Embed Size (px)
Citation preview

ARTIFICIAL INTELLIGENCE
Lecturer: Silja Renooij
Classical planning(goal-directed)
Utrecht University The Netherlands
These slides are part of the INFOB2KI Course Notes available fromwww.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2019-2020

Outline
We consider single‐agent, goal‐directed planning and assume the environment to be static anddeterministic
Planning languages/architectures: STRIPS (1971) Goal Oriented Action Planning (GOAP) Hierarchical planning: NOAH/HTN
2

Applications
Mobile robots– An initial motivator, and still being developed
Simulated environments– Goal‐directed agents for training or games
Web and grid environments– Composing queries or services– Workflows on a computational grid
Managing crisis situations– E.g. oil‐spill, forest fires, urban evacuation, in factories, …
And many more– Factory automation, flying autonomous spacecraft, …
3

Shakey (1966-1972)
Shakey is a robot which plansmoving from one location to another, turning the light switches on and off, opening and closing the doors, climbing up and down from rigid objects, and pushing movable objects around using…?
a) STRIPSb) GOAPc) HTNd) SHOP
4

Goal Oriented Behavior Agent has one or more (internal) goals Goals are used as specific targets to plan actions for Goals are explicit and can be updated, reasoned about, etc. There can be a separate level of behavior to manage the goals – e.g. preferences, importance…
5

Generating plans Given (similar to before):
– A way to describe the world– An initial state of the world– A goal description – A set of possible actions to change the world
Find:– A prescription for actions that are guaranteed to change the initial state into one that satisfies the goal(s)
Difference with before: we’re not optimizing an evaluation function How to choose actions ??
6

Actions
E.g.
Precondition: in(house,fire)Action: extinguish_firePostcondition: not in(house,fire)
7
Contain domain knowledge, not simplymapping state state

Actions & change
Actions change the world, but only partly Upon considering/comparing possible actions,we want to:– know how an action will alter the world– keep track of the history of world states (have we been here before?)
– answer questions about potential world states (what would happen if..?)
8

Planning sequences of actions:a search problem (?)
Use e.g. IDA* (Iterative Deepening A*) to create all possible sequences of actions for a single goal Heuristic should capture how far a sequence of actions is from achieving the goal Quite cumbersome: we do not use (available) information about the actions, their effects and their relations
9
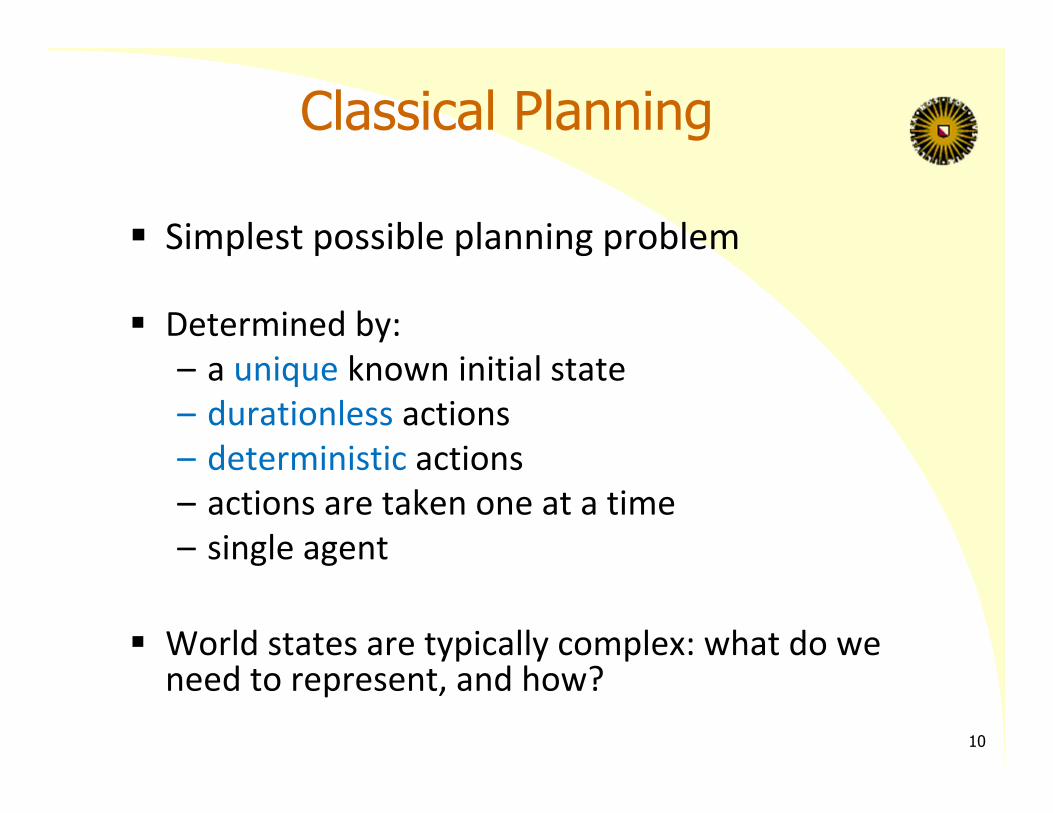
Classical Planning
Simplest possible planning problem
Determined by:– a unique known initial state– durationless actions– deterministic actions– actions are taken one at a time– single agent
World states are typically complex: what do we need to represent, and how?
10
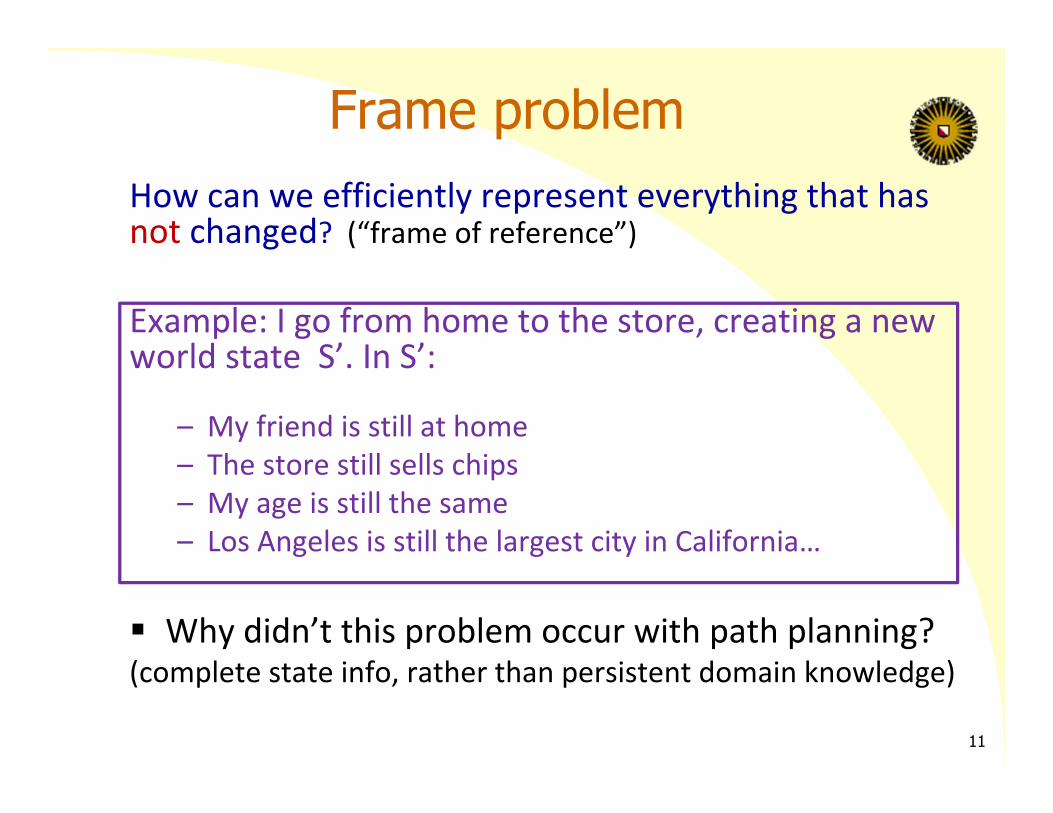
Frame problemHow can we efficiently represent everything that has not changed? (“frame of reference”)
Example: I go from home to the store, creating a new world state S’. In S’:
– My friend is still at home– The store still sells chips– My age is still the same– Los Angeles is still the largest city in California…
Why didn’t this problem occur with path planning? (complete state info, rather than persistent domain knowledge)
11

Ramification problem
Do we want to represent every change to the world in an action definition, even indirect effects? (= ramifications)
Example: I go from home to the store, creating a new situation S’. In S’:
– I am now in Marina del Rey– The number of people in the store went up by 1– The contents of my pockets are now in the store..
12
Linear planning
13

