Embed Size (px)
Citation preview

An Efficient Shared Memory An Efficient Shared Memory Based Virtual Based Virtual
Communication System for Communication System for Embedded SMP ClusterEmbedded SMP Cluster
Wenxuan YinWenxuan YinInstitute of Computing Technology
Chinese Academy of Sciences
Joint work with Xiang Gao, Xiaojing Zhu, ICT, CASand Deyuan Guo, Tsinghua University
NAS NAS 20112011

July 2011 Wenxuan Yin-NAS 2011
Background
• DilemmaDilemma in Embedded System in Embedded System– High performance
– Cost, power consumption, size, etc.
Video/media processing Space-born satellite

July 2011 Wenxuan Yin-NAS 2011
Background
• Why SMP cluster is popular in Why SMP cluster is popular in general computing?general computing?– High scalability
– Good cost-performance ratio
– Convenient for MPI programming
• It can also benefit the embedded It can also benefit the embedded domaindomain– Embedded Cluster
• Embedded processor nodes
• Commodity networks
– moderate performance cost/power efficiency
Tradeoff

July 2011 Wenxuan Yin-NAS 2011
Motivations
• Challenges by SMP nodesChallenges by SMP nodes– Two levels of communication
• inter-node: high-speed network• intra-node: shared memory/cache
– Memory management• memory hierarchy: local vs. remote• coherency maintenance
– MPI Inter-Process Communication (IPC)• process allocation in different parallelism
– Mutual exclusion and synchronization
Performance Gap!

July 2011 Wenxuan Yin-NAS 2011
Motivations
• Opportunities in SMP nodesOpportunities in SMP nodes– More computation capacity
– High-speed chip-to-chip interconnect fabrics• PCI-E : ARM Cortex A9 MPCore
• Serial RapidIO : Freescale 8641D
• HyperTransport : ICT Godson-3A
– Can we use the fabrics directly to replace traditional NIC based networks?
• get rid of NICs, switches, cables
How to How to do?do?

July 2011 Wenxuan Yin-NAS 2011
Proposed Design
Extending the Shared Memory Extending the Shared Memory Mechanism into Inter-Node Mechanism into Inter-Node
CommunicationsCommunications

