Embed Size (px)
Citation preview

Josh Clemmwww.linkedin.com/in/joshclemm
SCALING LINKEDINA BRIEF HISTORY

Scaling = replacing all the components of a car while driving it at 100mph
“
Via Mike Krieger, “Scaling Instagram”

LinkedIn started back in 2003 to “connect to your network for better job opportunities.”
It had 2700 members in first week.

First week growth guesses from founding team

0M
50M
300M
250M
200M
150M
100M
400M
32M
2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015
5
400M
350M
Fast forward to today...

LinkedIn is a global site with over 400 million members
Web pages and mobile traffic are served at tens of thousands of queries per second
Backend systems serve millions of queries per second
LINKEDIN SCALE TODAY

7
How did we get there?

Let’s start from
the beginning

LEO
DB

DB
LEO
● Huge monolithic app called Leo
● Java, JSP, Servlets, JDBC
● Served every page, same SQL database
LEO
Circa 2003
LINKEDIN’S ORIGINAL ARCHITECTURE

So far so good, but two areas to improve:
1. The growing member to member connection graph
2. The ability to search those members

● Needed to live in-memory for top performance
● Used graph traversal queries not suitable for the shared SQL database.
● Different usage profile than other parts of site
MEMBER CONNECTION GRAPH

MEMBER CONNECTION GRAPH
So, a dedicated service was created.LinkedIn’s first service.
● Needed to live in-memory for top performance
● Used graph traversal queries not suitable for the shared SQL database.
● Different usage profile than other parts of site

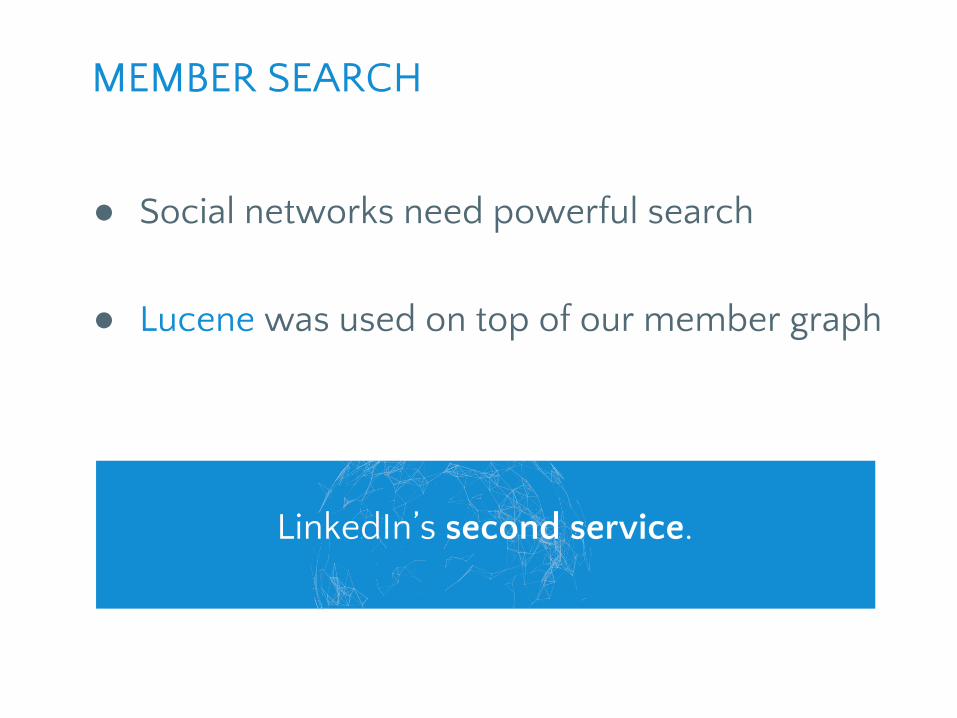
● Social networks need powerful search
● Lucene was used on top of our member graph
MEMBER SEARCH
● Social networks need powerful search
● Lucene was used on top of our member graph
MEMBER SEARCH
LinkedIn’s second service.

LINKEDIN WITH CONNECTION GRAPH AND SEARCH
Member GraphLEO
DB
RPC
Circa 2004
Lucene
Connection / Profile Updates

Getting better, but the single database was under heavy load.
Vertically scaling helped, but we needed to offload the read traffic...

