Embed Size (px)
Citation preview

Real-Time Big Data with Storm, Kafka and
GigaSpaces.
Building own Real-Time Google Analytics
Oleksiy DyagilevLead Software EngineerEpam Systems

Real-time
• must guarantee response within strict time constraints• deadline must be
met regardless of system loadABS (anti-lock brakes )
railway switching systemchess playing program
Near Real-time
• time delay introduced by data processing or network transmission
• "no significant delays"video streaming
analytical applications

Big Data
• data sets so large and complex that it becomes difficult to process using traditional data processing applications• volume (terabytes,
petabytes)• velocity (speed of data in
and out)• variety (various data
sources, structured and unstructured)
IoT(Internet of Things)mobile devicessensor data (meteo, genomics, geo, bio, etc)social mediaInternet searchuser activity trackingsoftware logs
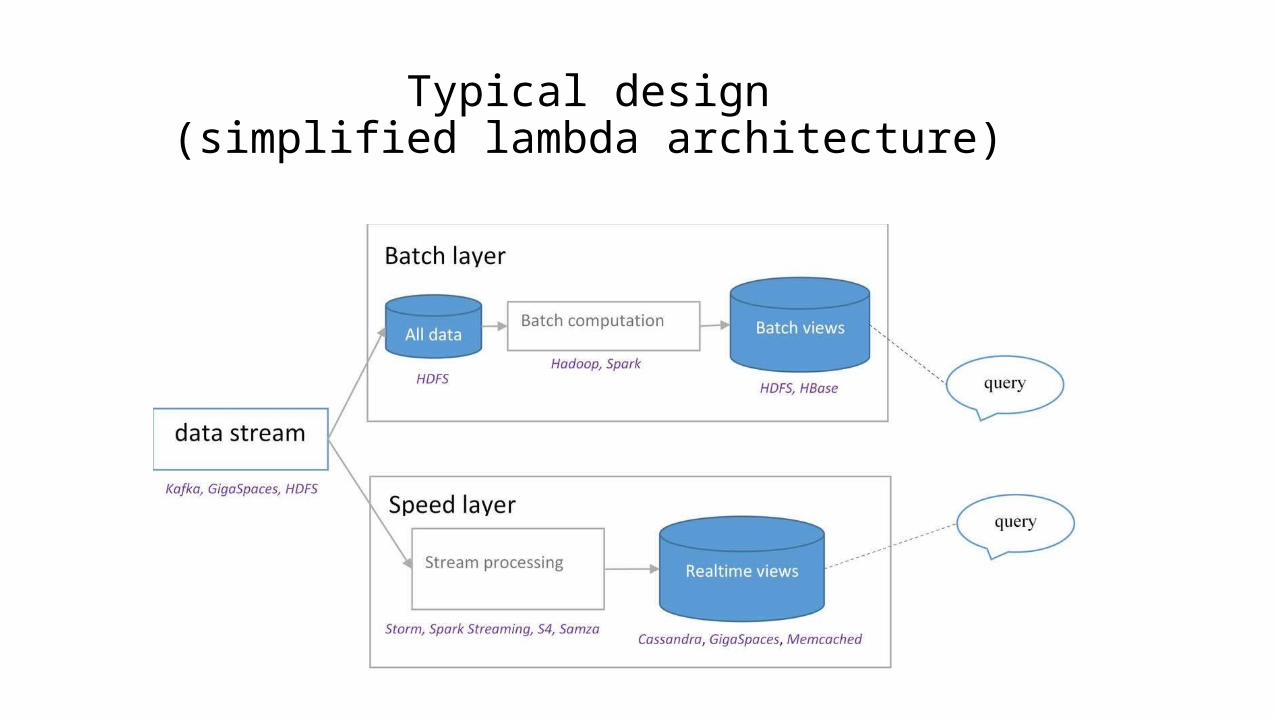
Typical design(simplified lambda architecture)

Questions?
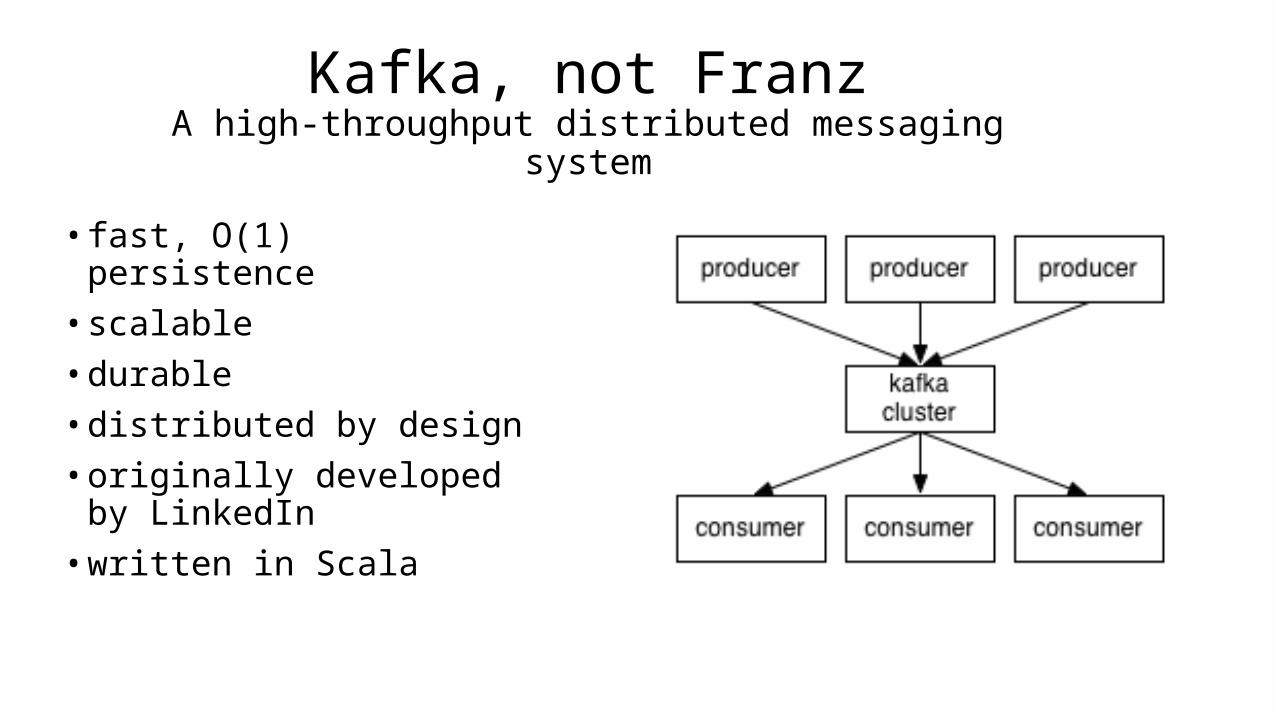
Kafka, not FranzA high-throughput distributed messaging
system
• fast, O(1) persistence• scalable• durable• distributed by design• originally developed by
LinkedIn• written in Scala
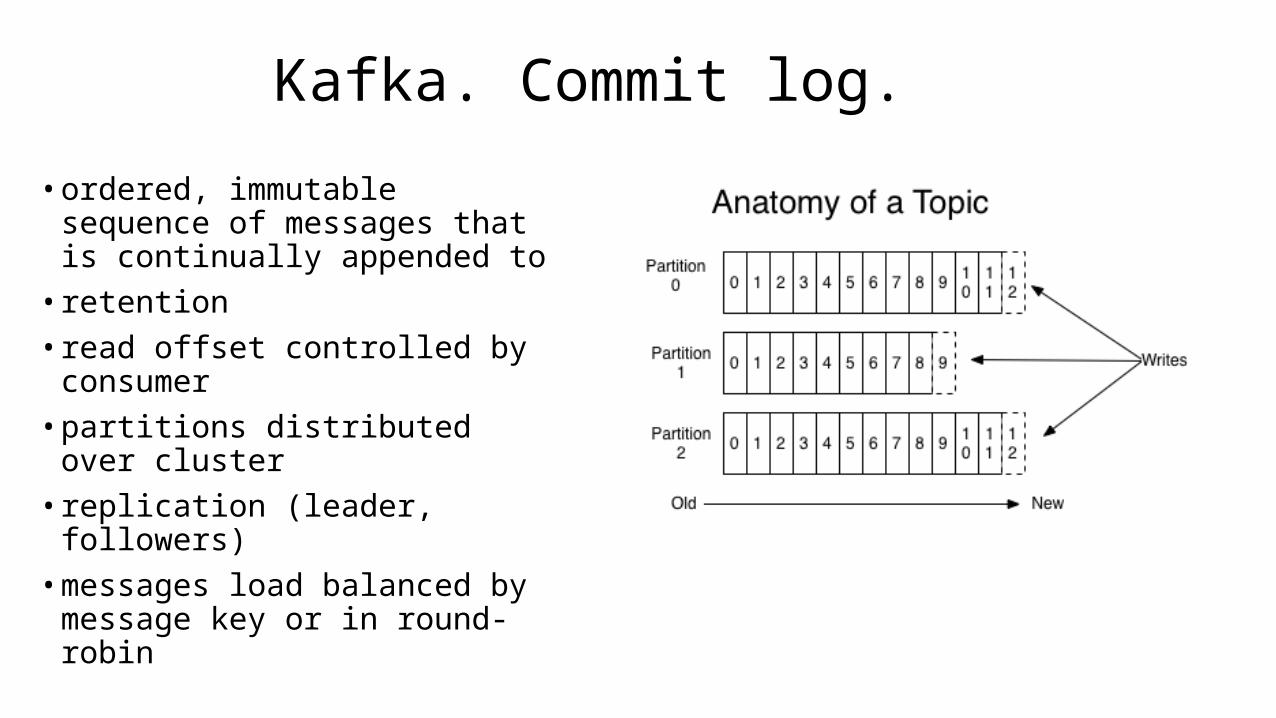
Kafka. Commit log.
• ordered, immutable sequence of messages that is continually appended to• retention• read offset controlled by
consumer• partitions distributed over
cluster• replication (leader, followers)• messages load balanced by
message key or in round-robin

