Embed Size (px)
Citation preview

© Copyright IBM Corporation 2008
Mining Political Blog Networks
Wojciech GrycYan Liu
Prem MelvilleClaudia Perlich
Richard D. Lawrence
Predictive Modeling GroupMathematical Sciences Department
IBM Research
June 13, 2008

Slide 2
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Overview
Blogs and other forms of social media provide us with a snapshot of people’s daily lives, opinions, and ideas – can we use this to learn more about trends within society?
Presentation Outline Overview of the political blogosphere Our work: a long-term plan Finding communities Text mining and information retrieval Combining text mining with graph mining Future work
Slide 3
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Web 2.0
The web as: participatory, customizable, and community-oriented Numerous opportunities for corporations – marketing, customer loyalty, and research

Slide 4
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Web 2.0 and Politics
Web 2.0 is also revolutionizing politics

Slide 5
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Blogs provide two key pieces of information: Textual data:
Information on relationships between bloggers:
Web 2.0, Blogs, and Social Networks
Web 2.0 is ultimately a social environment eBay as an auction system with its own social ecosystem Wikipedia as a collaborative environment Blogs, forums, and e-mail as social networks
There are over 77 million blogs, with about 100,000 added every day Blog: an online journal that an individual shares a running log of events and personal insights with online
audiences in a reverse chronological order.
“No, I am NOT Voting for McCain ... There has been some murmuring of Hillary Clinton supporters voting for McCain in pure protest of Barack Obama’s candidacy.”
HuffingtonPost
Daily Kos
Boing Boing
PoliticalWire
A
C
BD
Blog Cross-Reference Graph

Slide 6
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Literature Review: Political blog networks
Most political blog studies depend on hand-labeled information
Many (though not all) studies are limited to mainstream blogs – the most popular blogs in the blogosphere
Prior Work
Adamic & Glance, 2005. Analysis of political blogosphere between liberal and
conservative bloggers.
Ackland, 2005. Follow-up to Adamic & Glance, 2005.
Wallsten, 2005. Political blogosphere as an echo chamber, and
prominence of conservative bloggers.
Hand-labeled popular Liberal and Conservative blogs.
Analysis of linking patterns.
Analysis of less popular blogs (background discussions).

Slide 7
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Literature Review: Machine learning and political blogs
Studies focusing on machine learning and political blogs often focus on text classification
Prior Work
Tremayne, 2006 Preferential attachment and link prediction in
the war-focused blogosphere
Turney, 2002 Cultural discussions are much more difficult to
label than technical ones
Mullen & Malouf, 2006 Sentiment labeling of political discussion
boards, accuracies around 60%
Durant & Smith, 2006 Achieve accuracies around 90% in labeling
political blogs as left, right, or moderate
Analysis of linking patterns (topic-specific).
Post classification based on sentiment labels.
Notice differences in accuracies.

Slide 8
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
BANTER (Blog Analysis of Network Topology and Evolving Responses)
77M Blogs
Political Blogs PresidentialPrimary Blogs
1. How do we identify the relevant sub-universe of blogs? We submit set of relevant keywords to Technorati, include out-linked blogs,
and then refine this sub-universe via active learning
2. How do we determine “authorities” in this sub-universe? We use page-rank-like algorithms against cross-reference structure,
combined with SNA concepts (e.g. Information Flow)
3. How do we detect emerging topics and themes in this sub-universe? One approach is to predict link (cross-reference) formation using network
evolution and content (keywords) at the nodes (blogs)
4. How do we detect sentiment and topics associated with specific posts? One approach is to learn a model using background knowledge and a small
set of labeled examples.
5 10 15 20
050
100
150
200
OpenID Buzz in January
days
Num
ber
of O
ccur
renc
e
OpenID Buzz in January

Slide 9
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 1
First, how do we actually find the relevant blogs and communities?

Slide 10
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 1: How do we find a relevant sub-community of blogs (e.g. Lotus-related blogs)?
Develop text-based classification approach to rank blogs in terms of their relevance to a specific domain (e.g. Lotus software)
Politics DemocratsElections RepublicansPolicy Voting
TechnoratiBlog Search
Keywords Keyword SearchSubset of Blogs
Extended Blog Subset
Include out-linked blogs
Positive Examples
Negative Examples
Generate labels for classifier
Classify blogs asRelevant or Irrelevant
Classifier
BuildModel
54
32
1
Use Top-Ranked Blogs As New Subset
Repeat this process as many times as necessary to collect a larger universe of blogs.

