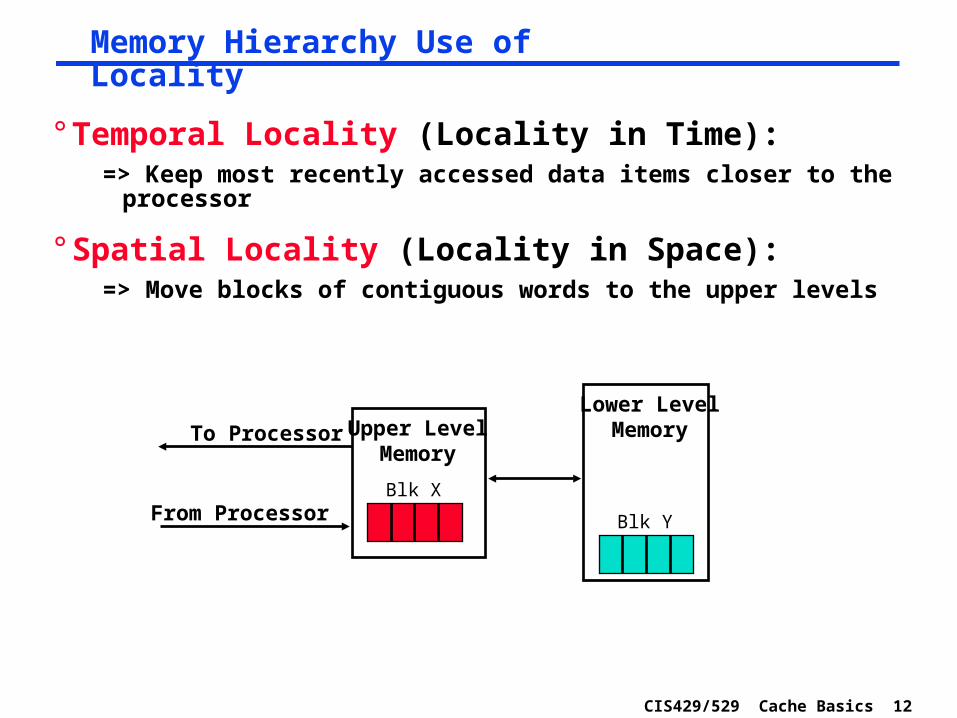
Programs with locality cache well ...
Donald J. Hatfield, Jeanette Gerald: Program Restructuring for Virtual Memory. IBM Systems Journal 10(3): 168-192 (1971)
Time
Mem
ory
Ad
dre
ss (
on
e d
ot
per
acc
ess)
SpatialLocality
Temporal Locality
Bad locality behavior
CIS429/529 Cache Basics 12
Memory Hierarchy Use of Locality
° Temporal Locality (Locality in Time):=> Keep most recently accessed data items closer to the processor
° Spatial Locality (Locality in Space):=> Move blocks of contiguous words to the upper levels
Lower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y

CIS429/529 Cache Basics 13
Memory Hierarchy: Terminology° Hit: data appears in some block in the upper level • Hit Rate: the fraction of memory access found in the upper level
• Hit Time: Time to access the upper level which consists of
Time to determine hit/miss + time to deliver block to processor
° Miss: data needs to be retrieve from a block in the lower level
• Miss Rate = 1 - (Hit Rate)
• Miss Time: Time to determine hit/miss + Time to replace a block in the upper level + Time to deliver the block to the processor
• Miss Penalty: Extra time incurred for a miss = Time to replace a block in the upper level
