Embed Size (px)
Citation preview

After Dark Generating High-Quality Recommendations using Real-time Advanced Analytics and Machine Learning with
Chris Fregly Data Solutions Engineer @ Databricks

Who am I?
2
Data Platform Engineer playboy.com
Streaming Platform Engineer
NetflixOSS Committer netflix.com, github.com/Netflix
Data Solutions Engineer
Apache Spark Contributor databricks.com, github.com/apache/spark

Why After Dark?
Playboy After Dark
Late 1960’s TV Show
Progressive Show For Its Time
And it rhymes!! 3
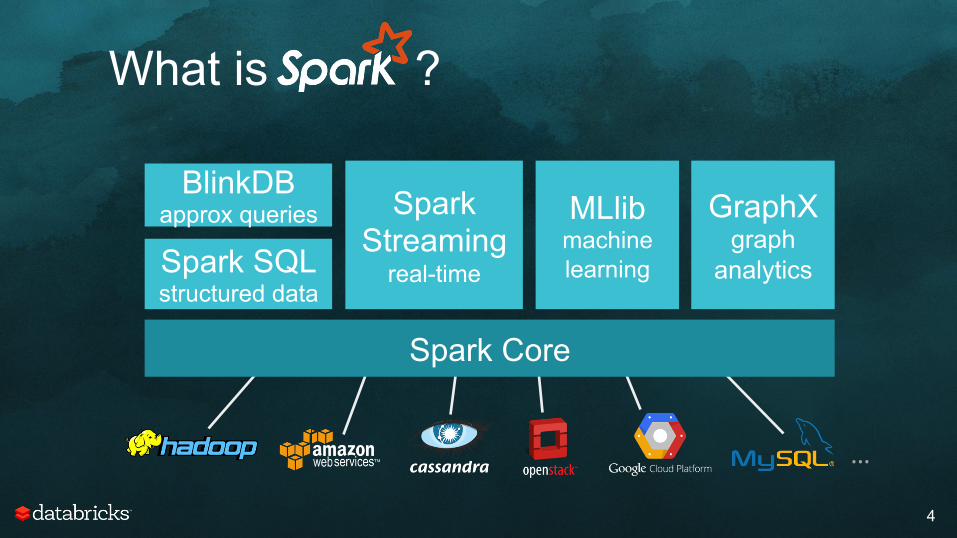
What is ?
4
Spark Core
Spark Streaming
real-time Spark SQL structured data
MLlib machine learning
GraphX graph
analytics
…
BlinkDB approx queries

in Production
5
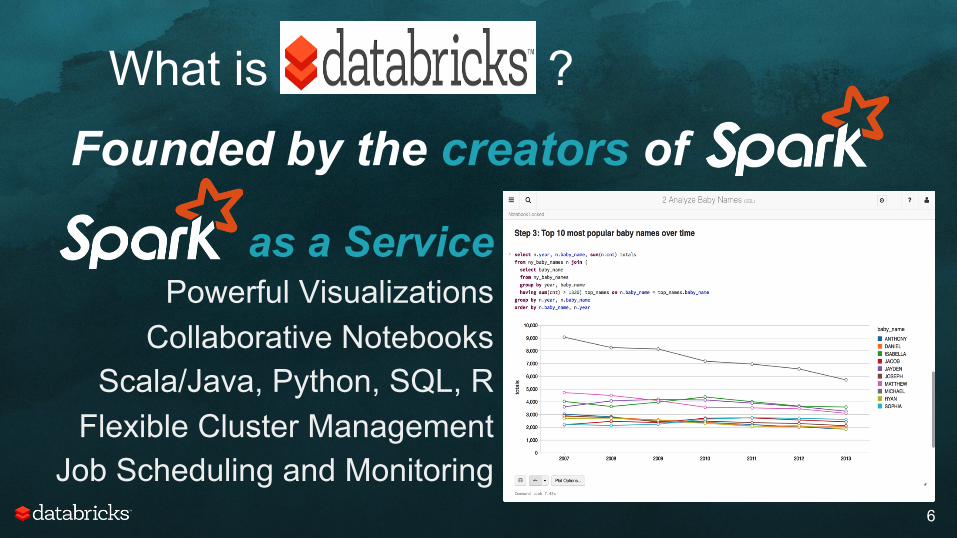
What is ?
6
Founded by the creators of
as a Service Powerful Visualizations
Collaborative Notebooks Scala/Java, Python, SQL, R
Flexible Cluster Management Job Scheduling and Monitoring

in Production
7

8
① Generate high-quality recommendations ② Demonstrate Spark high-level libraries:
③ Spark Streaming -> Kafka, Approximates ④ Spark SQL -> DataFrames, Cassandra ① GraphX -> PageRank, Shortest Path ① MLlib -> Matrix Factor, Word2Vec
Goals of After Dark?
Images courtesy of tinder.com. Not affiliated with Tinder in any way.

