Embed Size (px)
Citation preview

2014 GSPIA Amazing Analytics RaceFriday Training Camp
Sera LinardiAssistant Professor of Economics

8:30am Getting ready: Your To-Do ListIntroductionsAustin Holmes (IT) and TAs Jingyi Zhang and Nathan Karle (from last year’s Amazing Race). Introduce yourself to 2 new people around you.
1. Register: find your name, cross it out, get nametags + breakfast2. Get Stata if you haven’t already.3. Get online if you haven’t already. 4. Create a folder in your computer for all your files for math camp. 5. Go to http://www.linardi.gspia.pitt.edu/? page_id=564. Under Friday, download
Sampler, Slides, Business.dta, and Cars.dta into the folder6. Open STATA, go to File, Change Working directory to your math camp folder. 8. Read in Cars.dta: go to File, Open, and click on Cars.dta9. Done? Browse through the files in the sampler. Go to the next slide to see the
list of faculty you will meet today. Write down any questions that you would like to ask them about today.
10. We will start lecture at 9am, if not earlier.

Welcome! What are we doing today? We are beginning your GSPIA journey with the end in mind: a career solving real world problems
First, let’s define what this workshop will NOT do:• Guarantee you an A in Quant I or Micro or any quant class• Make you a math whiz• Explain any mathematical concept in depth
What this workshop aim to do:• Connect quant methods to the real world. Begin to demystify math for those who fear it.• Provide you with a hands-on experience of how quant methods can give you an additional
edge in tackling policy questions• Give a 1000 feet view of the variety of classes, faculty members, and research opportunities
that relates to quantitative methods
Remember that many of your classmates were waitlisted and were not able to get in this workshop due to space constraints. Please make everything you learn here a public good – make it a priority to know it well enough to explain to others and patiently and freely share it with anyone who may be struggling with these concepts.

Faculty you will meet today(and their FA 14 classes)
• Sera Linardi (me: Micro I, Quant II, Game theory/behavioral)10:30• Taylor Seybolt (Human Security, Ethnic Conflict) • Kevin Morrison (Intro Quant) 1:30• Sabina Dietrich (Neigh.& Comm Development)• Meredith Wilf (Global Gov, Financial Crisis)• Michael Lewin (Econ Pub Affairs, Macro)3:00• Luke Condra (Global Gov, Ethics & Nat’l Security)• Louise Comfort (Policy Design, Systems Theory)• John Mendeloff (Benefit Cost Analysis)

And.. what is GSPIA’s Amazing Analytics Race ?
• At the end of today, you will be randomly split into pairs for tomorrow.
• Your team will be given a mission tomorrow morning where you will solve a puzzle using real world data, the quantitative methods you learn today, and lots of creativity.
• You will be given your first clue at 9am and you will have 3 hours to accomplish it by interlocking a series of 10 clues.
• What’s at stake: 1st place team = a $200 Bookstore gift certificate. 2nd place team = $100. 3rd place = $50.
• After teams are formed today, we will brief you the rules of the race, and your team will have one evening to study together and strategize.

How today’s training camp works• In the lecture I will introduce quantitative methods around solving
a case study.• You have the slides in your computer, so you can always go back /
make notes, etc. • After every short lecture you will get time to practice the methods
in a quiz. You can work with students around you, and freely ask any of us questions (raise your hand and we will come by).
• Ask! There is no dumb question, this is a refresher workshop so forgetting basic stuff is totally okay.
• Please don’t browse the internet/ phone for unrelated stuff. If you are waiting for others to finish, see if anyone needs help. Check on your two new neighbors. Try new things in STATA.

Imagine you are an advisor to the mayor of Pittsburgh
• He is wondering whether approving 10 new businesses on a strip of a crowded highway will be good for him (because it brings jobs) or bad (because it worsens congestion)
• What you have to help you advise him: – Data on travel time on several highways given number of cars
(Cars.dta)– Data on number of cars given number of businesses along the
highway (Business.dta)– rumors about complaints to the mayor’s office given wait time in
traffic
Peduto, GSPIA’11

Breaking down the question into mathematical concepts
1. how long does it take to travel the highway? (random variable)
2. how does the # of cars affect travel time? (correlation, linear regression, slope)
3. comparing two highways (simultaneous equations)4. how does the # of businesses affect # of cars?(nonlinear
equations)5. what is the optimal # of business to have? (optimization,
derivatives, chain rule) We will emphasis time for practice, so we may not get all the way and that is ok.

