Embed Size (px)
Citation preview

Towards High Performance and Efficiency of Distributed Heterogeneous Systems
Sam Skalicky

04/15/2023
Outline
• Motivation – Compute-intensive applications– Heterogeneous systems
• Related work – state of the art• Proposed solution– Model-based framework – Graph-based modeling method
• Preliminary results• Conclusion – research objectives
2

04/15/2023 Motivation
Compute-intensive Applications
Data assimilation applications• Incorporate large amounts of data, examples:– Medical imaging, weather prediction, stock &
securities market analysis• Linear algebra computations:– Dot product, MV-multiply, MM-multiply, matrix
inverse, and matrix decomposition
• Execution time on GPP makes use impractical3/40
Compute-intensive problems requiring high performance

04/15/2023 Motivation
Medical Imaging
Data assimilation application• Medical diagnosis– NTEPI: Non-invasive Transmural
Electrophysiological Imaging• Kalman filter: ECG & model• 120 electrodes• Solves inverse propagation problem
4/40
Compute-intensive problems requiring high performance
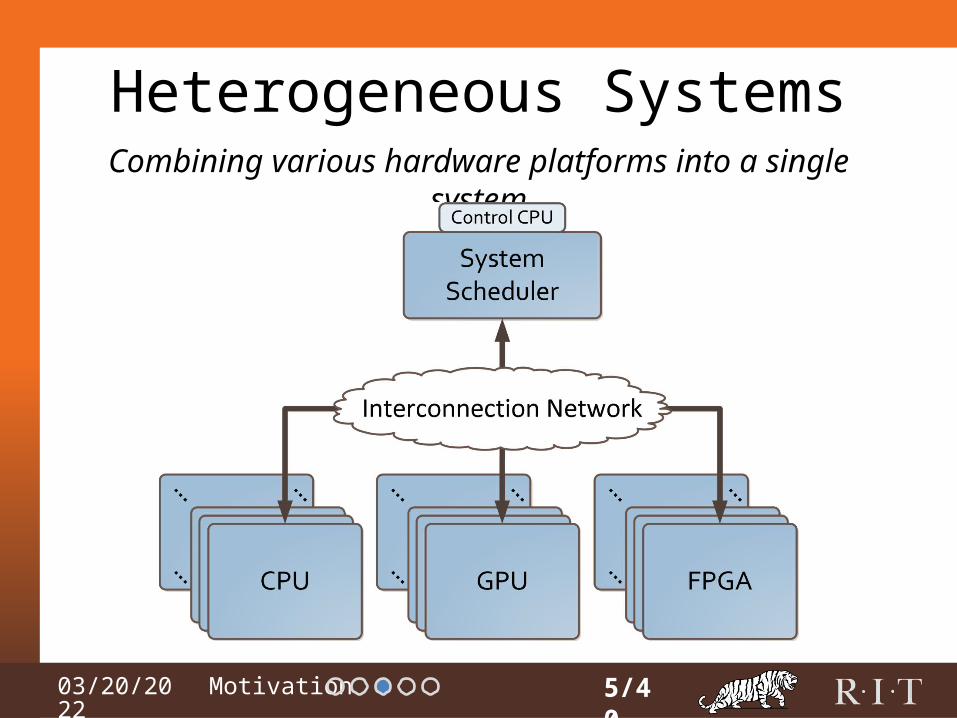
04/15/2023 Motivation
Heterogeneous Systems
5/40
Combining various hardware platforms into a single system

04/15/2023 Motivation
Heterogeneous Systems
Design decisions[29]
6/40
Taking advantage of capabilities from various hardware platforms

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design
6/40
Taking advantage of capabilities from various hardware platforms
Motivation

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design• Profiling and benchmarking
Taking advantage of capabilities from various hardware platforms
6/40Motivation

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design• Profiling and benchmarking• Partitioning and mapping (granularity of tasks)
Taking advantage of capabilities from various hardware platforms
6/40Motivation

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design• Profiling and benchmarking• Partitioning and mapping (granularity of tasks)• Hardware platform selection
Taking advantage of capabilities from various hardware platforms
6/40Motivation

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design• Profiling and benchmarking• Partitioning and mapping (granularity of tasks)• Hardware platform selection• Scheduling and synchronization
Taking advantage of capabilities from various hardware platforms
6/40Motivation

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design• Profiling and benchmarking• Partitioning and mapping (granularity of tasks)• Hardware platform selection• Scheduling and synchronization• Performance evaluation
Taking advantage of capabilities from various hardware platforms
6/40Motivation

04/15/2023
Heterogeneous Systems
Design decisions[29]
• Algorithm design• Profiling and benchmarking• Partitioning and mapping (granularity of tasks)• Hardware platform selection• Scheduling and synchronization• Performance evaluation
6/40
Taking advantage of capabilities from various hardware platforms
[6]
[32]
[36]
[19]
[45]
[40]
Motivation

04/15/2023 Motivation
Heterogeneous Systems
Research Statement:Compute-intensive applications can be accelerated using various platforms targeted to each type of computation. When used as a singular unit, these various platforms form a heterogeneous system.
7/40
A potential solution to performance for compute-intensive applications

04/15/2023 Related Work
Related Work
8/40
Evolution of heterogeneous system design

04/15/2023
Related Work
• Symmetric multi-processor architectures
8/40
Evolution of heterogeneous system design
General purpose computing research focus
Related Work

04/15/2023
Related Work
• Symmetric multi-processor architectures• Embedded heterogeneity
8/40
Evolution of heterogeneous system design
Applying new techniques to match specific tasks to specialized architectures
Related Work

04/15/2023
Related Work
• Symmetric multi-processor architectures• Embedded heterogeneity– Programming, multiple toolchains[10,11]
8/40
Evolution of heterogeneous system design
Carbon [11]: virtualization technique to abstract out architectural details
required for programming
Cao [10]: software not portable between different toolchains or achitectures
Related Work

04/15/2023
Related Work
• Symmetric multi-processor architectures• Embedded heterogeneity– Programming, multiple toolchains[10,11]
• Heterogeneous system simulators[6,16,26,44]
8/40
Evolution of heterogeneous system design
CPU/GPU [44]Abstract/FLOPS [26]CPU/FPGA [16]Abstract [6]
Related Work

04/15/2023
Related Work
• Symmetric multi-processor architectures• Embedded heterogeneity– Programming, multiple toolchains[10,11]
• Heterogeneous system simulators[6,16,26,44]
• Design frameworks & Implementation strategies[19,30,36,40]
8/40
Evolution of heterogeneous system design
Related WorkThese previous frameworks have been researched only for specific cases (OpenCL, FPGAs)

04/15/2023
Related Work
• Symmetric multi-processor architectures• Embedded heterogeneity– Programming, multiple toolchains[10,11]
• Heterogeneous system simulators[6,16,26,44]
• Design frameworks & Implementation strategies[19,30,36,40]
• Composition of hardware platforms[9,12,22,28,32,41]
8/40
Evolution of heterogeneous system design
CPU/GPU [32], CPU/FPGA [41], Abstractly CPU/GPU/FPGA [28]
Related Work

04/15/2023
Related Work
• Symmetric multi-processor architectures• Embedded heterogeneity– Programming, multiple toolchains[10,11]
• Heterogeneous system simulators[6,16,26,44]
• Design frameworks & Implementation strategies[19,30,36,40]
• Composition of hardware platforms[9,12,22,28,32,41]
8/40
Evolution of heterogeneous system design
Related Work

