Embed Size (px)
Citation preview

Hierarchical Scheduling forSymmetric Multiprocessors
Abhishek Chandra, Member, IEEE, and Prashant Shenoy, Senior Member, IEEE
Abstract—Hierarchical scheduling has been proposed as a scheduling technique to achieve aggregate resource partitioning among
related groups of threads and applications in uniprocessor and packet scheduling environments. Existing hierarchical schedulers are
not easily extensible to multiprocessor environments because 1) they do not incorporate the inherent parallelism of a multiprocessor
system while resource partitioning and 2) they can result in unbounded unfairness or starvation if applied to a multiprocessor system in
a naive manner. In this paper, we present hierarchical multiprocessor scheduling (H-SMP), a novel hierarchical CPU scheduling
algorithm designed for a symmetric multiprocessor (SMP) platform. The novelty of this algorithm lies in its combination of space and
time multiplexing to achieve the desired bandwidth partition among the nodes of the hierarchical scheduling tree. This algorithm is also
characterized by its ability to incorporate existing proportional-share algorithms as auxiliary schedulers to achieve efficient hierarchical
CPU partitioning. In addition, we present a generalized weight feasibility constraint that specifies the limit on the achievable CPU
bandwidth partitioning in a multiprocessor hierarchical framework and propose a hierarchical weight readjustment algorithm designed
to transparently satisfy this feasibility constraint. We evaluate the properties of H-SMP using hierarchical surplus fair scheduling
(H-SFS), an instantiation of H-SMP that employs surplus fair scheduling (SFS) as an auxiliary algorithm. This evaluation is carried out
through a simulation study that shows that H-SFS provides better fairness properties in multiprocessor environments as compared to
existing algorithms and their naive extensions.
Index Terms—Multiprocessor, hierarchical, scheduling, proportional share.
Ç
1 INTRODUCTION
1.1 Motivation
RECENT advances in computing have seen the emergenceof a wide diversity of computing environments,
including servers (for example, Web servers and multi-media servers), versatile desktop environments (runningcompilers, browsers, and multiplayer games), and parallelcomputing and scientific applications. These environmentscomprise collections of interacting threads, processes, andapplications. Such applications often have aggregate per-formance requirements, imposing the need to providecollective resource allocation to their constituent entities.In general, the notion of collective resource allocation arisesin several contexts:
. Resource sharing. Applications such as Web serversand FTP servers that partition resources such as CPUand network bandwidth and disk space betweendifferent (unrelated) concurrent client connectionscan benefit from the consolidation of their overallresource allocation.
. Physical resource partitioning. Multiple applicationsand threads may be grouped together as part of a
physically partitioned runtime environment. Acommon example of such an environment is avirtual-machine monitor [1], [2], where each virtualmachine may have certain resource requirements.
. Aggregate performance requirements. An applicationmay have collective performance requirementsfrom its components. For example, all threads ofa parallel application should be proceeding at thesame rate to minimize its “makespan” or comple-tion time.
. Scheduling criteria. Many applications can begrouped together into service classes to be sched-uled by a common scheduler specific to theirrequirements. For instance, different multimediaapplications such as audio and video servers mayrequire soft real-time (SRT) guarantees and hencemay be scheduled together by a SRT schedulerinstead of the default operating system scheduler.QLinux [3] is an operating system that providesclass-specific schedulers for the CPU, networkinterface, and the disk.
Such aggregation-based resource allocation is particu-
larly desirable in multiprocessor and multicore environ-
ments due to several reasons. First, resource partitioning
can help in making large multiprocessor systems scalable
by reducing excessive interprocessor communication, bus
contention, and cost of synchronization. Cellular Disco [4] is
an example of a virtual-machine-based system designed to
achieve resource partitioning in a large multiprocessor
environment. Moreover, a multiprocessor system provides
inherent opportunities for parallelism, which can be
exploited better by an application employing multiple
418 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
. A. Chandra is with the Department of Computer Science and Engineering,University of Minnesota, Minneapolis, MN 55455.E-mail: [email protected].
. P. Shenoy is with the Department of Computer Science, University ofMassachusetts, Amherst, MA 01003. E-mail: [email protected].
Manuscript received 20 Apr. 2006; revised 12 Feb. 2007; accepted 6 July 2007;published online 26 July 2007.Recommended for acceptance by D. Trystram.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number TPDS-0103-0406.Digital Object Identifier no. 10.1109/TPDS.2007.70755.
0098-5589/08/$25.00 � 2008 IEEE Published by the IEEE Computer Society

threads, requiring the system to provide some notion ofaggregate resource allocation to the application. Support forsuch applications in multiprocessor environments is be-coming critical as more systems move to multicoretechnology [5], [6].1 Dual-core machines are alreadycommon, and uniprocessors are expected to become theexception rather than the rule, particularly in serverenvironments.
Traditional operating system schedulers are not suitablefor collective resource allocation for several reasons. First,they typically perform fine-grained scheduling at theprocess or thread level. Moreover, they do not distinguishthreads of different applications from those of the sameapplication. Second, traditional schedulers are designed tomaximize systemwide metrics such as throughput orutilization and do not meet application-specific require-ments. Therefore, the resource allocation achieved by suchschedulers is largely agnostic of aggregate applicationrequirements or the system’s resource partitioning re-quirements. Some mechanisms such as scheduler activa-tions [7] and resource containers [8] can be used toaggregate resources and exploit parallelism. However,these mechanisms are mainly accounting and protectionmechanisms, and they require a complementary schedul-ing framework to exploit their properties.
Hierarchical scheduling is a scheduling framework thathas been proposed to group together processes, threads,and applications to achieve aggregate resource partition-ing. Hierarchical scheduling enables the allocation ofresources to collections of schedulable entities and furtherperform fine-grained resource partitioning among theconstituent entities. Such a framework meets many ofthe requirements for the scenarios presented above.Hierarchical scheduling algorithms have been developedfor uniprocessors [9] and packet scheduling [10]. How-ever, as we will show in this paper, these existingalgorithms are not easily extensible to multiprocessorenvironments because 1) they do not incorporate theinherent parallelism of a multiprocessor system whileresource partitioning and 2) they can result in unboundedunfairness or starvation if applied to a multiprocessorsystem in a naive manner. The design of a hierarchicalscheduling algorithm for multiprocessor environments isthe subject of this paper.
1.2 Research Contributions
This paper presents a novel hierarchical scheduling algo-rithm for multiprocessor environments. The design of thisalgorithm is motivated by the limitations of existinghierarchical algorithms in a multiprocessor environment,which are clearly identified in this paper. The design of thealgorithm has led to several key contributions.
First, we have designed hierarchical multiprocessor schedul-ing (H-SMP), a hierarchical scheduling algorithm that isdesigned specifically for multiprocessor environments. Thisalgorithm is based on a novel combination of space and timemultiplexing and explicitly incorporates the parallelism
inherent in a multiprocessor system, unlike existing hier-archical schedulers. One of its unique features is that itincorporates an auxiliary scheduler to achieve hierarchicalpartitioning in a multiprocessor environment. This auxiliaryscheduler can be selected from among several existingproportional-share schedulers [11], [12], [13], [14], [15], [16],[17], [18]. Thus, H-SMP is general in its construction and can
incorporate suitable schedulers based on trade-offs betweenefficiency and performance requirements. We show that H-SMP provides bounds on the achievable CPU partitioning,independent of the choice of the auxiliary scheduler,although this choice can affect how close H-SMP is to theideal partitioning.
Second, we have derived a generalized weight feasibility
constraint that specifies the limit on the achievable CPUbandwidth partitioning in a multiprocessor hierarchical
framework. This feasibility constraint is critical to avoid theproblem of unbounded unfairness and starvation faced byexisting uniprocessor schedulers in a multiprocessor en-vironment. We have developed a hierarchical weight read-
justment algorithm that is designed to transparently adjustthe shares of hierarchical scheduling tree nodes to satisfythe feasibility constraint. This readjustment algorithmtransforms any given weight assignment of the tree nodesto the “closest” feasible assignment. Moreover, this algo-rithm can be used in conjunction with any hierarchical
scheduling algorithm.Finally, we illustrate H-SMP through hierarchical
surplus fair scheduling (H-SFS), an instantiation of H-SMPthat employs surplus fair scheduling (SFS) [19] as theauxiliary scheduler, and we evaluate its propertiesthrough a simulation study. The results of this studyshow that H-SFS provides better fairness properties inmultiprocessor environments as compared to existinghierarchical algorithms and their naive extensions.
