Embed Size (px)
Citation preview

Dept. for Speech, Music and Hearing
Quarterly Progress andStatus Report
Acoustic analysis of voicesource dynamicsAnanthapadmanabha, T. V.
journal: STL-QPSRvolume: 25number: 2-3year: 1984pages: 001-024
http://www.speech.kth.se/qpsr


I I. SPEECH PRODUCTION 1
A. ACOUSTIC ANALYSIS OF VOICE SOURCE DYNAMICS T.V. Ananthapadmanabha
mtract A voice source model intended to capture the variations in the
inverse filter output (derivative of glottal pulses) of the acoustic speech data is described. The voice source modelling is proped in two stages: (a) analysis stage identifying five analysis variables, and (b) synthesis stage for reconstructing source pulses from the analysis variables. With such a distinction, the same analysis variables may be related to the parameters of already existing glottal pulse models or may be used to develop new models with a common set of variables. A specific computational scheme for the measurement of analysis variables from the acoustic data is proposed. Unlike the usual approach, the modelling is done directly on the inverse filter output rather than on its integral, the glottal pulses. Also, an important analysis variable is related to the nonabrupt glottal closure gesture which is highly
1 correlated to the relative abduction state of the vocal folds. The 1 present model thus allows an indirect tracking of the degree of abduc-
1 tion. Male, female and children's speech have accordingly been analysed and synthesised which has rendered high quality natural sounding speech. I
1. Introduction It has long been suspected that the quality of synthetic speech may
be improved at the acoustic level by an appropriate model for source during voiced segments of speech. Here at KTH, Fant has addressed this problem on two fronts: (i) by proping a dynamic three parameter glot- tal pulse model (Fant, 1979; 1980), (ii) by investigating source-filter (aerodynamic-acoustic) interaction (Fant, 1981; Fant and Liljencrants, 1979; Ananthapadmanabha and Fant, 1982; Fant and Ananthapadmanabha, 1982; Ananthapadmanatha, Nord, and Fant, 1982). In this article we will restrict our attention to the glottal pulse modelling for use in nonin- teractive source-f il ter synthesis models.
Fant (1979; 1980) made a detailed period by period measurement of the parameters of his source model on the inverse filter output for one complete utterance and described some general characteristics of voice source dynamics. The author tried to automate this procedure (Anantha- padmanabha, 1982). It was noticed that the three parameter model though economical is too constrained to capture the wide variations in the source pulse shapes. Hence, a five parameter mdel was proposed. This work which started in 1982 was not formally reported. mly the results were presented in a seminar and cited in an eariler article, (Anantha- padmanabha, 1982). Since then, the procedure has been made more r o b t and the model has been refined. Also, the analysis and synthesis has been performed on several utterances of male, female and child speakers. These results will now be presented.

STL-QPSR 2-3/1984
The voice source dynamics has several related aspects: (a) pitch and its variations, (b) relative intensity variations of speech sounds, (c) glottal pulse shape and its variations, and (d) underlying temporal patterns of vocal cord positioning (a~uction/adduction). Of these the first two aspects are generally represented and analysis tools are also well developed. The glottal pulse shape has been modelled by several researchers, ht, its relation to the physiological state has not been adequately treated. In this article we are concerned with studies of the last two aspects with an emphasis on inverse filtered waveforms and the abduction-adduction dimension.
(A) Measurement Data: The data on phonation can be acquired by direct physiological measurements such as photoglottcgraphy or electroglottcz- graphy. However, such techniques provide us with qualitative informa- tion only. Further, for synthesis we require the glottal air flow data which then has to be calculated based on the glottal area and other related physiological variables. A direct method of obtaining the glot- tal air flow data is by inverse filtering.
The acoustic speech data are recorded with a condenser microphone and digitized into the computer without any hardware preemphasis. We prefer this approach to the recording with a mthenberg's mask, (mthen- berg, 1973). In the latter approach a low frequency sensitive micro- phone is placed within a pneumotachograph mask and is supposed to give directly the volume velocity air flow at the lips. But, the following issues have to be noted: (a) The near field pressure within the mask is an approximation to the volume velocity air flow. (b) The radiation characteristics at the lips within the mask has to be properly dealt with. (c) The radiated acoustic pressure from only the mouth, excluding the output from the cavity wall vibrations, represents a pole-zero re- sponse. (d) The frequency response of the mask is limited to about 2 kHz. (e) The mask has to be designed carefully to adopt the speaker's physique. In the absence of a condenser microphone and for gross air flow measurements, mthenberg's mask gives a better s ignal recording. Ehowever, for a careful inverse filtering and glottal pulse modelling, recording the far field pressure by a condeser microphone is preferable. In this work inverse filtering has been performed after formant track- ing. Consonant sounds are also inverse filtered with only zeroes, instead of the zero-pole network. An example of inverse filtering of a nasal segment will be illustrated to study the approximation.
(B) Glottal Pulse Modelling: Unlike the acoustic theory of vocal trans- mission (Fant, 1960), we don't have a solid theoretical formulation to guide glottal pulse modelling. Titze (1984) has presented a sophis- ticated approach to model glottal pulses considering the effects of source-filter interaction and vocal fold mechanics. But, it presupposes that we have accurate formulations for aerodynamics, acoustics and vocal fold mechanics. Also, signal theoryis well developed for describing the spectra by pole-zero transfer functions. But, to describe the finite duration pulse like waveforms there is no established theory. Cne theoretical approach would be to describe the pulses by orthonormal

