Embed Size (px)
Citation preview

Evaluation of Regression Models
Data Analytics
João Gama, [email protected], P.Brazdil, [email protected]

MADSAD - Data Mining I 2
Overview
1. Loss Functions and Performance Metrics2. Bias and Variance3. Avoiding Overfitting4. BIC, Bayes Information Criterion5. Evaluation Methodology6. Feature Selection Methods for Regression Tasks

MADSAD - Data Mining I 3
1. Loss Functions for Regression
• Goal:
– Obtain reliable estimates of the error
• In the test set
– Compare different algorithms and assess whether they are significantly
different
• Other criteria:
– Interpretability of models
– Subjective and difficult to measure / compare
– computational complexity
– Theoretical analysis (analysis of algorithmic complexity)
• Measurements of the time of learning and testing
– Compressibility data
• The MDL principle
• Incorporates the interpretability (somehow) and the error in one
measurement.
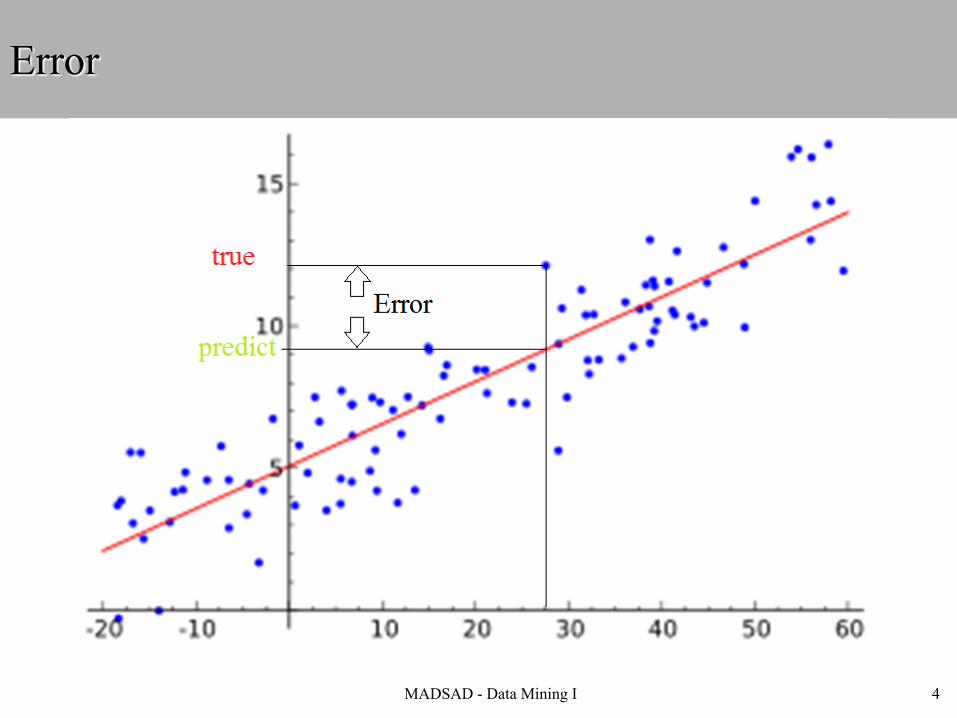
Error
4MADSAD - Data Mining I

MADSAD - Data Mining I 5
Loss Functions
• Mean Squared Error (MSE)
• Root Mean Squared Error (RMSE)
• Mean Absolute Error (MAE)
( ) ( )( )å=
-=n
iii ry
nrMSE
1
21x
( ) ( )( )å=
-=n
iii ry
nrRMSE
1
21x
( ) ( )å=
-=n
iii ry
nrMAE
1
1x

MADSAD - Data Mining I 6
Loss Functions
• Normalized (Relative) Mean Squared Error (NMSE)
• Normalized (Relative) Mean Absolute Error (NMAE)
• Coeficient of determination – ratio R2
( )( )
å
å
=
=
-
-= n
ii
n
iii
yy
ryrMAEN
1
1x
( )( )( )
( )å
å
=
=
-
-= n
ii
n
iii
yy
ryrMSEN
1
2
1
2x
( )( )( )
( )å
å
=
=
-
-= n
ii
n
ii
yy
yrrR
1
2
1
2
2x