2 BACKGROUND AND SYSTEM MODEL
2.1 Background
Hierarchical scheduling is a scheduling framework thatenables the grouping together of threads, processes, andapplications into service classes [3], [9], [10]. CPU band-width is then allocated to these classes based on thecollective requirement of their constituent entities.
In a hierarchical scheduling framework, the total system
CPU bandwidth is divided proportionately among variousservice classes. Proportional-share scheduling algorithms [11],[12], [13], [14], [15], [16], [17], [18], [20] are a class ofscheduling algorithms that meet this criterion. Anotherrequirement for hierarchical scheduling is that thescheduler should be insensitive to fluctuating CPU band-width available to it. This is because the CPU bandwidthavailable to a service class depends on the demand of theother service classes in the system, which may vary
dynamically. A proportional-share scheduling algorithmsuch as start-time fair queuing (SFQ) [14] has been shown tomeet all these requirements in uniprocessor environmentsand has been deployed in a hierarchical schedulingenvironment [9]. However, SFQ can result in unbounded
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 419
1. In the rest of this paper, we will refer to both multicore andmultiprocessor machines as multiprocessors. The issues raised and thesolutions presented are applicable to both environments.

unfairness and starvation when employed in multiproces-sor environments, as illustrated in [19].
This unbounded unfairness occurs, because it is notpossible to partition the CPU bandwidth arbitrarily in amultiprocessor environment, since a thread can utilize atmost one CPU at any given time. This requirement isformalized as a weight feasibility constraint [19] on theamount of achievable bandwidth partitioning in a multi-processor environment. SFS [19] and Group Ratio Round-Robin [16] achieve proportional-share scheduling inmultiprocessor environments by employing weight read-justment algorithms to explicitly satisfy the weightfeasibility constraint. However, as we will show inSection 3.2, this weight feasibility constraint is notsufficient for a hierarchical scheduling framework, andhence, these algorithms, by themselves, are inadequate fordirect use in an H-SMP environment.
Aside from the choice of a suitable scheduling algorithmto be employed within the hierarchical framework, existinghierarchical schedulers are also limited in that they aredesigned to handle only a single resource (such as auniprocessor). As we will illustrate in Section 3.1, theseschedulers are unable to exploit the inherent parallelism ina multiprocessor environment and cannot be extendedeasily to run multiple threads or processes belonging to aservice class in parallel.
Lottery scheduling [21] also proposes hierarchical alloca-tion of resources based on the notion of tickets and lotteries.Lottery scheduling itself is a randomized algorithm that canmeet resource requirements in a probabilistic manner, andextending it to multiprocessor environments is nontrivial.Tickets, by themselves, can be used as an accountingmechanism in a hierarchical framework and are orthogonalto our discussion here.
2.2 System Model
Our system model consists of a p-CPU symmetricmultiprocessor (SMP) system with n runnable threadsin the system. The threads are arranged in a hierarchicalscheduling framework consisting of a scheduling hierarchy(or scheduling tree) of height h. Each node in thescheduling tree corresponds to a thread2 or an aggrega-tion of threads such as an application or a service class.In particular, the leaf nodes of the tree correspond tothreads, whereas each internal (nonleaf) node in thehierarchy corresponds to either a service class or amultithreaded application.3 The root of the tree repre-sents the aggregation of all threads in the system. Fig. 1illustrates an example scheduling hierarchy.
The goal of hierarchical scheduling is to provide CPUallocation to each node in the tree according to itsrequirement. Every node in the tree is assigned a weightand receives a fraction of the CPU service allocated to itsparent node. The fraction that it receives is determined byits weight relative to its siblings. Thus, if P is an internal
node in the tree and CP is the set of its children nodes, then
the CPU service Ai received by a node i 2 CP is given by
Ai ¼wiPj2Cp wj
�AP ; ð1Þ
where AP is the CPU service available to the parent node P ,
and wj denotes the weight of a node j. For instance, based on
the node weights shown in Fig. 1, (1) specifies that the BE and
SRT classes should receive 25 percent and 75 percent of the
system CPU service, respectively. The FTP and Web servers
should then share the CPU service allocated to the BE class in
the ratio 1: 4, thus receiving 5 percent and 20 percent of the
system CPU service, respectively.For each node in the tree, we define two quantities—its
thread parallelism and its processor assignment—to account for
the node’s location in the scheduling tree and its resource
allocation, respectively. These quantities correspond respec-
tively to the total number of threads in a node’s subtree and
the number of CPUs assigned to the node for multiplexing
among threads in its subtree.
Definition 1: Thread parallelism �i. The thread parallelism of
a node i in a scheduling tree is defined to be the number of
independent schedulable entities (threads) in node i’s subtree,
that is, threads that node i could potentially schedule in
parallel on different CPUs.
The thread parallelism of a node is given by the
following relation:
�i ¼Xj2Ci
�j; ð2Þ
where Ci is the set of node i’s children nodes. This equation
states that the number of threads schedulable by a node is
the sum of the threads schedulable by its children nodes. By
this definition, �i ¼ 1 if node i corresponds to a thread in the
system.
420 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
2. In the rest of this paper, we will refer to the smallest independentlyschedulable entity in the system as a thread. In general, this couldcorrespond to a kernel thread, process, scheduler activation [7], etc.
3. In general, the leaf node of a tree could also correspond to a class-specific scheduler that schedules threads on the processors [3], [9].However, we consider leaf nodes to be threads here for ease of exposition.
Fig. 1. A scheduling hierarchy with two service classes: best effort (BE)and SRT. The BE class consists of an FTP and a multithreaded Webserver. The SRT class is further subdivided into two classes—video andaudio—that consist of multithreaded applications: MPEG, Quicktime,and MP3.

Definition 2: Processor assignment �i. Processor assignmentfor a node i in a scheduling tree is defined as the CPUbandwidth, expressed in units of the number of processors,assigned to node i for running threads in its subtree.
The processor assignment of a node depends on itsweight and the processor assignment of its parent node:
�i ¼wiPj2CP wj
� �P ; ð3Þ
where P is the parent node of node i, and CP is the set ofnode P ’s children nodes. This equation states that the CPUbandwidth available to a node for scheduling its threads isthe weighted fraction of the CPU bandwidth available to itsparent node. Since the root of the tree corresponds to anaggregation of all threads in the system, �root ¼ minðp; nÞ forthe root node in a p-CPU system with n runnable threads.4
Although the thread parallelism of a node is determinedsolely based on the structure of its subtree in the schedulinghierarchy, its processor assignment is dependent on itsweight assignment relative to its siblings and parent in thehierarchy. These quantities are independent of the schedul-ing algorithm being used and are useful for accountingpurposes within the hierarchy.
3 LIMITATIONS OF EXISTING HIERARCHICAL
SCHEDULING ALGORITHMS
We begin by describing how hierarchical scheduling isperformed in uniprocessor environments and show thelimitations of such approaches and their naive extensions inmultiprocessor environments. In particular, we present twoproblems: 1) that of inherent parallelism due to the presenceof multiple processors and 2) that of infeasible weights dueto the presence of monolithic schedulable entities or threadsat the lowest levels of the scheduling hierarchy.
3.1 Problem of Parallelism
Algorithm 1: hier_sched().
