Embed Size (px)
Citation preview



LearningApacheMahoutClassification

TableofContents
LearningApacheMahoutClassification
Credits
AbouttheAuthor
AbouttheReviewers
www.PacktPub.com
Supportfiles,eBooks,discountoffers,andmore
Whysubscribe?
FreeaccessforPacktaccountholders
Preface
Whatthisbookcovers
Whatyouneedforthisbook
Whothisbookisfor
Conventions
Readerfeedback
Customersupport
Downloadingtheexamplecode
Downloadingthecolorimagesofthisbook
Errata
Piracy
Questions
1.ClassificationinDataAnalysis
Introducingtheclassification
Applicationoftheclassificationsystem
Workingoftheclassificationsystem
Classificationalgorithms
Modelevaluationtechniques
Theconfusionmatrix
TheReceiverOperatingCharacteristics(ROC)graph
AreaundertheROCcurve

Theentropymatrix
Summary
2.ApacheMahout
IntroducingApacheMahout
AlgorithmssupportedinMahout
ReasonsforMahoutbeingagoodchoiceforclassification
InstallingMahout
BuildingMahoutfromsourceusingMaven
InstallingMaven
BuildingMahoutcode
SettingupadevelopmentenvironmentusingEclipse
SettingupMahoutforaWindowsuser
Summary
3.LearningLogisticRegression/SGDUsingMahout
Introducingregression
Understandinglinearregression
Costfunction
Gradientdescent
Logisticregression
StochasticGradientDescent
UsingMahoutforlogisticregression
Summary
4.LearningtheNaïveBayesClassificationUsingMahout
IntroducingconditionalprobabilityandtheBayesrule
UnderstandingtheNaïveBayesalgorithm
Understandingthetermsusedintextclassification
UsingtheNaïveBayesalgorithminApacheMahout
Summary
5.LearningtheHiddenMarkovModelUsingMahout
Deterministicandnondeterministicpatterns
TheMarkovprocess

IntroducingtheHiddenMarkovModel
UsingMahoutfortheHiddenMarkovModel
Summary
6.LearningRandomForestUsingMahout
Decisiontree
Randomforest
UsingMahoutforRandomforest
StepstousetheRandomforestalgorithminMahout
Summary
7.LearningMultilayerPerceptronUsingMahout
Neuralnetworkandneurons
MultilayerPerceptron
MLPimplementationinMahout
UsingMahoutforMLP
StepstousetheMLPalgorithminMahout
Summary
8.MahoutChangesintheUpcomingRelease
Mahoutnewchanges
MahoutScalaandSparkbindings
ApacheSpark
UsingMahout’sSparkshell
H2Oplatformintegration
Summary
9.BuildinganE-mailClassificationSystemUsingApacheMahout
Spame-maildataset
CreatingthemodelusingtheAssassindataset
Programtouseaclassifiermodel
Testingtheprogram
Secondusecaseasanexercise
TheASFe-maildataset
Classifierstuning

Summary
Index


LearningApacheMahoutClassification


LearningApacheMahoutClassificationCopyright©2015PacktPublishing
Allrightsreserved.Nopartofthisbookmaybereproduced,storedinaretrievalsystem,ortransmittedinanyformorbyanymeans,withoutthepriorwrittenpermissionofthepublisher,exceptinthecaseofbriefquotationsembeddedincriticalarticlesorreviews.
Everyefforthasbeenmadeinthepreparationofthisbooktoensuretheaccuracyoftheinformationpresented.However,theinformationcontainedinthisbookissoldwithoutwarranty,eitherexpressorimplied.Neithertheauthor,norPacktPublishing,anditsdealersanddistributorswillbeheldliableforanydamagescausedorallegedtobecauseddirectlyorindirectlybythisbook.
PacktPublishinghasendeavoredtoprovidetrademarkinformationaboutallofthecompaniesandproductsmentionedinthisbookbytheappropriateuseofcapitals.However,PacktPublishingcannotguaranteetheaccuracyofthisinformation.
Firstpublished:February2015
Productionreference:1210215
PublishedbyPacktPublishingLtd.
LiveryPlace
35LiveryStreet
BirminghamB32PB,UK.
ISBN978-1-78355-495-9
www.packtpub.com


CreditsAuthor
AshishGupta
Reviewers
SivaPrakash
TharinduRusira
VishnuViswanath
CommissioningEditor
AkramHussain
AcquisitionEditor
ReshmaRaman
ContentDevelopmentEditor
MerwynD’souza
TechnicalEditors
MonicaJohn
NovinaKewalramani
ShrutiRawool
CopyEditors
SarangChari
GladsonMonteiro
AartiSaldanha
RashmiSawant
ProjectCoordinator
NehaBhatnagar
Proofreaders
SimranBhogal
SteveMaguire
Indexer
MonicaAjmeraMehta
Graphics
SheetalAute

AbhinashSahu
ProductionCoordinator
ConidonMiranda
CoverWork
ConidonMiranda


AbouttheAuthorAshishGuptahasbeenworkinginthefieldofsoftwaredevelopmentforthelast8years.Hehasworkedindifferentcompanies,suchasSAPLabsandCaterpillar,asasoftwaredeveloper.Whileworkingforastart-upwherehewasresponsibleforpredictingpotentialcustomersfornewfashionapparelsusingsocialmedia,hedevelopedaninterestinthefieldofmachinelearning.Sincethen,hehasworkedonusingbigdatatechnologiesandmachinelearningfordifferentindustries,includingretail,finance,insurance,andsoon.Hehasapassionforlearningnewtechnologiesandsharingtheknowledgethusgainedwithothers.HehasorganizedmanybootcampsfortheApacheMahoutandHadoopecosystem.
Firstofall,Iwouldliketothankopensourcecommunitiesfortheircontinuouseffortsindevelopinggreatsoftwareforall.IwouldliketothankMerwynD’SouzaandReshmaRaman,myeditorsforthisproject.Specialthankstothereviewersofthisbook.
Nothingcanbeaccomplishedwithoutthesupportoffamily,friends,andlovedones.Iwouldliketothankmyfriends,family,andespeciallymywifeandmysonfortheircontinuoussupportthroughoutthewritingofthisbook.


AbouttheReviewersSivaPrakashisworkingasatechleadinBangalore.Hehasextensivedevelopmentexperienceintheanalysis,design,development,implementation,andmaintenanceofvariousdesktop,mobile,andweb-basedapplications.Helovestrekking,traveling,music,readingbooks,andblogging.
YoucanfindhimonLinkedInathttps://www.linkedin.com/in/techsivam.
TharinduRusiraiscurrentlyacomputerscienceandengineeringundergraduateattheUniversityofMoratuwa,SriLanka.Asastudentresearcher,hehasstronginterestsinmachinelearning,compilers,andhigh-performancecomputing.
TharinduhasalsoworkedasaresearchanddevelopmentsoftwareengineeringinternatZaiziAsia(Pvt)Ltd.,wherehefirststartedusingApacheMahoutduringtheimplementationofanenterprise-levelcontentmanagementandinformationretrievalsystem.
HeseesthepotentialofApacheMahoutasascalablemachinelearninglibraryforindustry-levelimplementationsandhasevencontributedtotheMahout0.9release,thelateststablereleaseofMahout.
HeisavailableonLinkedInathttps://www.linkedin.com/in/trusira.
VishnuViswanathisaseniorbigdatadeveloperwhohasmanyyearsofindustrialexpertiseinthearenaofmachinelearning.Heisatechenthusiastandispassionateaboutbigdataandhasexpertiseonmostbig-data-relatedtechnologies.
YoucanfindhimonLinkedInathttp://in.linkedin.com/in/vishnuviswanath25.


www.PacktPub.com

Supportfiles,eBooks,discountoffers,andmoreForsupportfilesanddownloadsrelatedtoyourbook,pleasevisitwww.PacktPub.com.
DidyouknowthatPacktofferseBookversionsofeverybookpublished,withPDFandePubfilesavailable?YoucanupgradetotheeBookversionatwww.PacktPub.comandasaprintbookcustomer,youareentitledtoadiscountontheeBookcopy.Getintouchwithusat<[email protected]>formoredetails.
Atwww.PacktPub.com,youcanalsoreadacollectionoffreetechnicalarticles,signupforarangeoffreenewslettersandreceiveexclusivediscountsandoffersonPacktbooksandeBooks.
https://www2.packtpub.com/books/subscription/packtlib
DoyouneedinstantsolutionstoyourITquestions?PacktLibisPackt’sonlinedigitalbooklibrary.Here,youcansearch,access,andreadPackt’sentirelibraryofbooks.

Whysubscribe?FullysearchableacrosseverybookpublishedbyPacktCopyandpaste,print,andbookmarkcontentOndemandandaccessibleviaawebbrowser

FreeaccessforPacktaccountholdersIfyouhaveanaccountwithPacktatwww.PacktPub.com,youcanusethistoaccessPacktLibtodayandview9entirelyfreebooks.Simplyuseyourlogincredentialsforimmediateaccess.


PrefaceThankstotheprogressmadeinthehardwareindustries,ourstoragecapacityhasincreased,andbecauseofthis,therearemanyorganizationswhowanttostorealltypesofeventsforanalyticspurposes.Thishasgivenbirthtoaneweraofmachinelearning.Thefieldofmachinelearningisverycomplexandwritingthesealgorithmsisnotapieceofcake.ApacheMahoutprovidesuswithreadymadealgorithmsintheareaofmachinelearningandsavesusfromthecomplextaskofalgorithmimplementation.
TheintentionofthisbookistocoverclassificationalgorithmsavailableinApacheMahout.Whetheryouhavealreadyworkedonclassificationalgorithmsusingsomeothertoolorarecompletelynewtothefield,thisbookwillhelpyou.So,startreadingthisbooktoexploretheclassificationalgorithmsinoneofthemostpopularopensourceprojectswhichenjoysstrongcommunitysupport:ApacheMahout.

WhatthisbookcoversChapter1,ClassificationinDataAnalysis,providesanintroductiontotheclassificationconceptindataanalysis.Thischapterwillcoverthebasicsofclassification,similaritymatrix,andalgorithmsavailableinthisarea.
Chapter2,ApacheMahout,providesanintroductiontoApacheMahoutanditsinstallationprocess.Further,thischapterwilltalkaboutwhyitisagoodchoiceforclassification.
Chapter3,LearningLogisticRegression/SGDUsingMahout,discusseslogisticregressionandStochasticGradientDescent,andhowdeveloperscanuseMahouttouseSGD.
Chapter4,LearningtheNaïveBayesClassificationUsingMahout,discussestheBayesTheorem,NaïveBayesclassification,andhowwecanuseMahouttobuildNaïveBayesclassifier.
Chapter5,LearningtheHiddenMarkovModelUsingMahout,coverstheHMMandhowtouseMahout’sHMMalgorithms.
Chapter6,LearningRandomForestUsingMahout,discussestheRandomforestalgorithmindetail,andhowtouseMahout’sRandomforestimplementation.
Chapter7,LearningMultilayerPerceptronUsingMahout,discussesMahoutasanearlylevelimplementationofaneuralnetwork.WewilldiscussMultilayerPerceptroninthischapter.Further,wewilluseMahout’simplementationofMLP.
Chapter8,MahoutChangesintheUpcomingRelease,discussesMahoutasaworkinprogress.WewilldiscussthenewmajorchangesintheupcomingreleaseofMahout.
Chapter9,BuildinganE-mailClassificationSystemUsingApacheMahout,providestwousecasesofe-mailclassification—spammailclassificationande-mailclassificationbasedontheprojectthemailbelongsto.Wewillcreatethemodel,andusethismodelinaprogramthatwillsimulatetherealworkingenvironment.


WhatyouneedforthisbookTousetheexamplesinthisbook,youshouldhavethefollowingsoftwareinstalledonyoursystem:
Java1.6orhigherEclipseHadoopMahout;wewilldiscusstheinstallationinChapter2,ApacheMahout,ofthisbookMaven,dependingonhowyouinstallMahout


WhothisbookisforIfyouareadatascientistwhohassomeexperiencewiththeHadoopecosystemandmachinelearningmethodsandwanttotryoutclassificationonlargedatasetsusingMahout,thisbookisidealforyou.KnowledgeofJavaisessential.