July 2011 Wenxuan Yin-NAS 2011
Objectives
• CompatibilityCompatibility– Software virtulized network TCP/IP protocol
• EfficiencyEfficiency– Remote memory Logical shared memory
– Narrow the gap between two levels
• EconomizationEconomization– Compact interconnect
Space and cost effective
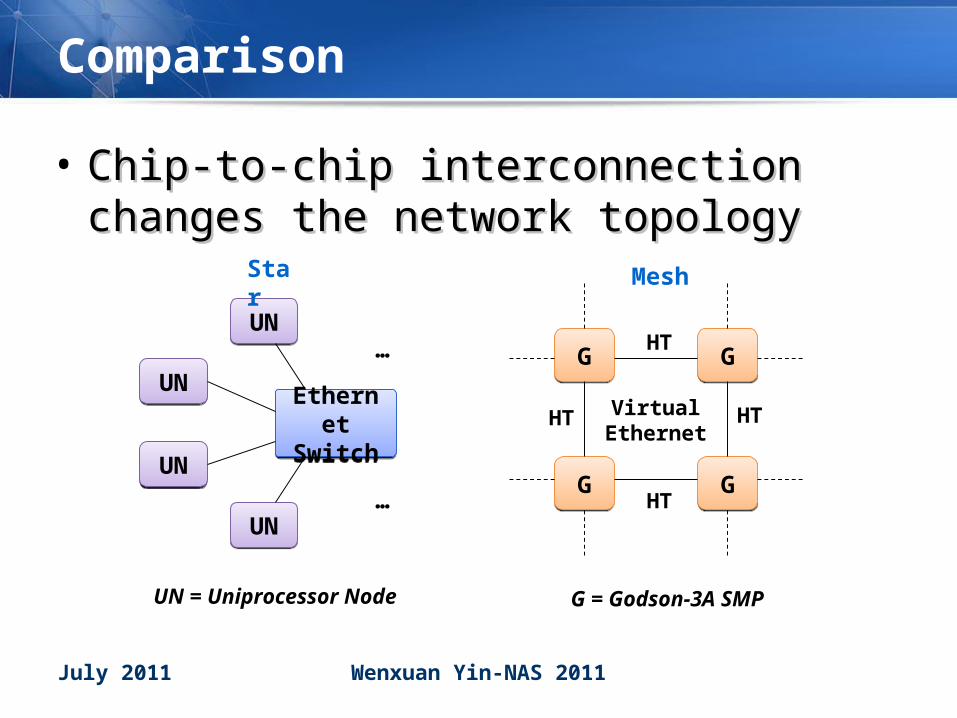
Comparison
• Chip-to-chip interconnection Chip-to-chip interconnection changes the network topologychanges the network topology
July 2011 Wenxuan Yin-NAS 2011
UNUN
Ethernet Switch
Ethernet Switch
UNUN
UNUN
UNUN
…
…
UN = Uniprocessor Node
GG GG
G = Godson-3A SMP
GG GG
HT
HT
HT
HTVirtual Ethernet
Star Mesh
July 2011 Wenxuan Yin-NAS 2011
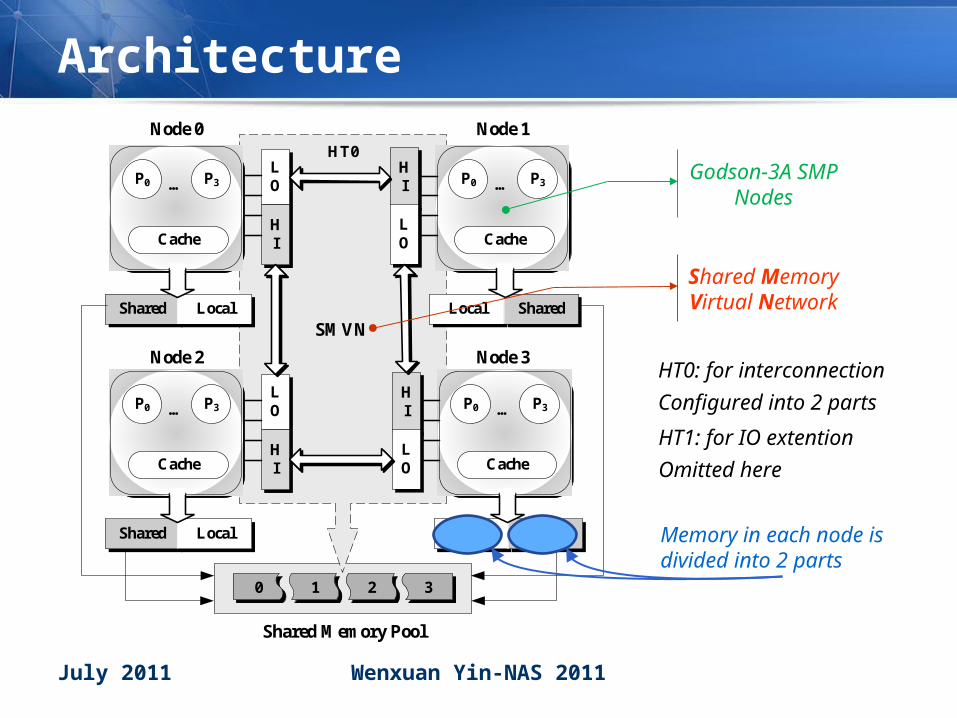
ArchitectureNode 0
Local
…
Cache
P0 P3
Shared
…
Cache
P0 P3
Local Shared
LO
HI
HI
LO
Shared
…
Cache
P0 P3
Local
HI
LO
Local
…
Cache
P0 P3
Shared
LO
HI
Shared Memory Pool
SMVN
HT0
Node 1
Node 2 Node 3
0 2 31
HT0: for interconnection
Configured into 2 parts
HT1: for IO extention
Omitted here
Memory in each node is divided into 2 parts
Shared Memory Virtual Network
Godson-3A SMP Nodes
July 2011 Wenxuan Yin-NAS 2011
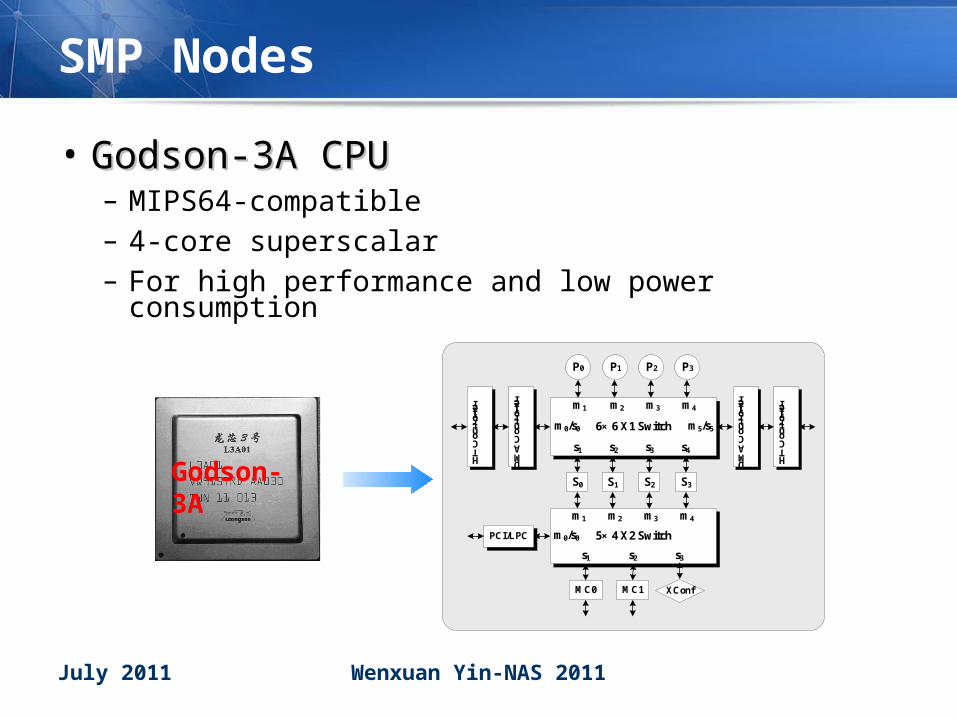
SMP Nodes
• Godson-3A CPUGodson-3A CPU– MIPS64-compatible– 4-core superscalar– For high performance and low power consumption
Godson-3A
P0 P3P2P1
6× 6 X1 Switch
m1 m2 m3 m4
m5/s5m0/s0
s1 s2 s3 s4
S0 S1 S2 S3
5× 4 X2 Switch
MC0 MC1
m1 m2 m3 m4
s1 s2 s3
m0/s0
XConf
DMA Controller
DMA Controller
HT Controller
HT Controller
PCI/LPC