MADSAD - Data Mining I 7
Other Performance Metrics
• Correlation Coefficient betweenpredictions (x) and true values (y)

MADSAD - Data Mining I 8
Observations
• Measures involving square errors amplify the large errors – So it may be good in areas where large errors are intolerable. – The MSE is not expressed in the units of Y.
• RMSE
• The MAE is not as sensitive to large errors – Gives a better indication of the "typical" error of the model because it
treats all errors the same way and is expressed in the same units of Y. • The measures have the advantage of independence of the
application domain• The correlation coefficient is invariant to scale changes.
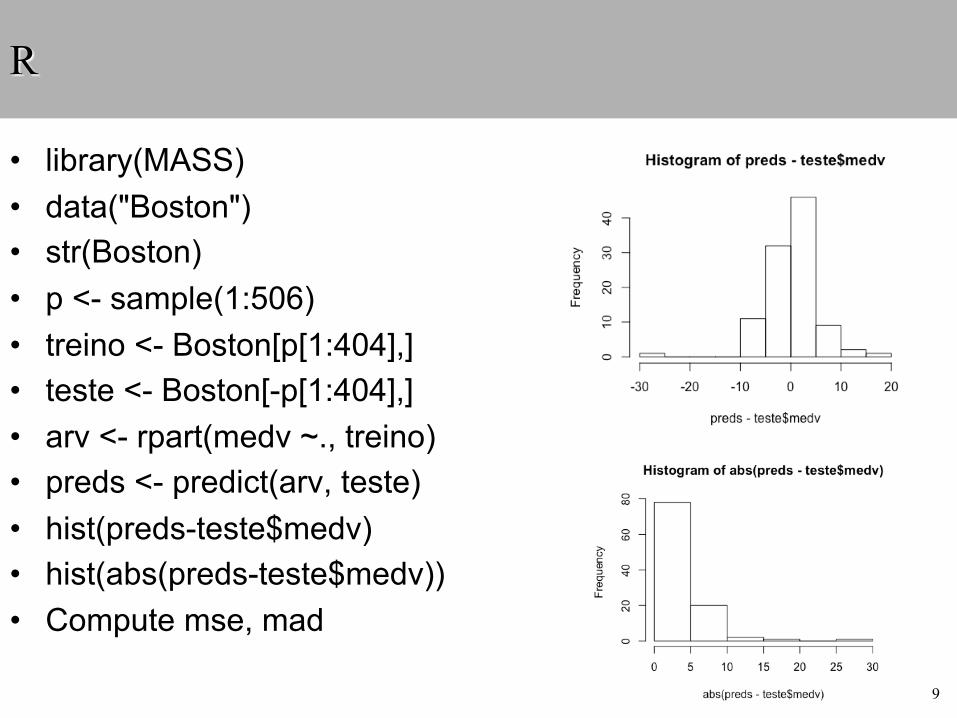
R
• library(MASS)• data("Boston")• str(Boston)• p <- sample(1:506)• treino <- Boston[p[1:404],]• teste <- Boston[-p[1:404],]• arv <- rpart(medv ~., treino)• preds <- predict(arv, teste)• hist(preds-teste$medv)• hist(abs(preds-teste$medv))• Compute mse, mad
9

