Embed Size (px)
Citation preview

Fast and Scalable NUMA-based Thread Parallel Breadth-first Search
*Yuichiro Yasui Kyushu University & JST COI
The 2015 International Conference on High Performance Computing & Simulation (HPCS2015)
July 20 – 24, 2015, Amsterdam, the Netherlands
Katsuki Fujisawa
Kyushu University & JST CREST
Session 9A: July 22, 14:45 − 16:00

1. Introduction – Graph analysis for large-scale networks – Breadth-first search and its applications
2. Graph500 & Green Graph500 benchmarks – Related work and our previous contributions
3. Proposal techniques – Vertex renumbering, graph representations, and data structures
4. Numerical results – Access frequency analysis – Intel Xeon server and SGI UV 2000
Outline
Collaboration with ISM and SGI corp.
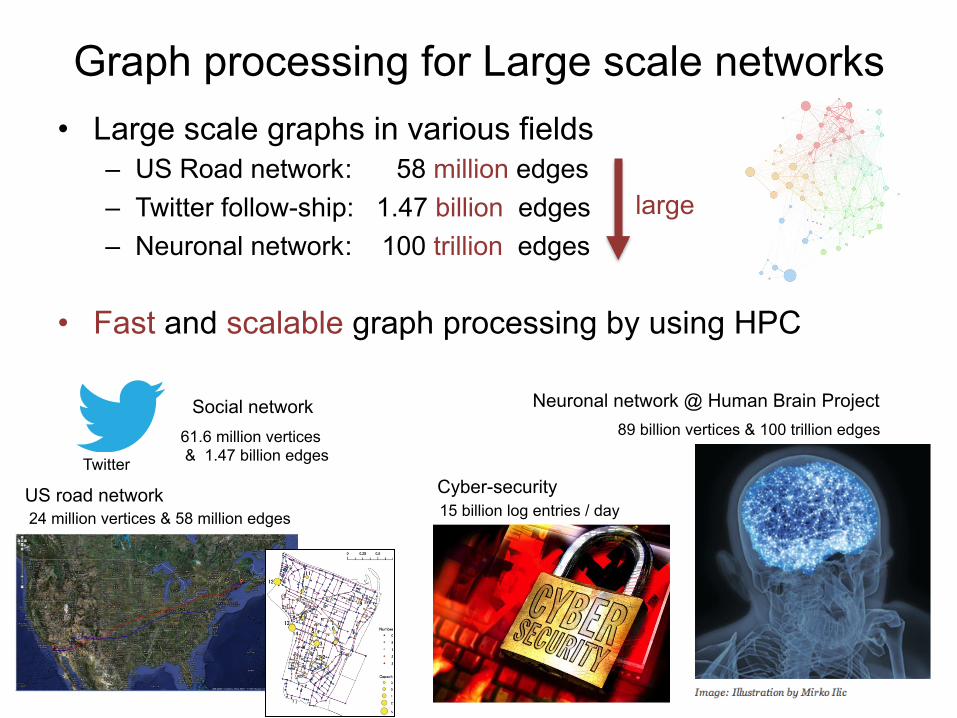
Graph processing for Large scale networks • Large scale graphs in various fields
– US Road network : 58 million edges – Twitter follow-ship: 1.47 billion edges – Neuronal network : 100 trillion edges
89 billion vertices & 100 trillion edges Neuronal network @ Human Brain Project
Cyber-security Twitter
US road network 24 million vertices & 58 million edges 15 billion log entries / day
Social network
• Fast and scalable graph processing by using HPC
large
61.6 million vertices & 1.47 billion edges
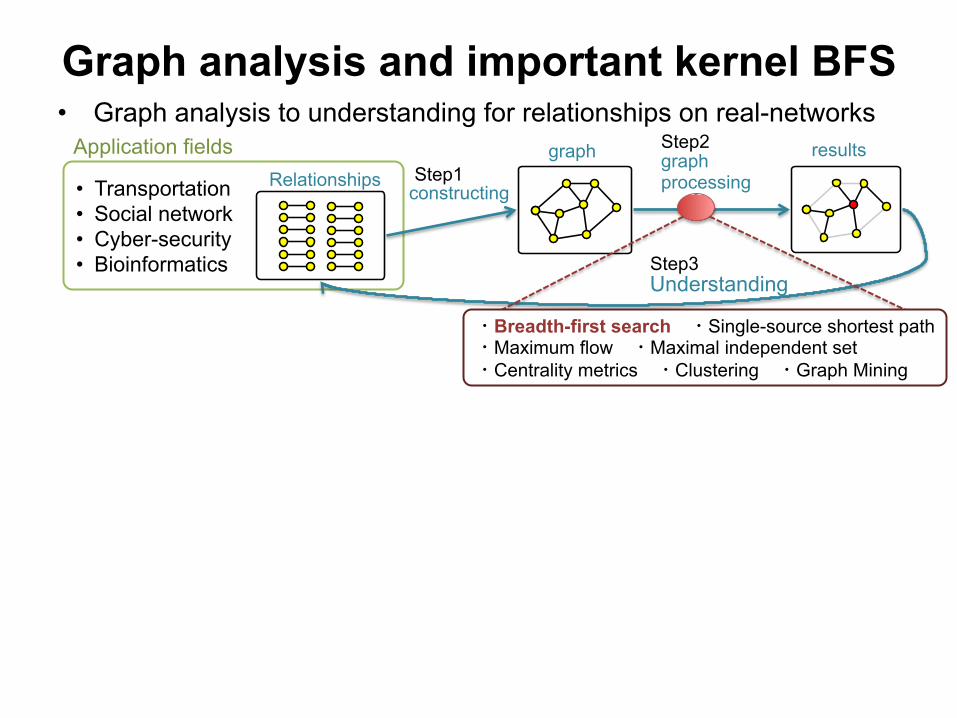
• Transportation • Social network • Cyber-security • Bioinformatics
Graph analysis and important kernel BFS • Graph analysis to understanding for relationships on real-networks
graph processing
Understanding
Application fields
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
Relationships - SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
graph
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
results Step1
Step2
Step3
constructing
・Breadth-first search ・Single-source shortest path ・Maximum flow ・Maximal independent set ・Centrality metrics ・Clustering ・Graph Mining
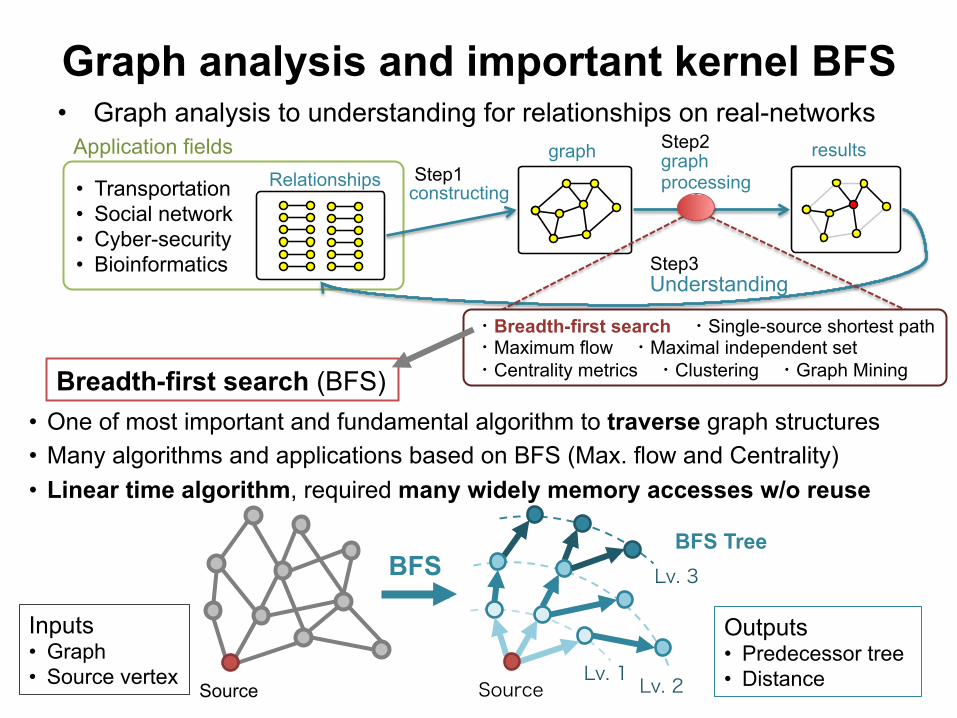
• One of most important and fundamental algorithm to traverse graph structures • Many algorithms and applications based on BFS (Max. flow and Centrality) • Linear time algorithm, required many widely memory accesses w/o reuse
Breadth-first search (BFS)
Source
BFS Lv. 3
Source Lv. 2 Lv. 1
Outputs • Predecessor tree • Distance
Inputs • Graph • Source vertex
• Transportation • Social network • Cyber-security • Bioinformatics
Graph analysis and important kernel BFS • Graph analysis to understanding for relationships on real-networks
graph processing
Understanding
Application fields
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
Relationships - SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
graph
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
results Step1
Step2
Step3
constructing
・Breadth-first search ・Single-source shortest path ・Maximum flow ・Maximal independent set ・Centrality metrics ・Clustering ・Graph Mining
BFS Tree
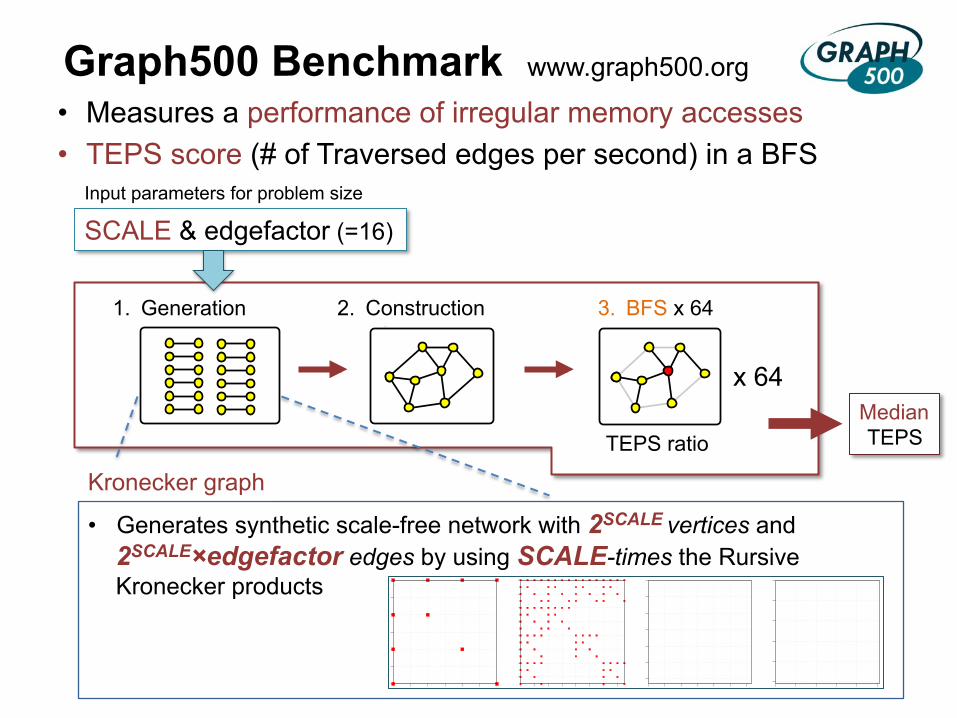
Graph500 Benchmark • Measures a performance of irregular memory accesses • TEPS score (# of Traversed edges per second) in a BFS
SCALE & edgefactor (=16)
Median TEPS
1. Generation
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