ConventionsInthisbook,youwillfindanumberoftextstylesthatdistinguishbetweendifferentkindsofinformation.Herearesomeexamplesofthesestylesandanexplanationoftheirmeaning.
Codewordsintext,databasetablenames,foldernames,filenames,fileextensions,pathnames,dummyURLs,userinput,andTwitterhandlesareshownasfollows:“Extractthesourcecodeandensurethatthefoldercontainsthepom.xmlfile.”
Ablockofcodeissetasfollows:
publicstaticMap<String,Integer>readDictionary(Configurationconf,
PathdictionaryPath){
Map<String,Integer>dictionary=newHashMap<String,Integer>();
for(Pair<Text,IntWritable>pair:newSequenceFileIterable<Text,
IntWritable>(dictionaryPath,true,conf)){
dictionary.put(pair.getFirst().toString(),
pair.getSecond().get());
}
returndictionary;
}
Whenwewishtodrawyourattentiontoaparticularpartofacodeblock,therelevantlinesoritemsaresetinbold:
publicstaticMap<String,Integer>readDictionary(Configurationconf,
PathdictionaryPath){
Map<String,Integer>dictionary=newHashMap<String,Integer>();
for(Pair<Text,IntWritable>pair:newSequenceFileIterable<Text,
IntWritable>(dictionaryPath,true,conf)){
dictionary.put(pair.getFirst().toString(),
pair.getSecond().get());
}
returndictionary;
}
Anycommand-lineinputoroutputiswrittenasfollows:
hadoopfs-mkdir/user/hue/KDDTrain
hadoopfs-mkdir/user/hue/KDDTest
hadoopfs–put/tmp/KDDTrain+_20Percent.arff/user/hue/KDDTrain
hadoopfs–put/tmp/KDDTest+.arff/user/hue/KDDTest
Newtermsandimportantwordsareshowninbold.Wordsthatyouseeonthescreen,forexample,inmenusordialogboxes,appearinthetextlikethis:“Now,navigatetothelocationformahout-distribution-0.9andclickonFinish.”
NoteWarningsorimportantnotesappearinaboxlikethis.
TipTipsandtricksappearlikethis.


ReaderfeedbackFeedbackfromourreadersisalwayswelcome.Letusknowwhatyouthinkaboutthisbook—whatyoulikedordisliked.Readerfeedbackisimportantforusasithelpsusdeveloptitlesthatyouwillreallygetthemostoutof.
Tosendusgeneralfeedback,simplye-mail<[email protected]>,andmentionthebook’stitleinthesubjectofyourmessage.
Ifthereisatopicthatyouhaveexpertiseinandyouareinterestedineitherwritingorcontributingtoabook,seeourauthorguideatwww.packtpub.com/authors.


CustomersupportNowthatyouaretheproudownerofaPacktbook,wehaveanumberofthingstohelpyoutogetthemostfromyourpurchase.

DownloadingtheexamplecodeYoucandownloadtheexamplecodefilesfromyouraccountathttp://www.packtpub.comforallthePacktPublishingbooksyouhavepurchased.Ifyoupurchasedthisbookelsewhere,youcanvisithttp://www.packtpub.com/supportandregistertohavethefilese-maileddirectlytoyou.

DownloadingthecolorimagesofthisbookWealsoprovideyouwithaPDFfilethathascolorimagesofthescreenshots/diagramsusedinthisbook.Thecolorimageswillhelpyoubetterunderstandthechangesintheoutput.Youcandownloadthisfilefromhttp://www.packtpub.com/sites/default/files/downloads/4959OS_ColoredImages.pdf.

ErrataAlthoughwehavetakeneverycaretoensuretheaccuracyofourcontent,mistakesdohappen.Ifyoufindamistakeinoneofourbooks—maybeamistakeinthetextorthecode—wewouldbegratefulifyoucouldreportthistous.Bydoingso,youcansaveotherreadersfromfrustrationandhelpusimprovesubsequentversionsofthisbook.Ifyoufindanyerrata,pleasereportthembyvisitinghttp://www.packtpub.com/submit-errata,selectingyourbook,clickingontheErrataSubmissionFormlink,andenteringthedetailsofyourerrata.Onceyourerrataareverified,yoursubmissionwillbeacceptedandtheerratawillbeuploadedtoourwebsiteoraddedtoanylistofexistingerrataundertheErratasectionofthattitle.
Toviewthepreviouslysubmittederrata,gotohttps://www.packtpub.com/books/content/supportandenterthenameofthebookinthesearchfield.TherequiredinformationwillappearundertheErratasection.
PiracyPiracyofcopyrightedmaterialontheInternetisanongoingproblemacrossallmedia.AtPackt,wetaketheprotectionofourcopyrightandlicensesveryseriously.IfyoucomeacrossanyillegalcopiesofourworksinanyformontheInternet,pleaseprovideuswiththelocationaddressorwebsitenameimmediatelysothatwecanpursuearemedy.
Pleasecontactusat<[email protected]>withalinktothesuspectedpiratedmaterial.
Weappreciateyourhelpinprotectingourauthorsandourabilitytobringyouvaluablecontent.

QuestionsIfyouhaveaproblemwithanyaspectofthisbook,youcancontactusat<[email protected]>,andwewilldoourbesttoaddresstheproblem.


Chapter1.ClassificationinDataAnalysisInthelastdecade,wesawahugegrowthinsocialnetworkingande-commercesites.IamsurethatyoumusthavegotinformationaboutthisbookonFacebook,Twitter,orsomeothersite.Chancesarealsohighthatyouarereadingane-copyofthisbookafterorderingitonyourphoneortablet.
ThismustgiveyouanideaofhowmuchdatawearegeneratingovertheInterneteverysingleday.Now,inordertoobtainallnecessaryinformationfromthedata,wenotonlycreatedatabutalsostorethisdata.Thisdataisextremelyusefultogetsomeimportantinsightsintothebusiness.Theanalysisofthisdatacanincreasethecustomerbaseandcreateprofitsfortheorganization.Taketheexampleofane-commercesite.Youvisitthesitetobuysomebook.Yougetinformationaboutbooksonrelatedtopicsorthesametopic,publisher,orwriter,andthishelpsyoutotakebetterdecisions,whichalsohelpsthesitetoknowmoreaboutitscustomers.Thiswilleventuallyleadtoanincreaseinsales.
Findingrelateditemsorsuggestinganewitemtotheuserisallpartofthedatascienceinwhichweanalyzethedataandtrytogetusefulpatterns.
Dataanalysisistheprocessofinspectinghistoricaldataandcreatingmodelstogetusefulinformationthatisrequiredtohelpindecisionmaking.Itishelpfulinmanyindustries,suchase-commerce,banking,finance,healthcare,telecommunications,retail,oceanography,andmanymore.
Let’staketheexampleofaweatherforecastingsystem.Itisasystemthatcanpredictthestateoftheatmosphereataparticularlocation.Inthisprocess,scientistscollecthistoricaldataoftheatmosphereofthatlocationandtrytocreateamodelbasedonittopredicthowtheatmospherewillevolveoveraperiodoftime.
Inmachinelearning,classificationistheautomationofthedecision-makingprocessthatlearnsfromexamplesofthepastandemulatesthosedecisionsautomatically.Emulatingthedecisionsautomaticallyisacoreconceptinpredictiveanalytics.Inthischapter,wewilllookatthefollowingpoints:
UnderstandingclassificationWorkingofclassificationsystemsClassificationalgorithmsModelevaluationmethods

IntroducingtheclassificationThewordclassificationalwaysremindsusofourbiologyclass,wherewelearnedabouttheclassificationofanimals.Welearnedaboutdifferentcategoriesofanimals,suchasmammals,reptiles,birds,amphibians,andsoon.
Ifyourememberhowthesecategoriesaredefined,youwillrealizethattherewerecertainpropertiesthatscientistsfoundinexistinganimals,andbasedontheseproperties,theycategorizedanewanimal.
Otherreal-lifeexamplesofclassificationcouldbe,forinstance,whenyouvisitthedoctor.He/sheasksyoucertainquestions,andbasedonyouranswers,he/sheisabletoidentifywhetheryouhaveacertaindiseaseornot.
Classificationisthecategorizationofpotentialanswers,andinmachinelearning,wewanttoautomatethisprocess.Biologicalclassificationisanexampleofmulticlassclassificationandfindingthediseaseisanexampleofbinaryclassification.
Indataanalysis,wewanttousemachinelearningconcepts.Toanalyzethedata,wewanttobuildasystemthatcanhelpustofindoutwhichclassanindividualitembelongsto.Usually,theseclassesaremutuallyexclusive.Arelatedprobleminthisareaisfindingouttheprobabilitythatanindividualbelongstoacertainclass.
Classificationisasupervisedlearningtechnique.Inthistechnique,machines—basedonhistoricaldata—learnandgainthecapabilitiestopredicttheunknown.Inmachinelearning,anotherpopulartechniqueisunsupervisedlearning.Insupervisedlearning,wealreadyknowtheoutputcategories,butinunsupervisedlearning,weknownothingabouttheoutput.Let’sunderstandthiswithaquickexample:supposewehaveafruitbasket,andwewanttoclassifyfruits.Whenwesayclassify,itmeansthatinthetrainingdata,wealreadyhaveoutputvariables,suchassizeandcolor,andweknowwhetherthecolorisredandthesizeisfrom2.3”to3.7”.Wewillclassifythatfruitasanapple.Oppositetothis,inunsupervisedlearning,wewanttoseparatedifferentfruits,andwedonothaveanyoutputinformationinthetrainingdataset,sothelearningalgorithmwillseparatedifferentfruitsbasedondifferentfeaturespresentinthedataset,butitwillnotbeabletolabelthem.Inotherwords,itwillnotbeabletotellwhichoneisanappleandwhichoneisabanana,althoughitwillbeabletoseparatethem.

ApplicationoftheclassificationsystemClassificationisusedforprediction.Inthecaseofe-mailcategorization,itisusedtoclassifye-mailasspamornotspam.Nowadays,Gmailisclassifyinge-mailsasprimary,social,andpromotionalaswell.Classificationisusefulinpredictingcreditcardfrauds,tocategorizecustomersforeligibilityofloans,andsoon.Itisalsousedtopredictcustomerchurnintheinsuranceandtelecomindustries.Itisusefulinthehealthcareindustryaswell.Basedonhistoricaldata,itisusefulinclassifyingparticularsymptomsofadiseasetopredictthediseaseinadvance.Classificationcanbeusedtoclassifytropicalcyclones.So,itisusefulacrossallindustries.