MADSAD - Data Mining I 10
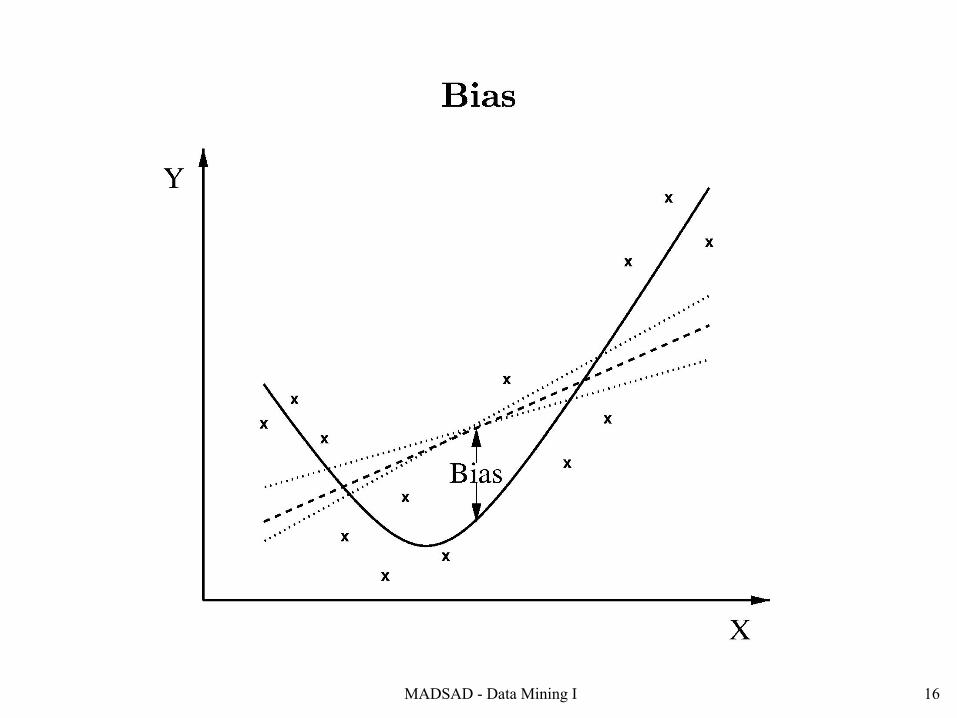
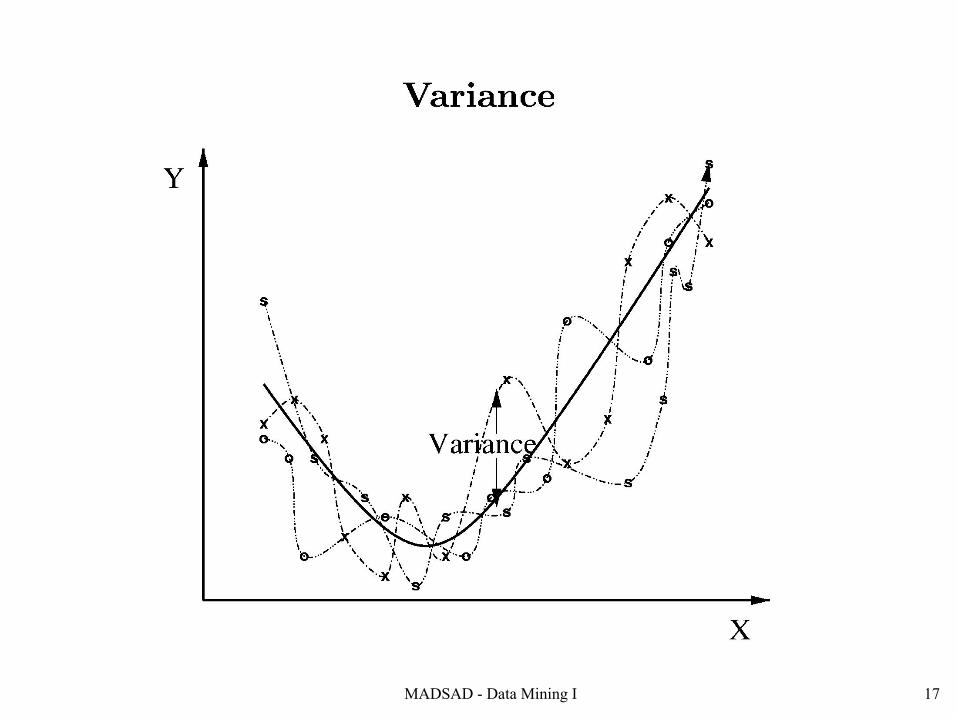
2. Bias and Variance
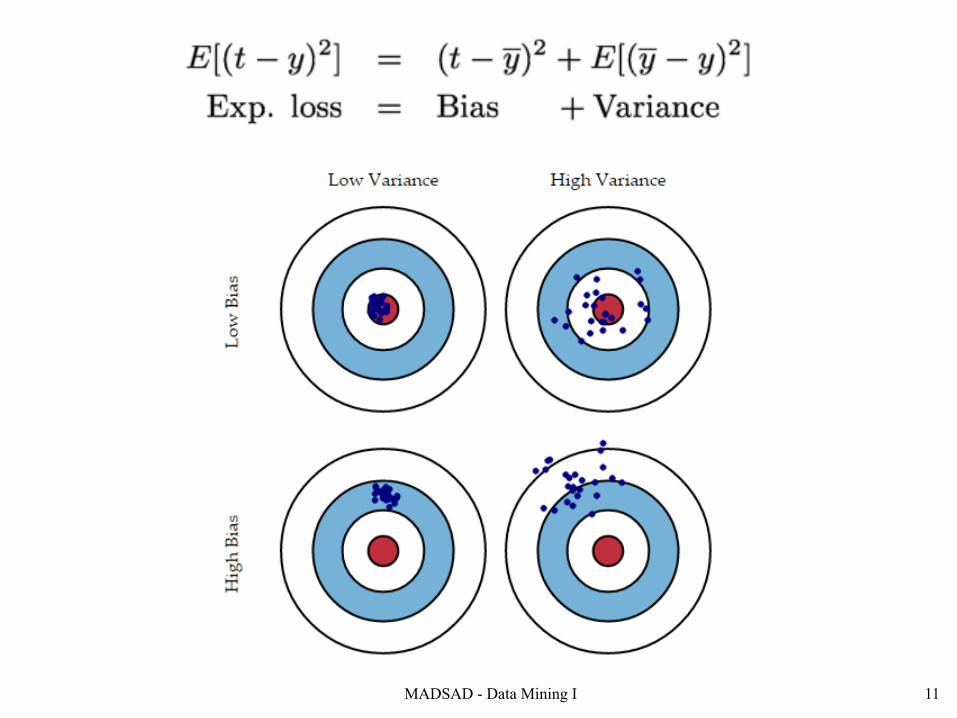
11MADSAD - Data Mining I
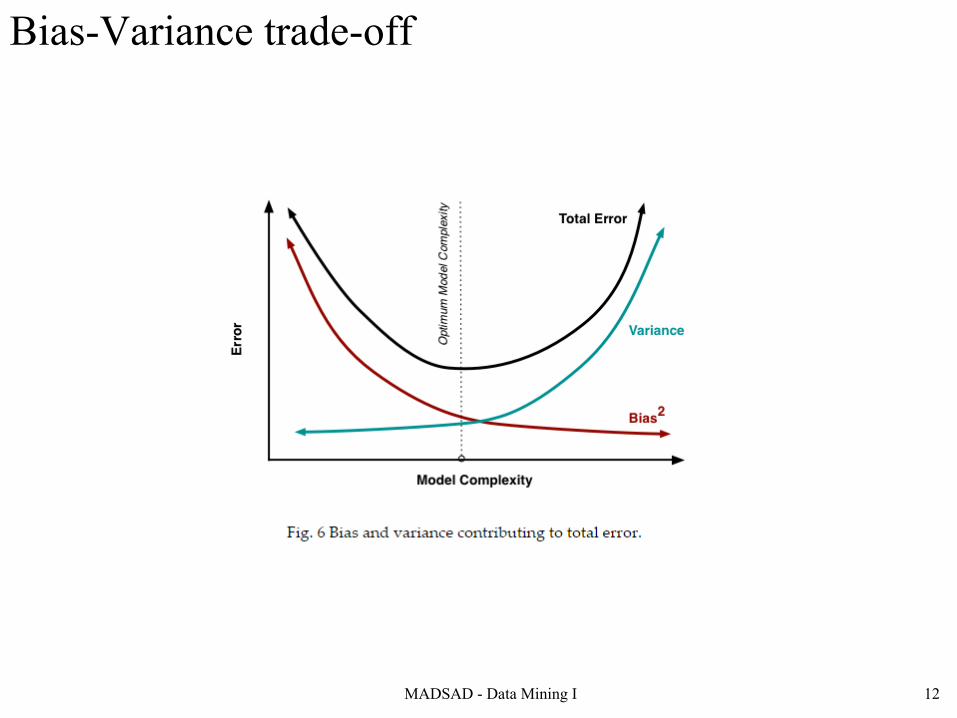
MADSAD - Data Mining I 12