Linear planning
A linear planner is a classical planner that assumes:
‐ no distinction between importance of goals‐ all (sub)goals are assumed to be independent (sub) goals can be achieved in arbitrary order
As a result, plans that achieve subgoals are combined by placing all steps of one subplan before or after all steps of the others (=non‐interleaved) .
14

STRIPS (Fikes and Nilsson 71)A non‐hierarchical, linear planner
Idea: State (or world model) represents a large number of facts and relations
Use formulas in first‐order predicate logic Use theorem‐proving within states, for action preconditions and goal tests
Use goal stack planning for going through state space
More recent: PDDL (just the language; includes a.o. negations) Alternatives backward chaining algorithm for searching through the state space & planning graphs (not discussed) 15

(generalised) STRIPSProblem space:
Initial world model: set of well‐formed formulas (wffs: conjunction of literals)
Set of actions, each represented with– Preconditions (list of predicates that should hold)– Delete list (list of predicates that will become invalid)– Add list (list of predicates that will become valid)Actions thus allow variables(we consider a proposition to be a special case of a predicate without variables)
A goal condition: stated as wff16

Example problem:
Initial state: at(home), ¬ have(beer)Goal: have(beer), at(home)
Actions:
Buy(X):Pre: at(store)Add: have(X)
Go (X, Y):Pre: at(X)Del: at(X)Add: at(Y)
17
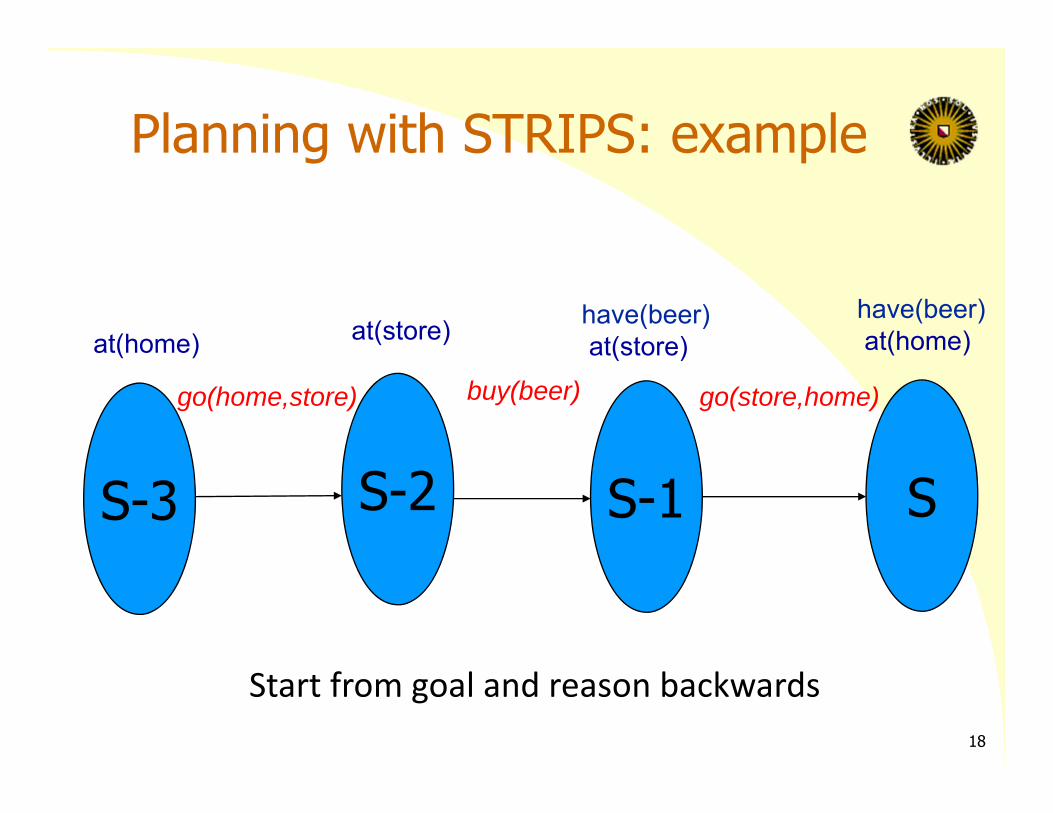
Planning with STRIPS: example
S
have(beer)at(home)
go(store,home)
S-1
have(beer)at(store)
S-2
at(store)
S-3
at(home)
go(home,store) buy(beer)
18
Start from goal and reason backwards

