Embed Size (px)
Citation preview

Tentative ASPLOS Paper Title: Inter-Core Cooperative TLB Prefetchers for Chip Multiprocessors
Abhishek BhattacharjeeGroup Talk: July 20th, 2009

Introduction
TLBs are performance critical (Clark & Emer, Huck & Hays, Nagle, Rosenblum …)
Conventional uniprocessor strategies TLB size, associativity, multilevel hierarchies [Chen, Borg &
Jouppi] Superpaging [Talluri] Prefetching [Kandiraju & Sivasubramaniam, Saulsbury,
Dahlgren & Stenstrom]
Challenge: Novel parallel workloads stress TLBs heavily [PACT-18]
Opportunity: Parallel workloads also exhibit commonality in TLB misses across cores

Commonality in TLB Miss Behavior
Black
scho
les
Canne
al
Face
sim
Ferre
t
Fluid
anim
ate
Stre
amclus
ter
Swap
tions
VIPS
x264
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Inter-Core Predictable Stride Inter-Core Shared (4 sharers)Inter-Core Shared (3 sharers)Inter-Core Shared (2 sharers)
DT
LB
Mis
se
s (
No
rm.
to T
ota
l D
TLB
Mis
se
s i
n 1
Mil
lio
n I
nst.
)
Goal: Use commonality in miss patterns to prefetch TLB entries to cores based on the behavior of other cores

Prefetching Challenges
Challenge 1: Timing (sufficient reaction time versus prefetching too early)
2 4 8 16 32 64 128
256
51210
2420
4840
9681
92
1638
4
3276
8
6553
6
1310
72
2621
44
5242
88
1048
576
2097
152
4194
304
8388
608
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
BlackscholesCannealFacesimFerretFluidanimateStreamclusterSwaptionsVIPSx264
Number of Cycles Between Use on Initiating Core and Prediction Core
CD
F o
f T
ota
l D
TLB
Mis
se
s

Prefetching Challenges
Challenge 2: Adapting to a wide variety of patterns (stride values, stride patterns etc.)
Benchmark Prominent Strides
Blackscholes +4, -4 pages
Canneal Inter-core Shared
Facesim Inter-core Shared, +2, -2, +3, -3 pages
Ferret Inter-core Shared
Fluidanimate Inter-core Shared, +1, -1, +2, -2 pages
Streamcluster Inter-core Shared
Swaptions Inter-core Shared, +1, -1, +2, -2 pages
VIPS Inter-core Shared, +1, -1, +2, -2 pages
x264 Inter-core Shared, +1, -1, +2, -2 pages

Our Approach
Explore two types of inter-core cooperative TLB prefetchers individually and then combine them (specifically for DTLBs)
Prefetcher 1: Leader-Follower TLB Prefetching Targeted at Inter-core Shared TLB Misses
Prefetcher 2: Distance-Based Cross-Core Prefetching Targeted at Inter-core Shared and Inter-core Stride TLB
Misses

Methodology Simics with Opal & Ruby (simulate 1 billion
instructions of parallel region)Parameter Description
Architecture Sparc (Out-of-order)
Number of Cores 4, 8, 16
MMU SW-managed, per-core
TLBs (I & D) 64-entry (2-way), 512-entry, 1024-entry (2-way)
Fetch/Issue/Commit Width
4
ROB 64-entry
Instruction Window 32-entry
L1 Cache Private, 32KB (4-way)
L2 Cache Shared, 16MB (4-way)
L2 Roundtrip 40 cycles (uncontested)
OS Solaris 10
Interconnection Network Mesh

Leader-Follower TLB Prefetching
Core 0
. .
.D-TLBPrefetc
h Buffer
Core 1
D-TLBPrefetc
h Buffer
Core N
D-TLBPrefetc
h Buffer
1. DTLB and PB miss, walk page table, repopulate DTLB
2. Prefetch the DTLB entry into PBs of other cores
3. DTLB miss but PB hit, remove from PB and insert in DTLB

Ideal Leader-Follower Prefetching Data Assume infinite prefetch buffer size
High elimination for high inter-core shared workloadsBla
cksc
hole
s
Canne
al
Face
sim
Ferre
t
Fluid
anim
ate
Stre
amclus
ter
Swap
tions
VIPS
x264
0
10
20
30
40
50
60
70
80
90
100
% D
TLB
Mis
se
s E
lim
ina
ted
(Id
ea
l Le
ad
er-
Fo
llo
we
r P
refe
tch
ing
)