● Master/slave concept
● Read-only traffic from replica
● Writes go to main DB
● Early version of Databus kept DBs in sync
REPLICA DBs
Main DBReplicaReplicaDatabus
relay Replica DB
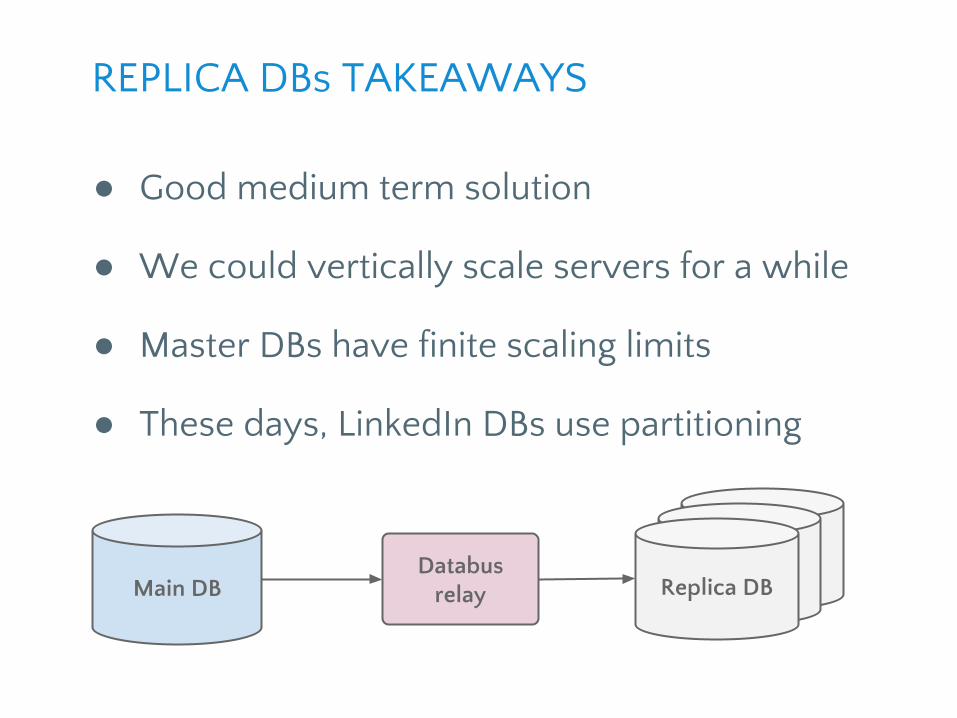
● Good medium term solution
● We could vertically scale servers for a while
● Master DBs have finite scaling limits
● These days, LinkedIn DBs use partitioning
REPLICA DBs TAKEAWAYS
Main DBReplicaReplicaDatabus
relay Replica DB

Member GraphLEO
RPC
Main DBReplicaReplicaDatabus relay Replica DB
Connection Updates
R/WR/O
Circa 2006
LINKEDIN WITH REPLICA DBs
Search
ProfileUpdates

As LinkedIn continued to grow, the monolithic application Leo was becoming problematic.
Leo was difficult to release, debug, and the site kept going down...




Kill LEOIT WAS TIME TO...

Public Profile Web App
Profile Service
LEO
Recruiter Web App
Yet another Service
Extracting services (Java Spring MVC) from legacy Leo monolithic application
Circa 2008 on
SERVICE ORIENTED ARCHITECTURE

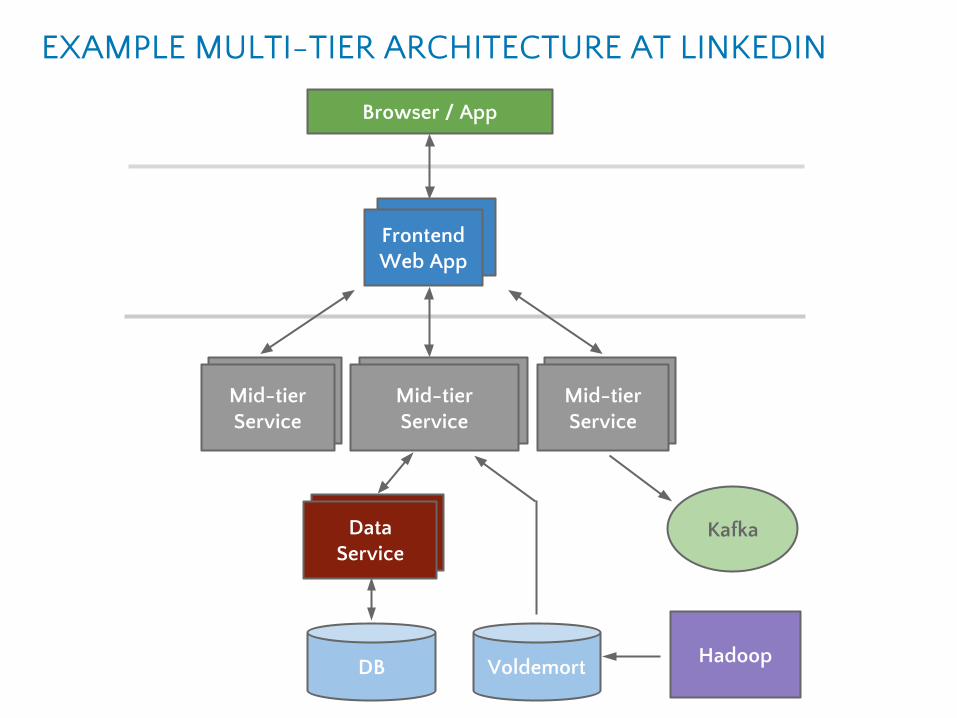
● Goal - create vertical stack of stateless services
● Frontend servers fetch data from many domains, build
HTML or JSON response
● Mid-tier services host APIs, business logic
● Data-tier or back-tier services encapsulate data domains
Profile Web App
Profile Service
Profile DB
SERVICE ORIENTED ARCHITECTURE

