Embed Size (px)
Citation preview

OCTOBER 11-‐14, 2016 • BOSTON, MA

Anyone can build a Recsys w/ Solr! Doug Turnbull
Relevance Consultant, OpenSource ConnecIons

I’m now available in book form!
https://www.manning.com/books/relevant-search Discount code: relsearch (38% off)
http://opensourceconnections.com/about-us/doug-turnbull/
Me The company...

field Body term laser doc 2
<metadata> doc 4
<metadata> term light doc 2 <metadata> term lightsaber doc 0
How do search engines work? The answer can be found in your textbook…
OpenSource Connections
Book Index: • Topics -> page no • Very efficient tool – compare to
scanning the whole book! Lucene uses an index: • Tokens => document ids: laser => [2, 4]
light => [2, 5] lightsaber => [0, 1, 5, 7]
What's the point?
OpenSource Connections
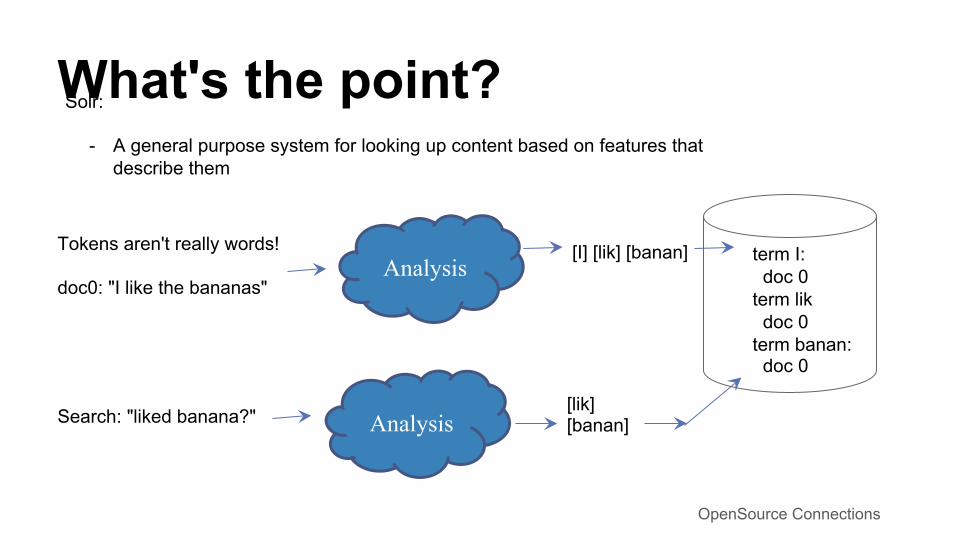
Solr:
- A general purpose system for looking up content based on features that describe them
Tokens aren't really words! doc0: "I like the bananas"
Analysis
Analysis
term I: doc 0 term lik doc 0 term banan: doc 0
[lik] [banan] Search: "liked banana?"
[I] [lik] [banan]
TF*IDF -- measuring feature weight
OpenSource Connections
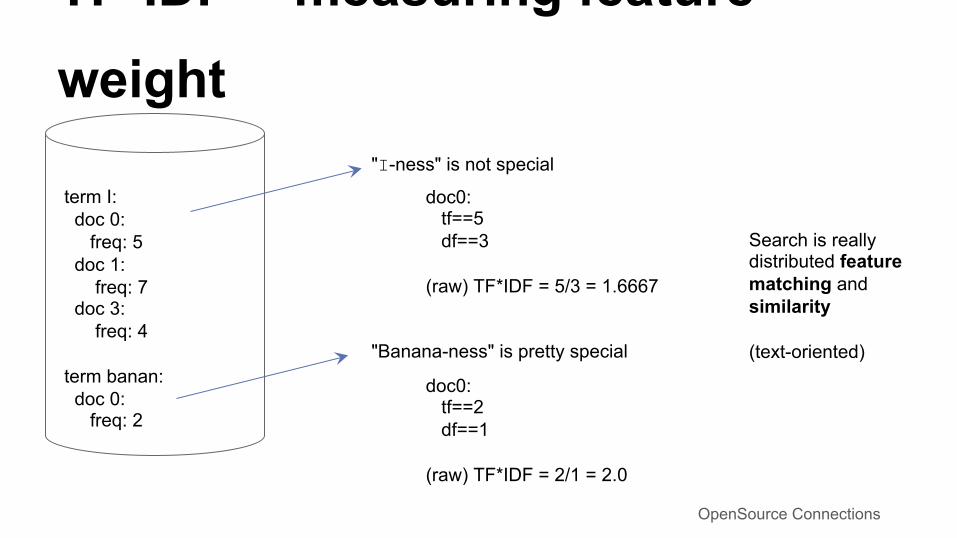
term I: doc 0: freq: 5 doc 1: freq: 7 doc 3: freq: 4 term banan: doc 0: freq: 2
"Banana-ness" is pretty special
"I-ness" is not special
doc0: tf==5 df==3 (raw) TF*IDF = 5/3 = 1.6667
doc0: tf==2 df==1 (raw) TF*IDF = 2/1 = 2.0
Search is really distributed feature matching and similarity (text-oriented)

