Embed Size (px)
Citation preview

DU BIG DATA VERS LE SMART DATASCENARIO D’UN PROCESSUS
ANALYSE TEMPS-REEL
CHAKER ALLAOUI

TABLE DE MATIERES
• Données • Big Data • Format JSON • Apache Zookeeper
01 02 03 04INTRO
• Apache Storm • Apache Kafka • Apache Cassandra • Apache Spark
05 06 07 08
• SparkSQL • SparkUI • D3 • SMART DATA
09 10 11 12
Scénario du processus

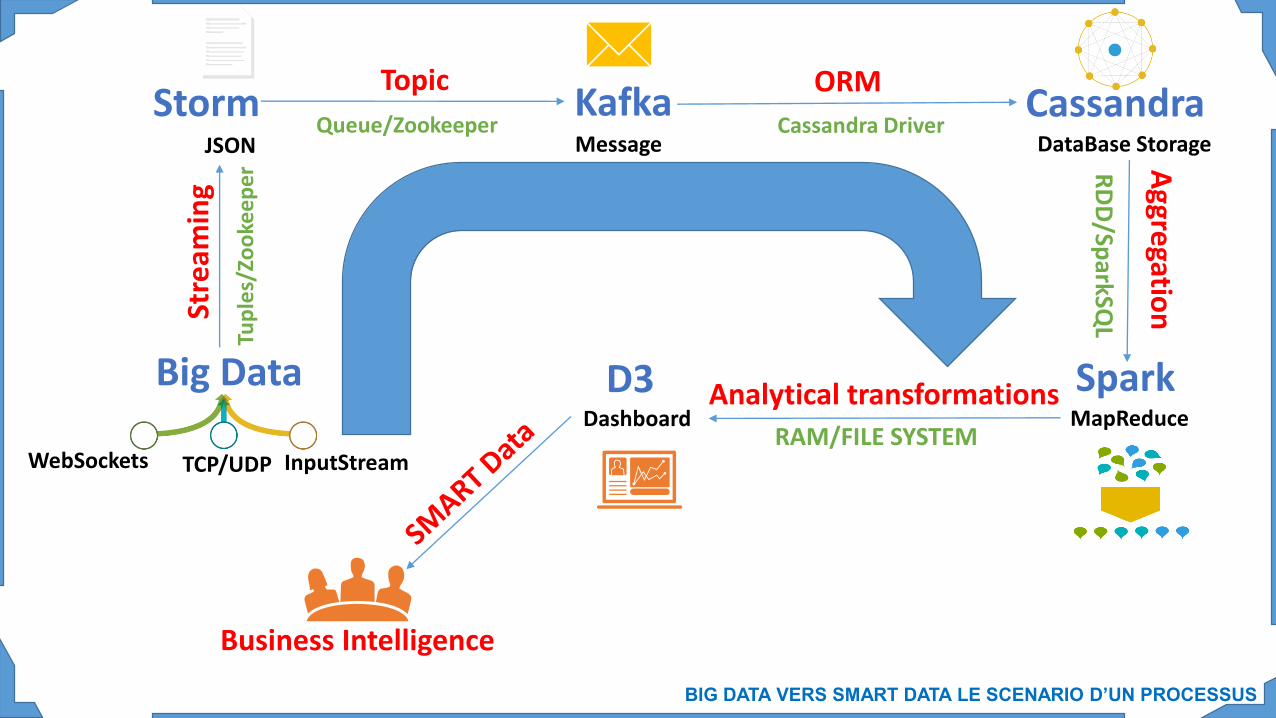
SCENARIO D’UN PROCESSUSBig Data vers SMART Data

Creative process
Analytical process
le Big data, désigne l’explosiondu volume des donnéesnumérisées, collectées par desparticuliers, des acteurspublics, des applicationsinformatiques qui regroupentdes communautésd’utilisateurs à l’échelle de laplanète. Il suffira de citerquelques exemples plus oumoins connus de tous : Google,son moteur de recherche et sesservices ; les réseaux ditsociaux : Facebook et sonmilliard d’utilisateurs quidéposent des images, destextes, des échanges ; les sitesde partage et de diffusiond’images et de photos (FlickR) ;les sites communautaires(blogs, forums, wikis) ; lesservices administratifs et leurs
Scénario du processus: Analytique & Créativeéchanges numérisés. Au centre de tous cesaspirateurs de données, on trouve Internet,le Web, et sa capacité à fédérer dansl’espace numérisé des milliardsd’utilisateurs, mais également la profusionde capteurs de toutes sortes, accumulant desdonnées scientifiques à un rythme inédit(images satellites par exemple). Pour enrester au Web, tous les messages, tous lesdocuments, toutes les images et vidéos sontcaptés par des applications qui, en échangedes services fournis, accumulentd’immenses banques de données.
On parle en millions de serveurs pourGoogle, Facebook ou Amazon, stockésdans d’immenses hangars qui, parailleurs, consomment une part nonnégligeable de l’électricité produite. Et lemouvement semble aller s’accélérant.D’où la nécessité de présenter un systèmede combinaison de ces multiples sources.Donc l’idée est de créer un scénariocomplet d’un processus de transformationdes ces données de masse en donnéesexploitable et présentatives pour faciliterleurs gestion et faire implémenterl’informatique décisionnelle pouranalyser et fédérer ces données.La solution comporte des softwares opensource dont la majorité sont issues desprojets de la fondation Apache.
Message
MapReduceDashboard
JSON
Kafka Cassandra
SparkD3
Storm
WebSockets
Stre
amin
g
Topic ORMA
ggregatio
n
Big Data
Tup
les/
Zoo
keep
er
Queue/Zookeeper Cassandra Driver
RD
D/Sp
arkSQL
RAM/FILE SYSTEMTCP/UDP
DataBase Storage
Business Intelligence
InputStream
BIG DATA VERS SMART DATA LE SCENARIO D’UN PROCESSUS
Analytical transformations

DonnéesWebSocketsTCP/UDPInputStream

Data
WebSocketsLe protocole WebSocket vise àdévelopper un canal decommunication full-duplex sur unsocket TCP pour les navigateurs etles serveurs web. L'interactivitécroissante des applications web,consécutive à l'amélioration desperformances des navigateurs, arapidement rendu nécessaire ledéveloppement de techniques decommunications bidirectionnellesentre l'application web et lesprocessus serveur. Des techniquesbasées sur l'appel par le client del'objet « XMLHttpRequest »et utilisant des requêtes HTTP avecun long TTL stockées par leserveur pour une réponseultérieure au client ont permis depallier ce manque par Ajax.
TCP/UDPUDP est un protocole orienté"non connexion« , lorsqu'unemachine A envoie des paquetsà destination d'une machine B,ce flux est unidirectionnel. Eneffet, la transmission desdonnées se fait sans prévenir ledestinataire (la machine B), etle destinataire reçoit lesdonnées sans effectuerd'accusé de réception versl'émetteur (la machine A).TCP est orienté "connexion".Lorsqu'une machine A envoiedes données vers une machineB, la machine B est prévenuede l'arrivée des données, ettémoigne de la bonneréception de ces données parun accusé de réception.
InputStreamLes flux d’entrées permettentd'encapsuler ces processusd'envoi et de réception dedonnées. Les flux traitenttoujours les données de façonséquentielle. Les flux peuventêtre divisés en plusieurscatégories: les flux de traitementde caractères et les flux detraitement d'octets.Les flux d’entrées peuvent êtredes webservices, un flus dedonnées venant des réseauxsociaux tels: twitter API etc...
Données: WebSockets-TCP/UDP-InputStream
Binary Data
Structured Data
Unstructured Data
API Interface
http://fr.wikipedia.org

Lire un contenu: cURL
Pour lire le contenu d’une source web, on vamanipuler: « cURL » (Client URL Request Library ), c’estune interface en ligne de commande destinée àrécupérer le contenu d'une ressource accessible par unréseau informatique. La ressource est désignée à l'aided'une URL et doit être d'un type supporté par le logiciel,il peut ainsi être utilisé en tant que client REST.La bibliothèque supporte notamment les protocoles FTP,FTPS, HTTP, HTTPS, TFTP, SCP, SFTP, Telnet, DICT, FILEet LDAP. L'écriture peut se faire en HTTP en utilisant lescommandes POST ou PUT.cURL est une interface générique nous permettant detraiter un flux de données.L’exemple ci-joint présente la lecture d’un contenued’un fichier JSON présent sur un serveur en local.L’idée est de savoir comment les logiciels de streamingtraite les requêtes de lecture, modification, ajout ousuppression de données distantes.Une requête de lecture peut se faire de cette façon:
> curl –i –H « Accept: application/json » -H « Content-Type:application/json » http://www.host.com/data.json
Commande cURL : lire un flux JSON

BIG DATAVolume-ValeurVélocité-Variété

La définition initiale donnéepar le cabinet McKinsey andCompany en 2011 s’orientaitd’abord vers la questiontechnologique, avec la célèbrerègle des 3V :un grand Volume de données,une importante Variété de cesmêmes données et une Vitessede traitement s’apparentantparfois à du temps réel.Ces technologies étaientcensées répondre à l’explosiondes données dans le paysagenumérique (le « data deluge »).Puis, ces qualificatifsont évolué, avec une visiondavantage économique portéepar le 4ème V:
Le Big Data s'accompagne dudéveloppement d'applications àvisée analytique, qui traitent lesdonnées pour en tirer du sens. Cesanalyses sont appelées Big Analyticsou «broyage de données». Ellesportent sur des donnéesquantitatives complexes avec desméthodes de calcul distribué. En2001, un rapport de recherche duMETA Group définit les enjeuxinhérents à la croissance desdonnées comme étant tri-dimensionnels :
les analyses complexesrépondent en effet à la règledite «des 3V» (volume, vélocitéet variété). Ce modèle estencore largement utiliséaujourd'hui pour décrire cephénomène.Le taux de croissance annuelmoyen mondial du marché dela technologie et des servicesdu Big Data sur la période2011-2016 devrait être de31,7%. Ce marché devrait ainsiatteindre 23,8 milliards dedollars en 2016 (d'après IDCmars 2013).Le Big Data devrait égalementreprésenter 8% du PIBeuropéen en 2020.
Oragnisationdes données
Centralisationdes données
Combinaisondes données
Support aux décisions
Big Data
http://recherche.cnam.fr/equipes/sciences-industrielles-et-technologies-de-l-information/big-data-decodage-et-analyse-des-enjeux-661198.kjsp
Le Valeur

Volume: C'est une dimension relative : le Big Datacomme le notait Lev Manovitch en 2011 définissaitautrefois « les ensembles de données suffisammentgrands pour nécessiter des super-ordinateurs »,mais il est rapidement devenu possible d'utiliser deslogiciels standards sur des ordinateurs de bureaupour analyser ou co-analyser de vastes ensemblesde données. Le volume des données stockées est enpleine expansion : les données numériques crééesdans le monde seraient passées de 1,2 Z-octets paran en 2010 à 1,8 Z-octets en 2011
Vélocité: représente à la fois lafréquence à laquelle les donnéessont générées, capturées etpartagées et mises à jour. Des fluxcroissants de données doivent êtreanalysés en quasi-temps réel pourrépondre aux besoins desprocessus chrono-sensibles. Parexemple, les systèmes mis en placepar la bourse et les entreprisesdoivent être capables de traiter cesdonnées avant qu’un nouveaucycle de génération n’aitcommencé, avec le risque pourl‘homme de perdre une grandepartie de la maîtrise du systèmequand les principaux opérateursdeviennent des "robots" capablesde lancer des ordres d'achat ou devente de l'ordre de lananoseconde, sans disposer detous les critères d'analyse pour lemoyen et long terme.
puis 2,8 Z-octets en 2012 ets'élèveront à 40 Z-octets en 2039.Par exemple Twitter générait enjanvier 2013, 7 Téraoctets/jour.Variété: Le volume des Big Datamet les data-centers devant unréel défi : la variété des données. Ilne s'agit pas de donnéesrelationnelles traditionnelles, cesdonnées sont brutes, semi-structurées voire non structurées.Ce sont des données complexesprovenant du web, au formattexte et images (Image Mining).Elles peuvent être publiques(Open Data, Web des données),géo-démographiques par îlot(adresses IP), ou relever de lapropriété des consommateurs. Cequi les rend difficilementutilisables avec les outilstraditionnels de gestions dedonnées pour en sortir le meilleur.
http://fr.wikipedia.org/wiki/Big_data