Kafka. Internals• disks are slow! .. oh wait ...• random access vs sequential matters a lot• 6*7200rpm SATA RAID-5 array. Random writes - 100k/sec.
Sequential - 600MB/sec [1]• according to ACM Queue article in some cases seq. write
of eight 15000 rpm SAS disks in RAID-5 can be faster than memory random access (mind artice date!)

Kafka. Internals
• OS pagecache, read-ahead, write-behind• flush after K seconds or N messages• no need to delete data(comparing to in-memory solutions)• no need to keep state what has been consumed (controlled
by consumer, one integer per partition in ZK)• no GC penalties• no overhead for JVM objects• batching• end-to-end batch compression • linux sendfile() system call: eliminate context switches and
memory copy (nio.FileChannel.transferTo())
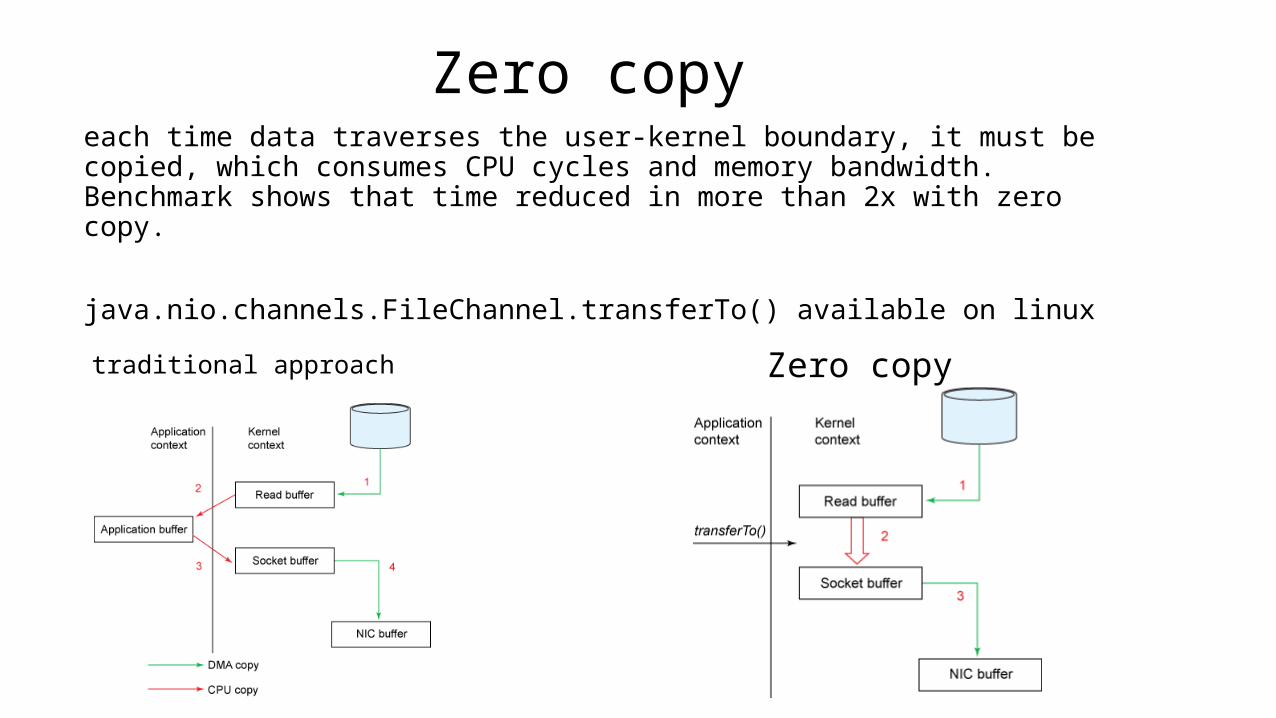
Zero copyeach time data traverses the user-kernel boundary, it must be copied, which consumes CPU cycles and memory bandwidth. Benchmark shows that time reduced in more than 2x with zero copy.
java.nio.channels.FileChannel.transferTo() available on linuxtraditional approach Zero copy

Kafka. Ordering guarantees.
• Messages sent by a producer to a particular topic partition will be appended in the order they are sent. • Messages delivered asynchronously to consumers, so may
arrive out of order on different consumers• Kafka assigns partition to consumer to guarantee ordering within partition, so that partition consumed by 1 consumer in the group.• No global ordering across partitions, the only way is to
have single partition and single consumer which doesn't scale.

Kafka. Delivery semanticsProducer:
• synchronous
• asynchronous
• wait for replication or not
To guarantee exactly-once:
• include PK and deduplicate on consumer
• or single writer per partition and check last message in case of network error
Consumer:
• at least once: read, process, commit position.
• at most once: read, commit position, process.
• exactly-once: need application level logic, keep offset together with data
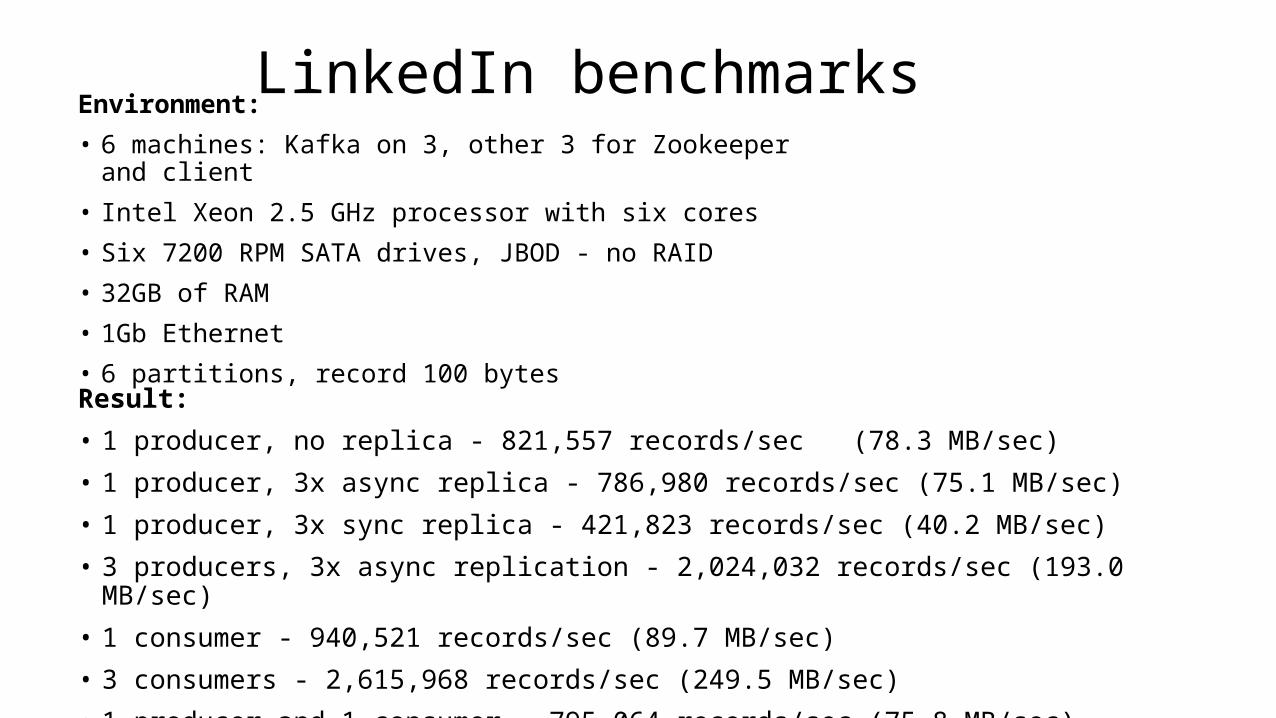
LinkedIn benchmarksEnvironment:
• 6 machines: Kafka on 3, other 3 for Zookeeper and client
• Intel Xeon 2.5 GHz processor with six cores
• Six 7200 RPM SATA drives, JBOD - no RAID
• 32GB of RAM
• 1Gb Ethernet
• 6 partitions, record 100 bytesResult:
• 1 producer, no replica - 821,557 records/sec (78.3 MB/sec)
• 1 producer, 3x async replica - 786,980 records/sec (75.1 MB/sec)
• 1 producer, 3x sync replica - 421,823 records/sec (40.2 MB/sec)
• 3 producers, 3x async replication - 2,024,032 records/sec (193.0 MB/sec)
• 1 consumer - 940,521 records/sec (89.7 MB/sec)
• 3 consumers - 2,615,968 records/sec (249.5 MB/sec)
• 1 producer and 1 consumer - 795,064 records/sec (75.8 MB/sec)

Questions?