1. random variable
How long does it take to travel through the highway?

Random variable
How long does it take to travel 15 miles (24km) on a city highway at 8am in the morning?
• What is the mean / median / mode?
• Different day, same highway, same number of cars = different time.• Statistics is learning to get the information out of this uncertainty.• ‘Time needed to travel’ is a random variable = the value is subject to variation
due to chance. • Is what is written on this board ALL possible travel time for the 15 mile highway
above? No. That would be the population. This is a sample. We usually only observe a sample of realizations of the random variable of interest.
• Note also that if I had asked a different group of people, I would have written different numbers on the board, and therefore get a different mean. The standard error of the mean tells me how the mean is likely to vary across different groups of people.

How much does your travel time vary?
• If you have an important meeting, how much time will you give yourself? Why? What is the probability you will be late given the time you picked?
• To know that we need to understand how travel time varies. Let’s do this systematically.
Standard deviation (σ): measuring variation in a random variable1. Calculate mean (μ) 2. Compute the difference of each data point from the mean, and square the result of each 3. Compute the average of these values, and take the square root. Bigger standard deviation, more uncertainty.
Let’s compute it. Now what can we do with it? Let’s suppose if we draw a histogram out of this data we get this bell-shaped curve

Normal distribution
• When the histogram looks like a bell curve the random variable is normally distributed. • Then everything becomes simpler (due to the symmetry and more in Quant I): • e.g the probability of getting values > any threshold can be computed.
• Prob of being late when you give yourself μ minutes is (100%) / 2 = 50%• Prob of being late when you give yourself μ+σ minutes is (100%-68%) / 2 = 16%• Prob of being late when you give yourself μ-σ minutes is 68%+16% = 84%• Prob of being late when you give yourself μ+2σ minutes is (100%-95.45%) / 2 = 2.275%
• Statistics is a study of random variable, its distribution, its relationship with other random variables, and what we can infer about populations from sample.

Let’s make it more concrete• You have Cars.dta loaded.• Now what?
Window-> Data editor lets you look around Look at highway names, you can copy and paste from here
You can get this with: “list” as well. +------------------------+ | v1 cars travel~e | |------------------------| 1. | 1 420 28.72146 | 2. | 2 270 23.77778 | 3. | 3 280 24.13987 | 4. | 4 930 42.37212 | 5. | 5 460 28.94638 | |------------------------| 6. | 6 630 36.20389 | 7. | 7 370 30.47713 |
• Too much – STOP! Control C or Ctrl-Break, or clicking on the red-button-with-white-X in the Stata window.
• How many variables? (4) What do they represent?
In case you’ve been playing around with other data files, “clear “ removes them from the memory so you can start from scratch

summarize
Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- v1 | 1674 837.5 483.3865 1 1674 cars | 1674 385.3883 232.479 0 1230 traveltime | 1674 26.71808 8.605933 11.16805 61.63294
You can also do it one at a time : “summarize cars”, “summarize traveltime”• How many observations are there? • What is the average travel time in this sample of highways? • How much does the travel time vary?
– Note rounding to the nearest integer, one decimal point, or any decimal points.
• In the 10 most congested observations, how many cars were in the highway? – Most crowded: 1230– Top 10? Sort the data first large to small, then list: gsort -cars (the negative sign is important – without it it sorts small to large)list in 1/10

Conditional statements (if, and (&), or (|) )
You often are interested in information for certain conditions.
How do you find the average travel time if there are fewer than 100 cars on the highway? What about for when there are more than 150 cars but fewer than 200?
summarize traveltime if cars < 100summarize traveltime if cars > 150 & cars < 200
How do you find the average travel time for highway “SqHill”? What about both “SqHill” and “Clarion”?
summarize traveltime if highway ==“SqHill” | highway == “Clarion”
How do you find the 3 most congested observation of SqHill?gsort –carslist if highway ==“SqHill” (just manually find the top 3)

Recording what you did in STATA
• In your classes (and in your job in the future) you will need to record what you did to the data.
• This is so that you can remember what you did and so that others can replicate your results. – Go to Window, Do File Editor, and choose New Do-file Editor. – This will open a new .do file.– Copy the commands you already ran into it. – Highlight one of the commands and click the “Execute (do)”
icon. It should run the command. You can also copy and paste directly to the command window.
– Save this file as FridayMathCamp.do– Continue adding commands into this file.

