Embed Size (px)
Citation preview

Relevance - Deal Personalization and Real Time Big Data Analytics
Prassnitha Sampath [email protected]

About Me
• Lead Engineer working on Real Time Data Infrastructure @ Groupon
• Graduate of Portland State and Madras University
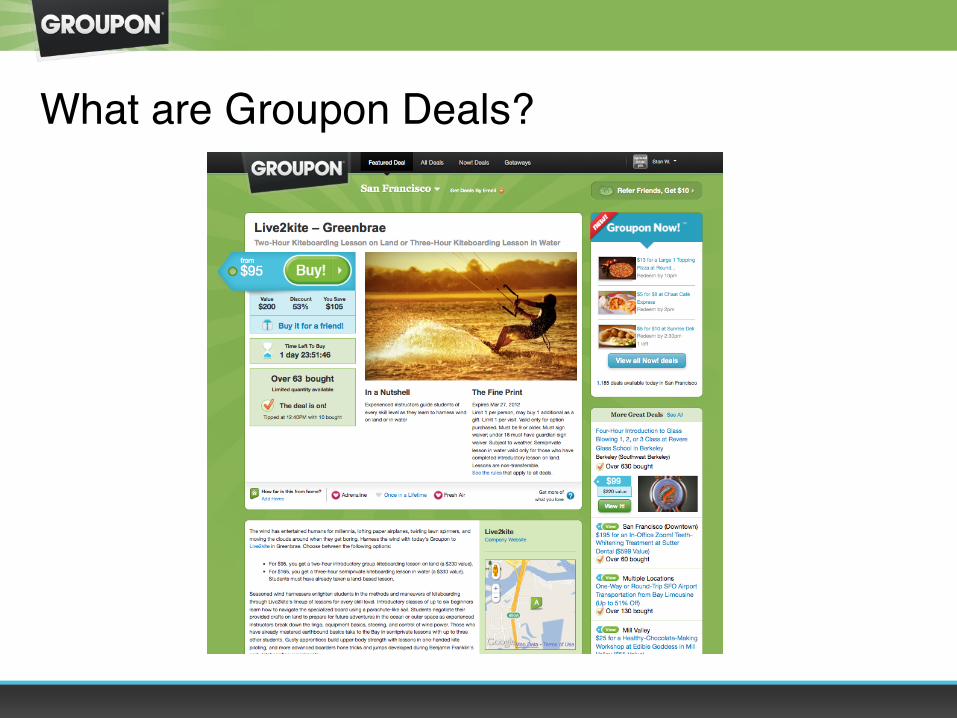
What are Groupon Deals?
Our Relevance ScenarioUsers

Scaling: Keeping Up With a Changing Business
2014 2011 2012
Growing Number of deals Growing Users
• 100 Million+ subscribers
• We need to store data like, user click history, email records, service logs etc. This is billions of data points and TB’s of data

Changing Business: Shift from Email to Mobile
• Growth in Mobile Business
• Reducing dependence on email markeOng
100 Million+ App Downloads
