Embed Size (px)
Citation preview

By
Sriram Study Point

Introduction to Big Data Properties of Big Data Introduction to Hadoop Core components in Hadoop MapReduce Hadoop Ecosystem tools Conclusion

A data which is beyond storage capacity and beyond
processing power
Properties of Big Data
According to IBM
Volume
Velocity
variety


1. Structured Data
RDBMS
2. Semi Structured Data
Log Files
3. Unstructured Data
text, audio, video, image etc..

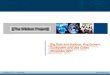
? ?
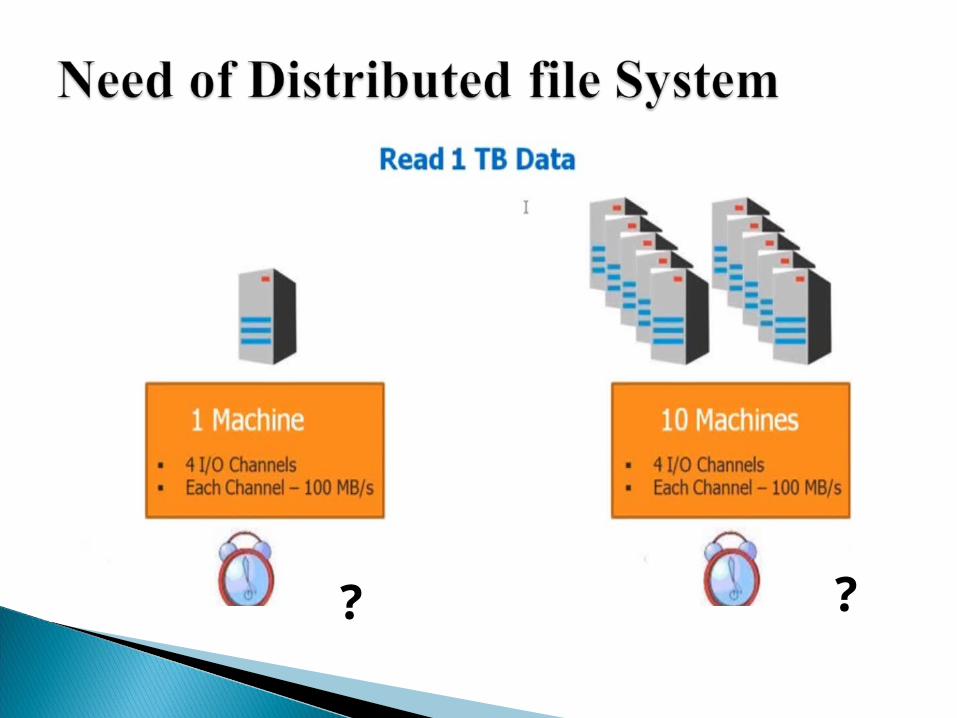
4.545


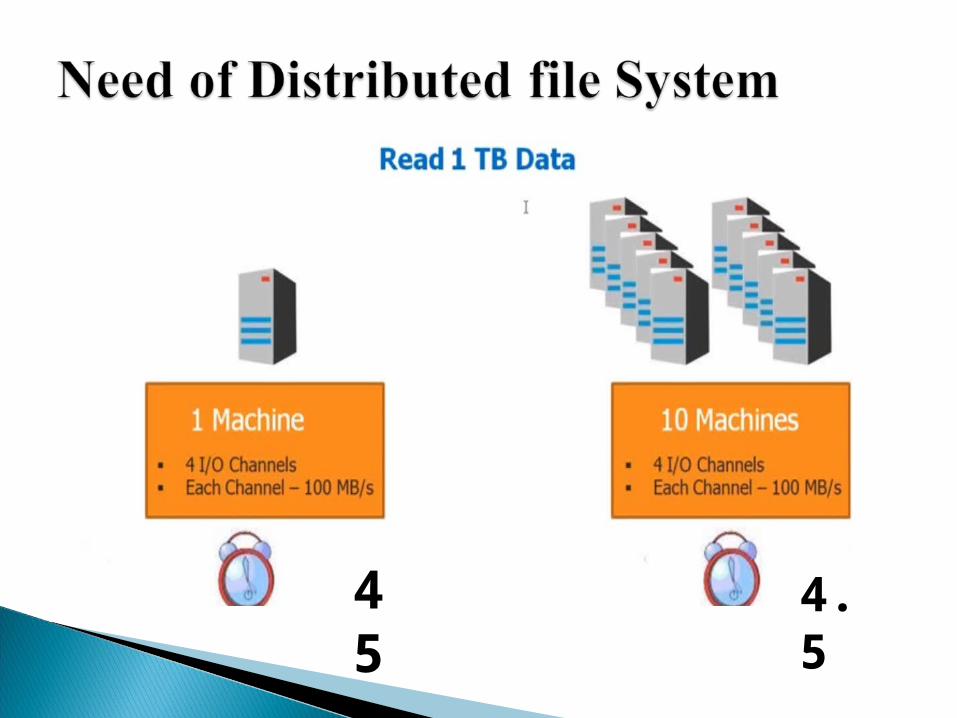
Name Node Master of the system Maintains and manages the blocks
of data nodes
Data Node salves and provides actual storage responsible for read and write operations

