Embed Size (px)
Citation preview

Summary of Analogical Reinforcement Learning
James M. Foster & Matt Jones
Methodology of Cognitive Science
Jin Hwa Kim Program in Cognitive Science
Seoul National University
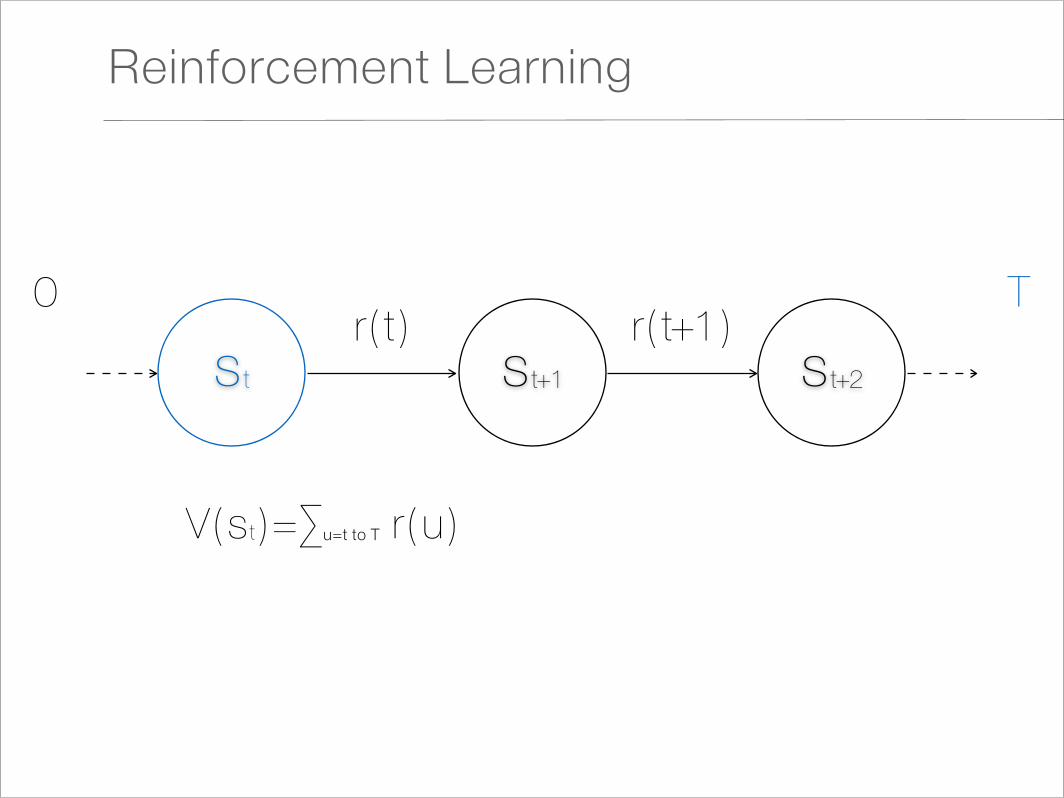
Reinforcement Learning
st st+1 st+2
r(t) r(t+1)T0
V(st)=∑u=t to T r(u)

