Embed Size (px)
Citation preview

Blog Mining
Rong Jin

Blog Data Mining Blogspace analysis Blog opinion extraction and retrieval

Blogspace Blog = web pages + chronological sequences Analysis of blogspace
Temporal perspective: evolve over time Spatial perspective: congregate according to
interests and demographics
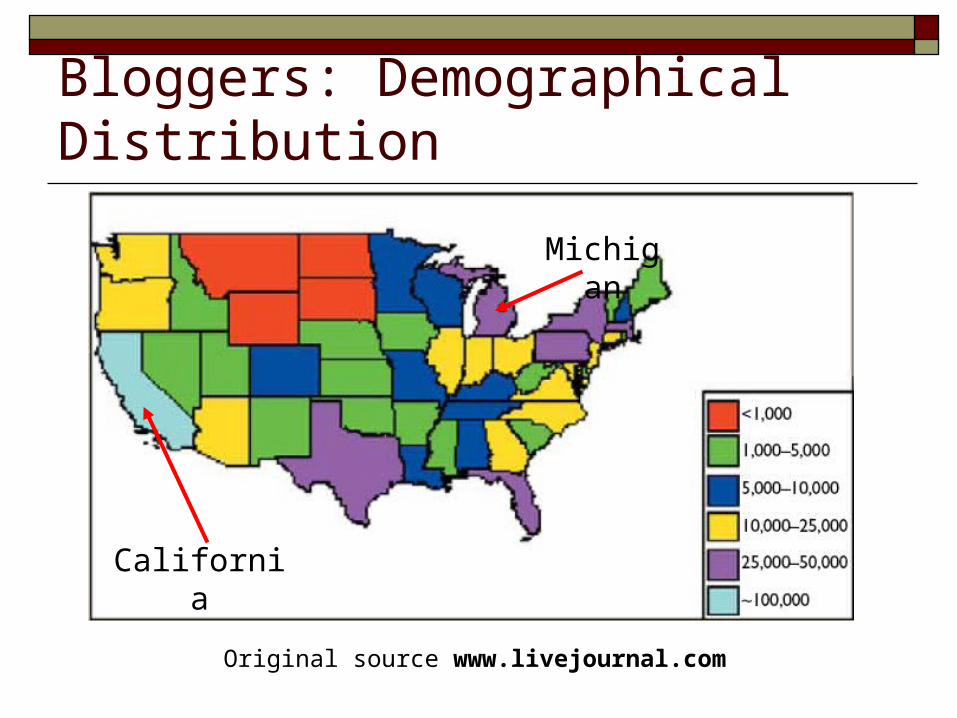
Bloggers: Demographical Distribution
Original source www.livejournal.com
Michigan
California

Blogger: Age Distribution
Original data source: www.livejournal.com
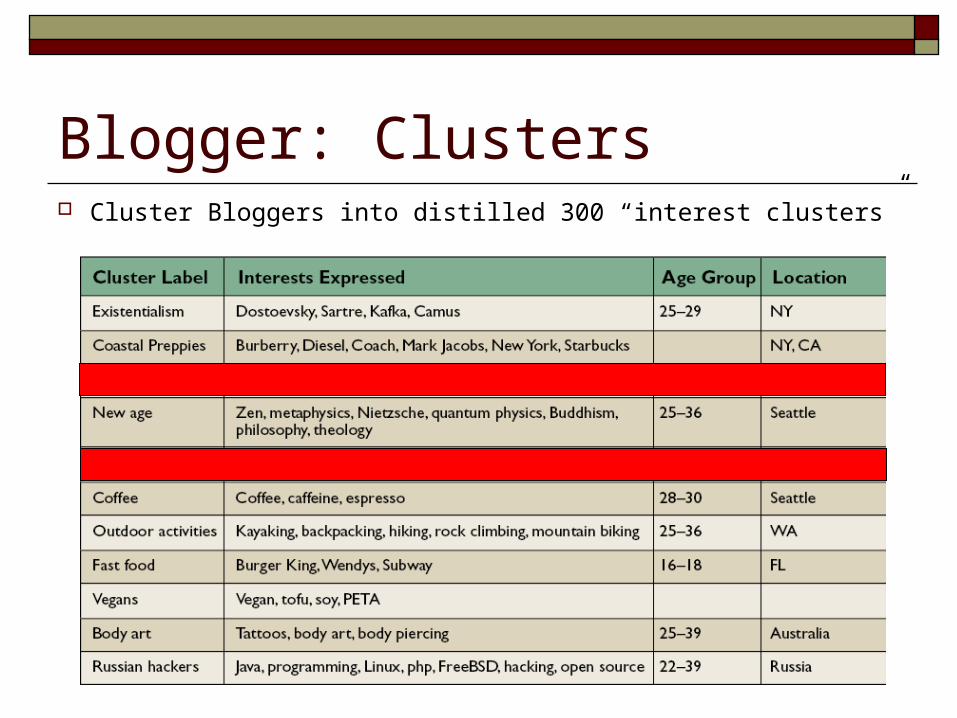
Blogger: Clusters Cluster Bloggers into distilled 300 “interest clusters”

Blogger: Connectivity On average, each blogger names 14 other bloggers
as friends. 80% friendship is mutual
Clustering coefficient The chance that two of my friends are themselves friends 20% tight clusters (why?) E.g., consider 1millon bloggers, what is the probability
for any two bloggers to be friends?
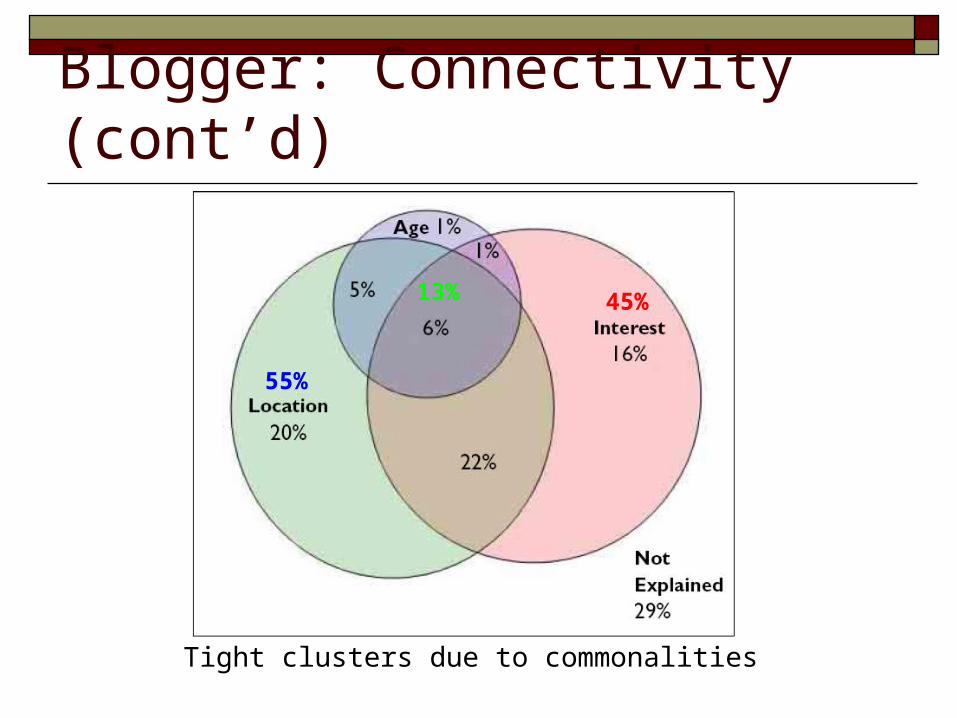
Blogger: Connectivity (cont’d)
Tight clusters due to commonalities
45%
55%
13%