Search often stands in for human interactions
I have a craving for a nice juicy cut of meat. What might you recommend?
I have JUST the thing!

Searching the market q=(juiciness:juicy meatiness:meaty)

Modeling arbitrary feature strength
OpenSource Connections
term juicy: steak: juiciness: 5 grapefruit: juiciness: 7 orange: juiciness: 4 term meaty: burger: meatiness: 2
What you want:
{ item: "steak", juiciness: ["juicy", "juicy", "juicy"], meatiness: ["meaty"] }
Use term frequency as feature strength:
{ item: "grapefruit", juiciness: ["juicy", "juicy", "juicy", "juicy", "juicy"], meatiness: [""] }
(remember, Solr doesn't need to store this)

TF*IDF -- measuring feature weight
OpenSource Connections
term juicy: doc 0: freq: 5 doc 1: freq: 7 doc 3: freq: 4 term meaty: doc 0: freq: 2
"meaty-ness" is pretty special
"juicy-ness" is pretty non-special
doc0: tf==5 df==3 (raw) TF*IDF = 5/3 = 1.6667
doc0: tf==2 df==1 (raw) TF*IDF = 2/1 = 2.0
Search is really distributed feature matching and similarity

Requesting something from my grocer
More juicy Less juicy
More meaty Less meaty
q=meaty juicy
Results: 1.
2.
3.

Recsys also stands in for human interactions Hi Jane, Recommend me something?
Hmm… <Tom likes limes, what is similar to limes?>

"Content Based" recommendations
Use existing properties of thing to recommend similar things
juicy
citrus
More like this for unstructured data
What features/tokens are most representative of this thing?
http://solr.quepid.com/solr/tmdb/select?q={!mlt%20qf=overview}97&fl=title,id,overview (movies like Tron)
juicy
citrus (search)
Here's some ideas...
{ item: "lime", juiciness: ["juicy", "juicy", "juicy"], citrusness: ["citrus", "citrus", "citrus"], meatiness: [""], partyness: ["party"] }

"Content Based" more-like-these
Use existing properties of thing to recommend similar things
juicy
meaty citrus
http://solr.quepid.com/solr/tmdb/select?q={!mlt%20qf=overview}97&fl=title,id,overview (movies like Tron)
Here's some ideas...
Jane knows a few more things that Tom likes...

Personalization metadata
Index extra data alongside your products { item: "hamburger", preferred_by_genders: ["m", …], preferred_by_ages: ["30_40"] }
age:30_40
gender:m
http://solr.quepid.com/solr/tmdb/select?q={!mlt%20qf=overview}97&fl=title,id,overview (movies like Tron)
Here's some ideas...
Jane knows a few things about Tom (30 yr old male)