1: node root
2: while node is not a leaf do
3: node gen schedðnodeÞ {gen sched is an
algorithm that selects a child of node for scheduling}
4: end while
Algorithm 1 shows a generic hierarchical schedulingalgorithm that has been used for hierarchical scheduling onuniprocessors [3], [9]. This algorithm works as follows:Whenever a CPU needs to be scheduled, the hierarchicalscheduler schedules a “path” from the root of the tree to aleaf node (or thread). In other words, the algorithmiteratively “schedules” a node at each level of the tree untilit reaches a thread. This thread is then selected to run on theCPU. Scheduling an internal node of the tree corresponds torestricting the choice of the next scheduled thread to thosein the node’s subtree. Fig. 2a illustrates this method ofscheduling by scheduling one node at a time along a pathfrom the root to a thread. The approach described above
requires certain properties from the algorithm gen_schedfor selecting a node at each level. In uniprocessor environ-
ments, a thread-scheduling5 proportional-share algorithmcan be employed to schedule internal nodes as well. Suchan algorithm runs for each set of sibling nodes (treating
them as threads), scheduling one node at each level toachieve proportional allocation among them. For instance,
the hierarchical SFQ algorithm [9] employs SFQ [14], athread-scheduling proportional-share algorithm.
However, using a similar approach, namely, using a
thread-scheduling algorithm to schedule the internal nodesof the scheduling tree, fails in a multiprocessor environment
because of the following reason. On a uniprocessor, only asingle thread can be scheduled to run on the CPU at any
given time so that only a single path from the root needs tobe scheduled at any instant (Fig. 2a). However, in a
multiprocessor environment, multiple threads can bescheduled to run on multiple CPUs concurrently. Thiscorresponds to choosing multiple paths from the root, many
of which could have overlapping internal nodes (Fig. 2b). Inother words, in multiprocessor scheduling, it is possible to
have multiple threads with a common ancestor noderunning in parallel on different CPUs. This inherent
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 421
4. Note that min is required in this relation to account for the casewhere n < p.
5. By a thread-scheduling algorithm, we mean a scheduling algorithmthat is designed to schedule individual threads or schedulable entities thatdo not have parallelism (unlike internal nodes in a scheduling tree thatconsist of multiple threads in their subtree, which can be scheduled inparallel).
Fig. 2. Hierarchical scheduling represented as scheduling of paths fromthe root to threads (leaf nodes). (a) A single thread, hence a single path,is scheduled in a uniprocessor environment. (b) Multiple threads, hencemultiple overlapping paths, in the scheduling tree can be concurrentlyscheduled in a multiprocessor environment.

parallelism can be achieved only by scheduling an internalnode multiple times concurrently, that is, by assigningmultiple CPUs to the node simultaneously.
This form of scheduling cannot be performed by athread-scheduling algorithm, because it is not designed toexploit the inherent parallelism of individual schedulableentities. The key limitation of a thread-scheduling algo-rithm is that it has no mechanism for assigning multipleCPUs to the same node concurrently. This limitationprevents it from scheduling multiple threads from thesame subtree in parallel. Therefore, a thread-schedulingproportional-share algorithm cannot be used to schedulethe internal nodes in a scheduling hierarchy on amultiprocessor.
From the discussion above, we see that a multiprocessorhierarchical algorithm should have the ability to assignmultiple CPUs to the same node concurrently. One way ofdesigning such an algorithm is to extend a thread-scheduling algorithm by allowing it to assign multipleCPUs to each node simultaneously. However, such anextension raises several questions such as the following:
. Which nodes should we select at a given schedulinginstant?
. How many CPUs should we assign to each nodeconcurrently?
. How do we ensure that the CPU assignmentsachieve fair bandwidth partitioning?
We present H-SMP in Section 4, which answers thesequestions and overcomes the problem of parallelismdescribed here.
3.2 Problem of Infeasible Weights
Aside from the lack of support for inherent parallelism, aproportional-share algorithm can also suffer from un-bounded unfairness or starvation problem in multiprocessorenvironments [19], as illustrated by the following example.
Example 1. Consider a server that employs the SFQalgorithm [14] to schedule threads. SFQ is aproportional-share scheduler that works as follows:SFQ maintains a counter Si for each thread with weightwi, which is incremented by q
wievery time the thread is
scheduled (q is the quantum duration). At eachscheduling instance, SFQ schedules the thread withthe minimum Si on a CPU. Assume that the server hastwo CPUs and runs two computationally bound threadsthat are assigned weights w1 ¼ 1 and w2 ¼ 10, respec-tively. In addition, let q ¼ 1 ms. Since both threads arecomputationally bound and SFQ is work conserving,6
each thread gets to continuously run on a processor.
After 1,000 quanta, we have S1 ¼ 1;0001 ¼ 1; 000 and
S2 ¼ 1;00010 ¼ 100. Assume that a third CPU-bound thread
arrives at this instant, with a weight w3 ¼ 1. The counter
for this thread is initialized to S3 ¼ 100 (newly arriving
threads are assigned the minimum value of Si over all
runnable threads). From this point on, threads 2 and 3
get continuously scheduled until S2 and S3 “catch up”
with S1. Thus, although thread 1 has the same weight as
thread 3, it starves for 900 quanta, leading to unfairness
in the scheduling algorithm.
Although this example uses SFQ as an illustrativealgorithm, this problem is common to most proportional-share algorithms. To overcome this unfairness problem, [19]presents a weight feasibility constraint that must be satisfiedby all threads in the system:
wiPj wj� 1
p; ð4Þ
where wi is the weight of a thread i, and p is the number ofCPUs in the system. A weight assignment for a set ofthreads is considered infeasible if any thread violates thisconstraint. This constraint is based on the observation thateach thread can run on at most one CPU at a time.
However, in the case of hierarchical scheduling, since anode in the scheduling tree divides its CPU bandwidthamong the threads in its subtree, it is possible for a node tohave multiple threads running in parallel. Thus, withmultiple threads in its subtree, a node in the schedulingtree can utilize more than one CPU in parallel. For instance,a node with three threads in a four-CPU system can utilize3/4 of the total CPU bandwidth and is thus not constrainedby the weight feasibility constraint (4). However, thenumber of CPUs that a node can utilize is still constrainedby the number of threads that it has in its subtree: for theabove example, the node cannot utilize more than 3/4 of thetotal CPU bandwidth. In particular, the number ofprocessors assigned to a node should not exceed thenumber of threads in its subtree. In other words
�i � �i ð5Þ
for any node i in the tree. Using the definition of processorassignment (3), (5) can be written as
wiPj2CP wj
� �i�P
; ð6Þ
where P is the parent node of node i, and CP is the set ofP ’s children nodes.
We refer to (6) as the generalized weight feasibility constraint.Intuitively, this constraint specifies that a node cannot beassigned more CPU capacity than what it can utilize throughits parallelism. Note that (6) reduces to the weight feasibilityconstraint (4) in a single-level scheduling hierarchy consist-ing only of threads. The generalized weight feasibilityconstraint is a necessary condition for any work-conservingalgorithm to achieve hierarchical proportional-share sche-duling in a multiprocessor system, as it satisfies the followingproperty (proved in Appendix B, which can be found on theComputer Society Digital Library at www.computer.org/tpds/archives.htm):
Theorem 1. No work-conserving scheduler can divide the CPUbandwidth among a set of nodes in proportion to their weightsif any node violates the generalized weight feasibilityconstraint.
In Section 5, we present a hierarchical weight readjustmentalgorithm designed to transparently satisfy this constraint.
422 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
6. A scheduling algorithm is said to be work conserving if it never lets aprocessor idle, so long as there are runnable threads in the system.

In the next section, we assume that the weights assigned tothe nodes in our scheduling tree satisfy this constraint.
4 HIERARCHICAL MULTIPROCESSOR SCHEDULING
In this section, we present H-SMP, a scheduling algorithmdesigned to achieve hierarchical scheduling in a multi-processor environment.
4.1 Hierarchical Multiprocessor Scheduling
H-SMP uses a combination of space and time multiplexingto achieve the desired partitioning of CPU bandwidthwithin the scheduling tree. H-SMP has the following salientfeatures. First, it is designed to assign multiple CPUs to atree node concurrently so that multiple threads from anode’s subtree can be run in parallel. Second, it employs anauxiliary thread-scheduling proportional-share algorithmto perform this CPU assignment in order to achieve thedesired CPU service for the tree nodes.