Evolution of Blogspace Busty activities
Interesting topic arises many responses becomes prominent recedes
How can we quantitatively describe busty activities? First, how do we identify the topics and online
communities? Linkage patterns among blog entries Community: set of blogs linking together and discussing Evolution of community topics
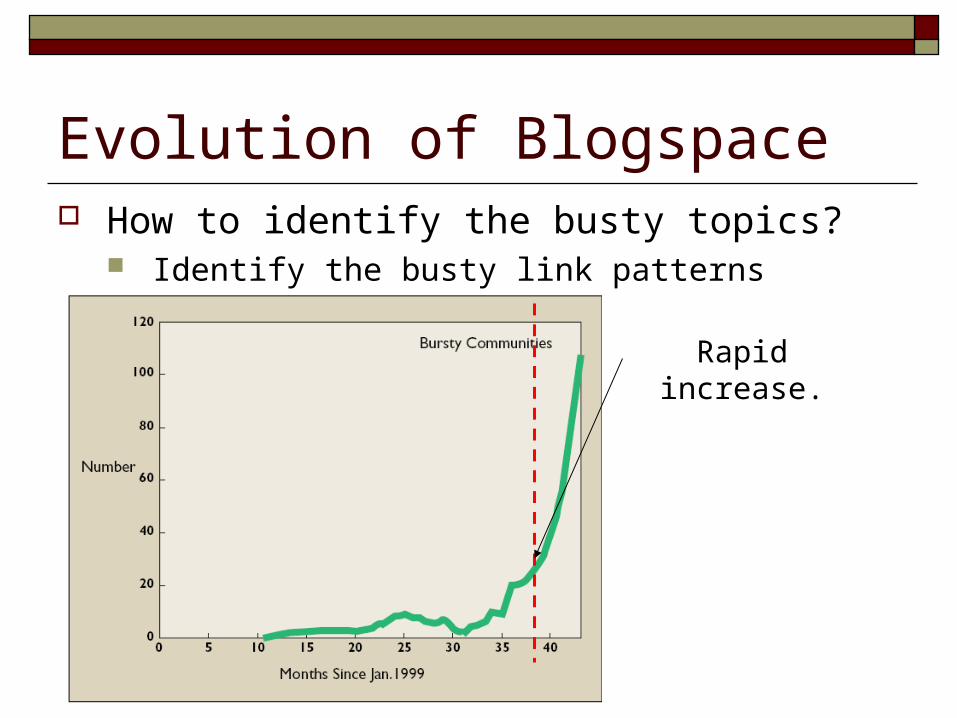
Evolution of Blogspace How to identify the busty topics?
Identify the busty link patterns
Rapid increase.

Structure of Blogspace Distribution of blogs over time Link structure among permalink docs Spam blogs (splog)

Dataset: Blog06 Test Collection Created by University of Glasgow Blogs
XML feeds describing recent postings 30% of feeds do not include full content Not include comments
HTML permalink documents Monitor 100,649 blogs of varying quality from 12/2005 to
02/2006 Top blogs (70, 701): blogs with high quality Spam blogs (17,969):
Gibberish, plagiarised content, and advertisement Fake blogs to create a link farm to fool the search engineer ranking
Blogs of general interests To introduce varieties.
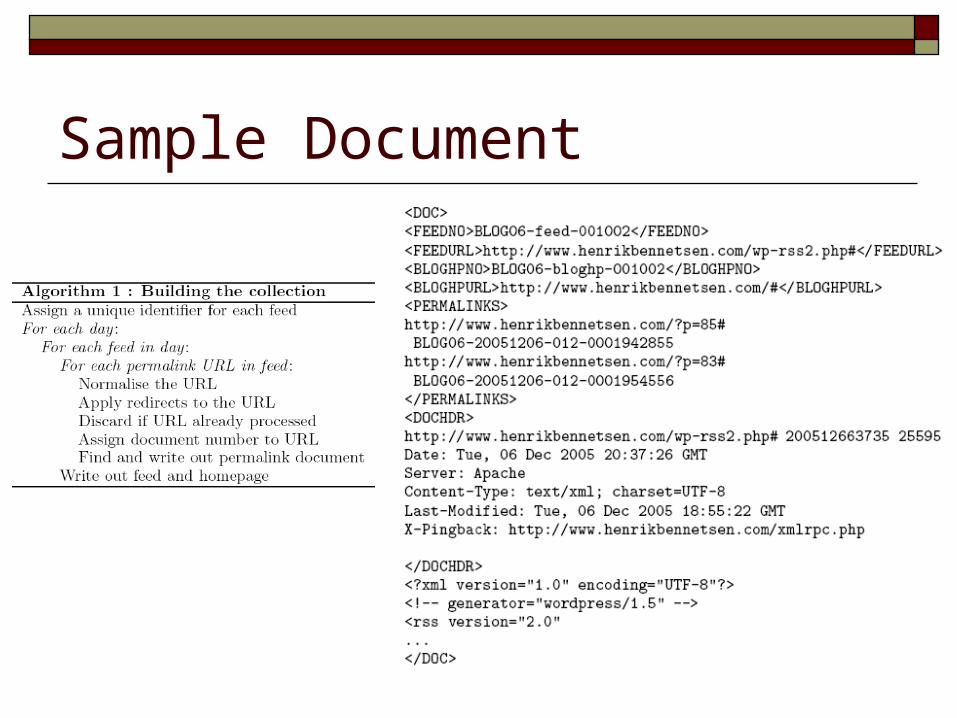
Sample Document