Reinforcement Learning
st+1 st+2
r(t) r(t+1)0
V(st)=∑u=t to T r(u)
(st)?
st
T

Introduction
1. Background
- To develop a computational understanding of how people learn abstract concepts (analogical reasoning),
- Recognizing structural similarities among relational system [Doumas et al., 2008; Gentner, 1983; Hummel & Holyoak, 2003]
2. Goal
- Integrate analogical learning with reinforcement learning (RL), which has neurophysiological support [e.g. Schultz et al., 1997]
- Representation through similarity-based generalization
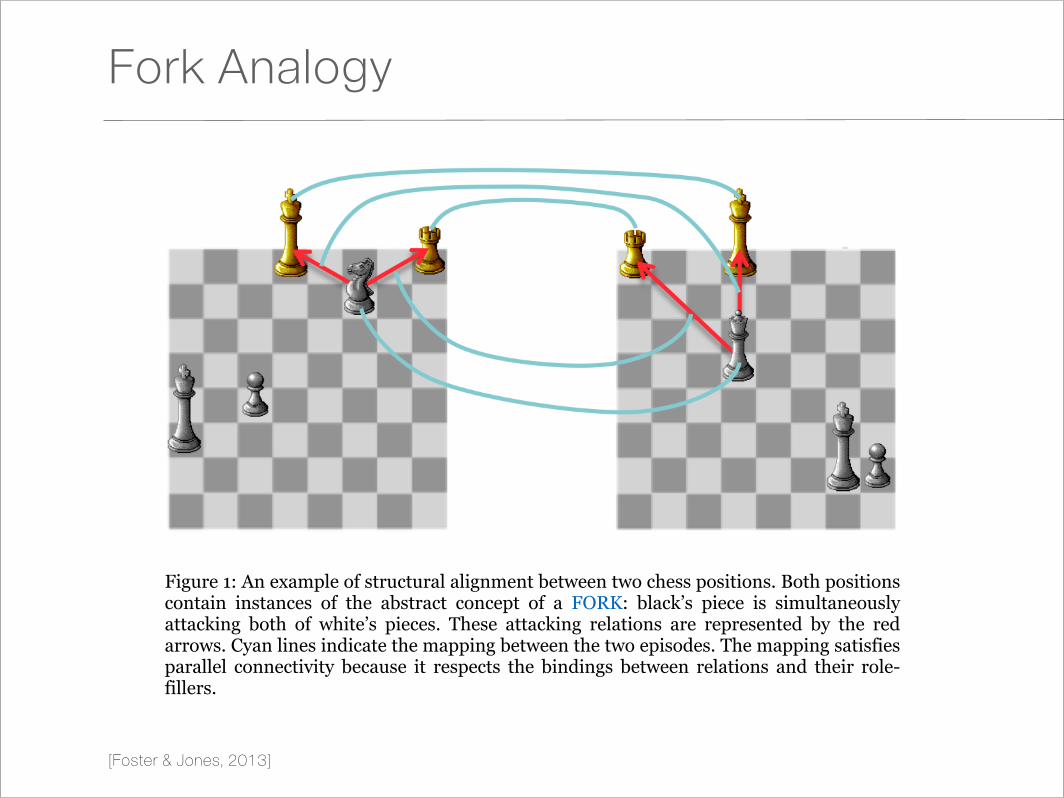
Fork Analogy
[Foster & Jones, 2013]
Figure 1: An example of structural alignment between two chess positions. Both positions contain instances of the abstract concept of a FORK: black’s piece is simultaneously attacking both of white’s pieces. These attacking relations are represented by the red arrows. Cyan lines indicate the mapping between the two episodes. The mapping satisfies parallel connectivity because it respects the bindings between relations and their role-fillers.

Structural Alignment
1. It is critical to learn abstract concepts
- Perceived similarity depends on it. [Markman & Gentner, 1993]
- For analogical transfer [Gick & Holyoak, 1980](e.g. in a different, but aligned position)
- Lead to schema induction
2. Need for selection
- Fork is an important not (only) because its frequency, but because it has significant wining chance.
- Let a reward of RL judges analogical schema.

Reinforcement Learning
1. Method
- Learning values for different states or actions, which represent the totally expected future reward
- Incrementally from temporal-difference (TD) error
2. Limitation
- Too many states for learning values Using a subset of the values for each exemplar states