Bias-Variance trade-off
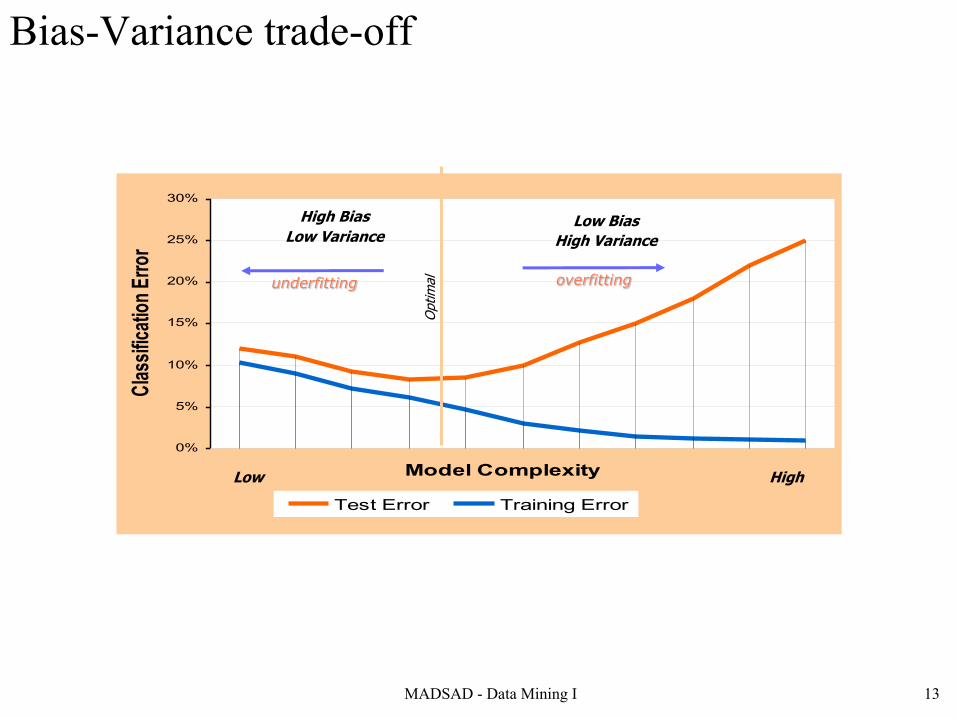
MADSAD - Data Mining I 13
Bias-Variance trade-off
0%
5%
10%
15%
20%
25%
30%
Model Complexity
Class
ificati
on Er
ror
Test Error Training Error
High BiasLow Variance
Low BiasHigh Variance