July 2011 Wenxuan Yin-NAS 2011
More Details
• Cache coherencyCache coherency– Directory based cache coherency
– HT holds coherency in the whole interconnection system, global addressing in remote accessing
– Transparent to programmers
• Reconfigurable memory poolReconfigurable memory pool– Each node can tune its shared memory size
contributing to the memory pool
– Extreme case: only master node cedes its shared part
July 2011 Wenxuan Yin-NAS 2011
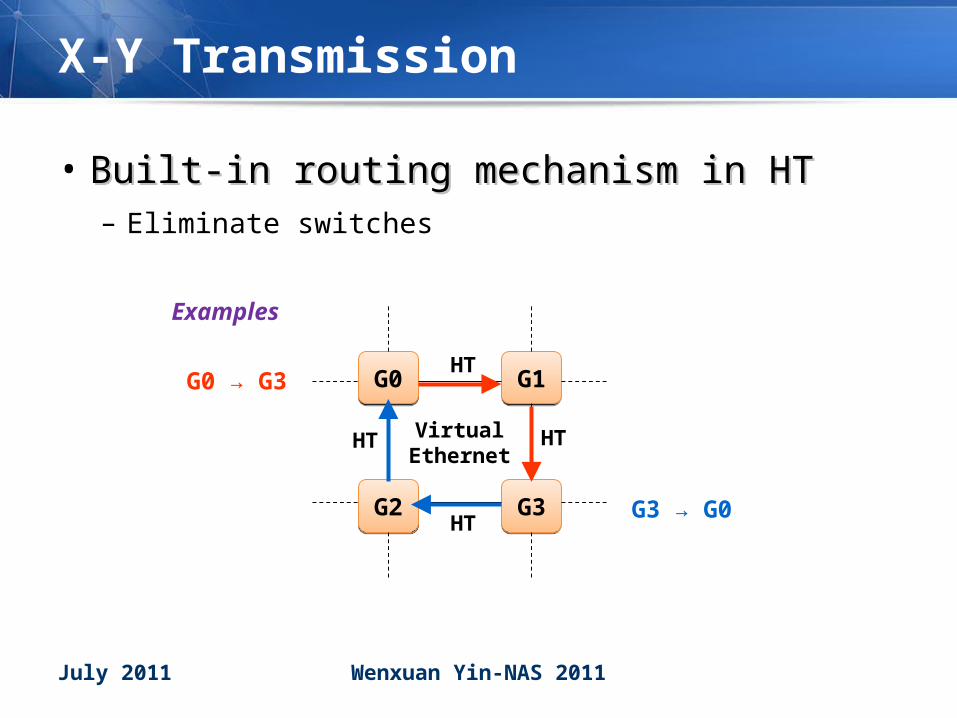
X-Y Transmission
• Built-in routing mechanism in HTBuilt-in routing mechanism in HT– Eliminate switches
G0G0 G1G1
G2G2 G3G3
HT
HT
HT
HTVirtual Ethernet
G0 → G3
G3 → G0
Examples