Apache StormFree and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing
for realtime processing what Hadoop did for batch processing
• scalable • fault-tolerant• guarantees data will be processed• originally written by Nathan Marz in Java/Clojure, then
adopted by Twitter• now in Apache incubator• used by dozens of companies• active community
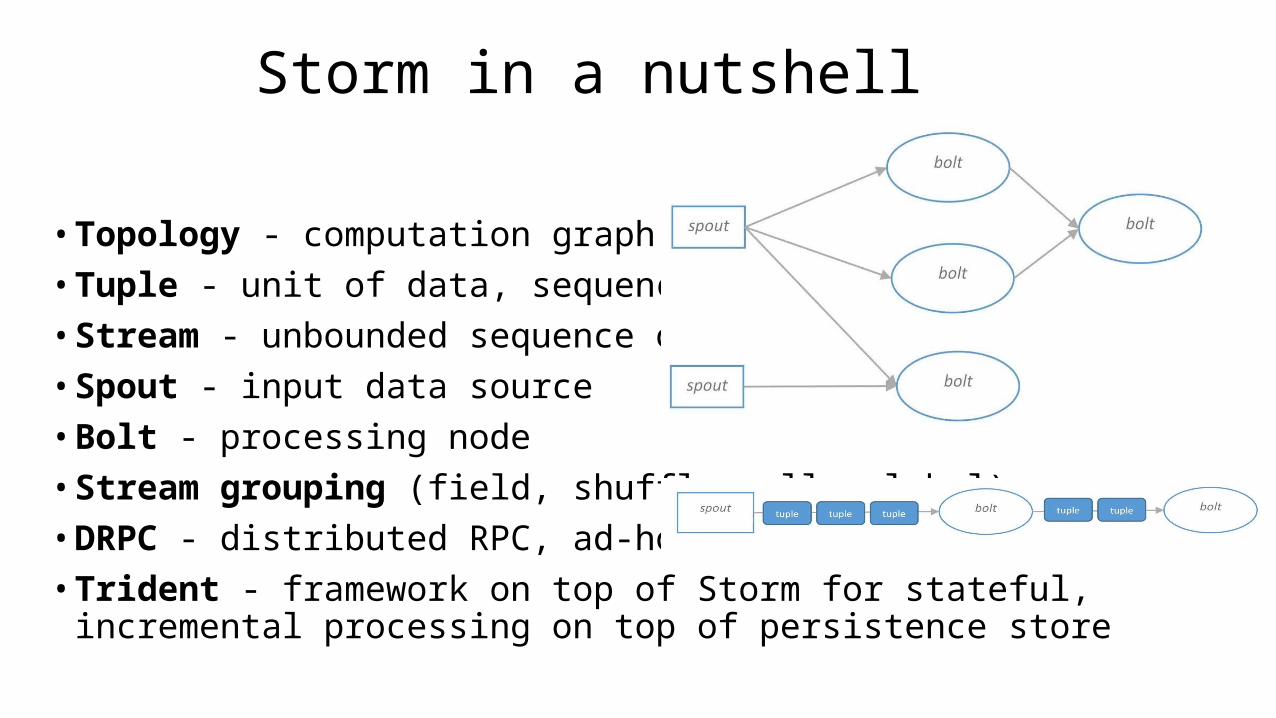
Storm in a nutshell
• Topology - computation graph• Tuple - unit of data, sequence of fields• Stream - unbounded sequence of tuples• Spout - input data source• Bolt - processing node• Stream grouping (field, shuffle, all, global)• DRPC - distributed RPC, ad-hoc queries• Trident - framework on top of Storm for stateful, incremental
processing on top of persistence store
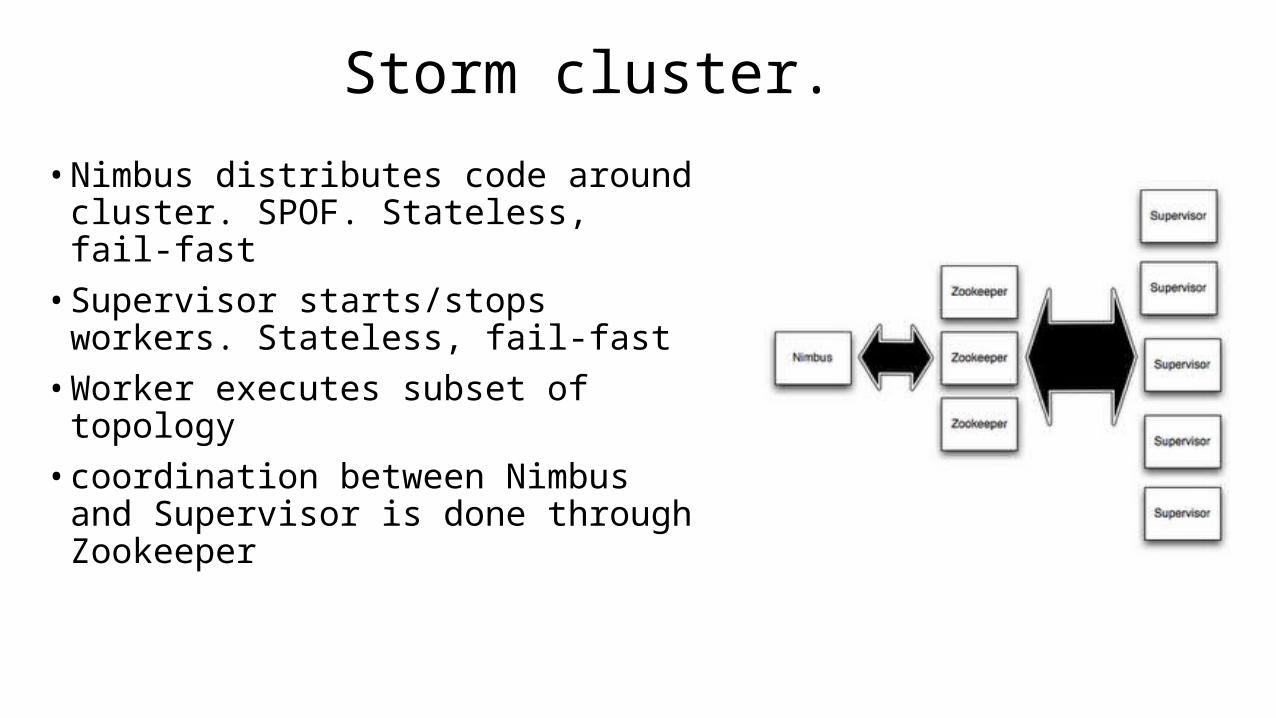
Storm cluster.
• Nimbus distributes code around cluster. SPOF. Stateless, fail-fast• Supervisor starts/stops workers.
Stateless, fail-fast• Worker executes subset of topology• coordination between Nimbus and
Supervisor is done through Zookeeper
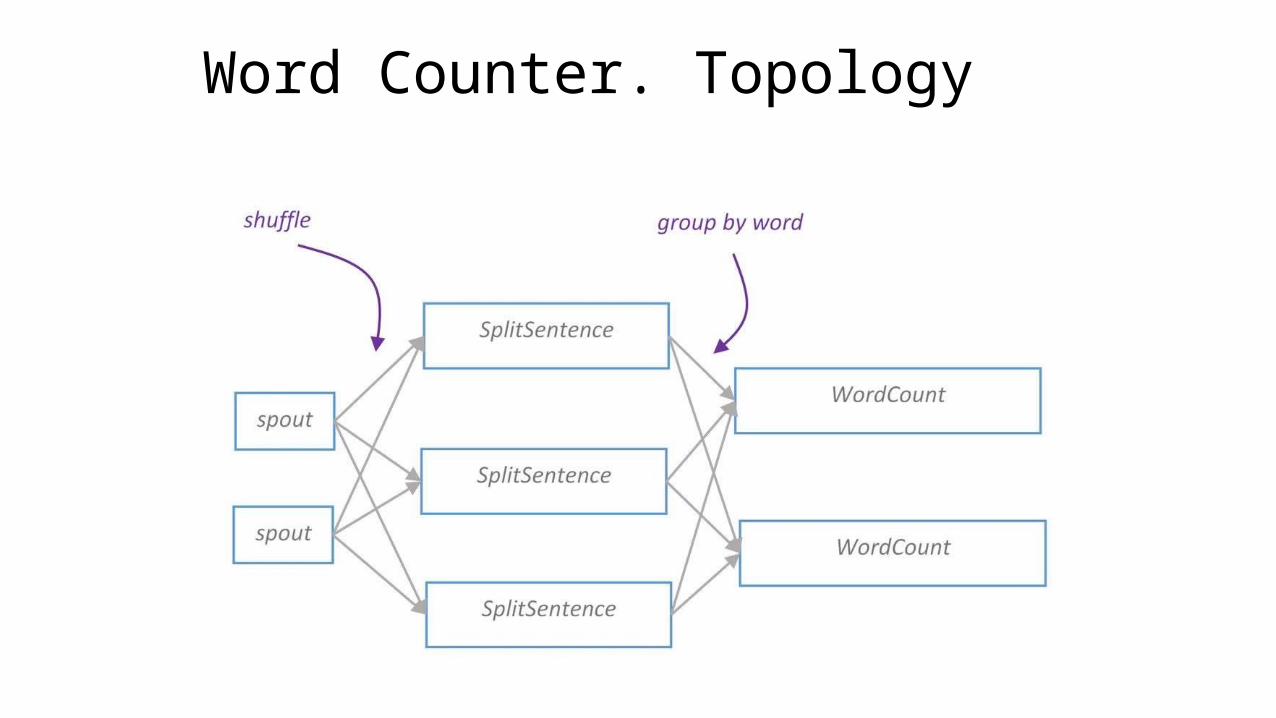
Word Counter. Topology