Format JSONJavaScriptObject Notation

Format JSONJSON (JavaScript Object Notation) est un format légerd'échange de données. Il est facile à lire ou à écrire pourdes humains. Il est aisément analysable ou généré pardes machines. Il est basé sur un sous-ensemble dulangage de programmation JavaScript. JSON est unformat texte complètement indépendant de tout langage,mais les conventions qu'il utilise seront familières à toutprogrammeur. JSON se base sur deux structures :Une collection de couples key/value. Divers langages laréifient par un objet, un enregistrement, une structure.
Ou un dictionnaire, une table de hachage, uneliste typée ou un tableau associatif. Une liste devaleurs ordonnées. La plupart des langages laréifient par un tableau, un vecteur, une liste ouune suite. Ces structures de données sontuniverselles. Pratiquement tous les langages deprogrammation modernes les proposent sousune forme ou une autre. Il est raisonnablequ'un format de données interchangeable avecdes langages de programmation se base aussisur ces structures. En JSON, elles prennent lesformes suivantes : Un objet, qui est un ensemblede couples key/value non ordonnés. Un objetcommence par « { » et se termine par « } ».Chaque nom est suivi de « : » et les coupleskey/value sont séparés par « , ».Un tableau est une collection de valeursordonnées. Un tableau commence par « [ »et setermine par « ] ». Les valeurs sont séparées par« , », les champs du tableau sont séparés par« : », et peuvent contenir des valeurs de type debase, comme les entiers, les chaines decaractères ou des types complexe: objets…
Donnéesstructurées
Universel
Traitement rapide
Riche encomposants
http://www.json.org/jsonfr.html
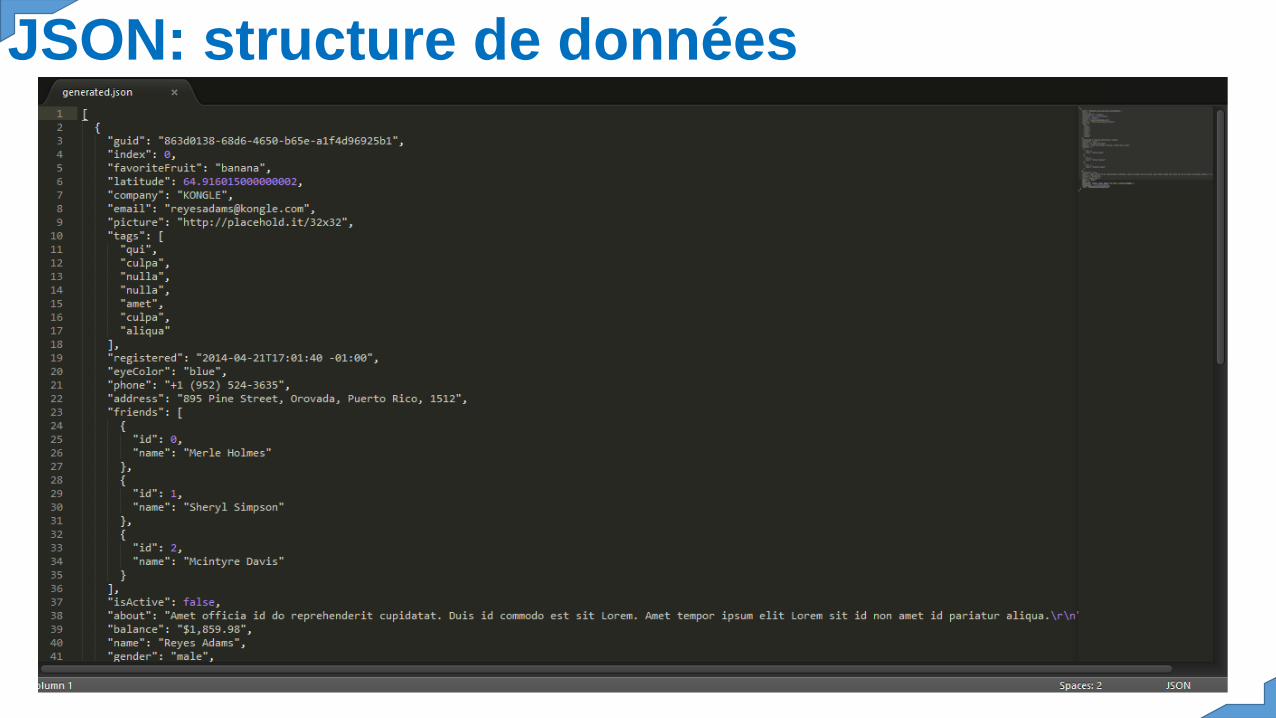
JSON: structure de données

APACHE ZOOKEEPERTravaillons avec les systèmes distribués

APACHE ZOOKEEPER ZooKeeper
Apache Zookeeper est unframework pour fédérer lescommunications entre des systèmesdistribués, il fonctionne enfournissant un espace mémoirepartagé par toutes les instancesd’un même ensemble de serveurs.Cet espace mémoire esthiérarchique, à la manière d’unsystème de fichier composé derépertoires et de fichiers. Il estdistribué, consiste en plusieursmachines connectées entre elles etqui résolvent ensemble unproblème, par opposition avec unsystème centralisé, donc une grossemachine unique qui prend tout à sacharge. Le cas de Google, pourlequel aucune machine unique nesaurait traiter toutes les requêtes. Lesimple fait d’avoir plusieurs
machines qui doivent travaillerensemble est une source deproblèmes, parmi lesquelles:La résistance aux pannes : siune machine tombe en pannedans le réseau, que faire. Si elleest la seule à porter desinformations importantes,celles-ci sont perdues. Dans cecas, on règle la question avec laredondance des informations,dupliquées sur plusieursmachines. La consistance del’information, en particulier sielle est dupliquée. Le but estd’offrir une indépendance de la
valeur de la donnée par rapport àsa source : on veut éviter quechaque machine porte une versiondifférente, d’une information donton a besoin. La répartition de lacharge : comment bien gérer sesressources pour éviter qu’une seulemachine ne soit trop sollicitée, alorsque les autres sont inactives.Comment une requête émise par unclient est-elle traitée, Qui le fait ? Etcomment garantir que le résultatest le bon, indépendamment de lamachine qui a traité la question.C’est le problème dit du consensus :on dit qu’il y a consensus si deuxmachines ayant les mêmes donnéesinitiales donnent le même résultatpour le même traitement.
Distibué
Implémentationen local
Implémentationdans le Cloud
Orchestrateur
http://blog.zenika.com/index.php?post/2014/10/13/Apache-Zookeeper-facilitez-vous-les-systemes-distribues2

Systèmes distribuésLa communication entre lesinstances ou machines se passe enmode asynchrone. Par exemple,vous voulez envoyer un message àun ensemble d’instances (uncluster) pour lancer un traitement.Vous avez aussi besoin de savoir siune instance est opérationnelle.Pour bien communiquer, uneméthode utilisée consiste en unequeue. Celle-ci permet d’envoyerdes messages directement ou parsujet, de les lire de manièreasynchrone. La communication enmode cluster se passe exactementcomme une communication, enmode local avec plusieursprocessus, et passe par lacoordination dans l’usage desressources. Concrètement, quandun nœud écrit sur un fichier, il estpréférable qu’il pose un verrou,
visible par tous les autresnœuds, sur le dit fichier.Un système de fichiers distribuéne souhaite pas savoir que telfichier est sur l’instancemachin. Il veut avoir l’illusionde manipuler un uniquesystème de fichiers, exactementcomme sur une seule machine.La gestion de la répartition desressources, avec ce qu’il fautfaire si une instance ne répondpas, n’est pas utile à savoir.Un service de nommage : pourle présenter, certes de manièreapproximative, on aimerait unesorte de Map<String,Object>qui soit répartie sur le réseau,que toutes les instancespuissent utiliser. Un exempletype serait JNDI. Le but duservice de nommage consiste à
avoir un système distribué d’accès aux objets.Un système robuste de traitement des requêtes est unearchitecture répartie qui accueille des données entemps réel. Dans le cas d’une structure avancées, on sesouhaite pas perdre la moindre données tels que: lesordres boursiers, l’idée est de faire un traitement quirécupère les données d’une instance avant qu’elletombe en panne ou sort du réseaux. La démarche deZookeeper est d’élir un leader à chaque mise enmarche de système, et ce dernier qui assure le partagede l’information et les cadres dans les quels uneinformation doit être persister dans le système pour engarder la trace, en prenant compte de l’avis de chaqueZnodes ou exactement la réponse pour fairesauvegarder une information, ainsi un nombresupérieur à n/2 où n est le nombre de nœuds ayantreçus et accepter l’ordre de l’écriture, ainsi l’opérationd’écriture sur tous les nœuds est lancée.
ZOOKEEPER: ZNodes> .\bin\zkServer.cmd> .\bin\zkCli.cmd 127.0.0.1:2181
Liste des noeuds Zookeeper
Instance Zookeeper

APACHE STORMStreaming temps-réel
Apache Storm est un systèmede calculs temps réel distribuéet tolérant aux pannes,développé à l’origine par lasociété BackType. Le projet estdevenu open-source aprèsl’acquisition de la société parTwitter. Il est disponible sous
licence Eclipse Public License1.0. De plus, Storm est entrédepuis quelques mois dans leprocessus d’incubation de lafondation Apache. Pour traiteren continu plusieurs flux dedonnées, Storm repose sur ladéfinition d’une topologie.
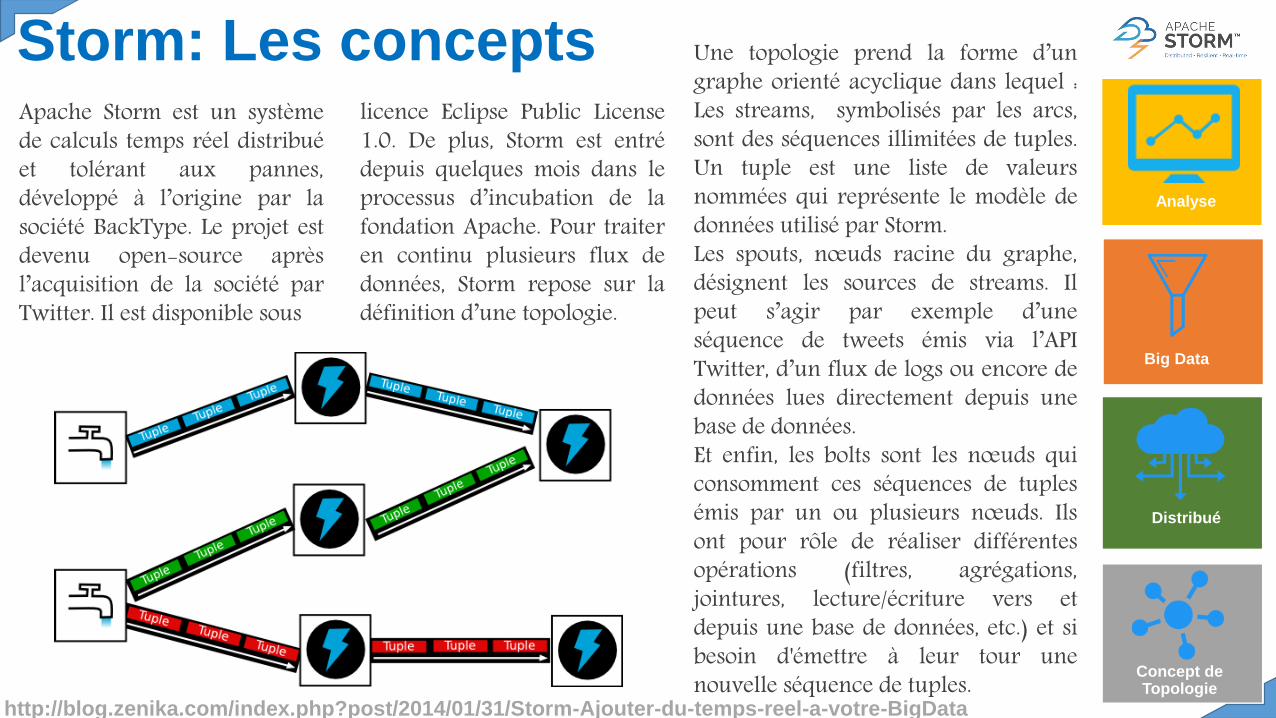
Une topologie prend la forme d’ungraphe orienté acyclique dans lequel :Les streams, symbolisés par les arcs,sont des séquences illimitées de tuples.Un tuple est une liste de valeursnommées qui représente le modèle dedonnées utilisé par Storm.Les spouts, nœuds racine du graphe,désignent les sources de streams. Ilpeut s’agir par exemple d’uneséquence de tweets émis via l’APITwitter, d’un flux de logs ou encore dedonnées lues directement depuis unebase de données.Et enfin, les bolts sont les nœuds quiconsomment ces séquences de tuplesémis par un ou plusieurs nœuds. Ilsont pour rôle de réaliser différentesopérations (filtres, agrégations,jointures, lecture/écriture vers etdepuis une base de données, etc.) et sibesoin d'émettre à leur tour unenouvelle séquence de tuples.
Storm: Les concepts
Analyse
Big Data
Distribué
Concept de Topologie
http://blog.zenika.com/index.php?post/2014/01/31/Storm-Ajouter-du-temps-reel-a-votre-BigData