July 2011 Wenxuan Yin-NAS 2011
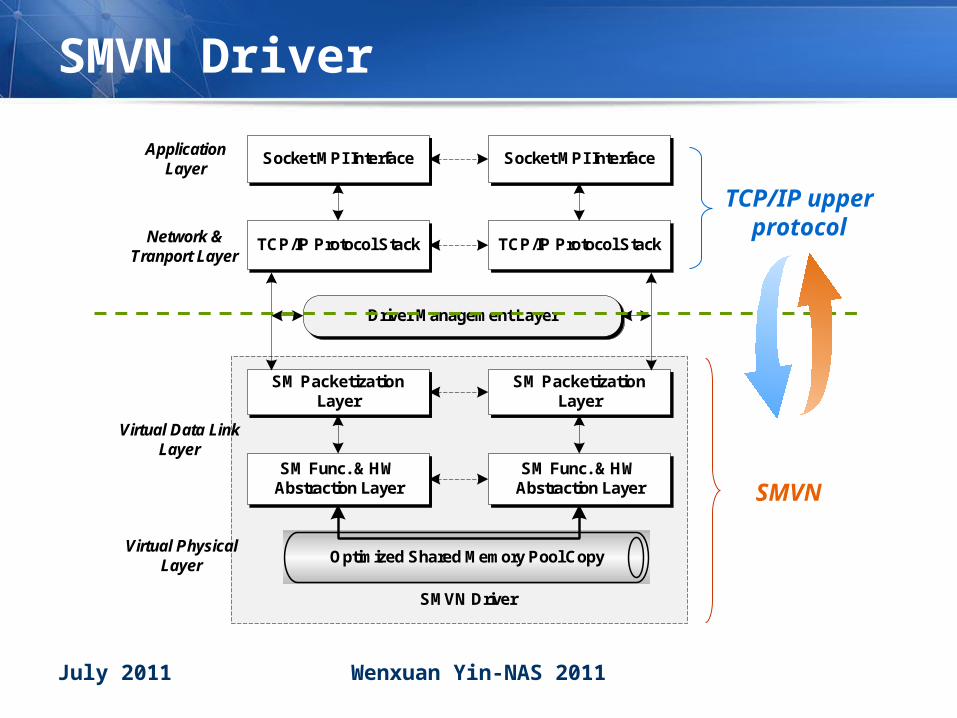
SMVN Driver
• Hierarchical designHierarchical design– Virtual physical layer
• Memory copy & optimization
– Virtual data link layer• Function and hardware abstraction• Packets encapsulation meet frame format of TCP/IP
– Driver management layer• Treat SMVN as a common NIC class device• OS inquiry them recurrently to load & start
– Splice SMVN and TCP/IP together!
July 2011 Wenxuan Yin-NAS 2011
SMVN Driver
SM Func. & HW Abstraction Layer
SM Packetization Layer
TCP/IP Protocol Stack
Socket MPI Interface
Virtual Physical Layer
Virtual Data Link Layer
Network & Tranport Layer
Application Layer
Driver Management Layer
SM Func. & HW Abstraction Layer
SM Packetization Layer
TCP/IP Protocol Stack
Socket MPI Interface
Optimized Shared Memory Pool Copy
SMVN Driver
SMVN
TCP/IP upper protocol
July 2011 Wenxuan Yin-NAS 2011
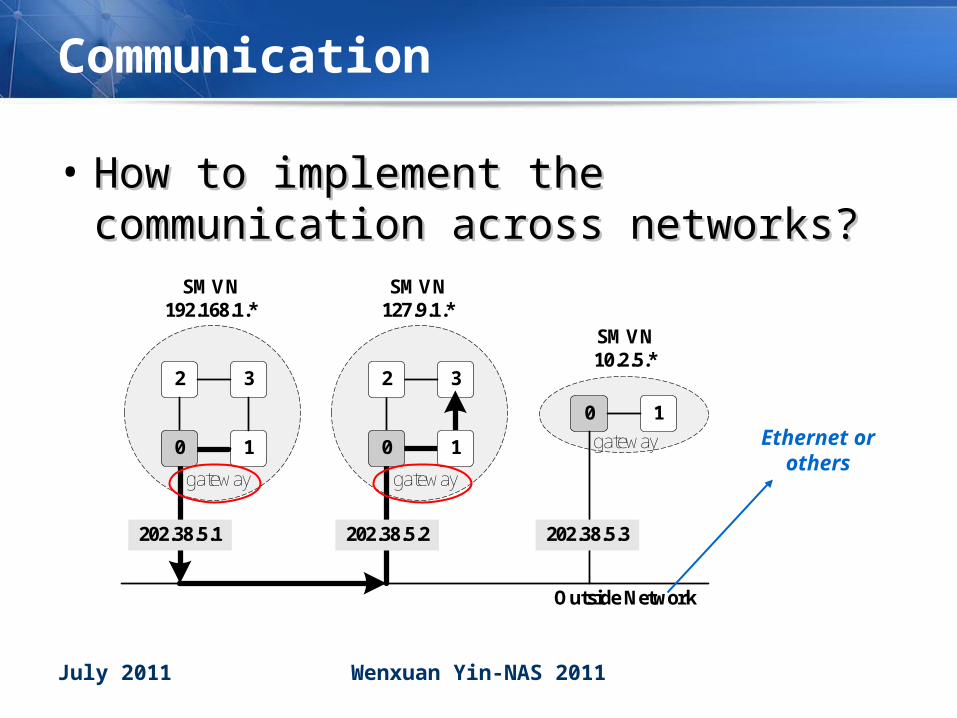
Communication
• How to implement the How to implement the communication across networks?communication across networks?
2
Outside Network
3
1
0 1
3
SMVN 192.168.1.*
202.38.5.3
SMVN 127.9.1.*
SMVN 10.2.5.*
202.38.5.2
0
2
0
202.38.5.1
1
gateway gateway
gateway Ethernet or others

