Embed Size (px)
Citation preview

1
The Apache Hadoop EcosystemEli CollinsSoftware Engineer, ClouderaHadoop Committer/PMC, Apache Software Foundation
@elicollins

2
This talk
My perspective on Hadoop & it’s ecosystem
A look at some new, interesting parts of the ecosystem, including slides I crib’d from Doug

3
What is Hadoop?
is a distributed, reliable, scalable, flexible storage and computation system.
It’s based on the architecture and designs of systems developed at Google (thanks, Google!)

4
Another perspective
Also a generalization of more specialized systems...
• Parallel databases and data warehouses• Parallel programming (HPC, Beowulf clusters)• Distributed storage & parallel file systems• High performance analytics• Log, stream, event & ETL processing systems

5
Yet another perspective
Plat·form (-noun): a hardware architecture and software framework for building applications
Also, a place to launch software, so Hadoop is the really kernel of a “data OS” or “data platform”

6
Last perspective
Like a data warehouse, but…
• More data• More kinds of data• More flexible analysis• Open Source• Industry standard hardware• More economical
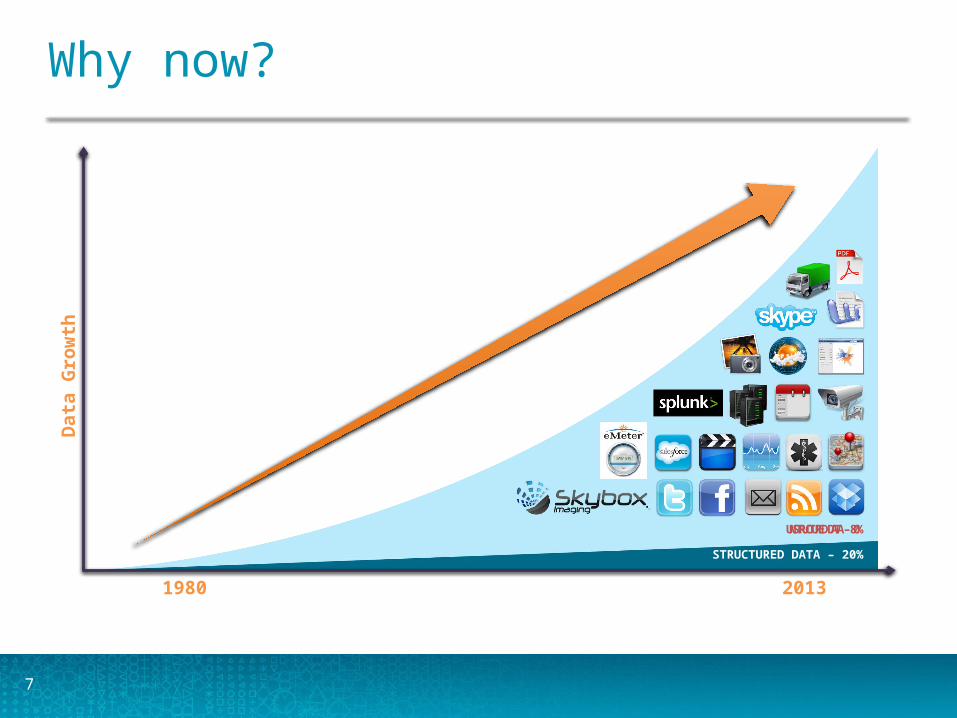
7
Why now?D
ata
Gro
wth
STRUCTURED DATA – 20%
1980 2013
UNSTRUCTURED DATA – 80%

