Embed Size (px)
Citation preview

Building Big Data Applications with
Serverless Architectures
AWS Monthly Webinar Series
June 15, 2017
Allan MacInnis
Solutions Architect, AWS

Agenda
What’s Serverless Real-Time Data Processing?
Serverless Processing of Real-Time Streaming Data
Serverless Streaming ETL & Analytics
Demo: Streaming ETL
Serverless Data Processing with Distributed Computing

What’s Serverless Real-Time
Data Processing?

AWS Lambda
Efficient performance at scale Easy to author, deploy,
maintain, secure & manage. Focus on business logic
to build back-end services that perform at scale.
Bring Your Own Code: Stateless, event-driven code
with native support for Node.js, Java, Python and C#
languages.
No Infrastructure to manage: Compute without
managing infrastructure like Amazon EC2 instances
and Auto Scaling groups.
Cost-effective: Automatically matches capacity to
request rate. Compute cost 100 ms increments.
Triggered by events: Direct Sync & Async API calls,
AWS service integrations, and 3rd party triggers.

Amazon
S3
Amazon
DynamoDB
Amazon
Kinesis
AWS
CloudFormation
AWS
CloudTrail
Amazon
CloudWatch
Amazon
Cognito
Amazon
SNSAmazon
SES
Cron
events
DATA STORES ENDPOINTS
CONFIGURATION REPOSITORIES EVENT/MESSAGE SERVICES
Lambda Event Sources
… and many more!
AWS
CodeCommit
Amazon
API Gateway
Amazon
AlexaAWS
IoT
AWS Step
Functions

Serverless Real-Time Data Processing Is..
Capture Data
Streams
IoT Data
Financial
Data
Log Data
No servers
to provision
or manage
EVENT SOURCE
Node.js
Python
Java
C#
Process Data
Streams
FUNCTION
Clickstream
Data
Output
Data
DATABASE
CLOUD
SERVICES

Amazon
DynamoDB
Amazon
Kinesis
Amazon
S3
Amazon
SNS
ASYNCHRONOUS PUSH MODEL
STREAM PULL MODEL
Lambda Real-Time Event Sources
Amazon
Alexa
AWS
IoT
SYNCHRONOUS PUSH MODEL
Mapping owned by Event Source
Mapping owned by Lambda
Invokes Lambda via Event Source API
Lambda function invokes when new
records found on stream
Resource-based policy permissions
Lambda Execution role policy permissions
Concurrent executions
Sync invocation
Async Invocation
Sync invocation
Lambda polls the streams
HOW IT WORKS

Serverless Processing of
Real-Time Streaming Data

Amazon Kinesis
Real-Time: Collect real-time data streams and
promptly respond to key business events and
operational triggers. Real-time latencies.
Easy to use: Focus on quickly launching data
streaming applications instead of managing
infrastructure.
Amazon Kinesis Offering: Managed services for
streaming data ingestion and processing.
• Amazon Kinesis Streams: Build applications
that process or analyze streaming data.
• Amazon Kinesis Firehose: Load streaming
data into Amazon S3, Amazon Redshift, and
Amazon Elasticsearch Service.
• Amazon Kinesis Analytics: Analyze data
streams using SQL queries.

Processing Real-Time Streams: Lambda + Amazon Kinesis
Streaming data sent to Amazon
Kinesis and stored in shards
Multiple Lambda functions can be
triggered to process same Amazon
Kinesis stream for “fan out”
Lambda can process data and store
results ex. to DynamoDB, S3
Lambda can aggregate data to
services like Amazon Elasticsearch
Service for analytics
Lambda sends event data and
function info to Amazon CloudWatch
for capturing metrics and monitoring
Amazon
Kinesis
AWS
Lambda
Amazon
CloudWatch
Amazn
DynamoDB
AWS
Lambda
Amazon
Elasticsearch Service
Amazon
S3