Word Counter. Topology
class SplitSentence extends BaseBasicBolt {
@Override public void execute(Tuple tuple, BasicOutputCollector collector) { String string = tuple.getString(0); for (String word : string.split(" ")) { collector.emit(new Values(word)); } }
@Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); }}

Storm. Word counter.class WordCount extends BaseBasicBolt { Map<String, Integer> counts = new HashMap<>();
@Override public void execute(Tuple tuple, BasicOutputCollector collector) { String word = tuple.getString(0); Integer count = counts.get(word); if (count == null) count = 0; count++; counts.put(word, count); collector.emit(new Values(word, count)); }
@Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word", "count")); }}

Storm. Word counter.
public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config(); conf.setNumWorkers(3); StormSubmitter.submitTopologyWithProgressBar("word-counter", conf, builder.createTopology());}
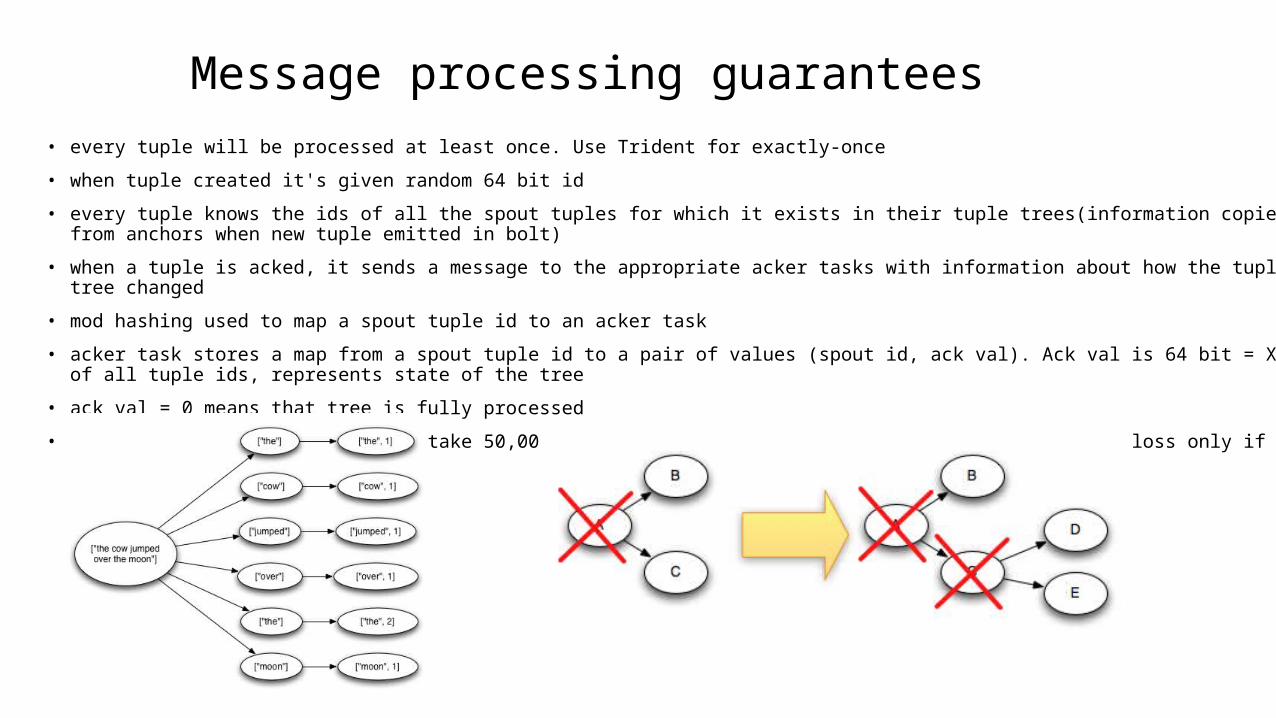
Message processing guarantees• every tuple will be processed at least once. Use Trident for exactly-once
• when tuple created it's given random 64 bit id
• every tuple knows the ids of all the spout tuples for which it exists in their tuple trees(information copied from anchors when new tuple emitted in bolt)
• when a tuple is acked, it sends a message to the appropriate acker tasks with information about how the tuple tree changed
• mod hashing used to map a spout tuple id to an acker task
• acker task stores a map from a spout tuple id to a pair of values (spout id, ack val). Ack val is 64 bit = XOR of all tuple ids, represents state of the tree
• ack val = 0 means that tree is fully processed
• at 10K acks per second, it will take 50,000,000 years until a mistake is made. Will cause data loss only if tuple fails

TridentTrident is a high-level abstraction for doing stateful, incremental processing on top of persistence store
• tuples are processed as small batches• exactly-once processing• “transactional” datastore persistence• functional API: joins, aggregations, grouping, functions, and
filters• compiles into as efficient of a Storm topology as possible