04/15/2023 Solution
Proposed Solution
• Utilize a heterogeneous mix of hardware platforms• Achieve high performance & efficiency• Enable regular use of these applications
Model-based Framework• Hardware platform selection• Scheduling and synchronization• Performance evaluationHigh-level Graph-based modeling method• Quickly estimate performance without implementation
9/40
Goal: enable regular use of compute-intensive applications
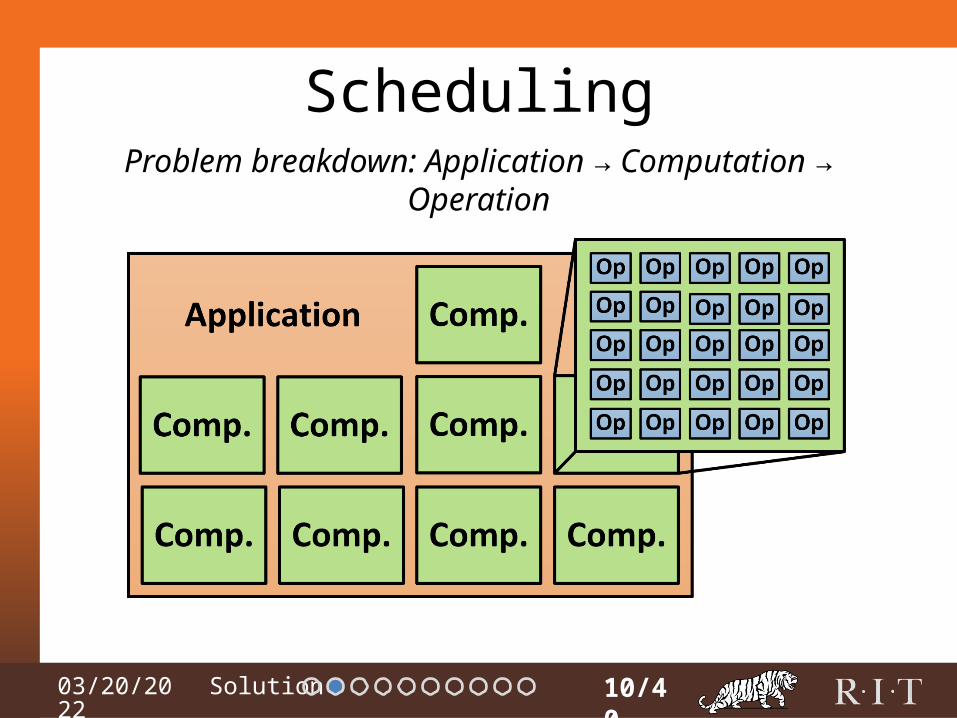
04/15/2023
Scheduling
10/40
Problem breakdown: Application → Computation → Operation
Solution
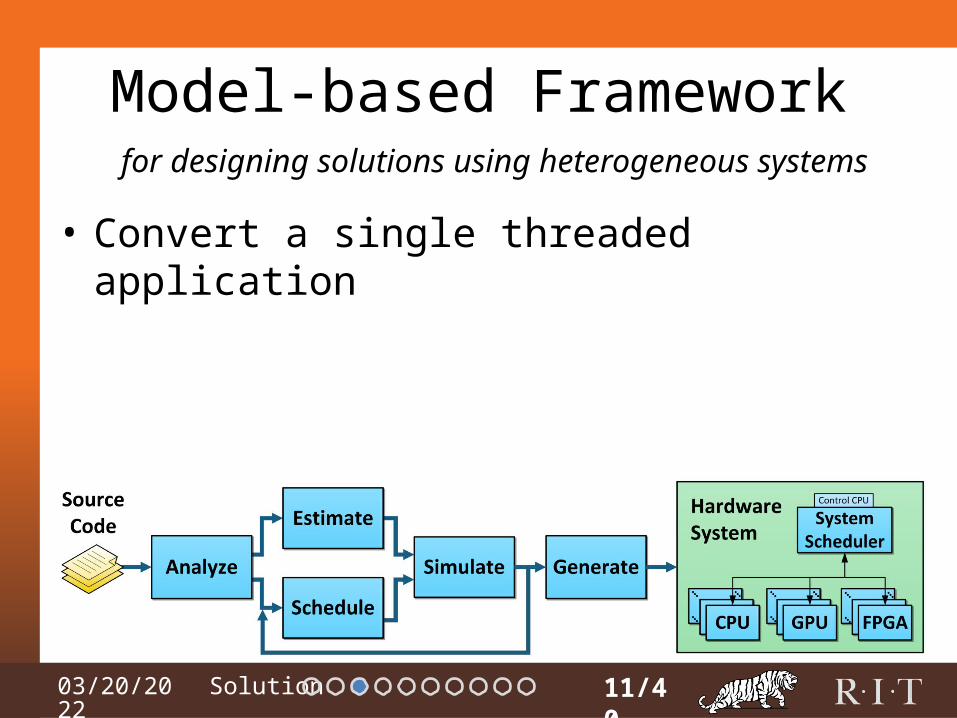
04/15/2023
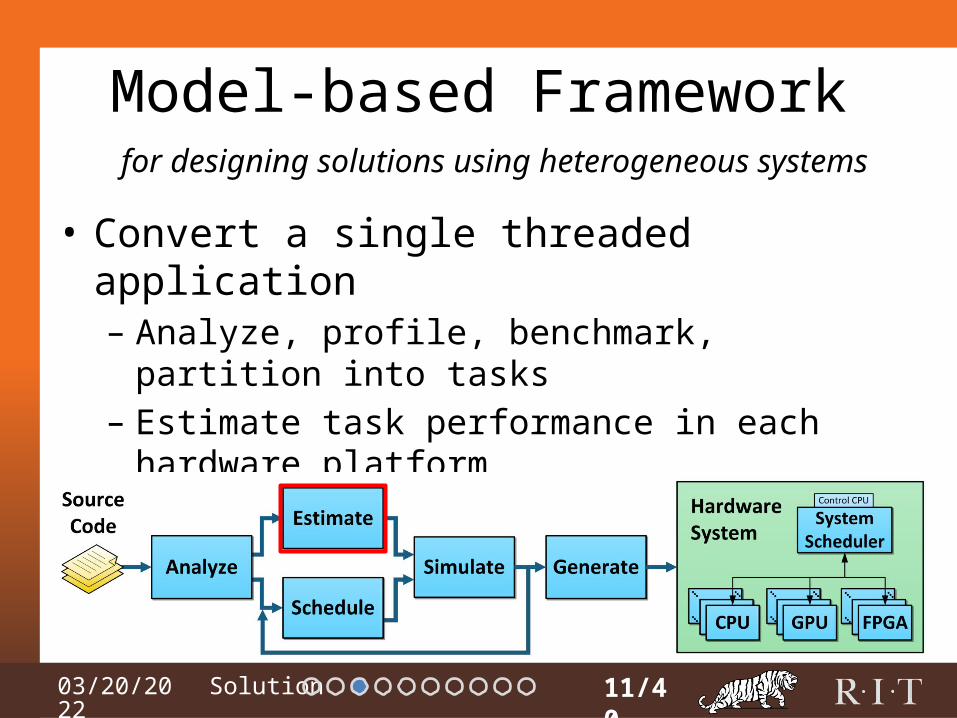
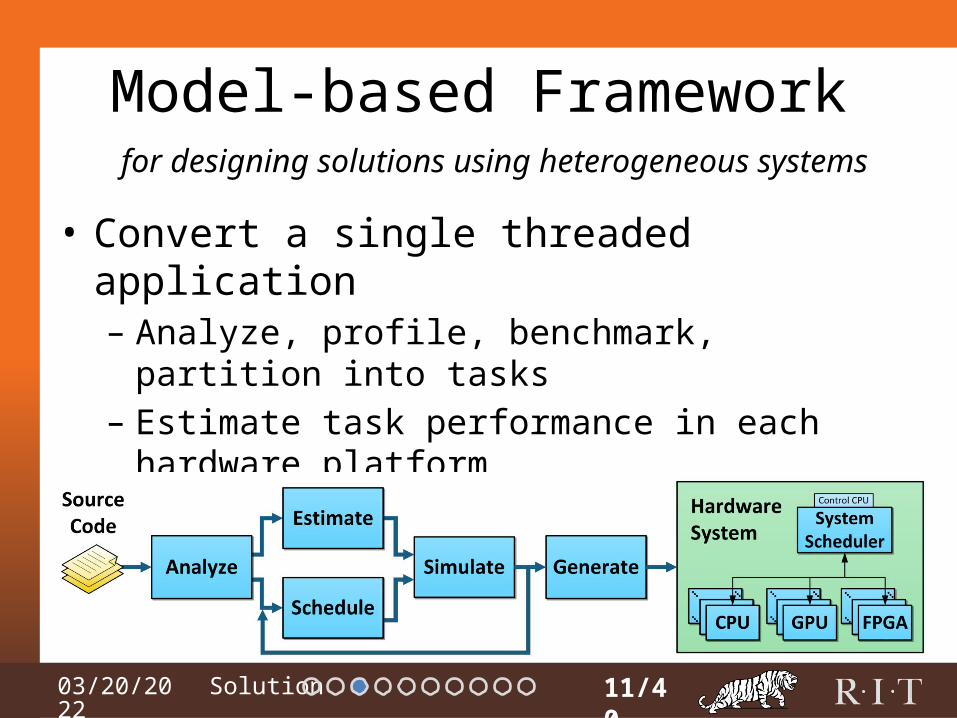
Model-based Framework
• Convert a single threaded application
11/40
for designing solutions using heterogeneous systems
Solution
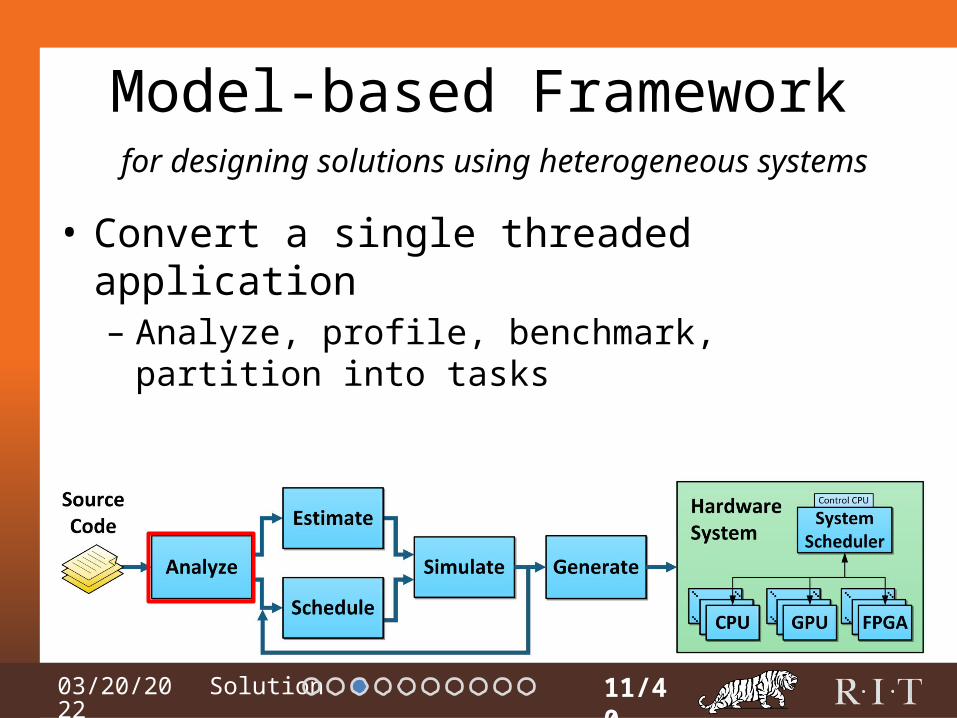
04/15/2023
Model-based Framework
• Convert a single threaded application– Analyze, profile, benchmark, partition into tasks
11/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
Model-based Framework
• Convert a single threaded application– Analyze, profile, benchmark, partition into tasks– Estimate task performance in each hardware platform
11/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
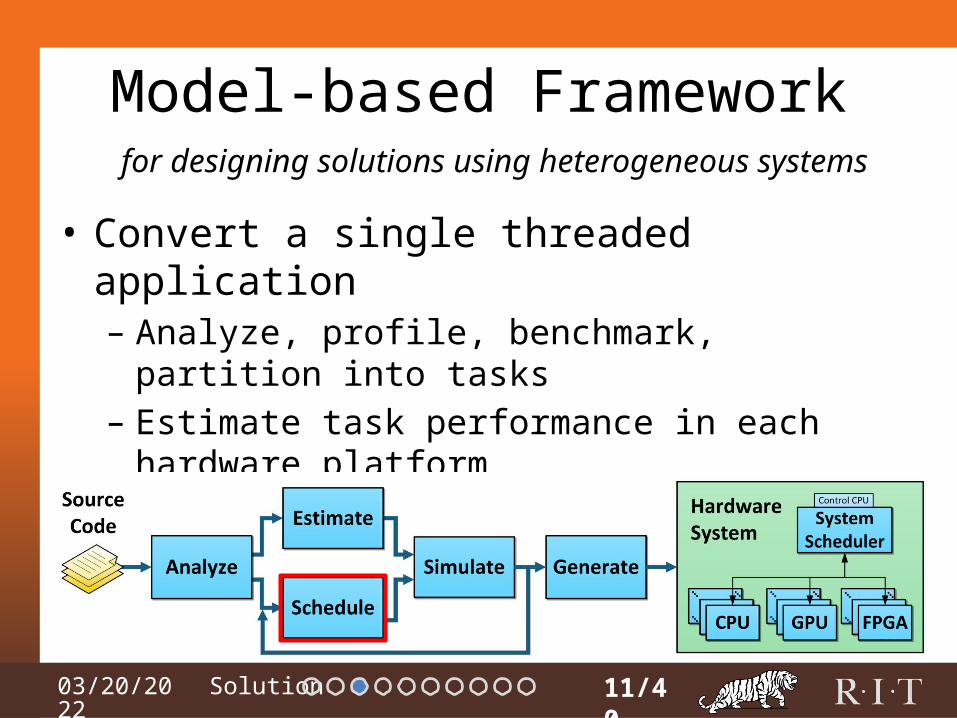
Model-based Framework
• Convert a single threaded application– Analyze, profile, benchmark, partition into tasks– Estimate task performance in each hardware platform– Map & schedule tasks to hardware platforms
11/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