Intuitively, H-SMP consists of two components: a spacescheduler and an auxiliary scheduler. The space scheduler is ascheduler that statically partitions the CPU bandwidth in anintegral number of CPUs to assign to each node in thehierarchy. The auxiliary scheduler is a thread-schedulingproportional-share algorithm (such as SFQ [14], SFS [19],etc.) that is used to partition the residual CPU bandwidthamong the tree nodes proportional to their weights. Thesecomponents work together as follows at each level of thescheduling tree: If the processor assignment of a node is �i,then the node should ideally be assigned �i CPUs at alltimes. However, since a node can be assigned only anintegral number of CPUs at each scheduling instant, H-SMPensures that the number of CPUs assigned to the node iswithin one CPU of its requirement. The space schedulerensures this property by first assigning b�ic number ofCPUs to the node at each scheduling instant. Thus, theresidual processor requirement of the node becomes�0i ¼ �i � b�ic. Meeting this requirement for the node isequivalent to meeting the processor requirement for avirtual node with processor assignment �0i. Since 0 � �0i < 1,this residual processor requirement can be achieved byemploying the auxiliary scheduler that time multiplexes theremaining CPU bandwidth among the virtual nodes tosatisfy their requirements �0i. Overall, H-SMP ensures thateach node is assigned either b�ic or d�ie number of CPUs ateach scheduling instant, thus providing lower and upperbounds on the CPU service received by the node.
In practice, the H-SMP algorithm works as follows on aset of sibling nodes in the scheduling tree: For each node inthe scheduling tree, the algorithm keeps track of thenumber of CPUs currently assigned to the node, a quantitydenoted by ri. Note that assigning a CPU to a nodecorresponds to scheduling a thread from its subtree on thatCPU. Therefore, for any node i in the scheduling tree,ri ¼
Pj2Ci rj, where Ci is the set of node i’s children. Then,
H-SMP partitions each set of sibling nodes in the schedulingtree into the following subsets based on their current CPUassignment:
. Deficit set. A node is defined to be in the deficit set ifthe number of CPUs currently assigned to the node
ri < b�ic. In other words, the current CPU assign-ment for a node in the deficit set is below the lowerthreshold of its requirement. The scheduler givespriority to deficit nodes, as scheduling a deficit nodefirst allows it to reach its lower threshold of b�icCPUs. Since the goal of H-SMP is to assign at leastb�ic CPUs to each node at all times, it is notimportant to order these nodes in any order forscheduling, and they can be scheduled in a FIFOorder by the space scheduler.
. Auxiliary set. This set consists of nodes for whichb�ic ¼ ri < d�ie. These are the nodes that arecurrently assigned the lower threshold of theirrequirement and are scheduled if there are no deficitnodes to be scheduled. Scheduling these nodesemulates the scheduling of corresponding virtualnodes with processor assignment �0i and are sched-uled by the auxiliary scheduler.
. Ineligible set. This set consists of nodes for whichri � d�ie, that is, the ones that are currently assignedat least the upper threshold of their requirement.These nodes are considered ineligible for scheduling.
A node can move between these sets by being selected by
H-SMP during a scheduling instant, by having one of itssubtree threads finish their quantum, due to the arrival/
departure of threads or due to changes in node weights in
the tree.
Algorithm 2: gen smpðtree node nodeÞ.1: new node NULL
2: if node:deficit set is nonempty then
3: new node get fromðnode:deficit setÞ4: rnew node rnew node þ 1
5: if rnew node � d�new nodee then
6: move to ineligible setðnew nodeÞ7: else if rnew node ¼ b�new nodec then
8: move to auxiliary setðnew nodeÞ9: end if
10: else if node:auxiliary set is nonempty then
11: new node auxiliary schedðnode:auxiliary setÞ{auxiliary sched is the auxiliary scheduling
algorithm}
12: rnew node rnew node þ 1
13: move to ineligible setðnew nodeÞ14: end if
15: returnðnew nodeÞAlgorithm 2 shows the pseudocode for the node
selection algorithm gen_smp employed by H-SMP at each
level of the tree when it needs to schedule a thread on aCPU. gen_smp can be thought to replace the gen_sched
algorithm specified in Algorithm 1. We next illustrate a
practical instantiation of H-SMP using SFS [19] as theauxiliary scheduler.
4.2 Hierarchical Surplus Fair Scheduling: AnInstantiation of Hierarchical MultiprocessorScheduling
H-SMP could theoretically employ any thread-schedulingproportional-share algorithm as its auxiliary scheduler.However, such an algorithm should be designed to work
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 423

on an SMP system and should reduce the discrepancybetween the ideal CPU service and the actual CPU servicereceived by the tree nodes as much as possible. We presentan instantiation of H-SMP using SFS [19], a multiprocessorproportional-share scheduling algorithm, as an auxiliaryscheduler. SFS maintains a quantity called surplus for eachthread that measures the excess CPU service that it hasreceived over its ideal service based on its weight. At eachscheduling instant, SFS schedules threads in the increasingorder of their surplus values. The intuition behind thisscheduling policy is to allow threads that lag behind theirideal share to catch up while restraining threads thatalready exceed their ideal share. Formally, the surplus �i fora thread i at time T is defined to be [19]
�i ¼ Aið0; T Þ �Aideali ð0; T Þ; ð7Þ
where Aið0; T Þ and Aideali ð0; T Þ are respectively the actual
and the ideal CPU service for thread i by time T .The choice of SFS as an auxiliary scheduler for H-SMP is
based on the following intuition. As described in theprevious section, a node with processor assignment �i canbe represented as a virtual node with processor assignment�0i ¼ �i � b�ic under H-SMP for the purpose of satisfying itsresidual service requirement. Then, it can be shown that thesurplus for the virtual node is the same as that for the actualnode. This can be seen by rewriting (7) as
�i ¼Aið0; T Þ � �i � T¼A0ið0; T Þ þ b�ic � T � b�ic þ �0i
� �� T
¼A0ið0; T Þ �A0iidealð0; T Þ
¼�0i;
where the dashed variables (such as A0i) correspond to thevalues for the virtual node with processor assignment �0i.These equations imply that scheduling nodes in the order oftheir surplus values is equivalent to scheduling the corre-sponding virtual nodes in the order of their surplus values.7
This property means that SFS can be used with original nodeweights to achieve the same schedule without having tomaintain a separate set of virtual nodes with residualweights and running the algorithm on them. This simplifiesthe implementation of H-SFS, as opposed to using a differentauxiliary algorithm, which does not satisfy this property.
Note that H-SFS reduces to SFS in a single-level hierarchy(corresponding to a thread-scheduling scenario). In that case,the weight feasibility constraint (4) requires that 0 < �i � 1,8i, implying that all threads are either in the auxiliary set (ifthey are not currently running) or are ineligible (if they arecurrently running) at any scheduling instant. The auxiliarythreads (that is, the ones in the run queue) are thenscheduled in the order of their surplus values.
4.3 Properties of HierarchicalMultiprocessor Scheduling
We now present the properties of H-SMP in a systemconsisting of a fixed scheduling hierarchy, with no arrivalsand departures of threads and no weight changes. Further-more, we assume that the scheduling on the processors is
synchronized. In other words, all p CPUs in the system are
scheduled simultaneously at each scheduling quantum. For
the nontrivial case, we would also assume that the number of
threadsn � p. In such a system, H-SMP satisfies the following
properties (the proof of these properties are given in
Appendix A, which can be found on the Computer Society
Digital Library at www.computer.org/tpds/archives.htm):
Theorem 2. After every scheduling instant, for any node i in the
scheduling tree, H-SMP ensures that
b�ic � ri � d�ie:
Corollary 1. For any time interval ½t1; t2Þ, H-SMP ensures that
the CPU service received by any node i in the scheduling tree
is bounded by
b�ic � ðt2 � t1Þ � Aiðt1; t2Þ � d�ie � ðt2 � t1Þ:
From Theorem 2, we see that H-SMP ensures that the
number of processors assigned to each node in the
scheduling tree at every scheduling quanta lies within
one processor of its requirement. This result leads to
Corollary 1, which states that the CPU service received by
each node in the tree is bounded by an upper threshold
and a lower threshold that are dependent on its processor
assignment. In Section 6, we relax the system assumptions
made here and discuss the impact on the properties and
performance of H-SMP.