Word counter with Trident
TridentState wordCounts = topology .newStream("spout1", spout).parallelismHint(16) .each(new Fields("sentence"), new Split(), new Fields("word")) .groupBy(new Fields("word")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")).parallelismHint(16);
topology.newDRPCStream("words", drpc) .each(new Fields("args"), new Split(), new Fields("word")) .groupBy(new Fields("word")) .stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count")) .each(new Fields("count"), new FilterNull()) .aggregate(new Fields("count"), new Sum(), new Fields("sum"));
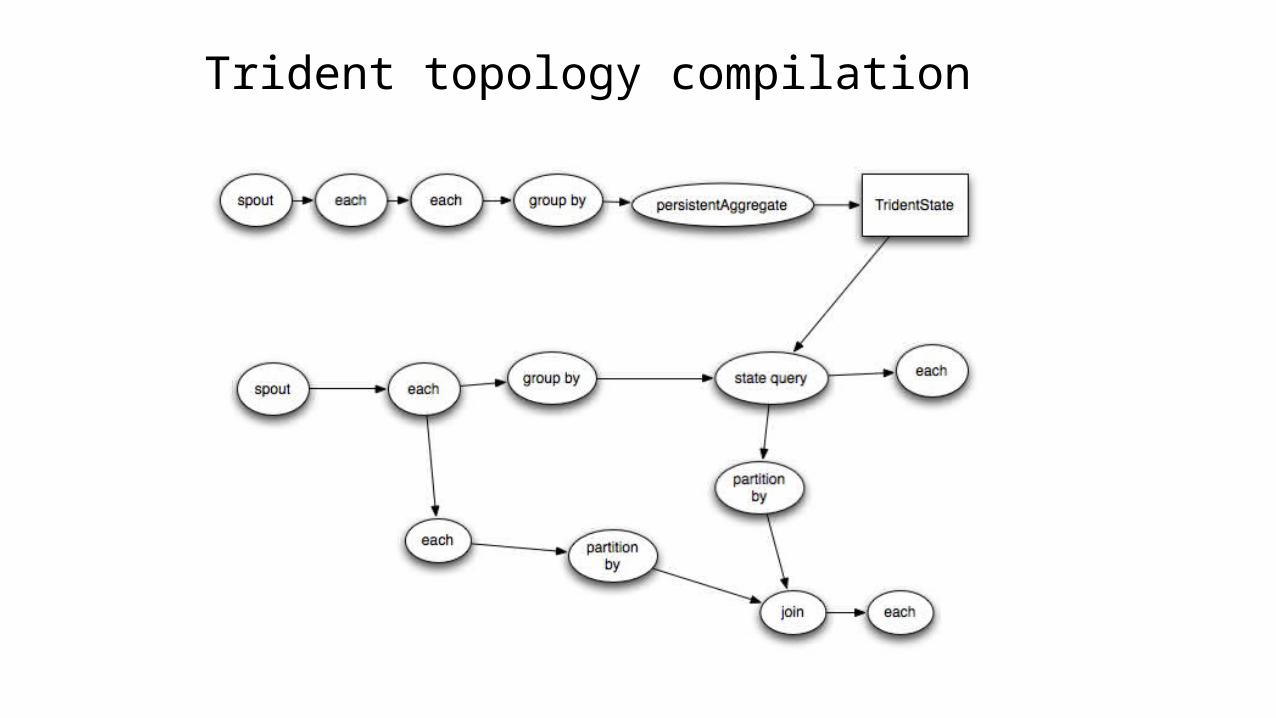
Trident topology compilation
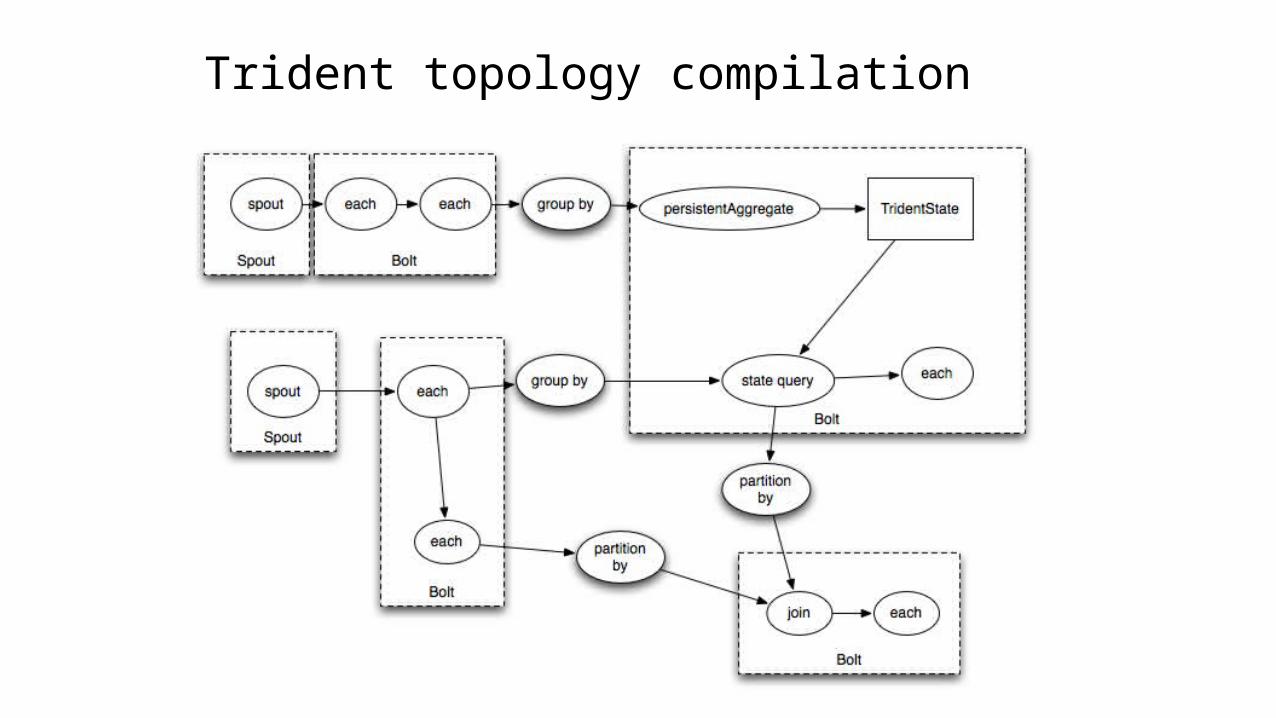
Trident topology compilation

How Trident guarantees exactly-once semantics?
• Each batch of tuples is given a unique id called the “transaction id” (txid). If the batch is replayed, it is given the exact same txid.
• State updates are ordered among batches. That is, the state updates for batch 3 won’t be applied until the state updates for batch 2 have succeeded. Note: pipelining
Consider 'transactional' spout:
1. Batches for a given txid are always the same. Replays of batches for a txid will exact same set of tuples as the first time that batch was emitted for that txid.
2. There’s no overlap between batches of tuples (tuples are in one batch or another, never multiple).
3. Every tuple is in a batch (no tuples are skipped)
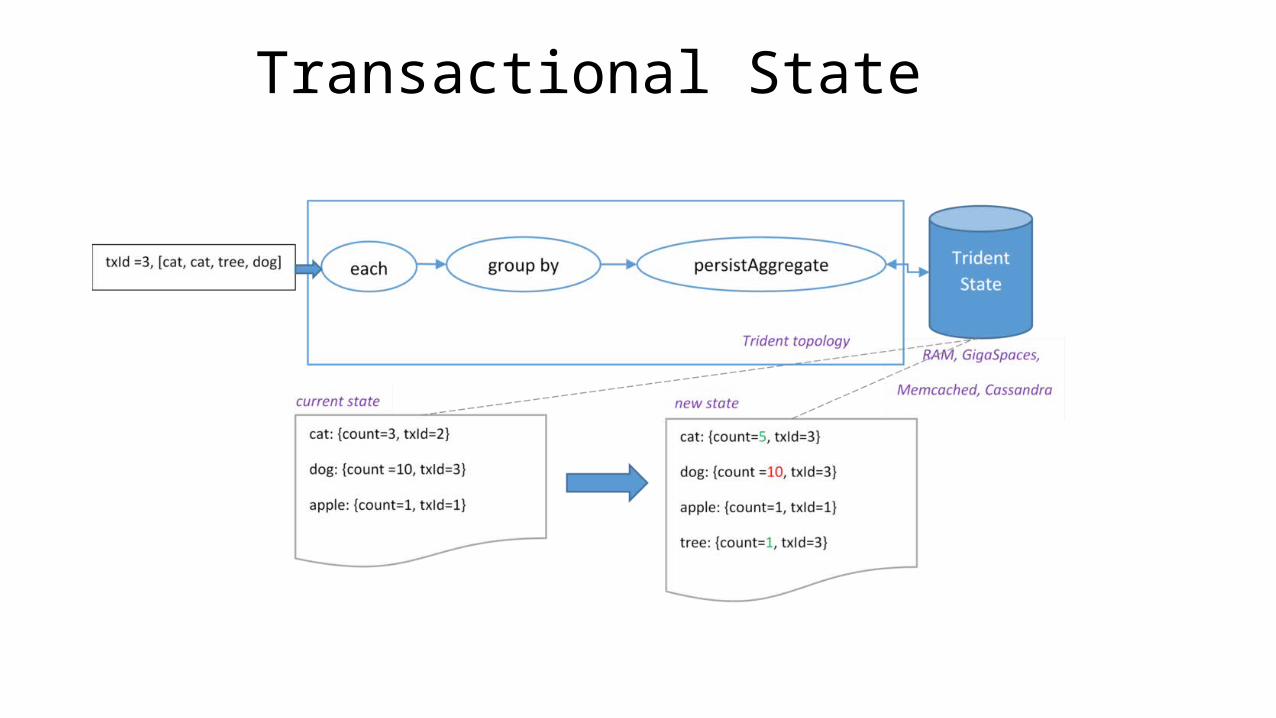
Transactional State