Groups Content Service
Connections Content Service
Profile Content Service
Browser / App
Frontend Web App
Mid-tier Service
Mid-tier Service
Mid-tierService
Edu Data ServiceData
Service
HadoopDB Voldemort
EXAMPLE MULTI-TIER ARCHITECTURE AT LINKEDIN
Kafka

PROS
● Stateless services easily scale
● Decoupled domains
● Build and deploy independently
CONS
● Ops overhead
● Introduces backwards compatibility issues
● Leads to complex call graphs and fanout
SERVICE ORIENTED ARCHITECTURE COMPARISON

bash$ eh -e %%prod | awk -F. '{ print $2 }' | sort | uniq | wc -l 756
● In 2003, LinkedIn had one service (Leo)
● By 2010, LinkedIn had over 150 services
● Today in 2015, LinkedIn has over 750 services
SERVICES AT LINKEDIN

Getting better, but LinkedIn was experiencing hypergrowth...


● Simple way to reduce load on servers and speed up responses
● Mid-tier caches store derived objects from different domains, reduce fanout
● Caches in the data layer
● We use memcache, couchbase, even Voldemort
Frontend Web App
Mid-tier Service
Cache
DB
Cache
CACHING

There are only two hard problems in Computer Science:
Cache invalidation, naming things, and off-by-one errors.
“
Via Twitter by Kellan Elliott-McCreaand later Jonathan Feinberg

CACHING TAKEAWAYS
● Caches are easy to add in the beginning, but complexity adds up over time.
● Over time LinkedIn removed many mid-tier caches because of the complexity around
invalidation
● We kept caches closer to data layer

CACHING TAKEAWAYS (cont.)
● Services must handle full load - caches improve speed, not permanent load bearing
solutions
● We’ll use a low latency solution like Voldemort when appropriate and precompute
results

LinkedIn’s hypergrowth was extending to the vast amounts of data it collected.
Individual pipelines to route that data weren’t scaling. A better solution was needed...


KAFKA MOTIVATIONS
● LinkedIn generates a ton of data○ Pageviews○ Edits on profile, companies, schools○ Logging, timing○ Invites, messaging○ Tracking
● Billions of events everyday
● Separate and independently created pipelines routed this data

A WHOLE LOT OF CUSTOM PIPELINES...

A WHOLE LOT OF CUSTOM PIPELINES...
As LinkedIn needed to scale, each pipeline needed to scale.

Distributed pub-sub messaging platform as LinkedIn’s universal data pipeline
KAFKA
Kafka
Frontend service
Frontend service
Backend Service
DWH Monitoring Analytics HadoopOracle

BENEFITS
● Enabled near realtime access to any data source
● Empowered Hadoop jobs
● Allowed LinkedIn to build realtime analytics
● Vastly improved site monitoring capability
● Enabled devs to visualize and track call graphs
● Over 1 trillion messages published per day, 10 million messages per second
KAFKA AT LINKEDIN

OVER 1 TRILLION PUBLISHED DAILYOVER 1 TRILLION PUBLISHED DAILY

Let’s end with
the modern years


● Services extracted from Leo or created new were inconsistent and often tightly coupled
● Rest.li was our move to a data model centric architecture
● It ensured a consistent stateless Restful API model across the company.
REST.LI

● By using JSON over HTTP, our new APIs supported non-Java-based clients.
● By using Dynamic Discovery (D2), we got load balancing, discovery, and scalability of
each service API.
● Today, LinkedIn has 1130+ Rest.li resources and over 100 billion Rest.li calls per day
REST.LI (cont.)