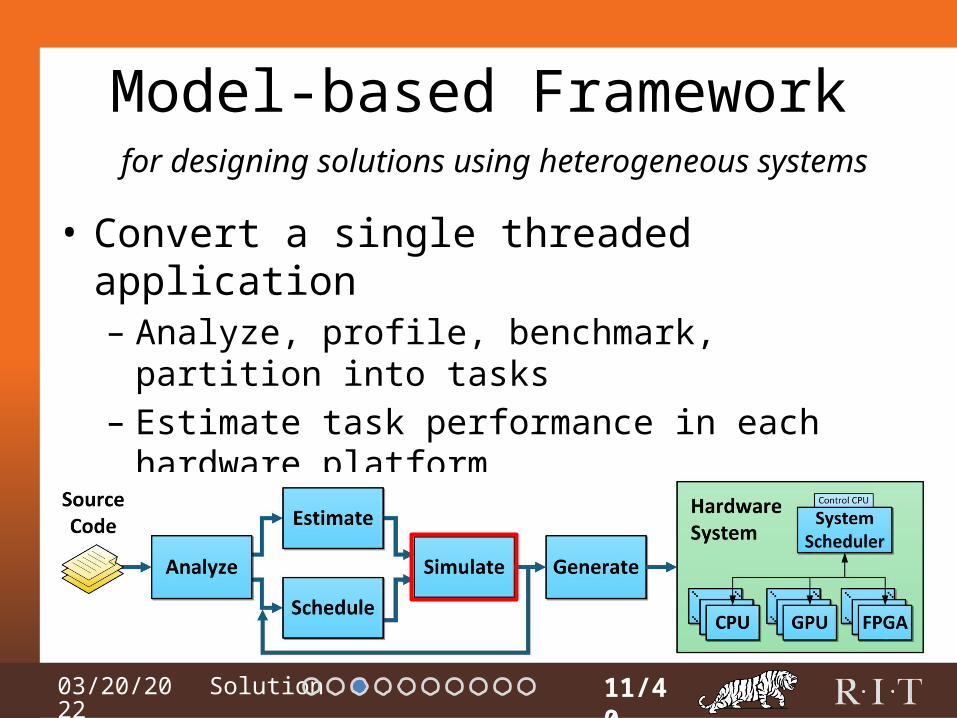
Model-based Framework
• Convert a single threaded application– Analyze, profile, benchmark, partition into tasks– Estimate task performance in each hardware platform– Map & schedule tasks to hardware platforms– Simulate to estimate performance
11/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
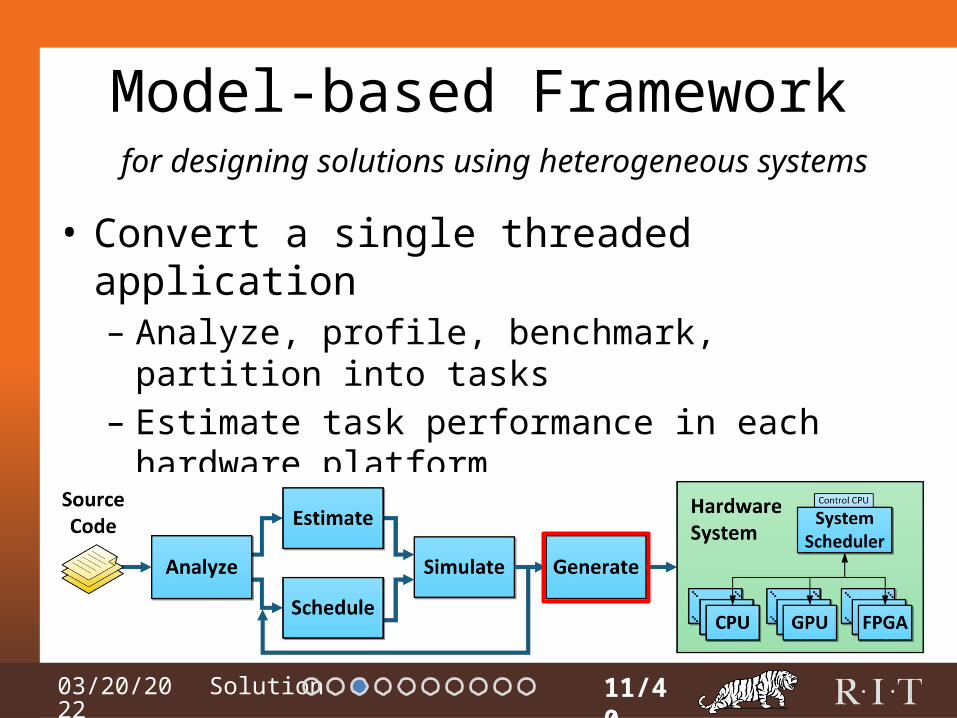
Model-based Framework
• Convert a single threaded application– Analyze, profile, benchmark, partition into tasks– Estimate task performance in each hardware platform– Map & schedule tasks to hardware platforms– Simulate to estimate performance
11/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
Model-based Framework
• Convert a single threaded application– Analyze, profile, benchmark, partition into tasks– Estimate task performance in each hardware platform– Map & schedule tasks to hardware platforms– Simulate to estimate performance
11/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
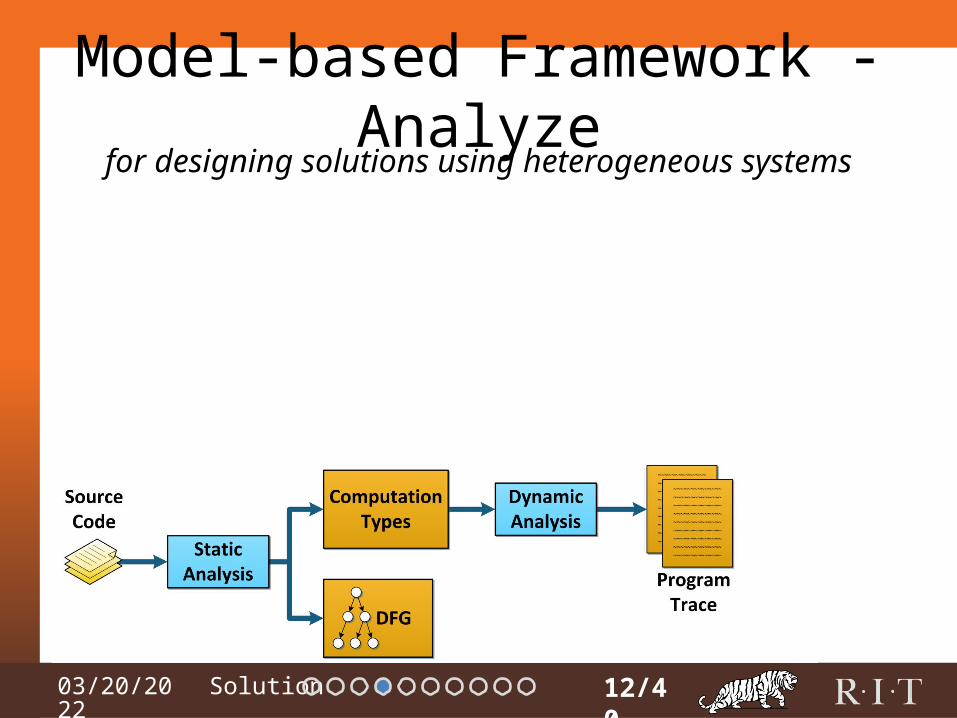
Model-based Framework - Analyze
12/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
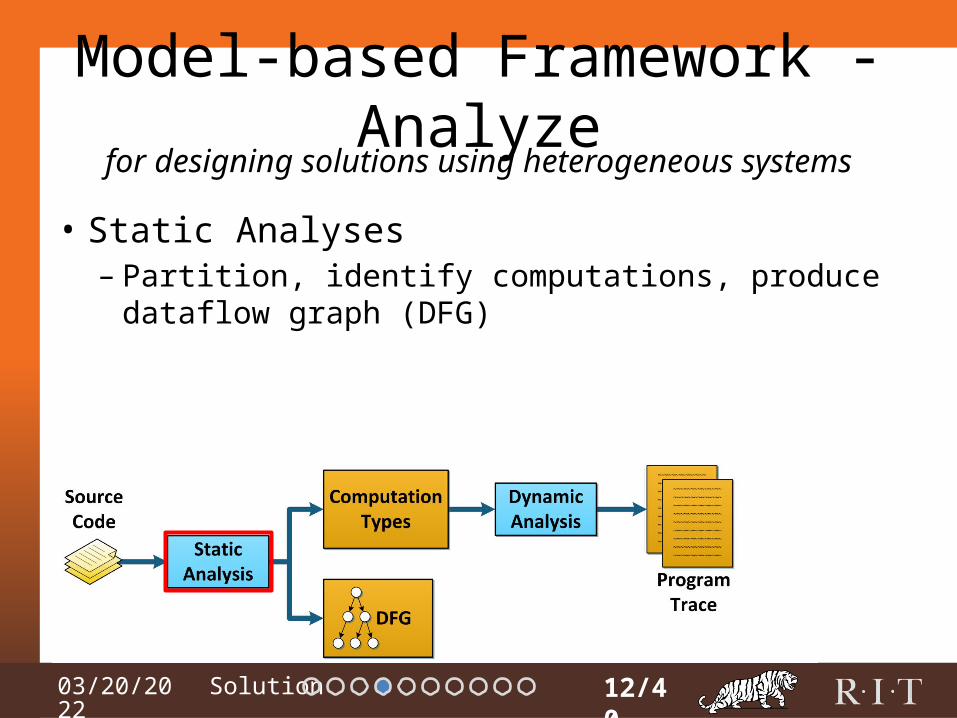
Model-based Framework - Analyze
• Static Analyses– Partition, identify computations, produce dataflow graph
(DFG)
12/40
for designing solutions using heterogeneous systems
Solution
04/15/2023
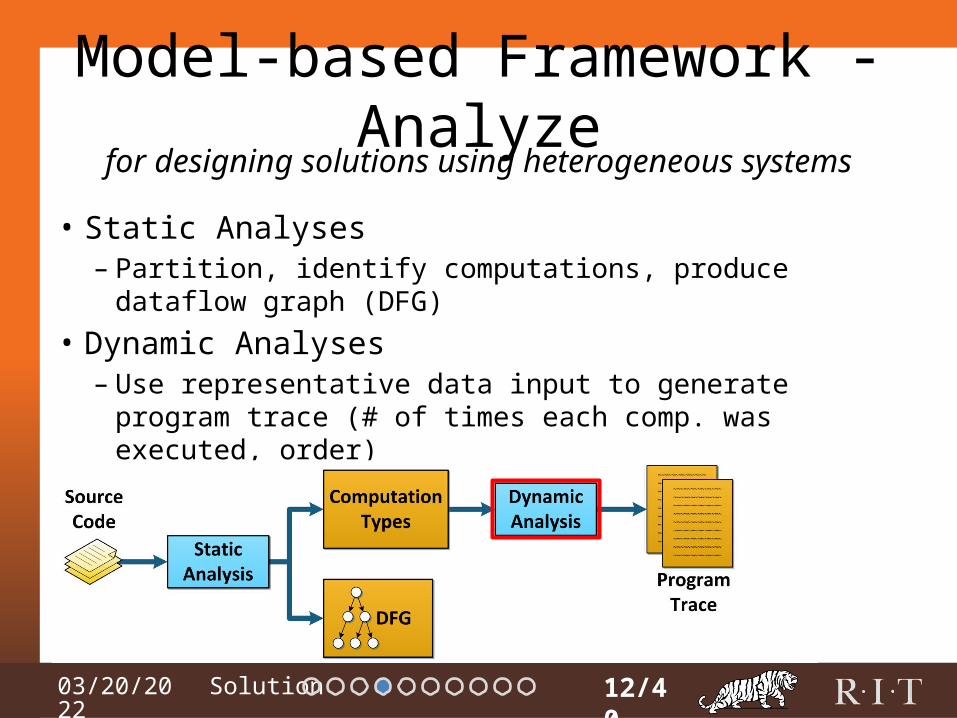
Model-based Framework - Analyze
• Static Analyses– Partition, identify computations, produce dataflow graph
(DFG)• Dynamic Analyses– Use representative data input to generate program trace (#