Slide 11
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 1: Technorati results
31 political tags were submitted to Technorati, based on terms surrounding the Presidential Primaries and policy areas currently making headlines (e.g. “Iraq”, “economy”)
The following table shows the number of blogs tagged with a specific term
Tag Blog Countpolitics 56460political 13990government 8090washington 7580president 6579bush 6370iraq 5100current events 5060economics 4440vote 3760economy 3740republican 3590election 3210iran 3110clinton 2769democrat 2720
Tag Blog Countprimary 2420obama 2320democrats 2140current affairs 2040elections 2010taxes 1740republicans 1320afghanistan 1070mccain 937governance 737public policy 457recession 159primaries 103nuclear proliferation 21budget deficit 6

Slide 12
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 1: Current data sets
Initial set of 100 “influential” political blogs Crawled from January 10, 2008 until the present Includes influential sites taken from previous political blog papers and listings such
as Technorati’s Top 100 blogs Includes blogs like Huffington Post, Wonkette, Daily Kos, etc
Larger set of 11788 blogs (317566 posts) being crawled since April 22, 2008 This includes the smaller data set above Built through the Technorati tag system
Slide 13
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
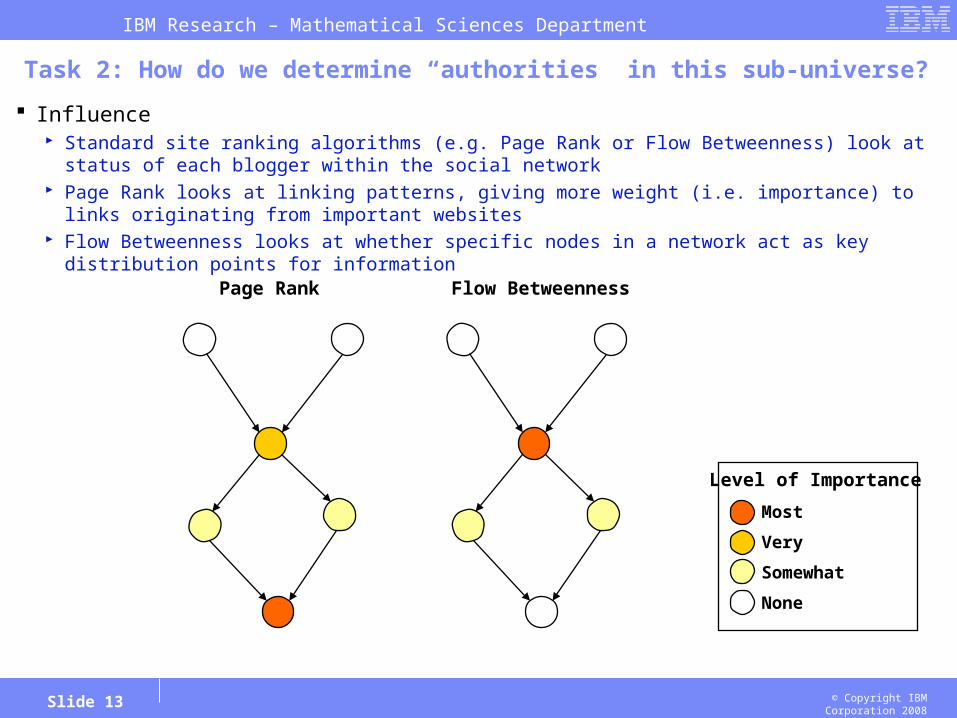
Task 2: How do we determine “authorities” in this sub-universe?
Influence Standard site ranking algorithms (e.g. Page Rank or Flow Betweenness) look at status of each blogger
within the social network Page Rank looks at linking patterns, giving more weight (i.e. importance) to links originating from
important websites Flow Betweenness looks at whether specific nodes in a network act as key distribution points for
information
Most
Very
Somewhat
None
Level of Importance
Page Rank Flow Betweenness
Slide 14
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
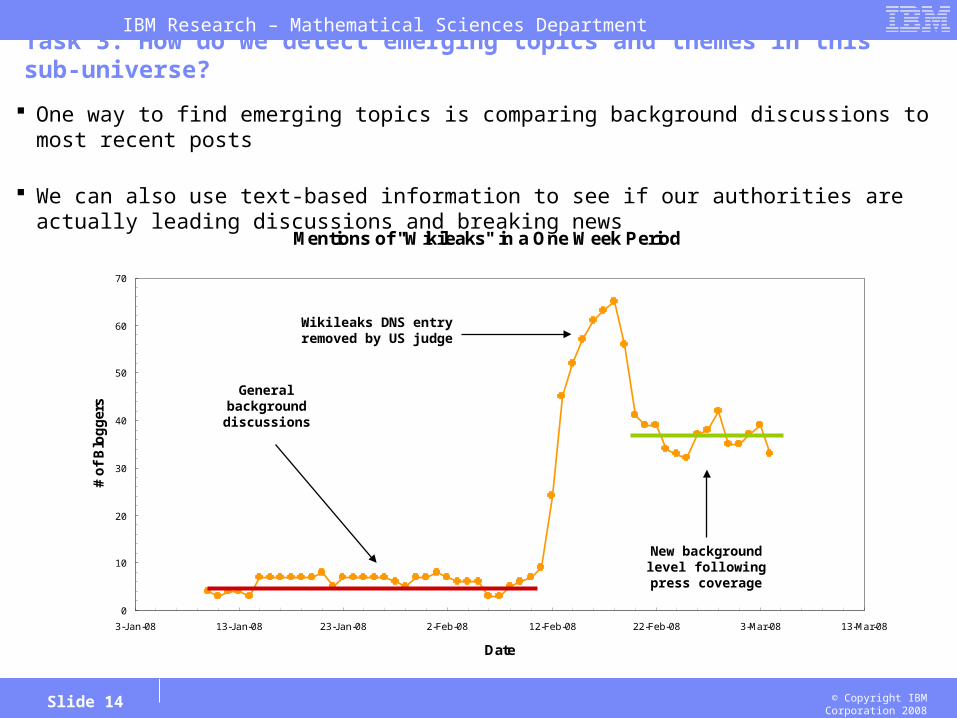
Task 3: How do we detect emerging topics and themes in this sub-universe?
One way to find emerging topics is comparing background discussions to most recent posts
We can also use text-based information to see if our authorities are actually leading discussions and breaking news
Mentions of "Wikileaks" in a One Week Period
0
10
20
30
40
50
60
70
3-Jan-08 13-Jan-08 23-Jan-08 2-Feb-08 12-Feb-08 22-Feb-08 3-Mar-08 13-Mar-08
Date
# o
f B
log
ger
s
Generalbackgrounddiscussions
Wikileaks DNS entryremoved by US judge
New backgroundlevel followingpress coverage