WorkingoftheclassificationsystemLet’sunderstandtheclassificationprocessinmoredetail.Intheprocessofclassification,withthedatasetgiventous,wetrytofindoutinformativevariablesusingwhichwecanreducetheuncertaintyandcategorizesomething.Theseinformativevariablesarecalledexplanatoryvariablesorfeatures.
Thefinalcategoriesthatweareinterestedarecalledtargetvariablesorlabels.Explanatoryvariablescanbeanyofthefollowingforms:
Continuous(numerictypes)CategoricalWord-likeText-like
NoteIfnumerictypesarenotusefulforanymathematicalfunctions,thosewillbecountedascategorical(zipcodes,streetnumbers,andsoon).
So,forexample,wehaveadatasetofcustomer’s’loanapplications,andwewanttobuildaclassifiertofindoutwhetheranewcustomeriseligibleforaloanornot.Inthisdataset,wecanhavethefollowingfields:
CustomerAgeCustomerIncome(PA)CustomerAccountBalanceLoanGranted
Fromthesefields,CustomerAge,CustomerIncome(PA)andCustomerAccountBalancewillworkasexplanatoryvariablesandLoanGrantedwillbethetargetvariable,asshowninthefollowingscreenshot:
Tounderstandthecreationoftheclassifier,weneedtounderstandafewterms,asshowninthefollowingdiagram:
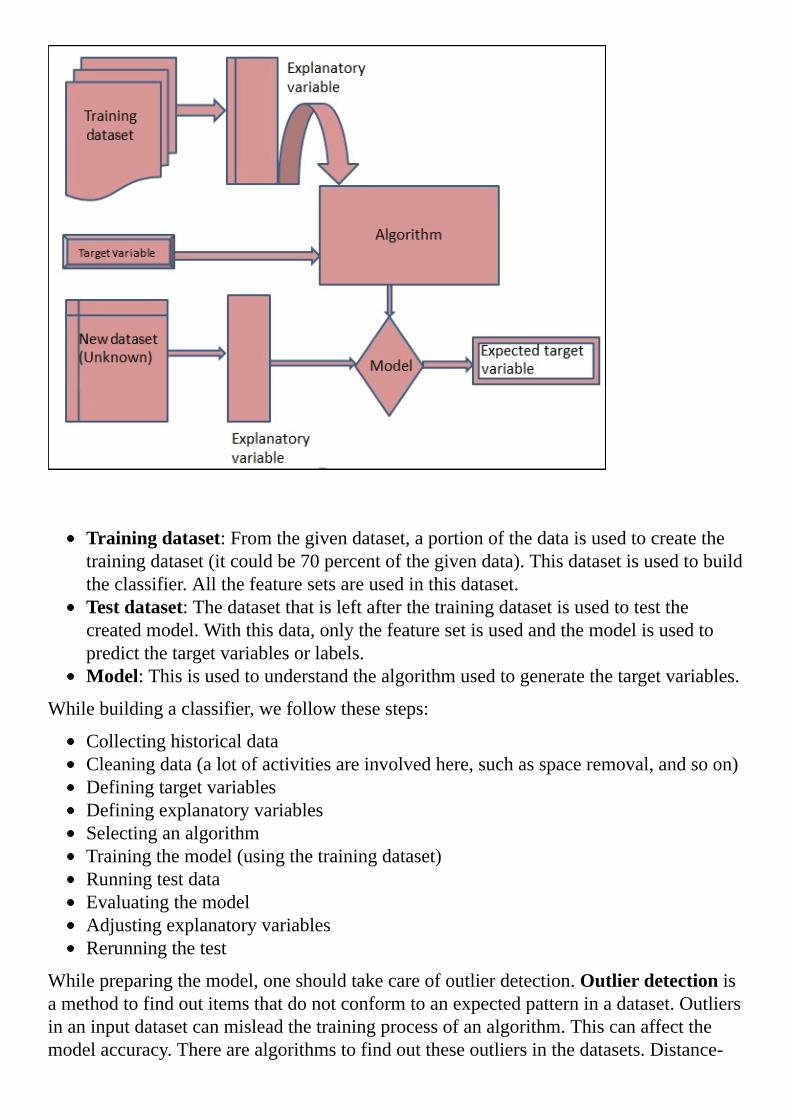
Trainingdataset:Fromthegivendataset,aportionofthedataisusedtocreatethetrainingdataset(itcouldbe70percentofthegivendata).Thisdatasetisusedtobuildtheclassifier.Allthefeaturesetsareusedinthisdataset.Testdataset:Thedatasetthatisleftafterthetrainingdatasetisusedtotestthecreatedmodel.Withthisdata,onlythefeaturesetisusedandthemodelisusedtopredictthetargetvariablesorlabels.Model:Thisisusedtounderstandthealgorithmusedtogeneratethetargetvariables.
Whilebuildingaclassifier,wefollowthesesteps:
CollectinghistoricaldataCleaningdata(alotofactivitiesareinvolvedhere,suchasspaceremoval,andsoon)DefiningtargetvariablesDefiningexplanatoryvariablesSelectinganalgorithmTrainingthemodel(usingthetrainingdataset)RunningtestdataEvaluatingthemodelAdjustingexplanatoryvariablesRerunningthetest
Whilepreparingthemodel,oneshouldtakecareofoutlierdetection.Outlierdetectionisamethodtofindoutitemsthatdonotconformtoanexpectedpatterninadataset.Outliersinaninputdatasetcanmisleadthetrainingprocessofanalgorithm.Thiscanaffectthemodelaccuracy.Therearealgorithmstofindouttheseoutliersinthedatasets.Distance-
basedtechniquesandfuzzy-logic-basedmethodsaremostlyusedtofindoutoutliersinthedataset.Let’stalkaboutoneexampletounderstandtheoutliers.
Wehaveasetofnumbers,andwewanttofindoutthemeanofthesenumbers:
10,75,10,15,20,85,25,30,25
Justplotthesenumbersandtheresultwillbeasshowninthefollowingscreenshot:
Clearly,thenumbers75and85areoutliers(farawayintheplotfromtheothernumbers).
Mean=sumofvalues/numberofvalues=32.78
Meanwithouttheoutliers:=19.29
So,nowyoucanunderstandhowoutlierscanaffecttheresults.
Whilecreatingthemodel,wecanencountertwomajorlyoccurringproblems—OverfittingandUnderfitting.
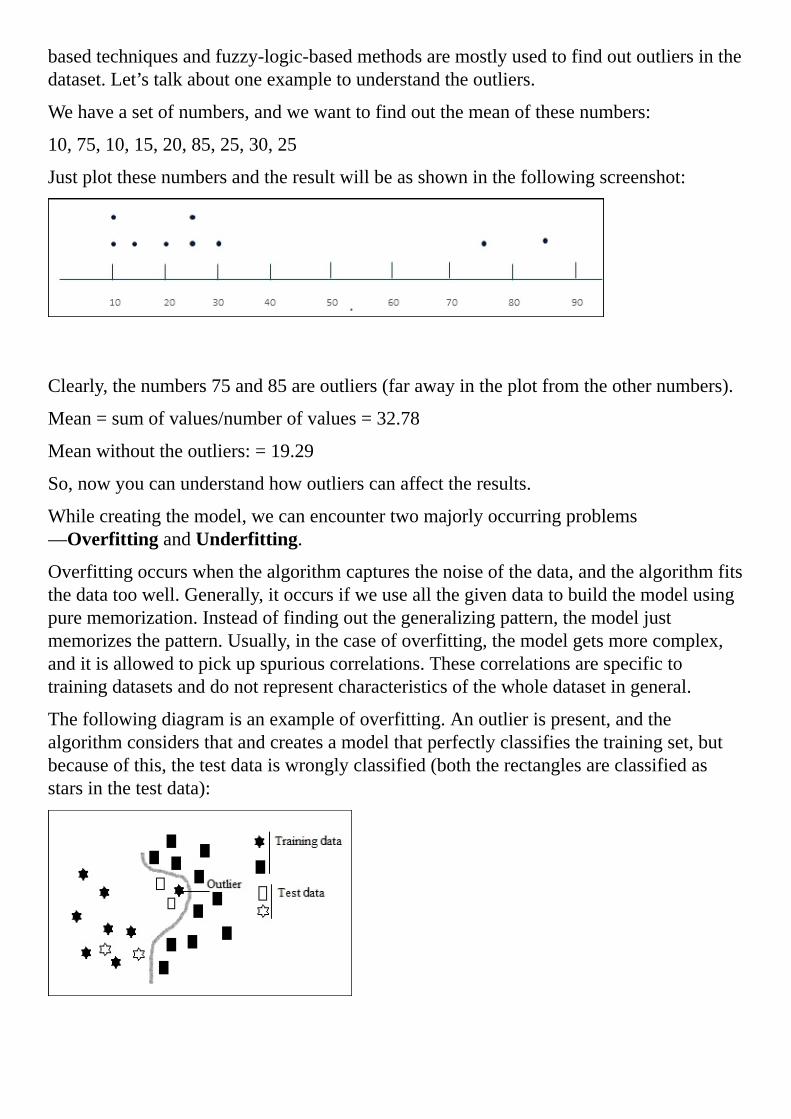
Overfittingoccurswhenthealgorithmcapturesthenoiseofthedata,andthealgorithmfitsthedatatoowell.Generally,itoccursifweuseallthegivendatatobuildthemodelusingpurememorization.Insteadoffindingoutthegeneralizingpattern,themodeljustmemorizesthepattern.Usually,inthecaseofoverfitting,themodelgetsmorecomplex,anditisallowedtopickupspuriouscorrelations.Thesecorrelationsarespecifictotrainingdatasetsanddonotrepresentcharacteristicsofthewholedatasetingeneral.
Thefollowingdiagramisanexampleofoverfitting.Anoutlierispresent,andthealgorithmconsidersthatandcreatesamodelthatperfectlyclassifiesthetrainingset,butbecauseofthis,thetestdataiswronglyclassified(boththerectanglesareclassifiedasstarsinthetestdata):

Thereisnosinglemethodtoavoidoverfitting;however,wehavesomeapproaches,suchasareductioninthenumberoffeaturesandtheregularizationofafewofthefeatures.Anotherwayistotrainthemodelwithsomedatasetandtestwiththeremainingdataset.Acommonmethodcalledcross-validationisusedtogeneratemultipleperformancemeasures.Inthisway,asingledatasetissplitandusedforthecreationofperformancemeasures.
Underfittingoccurswhenthealgorithmcannotcapturethepatternsinthedata,andthedatadoesnotfitwell.Underfittingisalsoknownashighbias.Itmeansyouralgorithmhassuchastrongbiastowardsitshypothesisthatitdoesnotfitthedatawell.Foranunderfittingerror,moredatawillnothelp.Itcanincreasethetrainingerror.Moreexplanatoryvariablescanhelptodealwiththeunderfittingproblem.Moreexplanatoryfieldswillexpandthehypothesisspaceandwillbeusefultoovercomethisproblem.
Bothoverfittingandunderfittingprovidepoorresultswithnewdatasets.


ClassificationalgorithmsWewillnowdiscussthefollowingalgorithmsthataresupportedbyApacheMahoutinthisbook:
Logisticregression/StochasticGradientDescent(SGD):Weusuallyreadregressionalongwithclassification,butactually,thereisadifferencebetweenthetwo.Classificationinvolvesacategoricaltargetvariable,whileregressioninvolvesanumerictargetvariable.Classificationpredictswhethersomethingwillhappen,andregressionpredictshowmuchofsomethingwillhappen.WewillcoverthisalgorithminChapter3,LearningLogisticRegression/SGDUsingMahout.MahoutsupportslogisticregressiontrainedviaStochasticGradientDescent.NaïveBayesclassification:Thisisaverypopularalgorithmfortextclassification.NaïveBayesusestheconceptofprobabilitytoclassifynewitems.ItisbasedontheBayestheorem.WewilldiscussthisalgorithminChapter4,LearningtheNaïveBayesClassificationUsingMahout.Inthischapter,wewillseehowMahoutisusefulinclassifyingtext,whichisrequiredinthedataanalysisfield.Wewilldiscussvectorization,bagofwords,n-grams,andothertermsusedintextclassification.HiddenMarkovModel(HMM):Thisisusedinvariousfields,suchasspeechrecognition,parts-of-speechtagging,geneprediction,time-seriesanalysis,andsoon.InHMM,weobserveasequenceofemissionsbutdonothaveasequenceofstateswhichamodelusestogeneratetheemission.InChapter5,LearningtheHiddenMarkovModelUsingMahout,wewilltakeonemorealgorithmsupportedbyMahoutHiddenMarkovModel.WewilldiscussHMMindetailandseehowMahoutsupportsthisalgorithm.RandomForest:Thisisthemostwidelyusedalgorithminclassification.RandomForestconsistsofacollectionofsimpletreepredictors,eachcapableofproducingaresponsewhenpresentedwithasetofexplanatoryvariables.InChapter6,LearningRandomForestUsingMahout,wewilldiscussthisalgorithmindetailandalsotalkabouthowtouseMahouttoimplementthisalgorithm.Multi-layerPerceptron(MLP):InChapter7,LearningMultilayerPerceptronUsingMahout,wewilldiscussthisnewlyimplementedalgorithminMahout.AnMLPconsistsofmultiplelayersofnodesinadirectedgraph,witheachlayerfullyconnectedtothenextone.Itisabasefortheimplementationofneuralnetworks.WewilldiscussneuralnetworksalittlebutonlyafteradetaileddiscussiononMLPinMahout.
WewilldiscussalltheclassificationalgorithmssupportedbyApacheMahoutinthisbook,andwewillalsocheckthemodelevaluationtechniquesprovidedbyApacheMahout.