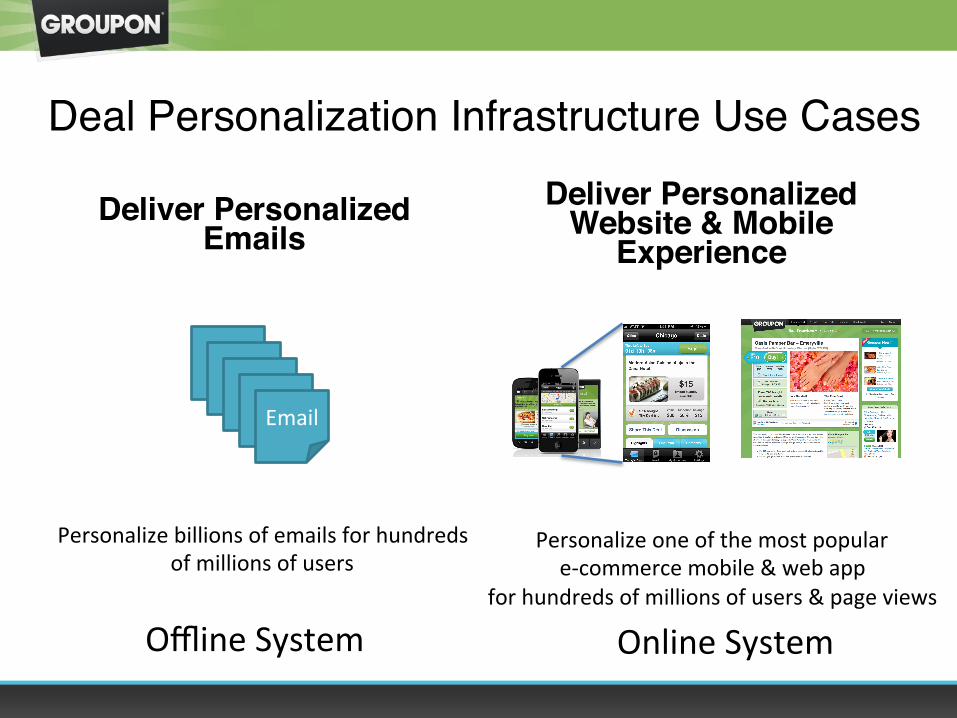
Deal Personalization Infrastructure Use Cases
Deliver Personalized Emails
Deliver Personalized Website & Mobile
Experience
Offline System Online System
Personalize billions of emails for hundreds of millions of users
Personalize one of the most popular e-‐commerce mobile & web app
for hundreds of millions of users & page views

Deal Personalization Infrastructure Use CasesDeliver Personalized
Website, Mobile and Email Experience
Deal Performance Understand User Behavior
Deliver Relevant Experience with High Quality Deals
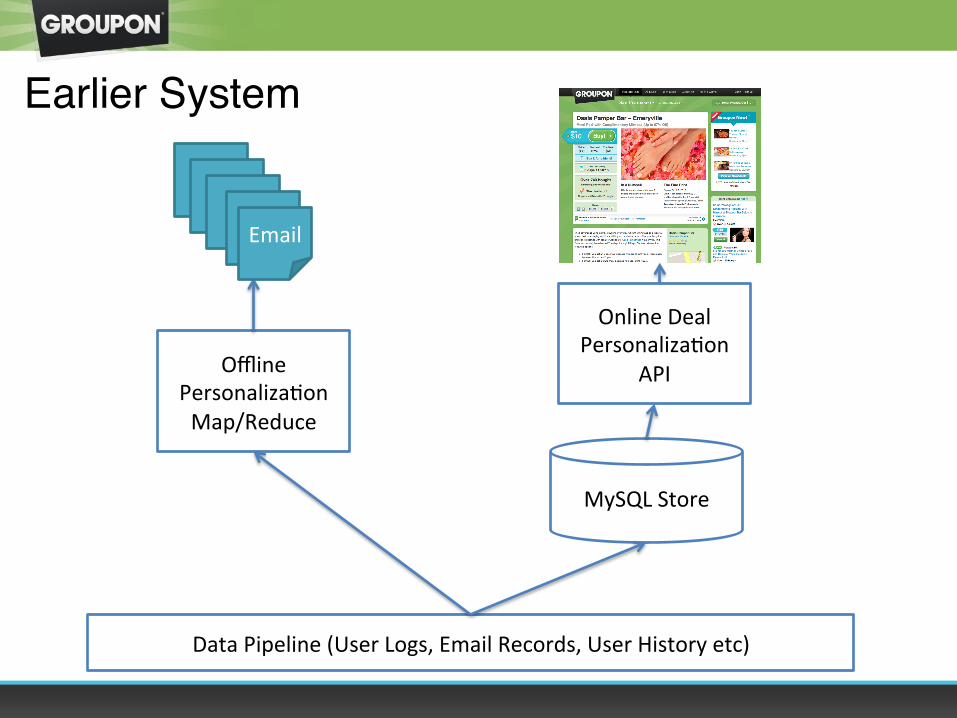
Earlier System
Offline PersonalizaOon Map/Reduce
Data Pipeline (User Logs, Email Records, User History etc)
Online Deal PersonalizaOon
API