Popular Dating Sites
9

Themes of this Talk
10
① Performance ② Parallelism ③ Columnar Storage ④ Approximations ⑤ Similarity ⑥ Minimize Shuffle

Performance
11
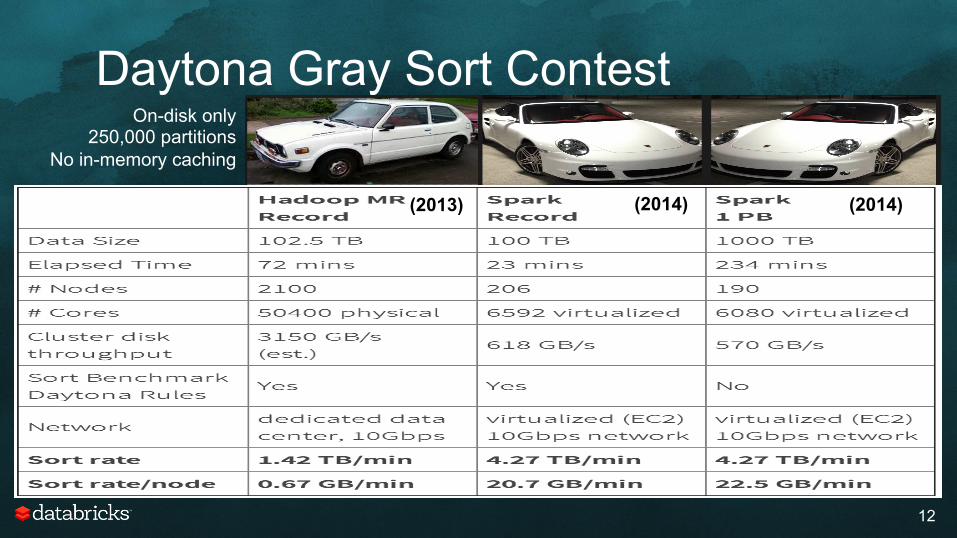
Daytona Gray Sort Contest
12
On-disk only 250,000 partitions
No in-memory caching
(2014) (2013) (2014)

Improved Shuffle and Network Layer
13
① Introduced sort-based shuffle Mapper maintains large buffer grouped by keys Reducer seeks directly to group and scans
② Minimizes OS resources Less mapper-reducer open files,connections
③ Netty: Async keeps CPU hot, reuse ByteBuffer ④ epoll: disk-network comm in kernel space only

Project Tungsten: CPU and Memory
14
① Largest change to Spark exec engine to date ② Cache-aware data structs and sorting
->
③ Expand JVM bytecode gen, JIT optimizations ④ Custom mem manage, serializers, HashMap
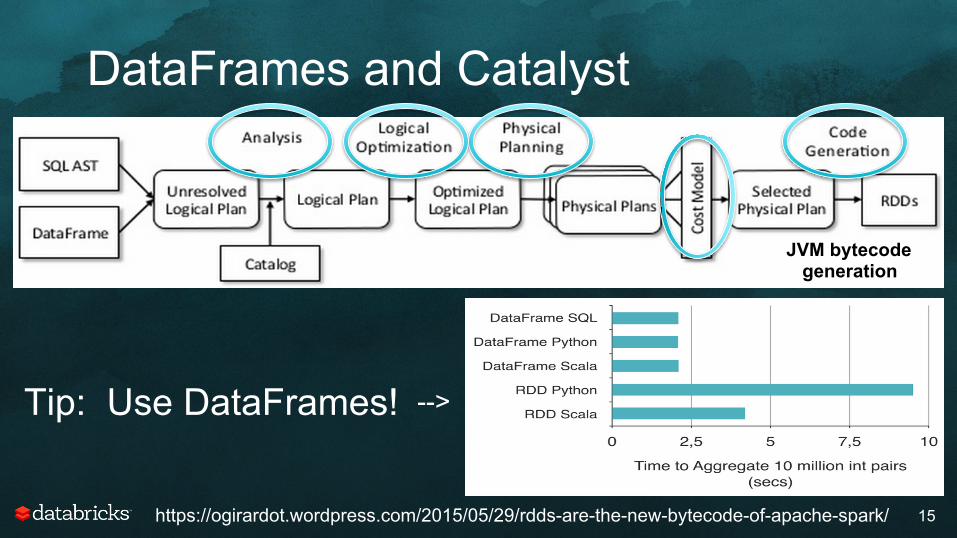
DataFrames and Catalyst
15
15
https://ogirardot.wordpress.com/2015/05/29/rdds-are-the-new-bytecode-of-apache-spark/
Tip: Use DataFrames! -->
JVM bytecode generation