of times each comp. was executed, order)
12/40
for designing solutions using heterogeneous systems
Solution
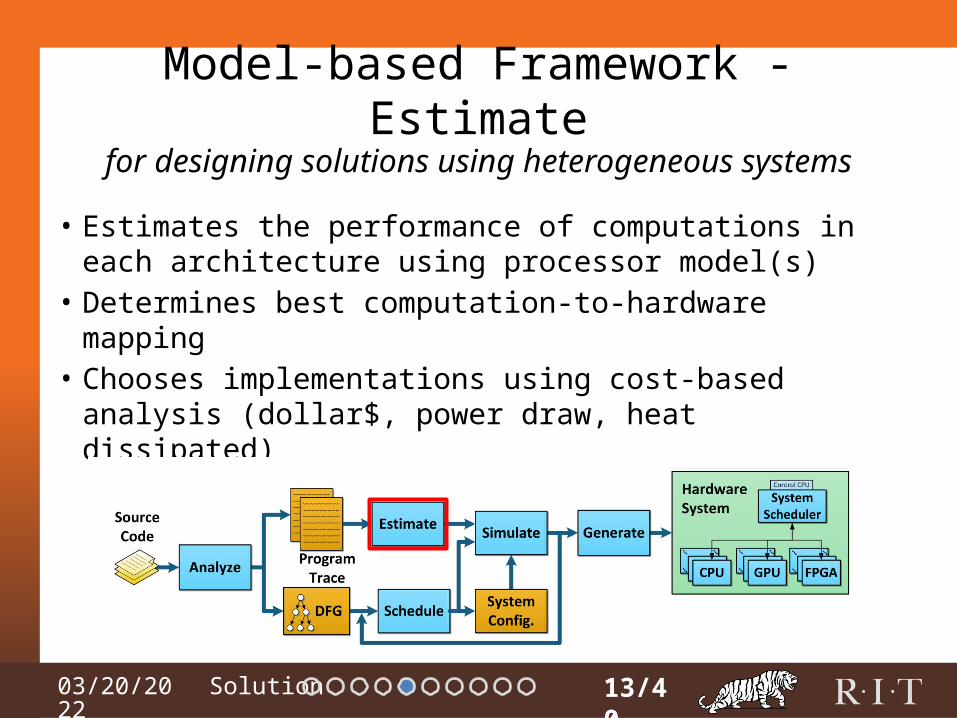
04/15/2023
Model-based Framework - Estimate
• Estimates the performance of computations in each architecture using processor model(s)
• Determines best computation-to-hardware mapping• Chooses implementations using cost-based analysis
(dollar$, power draw, heat dissipated)
13/40
for designing solutions using heterogeneous systems
Solution
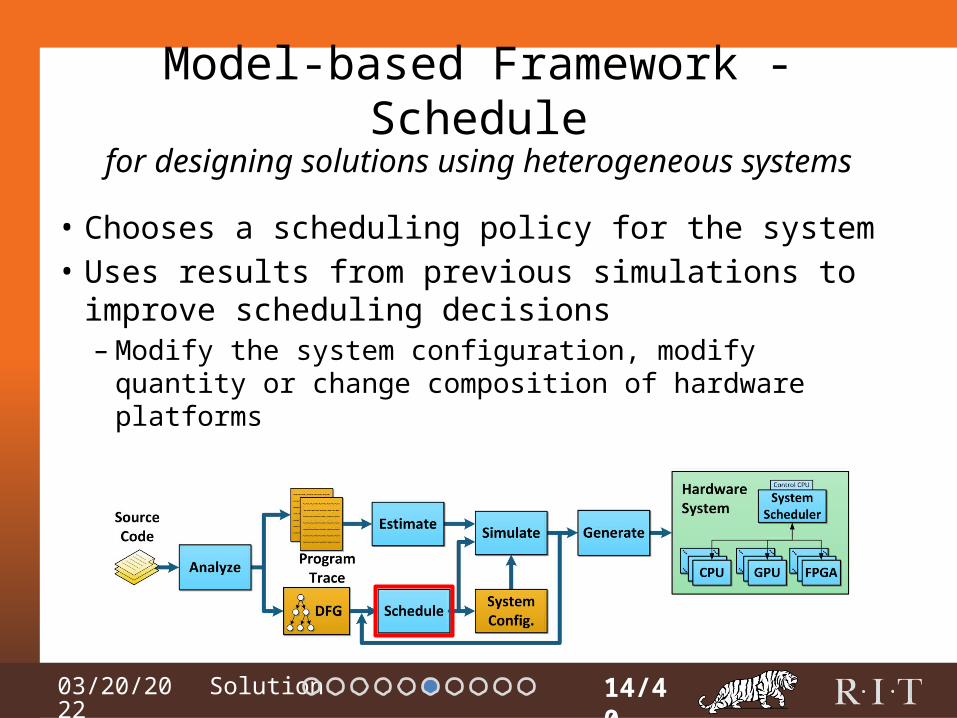
04/15/2023
Model-based Framework - Schedule
• Chooses a scheduling policy for the system• Uses results from previous simulations to
improve scheduling decisions– Modify the system configuration, modify quantity
or change composition of hardware platforms
14/40
for designing solutions using heterogeneous systems
Solution
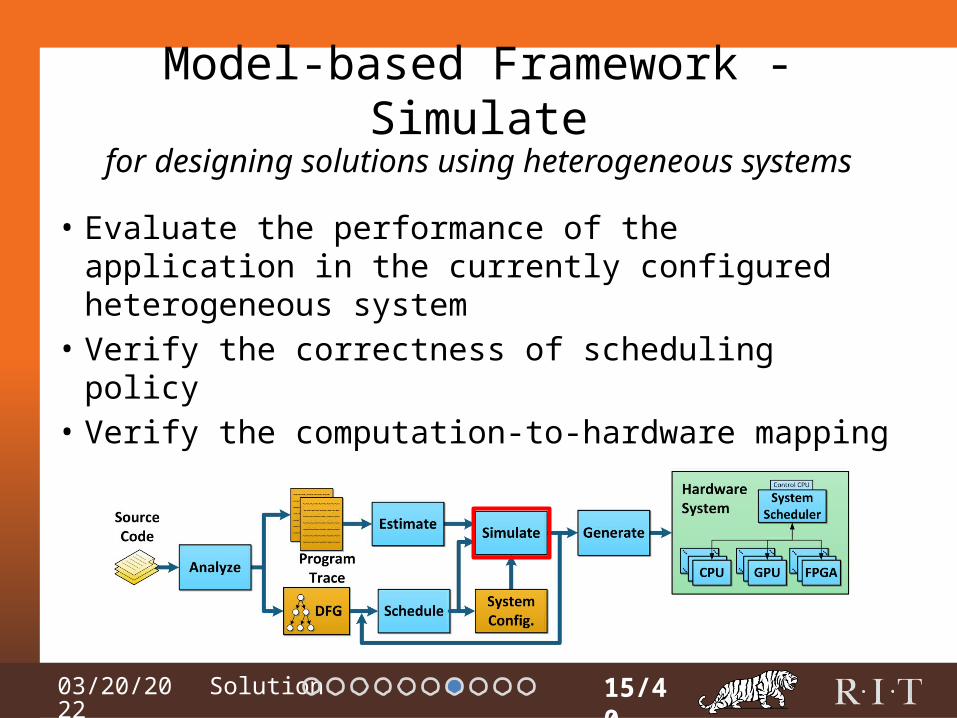
04/15/2023
Model-based Framework - Simulate
• Evaluate the performance of the application in the currently configured heterogeneous system
• Verify the correctness of scheduling policy• Verify the computation-to-hardware mapping
15/40
for designing solutions using heterogeneous systems
Solution
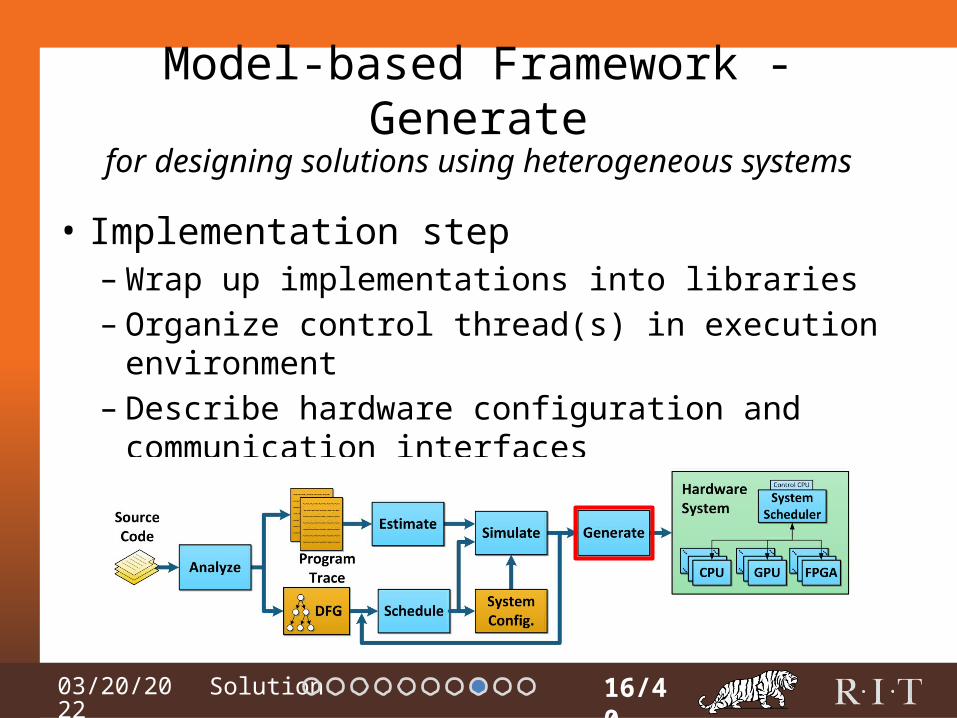
04/15/2023
Model-based Framework - Generate
• Implementation step– Wrap up implementations into libraries– Organize control thread(s) in execution environment– Describe hardware configuration and communication
interfaces
16/40
for designing solutions using heterogeneous systems
Solution