ModelevaluationtechniquesWecannothaveasingleevaluationmetricthatcanfitalltheclassifiermodels,butwecanfindoutsomecommonissuesinevaluation,andwehavetechniquestodealwiththem.WewilldiscussthefollowingtechniquesthatareusedinMahout:
ConfusionmatrixROCgraphAUCEntropymatrix
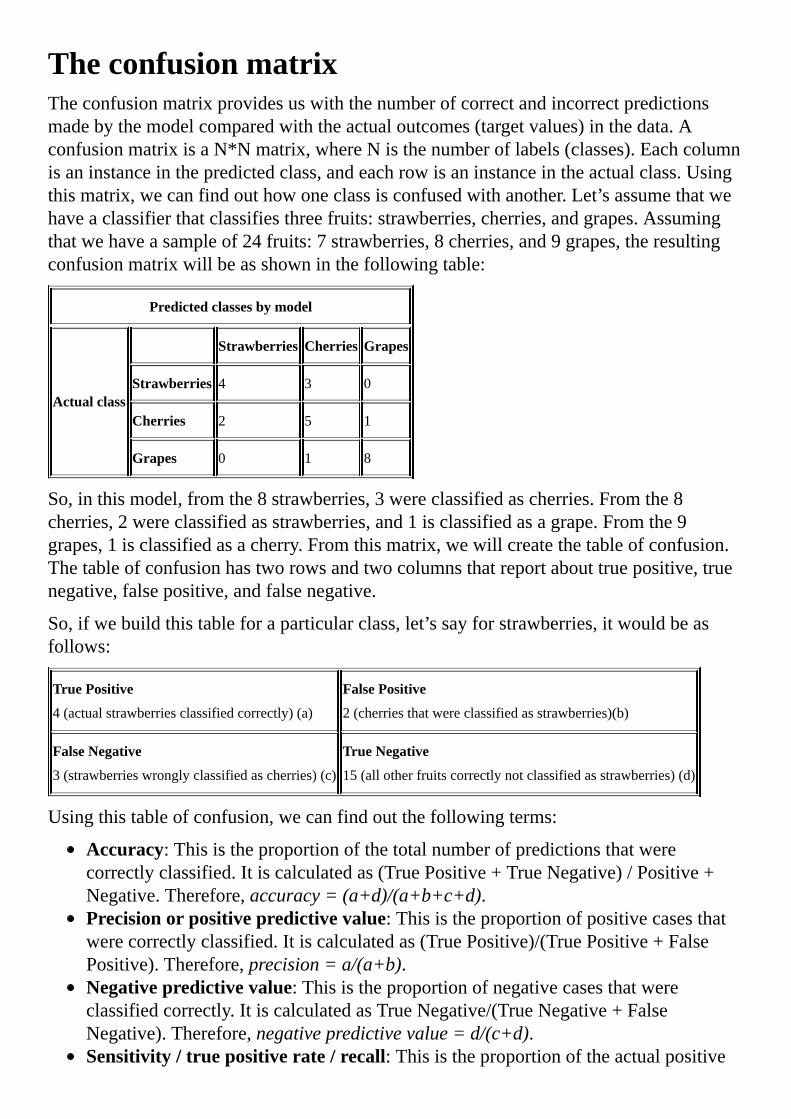
TheconfusionmatrixTheconfusionmatrixprovidesuswiththenumberofcorrectandincorrectpredictionsmadebythemodelcomparedwiththeactualoutcomes(targetvalues)inthedata.AconfusionmatrixisaN*Nmatrix,whereNisthenumberoflabels(classes).Eachcolumnisaninstanceinthepredictedclass,andeachrowisaninstanceintheactualclass.Usingthismatrix,wecanfindouthowoneclassisconfusedwithanother.Let’sassumethatwehaveaclassifierthatclassifiesthreefruits:strawberries,cherries,andgrapes.Assumingthatwehaveasampleof24fruits:7strawberries,8cherries,and9grapes,theresultingconfusionmatrixwillbeasshowninthefollowingtable:
Predictedclassesbymodel
Actualclass
Strawberries Cherries Grapes
Strawberries 4 3 0
Cherries 2 5 1
Grapes 0 1 8
So,inthismodel,fromthe8strawberries,3wereclassifiedascherries.Fromthe8cherries,2wereclassifiedasstrawberries,and1isclassifiedasagrape.Fromthe9grapes,1isclassifiedasacherry.Fromthismatrix,wewillcreatethetableofconfusion.Thetableofconfusionhastworowsandtwocolumnsthatreportabouttruepositive,truenegative,falsepositive,andfalsenegative.
So,ifwebuildthistableforaparticularclass,let’ssayforstrawberries,itwouldbeasfollows:
TruePositive
4(actualstrawberriesclassifiedcorrectly)(a)
FalsePositive
2(cherriesthatwereclassifiedasstrawberries)(b)
FalseNegative
3(strawberrieswronglyclassifiedascherries)(c)
TrueNegative
15(allotherfruitscorrectlynotclassifiedasstrawberries)(d)
Usingthistableofconfusion,wecanfindoutthefollowingterms:
Accuracy:Thisistheproportionofthetotalnumberofpredictionsthatwerecorrectlyclassified.Itiscalculatedas(TruePositive+TrueNegative)/Positive+Negative.Therefore,accuracy=(a+d)/(a+b+c+d).Precisionorpositivepredictivevalue:Thisistheproportionofpositivecasesthatwerecorrectlyclassified.Itiscalculatedas(TruePositive)/(TruePositive+FalsePositive).Therefore,precision=a/(a+b).Negativepredictivevalue:Thisistheproportionofnegativecasesthatwereclassifiedcorrectly.ItiscalculatedasTrueNegative/(TrueNegative+FalseNegative).Therefore,negativepredictivevalue=d/(c+d).Sensitivity/truepositiverate/recall:Thisistheproportionoftheactualpositive

casesthatwerecorrectlyidentified.ItiscalculatedasTruePositive/(TruePositive+FalseNegative).Therefore,sensitivity=a/(a+c).Specificity:Thisistheproportionoftheactualnegativecases.ItiscalculatedasTrueNegative/(FalsePositive+TrueNegative).Therefore,specificity=d/(b+d).F1score:Thisisthemeasureofatest’saccuracy,anditiscalculatedasfollows:F1=2.((Positivepredictivevalue(precision)*sensitivity(recall))/(Positivepredictivevalue(precision)+sensitivity(recall))).
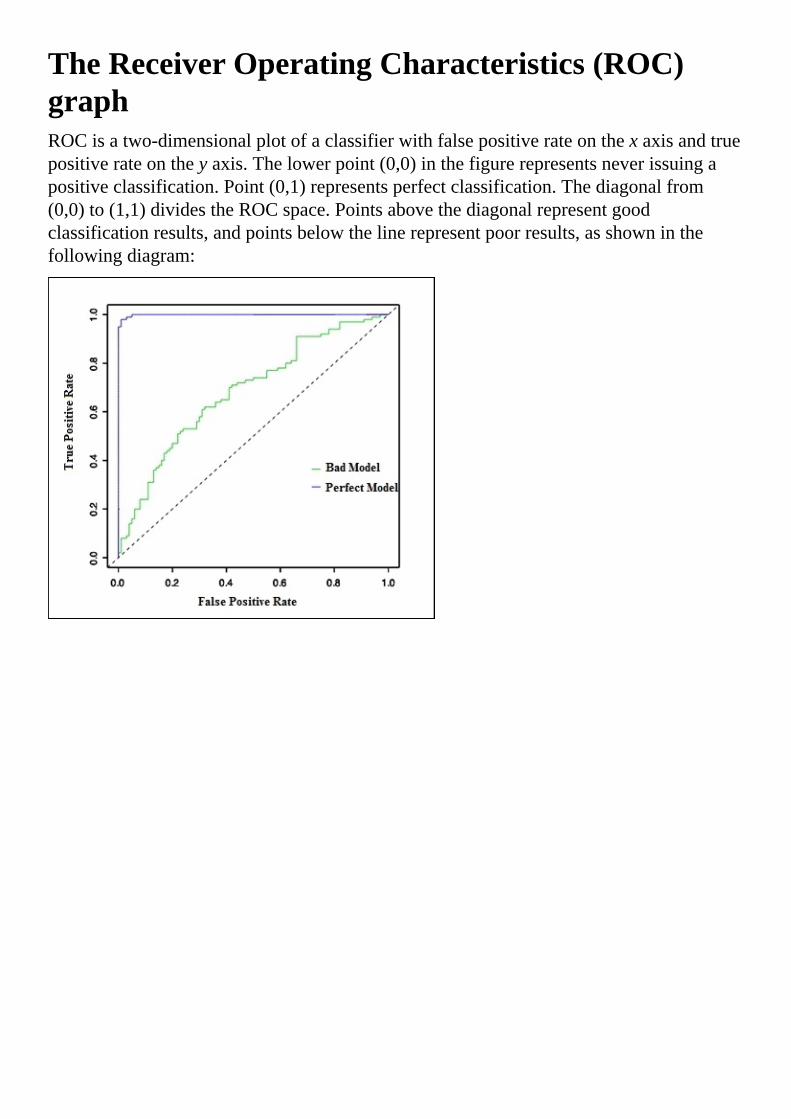
TheReceiverOperatingCharacteristics(ROC)graphROCisatwo-dimensionalplotofaclassifierwithfalsepositiverateonthexaxisandtruepositiverateontheyaxis.Thelowerpoint(0,0)inthefigurerepresentsneverissuingapositiveclassification.Point(0,1)representsperfectclassification.Thediagonalfrom(0,0)to(1,1)dividestheROCspace.Pointsabovethediagonalrepresentgoodclassificationresults,andpointsbelowthelinerepresentpoorresults,asshowninthefollowingdiagram:

AreaundertheROCcurveThisistheareaundertheROCcurveandisalsoknownasAUC.Itisusedtomeasurethequalityoftheclassificationmodel.Inpractice,mostoftheclassificationmodelshaveanAUCbetween0.5and1.Thecloserthevalueisto1,thegreaterisyourclassifier.

TheentropymatrixBeforegoingintothedetailsoftheentropymatrix,firstweneedtounderstandentropy.TheconceptofentropyininformationtheorywasdevelopedbyShannon.
Entropyisameasureofdisorderthatcanbeappliedtoaset.Itisdefinedas:
Entropy=-p1log(p1)–p2log(p2)-…….
Eachpistheprobabilityofaparticularpropertywithintheset.Let’srevisitourcustomerloanapplicationdataset.Forexample,assumingwehaveasetof10customersfromwhich6areeligibleforaloanand4arenot.Here,wehavetwoproperties(classes):eligibleornoteligible.
P(eligible)=6/10=0.6
P(noteligible)=4/10=0.4
So,entropyofthedatasetwillbe:
Entropy=-[0.6*log2(0.6)+0.4*log2(0.4)]
=-[0.6*-0.74+0.4*-1.32]
=0.972
Entropyisusefulinacquiringknowledgeofinformationgain.Informationgainmeasuresthechangeinentropyduetoanynewinformationbeingaddedinmodelcreation.So,ifentropydecreasesfromnewinformation,itindicatesthatthemodelisperformingwellnow.Informationgainiscalculatedas:
IG(classes,subclasses)=entropy(class)–(p(subclass1)*entropy(subclass1)+p(subclass2)*entropy(subclass2)+…)
Entropymatrixisbasicallythesameastheconfusionmatrixdefinedearlier;theonlydifferenceisthattheelementsinthematrixaretheaveragesofthelogoftheprobabilityscoreforeachtrueorestimatedcategorycombination.Agoodmodelwillhavesmallnegativenumbersalongthediagonalandwillhavelargenegativenumbersintheoff-diagonalposition.


SummaryWehavediscussedclassificationanditsapplicationsandalsowhatalgorithmandclassifierevaluationtechniquesaresupportedbyMahout.Wediscussedtechniqueslikeconfusionmatrix,ROCgraph,AUC,andentropymatrix.
Now,wewillmovetothenextchapterandsetupApacheMahoutandthedeveloperenvironment.WewillalsodiscussthearchitectureofApacheMahoutandfindoutwhyMahoutisagoodchoiceforclassification.