° Hit Time << Miss Penalty and Miss TimeLower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y

CIS429/529 Cache Basics 14
° Q1: Where can a block be placed in the upper level? (Block placement)
° Q2: How is a block found if it is in the upper level? (Block identification)
° Q3: Which block should be replaced on a miss? (Block replacement)
° Q4: What happens on a write? (Write strategy)
Four Organizing Principles for Caches and
Memory Hierarchy
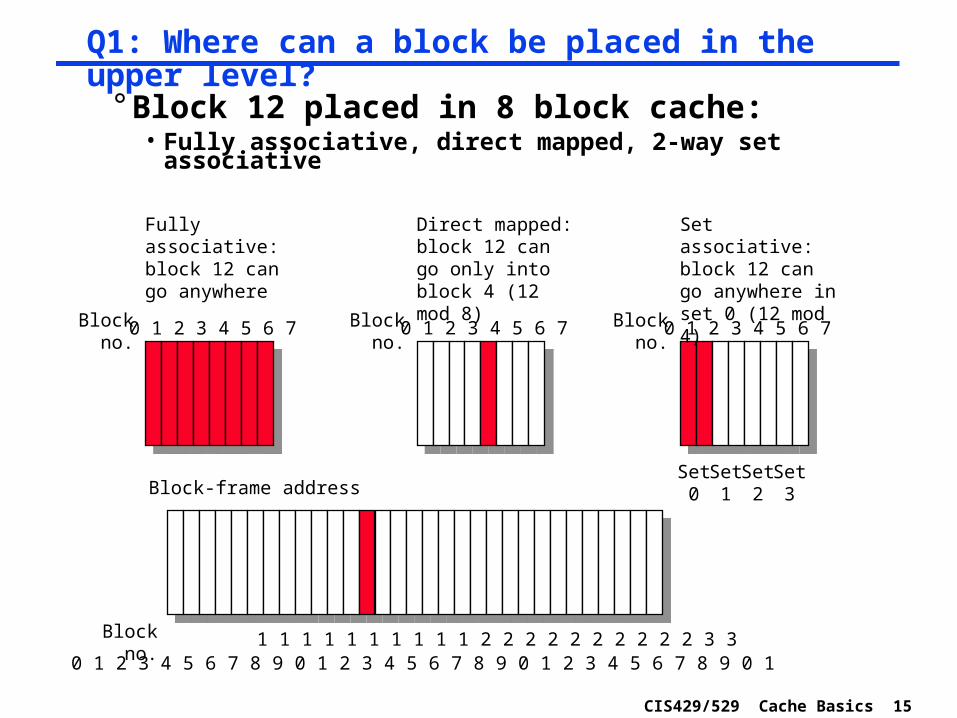
CIS429/529 Cache Basics 15
° Block 12 placed in 8 block cache:• Fully associative, direct mapped, 2-way set associative
0 1 2 3 4 5 6 7Blockno.
Fully associative:block 12 can go anywhere
0 1 2 3 4 5 6 7Blockno.
Direct mapped:block 12 can go only into block 4 (12 mod 8)
0 1 2 3 4 5 6 7Blockno.
Set associative:block 12 can go anywhere in set 0 (12 mod 4)
Set0
Set1
Set2
Set3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
Block-frame address
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3Blockno.
Q1: Where can a block be placed in the upper level?
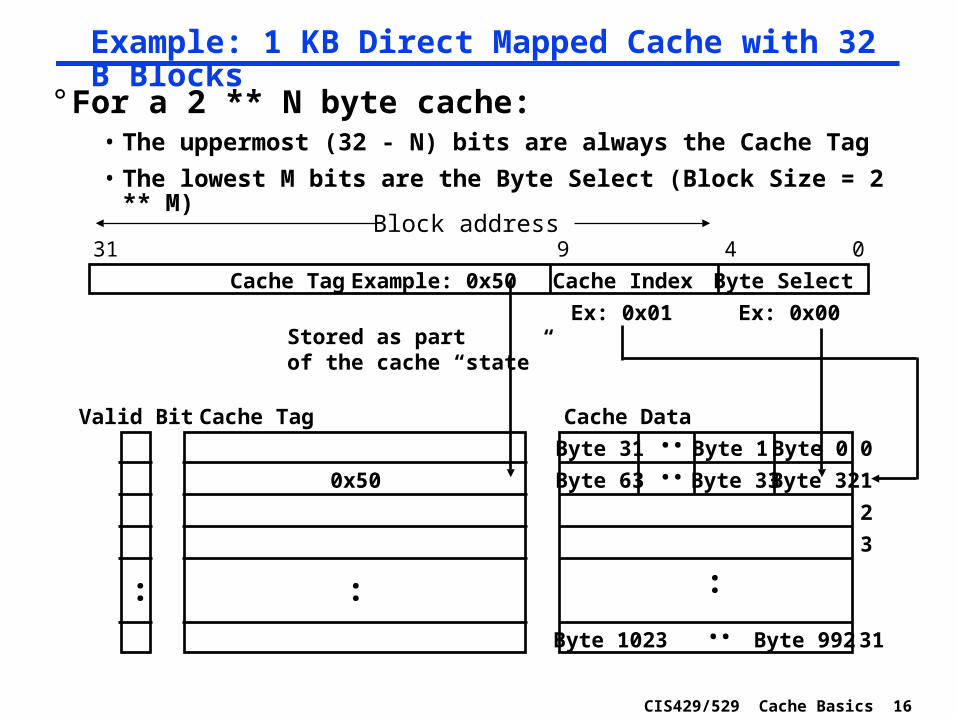
CIS429/529 Cache Basics 16
Example: 1 KB Direct Mapped Cache with 32 B Blocks
° For a 2 ** N byte cache:• The uppermost (32 - N) bits are always the Cache Tag
• The lowest M bits are the Byte Select (Block Size = 2 ** M)
Cache Index