8
Digression …what’s it for?
Data processing – Search index building, log processing, click stream sessionization, Telco/POS processing, trade reconciliation, genetics, ETL processing, image processing, etc.
Analytics – Ad-hoc queries, reporting, fraud analysis, ML, forecasting, infra management , etc.
Real time serving if you’re brave.
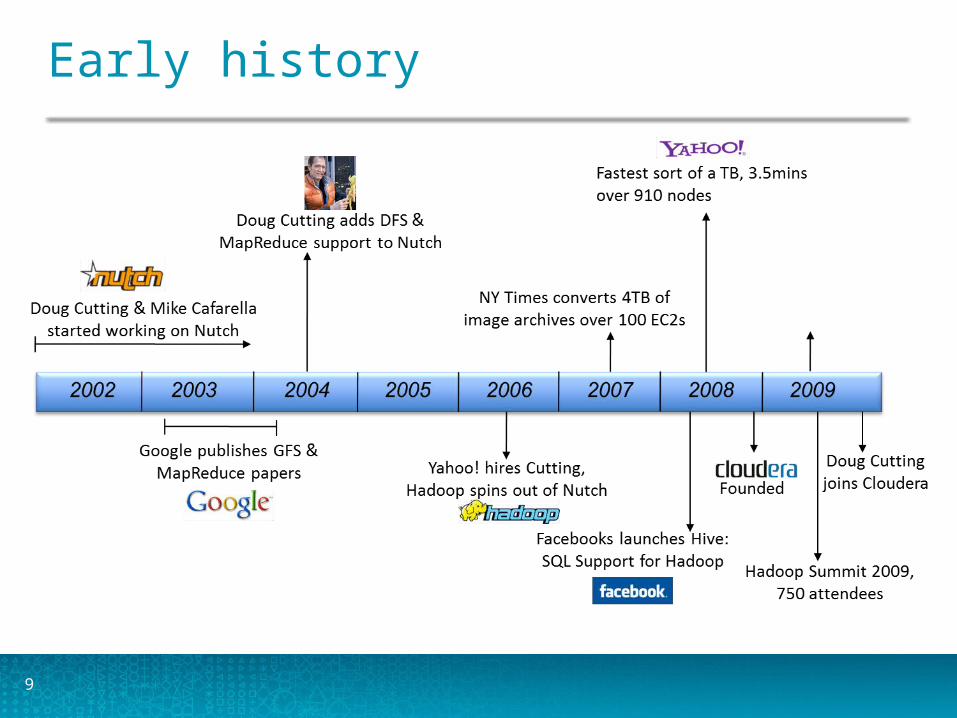
9
Early history

10
The Hadoop ecosystem
ec·o·sys·tem (-noun): a system of interconnecting and interacting parts
• Not centrally planned - interaction and feedback loop• Components leverage each other, deps & conventions• Components co-designed in parallel, over time• Components innovate individually & quickly• Boundaries are not fixed
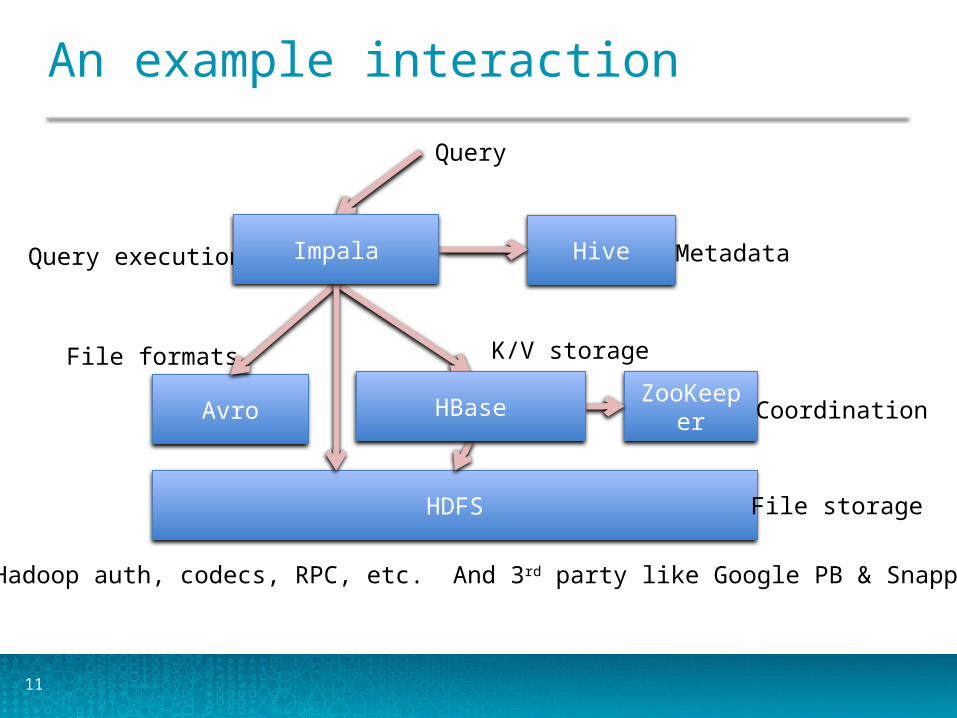
11
An example interaction
HDFS
Hive
Avro
Metadata
K/V storage
File storage
Query execution
File formats
ZooKeeper Coordination
Hadoop auth, codecs, RPC, etc. And 3rd party like Google PB & Snappy, etc.
Query
Impala
HBase

12
What are the implications?
Highly adaptable (itself & co-located systems)Hadoop grows incrementallyHighly parallel development, e.g. “rule of three”
Complex system Integration is key Manage change over time Open source > open standards