5 HIERARCHICAL WEIGHT READJUSTMENT
As described in Section 3.2, the weights assigned to the
nodes in a scheduling hierarchy must satisfy the generalized
weight feasibility constraint (6) to avoid unbounded unfair-
ness or starvation. However, it is possible that some nodes
in the hierarchy have infeasible weights. This is possible,
because node weights are typically assigned externally
based on the requirements of applications and application
classes and may not satisfy the feasibility constraint. Even if
the weights are chosen carefully to be feasible to begin with,
the constraint may be violated because of the arrival and
departure of threads or changes in weights and tree
structure. We now present an algorithm that transparently
adjusts the weights of the nodes in the tree so that they all
satisfy the generalized weight feasibility constraint, even if
the original weights violate the constraint.
5.1 Generalized Weight Readjustment
Algorithm 3: gen readjustðarray ½w1 . . .wn�; float �Þ,returns ½�1 . . .�n�.
1: if w1Pn
j¼1wj> �1
�
� �then
2: gen readjustð½w2 . . .wn�; �� �1Þ
3: �1 �1
���1
� ��Pn
j¼2 �j4: else
5: �i wi, 8i ¼ 1; . . . ; n
6: end if
424 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
7. In practice, SFS approximates the ideal definition of surplus and,hence, the relative ordering of nodes is also an approximation of the desiredordering.

Algorithm 3 shows the generalized weight readjustmentalgorithm that modifies the weights of a set of sibling nodes ina scheduling tree so that their modified weights satisfy (6).This algorithm determines the adjusted weight of a nodebased on its original weight and the number of threads that itcan schedule. Intuitively, if a node demands more CPUs thanthe number of threads that it can schedule, the algorithmassigns it as many CPUs as what is allowed by its threadparallelism; otherwise, the algorithm assigns CPUs to thenode based on its weight.
As input, the algorithm takes a list of node weights,where the nodes are sorted in the nonincreasing order of
their weight-parallelism ratio wi�i
� �. The algorithm then
recursively adjusts the weights of the nodes until it finds a
node that satisfies (6). Ordering the nodes by their weight-
parallelism ratio ensures that infeasible nodes are always
placed before feasible nodes.8 This ordering makes the
algorithm efficient, as it enables the algorithm to first
examine the infeasible nodes, allowing it to terminate as
soon as it encounters a feasible node.
Algorithm 4: hier_readjust(tree_node node).
1: gen readjustðnode:weight list; �nodeÞ2: for all child in the set of node’s children Cnode do
3: �child �childPj2Cnode
�j
� �� �node
4: hier_readjust(child)
5: end for
The generalized weight readjustment algorithm can beused to adjust the weights of all the nodes in the tree in atop-down manner using a hierarchical weight readjustmentalgorithm (Algorithm 4). Intuitively, this algorithm traversesthe tree in a depth-first manner,9 and for each node P , thealgorithm 1) applies the generalized weight readjustmentalgorithm to the children of node P and 2) computes theprocessor assignment for the children of P by using (3)based on their adjusted weights �i.
5.2 Properties of Hierarchical Weight Readjustment
In this section, we first present the properties of thegeneralized weight readjustment algorithm. We then pre-sent its runtime complexity that allows us to determine thetime complexity of the hierarchical weight readjustmentalgorithm. Detailed proofs and derivations of the propertiesand results presented in this section can be found inAppendix B, which can be found on the Computer SocietyDigital Library at www.computer.org/tpds/archives.htm.
First, the generalized weight readjustment algorithm iscorrect in that it ensures that no node demands more CPUservice than what it can utilize, as stated by the followingtheorem:
Theorem 3. The adjusted weights assigned by the generalizedweight readjustment algorithm satisfy the generalized weightfeasibility constraint.
Aside from satisfying the generalized weight feasibilityconstraint, the adjusted weights assigned by the generalizedweight readjustment algorithm are also “closest” to theoriginal weights in the sense that the weights of nodesviolating the generalized weight feasibility constraint arereduced by the minimum amount to make them feasible,whereas the remaining nodes retain their original weights.This property of the generalized weight readjustmentalgorithm is stated in the following theorem:
Theorem 4. The adjusted weights assigned by the generalizedweight readjustment algorithm satisfy the following properties:
1. Nodes that are assigned fewer CPUs than their threadparallelism retain their original weights.
2. Nodes with an original CPU demand exceeding theirthread parallelism receive the maximum possible sharethat they can utilize.
These properties intuitively specify that the algorithmdoes not change the weight of a node, unless it is requiredto satisfy the feasibility constraint, and then, the change isthe minimum required to make the node feasible.
To examine the time complexity of the generalizedweight readjustment algorithm, note that for a given set ofsibling nodes in the scheduling tree, the number ofinfeasible nodes can never exceed the processor assignmentof their parent node.10 Since the generalized weightreadjustment algorithm examines only the infeasible nodes,its time complexity is given by the following theorem:
Theorem 5. The worst-case time complexity T ðn; �Þ of thegeneralized weight readjustment algorithm for n nodes and� processors is Oð�Þ.
Since the hierarchical weight readjustment algorithmemploys the generalized weight readjustment algorithm toadjust the weights of sibling nodes at each level of the tree,we can extend the analysis of the generalized weightreadjustment algorithm to analyze the complexity of thehierarchical weight readjustment algorithm, which is givenby the following theorem:
Theorem 6. The worst-case time complexity T ðn; h; pÞ of thehierarchical weight readjustment algorithm for a schedulingtree of height h, with n nodes running on a p-CPU system, isOðp � hÞ.
Theorem 6 states that the runtime of the hierarchicalweight readjustment algorithm depends only on the heightof the scheduling tree and the number of processors in thesystem and is independent of the number of runnablethreads in the system.
6 IMPLEMENTATION CONSIDERATIONS
In this section, we discuss some of the system issues andconsiderations for implementing the H-SMP and hier-archical weight readjustment algorithms in a real system.
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 425
8. We prove this property of the ordering in Appendix B, which can befound on the Computer Society Digital Library at www.computer.org/tpds/archives.htm. The intuitive reason is that nodes that have higherweights or have smaller number of threads to schedule are more likely toviolate the feasibility constraint (6).
9. We can also use other top-down tree traversals such as breadth first,where a parent node is always visited before its children nodes.
10. This is because if a node demands more CPU service than its threadparallelism, then its demand exceeds at least one processor (since its threadparallelism > 0), and the number of nodes demanding more than oneprocessor cannot exceed the number of processors available to them,namely, the parent node’s processor assignment �.

Height of scheduling hierarchy. Each internal node of ascheduling tree typically corresponds to either a multi-threaded application or an application class. Most systemshave the need for only a few statically defined applicationclasses (such as BE, real time, etc.), and hence, schedulingtrees in real implementations can be expected to be broadrather than deep. The height h of a typical scheduling treecan thus be expected to be a small constant. A special caseis that of a two-level hierarchy, consisting only ofindependent threads and no further grouping into applica-tion classes, which can be the default configuration of thescheduling tree at system initialization. Note that the heightof the tree h is not dependent on the number of threads n inthe system (for example, h 6¼ OðlogðnÞÞ, which is the usualassumption in many parallel models [22]). This is because ascheduling tree is not binary (or k-ary for a constant k), andthere can be an arbitrary number of children attached toeach node in the tree. Thus, the time complexity of thehierarchical scheduling algorithm (Theorem 6) in realimplementations is likely to be truly independent of thenumber of threads in the system.
Arrivals and departures of threads. Although we madeassumptions of a statically known tree of threads inSection 4.3 for the tractability of the proofs, H-SMP is notconstrained by these assumptions for its actual function-ality. Arrivals and departures of threads or weight mod-ifications in the tree would essentially require thehierarchical weight readjustment to be performed in thetree. This is because these events change the parallelism �ior processor availability �i of the nodes to which they areattached, thus possibly making some of the weights in thetree infeasible. Due to the readjustment in weights, it ispossible that some of the nodes in the system maytemporarily violate the bounds of b�ic and d�ie on theircurrent assignment ri (Theorem 2). One possibility ofpreventing this violation is to reschedule all the CPUs withthe H-SMP algorithm immediately upon each weightreadjustment. However, a less expensive approach is toignore such temporary violations and allow subsequentscheduling events to gradually restore the above propertyfor all nodes. In fact, in our simulations presented inSection 7, we allow arrivals and departures of threads,resulting in such temporary violations, but our results showtheir impact on the allocation fairness to be negligible.
