Embed Size (px)
Citation preview

Tensor Train in machine learning
Alexander Novikov
October 11, 2016
Alexander Novikov Tensor Train in machine learning October 11, 2016 1 / 26

Recommender systems
Assume low-rank structure.
Alexander Novikov Tensor Train in machine learning October 11, 2016 2 / 26

Tensor Train summary
Tensor Train (TT) decomposition [Oseledets 2011]:
A compact representation for tensors (=multidimensional array);
Allows for efficient application of linear algebra operations.
Alexander Novikov Tensor Train in machine learning October 11, 2016 3 / 26

Low-rank decomposition
A23 =
G1 G2
i2 = 3i1 = 2
Ai1i2 = G1[i1]︸ ︷︷ ︸1×r
G2[i2]︸ ︷︷ ︸r×1
A = G1G2
G1 – collection of rows, G2 – collection of columns:
Alexander Novikov Tensor Train in machine learning October 11, 2016 4 / 26

Tensor Train decomposition
A2423 =
G1 G2 G3 G4
i2 = 4 i3 = 2 i4 = 3i1 = 2
Ai1...id = G1[i1]︸ ︷︷ ︸1×r
G2[i2]︸ ︷︷ ︸r×r
. . . Gd [id ]︸ ︷︷ ︸r×1
An example of computing one element of 4-dimensional tensor:
Alexander Novikov Tensor Train in machine learning October 11, 2016 5 / 26

Tensor Train decomposition Cont’d
Tensor A is said to be in the TT-format, ifAi1,...,id = G1[i1] G2[i2] · · · Gd [id ], ik ∈ {1, . . . , n},
where Gk [ik ] — is a matrix of size rk−1 × rk , r0 = rd = 1.Notation & terminology:
Gk — TT-cores;rk — TT-ranks;r = max
k=0,...,drk — the maximal TT-rank.
The TT-format uses O(ndr2) memory to store nd elements. Efficient only
if the TT-rank is small.
Alexander Novikov Tensor Train in machine learning October 11, 2016 6 / 26

TT-format: example
Ai1,i2,i3 = i1 + i2 + i3,
i1 ∈ {1, 2, 3}, i2 ∈ {1, 2, 3, 4}, i3 ∈ {1, 2, 3, 4, 5}.
Ai1,i2,i3 = G1[i1]G2[i2]G3[i3],
G1[i1] =[
i1 1]
G2[i2] =[
1 0i2 1
]G3[i3] =
[1i3
]Lets check:
A(i1, i2, i3) =[
i1 1] [ 1 0
i2 1
] [1i3
]=
=[
i1 + i2 1] [ 1
i3
]= i1 + i2 + i3.
Alexander Novikov Tensor Train in machine learning October 11, 2016 7 / 26

TT-format: example
Ai1,i2,i3 = i1 + i2 + i3,
i1 ∈ {1, 2, 3}, i2 ∈ {1, 2, 3, 4}, i3 ∈ {1, 2, 3, 4, 5}.
Ai1,i2,i3 = G1[i1]G2[i2]G3[i3],
G1[i1] =[
i1 1]
G2[i2] =[
1 0i2 1
]G3[i3] =
[1i3
]Lets check:
A(i1, i2, i3) =[
i1 1] [ 1 0
i2 1
] [1i3
]=
=[
i1 + i2 1] [ 1
i3
]= i1 + i2 + i3.
Alexander Novikov Tensor Train in machine learning October 11, 2016 7 / 26

TT-format: example
Ai1,i2,i3 = i1 + i2 + i3,
i1 ∈ {1, 2, 3}, i2 ∈ {1, 2, 3, 4}, i3 ∈ {1, 2, 3, 4, 5}.
Ai1,i2,i3 = G1[i1]G2[i2]G3[i3],
G1 =([
1 1]
,[2 1
],[3 1
])G2 =
([1 01 1
],
[1 02 1
],
[1 03 1
],
[1 04 1
])
G3 =([
11
],
[12
],
[13
],
[14
],
[15
])The tensor has 3 · 4 · 5 = 60 elements.The TT-format use 32 parameters to describe it.
Alexander Novikov Tensor Train in machine learning October 11, 2016 8 / 26