basis functions such as s ine and cosine terms o r Taguerre polynomials etc. But, t h e s e funct ions are n o t piecewise continuous which is re- quired, the convergence may be slow, and mean square e r ror minimization may not be d e s i r a b l e (Gibbs phenomenon). W e don't have a s i g n i f i c a n t insight i n t a the perceptual significance of the features of the g l o t t a l pulses. Because of these reasons, modelling of g l o t t a l pulses has been mainly empirical.
A g l o t t a l pulse description given by Rxenberg (1971) is shown in Fig. la. menberg (1971) studied several pulse shape models, kt, the one r e f e r r e d to has had a s i g n i f i c a n t in f luence on other researchers . Strube (1974) only reexpressed the same equations differently. menberg (1971) and H o l m e s (1973) sca led t h e pu l se i n du ra t ion f o r p i t c h var ia - t i o n s thus r e t a i n i n g a cons tan t open q u o t i e n t or pu l se shape. Fant (1979) made the pulse shape (Fig.lb) variable by controll ing the ampli- t ude of the cos ine segment over the c los ing phase. Some o t h e r t i m e domain models a r e a l so skrown i n Fig.1. Also, see Titze (1980).
Ananthapadmanalh (1982) proposed a five-parameter model (Fig.1 d) based d i r e c t l y on t h e unin tegra ted inve r se f i l t e r ou tpu t in s t ead of g l o t t a l pulses, as is usually done. To keep this dis t inct ion we re fe r to t h e volume v e l o c i t y of a i r f low as g l o t t a l pu lses and t h e inve r se f i l t e r output as voice source pulses. This also keeps the physiological function as d i s t i n c t from the acoustically measured function. Modelling of voice source pulses in s t ead of g l o t t a l pu lses w a s based on s e v e r a l considerations: ( i ) It is w e l l known that the acoustically s ignif icant e x c i t a t i o n occurs a t t h e epoch near g l o t t a l c l o s u r e which is e a s i l y d e t e c t a b l e from t h e inve r se f i l t e r output , ( i i ) the i n t e g r a t i o n f o r obtaining g l o t t a l pulses often introduces l o w frequency d r i f t s and mdkes measurements d i f f i cu l t , and ( i i i ) optimization of model parameters on g l o t t a l pulses is undesirable since the signal has nearly zero level a t the acoustically s ignif icant instants of the waveform (viz., the g l o t t a l onset and g l o t t a l closure). W e n t modelling ef for t s by Lil jencrants (1984) and Fant (1984) a r e a l s o based on t h e d e r i v a t i v e of t h e g l o t t a l f low. A n important feature of the model (Fig. Id), proposed in 1982, is t h e nonabrupt te rminat ion of t h e g l o t t a l a i r f low towards closure. Fant's model (Fig. l g ) r ep resen t s another method of r e a l i z i n g such a nonabrupt terminat ion. An extension of t h e earlier model w i l l be d i s - cussed i n Sec. 3.
(C) AMuction/~duct ion is an extremely important ac t iv i ty of the vocal folds during the production of speech (Gauff in, 1972a; 1972b; Fujimura, 1977; Shipp, 1982). I n the f u l l e x t e n t of abduction, t h e vocal f o l d s don't col l ide during phonation, kt, rather, leave a gap through out the g l o t t a l cycle. The increas ing gap a r e a is brought about by abduction and t h e c los ing of t h e gap by adduction of the vocal fo lds . These actions occur during voice onset (adduction), voicing decay (abduction), production of stop and other consonants (abduction). The photoglotto- graphic record fo r a f ina l vowel ending (voicing decay) is sWwn in Fig. 2 to i l l u s t r a t e these remarks. This record from the termination of a vowel i n an open s y l l a b l e de r ives from an unpublished s tudy by Fant, Gauffin, Kitzing anl mfqvist .

A, TP, TN 747 ka Derivative
UO, FG, K A Rosen berg, 1971 Fant, 1979
Ananthapadmanabha, 1982
Rothenberg, 1981
. Fant, 1982
Fig. 1. Scare examples of time dcaMin models of glottal pulses.
Z/FG A 2 A20
v
A0 exp (+ag t 1 sin ( 2 rr FG tl
Li ljencrants, 1986 Fant, 1984
A,O e-aet I