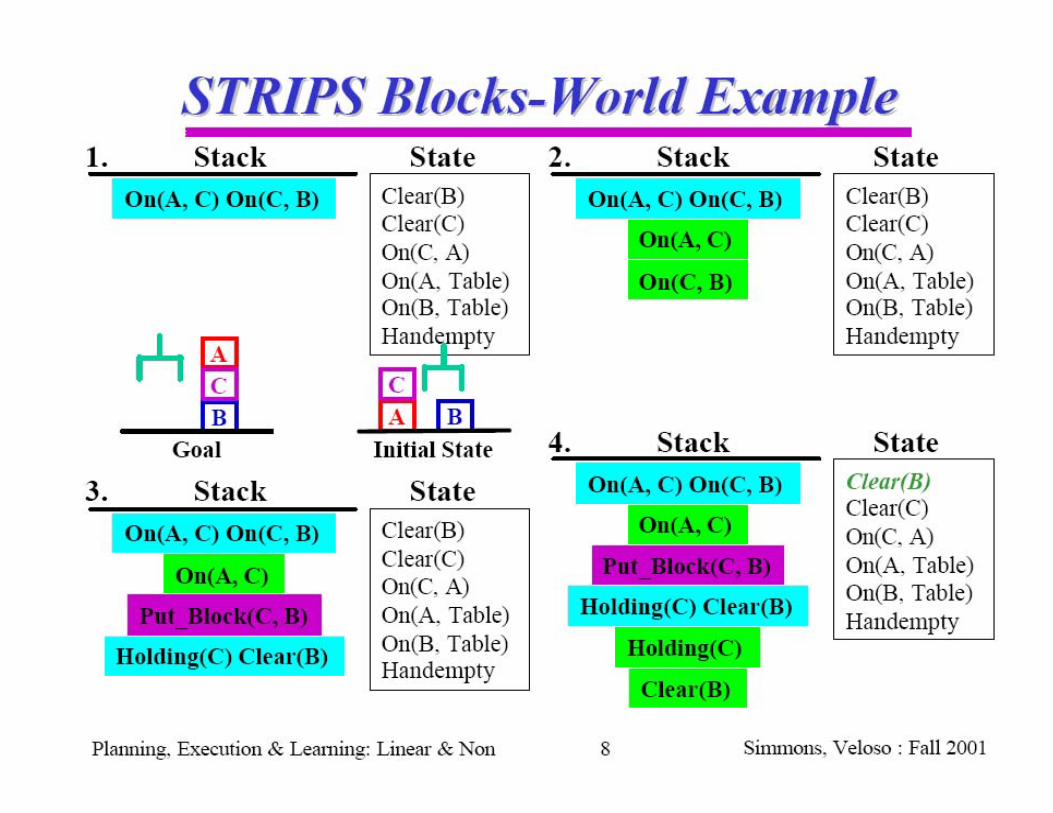
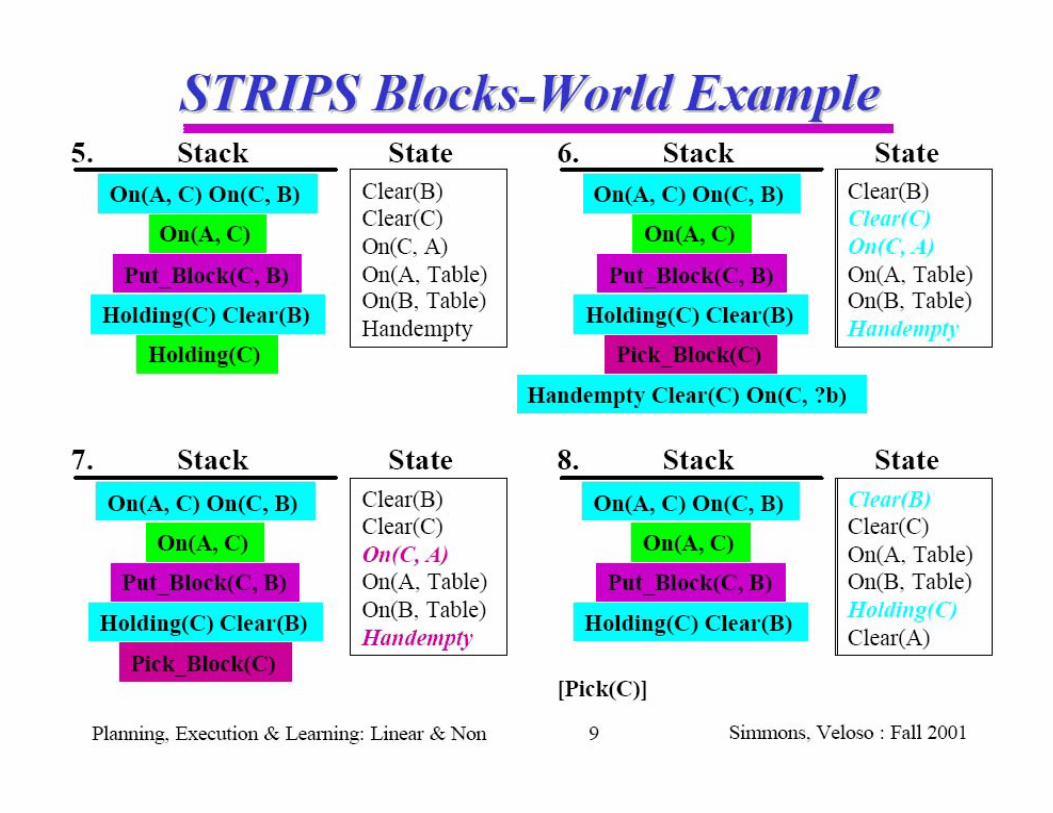
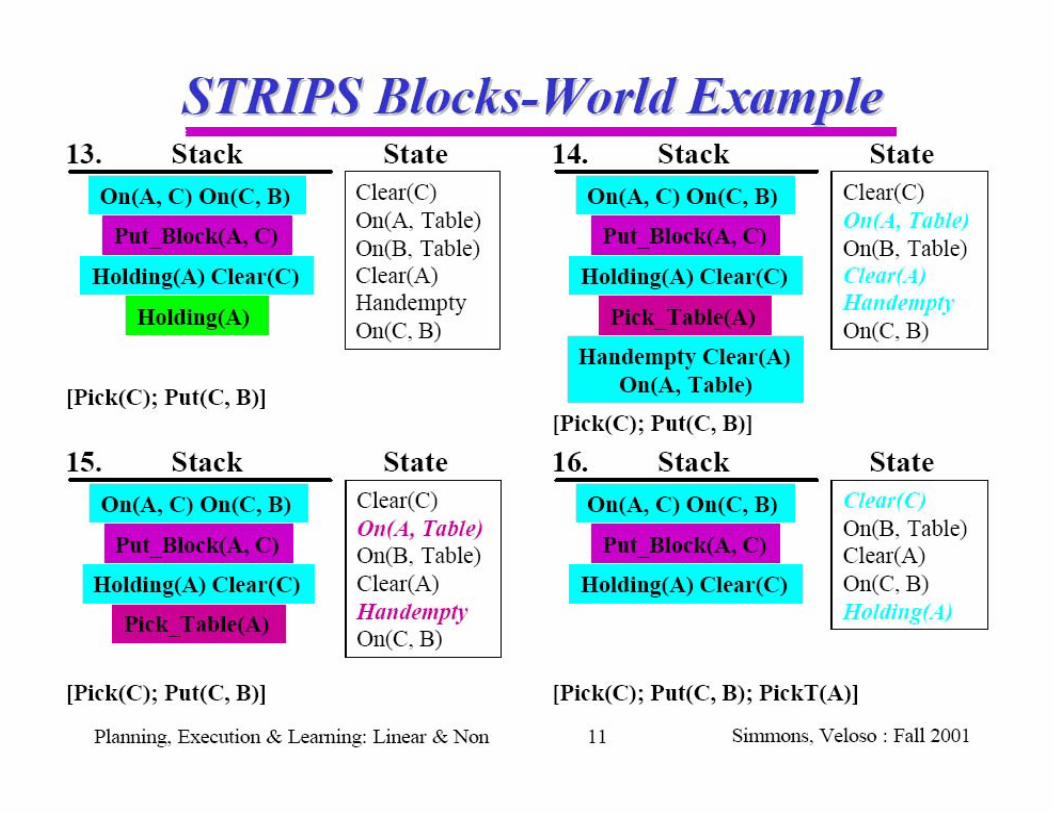
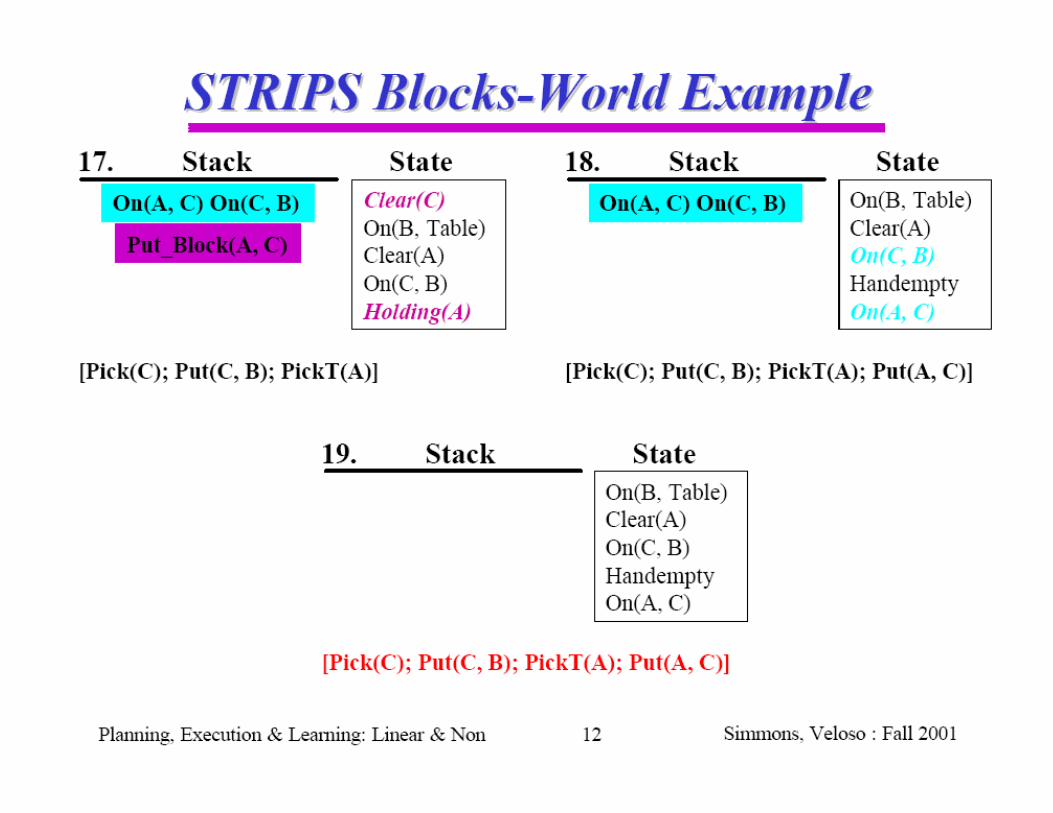
Goal stack planning with STRIPSSearch strategy idea:
Identify differences between present world model and the goal
Identify actions that are relevant for reducing the differences
Satisfy preconditions: turn preconditions of relevant actions into new subgoals; solve subproblems
Use a stack to push (and pop) preconditions and actions
19

20

21
22
23

24
25
26

27

28

STRIPS & frame problemHow can we efficiently represent everything that hasn’t changed?
Example: I go from home to the store, creating a new situation S’. In S’:
– The store still sells chips– My age is still the same– Los Angeles is still the largest city in California…
STRIPS solution for simple actions: every satisfied formula not explicitly deleted by an operator continues to hold after the operator is executed
29

STRIPS & ramification problem Do we want to represent every change to the world in an action definition?
Example: I go from home to the store, creating a new situation S’. In S’:
– I am now in Marina del Rey– The number of people in the store went up by 1– The contents of my pockets are now in the store..
STRIPS solution: some facts are inferred within a world state
– e.g. the number of people in the store
‘inferred’ facts are not carried over and must be re‐inferred– Avoids making mistakes, perhaps inefficient.
30

