Embed Size (px)
DESCRIPTION
CCN LAB MANUAL VTU 7TH SEMESTER Telecommunication Engineering
Citation preview

T.JOHN INSTITUTE OF TECHNOLOGY BANGALORE-83
DEPARTMENT OF TELECOMMUNICATION ENGINEERING.
CCN LAB MANUAL
Prepared By
Mr.NARAYANA SWAMY.RAssoc.Prof, Dept of TCE
TJIT, BANGALORE

CONTENTS
I. CCN Programming Experiments in C/C++ (3 lab sessions of 3 hrs each)
1. Simulate bit/character stuffing & de-stuffing using HDLC
2. Simulate the shortest path algorithm
3. Encryption and decryption of a given message
4. Find minimum spanning tree of a subnet
5. Compute polynomial code checksum for CRC-CCITT
II. CCN Experiments using Hardware (1 lab session of 3 Hrs each)1. Asynchronous and Synchronous Communication using RS 232/ Optical
Fiber/ Twisted pair / RJ452. Using fork function creates TWO processes and communicates between them.3. Communicate between TWO PCs, using simple socket function.
III. Demonstrate the operations of rlogin and telnet
IV. Demonstrate the operations of ftp, mailbox.

What is DLL (Data Link Layer)
The Data Link Layer is the second layer in the OSI model, above the Physical Layer, which ensures that the error free data is transferred between the adjacent nodes in the network. It breaks the datagrams passed down by above layers and converts them into frames ready for transfer. This is called Framing. It provides two main functionalities
Reliable data transfer service between two peer network layers Flow Control mechanism which regulates the flow of frames such that data congestion is not there at
slow receivers due to fast senders.
What is framing?
Since the physical layer merely accepts and transmits a stream of bits without any regard to meaning or structure, it is up to the data link layer to create and recognize frame boundaries. This can be accomplished by attaching special bit patterns to the beginning and end of the frame. If these bit patterns can accidentally occur in data, special care must be taken to make sure these patterns are not incorrectly interpreted as frame delimiters.
The four framing methods that are widely used are 1. Character count 2. Starting and ending characters, with character stuffing 3. Starting and ending flags, with bit stuffing 4. Physical layer coding violations
1. Character CountThis method uses a field in the header to specify the number of characters in the frame. When the data link layer at the destination sees the character count, it knows how many characters follow, and hence where the end of the frame is. The disadvantage is that if the count is garbled by a transmission error, the destination will lose synchronization and will be unable to locate the start of the next frame. So, this method is rarely used.
2. Character stuffingIn the second method, each frame starts with the ASCII character sequence DLE STX and ends with the sequence DLE ETX.(where DLE is Data Link Escape, STX is Start of TeXt and ETX is End of TeXt.) This method overcomes the drawbacks of the character count method. If the destination ever loses synchronization, it only has to look for DLE STX and DLE ETX characters. If however, binary data is being transmitted then there exists a possibility of the characters DLE STX and DLE ETX occurring in the data. Since this can interfere with the framing, a technique called character stuffing is used.
Solution: Use characterstuffing; within the frame, replace every occurrence of DLE with the two-character sequence DLE DLE. The receiver reverses the processes, replacing every occurrence of DLE DLE with a single DLEbefore this data is given to the network layer.
Example: If the frame contained ``A B DLE D E DLE'', the characters transmitted over the channel would be ``DLE STX A B DLE DLE D E DLE DLE DLE ETX''.
Disadvantage: character is the smallest unit that can be operated on; not all architectures are byte oriented and this is a major hurdle in transmitting arbitrary sized characters.
3. Bit stuffingThe third method allows data frames to contain an arbitrary number of bits and allows character codes with an arbitrary number of bits per character. Bit stuffing is used for various purposes, such as
a. For bringing bit streams that do not necessarily have the same or rationally related bit rates up to a common rate, or to fill buffers or frames. The location of the stuffing bits is communicated to the receiving end of the data link, where these extra bits are removed to return the bit streams to their original bit rates or form. Bit stuffing may be used to synchronize several channels before multiplexing or to rate-match two single channels to each other.