Abduction is commonly described as a superposition of a low fre- quency (DC) flow on the regular on-going phonation activity. Since the duration of such an abduction gesture has a duration of about 50 msec, this superposed component w i l l correspond to a frequency of the order of 20 Hz and hence may be deerned to be perceptually unimportant. The abduction component does not tend to be superposition only. The main effect is a rather drastic change of pulse shape. This is illustrated i n Fig. 2 by comparing the photoglottqraphic recording with the inverse filter output. The radiated acoustic pressure of the same vowel sample was inverse filtered (Courtsey: L. Nord). A progressive and significant change occurs i n the derivative of the glottal pulses immediately after the negative maximum of the pulse (marked a,b,c i n Fig. 2). I t may also be observed from the inverse f i l t e r output of a voiced /h/-sound (Fant, 1980).
The derivative of the pulses is not s t r i c t ly zero mean for every pitch period, the bias i n the derivative accounting for the DC com- ponent. Thus, the abduction activity may be okserved in the f i rs t place by the relative changes i n the decay characteristic of the source pulse after the negative maximum and, secondly, by the variations i n the DC bias on a period by period basis. The la t te r is diff icult to monitor and not very reliable. We shall i l lustrate i n Sec. 4 the dynamic variations of the abduction component as measured from the acoustic signal .
3 . Proposed voice source &el A t present we don't have any rigorous standards to recommend the
use of one model over another. The presence of diverse models m a k e s it difficult to scientifically communicate the results. To avoid this situation, the author proposes to model voice source pulses i n two stages : (a) an analysis stage and (b) a synthesis stage. In the anal- ysis stage certain variables are identified from the waveform based on certain features of source pulses and a mathematical theorem for de- scribing finite duration pulses. The author hopes that these variables may be adequate to characterize the source pulses for speech sounds produced by nonpathological phonations. The measurement technique estimates these analysis variables. The synthesis stage consists of a model for constructing the pulse waveform. The parameters of the syn- thesis model are then related to the analysis variables. Thus, with the same analysis variables, one can construct different pulse waveforms. We w i l l describe one p s i b l e model for reconstructing the source pulses.
3.1. Analysis variables for voice source The terrns glottal onset, glottal peak, glottal closure, opening
phase, closing phase, open phase, clmed phase, glottal abduction etc. have generally been used i n describing the glottal pulses. Such terms are related to the physiological mechanism of phonation, the movement of the vocal folds. If we are modelling the glottal pulses obtained from inverse filtering, there may be some deviations between such physiologi-

Fig. 2. (i) Glottal area function and (ii) inverse filter output during a segmmt of vowel termination. Note the effect of glottal abduction on the pulse shape (marked a, b and c) .