Parallelism
16
Brady Bunch circa 1980
17
Season 5, Episode 18: “Two Petes in a Pod”
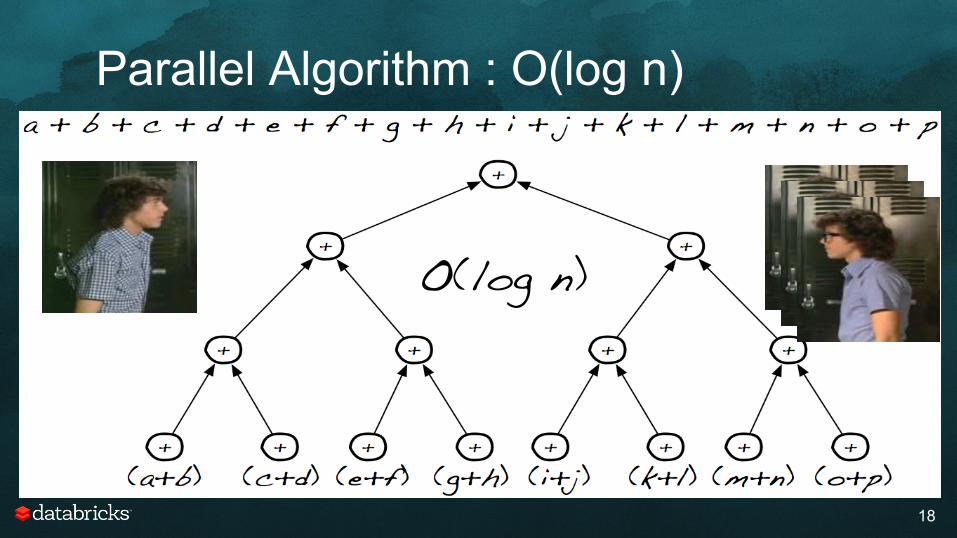
Parallel Algorithm : O(log n)
18
O(log n)

Non-parallel Algorithm : O(n)
19
O(n)

Columnar Storage
20
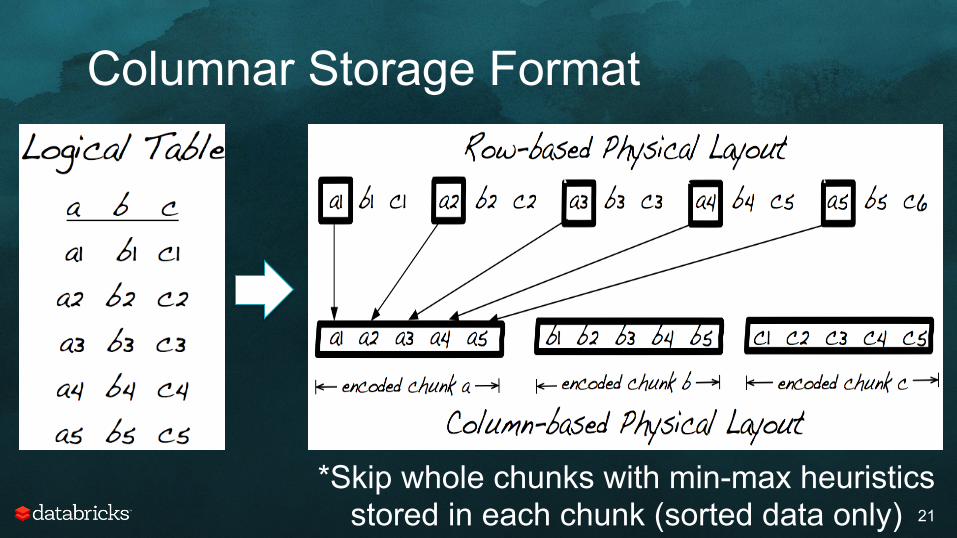
Columnar Storage Format
21
*Skip whole chunks with min-max heuristics stored in each chunk (sorted data only)

Parquet File Format
22
① Based on Google Dremel Paper ② Implemented by Twitter and Cloudera ③ Columnar storage format ④ Optimized for fast columnar aggregations ⑤ Tight compression ⑥ Supports pushdowns ⑦ Nested, self-describing, evolving schema

Types of Compression
23
① Run Length Encoding Repeated data
② Dictionary Encoding Fixed set of values
③ Delta, Prefix Encoding Sorted dataset

