Embed Size (px)
Citation preview

A CoA Co--Evaluation Framework for Evaluation Framework for
Improving Segmentation EvaluationImproving Segmentation Evaluation
Hui Zhang, Jason Fritts, and Sally Goldman
Washington University in St. Louis
Department of Computer Science and Engineering

� Image Segmentation & Evaluation
� Co-Evaluation Framework
� Experiments
� Human vs. Machine Segmentation
� Machine vs. Machine Segmentation
� Conclusions & Future Work
Outline

� Partitioning an image into separate regions
Image Segmentation
� A critical early step towards content analysis and image understanding
A B C

� Three categories of segmentation methods
� Pixel-based
� Histogram thresholding, etc
Image Segmentation
� Region-based� Split-and-merge, region growing, etc
� Edge-based� Edge flow, color snakes, etc

� Problems
� Unable to compare different segmentation
methods, or even different parameterizations of a
single method
� Unable to determine whether one segmentation
method is appropriate for different types of images
� Segmentation evaluation is of critical
importance
Image Segmentation
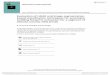
Segmentation Evaluation
Original image
HS
IHS
JSEG
Image-
Magick
Edison
eCognition

Original image
Improved Hierarchical Segmentation (IHS)
10 15 20
Different parameterizations
Of a single method:
Segmentation Evaluation

Image
Segmentation
evaluationObjective
evaluation
Subjective
evaluation
System-level
evaluation
Direct
evaluation
Analytical
methods
Empirical
methods
Relative
methods
Stand-alone
methods
[ Taxonomy ]
Segmentation Evaluation

� Relative Evaluation (a.k.a. Empirical Discrepancy Measures)
� Most widely used objective evaluation methods
� Comparing results to manually-segmented reference
image
Original image reference image Result from EDISON
Measure the discrepancy
Objective Segmentation Evaluation

� Stand-alone Evaluation (a.k.a. empirical goodness measures)� No reference image is needed
� Examine how well it matches the desired characteristics of segmented images, based on human intuition
� A goodness score is given for each segmentation result
Segmentation
Result 1
Result 2 from
EDISON
Stand-alone Objective Evaluation
Stand-alone Evaluation
Goodness Score: 6.1345 Goodness Score: 8.2733

� Intra-region uniformity measures
� Color variance
� Squared color error
� Texture
� Inter-region disparity measures
� Average color difference between regions
� Average color difference along boundary
� Semantic measures
� Shape
Stand-alone Objective Evaluation

� Liu and Yang’s F function:
� Borsotti et al.’s Q function:
� Correia and Pereira’s V Functions:
Stand-Alone Objective Evaluation
Functions
contrastcompactelongcircRvs 55.225._225.)( ++=
contrastcompactelongcircRvm 40.30._30.)( ++=
( )∑
=
+
+×=
N
j j
j
j
j
I S
SN
S
eN
SIQ
1
22
log11000
1)(
∑=
=N
i i
i
S
eNIF
1
2
1000
1)(