More questions about STRIPS What if the order of goals at(home), have(beer) was reversed?
Would require re‐planning a goal that already seemed fulfilled; is that guaranteed?
Is STRIPS complete (always finds a plan if there is one)?No; (Sometimes fixable through conjunction of goals, but computationally inefficient)
When STRIPS returns a plan, is it sound (always correct)? And is the plan returned efficient?
It is sound, but ‘detours’ (unnecessary series of ops) possible
31
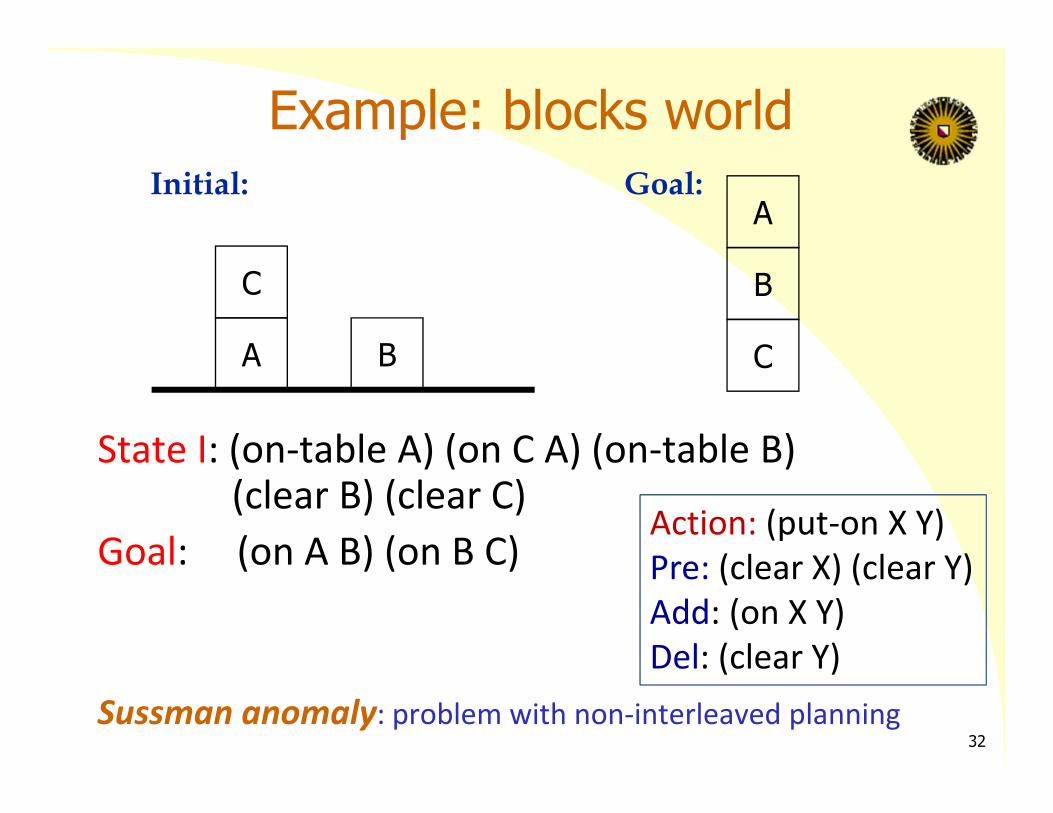
Example: blocks world
State I: (on‐table A) (on C A) (on‐table B) (clear B) (clear C)
Goal: (on A B) (on B C)
Sussman anomaly: problem with non‐interleaved planning
A B
C
A
B
C
Initial: Goal:
32
Action: (put‐on X Y)Pre: (clear X) (clear Y)Add: (on X Y)Del: (clear Y)
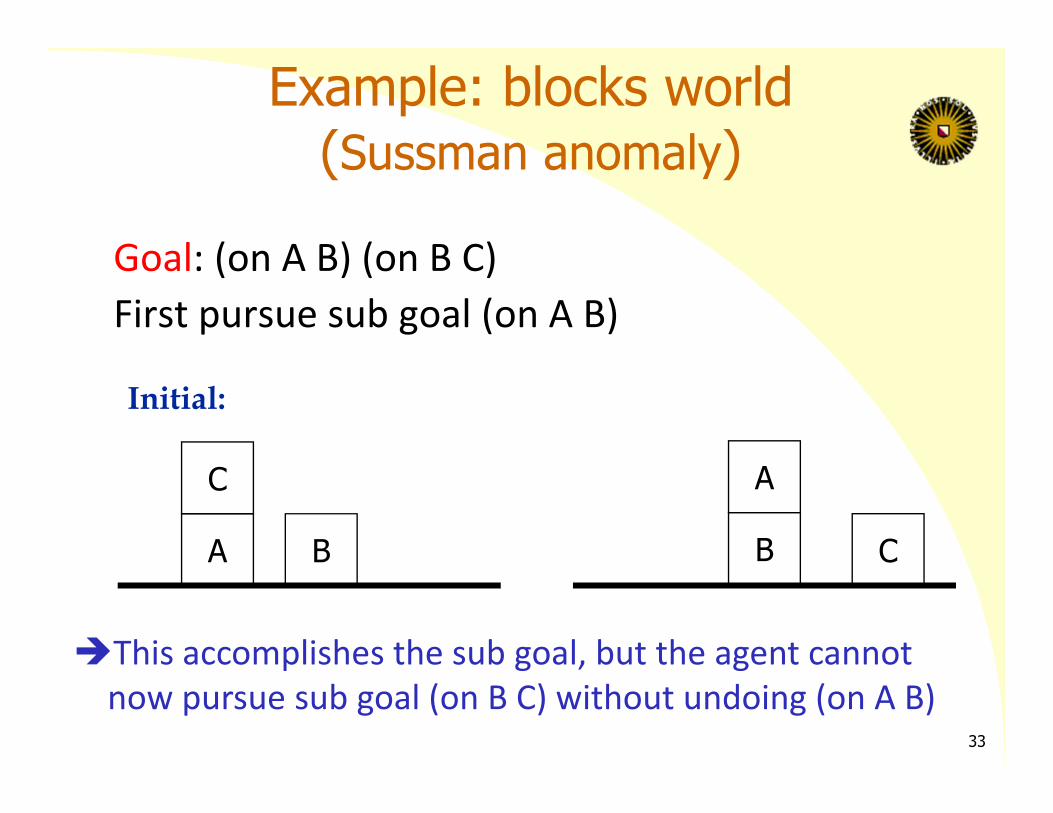
Example: blocks world (Sussman anomaly)
Goal: (on A B) (on B C)First pursue sub goal (on A B)
A B
C
Initial:
A
B C
This accomplishes the sub goal, but the agent cannot now pursue sub goal (on B C) without undoing (on A B)
33
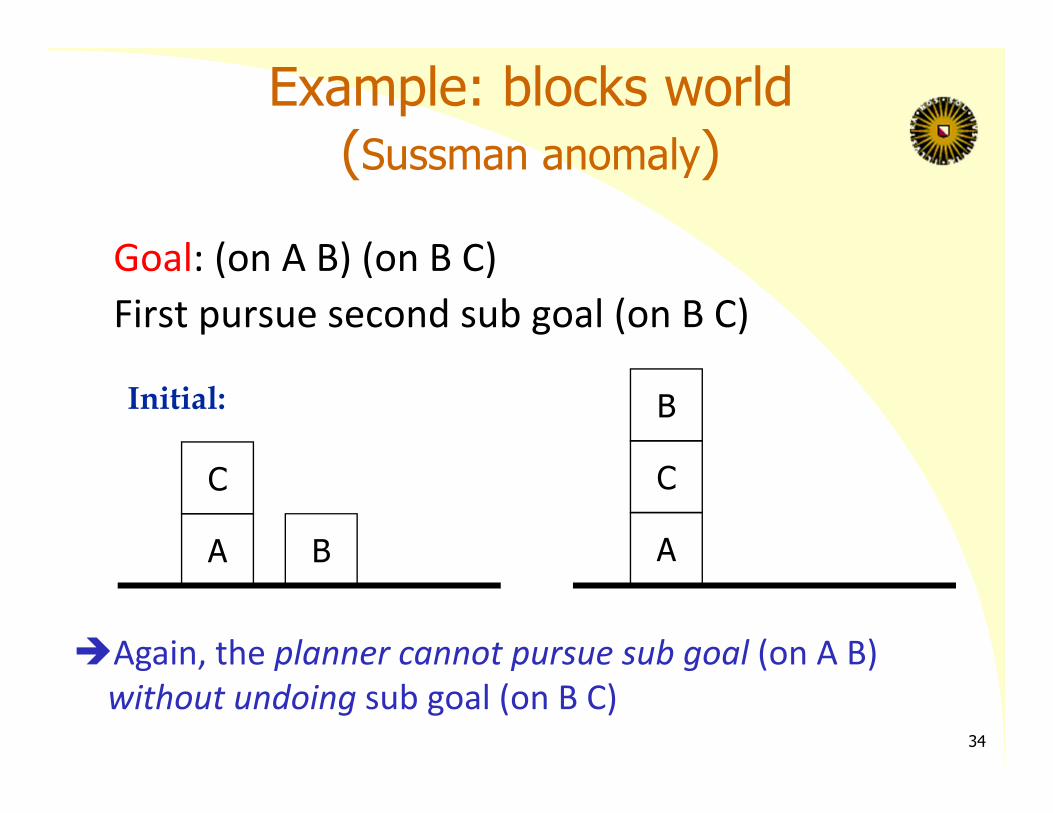
Example: blocks world (Sussman anomaly)
Goal: (on A B) (on B C)First pursue second sub goal (on B C)
A B
C
Initial:
C
A
B
Again, the planner cannot pursue sub goal (on A B) without undoing sub goal (on B C)
34