Applications include Plesiochronous Digital Hierarchy and Synchronous Digital Hierarchy.
b. Another use of bit stuffing is for run length limited coding: to limit the number of consecutive bits of the same value in the data to be transmitted. A bit of the opposite value is inserted after the maximum allowed number of consecutive bits. Since this is a general rule the receiver doesn't need extra information about the location of the stuffing bits in order to do the destuffing. This is done to create additional signal transitions to ensure reliable transmission or to escape special reserved code words such as frame sync sequences when the data happens to contain them.
Applications include Controller Area Network, HDLC, and Universal Serial Bus.
Bit stuffing does not ensure that the payload is intact (i.e. not corrupted by transmission errors); it is merely a way of attempting to ensure that the transmission starts and ends at the correct places. Error detection and correction techniques are used to check the frame for corruption after its delivery and, if necessary, the frame will be resent.
Zero-bit insertion
Zero-bit insertion is a particular type of bit stuffing (in the latter sense) used in some data transmission protocols. It was popularized by IBM's SDLC (later renamed HDLC), to ensure that the Frame Sync Sequence (FSS) never appears in a data frame. An FSS is the method of frame synchronization used by HDLC to indicate the beginning and/or end of a frame. The name relates to the insertion of only 0 bits. No 1 bits are inserted to limit sequences of 0 bits.
The bit sequence "01111110" containing six adjacent 1 bits is commonly used as a "Flag byte" or FSS. To ensure that this pattern never appears in normal data, a 0 bit is stuffed after every five 1 bits in the data. This typically adds 1 stuffed bit to every 32 random payload bits, on average. Note that this stuffed bit is added even if the following data bit is 0, which could not be mistaken for a sync sequence, so that the receiver can unambiguously distinguish stuffed bits from normal bits. When the receiver sees five consecutive 1s in the incoming data stream, followed by a zero bit, it automatically destuffs the 0 bit. The boundary between two frames can be determined by locating the flag pattern.
4. Physical layer coding violations
The final framing method is physical layer coding violations and is applicable to networks in which the encoding on the physical medium contains some redundancy. In such cases normally, a 1 bit is a high-low pair and a 0 bit is a low-high pair. The combinations of low-low and high-high which are not used for data may be used for marking frame boundaries.

//**************************************// Name: bit stuffing// Description: performs bit stuffing/destuffing on an input data stream //**************************************
#include<stdio.h>#include<stdlib.h>#define MAXSIZE 100
int main(){
char *p,*q;char temp;char in[MAXSIZE];char stuff[MAXSIZE];char destuff[MAXSIZE];
int count=0;
printf("enter the input character string (0’s & 1’s only):\n");scanf("%s",in);
p=in;q=stuff;
while(*p!='\0'){
if(*p=='0'){
*q=*p;q++;p++;
}else{
while(*p=='1' && count!=5){
count++;*q=*p;q++;p++;
}
if(count==5){
*q='0';q++;
}count=0;
}}*q='\0';printf("\nthe stuffed character string is");printf("\n%s",stuff);
p=stuff;q=destuff;
while(*p!='\0'){
if(*p=='0')

{*q=*p;q++;p++;
}else{
while(*p=='1' && count!=5){
count++;*q=*p;q++;p++;
}if(count==5){
p++;}count=0;
}}*q='\0';printf("\nthe destuffed character string is");printf("\n%s\n",destuff);return 0;
}
enter the input character string (0’s & 1’s only):1 0 1 0 1 1 1 1 1 1
the stuffed character string is1 0 1 0 1 1 1 1 1 0 1
the destuffed character string is
1 0 1 0 1 1 1 1 1 1

//**************************************// Name: character stuffing// Description:to perform character stuffing on input data stream(networking // link layer activity)//**************************************
#include<stdio.h>#include<stdlib.h>#define MAXSIZE 100int main(){
char in[MAXSIZE],stuff[MAXSIZE],destuff[MAXSIZE];char *p,*q;int i;
printf("enter the string to be character stuffed\n");scanf("%s",in);p=in;q=stuff;while(*p!='\0'){
if(*p=='d'){
*q=*p;p++;q++;if(*p=='l'){
*q=*p;p++;q++;if(*p=='e'){
*q=*p;p++;q++;*(q++)='d';*(q++)='l';*(q++)='e';
}}
}else{
*q=*p;q++;p++;
}}
*q='\0';printf("\nthe stuffed string is");printf("\n%s",stuff);
p=stuff;q=destuff;
while(*p!='\0'){
if(*p=='d'){
*q=*p;p++;q++;if(*p=='l'){
*q=*p;

p++;q++;if(*p=='e'){
*q=*p;p++;q++;
for(i=1;i<=3;i++)p++;
}
}}else{
*q=*p;q++;p++;
}}*q='\0';printf("\nthe destuffed string is");printf("\n%s\n",destuff);return 0;
}