3. BFS x 64 2. Construction
x 64
TEPS ratio
• Generates synthetic scale-free network with 2SCALE vertices and 2SCALE×edgefactor edges by using SCALE-times the Rursive Kronecker products
www.graph500.org
G1 G2 G3 G4
Kronecker graph
Input parameters for problem size
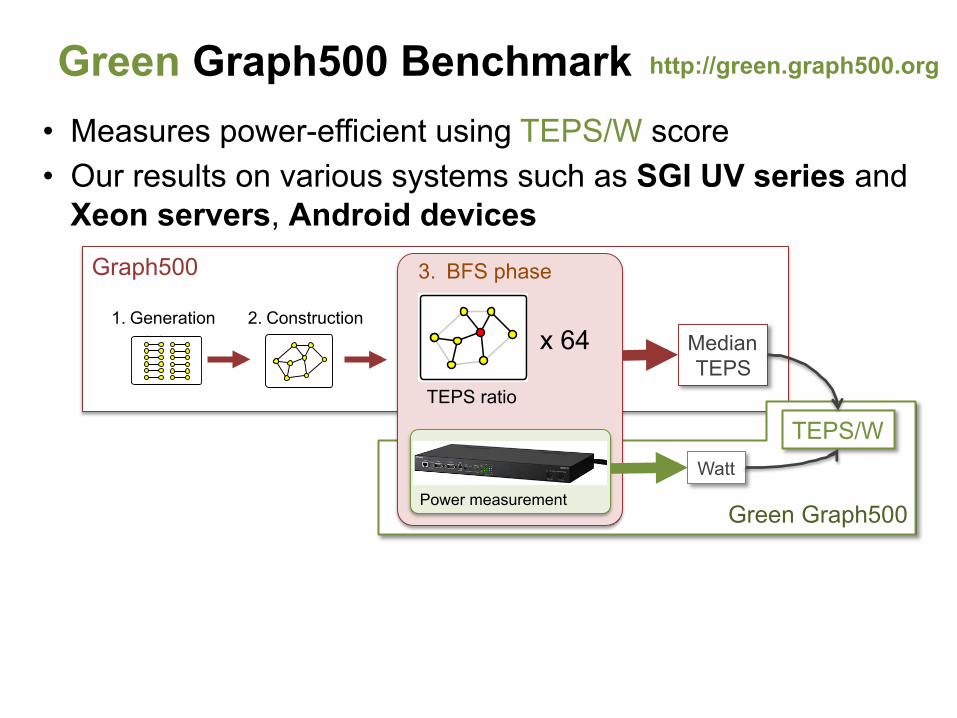
Green Graph500 Benchmark • Measures power-efficient using TEPS/W score • Our results on various systems such as SGI UV series and
Xeon servers, Android devices
http://green.graph500.org
Median TEPS
1. Generation
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
- SCALE- edgefactor
- SCALE- edgefactor- BFS Time- Traversed edges- TEPS
Input parameters ResultsGraph generation Graph construction
TEPSratio
ValidationBFS
64 Iterations
3. BFS phase
2. Construction x 64
TEPS ratio
Watt TEPS/W
Power measurement Green Graph500
Graph500
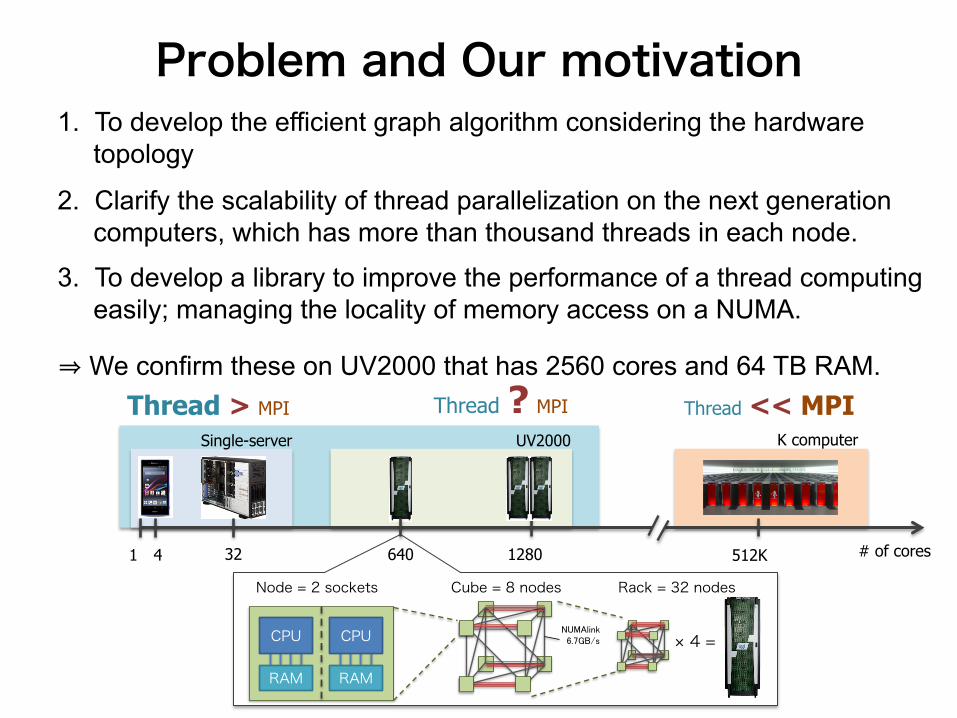
Problem and Our motivation
Thread ? MPI
# of cores 1 4 32 640 512K 1280
K computer
Thread << MPI UV2000 Single-server
Thread > MPI
1. To develop the efficient graph algorithm considering the hardware topology
2. Clarify the scalability of thread parallelization on the next generation computers, which has more than thousand threads in each node.
3. To develop a library to improve the performance of a thread computing easily; managing the locality of memory access on a NUMA.
Node = 2 sockets Cube = 8 nodes Rack = 32 nodes
CPU
RAM
CPU
RAM
× 4 =
⇒ We confirm these on UV2000 that has 2560 cores and 64 TB RAM.
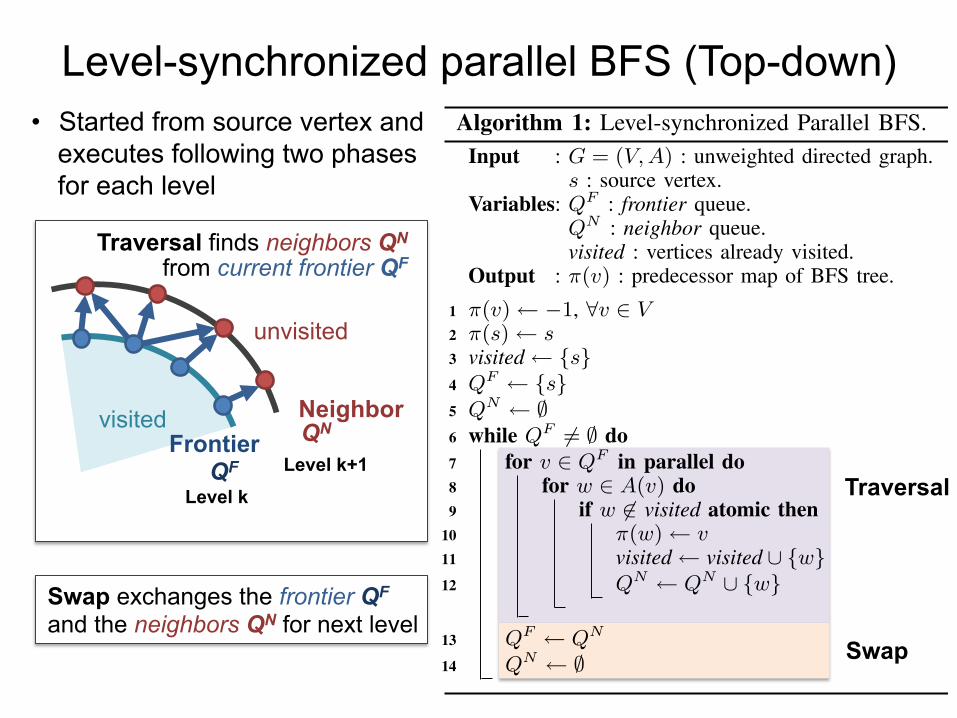
Level-synchronized parallel BFS (Top-down) • Started from source vertex and
executes following two phases for each level
3) BFS iterations (timed).: This step iterates the timedBFS-phase and the untimed verify-phase 64 times. The BFS-phase executes the BFS for each source, and the verify-phaseconfirms the output of the BFS.
This benchmark is based on the TEPS ratio, which iscomputed for a given graph and the BFS output. Submissionagainst this benchmark must report five TEPS ratios: theminimum, first quartile, median, third quartile, and maxi-mum.
III. PARALLEL BFS ALGORITHM
A. Level-synchronized Parallel BFSWe assume that the input of a BFS is a graph G = (V, E)
consisting of a set of vertices V and a set of edges E.The connections of G are contained as pairs (v, w), wherev, w ∈ V . The set of edges E corresponds to a set ofadjacency lists A, where an adjacency list A(v) containsthe outgoing edges (v, w) ∈ E for each vertex v ∈ V . ABFS explores the various edges spanning all other verticesv ∈ V \{s} from the source vertex s ∈ V in a given graphG and outputs the predecessor map π, which is a map fromeach vertex v to its parent. When the predecessor map π(v)points to only one parent for each vertex v, it represents atree with the root vertex s. However, some applications, suchas the betweenness centrality [1], require all of the parentsfor each vertex, which is equivalent to the number of hopsfrom the source. Therefore, the output predecessor map isrepresented as a directed adjacency graph (DAG). In thispaper, we focus on the Graph500 benchmark, and assumethat the BFS output is a predecessor map that is representedby a tree.