MySQL Store
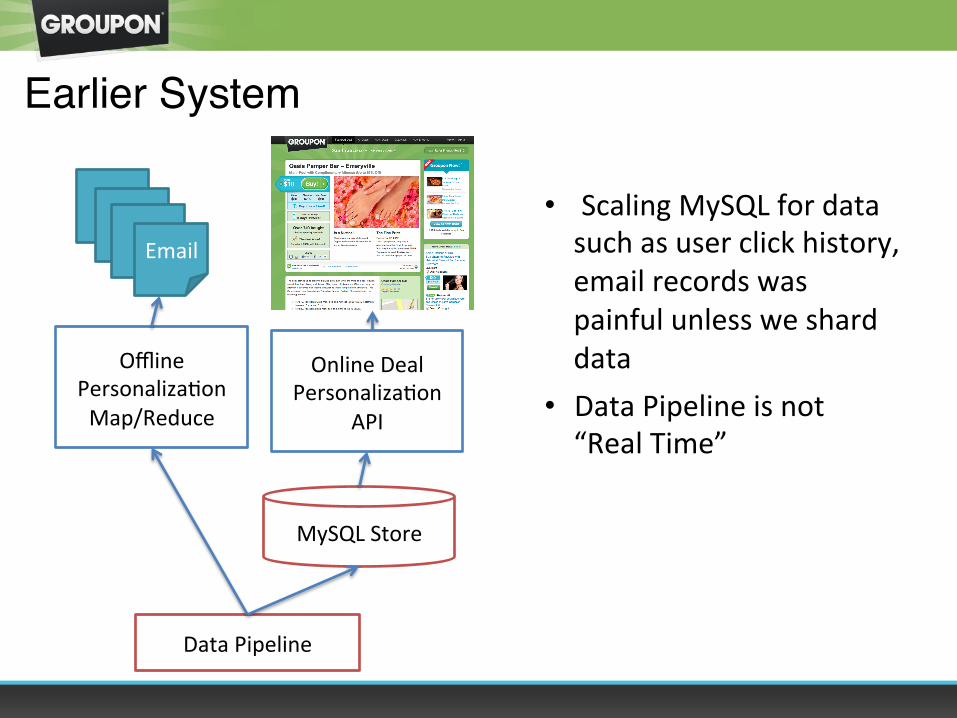
Earlier System
Offline PersonalizaOon Map/Reduce
Data Pipeline
Online Deal PersonalizaOon
API
MySQL Store
• Scaling MySQL for data such as user click history, email records was painful unless we shard data
• Data Pipeline is not “Real Time”
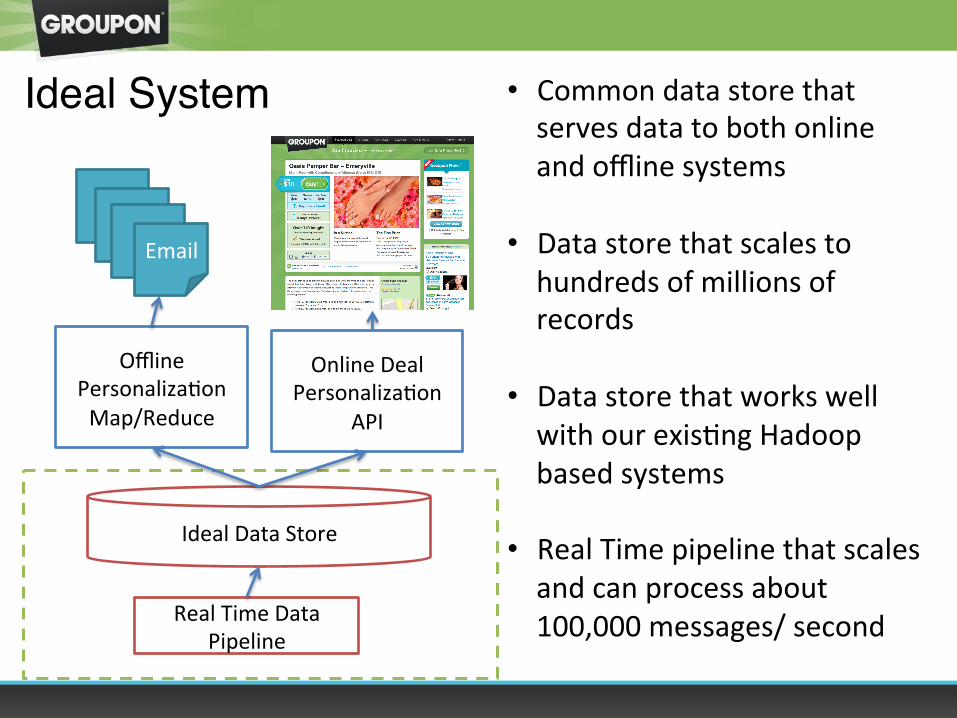
Offline PersonalizaOon Map/Reduce
Real Time Data Pipeline
Online Deal PersonalizaOon
API
Ideal Data Store
• Common data store that serves data to both online and offline systems
• Data store that scales to hundreds of millions of records
• Data store that works well with our exisOng Hadoop based systems
• Real Time pipeline that scales and can process about 100,000 messages/ second
Ideal System
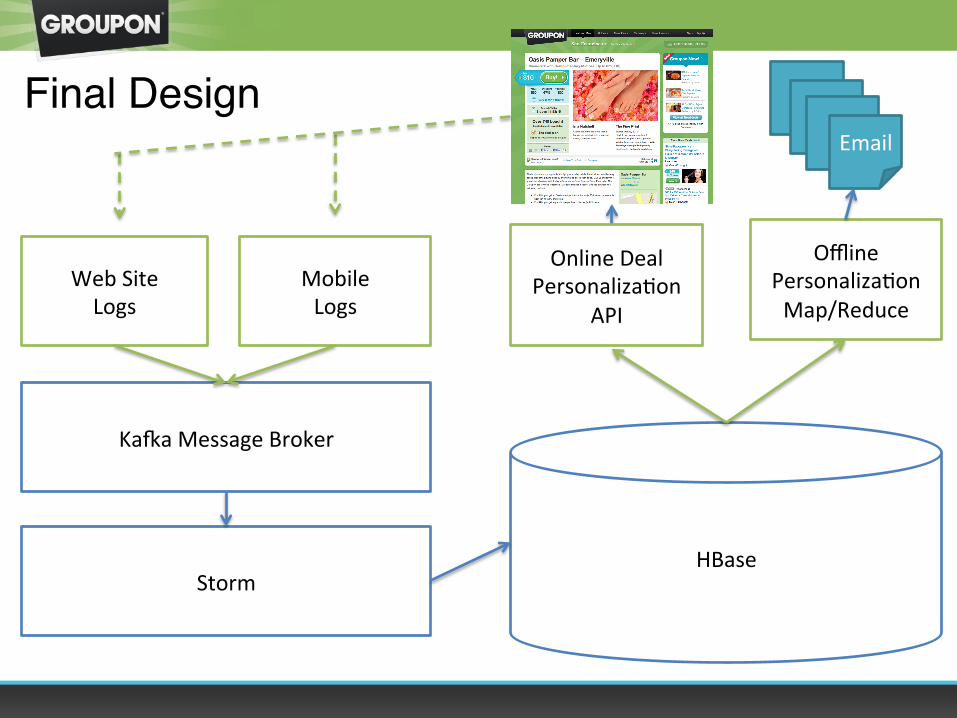