Le regroupement de fluxrépond à la question suivante:lorsqu’un tuple est émis, versquels bolts doit-il être dirigé.En d’autres termes, il s’agit despécifier la manière dont lesflux sont partitionnés entre lesdifférentes instances d’unmême composant spout oubolt. Pour cela, Storm fournitun ensemble deregroupements prédéfinis,dont voici les principalesdéfinitions :- Shuffle grouping : Les tuplessont distribués aléatoirementvers les différentes instancesbolts de manière à ce quechacune reçoive un nombreégal de tuples.
Streams: grouping, worker, executor- Fields grouping : Le flux estpartitionné en fonction d’un ouplusieurs champs.- All grouping: Le flux estrépliqué vers l’ensemble desinstances. Cette méthode est àutiliser avec précautionpuisqu'elle génère autant de fluxqu’il y a d’instances.- Global grouping: L’ensemble duflux est redirigé vers une mêmeinstance. Dans le cas, où il y en aplusieurs pour un même bolt, leflux est alors redirigé vers celleayant le plus petit identifiant.
Lorsqu’une topologie est soumise à Storm, celui-cirépartit l’ensemble des traitements implémentés parvos composants à travers le cluster. Chaquecomposant est alors exécuté en parallèle sur une ouplusieurs machines.Storm exécute une topologie composée d’un spout etde deux bolts. Pour chaque topologie, Storm gère unensemble d’entités distinctes:Un « worker process » est une JVM s’exécutant surune machine du cluster. Il a pour rôle de coordonnerl'exécution d'un ou plusieurs composants (spouts oubolts) appartenant à une même topologie. Ainsi lenombre de workers associés à une topologie peutchanger au cours du temps.Un « executor » est un thread lancé par un « workerprocess ». Il est chargé d'exécuter une ou plusieurs« task » pour un bolt ou spout spécifique. Ainsi lenombre d’exécuteurs associés à un composant peutchanger au cours du temps.Les « tasks » effectuent les traitements à appliquer surles données. Chaque « task » représente une instanceunique d'un bolt ou d’un spout.
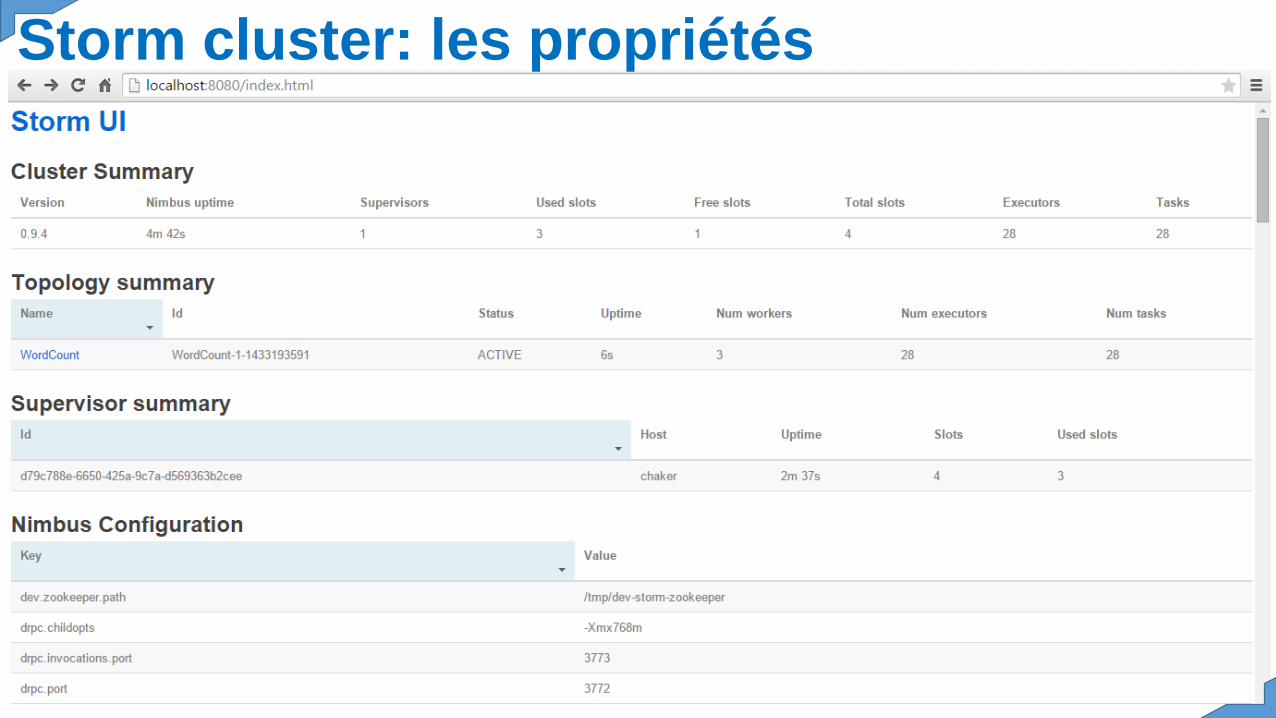
Storm cluster: les propriétés
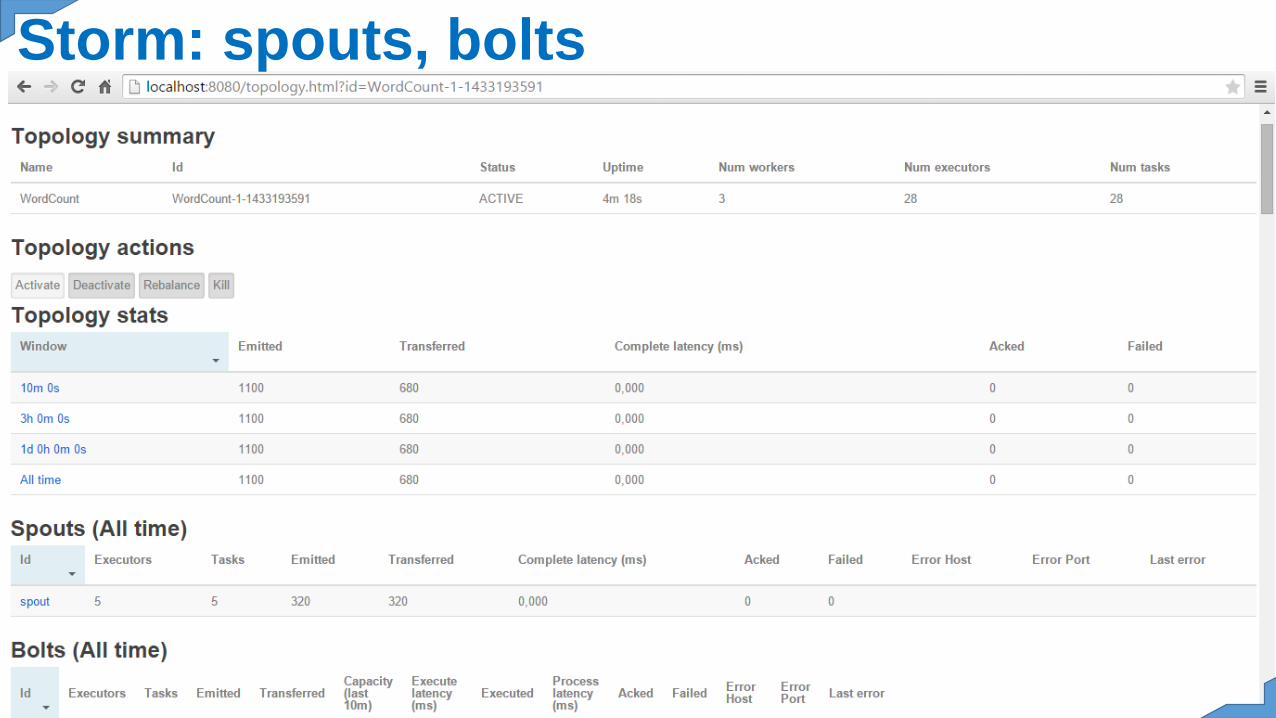
Storm: spouts, bolts
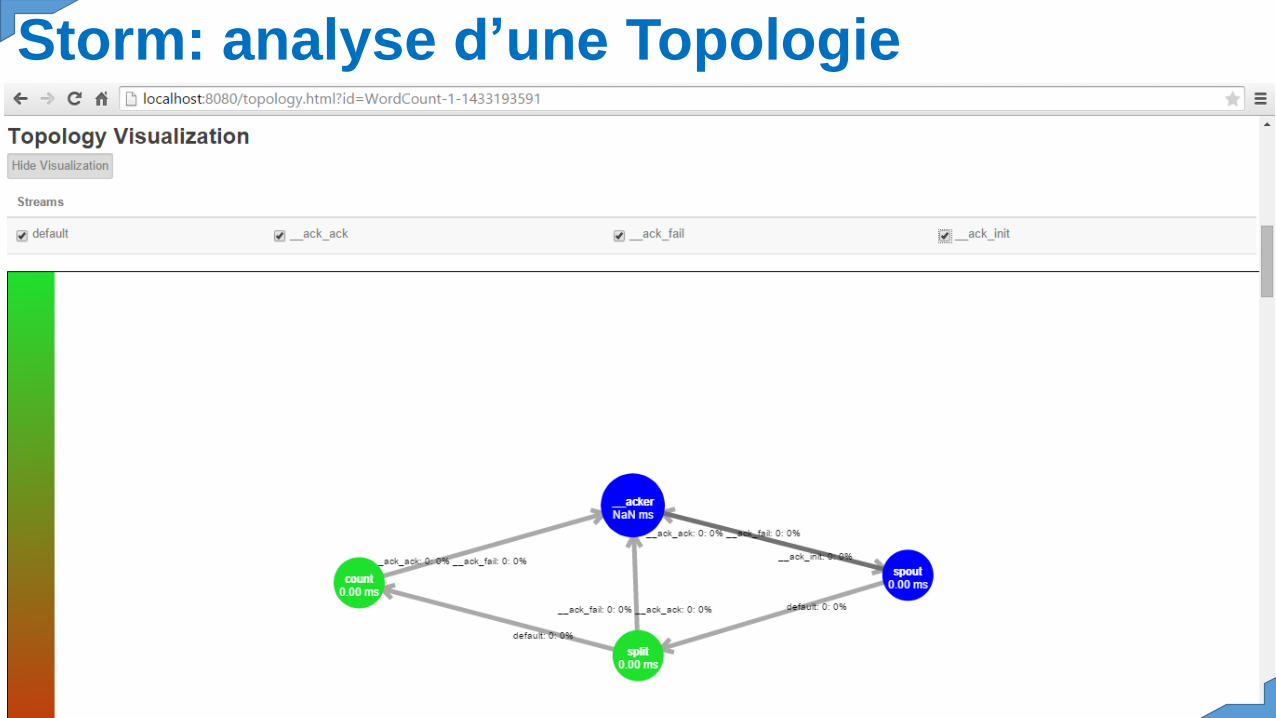
Storm: analyse d’une Topologie

Storm: Traitement du JSON avec les spouts
Parsing du flux JSON avec Storm Java API

APACHE KAFKAProducteur-Consommateur de Contenu

Apache a publié Kafka 0.8, lapremière version majeure de Kafka,depuis que le projet est devenu unprojet de top niveau de la FondationLogicielle Apache. Apache Kafka estun système orienté message de typepublication-souscription implémentécomme système de tracestransactionnel distribué, adapté pourla consommation de messages en-ligne et hors ligne. Il s'agit d'unsystème orienté message développé àl'origine à LinkedIn pour la collectionet la distribution de volumes élevésd'évènements et de données de trace àlatence faible. La dernière versioncomprend la réplication intra-clusteret le support de multiples répertoiresde données. Les fichiers de tracepeuvent être permutés par âge, et lesniveaux de trace peuvent être
valorisés dynamiquement parJMX. Un outil de test deperformance a été ajouté, pouraider à traiter les inquiétudes et àchercher les améliorationsconcernant les performances.Kafka est un service de commit detraces distribué, partitionné etrépliqué.Les producteurs publient desmessages dans des sujets Kafka,
les consommateurss'abonnent à ces sujets etconsomment lesmessages. Un serveur dansun cluster Kafka est appeléun intermédiaire. Pourchaque sujet, le cluster Kafkamaintient une partition pourla montée en charge, leparallélisme et la résistanceaux pannes.
Temps-réel
Distibué
Gestionde la mémoire
Tracabilité
http://www.infoq.com/fr/news/2014/01/apache-afka-messaging-system
Apache Kafka

La remédiation est contrôléepar le consommateur. Unconsommateur typique traiterale message suivant dans laliste, bien qu'il puisseconsommer les messages dansn'importe quel ordre, car lecluster Kafka conserve tous lesmessages publiés pour unepériode de temps configurable.Cela rend les consommateurstrès économiques, car ils vontet viennent sans beaucoupd'impact sur le cluster, etautorisent les consommateursdéconnectés comme les
clusters Hadoop. Lesproducteurs sont capables dechoisir le sujet, et la partitionau sein du sujet, dans lequelpublier le message. Lesconsommateurs s'auto-affectent un nom de groupe deconsommateur, et chaquemessage est distribué à unconsommateur dans chaquegroupe de consommateursabonnés. Si tous lesconsommateurs ont desgroupes différents, alors lesmessages sont diffusés àchaque consommateur. Kafkapeut être utilisé comme unmiddleware de messagetraditionnel. Il offre un débitélevé et dispose de capacités departionnement natif, deréplication et de résistance auxpannes, ce qui en fait unebonne solution pour les
applications de traitement de messages de grandeampleur. Kafka peut également être employé pour lesuivi de sites web à fort volume. L'activité du site peutêtre publiée et traitée en temps réel, ou chargée danssystème d'entrepôt de données Hadoop ou hors-ligne.Kafka peut également être utilisé comme solutiond'agrégation de traces. Au lieu de travailler avec desfichiers, les traces peuvent être traitées comme des fluxde messages. Kafka est utilisé à LinkedIn et il gère plusde 10 milliards d'écritures par jour avec une chargesoutenue qui avoisine 172 000 messages par seconde. Ily a une utilisation massive de support multi-abonnés
Topic Kakfa
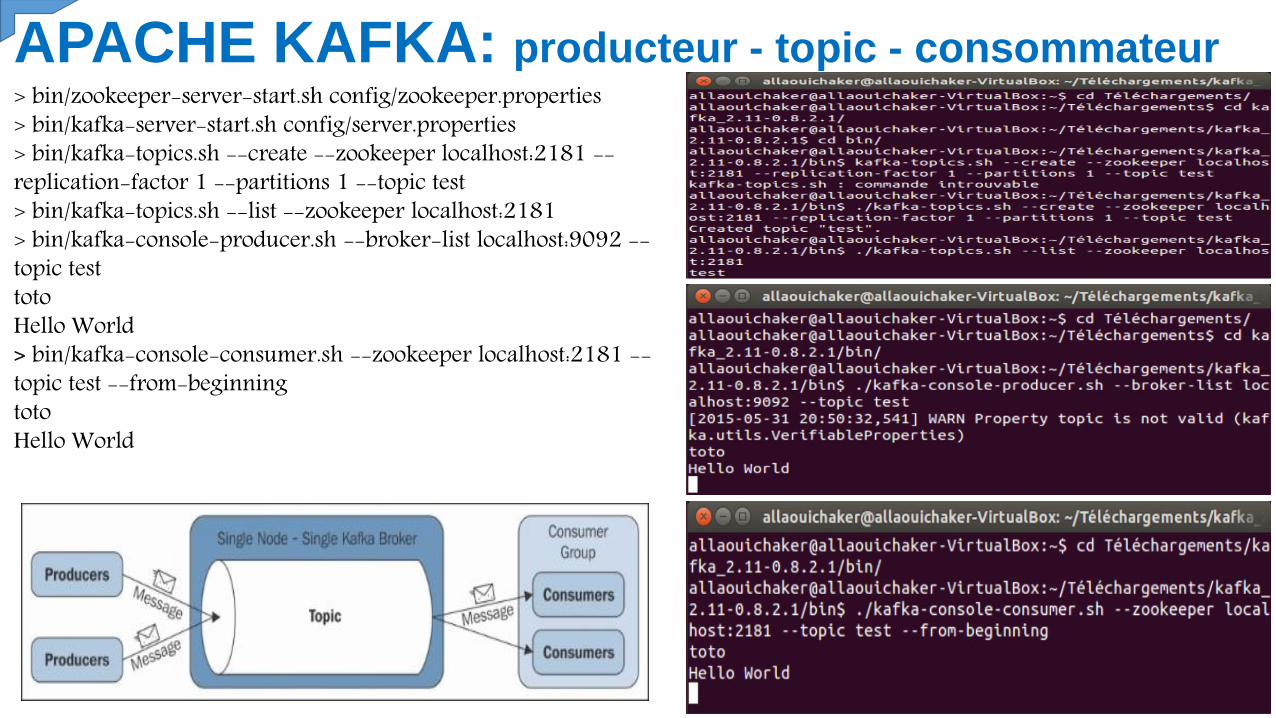
APACHE KAFKA: producteur - topic - consommateur> bin/zookeeper-server-start.sh config/zookeeper.properties> bin/kafka-server-start.sh config/server.properties> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test> bin/kafka-topics.sh --list --zookeeper localhost:2181> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test totoHello World> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginningtotoHello World