Types of Pushdowns
24
① Column, Partition Pruning ② Row, Predicate Filtering

Approximations
25

Sketch Algorithm: Count Min Sketch
26
① Approximate counters ② Better than HashMap ③ Fixed, low memory ④ Known error bounds ⑤ Large num of counters ⑥ Available in Twitter’s Algebird ⑦ Streaming example in Spark

Probabilistic Data Structure: HyperLogLog
27
① Fixed memory ② Known error distribution ③ Measures set cardinality ④ Approx count distinct ⑤ Number of unique users ⑥ From Twitter’s Algebird ⑦ Streaming example in Spark ⑧ RDD: countApproxDistinctByKey()

Similarity
28

Types of Similarity
29
① Euclidean: linear measure Magnitude bias
② Cosine: angle measure Adjusts for magnitude bias
③ Jaccard: set intersection divided by union Popularity bias
④ Log Likelihood Adjusts for bias -->
Ali Matei Reynold Patrick Andy Kimberly 1 1 1 1 Paula 1 Lisa 1 Cindy 1 1 Holden 1 1 1 1 1
z

All-pairs Similarity
30
① Compare everything to everything ② aka. “pair-wise similarity” or “similarity join” ③ Naïve shuffle: O(m*n^2); m=rows, n=cols ④ Minimize shuffle: reduce data size & approx
Reduce m (rows) Sampling and bucketing Reduce n (cols) Remove most frequent value (0?)

Minimize Shuffle
31
Sampling Algo: DIMSUM
32
① "Dimension Independent Matrix Square Using MR”
② Remove rows with low similarity probability ③ MLlib: RowMatrix.columnSimilarities(…) ④ Twitter: 40% efficiency gain over Cosine

Bucket Algo: Locality Sensitive Hashing
33
① Split into b buckets using similarity hash algo Requires pre-processing of data
② Compare bucket contents in parallel ③ Converts O(m*n^2) -> O(m*n/b*b^2);
m=rows, n=cols, b=buckets ④ Example: 500k x 500k matrix
O(1.25E17) -> O(1.25E13); b=50 ⑤ github.com/mrsqueeze/spark-hash

MLlib: SparseVector vs. DenseVector
34
① Remove columns using sparse vectors ② Converts O(m*n^2) -> O(m*nnz^2);
nnz=num nonzeros, nnz << n
Tip: Choose most frequent value … may not be 0

Interactive Demo!
35
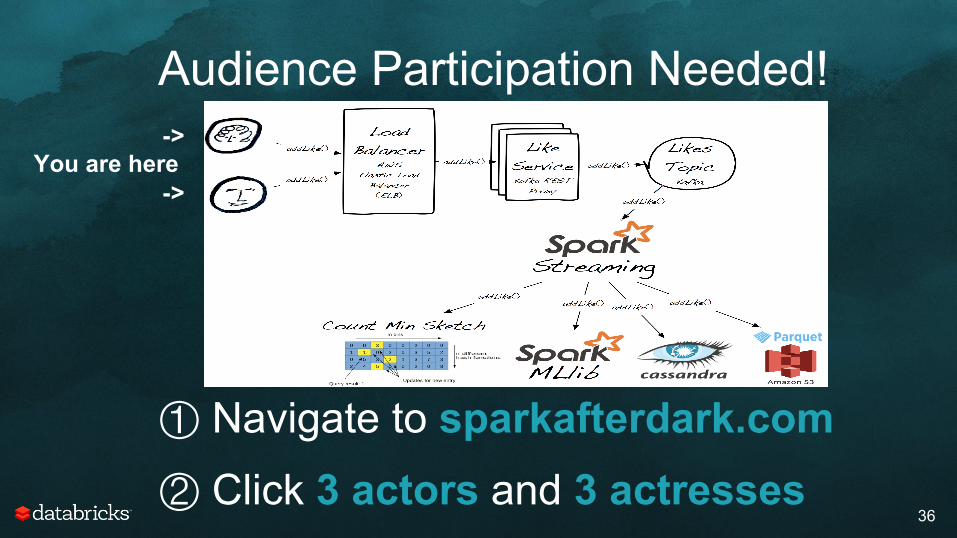
Audience Participation Needed!
36
① Navigate to sparkafterdark.com
② Click 3 actors and 3 actresses
-> You are here
->

Recommendation Terminology
37
① User User seeking likeable recommendations
② Item User who has been liked *Also a user seeking likeable recommendations!
③ Types of Feedback Explicit: Ratings, Like/Dislike Implicit: Search, Click, Hover, View, Scroll