But, Jane's intuition transcends words!
age:30_40
gender:m
Currently we're stuck with predefined labels:
citrus juicy
meaty
We're curating using known vocabularies
(can we describe everything?)
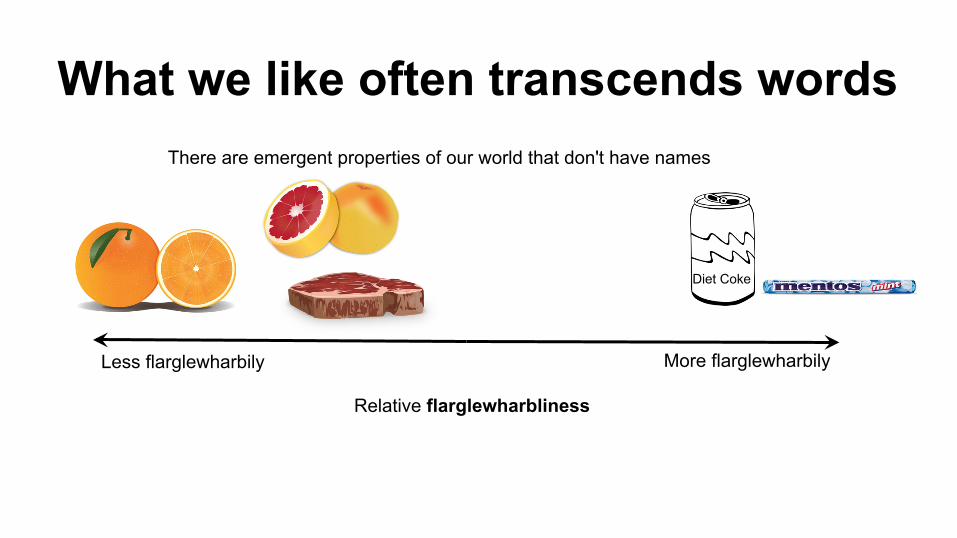
What we like often transcends words There are emergent properties of our world that don't have names
Relative flarglewharbliness
More flarglewharbily Less flarglewharbily
Diet Coke
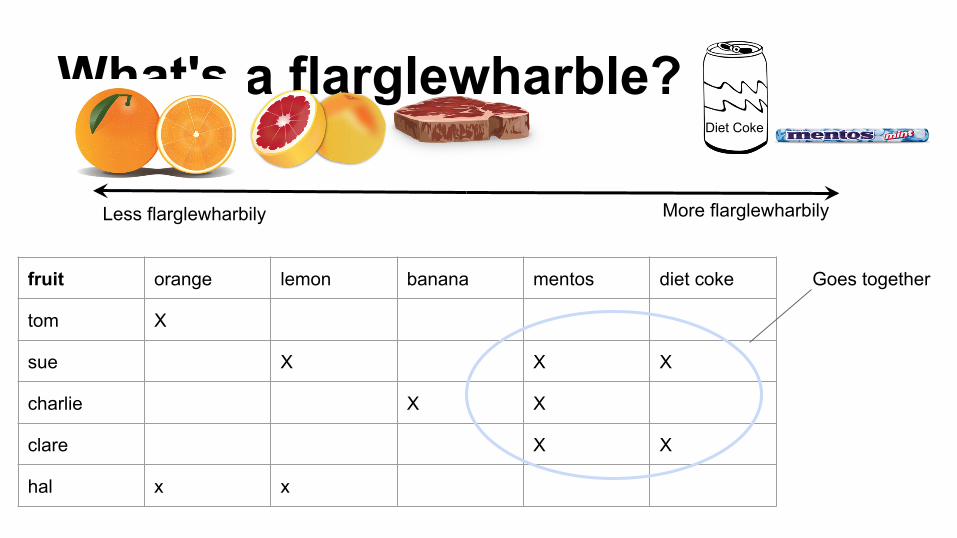
What's a flarglewharble?
More flarglewharbily Less flarglewharbily
fruit orange lemon banana mentos diet coke
tom X
sue X X X
charlie X X
clare X X
hal x x
Goes together
Diet Coke

Can search find the flargles?
q=(flargliwharbliness:very)
term flarglewharble: diet-‐coke: flargleness: 4 mentos: flargleness: 3 banana flargleness: 1
Can we somehow build?
Diet Coke

person\food orange lemon banana mentos diet coke
tom X X
sue X X X X
charlie X X
clare X X
hal x x X
Goes together
flarglewharble!
Babies often use made-up words based on emergent patterns in their universe They are less committed to our language

What's the point? Collaborative filtering
Latent vocabulary (the flarglewharbles)
Pure Search Content-based Recs
Predefined vocabulary
Can Solr discover the latent/emergent vocabularies?

Can Solr discover the latent/emergent vocabularies? Well first let's tell Solr about our users
{ user: "Sue" foods_bought: ["lemon", "banana", "mentos", "diet coke"] } { user: "Charlie" foods_bought: ["banana", "mentos", "diet coke"] }

Faceting? We need a way to look across users and look for patterns (analyze all the baskets that contain mentos) q=foods_bought:mentos&facet=true&facet.field=foods_bought
facets: mentos: 3 diet-coke: 3 banana: 2
Hmm: - Bananas are globally popular - Diet-coke is probably what matters

Counts don't work: importance of significance q=foods_bought:mentos&facet=true&facet.field=foods_bought
facets: mentos: 3 diet-coke: 3 banana: 2
Diet Coke: Global popularity: diet coke (3) Local popularity: 3 Score: 3/3 = 1
Banana: Global popularity: banana
(4) Local popularity: 2
Score: 2/4 = 0.5
by-significance: diet-coke: 1 banana: 0.5

Streaming Expressions
/select?q=*:*&facet=true&facet.field=liked_movies
But there's a new sheriff in town!
One option: we could go about and gather global doc freqs & compare those locally.
Terms component another option… plugins...
Streaming expressions -- distributed stream computation system on top of Solr Cloud You must ALWAYS cross the streams!