APACHE KAFKA: Transmission d’un flux JSONimport java.io.FileInputStream;import java.io.IOException;import java.util.Properties;import kafka.producer.KeyedMessage;import kafka.producer.ProducerConfig;public class KafkaProducer {private static kafka.javaapi.producer.Producer<Integer, String> producer = null;private static String topic = "topic_message";private static Properties props = new Properties();public KafkaProducer() { }public void sendMessage() {try {props.put("serializer.class", "kafka.serializer.StringEncoder");props.put("metadata.broker.list", « 127.0.0.1:9092");producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));BufferedReader br = null;String sCurrentLine;br = new BufferedReader(new FileReader(« ./data.json"));while ((sCurrentLine = br.readLine()) != null) {producer.send(new KeyedMessage<Integer, String>(topic, sCurrentLine));}producer.send(new KeyedMessage<Integer, String>(topic, new String(content)));} catch (IOException e) {e.printStackTrace();}finally {try {if (br != null)br.close();} catch (IOException ex) {ex.printStackTrace();}}}}

APACHE CASSANDRABase de données NoSQL

réplication désigne le nombre denœuds où la donnée estrépliquée. Par ailleurs,l'architecture de Cassandradéfinit le terme de cluster commeétant un groupe d'au moins deuxnœuds et un data-center commeétant des clusters délocalisés.Cassandra permet d'assurer laréplication à travers différentsdata-center. Les nœuds qui sonttombés peuvent être remplacéssans indisponibilité du service.• Décentralisé : dans un clustertous les nœuds sont égaux. Il n'ypas de notion de maitre, nid'esclave, ni de processus quiaurait à sa charge la gestion, nimême de goulet d'étranglementau niveau de la partie réseau. Leprotocole
Apache Cassandra est une base dedonnées de la famille NoSQL trèsen vogue. Elle se classe parmi lesbases orientées colonnes toutcomme HBase, Apache Accumulo,Big Table. Cette base a étédéveloppée à l'origine par desingénieurs de Facebook pour leursbesoins en interne avant d'êtremise à la disposition du grandpublic en open-source.CARACTERISTIQUES• Tolérance aux pannes : lesdonnées d'un nœud (un nœud estune instance de Cassandra) sontautomatiquement répliquées versd'autres nœuds (différentesmachines). Ainsi, si un nœud esthors service les données présentessont disponibles à travers d'autresnœuds. Le terme de facteur de
GOSSIP assure la découvert, lalocalisation et la collecte de toutesles informations sur l'état desnœuds d'un cluster.• Modèle de données riche : lemodèle de données proposé parCassandra basé sur la notion dekey/value permet de développerde nombreux cas d'utilisationdans le monde du Web.• Élastique : la scalabilité estlinéaire. Le débit d'écriture et delecture augmente de façonlinéaire lorsqu'un nouveauserveur est ajouté dans le cluster.Par ailleurs, Cassandra assurequ'il n'y aura pas d'indisponibilitédu système ni d'interruption auniveau des applications.
Analyse
Stockage
Distribué
Gestionde la mémoire
APACHE Cassandra
http://www.infoq.com/fr/articles/modele-stockage-physique-cassandra-details
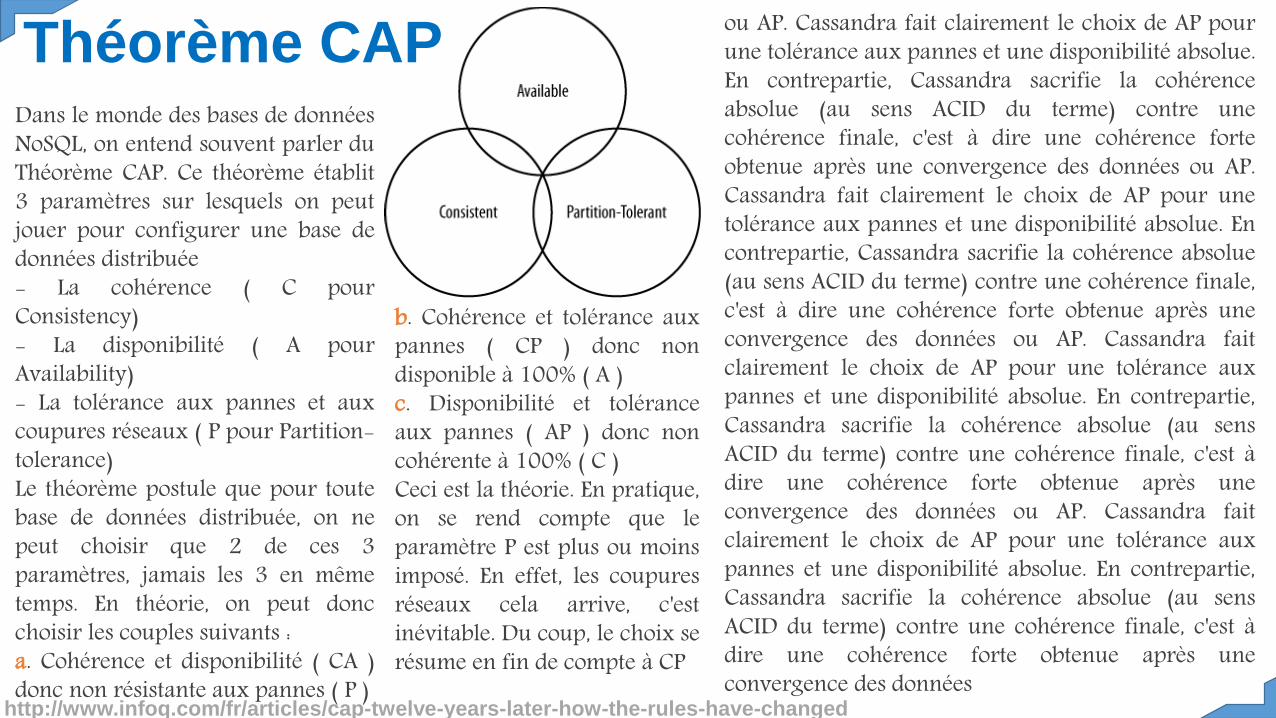
Dans le monde des bases de donnéesNoSQL, on entend souvent parler duThéorème CAP. Ce théorème établit3 paramètres sur lesquels on peutjouer pour configurer une base dedonnées distribuée- La cohérence ( C pourConsistency)- La disponibilité ( A pourAvailability)- La tolérance aux pannes et auxcoupures réseaux ( P pour Partition-tolerance)Le théorème postule que pour toutebase de données distribuée, on nepeut choisir que 2 de ces 3paramètres, jamais les 3 en mêmetemps. En théorie, on peut doncchoisir les couples suivants :a. Cohérence et disponibilité ( CA )donc non résistante aux pannes ( P )
b. Cohérence et tolérance auxpannes ( CP ) donc nondisponible à 100% ( A )c. Disponibilité et toléranceaux pannes ( AP ) donc noncohérente à 100% ( C )Ceci est la théorie. En pratique,on se rend compte que leparamètre P est plus ou moinsimposé. En effet, les coupuresréseaux cela arrive, c'estinévitable. Du coup, le choix serésume en fin de compte à CP
ou AP. Cassandra fait clairement le choix de AP pourune tolérance aux pannes et une disponibilité absolue.En contrepartie, Cassandra sacrifie la cohérenceabsolue (au sens ACID du terme) contre unecohérence finale, c'est à dire une cohérence forteobtenue après une convergence des données ou AP.Cassandra fait clairement le choix de AP pour unetolérance aux pannes et une disponibilité absolue. Encontrepartie, Cassandra sacrifie la cohérence absolue(au sens ACID du terme) contre une cohérence finale,c'est à dire une cohérence forte obtenue après uneconvergence des données ou AP. Cassandra faitclairement le choix de AP pour une tolérance auxpannes et une disponibilité absolue. En contrepartie,Cassandra sacrifie la cohérence absolue (au sensACID du terme) contre une cohérence finale, c'est àdire une cohérence forte obtenue après uneconvergence des données ou AP. Cassandra faitclairement le choix de AP pour une tolérance auxpannes et une disponibilité absolue. En contrepartie,Cassandra sacrifie la cohérence absolue (au sensACID du terme) contre une cohérence finale, c'est àdire une cohérence forte obtenue après uneconvergence des données
Théorème CAP
http://www.infoq.com/fr/articles/cap-twelve-years-later-how-the-rules-have-changed

CQLSHCQL veut dire CassandraQuery Language, et noussommes à la version 4. Lapremière version a été unetentative expérimentaled'introduire un langage derequête pour Cassandra. Ladeuxième version de CQL a étéconçue pour requêter les widerows mais n'était pas assezflexible pour s'adapter à tous
les types de modélisation quiexistent dans ApacheCassandra. Cependant, il estconseillé d'utiliser plutôt unedeuxième clé d'indexationpositionnée sur la colonnecontenant les informationsvoulues. En effet, utiliser lastratégie Ordered Partitionnersa les conséquences suivantes :l'écriture séquentielle peutentraîner des hotspots : sil'application tente d'écrire ou
de mettre à jour un ensemble séquentiel de lignes,alors l'écriture ne sera pas distribuée dans le cluster ;un overhead accru pour l'administration du loadbalancer dans le cluster : les administrateurs doiventcalculer manuellement les plages de jetons afin de lesrépartir dans le cluster ; répartition inégale de chargepour des familles de colonnes multiples.L’interface de CQLSH est écrite en python, doncnécessite l’installation de l’utilitaire python pour uneversion supérieure à 2.7 pour pouvoir bénéficier decette interface de communication directe avec la basede données Cassandra. Le langage de requête enversion 4 est très semblable au SQL2. Ainsi plusieurstermes sont les mêmes, mais leurs utilités estdifférentes, par exemple une clé primaire dansCassandra n’est pas équivalente à celle dans SQL2.Exemple:CREATE TABLE developer(
developer_id bigint,firstname text,lastname text,age int,task varchar,PRIMARY KEY(developer_id));Interface python de la CQLSH 4.1

Apache Cassandra est unsystème permettant de gérerune grande quantité dedonnées de manière distribuée.Ces dernières peuvent êtrestructurées, semi-structuréesou pas structurées du tout.Cassandra a été conçu pourêtre hautement scalable sur ungrand nombre de serveurs touten ne présentant pas de SinglePoint Of Failure (SPOF).Cassandra fournit un schémade données dynamique afind'offrir un maximum deflexibilité et de performance.Mais pour bien comprendrecet outil, il faut tout d'abordbien assimiler le vocabulaire
- Cluster : un cluster est unregroupement des nœuds quise communiquent pour lagestion de données.- Keyspace : c'est l'équivalentd'une database dans le mondedes bases de donnéesrelationnelles. À noter qu'il estpossible d'avoir plusieurs «Keyspaces » sur un mêmeserveur.- Colonne (Column) : unecolonne est composée d'unnom, d'une valeur et d'untimestamp.- Ligne (Row) : les colonnessont regroupées en Rows. UneRow est représentée par uneclé et une valeur.
Il est possible de configurer le partitionnement pourune famille de colonnes en précisant que l'on veut quecela soit géré avec une stratégie de type OrderedPartitioners. Ce mode peut, en effet, avoir un intérêt sil'on souhaite récupérer une plage de lignes comprisesentre deux valeurs (chose qui n'est pas possible si lehash MD5 des clés des lignes est utilisé). Il est possiblede configurer le partitionnement pour une famille decolonnes en précisant que l'on veut que cela soit géréavec une stratégie de type Ordered Partitioners. Cemode peut, en effet, avoir un intérêt si l'on souhaiterécupérer une plage de lignes comprises entre deuxvaleurs (chose qui n'est pas possible si le hash MD5 des
C*: Cluster-Keyspace-Column-Row
C* cluster: configuration des noeuds
Configuration d’un cluster Cassandra avec l’interface OpsCenter

C* Stockage des données: Le Modelimport java.io.Serializable;import java.util.Date;import java.util.UUID;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import org.apache.commons.lang3.builder.EqualsBuilder;import org.apache.commons.lang3.builder.HashCodeBuilder;import org.apache.commons.lang3.builder.ToStringBuilder;import org.apache.commons.lang3.builder.ToStringStyle;import org.easycassandra.Index;@Entity(name = "tweet")public class Tweet implements Serializable {@Idprivate UUID id;@Index@Column(name = "nickName")private String nickName;@Column(name = "message")private String message;@Column(name = "time")private Date time;
public UUID getId() {return id; }public void setId(UUID id) {this.id = id;}public String getNickName() {return nickName; }public void setNickName(String nickName) {this.nickName = nickName;}public String getMessage() {return message;}public void setMessage(String message) {this.message = message;}public Date getTime() {return time;}public void setTime(Date time) {this.time = time; }@Overridepublic boolean equals(Object obj) {if(obj instanceof Tweet) {Tweet other = Tweet.class.cast(obj);return new EqualsBuilder().append(id, other.id).isEquals();}return false;}@Overridepublic int hashCode() {return new HashCodeBuilder().append(id).toHashCode();}@Overridepublic String toString() {return ToStringBuilder.reflectionToString(this,ToStringStyle.SHORT_PREFIX_STYLE);}}