Data Encryption and Decryption
Encryption is the process of translating plain text data (plaintext) into something that appears to be random and meaningless (cipher text). Decryption is the process of converting cipher text back to plaintext.
To encrypt more than a small amount of data, symmetric encryption is used. A symmetric key is used during both the encryption and decryption processes. To decrypt a particular piece of cipher text, the key that was used to encrypt the data must be used.
The goal of every encryption algorithm is to make it as difficult as possible to decrypt the generated cipher text without using the key. If a really good encryption algorithm is used, there is no technique significantly better than methodically trying every possible key. For such an algorithm, the longer the key, the more difficult it is to decrypt a piece of cipher text without possessing the key.
//**************************************// Name: Encryption and Decryption of string//**************************************
#include <stdio.h>#include <string.h>
void encrypt(char str[],int key){ unsigned int i; for(i=0;i<strlen(str);++i) { str[i] = str[i] - key; }}
void decrypt(char str[],int key){ unsigned int i; for(i=0;i<strlen(str);++i) { str[i] = str[i] + key; }}int main(){ char str[] = "smurffANDkdo"; printf("Passwrod = %s\n",str); encrypt(str,0xFACA); printf("Encrypted value = %s\n",str); decrypt(str,0xFACA); printf("Decrypted value = %s\n",str); return 0;}

Shortest path problem
In graph theory, the shortest path problem is the problem of finding a path between two vertices (or nodes) in a graph such that the sum of the weights of its constituent edges is minimized.
The most important algorithms for solving this problem are:
Dijkstra's algorithm solves the single-source shortest path problems. Bellman–Ford algorithm solves the single-source problem if edge weights may be negative. A* search algorithm solves for single pair shortest path using heuristics to try to speed up the search. Floyd–Warshall algorithm solves all pairs shortest paths. Johnson's algorithm solves all pairs shortest paths, and may be faster than Floyd–Warshall on sparse
graphs.
Additional algorithms and associated evaluations may be found in Cherkassky et al.[1]
Definition
The shortest path problem can be defined for graphs whether undirected, directed, or mixed. It is defined here for undirected graphs; for directed graphs the definition of path requires that consecutive vertices be connected by an appropriate directed edge.Two vertices are adjacent when they are both incident to a common edge. A path in an undirected graph is a sequence of vertices Such that is adjacent to for . Such a path is called a path of length from to . (The are variables; their numbering here relates to their position in the sequence and needs not to relate to any canonical labeling of the vertices.)
Let be the edge incident to both and . Given a real-valued weight function , and an undirected
(simple) graph , the shortest path from to is the path (where and )
that over all possible minimizes the sum When each edge in the graph has unit weight or , this is equivalent to finding the path with fewest edges.
The problem is also sometimes called the single-pair shortest path problem, to distinguish it from the following variations:
The single-source shortest path problem, in which we have to find shortest paths from a source vertex v to all other vertices in the graph.
The single-destination shortest path problem, in which we have to find shortest paths from all vertices in the directed graph to a single destination vertex v. This can be reduced to the single-source shortest path problem by reversing the arcs in the directed graph.
The all-pairs shortest path problem, in which we have to find shortest paths between every pair of vertices v, v' in the graph.
These generalizations have significantly more efficient algorithms than the simplistic approach of running a single-pair shortest path algorithm on all relevant pairs of vertices.

Dijkstra's AlgorithmDijkstra's algorithm is a greedy algorithm that solves the shortest path problem for a directed graph G.Dijkstra's algorithm solves the single-source shortest-path problem when all edges have non-negative weights.
Dijkstra's Algorithm
DIJKSTRA(G, w, s)1 INITIALIZE-SINGLE-SOURCE(G, s)2 S ←Ø3 Q ←V[G]4while Q ≠Ø5 do u ← EXTRACT-MIN(Q)6 S ← S {u}7 for each vertex v Adj[u]8 doRELAX(u, v, w)
Example
Procedure for Dijkstra's Algorithm
Step1
Consider A as source vertex
No. of Nodes A B C D E
Distance 0 10 3 ∞ ∞
Distance From A A