Chapter2.ApacheMahoutInthepreviouschapter,wediscussedclassificationandlookedintothealgorithmsprovidedbyMahoutinthisarea.Beforegoingtothosealgorithms,weneedtounderstandMahoutanditsinstallation.Inthischapter,wewillexplorethefollowingtopics:
WhatisApacheMahout?AlgorithmssupportedinMahoutWhyisitagoodchoiceforclassificationproblems?SettingupthesystemforMahoutdevelopment

IntroducingApacheMahoutAmahoutisapersonwhoridesandcontrolsanelephant.MostofthealgorithmsinApacheMahoutareimplementedontopofHadoop,whichisanotherApache-licensedprojectandhasthesymbolofanelephant(http://hadoop.apache.org/).AsApacheMahoutridesoverHadoop,thisnameisjustified.
ApacheMahoutisaprojectofApacheSoftwareFoundationthathasimplementationsofmachinelearningalgorithms.MahoutwasstartedasasubprojectoftheApacheLuceneprojectin2008.Aftersometime,anopensourceprojectnamedTaste,whichwasdevelopedforcollaborativefiltering,anditwasabsorbedintoMahout.MahoutiswritteninJavaandprovidesscalablemachinelearningalgorithms.Mahoutisthedefaultchoiceformachinelearningproblemsinwhichthedataistoolargetofitintoasinglemachine.MahoutprovidesJavalibrariesanddoesnotprovideanyuserinterfaceorserver.Itisaframeworkoftoolstobeusedandadaptedbydevelopers.
Tosumitup,Mahoutprovidesyouwithimplementationsofthemostfrequentlyusedmachinelearningalgorithmsintheareaofclassification,clustering,andrecommendation.Insteadofspendingtimewritingalgorithms,itprovidesuswithready-to-consumesolutions.
MahoutusesHadoopforitsalgorithms,butsomeofthealgorithmscanalsorunwithoutHadoop.Currently,Mahoutsupportsthefollowingusecases:
Recommendation:Thistakestheuserdataandtriestopredictitemsthattheusermightlike.Withthisusecase,youcanseeallthesitesthataresellinggoodstotheuser.Basedonyourpreviousaction,theywilltrytofindoutunknownitemsthatcouldbeofuse.Oneexamplecanbethis:assoonasyouselectsomebookfromAmazon,thewebsitewillshowyoualistofotherbooksunderthetitle,CustomersWhoBoughtThisItemAlsoBought.Italsoshowsthetitle,WhatOtherItemsDoCustomersBuyAfterViewingThisItem?AnotherexampleofrecommendationisthatwhileplayingvideosonYouTube,itrecommendsthatyoulistentosomeothervideosbasedonyourselection.MahoutprovidesfullAPIsupporttodevelopyour

ownuser-basedoritem-basedrecommendationengine.Classification:Asdefinedintheearlierchapter,classificationdecideshowmuchanitembelongstooneparticularcategory.E-mailclassificationforfilteringoutspamisaclassicexampleofclassification.MahoutprovidesarichsetofAPIstobuildyourownclassificationmodel.Forexample,Mahoutcanbeusedtobuildadocumentclassifierorane-mailclassifier.Clustering:Thisisatechniquethattriestogroupitemstogetherbasedonsomesortofsimilarity.Here,wefindthedifferentclustersofitemsbasedoncertainproperties,andwedonotknowthenameoftheclusterinadvance.Themaindifferencebetweenclusteringandclassificationisthatinclassification,weknowtheendclassname.Clusteringisusefulinfindingoutdifferentcustomersegments.GoogleNewsusestheclusteringtechniqueinordertogroupnews.Forclustering,Mahouthasalreadyimplementedsomeofthemostpopularalgorithmsinthisarea,suchask-means,fuzzyk-means,canopy,andsoon.Dimensionalreduction:Aswediscussedinthepreviouschapter,featuresarecalleddimensions.Dimensionalreductionistheprocessofreducingthenumberofrandomvariablesunderconsideration.Thismakesdataeasytouse.Mahoutprovidesalgorithmsfordimensionalreduction.SingularvaluedecompositionandLanczosareexamplesofthealgorithmsthatMahoutprovides.Topicmodeling:Topicmodelingisusedtocapturetheabstractideaofadocument.Atopicmodelisamodelthatassociatesprobabilitydistributionwitheachdocumentovertopics.Giventhatadocumentisaboutaparticulartopic,onewouldexpectparticularwordstoappearinthedocumentmoreorlessfrequently.“Football”and“goal”willappearmoreinadocumentaboutsports.LatentDirichletAllocation(LDA)isapowerfullearningalgorithmfortopicmodeling.InMahout,collapsedvariationalBayesisimplementedforLDA.


AlgorithmssupportedinMahoutTheimplementationofalgorithmsinMahoutcanbecategorizedintotwogroups:
Sequentialalgorithms:ThesealgorithmsareexecutedsequentiallyanddonotuseHadoopscalableprocessing.TheyareusuallytheonesderivedfromTaste.Forexample:user-basedcollaborativefiltering,logisticregression,HiddenMarkovModel,multi-layerperceptron,singularvaluedecomposition.Parallelalgorithms:ThesealgorithmscansupportpetabytesofdatausingHadoop’smapandhencereduceparallelprocessing.Forexample,RandomForest,NaïveBayes,canopyclustering,k-meansclustering,spectralclustering,andsoon.


ReasonsforMahoutbeingagoodchoiceforclassificationInmachinelearningsystems,themoredatayouuse,themoreaccuratethesystembuiltwillbe.Mahout,whichusesHadoopforscalability,iswayaheadofothersintermsofhandlinghugedatasets.Asthenumberoftrainingsetsincreases,Mahout’sperformancealsoincreases.Iftheinputsizefortrainingexamplesisfrom1millionto10million,thenMahoutisanexcellentchoice.
Forclassificationproblems,increaseddatafortrainingisdesirableasitcanimprovetheaccuracyofthemodel.Generally,asthenumberofdatasetsincreases,memoryrequirementalsoincreases,andalgorithmsbecomeslow,butMahout’sscalableandparallelalgorithmsworkbetterwithregardstothetimetaken.Eachnewmachineaddeddecreasesthetrainingtimeandprovideshigherperformance.


InstallingMahoutNowlet’strytheslightlychallengingpartofthisbook:Mahoutinstallation.Basedoncommonexperiences,Ihavecomeupwiththefollowingquestionsorconcernsthatusersfacebeforeinstallation:
IdonotknowanythingaboutMaven.HowwillIcompileMahoutbuild?HowcanIsetupEclipsetowritemyownprogramsinMahout?HowcanIinstallMahoutonaWindowssystem?
So,wewillinstallMahoutwiththehelpofthefollowingsteps.Eachstepisindependentfromtheother.Youcanchooseanyoneofthese:
BuildingMahoutcodeusingMavenSettingupadevelopmentenvironmentusingEclipseSettingupMahoutforaWindowsuser
Beforeanyofthesteps,someoftheprerequisitesare:
YoushouldhaveJavainstalledonyoursystem.Wikihowisagoodsourceforthisathttp://www.wikihow.com/Install-Java-on-LinuxYoushouldhaveHadoopinstalledonyoursystemfromthehttp://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleNodeSetup.htmlURL

BuildingMahoutfromsourceusingMavenMahout’sbuildandreleasesystemisbasedonMaven.
InstallingMaven1. Createthefolder/usr/local/maven,asfollows:
mkdir/usr/local/maven
2. Downloadthedistributionapache-maven-x.y.z-bin.tar.gzfromtheMavensite(http://maven.apache.org/download.cgi)andmovethisto/usr/local/maven,asfollows:
mvapache-maven-x.y.z-bin.tar.gz/usr/local/maven
3. Unpacktothelocation/usr/local/maven,asfollows:
tar–xvfapache-maven-x.y.z-bin.tar.gz
4. Editthe.bashrcfile,asfollows:
exportM2_HOME=/usr/local/apache-maven-x.y.z
exportM2=$M2_HOME/bin
exportPATH=$M2:$PATH
NoteFortheEclipseIDE,gotoHelpandselectInstallnewSoftware.ClickontheAddbutton,andinthepopup,typethenameM2Eclipse,providethelinkhttp://download.eclipse.org/technology/m2e/releases,andclickonOK.
BuildingMahoutcodeBydefault,MahoutassumesthatHadoopisalreadyinstalledonthesystem.MahoutusestheHADOOP_HOMEandHADOOP_CONF_DIRenvironmentvariablestoaccessHadoopclusterconfigurations.ForsettingupMahout,executethefollowingsteps:
1. DownloadtheMahoutdistributionfilemahout-distribution-0.9-src.tar.gzfromthelocationhttp://archive.apache.org/dist/mahout/0.9/.
2. ChooseaninstallationdirectoryforMahout(/usr/local/Mahout),andplacethedownloadedsourceinthefolder.Extractthesourcecodeandensurethatthefoldercontainsthepom.xmlfile.Thefollowingistheexactlocationofthesource:
tar-xvfmahout-distribution-0.9-src.tar.gz
3. InstalltheMahoutMavenproject,andskipthetestcaseswhileinstalling,asfollows:
mvninstall-Dmaven.test.skip=true
4. SettheMAHOUT_HOMEenvironmentvariableinthe~/.bashrcfile,andupdatethePATHvariablewiththeMahoutbindirectory:
exportMAHOUT_HOME=/user/local/mahout/mahout-distribution-0.9
exportPATH=$PATH:$MAHOUT_HOME/bin
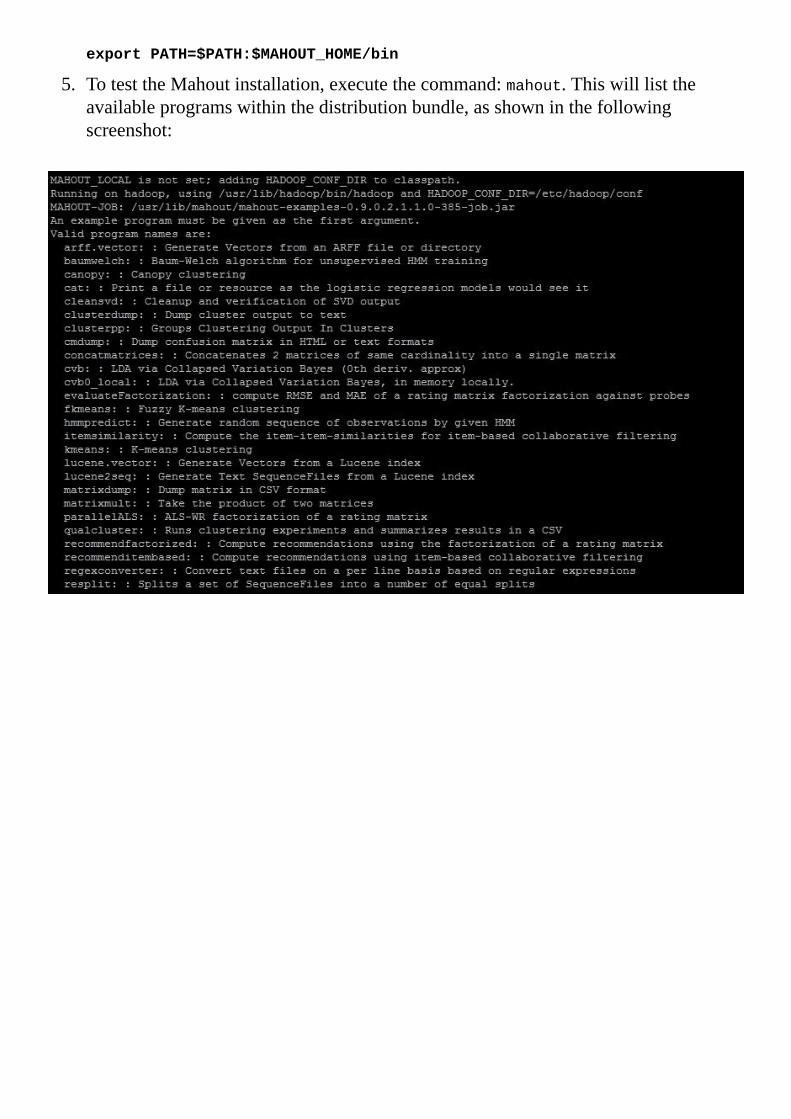
5. TotesttheMahoutinstallation,executethecommand:mahout.Thiswilllisttheavailableprogramswithinthedistributionbundle,asshowninthefollowingscreenshot:

SettingupadevelopmentenvironmentusingEclipseForthissetup,youshouldhaveMaveninstalledonthesystemandtheMavenpluginforEclipse.RefertotheInstallingMavenstepexplainedintheprevioussection.Thissetupcanbedoneinthefollowingsteps:
1. DownloadtheMahoutdistributionfilemahout-distribution-0.9-src.tar.gzfromthelocationhttp://archive.apache.org/dist/mahout/0.9/andunzipthis:
tarxzfmahout-distribution-0.9-src.tar.gz
2. Let’screateafoldernamedworkspaceunder/usr/local/workspace,asfollows:
mkdir/usr/local/workspace
3. Movethedownloadeddistributiontothisfolder(fromthedownloadsfolder),asfollows:
mvmahout-distribution-0.9/usr/local/workspace/
4. Movetothefolder/usr/local/workspace/mahout-distribution-0.9andmakeanEclipseproject(thiscommandcantakeuptoanhour):
mvneclipse:eclipse
5. SettheMahouthomeinthe.bashrcfile,asexplainedearlierintheBuildingMahoutcodesection.
6. NowopenEclipse.Selectthefile,importMaven,andExistingMavenProjects.Now,navigatetothelocationformahout-distribution-0.9andclickonFinish.