C* Stockage des données: Repository-Requêteimport java.util.List;import java.util.UUID;import org.easycassandra.persistence.cassandra.Persistence;public class TweetRepository {private Persistence persistence;public List<Tweet> findByIndex(String nickName) {return persistence.findByIndex("nickName", nickName, Tweet.class);}{this.persistence = CassandraManager.INSTANCE.getPersistence();}public void save(Tweet tweet) {persistence.insert(tweet);}public Tweet findOne(UUID uuid) {return persistence.findByKey(uuid, Tweet.class);}}
import java.util.Date;import java.util.UUID;public class App{public static void main( String[] args ){TweetRepository personService = new TweetRepository();Tweet tweet = new Tweet();tweet.setNickName("allaoui chaker");UUID uuid = UUID.randomUUID();tweet.setId(uuid);tweet.setNickName("allaoui chaker");tweet.setMessage("test cassandra mapping");tweet.setTime(new Date());tweet.setId(UUID.randomUUID());personService.save(tweet);Tweet findTweet=personService.findOne(uuid);System.out.println(findTweet);}}
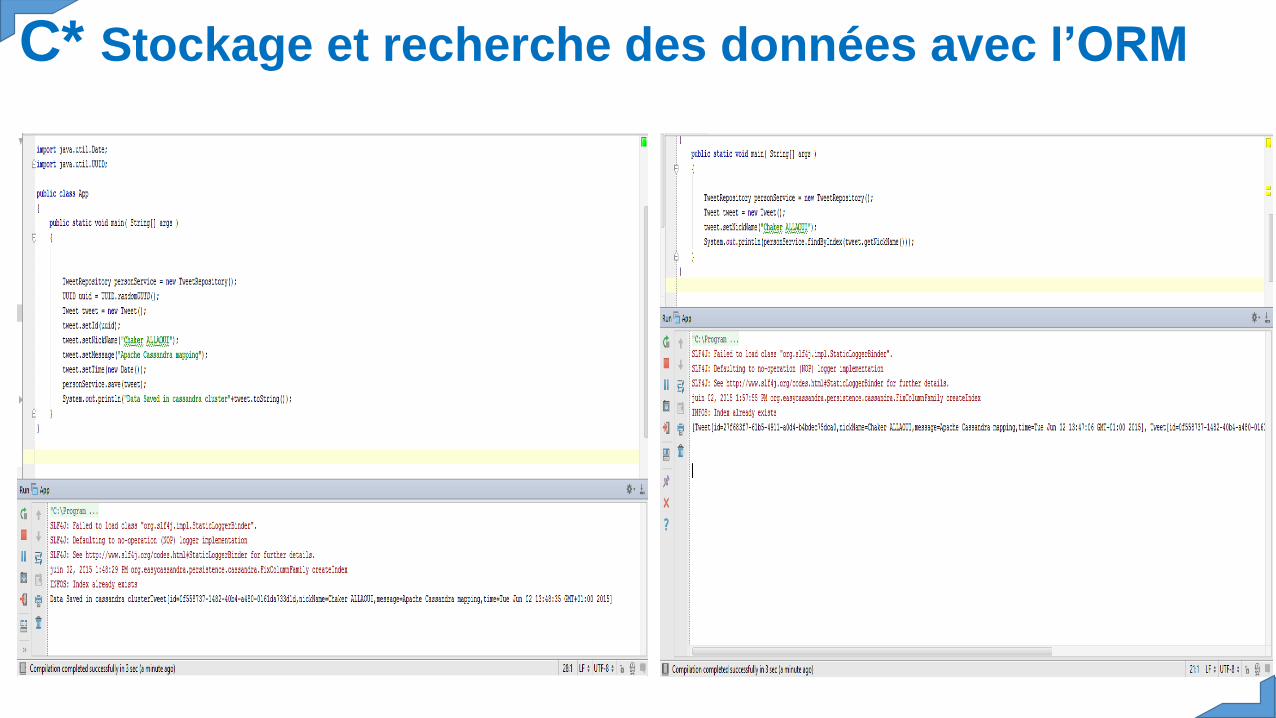
C* Stockage et recherche des données avec l’ORM
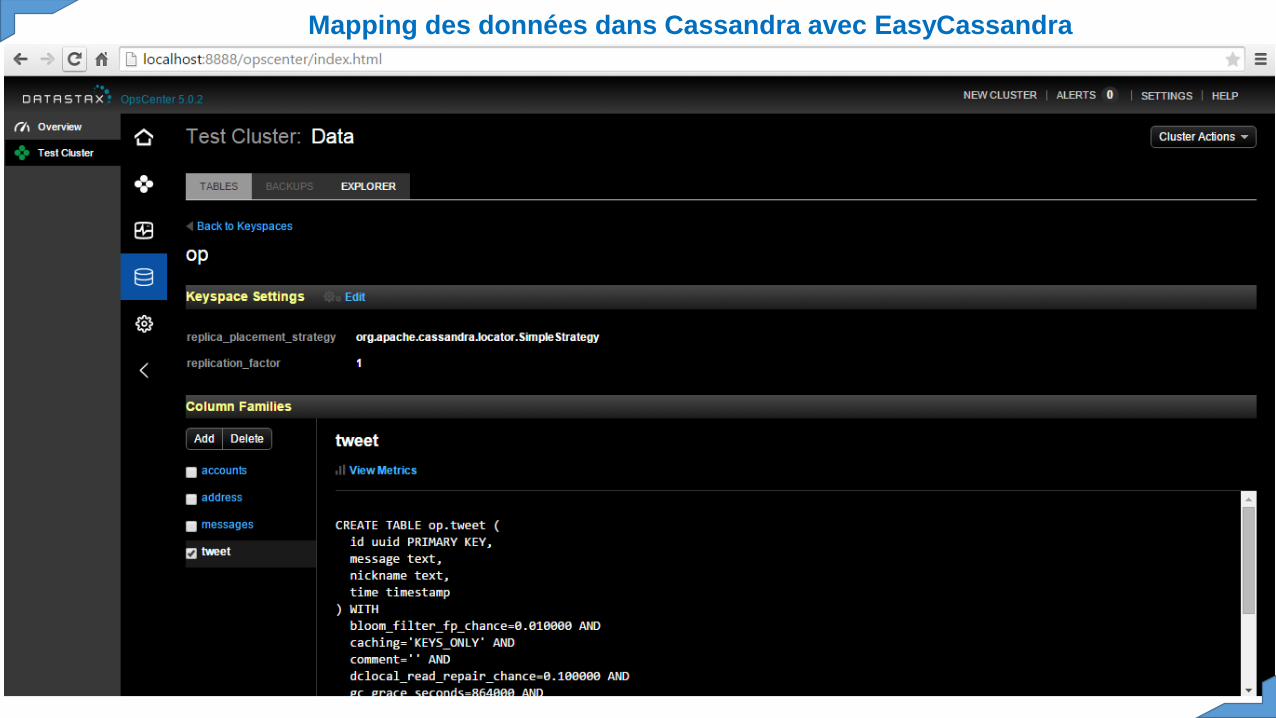
Mapping des données dans Cassandra avec EasyCassandra

APACHE SPARKL’éco-Système Big Data
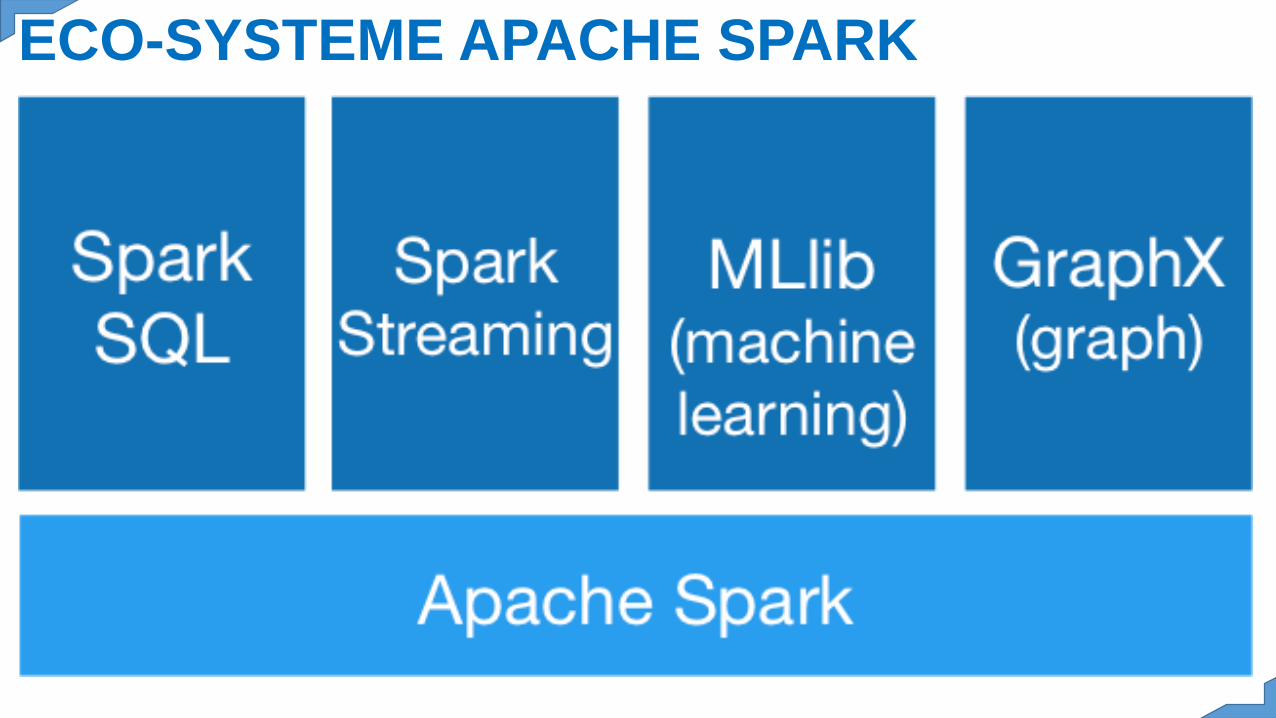
ECO-SYSTEME APACHE SPARK
Apache Spark est un framework detraitements Big Data open sourceconstruit pour effectuer desanalyses sophistiquées et conçupour la rapidité et la facilitéd’utilisation. Celui-ci aoriginellement été développé parAMPLab, de l’Université UCBerkeley, en 2009 et passé opensource sous forme de projet Apacheen 2010. Spark présente plusieursavantages par rapport aux autrestechnologies big data etMapReduce comme Hadoop etStorm. D’abord, Spark propose unframework complet et unifié pourrépondre aux besoins detraitements Big Data pour diversjeux de données, divers par leurnature (texte, graphe, etc.) aussibien que par le type de source.
Ensuite, Spark permet à desapplications sur clusters Hadoopd’être exécutées jusqu’à 100 foisplus vite en mémoire, 10 fois plusvite sur disque. Il vous permetd’écrire rapidement desapplications en Java, Scala ouPython et inclut un jeu de plus de80 opérateurs haut-niveau.
De plus, il est possible del’utiliser de façon interactivepour requêter les donnéesdepuis un shell. Enfin, en plusdes opérations de Map etReduce, Spark supporte lesrequêtes SQL et le streamingde données et propose desfonctionnalités de ML.
Analyse
Distibué
ImplémentationEn local
Implémentationdans le Cloud
Apache Spark: SQL, Streaming, ML, GraphX
http://www.infoq.com/fr/articles/apache-spark-introduction
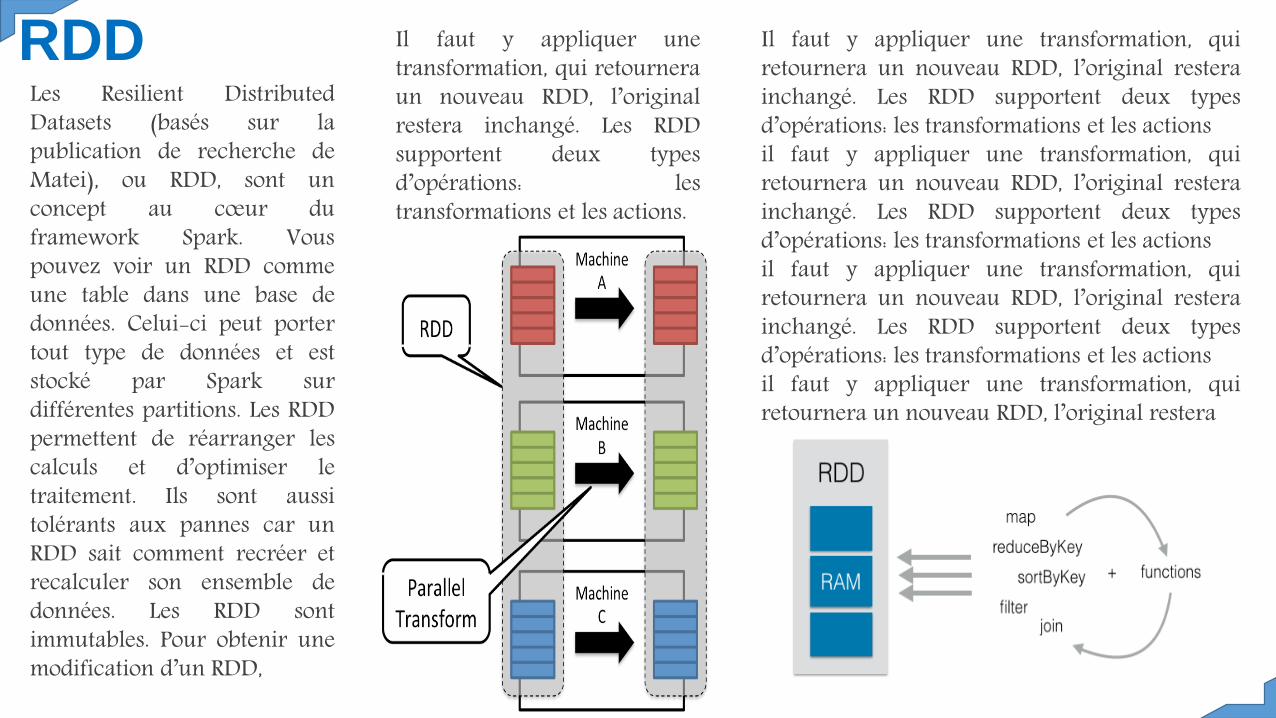
RDDLes Resilient DistributedDatasets (basés sur lapublication de recherche deMatei), ou RDD, sont unconcept au cœur duframework Spark. Vouspouvez voir un RDD commeune table dans une base dedonnées. Celui-ci peut portertout type de données et eststocké par Spark surdifférentes partitions. Les RDDpermettent de réarranger lescalculs et d’optimiser letraitement. Ils sont aussitolérants aux pannes car unRDD sait comment recréer etrecalculer son ensemble dedonnées. Les RDD sontimmutables. Pour obtenir unemodification d’un RDD,
Il faut y appliquer unetransformation, qui retourneraun nouveau RDD, l’originalrestera inchangé. Les RDDsupportent deux typesd’opérations: lestransformations et les actions.
Il faut y appliquer une transformation, quiretournera un nouveau RDD, l’original resterainchangé. Les RDD supportent deux typesd’opérations: les transformations et les actionsil faut y appliquer une transformation, quiretournera un nouveau RDD, l’original resterainchangé. Les RDD supportent deux typesd’opérations: les transformations et les actionsil faut y appliquer une transformation, quiretournera un nouveau RDD, l’original resterainchangé. Les RDD supportent deux typesd’opérations: les transformations et les actionsil faut y appliquer une transformation, quiretournera un nouveau RDD, l’original restera

Actions/TransformationsLes transformations : lestransformations ne retournentpas de valeur seule, ellesretournent un nouveau RDD.Rien n’est évalué lorsque l’onfait appel à une fonction detransformation, cette fonctionprend juste un RDD etretourne un nouveau RDD. Lesfonctions de transformationsont par exemple
Les actions : les actionsévaluent et retournent unenouvelle valeur. Au momentoù une fonction d’action estappelée sur un objet RDD,toutes les requêtes detraitement des données sontcalculées et le résultat estretourné. Les actions sont parexemple reduce, collect, count,first, take, countByKey
Transformations: Les deux transformations les pluscommunes que vous utiliserez probablement sont lamap() et filter(). La transformation prend dans unefonction et l'applique à chaque élément dans le RDDavec le résultat de la fonction étant la nouvelle valeurde chaque élément dans RDD résultant. Latransformation prend dans une fonction et rend unRDD qui a seulement les éléments qui passent lerésultat à la fonction.Actions: L'action la plus commune sur RDDS de baseque vous utiliserez probablement est reduce(), quiprend une fonction qui opère sur deux éléments dutype dans votre RDD et rend un nouvel élément dumême type. Un exemple simple d'une telle fonction est« + », que nous pouvons utiliser pour additionner notreRDD. Avec reduce(), nous pouvons facilementadditionner les éléments de notre RDD, compter lenombre d'éléments et exécuter d'autres typesd'accumulations. La fonction aggregate() nous libèrede la contrainte d'avoir le retour être le même type quele RDD sur lequel nous travaillons. Avec aggregate(),comme le fold(), nous fournissons une valeur zéroinitiale du type que nous voulons rendre.