Step2
Now consider vertex C
No. of Nodes A B C D E
Distance 0 7 3 11 5
Distance From C C C C
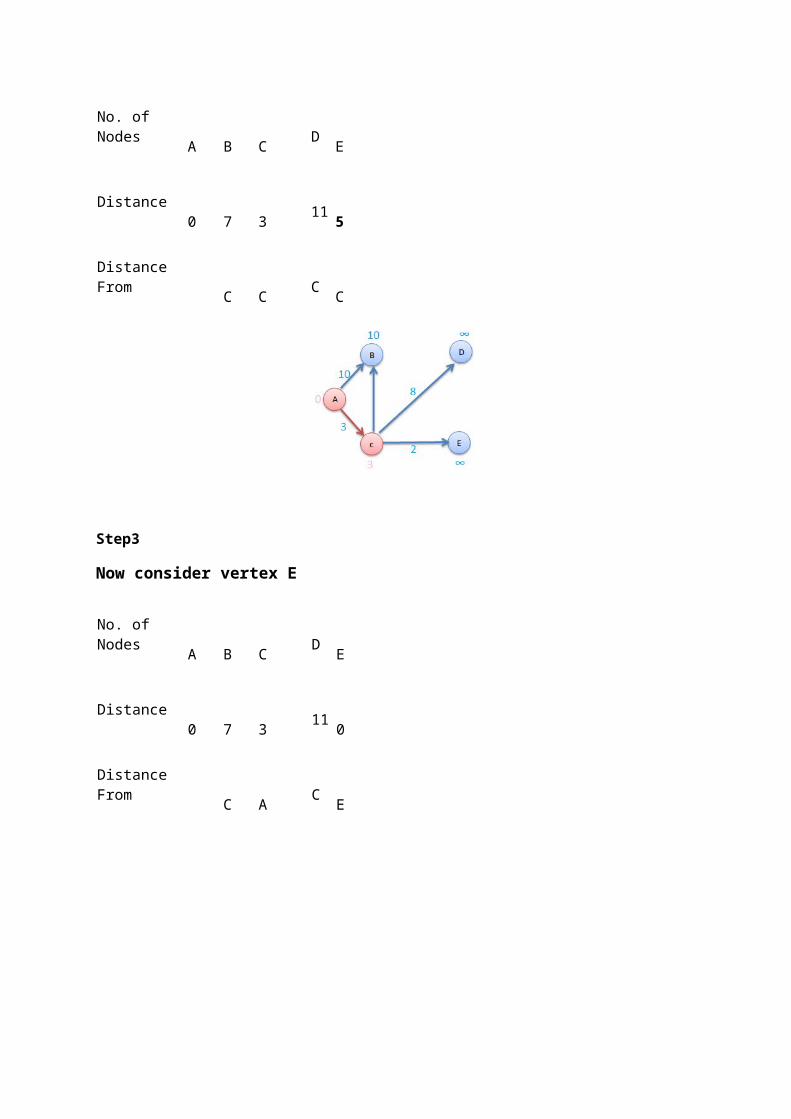
Step3
Now consider vertex E
No. of Nodes A B C D E
Distance 0 7 3 11 0
Distance From C A C E

Step4
Now consider vertex B
No. of Nodes A B C D E
Distance 0 7 3 9 5
Distance From C A B C
Step5
Now consider vertex D
No. of Nodes A B C D E
Distance 0 7 3 9 11
Distance From A C A B C

A B C D E
0 ∞ ∞ ∞ ∞
A 0 10 3 ∞ ∞
C 7 3 11 5
E 14 5
B 9
D 16
//**************************************// Name: shortest path algorithm//**************************************
#include<stdio.h>#include<conio.h>void main(){int path[5][5],i,j,min,a[5][5],p,st=1,ed=5,stp,edp,t[5],index;
clrscr();
printf("enter the cost matrix\n");for(i=1;i<=5;i++)
for(j=1;j<=5;j++)scanf("%d",&a[i][j]);
printf("enter number of paths\n");scanf("%d",&p);
printf("enter possible paths\n");for(i=1;i<=p;i++)
for(j=1;j<=5;j++)scanf("%d",&path[i][j]);
for(i=1;i<=p;i++){
t[i]=0;stp=st;
for(j=1;j<=5;j++){
edp=path[i][j+1];t[i]=t[i]+a[stp][edp];
if(edp==ed)break;
elsestp=edp;
}}
min=t[st];index=st;
for(i=1;i<=p;i++){
if(min>t[i]){
min=t[i];index=i;
}}
printf("minimum cost %d",min);printf("\n minimum cost path ");
for(i=1;i<=5;i++){

printf("--> %d",path[index][i]);if(path[index][i]==ed)break;
}
getch();}
/*OUTPUT:enter the cost matrix :0 1 4 2 00 0 0 2 30 0 0 3 00 0 0 0 50 0 0 0 0enter number of paths : 4enter possible paths :1 2 4 5 01 2 5 0 01 4 5 0 01 3 4 5 0minimum cost : 4minimum cost path :1–>2–>5*/