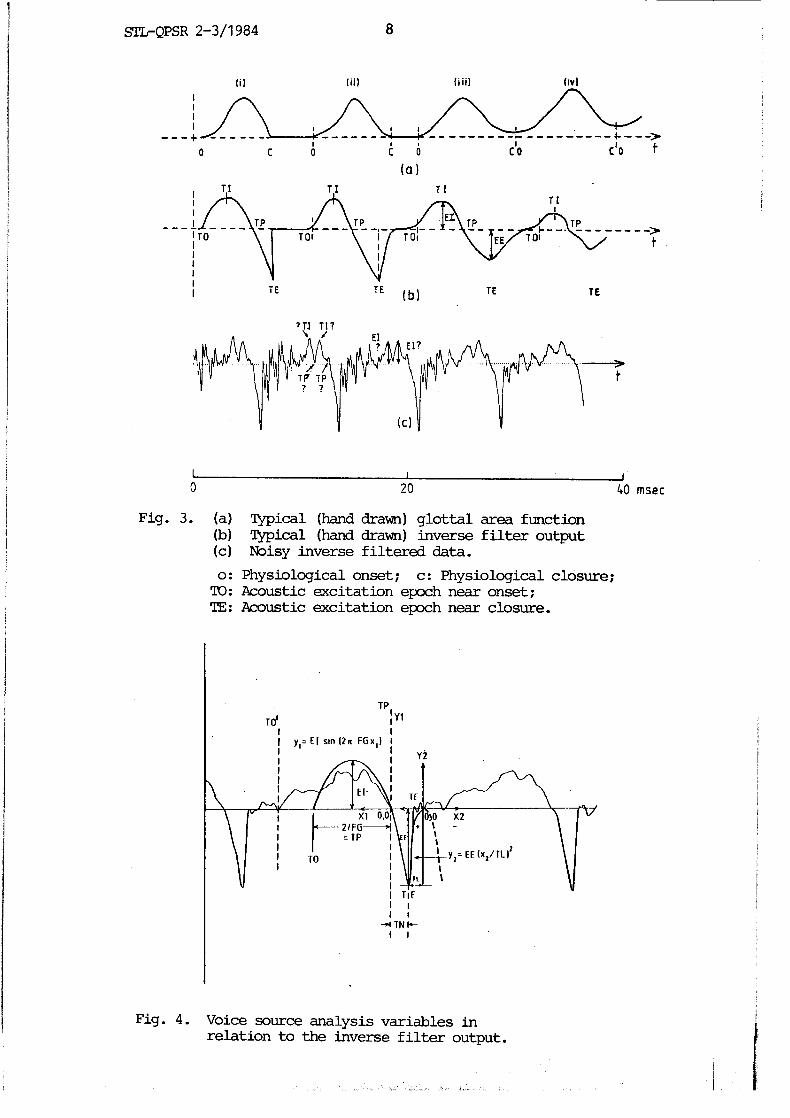
cal terms and what is seen i n the signal waveform. A w e l l known example is the instant of peak of the g lo t t a l pulse which does not correpond to t h e i n s t a n t of maximum separa t ion of t h e (projec ted) vocal folds. I n Fig. 3, a typical hand drawn g lo t t a l area waveform fo r a t ransi t ion from a vowel to a consonant is compared with the inverse f i l t e r output. When the vocal folds do not close completely (cycles iii, iv), physiological- ly, the instant of the g lo t t a l closure and the g lo t t a l onset coincide. W l t such instants may not be acoustically significant. Therefore, the important temporal instants which possess significant acoustic influence have to be defined.
Based on these considerat ions, t h e author defined t h e term "epoch" using an asymptotic expansion t h e o r e r n for f i n i t e duration pulses ( Papoulis , 1968). This theorem suggests t h a t the important i n s t a n t s (epochs) and variables for a f i n i t e duration signal are the instants of discontinuity i n the waveform o r its higher order derivatives, and the slope and curvature change a t these instants. Thus, w e can define the i n s t a n t onse t epoch, (TO) t h e c losure epoch, (TE), where these a r e determined by t h e s i g n a l p roper t i e s r a t h e r than by t h e physiological considerations. These are shown marked i n Fig. 3b. The instant TE can be e a s i l y and r e l i a b l y i d e n t i f i e d from t h e voice source pulse a s t h e i n s t a n t of t h e maximum negative amplitude wi th in the p i t c h period. From our knowledge of the g lo t t a l area measurements, we know that there has t o be a zero crossing (TP) i n t h e d e r i v a t i v e between the onset and t h e closure. This i n s t a n t TP corresponds t o t h e peak of t h e g l o t t a l pulse. I t can be r e l i a b l y i d e n t i f i e d from t h e waveform and is shown marked i n the Fig. 3b. The instant of peak i n the derivative Letween TO and TP w i l l be r e fe r red t o a s the po in t of in f l ex ion ( T I ) , s i n c e the second derivative of the g lo t t a l pulse changes its sign here.
The above defintions have been given assuming clean inverse f i l t e r output. But, t h e g l o t t a l flow has r i p p l e components due t o source- f i l t e r interaction effects and due to improper inverse f i l t e r settings. An example of such an exaggerated case is shown i n Fig. 3c. l'he impro- perly inverse f i l t e red output shows double maxima and double zero cras- s ings between TO and TE. In such cases TP r e f e r s to t h e zero cross ing closest to TE. Also, the instant TO may not ke defined clearly. The i n s t a n t s TO and T I a r e determined by imposing a higher l e v e l s i g n a l structure which appears reasonable. An i n i t a l estimate of TO is made as TO', Fig.4. I t is assumed t h a t t h e s i g n a l between t h e TO' and TP is a ha l f s i n e wave of unknown frequency, FG, and p o s i t i v e amplitude, E I , Fig. 4. The s i n e wave frequency (FG) and t h e amplitude ( E I ) a r e ob- tained by an optimization procedure. The instant TO is marked backwards from TP as a half s ine wave onset point.
When t h e g l o t t a l c losure is not abrupt, the re has t o be an addi- t i o n a l parameter t o determine t h e degree of nonabruptness. Let t h e signal between TE and the immediately following zero crossing be mod-
e l l e d as a parabol ic segment, a s shown i n Fig. 4. This parabol ic seg- ment has a t i m e W e equal t o TL. The value TL is obtained by minimiz- i n y t h e meansquare e r r o r between the a c t u a l s i g n a l and the parabol ic
STL-QPSR 2-3/1984 8
1 I
0 1
20 40 msec
Fig. 3. (a) Typical (hand drawn) glottal area function (b) mica1 (hand drawn) inverse filter output (c) Noisy inverse filtered data.
0: Physiological onset; c: Physiological closure; TO: Acoustic excitation epoch near onset; TE: Acoustic excitation epoch near closure.
I I I y,= E l sln (2n F G x l ) I I
I I T I E
Fig. 4. Voice source analysis variables in relation to the inverse filter output.