Sum of tensors
Tensors A and B are in the TT-format:Ai1...id = GA
1 [i1] · · ·GAd [id ], Bi1...id = GB
1 [i1] · · ·GBd [id ].
Find the TT-format ofC = A + B,
Ci1...id = Ai1...id + Bi1...id .
TT-cores of the result:
GCk [ik ] =
[GA
k [ik ] 00 GB
k [ik ]
], k = 2, . . . , d − 1,
GC1 [i1] =
[GA
1 [i1] GB1 [i1]
], GC
d [id ] =[
GAd [id ]
GBd [id ]
].
TT-ranks of the result are sums of the TT-ranks.
Alexander Novikov Tensor Train in machine learning October 11, 2016 9 / 26

Sum of tensors
Tensors A and B are in the TT-format:Ai1...id = GA
1 [i1] · · ·GAd [id ], Bi1...id = GB
1 [i1] · · ·GBd [id ].
Find the TT-format ofC = A + B,
Ci1...id = Ai1...id + Bi1...id .
TT-cores of the result:
GCk [ik ] =
[GA
k [ik ] 00 GB
k [ik ]
], k = 2, . . . , d − 1,
GC1 [i1] =
[GA
1 [i1] GB1 [i1]
], GC
d [id ] =[
GAd [id ]
GBd [id ]
].
TT-ranks of the result are sums of the TT-ranks.
Alexander Novikov Tensor Train in machine learning October 11, 2016 9 / 26

TT-rounding
Given a tensor A in the TT-format with rank r , the TT-rounding[Oseledets, 2011]:
A = tt-round(A, ε), ε > 0
finds the tensor A such that1 ‖A− A‖F ≤ ε‖A‖F ;
2 TT-rank of A is minimal among all B:‖A−B‖F ≤ ε√
d−1‖A‖F .
Where ‖A‖F =√∑
i1,...,id A2i1,...,id .
Alexander Novikov Tensor Train in machine learning October 11, 2016 10 / 26

How to find TT-decomposition of a given tensor
Analytical formulas for special cases;
An exact algorithm based on SVD for medium tensor. E.g. for a58 ≈ 400 000 tensor takes 8 ms on my laptop;
For large tensors (e.g. 250), approximate algorithms that look at afraction of the tensor elements: DMRG-cross [Savostyanov andOseledets, 2011], AMEn-cross [Dolgov and Savostyanov, 2013].
Alexander Novikov Tensor Train in machine learning October 11, 2016 11 / 26

TT-format operations
Operation Rank of the result
C = c ·A r(C) = r(A)C = A + c r(C) = r(A)+1C = A + B r(C) ≤ r(A)+r(B)C = A�B r(C) ≤ r(A)r(B)C = round(A, ε) r(C) ≤ r(A)sumA –‖A‖F –
(Ask me about differential equations)
Alexander Novikov Tensor Train in machine learning October 11, 2016 12 / 26

Example application: TensorNet
1 Neural networks use fully-connected layers: y = f (Wx + b).2 The matrix W is of millions parameters.3 Lets store and train the matrix W in the TT-format.
Can’t work for general matrices, but for VGG-16 net we compressed4048× 4048 matrix to 320 params without loss of accuracy.
Alexander Novikov Tensor Train in machine learning October 11, 2016 13 / 26

Linear model
Modely(x) = wᵀx + b,
b ∈ R, w ∈ Rd
Loss functionN∑
k=1`(wᵀx(k) + b, y (k)
).
Linear regressionLogistic regressionLinear SVM...
Alexander Novikov Tensor Train in machine learning October 11, 2016 14 / 26

Need for interactions
Linear models give everyone same recommendationsSame story e.g. in bag-of-words text tasksUse interactions (products of features)!
Alexander Novikov Tensor Train in machine learning October 11, 2016 15 / 26

Models with interactions
y(x) = b + wᵀx +∑i ,j
Pijxixj ,
b ∈ R, w ∈ Rd , P ∈ Rd×d
For d features d2 parameters: overfitting on sparse data
Complexity is also d2
For recommender systems d is millions
SVM with polynomial kernel has same drawbacks
Alexander Novikov Tensor Train in machine learning October 11, 2016 16 / 26