Highly fault-tolerant
High Throughput
Suitable for applications with large data dets
Write once and read many times
Can be built by commodity hardware
Replicating data across different data nodes

Low latency data access(quickly access small data) Lots of small files Multiple writes, arbitrary file modifications
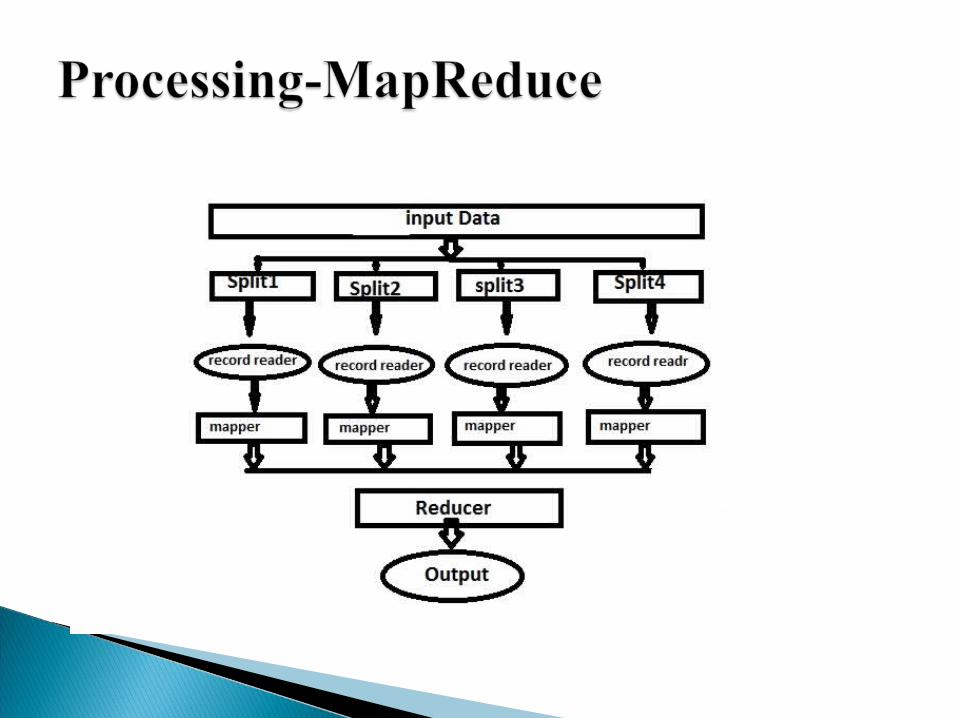
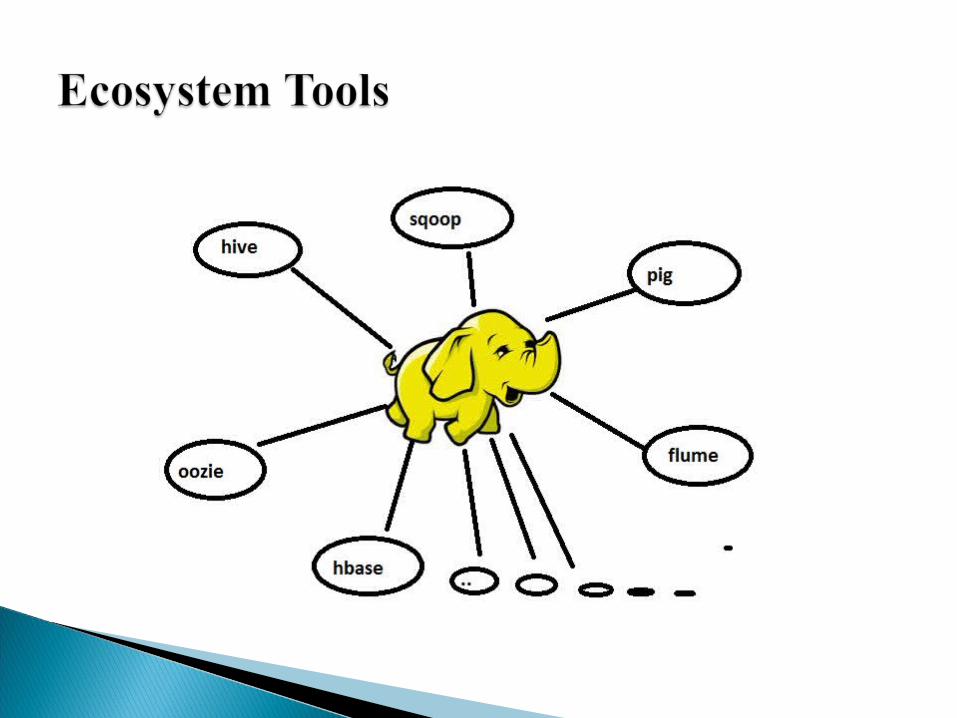

Familiar with SQL use
Initially given by Facebook
Internally runs with MapReduce
HiveQL-Hive Query Language act as interpreter
Can load thousands of rows at a time