Planning in Games
35

Goal oriented action planningGOAP: simplified STRIPS‐like planning architecture specifically designed for real‐time control of autonomous character behavior in games used in FPSs since ~2005
Goals (a.k.a. motives):– Have different levels of importance (insistence)– High insistence affects behavior more– Character tries to fulfill goals, by reducing insistence
36

GOAP Goals can be seen as motives for taking action.
Example goals: Eat, Sleep, Kill
Priority for fulfilling goals is given by insistence IExample: goal g = Eat
I(g) = 4 (I {0,…,5}, 5 highest)
Actions specify to which goal they contribute and how they affect insistence
Example: Action: get‐food: I(Eat) I(Eat) − 3
Different action‐selection methods possible37

Action selection: most pressingWhat action to choose?
Goals of Agent X (with current insistence I):Goal: Eat (I=4) Goal: Sleep (I=3)
Actions available to Agent X:Action: get‐food (Eat; I I − 3)Action: get‐snack (Eat; I I − 2)Action: sleep‐in‐bed (Sleep; I I − 4)Action: sleep‐on‐sofa (Sleep; I I − 2)
38

Utility-based action selectionDiscontentment =
Goal: Eat (I=4) Goal: Bathroom (I=3)
Action: drink‐soda (Eat I I – 2; Bathroom I I + 2)
new State where I(Eat) = 2, I(Bathroom)=5so discontentment of state = 29
Action: visit‐bathroom (Bathroom I I – 4)
new State where I(Eat) = 4, I(Bathroom)=0so discontentment of state = 16
39

Time-based action selectionGOAP does not assume actions to be durationless!
Possibilities for including time:
Incorporate time directly in utility (discontentment)
Prefer short actions Take consequence of extra time into account by changing goal insistences(affects only instances of goals not addressed by the action!!)
40

Utility- and time-based action selection
Goal: Eat (I=4; increases +4/hour)Goal: Bathroom (I=3; increases +2/hour)
Action: eat‐snack (I(Eat) I − 2) .25 hoursState where I(Eat)=2, I(Bathroom)=3.5,discontentment=16.25
Action: eat‐meal (I(Eat) I − 4) 1 hourState where I(Eat)=0, I(Bathroom)=5,discontentment=25
Action: visit‐bathroom (I(Bathroom) I − 4) .25 hoursState where I(Eat)=5, I(Bathroom)=0,discontentment=25
41

Dependencies between actionsGreedily choosing the best action each step doesn’t necessarily give the best sequence of actions!
1. An action may use a resource needed by other actionsE.g. buy snack now and have no money left for meal later Local optimal action prevents later actions Solution: introduce more goals
2. An action is only useful if followed by another action later onE.g. buy food now to eat later Solution: consider sequences of actions (as before)
42

Hierarchical planning
43
• Net of action hierarchies (NOAH)• Hierarchical Task Networks (HTN)• SHOP

Hierarchical Planning Brief History
Originally developed in the late 1970s– NOAH [Sacerdoti, IJCAI 1977]– NONLIN [Tate, IJCAI 1977]
Knowledge‐based Scalable– Task Hierarchy is a form of domain‐specific knowledge
Practical, applied to real world problems Lack of theoretical understanding until early 1990’s
[Erol et al, 1994] [Yang 1990] [Kambhampati 1992]
– Formal semantics, sound/complete algorithm, complexity analysis [Erol et al, 1994]
44

NOAH (Sacerdoti 75)
Consultant system that advises a human amateur in a repair task
Non‐linear planner (i.e. interleaved)
Explicitly views plans as a partial order of steps. Add ordering into the plan as needed to guarantee it will succeed.
Avoids the problem in STRIPS, that focusing on one sub‐goal forces the actions that resolve that goal to be contiguous.
45