At this point your .do file should look like this
* I loaded cars.dta using File, Opendescribelist* This displayed everything – I had to * stop it with Ctrl Csummarizesummarize carssummarize traveltimemean traveltime
Remember to save!
---------You can write comments to remind yourself of what you are doing when you preceed your notes with a *

How is this data distributed?
• you still really don’t feel like you get what the data looks like.
• To see the “distribution” of the data, let’s explore these graphing options today: – Boxplot (one variable)– Histogram (one variable)– Kernel density estimate (like histogram but just a line)– Scatterplot (two variables)

Showing distribution of data: boxplot
The whiskers can mean many things, so we won’t focus on it here.

What is the median mileage for a 6 cylinder car?What cylinder number has the most unpredictable mileage?
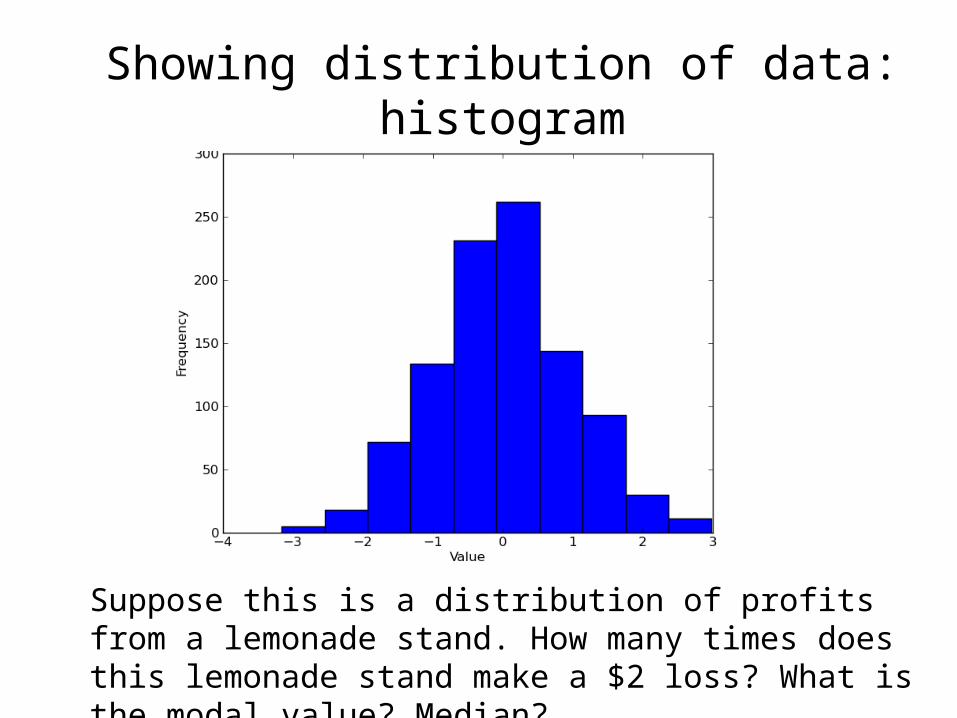
Showing distribution of data: histogram
Suppose this is a distribution of profits from a lemonade stand. How many times does this lemonade stand make a $2 loss? What is the modal value? Median?
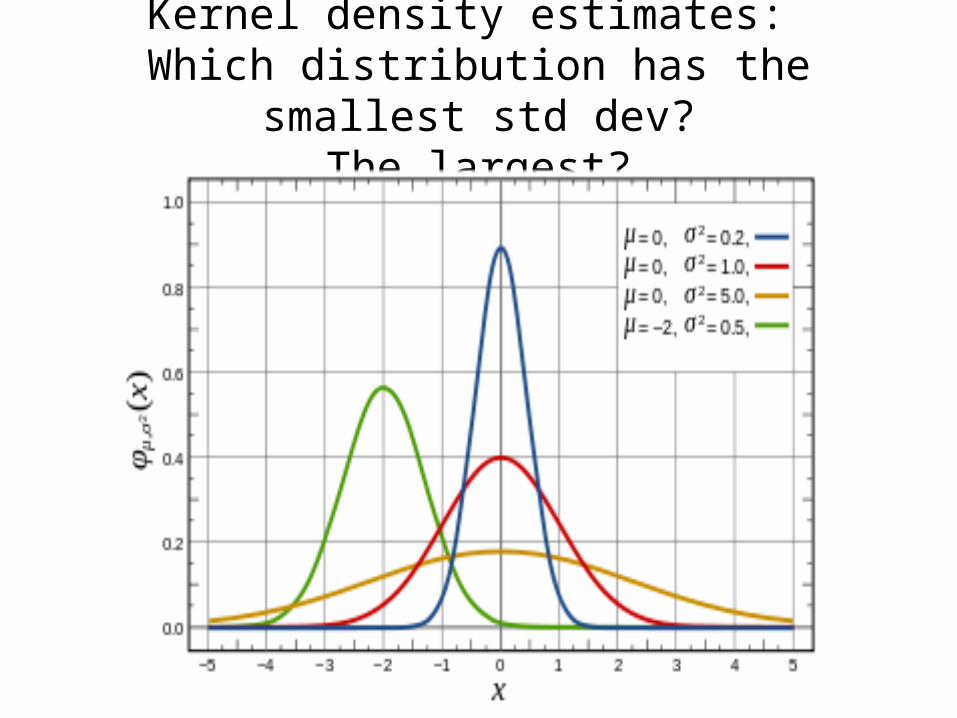
Kernel density estimates: Which distribution has the smallest std dev?
The largest?