July 2011 Wenxuan Yin-NAS 2011
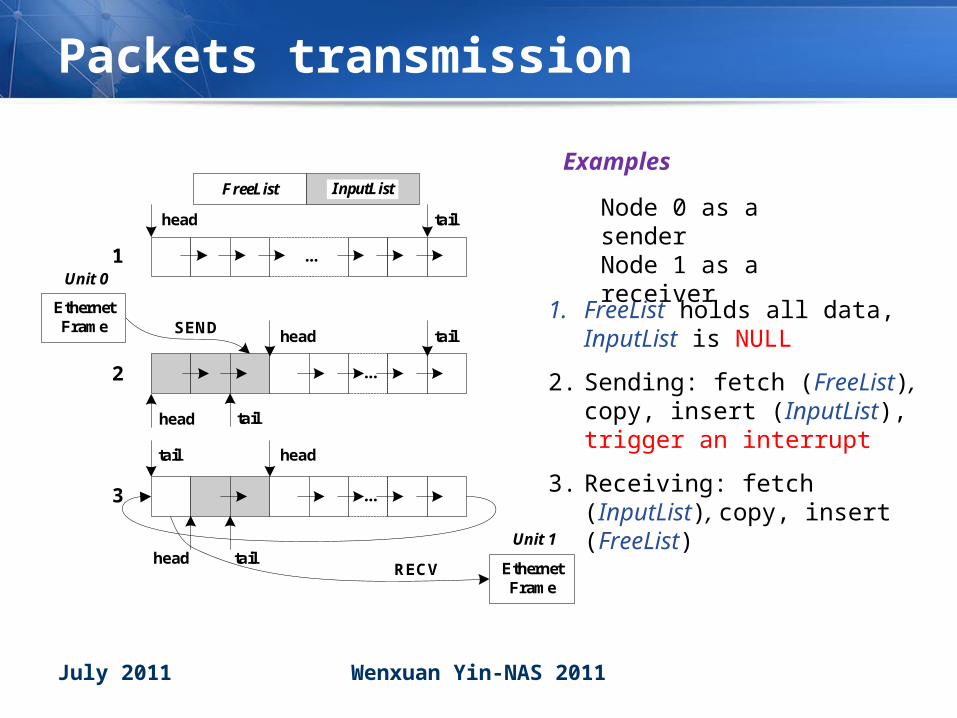
Memory management
• Data structures on SMVN buffer Data structures on SMVN buffer – Singly Linked List (SLL)
PacketPacket PacketPacket PacketPacket PacketPacket…………
Shared memory pool →L
FreeList: global, unique
InputList: each node maintains one
No Extra Memory Allocation!No Extra Memory Allocation!
PacketPacket PacketPacket PacketPacket PacketPacket…………
head tail
July 2011 Wenxuan Yin-NAS 2011
Packets transmission
1. FreeList holds all data, InputList is NULL
2. Sending: fetch (FreeList), copy, insert (InputList), trigger an interrupt
3. Receiving: fetch (InputList), copy, insert (FreeList)
Examples
Node 0 as a senderNode 1 as a receiver
...
...
...
head tail
head tail
head tail
headtail
head tail
SEND
RECV
Ethernet Frame
1
2
3
Unit 0
Unit 1
Ethernet Frame
FreeList InputList