Rest.li Automatic API-documentation
REST.LI (cont.)

Rest.li R2/D2 tech stack
REST.LI (cont.)

LinkedIn’s success with Data infrastructure like Kafka and Databus led to the development of more and more scalable Data infrastructure solutions...

● It was clear LinkedIn could build data infrastructure that enables long term growth
● LinkedIn doubled down on infra solutions like:○ Storage solutions
■ Espresso, Voldemort, Ambry (media)
○ Analytics solutions like Pinot
○ Streaming solutions
■ Kafka, Databus, and Samza
○ Cloud solutions like Helix and Nuage
DATA INFRASTRUCTURE

DATABUS

LinkedIn is a global company and was continuing to see large growth. How else to scale?

● Natural progression of horizontally scaling
● Replicate data across many data centers using storage technology like Espresso
● Pin users to geographically close data center
● Difficult but necessary
MULTIPLE DATA CENTERS

● Multiple data centers are imperative to maintain high availability.
● You need to avoid any single point of failure not just for each service, but the entire site.
● LinkedIn runs out of three main data centers, additional PoPs around the globe, and more
coming online every day...
MULTIPLE DATA CENTERS
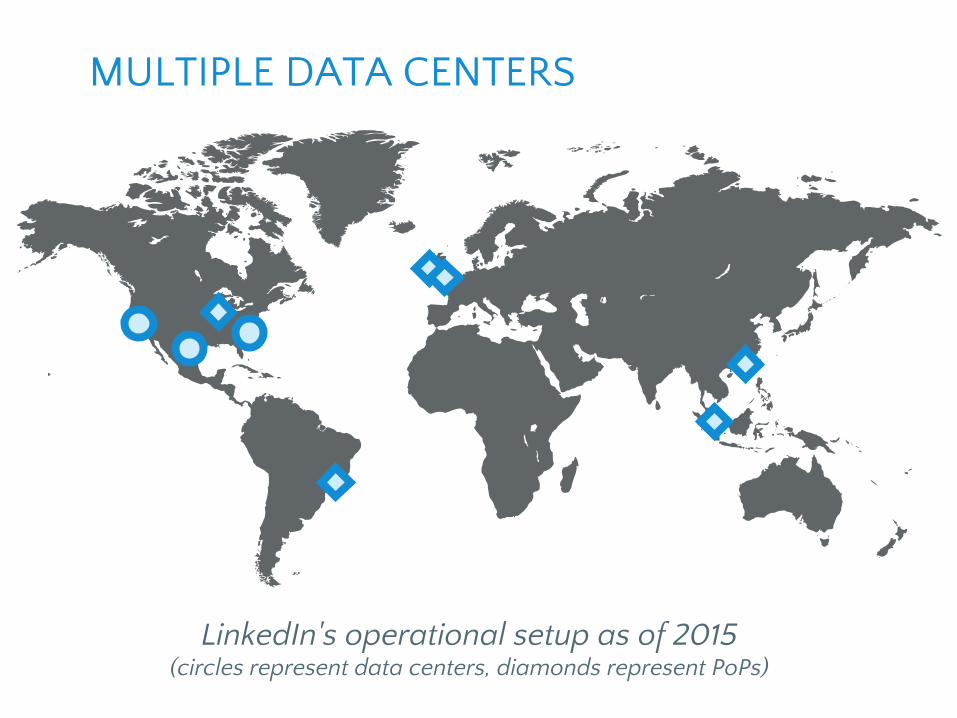
MULTIPLE DATA CENTERS
LinkedIn's operational setup as of 2015(circles represent data centers, diamonds represent PoPs)

Of course LinkedIn’s scaling story is never this simple, so what else have we done?

● Each of LinkedIn’s critical systems have undergone their own rich history of scale
(graph, search, analytics, profile backend,
comms, feed)
● LinkedIn uses Hadoop / Voldemort for insights like People You May Know, Similar profiles,
Notable Alumni, and profile browse maps.
WHAT ELSE HAVE WE DONE?

● Re-architected frontend approach using○ Client templates
○ BigPipe
○ Play Framework
● LinkedIn added multiple tiers of proxies using Apache Traffic Server and HAProxy
● We improved the performance of servers with new hardware, advanced system tuning, and
newer Java runtimes.
WHAT ELSE HAVE WE DONE? (cont.)