Distance-Based Cross-Core Prefetching Targeted at eliminating inter-core stride TLB misses The idea: use distances between subsequent TLB
miss virtual pages from single core to prefetch entries
ExampleCore0 Core 1VP: 1 VP: 5VP: 2 VP: 6VP: 4 VP: 8VP: 5 VP:9VP: 7 VP:11VP: 8 VP: 12
Stride: 4 pages
Common distance pairs: (1, 2), (2, 1)
Assume core 0 runs ahead and gets to VP:5 before core 1
misses
6 of the TLB misses become predictable
based on pairs This approach can capture various stride patterns among cores effectively (and also capture within-core TLB miss patterns)

Distance-Based Prefetching HW
Core 0
. .
.D-TLBPrefetc
h Buffer
Core 1
D-TLBPrefetc
h Buffer
Core N
D-TLBPrefetc
h Buffer
Distance Table(Shared, central
location)
1. DTLB and PB miss, walk page table, repopulate DTLB
2. Send missed VP to Distance Table to look up prefetches and update Distance Table pattern
3. Send prefetched VPs to PB (possibly based on pattern from another core)
4. DTLB miss but PB hit, remove entry from PB and insert in DTLB
5. Send PB hit VP to Distance Table to look up prefetches and update Distance Table pattern
6. Send prefetched VPs to PB (possibly based on a pattern from another core)

Distance-Based Prefetching Table Details
N-way set associative
Distance Table<Tag > <Ctx> <CPU #> <Pred. Dist.>
Last VP Table
Last Distance Table
1. Find the last VP for this core. Current Distance = Last VP – Current VP.
2. Index into Distance Table using lower bits of Current Distance. 3. Scan through all ways in the set
for matching tag and context. For match, predicted next VP is Current VP + Predicted Distance (max of n-prefetches in n-way set associative distance table).
4. Find the Last Distance for this core.
5. Use Last Distance lower bits to index into Distance Table .
6. Scan through all ways for matching tag, context, CPU. Place Current Distance in the Predicted Distance Slot. Ensure no <Tag, Context, Predicted Distance> duplicates exist.

Some Other Details…
Once the predicted distance is made, ideally we would like to have an FSM that walks page table for physical page translation This exists in HW-managed MMUs but not SW-managed (for
now assume that this FSM exists)
Other option is to do the walk on an interrupt as with SW-managed MMUs
If suggested prefetch already exists in PB, just put it the top of LRU stack but do not prefetch
In case of shootdowns, remove entry from PB

Scope for Using Distance-Prefetching
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
Blackscholes
Canneal Facesim Ferret Fluidan-imate
Streamclus-ter
Swaptions VIPS x264
100
1000
10000
100000
1000000
10000000
Un
iqu
e D
ista
nce
P
air
s
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
1 s
hare
r2 s
hare
rs3 s
hare
rs4 s
hare
rs
Blackscholes Canneal Facesim Ferret Fluidanimate Streamclus-ter
Swaptions VIPS x264
1
10
100
1000
10000
100000
1000000
Avg
. R
eu
se p
er
Dis
tan
ce
Pa
ir

Ideal Distance-Based Prefetching
Assume infinite prefetch buffer, vary dist. table size (4-way)
High elimination across all workloads, especially with inter-core stride misses (eg. Blackscholes)
We select 512 entries 4.5 KB distance table
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
8K
entr
ies
4K
entr
ies
2K
entr
ies
1K
entr
ies
512 e
ntr
ies
256 e
ntr
ies
128 e
ntr
ies
Blackscholes Canneal Facesim Ferret Fluidanimate Streamcluster Swaptions VIPS x264
0
20
40
60
80
100
120
140% Eliminated DTLB Misses (Cross-Core)% Eliminated DTLB Misses (Within-Core)
% D
TLB
Mis
se
s

Combining the Two Prefetching Schemes Keep infinite size prefetch buffer and see how
combining leader-follower and distance-prefetching (512-entry) does
0
10
20
30
40
50
60
70
80
90
100 Leader-Follower PrefetchingDistance-Based PrefetchingCombined Inter-Core Cooperative Prefetch-ing
Eli
min
ate
d D
-TLB
Mis
se
s

Setting a Realistic Prefetch Buffer Size Use both prefetching schemes with 512-entry
distance table
We use 16-entry PB from now but note that Canneal & Streamcluster most adversely affected by PB size decrease
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
8 e
ntr
ies
16 e
ntr
ies
32 e
ntr
ies
64 e
ntr
ies
128 e
ntr
ies
Infinit
e
Blackscholes Canneal Facesim Ferret Fluidanimate Streamclus-ter
Swaptions VIPS x264
0
10
20
30
40
50
60
70
80
90
100 Leader-Follower PrefetchingDistance-Based Prefetching (Cross-Core)
Eli
min
ate
d D
TLB
Mis
se
s