0
1
2
3
:
Cache Data
Byte 0
0431
:
Cache Tag Example: 0x50
Ex: 0x01
0x50
Stored as partof the cache “state”
Valid Bit
:
31
Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :Byte 992Byte 1023 :
Cache Tag
Byte Select
Ex: 0x00
9Block address
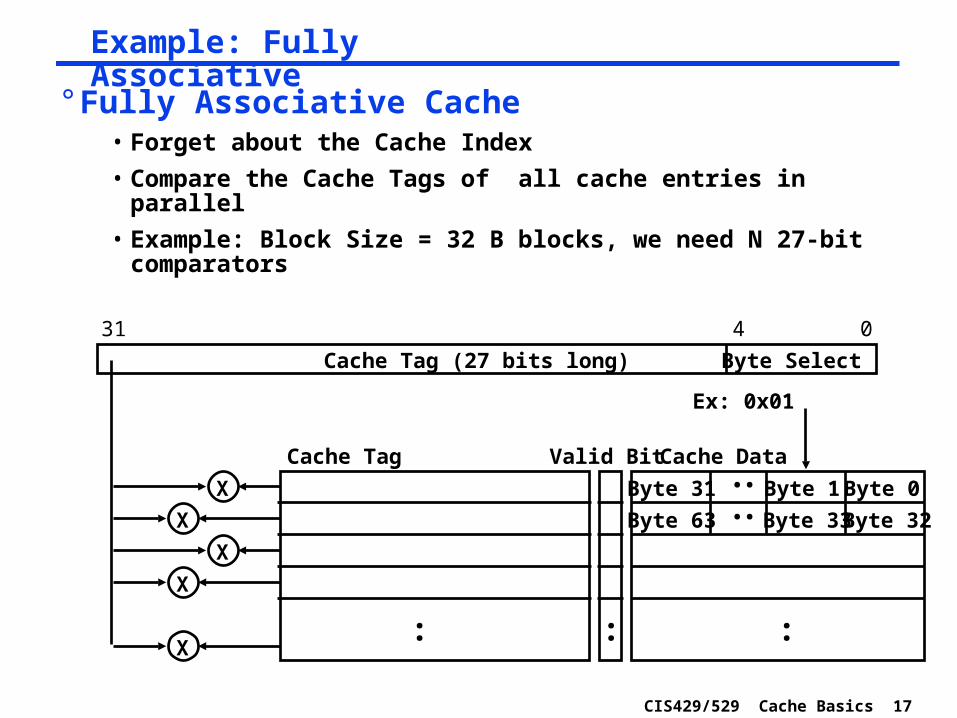
CIS429/529 Cache Basics 17
Example: Fully Associative
° Fully Associative Cache• Forget about the Cache Index
• Compare the Cache Tags of all cache entries in parallel
• Example: Block Size = 32 B blocks, we need N 27-bit comparators
:
Cache Data
Byte 0
0431
:
Cache Tag (27 bits long)
Valid Bit
:
Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :
Cache Tag
Byte Select
Ex: 0x01
X
X
X
X
X
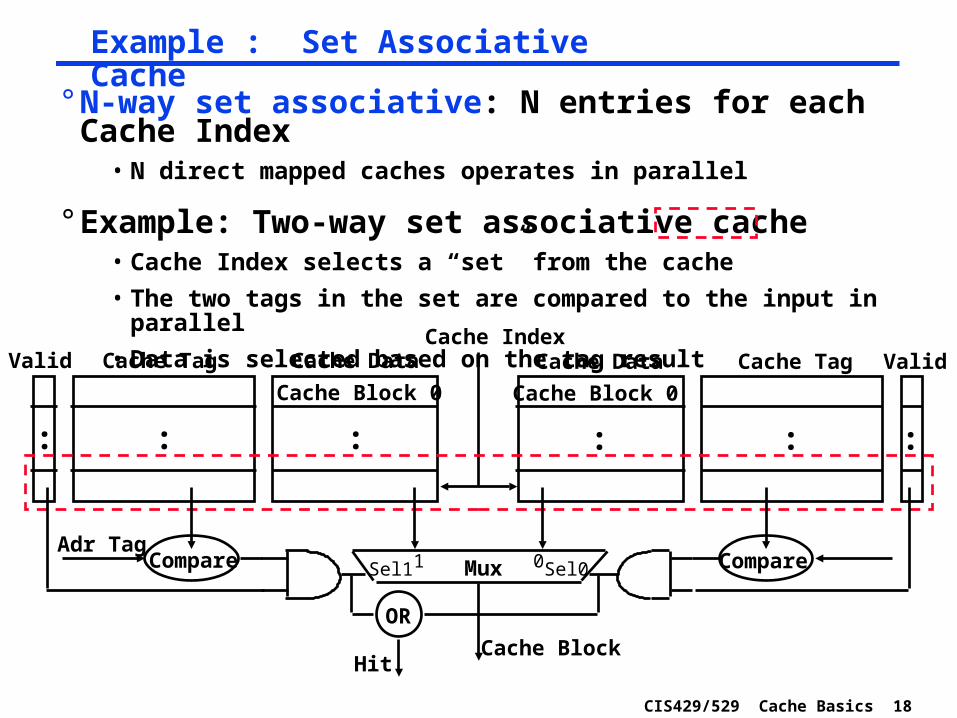
CIS429/529 Cache Basics 18
Example : Set Associative Cache
° N-way set associative: N entries for each Cache Index• N direct mapped caches operates in parallel
° Example: Two-way set associative cache• Cache Index selects a “set” from the cache
• The two tags in the set are compared to the input in parallel
• Data is selected based on the tag result
Cache Data
Cache Block 0
Cache TagValid
:: :
Cache Data
Cache Block 0
Cache Tag Valid
: ::
Cache Index
Mux 01Sel1 Sel0
Cache Block
CompareAdr Tag
Compare
OR
Hit

CIS429/529 Cache Basics 19