Slide 15
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 3: How do we detect emerging topics and themes in this sub-universe?
Assortativity and homophily play a key role in our analysis
Our approach to homophily is based on measuring within- and between-group edges
Homophily is only observed in certain contexts Blogs focusing on similar topics are more likely to link to each other Blogs are not homophilous when it comes political sentiment Node level versus network level
Homophilous Heterophilous

Slide 16
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 3: Analyzing discussions and network structure
To use assortativity in analyzing “buzz”, label bloggers by their mentioning a specific term or set of terms
In this case, correlation between # of bloggers and assortativity: -0.799
Tracking "wikileaks"
0
10
20
30
40
50
60
70
3-Jan-08 13-Jan-08 23-Jan-08 2-Feb-08 12-Feb-08 22-Feb-08 3-Mar-08 13-Mar-08
Date
Nu
mb
er o
f B
log
ger
s
-4.500E-05
-4.000E-05
-3.500E-05
-3.000E-05
-2.500E-05
-2.000E-05
-1.500E-05
-1.000E-05
-5.000E-06
0.000E+00
5.000E-06
Ass
ort
ativ
ity
Co
effi
cien
t
Counts Assortativity

Slide 17
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Labeling political posts and blogs
Depending on the information we want to extract, there are numerous labels we may want to apply to posts or blogs
An extension of our data sets: 260 posts labeled as “positive”, “negative” in relation to
Hillary Clinton and Barack Obama 360 posts labeled as “relevant” or “not relevant” in relation
to the Democratic Primaries
Potential Labels
Relevant or not relevant Subjective or objective Positive or negative
More on Our Data
260 posts on sentiment surrounding Obama, Clinton
360 posts on relevance to Democratic Primaries
Is post
relevant?
Is post
subjective?Posts
Positive
Negative

Slide 18
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Labeling political posts and blogs
Key question: how can we improve our classifiers with such a limited set of labeled examples?
Transfer learning: using other data sets Using background knowledge

Slide 19
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Precocious Naïve Bayes
Using Naïve Bayes classification, we can use a bag-of-words approach to build text-based classifiers
Problem: when training a classifier like this, we start with a “blank slate” – equal probabilities for all features
It may also be useful to include background knowledge in classification systems Lexicons containing sentiment-focused information Related data sets and labeled information
nF
F
...
1
n
i
in CFpCpZ
FFCp1
1 )|()(1
),...,|(
Slide 20
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
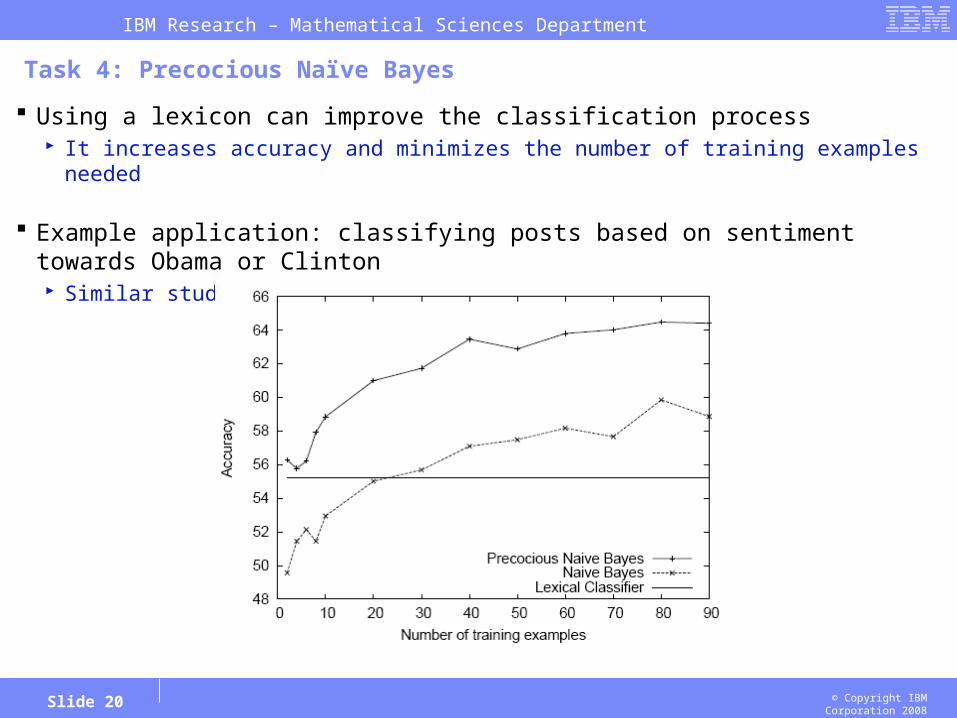
Task 4: Precocious Naïve Bayes
Using a lexicon can improve the classification process It increases accuracy and minimizes the number of training examples needed
Example application: classifying posts based on sentiment towards Obama or Clinton Similar studies achieve accuracies of about 60%

Slide 21
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Precocious Naïve Bayes
Using machine learning and information retrieval models can also help clarify linguistic patterns within political posts and blogs
For example, explore the term “truth” In general, “truth” has positive connotations Yet our models see it as negative
Evidence as to why “truth” is negative Often used in sarcastic or accusatory messages Associated with negative events
Another down-weighted term: “liberal” More evidence of a conservative blogosphere?
“Spinning the truth.”
“Transform a lie into a truth.”
“There is a lot of truth to Wright's sermons.”