Reducing tree traversals. Another approach to reduce theoverhead of traversing the whole tree at every schedulinginstant is by using a different granularity of scheduling/readjustment across different levels of the tree. For instance,a different scheduling quantum size Q can be associatedwith each level of the tree such as QðlÞ ¼ 2h�l � q, where h isthe height of the tree, l is a tree level (with lroot ¼ 0), and q isthe baseline quantum size used by the system for threads.In this case, scheduling at level l will be done only after QðlÞtime units so that scheduling at lower levels of the tree isperformed more frequently than at higher levels. Forinstance, although threads will be scheduled at the systemquantum, node selection at upper levels would take placeless frequently. Such a use of different granularities willalso lead to more effective space partitioning of the CPUs.Of course, such an approach would lead to load imbalances
and unfairness within the quantum durations but wouldlead to more efficient execution.
List management overheads. As outlined in the descrip-tion of H-SMP, each internal node in the tree maintainsthree lists: deficit, auxiliary, and ineligible. The deficit listand the ineligible list do not require any specificordering, and hence, insertions/deletions from these listswill be Oð1Þ. The auxiliary list is typically maintainedaccording to the priority order assigned by the auxiliaryalgorithm (for example, ordered by surplus for SFS). Theinsertions/deletions from this list could be madeOðlogðnÞÞ by maintaining suitable data structures for thelist implementation such as heaps. Similarly, the weightreadjustment algorithm maintains a sorted list of nodesby their weight-parallelism ratios. Such a list willtypically have to be modified much less frequently,although similar data structures could be employed here.
7 SIMULATION STUDY
We now present a simulation study to evaluate theproperties of the H-SMP algorithm and compare it to otherexisting algorithms and their extensions. We first presentour simulation methodology and metrics used in ourevaluation, followed by the results of the study.
7.1 Simulation Methodology
In our study, we used an event-based simulator to simulatemultiprocessor systems with different numbers of proces-sors p. For each simulation, we generated a scheduling treehierarchy with a given number of internal nodes N and agiven number of threads n. These nodes and threads werearranged in the tree in the following manner. The parent ofan internal node was chosen uniformly at random from theset of other internal nodes, whereas the parent of a threadwas selected uniformly at random from the set of internalnodes without children (to prevent a thread and an internalnode from being siblings in the tree). These nodes andthreads were then assigned weights chosen uniformly atrandom from a fixed range of values (1-100).
Each run of the simulation is conducted as follows:Similar to a real operating system, the system time ismeasured in ticks, and the maximum scheduling quantumis defined to be 10 ticks. Each CPU is interrupted at a timechosen uniformly at random within its quantum,11 at whichpoint it calls the hierarchical scheduler to assign the nextthread to run on the CPU. Each thread is assigned a servicetime at creation, which is generated from a heavy-taileddistribution ðPareto; a ¼ 1:01Þ. A thread departs the systemwhen it has received a CPU service equal to its desiredservice time. We model arrivals of new threads as a Poissonprocess, and thread arrival times are generated from anexponential distribution.12 Furthermore, we used differentrandom-number streams for each of the different distribu-tions (parent IDs, weights, scheduling times, service times,and arrival times).
426 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
11. Threads may not use full quantum lengths either because of havingused up partial quantum lengths in their previous runs or due topreemption or blocking events.
12. To emulate a stable system (with the number of arrivalsapproximating the number of departures), we used a mean � / 1
p .

In our study, we simulated multiprocessor systems with2, 4, 8, 16, and 32 CPUs, respectively. We generatedscheduling trees with 2, 4, 6, 8, and 10 internal nodes anda set of values for the number of threads in the system,varying from 3 to 100. Each simulation (with each of theseparameter combinations) was run for 10,000 ticks andrepeated 100 times with a different random seed to simulatedifferent thread mixes and tree structures for the sameparameter combinations.
In our study, we use H-SFS as an instantiation of H-SMPfor evaluation purposes. We compare the H-SFS algorithmwith the following algorithms that represent existingalgorithms and their extensions for use in a hierarchicalscheduling framework.
7.1.1 Surplus Fair Scheduling
As a representative of a uniprocessor hierarchical scheduler(Algorithm 1), we employed SFS algorithm directly toschedule nodes at each level of the scheduling hierarchy.Note that even though SFS is a proportional-share algo-rithm designed to schedule threads in a multiprocessorenvironment, it cannot exploit the inherent parallelism ofinternal tree nodes.
7.1.2 Extended Surplus Fair Scheduling
This algorithm is an extension of SFS for hierarchicalscheduling that works as follows: At each scheduling instant,at each level of the scheduling hierarchy, it selects a nodewith the minimum surplus among a set of sibling nodes andassigns it d�ie number of CPUs. This is a generalization ofSFS, as SFS algorithm assigns d�ie ¼ 1 CPU to each selectedthread, where 0 < �i � 1 for all threads in that case. Thus,this algorithm is designed to extract parallelism for eachinternal node in the scheduling tree. However, note that thisalgorithm does not guarantee that b�ic � ri � d�ie for allnodes in the scheduling tree, as shown for H-SMP. We useExt-SFS to represent one possible extension of an existingmultiprocessor proportional-share algorithm.
7.1.3 Hierarchical Round Robin
Hierarchical Round Robin (H-RR) is an instantiation ofH-SMP that employs the Round-Robin algorithm as theauxiliary scheduler. This algorithm also employs a spacescheduler (and the notions of deficit, auxiliary, andineligible sets) to assign processors to nodes. However,the nodes in the auxiliary set are scheduled using theRound-Robin scheduler instead of SFS or anotherproportional-share algorithm. We use this algorithm forcomparison to illustrate that a naive choice of auxiliaryscheduler can result in deviations from the fair allocationof bandwidth, even when employing the space scheduleras the first component of the hierarchical scheduler.
To quantify the performance of an algorithm, wemeasure the normalized deviation Di of each node i in
the scheduling tree from its ideal share: Di ¼ Ai�Aideali
Atotal
��� ���,where Ai and Atotal denote the CPU service received by
node i and the total CPU service in the system, respectively,
and Aideali is the ideal CPU service that the node should have
received based on its relative weight in the hierarchy. We
then use statistics such as the mean and maximum
deviation of all the nodes in the scheduling tree to quantify
the unfairness of the algorithm. Thus, an algorithm with
smaller deviation values is better able to satisfy the CPU
requirements of the tree nodes.
7.2 Comparison of Schedulers
We first compare the performance of the various schedulersdescribed above in terms of their ability to satisfy the CPUrequirements of the threads and nodes in the schedulingtree. We present results only for some of the parametercombinations due to space constraints.
7.2.1 No Arrivals and Departures
In our first set of experiments, we assume a fixed set ofthreads and a fixed scheduling hierarchy during each run;that is, there are no thread arrivals/departures. Fig. 3shows the comparison of the algorithms described abovefor 2, 8, and 32-processor systems for a scheduling treewith 10 internal nodes. The figure plots both the mean andthe maximum deviation from the ideal share for all thenodes in the tree. Based on the graphs, the SFS algorithmhas the highest deviation. This is because SFS assigns atmost one CPU to each node, resulting in large deviationsfor nodes that have a requirement of multiple CPUs. Thepoor performance of SFS shows the inability of a thread-scheduling algorithm to exploit thread parallelism withinthe tree. The H-RR algorithm also performs relativelypoorly. However, in Figs. 3b, 3d, and 3f, which plot themaximum deviation for any node in the tree, we see that themaximum deviation of any node in the tree, in the presenceof H-RR, is bounded by about 17.1 percent, 5.89 percent, and1.75 percent for 2-, 8-, and 32-CPU systems, respectively,which translates to a maximum deviation of about 0.34, 0.47,and 0.54 CPUs, respectively. Since the maximum deviation< 1, this result shows that the number of CPUs available toany node in the scheduling tree is bounded by the upper andlower thresholds of its processor requirement. However,since the Round-Robin algorithm does not differentiatebetween the requirements of different nodes, the residualbandwidth is not divided proportionately among the nodes.Finally, we see that the Ext-SFS and H-SFS algorithms havesmall deviation values, indicating that employing a general-ization of a proportional-share algorithm is crucial inmeeting the requirements. Furthermore, we see that H-SFShas the smallest deviation values, which indicates that acombination of threshold bounds and a proportional-sharealgorithm provides the best performance in terms ofachieving proportional-share allocation.