Analogical RL
1. Synergy of Analogy and RL
- Structural alignment yields an abstract form of psychological similarity that can support sophisticated generalization [Gick & Holyoak, 1980; Markman & Gentner, 1993](e.g. quickly learn to create forks and to avoid forks by the opponent)
- Drive analogical learning by guiding schema induction (e.g. sequential attacking strategy)
2. Generating schemas
- Initially exemplars are episodic states.
- Whenever the structural alignment between a state and an exemplar produce a sufficient reduction in prediction error, the induced schema is added to the collection of exemplars.
- Thus the model’s representation transits from initially episodic to more abstract and conceptual.
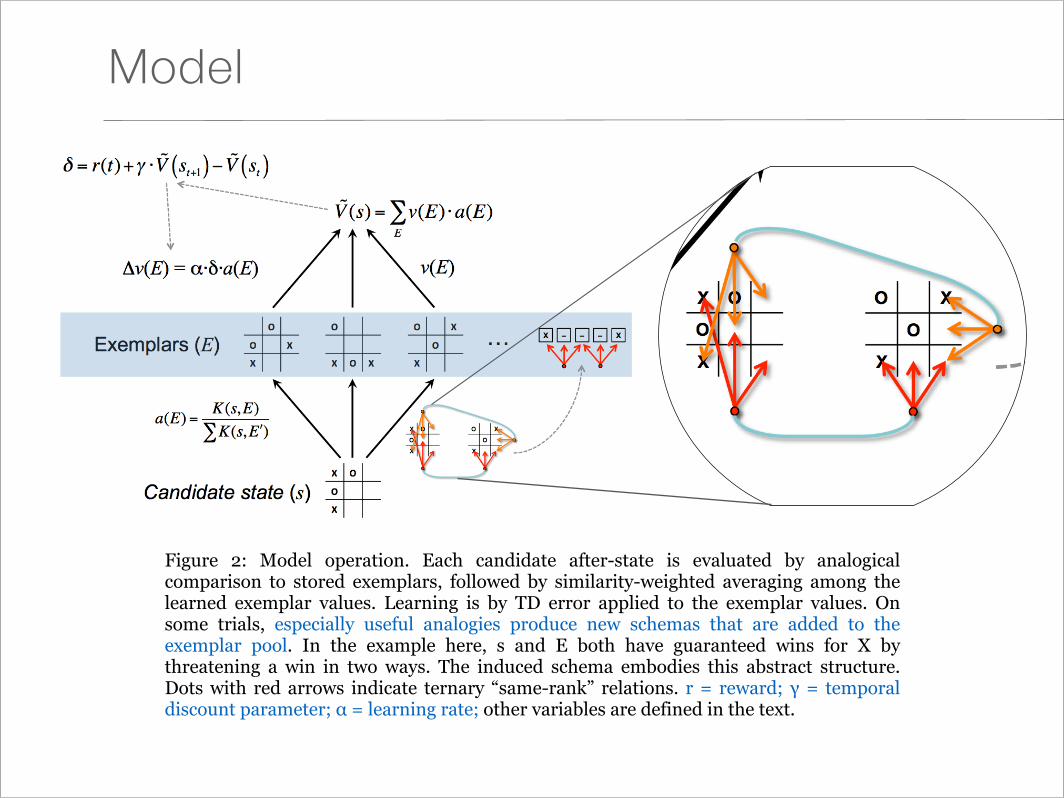
Model
Figure 2: Model operation. Each candidate after-state is evaluated by analogical comparison to stored exemplars, followed by similarity-weighted averaging among the learned exemplar values. Learning is by TD error applied to the exemplar values. On some trials, especially useful analogies produce new schemas that are added to the exemplar pool. In the example here, s and E both have guaranteed wins for X by threatening a win in two ways. The induced schema embodies this abstract structure. Dots with red arrows indicate ternary “same-rank” relations. r = reward; γ = temporal discount parameter; α = learning rate; other variables are defined in the text.