04/15/2023
Scheduling
• Encountered at two levels: computation, system• In general scheduling is known to be NP-hard[17]
• General problem: (P | Cmax)– P : number of identical processors– Cmax : objective, minimize max. completion time
• Our computation-level problem includes precedence constraints: (P | prec | Cmax)
• Our system level problem includes unrelated processors: (R | prec | Cmax)
17/40
A quick introduction
Solution

04/15/2023
High-level Graph-based modeling
• Approach: schedule operations from dataflow graph of computation onto available computational units of a processor
• Goal: estimate the number of clock cycles required to complete all operations.
• Benefits: operates on algorithmic implementation, for any hardware platform
18/40
To quickly estimate performance without implementation
7. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “High-Level Graph-Based Methodology for Improving Performance of Pipelined Architectures”. ACM SIGMETRICS, 2014, Submitted – under review.
Solution

04/15/2023 Preliminary Results
Preliminary Results
• Design space for computation-to-hardware mapping, and performance of relevant computations
• System configurations of various hardware platforms (CPU, GPU, and FPGA)
• System-level scheduling of linear algebra-based applications in heterogeneous hardware platforms
19/40
For using compute-intensive applications in heterogeneous systems

04/15/2023 Design Space
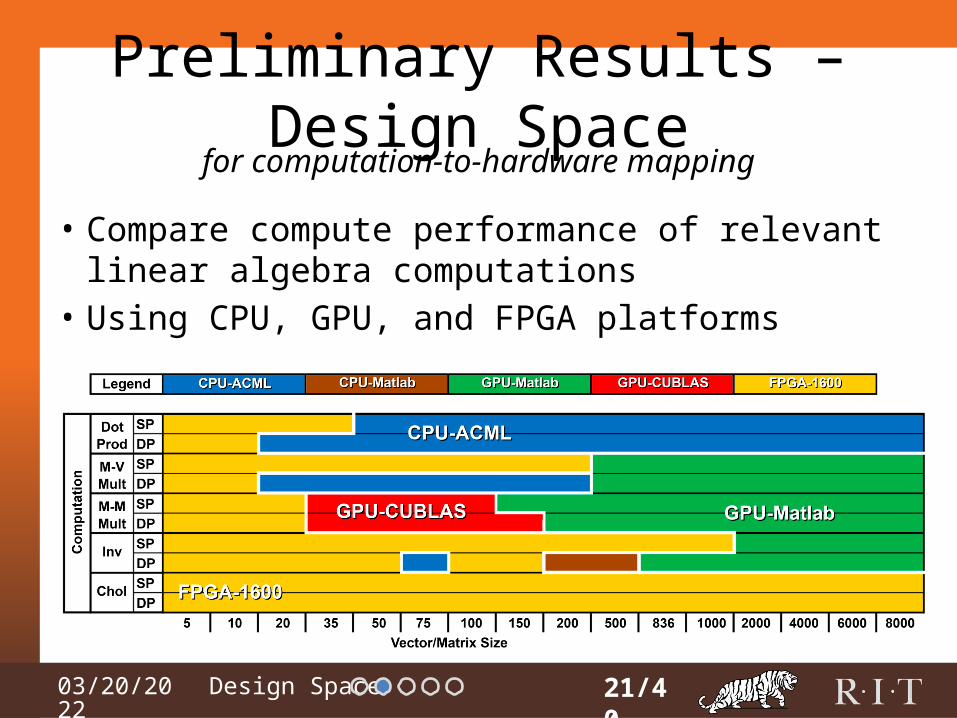
Preliminary Results – Design Space
• Compare compute performance of relevant linear algebra computations
• Using CPU, GPU, and FPGA platforms
20/40
for computation-to-hardware mapping
2. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, James Letendre and David Gasser, “Linear Algebra Computations in Heterogeneous Systems”. IEEE International Conference on Application-specific Systems, Architectures and Processors, June 2013, Washington DC, USA.
04/15/2023
Preliminary Results – Design Space
• Compare compute performance of relevant linear algebra computations
• Using CPU, GPU, and FPGA platforms
21/40
for computation-to-hardware mapping
Design Space
04/15/2023
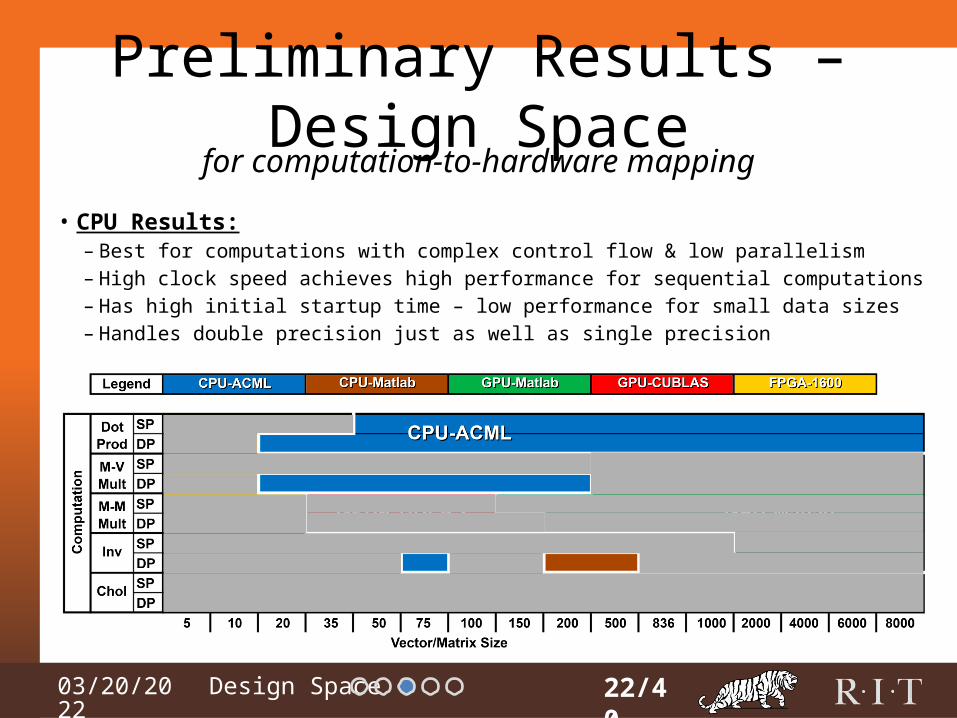
Preliminary Results – Design Space
• CPU Results:– Best for computations with complex control flow & low parallelism– High clock speed achieves high performance for sequential computations– Has high initial startup time – low performance for small data sizes– Handles double precision just as well as single precision
22/40
for computation-to-hardware mapping
Design Space
04/15/2023
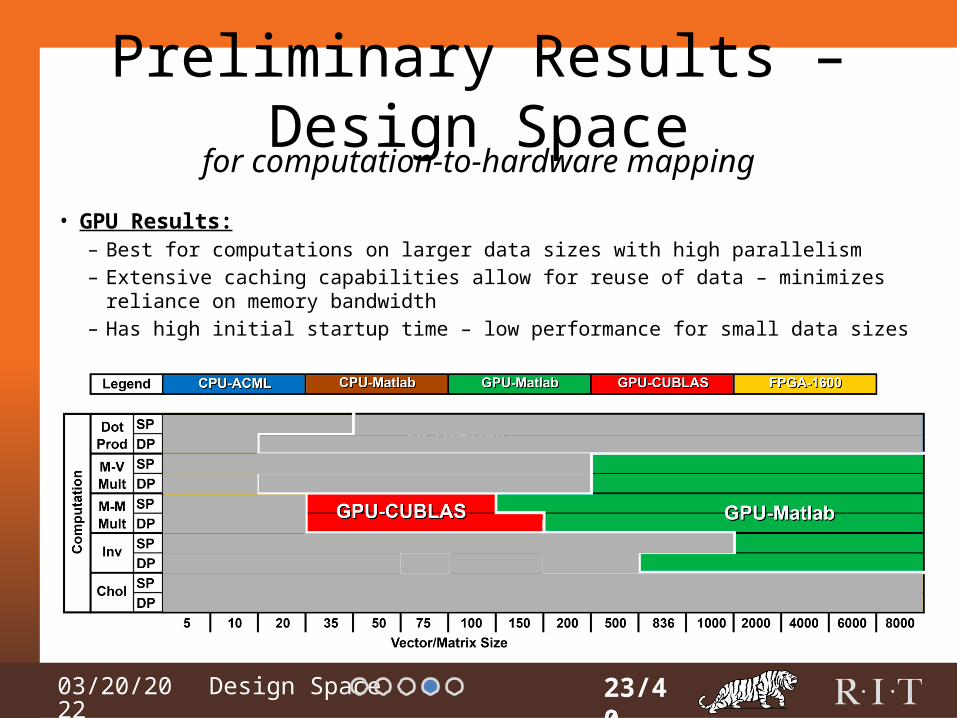
Preliminary Results – Design Space
• GPU Results:– Best for computations on larger data sizes with high parallelism– Extensive caching capabilities allow for reuse of data – minimizes reliance on
memory bandwidth– Has high initial startup time – low performance for small data sizes
23/40
for computation-to-hardware mapping
Design Space
04/15/2023
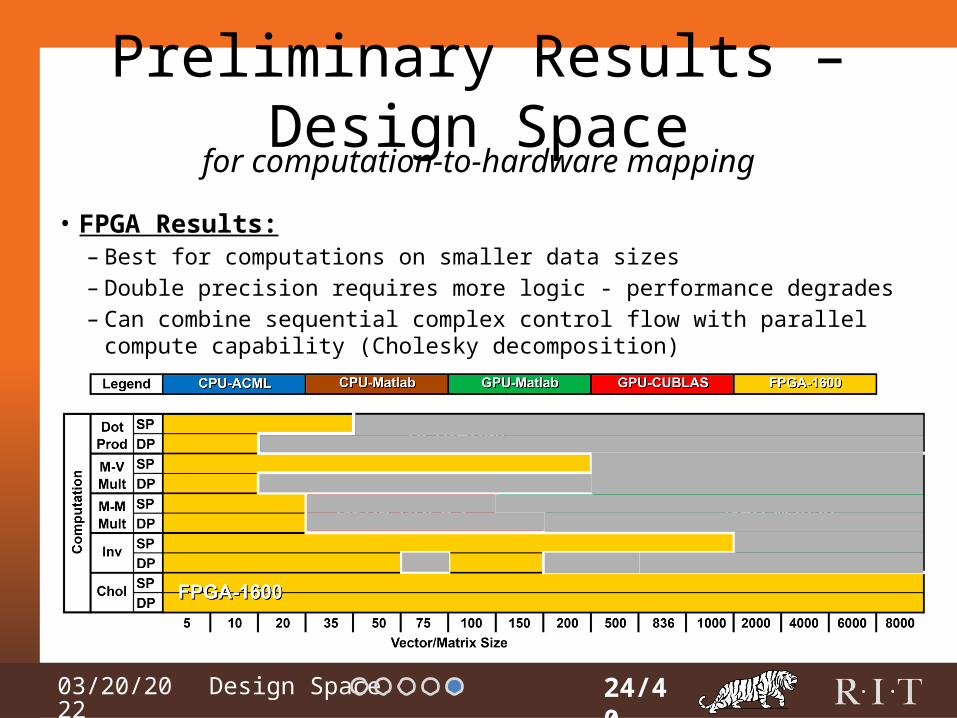
Preliminary Results – Design Space
• FPGA Results:– Best for computations on smaller data sizes– Double precision requires more logic - performance degrades– Can combine sequential complex control flow with parallel compute
capability (Cholesky decomposition)
24/40
for computation-to-hardware mapping
Design Space