Spark: cluster managerUn cluster Spark se compose d’un master et d’un ou plusieursworkers. Le cluster doit être démarré et rester actif pour pouvoirexécuter des applications.Le master a pour seul responsabilité la gestion du cluster et iln’exécute donc pas de code MapReduce. Les workers, en revanche,sont les exécuteurs. Ce sont eux qui apportent des ressources aucluster, à savoir de la mémoire et des cœurs de traitement.Pour exécuter un traitement sur un cluster Spark, il faut soumettreune application dont le traitement sera piloté par un driver. Deuxmodes d’exécution sont possibles :- mode client : le driver est créé sur la machine qui soumetl’application- mode cluster : le driver est créé à l’intérieur du cluster.Communication au sein du clusterLes workers établissent une communication bidirectionnelle avec lemaster : le worker se connecte au master pour ouvrir un canal dansun sens, puis le master se connecte au worker pour ouvrir un canaldans le sens inverse. Il est donc nécessaire que les différents nœudsdu cluster puissent se joindre correctement (résolution DNS…).La communication entre les nœuds s’effectue avec le frameworkAkka. C’est utile à savoir pour identifier les lignes de logs traitantdes échanges entre les nœuds.
Les nœuds du cluster (master comme workers)exposent par ailleurs une interface Web permettant desurveiller l’état du cluster ainsi que l’avancement destraitements. Chaque nœud ouvre donc deux ports :- un port pour la communication interne : port 7077par défaut pour le master, port aléatoire pour lesworkers.- un port pour l’interface Web : port 8080 par défautpour le master, port 8081 par défaut pour les workers.La création d’un cluster Spark permet d’exploiter lapuissance de traitement de plusieurs machines. Sa miseen place est relativement simple. Il faudra simplementprendre garde à rendre le master résilient en utilisantZooKeeper.Par ailleurs, l’exécution d’une application ne requiertpas de modification du code de traitement. Lacontrainte principale est de s’assurer que les donnéessont lues et écrites depuis/vers des systèmes distribués.

http://www.infoq.com/fr/articles/apache-spark-introduction

SparkSQL: SchemaRDDSpark travail avec des données structurées et semi-structurées. Lesdonnées Structurées sont n'importe quelles données qui ont unschéma c'est-à-dire un ensemble connu de champs(domaines) pourchaque rapport(record). Quand vous avez ce type de données, leSQL d'Étincelle le fait tant plus facile que plus efficace charger etquestionner. Particulièrement le SQL d'Étincelle fournit troiscapacités principales.• Il peut charger des données d'une variété de sources structurées:
JSON, Hive, etc…• Il vous laisse questionner les données utilisant le SQL, tant à
l'intérieur d'un programme Spark que de les outils externes quiunissent(connectent) au SQL d'Étincelle par des connecteurs debase de données standard (JDBC/ODBC), comme outils de veilleéconomique comme Tableau.
• Quand utilisé dans un programme Spark, le SparkSQL fournitl'intégration riche entre le SQL et Python / Java / Scala, y comprisla capacité de joindre RDDs et des tables de SQL, exposer lacoutume fonctionne dans le SQL et plus. Beaucoup d'emploissont plus faciles d'écrire l'utilisation de cette combinaison. Pourmettre en œuvre ces capacités, le SparkSQL fournit un typespécial de RDD appelé SchemaRDD.
Une étape de préparation des données est nécessairepour permettre à l’interpréteur SQL de connaître lesdonnées. Le concept de RDD est réutilisé et nécessitesimplement d’être enrichi d’un schéma. La classemanipulée devient un SchemaRDD. Deux optionsexistent pour construire un SchemaRDD :- En utilisant le type générique Row et en décrivant leschéma manuellement.- En utilisant des types personnalisés et en laissantSpark SQL découvrir le schéma par réflexion.
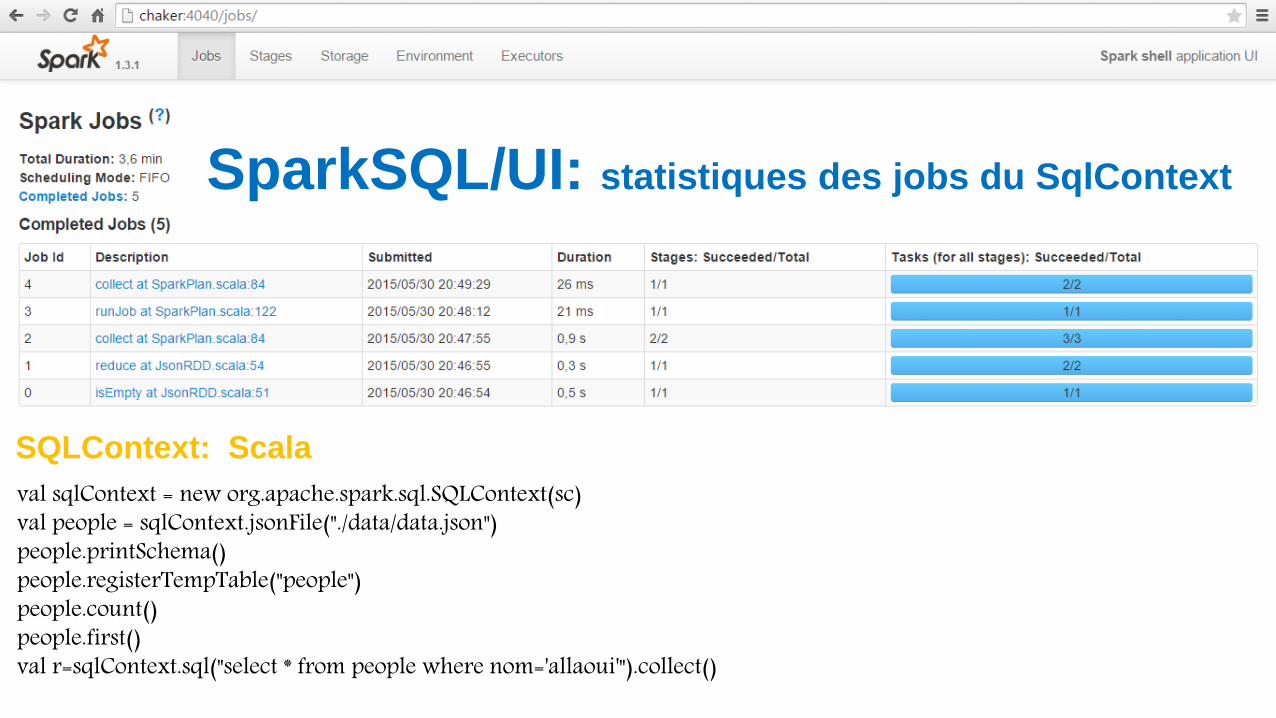
val sqlContext = new org.apache.spark.sql.SQLContext(sc)val people = sqlContext.jsonFile("./data/data.json")people.printSchema()people.registerTempTable("people")people.count()people.first()val r=sqlContext.sql("select * from people where nom='allaoui'").collect()
SparkSQL/UI: statistiques des jobs du SqlContext
SQLContext: Scala
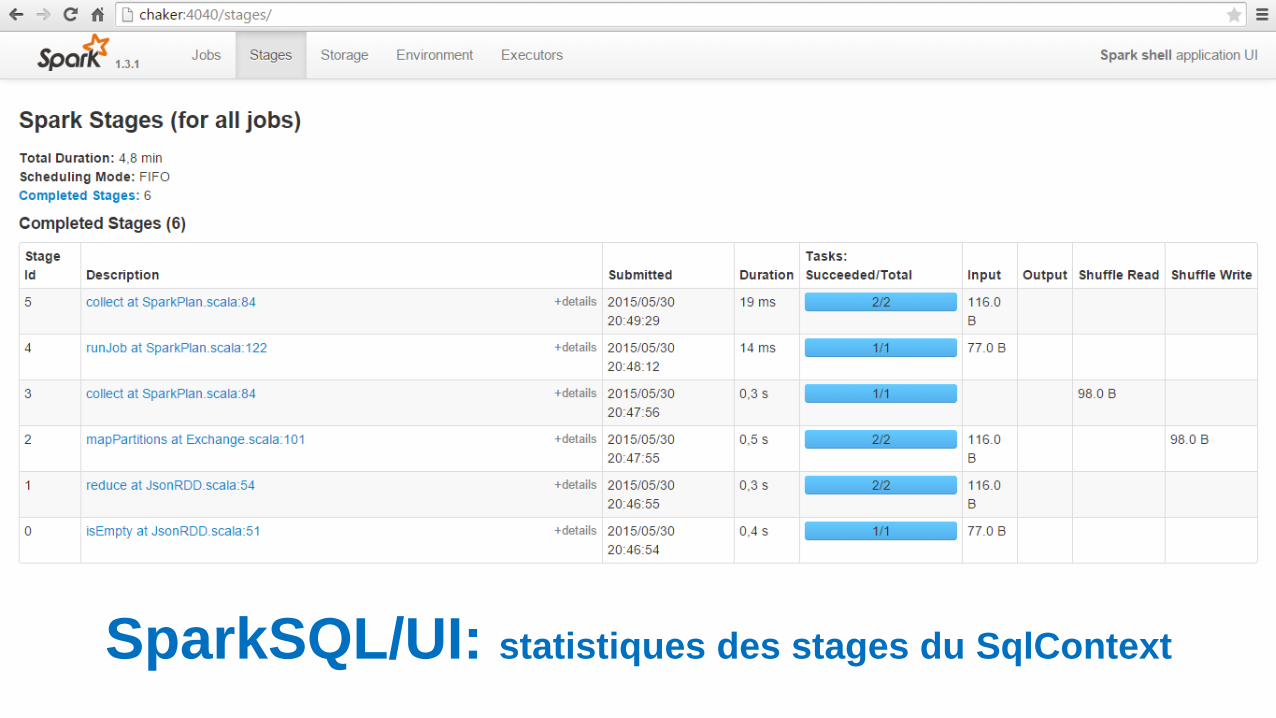
SparkSQL/UI: statistiques des stages du SqlContext

import org.apache.commons.lang.StringUtils;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import static com.datastax.spark.connector.japi.CassandraJavaUtil.*;import com.datastax.spark.connector.japi.CassandraRow;public class FirstRDD {public static void main(String[] args) {SparkConf conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1").setAppName("CassandraConnection").setMaster("local[*]");JavaSparkContext sc = new JavaSparkContext("local[*]", "test", conf);JavaRDD<String> cassandraRowsRDD = javaFunctions(sc).cassandraTable("java_api","products").map(new Function<CassandraRow, String>() {@Overridepublic String call(CassandraRow cassandraRow) throws Exception {return cassandraRow.toString();}});System.out.println("--------------- SELECT CASSANDRA ROWS ---------------");System.out.println("Data as CassandraRows: \n" + StringUtils.join(cassandraRowsRDD.toArray(), "\n"));}}
SparkSQL avec cassandraRDD
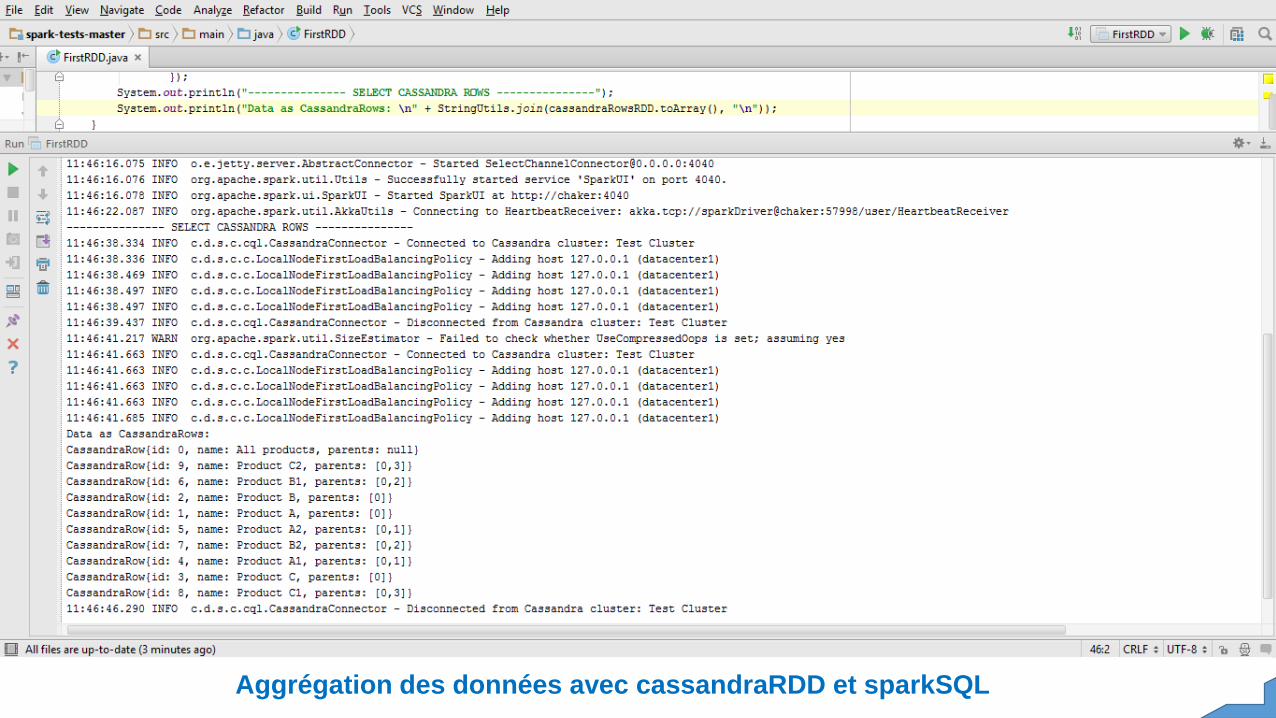
Aggrégation des données avec cassandraRDD et sparkSQL