Processing Streams: Set Up Amazon Kinesis Stream
Streams
Made up of Shards
Each Shard ingests/reads data up to 1 MB/sec
Each Shard emits/writes data up to 2 MB/sec
Each shard supports 5 reads/sec
DataAll data is stored for 24 hours, configurable to 7 days
Make sure partition key distribution is even to optimize parallel throughput
Partition key used to distribute PUTs across shards, choose key with more groups than
shards
Best Practice
Determine an initial size/shards to plan for expected maximum demand
Leverage “Help me decide how many shards I need” option in Console
Use formula for Number Of Shards:
max(incoming_write_bandwidth_in_KB/1000, outgoing_read_bandwidth_in_KB / 2000)

Processing Streams: Create Lambda functionsMemory
CPU allocation proportional to the memory configured
Increasing memory makes your code execute faster (if CPU bound)
Increasing memory allows for larger record sizes processed
Timeout
Increasing timeout allows for longer functions, but longer wait in case of errors
Permission model
Execution role defined for Lambda must have permission to access the stream
Retries
With Amazon Kinesis, Lambda retries until the data expires
(24 hours)
Best Practice
Write Lambda function code to be stateless

Processing Streams: Configure Event Source
Amazon Kinesis mapped as event source in Lambda
Batch size
Max number of records that Lambda will send to one invocation
Not equivalent to effective batch size
Effective batch size is every 250 ms – Calculated as:
MIN(records available, batch size, 6MB)
Increasing batch size allows fewer Lambda function invocations with more
data processed per function
Best Practices
Set to “Trim Horizon” for reading from start of
stream (all data)
Set to “Latest” for reading most recent data (LIFO) (latest data)
Processing streams: How It Works
PollingConcurrent polling and processing per shardLambda polls every 250 ms if no records foundWill grab as much data as possible in one GetRecords call (Batch)
BatchingBatches are passed for invocation to Lambda throughfunction parameters
Batch size may impact duration if the Lambda functiontakes longer to process more records
Sub batch in memory for invocation payload
Synchronous invocationBatches invoked as synchronous RequestResponse typeLambda honors Amazon Kinesis at least once semanticsEach shard blocks in order of synchronous invocation
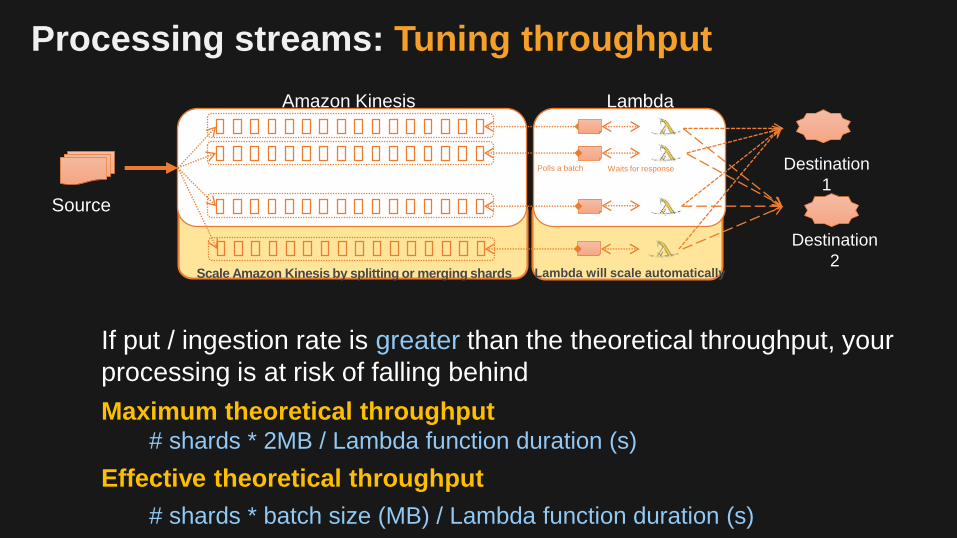
Processing streams: Tuning throughput
If put / ingestion rate is greater than the theoretical throughput, your
processing is at risk of falling behind
Maximum theoretical throughput # shards * 2MB / Lambda function duration (s)
Effective theoretical throughput
# shards * batch size (MB) / Lambda function duration (s)
… …Source
Amazon Kinesis
Destination
1
Lambda
Destination
2
FunctionsShards
Lambda will scale automaticallyScale Amazon Kinesis by splitting or merging shards
Waits for responsePolls a batch