Questions?
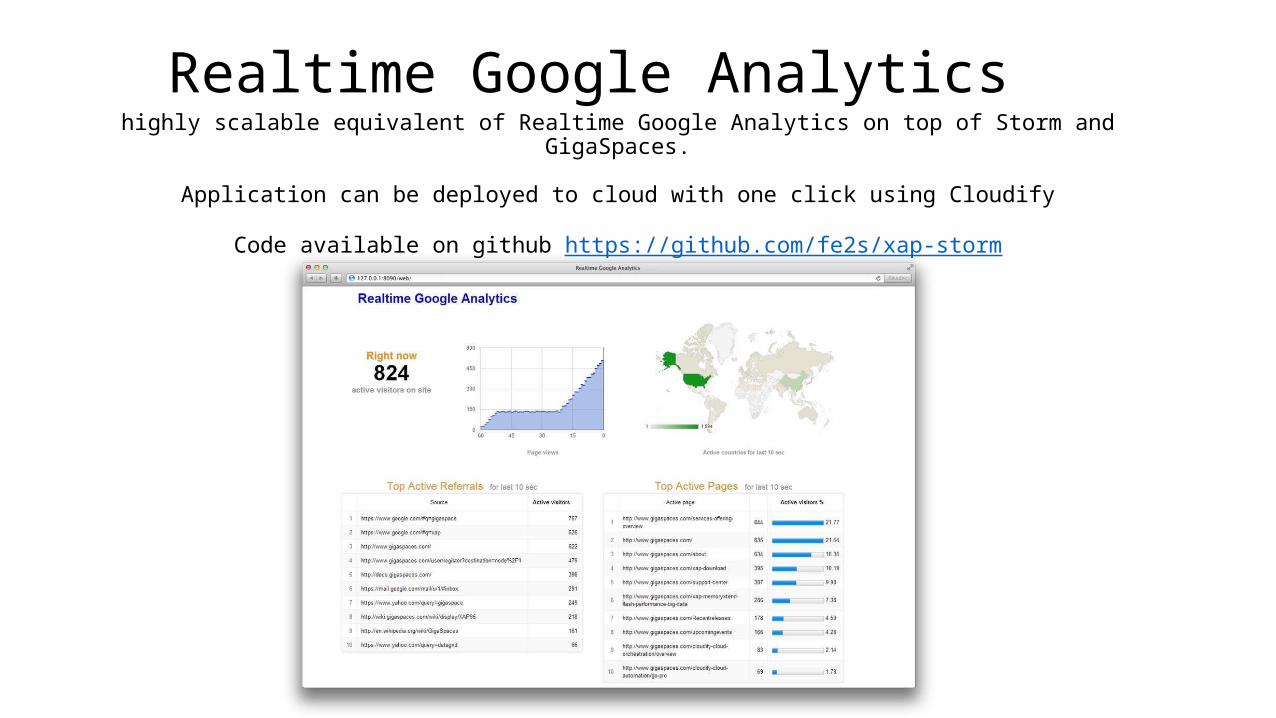
Realtime Google Analyticshighly scalable equivalent of Realtime Google Analytics on top of Storm and GigaSpaces.
Application can be deployed to cloud with one click using Cloudify
Code available on github https://github.com/fe2s/xap-storm

