Embed Size (px)
Citation preview

Like-for-Like Comparsion of Machine LearningAlgorithms
Sensitivity Analysis of ML Hyperparameters
Dominik Dahlem
2016-09-25 Sun

Who am I?
• Dominik Dahlem, Lead Data Scientist, Boxever [email protected] http://ie.linkedin.com/in/ddahlem http://github.com/dahlem @dahlemd

Introduction
Outline
1 Introduction
2 Building ML Models
3 Example: RL Gridworld
4 Summary

Introduction
Boxever
• Boxever is a Data Science company with a CustomerIntelligence Cloud for Travel
• Our cloud analytical services need to be well-tuned and robust• e.g., recommendation models, propensity models, etc.

Introduction
Machine Learning Models are like…

Introduction
Goal
• Tuning• ML algorithms tend to be governed by tunable parameters
typically referred as hyperparameters• They are not trained• Require trial-and-error fine tuning
• Sensitivity Analysis• Does a small perburbation in the parameters change the output
dramatically?• Visual inspection easy in ML algorithms with very few
hyperparameters• But mathematical treatment necessary in high dimensions

Building ML Models
Outline
1 Introduction
2 Building ML Models
3 Example: RL Gridworld
4 Summary

Building ML Models
Evaluating a ML Model Hypothesis
• A hypothesis (given the hyperparameters) may overfit → Howdo we know?
• We have a low error, but the model is still inaccurate• Test-driven development and debugging↔ Statistical Diagnostics
1 With a given dataset, split into two sets: training and test2 Fix hyperparameters3 Learn model parameters and minimise the corresponding error
using the training set4 Compute the test error using the test set

Building ML Models
Model Selection
• Without the validation set• Optimise ML parameters using the training set for each
hypothesis (e.g., polynomial degree)• Select the hypothesis with the smallest test error• Estimate the generalisation error also using the test set →
optimistic error estimates• With validation set
• Optimise ML parameters using the training set for eachhypothesis (e.g., polynomial degree)
• Select the hypothesis with the smallest cross-validation error• Estimate the generalisation error also using the test set

Building ML Models
General ML Pipeline
• Parameter search• grid vs random vs active
learning• We found well-performing model,
but• are the parameters sensitive to
minute changes?

Building ML Models
Sensitivity Analysis1
• Hyperparameter tuning usinge.g., Spearmint
• integrate uncertainty of thek-fold CV
• model the parameter surfaceon the mean error metric fromCV
• Characterise the nature of thehyperparameter surface in thevicinity of the optimal point (e.g.,the one that minimised the errorof the ML algorithm)
1George E. P. Box and Norman R. Draper (2007). Response Surfaces, Mixtures, and Ridge Analyses. 2nd ed.Wiley-Interscience.

Building ML Models
Bias vs. Variance
Jtraining(θ)
JCV(θ)
Optimal
Underfitting(high bias)
Overfitting(high variance)
d (polynomial degree)
J(θ
)
• What is the source of bad predictions?

Building ML Models
Regularisation and Bias/Variance
Jtraining(θ)
JCV(θ)
Optimal
Overfitting(high variance)
Underfitting(high bias)
λ (regularisation)
J(θ
)

Building ML Models
Learning Curves (High Bias)
Jtest(θ)
Jtraining(θ)
Desired
N (training set size)
J(θ
)
• More training data will not help!

Building ML Models
Learning Curves (High Variance)
Jtest(θ)
Jtraining(θ)
Desired
N (training set size)
J(θ
)
• More training data will likely help!

Example: RL Gridworld
Outline
1 Introduction
2 Building ML Models
3 Example: RL Gridworld
4 Summary

Example: RL Gridworld
Overview
• Teach a computer to find apath to a goal
• Actions: N, E, S, W• Classifying grids?• Trial and Error?

Example: RL Gridworld
SARSA(λ)
• SARSA update rule:Q(s,a)← Q(s,a) + α [r′ + γQ(s′,a′) −Q(s,a)] . (1)
• s: the state, i.e., cell on the grid• a: the action, i.e., N, E, S, W• Q(s, a): state-action value function
• here: lookup table• r: the reward received for performing action a′ in state s′
• α: the learning rate• γ: the discount factor

Example: RL Gridworld
RL Gridworld Pipeline
• Optimise the learning rate andthe discount factor
• α ∈ [0.0001, 0.3]• γ ∈ [0.01, 0.95]
• Fixed parameters for brevity:• greedy policy ε• the eligibility traces λ• episodes N = 2000

Example: RL Gridworld
Hyperparameter Tuning
Example: RL Gridworld
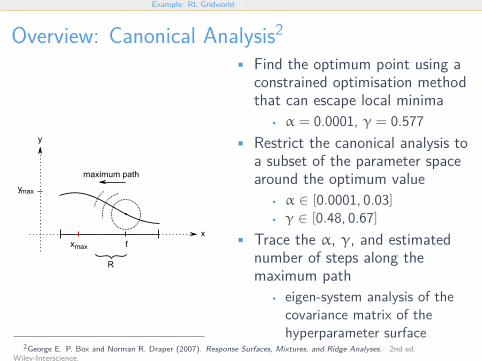
Overview: Canonical Analysis2
• Find the optimum point using aconstrained optimisation methodthat can escape local minima
• α = 0.0001, γ = 0.577• Restrict the canonical analysis to
a subset of the parameter spacearound the optimum value
• α ∈ [0.0001, 0.03]• γ ∈ [0.48, 0.67]
• Trace the α, γ, and estimatednumber of steps along themaximum path
• eigen-system analysis of thecovariance matrix of thehyperparameter surface
2George E. P. Box and Norman R. Draper (2007). Response Surfaces, Mixtures, and Ridge Analyses. 2nd ed.Wiley-Interscience.

Example: RL Gridworld
Maximum Path
0.15 0.2 0.25
0.3
0.4
0.5
Scal
edPa
ram
eter
sαγ
0.15 0.2 0.25
90
91
92
93
R
y

Example: RL Gridworld
Tuned Gridworld

Summary
Outline
1 Introduction
2 Building ML Models
3 Example: RL Gridworld
4 Summary

Summary
• Enable like-for-like ML model evaluations• Tuning, e.g.,
• Spearmint: https://github.com/JasperSnoek/spearmint• SMAC: http://www.cs.ubc.ca/labs/beta/Projects/SMAC/• hyperopt: http://hyperopt.github.io/hyperopt/
• Canonical Anlaysis• Sensitivity of the hyperparameters when subjected to small
perturbations around the optimum• Assess the sensitivity of the HP between competing ML models• Choose an ML model that does not exhibit minima that are
surrounded by very steep slopes in the hyperparameter surface

BoxeverThank [email protected]

Acknowledgements
• Images:• Rube Goldberg’s Self-Operating Napkin





