04/15/2023
Preliminary Results – System Config.
• Evaluated the compute-intensive NTEPI application using various combinations of CPU, GPU, and FPGA platforms
• Results show execution time for each configuration relative to the CPU+GPU+FPGA system
System Config. 25/40
Evaluating the added performance of various hardware platforms
3. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “Distributed Execution of Transmural Electrophysiological Imaging with CPU, GPU, and FPGA”. International Conference on ReConFigurable Computing and FPGAs, December 2013, Cancun, Mexico.

04/15/2023
Preliminary Results – System Config.
• Evaluated the compute-intensive NTEPI application using various combinations of CPU, GPU, and FPGA platforms
• Results show execution time for each configuration relative to the CPU+GPU+FPGA system
26/40
Evaluating the added performance of various hardware platforms
System Config.

04/15/2023
Preliminary Results – System Config.
• Evaluated the compute-intensive NTEPI application using various combinations of CPU, GPU, and FPGA platforms
• Results show execution time for each configuration relative to the CPU+GPU+FPGA system
26/40
Evaluating the added performance of various hardware platforms
CPU+GPU+FPGA was 1.2x faster than just GPU
System Config.

04/15/2023
Preliminary Results – System Config.
• Evaluated the compute-intensive NTEPI application using various combinations of CPU, GPU, and FPGA platforms
• Results show execution time for each configuration relative to the CPU+GPU+FPGA system
26/40
Evaluating the added performance of various hardware platforms
CPU+GPU+FPGA was 1.1x faster than just GPU
System Config.

04/15/2023
Preliminary Results – System Config.
• Evaluated the compute-intensive NTEPI application using various combinations of CPU, GPU, and FPGA platforms
• Results show execution time for each configuration relative to the CPU+GPU+FPGA system
26/40
Evaluating the added performance of various hardware platforms
CPU+GPU+FPGA was 100x faster than just FPGA
System Config.

04/15/2023
Preliminary Results – System Config.
• For the NTEPI application, MM-Multiply dominates and so GPU provide most benefit
• Three-platform system achieves speedups of up to 62x, 2x, and 1605x against CPU, GPU, FPGA
• Adding FPGA to CPU+GPU achieves 2x speedup
27/40
Evaluating the added performance using various hardware platforms
System Config.

04/15/2023 System Schedule
Preliminary Results – System Schedule
• Analyzed the performance of the NTEPI application in a CPU, GPU, and FPGA system
• Using well researched heterogeneous scheduling algorithms– Static: HEFT[52], PEFT[1]
– Dynamic: SPN[29], MET[7], SS[33],AG[55]
28/40
of linear algebra-based applications using heterogeneous h/w platforms
6. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “Scheduling Policies for Distributed Heterogeneous CPU+GPU+FPGA Systems: A Medical Imaging Case Study”. IEEE International Parallel & Distributed Processing Symposium, 2014, Submitted – under review.

04/15/2023
Preliminary Results – System Schedule
Scheduling assumptions:• Let V be the set of all computations in the application
– Let I⊂V, containing unexecuted computations whose dependencies have already been completed
• Let P be the set of all hardware platforms in the system– Let A⊂P containing only idle hardware platforms
29/40
of linear algebra-based applications using heterogeneous h/w platforms
System Schedule

04/15/2023
Preliminary Results – System Schedule
Scheduling assumptions:• Let V be the set of all computations in the application
– Let I⊂V, containing unexecuted computations whose dependencies have already been completed
• Let P be the set of all hardware platforms in the system– Let A⊂P containing only idle hardware platforms
29/40
of linear algebra-based applications using heterogeneous h/w platforms
Summary:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available hardware platforms
System Schedule

04/15/2023
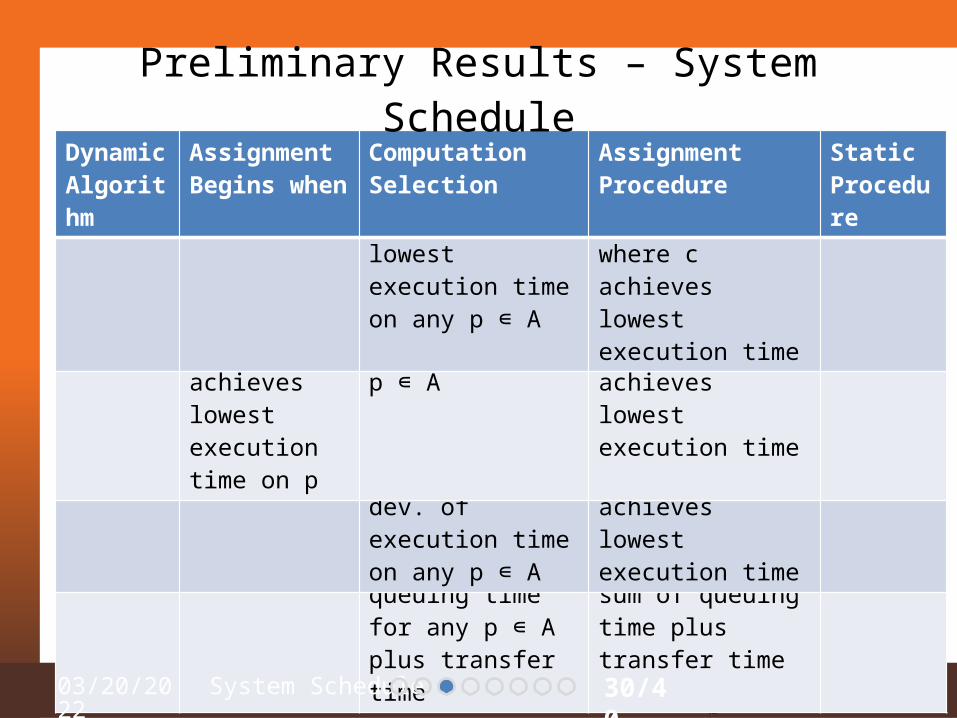
DynamicAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
30/40System Schedule

04/15/2023
SPN A≠ & I≠ c ∊ I with lowest execution time on any p ∊ A
c to p ∊ A where c achieves lowest execution time
None
DynamicAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
30/40System Schedule

04/15/2023
MET c ∊ I & p ∊ A c achieves lowest execution time on p
c ∊ I whose best platform p ∊ A
c to p ∊ A where c achieves lowest execution time
None
SPN A≠ & I≠ c ∊ I with lowest execution time on any p ∊ A
c to p ∊ A where c achieves lowest execution time
None
DynamicAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
30/40System Schedule