Processing streams: Tuning Throughput w/ Retries
Retries
Will retry on execution failures until the record is expired
Throttles and errors impacts duration and directly impacts throughput
Best Practice
Retry with exponential backoff of up to 60s
Effective theoretical throughput with retries
( # shards * batch size (MB) ) / ( function duration (s) * retries until expiry)
… …Source
Amazon Kinesis
Destination
1
Lambda
Destination
2
FunctionsShards
Lambda will scale automaticallyScale Amazon Kinesis by splitting or merging shards
Receives errorPolls a batch
Receives error
Receives success

Processing streams: Common observations
Effective batch size may be less than configured during low throughput
Effective batch size will increase during higher throughput
Increased Lambda duration -> decreased # of invokes and GetRecord calls
Too many consumers of your stream may compete with Amazon Kinesis read
limits and induce ReadProvisionedThroughputExceeded errors and metrics
Amazon
Kinesis
AWS
Lambda

Processing streams: Monitoring with Cloudwatch
• GetRecords: (effective throughput)
• PutRecord : bytes, latency, records, etc
• GetRecords.IteratorAgeMilliseconds: how old your
last processed records were
Monitoring Amazon Kinesis Streams
Monitoring Lambda functions• Invocation count: Time function invoked
• Duration: Execution/processing time
• Error count: Number of Errors
• Throttle count: Number of time function throttled
• Iterator Age: Time elapsed from batch received &
final record written to stream
• Review All Metrics
• Make Custom logs
• View RAM consumed
• Search for log events
Debugging
Serverless Streaming ETL

Streaming ETL: What is it?
Traditional ETL
• Batch-oriented
• Servers run scheduled jobs
• Latent
Streaming ETL
• Process data as it gets created
• Runs continuously
• Can produce real-time results
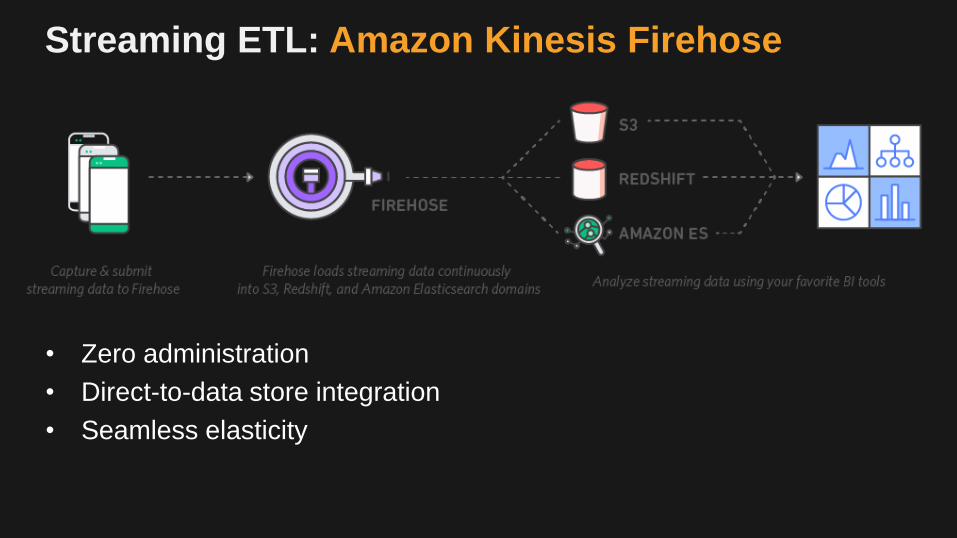
Streaming ETL: Amazon Kinesis Firehose
• Zero administration
• Direct-to-data store integration
• Seamless elasticity