° Direct indexing (using index and block offset), tag compares, or combination
° Increasing associativity shrinks index, expands tag
Blockoffset
Block AddressTag Index
Q2: How is a block found if it is in the upper level?

CIS429/529 Cache Basics 20
° Easy for Direct Mapped
° Set Associative or Fully Associative:• Random
• LRU (Least Recently Used)
Associativity: 2-way 4-way 8-way
Size LRU Random LRU Random LRU Random
16 KB 5.2% 5.7% 4.7% 5.3% 4.4% 5.0%
64 KB 1.9% 2.0% 1.5% 1.7% 1.4% 1.5%
256 KB 1.15% 1.17% 1.13% 1.13% 1.12% 1.12%
Q3: Which block should be replaced on a miss?

CIS429/529 Cache Basics 21
° Writes occur less frequently than reads:• Under MIPS: 7% of all memory traffic are writes
• 25% of all data traffic are writes
° Thus, Amdahl’s Law implies that caches should be optimized for reads. However, we cannot ignore writes.
° Problems with writes:• Must check tag BEFORE writing into the cache
• Only a portion of the cache block is modified
• Write stalls - CPU must wait until the write completes
Q4: What happens on a write?

CIS429/529 Cache Basics 22
° Write through—The information is written to both the block in the cache and to the block in the lower-level memory.
° Write back—The information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced.
• is block clean or dirty?