Similarly, Figs. 4a and 4b show the comparison ofthe algorithms for scheduling trees with different sizes(6 and 10 internal nodes, respectively) and running on a32-processor system. As shown in the figures, theresults are similar to those obtained above, and theH-SFS algorithm again has the least mean deviationvalues among the algorithms considered here.
7.2.2 Arrivals and Departures
Next, we allow thread arrivals and departures in the systemby using the methodology described in Section 7.1. Fig. 5shows the mean deviation for the different algorithms for 4, 8,16, and 32-CPU systems with 10 internal nodes, respectively.Here, we have the initial number of threads in the system onthe x-axis (the actual number of threads vary over theduration of the run as threads arrive and depart). Once again,
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 427

we notice that SFS performs the worst and H-SFS performs
the best in all cases. However, we notice an interesting trend
with respect to the performance of H-RR and Ext-SFS. As the
number of CPUs increases, the performance of Ext-SFS
becomes comparatively worse, whereas that of H-RR
improves marginally. This happens, because with an increas-
ing number of CPUs, there are more arrivals/departures in
the system.13 This result indicates that H-SMP-based algo-
rithms (H-SFS and H-RR) are able to maintain the processor
requirement bounds more effectively in the presence of an
increasing number of thread arrivals/departures. Moreover,the impact of such arrivals/departures on H-SMP can be seento be minimal in terms of maintaining these bounds.
Overall, these results demonstrate that a combination ofspace scheduling coupled with a proportional-share algo-rithm such as SFS as an auxiliary scheduler achieves the mostdesirable allocation. We see that a thread-scheduling algo-rithm is ineffective for exploiting thread parallelism in ascheduling tree. We also see that although a simple extensionof a proportional-share algorithm such as SFS is fairlyeffective in achieving a desirable allocation, its performanceis adversely affected by frequent thread arrivals/departures.Finally, fitting a naive algorithm such as Round Robin in thehierarchical framework does not maintain the desired shareseffectively.
428 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
13. There are more processors available for parallel execution, thusallowing threads to finish faster. In addition, recall that we use a higherarrival rate for more CPUs to balance out the large departure rate in ourexperiments.
Fig. 3. Mean and maximum deviation for scheduling trees with 10 internal nodes on different sizes of multiprocessor systems and no arrivals/
departures. (a) Two CPUs: mean deviation. (b) Two CPUs: maximum deviation. (c) Eight CPUs: mean deviation. (d) Eight CPUs: maximum
deviation. (e) Thirty-two CPUs: mean deviation. (f) Thirty-two CPUs: maximum deviation.

7.3 Impact of System Parameters
Now, we consider the effect of system parameters such
as the number of threads, number of processors, and
tree size on the performance of H-SFS. All of these
results are for the scenario with arrivals/departures of
threads.
7.3.1 Impact of the Number of Threads
The impact of increasing the number of threads on H-SFS
can be seen in Figs. 3, 4, and 5 (the lowest curve in all
figures), which show that the number of threads has little
impact on the allocation deviation, indicating that H-SFS
is largely unaffected by the number of threads in the
system.
7.3.2 Impact of the Number of Processors
In Fig. 6, we plot the mean deviation as the number of CPUs
is varied. In the figure, we see that the mean deviation
increases as we increase the number of processors in the
system. This result can be explained due to more arrivals/
departures happening with more CPUs, as explained in the
previous section. Such frequent arrivals/departures impact
the adjusted weights more frequently and lead to more
temporary imbalances in processor allocation.
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 429
Fig. 4. Mean deviation for scheduling trees with different sizes on a 32-processor system and no arrivals/departures. (a) Six internal nodes.
(b) Ten internal nodes.
Fig. 5. Mean deviation for scheduling trees with 10 internal nodes on different sizes of multiprocessor systems and with arrivals/departures.
(a) Four CPUs. (b) Eight CPUs. (c) Sixteen CPUs. (d) Thirty-two CPUs.
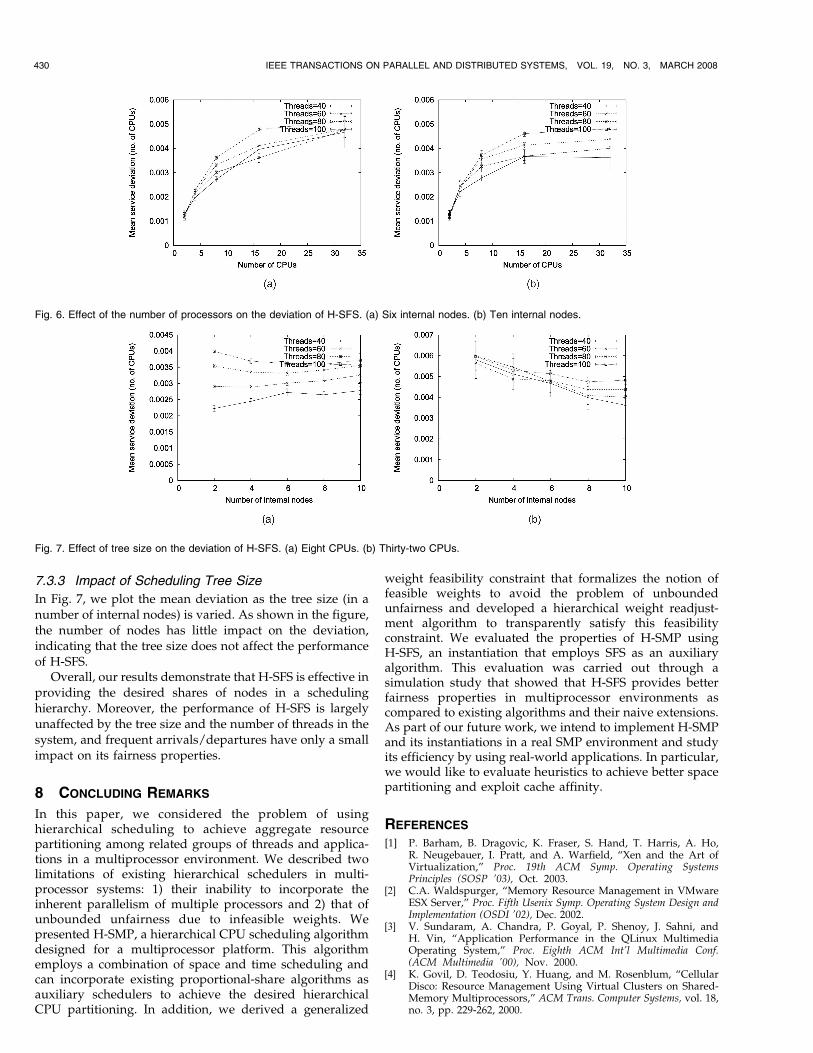
7.3.3 Impact of Scheduling Tree Size
In Fig. 7, we plot the mean deviation as the tree size (in anumber of internal nodes) is varied. As shown in the figure,the number of nodes has little impact on the deviation,indicating that the tree size does not affect the performanceof H-SFS.
Overall, our results demonstrate that H-SFS is effective inproviding the desired shares of nodes in a schedulinghierarchy. Moreover, the performance of H-SFS is largelyunaffected by the tree size and the number of threads in thesystem, and frequent arrivals/departures have only a smallimpact on its fairness properties.