Collection Statistics
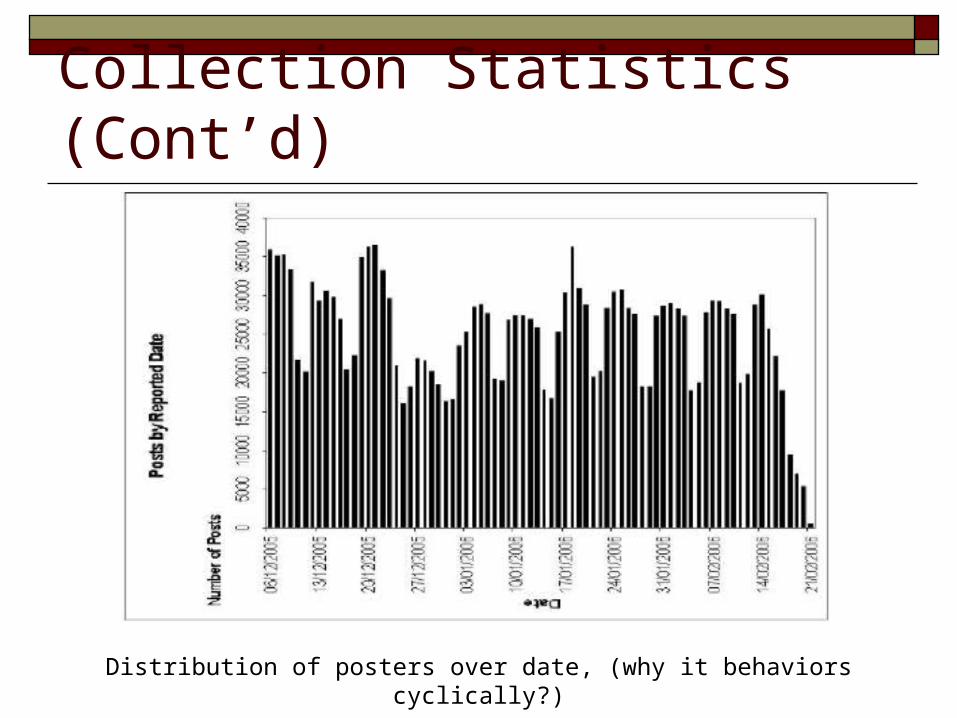
Collection Statistics (Cont’d)
Distribution of posters over date, (why it behaviors cyclically?)
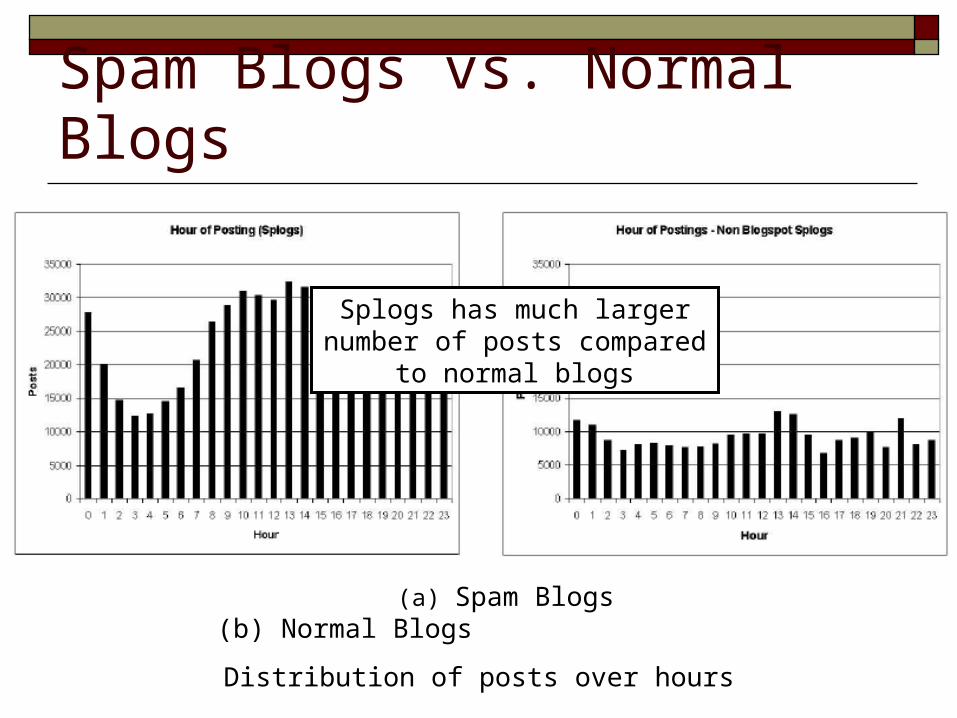
Spam Blogs vs. Normal Blogs
(a) Spam Blogs (b) Normal Blogs
Distribution of posts over hours
Splogs has much larger number of posts compared to normal blogs

Spam Blogs vs. Normal Blogs (cont’d)
No obvious difference between Spam and normal blogs in their usage of offensive words offensive words list supplied by a major British broadcaster
However, there is clear difference in the usage of content words between spam blogs and normal blogs

Link Structure: Normal Blogs Power law for inlink and outlink of Permalink docs
Straight line Power law
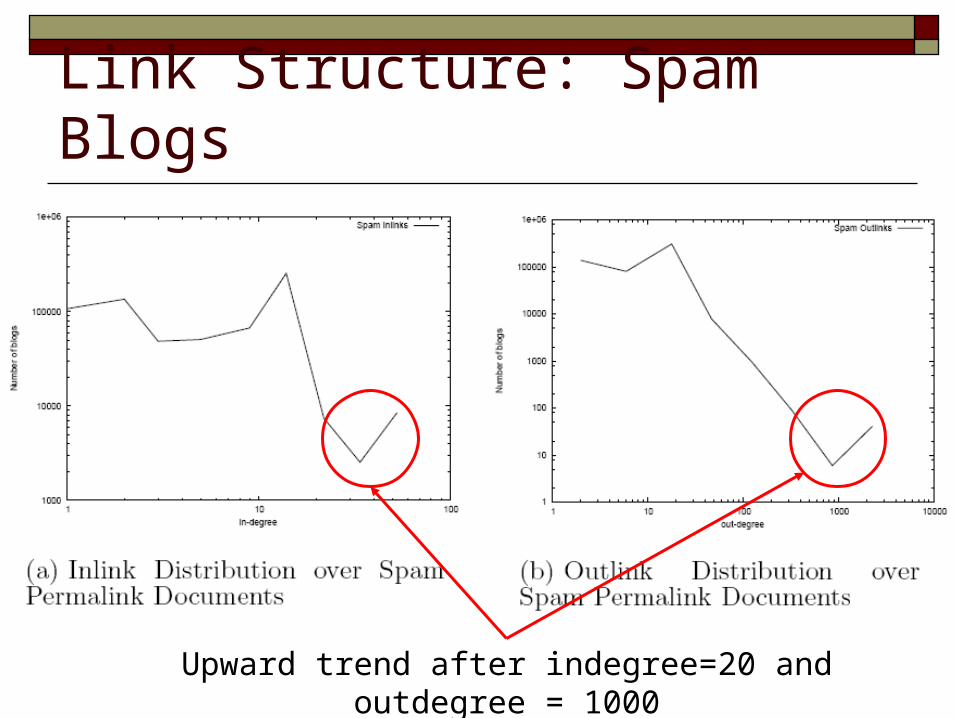
Link Structure: Spam Blogs
Upward trend after indegree=20 and outdegree = 1000