I I I
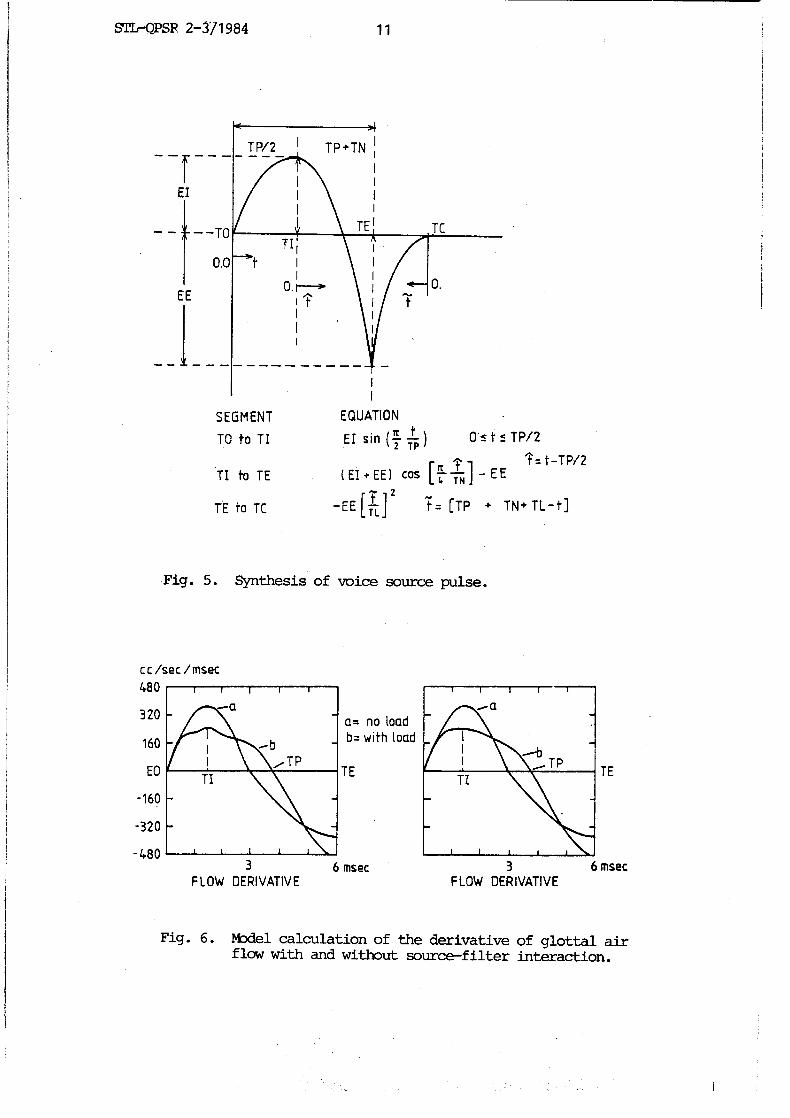
SEGMENT EQUATION
TO t o T I EI sin ($4) 0 s t 5 TP/2 n
IT '? t = t -TP f2 T I to TE I E I + E E I [cy,] - E E
." TE to TC -EE[;l2 ~ = [ T P + TN+TL-t]
Fig. 5. Synthesis of voice source pulse.
a= no load b= with load
TE
3 6 msec FLOW DERIVATIVE
3 6 msec FLOW DERIVATIVE
Fig. 6. PMel calculation of the derivative of glottal air flow with and without source-filter interaction.


+Fig. 7. IAg spckrm of a typical voice source pulse and spectral features.
0 5 msec 10 0 2 kHz L
0 5 msec 10 0 2 kHz 4
Fig. 8. Effect of varying EI/EE on the log spectrum of the voice source pulse. (a) With the analysis variables TP and TN fixed. (b) With the synthesis variables TP and TN fixed.

