Embed Size (px)
Citation preview

© 201 IBM Corporation
Geospatial Big Data @normanbarker
Foss4g-NA

© 2015 IBM Corporation‹#›
Overview
▪ CouchDB / Cloudant ▪ A brief history
▪What is Big Data ▪ NoSQL ▪ Consistent Hashing / Sharding ▪ CAP Theorem ▪Multi-Master database ▪ Image Classification Example ▪ Geospatial Querying using Secondary Indexes
▪ libspatialindex / geos

© 2015 IBM Corporation‹#›
CouchDB
▪ NoSQL document store with map/reduce initially developed by Damien Katz
▪ Cloudant/Couchbase were the primary developers ▪ Now a large diverse community
▪ Written in Erlang ▪ GeoCouch, Lucene FTI ▪ JSON/GeoJSON
▪ Cloudant ▪ Donated BigCouch to enable clustering of CouchDB
▪ Cluster Of Unreliable Commodity Hardware ▪ Runs a DBaaS on top of CouchDB

© 2015 IBM Corporation‹#›
NoSQL
▪ Unstructured text ▪ JSON
▪ Schemas are enforced on READs
© 2015 IBM Corporation‹#›
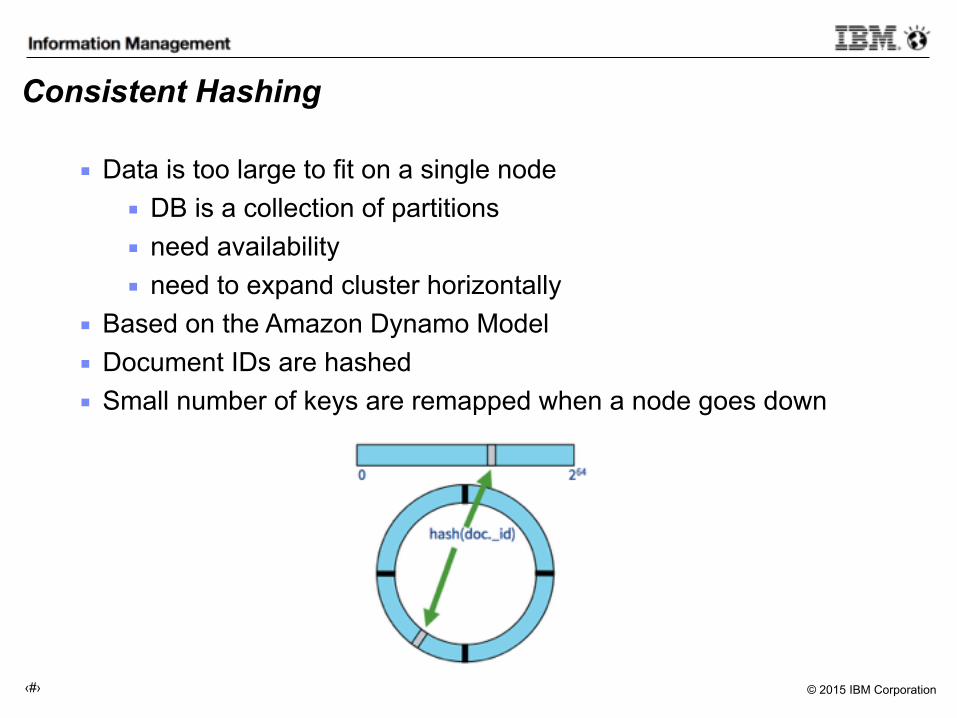
Consistent Hashing
▪ Data is too large to fit on a single node ▪ DB is a collection of partitions ▪ need availability ▪ need to expand cluster horizontally
▪ Based on the Amazon Dynamo Model ▪ Document IDs are hashed ▪ Small number of keys are remapped when a node goes down

© 2015 IBM Corporation‹#›
Consistent hashing for data availability

© 2015 IBM Corporation‹#›
GeoHash as a consistent hash
▪ GeoHash is a Morton Key ▪ Can assign geometries to nodes ▪ Fixed data ▪ Hot spots

© 2015 IBM Corporation‹#›
CAP Theorem
▪ Distributed systems can provide two of the following
Consistency (all nodes see the same data at the same time) Availability (a guarantee that every request receives a response about whether it succeeded or failed)
Partition Tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
Mathematical proof by contradiction: http://bit.ly/1FbnmrC

© 2015 IBM Corporation‹#›
Multi-Master (Peers)
▪ CouchDB is an eventually consistent distributed system ▪ Pick Two
▪ Availability ▪ Partition Tolerance
▪ Eventual Consistency ▪ Multi-Master system ▪ Sync (Changes Feed)
▪ Data Collection ▪ Online/Offline
▪ Distributed Big Geo Data

© 2015 IBM Corporation‹#›
Multi-Master (Peers)
Distributed geo big data

© 2015 IBM Corporation‹#›
PouchDB is an open-source JavaScript database inspired by Apache CouchDB that is designed to run well within the browser.

© 2015 IBM Corporation‹#›
Multi-Master (Data Centres)
▪ High availability ▪ High velocity

© 2015 IBM Corporation‹#›
Image Classification
▪ Traditional ▪ Input is a large GeoTiff file where the pixel values represent a
data class (e.g. water, vegetation) ▪ Using ENVI / GRASS / GDAL export as shape file per class
and overlay on a map ▪ Possibly store results in a WFS

© 2015 IBM Corporation‹#›
▪ CouchDB ▪ Split the image into tiles and process classes as vectors as above
▪ note: potrace is a utility for this that exports to geojson ▪ Store the result as GeoJSON within CouchDB ▪ Data is highly available, redundant ▪ Field user can edit the classes and sync back to a server (multi-master)
▪ MVCC ▪ Eventual consistency can be managed
Image Classification

© 2015 IBM Corporation‹#›
Geospatial Indexes▪ Distributed spatial index ▪ Always going to be slower on writes (redundancy) ▪ Need to make READs quick
R-Tree R*-Tree

© 2015 IBM Corporation‹#›
Temporal Indexes▪ Index speed is related to index size ▪When using temporal data, use an appropriate tree! ▪ TPR*-Tree, MVR*-Tree

© 2015 IBM Corporation‹#›
Cloudant Geo
▪ Secondary geospatial indexes ▪ libspatialindex
▪ R*-Tree, MVR-Tree, TPR-Tree ▪ libgeos ▪ CS-Map
▪ CouchDB / BigCouch ▪ Sync

© 2015 IBM Corporation‹#›
Geo Big Data Summary
▪ A CouchDB View of the World ▪ data can and should be distributed ▪ Sync significant data between masters
▪multi-master, eventually consistent ▪ Secondary indexes enable complex queries ▪ Use a cluster to archive data

© 2015 IBM Corporation‹#›
Issues▪Within geospatial systems transactions are assumed ▪ Need a revision model for eventual consistency
▪ Feature data is ok for MVCC ▪What about big raster data? ▪ Image streaming ▪ Versioning

© 2015 IBM Corporation‹#›
Questions?
@normanbarker
BoF Tonight 7:30 - 9:30pm Sandpebble CDE





