To find the relationship, we can try to fit a line across this scatterplot that is the closest possible to ALL the points. This is a regression line.
Scatterplot shows correlation between two variables.

Let’s do it with our dataRemember: what are you, the mayor’s advisor, interested in learning from cars. csv?
• Boxplot: graph box traveltime
• Histogram: hist traveltime
• Kernel density estimate: kdensity traveltime
Now scatterplot is a relationship between two things. In our data we have cars on the highway and how long it takes to travel 15miles. You have to think hard about what relationships you want to examine.
• Scatterplot: scatter traveltime cars
How to save your graphs? File– Save As – (I usually do .pdf)Or: Win users: right click and click Copy and then paste into your word doc.
Try it.

This is what you will get with our data0
.01
.02
.03
.04
.05
De
nsity
10 20 30 40 50 60travelTime
10
20
30
40
50
60
trave
lTim
e
0 500 1000 1500cars
1020
3040
5060
trave
lTim
e
0
.01
.02
.03
.04
.05
De
nsity
10 20 30 40 50 60travelTime
kernel = epanechnikov, bandwidth = 1.7101Kernel density estimate

Let’s practice with Quiz 19:45-10am
Remember: this is not a test. It’s an opportunity to practice and ask questions.

2. correlation, linear regression, slope / rate / derivative
how does the # of cars affect travel time?

Linear functionsFirst, let’s look at how average traveltime changes every 100 cars. • mean traveltime if cars<100 • mean traveltime if cars>=100 & cars<200• mean traveltime if cars>=200 & cars<30016.53 to 19.49, then to 22.26 as cars increase by 100
You can then use Stata as a calculator:• display 19.49-16.53• display 22.26 -19.49
It appears that as cars increase by 100, you wait 3 mins longer in traffic. But what if there are 400 cars? 500?
How do we know in general how travel time is affected by cars?

Recall the correlation between cars and travel time
1020
3040
5060
trav
elT
ime
0 500 1000 1500cars
If we can describe this relationship with an equation, we can tell how travel time is affected by cars more generally.

Regression
traveltime = 14.7 + 0.03*cars What does it mean?
When there’s 0 cars, it takes 14.7 minutes to travel? (Intercept)With every additional cars, it takes another 0.03 minutes to travel. (Slope)In other words: derivative of travel time with respect to cars Or: d traveltime / d cars = 0.03 (Now you know the many ways to refer to this rate of change.)
It doesn’t matter how many cars are already on the highway. This is what it means to be a linear function.
reg traveltime cars------------------------------------------------------------------------------ traveltime | Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+---------------------------------------------------------------- cars | .0311483 .0004892 63.67 0.000 .0301888 .0321078 _cons | 14.7139 .2201573 66.83 0.000 14.28208 15.14571-----------------------------------------------------------------------------