are f ixed , t h e recons t ruc ted pu l se shape s h o w s variation of TP and TN for variations i n E I due t o the part icular synthesis procedure (Fig. 5). But, i n Fig. 8b w e have kep t TP and TN i n t h e synthesized pu l se nea r ly constant . As E I increases , t h e r i p p l e s (DK) I n the spectrum become stronger due to the re la t ive ly greater importance of excitation a t the onset. The lowering of FL may a l s o be noted. For very low EI/EE, t h e spectrum approaches that of an exponential pulse.
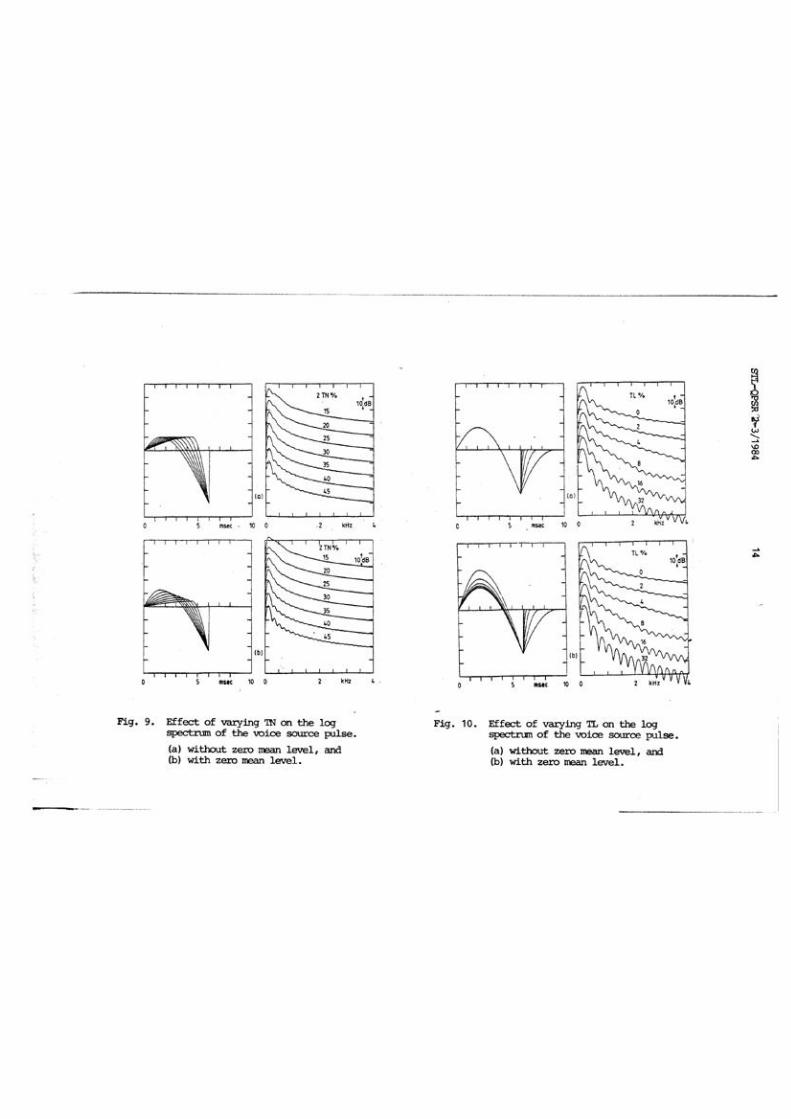
The e f f e c t of varying TN f o r f ixed (TP+TN) , E I and EE is shown i n Fig. 9a. The main e f f e c t on t h e spectrum is t o change t h e 12 dB down bandwidth BL which decreases as TN increases. Also, the prominence of t h e spectrum peak, DL, increases . For very low TN, t h e spectrum ap- proaches that of an exponent ial pulse . The frequency FL decreases s l igh t ly as TN increases. This shows t h a t FG and FL could be different. I n Fant's rnodel (1979), t h e same s inuso ida l frequency is used over t h e en t i r e cycle which makes EG to be determined by the opening phase only. As TN is var ied , t h e s i g n a l pu l se is not zero mean, bu t has been ren- dered nea r ly ze ro mean by changing E I , as i n Fig. 9b. However, t h e variations i n the spectral shape a r e still mainly due to the variations i n TN.
The ef fec t of varying TL keeping a l l other analysis variables fixed is shown i n Fig. 10a. The main e f f e c t is t o reduce t h e h igh frequency prominence (DH). The relat ion of the decrease i n Ixr t o TL seem t o obey a logarit lmic law as equal changes i n DH a re obtained fo r powers of two of TL. As TL increases , the l o c a t i o n of FL decreases f o r t h e same FG and the prominence of t h e spectrum peak increases . lilso, t h e r i p p l e com- ponents become stronger, as shown by increased values of DR. For large TLthe e f f e c t i v e e x c i t a t i o n s t r e n g t h a t c losu re epochdecreases , thus becoming comparable to the onset excitation resulting i n spectrum r i p ples. The mean level has once again been nearly compensated by c-ging EI, Fig. lob. But, the ef fec t of TI, variation dominates.
I t appears t h a t f o r sma l l DC l e v e l changes, the spectrum of t h e pulse is not a l tered significarltly. The spectrum shape is mainly deter- mined by the competing e x c i t a t i o n s t r e n g t h s a t t h e onse t and c losu re epochs, Ananthapadmanabha and Yegnanarayana (1477).
4. R e ~ u l t s Lie sha l l n w present sane resul ts fo r rea l speech data. The inverse f i l t e r i n g should be s t r i c t l y done w i t h a zero-pole
network for nasals and laterals . Eut, we have used only zeroes i n the inverse f i l t e r . l%e consequent e f f e c t on t h e inverse f i l t e r output w i l l now be i l l u s t r a t e d . Using t h e ILJF. program of L i l jencrants , Nord has inve r se f i l t e r e d a nasa l segment i n t h e context of t h e u t t e rance / i :na/. The r e s u l t is shown i n Fig. l lb. The inve r se f i l t e r i r l y ob- tained using only zeroes is shown in Fig. llc. A comparison slio~lrs that inverse f i l t e r i n g with only zeroes is adequate f o r the purpose of model matching. This r e s u l t is no t unexpected s i n c e t h e uncancelled nasa l pole-zero pairs correspond to an a l m o s t f l a t spectral trend with nearly zero phase.

F H z B H z Q
'Fig. 11. Inverse filtering of a nasal segment.
(a) Speech waveform and the output of inverse filter (b) for zeroes and poles, (c) for zeroes only.

(Xlr a i m here is to determine if the five analysis variables and the
synthesis model proposed are adequate to capture a variety of source pulse shapes. A l l the results to be presented have been obtained by using the computer software package VISHRANTH developed by the a u w r for speech analysis and synthesis. Some editing in an user interactive mode has been made since our aim here is to t e s t the model and not the algorithms used for matching.
The vowel sound /a/ in the Swedish utterance "Jag heter..." spoken by a male, a female and a child is now considered for illustration. The matching i s performed only for one selected pitch period, but the pulses are synthesized assuming a periodic signal with the given analysis variables. This is to check that the pulses are appropriately connected in a dynamic situation. The inverse f i l ter output and the synthesized pulses are shown in Figs. 12-14. The selected period for matching has dotted line markers indicating the initial estimates of TO, TI, TP, TE and TE of the next pitch period. The error signal for t h i s period alone has to be considered. The log spectra of one pitch period of the signal are shown. The inset shows the pitch i n Hz, and the analysis variables .
The matching i n time domain appears reasonable for a l l the three speaker categories. The error signal is approximately zero mean and appears to contain the ripple components only. The source pulses tend to be sinusoidal for female and child voices. This can be seen both by
the large value of the variable TL and the low ratio of E I t o EE. Near the frequency EL, the log spectrum shows a narrow peak for male voice, and this peak is considerably koadened for female and child voices.
There are small discrepancies with regard to spectral matching. These arise since the inverse filtering has been performed with inap- propriate bandwidth settings derived from automatic analysis and i n case of nonabrupt closure, the effect of subglottal system might influ- ence the results. An improper setting of the bandwidth is equivalent to an excitation of the formant, either as a pole or as a zero depending an whether the estimated bandwidth is too narrow or too broad. The cumula- tive effect of several formants can introduce a gross spectral roll-off. The optimal spectral matching may be expected only for models with source-filter interaction. Since the matching is acceptable i n the time domain, we thus consider the small mismatch in the spectral domain to be of lesser importance.
The results for the sound /h/ for the above male voice i n the same Swedish utterance is illustrated in Fig. 15. The TL variable assumes a large value i n th i s case. The value of TL is comparable to that for vowel /a/ of a child voice. But, the spectrum of the /h/ sound of the male voice still shows a narrow spectral peak due to the high ratio of EE/EI. The spectral ripple a t high frequency in the input signal may be due to the aspiration noise of the /h/ sound.
In keeping with the t i t le , we shall now present an example of the dynamic variations of the analysis variables for connected speech. M inverse filtered waveform over a part of a sentence is illustrated i n