Algorithm 1 is a fundamental parallel algorithm for aBFS. This requires the synchronization of each level thatis a certain number of hops away from the source. We callthis the level-synchronized parallel BFS [6]. Each traversalexplores all outgoing edges of the current frontier, which isthe set of vertices discovered at this level, and finds theirneighbors, which is the set of unvisited vertices at the nextlevel. We can describe this algorithm using a frontier queueQF and a neighbor queue QN , because unvisited verticesw are appended to the neighbor queue QN for each frontierqueue vertex v ∈ QF in parallel with the exclusive controlat each level (Algorithm 1, lines 7–12), as follows:
QN ←!w ∈ A(v) | w ̸∈ visited, v ∈ QF
". (1)
B. Hybrid BFS Algorithm of Beamer et al.The main runtime bottleneck of the level-synchronized
parallel BFS (Algorithm 1) is the exploration of all outgoingedges of the current frontier (lines 7–12). Beamer et al. [8],[9] proposed a hybrid BFS algorithm (Algorithm 2) thatreduced the number of edges explored. This algorithmcombines two different traversal kernels: top-down and
Algorithm 1: Level-synchronized Parallel BFS.Input : G = (V, A) : unweighted directed graph.
s : source vertex.Variables: QF : frontier queue.
QN : neighbor queue.visited : vertices already visited.
Output : π(v) : predecessor map of BFS tree.1 π(v)← −1, ∀v ∈ V2 π(s)← s3 visited← {s}4 QF ← {s}5 QN ← ∅6 while QF ̸= ∅ do7 for v ∈ QF in parallel do8 for w ∈ A(v) do9 if w ̸∈ visited atomic then
10 π(w)← v11 visited← visited ∪ {w}12 QN ← QN ∪ {w}
13 QF ← QN
14 QN ← ∅
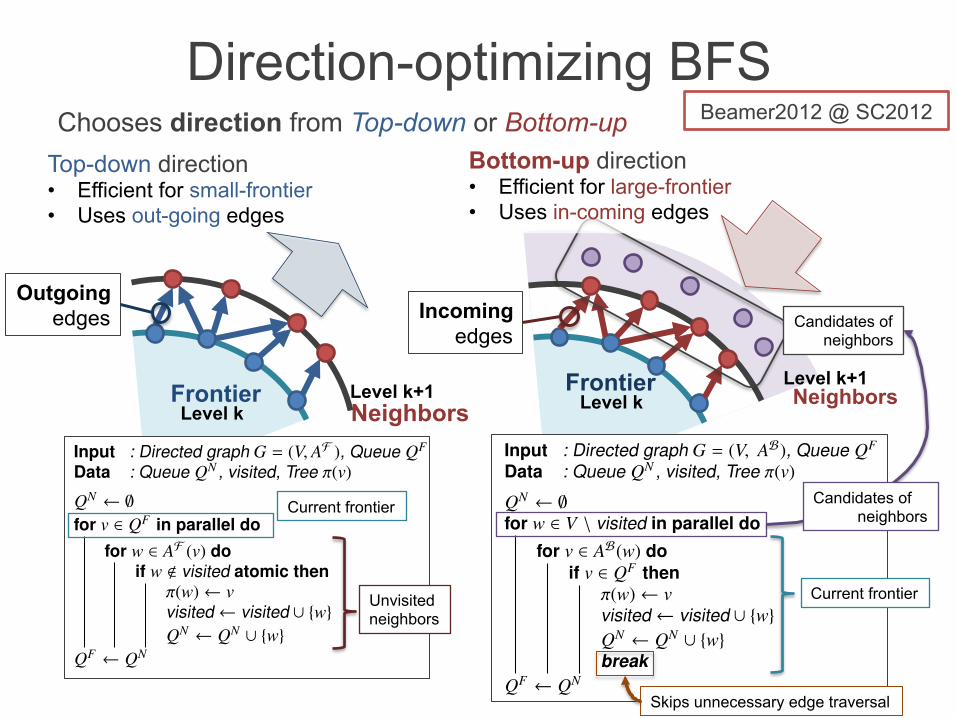
bottom-up. Like the level-synchronized parallel BFS, top-down kernels traverse neighbors of the frontier. Conversely,bottom-up kernels find the frontier from vertices in candidateneighbors. In other words, a top-down method finds thechildren from the parent, whereas a bottom-up method findsthe parent from the children. For a large frontier, bottom-upapproaches reduce the number of edges explored, becausethis traversal kernel terminates once a single parent is found(Algorithm 2, lines 16–21).
Table III lists the number of edges explored at each levelusing a top-down, bottom-up, and combined hybrid (oracle)approach. For the top-down kernel, the frontier size mF atlow and high levels is much less than that at mid-levels.In the case of the bottom-up method, the frontier size mBis equal to the number of edges m = |E| in a given graphG = (V, E), and decreases as the level increases. Bottom-upkernels estimate all unvisited vertices as candidate neighborsQN , because it is difficult to determine their exact numberprior to traversal, as shown in line 15 of Algorithm 2. Thislazy estimation of candidate neighbors increases the numberof edges traversed for a small frontier. Hence, consideringthe size of the frontier and the number of neighbors, wecombine top-down and bottom-up approaches in a hybrid(oracle). This loop generally only executes once, so thealgorithm is suitable for a small-world graph that has a largefrontier, such as a Kronecker graph or an R-MAT graph.Table III shows that the total number of edges traversed bythe hybrid (oracle) is only 3% of that in the case of thetop-down kernel.
We now explain how to determine a traversal policy(Table II(a)) for the top-down and bottom-up kernels. The
395
Traversal
Swap
Frontier Neighbor
Level k Level k+1 QF
QN
Swap exchanges the frontier QF and the neighbors QN for next level
Traversal finds neighbors QN from current frontier QF
visited
unvisited
Frontier Level k
Level k+1 Neighbors Frontier
Neighbors Level k Level k+1
Candidates of neighbors
前方探索と後方探索でのデータアクセスの観察• 前方探索でのデータの書込み
v→ w
v
w
Input : Directed graph G = (V, AF ), Queue QF
Data : Queue QN , visited, Tree π(v)
QN ← ∅for v ∈ QF in parallel do
for w ∈ AF (v) doif w ! visited atomic thenπ(w)← vvisited← visited ∪ {w}QN ← QN ∪ {w}
QF ← QN
• 後方探索でのデータの書込み
w→ v
v w
Input : Directed graph G = (V, AB), Queue QF
Data : Queue QN , visited, Tree π(v)
QN ← ∅for w ∈ V \ visited in parallel do
for v ∈ AB(w) doif v ∈ QF thenπ(w)← vvisited← visited ∪ {w}QN ← QN ∪ {w}break
QF ← QN
• どちらも wに関する変数 π(w)と visitedに書込みを行っている (vは点番号の参照)
6 / 12
Direction-optimizing BFS Top-down direction • Efficient for small-frontier • Uses out-going edges
Bottom-up direction • Efficient for large-frontier • Uses in-coming edges
前方探索と後方探索でのデータアクセスの観察• 前方探索でのデータの書込み
v→ w
v
w
Input : Directed graph G = (V, AF ), Queue QF
Data : Queue QN , visited, Tree π(v)
QN ← ∅for v ∈ QF in parallel do
for w ∈ AF (v) doif w ! visited atomic thenπ(w)← vvisited← visited ∪ {w}QN ← QN ∪ {w}
QF ← QN
• 後方探索でのデータの書込み
w→ v
v w
Input : Directed graph G = (V, AB), Queue QF
Data : Queue QN , visited, Tree π(v)
QN ← ∅for w ∈ V \ visited in parallel do
for v ∈ AB(w) doif v ∈ QF thenπ(w)← vvisited← visited ∪ {w}QN ← QN ∪ {w}break
QF ← QN
• どちらも wに関する変数 π(w)と visitedに書込みを行っている (vは点番号の参照)
6 / 12
Current frontier
Unvisited neighbors
Current frontier
Candidates of neighbors
Skips unnecessary edge traversal
Outgoing edges Incoming
edges
Chooses direction from Top-down or Bottom-up Beamer2012 @ SC2012
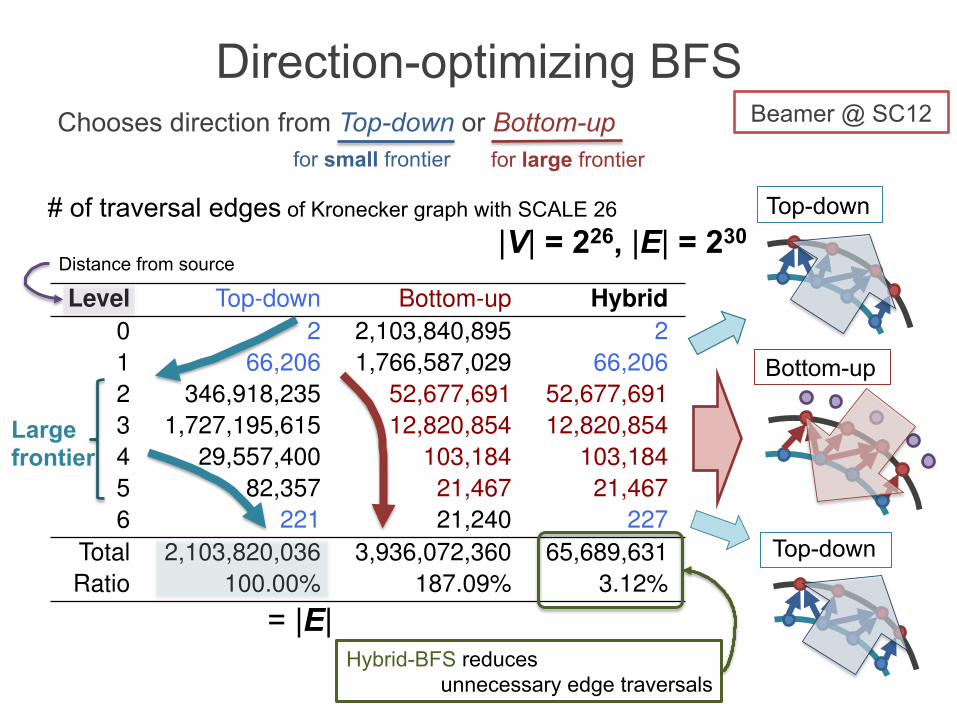
# of traversal edges of Kronecker graph with SCALE 26
Hybrid-BFS reduces unnecessary edge traversals
Direction-optimizing BFS
Top-down 幅優先探索に対する前方探索 (Top-down)と後方探索 (Bottom-up)
Level Top-down Bottom-up Hybrid0 2 2,103,840,895 21 66,206 1,766,587,029 66,2062 346,918,235 52,677,691 52,677,6913 1,727,195,615 12,820,854 12,820,8544 29,557,400 103,184 103,1845 82,357 21,467 21,4676 221 21,240 227
Total 2,103,820,036 3,936,072,360 65,689,631Ratio 100.00% 187.09% 3.12%
6 / 14
Bottom-up
Top-down
Distance from source |V| = 226, |E| = 230
= |E|
Chooses direction from Top-down or Bottom-up Beamer @ SC12
for small frontier for large frontier
Large frontier
0
10
20
30
40
50
2011 SC10 SC12 BigData13ISC14
G500,ISC14
GT
EPS
Ref
eren
ce
NU
MA-a
war
e
Dir.