Blog Opinion Retrieval Blog is unlike news articles
Opinionated name: many for self-expression Opinion oriented user information needs
Many blog queries are person names, both celebrities and unknown, and the underlying users information needs seem to be of an opinion, or perspective-finding nature, rather than fact-finding
Different genres Specific topic Multiple topics Personal life

Blog Opinion Retrieval Started in TREC 2006 Locate posts that express an opinion about a given target.
What do people think about X? What are the targets?
Named entities (a person, location, or organization) Concepts (e.g., a type of technology, a product name, or an event)
Application Uncover the public sentiment towards a given entity (the “target”) Track consumer-generated content, brand monitoring, and, more
generally, media analysis.

Blog Opinion Retrieval: Example Target: skype
An opinionated post:
An unopinionated post:
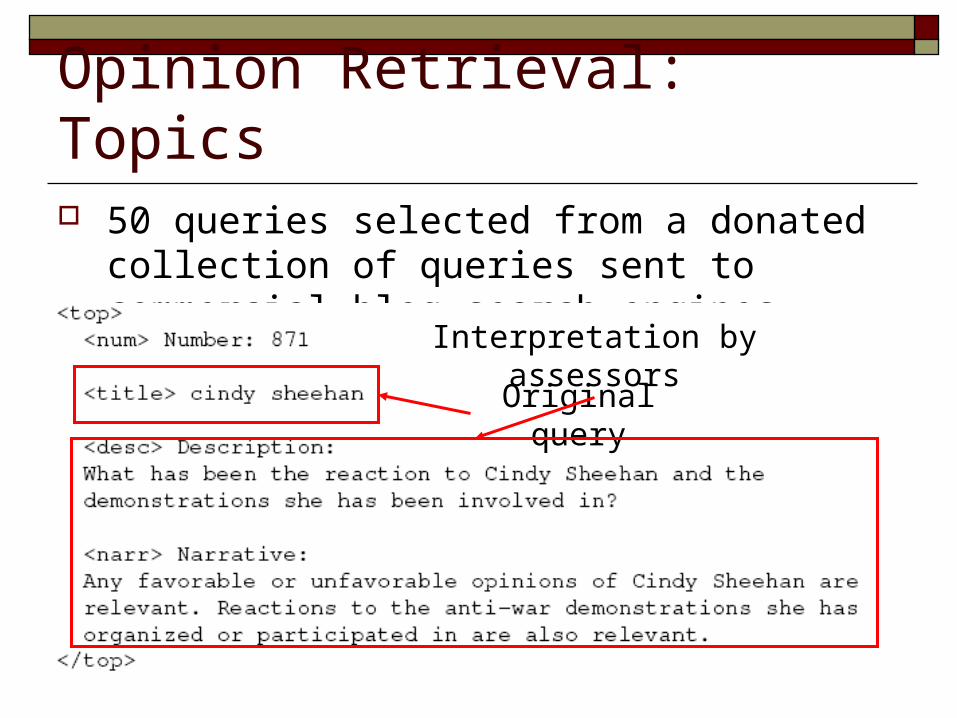
Opinion Retrieval: Topics 50 queries selected from a donated collection of
queries sent to commercial blog search engines
Original query
Interpretation by assessors

Opinion Retrieval: Approaches Two-stage process
Retrieve relevant blogs Classify opinionated blogs
Retrieve relevant blogs off-the-shelf retrieval models (e.g., language
models, vector space, tf.idf weighting)

Opinion Retrieval: Approaches (cont’d) Classify opinionated blogs
Dictionary-based approaches Lists of terms and their semantic orientation values Rank documents based on the frequency of semantic words
Text categorization approaches Limited success, may because of the difference between training
data and the actual opinionated content in blog posts.
Shallow linguistic approaches Frequency of pronouns or adjectives as indicators Limited success

Opinion Retrieval: Assessment -1: Not judged 0: Not relevant 1: Relevant
2: Negative opinion 3: Mixed opinion 4: Positive opinion
Relevance judgment
Opinion judgment