Fig. 16a. Because of the automatic analysis procedure and erroneous bandwidths, uncancelled formant ripples are seen i n the inverse filtered waveform. However, the program to estimate the voice source analysis variables is robust against such errors. The souce pulses are recon- struced after a running analysis to estimate the souce variables, Fig. 16b. It may be seen that the dynamic variations in the pulse shapes are well reproduced i n the reconstructed source pulses. Also, the nonabrupt glottal closure for consonant sounds may be noted.
The utterance i n Swedish "Jag heter Lennart" spoken by an adult male speaker is then considered for analysis. The source variables and the formant frequencies estimated by a running analysis procedure are shown i n Fig. 17. Several interesting points may be noted. The TL parameter shows large values over the voiced consonants, / j/, /h/ and /n/ contrasting with the low values over vowel segments. Also TL is large a t the vowel onset after /t/ and i n the final ending vowel. This highly correlates with the glottal abduction activity. The variable EE appears to follow the same trend as the probable course of transglottal pressure variation (not shown i n the figure) wer the utterance. This variable EE has a low value when there is an oral constriction as for / j , and 1 Also th i s variable shows a sudden increase over a de- creasing general trend for the vowel where the primary stress of the sentence occurs ( a t the position marked by arrow for label EE i n Fig.17). The variable E I is dominating over EE for the final ending vowel where TL is decreasing with an increase i n TP. This indicates that the vowel onset (adduction) and the vowel decay (abduction) may have different characteris tics.
APPLICATIONS: One important application of estimating the source dyna- mics is i n the synthesis. We have analysed and synthesized utterances spoken by male, female and child voices. Compared to the use of either exponential pulses or fixed shape glottal pulses, or pulses with abrupt glottal closure, the synthesis with a dynamic voice source model gives a more natural sounding synthetic speech which retains the identity of the speaker. This procedure can be used i n the development of a Text-to- Speech system, i n speech coding (voice response) and i n speech communi- cation (vocoders ) .
More elaborate experiments on the relative perceptual importance of the source variables, pulse shapes etc. are needed. Systematic acous- tic-phonetic studies for deriving dynamic source parameters are planned. Simultaneous recordings of the radiated acoustic pressure, oral pres- sure, suhglottal pressure, photoglottograhs are available (Fant, Gauf-
fin, Kitzing and ~ f q u i s t ) . This data w i l l be analyzed to correlate the physiological variables, such as glottal abduction, transglottal pres- sure variations etc. w i t h the voice source variables measured acousti- cally.
The variables EE and TL together with pitch variations can be used for segmentation of continuous speech. This could be useful i n speech recognition and measurement of the phoneme durations.

I I J I I
0 1
50 100 nlsec 0 50 100 msec
(a) (b)
Fig. 16. (a) Inverse filter output and (b) reconstructed d e l pulses for connected speech: /elva/ in the utterance "aksell var d*". (Automatic procedure. ) --
Fig. 17. Source variables and f o m t frequencies for one complete utterance.
6 . 1 6 2 5 3 6 4 5 6 6 6 7 5 8
kHz - cn
6- U Z W -
Hz 250 - - FO
I I- \
4 h
I SPEAKER IDENTITY CT SQMP FREQ LN JAGHETER 3
WD8564 0 16
1984-09-04 17: 59: 47 XMQG: 100