° Pros and Cons of each?• WT: read misses don’t cause writes; easier to implement; copy
of data always exists
• WB: write at the speed of the cache; multiple writes to cache before write to memory; less memory BW consumed
Q4: What happens on a write: Design Options
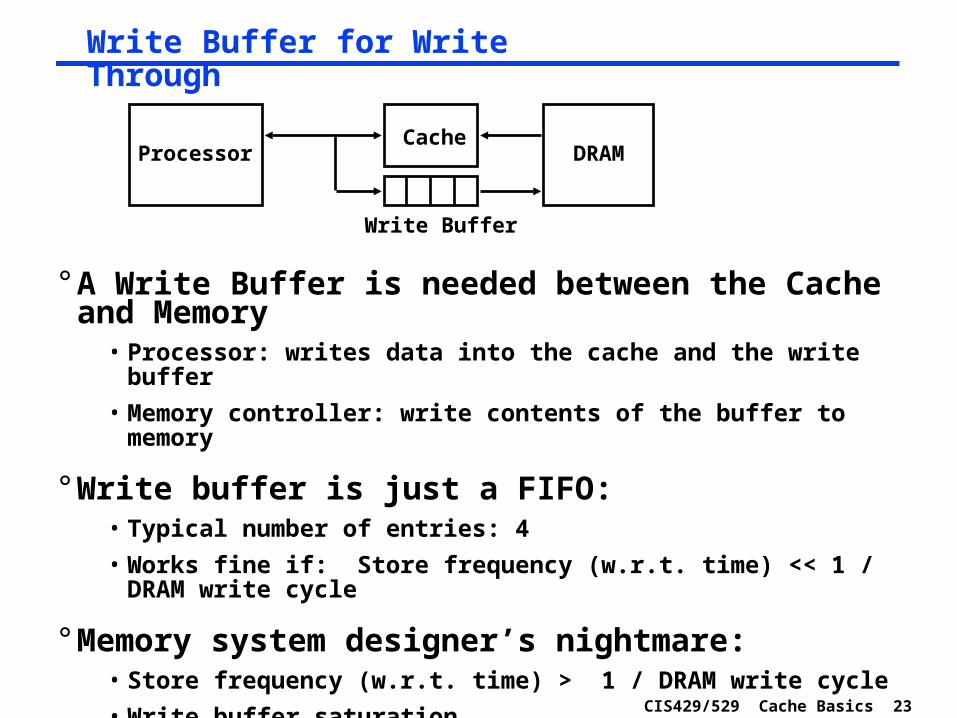
CIS429/529 Cache Basics 23
° A Write Buffer is needed between the Cache and Memory
• Processor: writes data into the cache and the write buffer
• Memory controller: write contents of the buffer to memory
° Write buffer is just a FIFO:• Typical number of entries: 4
• Works fine if: Store frequency (w.r.t. time) << 1 / DRAM write cycle
° Memory system designer’s nightmare:• Store frequency (w.r.t. time) > 1 / DRAM write cycle
• Write buffer saturation
ProcessorCache
Write Buffer
DRAM
Write Buffer for Write Through
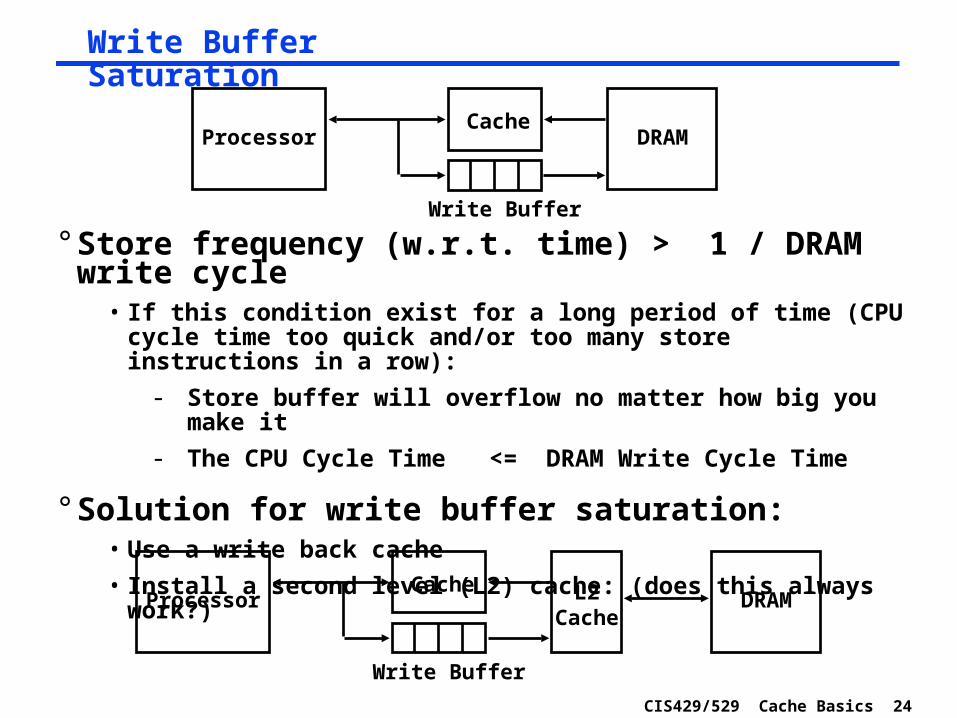
CIS429/529 Cache Basics 24
Write Buffer Saturation
° Store frequency (w.r.t. time) > 1 / DRAM write cycle• If this condition exist for a long period of time (CPU cycle time too
quick and/or too many store instructions in a row):
- Store buffer will overflow no matter how big you make it
- The CPU Cycle Time <= DRAM Write Cycle Time