Opinion Retrieval: Evaluation Mean Average Precision (MAP)
The most important R-precision (R-prec) Binary Preference (bPref) Precision at 10 documents (P@10)
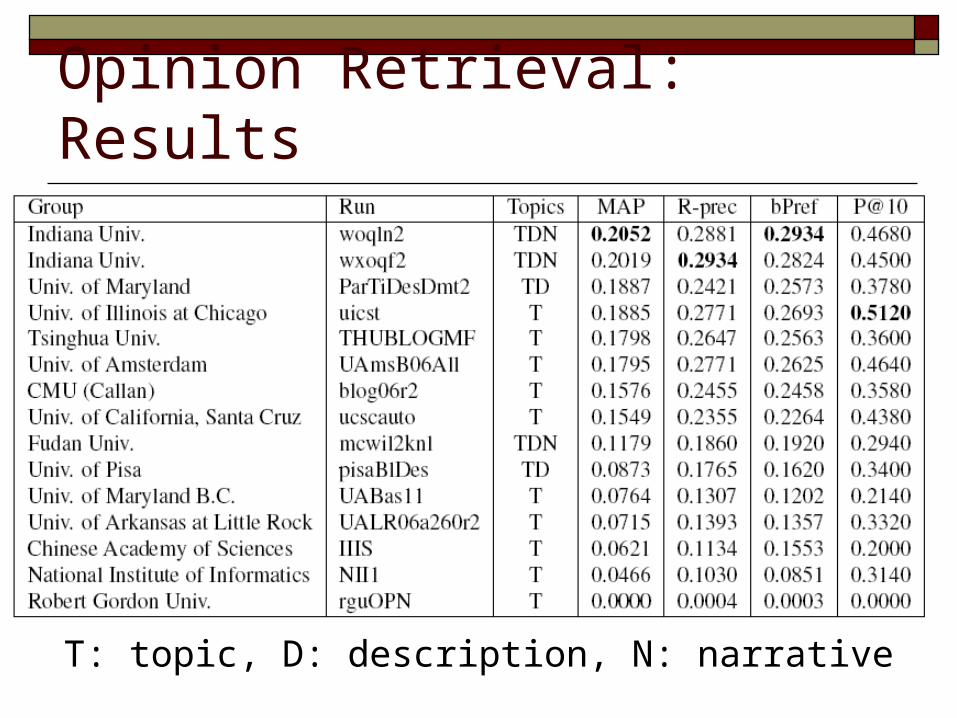
Opinion Retrieval: Results
T: topic, D: description, N: narrative
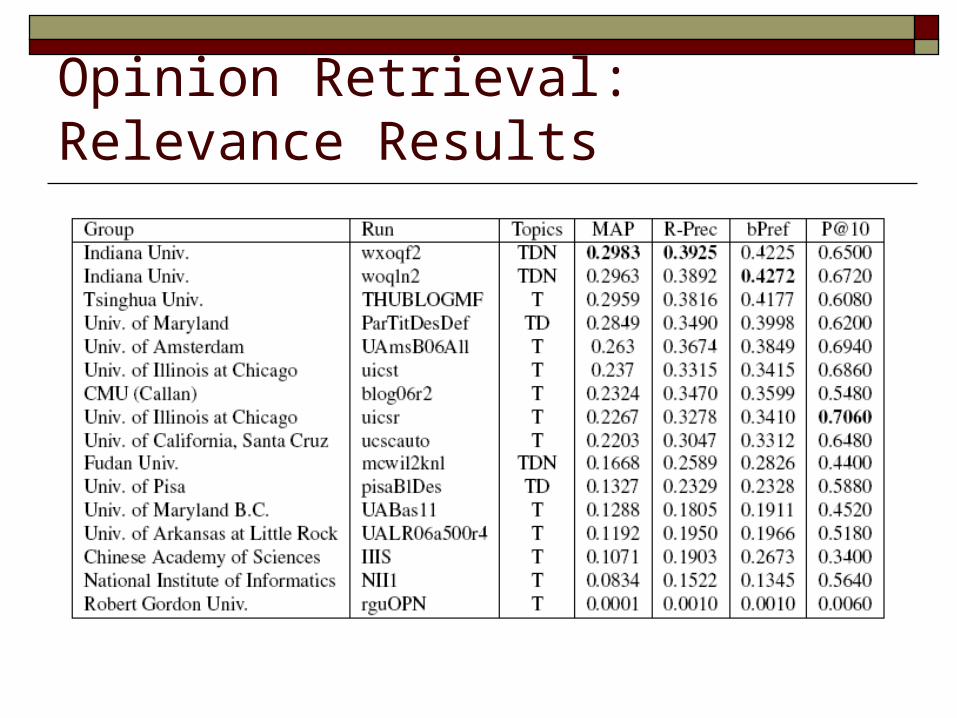
Opinion Retrieval: Relevance Results
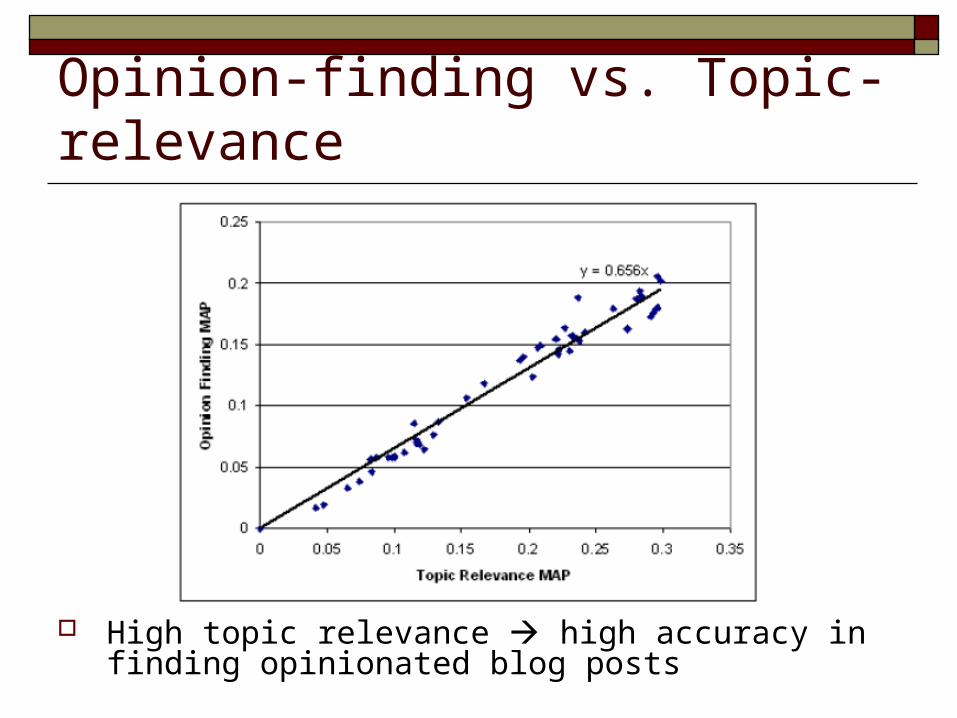
Opinion-finding vs. Topic-relevance
High topic relevance high accuracy in finding opinionated blog posts
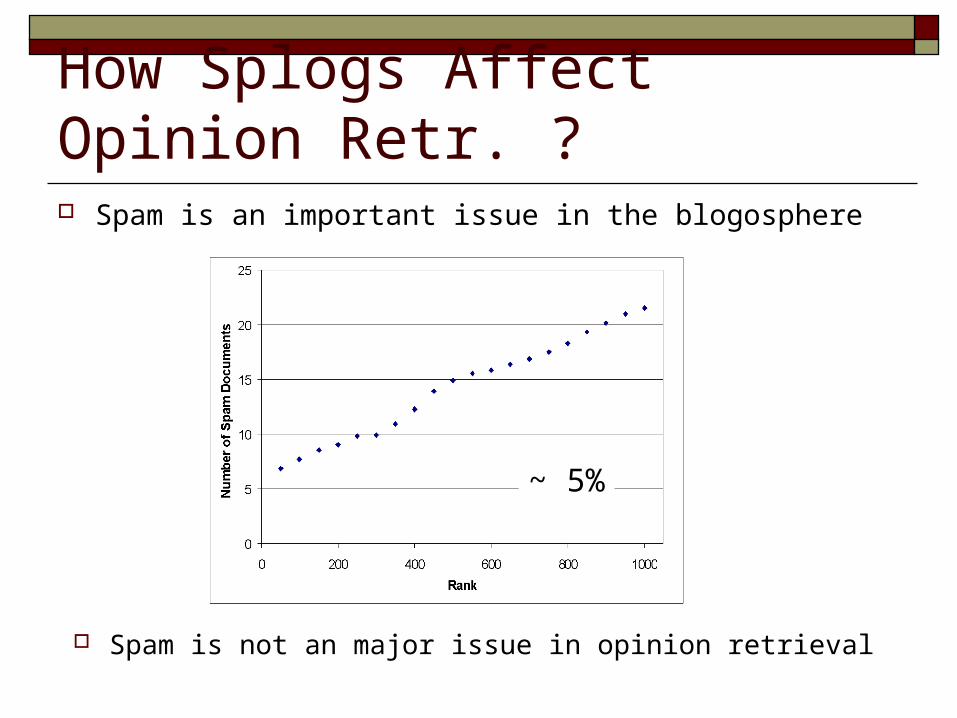
How Splogs Affect Opinion Retr. ? Spam is an important issue in the blogosphere
~ 5%
Spam is not an major issue in opinion retrieval
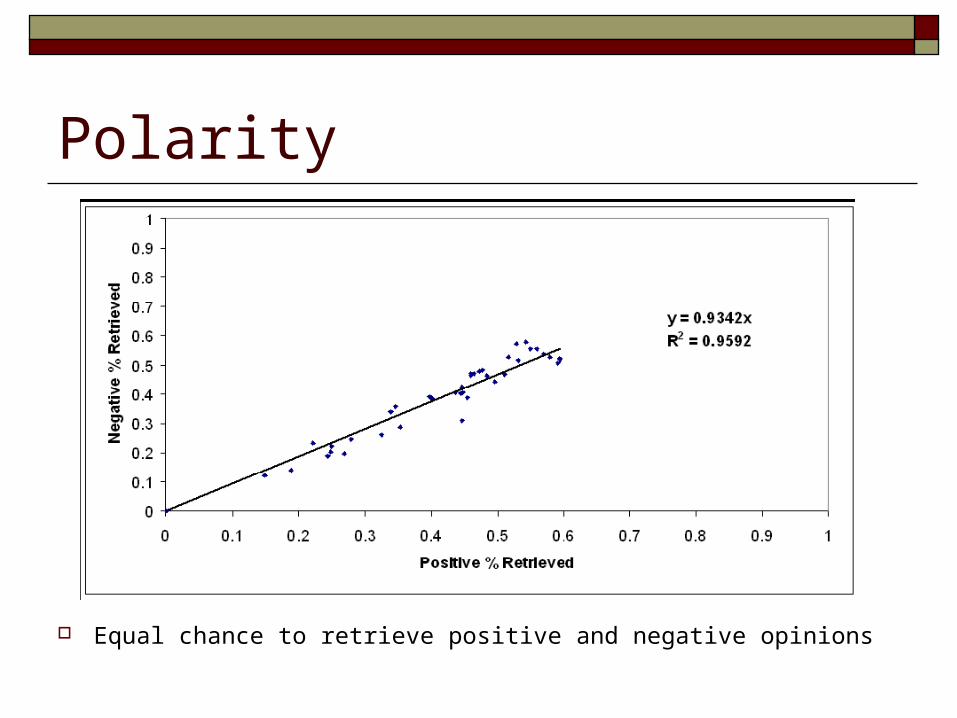
Polarity
Equal chance to retrieve positive and negative opinions