4. Conclusions A dynamic voice source model is proposed. Two s t a g e s are con-
sidered, an analysis stage and a synthesis stage. The author hopes that
the analysis variables proposed may receive a general consent amongst speech researchers so that we can communicate our resu l t s m o r e easily. An extension of the analysis variables to di f fe rent types of pkmations, inc luding voice pa thologies , needs to be made. W e have proposed one p o s s i b l e scheme f o r r econs t ruc t ing source pu l ses . The e r r o r s i g n a l between the inverse f i l t e r output and the reconstructed pulses could be used to estimate a high frequency noise component f o r a mixed noise and voice source excitation. An important outcome of the present study is t h e a c o u s t i c measurement of t h e g l o t t a l abduction parameter and t h e probable correlation of the EE variable with the transglot ta l pressure variations.
The author is grateful to Prof. Fant f o r his critical oomments and encouragement. These comments have contr ibuted s ignif icant ly to the a u ~ r ' s thinking. The author would a l so l i k e to thank LRnnart Nord wlm bore much of the lxrden of the data preparation, and participated in the synthesis of male, female and chi ld voices, and also gave many useful feedbacks during the development of t h i s work.
References Ananthapadmanabha, T.V. ( 1982) : " I n t e l l i g i b i l i t y c a r r i e d by speech- source functions: Implication f o r theory of speech percept ion", STL- QPSR 4/1982, pp. 49-64.
Ananthapadmanabha, T.V. and Fant , G. ( 1982) : "Calculat ion of t r u e g l o t t a l f low and its components", Speech Communication 1, nos. 3-4, - Dee., pp. 167-184.
Ananthapadmanabha, T.V., Nord, L., and Fant. G. ( 1982) : "Perceptual d i s c r i m i n a b i l i t y o f nonexponential/exponential damping of t h e f i r s t formant of vowel sounds", pp. 217-222 i n ( ~ . C a r l s o n C B.Granstrom. - - eds.) The Representation of Speech i n t h e per iphera l Auditory System, Elsevier Biomedical Press, Amsterdam.
Ananthapadmanabha, T.V., and Yegnanarayana, Be, ( 1977) : "Zero-phase inve r se f i l t e r i n g f o r e x t r a c t i o n of source c h a r a c t e r i s t i c s " , i n Conf. Rec., IEEE Int. Conf. on Amust., Speech and Signal Processing, pp. 336- 339.
Fant, G. (1960): Acoustic-Theory-of-Speech-Production, Mouton, The Hague.
Fant, G. (1979): '"Vocal source analysis - a progress report", STGQpSR 3-4/1979, p ~ . 31-54.
Fant, G. (1980): "Voice source dynamics", STGQPSK 2-3/1980, pp. 17-37.
Fant, G. ( 1981 ) : "The source-f i l ter concept i n voice production", STL- QPSR 1/1981, pp. 21-37.
Fant, G. (1982): "The voice source - a c o u s t i c modelling", STL-QPSR 4/1982, pp. 28-48. k

Fant, G. and Ananthapadmarnabha, T.V. (1982) : "Truncation and superposi- tion", STGQPSR 2-3/1982, pp. 1-17.
Fant, G. and Lil jencrants, J. (1979) : "Perception of vowels with trun- cated intraprid decay envelopes", STL-QPSR 1/1979, pp. 79-84.
Fant, G. (1984): Personal camnmication.
Flanagan, J. (1958): "Some properties of glottal sound source", J. Speech Hear. Res. - 1, pp. 99-116.
Fujimura, 0. (1977): "Physiological functions of the larynx in pkronetic C!~ntrol", Int.Congr.Phon.Sciences, Miami, Dec. 1977.
HOlme~, J.N. (1973): "The influence of glottal waveform in the natural- ness of speech from a parallel formant synthesizer", IEEE Trans. Audio and Electro Acoust. AU-21, pp. 298-305.
Lil jencrants , J. (1984) : "Glottal waveform modelled with unstable fil- ter", (unpublished report), Personal communication.
Lindqvist-Gauff in, J. (1972a) : "A descriptive model of laryngeal ar- ticulation in speech", STL-QPSR 2-3/1972, pp. 1-9.
Lindqvis t-Gauf f in, J. ( 1972b) : "Laryngeal articulation studied on Swed- ish subjects", STL-QPSR 2-3/1972, pp. 10-27.
Matausek, M.R. and Batalev, V.S. (1980): "A new approach to the deter- mination of glottal waveform", IEEE Trans. ASSP-28, pp. 616-622.
Mathews, M.V., Miller, J.E., and David, E.E. (1961) : "Pitch synchronous analysis of voiced sounds", J.Acoust.Soc.Am. 33, pp. 179-186. - Miller, R.L. ( 1959) : "Nature of vocal cord wave", J.Acoust.Soc.Am. 31 , - pp. 667-677.
Monsen, R.B. and Engebretsson, A.M. (1977): "Study of variation in the male and female glottal wave", JAxmst.Soc.Am. 62, pp. 981-993. - Papoulis , A. ( 1968) : Sys term and Transforms with Applications in op- tics, McGraw-Hill, New York, ch. 7. - F&senberg, RE. (1971): "Effect of glottal pulse shape on the quality of natural vowels," J.Acoust.Soc.Am. 49, pp. 583-590. - Wthenbexy, M. (1973) : "A new inverse filterinq technique for deriviw the air flow waveform during voicing,"- ~.Acous~~oc&. 53, & - 1632-1645.
Rothenberg, M. (1981) : "An interactive model for the voice source", STGOPSR 4/1981, pp. 1-17.
Shipp. T. (1982) : "Aspects of voice production and motor control", in (S. Grillner, B. Lindblom, J. Lubker, and A. Persson, eds.) Speech Motor Control, Wenner-Gren Symposium series-Vol. 36, Pergamon Press, Oxford.
Strube, H.W. (1974) : "Determination of the instant of glottal closure from the speech wave", JJlcoust,Soc.Am. 56, pp. 1625-1629. -





