Low High
Optimal overfittingunderfitting
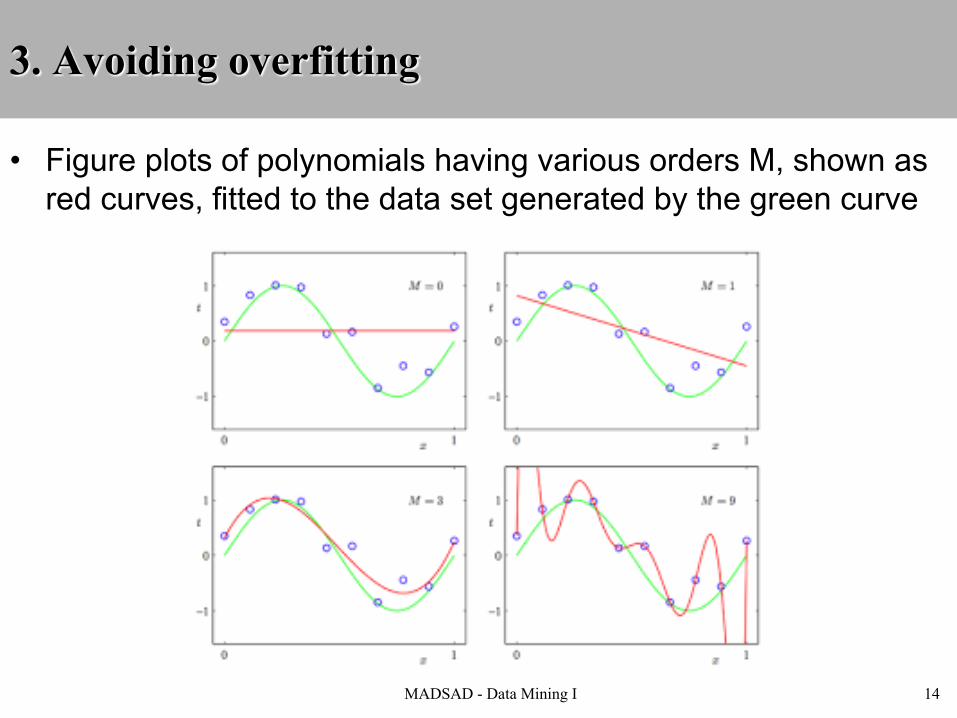
3. Avoiding overfitting
• Figure plots of polynomials having various orders M, shown as red curves, fitted to the data set generated by the green curve
MADSAD - Data Mining I 14