Offline PersonalizaOon Map/Reduce
Web Site Logs
Online Deal PersonalizaOon
API
HBase
Final Design
Mobile Logs
Ka`a Message Broker
Storm
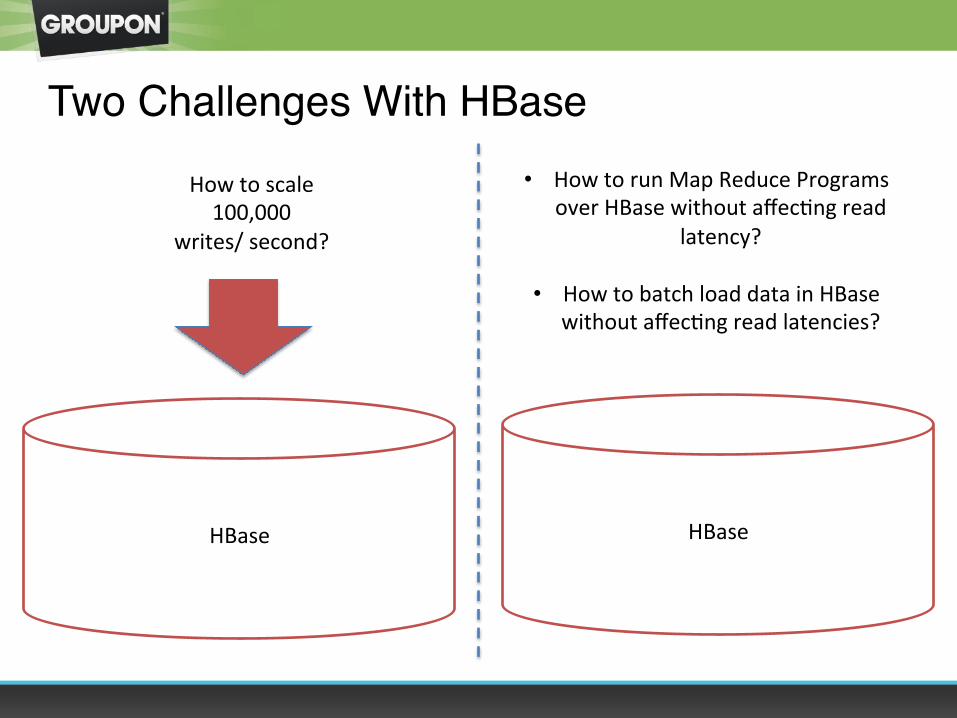
Two Challenges With HBase
HBase
How to scale 100,000
writes/ second?
HBase
• How to run Map Reduce Programs over HBase without affecOng read
latency?
• How to batch load data in HBase without affecOng read latencies?
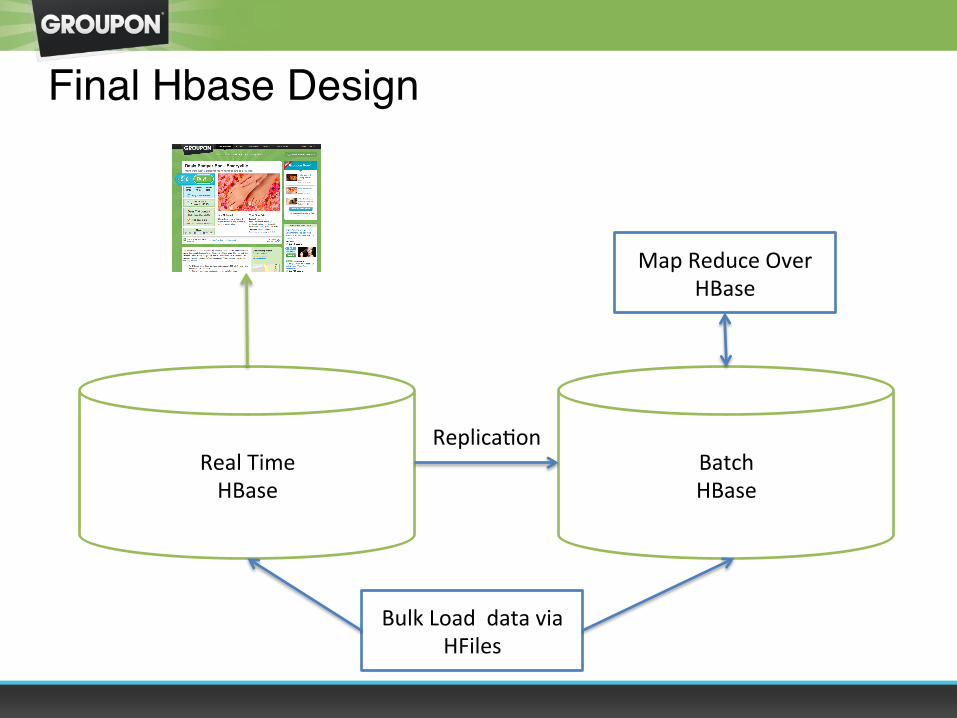
Final Hbase Design
Real Time HBase
Batch HBase
Bulk Load data via HFiles
ReplicaOon
Map Reduce Over HBase

Leveraging System for Real Time Analytics
Various requirements from relevance algorithms to pre-‐compute real 6me analy6cs for be9er targe6ng
Category Level
MulOdimensional Performance
Metrics