Live demo
• web • xap • storm ui• cloudify
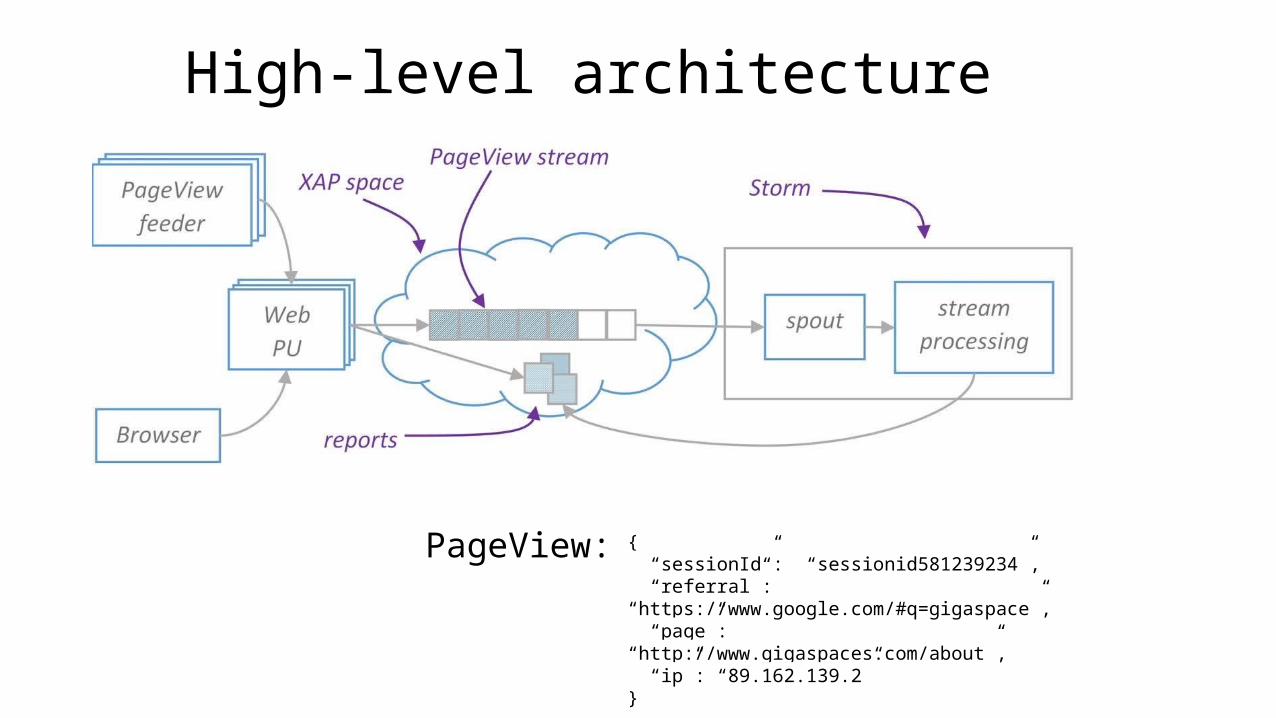
High-level architecture
{ “sessionId”: “sessionid581239234”, “referral”: “https://www.google.com/#q=gigaspace”, “page”: “http://www.gigaspaces.com/about”, “ip”: “89.162.139.2”}
PageView:
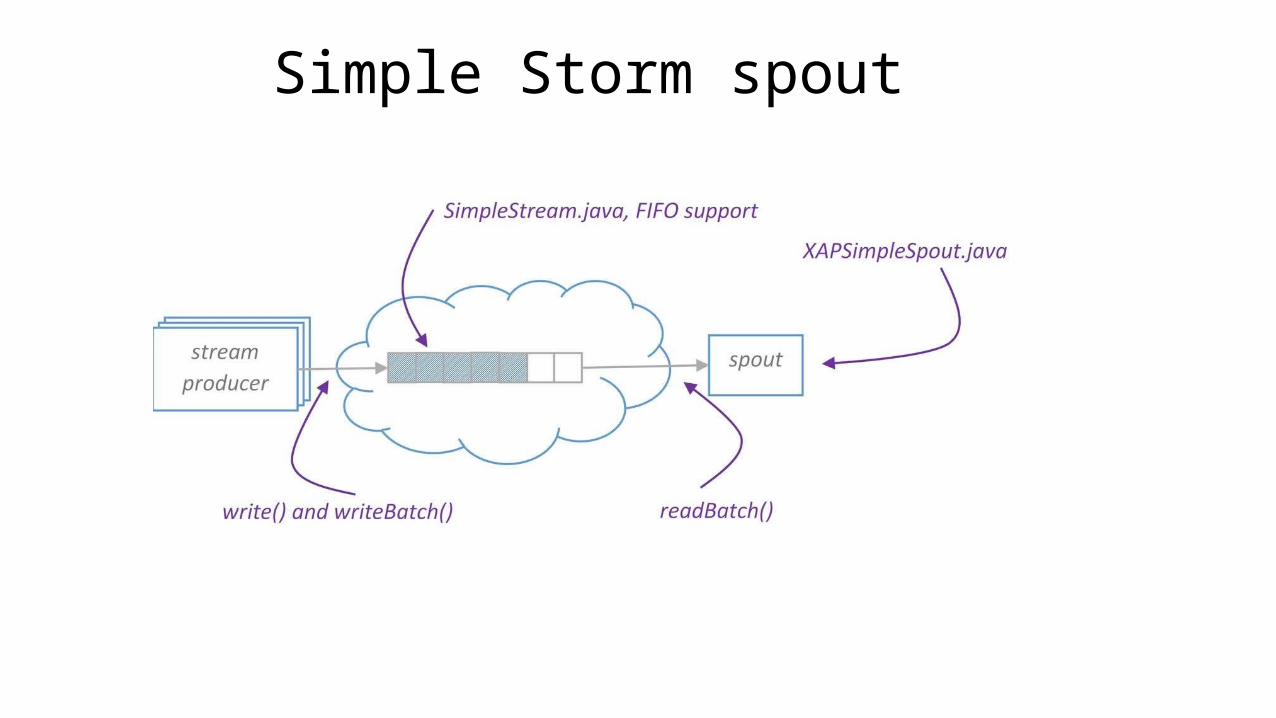
Simple Storm spout
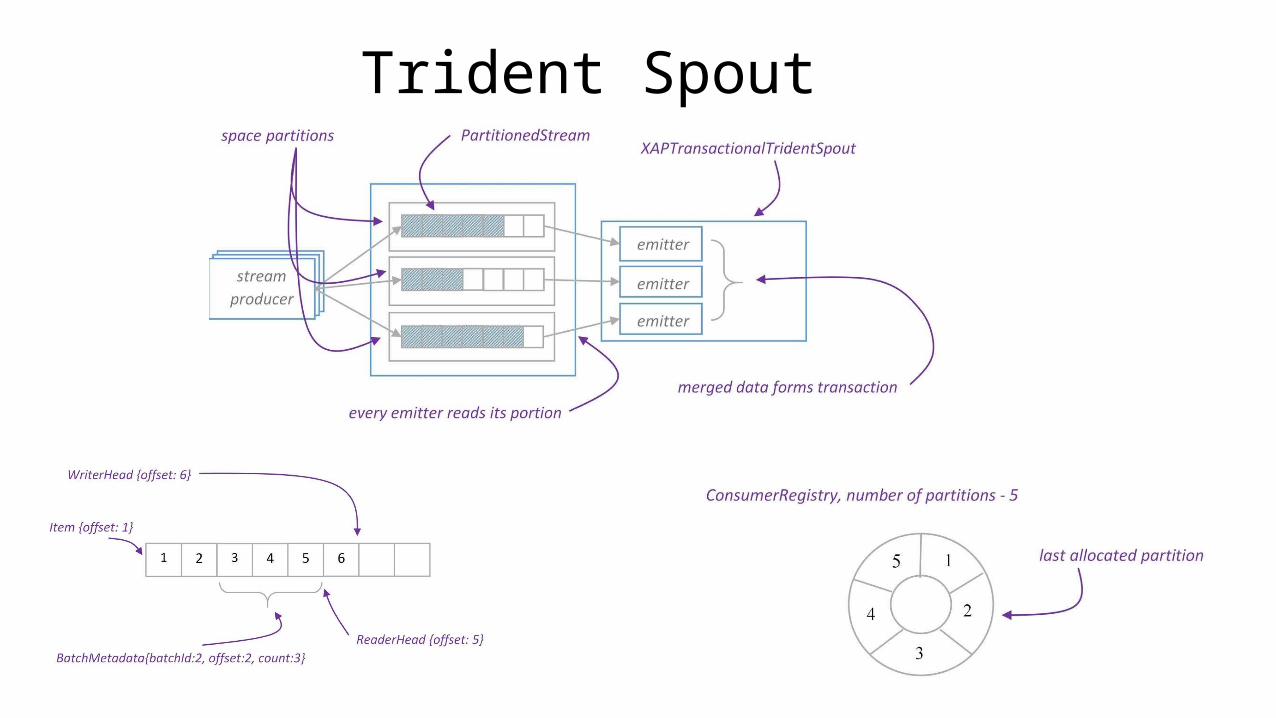
Trident Spout
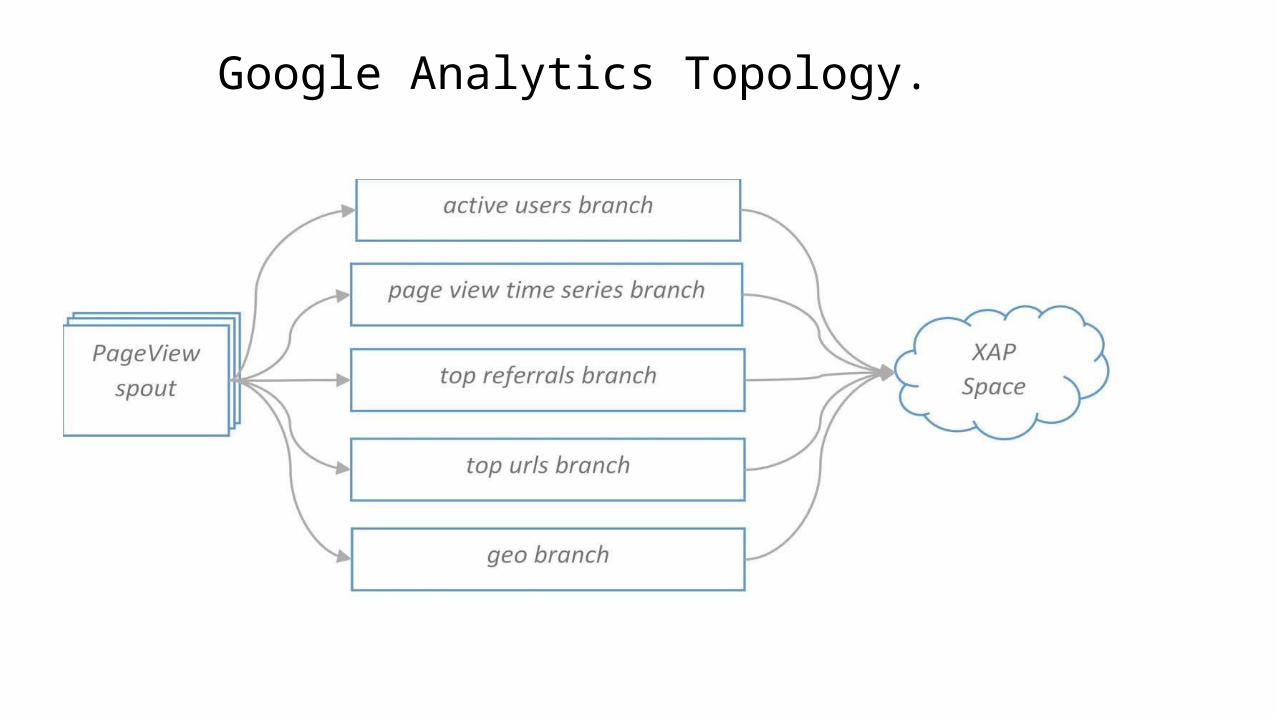
Google Analytics Topology.
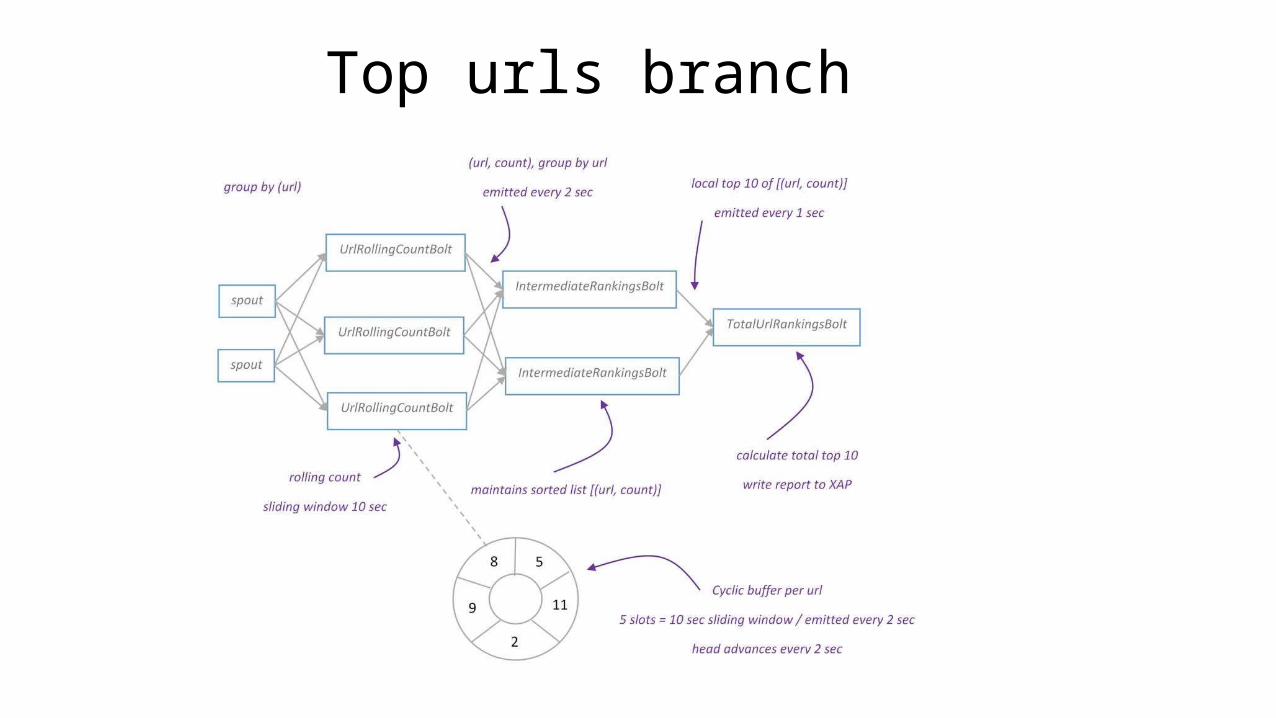
Top urls branch
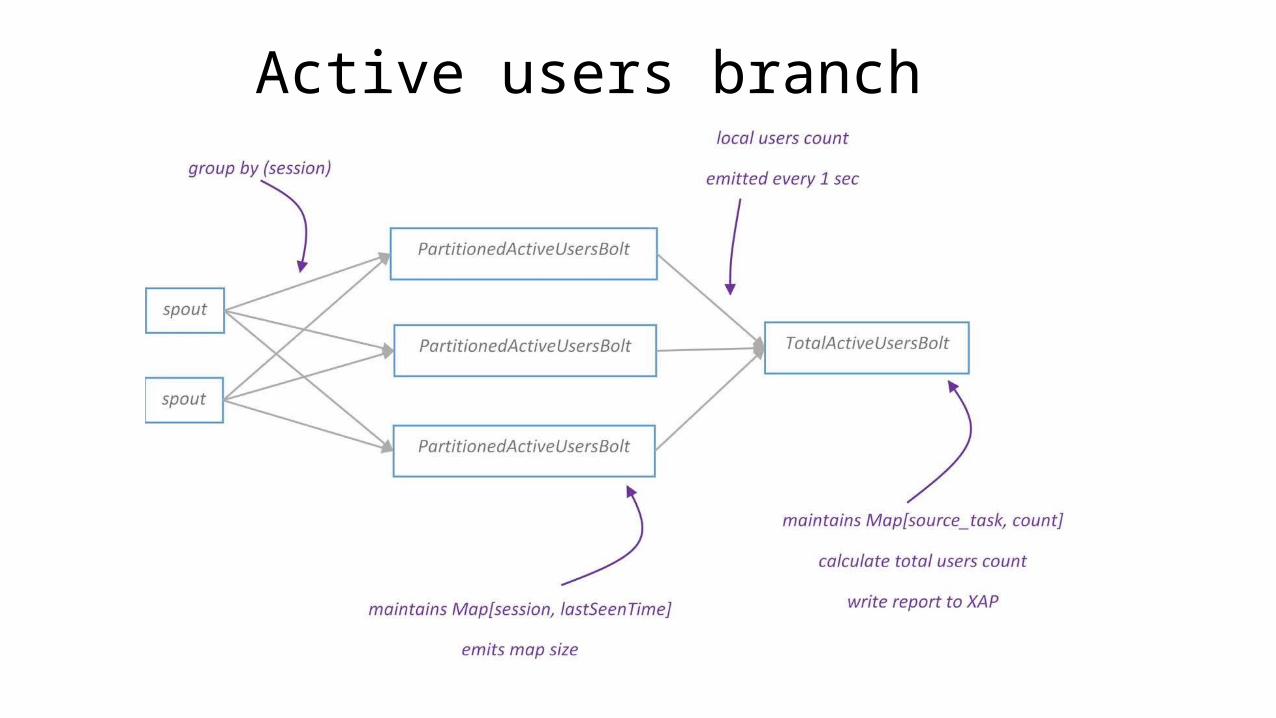