Factorization machines
y(x) = b + wᵀx +∑i ,j
Pijxixj
Factorization machines [Rendle 2010] use rank r for P
y(x) =b + wᵀx +∑i ,j
( r∑f =1
Vif Vjf
)xixj ,
b ∈ R, w ∈ Rd , V ∈ Rd×r
Matrix P = VV ᵀ is not sparse, but structured (low rank)Control the number of parameters with rCan represent almost any matrix with large r
Alexander Novikov Tensor Train in machine learning October 11, 2016 17 / 26

High order analysis
Factorization machines model (3rd order)
y(x) =b + wᵀx +∑i ,j
( r∑f =1
Vif Vjf
)xixj
+∑i ,j,k
( r∑f =1
Uif Ujf Ukf
)xixjxk .
In fact, Factorization machines just use CP-decomposition for the weighttensor Pi ,j,k :
Pijk =r∑
f =1Uif Ujf Ukf
ButConverge poorly with high order
Complexity of inference and learning
Alexander Novikov Tensor Train in machine learning October 11, 2016 18 / 26

Exponential machinesLets encode interactions by binary code. Every bit indicates ifcorresponded feature is included or not in current interaction.Exponential machines example (d = 3):
y(x) = W000 + W100 x1 + W010 x2 + W001x3
+ W110 x1x2 + W101 x1x3 + W011 x2x3
+ W111 x1x2x3.
In general:
y(x) =1∑
i1=0. . .
1∑id =0
Wi1,...,id x i11 . . . x id
d ,
W ∈ R2×...×2 with TT-rank r
Captures all 2d interactionsControl the number of parameters with TT-rank rCan represent any polynomial function with large r
Alexander Novikov Tensor Train in machine learning October 11, 2016 19 / 26

Exponential machinesLets encode interactions by binary code. Every bit indicates ifcorresponded feature is included or not in current interaction.Exponential machines example (d = 3):
y(x) = W000 + W100 x1 + W010 x2 + W001x3
+ W110 x1x2 + W101 x1x3 + W011 x2x3
+ W111 x1x2x3.
In general:
y(x) =1∑
i1=0. . .
1∑id =0
Wi1,...,id x i11 . . . x id
d ,
W ∈ R2×...×2 with TT-rank r
Captures all 2d interactionsControl the number of parameters with TT-rank rCan represent any polynomial function with large rAlexander Novikov Tensor Train in machine learning October 11, 2016 19 / 26

Exponential machines inference
Linear O(r2d) inference:
y(x) =∑
i1,...,idG1[i1] . . . Gd [id ]
( d∏k=1
x ikk
)
=∑
i1,...,idx i1
1 G1[i1] . . . x idd Gd [id ]
=
1∑i1=0
x i11 G1[i1]
. . .
1∑id =0
x idd Gd [id ]
= A1︸︷︷︸
1×r
A2︸︷︷︸r×r
. . . Ad︸︷︷︸r×1
,
Alexander Novikov Tensor Train in machine learning October 11, 2016 20 / 26

Exponential machines learning
minimizeW
N∑k=1
`(〈W , X (k)〉, y (k)
),
subject to TT-rank(W) = r0,
1 Autodiff to compute gradients with respect to TT-cores G2 OR Riemannian optimization
Theorem [Holtz, 2012]The set of all d-dimensional tensors with fixed TT-rank r
Mr = {W ∈ R2×...×2 : TT-rank(W) = r}forms a Riemannian manifold.
Alexander Novikov Tensor Train in machine learning October 11, 2016 21 / 26

Riemannian optimization
− ∂L∂Wt
TWMr
−Gt
TT-roundWt+1
Mr
projection
Wt
Alexander Novikov Tensor Train in machine learning October 11, 2016 22 / 26