Deal Level
Performance Metrics
How do women in Dublin convert for Pizza deals?
How do women in Dublin convert for a parOcular pizza
deal?

Leveraging System for Real Time Analytics More Complex Examples
Category Level
MulOdimensional Performance Metrics
Deal Level
Performance Metrics
How do women in Dublin from the Dundrum area aged 30-‐35 convert for New York Style Pizza, when deal is
located within 2 miles, and when deal is priced between
€10-‐€20?
How do women in Dublin from Dundrum area aged 30-‐35 convert for a parOcular deal?

Leveraging System for Real Time AnalyticsEven More Complex Examples
How do women in Dublin from the Dundrum area aged 30-‐35 who also like
acOviOes like Biking and are acOve customers on our mobile plahorm convert
when deal is located within 2 miles, and when deal is priced between €10-‐€20?
How do women in Dublin from the Dundrum area aged 30-‐35 who also like acOviOes such as biking and are acOve customers of Groupon deals on mobile plahorm convert for this
parOcular deal?

Power of Simple Counting
Turns out all earlier quesOons can be answered if we could count appropriate events in appropriate bucket
No Deal Impressions by Women in Dublin for Pizza Deals
No of Purchases by Women in Dublin for Pizza Deals Conversion rate
for pizza deals for women in
Dublin
=
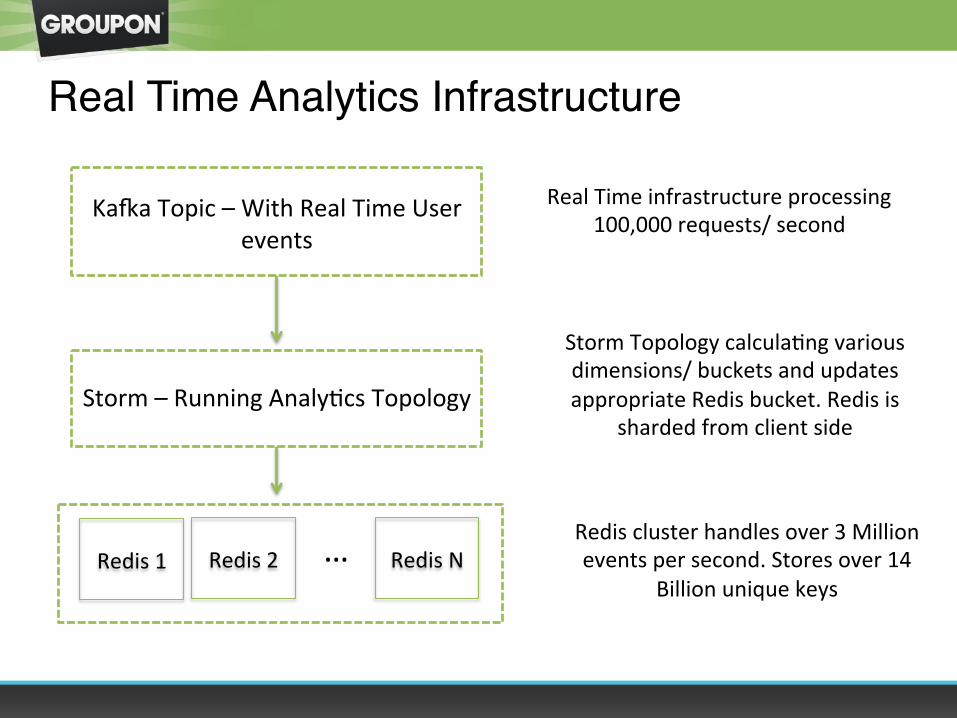
Real Time Analytics Infrastructure
Ka`a Topic – With Real Time User events
Storm – Running AnalyOcs Topology
Real Time infrastructure processing 100,000 requests/ second