� Utilize minimum description length (MDL) principle
� regards segmentation as a modeling process
� MDL provides effective balance between:
� uniformity within a region
� complexity of segmentation
� Our evaluation function, E, based on MDL:
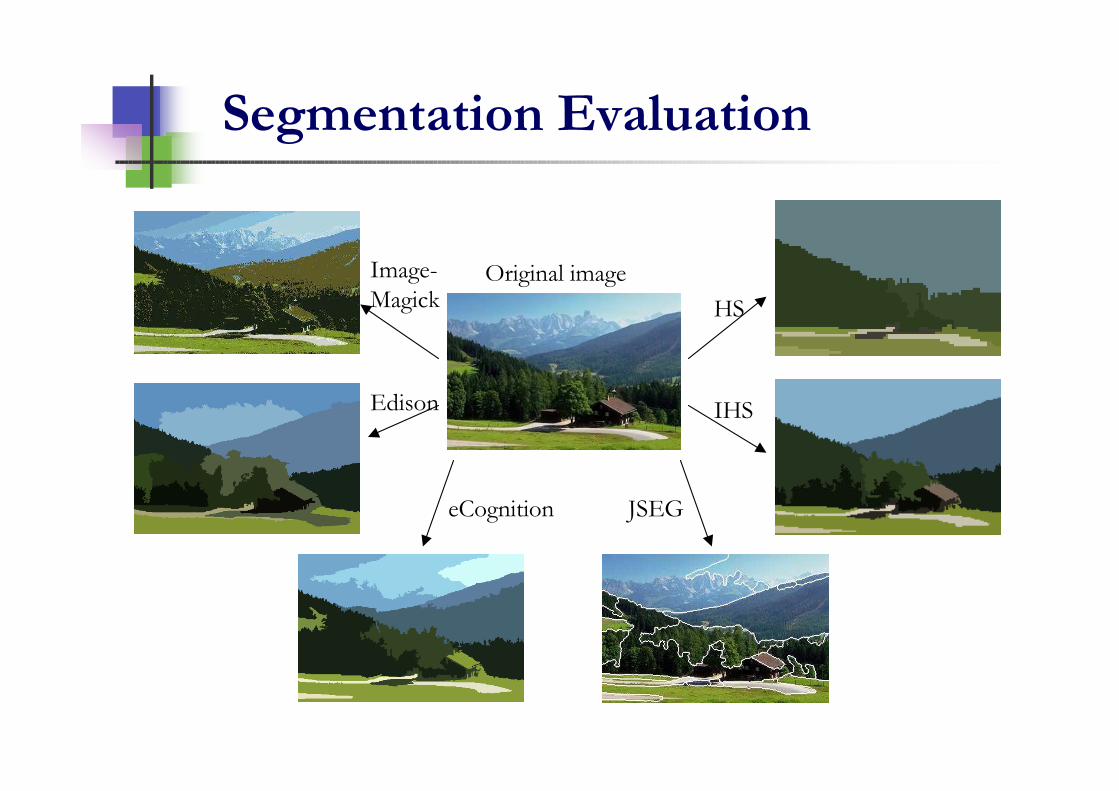
Evaluation function E
)()()|()( IHIHSRLSLE rl +=+=
Evaluation function E
Region entropy
Layout entropy
E
Original image
Segmentation 1ayout