Studying Useless Prefetches
Useless prefetch = prefetch into PB but evict without using (entry might be used later or never used)
Over-aggressive prefetching might prematurely evict what could be useful entries
Study for 16-entry PB
Black
scho
les
Canne
al
Face
sim
Ferre
t
Fluid
anim
ate
Stre
amclus
ter
Swap
tions
VIPS
x264
0102030405060708090
100
Leader-FollowerDistance-Based
% o
f P
refe
tches U
sele
ss
Note that here, Canneal and Streamcluster have highest usless prefetches (large leader-follower contributions

Eliminating Useless Prefetches
“Blind” leader-follower prefetches VP into all cores though they may be unused (eg. Streamcluster 22% misses in 2 cores, 45% in 3 cores, 28% in 4 cores)
Each core has 2-bit saturating counters (one per each target core) indicating whether to leader-follower prefetch
Adapt to varying sharing patterns

Eliminating Useless Prefetches
Core 0DTLB PB
Conf. Counters
CPU 1: 10
CPU N: 10
Core 1DTLB PB
Conf. Counters
CPU 0: 11
CPU N: 11
Core NDTLB PB
Conf. Counters
CPU 0: 11
CPU 1: 11. . .
1. DTLB and PB miss on VP, check counters, prefetch to core 0 and N
Core 0DTLB PB
Conf. Counters
CPU 1: 10
CPU N: 10
Core 1DTLB PB
Conf. Counters
CPU 0: 11
CPU N: 11
Core NDTLB PB
Conf. Counters
CPU 0: 11
CPU 1: 11. . .
CPU 0, VP1 CPU 0, VP1
2. DTLB miss but PB hit on VP sent by core 0, send message to core 0 to increment counter

Eliminating Useless Prefetches
Core 0DTLB PB
Conf. Counters
CPU 1: 11
CPU N: 10
Core 1DTLB PB
Conf. Counters
CPU 0: 11
CPU N: 11
Core NDTLB PB
Conf. Counters
CPU 0: 11
CPU 1: 11. . .
CPU 0, VP1 CPU 0, VP1
3. PB entry VP from core 0 gets evicted without use, send message to core 0 to decrement counter
Core 0DTLB PB
Conf. Counters
CPU 1: 11
CPU N: 01
Core 1DTLB PB
Conf. Counters
CPU 0: 11
CPU N: 11
Core NDTLB PB
Conf. Counters
CPU 0: 11
CPU 1: 11. . .
CPU 0, VP1 CPU 0, VP1
4. DTLB and PB miss, check counters, only prefetch to core 1