Redis 1 …
Storm Topology calculaOng various dimensions/ buckets and updates appropriate Redis bucket. Redis is
sharded from client side
Redis cluster handles over 3 Million events per second. Stores over 14
Billion unique keys Redis 2 Redis N
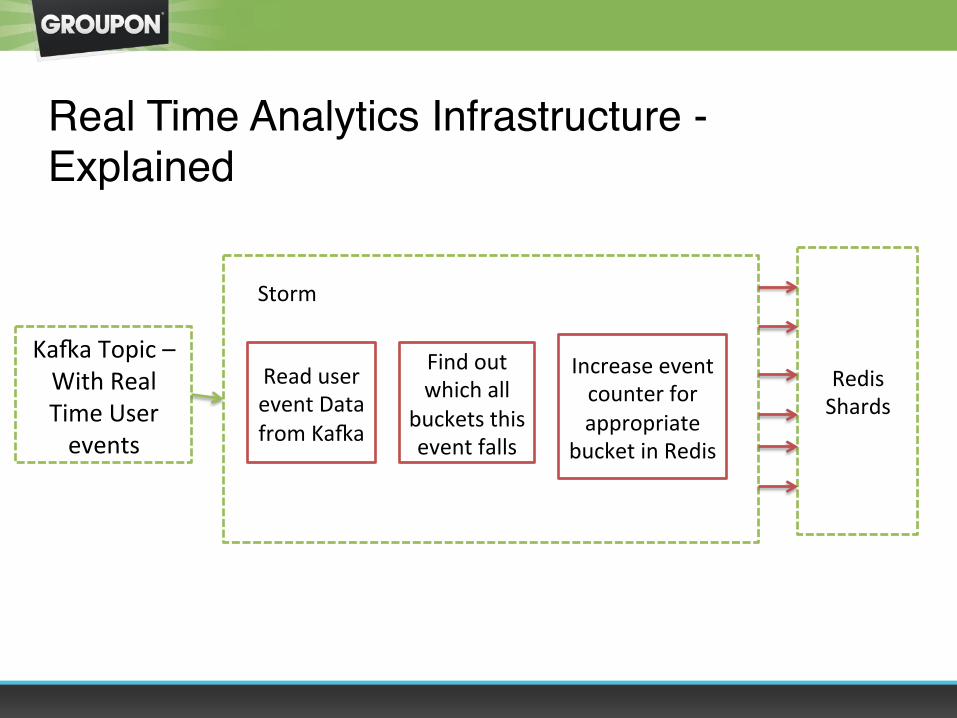
Real Time Analytics Infrastructure - Explained
Ka`a Topic – With Real Time User events
Read user event Data from Ka`a
Find out which all
buckets this event falls
Increase event counter for appropriate
bucket in Redis
Redis Shards
Storm

Scaling Challenges - Kafka - Storm
• Storm was hard to scale. We had to try various number of combinaOons to
finalize how many bolts of each type are required for steady state operaOons and overall how many workers are needed.
