Embed Size (px)
Citation preview


Sandeep GiriHadoop
• A Scalable Machine Learning Library built on Hadoop, written in Java • Driven by Ng et al.’s paper “MapReduce for Machine Learning on Multicore” • Started as a Lucene sub-project. Became Apache TLP in Apr’10. • Mahout – Keeper/Driver of Elephants.

Sandeep GiriHadoop
MACHINE LEARNING“Programming Computers to optimize a
Performance using Example Data or Past Experience”
• Branch of Artificial Intelligence • Design and Development of Algorithms • Computers Evolve Behaviour based on Empirical Data

Sandeep GiriHadoop
MACHINE LEARNING - TYPES
Supervised Learning Using Labeled training data, to create a Classifier that can predict output for unseen inputs. !Unsupervised Learning Using Unlabeled training data to create a function that can predict output. !Semi-Supervised Learning Make use of unlabeled data for training - typically a small amount of labeled data with a large amount of unlabeled data.

Sandeep GiriHadoop
MACHINE LEARNING - APPLICATIONS• Recommend Friends, Dates, Products to end-user. • Classify content into pre-defined groups. • Find Similar content based on Object Properties. • Identify key topics in large Collections of Text. • Detect Anomalies within given data. • Ranking Search Results with User Feedback Learning. • Classifying DNA sequences. • Sentiment Analysis/ Opinion Mining • Computer Vision. • Natural Language Processing, • BioInformatics. • Speech and HandWriting Recognition.

Sandeep GiriHadoop
MACHINE LEARNING - TOOLSDATA SIZE CLASSFICATION TOOLS
Lines Sample Data
Analysis and Visualization Whiteboard,…
KBs - low MBs Prototype Data
Analysis and Visualization
Matlab, Octave, R, Processing,
MBs - low GBs Online Data
Analysis NumPy, SciPy, Weka, BLAS/LAPACK
Visualization Flare, AmCharts, Raphael, Protovis
GBs - TBs - PBs Big Data Analysis Mahout, Giraph
MLlib
Sandeep GiriHadoop
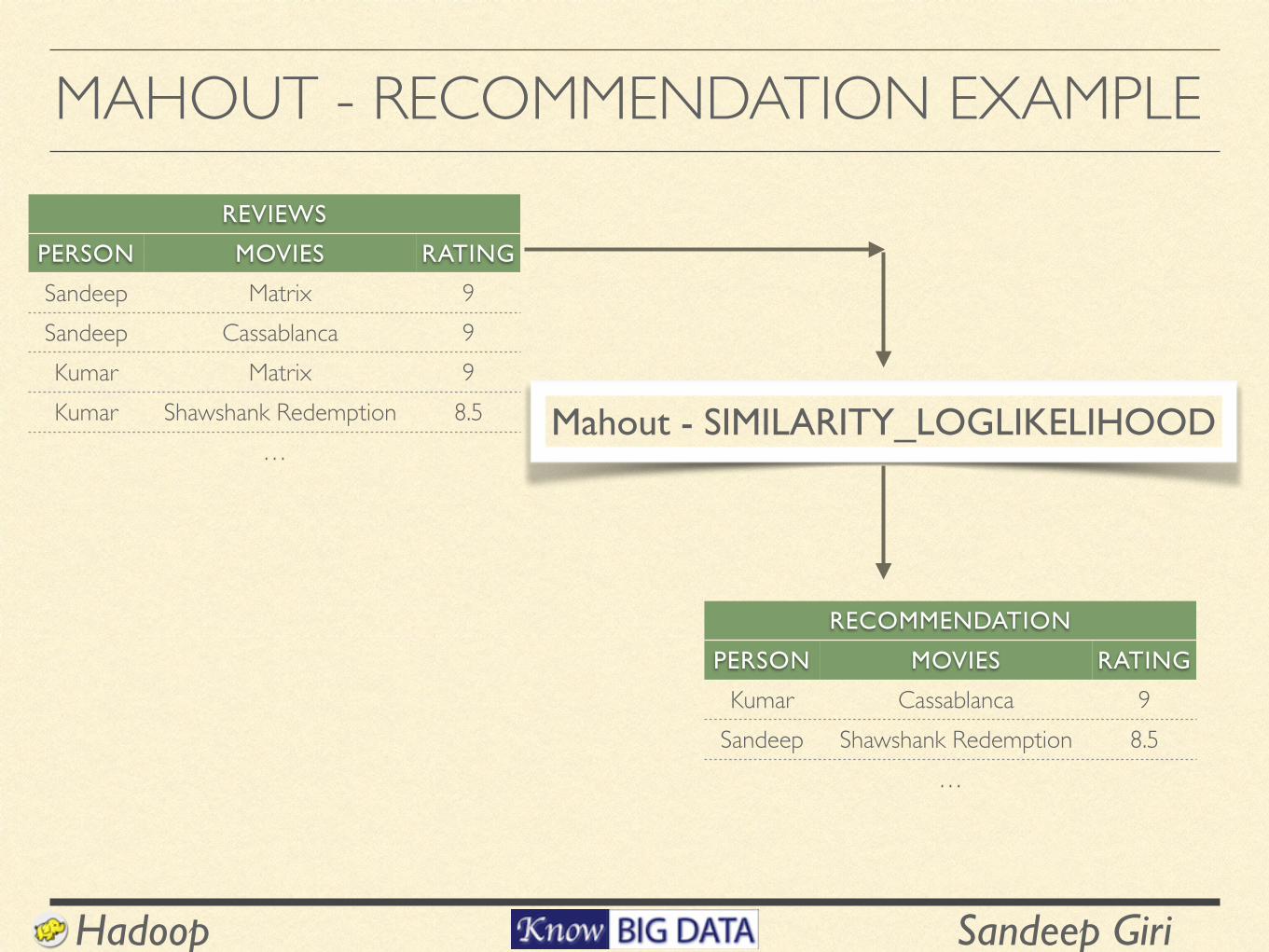
MAHOUT - RECOMMENDATION EXAMPLEREVIEWS
PERSON MOVIES RATING
Sandeep Matrix 9Sandeep Cassablanca 9Kumar Matrix 9Kumar Shawshank Redemption 8.5
…
RECOMMENDATION
PERSON MOVIES RATING
Kumar Cassablanca 9Sandeep Shawshank Redemption 8.5
…
Mahout - SIMILARITY_LOGLIKELIHOOD