Drawing the graph: traveltime = 14.7 + 0.03*cars Where does the line hit 0? 14.7 This is a (intercept) When cars increase by 1, travel time increase by 0.03 minutes. This is b (slope).When drawing with slopes that are small it helps to use larger increases in x (e.g when cars increase by 1000, travel time increases by 0.03*1000 = 30 minutes)In STATA we can do: twoway (scatter traveltime cars) (lfit traveltime cars)
1020
3040
5060
0 500 1000 1500cars
travelTime Fitted values
Linear function: Y=a+bXTravel time = a+b carsWith a straight line, an increase in X increases Y by the same amount regardless of what X is currently at.
30

Inverting a linear function
• traveltime = 14.7 + 0.03*cars • If it takes you 20 minutes to travel, how many
cars are on a freeway?

Inverting a linear functionYou know travel time as a function of cars traveltime = 14.7 + 0.03*cars
You want cars as a function of travel time: Traveltime- 14.7 = 0.03*carsCars = (Traveltime- 14.7) / 0.03Cars = (Traveltime- 14.7)*100 /3Cars = 33.3*Traveltime - 490
Now, it’s easier to answer this question: If it takes you 20 minutes to travel, how many cars are on a freeway? Cars = 33.3*20 - 490 =176
(BTW: what is the intercept and slope of this inverted function? What is dCars / dTraveltime ?)

When will you have to invert linear functions?
• Quite often actually. For example in microeconomics. • Here is a demand function
Qd = 100 - 2PIt is natural to draw this with Qd in the Y axis and P in the X axis (with 100 as the intercept and a -2 slope). But the convention is to draw it with P in the Y axis – price as a function of quantity. • Here is the inverted demand function
2P = 100 - Qd P = 50-Qd/2
Now you are ready draw the demand function.

Statistical significance in regressions
• When traffic is very sparse( cars<50), how does an additional car affect travel time? reg traveltime cars if cars<50------------------------------------------------------------------------------ traveltime | Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+---------------------------------------------------------------- cars | .0078617 .0180347 0.44 0.664 -.0281668 .0438901 _cons | 15.7433 .4229513 37.22 0.000 14.89835 16.58824------------------------------------------------------------------------------
• Compare the ratio between coefficient and standard error on cars for this regressions and the earlier one
reg traveltime cars------------------------------------------------------------------------------ traveltime | Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+---------------------------------------------------------------- cars | .0311483 .0004892 63.67 0.000 .0301888 .0321078 _cons | 14.7139 .2201573 66.83 0.000 14.28208 15.14571-----------------------------------------------------------------------------

When we compare the ratio between coefficient and standard error on cars for the 1st and 2nd regression we get:
0.00786/0.018 = 0.44 .031148 /.000489 = 63.67 This says that if μ=0, the first coeff on car is the blue arrow and second coeff on car is red.
Or: effect of # car on travel time is statistically indistinguishable From 0 when traffic is very sparse.The pvalue summarizes the statistical significance.Pval = prob that we get this coefficient when the actual effect of cars on travel time is actually zero.For the first one, it is very like (66.4%)For the second regression, it is highly unlikely (0.00%)
0

15 minutes breakWhen we return:
Taylor Seybolt Kevin Morisson
Practice with Quiz 2Systems of equations

Practice: Quiz 211-11:15 am

Breaking down the question into mathematical concepts
1. how long does it take to travel the highway? (random variable)
2. how does the # of cars affect travel time? (correlation, linear regression, slope)
3. comparing two highways (simultaneous equations)4. how does the # of businesses affect # of cars?(nonlinear
equations)5. what is the optimal # of business to have? (optimization,
derivatives, chain rule) We will emphasis time for practice, so we may not get all the way and that is ok.

3. comparing two highways: should you adopt another traffic system?
(simultaneous equations, or, systems of equations)

• Previously you learned that for Pittsburgh highways, traveltime = 14.7 + 0.03*cars.
• A colleague suggested that in anticipation of congestion from the new businesses, you should consider a traffic system that has been adopted by Cleveland to reduce travelling time. There, traveltime = 8.7 + 0.05 cars.
• Should you do that? What is the maximum # of cars such that travelling with the Cleveland system is faster than the Pittsburgh system?