• Use “topology.max.spout.pending” senng in Storm topologies. We found it to be very useful to shield your topologies from sudden surge in traffic.
• Build your enOre infrastructure – where data duplicates are allowed

Scaling Challenges - Redis
• Reduce memory footprint – use hashes. Very memory efficient compared to normal Redis keys
• In order to support high write operaOons turned off AOF, turned on RDB backups
Easiest of all other infrastructure pieces – Ka`a, Storm, HBase

When Small is Big – Bloom Filters• Since both Ka`a and Storm can send same data twice specially at
scale, it was important to build downstream infrastructure that can handle duplicate data.
• However, by very nature AnalyOcs Topology (CounOng Topology) cannot handle duplicates
• Storing individual messages for billions of messages is way too expensive and would take lot more memory
• So we used bloom filters. At a very small % error rate, we could
effecOvely de-‐dupe data with a very small memory footprint.

Avoiding Errors – Backups/ Recovery StrategyFor a high volume system, which also drives so much revenue for the company good
backup/recovery strategy is necessary
Redis
RDB Backups every few hours. RDB
backups are stored in HDFS for later
use
HBase
HBase Snapshot funcOonality is
used. Snapshot are taken every few
hours.
Ka`a/ Storm
All input into Ka`a topic is stored in HDFS for 30 days. So any hour/ day can be replayed from HDFS if necessary.
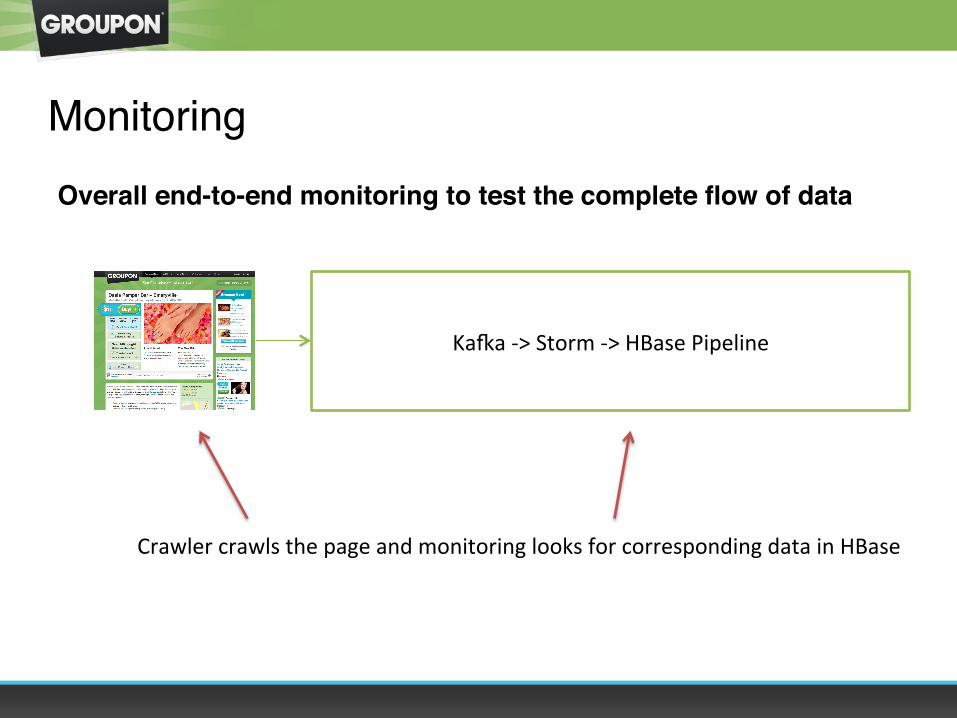
MonitoringOverall end-to-end monitoring to test the complete flow of data
Ka`a -‐> Storm -‐> HBase Pipeline
Crawler crawls the page and monitoring looks for corresponding data in HBase