Riemannian optimization Cont’d
Loss function
L(W) =N∑
k=1`(〈W , X (k)〉, y (k)
)Gradient
∂L∂W =
N∑k=1
∂`
∂y X (k).
Where X is of TT-rank 1!
X i1...id =d∏
k=1x ik
k .
Alexander Novikov Tensor Train in machine learning October 11, 2016 23 / 26
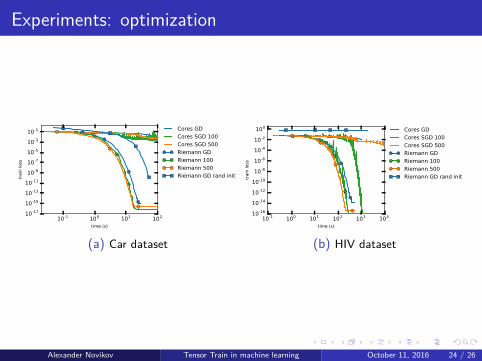
Experiments: optimization
10-1 100 101 102
time (s)
10-17
10-15
10-13
10-11
10-9
10-7
10-5
10-3
10-1
train
loss
Cores GD
Cores SGD 100
Cores SGD 500
Riemann GD
Riemann 100
Riemann 500
Riemann GD rand init
(a) Car dataset
10-1 100 101 102 103 104
time (s)
10-16
10-14
10-12
10-10
10-8
10-6
10-4
10-2
100
train
loss
Cores GD
Cores SGD 100
Cores SGD 500
Riemann GD
Riemann 100
Riemann 500
Riemann GD rand init
(b) HIV dataset
Alexander Novikov Tensor Train in machine learning October 11, 2016 24 / 26
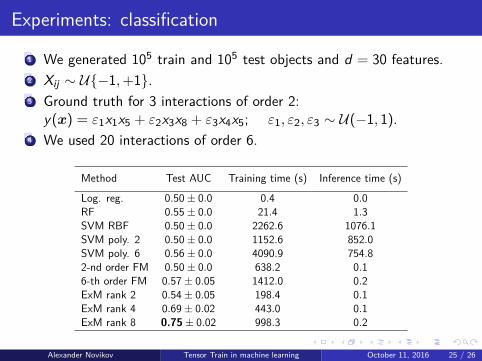
Experiments: classification
1 We generated 105 train and 105 test objects and d = 30 features.2 Xij ∼ U{−1, +1}.3 Ground truth for 3 interactions of order 2:
y(x) = ε1x1x5 + ε2x3x8 + ε3x4x5; ε1, ε2, ε3 ∼ U(−1, 1).4 We used 20 interactions of order 6.
Method Test AUC Training time (s) Inference time (s)
Log. reg. 0.50± 0.0 0.4 0.0RF 0.55± 0.0 21.4 1.3SVM RBF 0.50± 0.0 2262.6 1076.1SVM poly. 2 0.50± 0.0 1152.6 852.0SVM poly. 6 0.56± 0.0 4090.9 754.82-nd order FM 0.50± 0.0 638.2 0.16-th order FM 0.57± 0.05 1412.0 0.2ExM rank 2 0.54± 0.05 198.4 0.1ExM rank 4 0.69± 0.02 443.0 0.1ExM rank 8 0.75± 0.02 998.3 0.2
Alexander Novikov Tensor Train in machine learning October 11, 2016 25 / 26

Conclusion
Tensor Train decomposition compactly represent tensors.
Can parametrize machine learning models with TT-tensors.
E.g. the weights of a neural network.
Or modeling all 2d interactions (products of features).
Control the number of underlying parameters via TT-rank.
Riemannian optimization learning sometimes outperforms SGD.
There is a Python code for everything: TT, TensorNet, andExponential Machines.
Alexander Novikov Tensor Train in machine learning October 11, 2016 26 / 26



![Ranking Methods for Tensor Components Analysis and their ...cet/TieneFilisbino_sibgrapi13.pdf · [6], tensor discriminant analysis (TDA) [7], [8] and tensor rank-one decomposition](https://img.pdfslide.us/doc/110x75/5f78fbe48023322255060d71/ranking-methods-for-tensor-components-analysis-and-their-cettienefilisbino.jpg)






![arXiv:1602.08614v2 [cs.IT] 8 Mar 2019 · total mass minimization (4) defines the tensor nuclear norm, and the according tensor decomposition is a tensor nuclear decomposition. Remark](https://img.pdfslide.us/doc/110x75/5eb8c67c7941c66f8e12144d/arxiv160208614v2-csit-8-mar-2019-total-mass-minimization-4-deines-the-tensor.jpg)