• Pittsburgh: Traveltime = 14.7 + 0.03 cars• Cleveland : Traveltime = 8.7 + 0.05 cars• The question asks for what is cars such that traveltime is
equal to each other.
Several methods:You can solve a linear systems by:1. Graphing: draw both lines and see where they meet. 2. Substitution:Traveltime = 8.7 + 0.05 cars14.7 + 0.03 cars = 8.7 + 0.05 cars6 = 0.02 cars. Cars = 300
• Given that mean # of cars on Pittsburgh highways is 385 (see data), the Cleveland system would actually cause more congestion.
Traveltime
cars

x
y
5–5
5
–5
(4, 2)
x
y
5–5
5
–5
x
y
5–5
5
–5
(A) 2x – 3y= 2 x + 2y= 8
(B) 4x + 6y= 12 2x + 3y= –6
Lines intersect at one point only.Exactly one solution: x = 4, y = 2
Lines are parallel
No solution.(C) 2x – 3y = –6
–x + 3/2 y = 3
Lines coincide. Infinitely many solutions.
Nature of Solutions to Systems of Equations
8-1-85

You will also see a lot of simultaneous equations in economics, so let’s preview them.
Price
P*
demand
quantityQ*
Earlier in linear functions
E.g Qd = 160-8PNote:To draw, invert it:8P = 160-QdP = 20 – Qd/8Y intercept = 20To draw the x intercept, use the y intercept in the non inverted function (160)
20
160

Now: Two linear functions: for example: Supply-demand equilibrium in perfect competition
supply
demand
quantity
Q*
P*
Qd = 160-8P Qs = 70+7P
The intersection of the supply and demand curve (P*, Q*) represents the equilibrium.Equilibrium price: price where there is the same number of people who wants to buy as there are people who wants to sell

Why do we care about the equilibrium?
supply
demand
quantity
Q*
P*
Qd = 160-8P Qs = 70+7P
We often want to know how well people are doing given a certain economic policy. For example, how the consumers are doing in this market. This is called consumer surplus, and is represented by the shaded triangle. You’ll get a chance to practice this application in the quiz.

Other applications: making inferencesAn NGO is running a refugee camp. Cost per day is on average $1.50 for children and $4.00 for adults. On a certain day, 2200 people were living in the camp and $5050 was spent that day. How many children and how many adults are in the camp?
number of adults: anumber of children: ctotal number: a + c = 2200 total cost: 4a + 1.5c = 5050
a = 2200 – c4(2200 – c) + 1.5c = 5050 8800 – 4c + 1.5c = 5050 8800 – 2.5c = 5050 –2.5c = –3750 c = 1500a = 2200 – (1500) = 700There were 1500 children and 700 adults.

Practice: Quiz 311:40-12 pm

Lunch break
• 12-1:20• Return 1:20 sharp. • Solutions to Quiz 1-3 posted online over lunch• 1:30-1:55pm • Sabina Dietrich (Neigh.& Comm Development)• Meredith Wilf (Global Gov, Financial Crisis)• Michael Lewin (Econ Pub Affairs, Macro)

4. Nonlinear function
We will now use our other data set, “business.csv”This data set has # of businesses on a highway and the number of commuter cars associated with these businesses.
what would new businesses do to
highway congestion?

clear (you must clear out the old data)cd “your directory”insheet using Business.csvdescribe• v1 int %8.0g • business byte %8.0g • commutecars int %8.0g • -----------------------------
Now what do you think we should do?

0
500
1000
1500
2000
com
mut
eca
rs
0 20 40 60 80 100business
Is this a linear function?Will a straight line give you the smallest error?
scatter commutecars business

Nonlinear functions
Let’s find what our function resembles: • Quadratic function• Logarithmic function• Exponential function

Quadratic function
x Y
-3 9
-2 4
-1 1
0 0
1 1
2 4
3 9
simplest quadratic function, which has the equation of y = x2. A table of x and y values of this function might look like this:
Notice how Y changes as X change.It’s no longer the same (“constant”)The change here is 1,3,5

Other quadratic functions
y = ax2 + bx + cy = (ax + b)(cx + d)
y = a(x+b)2 + cIs a>0 or a<0 here?
Is the Business.csv data a quadratic function?