Optimization
• Essentially an optimization to Essentially an optimization to memory operationsmemory operations!!
• Increase the concurrencyIncrease the concurrency– Pipelining effect
• Minimize memory access numbersMinimize memory access numbers– Zero-copy scheme
• Reduce memory access timeReduce memory access time– Instruction-level optimization
July 2011 Wenxuan Yin-NAS 2011
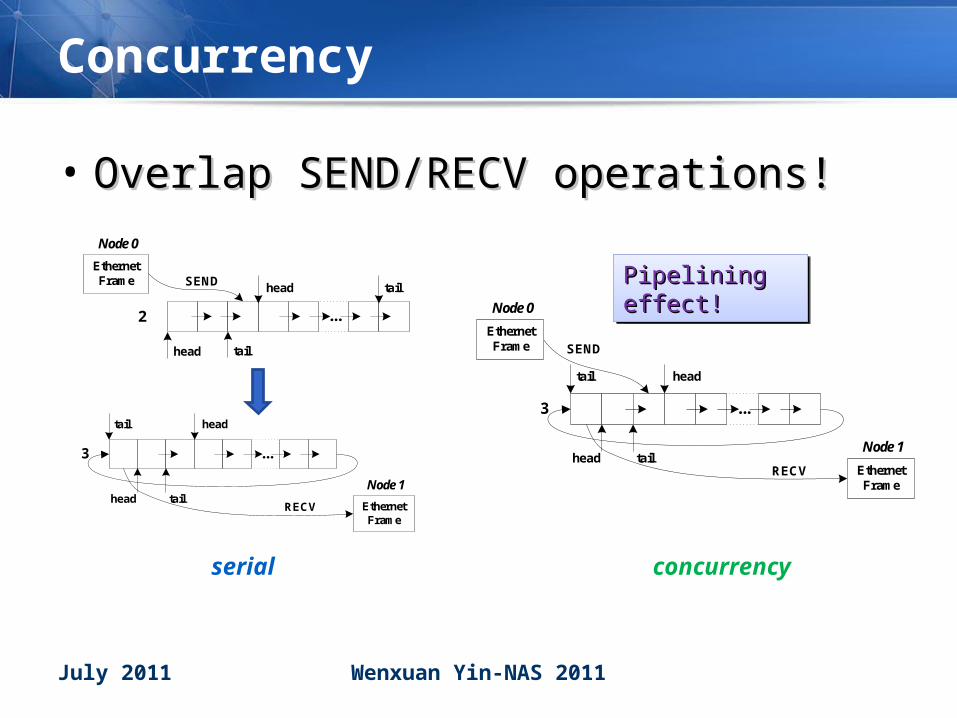
Concurrency
• Overlap SEND/RECV operations!Overlap SEND/RECV operations!
July 2011 Wenxuan Yin-NAS 2011
...
head tail
head tail
SENDEthernet Frame
2
Node 0
...
headtail
head tailRECV
3
Node 1
Ethernet Frame
...
headtail
head tailRECV
3
Node 1
Ethernet Frame
SENDEthernet Frame
Node 0
serial concurrency
Pipelining effect!Pipelining effect!Pipelining effect!Pipelining effect!

Zero-Copy
July 2011 Wenxuan Yin-NAS 2011
FreeListFreeList InputListInputList
Shared memory pool (L)Shared memory pool (L)
Packets migration
head tail head tail
• Change the head/tail pointersChange the head/tail pointers
• Change the relationship which list the packets belong toChange the relationship which list the packets belong to
SMVN mem pool Network mem pool
Data copyOnly scenario
• Extra benefit: reduce power consumption!Extra benefit: reduce power consumption!

Bottom Optimization
• To accelerate To accelerate memcpy memcpy
– Using cache coherency maintained by hardware
• Using cached address space
• Do not need flush/invalidate by programmers
– Godson-3A double-word (64bit) RW
– Unaligned memory access
July 2011 Wenxuan Yin-NAS 2011

Mutual Exclusion
• Why we need this?Why we need this?– Concurrency leads to an unpredictable outcome
• Solution: Solution: spinlockspinlock– Keep atomic in shared resources operations
– Test-And-Set (TAS) primitive
– In Godson-3A nodes• ll (load-linked) & sc (store-conditional) instruction pair
July 2011 Wenxuan Yin-NAS 2011

Simple Lock
July 2011 Wenxuan Yin-NAS 2011
Lock(a0)TryAgain:
ll t0, 0x0(a0)bnez t0, TryAgainnopaddiu t0, t0, 1sc t0, 0x0(a0)beqz t0, TryAgainnopjr ranop
Unlock(a0)sw zero, 0x0(a0)
TAS primitive
• ll will record address while loading
• sc can judge whether the address is modified by competitive accesses
• If NO, store successively• If YES, mark a failure status
in a register implicitly
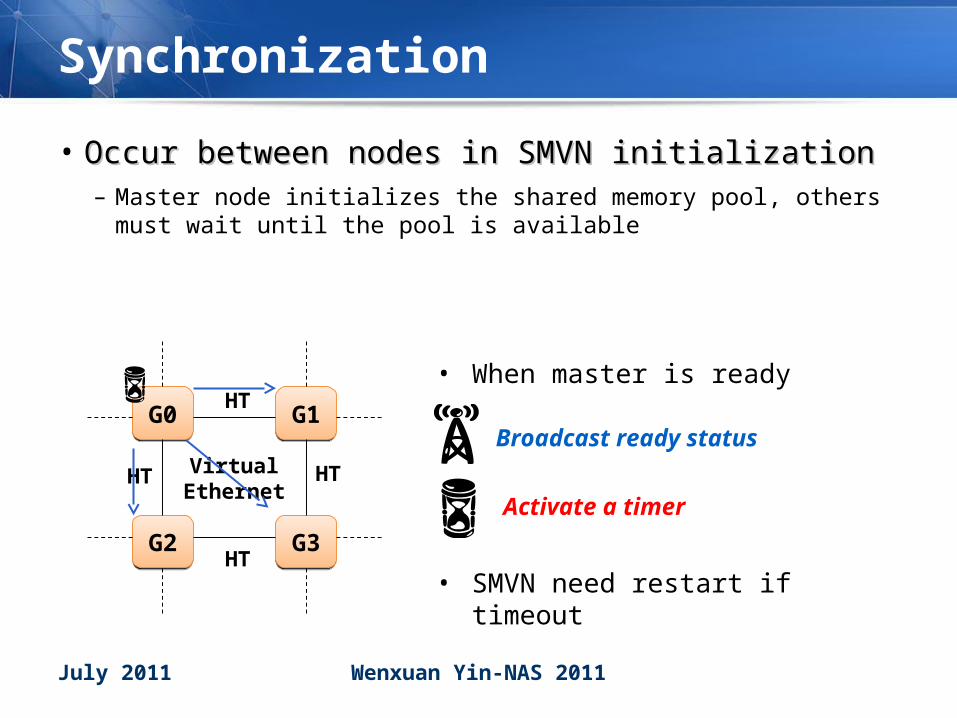
Synchronization
• Occur between nodes in SMVN initializationOccur between nodes in SMVN initialization– Master node initializes the shared memory pool, others must wait
until the pool is available
July 2011 Wenxuan Yin-NAS 2011
G0G0 G1G1
G2G2 G3G3
HT
HT
HT
HTVirtual Ethernet
Broadcast ready status
Activate a timer
• When master is ready
• SMVN need restart if timeout