13
Switching gears….
A sample of some new/interesting things.

14
Hadoop Yarn (Yet Another Resource Negotiator)
• Generic scheduler for distributed applications• Not just MapReduce applications
• Consists of:• Resource Manager (per cluster)• Node Manager (per machine)
• Runs Application Managers (per job)• Runs Application Containers (per task)
• In Hadoop 2.0• Replaces the Job Tracker and Task Tracker (aka MR1)
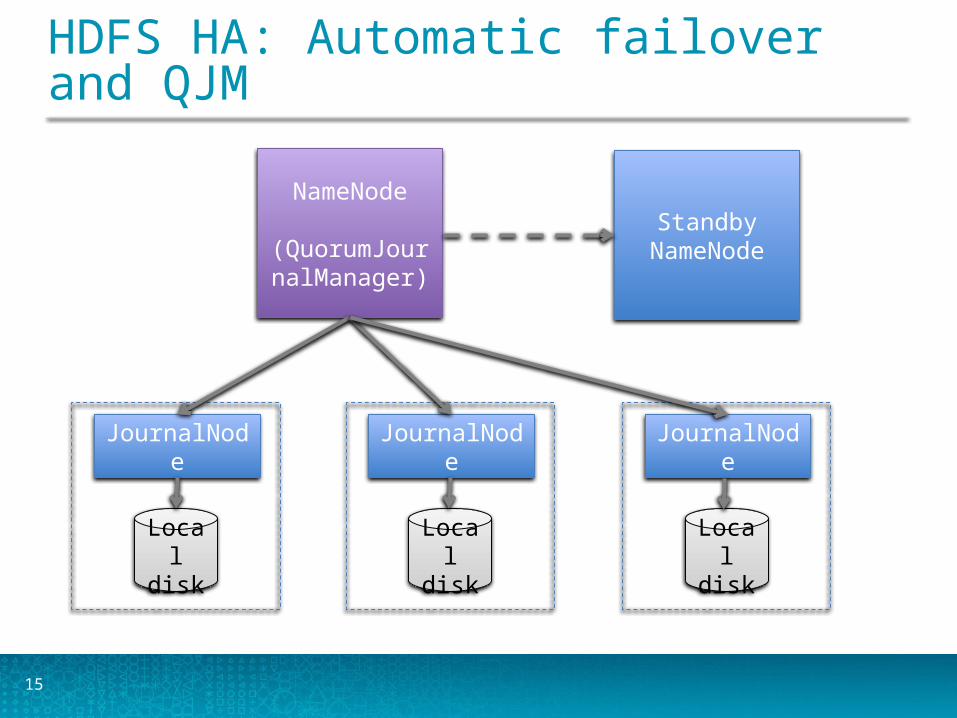
15
HDFS HA: Automatic failover and QJM
NameNode
(QuorumJournalManager)
JournalNode
Local disk
JournalNode
Local disk
JournalNode
Local disk
StandbyNameNode

16
Impala: a modern SQL engine for Hadoop
• General purpose SQL engine• Supports queries that take from milliseconds to hours
• Runs directly within Hadoop• Reads widely used Hadoop formats• Talks to widely used Hadoop storage managers• Runs on the same Hadoop nodes
• High Performance• Completely new engine (no MR)• Runtime code generation

17
Avro: a format for big data
• Expressive• Records, arrays, unions, enums
• Efficient• Compact binary, compressed, splittable
• Interoperable• Langs: C, C++, C#, Java, Perl, Python, Ruby, PHP• Tools: MR, Pig, Hive, Crunch, Flume, Sqoop, etc.
• Dynamic• Can read & write w/o generating code first
• Evolvable

18
Crunch
• An API for MapReduce• Alternative to Pig and Hive• Inspired by Google’s FlumeJava paper• In Java (& Scala)
• Easier to integrate application logic• With a full programming language
• Concepts• PCollection: set of values w/ parallelDo operator• PTable: key/value mapping w/ groupBy operator• Pipeline: executor that runs MapReduce jobs

19
Crunch Word Count
public class WordCount { public static void main(String[] args) throws Exception { Pipeline pipeline = new MRPipeline(WordCount.class); PCollection lines = pipeline.readTextFile(args[0]);
PCollection words = lines.parallelDo("my splitter", new DoFn() { public void process(String line, Emitter emitter) { for (String word : line.split("\\s+")) { emitter.emit(word); } } }, Writables.strings());
PTable counts = Aggregate.count(words);
pipeline.writeTextFile(counts, args[1]); pipeline.run(); }}

20
Scrunch Word Count
class WordCountExample { val pipeline = new Pipeline[WordCountExample]
def wordCount(fileName: String) = { pipeline.read(from.textFile(fileName)) .flatMap(_.toLowerCase.split("\\W+")) .filter(!_.isEmpty()) .count }}

21
Thank You!Eli Collins
@elicollins





























