Embed Size (px)
DESCRIPTION
Dr. Scott Clark presents concepts for optimal learning, as well as the system built by Yelp for the purpose (MOE)
Citation preview

Optimal Learning for Fun and Profit
Scott Clark, Ph.D.Yelp Open House
11/20/13
[email protected] @DrScottClark

Outline of Talk
● Optimal Learning○ What is it?○ Why do we care?
● Multi-armed bandits○ Definition and motivation○ Examples
● Bayesian global optimization○ Optimal experiment design○ Uses to extend traditional A/B testing

Optimal learning addresses the challenge of how to collect information as efficiently as possible, primarily for settings where collecting information is time consuming and expensive.
Source: optimallearning.princeton.edu
What is optimal learning?

Part I:Multi-Armed Bandits

What are multi-armed bandits?
THE SETUP
● Imagine you are in front of K slot machines.● Each one is set to "free play" (but you can still win $$$)● Each has a possibly different, unknown payout rate● You have a fixed amount of time to maximize payout
GO!

What are multi-armed bandits?
THE SETUP(math version)
[Robbins 1952]

Modern Bandits
● Maps well onto Click Through Rate (CTR)○ Each arm is an ad or search result○ Each click is a success○ Want to maximize clicks
● Can be used in experiments (A/B testing)○ Want to find the best solutions, fast○ Want to limit how often bad solutions are used
Why do we care?

Tradeoffs
Exploration vs. ExploitationGaining knowledge about the system
vs.Getting largest payout with current knowledge

Naive Example
Epsilon First Policy
● Sample sequentially εT < T times○ only explore
● Pick the best and sample for t = εT+1, ..., T○ only exploit

p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
0
0
-
0
0
-
0
0
-
Example (K = 3, t = 1)

Example (K = 3, t = 1)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
1
1
1
0
0
-
0
0
-

Example (K = 3, t = 2)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
1
1
1
1
1
1
0
0
-

Example (K = 3, t = 3)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
1
1
1
1
1
1
1
0
0

Example (K = 3, t = 4)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
2
1
0.5
1
1
1
1
0
0
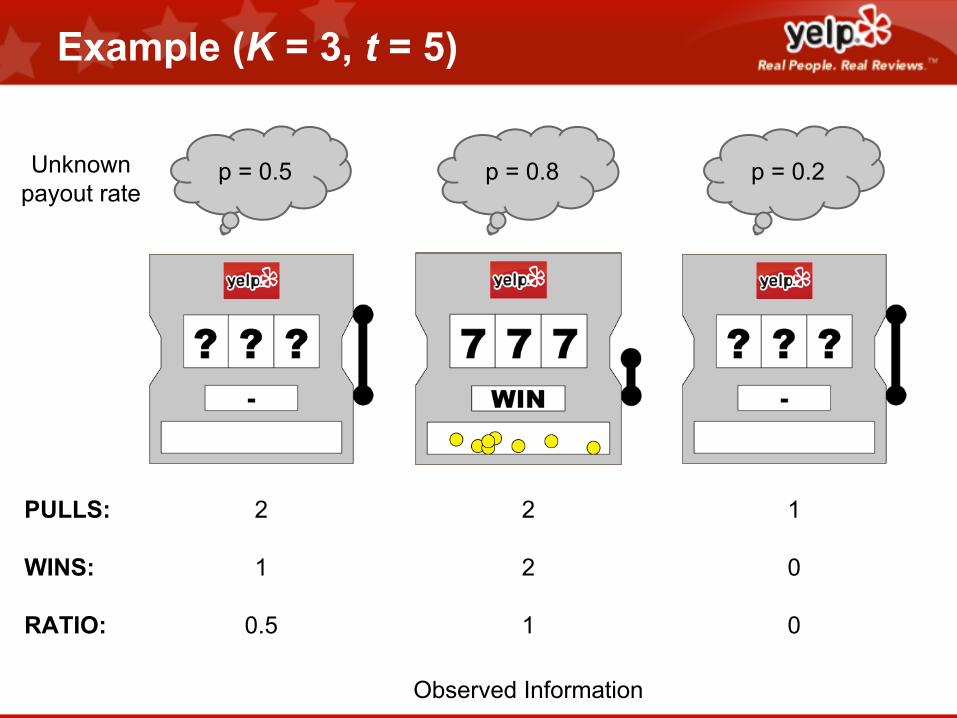
Example (K = 3, t = 5)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
2
1
0.5
2
2
1
1
0
0

Example (K = 3, t = 6)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
2
1
0.5
2
2
1
2
0
0

Example (K = 3, t = 7)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
3
2
0.66
2
2
1
2
2
0

Example (K = 3, t = 8)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
3
2
0.66
3
3
1
2
0
0

Example (K = 3, t = 9)
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
3
2
0.66
3
3
1
3
1
0.33

Example (K = 3, t > 9)
Exploit!
Profit!
Right?