Streaming Expressions /stream?expr=scoreNodes(facet(...)...)
facet(movielens, q="*:*", buckets="liked_movies", bucketSorts="count(*) desc", bucketSizeLimit="100", count(*))
Faceting with Streaming Expressions:
Output:
{ "result-set": {"docs":[ { "count(*)":55807, "liked_movies":"318"}, { "count(*)":52352, "liked_movies":"296"}, { "count(*)":50114, "liked_movies":"593"}
Nodes to be transformed

Significance with streaming expr /stream?expr=scoreNodes(facet(...)...)
scoreNodes( select( facet(movielens, q="liked_movies:2571 OR liked_movies:4993", buckets="liked_movies", bucketSorts="count(*) desc", bucketSizeLimit="100", count(*)), liked_movies as node, "count(*)", replace(collection, null, withValue=movielens), replace(field, null, withValue=liked_movies)) )
1. facet (just like above, just with streaming expr) 2. select to format data for scoreNodes 3. scoreNodes to score using TF*IDF
Banana occurs in 2 documents here, 4 globally -- 2/4 = 0.5 Diet coke occurs 2 documents here, 2 globally -- 2/2 = 1.0
Thinking back on my shoppers behaviors, here's some other items you might like:
(thanks Joel Bernstein!)
Diet Coke

Lots of power here /stream?expr=scoreNodes(facet(...)...)
scoreNodes( select( facet(movielens, q="juiciness_pref:juicy", buckets="liked_movies", bucketSorts="count(*) desc", bucketSizeLimit="100", count(*)), liked_movies as node, "count(*)", replace(collection, null, withValue=movielens), replace(field, null, withValue=liked_movies)) )
Find users that like juicy things, what do they like? Perhaps bucket over the aisle they like? Construct our query to focus on a date range? Many insights (thanks Joel Bernstein!)
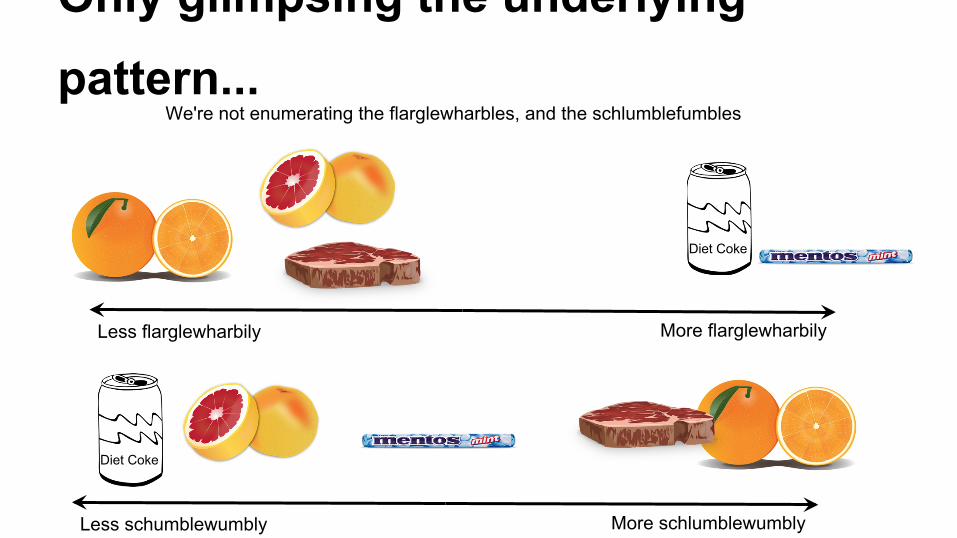
Only glimpsing the underlying pattern...
We're not enumerating the flarglewharbles, and the schlumblefumbles
More flarglewharbily Less flarglewharbily
Diet Coke
More schlumblewumbly Less schumblewumbly
Diet Coke

Coming soon (Solr 6.3) http://yonik.com/solr-6-3/ https://issues.apache.org/jira/browse/SOLR-9258
- Models for training classifiers - Then in turn updating documents Progress is being made! - Clustering?

Questions? The Flarglewharbles





