Simulation
1. Three models
1) Featural model is the simplest one using only literal mappings.
2) Relational model includes rigid rotation and reflection of the board.
3) Schema model includes two hand-coded schemas in addition to the above relational model. (111, immediate win; and 022, risks immediate loss)
2. Limitation
- The purpose of the schema model was to test the utility of having schemas that capture task-relevant structures.
- To integrate a solution into the present model soon.
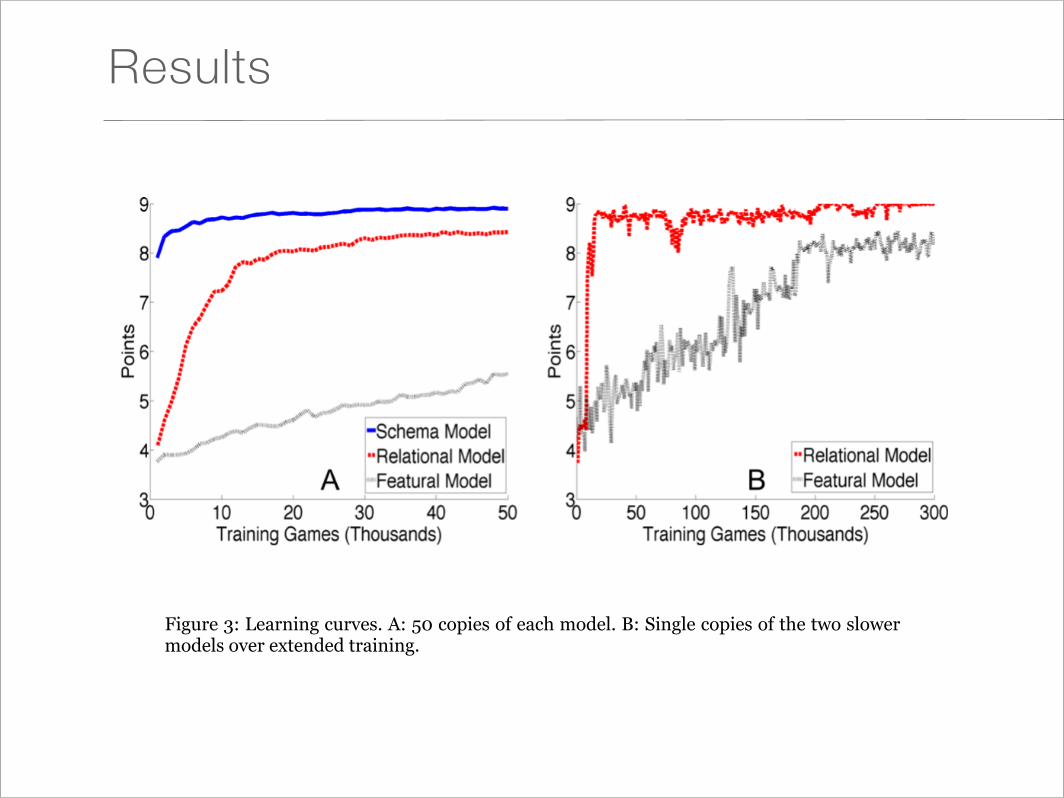
Results
Figure 3: Learning curves. A: 50 copies of each model. B: Single copies of the two slower models over extended training.

Discussion
1. Limitations
- Not included a mechanism for inducing new schemas.
- Learning is slow due to the nature of gradient descent operating.(ref. One-shot learning with bayesian networks [Maas & Kemp, 2009])
2. Bottom-up and Top-down
- Whereas the analogical RL builds up schemas from simpler representations, the Bayesian approach takes a top-down approach.
- The question is how the human mind discovers new, abstract concepts.
!!
†

Q/A
1. Analogical RL의 실례로 체스의 경우를 들고 있습니다. fork의 경우들을 학습하는 대신에 fork 개념 자체를 학습하는 것으로 설명하고 있는데, 다소 이해가 어렵습니다. 개념을 직접 학습하는데에 fork의 경우 등의 사전지식이 불필요함을 이야기하는 것인지, 단지 "모든 경우의 수"를 다 알 필요는 없다는 뜻인지 궁금합니다.

Q/A
2. RL이 temporal difference error를 사용하는 것에 대해 인간의 뇌가 이 방식을 사용한다는 증거가 있기 때문이라 말합니다. 인간의 뇌가 이 방식을 사용한다는 점에 대한 보다 자세한 설명 부탁드리고요. [Schultz et al., 1997]

Q/A
3. TD이외의 방식들과 TD의 차이는 무엇인지 궁금합니다. RL에서 TD error를 활용하는 의의는 무엇일까요?
Sarsa
Q-Learning

Q/A
4. 저자가 말하는 제안된 모델의 단점은 주로 기술적인 부분에 있는 것 같습니다. 발제자가 생각하시는 이 방식의 단점/보완되어야 하는 점은 무엇인지 궁금합니다.
!





