Slide 22
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Transfer learning for sentiment prediction
Can we apply a model trained for movie reviews (or other product reviews) to predict sentiment in Lotus blogs?
We examined several labeled sentiment datasets from other domains to predict the sentiment of our Lotus-universe blogs Movielens: 1000 positive and 1000 negative movie reviews from www.movielens.org Epinions: 97 enterprise software reviews from epinions.com Amazon: 13040 software reviews from amazon.com
Testing (Accuracy)
Training Movie Epinions(Enterprise software)
Amazon(Software)
Lotus Data2-class (3-class)
Movie 81.5 65.9 60.1 79.3
Epinions 33.7 67.5 34.9 50.3
Amazon 67.2 60.9 73.8 76.6

Slide 23
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Labeling political posts and blogs
Final question: can we learn more by combining graph-based information with our text-based models?

Slide 24
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Topic-Link Latent Dirichlet Allocation (LDA)
We wish to incorporate both content and network structure in modeling the political blogosphere Members of a “community” are more likely to link to each other
An application: predicting links between new posts in our data set Predicting linking patterns can help predict (or observe) major patterns in the blogosphere
Simple text-based models can even be somewhat effective The chart below shows the probability of a link existing between two posts based on those two posts’
content similarities
Slide 25
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Task 4: Topic-Link Latent Dirichlet Allocation (LDA)
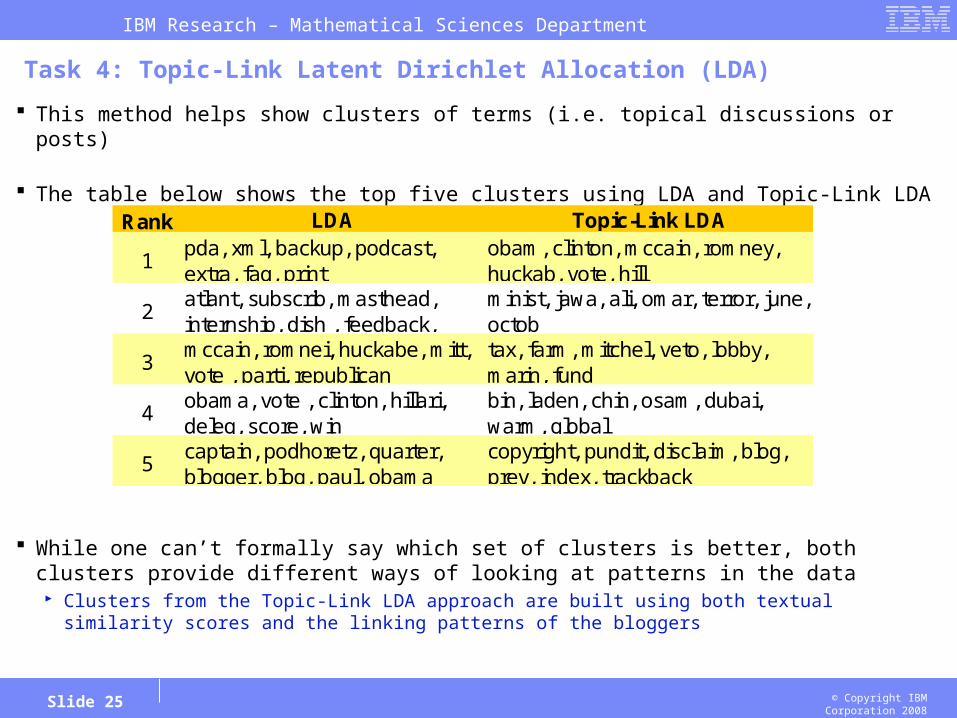
This method helps show clusters of terms (i.e. topical discussions or posts)
The table below shows the top five clusters using LDA and Topic-Link LDA
While one can’t formally say which set of clusters is better, both clusters provide different ways of looking at patterns in the data Clusters from the Topic-Link LDA approach are built using both textual similarity scores and the linking
patterns of the bloggers
Rank LDA Topic-Link LDA