04/15/2023
SS A≠ & I≠ c ∊ I with highest std. dev. of execution time on any p ∊ A
c to p ∊ A where c achieves lowest execution time
None
MET c ∊ I & p ∊ A c achieves lowest execution time on p
c ∊ I whose best platform p ∊ A
c to p ∊ A where c achieves lowest execution time
None
SPN A≠ & I≠ c ∊ I with lowest execution time on any p ∊ A
c to p ∊ A where c achieves lowest execution time
None
DynamicAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
30/40System Schedule
04/15/2023
AG A≠ & I≠ c ∊ I with lowest sum of queuing time for any p ∊ A plus transfer time
c to p ∊ A with lowest sum of queuing time plus transfer time
None
SS A≠ & I≠ c ∊ I with highest std. dev. of execution time on any p ∊ A
c to p ∊ A where c achieves lowest execution time
None
MET c ∊ I & p ∊ A c achieves lowest execution time on p
c ∊ I whose best platform p ∊ A
c to p ∊ A where c achieves lowest execution time
None
SPN A≠ & I≠ c ∊ I with lowest execution time on any p ∊ A
c to p ∊ A where c achieves lowest execution time
None
DynamicAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
30/40System Schedule

04/15/2023
StaticAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
31/40System Schedule

04/15/2023
HEFT c ∊ I with highest rank & p ∊ A where time left plus execution time for c is lowest
c ∊ I with highest rank
c to p ∊ A where time left plus execution time for c is lowest
Upward ranking based on max(successor) plus average transfer time
StaticAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
31/40System Schedule

04/15/2023
PEFT c ∊ I with highest average rank & p ∊ A where rank(c, p) plus execution time for c is lowest
c ∊ I with highest average rank
c to p ∊ A where rank(c, p) plus execution time for c is lowest
Upward ranking based on sum of: min(successors), execution time for c on p, transfer time
HEFT c ∊ I with highest rank & p ∊ A where time left plus execution time for c is lowest
c ∊ I with highest rank
c to p ∊ A where time left plus execution time for c is lowest
Upward ranking based on max(successor) plus average transfer time
StaticAlgorithm
AssignmentBegins when
ComputationSelection
AssignmentProcedure
StaticProcedure
Preliminary Results – System Schedule
31/40System Schedule
04/15/2023
Preliminary Results – System Schedule
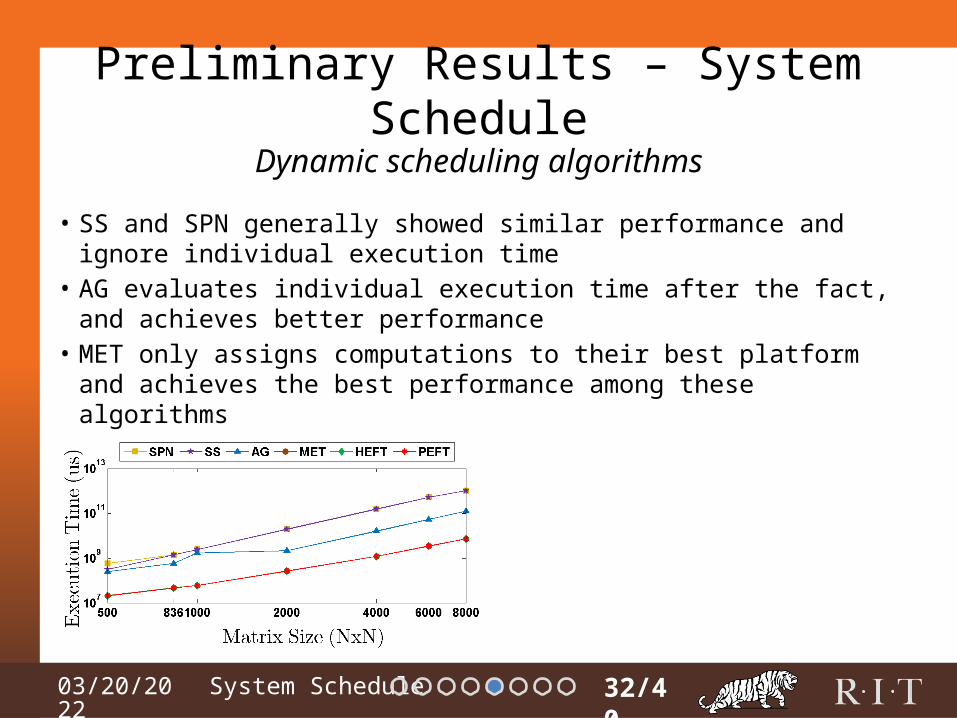
• SS and SPN generally showed similar performance and ignore individual execution time
• AG evaluates individual execution time after the fact, and achieves better performance
• MET only assigns computations to their best platform and achieves the best performance among these algorithms
32/40
Dynamic scheduling algorithms
System Schedule
04/15/2023
Preliminary Results – System Schedule
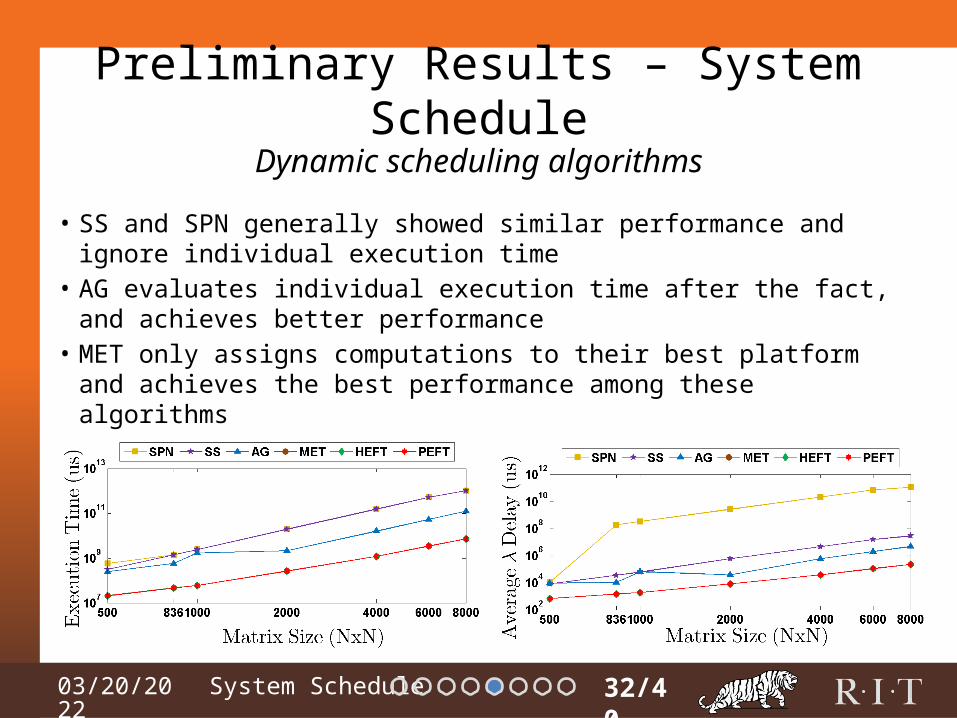
• SS and SPN generally showed similar performance and ignore individual execution time
• AG evaluates individual execution time after the fact, and achieves better performance
• MET only assigns computations to their best platform and achieves the best performance among these algorithms
32/40
Dynamic scheduling algorithms
System Schedule
04/15/2023
Preliminary Results – System Schedule
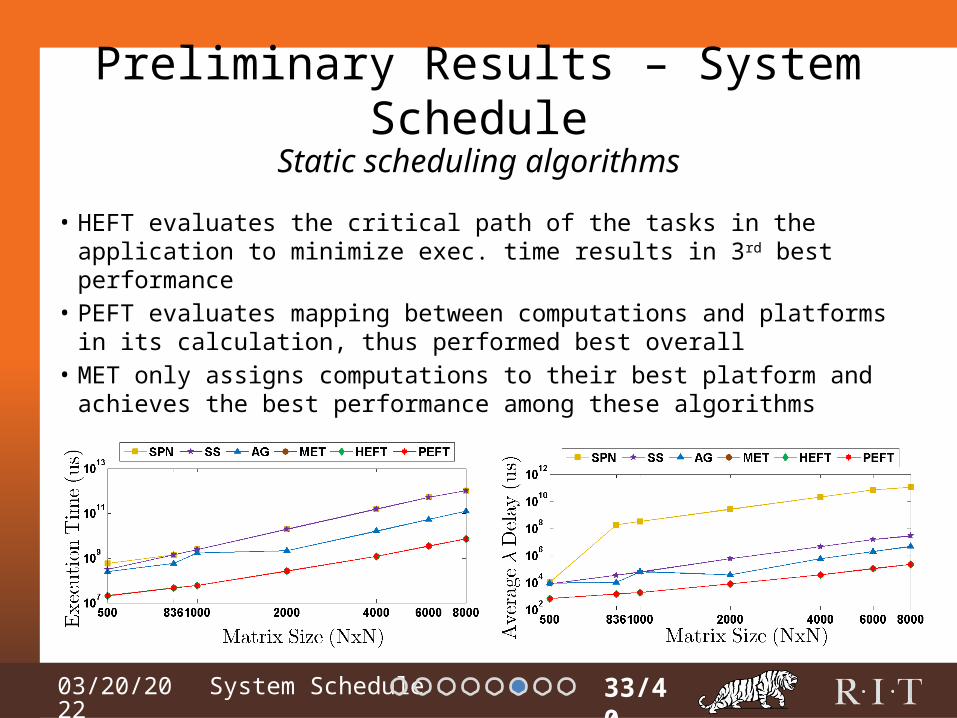
• HEFT evaluates the critical path of the tasks in the application to minimize exec. time results in 3rd best performance
• PEFT evaluates mapping between computations and platforms in its calculation, thus performed best overall
• MET only assigns computations to their best platform and achieves the best performance among these algorithms
33/40
Static scheduling algorithms
System Schedule

04/15/2023
Preliminary Results – System Schedule
• HEFT evaluates the critical path of the tasks in the application to minimize exec. time results in 3rd best perf.
• PEFT evaluates mapping between computations and platforms in its calculation, thus performed best overall
• MET only assigns computations to their best platform and achieves the 2nd best performance among these algorithms
34/40
Dynamic MET vs. Static HEFT & PEFT
System Schedule

04/15/2023
Preliminary Results – System Schedule
• MET is most simplistic of the three and needs no calculation compared to HEFT and PEFT
• Performance of these policies differed by up to 1%• Previous work evaluated systems with less heterogeneity and found that:
• PEFT was 20% better than HEFT[1]
• MET was worse than SPN[7]
35/40
Dynamic MET vs. Static HEFT & PEFT
System Schedule

04/15/2023
Preliminary Results – System Schedule
• MET is most simplistic of the three and needs no calculation compared to HEFT and PEFT
• Performance of these policies differed by up to 1%• Previous work evaluated systems with less heterogeneity and found that:
• PEFT was 20% better than HEFT[1]
• MET was worse than SPN[7]
35/40
Dynamic MET vs. Static HEFT & PEFT
Conclusion: when differences in exec. times for each platform are orders of magnitude, most important factor is to achieve the lowest exec. time for each computation.
System Schedule