Nets Of Action Hierarchies
on(a, b)
on(b, c)S J
puton(a, b)
puton(b, c)
S J
clear(a)
clear(b)S J
clear(b)
clear(c)S J
refine
(Blocksworld example)
Split into sub goals, which should be Joined46
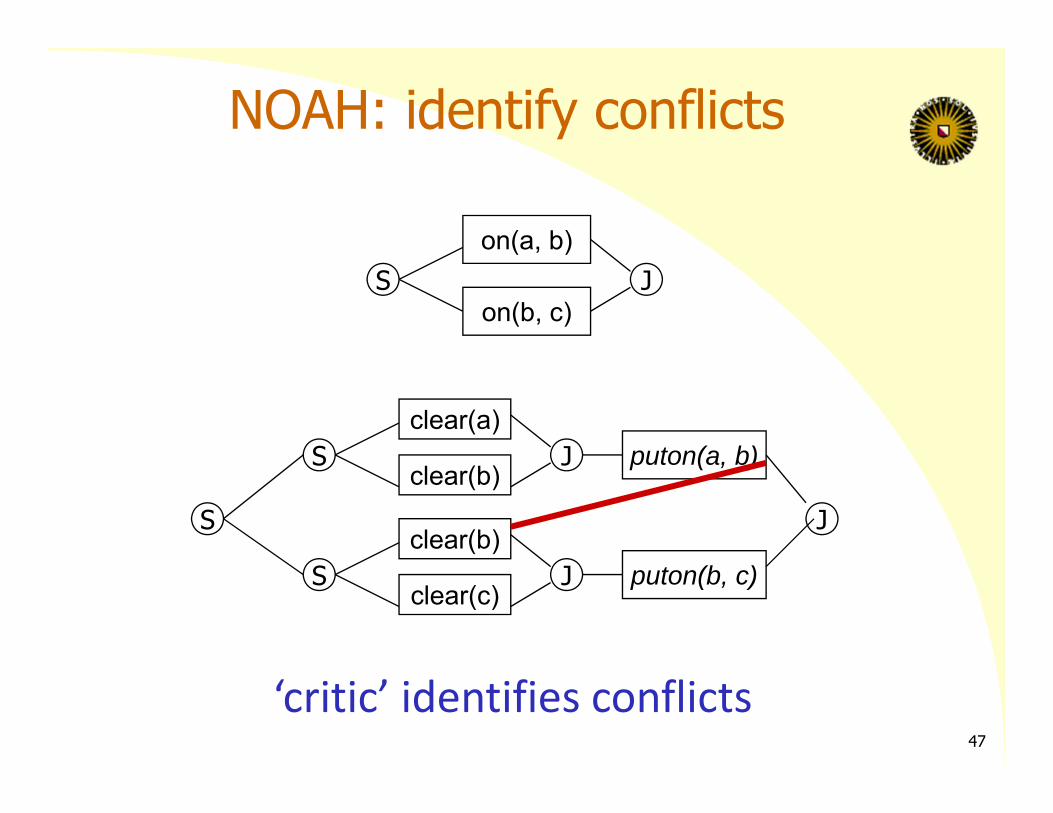
NOAH: identify conflicts
on(a, b)
on(b, c)S J
puton(a, b)
puton(b, c)
S J
clear(a)
clear(b)S J
clear(b)
clear(c)S J
‘critic’ identifies conflicts47
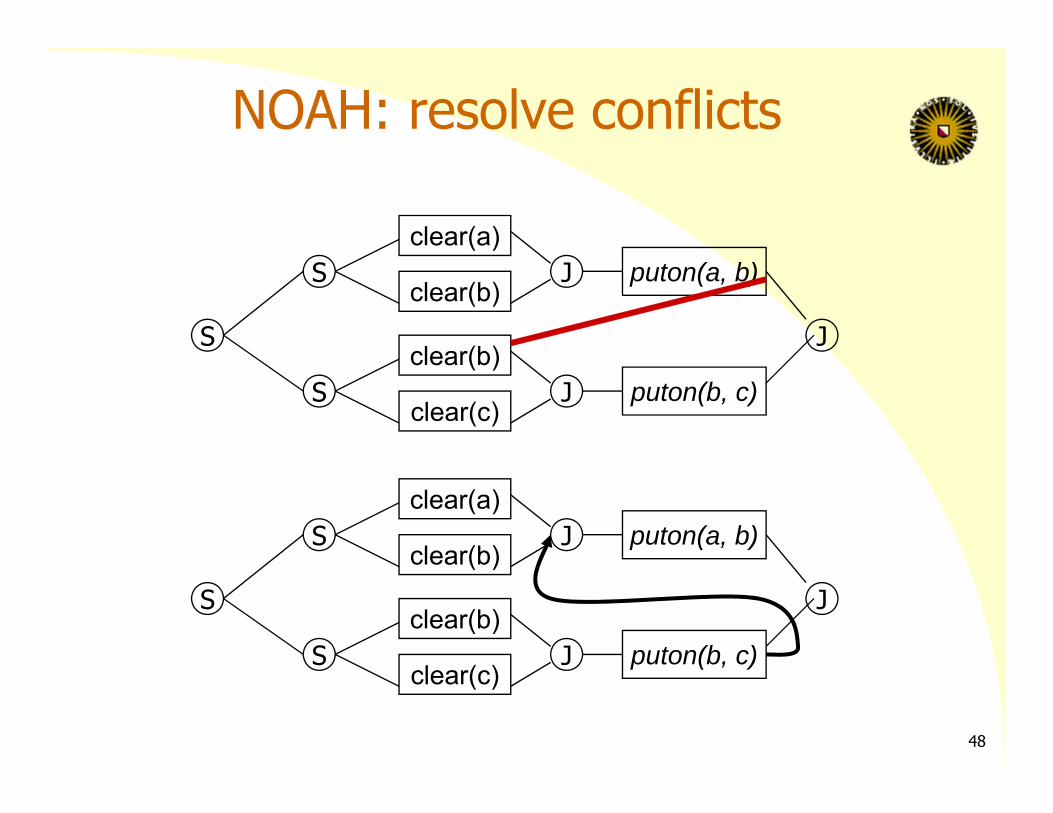
NOAH: resolve conflicts
puton(a, b)
puton(b, c)
S J
clear(a)
clear(b)S J
clear(b)
clear(c)S J
puton(a, b)
puton(b, c)
S J
clear(a)
clear(b)S J
clear(b)
clear(c)S J
48
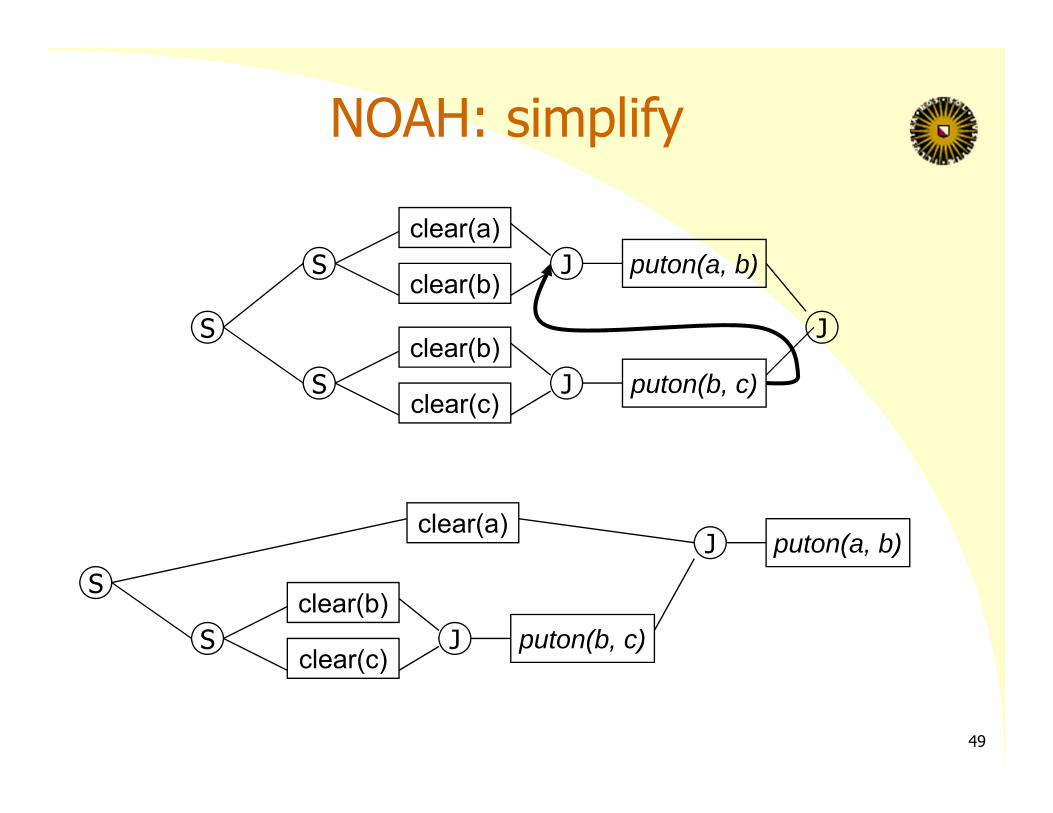
NOAH: simplify
puton(a, b)
puton(b, c)
S J
clear(a)
clear(b)S J
clear(b)
clear(c)S J
puton(a, b)
puton(b, c)
S
clear(a)J
clear(b)
clear(c)S J
49
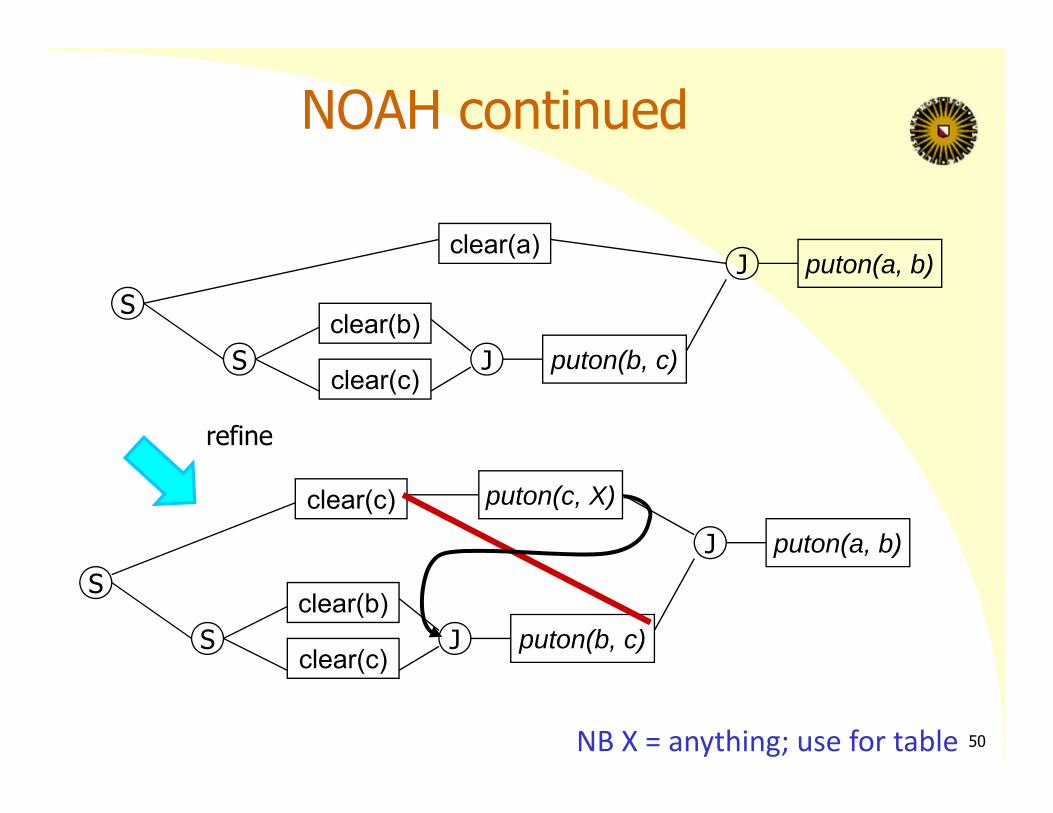
NOAH continued
puton(a, b)
puton(b, c)
S
clear(a)J
clear(b)
clear(c)S J
puton(a, b)
puton(b, c)
SJ
clear(b)
clear(c)S J
puton(c, X)clear(c)
refine
50NB X = anything; use for table
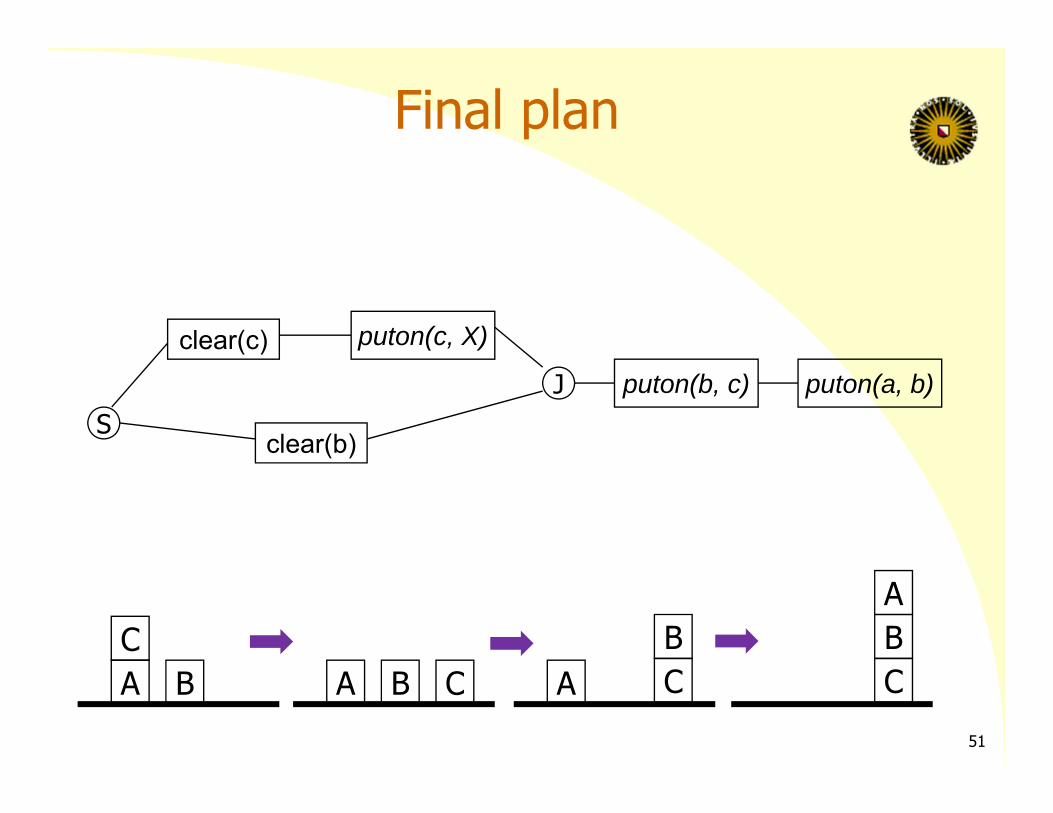
Final plan
puton(a, b)puton(b, c)S
clear(b)
J
puton(c, X)clear(c)
A BC
A B C ABC
ABC
51