Opt
.
NU
MA-O
pt.
NU
MA-O
pt.
+D
eg.a
war
e
NU
MA-O
pt.
+D
eg.a
war
e+
Vtx
.Sor
t
87M 800M
5G
11G
29G
42G
⇥1 ⇥9
⇥58
⇥125
⇥334
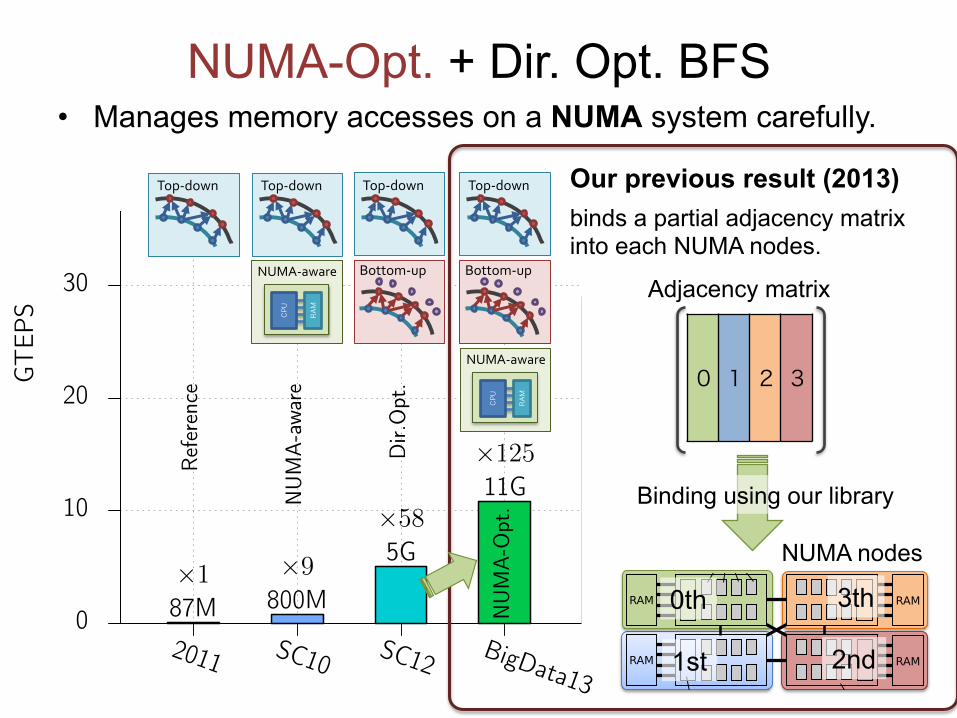
⇥489NUMA-Opt. + Dir. Opt. BFS
• Manages memory accesses on a NUMA system carefully.
Top-‐down Top-‐down
Bottom-‐up
Top-‐down
CPU
RAM
NUMA-‐aware Bottom-‐up
Top-‐down
CPU
RAM
NUMA-‐aware
Our previous result (2013)
RAM RAM
processor core & L2 cache
8-core Xeon E5 4640shared L3 cache
RAM RAM
RAM RAM
processor core & L2 cache
8-core Xeon E5 4640shared L3 cache
RAM RAM
RAM RAM
processor core & L2 cache
8-core Xeon E5 4640shared L3 cache
RAM RAM0th 3th
1st 2nd
0 1 2 3
Adjacency matrix
binds a partial adjacency matrix into each NUMA nodes.
Binding using our library
NUMA nodes
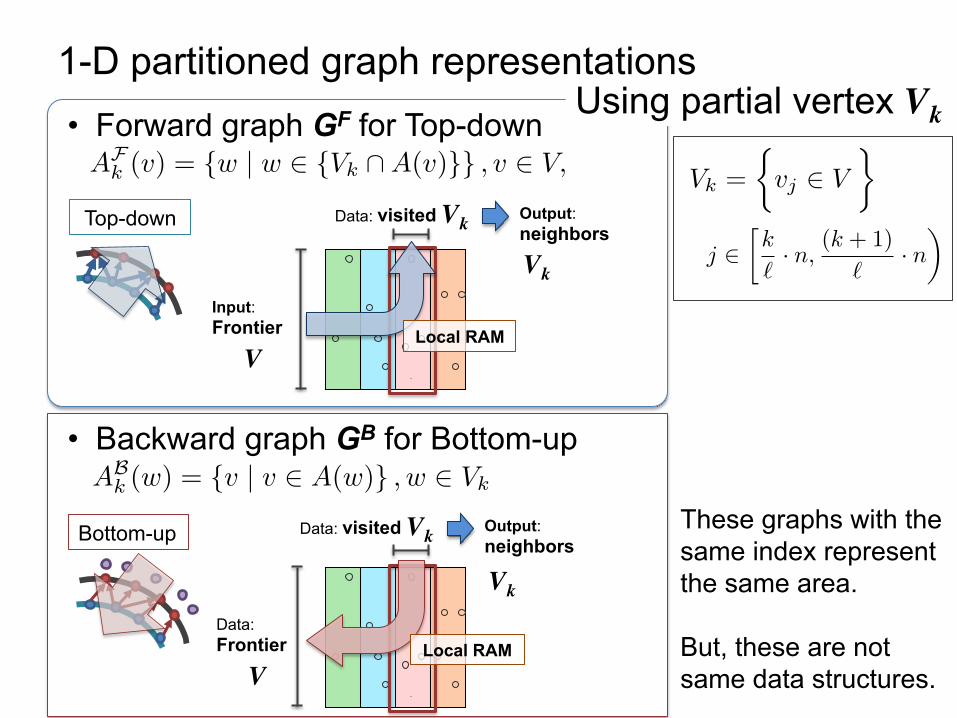
• Forward graph GF for Top-down
• Backward graph GB for Bottom-up
A0
A1
A2
A3
A0
A1
A2
A3
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Input: Frontier V
Data: Frontier V
Data: visited Vk Output: neighbors Vk
Data: visited Vk Output: neighbors
Vk
Top-down
Bottom-up
Local RAM
Local RAM
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Using partial vertex Vk 1-D partitioned graph representations
These graphs with the same index represent the same area. But, these are not same data structures.
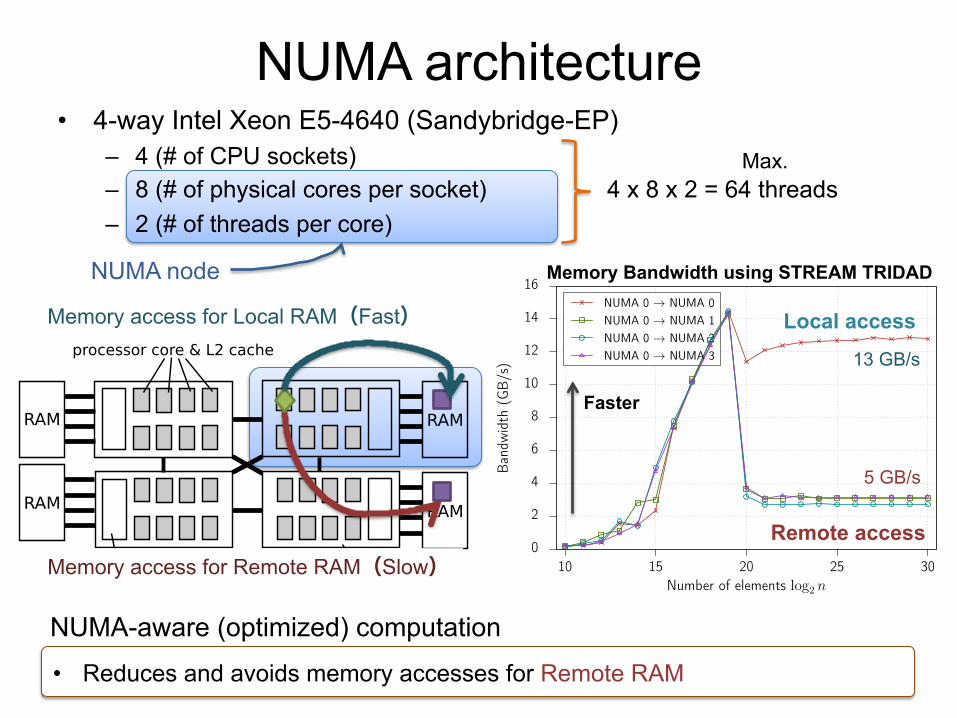
NUMA architecture
RAM RAM
processor core & L2 cache
8-core Xeon E5 4640shared L3 cache
RAM RAM
Memory access for Local RAM(Fast)
Memory access for Remote RAM(Slow)
• Reduces and avoids memory accesses for Remote RAM
• 4-way Intel Xeon E5-4640 (Sandybridge-EP) – 4 (# of CPU sockets) – 8 (# of physical cores per socket) – 2 (# of threads per core)
4 x 8 x 2 = 64 threads
NUMA node
Max.