Types of Recommendations
38
① Non-personalized Cold Start No preference or behavior data for user, yet
② Personalized Items that others with similar prefs have liked
User-Item Similarity Items similar to your previously-liked items
Item-Item Similarity

Non-personalized Recommendations
39
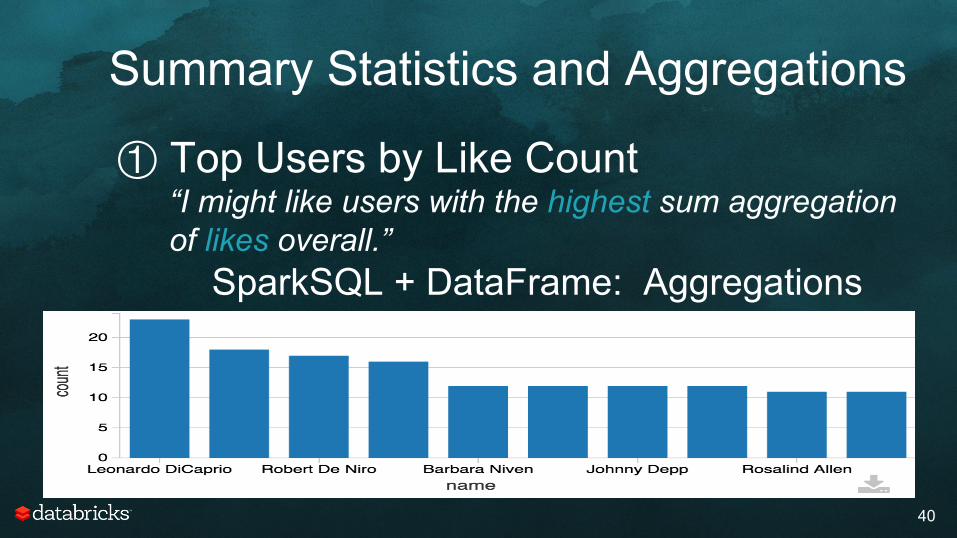
Summary Statistics and Aggregations
40
① Top Users by Like Count “I might like users with the highest sum aggregation of likes overall.”
SparkSQL + DataFrame: Aggregations

Like Graph Analysis
41
② Top Influencers by Like Graph “I might like users who have the highest probability of me liking them randomly while walking the like graph.”
GraphX: PageRank

Demo! Spark SQL + DataFrames + GraphX
42

Personalized Recommendations
43

Collaborative Filtering Personalized Recs
44
③ Like behavior of similar users “I like the same people that you like. What other people did you like that I haven’t seen?” MLlib: Matrix Factorization, User-Item Similarity

Text-based Personalized Recs
45
④ Similar profiles to each other “Our profiles have similar, unique k-skip n-grams. We might like each other.” MLlib: Word2Vec, TF/IDF, Doc Similarity
More Text-based Personalized Recs
46
⑤ Similar profiles from my past likes “Your profile shares a similar feature vector space to others that I’ve liked. I might like you.” MLlib: Word2Vec, TF/IDF, Doc Similarity

More Text-based Personalized Recs
47
⑥ Relevant, High-Value Emails “Your initial email has similar named entities to my profile. I might like you just for making the effort.” MLlib: Word2Vec, TF/IDF, Entity Recognition
^
Her Email < My Profile

Demo! MLlib + ALS + Word2Vec + TF/IDF
48

Bonus! The Future of Recommendations
49

Facial Recognition
50
⑦ Eigenfaces “Your face looks similar to others that I’ve liked. I might like you.”
MLlib: RowMatrix, PCA, Item-Item Similarity
Image courtesy of http://crockpotveggies.com/2015/02/09/automating-tinder-with-eigenfaces.html

Conversation Starter Bot
51
⑧ NLP and DecisionTrees “If your responses to my trite opening lines are positive, I might actually read your profile.” MLlib: TF/IDF, DecisionTree,
Sentiment Analysis
Positive responses ->
Negative <- responses
Image courtesty of http://crockpotveggies.com/2015/02/09/automating-tinder-with-eigenfaces.html

Double Bonus!
52
Maintaining the

Compromise Recommendations (Couples)
53
⑨ Similarity Pathways “I want Mad Max. You want Message In a Bottle. Let’s find something in between to watch tonight.”
MLlib: RowMatrix, Item-Item Similarity GraphX: Nearest Neighbors, Shortest Path
similar similar plots -> <- actors … …

And the Final,
54
⑩ Personalized Recommendation

My Personalized Recommendation
55
⑩ Get Off Your Computer and Be Social!!
Thank you! [email protected] @cfregly
Image courtesy of http://www.duchess-france.org/