Working with power more generallyExample: • Y=3x8 Q=.4P1/3 Generally: Y=mxc
Identify: m constant, x variable, c exponent • Some special ones:• x1 = x x-1 = 1/x x0 = 1 x1/2 = sqrt(x)• When there is no constant, the ”hidden” constant is 1.
Recall for linear function the rate of change (derivative) is just the slope. For nonlinear function you need the power rule: if Y=mxc , dY/dX= mcxc-1
• y=3x2. constant=3, var =x, exponent=2. dy/dx=3*2x(2-1) =6x• y=x-1. constant=1, var=x, exponent=-1. dy/dx=1*-1x(-1-1) = -1x-2 = -1/x2
If you see things like this: y = ax5 + bx3 + cx – it’s just the same =mxc
you can deal with the terms one at a time.
But you may need to simplify these polynomials first.

Rules for simplification
Product rulesx n · x m = x n+m 23 · 24 = 23+4 = 128
x n · b n = (x · b) n 32 · 42 = (3·4)2 = 144
Quotient rulesx n / x m = x n-m 25 / 23 = 25-3 = 4
x n / b n = (x / b) n 43 / 23 = (4/2)3 = 8
Power rules (x n) m = x n·m (23)2 = 23·2 = 64

Exponential function
• The growth of a terrorist cell:• At month 0 there’s 1 person 1• At month 1 this person recruited 2 people 2• At month 2 each persons recruited 2 people 4• What is the function that describe the growth?• f=2x where x is time (month)
This is an exponential functions Notice it “asymptotes” at the y axis.
Is this the Business.csv data an exponential function?

Logarithmic function• Time since the inception of the terrorist cell• If there is 1 member it must have just started t=0• If there are 2 members it must have been last month. t=1• If there are 32 members t =?
(5 months)• Equation: y=log2x where x is # of members and y is months
• "loga x" means "to what power (exponent) must a be raised to get x?
• This is the inverse of the exponential function• Notice it “asymptotes” at the x axis.
Is this the Business.csv data an logarithmic function?

2x and exp(x)Logs and natural logs
Exp(x) = 2.72x
This quantity is often used when quantities grow proportionally to it’s value. It is often seen in math, physics, and chemistry.

Some rules for dealing with exp and logs
• Log2 2 = 1 since 2^1 = 2
• Log2 4= 2 since 2^2 = 4• Log 32 = Log 2*16 = Log 2 + Log 16 since 21 * 24 = 25=16• Log 1/16 = Log 1 - Log 16• since 20 / 24 = 2-4
• ln e = 1. since e^1 = e• ln ab = ln a + ln b.• ln a / b = ln a - ln b.• ln an = n ln a.

Back to dataComparing various models: Look at Adjusted R2 (bigger better fit) and pvalue.
Create a new variable:• gen businesssq = business^2• reg commutecars business (Adj R2= 0.7155)• reg commutecars businesssq (Adj R2=0.5517)• reg commutecars business businesssq (Adj R2 = 0.829)
gen logbusiness = log(business) default log for stata is ln
• reg commutecars logbusiness (Adj R2 = 0.8819)
• reg commutecars logbusiness businesssq (Adj R2 = 0.8821)
Note that pvalue for businesssq is > than 0.10 here. Here, effect of adding businesssq is not significantly different from 0. So the relationship between business and commuter cars is best described with a logarithmic function:

gen logbusiness = log(business) default log for stata is lnscatter commutecars logbusiness, msize(small)
0
500
1000
1500
2000
com
mut
eca
rs
0 1 2 3 4 5logbusiness

. reg commutecars logbusiness (REMEMBER log for stata is ln)
R-squared = 0.8821------------------------------------------------------------------------------ commutecars | Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+---------------------------------------------------------------- logbusiness | 291.4614 3.373543 86.40 0.000 284.8414 298.0815 _cons | 129.9403 12.6939 10.24 0.000 105.0305 154.8501------------------------------------------------------------------------------
. reg commutecars business
R-squared = 0.7158------------------------------------------------------------------------------ commutecars | Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+---------------------------------------------------------------- business | 8.209237 .1637584 50.13 0.000 7.887887 8.530588 _cons | 781.3557 9.469157 82.52 0.000 762.774 799.9375------------------------------------------------------------------------------
The equation is: cars = 130+290*ln(business)

Some STATA things • gen vs egen• They both create a new variable, but work with different sets of
functions. • gen: simple transformations of other variables
gen travelsq = traveltime^2• egen for groups, eg:
egen timehighway=mean (traveltime), by(highway)
• What if you mess up making a variable and want to recreate it? Eg. You want travelsq to be ½*traveltime^2
drop travelsqgen travelsq = (1/2)* traveltime^2