SettingupMahoutforaWindowsuserAWindowsusercanuseCygwin(alargecollectionofGNUandopensourcetoolsthatprovidesfunctionalitysimilartoaLinuxdistributiononWindows)tosetuptheirenvironment.Thereisalsoanotherwaythatiseasytouse,asshowninthefollowingsteps:
1. DownloadHortonworksSandboxforvirtualboxonyoursystemfromthelocationhttp://hortonworks.com/products/hortonworks-sandbox/#install.HortonworksSandboxonyoursystemwillbeapseudo-distributedmodeofHadoop.
2. Logintotheconsole.UseAlt+F5oralternativelydownloadPuttyandprovide127.0.0.1asthehostnameand2222intheport,asshowninthefollowingfigure.Loginwiththeusernamerootandpassword-hadoop.
3. Enterthefollowingcommand:
yuminstallmahout
Now,youwillseeascreenlikethis:

4. Entery,andyourMahoutwillstartinstalling.Oncethisisdone,youcantestbytypingthecommandmahoutandthiswillshowyouthesamescreenasshownintheSettingupadevelopmentenvironmentusingEclipserecipeseenearlier.


SummaryWediscussedApacheMahoutindetailinthischapter.WecoveredtheprocessofinstallingMahoutonoursystem,alongwithsettingupadevelopmentenvironmentthatisreadytoexecuteMahoutalgorithms.WehavealsotakenalookatthereasonsbehindMahoutbeingconsideredagoodchoiceforclassification.Now,wemovetothenextwherewewillunderstandaboutlogisticregressionandlearnabouttheprocessthatneedstobefollowedtoexecuteourfirstalgorithminMahout.


Chapter3.LearningLogisticRegression/SGDUsingMahoutInsteadofjumpingdirectlyintologisticregression,let’strytounderstandafewofitsconcepts.Inthischapter,wewillexplorethefollowingtopics:
IntroducingregressionUnderstandinglinearregressionCostfunctionGradientdescentLogisticregressionUnderstandingSGDUsingMahoutforlogisticregression

IntroducingregressionRegressionanalysisisusedforpredictionandforecasting.Itisusedtofindouttherelationshipbetweenexplanatoryvariablesandtargetvariables.Essentially,itisastatisticalmodelthatisusedtofindouttherelationshipamongvariablespresentinthedatasets.Anexamplethatyoucanrefertoforabetterunderstandingofthistermisthis:determinetheearningsofworkersinaparticularindustry.Here,wewilltrytofindoutthefactorsthataffectaworker’ssalary.Thesefactorscanbeage,education,yearsofexperience,particularskillset,location,andsoon.Wewilltrytomakeamodelthatwilltakeallthesevariablesintoconsiderationandtrytopredictthesalary.Inregressionanalysis,wecharacterizethevariationofthetargetvariablearoundtheregressionfunction,whichcanbedescribedbyaprobabilitydistributionthatisalsoofinterest.Thereareanumberofregressionanalysistechniquesthatareavailable.Forexample,linearregression,ordinaryleastsquaresregression,logisticregression,andsoon.

UnderstandinglinearregressionInlinearregression,wecreateamodeltopredictthevalueofatargetvariablewiththehelpofanexplanatoryvariable.Tounderstandthisbetter,let’slookatanexample.
AcompanyXthatdealsinsellingcoffeehasnoticedthatinthemonthofmonsoon,theirsalesincreasedtoquiteanextent.Sotheyhavecomeupwithaformulatofindtherelationbetweenrainandtheirpercupcoffeesale,whichisshownasfollows:
C=1.5R+800
So,for2mmofrain,thereisademandof803cupsofcoffee.Nowifyougointominutedetails,youwillrealizethatwehavethedataforrainfallandpercupcoffeesale,andwearetryingtobuildamodelthatcanpredictthedemandforcoffeebasedontherainfall.Wehavedataintheformof(R1,C1),(R2,C2)….(Ri,Ci).Here,wewillbuildthemodelinamannerthatkeepstheerrorintheactualandpredictedvaluesataminimum.
CostfunctionIntheequationC=1.5R+800,thetwovalues1.5and800areparametersandthesevaluesaffecttheendresult.WecanwritethisequationasC=p0+p1R.Aswediscussedearlier,ourgoalistoreducethedifferencebetweentheactualvalueandthepredictedvalue,andthisisdependentonthevaluesofp0andp1.Let’sassumethatthepredictedvalueisCpandtheactualvalueisCsothatthedifferencewillbe(Cp-C).Thiscanbewrittenas(p0+p1R-C).Tominimizethiserror,wedefinetheerrorfunction,whichisalsocalledthecostfunction.
Thecostfunctioncanbedefinedwiththefollowingformula:
Here,iistheithsampleandNisthenumberoftrainingexamples.Wecalculatecostsfordifferentsetsofp0andp1andfinallyselectthep0andp1thatgivestheleastcost(C).Thisisthemodelthatwillbeusedtomakepredictionsfornewinput.
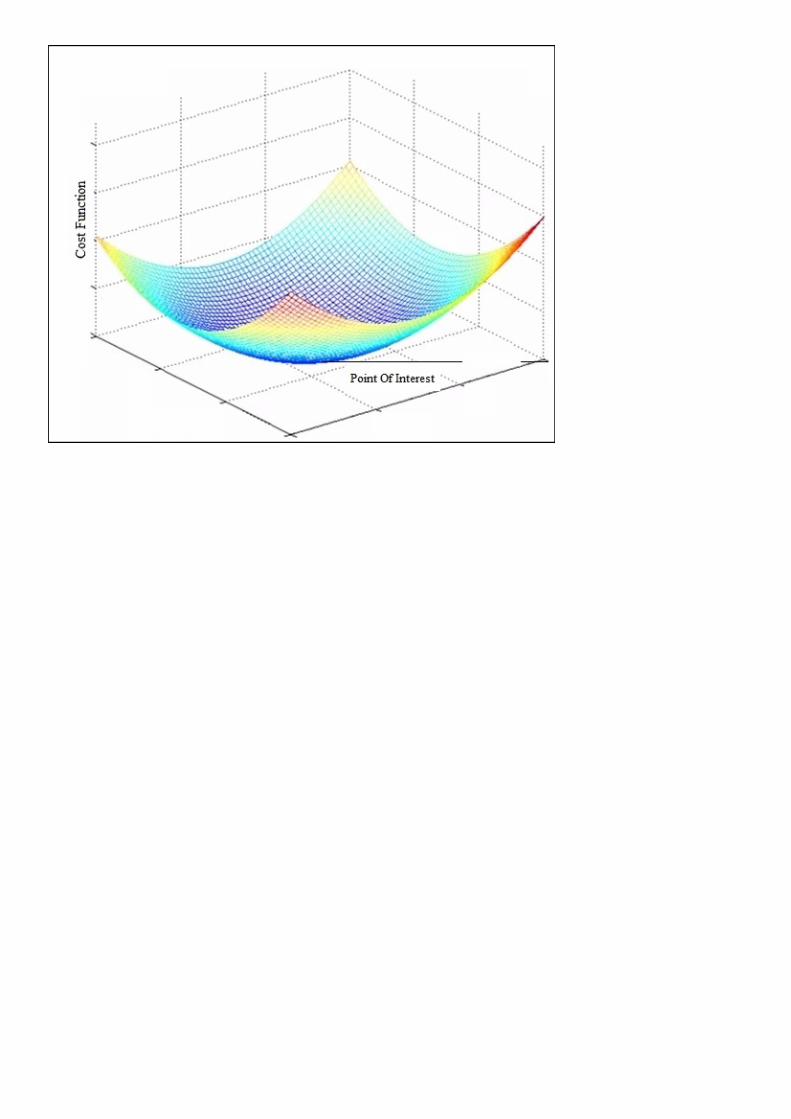
GradientdescentGradientdescentstartswithaninitialsetofparametervalues,p0andp1,anditerativelymovestowardsasetofparametervaluesthatminimizesthecostfunction.Wecanvisualizethiserrorfunctiongraphically,wherewidthandlengthcanbeconsideredastheparametersp0andp1andheightasthecostfunction.Ourgoalistofindthevaluesforp0andp1inawaythatourcostfunctionwillbeminimal.Westartthealgorithmwithsomevaluesofp0andp1anditerativelyworktowardstheminimumvalue.Agoodwaytoensurethatthegradientdescentisworkingcorrectlyistomakesurethatthecostfunctiondecreasesforeachiteration.Inthiscase,thecostfunctionsurfaceisconvexandwewilltrytofindouttheminimumvalue.Thiscanbeseeninthefollowingfigure:

LogisticregressionLogisticregressionisusedtoascertaintheprobabilityofanevent.Generally,logisticregressionreferstoproblemswheretheoutcomeisbinary,forexample,inbuildingamodelthatisbasedonacustomer’sincome,traveluses,gender,andotherfeaturestopredictwhetherheorshewillbuyaparticularcarornot.So,theanswerwillbeasimpleyesorno.Whentheoutcomeiscomposedofmorethanonecategory,thisiscalledmultinomiallogisticregression.
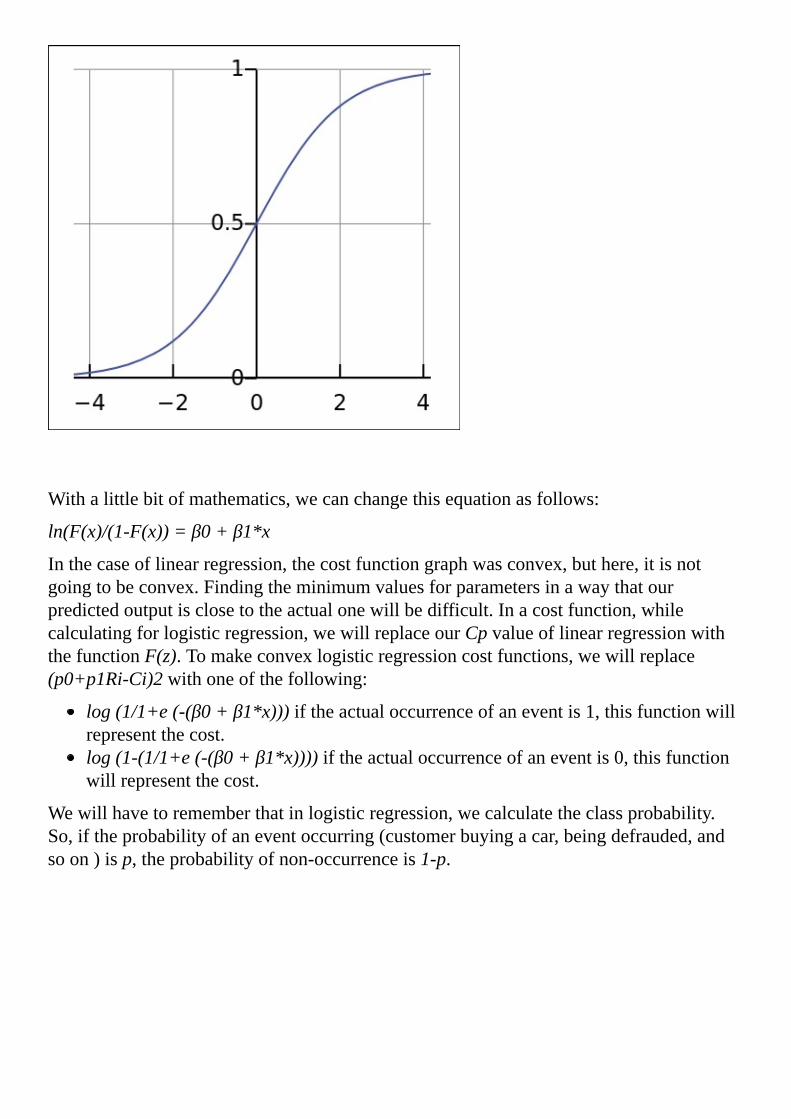
Logisticregressionisbasedonthesigmoidfunction.Predictorvariablesarecombinedwithlinearweightandthenpassedtothisfunction,whichgeneratestheoutputintherangeof0–1.Anoutputcloseto1indicatesthatanitembelongstoacertainclass.Let’sfirstunderstandthesigmoidorlogisticfunction.Itcanbedefinedbythefollowingformula:
F(z)=1/1+e(-z)
Withasingleexplanatoryvariable,zwillbedefinedasz=β0+β1*x.Thisequationisexplainedasfollows:
z:Thisiscalledthedependentvariable.Thisisthevariablethatwewouldliketopredict.Duringthecreationofthemodel,wehavethisvariablewithusinthetrainingset,andwebuildthemodeltopredictthisvariable.Theknownvaluesofzarecalledobservedvalues.x:Thisistheexplanatoryorindependentvariable.Thesevariablesareusedtopredictthedependentvariablez.Forexample,topredictthesalesofanewlylaunchedproductataparticularlocation,wemightincludeexplanatoryvariablessuchasthepriceoftheproduct,theaverageincomeofthepeopleofthatlocation,andsoon.β0:Thisiscalledtheregressionintercept.Ifallexplanatoryvariablesarezero,thenthisparameterisequaltothedependentvariablez.β1:Thesearevaluesforeachexplanatoryvariable.
Thegraphofthelogisticfunctionisasfollows:
Withalittlebitofmathematics,wecanchangethisequationasfollows:
ln(F(x)/(1-F(x))=β0+β1*x
Inthecaseoflinearregression,thecostfunctiongraphwasconvex,buthere,itisnotgoingtobeconvex.Findingtheminimumvaluesforparametersinawaythatourpredictedoutputisclosetotheactualonewillbedifficult.Inacostfunction,whilecalculatingforlogisticregression,wewillreplaceourCpvalueoflinearregressionwiththefunctionF(z).Tomakeconvexlogisticregressioncostfunctions,wewillreplace(p0+p1Ri-Ci)2withoneofthefollowing:
log(1/1+e(-(β0+β1*x)))iftheactualoccurrenceofaneventis1,thisfunctionwillrepresentthecost.log(1-(1/1+e(-(β0+β1*x))))iftheactualoccurrenceofaneventis0,thisfunctionwillrepresentthecost.
Wewillhavetorememberthatinlogisticregression,wecalculatetheclassprobability.So,iftheprobabilityofaneventoccurring(customerbuyingacar,beingdefrauded,andsoon)isp,theprobabilityofnon-occurrenceis1-p.

