Embed Size (px)
Citation preview

Hibernate performance tuning by Igor Dmitriev


In the beginning
• The most difficult to configure an application
• Default settings.

• The huge amount of data stored in database has a great impact on performance.
• Customers have major concerns over slow performance of the application.

What should I do? To grap statistics
• Aspect for Service method execution time
• P6Spy for SQL logging
• High load testing
• Be careful :
- Testing in stable state
- Do a few iterations
- DB SQL cache
- Second or Query cache

Most popular reasons

Slow running queries

There are lots of queries

Database locks

Settings
Hibernate : 5.0.0.Final DB : Postgresql
Java : 8


1. @OneToOne is not working?


There are several possible mappings for one-to-one associations
• Sharing Primary key
- required @PrimaryKeyJoinColumn and @OneToOne(fetch = FetchType.LAZY, optional = false)

• Lazy loading with bytecode instrumentation
• Using a Join Table with mapping table
• @OneToMany instead of @OneToOne trick
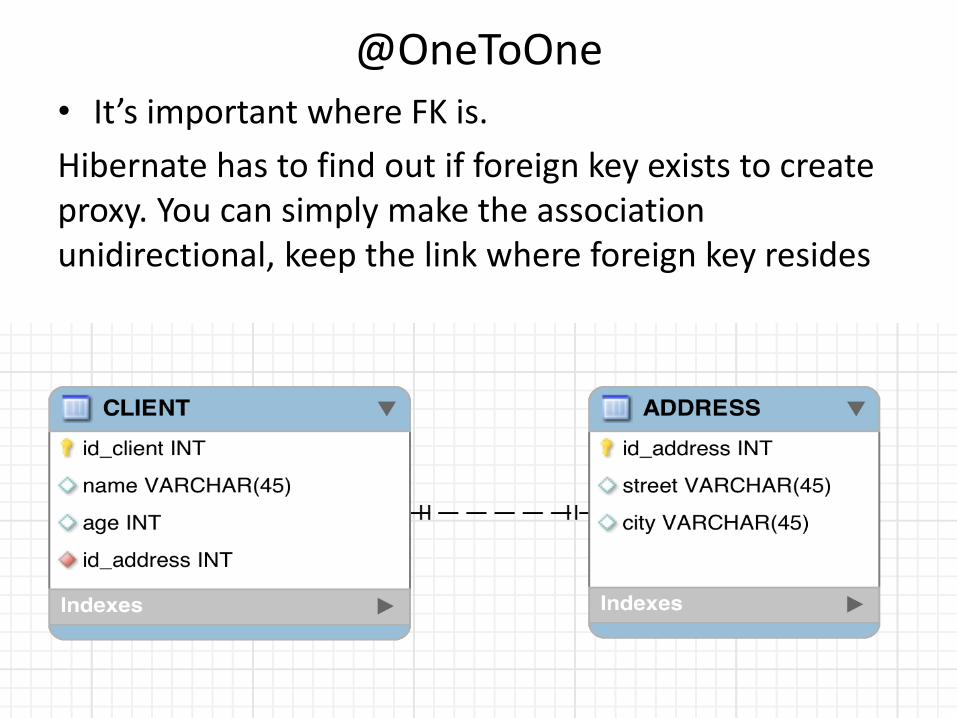
@OneToOne • It’s important where FK is.
Hibernate has to find out if foreign key exists to create proxy. You can simply make the association unidirectional, keep the link where foreign key resides

• Do you really need a separate table?
- one table for one-to-one mapping
- use @Embeddable

2. EAGER is not working?


3. N+1


There are a lot of different approaches to resolve N+1
• Prefetching collections with subselects
@Fetch(FetchMode.SUBSELECT)
- just for collections
- Hibernate remembers the original query used to load the elements.

• Prefetching data in batches
@BatchSize(size=10)
- blind-guess optimization

• Prefetching data in batches
@BatchSize(size=10)
- blind-guess optimization
- Batch size = 50
[50, 25, 12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1]

• HQL, Criteria or SQL fetch join

• Hibernate Fetch Profile

• EntityGraph
- JPA 2.1

4. Cartesian product


• “Every time you think have to map a collection you have to ask yourself why. A mapped persistent collection is a feature, not a requirement.”
Christian Bauer Jan 26, 2006

EclipseLink
• @JoinFetch
• query.setHint(“eclipselink.join-fetch”,”client.accounts”)
• @BatchFetch(type=BatchFetchType.EXISTS) (JOIN,IN)
• query.setHint(“eclipselink.batch.type”,”EXISTS”)
• query.setHint(“eclipselink.batch”,”client.accounts”)

Keys

Batch processing Update or insert huge amount of entity objects
• flush + clear
• ScrollableResults
• StatelessSession
- does not have a persistence context cache and does not interact with second and query cache, no dirty checking
- all retrieved entities are in detached state
- it bypasses any enabled Interceptor or event listeners or event callback methods
- no batching
- It’s a lower-level abstraction that is much closer to JDBC


Read-only • HQL constructor Expressions, Criteria
Projections, ResultSetTransformer for read-only data
• @Immutable
• @Transactional(readOnly=true)

Caching data
• Second-level cache (Reference data is an excellent candidate for shared caching)

• Query cache
- You must ask yourself how often you’re going
to execute the same query repeatedly, with the same arguments.
- Use the query cache in conjunction with the second-level cache !!!
- Query.setCacheable(true)

Bytecode enhancement
• @Basic(fetch=FetchType.LAZY)
- Blob
- @Formula
- Dirty checking enhancement
Hibernate 5.0+ version


The most useful recommendation
• Control your queries

Useful references
• Hibernate documentation

• JPA 2.1 specification

• Java Persistence with Hibernate 2nd edition 2016

Questions?





