NUMA-aware (optimized) computation
0
2
4
6
8
10
12
14
16
10 15 20 25 30
Bandw
idth
(G
B/s)
Number of elements log2 n
NUMA 0 ! NUMA 0NUMA 0 ! NUMA 1NUMA 0 ! NUMA 2NUMA 0 ! NUMA 3
Local access
Remote access
Faster
Memory Bandwidth using STREAM TRIDAD
5 GB/s
13 GB/s

CPU and memory affinity using ULIBC
ULIBC provides CPU and memory affinity on a NUMA system ü Predefined affinity settings; scatter (spread) and compact (close) ü Supports some operating systems; Linux, Solaris, AIX, … ü Easily manage processor/memory topology and location of
running threads on a NUMA system; Sockets, Cores, SMT
https://bitbucket.org/yuichiro_yasui/ulibc
Related libraries; • Thread affinity of OpenMP 4.0
ü Predefined typical affinity settings; scatter (spread) and compact (close)
• Intel Thread Affinity Interface of Intel compiler ü Predefined typical affinity settings; scatter (spread) and compact (close) ☓ Only for Linux and Windows
Difference between ULIBC and other libraries;
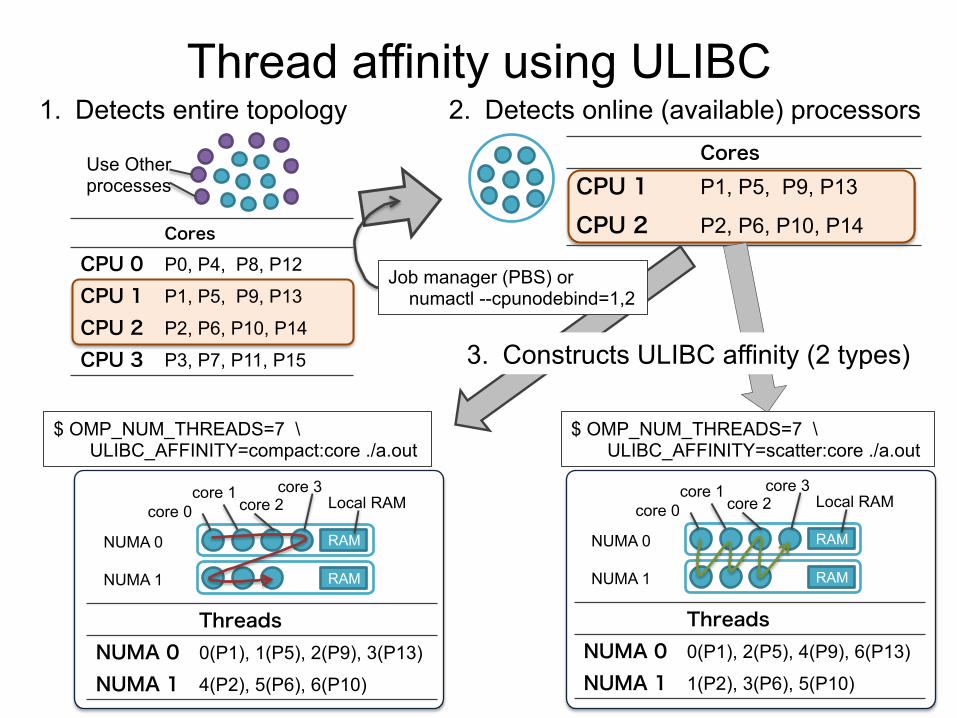
1. Detects entire topology Cores
CPU 1 P1, P5, P9, P13 CPU 2 P2, P6, P10, P14
2. Detects online (available) processors
Threads NUMA 0 0(P1), 2(P5), 4(P9), 6(P13) NUMA 1 1(P2), 3(P6), 5(P10)
$ OMP_NUM_THREADS=7 \ ULIBC_AFFINITY=compact:core ./a.out
Thread affinity using ULIBC
Cores
CPU 0 P0, P4, P8, P12 CPU 1 P1, P5, P9, P13 CPU 2 P2, P6, P10, P14 CPU 3 P3, P7, P11, P15
Use Other processes
NUMA 0
NUMA 1
core 0 core 1
core 2 core 3
RAM
RAM
Local RAM
Threads NUMA 0 0(P1), 1(P5), 2(P9), 3(P13) NUMA 1 4(P2), 5(P6), 6(P10)
NUMA 0
NUMA 1
core 0 core 1
core 2 core 3
RAM
RAM
Local RAM
Job manager (PBS) or numactl --cpunodebind=1,2
3. Constructs ULIBC affinity (2 types)
$ OMP_NUM_THREADS=7 \ ULIBC_AFFINITY=scatter:core ./a.out
0
10
20
30
40
50
2011 SC10 SC12 BigData13ISC14
G500,ISC14
GT
EPS
Ref
eren
ce
NU
MA-a
war
e
Dir.
Opt
.
NU
MA-O
pt.
NU
MA-O
pt.
+D
eg.a
war
e
NU
MA-O
pt.
+D
eg.a
war
e+
Vtx
.Sor
t
87M 800M
5G
11G
29G
42G
⇥1 ⇥9
⇥58
⇥125
⇥334
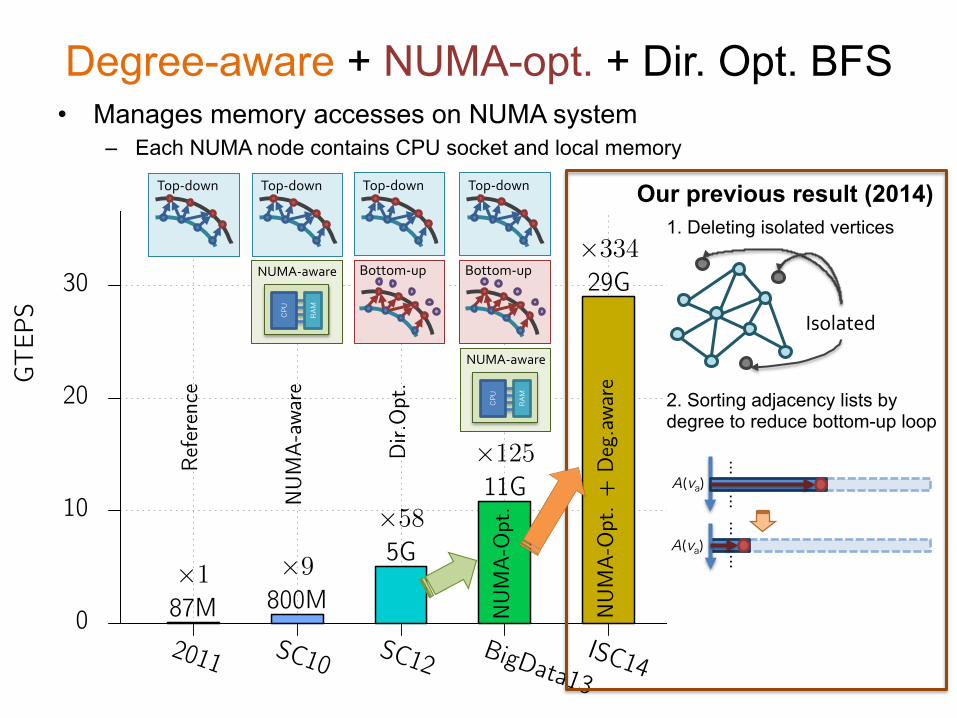
⇥489Degree-aware + NUMA-opt. + Dir. Opt. BFS
• Manages memory accesses on NUMA system – Each NUMA node contains CPU socket and local memory
Top-‐down Top-‐down
Bottom-‐up
Top-‐down
CPU
RAM
NUMA-‐aware Bottom-‐up
Top-‐down
CPU
RAM
NUMA-‐aware
2. Sorting adjacency lists by degree to reduce bottom-up loop
1. Deleting isolated vertices Our previous result (2014)
Isolated
A(va)
…
…
A(va)
…
…

adjacency vertex w, the maximum degree of which is givenby:
AB+(v) = arg maxw∈AB(v)
{|dG(w)|} , v ∈ V . (10)
We now explain the construction of AB+(v) and AB−(v)for each vertex v ∈ V . First, the given adjacency vertices
AB(v) =!w0, w1, ..., wdegG(v)−1
"(11)
are sorted by out-degree as follows:
degG(w0) ≥ degG(w1) ≥ ... ≥ degG(wdegG(v)−1). (12)
The sorted A(v) is then separated as follows:
AB+(v) = {w0} , AB−(v) =!w1, ..., wdegG(v)−1
". (13)
This graph representation requires an additional computa-tional overhead for sorting the adjacency vertex list, but doesnot require increased memory. We focus on the fact that halfof the total number of vertices are zero-degree vertices. Thisproperty does not significantly affect the performance of thetop-down search. However, the bottom-up search is affected,because the frontier is searched from all unvisited vertices,including zero- and nonzero-degree vertices. To avoid theaccess cost associated with zero-degree vertices, we proposezero-degree vertex suppression, which renumbers the vertex IDof all nonzero vertices during graph construction. Algorithm 4describes the degree-aware bottom-up BFS. This uses a graphrepresentation that separates the highest-degree adjacency ver-tex AB+ and the remaining adjacency vertices AB−. Thisalgorithm separates two major loops involved in this process,namely lines 3–8 and lines 9–15.
F. Sorting Vertex Indices by Out-degree (Proposal)
In this section, we propose a vertex sorting technique that issimilar to that in [31]. Our new graph representation combinesour degree-aware speedup technique and a vertex sortingtechnique based on a NUMA-aware implementation. First, inthe graph construction, our vertex sorting technique constructsvertex indices {0, 1, ..., n− 1} as follows:
degG(v0) ≥ degG(v1) ≥ ... ≥ degG(vn−1).
A degree-aware graph representation is then constructed usingonly those vertices with non-zero degree. In Table V, ourspeedup techniques for a Kronecker graph are compared withSCALE 27 on a SandyBridge-EP system. The results showthat our new algorithm is 1.47 (= 42.5
29.0 ) times faster than ourprevious method. The entire speedup is 8.33 (= 42.5
5.1 ) timesfaster than that of the original direction-optimizing algorithm.This technique improves the locality of memory accesses.More details of this are given in the next section.
Algorithm 4: Degree-aware Bottom-up BFSInput : NUMA node indices k ∈ {0, 1, ..., ℓ− 1},
NUMA-local threads T = {Tk}, directed graphG = {Gk} = {(Vk, A
B+k , AB−
k )}, duplicated frontierqueues CQ = {CQk}, visited vertices VS = {VSk},and predecessor map π = {πk}.
Output: Neighbor queues NQ = {NQk}.1 Procedure Degree-aware-NUMA-Bottom-up(G,CQ,VS,π)2 NQk ← ∅3 for w ∈ Vk \ VSk parallel(Tk) do4 v ← AB+
k (w)5 if v ∈ CQk then6 πk(w)← v7 VSk ← VSk ∪ {w}8 NQk ← NQk ∪ {w}
9 for w ∈ Vk \ VSk parallel(Tk) do10 for v ∈ AB−
k (w) do11 if v ∈ CQk then12 πk(w)← v13 VSk ← VSk ∪ {w}14 NQk ← NQk ∪ {w}15 break
16 return NQk
TABLE V: Comparison of Our Speedup Techniques.
Implementation SCALE TEPSDir. Opt. (baseline) [4], [5] 28 5.1 G+ NUMA Opt. [35] 27 10.9 G+ NUMA Opt. + Degree Opt. [36] 27 29.0 GThis paper (DG-V)+ NUMA Opt. + Degree Opt. + Vertex Sorting 27 42.5 G
G. Implementation Variants (Proposal)
We have various implementations that use graph represen-tations and queue data structures for a subset of vertices. OurNUMA-optimized BFS algorithm needs two types of graphrepresentation: GF for use with Top-down policies, called aForward graph, and GB for use on Bottom-up policies, calleda Backward graph. This model achieves high performance on aNUMA system with a few CPU sockets. However, the memoryrequirements of this model are O(n+m
ℓ ) for GF and O(n+mℓ )
for GB for each NUMA node on an ℓ-way NUMA system.Note that the forward graph requires more memory than thebackward graph, because the memory usage of the index arrayin the forward graph does not depend on the number of NUMAnodes ℓ.