Active users branch
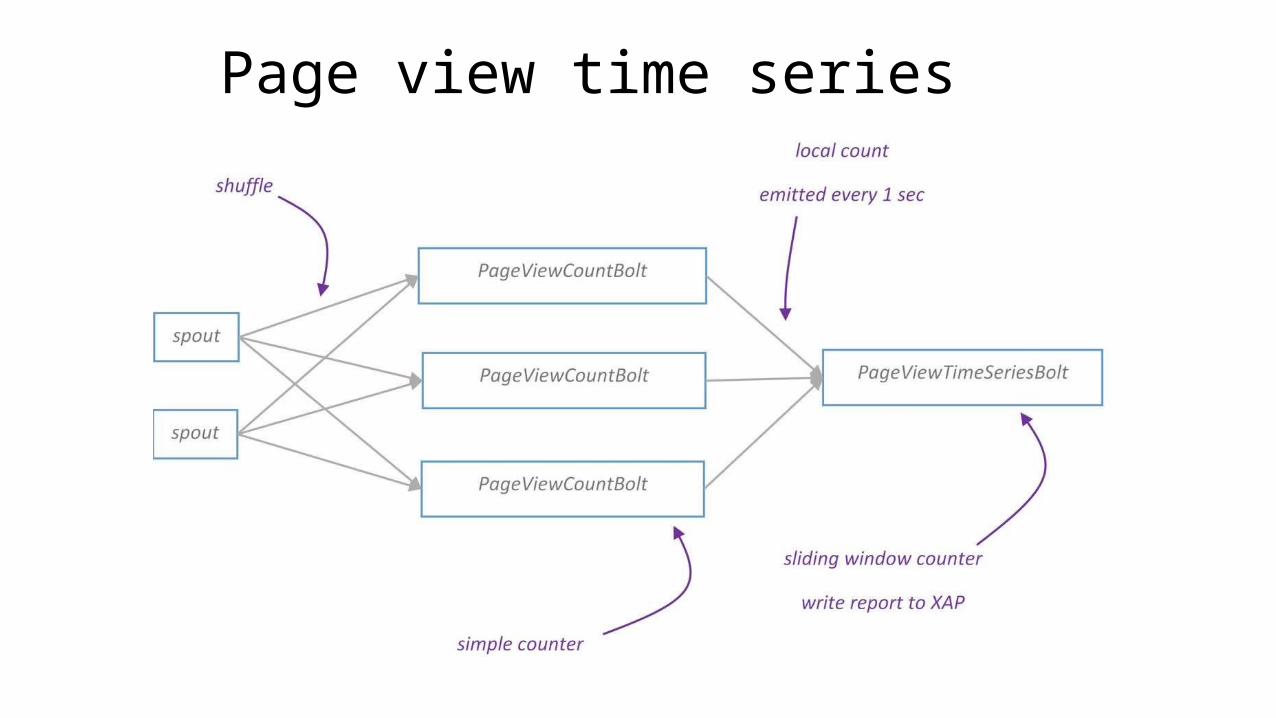
Page view time series
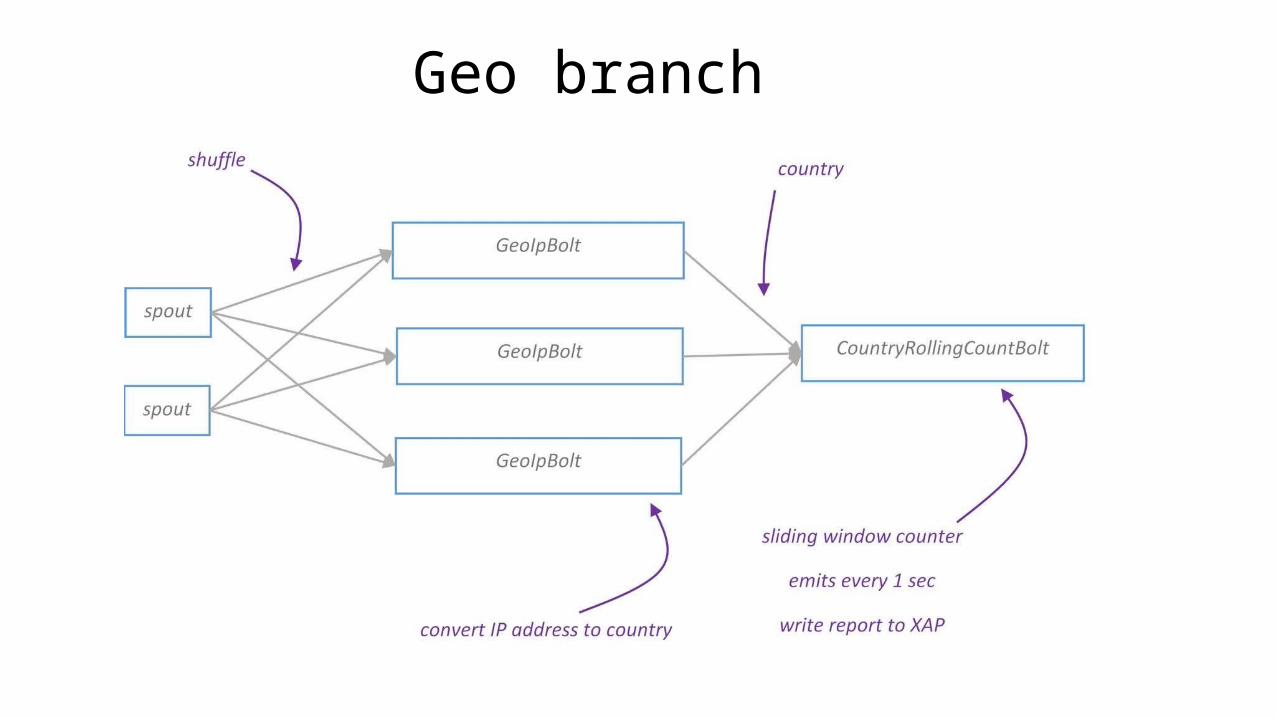
Geo branch

Thanks!
Presentation and detailed blog post available at http://dyagilev.org
Resources:• Kafka benchmarking• The Linux Page Cache and pdflush: Theory of Operation and Tuning for Write-Heavy Loads• Kafka documentation• The Lambda architecture: principles for architecting realtime Big Data systems• Efficient data transfer through zero copy• RabbitMQ Performance Measurements• GigaSpaces and Storm Integration