SparkConf conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1").setAppName("SparkCassandra").setMaster("local[*]");JavaSparkContext sc = new JavaSparkContext("local[*]", "CassandraActionsSpark", conf);JavaRDD<String> cassandraRowsRDD = javaFunctions(sc).cassandraTable("network", "storage").map(new Function<CassandraRow, String>() {@Overridepublic String call(CassandraRow cassandraRow) throws Exception {return cassandraRow.toString();}});System.out.println("StringUtils.join(cassandraRowsRDD.toArray()));System.out.println(cassandraRowsRDD.first());System.out.println(cassandraRowsRDD.collect());System.out.println(cassandraRowsRDD.id());System.out.println(cassandraRowsRDD.countByValue());System.out.println(cassandraRowsRDD.name());System.out.println(cassandraRowsRDD.count());System.out.println(cassandraRowsRDD.partitions());
Spark Actions avec CassandraRowRDD
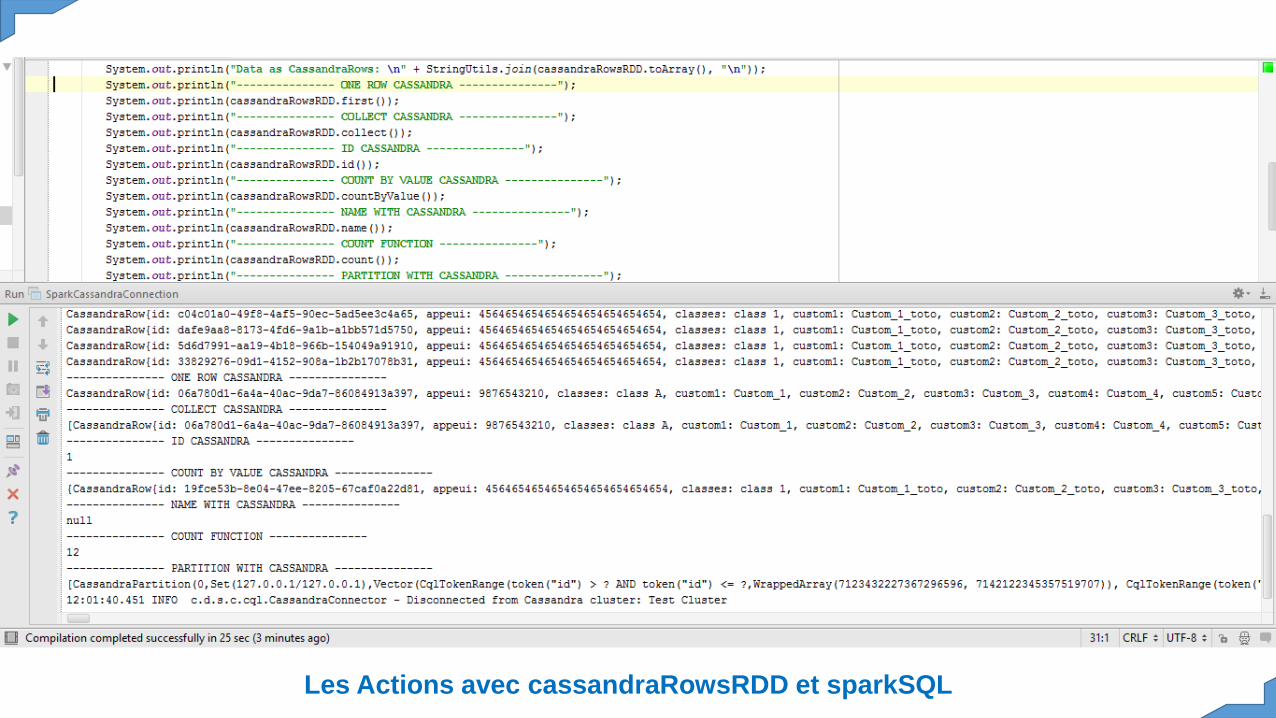
Les Actions avec cassandraRowsRDD et sparkSQL

package scala.exampleobject Person {var fisrstname:String="CHAKER"var lastname:String="ALLAOUI"def show(){println(" Firstname : "+ firstname+" Lastname : "+ lastname)}}def main(args: Array[String]){Person p=new Person()println("Show Infos")p.show()}}
SparkUI: Monitoring
val textFile = sc.textFile("DATA.txt")textFile.count()textFile.first()val linesWithSpark = textFile.filter(line => line.contains("Spark"))textFile.filter(line => line.contains("Spark")).count()
Il y a plusieurs façons de contrôler des applications Spark : dont SparkUIest le pilier de monitoring et instrumentation externe. ChaqueSparkContext lance un Web(tissu) UI, par défaut sur le port 4040, quiaffiche des informations utiles sur l'application. Ceci inclut :Une liste d'étapes de planificateur et tâchesUn résumé de tailles RDD et utilisation de mémoire(souvenir)Informations environnementales.Informations sur les exécuteurs courantsVous pouvez avoir accès à cette interface en ouvrant simplement« http://hostname:4040 » dans un navigateur Internet. Si des multiplesSparkContext qui s’exécutent sur le même hôte, ils seront disponibles enécoutent sur les ports successifs commençant par 4040, 4041, 4042
SparkContext: Scala
Notez que ces informations sont seulementdisponibles pour la durée de vie del'application par défaut. Pour voir le rendu deSparkUI et profiter de l’interface demonitoring, mettez « spark.eventLog.enabled »à « true ». Ceci configure Spark pourenregistrer les événements qui contiennentles informations nécessaires pour monitorerles évènnement de Spark dans SparkUI etvisualiser les données persistées.
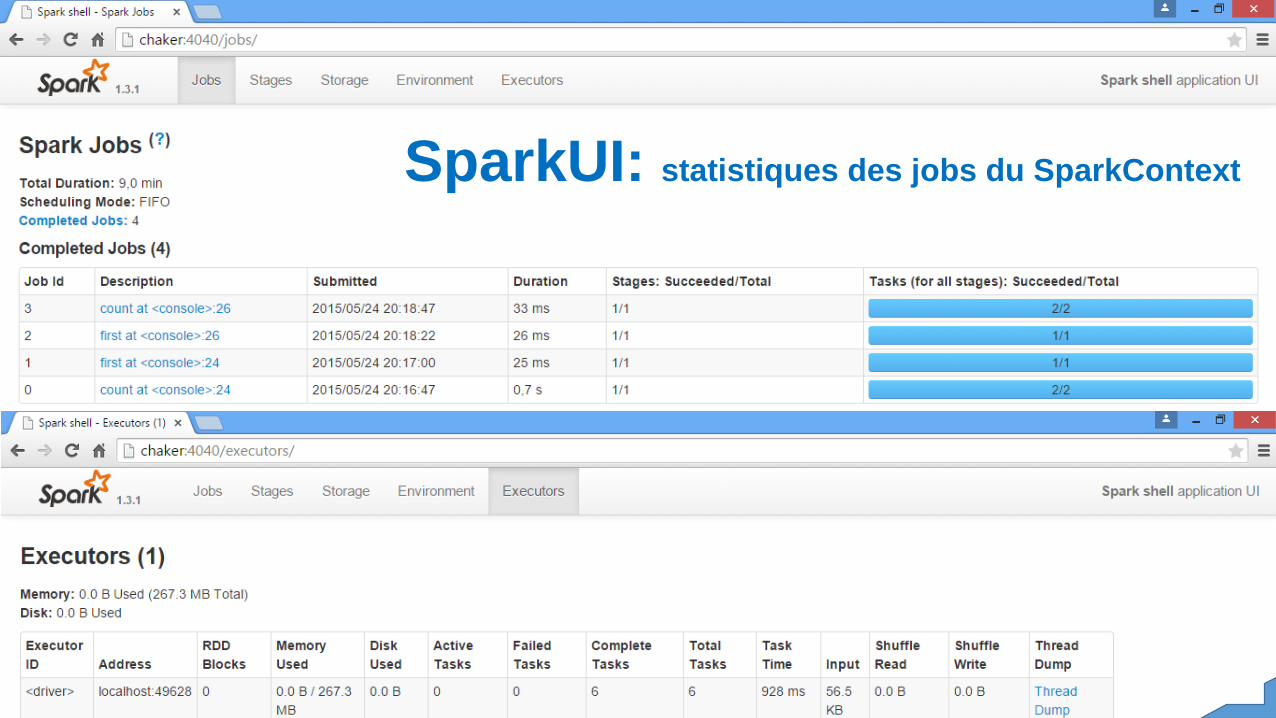
SparkUI: statistiques des jobs du SparkContext
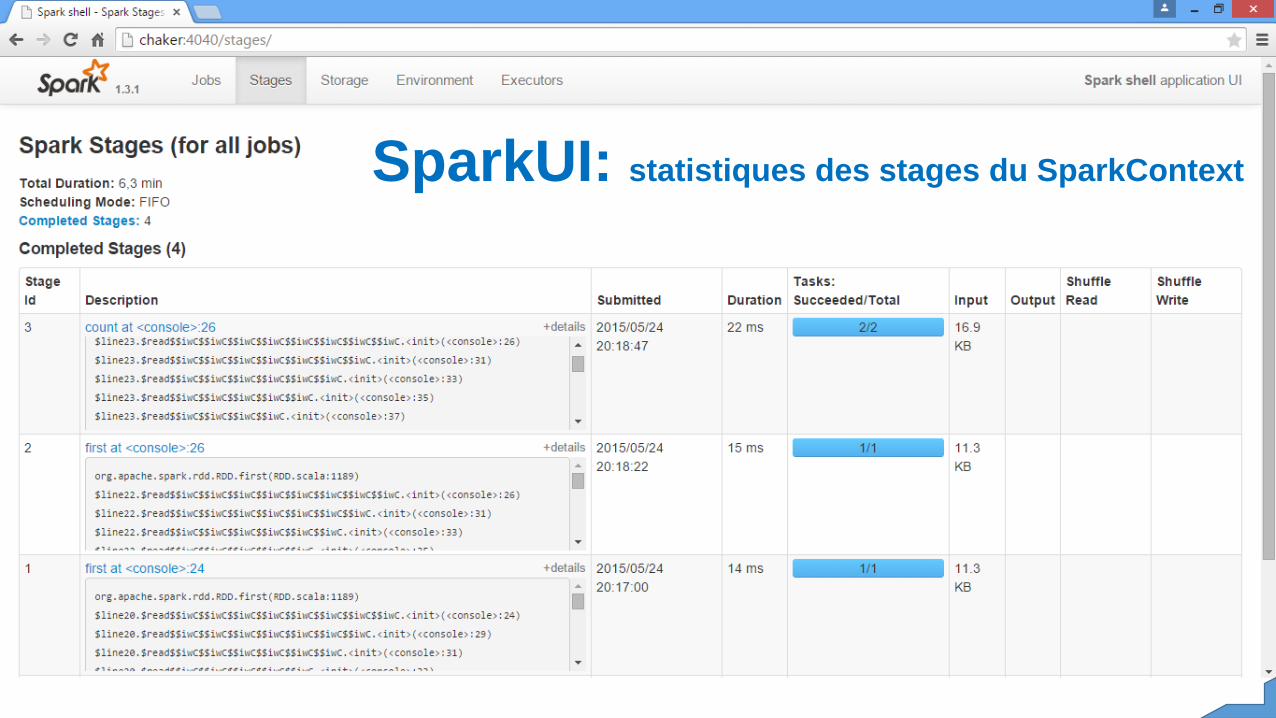
SparkUI: statistiques des stages du SparkContext