Sandeep GiriHadoop
MAHOUT - USE CASESCollaborative filtering Mines user behaviour and makes product recommendations (e.g. Amazon recommendations) !Clustering Takes items in a particular class (such as web pages or newspaper articles) and organizes them into naturally occurring groups, such that items belonging to the same group are similar to each other !Classification Learns from existing categorisations and then assigns unclassified items to the best category !Frequent itemset mining analyzes items in a group (e.g. items in a shopping cart or terms in a query session) and then identifies which items typically appear together

Sandeep GiriHadoop
MAHOUT LIVE EXAMPLE
1. Download the Dataset from movie lens cd sgiri/ wget -nc http://www.grouplens.org/system/files/ml-1m.zip
!2. Unzip unzip ml-1m.zip
!3. Prepare comma separated format of: user, movie, ratings cat ml-1m/ratings.dat|awk -F:: '{print $1","$2","$3}' > ratings.csv

Sandeep GiriHadoop
MAHOUT LIVE EXAMPLE
4. Copy Data to Hadoop hadoop fs -copyFromLocal ratings.csv sgiri/
!5. Run mahout export JAVA_HOME=/usr/lib/jvm/jre-1.7.0-openjdk.x86_64/ mahout recommenditembased -s SIMILARITY_LOGLIKELIHOOD \ -i sgiri/ratings.csv -o sgiri/recos

Sandeep GiriHadoop
MAHOUT LIVE EXAMPLE
6. Print Results hadoop fs -cat recos/part-r-00000 =========== 6029 [2712:5.0, 1358:5.0, 1283:5.0, ...] 6030 [349:5.0, 2478:5.0,724:5.0, ...] 6031 [805:5.0, 2478:5.0,3108:5.0, ...] 6032 [3507: 5.0, 3097:5.0,3614:5.0, ...]

Sandeep GiriHadoop
MAHOUT - OTHER RECOMMENDER ALGOS
SIMILARITY_LOGLIKELIHOOD SIMILARITY_COOCCURRENCE SIMILARITY_TANIMOTO_COEFFICIENT SIMILARITY_CITY_BLOCK SIMILARITY_COSINE SIMILARITY_PEARSON_CORRELATION SIMILARITY_EUCLIDEAN_DISTANCE

Sandeep GiriHadoop
MAHOUT - USE CASESCollaborative filtering Mines user behaviour and makes product recommendations (e.g. Amazon recommendations) !Clustering Takes items in a particular class (such as web pages or newspaper articles) and organizes them into naturally occurring groups, such that items belonging to the same group are similar to each other !Classification Learns from existing categorisations and then assigns unclassified items to the best category !Frequent itemset mining analyzes items in a group (e.g. items in a shopping cart or terms in a query session) and then identifies which items typically appear together






