Prim's Algorithm
Prim's algorithm is a greedy algorithm that finds a minimum spanning tree for a connected weighted undirected graph. It finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized.
This algorithm is directly based on the MST (minimum spanning tree) property.
Example
A Simple Weighted Graph Minimum-Cost Spanning Tree
Prim's AlgorithmMST-PRIM(G, w, r)1. for each u V [G]2. do key[u] ← ∞3. π[u] ← NIL4. key[r] ← 05. Q ← V [G]6. while Q ≠ Ø7. do u ← EXTRACT-MIN(Q)8. for each v Adj[u]9. do if v Q and w(u, v) < key[v]10. then π[v] ← u11. key[v] ← w(u, v)
Example

Procedure for finding Minimum Spanning TreeStep1
No. of Nodes 0 1 2 3 4 5Distance 0 3 1 6 ∞ ∞Distance From 0 0 0
Step2
No. of Nodes 0 1 2 3 4 5Distance 0 3 0 5 6 4Distance From 0 2 2 2
Step3
No. of Nodes 0 1 2 3 4 5Distance 0 0 0 5 3 4Distance From 2 1 2
Step4
No. of Nodes 0 1 2 3 4 5Distance 0 0 0 5 0 4Distance From 2 2
Step5
No. of Nodes 0 1 2 3 4 5Distance 0 0 0 3 0 0Distance From 2 2
Minimum Cost = 1+2+3+3+4 = 13

C IMPLEMETATION of prim's Algorithm#include<stdio.h>#include<conio.h>inta,b,u,v,n,i,j,ne=1;int visited[10]={0},min,mincost=0,cost[10][10];void main(){
clrscr();printf("\nEnter the number of nodes:");scanf("%d",&n);printf("\nEnter the adjacency matrix:\n");for(i=1;i<=n;i++)for(j=1;j<=n;j++){
scanf("%d",&cost[i][j]);if(cost[i][j]==0)
cost[i][j]=999;}visited[1]=1;printf("\n");while(ne < n){
for(i=1,min=999;i<=n;i++)for(j=1;j<=n;j++)if(cost[i][j]< min)if(visited[i]!=0){
min=cost[i][j];a=u=i;b=v=j;
}if(visited[u]==0 || visited[v]==0){
printf("\n Edge %d:(%d %d) cost:%d",ne++,a,b,min);mincost+=min;visited[b]=1;
}cost[a][b]=cost[b][a]=999;
}printf("\n Minimun cost=%d",mincost);getch();
}
Output

This is a C Program for implementing CRC (Cyclic Redundancy Check Code)#include <stdio.h>#include <conio.h>#include <string.h>voidmain(){inti,j,keylen,msglen;charinput[100],key[30],temp[30],quot[100],rem[30],key1[30];clrscr();printf("Enter Data: ");gets(input);printf("Enter Key: ");gets(key);keylen=strlen(key);msglen=strlen(input);strcpy(key1,key);for(i=0;i<keylen-1;i++){input[msglen+i]='0';}for(i=0;i<keylen;i++)temp[i]=input[i];for(i=0;i<msglen;i++){quot[i]=temp[0];if(quot[i]=='0')for(j=0;j<keylen;j++)key[j]='0';elsefor(j=0;j<keylen;j++)key[j]=key1[j];for(j=keylen-1;j>0;j--){if(temp[j]==key[j])rem[j-1]='0';elserem[j-1]='1';}rem[keylen-1]=input[i+keylen];strcpy(temp,rem);}strcpy(rem,temp);printf("\nQuotient is ");for(i=0;i<msglen;i++)printf("%c",quot[i]);

printf("\nRemainder is ");for(i=0;i<keylen-1;i++)printf("%c",rem[i]);printf("\nFinal data is: ");for(i=0;i<msglen;i++)printf("%c",input[i]);for(i=0;i<keylen-1;i++)printf("%c",rem[i]);getch();}
Output:
tags: Error Checking and Correction, CRC program, C program of CRC,Cyclic Redundancy Check Code, protocols












![35354468 Analog Communication Lab Manual VTU[1]](https://img.pdfslide.us/doc/110x75/54f80d1c4a79591c638b50d1/35354468-analog-communication-lab-manual-vtu1.jpg)
