What if our ratio is a poor approx?
p = 0.5 p = 0.8 p = 0.2
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
3
2
0.66
3
3
1
3
1
0.33

What if our ratio is a poor approx?
p = 0.9 p = 0.5 p = 0.5
Observed Information
Unknownpayout rate
PULLS:
WINS:
RATIO:
3
2
0.66
3
3
1
3
1
0.33

Fixed exploration fails
Regret is unbounded!
Amount of explorationneeds to depend on data
We need better policies!

What should we do?
Many different policies● Weighted random choice (another naive approach)
● Epsilon-greedy○ Best arm so far with P=1-ε, random otherwise
● Epsilon-decreasing*○ Best arm so far with P=1-(ε * exp(-rt)), random otherwise
● UCB-exp*● UCB-tuned*● BLA*● SoftMax*● etc, etc, etc (60+ years of research)
*Regret bounded as t->infinity

Extensions and complications
What if...● Hardware constraints limit real-time knowledge? (batching)
● Payoff noisy? Non-binary? Changes in time? (dynamic content)
● Parallel sampling? (many concurrent users)
● Arms expire? (events, news stories, etc)
● You have knowledge of the user? (logged in, contextual history)
● The number of arms increases? Continuous? (parameter search)
Every problem is different.This is an active area of research.

Part II:Global Optimization

What is global optimization?
● Optimize some objective function ○ CTR, revenue, delivery time, or some combination thereof
● given some parameters ○ config values, cuttoffs, ML parameters
● CTR = f(parameters)○ Find best parameters
THE GOAL
(more mathy version)

What is MOE?
Metrics Optimization EngineA global, black box method for parameter optimization
MOE
History of how past parameters have performed
New, optimal parameters

What does MOE do?
● MOE optimizes a metric (like CTR) given some parameters as inputs (like scoring weights)
● Given the past performance of different parametersMOE suggests new, optimal parameters to test
Results of A/B tests run so far
MOE
New, optimal values to A/B test

Example Experiment
Parameters + Obj Func
distance_cutoffs = {‘shopping’: 20.0,‘food’: 14.0,‘auto’: 15.0,…}
objective_function = {‘value’: 0.012,‘std’: 0.00013}
MOENew Parameters
distance_cutoffs = {‘shopping’: 22.1,‘food’: 7.3,‘auto’: 12.6,…}
Biz details distance in ad● Setting a different distance cutoff for each category
to show “X miles away” text in biz_details ad● For each category we define a maximum distance
MapReduce, MongoDB, python

Why do we need MOE?
● Parameter optimization is hard○ Finding the perfect set of parameters takes a long time○ Hope it is well behaved and try to move in the right direction○ Not possible as number of parameters increases
● Intractable to find best set of parameters in all situations○ Thousands of combinations of program type, flow, category ○ Finding the best parameters manually is impossible
● Heuristics quickly break down in the real world○ Dependent parameters (changes to one change all others)○ Many parameters at once (location, category, map, place, ...)○ Non-linear (complexity and chaos break assumptions)
MOE solves all of these problems in an optimal way

How does it work?
MOE1. Build Gaussian Process (GP)
with points sampled so far2. Optimize covariance
hyperparameters of GP3. Find point(s) of highest
Expected Improvementwithin parameter domain
4. Return optimal next best point(s) to sample

Gaussian Processes
Rasmussen and Williams GPMLgaussianprocess.org

Optimizing Covariance Hyperparameters
Rasmussen and Williams Gaussian Processes for Machine Learning
Finding the GP model that fits best
● All of these GPs are created with the same initial data○ with different hyperparameters (length scales)
● Need to find the model that is most likely given the data○ Maximum likelihood, cross validation, priors, etc

[Jones, Schonlau, Welsch 1998][Clark, Frazier 2012]
Find point(s) of highest expected improvementExpected Improvement of sampling two points
We want to find the point(s) that are expected to beat the best point seen so far the most.

What is MOE doing right now?
MOE is now live in production ● MOE is informing active experiments
● MOE is successfully optimizing towards all given metrics
● MOE treats the underlying system it is optimizing as a black box, allowing it to be easily extended to any system
Ongoing:● Looking into best path towards contributing it back to the
community, if/when we decide to open source.● MOE + bandits = <3


![Discovering Yelp Elites: Reifying Yelp Elite Selection Criterion · 2018-02-05 · A. Yelp Challenge Dataset We obtain the dataset from the Yelp Dataset Challenge [4] which includes](https://img.pdfslide.us/doc/110x75/5f23397707fa8e71780e4974/discovering-yelp-elites-reifying-yelp-elite-selection-criterion-2018-02-05-a.jpg)