import java.lang.Mathval textFile = sc.textFile("DATA.txt")textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)wordCounts.collect()
MapReduce: map, key, value, reduceSpark offre une alternative à MapReduce car il exécute les jobs dans des micro-lots avec des intervalles de cinq secondes oumoins. Soit une sorte de fusion entre le batch et le temps réel ou presque. Il fournit également plus de stabilité que d'autresoutils de traitement temps réel, comme Twitter Storm, greffés sur Hadoop. Le logiciel peut être utilisé pour une grande variétéd'usages, comme une analyse permanente des données en temps réel, et, grâce à une bibliothèque de logiciels, des emplois plusnombreux pour les calculs en profondeur impliquant l'apprentissage automatique et un traitement graphique. Avec Spark, lesdéveloppeurs peuvent simplifier la complexité du code MapReduce et écrire des requêtes d'analyse de données en Java, Scalaou Python, en utilisant un ensemble de 80 routines de haut niveau. Avec cette version 1.0 de Spark, Apache propose désormaisune API stable, que les développeurs peuvent utiliser pour interagir avec leurs propres applications. Autre nouveauté de laversion 1.0, un composant Spark SQL pour accéder aux données structurées, permettant ainsi aux données d'être interrogéesaux côtés de données non structurées lors d'une opération analytique. Spark Apache est bien sûr compatible avec le système defichiers HDFS (Hadoop's Distributed File System), ainsi que d'autres composants tels que YARN (Yet Another ResourceNegotiator) et la base de données distribuée HBase. L'Université de Californie, et plus précisément le laboratoire AMP(Algorithms, Machines and People) de Berkeley est à l'origine du développement de Spark que la fondation Apache a adopté entant que projet en juin 2013. Des entreprises IT comme Cloudera, Pivotal, IBM, Intel et MapR ont déjà commencé à intégrerSpark dans leur distribution Hadoop.SparkContext MapReduce: Scala
http://www.lemondeinformatique.fr/actualites/lire-la-fondation-apache-reveille-hadoop-avec-spark-57639.html
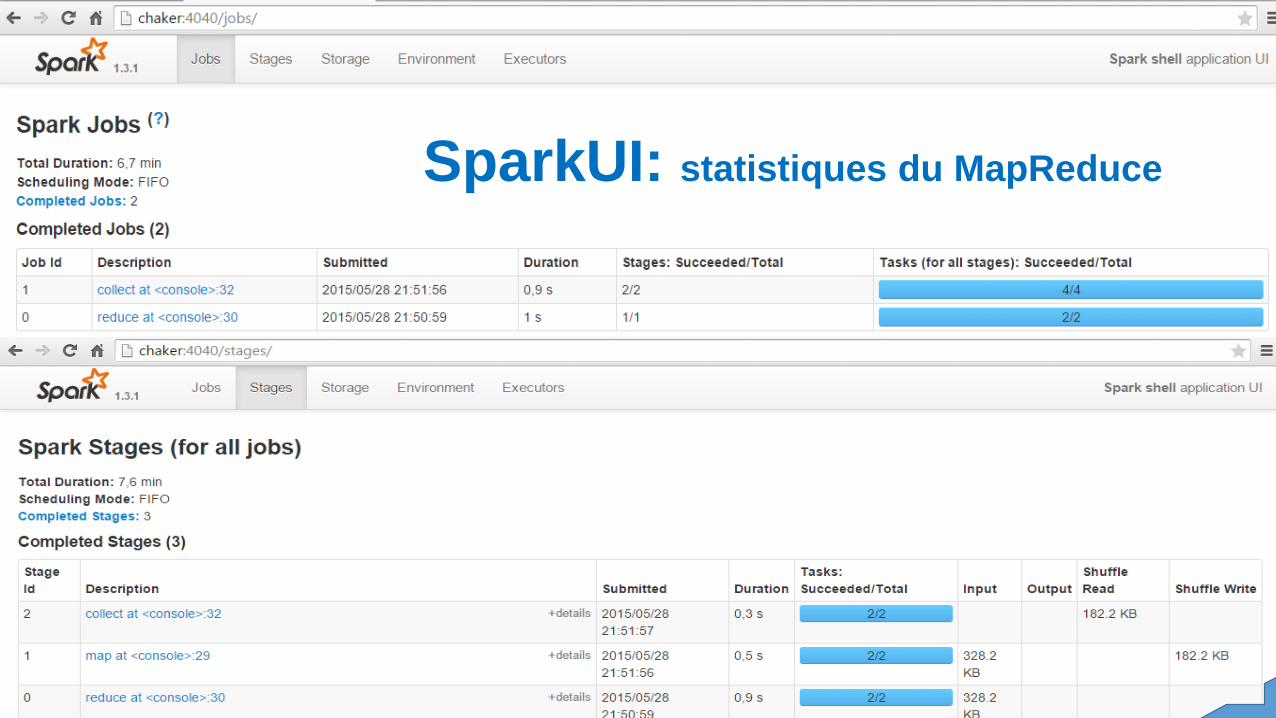
SparkUI: statistiques du MapReduce

Data-Driven DocumentsPrésentation graphique des données

Data-Driven Documents
Présentation
Big Data
Design
Riche en composants
La production exponentielle de données par les systèmesinformatiques est un fait bien établi. Cette réalité nourritle phénomène Big data. L’analyse statistique ou prédictivedoit faire appel à l’art de la représentation visuelle desdonnées afin de leur donner du sens et de mieux lescomprendre. La Visualisation des données ou Datavisualization est appelée à prendre une place grandissanteet ce, en proportion du volume de données produites parles systèmes d’information.A ce titre, nous sommes absolument convaincus que lalibrairie D3, objet de cet article, y prendra toute sa placeet ce, pas uniquement en raison de ses qualitésesthétiques. Créée par Mike Bostock, D3 est souventprésentée comme une librairie graphique alors que sonacronyme - D3 pour Data Driven Documents - montrequ’elle est d’abord, à l’instar de jQuery, une librairieJavaScript facilitant la manipulation d’un arbre DOM. D3implémente des routines permettant de charger desdonnées externes dont les formats JSON, XML, CSV outexte sont nativement supportés. Le développeur écrit lalogique de transformation des données en éléments HTMLou SVG afin d’en avoir une représentation.
Ainsi, la représentation peut tout aussi bienprendre la forme d’un tableau (élémentsHTML) que d’une courbe (éléments SVG). D3permet donc de produire des DocumentsOrientés Données. Dont plusieurs modèlessont disponibles sur le site www.d3js.org.
Présentation en DENDOGRAM du JSON

D3.js (D-D-D pour Data-Driven Documents) est unebibliothèque graphiqueJavaScript qui permetl'affichage de donnéesnumériques sous une formegraphique et dynamique. Ils'agit d'un outil importantpour la conformation auxnormes W3C qui utilise lestechnologies courantes SVG,JavaScript et CSS pour lavisualisation de données. D3est le successeur officiel duprécédent FrameworkProtovis1. Contrairement auxautres bibliothèques, celle-cipermet un plus ample contrôledu résultat visuel final2. Sondéveloppement se popularisaen 20113, à la sortie de laversion 2.00 en août 2014. Enaoût 2012, la bibliothèqueavait atteint la version 2.10.05.
Intégrée dans une page webHTML, la bibliothèqueJavaScript D3.js utilise desfonctions préconstruites deJavaScript pour sélectionnerdes éléments, créer des objetsSVG, les styliser, ou y ajouterdes transitions, des effetsdynamiques ou des infobulles.Ces objets peuvent aussi êtrestylisés à grande échelle àl'aide du célèbre langage CSS.De plus, de grandes bases dedonnées avec des valeursassociées peuvent alimenter lesfonctions JavaScript pourgénérer des documentsgraphiques conditionnels et/ouriches. Ces documents sont leplus souvent des graphiques.Les bases de données peuventêtre sous de nombreuxformats, le plus souvent JSON,CSV, GeoJSON.
Ainsi, l'analyse des données est le processus qui consisteà examiner et à interpréter des données afin d'élaborerdes réponses à des questions. Les principales étapes duprocessus d'analyse consistent à cerner les sujetsd'analyse, à déterminer la disponibilité de donnéesappropriées, à décider des méthodes qu'il y a lieud'utiliser pour répondre aux questions d'intérêt, àappliquer les méthodes et à évaluer, résumer etcommuniquer les résultats.
Représentative graphique du flux de données

Possibilités de représentations graphiques avec D3

SMART DATALa force d’une décision

SMART DataSMART DATA
Présentation
Design
Support aux décisions
Intélligente
Aujourd’hui, le Big Data est pour les responsables marketing à la fois une incroyable source de données surles consommateurs et, dans le même temps, un incroyable challenge à relever. Les stratégies de marketing «digitales » prennent désormais en compte textes, conversations, comportements, etc. dans un environnementou le volume de ces informations à traiter croissent de façon exponentielle. Il serait donc totalementillusoire de s’imaginer gérer l’intégralité de ces données. et L’enjeu du marketing digital est donc désormaisla gestion intelligente du Big Data afin d’identifier, de classer et d’exploiter les informations consommateursignificatives permettant aux professionnels du marketing de mettre en place leurs stratégies.Le Smart Data est le processus qui permet de passer des données brutes à des informations ultra qualifiéessur chacun des consommateurs. L’objectif est d’avoir une vision à 360° des clients, reposant sur desinformations collectées à travers des mécanismes marketing adaptés, qu’ils soient classiques ou innovants(jeux concours, réseaux sociaux, achats lors des passages en caisse, utilisation des applications mobiles,géolocalisation, etc.). Pour y parvenir, les entreprises se dotent de plates-formes marketing cross-canalcapables de stocker et d’analyser chaque information afin de « pousser » le bon message au meilleurmoment pour chaque consommateur. L’objectif final est non seulement de séduire de nouveaux clients maissurtout d’augmenter leur satisfaction et leur fidélité en anticipant leurs éventuels besoins.Cela signifie, entre autres, instaurer un véritable dialogue avec chacun de ses clients et mesurerefficacement les performances marketing et commerciales de la marque.Cibler de manière fine selon plusieurs critères tout en respectant les préférences clients, gérer lapersonnalisation, la pertinence et la cohérence des messages cross canal délivrés par e-mail, courrier, webet call center sont devenus des impératifs que le Smart Data permet enfin de tacler de façon efficace.Oublions le "Big" et intéressons-nous sur le "Smart" car la pertinence des stratégies marketing dépendratoujours de la qualité des données clients.
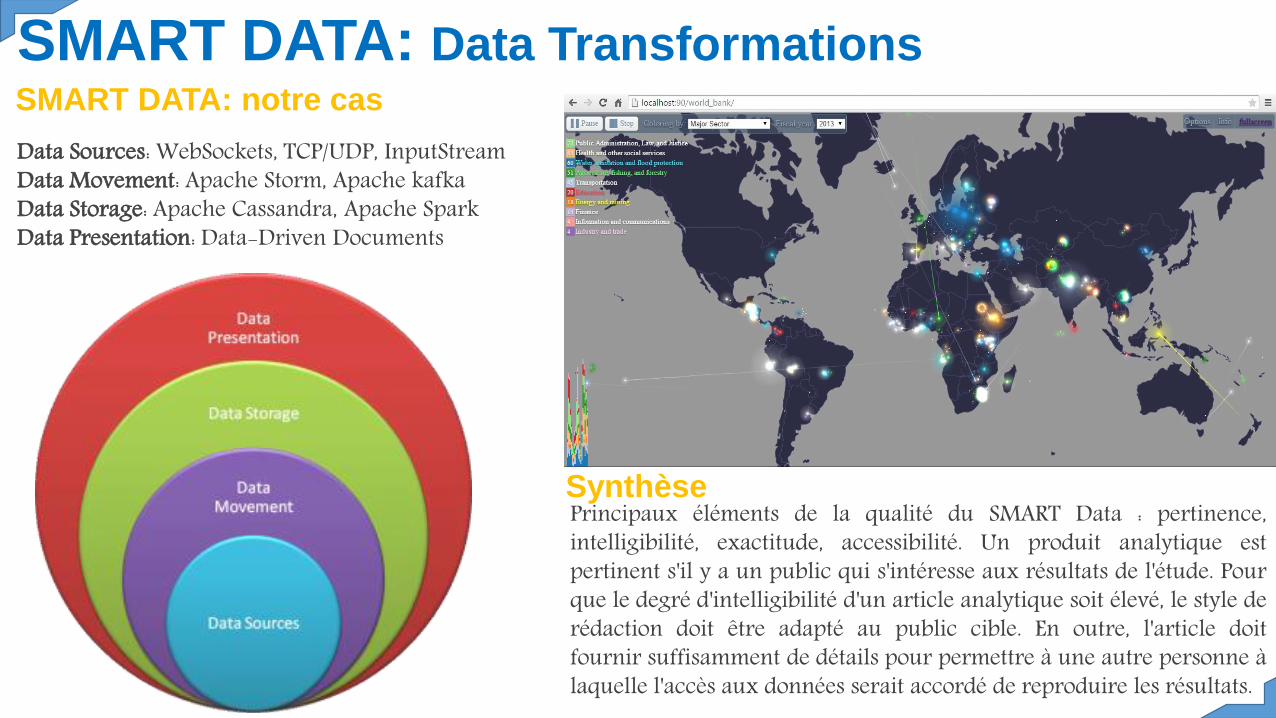
SMART DATA: Data Transformations
Data Sources: WebSockets, TCP/UDP, InputStreamData Movement: Apache Storm, Apache kafkaData Storage: Apache Cassandra, Apache SparkData Presentation: Data-Driven Documents
Principaux éléments de la qualité du SMART Data : pertinence,intelligibilité, exactitude, accessibilité. Un produit analytique estpertinent s'il y a un public qui s'intéresse aux résultats de l'étude. Pourque le degré d'intelligibilité d'un article analytique soit élevé, le style derédaction doit être adapté au public cible. En outre, l'article doitfournir suffisamment de détails pour permettre à une autre personne àlaquelle l'accès aux données serait accordé de reproduire les résultats.
SMART DATA: notre cas
Synthèse
BIBusiness Intelligence

Mots clés
WebSockets – HTTP – TCP/UDP – InputStream – TwitterStream – WebServices – JSON – Data - Big Data – SMART DATA -Process Big Data – Business Iintelligence – Data Storage – Data Sources – Data Presentation – Data Mining - DataExploration - Apache Storm – Apache Zookeeper – Apache Kafka – Apache Cassandra – Apache Spark – SparkSQL –SparkUI – D3 - Data-Driven Documents – Storm cluster – StormUI – Storm Topology – Zookeeper cluster – Distrubutedserver – Topics – Message – Queue – Data Transmit – OpsCenter – EasyCassandra- Keyspace – Column – CQLSH -CassandraColumn – CassandraRow- Cassandra cluster – Storage Data – Aggregation – RDD – SchemaRDD - Spark Actions– Spark Transformations – Spark cluster - MapReduce – Jobs – Stages – Excutors – Data Transformations –SMART – Apache

Liens utiles
Apache Stormhttps://storm.apache.org
Apache Zookeeperhttps://zookeeper.apache.org
Apache Kafkahttp://kafka.apache.org/
Apache Cassandra
https://spark.apache.org
Data-Driven Documentshttp://d3js.org/
Apache Spark
http://cassandra.apache.org

Idea Create Refine
Contact
Visitez mon profil sur LinkedIn
Visitez mon site web
http://tn.linkedin.com/in/chakerallaoui
http://allaoui-chaker.github.io





