StochasticGradientDescentGradientdescentminimizesthecostfunction.Forverylargedatasets,gradientdescentisaveryexpensiveprocedure.StochasticGradientDescent(SGD)isamodificationofthegradientdescentalgorithmtohandlelargedatasets.Gradientdescentcomputesthegradientusingthewholedataset,whileSGDcomputesthegradientusingasinglesample.So,gradientdescentloadsthefulldatasetandtriestofindoutthelocalminimumonthegraphandthenrepeatthefullprocessagain,whileSGDadjuststhecostfunctionforeverysample,onebyone.AmajoradvantagethatSGDhasovergradientdescentisthatitsspeedofcomputationisawholelotfaster.LargedatasetsinRAMgenerallycannotbeheldasthestorageislimited.InSGD,theburdenontheRAMisreduced,whereineachsampleorbatchofsamplesareloadedandworkedwith,theresultsforwhicharestored,andsoon.

UsingMahoutforlogisticregressionMahouthasimplementationsforlogisticregressionusingSGD.Itisveryeasytounderstandanduse.Solet’sgetstarted.
Dataset
WewillusetheWisconsinDiagnosticBreastCancer(WDBC)dataset.Thisisadatasetforbreastcancertumorsanddataisavailablefrom1995onwards.Ithas569instancesofbreasttumorcasesandhas30featurestopredictthediagnosis,whichiscategorizedaseitherbenignormalignant.
NoteMoredetailsontheprecedingdatasetisavailableathttp://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.names.
Preparingthetrainingandtestdata
Youcandownloadthewdbc.datadatasetfromhttp://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data.
Now,saveitasaCSVfileandincludethefollowingheaderline:ID_Number,Diagnosis,Radius,Texture,Perimeter,Area,Smoothness,Compactness,Concavity,ConcavePoints,Symmetry,Fractal_Dimension,RadiusStdError,TextureStdError,PerimeterStdError,AreaStdError,SmoothnessStdError,CompactnessStdError,ConcavityStdError,ConcavePointStdError,Symmetrystderror,FractalDimensionStderror,WorstRadius,worsttexture,worstperimeter,worstarea,worstsmoothness,worstcompactness,worstconcavity,worstconcavepoints,worstsymmentry,worstfractaldimensions
Now,wewillhavetoperformthefollowingstepstopreparethisdatatobeusedbytheMahoutlogisticregressionalgorithm:
1. Wewillmakethetargetclassnumeric.Inthiscase,thesecondfielddiagnosisisthetargetvariable.Wewillchangemalignantto0andbenignto1.Usethefollowingcodesnippettointroducethechanges.Wecanusethisstrategyforsmalldatasets,butforhugedatasets,wehavedifferentstrategies,whichwewillcoverinChapter4,LearningtheNaïveBayesClassificationUsingMahout:
publicvoidconvertTargetToInteger()throwsIOException{
//Readthedata
BufferedReaderbr=newBufferedReader(newFileReader("wdbc.csv"));
Stringline=null;
//Createthefiletosavetheresulteddata
FilewdbcData=newFile("<YourDestinationlocationforfile.>");
FileWriterfw=newFileWriter(wdbcData);
//Weareaddingheadertothenewfile
fw.write("ID_Number"+","+"Diagnosis"+","+"Radius"+","+"Texture"+","+"Pe
rimeter"+","+"Area"+","+"Smoothness"+","+"Compactness"+","+"Concavity"+
","+"ConcavePoints"+","+"Symmetry"+","+"Fractal_Dimension"+","+"RadiusS
tdError"+","+"TextureStdError"+","+"PerimeterStdError"+","+"AreaStdErro
r"+","+"SmoothnessStdError"+","+"CompactnessStdError"+","+"ConcavityStd
Error"+","+"ConcavePointStdError"+","+"Symmetrystderror"+","+"FractalDi
mensionStderror"+","+"WorstRadius"+","+"worsttexture"+","+"worstperimet
er"+","+"worstarea"+","+"worstsmoothness"+","+"worstcompactness"+","+"w
orstconcavity"+","+"worstconcavepoints"+","+"worstsymmentry"+","+"worst
fractaldimensions"+"\n");

/*Inthewhileloopwearereadinglinebylineandcheckingthelast
field-parts[1]andchangingittonumericvalueaccordingly*/
while((line=br.readLine())!=null){
String[]parts=line.split(",");
if(parts[1].equals("M")){
fw.write(parts[0]+","+"0"+","+parts[2]+","+parts[3]+","+parts[4]+","+pa
rts[5]+","+parts[6]+","+parts[7]+","+parts[8]+","+parts[9]+","+parts[10
]+","+parts[11]+","+parts[12]+","+parts[13]+","+parts[14]+","+parts[15]
+","+parts[16]+","+parts[17]+","+parts[18]+","+parts[19]+","+parts[20]+
","+parts[21]+","+parts[22]+","+parts[23]+","+parts[24]+","+parts[25]+"
,"+parts[26]+","+parts[27]+","+parts[28]+","+parts[29]+","+parts[30]+",
"+parts[31]+"\n");
}
if(parts[1].equals("B")){
fw.write(parts[0]+","+"1"+","+parts[2]+","+parts[3]+","+parts[4]+","+pa
rts[5]+","+parts[6]+","+parts[7]+","+parts[8]+","+parts[9]+","+parts[10
]+","+parts[11]+","+parts[12]+","+parts[13]+","+parts[14]+","+parts[15]
+","+parts[16]+","+parts[17]+","+parts[18]+","+parts[19]+","+parts[20]+
","+parts[21]+","+parts[22]+","+parts[23]+","+parts[24]+","+parts[25]+"
,"+parts[26]+","+parts[27]+","+parts[28]+","+parts[29]+","+parts[30]+",
"+parts[31]+"\n");
}
}
fw.close();
br.close();
}
TipDownloadingtheexamplecode
Youcandownloadtheexamplecodefilesfromyouraccountathttp://www.packtpub.comforallthePacktPublishingbooksyouhavepurchased.Ifyoupurchasedthisbookelsewhere,youcanvisithttp://www.packtpub.com/supportandregistertohavethefilese-maileddirectlytoyou.
2. Wewillhavetosplitthedatasetintotrainingandtestdatasetsandthenshufflethedatasetssothatwecanmixthemup,whichcanbedoneusingthefollowingcodesnippet:
publicvoiddataPrepration()throwsException{
//Readingthedatasetcreatedbyearliermethod
convertTargetToIntegerandhereweareusinggoogleguavaapi's.
List<String>result=
Resources.readLines(Resources.getResource("wdbc.csv"),Charsets.UTF_8);
//Thisistoremoveheaderbeforetherandomizationprocess.
Otherwiseitcanappearinthemiddleofdataset.
List<String>raw=result.subList(1,570);
Randomrandom=newRandom();
//Shufflingthedataset.
Collections.shuffle(raw,random);
//Splittingdatasetintotrainingandtestexamples.

List<String>train=raw.subList(0,470);
List<String>test=raw.subList(470,569);
FiletrainingData=newFile("<yourLocation>/wdbcTrain.csv");
FiletestData=newFile("<yourLocation>/wdbcTest.csv");
writeCSV(train,trainingData);
writeCSV(test,testData);
}
//Thismethodiswritingthelisttodesiredfilelocation.
publicvoidwriteCSV(List<String>list,Filefile)throwsIOException{
FileWriterfw=newFileWriter(file);
fw.write("ID_Number"+","+"Diagnosis"+","+"Radius"+","+"Texture"+","+"Pe
rimeter"+","+"Area"+","+"Smoothness"+","+"Compactness"+","+"Concavity"+
","+"ConcavePoints"+","+"Symmetry"+","+"Fractal_Dimension"+","+"RadiusS
tdError"+","+"TextureStdError"+","+"PerimeterStdError"+","+"AreaStdErro
r"+","+"SmoothnessStdError"+","+"CompactnessStdError"+","+"ConcavityStd
Error"+","+"ConcavePointStdError"+","+"Symmetrystderror"+","+"FractalDi
mensionStderror"+","+"WorstRadius"+","+"worsttexture"+","+"worstperimet
er"+","+"worstarea"+","+"worstsmoothness"+","+"worstcompactness"+","+"w
orstconcavity"+","+"worstconcavepoints"+","+"worstsymmentry"+","+"worst
fractaldimensions"+"\n");
for(inti=0;i<list.size();i++){
fw.write(list.get(i)+"\n");
}
fw.close();
}
Trainingthemodel
Wewillusethetrainingdatasetandtrainlogisticalgorithmtopreparethemodel.Usethefollowingcommandtocreatethemodel:
mahouttrainlogistic--input/tmp/wdbcTrain.csv--output/tmp//model--
targetDiagnosis--categories2--predictorsRadiusTexturePerimeterArea
SmoothnessCompactnessConcavityConcavePointsSymmetryFractal_Dimension
RadiusStdErrorTextureStdErrorPerimeterStdErrorAreaStdError
SmoothnessStdErrorCompactnessStdErrorConcavityStdError
ConcavePointStdErrorSymmetrystderrorFractalDimensionStderrorWorstRadius
worsttextureworstperimeterworstareaworstsmoothnessworstcompactness
worstconcavityworstconcavepointsworstsymmentryworstfractaldimensions--
typesnumeric--features30--passes90--rate300
Thiscommandwillgiveyouthefollowingoutput:

Let’sunderstandtheparametersusedinthiscommand:
trainlogistic:ThisisthealgorithmthatMahoutprovidestobuildthemodelusingyourinputparameters.input:Thisisthelocationoftheinputfile.output:Thisisthelocationofthemodelfile.target:Thisisthenameofthetargetvariablethatwewanttopredictfromthedataset.categories:Thisreferstothenumberofpredictedclasses.predictors:Thisfeaturesinthedatasetusedtopredictthetargetvariable.types:Thisisalistofthetypesofpredictorvariables.(Hereallarenumericbutitcouldbewordortextaswell.)features:Thisisthesizeofthefeaturevectorusedtobuildthemodel.passes:Thisspecifiesthenumberoftimestheinputdatashouldbere-examinedduringtraining.Smallinputfilesmayneedtobeexamineddozensoftimes.Verylargeinputfilesprobablydon’tevenneedtobecompletelyexamined.rate:Thissetstheinitiallearningrate.Thiscanbelargeifyouhavelotsofdataoruselotsofpassesbecauseitdecreasesprogressivelyasdataisexamined.
Nowourmodelisreadytomoveontothenextstepofevaluation.Toevaluatethemodelfurther,wecanusethesamedatasetandchecktheconfusionandAUCmatrix.Thecommandforthiswillbeasfollows:
mahoutrunlogistic--input/tmp/wdbcTrain.csv--model/tmp//model--auc--
confusion
runlogistic:Thisisthealgorithmtorunthelogisticregressionmodeloveraninputdatasetmodel:Thisisthelocationofthemodelfileauc:ThisprintstheAUCscoreforthemodelversustheinputdataafterthedataisreadconfusion:Thisprintstheconfusionmatrixforaparticularthreshold
Theoutputofthepreviouscommandisshowninthefollowingscreenshot:

Now,thesematricesshowthatthemodelisnotbad.Having0.88asthevalueforAUCisgood,butwewillcheckthisontestdataaswell.Theconfusionmatrixinformsusthatoutof172malignanttumors,ithascorrectlyclassified151instancesandthat34benigntumorsarealsoclassifiedasmalignant.Inthecaseofbenigntumors,outof298,ithascorrectlyclassified264.
Ifthemodeldoesnotprovidegoodresults,wehaveanumberofoptions.
Changetheparametersinthefeaturevector,increasingthemifweareselectingfewfeatures.Thisshouldbedoneoneatatime,andweshouldtesttheresultagainwitheachgeneratedmodel.WeshouldgetamodelwhereAUCiscloseto1.
Let’srunthesamealgorithmontestdataaswell:
mahoutrunlogistic--input/tmp/wdbcTest.csv--model/tmp//model--auc–
confusion
Sothismodelworksalmostthesameontestdataaswell.Ithasclassified34outofthe40malignanttumorscorrectly.