° Solution for write buffer saturation:• Use a write back cache
• Install a second level (L2) cache: (does this always work?)
ProcessorCache
Write Buffer
DRAM
ProcessorCache
Write Buffer
DRAML2Cache

CIS429/529 Cache Basics 25
Write Miss Design Options
° Write allocate (“fetch on write”) - block is loaded on a write miss, followed by the write.
° No-write allocate (“write around”) - block is modified in the lower level, not loaded into the cache.

CIS429/529 Cache Basics 26
° Assume: a 16-bit write to memory location 0x0 and causes a miss
• Do we read in the block?
- Yes: Write Allocate
- No: Write Not Allocate
Cache Index
0
1
2
3
:
Cache Data
Byte 0
0431
:
Cache Tag Example: 0x00
Ex: 0x00
0x50
Valid Bit
:
31
Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :Byte 992Byte 1023 :
Cache Tag
Byte Select
Ex: 0x00
9
Write-miss Policy: Write Allocate versus Not Allocate
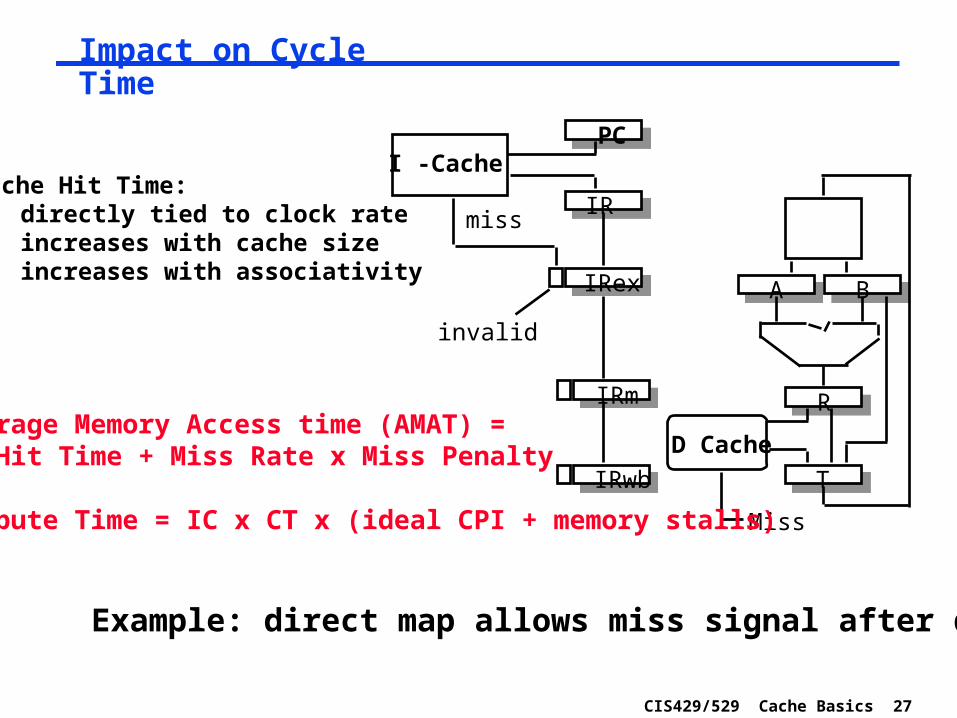
CIS429/529 Cache Basics 27
Impact on Cycle Time
Example: direct map allows miss signal after data
IR
PCI -Cache
D Cache
A B
R
T
IRex
IRm
IRwb
miss
invalid
Miss
Cache Hit Time:directly tied to clock rateincreases with cache sizeincreases with associativity
