Embed Size (px)
Citation preview

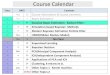
Course Calendar Class DATE Contents
1 Sep. 26 Course information & Course overview
2 Oct. 4 Bayes Estimation
3 〃 11 Classical Bayes Estimation - Kalman Filter -
4 〃 18 Simulation-based Bayesian Methods
5 〃 25 Modern Bayesian Estimation :Particle Filter
6 Nov. 1 HMM(Hidden Markov Model)
Nov. 8 No Class
7 〃 15 Bayesian Decision
8 〃 29 Non parametric Approaches
9 Dec. 6 PCA(Principal Component Analysis)
10 〃 13 ICA(Independent Component Analysis)
11 〃 20 Applications of PCA and ICA
12 〃 27 Clustering, k-means et al.
13 Jan. 17 Other Topics 1 Kernel machine.
14 〃 22(Tue) Other Topics 2

Lecture Plan
Principal Component Analysis
1. Introduction
Dimensionality Reduction
2. Principal Component Analysis (PCA)
3. Linear Discriminative Analysis(LDA)

3
1. Dimensionality of Feature Space For given sample data there would exist a maximum dimension of
features above which the performance of Bayes classifier will
degrade rather than improve.
Two Approaches
Feature Selection: Choose a subset of overall features
Feature Extraction: Create a subset of new features by combining
the original features.
11
21
1 2where (1,2, , ) ( , , , )
i
im
imn
xx
xx
n i i i
xx
1 11
2 21
mn n
x xy
x xy
f
yx x

4
2
,
,
2
, :1 ex. m=256
where, is image intensity at pixel ,
From an array data to a dimensional vector .
By lexicographic ordering of m m images into
a set of vectors,
i j
i j
m
I i j m
I i j
m
R
I
Vectorization
I x
x
2 2ex. =256 65,536 dimentionm
Example : Representation of images

5
Restricting the transforms within linear(*) functions, we have the
form
(* Several nonlinear transformations such as multi-layer
perceptron, manifold learning and kernel methods are known.)
y Wx
1 11 11 1
2 21
1
. .
. .. .
. ... .
. .
n
m mnmn n
x xy w w
x xy
w wyx x

6 x1
x2
x1
x2
Signal Representation (PCA) vs. Classification (LDA)
When the aim of feature extraction is to represent a signal, the
Principal Component Analysis(PCA) is applied. Whereas for a data-
classification under supervised learning problem the Linear
Discriminative Analysis (LDA) is applied.
(a) PCA for representation (b) LDA for classification

7
2. PCA by variance maximization
- Random vector with n elements x
- Samples xi , i=1~N
- The first and second order statistics are given or, in practice, are
calculated from the samples
- Subtracting the mean of vector x, that is
(where E means the expectation over x, and henceforth x in the PCA
part of this lecture is assumed zero means vector)
Consider a linear combination of the elements of x.
y1 is called the first principal component of x, if the variance of y1 is
maximum.
Newx E x x
1 1 1
1
1 1
where ' are weights, and is the vector form of the weights.
nT
k k
k
k
y w x
w s
w x
w

8
2
21 1 1 1 1 1 1
1
:
=1
The matrix is the n n covariance metrix of .
T T T TPCA x
x
J E y E
PCA Criterion
w w x w E xx w = w C w
w
C x
The solution of PCA problem
-Results from matrix theory
1 2
1 22
1 1 1 1
1
( )
nT
k
k
w w w w
1, ,
1, 1 2
1
1 1
- Define unity-norm eignvectors of the matrix
- Corresponding eigenvalues satisfy 0
The solution of maximizing is given by
This indicates
n x
n n
PCAJ
e e C
w
w e
1 1
that the first principle component of is
T
x
y e x
1
1PCAMax Jw
w

9
2
2 2
2 2
1
2 1
- The second principal component of with weight vector
The variance of is maximized under the condition that is
with .
0
This co
Ty
y y
y
E y y
uncorrelated
x w
w x
ndition derives
2 1 2 1 2 1 1 2 1
2 1
22
2 2
0
The right most equation means that the is orthognal to .
- The problem is to seek the maximum variance of
in the orthogonal subspace
T T T Tx
T
E y y E
E y E
w x w x w C w w e
w e
w x
1
2 3
to the first eignvector
(namely, this subspace is spanned by , , ).n
e
e e e

10
2 2
- The solution is hence given by
, we may derive all principal components, thus
,
where ( 1 ~ )
k k
k k
Likewise
y
k n
w e
w x
w e

11
3. LDA –Fisher’s Ratio Maximization-
1 2
1 2 1 2
1 2
We are given data
, , ,
which are divided into two subsets D and D (N and N data subsets)
corresponding to two classes and respectively.
The problem is to find a projection
N
x x x
1 2
1 2
onto a line
where we want to separate sample data into the subsets Y and Y
corresponding to D and D are well as possible.
Ty w x
The LDA tries to find directions that are efficient for classification or
discrimination of samples in supervised learning problems.
2
1 2
2 2
1 2
An evaluation function of the best separability can be defined
(Fisher ratio)m m
Js s
w

12
22
where
1
is the sample mean of the projected sample for each class , and
is the scatter value for the projected samples with label .
i
i
i y Yi
i
i iy Y
i
m yN
s y m
1 2
:
To rewrite the Fisher's ratio, we define the scatter matrices
1, where
,the
and the
i i
T
i i i iix D D
W
N
Fisher ratio as a function of
within - class scatter matrix
between -
x
w
S x m x m m x
S S S
1 2 1 2 T
B
class scatter matrix
S m m m m

13
Then the Fisher ratio becomes
and the optimal weight vector for maximizing can be
obtained as the solution of the generalized eignvalue problem
TB
Tw
B
J
J
w S ww
w S w
w w
S w S
1
Since the matrix is symmetric and positive semidefinite(*) and
it is usually positive definete(*), hence is non-singular, the solution
is given by
Futhermore, if we ign
w
W
w B
w
S
S S w w
11 2
ore the magnitude of , we can rewrite
the solution as follow.
*; For any , 0, **; For any , 0
w
T Tw w
w
w S m m
w w S w w w S w

14
Fig. Comparison of PCA(First principal Magenta line ) and LDA Discriminate Line (Green Line ) [3]

15
References: [1] R.O. Duda, P.E. Hart, and D. G. Stork, “Pattern Classification”, John Wiley & Sons, 2nd edition, 2004 [2] C. M. Bishop, “Pattern Recognition and Machine Learning”, Springer, 2006 [3] All data files of Bishop’s book are available at the “http://research.microsoft.com/~cmbishop/PRML” [4] ] A. Hyvarinen et al. “Independent Component Analysis” , Wiley-InterScience, 2001












![Generalized Correspondence-LDA Models (GC-LDA) for ... · The GC-LDA and Correspondence-LDA models are extensions of Latent Dirichlet Allocation (LDA) [3]. Several Bayesian methods](https://img.pdfslide.us/doc/110x75/6011a7de37d63b741248406f/generalized-correspondence-lda-models-gc-lda-for-the-gc-lda-and-correspondence-lda.jpg)