� Image Segmentation & Evaluation
� Co-Evaluation Framework
� Experiments
� Human vs. Machine Segmentation
� Machine vs. Machine Segmentation
� Conclusions & Future Work
Outline
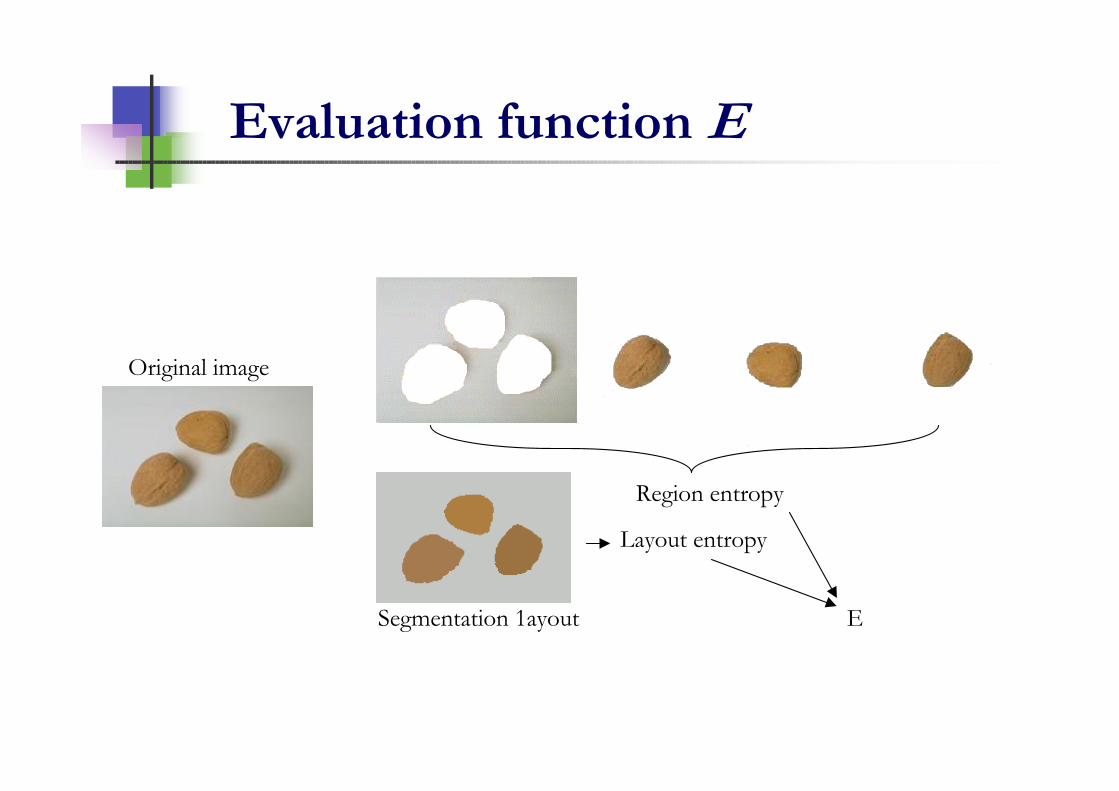
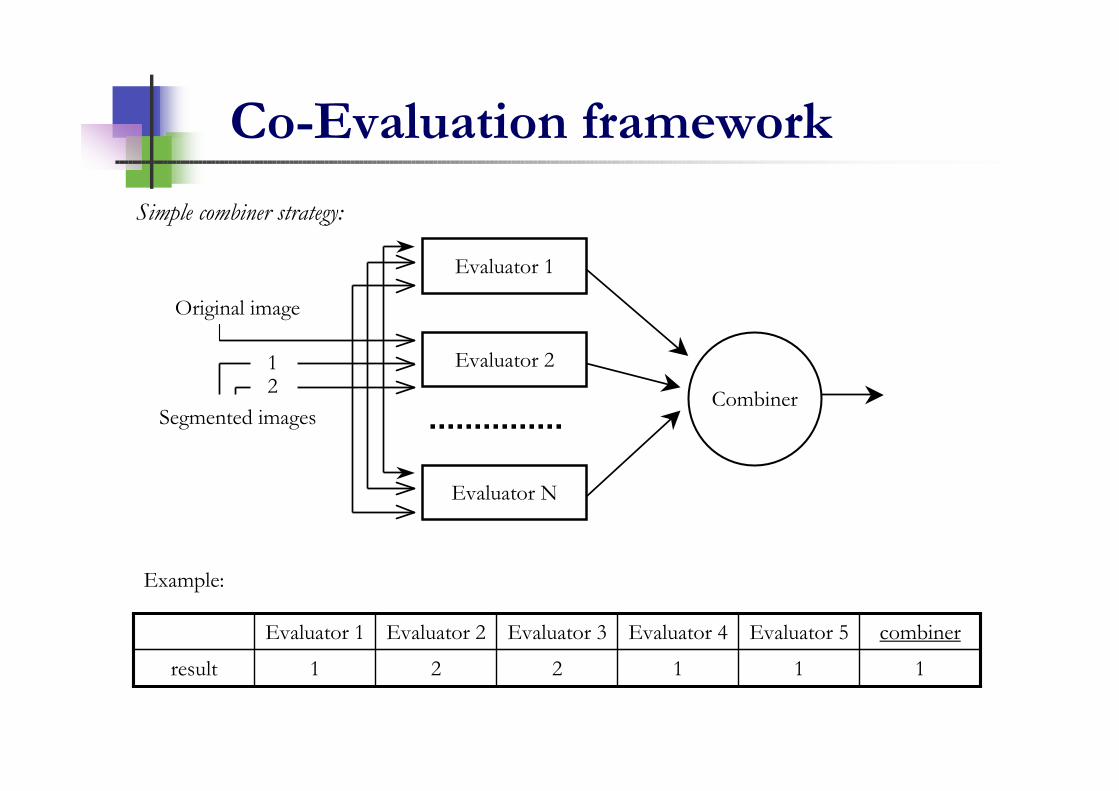
Co-Evaluation framework
Co-Evaluation framework
Evaluator 1
Evaluator 2
Evaluator N
Combiner
Original image
Segmented images
12
Simple combiner strategy:
111221result
combinerEvaluator 5Evaluator 4Evaluator 3Evaluator 2Evaluator 1
Example:
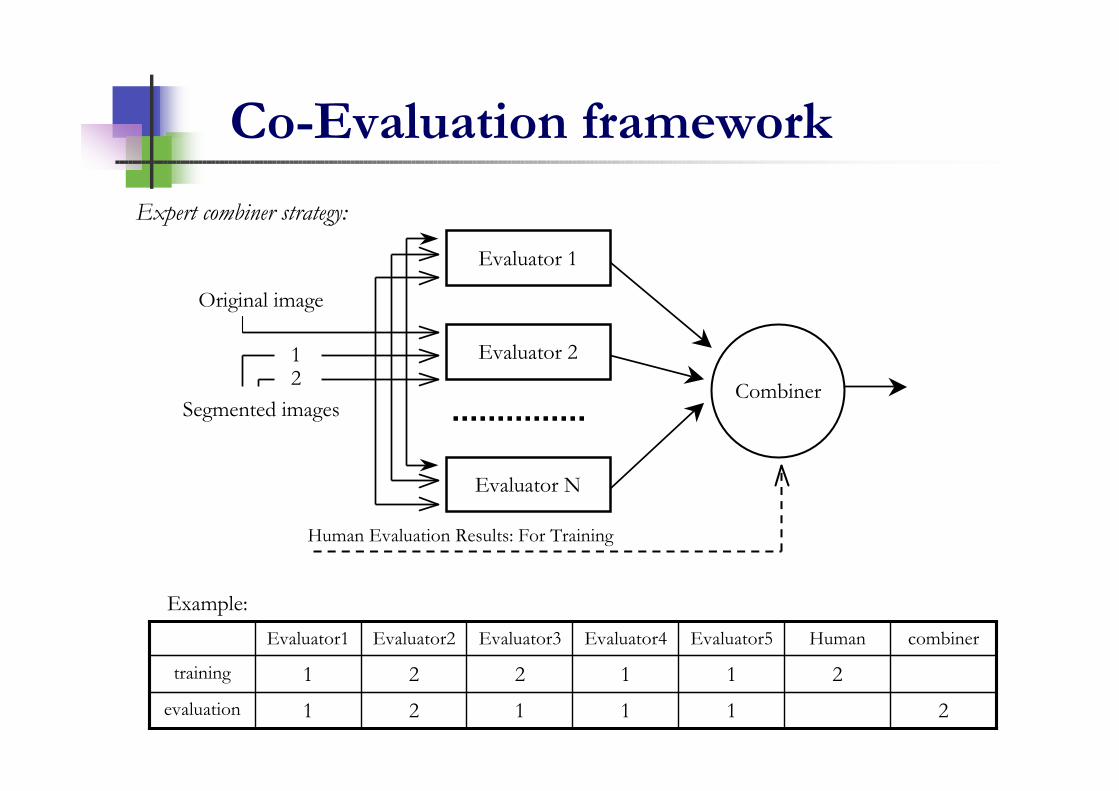
Co-Evaluation framework
Evaluator 1
Evaluator 2
Evaluator N
Combiner
Original image
Segmented images
12
Human Evaluation Results: For Training
Expert combiner strategy:
Example:
211121evaluation
211221training
combinerHumanEvaluator5Evaluator4Evaluator3Evaluator2Evaluator1