The performance characteristics of BFS implementations,such as the memory requirements and number of memoryaccesses, differ for each data structure used. Our BFS im-plementations use vertices for the current queue CQ and nextqueue NQ, and visited vertices VS are represented by a Sparse-vector (V ), Bitmaps (B), or Bitmaps-and-summary (S). V isone of the simplest representations for a subset of vertices,and represents each vertex index using each element of the
Proposal; Sorting Vertex Indices by Out-degree
• Combines following techniques; – Yasui et al. (ISC’14)’s the degree aware optimizations
• Ignoring the zero-degree vertices • sorting vertices in each adjacent list
– Ueno et al. (HPDC’12)’s the vertex sorting • renumbering vertex indices by degree
• Kronecker graph has many zero-degree (isolated) vertices – c.g.) SCALE32; more than half of all vertices
2.66X by Yasui’s
1.47X by Ueno’s This paper
Graph500 benchmark on a 4-way Intel Xeon
NUMA
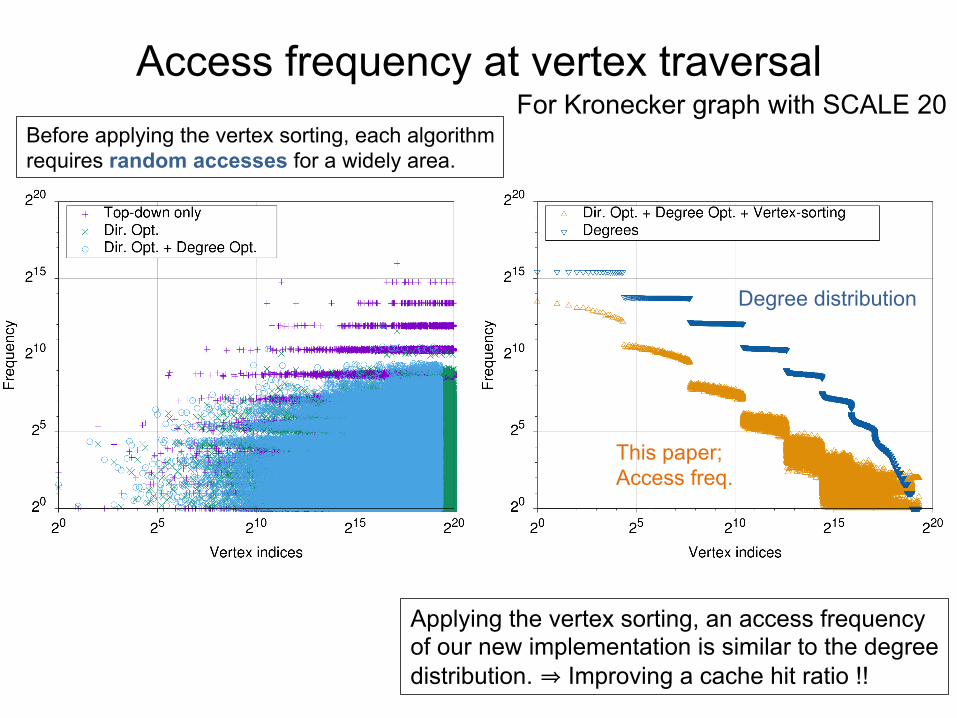
Access frequency at vertex traversal For Kronecker graph with SCALE 20
Degree distribution
This paper; Access freq.
Before applying the vertex sorting, each algorithm requires random accesses for a widely area.
Applying the vertex sorting, an access frequency of our new implementation is similar to the degree distribution. ⇒ Improving a cache hit ratio !!
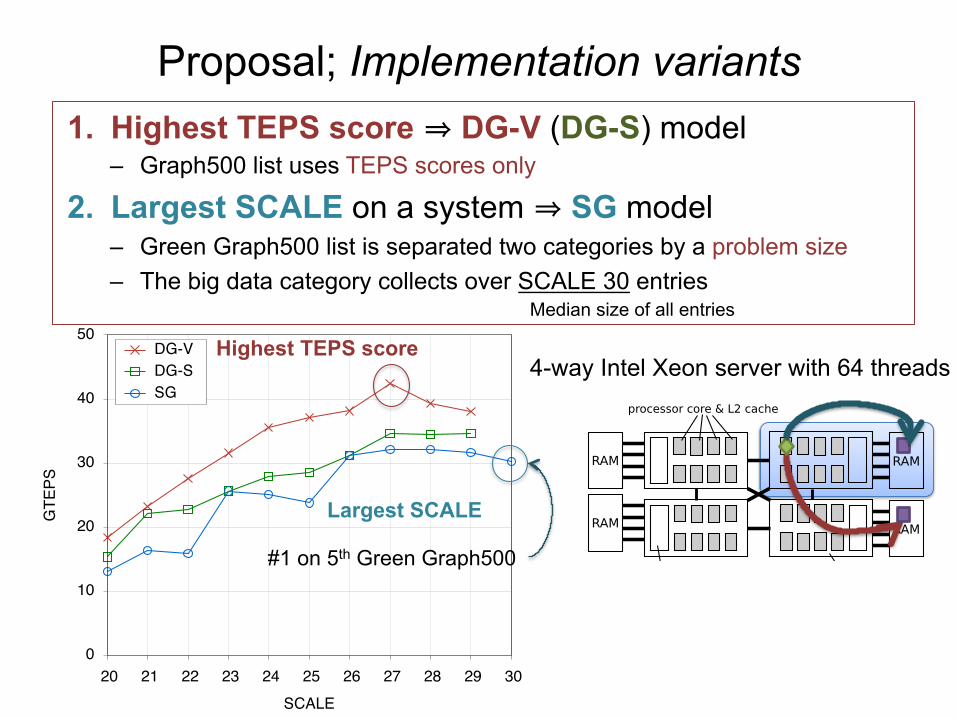
Proposal; Implementation variants 1. Highest TEPS score ⇒ DG-V (DG-S) model
– Graph500 list uses TEPS scores only
2. Largest SCALE on a system ⇒ SG model – Green Graph500 list is separated two categories by a problem size – The big data category collects over SCALE 30 entries
Median size of all entries
0
10
20
30
40
50
20 21 22 23 24 25 26 27 28 29 30
GTE
PS
SCALE
DG-VDG-SSG
Highest TEPS score
Largest SCALE
#1 on 5th Green Graph500
RAM RAM
processor core & L2 cache
8-core Xeon E5 4640shared L3 cache
RAM RAM
4-way Intel Xeon server with 64 threads
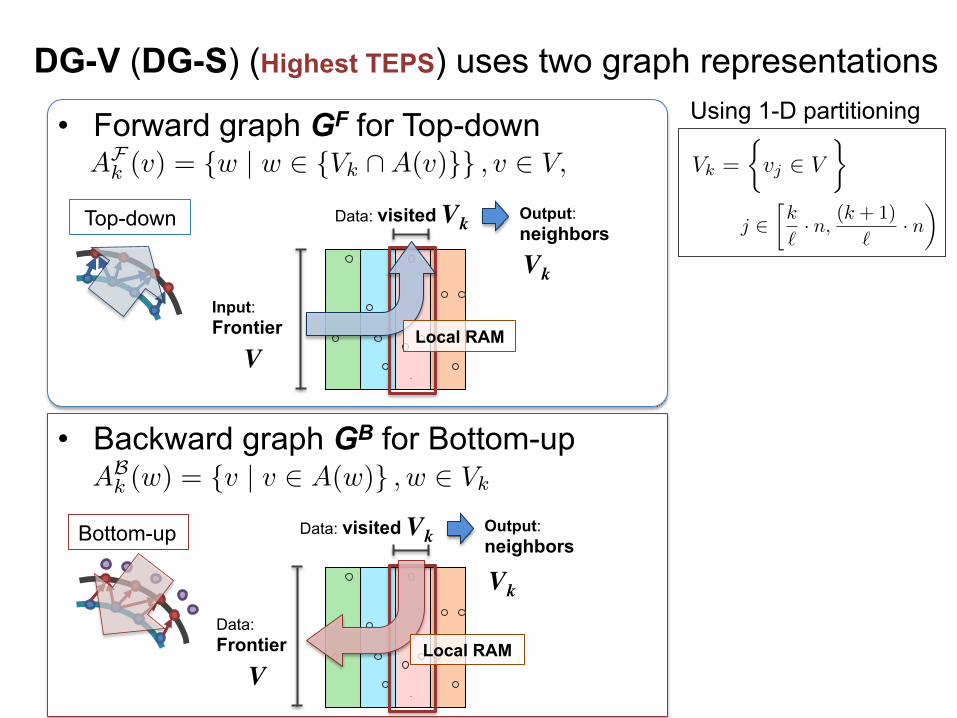
DG-V (DG-S) (Highest TEPS) uses two graph representations • Forward graph GF for Top-down
• Backward graph GB for Bottom-up
A0
A1
A2
A3
A0
A1
A2
A3
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Input: Frontier V
Data: Frontier V
Data: visited Vk Output: neighbors Vk
Data: visited Vk Output: neighbors
Vk
Top-down
Bottom-up
Local RAM
Local RAM
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Using 1-D partitioning
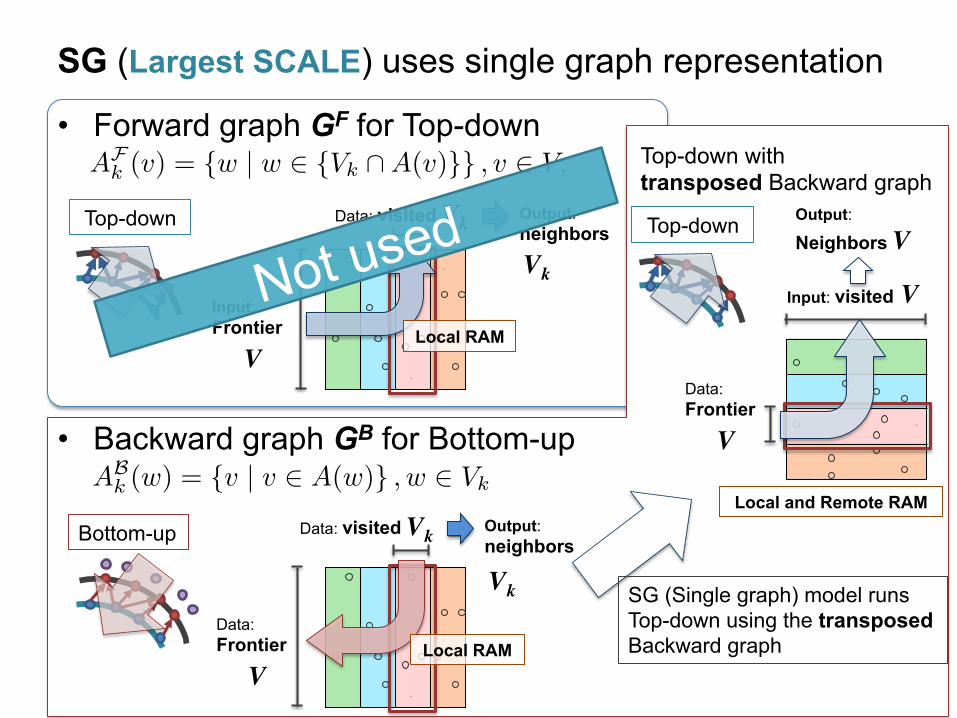
SG (Largest SCALE) uses single graph representation • Forward graph GF for Top-down
• Backward graph GB for Bottom-up
A0
A1
A2
A3
A0
A1
A2
A3
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Algorithm 2: Direction-optimizing BFSInput : Directed graph G = (V,AF , AB), source vertex s,
frontier queue CQ, neighbor queue NQ, and visitedvertices VS.