Analysis across Topics High performance topics
Named entities, e.g., “Heineken”, “netflix”, “Ann Coulter”
Low performance topics high-level concepts, e.g., “cholesterol”, “Business
Intelligence Resources

Embarrassing Performance
Performance by simple document retrieval
Best performance by simple document retrieval

Information Propagation with Blogspace Characterize information propagation in two
dimensions Topics:
Chatter: long-term, internally driven (i.e., subtopics are determined by the authors)
Spikes: short-term, externally driven (i.e., subtopics are decided by real-world events)
Individuals: Four categories of posting behavior Based on the spread of infectious diseases

Modeling Topics How to identify and track topics?
Topic detection and tracking (TDT) Strategies
Recurring sequences of words as topics Common phrases “I don’t think I will”
Entities defined in the TAP ontology 3700 distinct ones, most of them appear only a few times
Proper nouns: 11K, half of them 10
Term frequency ratio (tfcidf) 20K terms (tf(i) > 10, ratio > 3)
(i ¡ 1)tf (i)=(P i ¡ 1
j =1tf (j ))
Examples of Selected Words
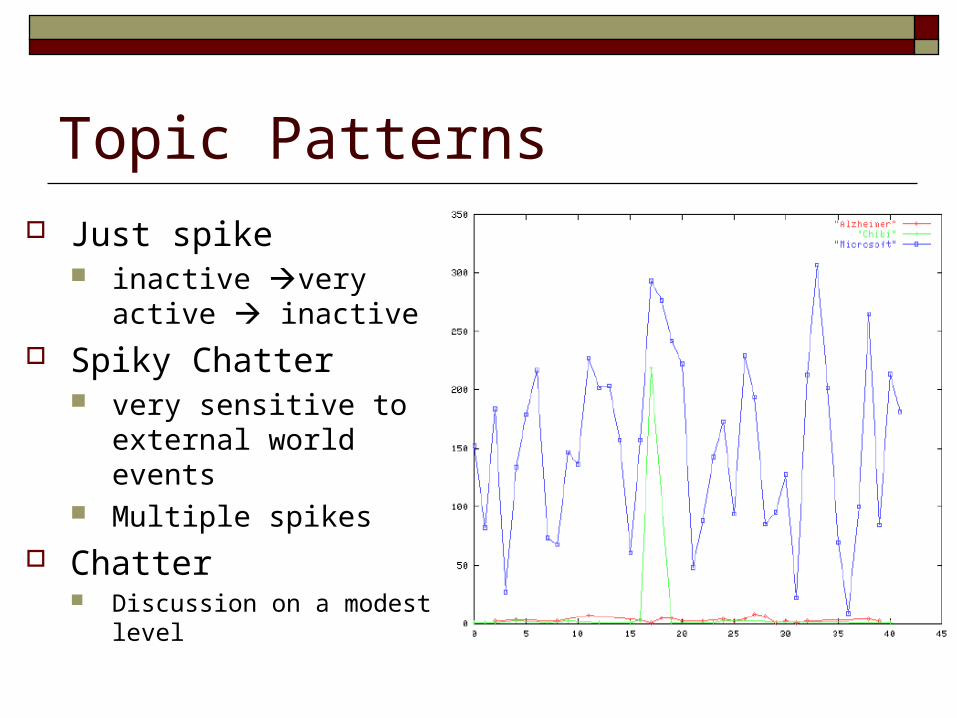
Topic Patterns
Just spike inactive very active
inactive Spiky Chatter
very sensitive to external world events
Multiple spikes Chatter
Discussion on a modest level