MPI Processes
• Worker Process (WP)Worker Process (WP)– Its number decides the parallel degree
– Real working process
• Daemon Process (DP)Daemon Process (DP)– Its mapping decides WP’s allocation which reflects
the parallel granularity• Intra-node or inter-node
– At most one DP starting in each node
– At least one DP residing in the cluster
July 2011 Wenxuan Yin-NAS 2011

Mapping & Allocation
July 2011 Wenxuan Yin-NAS 2011
• Mapping DPs into a binary tree connectionMapping DPs into a binary tree connection0
32
1 0
32
1 0
32
1 0
32
1
DP = 1 DP = 2 DP = 3 DP = 4
• WP is allocated to nodes with DPs in WP is allocated to nodes with DPs in breadth-firstbreadth-first traversal algorithm traversal algorithm
DP, 1 ≤ m ≤ 4WP, n ≥ 1Node(i): num of WPs on Node I 0 ≤ i ≤ 3
1, mod( )
, mod
n m i n mNode i
n m i n m
OS SMP scheduling!OS SMP scheduling!More than 1More than 1

Real Platform
July 2011 Wenxuan Yin-NAS 2011
Port MPICH2 library in our real Port MPICH2 library in our real systemsystem
Based on socket interface Based on socket interface supported by supported by SMVNSMVN
Godson-3A SMP Node
SharedMemoryVirtualNetwork

Performance tests
• BenchmarkBenchmark– OMB micro-benchmarks for MPI IPC evaluation
– We choose two metrics• Ping-pong latency
• Unidirection bandwidth
• Performance comparison betweenPerformance comparison between– Inter-node vs. intra-node
– Cached vs. uncached
July 2011 Wenxuan Yin-NAS 2011