1pda, xml, backup, podcast, extra, faq, print
obam, clinton, mccain, romney, huckab, vote, hill
2atlant, subscrib, masthead, internship, dish , feedback,
minist, jawa, ali, omar, terror, june, octob
3mccain, romnei, huckabe, mitt, vote , parti, republican
tax, farm, mitchel, veto, lobby, marin, fund
4obama, vote , clinton, hillari, deleg, score, win
bin, laden, chin, osam, dubai, warm, global
5captain, podhoretz, quarter, blogger, blog, paul, obama
copyright, pundit, disclaim, blog, prev, index, trackback
Slide 26
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
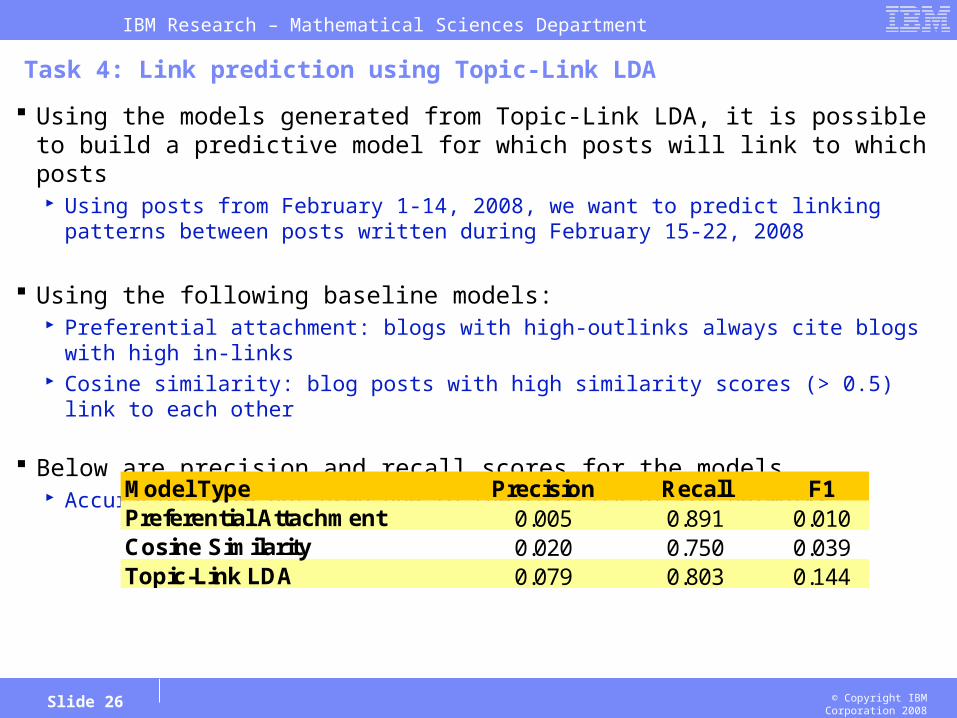
Task 4: Link prediction using Topic-Link LDA
Using the models generated from Topic-Link LDA, it is possible to build a predictive model for which posts will link to which posts Using posts from February 1-14, 2008, we want to predict linking patterns between posts
written during February 15-22, 2008
Using the following baseline models: Preferential attachment: blogs with high-outlinks always cite blogs with high in-links Cosine similarity: blog posts with high similarity scores (> 0.5) link to each other
Below are precision and recall scores for the models Accuracies were not used due to the sparsity of the networks
Model Type Precision Recall F1Preferential Attachment 0.005 0.891 0.010Cosine Similarity 0.020 0.750 0.039Topic-Link LDA 0.079 0.803 0.144

Slide 27
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Future Work and Potential Extensions
Graph transduction and assortativity of networks Multidimensional assortativity Graph transduction dependent on assortativity
Authority scores based on both network structure and text Who is driving the discussions, based on linguistic patterns and term frequencies? Page rank, betweenness, etc. are good network measures for driving discussions,
but need to be validated
Early detection of “buzz” and discussions Building on models of “post cascades” Incorporating new definition of authority using both textual and network-based data

Slide 28
IBM Research – Mathematical Sciences Department
© Copyright IBM Corporation 2008
Thank You





