8 CONCLUDING REMARKS
In this paper, we considered the problem of usinghierarchical scheduling to achieve aggregate resourcepartitioning among related groups of threads and applica-tions in a multiprocessor environment. We described twolimitations of existing hierarchical schedulers in multi-processor systems: 1) their inability to incorporate theinherent parallelism of multiple processors and 2) that ofunbounded unfairness due to infeasible weights. Wepresented H-SMP, a hierarchical CPU scheduling algorithmdesigned for a multiprocessor platform. This algorithmemploys a combination of space and time scheduling andcan incorporate existing proportional-share algorithms asauxiliary schedulers to achieve the desired hierarchicalCPU partitioning. In addition, we derived a generalized
weight feasibility constraint that formalizes the notion offeasible weights to avoid the problem of unboundedunfairness and developed a hierarchical weight readjust-ment algorithm to transparently satisfy this feasibilityconstraint. We evaluated the properties of H-SMP usingH-SFS, an instantiation that employs SFS as an auxiliaryalgorithm. This evaluation was carried out through asimulation study that showed that H-SFS provides betterfairness properties in multiprocessor environments ascompared to existing algorithms and their naive extensions.As part of our future work, we intend to implement H-SMPand its instantiations in a real SMP environment and studyits efficiency by using real-world applications. In particular,we would like to evaluate heuristics to achieve better spacepartitioning and exploit cache affinity.
REFERENCES
[1] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho,R. Neugebauer, I. Pratt, and A. Warfield, “Xen and the Art ofVirtualization,” Proc. 19th ACM Symp. Operating SystemsPrinciples (SOSP ’03), Oct. 2003.
[2] C.A. Waldspurger, “Memory Resource Management in VMwareESX Server,” Proc. Fifth Usenix Symp. Operating System Design andImplementation (OSDI ’02), Dec. 2002.
[3] V. Sundaram, A. Chandra, P. Goyal, P. Shenoy, J. Sahni, andH. Vin, “Application Performance in the QLinux MultimediaOperating System,” Proc. Eighth ACM Int’l Multimedia Conf.(ACM Multimedia ’00), Nov. 2000.
[4] K. Govil, D. Teodosiu, Y. Huang, and M. Rosenblum, “CellularDisco: Resource Management Using Virtual Clusters on Shared-Memory Multiprocessors,” ACM Trans. Computer Systems, vol. 18,no. 3, pp. 229-262, 2000.
430 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 19, NO. 3, MARCH 2008
Fig. 6. Effect of the number of processors on the deviation of H-SFS. (a) Six internal nodes. (b) Ten internal nodes.
Fig. 7. Effect of tree size on the deviation of H-SFS. (a) Eight CPUs. (b) Thirty-two CPUs.

[5] Intel Dual-Core Server Processor, http://www.intel.com/business/bss/products/server/dual-core.htm, 2006.
[6] IBM xSeries with Dual-Core Technology, http://www.intel.com/business/bss/products/server/dual-core.htm, 2006.
[7] T.E. Anderson, B.N. Bershad, E.D. Lazowska, and H.M. Levy,“Scheduler Activations: Effective Kernel Support for the User-Level Management of Parallelism,” ACM Trans. Computer Systems,vol. 10, no. 1, pp. 53-79, Feb. 1992.
[8] G. Banga, P. Druschel, and J. Mogul, “Resource Containers: ANew Facility for Resource Management in Server Systems,” Proc.Third Usenix Symp. Operating System Design and Implementation(OSDI ’99), pp. 45-58, Feb. 1999.
[9] P. Goyal, X. Guo, and H. Vin, “A Hierarchical CPUScheduler for Multimedia Operating Systems,” Proc. SecondUsenix Symp. Operating System Design and Implementation(OSDI ’96), pp. 107-122, Oct. 1996.
[10] J. Bennett and H. Zhang, “Hierarchical Packet Fair QueuingAlgorithms,” Proc. ACM SIGCOMM ’96, pp. 143-156, Aug. 1996.
[11] A. Demers, S. Keshav, and S. Shenker, “Analysis and Simula-tion of a Fair Queueing Algorithm,” Proc. ACM SIGCOMM ’89,pp. 1-12, Sept. 1989.
[12] K. Duda and D. Cheriton, “Borrowed Virtual Time (BVT)Scheduling: Supporting Latency-Sensitive Threads in a General-Purpose Scheduler,” Proc. 17th ACM Symp. Operating SystemsPrinciples (SOSP ’99), pp. 261-276, Dec. 1999.
[13] S.J. Golestani, “A Self-Clocked Fair Queueing Scheme for High-Speed Applications,” Proc. IEEE INFOCOM ’94, pp. 636-646,Apr. 1994.
[14] P. Goyal, H.M. Vin, and H. Cheng, “Start-Time Fair Queuing: AScheduling Algorithm for Integrated Services Packet SwitchingNetworks,” Proc. ACM SIGCOMM ’96, pp. 157-168, Aug. 1996.
[15] J. Nieh and M.S. Lam, “The Design, Implementation andEvaluation of SMART: A Scheduler for Multimedia Applica-tions,” Proc. 16th ACM Symp. Operating Systems Principles(SOSP ’97), pp. 184-197, Dec. 1997.
[16] B. Caprita, W. Chan, J. Nieh, C. Stein, and H. Zheng, “GroupRatio Round-Robin: O(1) Proportional Share Scheduling forUniprocessor and Multiprocessor Systems,” Proc. Usenix Ann.Technical Conf. ’05, Apr. 2005.
[17] Solaris Resource Manager 1.0: Controlling System Resources Effec-tively. Sun Microsystems, Inc., http://www.sun.com/software/white-papers/wp-srm/, 1998.
[18] C. Waldspurger and W. Weihl, “Stride Scheduling: DeterministicProportional-Share Resource Management,” Technical ReportTM-528, Laboratory for Computer Science, Mass. Inst. ofTechnology, June 1995.
[19] A. Chandra, M. Adler, P. Goyal, and P. Shenoy, “Surplus FairScheduling: A Proportional-Share CPU Scheduling Algorithm forSymmetric Multiprocessors,” Proc. Fourth Usenix Symp. OperatingSystem Design and Implementation (OSDI ’00), Oct. 2000.
[20] I. Stoica, H. Abdel-Wahab, K. Jeffay, S. Baruah, J. Gehrke, andG. Plaxton, “A Proportional-Share Resource Allocation Algo-rithm for Real-Time, Time-Shared Systems,” Proc. 17th IEEEReal Time Systems Symp. (RTSS ’96), pp. 289-299, Dec. 1996.
[21] C.A. Waldspurger and W.E. Weihl, “Lottery Scheduling: FlexibleProportional-Share Resource Management,” Proc. First UsenixSymp. Operating System Design and Implementation (OSDI ’94),Nov. 1994.
[22] R.M. Karp and V. Ramachandran, “Parallel Algorithms forShared-Memory Machines,” Handbook of Theoretical ComputerScience—Volume A: Algorithms and Complexity, pp. 869-941, 1990.
Abhishek Chandra received the BTech degreein computer science and engineering from theIndian Institute of Technology, Kanpur, India, in1997 and the MS and PhD degrees in computerscience from the University of Massachusetts,Amherst, in 2000 and 2005, respectively. He iscurrently an assistant professor in the Depart-ment of Computer Science and Engineering,University of Minnesota. His research interestsinclude operating systems, distributed systems,
and Internet systems. He received a US National Science FoundationFaculty Early Career Development (CAREER) Award in 2007, and hisPhD dissertation “Resource Allocation for Self-Managing Servers” wasnominated for the ACM Dissertation Award in 2005. He is a member ofthe IEEE, the ACM, and the Usenix.
Prashant Shenoy received the BTech degree incomputer science and engineering from theIndian Institute of Technology (IIT), Bombay, in1993 and the MS and PhD degrees in computerscience from the University of Texas at Austin(UT) in 1994 and 1998, respectively. He iscurrently an associate professor of computerscience at the University of Massachusetts,Amherst. His research interests include operat-ing and distributed systems, sensor networks,
Internet systems and pervasive multimedia. He is the recipient of a USNational Science Foundation Faculty Early Career Development(CAREER) Award, the IBM Faculty Development Award, the LillyFoundation Teaching Fellowship, the UT Computer Science BestDissertation Award, and an IIT Silver Medal. He is a senior member ofthe IEEE and the ACM.
. For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
CHANDRA AND SHENOY: HIERARCHICAL SCHEDULING FOR SYMMETRIC MULTIPROCESSORS 431





