Testbed Setup
• Towards the Towards the embeddedembedded environment environment– Frequency: 525MHz
– Cache size• L1: 64KB×2 (including instruction and data)• L2: 4MB
– Memory size• local in real-time OS kernel is 256MB• shared for SMVN buffer is 2MB
– DDR2 working at 200MHz
– HT frequency: 800MHz
July 2011 Wenxuan Yin-NAS 2011
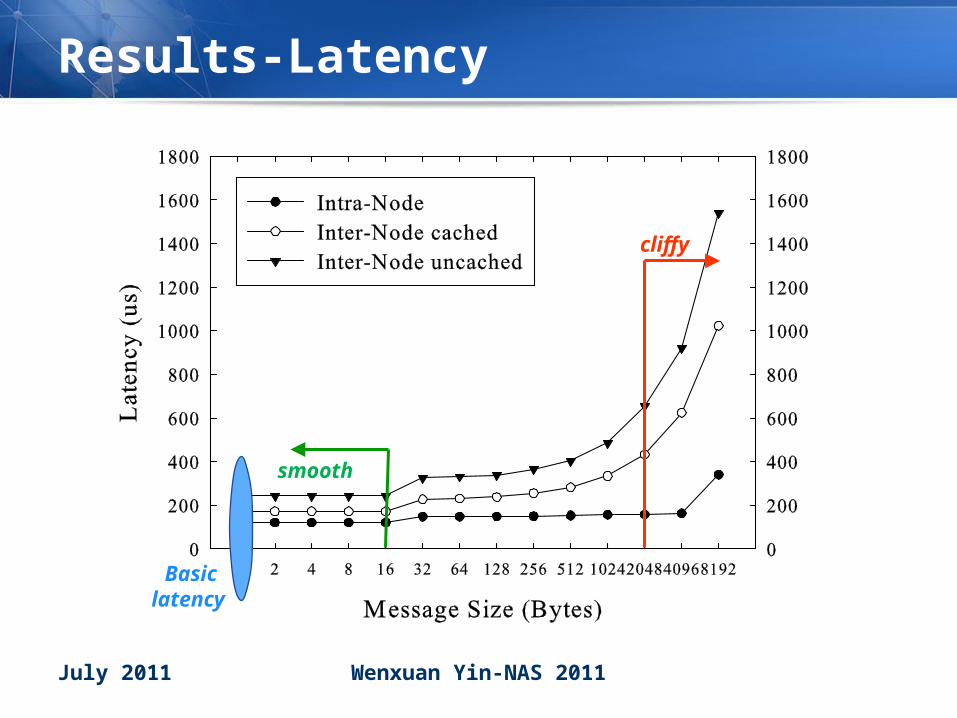
Results-Latency
July 2011 Wenxuan Yin-NAS 2011
smooth
Basic latency
cliffy
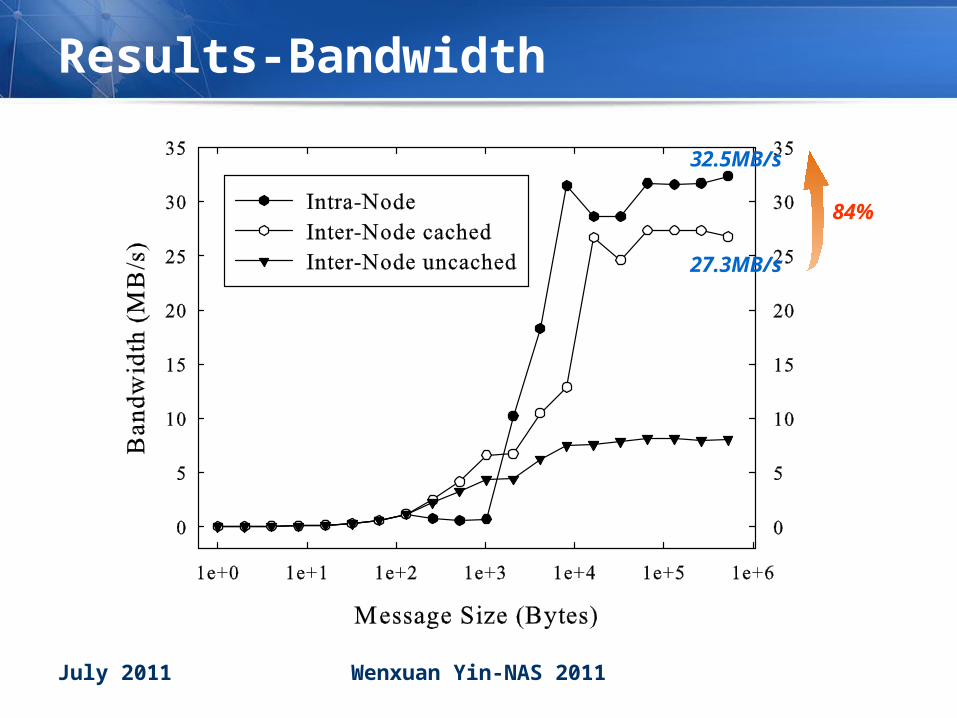
Results-Bandwidth
July 2011 Wenxuan Yin-NAS 2011
32.5MB/s
27.3MB/s
84%

Observations
• Much better than Fast Ethernet (100Mb) Much better than Fast Ethernet (100Mb) typically used in traditional embedded typically used in traditional embedded clustersclusters– Cache is helpful! Avoid flush/invalidate by software
– Tradeoff between performance and embedded constraints
• Narrow the gap between two levelsNarrow the gap between two levels– Even superior than some high-end system although our
absolute performance is lower
– Introduce shared memory in both intra- and inter-node communications
– Compact mesh topology in system
July 2011 Wenxuan Yin-NAS 2011
More than twice
84% approximability

Related Works
• Comparison of data transfer methods Comparison of data transfer methods – User/kernel level shared memory [Buntinas et al.]
– High-speed NIC based copy
• MPI communication system (shared MPI communication system (shared memory)memory)– Nemesis [Buntinas et al.]
– High-performance and good scalability system [Chai et al.]
• RDMA systemRDMA system– InfiniBand [Mamidala et al.]
– Quadrics QsNetII[Qian et al.]
July 2011 Wenxuan Yin-NAS 2011

Conclusion
• Proposed a novel shared memory based Proposed a novel shared memory based virtual communication system --- SMVNvirtual communication system --- SMVN
• Goal: make a uniform infrastructure in Goal: make a uniform infrastructure in different communication levels to different communication levels to implement efficient MPI IPC under implement efficient MPI IPC under embedded constraintsembedded constraints– Adequate performace
– Compact size, low power consumption, low cost (no NICs, no switches, no cables)
• Direction: scalability for large system Direction: scalability for large system expansionexpansion
July 2011 Wenxuan Yin-NAS 2011

Thanks for your attention!
Questions?





