Scaling sounds easy and quick to do, right?

Hofstadter's Law: It always takes longer than you expect, even when you take
into account Hofstadter's Law.
“
Via Douglas Hofstadter, Gödel, Escher, Bach: An Eternal Golden Braid

Josh Clemmwww.linkedin.com/in/joshclemm
THANKS!

● Blog version of this slide deckhttps://engineering.linkedin.com/architecture/brief-history-scaling-linkedin
● Visual story of LinkedIn’s historyhttps://ourstory.linkedin.com/
● LinkedIn Engineering bloghttps://engineering.linkedin.com
● LinkedIn Open-Sourcehttps://engineering.linkedin.com/open-source
● LinkedIn’s communication system slides which include earliest LinkedIn architecture http://www.slideshare.
net/linkedin/linkedins-communication-architecture
● Slides which include earliest LinkedIn data infra workhttp://www.slideshare.net/r39132/linkedin-data-infrastructure-qcon-london-2012
LEARN MORE

● Project Inversion - internal project to enable developer productivity (trunk based model), faster deploys, unified serviceshttp://www.bloomberg.com/bw/articles/2013-04-10/inside-operation-inversion-the-code-freeze-that-saved-linkedin
● LinkedIn’s use of Apache Traffic serverhttp://www.slideshare.net/thenickberry/reflecting-a-year-after-migrating-to-apache-traffic-server
● Multi Data Center - testing fail overshttps://www.linkedin.com/pulse/armen-hamstra-how-he-broke-linkedin-got-promoted-angel-au-yeung
LEARN MORE (cont.)

● History and motivation around Kafkahttp://www.confluent.io/blog/stream-data-platform-1/
● Thinking about streaming solutions as a commit loghttps://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
● Kafka enabling monitoring and alertinghttp://engineering.linkedin.com/52/autometrics-self-service-metrics-collection
● Kafka enabling real-time analytics (Pinot)http://engineering.linkedin.com/analytics/real-time-analytics-massive-scale-pinot
● Kafka’s current use and future at LinkedInhttp://engineering.linkedin.com/kafka/kafka-linkedin-current-and-future
● Kafka processing 1 trillion events per dayhttps://engineering.linkedin.com/apache-kafka/how-we_re-improving-and-advancing-kafka-linkedin
LEARN MORE - KAFKA

● Open sourcing Databushttps://engineering.linkedin.com/data-replication/open-sourcing-databus-linkedins-low-latency-change-data-capture-system
● Samza streams to help LinkedIn view call graphshttps://engineering.linkedin.com/samza/real-time-insights-linkedins-performance-using-apache-samza
● Real-time analytics (Pinot)http://engineering.linkedin.com/analytics/real-time-analytics-massive-scale-pinot
● Introducing Espresso data storehttp://engineering.linkedin.com/espresso/introducing-espresso-linkedins-hot-new-distributed-document-store
LEARN MORE - DATA INFRASTRUCTURE

● LinkedIn’s use of client templates○ Dust.js
http://www.slideshare.net/brikis98/dustjs
○ Profilehttp://engineering.linkedin.com/profile/engineering-new-linkedin-profile
● Big Pipe on LinkedIn’s homepagehttp://engineering.linkedin.com/frontend/new-technologies-new-linkedin-home-page
● Play Framework
○ Introduction at LinkedIn https://engineering.linkedin.
com/play/composable-and-streamable-play-apps
○ Switching to non-block asynchronous modelhttps://engineering.linkedin.com/play/play-framework-async-io-without-thread-pool-and-callback-hell
LEARN MORE - FRONTEND TECH

● Introduction to Rest.li and how it helps LinkedIn scale
http://engineering.linkedin.com/architecture/restli-restful-service-architecture-scale
● How Rest.li expanded across the company
http://engineering.linkedin.com/restli/linkedins-restli-moment
LEARN MORE - REST.LI

● JVM memory tuning
http://engineering.linkedin.com/garbage-collection/garbage-collection-optimization-high-
throughput-and-low-latency-java-applications
● System tuning
http://engineering.linkedin.com/performance/optimizing-linux-memory-management-
low-latency-high-throughput-databases
● Optimizing JVM tuning automatically
https://engineering.linkedin.com/java/optimizing-java-cms-garbage-collections-its-
difficulties-and-using-jtune-solution
LEARN MORE - SYSTEM TUNING

LinkedIn continues to grow quickly and there’s still a ton of work we can do to improve.
We’re working on problems that very few ever get to solve - come join us!
WE’RE HIRING