Streaming ETL: Firehose Data Transformation
• Firehose buffers up to 3MB of ingested data
• When buffer is full, automatically invokes Lambda function,
passing array of records to be processed
• Lambda function processes and returns array of transformed
records, with status of each record
• Transformed records are saved to configured destination
[{"
"recordId": "1234",
"data": "encoded-data"
},
{
"recordId": "1235",
"data": "encoded-data"
}
]
[{
"recordId": "1234",
"result": "Ok"
"data": "encoded-data"
},
{
"recordId": "1235",
"result": "Dropped"
"data": "encoded-data"
}
]

Streaming ETL: Firehose delivery architecture
with transformations
S3 bucket
source records
data source
source records
Amazon Elasticsearch
ServiceFirehose
delivery stream
transformed
records
delivery failure
Data transformation
function
transformation failure
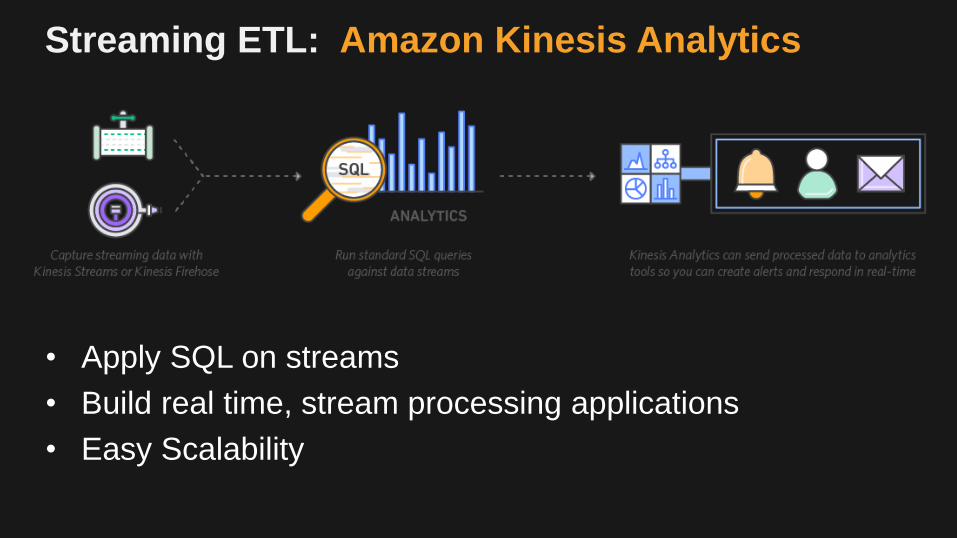
Streaming ETL: Amazon Kinesis Analytics
• Apply SQL on streams
• Build real time, stream processing applications
• Easy Scalability

Streaming Analytics: Kinesis Analytics
Easily write SQL code to process
streaming data
Connect to streaming source
Continuously deliver SQL results

Connect to streaming source
• Single streaming source, Kinesis Firehose or Streams
• Single reference source up to 1 GB from S3
• Input formats include JSON, CSV, unstructured text (log
files)
• Each input exposed to has a schema
• Schema is inferred but you can edit
• Deep nesting (2+ levels) and multiple even types
supported
• Best practice for formats not supported: pre-process
data using an AWS Lambda function for transformation
Streaming Analytics: Kinesis Analytics

Write SQL code
• Build streaming applications with one to many SQL
statements
• Extensions to the SQL standard to work seamlessly with
streaming data (STREAM, Windows, ROWTIME)
• Robust SQL support including large number of functions
including:
• Simple mathematical operators (AVG, STDEV, etc.)
• String manipulations (SUBSTRING, POSITION)
• Advanced analytics (random sampling, anomaly detection)
• Support for at-least-once processing semantics
Streaming Analytics: Kinesis Analytics