Spiky Chatter Level of subtopics arises due to the real-world event Identify subtopics (x) given the target topic (t)
Support: co-occurrence Conditional probability P r(tjx) =
co-ccur(x;t)occur(x)
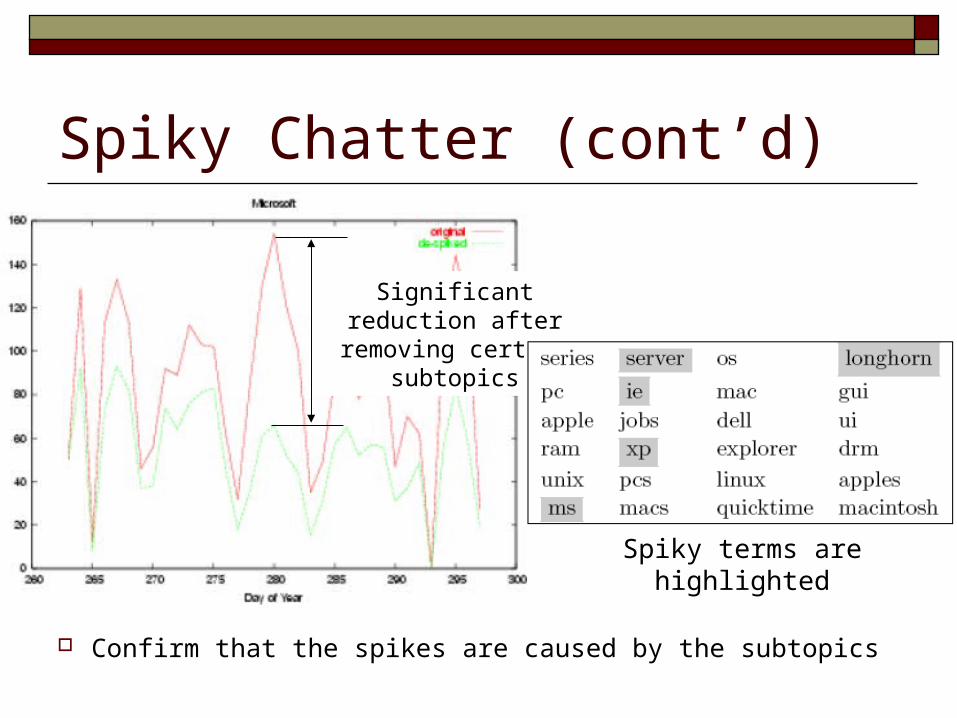
Spiky Chatter (cont’d)
Confirm that the spikes are caused by the subtopics
Significant reduction after removing certain subtopics
Spiky terms are highlighted
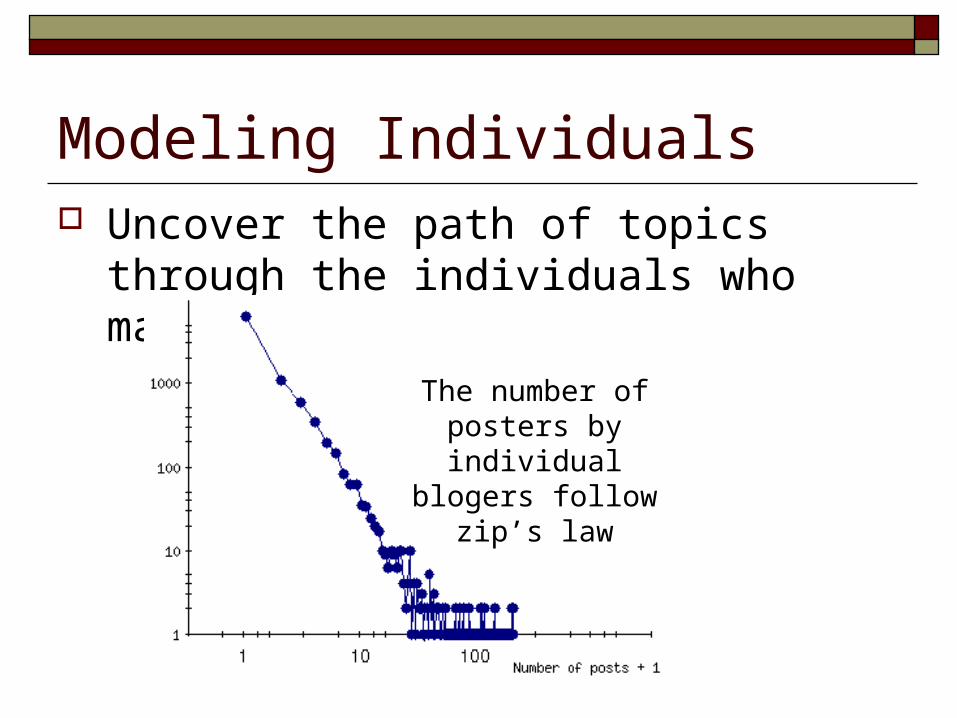
Modeling Individuals Uncover the path of topics through the
individuals who make up blogspace
The number of posters by individual blogers
follow zip’s law
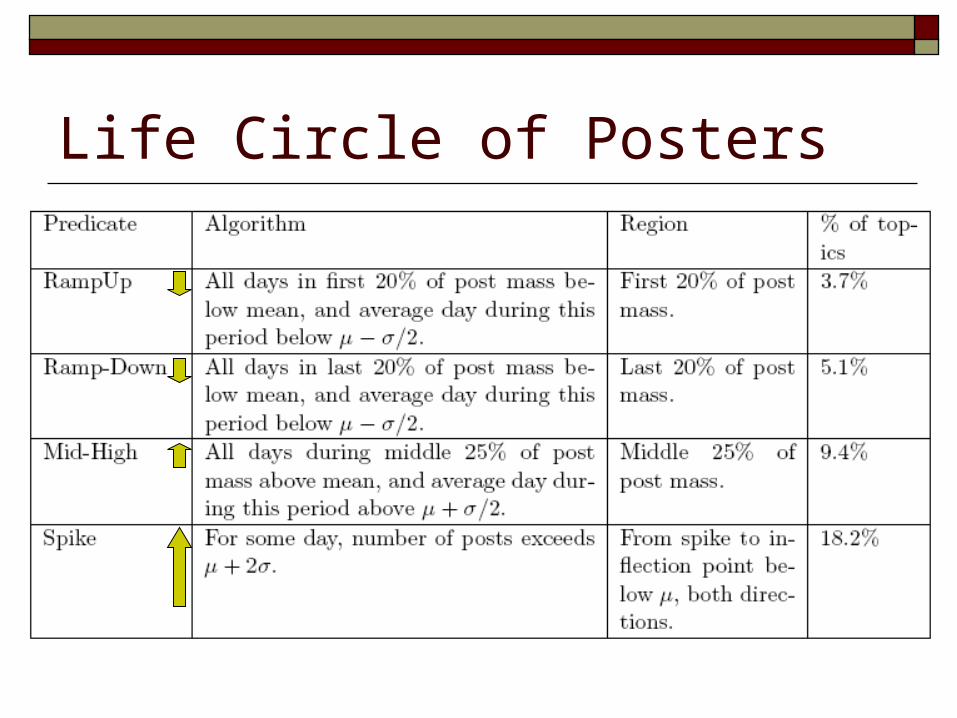
Life Circle of Posters