• Practice with quiz 4 (online)• 3pm • Luke Condra (Global Gov, Ethics & Nat’l Security)• Louise Comfort (Policy Design, Systems Theory)• John Mendeloff (Benefit Cost Analysis)

5. what is the optimal # of business to have? (optimization, compound functions)

General Optimization
Preview: Power rule: if Y=mxc , dY/dX= mcxc-1
• y=8x This is equal to 8x1. constant=8, var =x, exponent=1. • dy/dx=8*x(1-1) =8
We can use this to find where a nonlinear function has a slope of 0.
Supposed you are asked to maximize a function: Y = 8X-.8X2
First we have to take a derivative:Y = 8X-.8X2
dY/dx = 8*1X1-1-.8*2X2-1 = 8-1.6XThen when we set it to 0, we can solve for X that maximizes the function 8-1.6X = 0 X = 8/1.6 = 5

Y = 8X-0.8X2
dY/dX = 8 – 0.8*2*X = 8-1.6X
X Y0 01 7.22 12.83 16.84 19.25 206 19.27 16.88 12.89 7.2
10 011 -8.812 -19.2
1 2 3 4 5 6 7 8 9 10 11 12 13
-10
-5
0
5
10
15
20

Special rules for logs and exp
• y=ax dy/dx=ax ln a• y=ex dy/dx=ex
• (because ln e = 1)• • y=log a (x) dy/dx= 1/ (x ln a)• y=ln (x) = log e (x) dy/dx= 1/ x • (because ln (x) = log e (x) , and ln e=1)

Your turn
Remember the rule: Y = mXc
dY/dX = mcXc-1
• Find the first derivative:
• Answer: 9x2+ 6x-3
Minimize this function:
• Steps: find 1st derivative, then set it to 0• Answer: 2x+3 = 0 x= 3/2

REVIEW Optimization: Quiz 5

Let’s break this down:1. How does business affect travel time?2. Suppose his public opinion expert says:complaints = travel time, praise = # of business2/2Then how can he maximize:
complaints – praise
How many businesses should be on the
highway?

• You have cars and traveltime• You have business and carsHow do you combine them? What will 1 extra business do to traffic?
• cars = 130+290*ln(business)• traveltime = 14.7 + 0.03*cars • traveltime = 14.7 + 0.03* (130+290*ln(business) )• traveltime = 18.6+8.7ln(business)
How does an additional business affect travel time?• dt/db = 8.7/business • If there’s 1 business on the highway, 1 extra business will add 8.7/1 = 8.7
minutes to traffic• If there are 10, 1 extra will add 8.7/10 = 0.87 minutes to traffic• If there are 100, 1 extra will add 8.7/100 = 0.087 minutes to traffic
20
30
40
50
60
pre
dict
edtr
ave
ltim
e
0 20 40 60 80 100business

Now we are ready to use the info from the public opinions guy:• complaints = traveltime = 18.6+8.7ln(business)• praise = # of business2/2• Optimize:• Benefit to Mayor = Praise – Complaints• Benefit = business2/2 -18.6-8.7ln(business)• Take derivative: • d Benefit / d business = business – 8.7/business• Set to 0, we get:• 0 = business – 8.7/business• 8.7/business = business• 8.7 = business2
• Optimal number of business = sqrt(8.7) = 2.95 or 3 businesses

Training done!
Pack up and get ready to meet your teammate.

On to the Race!Here are the teams
• Come up and meet your teammate as your name is called.
• Show Race Packet Materials. • Tomorrow: you will absolutely need your computer.• You will be coding and thinking and racing from room to room, so make sure you are
comfortable.• There will be 10 clues. Solving each clue under three tries will earn your team 1 point.
The team with the highest number of points wins the race. Ties are broken by how quickly you complete the race.
• There will be Roadblocks. In Roadblocks each person in the team must solve a puzzle individually.

How to win?
• Review all the material tonight with your teammate and decide on how you want to handle roadblocks and other scenarios. The math will be simple but will require creative applications.
• Quiz answers posted online. • Stata commands: You MUST get familiar with all the
commands we did today.• When getting your answers checked you can send just
one person so one of you can continue working.• See you tomorrow at 9am.






