Average Memory Access time (AMAT) = Hit Time + Miss Rate x Miss Penalty
Compute Time = IC x CT x (ideal CPI + memory stalls)
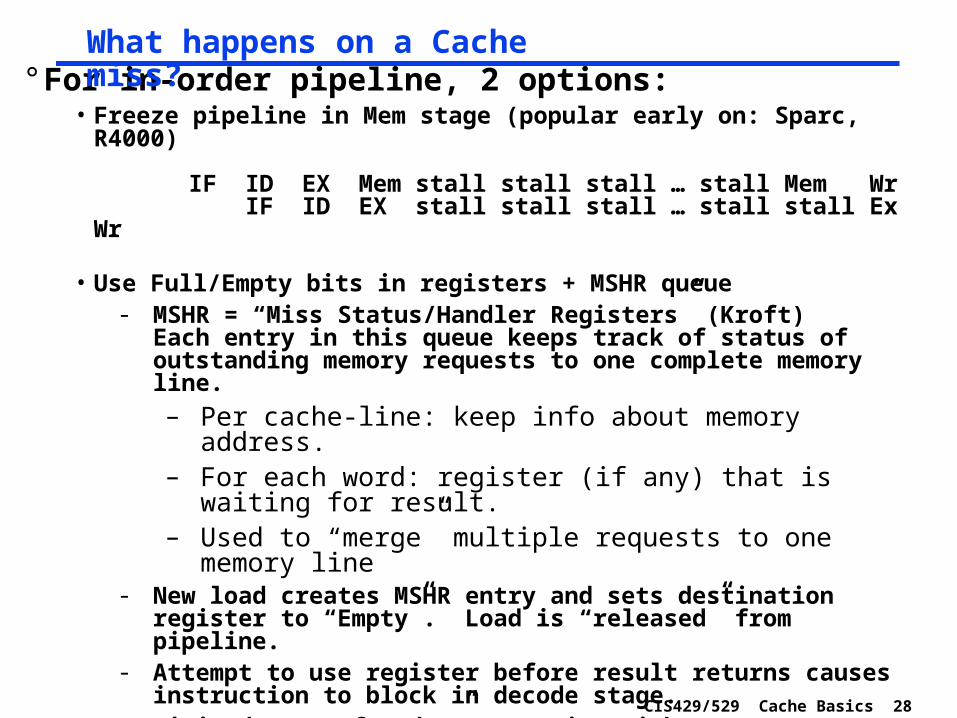
CIS429/529 Cache Basics 28
° For in-order pipeline, 2 options:• Freeze pipeline in Mem stage (popular early on: Sparc, R4000)
IF ID EX Mem stall stall stall … stall Mem Wr
IF ID EX stall stall stall … stall stall Ex Wr
• Use Full/Empty bits in registers + MSHR queue- MSHR = “Miss Status/Handler Registers” (Kroft)
Each entry in this queue keeps track of status of outstanding memory requests to one complete memory line.– Per cache-line: keep info about memory address.– For each word: register (if any) that is waiting for result.– Used to “merge” multiple requests to one memory line
- New load creates MSHR entry and sets destination register to “Empty”. Load is “released” from pipeline.
- Attempt to use register before result returns causes instruction to block in decode stage.
- Limited “out-of-order” execution with respect to loads. Popular with in-order superscalar architectures.
° Out-of-order pipelines already have this functionality built in… (load queues, etc).
What happens on a Cache miss?





