Importing data from RDBMS to HDFSExporting data from HDFS to RBMSUsed to Store data in HbaseUsed to upload data to Hive

No need of lot of knowledge in programming and
SQL
Simplifies the work done by mapreduce programs
Initially given by Yahoo
Own language “Pig Latin Scripting”

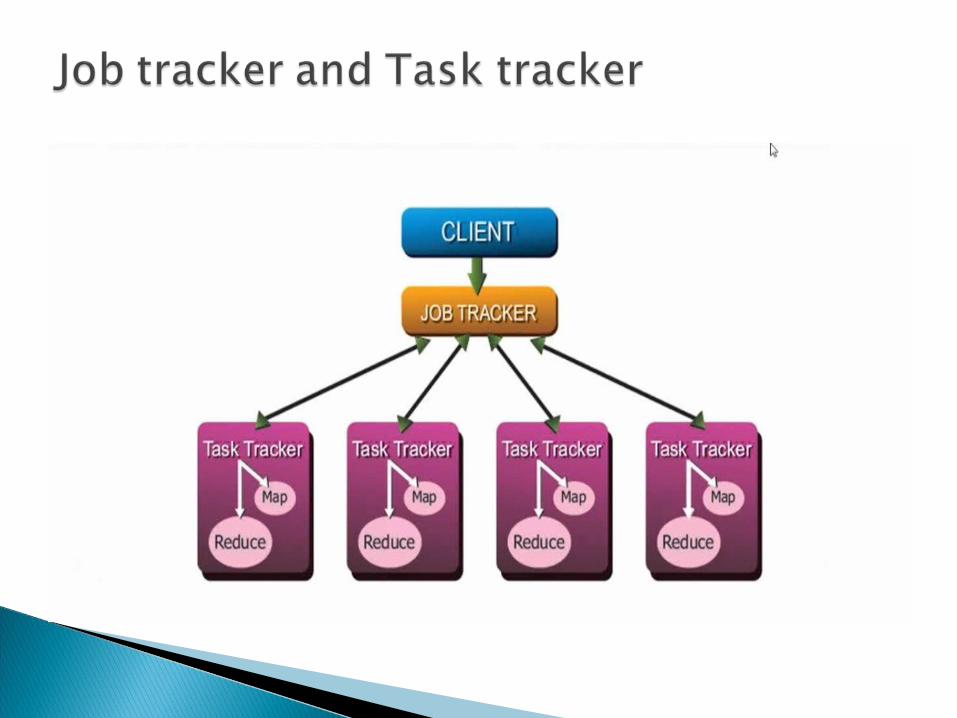
Works as a server
Coordinating more than one job at a time
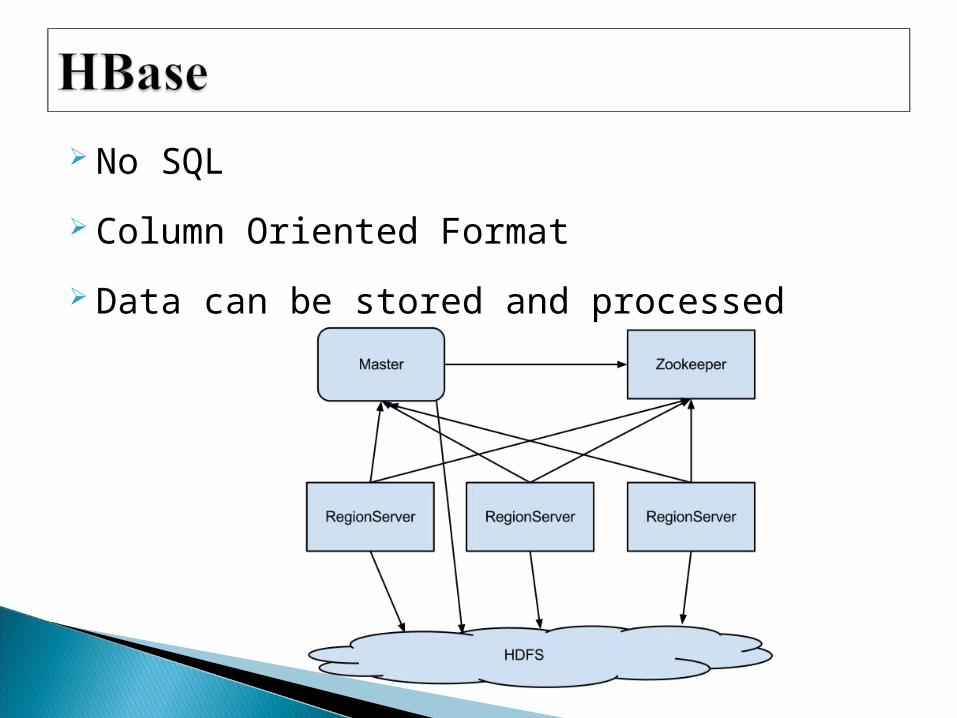
No SQL
Column Oriented Format
Data can be stored and processed

Hadoop can handle any type of data
Open Source from Apache
Fault Tolerant
Provides tools for various domain knowledge
Works very fast compared to others