Eliminating Useless Prefetches
Core 0DTLB PB
Conf. Counters
CPU 1: 11
CPU N: 10
Core 1DTLB PB
Conf. Counters
CPU 0: 11
CPU N: 11
Core NDTLB PB
Conf. Counters
CPU 0: 11
CPU 1: 11. . .
CPU 0, VP1 CPU 0, VP1
5. DTLB and PB miss on core N, send message to all cores to increment counters
Core 0DTLB PB
Conf. Counters
CPU 1: 11
CPU N: 10
Core 1DTLB PB
Conf. Counters
CPU 0: 11
CPU N: 11
Core NDTLB PB
Conf. Counters
CPU 0: 11
CPU 1: 11
CPU 0, VP1 CPU 0, VP1
6. DTLB and PB miss, check counters, again prefetch to both cores 1 and N
CPU 0, VP2
CPU 0, VP2
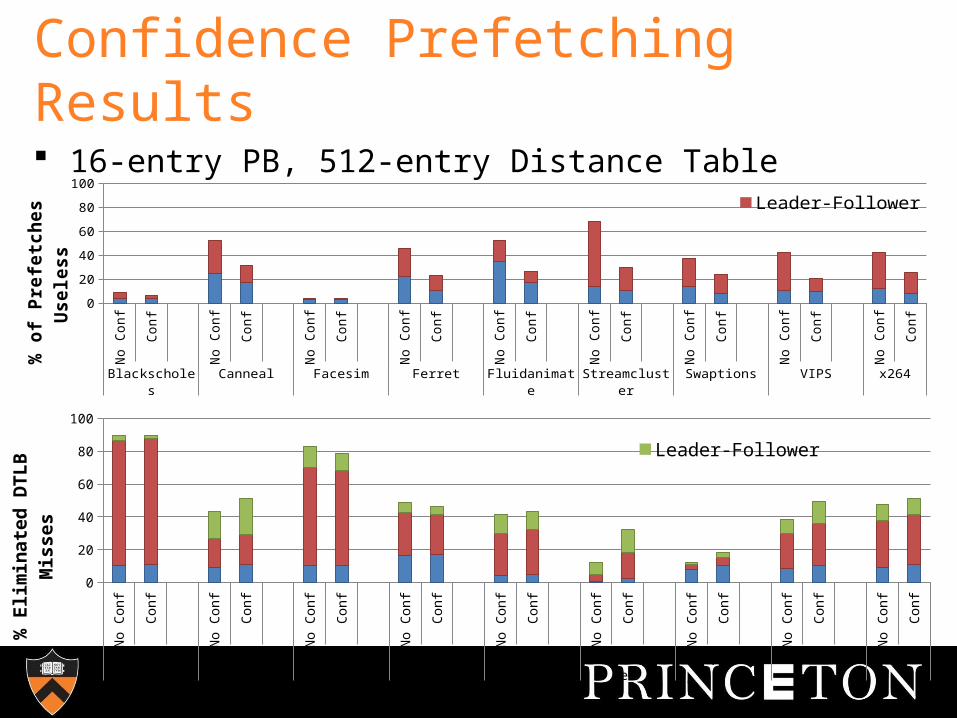
Confidence Prefetching Results
16-entry PB, 512-entry Distance Table
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
Blackscholes Canneal Facesim Ferret Fluidanimate Streamclus-ter
Swaptions VIPS x264
0
20
40
60
80
100
Leader-Follower
% o
f P
refe
tch
es
Use
less
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
No C
onf
Conf
Blackscholes Canneal Facesim Ferret Fluidanimate Streamclus-ter
Swaptions VIPS x264
0102030405060708090
100
Leader-Follower
% E
lim
ina
ted
DT
LB
M
isse
s

Comparison Against Larger TLB
We are putting 16 PB entries on critical path – could argue that we might just make DTLB 16 entries larger
Find performance benefits of our approach versus larger DTLB
Black
scho
les
Canne
al
Face
sim
Ferre
t
Fluid
anim
ate
Stre
amclus
ter
Swap
tions
VIPS
x264
0
1
2
3
4
5
Ra
tio
of
Eli
min
ate
d D
TLB
M
isse
s f
rom
Pre
fetc
he
r V
s 1
6 A
dd
itio
na
l T
LB
En
-tr
ies
45.3

Some HW Particulars…
So in HW-managed TLBs with separate FSMs to walk page table, prefetches can be accomplished under covers
What about SW-managed TLBs without FSMs? Leader-follower prefetching – unaffected since translations
known Distance-prefetching
TLB & PB miss unaffected since we are interrupt and can walk page table
TLB miss but PB hit – problem since we do not want interrupts on these! Solution 1: only prefetch on TLB & PB miss (poor performance …) Solution 2: re-index into distance table and burst-prefetch every time
interrupt is invoked due to TLB and PB miss

Reindexed Burst Distance Prefetching Assuming we allow up to 8 additional prefetches on
an interrupt – close to performance of ideal case with FSM
Black
scho
les
Canne
al
Face
sim
Ferre
t
Fluid
anim
ate
Stre
amclus
ter
Swap
tions
VIPS
x264
0
10
20
30
40
50
60
70
80
90
100
Prefetch on PB Hit and MissPrefetch on PB MissPrefetch Burst on PB Miss
% D
TLB
Mis
se
s E
lim
ina
ted

Next Steps (or why I will live in EQuad…) All data presented so far assumes ideal HW (no
access latency etc.). So we need to find performance improvements on 3 TLB sizes on 4 core with: Ideal HW case (0 latency, page walk FSM) HW structures with latency (L2 access for distance table)
and FSM HW structures with latency, without FSM (reindexed burst
prefetching), and prefetching in interrupt (results for page table entries in L1 cache and L2 cache)
SW distance table with reindexed burst prefetching (results for entries in L1 cache and L2 cache)
Opal terribly slow at higher core counts – find ideal HW case performance benefits for 8 cores and 16 cores too





![asplos-umdd-v14pages.cs.wisc.edu/~kadav/study/asplos-umdd-slides.pdf · 3/6/12 2 Improvement System Validation Drivers Bus Classes New functionality Shadow driver migration [OSR09]](https://img.pdfslide.us/doc/110x75/5f5ce2028dfc884a1f66bcbd/asplos-umdd-kadavstudyasplos-umdd-slidespdf-3612-2-improvement-system-validation.jpg)