Planning with Hierarchical Task Networks
Capture hierarchical structure of the planning domain Planning domain contains non‐primitive actions (tasks) and schemas for reducing them Reduction schemas:
– given by the designer– express preferred ways to accomplish a task
52
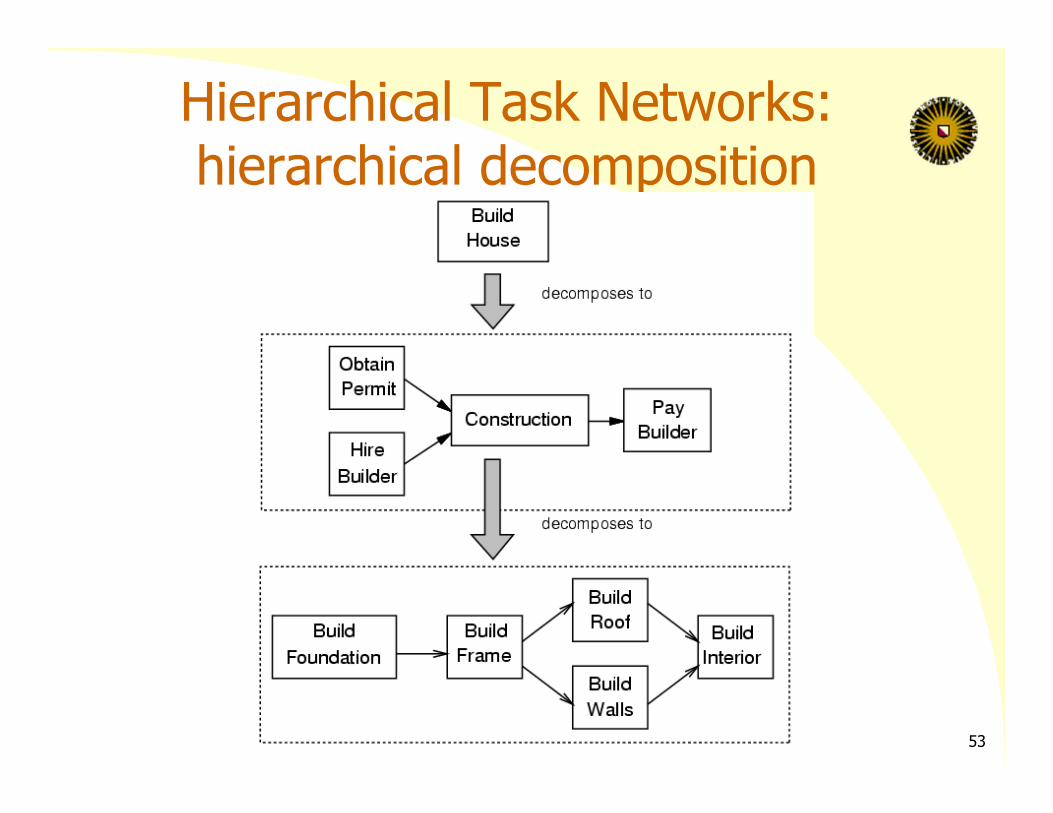
Hierarchical Task Networks:hierarchical decomposition
53
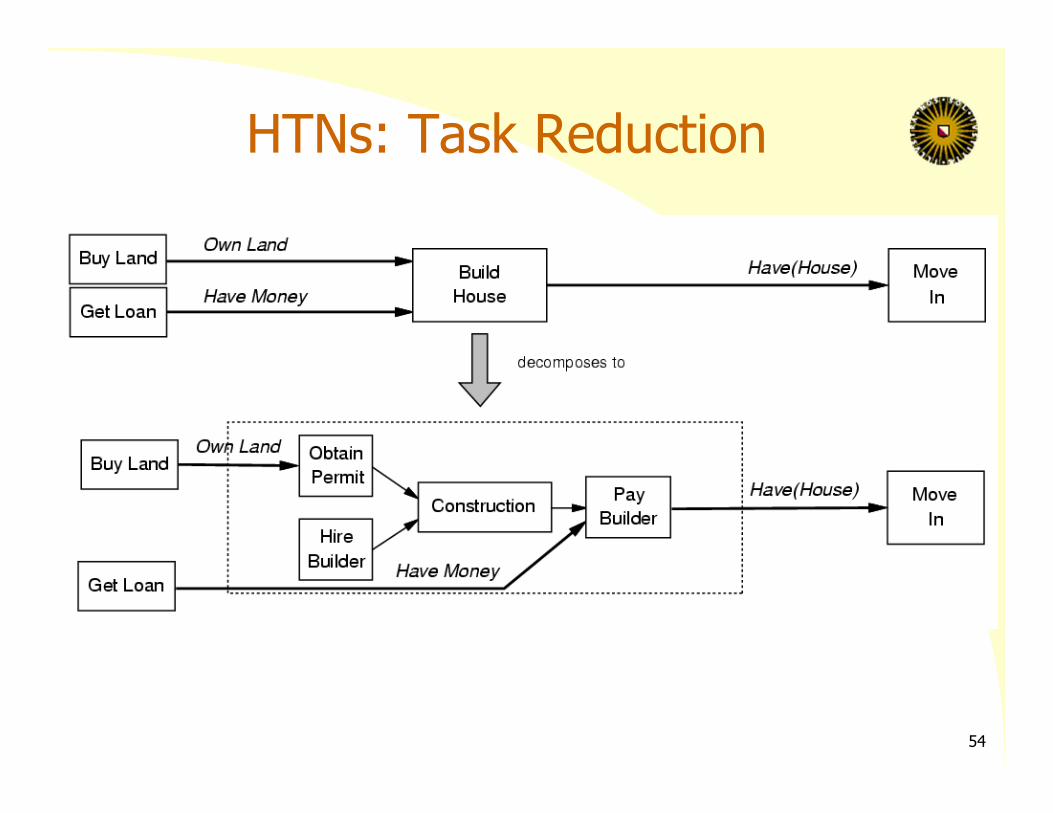
HTNs: Task Reduction
54

HTN Planning Algorithm (intuition)
Problem reduction: Decompose tasks into subtasks Handle constraints (binding, ordering,…) Resolve interactions If necessary, backtrack and try other decompositions
55

Deployed, Practical Planners SHOP, SHOP2, JSHOP: ordered task decomposition(adaptation of HTN with total order on subtasks; decompose left‐to‐right)
Applications:– Logistics
• Military operations planning: Air campaign planning, Non‐Combatant Evacuation Operations
• Crisis Response: Oil Spill Response – Production line scheduling – Construction planning: Space platform building, house
construction– Space applications: mission sequencing, satellite control– Software Development: Web Service Composition
56

SHOP (Simple Hierarchical Ordered Planner) Domain‐independent algorithm forOrdered Task Decomposition– Sound/complete
Input:– State: a set of ground atoms– Task List: a linear list of tasks (given at highest level)– Domain: methods, operators, axioms
Output: one or more plans, it can return:– the first plan it finds, all possible plans,
a least‐cost plan, all least‐cost plans
57