Output: Predecessor map π(v).1 π(v)←⊥, ∀v ∈ V \{s}2 π(s)← s3 VS← {s}4 CQ← {s}5 NQ← ∅6 while CQ ̸= ∅ do7 if is top down direction(CQ,NQ,VS) then8 NQ← Top-down(G,CQ,VS,π)9 else
10 NQ← Bottom-up(G,CQ,VS,π)11 swap(CQ,NQ)
12 Procedure Top-down(G,CQ,VS,π)13 NQ← ∅14 for v ∈ CQ in parallel do15 for w ∈ AF (v) do16 if w ̸∈ VS atomic then17 π(w)← v18 VS← VS ∪ {w}19 NQ← NQ ∪ {w}
20 return NQ
21 Procedure Bottom-up(G,CQ,VS,π)22 NQ← ∅23 for w ∈ V \ VS in parallel do24 for v ∈ AB(w) do25 if v ∈ CQ then26 π(w)← v27 VS← VS ∪ {w}28 NQ← NQ ∪ {w}29 break
30 return NQ
has local memory, and these connect to one another via aninterconnect such as the Intel QPI, AMD HyperTransport,or SGI NUMAlink 6. On such systems, processor cores canaccess their local memory faster than they can access remote(non-local) memory (i.e., memory local to another processoror memory shared between processors). To some degree, theperformance of BFS depends on the speed of memory access,because the complexity of memory accesses is greater than thatof computation. Therefore, in this paper, we propose a generalmanagement approach for processor and memory affinities ona NUMA system. However, we cannot find a library for obtain-ing the position of each running thread, such as the CPU socketindex, physical core index, or thread index in the physicalcore. Thus, we have developed a general management libraryfor processor and memory affinities, the ubiquity library forintelligently binding cores (ULIBC). The latest version of thislibrary is based on the HWLOC (portable hardware locality)library, and supports many operating systems (although we
have only confirmed Linux, Solaris, and AIX). ULIBC can beobtained from
https://bitbucket.org/ulibc.
The HWLOC library manages computing resources usingresource indices. In particular, each processor is managed bya processor index across the entire system, a socket indexfor each CPU socket (NUMA node), and a core index foreach logical core. However, the HWLOC library does notprovide a conversion table between the running thread andeach processor’s indices. ULIBC provides an “MPI rank”-likeindex, starting at zero, for each CPU socket, each physical corein each CPU socket, and each thread in each physical core,which are available for the corresponding process, respectively.We have already applied ULIBC to graph algorithms for theshortest path problem [34], BFS [18], [19], [35], [36], andmathematical optimization problems [15].
D. NUMA-optimized BFS
Our NUMA-optimized algorithm, which improves the ac-cess to local memory, is based on Beamer et al.’s direction-optimizing algorithm. Thus, it requires a given graph repre-sentation and working variables to allow a BFS to be dividedover the local memory before the traversal. In our algorithm,all accesses to remote memory are avoided in the traversalphase using the following column-wise partitioning:
V =!V0 | V1 | · · · | Vℓ−1
", (4)
A =!A0 | A1 | · · · | Aℓ−1
", (5)
and each set of partial vertices Vk on the k-th NUMA nodeis defined by
Vk =
#vj ∈ V | j ∈
$k
ℓ· n, (k + 1)
ℓ· n
%&, (6)
where n is the number of vertices and the divisor ℓ is set tothe number of NUMA nodes (CPU sockets). In addition, toavoid accessing remote memory, we define partial adjacencylists AF
k and ABk for the Top-down and Bottom-up policies as
follows:
AFk (v) = {w | w ∈ {Vk ∩A(v)}} , v ∈ V, (7)
ABk (w) = {v | v ∈ A(w)} , w ∈ Vk. (8)
Furthermore, the working spaces NQk, VSk, and πk forpartial vertices Vk are allocated to the local memory on the k-th NUMA node with the memory pinned. Note that the rangeof each current queue CQk is all vertices V in a given graph,and these are allocated to the local memory on the k-th NUMAnode. Algorithm 3 describes the NUMA-optimized Top-downand Bottom-up processes. In both traversal directions, eachlocal thread Tk binds to the processor cores of the k-th NUMAnode, and only traverses the local neighbors NQk from thelocal frontier CQk on the local memory. The computationalcomplexities are O(m) (Top-down) and O(m·diamG) (Bottom-up), where m is the number of edges and diamG is the
Input: Frontier V
Data: Frontier V
Data: visited Vk Output: neighbors Vk
Data: Frontier V
Input: visited V
A0
A1
A2
A3
Output:
Neighbors V
Data: visited Vk Output: neighbors
Vk
Top-down
Bottom-up
Top-down
Local RAM
Local RAM
Local and Remote RAM
Not used Top-down with transposed Backward graph
SG (Single graph) model runs Top-down using the transposed Backward graph
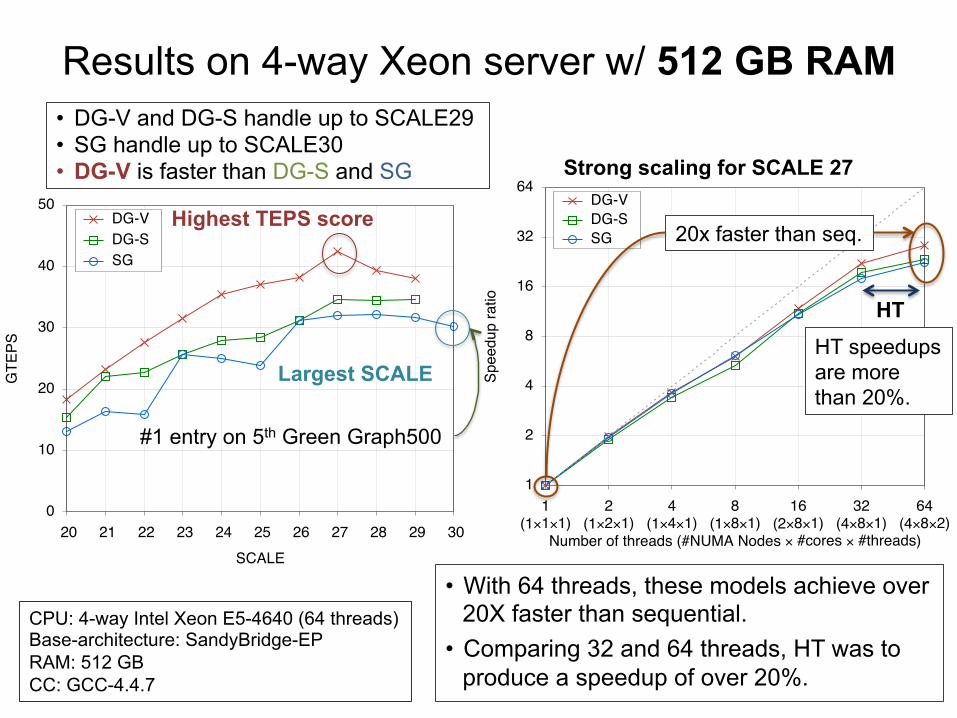
Results on 4-way Xeon server w/ 512 GB RAM
0
10
20
30
40
50
20 21 22 23 24 25 26 27 28 29 30
GTE
PS
SCALE
DG-VDG-SSG
1
2
4
8
16
32
64
1(1×1×1)
2(1×2×1)
4(1×4×1)
8(1×8×1)
16(2×8×1)
32(4×8×1)
64(4×8×2)
Spee
dup
ratio
Number of threads (#NUMA Nodes × #cores × #threads)
DG-VDG-SSG
• DG-V and DG-S handle up to SCALE29 • SG handle up to SCALE30 • DG-V is faster than DG-S and SG Strong scaling for SCALE 27
• With 64 threads, these models achieve over 20X faster than sequential.
• Comparing 32 and 64 threads, HT was to produce a speedup of over 20%.
HT speedups are more than 20%.
Highest TEPS score
Largest SCALE
20x faster than seq.
#1 entry on 5th Green Graph500
HT
CPU: 4-way Intel Xeon E5-4640 (64 threads) Base-architecture: SandyBridge-EP RAM: 512 GB CC: GCC-4.4.7

SGI UV 2000 system • SGI UV 2000
– Shared-memory supercomputer based on cc-NUMA arch. – Running with a single Linux OS – User handles a large memory space by the thread parallelization
e.g. OpenMP or Pthreads (also can use MPI) – The full-spec. UV 2000 (4 racks) has 2,560 cores and 64 TB memory
• ISM, SGI, and us collaborate for the Graph500 benchmarks
The Institute of Statistical Mathematics • Japan's national research institute for statistical science.