MADSAD - Data Mining I 15
MADSAD - Data Mining I 16
MADSAD - Data Mining I 17

MADSAD - Data Mining I 18

MADSAD - Data Mining I 19

MADSAD - Data Mining I 20
4. BIC – Bayes Information Criterion
• BIC enables to estimate the true error (on test data) on the basis of the training error.
– When fitting models, it is possible to increase the likelihood by adding parameters, but doing so may result in overfitting.
• BIC resolves this problem by introducing a penalty term for the number of parameters in the model.
• BIC = -2 * ln(L) + p* ln(N)– L .. Maximized value of likelihood function
L(q) = P p^(x(i), q)– N .. number of training examples– p .. Number of free parameters

MADSAD - Data Mining I 21
BIC – Bayes Information Criterion
Assuming that errors are independent and identically distributed (i.i.d.), this becomes:
• BIC = N * ln(MSE) + p* ln(N) (sometimes p is added)
whereMSE .. mean square error (= s2, true variance)
Normalized version:
BIC’ = BIC/N = ln(MSE) + p* ln(N)/N

MADSAD - Data Mining I 22
Other Criteria – AIC and DIC
AIC – Akaike information criterionis founded in information theory.
AIC = 2*p – ln(L)
DIC – Deviance Information Criterionuseful in Bayesian model selection, when posterior distribution of models has been obtained byMarkov chain Monte Carlo (MCMC)

MADSAD - Data Mining I 23
5. Experimental Methodology
• The same observations made in the study of this subject for classification methods are valid.
• Common methods – N-fold Cross Validation (typically 10-fold) – Bootstrap (more suitable for small sample sizes) – Holdout (adequate and sufficient for very large samples)
• The most commonly used – 10-fold CV – Assessment about statistical significance of the mean using paired t-
tests.

MADSAD - Data Mining I 24
5. Feature Selection Methods for Regression Tasks
• We can use both:– filter methods,– backward elimination / forward selection (i.e. closed-loop methods) as in classification.
The filter methods need to use appropriate measure, such as:– correlation
(instead of IG, information gain, used in classification)





