Associate Users with Post Life Cycle
Small numbers of users involved in the regions of RampUp and RampDown
Many more users involved in the regions of Mid-High and Cycle

Propagation Model How blog a is affected by the topic raised in blog b? Independent Cascade model (random walk)
A directed graph: Each node is a bloger Edge (u, w) is associated with a copy probability
When u writes an article at time t, each node w that has an arc from u to w writes an article about the topic at time t + 1 with probability
: Probability that u reads w’s blog
· u;w
· u;w
ru;w
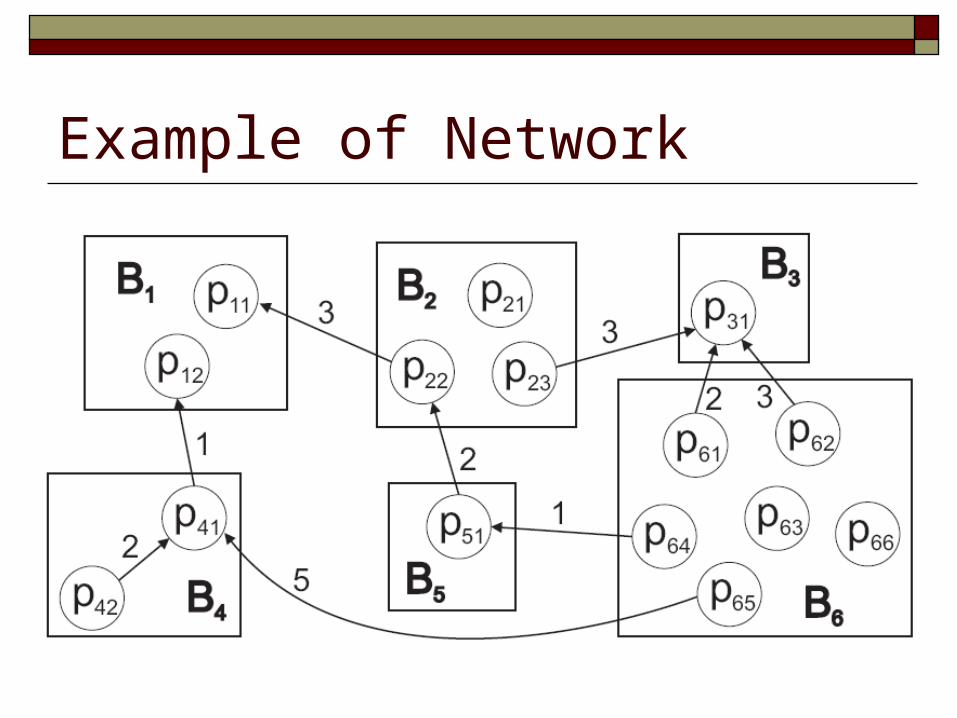
Example of Network

Propagation Model: Procedure Start: u wrote about certain topic at a given day First, v reads the topic from node u with probability
ru,v by a delay follows an exponential distribution Then, with probability , v will choose to write
about it. If v reads the topic and chooses not to copy it, then v will
never copy that topic from u A single opportunity for a topic to propagate along any
given edge.
· u;v
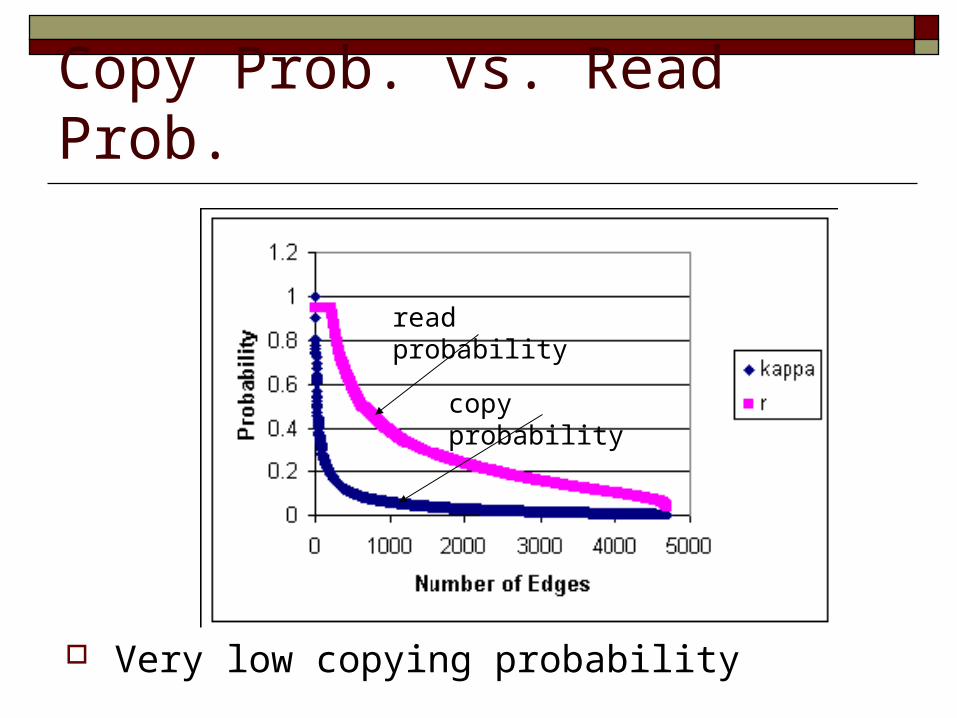
Copy Prob. vs. Read Prob.
Very low copying probability
read probability
copy probability




