#2 system
ISM has two Full-spec. UV 2000 (totality 8 racks)
#1 full spec. UV 2K
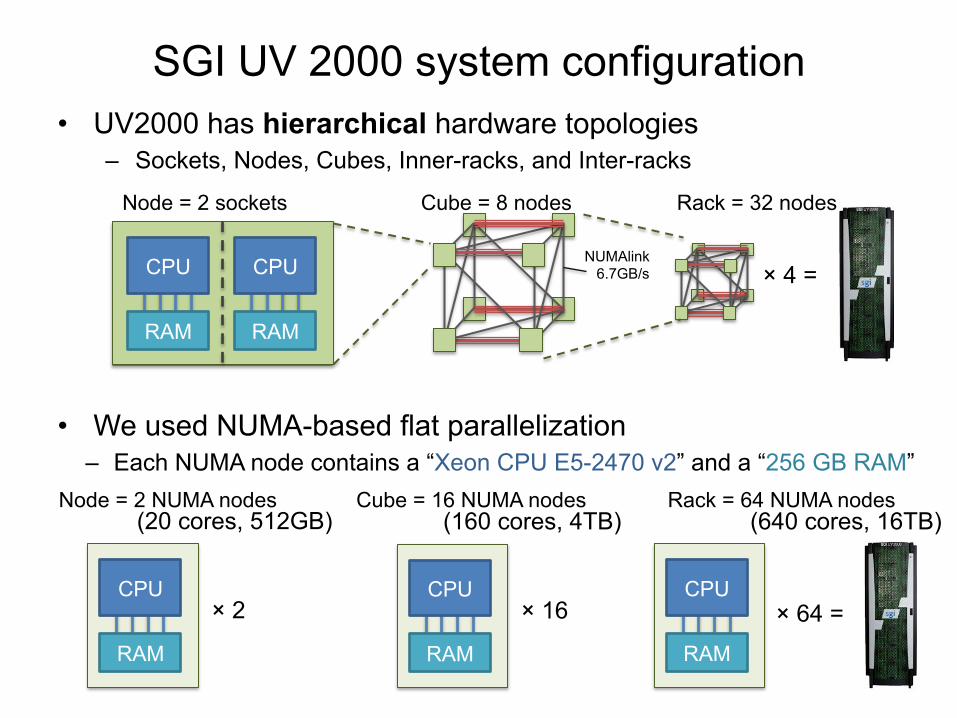
SGI UV 2000 system configuration • UV2000 has hierarchical hardware topologies
– Sockets, Nodes, Cubes, Inner-racks, and Inter-racks Node = 2 sockets Cube = 8 nodes Rack = 32 nodes
• We used NUMA-based flat parallelization – Each NUMA node contains a “Xeon CPU E5-2470 v2” and a “256 GB RAM”
CPU
RAM
CPU
RAM
× 4 =
CPU
RAM
Node = 2 NUMA nodes Rack = 64 NUMA nodes
× 64 = CPU
RAM
Cube = 16 NUMA nodes
× 2 CPU
RAM
× 16
NUMAlink 6.7GB/s
(20 cores, 512GB) (160 cores, 4TB) (640 cores, 16TB)
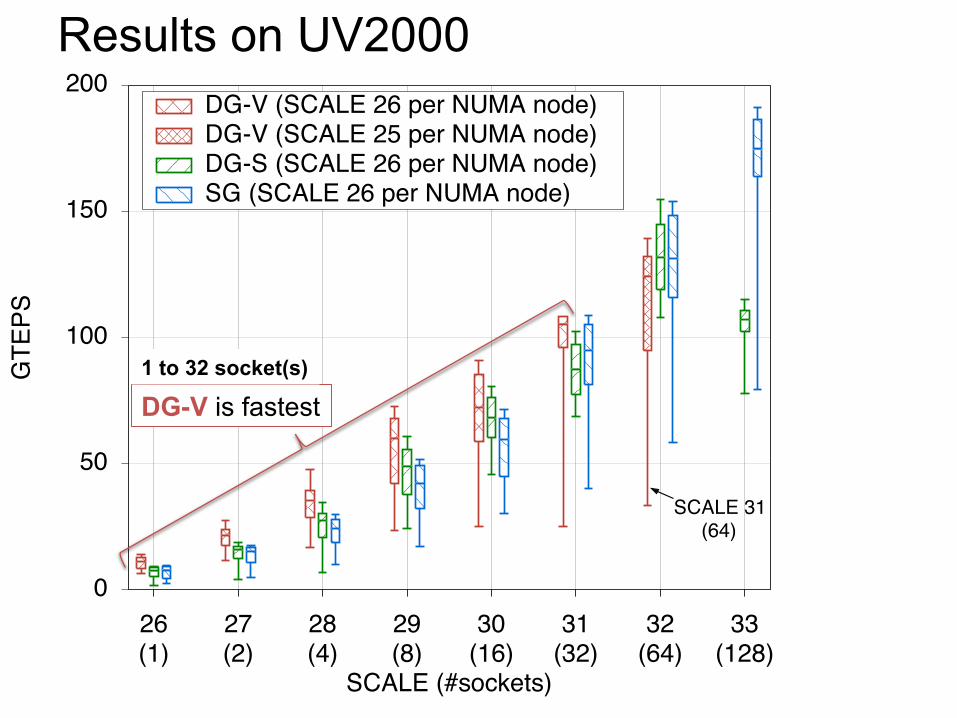
0
50
100
150
200
26(1)
27(2)
28(4)
29(8)
30(16)
31(32)
32(64)
33(128)
SCALE 31 (64)
GTE
PS
SCALE (#sockets)
DG-V (SCALE 26 per NUMA node)DG-V (SCALE 25 per NUMA node)DG-S (SCALE 26 per NUMA node)SG (SCALE 26 per NUMA node)
Results on UV2000
DG-V is fastest 1 to 32 socket(s)
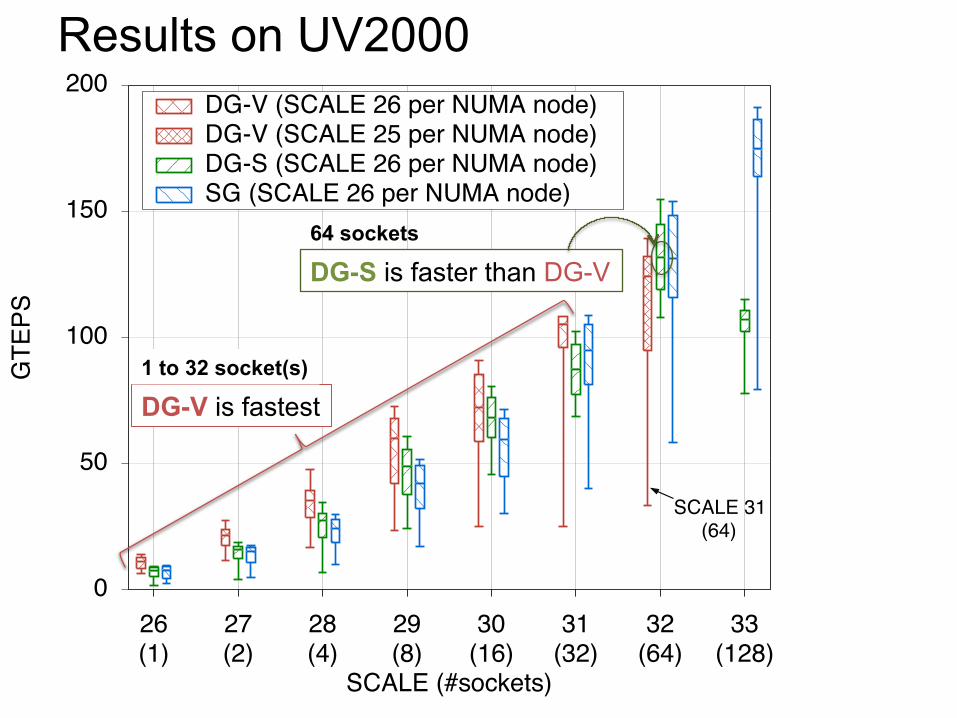
0
50
100
150
200
26(1)
27(2)
28(4)
29(8)
30(16)
31(32)
32(64)
33(128)
SCALE 31 (64)
GTE
PS
SCALE (#sockets)
DG-V (SCALE 26 per NUMA node)DG-V (SCALE 25 per NUMA node)DG-S (SCALE 26 per NUMA node)SG (SCALE 26 per NUMA node)
Results on UV2000
64 sockets
DG-S is faster than DG-V
DG-V is fastest 1 to 32 socket(s)
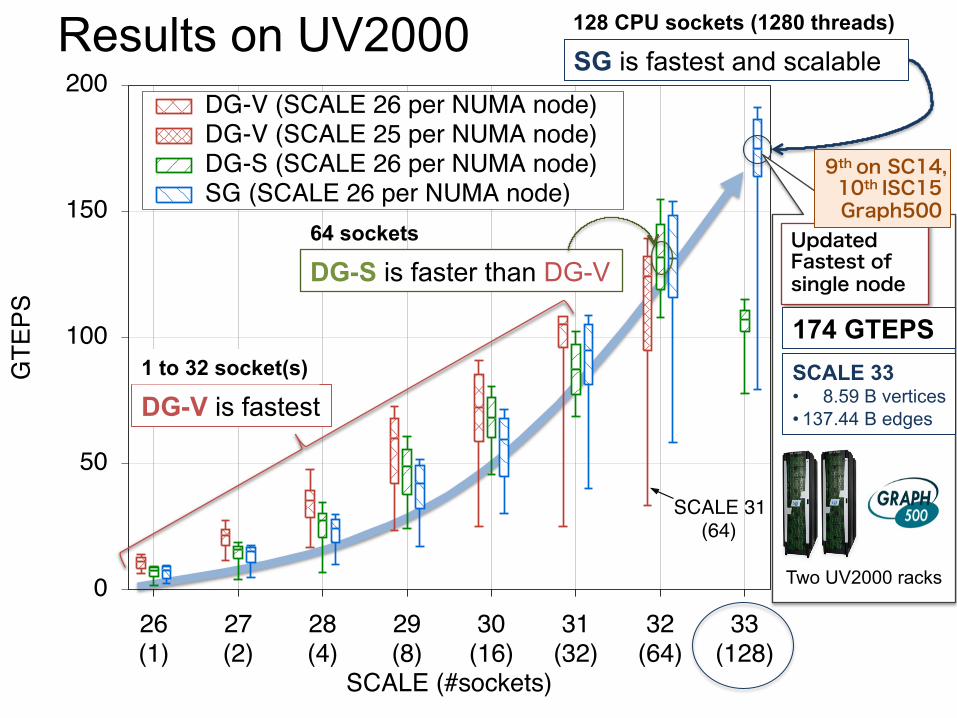
0
50
100
150
200
26(1)
27(2)
28(4)
29(8)
30(16)
31(32)
32(64)
33(128)
SCALE 31 (64)
GTE
PS
SCALE (#sockets)
DG-V (SCALE 26 per NUMA node)DG-V (SCALE 25 per NUMA node)DG-S (SCALE 26 per NUMA node)SG (SCALE 26 per NUMA node)
Results on UV2000
DG-V is fastest
SG is fastest and scalable
1 to 32 socket(s)
128 CPU sockets (1280 threads)
64 sockets Updated Fastest of single node
174 GTEPS
9th on SC14, 10th ISC15 Graph500
SCALE 33 • 8.59 B vertices • 137.44 B edges
Two UV2000 racks
DG-S is faster than DG-V

• 4-way Intel Xeon server – DG-V (High-TEPS) model achieves
the fastest single-server entries – SG (Largest-SCALE) model won
3rd, 4th, 5th Green Graph500 lists
5th Green Graph500 list 62.93 MTEPS/W 31.33 GTEPS
Our achievements of Graph500 benchmarks • UV 2000
– DG-S (Middle) model achieves 131 GTEPS with 640 threads and the most power-efficient of commercial supercomputers
4th Green Graph500 list 61.48 MTEPS/W 28.61 GTEPS
3rd Green Graph500 list 59.12 MTEPS/W 28.48 GTEPS
#1
#1
#1
ISC15 in Last week
#7 on 3rd list #9 on 4rd list
– SG (Largest-SCALE) model achieves 174 GTEPS for SCALE 33 with 1,280 threads and the fastest single-node entry

Conclusion 1. To develop the efficient graph algorithm considering the
hardware topology
⇒ New efficient implementation proposed.
2. Clarify the scalability of thread parallelization on the next generation computers, which has more than thousand threads in each node.
⇒ Our new impl. scales up to 1280 threads with OpenMP
3. To develop a library to improve the performance of a thread computing easily; managing the locality of memory access on a NUMA system.
⇒ Our library, called ULIBC, is available at Bitbucket;
https://bitbucket.org/yuichiro_yasui/ulibc �




