04/15/2023 Conclusion
Conclusion
• Heterogeneous systems show great potential to speed up compute-intensive applications
• Framework is a three step process of converting an application, mapping and scheduling, and evaluating performance to design a system
36/40

04/15/2023 Research Objectives
Research Objectives
• New method to estimate the performance of each computation on different hardware platforms– evaluating the connection between the algorithm and the
specific architectural features of the platform. • Evaluate the exec. of the application as a combination of
computations scheduled on heterogeneous set of hardware platforms. – We will analyze various scheduling strategies and determine
the best strategy for constraints such as performance, efficiency, or power.
37/40

04/15/2023 References
References[1] H. Arabnejad and J. Barbosa. List Scheduling Algorithm for Heterogeneous Systems by an Optimistic Cost Table. IEEE Transactions on Parallel and Distributed Systems, PP(99), Mar. 2013.
[6] K. Branco and M. Santana. A Novel Simulator for Evaluating Performance Indices on Heterogeneous Distributed Systems Environments. IEEE International Symposium on Industrial Electronics, July 2006.
[7] T. D. Braun, H. J. Siegel, N. Beck, L. L. Blni, M. Maheswaran, A. I. Reuther, J. P. Robertson, M. D. Theys, B. Yao, D. Hensgen, and R. F. Freund. A Comparison of Eleven Static Heuristics for Mapping a Class of Independent Tasks onto Heterogeneous Distributed Computing Systems. Journal of Parallel and Distributed Computing, 61(6), June 2001.
[9] C. Brunelli, F. Cinelli, D. Rossi, and J. Nurmi. A VHDL Model and Implementation of a Coarse-Grain Reconfigurable Coprocessor for a RISC Core. Research in Microelectronics and Electronics, June 2006.
[10] T. Cao, S. M. Blackburn, T. Gao, and K. S. McKinley. The Yin and Yang of Power and Performance for Asymmetric Hardware and Managed Software. International Symposium on Computer Architecture, June 2012.
[11] A. Carbon, Y. Lhuillier, and H.-P. Charles. Hardware Acceleration for Just-In-Time Compilation on Heterogeneous Embedded Systems. IEEE International Conference on Application specific Systems, Architectures and Processors, June 2013.
[12] J. Cong, M. Ghodrat, and M. Gill. CHARM: A Composable Heterogeneous Accelerator-rich Microprocessor. ACM/IEEE International Symposium on Low Power Electronics and Design, July 2012.
[16] F. Fummi, M. Loghi, M. Poncino, and G. Pravadelli. A Cosimulation Methodology for HW/SW Validation and Performance Estimation. ACM Transactions on Design Automation of Electronic Systems, Mar. 2009.
[17] M. R. Garey and D. S. Johnson. Strong NP-Completeness Results: Motivation, Examples, and Implications. Journal of the ACM, 25(3), July 1978.
[19] P. Grigoras, X. Niu, J. G. F. Coutinho, W. Luk, J. Bower, and O. Pell. Aspect Driven Compilation for Dataflow Designs. IEEE International Conference on Application-specific Systems, Architectures and Processors, June 2013.
38/40

04/15/2023
References[26] B. Hong and V. Prasanna. A modular and extensible simulator for performance evaluation of adaptive applications in heterogeneous computing environments. International Conference on Algorithms and Architectures for Parallel Processing, Oct. 2002.[28] R. Inta, D. J. Bowman, and S. M. Scott. The Chimera: An Off-The-Shelf CPU/GPGPU/FPGA Hybrid Computing Platform. International Journal of Reconfigurable Computing, 2012(2012), Jan. 2012.[29] A. Khokhar, V. Prasanna, M. Shaaban, and C.-L. Wang. Heterogeneous Computing: Challenges and Opportunities. Computer, 26(6), June 1993.[32] D. Li, K. Sajjapongse, H. Truong, G. Conant, and M. Becchi. A Distributed CPU-GPU Framework for Pairwise Alignments on Large-Scale Sequence Datasets. IEEE International Conference on Application-specific Systems, Architectures and Processors, June 2013.[33] C. Liu and S. Yang. A Heuristic Serial Schedule Algorithm for Unrelated Parallel Machine Scheduling with Precedence Constraints. Journal of Software, 6(6), June 2011.[36] J. Maassen, N. Drost, H. E. Bal, and F. J. Seinstra. Towards Jungle Computing with Ibis/Constellation. Dynamic Distributed Data-intensive Applications, Programming Abstractions, and Systems, June 2011.[40] K. Shagrithaya, K. Kepa, and P. Athanas. Enabling Development of OpenCL Applications on FPGA platforms. IEEE International Conference on Application-specific Systems, Architectures and Processors, June 2013.[41] H. Shen and Q. Qiu. An FPGA-Based Distributed Computing System with Power and Thermal Management Capabilities. International Conference on Computer Communications and Networks, July 2011.[44] R. Sinha, A. Prakash, and H. D. Patel. Parallel Simulation of Mixed-abstraction SystemC Models on GPUs and Multicore CPUs. Asia and South Pacific Design Automation Conference, Jan. 2012.[45] S. Skalicky, S. Lopez, and M. Lukowiak. Distributed Execution of Transmural Electrophysiological Imaging with CPU, GPU, and FPGA. International Conference on Reconfigurable Computing and FPGAs, 2013.[52] H. Topcuoglu, S. Hariri, and M.-Y. Wu. Performance-Effective and Low-Complexity Task Scheduling for Heterogeneous Computing. IEEE Transactions on Parallel and Distributed Systems, 13(3), Mar. 2002.[55] J. Wu, W. Shi, and B. Hong. Dynamic Kernel/Device Mapping Strategies for GPU-Assisted HPC Systems. Job Scheduling Strategies for Parallel Processing, May 2012. 39/40References

04/15/2023 Publications
Publications1. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, James Letendre, Matthew Ryan, “Performance Modeling of Pipelined
Linear Algebra Architectures on FPGAs”. International Symposium on Applied Reconfigurable Computing, March 2013, Los Angeles, CA, USA.
2. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, James Letendre and David Gasser, “Linear Algebra Computations in Heterogeneous Systems”. IEEE International Conference on Application-specific Systems, Architectures and Processors, June 2013, Washington DC, USA.
3. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “Distributed Execution of Transmural Electrophysiological Imaging with CPU, GPU, and FPGA”. International Conference on ReConFigurable Computing and FPGAs, December 2013, Cancun, Mexico.
4. Sam Skalicky, Marcin Lukowiak, Matthew Ryan, Christopher Wood, “High Level Synthesis: Where Are We? A Case Study on Matrix Multiplication”. International Conference on ReConFigurable Computing and FPGAs, December 2013, Cancun, Mexico.
5. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “Performance Modeling of Pipelined Linear Algebra Architectures on FPGAs”. Computers and Electrical Engineering, 2014, Accepted.
6. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “Scheduling Policies for Distributed Heterogeneous CPU+GPU+FPGA Systems: A Medical Imaging Case Study”. IEEE International Parallel & Distributed Processing Symposium, 2014, Submitted – under review.
7. Sam Skalicky, Sonia Lopez, Marcin Lukowiak, “High-Level Graph-Based Methodology for Improving Performance of Pipelined Architectures”. ACM SIGMETRICS, 2014, Submitted – under review.
40/40

04/15/2023 High Performance Research Group 41

04/15/2023 High Performance Research Group
Backup Slides
42

04/15/2023 High Performance Research Group 77
Preliminary Results – System Schedule
Scheduling assumptions:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available (idle) hardware platforms
of linear algebra-based applications using heterogeneous h/w platforms
Shortest process next (SPN) [29]
• Chooses a computation from I with the minimum execution time on any of the hardware platforms from A
• Makes assignments whenever hardware platforms are idle and there are computations in I

04/15/2023 High Performance Research Group 78
Preliminary Results – System Schedule
Scheduling assumptions:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available (idle) hardware platforms
of linear algebra-based applications using heterogeneous h/w platforms
Minimum execution time (MET) [7]
• Chooses a computation from I and assigns them to the platform with the lowest execution time
• If the computation’s best platform is not currently available it is not assigned to another platform.
• A platform will sit idle if there are no computations in I that are suitable for it.

04/15/2023 High Performance Research Group 79
Preliminary Results – System Schedule
Scheduling assumptions:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available (idle) hardware platforms
of linear algebra-based applications using heterogeneous h/w platforms
Serial scheduling (SS) [33]
• For each computation in I calculates the mean and std. dev. of the compute times for each platform in A
• Chooses a computation from I with the highest std. dev. and assigns it to the platform from A in which the computation has the lowest execution time
• Assignments are made as long as I and A are not empty

04/15/2023 High Performance Research Group 80
Preliminary Results – System Schedule
Scheduling assumptions:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available (idle) hardware platforms
of linear algebra-based applications using heterogeneous h/w platforms
Adaptive greedy (AG) [55]
• Maintains queues for each platform in P• Calculates wait time based on: queuing delay + data transfer time • Queuing delay is the sum of the compute times for computations in the queue• Chooses the platform from A for a computation in I with the lowest total time

04/15/2023 High Performance Research Group 81
Preliminary Results – System Schedule
Scheduling assumptions:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available (idle) hardware platforms
of linear algebra-based applications using heterogeneous h/w platforms
Heterogeneous Earliest Finish Time (HEFT) [52]
• Statically ranks all computations in V using an upward ranking:– Average computation time on all platforms– Maximum rank of all its successors
• Assigns highest ranked computation in I to platform from A with least:– time remaining for any previous computation that is currently executing– execution time of the computation on that platform

04/15/2023 High Performance Research Group 82
Preliminary Results – System Schedule
Scheduling assumptions:• V – set of all computations in the application• I – set of all independent & ready to schedule computations• P – set of all hardware platforms in the system• A – set of all available (idle) hardware platforms
of linear algebra-based applications using heterogeneous h/w platforms
Predict Earliest Finish Time (PEFT) [1]
• Similar to HEFT except ranks are based on a pre-computed cost table that enables a forecasting ability
• Assigns highest ranked computation in I to platform from A with least:– time remaining for any previous computation that is currently executing– execution time of the computation on that platform

























![La Grande Arche De La Defense2.ppt [Read-Only]](https://img.pdfslide.us/doc/110x75/619aa73fba7b6e0201301508/la-grande-arche-de-la-read-only.jpg)