Example SQL code
Streaming Analytics: Kinesis Analytics
SELECT STREAM
DEVICE_ID,
MAX(MEASURED_TEMP) AS HIGH_TEMP
FROM SOURCE_SQL_STREAM
GROUP BY
DEVICE_ID,
STEP(SOURCE_SQL_STREAM.ROWTIME BY INTERVAL '15'
MINUTE);

Continuously deliver SQL results
• Up to three outputs, including S3, Redshift, and
Elasticsearch (through Kinesis Firehose), Kinesis Streams.
• Firehose allows Kinesis Analytics to separates of processing and
delivery data
• Delivery speed will be heavily dependent upon your SQL queries (i.e.
simple ETL versus 10 minute aggregations)
• Output formats include JSON, CSV, variable column (TSV,
pipe-delimited)
• Best practice for destinations not supported: emit data to a
stream and use AWS Lambda for delivery
Streaming Analytics: Kinesis Analytics

Real-time analytical patterns
• Pre-processing: filtering, transformations
• Basic Analytics: Simple counts, aggregates over
windows
• Advanced Analytics: Detecting anomalies, event
correlation
• Post-processing: Alerting, triggering, final filters
Streaming Analytics: Kinesis Analytics

Amazon S3
IngestStreaming
ETLPersist Analyze
AWS
Lambda
0 msec seconds < 5 minutes
Amazon
Kinesis
Firehose
Amazon
Redshift
Amazon
Elasticsearch
Amazon
Athena
Amazon
Kinesis
Analytics
Amazon
Redshift
SpectrumAmazon
Kinesis
Streams
Streaming Analytics: Big Picture

Data’s destination is S3, Redshift, or ES?
• Consider Kinesis Firehose. Transform streaming data with Lambda
before it gets delivered.
Require stateful processing, such as aggregations over a time
period?
• Consider Kinesis Analytics. Persist your aggregated data using Kinesis
Streams with Lambda, or Kinesis Firehose.
Require stateless processing, with varied destinations?
• Consider Kinesis Streams with Lambda.
Serverless Stream Processing: Which Approach?
Serverless Data Processing with
Distributed Computing
10101101
11001010
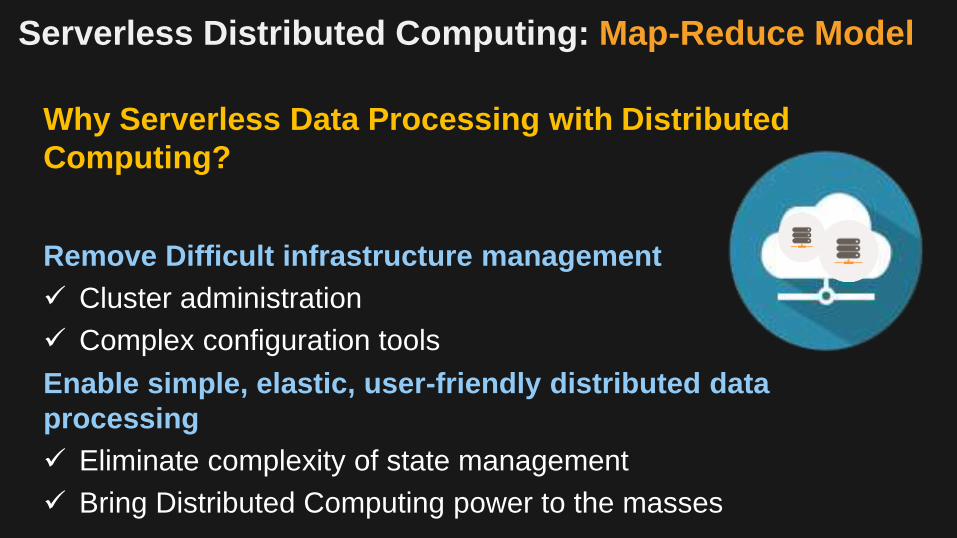
Serverless Distributed Computing: Map-Reduce Model
Why Serverless Data Processing with Distributed
Computing?
Remove Difficult infrastructure management
Cluster administration
Complex configuration tools
Enable simple, elastic, user-friendly distributed data
processing
Eliminate complexity of state management
Bring Distributed Computing power to the masses