� Image Segmentation & Evaluation
� Co-Evaluation Framework
� Experiments
� Human vs. Machine Segmentation
� Machine vs. Machine Segmentation
� Conclusions & Future Work
Outline

Human vs. Machine
Segmentation Evaluation
� 5 evaluators: E, F, Q, Vs, Vm
� Image pair (human segmentation, machine segmentation)
� 108 training sets from Berkeley dataset and Military Graphics Collection (aircraft)

Human vs. Machine
Segmentation Evaluation Results
� 108 training pairs
� Results for 92 evaluation pairs:
Single evaluation method:
Co-Evaluation:

� Image Segmentation & Evaluation
� Co-Evaluation Framework
� Experiments
� Human vs. Machine Segmentation
� Machine vs. Machine Segmentation
� Conclusions & Future Work
Outline

Machine vs. Machine
Segmentation Evaluation Results
� 6 subjective evaluators determined 3 best and 3 worst segmentations across image regressions of 2 to 20 segments
� Most common best and worst segmentations from each image used toform Best set and Worst set
� 125 pairs of (Best, Worst) used for training
� 124 pairs used for evaluation
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
E F Q Vs Vm SC WM NB SVM
Ac
cu
rac
y

Conclusions
� By themselves,
� E is best at determining human vs. machine segmentations
� Q is best at comparing machine vs. machine segmentations
� Using the Co-Evaluation framework,
� Naive Bayesian combiner does best
� Weighted Majority and Support Vector Machines are also
good, much better than a simple combiner
� Some gain from Co-Evaluation framework, but
expect we can do better…
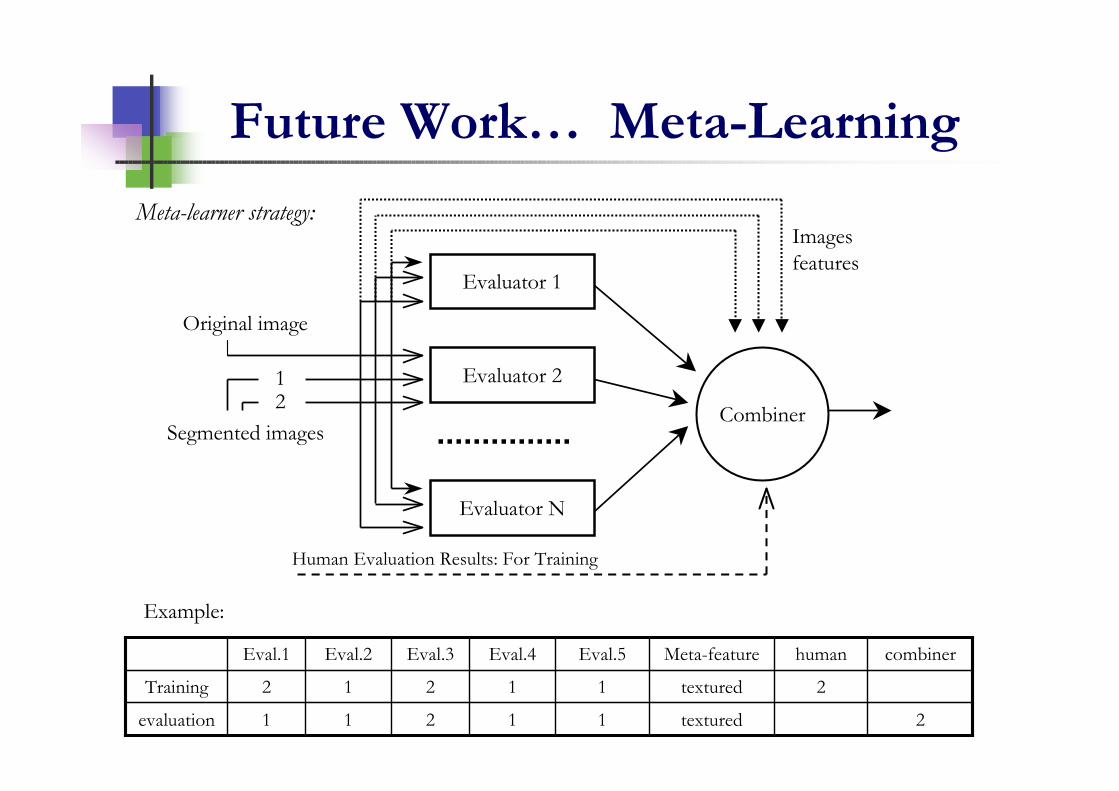
Future Work… Meta-Learning
Evaluator 1
Evaluator 2
Evaluator N
Combiner
Original image
Segmented images
12
Human Evaluation Results: For Training
Images
features
Meta-learner strategy:
2textured11211evaluation
2textured11212Training
combinerhumanMeta-featureEval.5Eval.4Eval.3Eval.2Eval.1
Example:

Thank You!
� More information:
� http://www.cse.wustl.edu/~jefritts/