Embed Size (px)
Citation preview

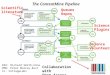
Architecture of TheContentMine
These slides are for enlightenment and presentations. Use http://discuss.contentmine.org/t/overall-architecture/142 for up-to-date info. Questions, comments and critiques welcome! All s/w is Open (BSD/Apache2)
Some diagrams are autogenerated from *.dot files which are located in the projects (mainly Norma and AMI)

catalogue
getpapers
query
DailyCrawl
EuPMC, arXivCORE , HAL,(UNIV repos)
ToCservices
PDF HTMLDOC ePUB TeX XML
PNGEPS CSV
XLSURLsDOIs
crawl
quickscrape
normaNormalizerStructurerSemanticTagger
Text
DataFigures
ami
UNIVRepos
search
LookupCONTENTMINING
Chem
Phylo
Trials
CrystalPlants
COMMUNITY
plugins
Visualizationand Analysis
PloSONE, BMC, peerJ… Nature, IEEE, Elsevier…
Publisher Sites
scrapersqueries
taggers
abstract
methods
references
CaptionedFigures
Fig. 1
HTML tables
30, 000 pages/day Semantic ScholarlyHTML
Facts
Latest 20150908

quickscrape Norma Index &Transform
XML
URL
DOI
DOC
CSV
sHTML
Plugins
SequencesSpecies
BespokeScrapers XPath
Taggers
Per- Journal
Chemistry
Phylogenetics Plants
AMI
BadHTML
OCR
Diagrams
CAT-alogue index
getpapersquery
Titles+ links
DailyCrawl/feed
EuPMC
JToCs
Latest 20150908; limited in scope

Starting points for ingestion(getpapers/quickscrape/Norma)
• Search/Crawl/Feed-> PMCID,DOI,URL -> quickscrape -> CTree(PDF,HTML,XML,images/,meta) -> Norma -> CMDir(sHTML|TXT|SVG|image) good
• PDF,XML,TXT,HTML -> Norma -> CTree(PDF,rawHTML,TXT,images/,meta?) -> NormaOCR|TXT2HTML -> CTree(sHTML,TXT,SVG) variable
20150908

Norma Conversions
• Paper-> Scanned -> TIFF (avoid) • PDF,TIFF,PNG -> Tesseract-N -> HTML, SVG
fast, variable• PDF -> PDF2SVG-N -> sHTML, SVG, images/.
slow, accurate-ish• PDF -> PDF2TXT-N -> TXT fast, variable• PDF -> PDF2Image-N -> PNG fast, accurate
20150908

Norma End points
• Norma -> CTree(OpenSHTML-SVG) -> everything?• Norma -> CTree(sHTML. sections) -> AMI -> all
text + species, chemText, sequences)• Norma -> CTree(TXT (unsectioned)) -> AMI ->
bagOfWords, regex, IDs, species?• Norma -> CTree(PNG) -> AMI -> phylo, bar/xy-
plots, • Norma -> CTree(SVG) -> AMI -> phylo, bar/xy-
plots, chemistry

Pre/early Norma toolchainTransforming PDF and PNG into higher value components
20150908Diagram autogenerated from *.dot graph

getpapers/quickscrape/Norma workflow
20150908Diagram autogenerated from *.dot graph

20150908Diagram autogenerated from *.dot graph
Getpapers/quickscrape/Norma: commonest uses

20150908Diagram autogenerated from *.dot graph
AMI: inputs and outputs for common plugins

Earlier diagrams
Probably significantly out of date, but may contain useful info.

NORMALIZE
NormaConvert PDF,XMLTo sHTMLTag sections
Normalized Scientific Literature
AMIIndexTransformExtractSearch
PDF2SVGXSL stylesheetsTaggers
normalizationParameters
“Permanent” Filestore
Temporary Filestore
Extracted factsindexes
PluginsRegex

PDFNon-UnicodePixel glyphsNo wordsNo structures
ScholarlyHTML
SVG
High-levelgraphics
PDF2SVG
characters
SentencesParastables
PNG OCR
TaggedSections
SVGBuilder
CaptionedFigures
NORMA
XSLT1/2

Raw HTMLNot wellformedBad charactersemantics
ScholarlyHTML
Well-formed XHTML
PNG
TaggedSections
CaptionedFigures
Tables
CaptionedTables
XMLHtmlTidyJsoupHtmlUnit
XSLT1/2
XSLT1/2
NORMA
Per-journalStylesheets

RSU: Richard Smith-UnnaPMR: Peter Murray-RustCL: CottageLabs
QueuesRepos
Scientificliterature
SciencePlugins
ScienceVolunteers
Collaboration with Open Access Button

quickscrapeCrawlFeed Norma Index &
Transform
TXTXML
URL
DOI
Scientificliterature
Repositories DOC
CSV
sHTML
PluginsRegex
SequencesSpecies
Bespoke
ScrapersXPathPer-Journal
TaggersPer- Journal
MetadataChemistry
Phylogenetics Farming
AMI
BadHTML
OCR
Diagrams
Open NORMA-lized Scientific Literature + Facts
CANARY pipeline
CAT-alogue index