Serverless Distributed Computing: Map-Reduce Model
Why Serverless Data Processing with Distributed
Computing?
Eliminate utilization concerns
Makes code simpler by removes complexities of multi-
threading processing to optimize server usage
Cost-effective option to run ad hoc MapReduce jobs
Easier, automatic horizontal scaling
Provide ability to process scientific and analytics
applications

Serverless Distributed Computing: MapReduce
Input Bucket
1
2
Driver
job state
Mapper Functions
map phase
S3
event
source
mapper
output3 Coordinator
4
Reducer step 1
reducer output
5
recursively
create
n‘th reducer
step
ResultFinal Reducer
reduce phase
6

Serverless Distributed Computing: PyWren
PyWren Prototype Developed at University of California, Berkeley
Uses Python with AWS Lambda stateless functions for large scale data
analytics
Achieved @ 30-40 MB/s write and read performance per-core to S3
object store
Scaled to 60-80 GB/s across 2800 simultaneous functions

Serverless Distributed Computing: Benchmark
Using Amazon MapReduce Reference Architecture Framework
with Lambda
Dataset
Queries:
Scan query (90 M Rows, 6.36 GB of data)
Select query on Page Rankings
Aggregation query on UserVisits ( 775M rows, ~127GB of
data)
Rankings
(rows)
Rankings
(bytes)
UserVisits
(rows)
UserVisits
(bytes)
Documents
(bytes)
90 Million 6.38 GB 775 Million 126.8 GB 136.9 GB

Serverless Distributed Computing: Benchmark
Using Amazon MapReduce Reference Architecture Framework
with Lambda
Subset of the Amplab benchmark ran to compare with other data
processing frameworks
Performance Benchmarks: Execution time for each workload in seconds
TECHNOLOGY SCAN 1A SCAN 1B AGGREGATE 2A
Amazon Redshift (HDD) 2.49 2.61 25.46
Serverless MapReduce 39 47 200
Impala - Disk - 1.2.3 12.015 12.015 113.72
Impala - Mem - 1.2.3 2.17 3.01 84.35
Shark - Disk - 0.8.1 6.6 7 151.4
Shark - Mem - 0.8.1 1.7 1.8 83.7
Hive - 0.12 YARN 50.49 59.93 730.62
Tez - 0.2.0 28.22 36.35 377.48

Demo: Streaming ETL

Requirements and Architecture
• BI team needs to run ad-hoc queries against all order data.
• Real-time dashboard needs to display top 20 products sold
in the past 5 minutes.
Streaming ETL Demo: E-commerce Events
Amazon Kinesis
Firehose
Amazon Kinesis
Streams
Amazon Kinesis
Analytics
Amazon
Redshift
AWS LambdaAmazon
DynamoDB
E-commerce
Orders
BI
Users
Reports
Dashboards

Next Steps

Serverless Big Data Applications: Next steps
Learn more about AWS Serverless at https://aws.amazon.com/serverless
Explore the AWS Lambda Reference Architecture on GitHub:
Real-Time Streaming:
https://github.com/awslabs/lambda-refarch-
streamprocessing
Distributed Computing Reference Architecture
(serverless MapReduce)
https://github.com/awslabs/lambda-refarch-mapreduce

Create an Amazon Kinesis stream or Kinesis Firehose delivery
stream. Visit the Amazon Kinesis Console and configure a stream
to receive data.
Send test data to your stream using the Amazon Kinesis Data
Generator.
Create & test a Lambda function to process streams from Amazon
Kinesis by visiting Lambda console. First 1M requests each month
are on us!
Serverless Big Data Applications: Next steps

Read the Developer Guide and try the Lambda and Amazon
Kinesis Tutorial:
http://docs.aws.amazon.com/lambda/latest/dg/with-
kinesis.html
Send questions, comments, feedback to the AWS Lambda Forums
Serverless Big Data Applications: Next steps

Thank You!





