Initial task list: ((travel home park)) Initial state: ((at home) (cash 20) (distance home park 8)) Methods (task, preconditions, subtasks):
– (:method (travel ?x ?y)((at ?x) (walking‐distance ?x ?y)) ' ((!walk ?x ?y)) 1)
– (:method (travel ?x ?y)((at ?x) (have‐taxi‐fare ?x ?y))' ((!call‐taxi ?x) (!ride ?x ?y) (!pay‐driver ?x ?y)) 1)
Axioms:– (:‐ (walking‐dist ?x ?y) ((distance ?x ?y ?d) (eval (<= ?d 5))))– (:‐ (have‐taxi‐fare ?x ?y)
((have‐cash ?c) (distance ?x ?y ?d) (eval (>= ?c (+ 1.50 ?d)))) Primitive operators (task, delete list, add list)
– (:operator (!walk ?x ?y) ((at ?x)) ((at ?y)))– …
Simple Example
Optional cost;default is 1
58
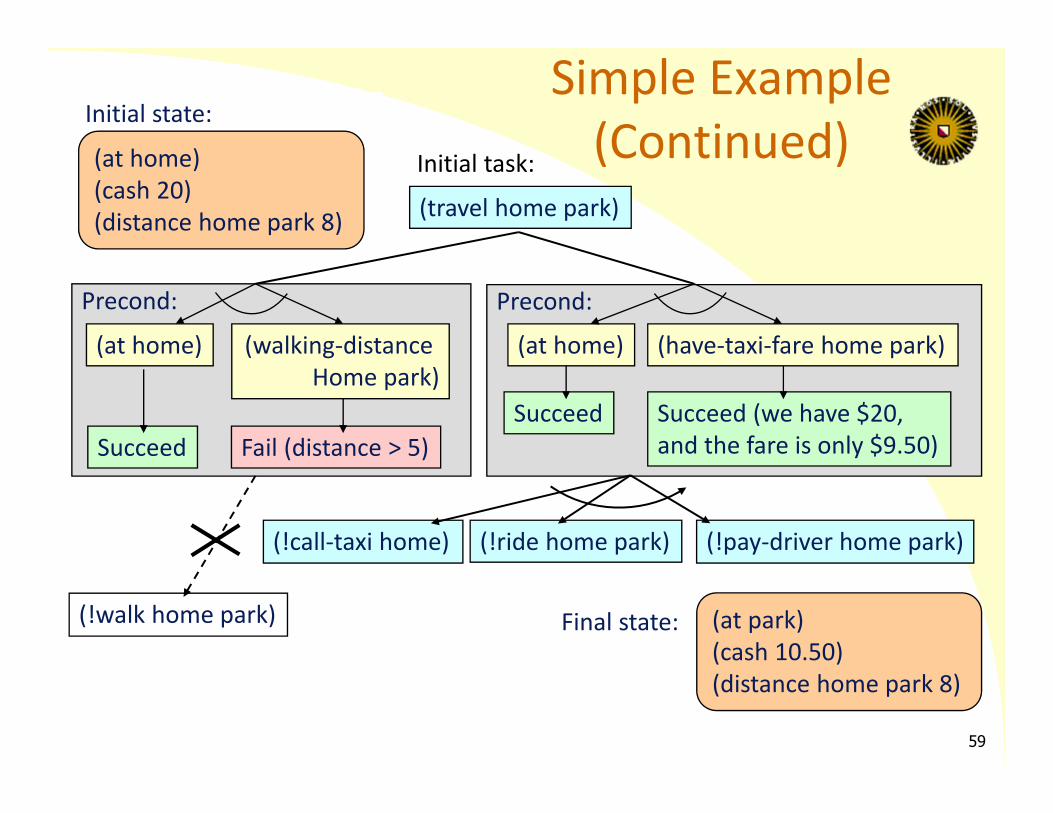
Precond: Precond:
(travel home park)
(!walk home park)
(!call‐taxi home) (!ride home park) (!pay‐driver home park)
Fail (distance > 5)Succeed (we have $20,and the fare is only $9.50)Succeed
Succeed
(at home)(walking‐distance Home park)
(have‐taxi‐fare home park)
(at park)(cash 10.50)(distance home park 8)
Simple Example(Continued)
(at home)
Initial state:
Final state:
(at home)(cash 20)(distance home park 8)
Initial task:
59
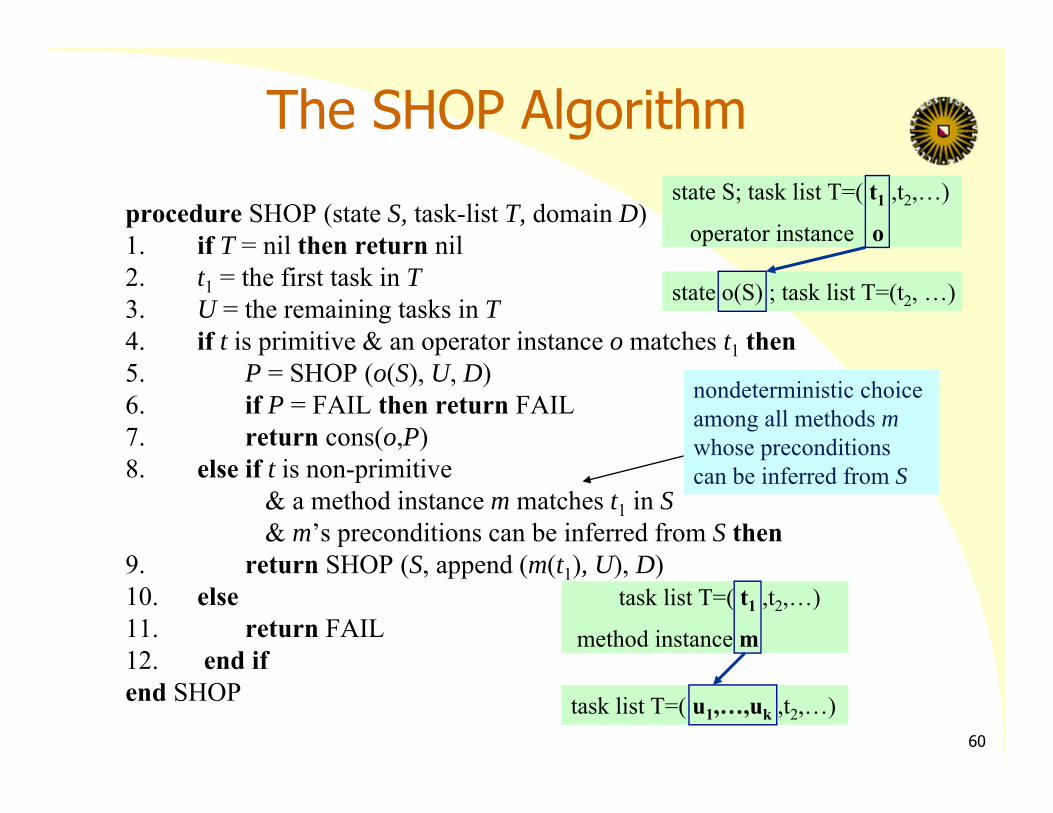
The SHOP Algorithmprocedure SHOP (state S, task-list T, domain D) 1. if T = nil then return nil2. t1 = the first task in T3. U = the remaining tasks in T4. if t is primitive & an operator instance o matches t1 then5. P = SHOP (o(S), U, D)6. if P = FAIL then return FAIL7. return cons(o,P)8. else if t is non-primitive
& a method instance m matches t1 in S& m’s preconditions can be inferred from S then
9. return SHOP (S, append (m(t1), U), D)10. else11. return FAIL12. end ifend SHOP
state S; task list T=( t1 ,t2,…)
operator instance o
state o(S) ; task list T=(t2, …)
task list T=( t1 ,t2,…)
method instance m
task list T=( u1,…,uk ,t2,…)
nondeterministic choice among all methods mwhose preconditions can be inferred from S
60

SummaryWe considered single‐agent, goal‐oriented planning in a static and deterministic environment
STRIPS– Linear = non‐interleaved, non‐hierarchical planner– Incomplete, not optimal
Goal Oriented Action Planning (GOAP)– Simple + more flexible, STRIPS‐like– Action duration, goal insistence
NOAH and Hierarchical Task Networks– Non‐linear planners– Ordered versions with total order on subtasks
61

Shakey (1966-1972)
Shakey is a robot which plansmoving from one location to another, turning the light switches on and off, opening and closing the doors, climbing up and down from rigid objects, and pushing movable objects around using…?
a) STRIPSb) GOAPc) HTNd) SHOP
62





