SummaryInthischapter,wediscussedlogisticregressionandhowwecanusethisalgorithmavailableinApacheMahout.WeusedtheWisconsinDiagnosticBreastCancerdatasetandrandomlybrokeitintotwodatasets:onefortrainingandtheotherfortesting.WecreatedthelogisticregressionmodelusingMahoutandalsorantestdataoverthismodel.Now,wewillmoveontothenextchapterwhereyouwilllearnabouttheNaïveBayesclassificationandalsothemostfrequentlyusedclassificationtechnique:textclassification.


Chapter4.LearningtheNaïveBayesClassificationUsingMahoutInthischapter,wewillusetheNaïveBayesclassificationalgorithmtoclassifyasetofdocuments.Classifyingtextdocumentsisalittletrickybecauseofthedatapreparationstepsinvolved.Inthischapter,wewillexplorethefollowingtopics:
ConditionalprobabilityandtheBayesruleUnderstandingtheNaïveBayesalgorithmUnderstandingtermsusedintextclassificationUsingtheNaïveBayesalgorithminApacheMahout

IntroducingconditionalprobabilityandtheBayesruleBeforelearningtheNaïveBayesalgorithm,youshouldhaveanunderstandingofconditionalprobabilityandtheBayesrule.
Inverysimpleterms,conditionalprobabilityistheprobabilitythatsomethingwillhappen,giventhatsomethingelsehasalreadyhappened.ItisexpressedasP(A/B),whichcanbereadasprobabilityofAgivenB,anditfindstheprobabilityoftheoccurrenceofeventAonceeventBhasalreadyhappened.
Mathematically,itisdefinedasfollows:
Forexample,ifyouchooseacardfromastandardcarddeckandifyouwereaskedabouttheprobabilityforthecardtobeadiamond,youwouldquicklysay13/52or0.25,asthereare13diamondcardsinthedeck.However,ifyouthenlookatthecardanddeclarethatitisred,thenwewillhavenarrowedthepossibilitiesforthecardto26possiblecards,andtheprobabilitythatthecardisadiamondnowis13/26=0.5.So,ifwedefineAasadiamondcardandBasaredcard,thenP(A/B)willbetheprobabilityofthecardbeingadiamond,givenitisred.
Sometimes,foragivenpairofevents,conditionalprobabilityishardtocalculate,andBayes’theoremhelpsusherebygivingtherelationshipbetweentwoconditionalprobabilities.
Bayes’theoremisdefinedasfollows:
Thetermsintheformulaaredefinedasfollows:
P(A):ThisiscalledpriorprobabilityorpriorP(B/A):ThisiscalledconditionalprobabilityorlikelihoodP(B):ThisiscalledmarginalprobabilityP(A/B):Thisiscalledposteriorprobabilityorposterior
Thefollowingformulaisderivedonlyfromtheconditionalprobabilityformula.WecandefineP(B/A)asfollows:

Whenrearranged,theformulabecomesthis:
Now,fromtheprecedingconditionalprobabilityformula,wegetthefollowing:
Let’stakeanexamplethatwillhelpustounderstandhowBayes’theoremisapplied.
Acancertestgivesapositiveresultwithaprobabilityof97percentwhenthepatientisindeedaffectedbycancer,whileitgivesanegativeresultwith99percentprobabilitywhenthepatientisnotaffectedbycancer.Ifapatientisdrawnatrandomfromapopulationwhere0.2percentoftheindividualsareaffectedbycancerandheorsheisfoundtobepositive,whatistheprobabilitythatheorsheisindeedaffectedbycancer?Inprobabilisticterms,whatweknowaboutthisproblemcanbedefinedasfollows:
P(positive|cancer)=0.97
P(positive|nocancer)=1-0.99=0.01
P(cancer)=0.002
P(nocancer)=1-0.002=0.998
P(positive)=P(positive|cancer)P(cancer)+P(positive|nocancer)P(nocancer)
=0.97*0.002+0.01*0.998
=0.01192
NowP(cancer|positive)=(0.97*0.002)/0.01192=0.1628
Soevenwhenfoundpositive,theprobabilityofthepatientbeingaffectedbycancerinthisexampleisaround16percent.


UnderstandingtheNaïveBayesalgorithmInBayes’theorem,wehaveseenthattheoutcomeisbasedonlyononeevidence,butinclassificationproblems,wehavemultipleevidencesandwehavetopredicttheoutcome.InNaïveBayes,weuncouplemultiplepiecesofevidenceandtreateachoneofthemindependently.Itisdefinedasfollows:
P(outcome|multipleEvidence))=P(Evidence1|outcome)*P(Evidence2|outcome)*P(Evidence3|outcome)…./P(Evidence)
Runthisformulaforeachpossibleoutcome.Sincewearetryingtoclassify,eachoutcomewillbecalledaclass.Ourtaskistolookattheevidence(features)toconsiderhowlikelyitisforittobeofaparticularclassandthenassignitaccordingly.Theclassthathasthehighestprobabilitygetsassignedtothatcombinationofevidences.Let’sunderstandthiswithanexample.
Let’ssaythatwehavedataon1,000piecesoffruit.Theyhappentobebananas,apples,orsomeotherfruit.Weareawareofthreecharacteristicsofeachfruit:
Size:TheyareeitherlongornotlongTaste:TheyareeithersweetornotsweetColor:Theyareeitheryellowornotyellow
Assumethatwehaveadatasetlikethefollowing:
Fruittype Taste–sweet Taste–notsweet Color–yellow Color–notyellow Size–long Size–notlong Total
Banana 350 150 450 50 400 100 500
Apple 150 150 100 200 0 300 300
Other 150 50 50 150 100 100 200
Total 650 350 600 400 500 500 1000
Nowlet’slookatthethingswehave:
P(Banana)=500/1000=0.5
P(Apple)=300/1000=0.3
P(Other)=200/1000=0.2
Let’slookattheprobabilityofthefeatures:
P(Sweet)=650/1000=0.65
P(Yellow)=600/1000=0.6
P(long)=500/1000=0.5
P(notSweet)=350/1000=0.35
P(notyellow)=400/1000=0.4

P(notlong)=500/1000=0.5
Nowwewanttoknowwhatfruitwewillhaveifitisnotyellowandnotlongandsweet.Theprobabilityofitbeinganappleisasfollows:
P(Apple|sweet,notlong,notyellow)=P(sweet|Apple)*P(notlong|Apple)*P(notyellow|Apple)*P(Apple)/P(sweet)*P(notlong)*P(notyellow)
=0.5*1*0.67*0.3/P(Evidence)
=0.1005/P(Evidence)
Theprobabilityofitbeingabananaisthis:
P(banana|sweet,notlong,notyellow)=P(sweet|banana)*P(notlong|banana)*P(notyellow|banana)*P(banana)/P(sweet)*P(notlong)*P(notyellow)
=0.7*0.2*0.1*0.5/P(Evidence)
=0.007/P(Evidence)
Theprobabilityofitbeinganyotherfruitisasfollows:
P(otherfruit|sweet,notlong,notyellow)=P(sweet|otherfruit)*P(notlong|otherfruit)*P(notyellow|otherfruit)*P(otherfruit)/P(sweet)*P(notlong)*P(notyellow)
=0.75*0.5*0.75*0.2/P(Evidence)
=0.05625/P(Evidence)
Sofromtheresults,youcanseethatifthefruitissweet,notlong,andnotyellow,thenthehighestprobabilityisthatitwillbeanapple.Sofindoutthehighestprobabilityandassigntheunknownitemtothatclass.
NaïveBayesisaverygoodchoicefortextclassification.BeforewemoveontotextclassificationusingNaïveBayesinMahout,let’sunderstandafewtermsthatarereallyusefulfortextclassification.


UnderstandingthetermsusedintextclassificationTopreparedatasothatitcanbeusedbyaclassifierisacomplexprocess.Fromrawdata,wecancollectexplanatoryandtargetvariablesandencodethemasvectors,whichistheinputoftheclassifier.
Vectorsareorderedlistsofvaluesasdefinedintwo-dimensionalspace.Youcantakeacluefromcoordinategeometryaswell.Apoint(3,4)isapointinthexandyplanes.InMahout,itisdifferent.Here,avectorcanhave(3,4)or10,000dimensions.
Mahoutprovidessupportforcreatingvectors.TherearetwotypesofvectorimplementationsinMahout:sparseanddensevectors.Thereareafewtermsthatweneedtounderstandfortextclassification:
Bagofwords:Thisconsiderseachdocumentasacollectionofwords.Thisignoreswordorder,grammar,andpunctuation.So,ifeverywordisafeature,thencalculatingthefeaturevalueofthedocumentwordisrepresentedasatoken.Itisgiventhevalue1ifitispresentor0ifnot.Termfrequency:Thisconsidersthewordcountinthedocumentinsteadof0and1.Sotheimportanceofawordincreaseswiththenumberoftimesitappearsinthedocument.Considerthefollowingexamplesentence:
ApplehaslaunchediPhoneanditwillcontinuetolaunchsuchproducts.OthercompetitorsarealsoplanningtolaunchproductssimilartothatofiPhone.
Thefollowingisthetablethatrepresentstermfrequency:
Term Count
Apple 1
Launch 3
iPhone 2
Product 2
Plan 1
Thefollowingtechniquesareusuallyappliedtocomeupwiththistypeoftable:
Stemmingofwords:Withthis,thesuffixisremovedfromthewordso“launched”,“launches”,and“launch”areallconsideredas“launch”.Casenormalization:Withthis,everytermisconvertedtolowercase.Stopwordremoval:Therearesomewordsthatarealmostpresentineverydocument.Wecallthesewordsstopwords.Duringanimportantfeatureextractionfromadocument,thesewordscomeintoaccountandtheywillnotbehelpfulinthe

overallcalculation.Examplesofthesewordsare“is,are,the,that,andsoon.”So,whileextracting,wewillignorethesekindofwords.Inversedocumentfrequency:Thisisconsideredastheboostatermgetsforbeingrare.Atermshouldnotbetoocommon.Ifatermoccursineverydocument,itisnotgoodforclassification.Thefewerdocumentsinwhichatermoccurs,themoresignificantitislikelytobeforthedocumentsitdoesoccurin.Foratermt,inversedocumentfrequencyiscalculatedasfollows:
IDF(t)=1+log(totalnumberofdocuments/numberofdocumentscontainingt)
Termfrequencyandinversetermfrequency:Thisisoneofthepopularrepresentationsofthetext.Itistheproductoftermfrequencyandinversedocumentfrequency,asfollows:
TFIDF(t,d)=TF(t,d)*IDF(t)
Eachdocumentisafeaturevectorandacollectionofdocumentsisasetofthesefeaturevectorsandthissetworksastheinputfortheclassification.Nowthatweunderstandthebasicconceptsbehindthevectorcreationoftextdocuments,let’smoveontothenextsectionwherewewillclassifytextdocumentsusingtheNaïveBayesalgorithm.


UsingtheNaïveBayesalgorithminApacheMahoutWewilluseadatasetof20newsgroupsforthisexercise.The20newsgroupsdatasetisastandarddatasetcommonlyusedformachinelearningresearch.Thedataisobtainedfromtranscriptsofseveralmonthsofpostingsmadein20Usenetnewsgroupsfromtheearly1990s.Thisdatasetconsistsofmessages,oneperfile.Eachfilebeginswithheaderlinesthatspecifythingssuchaswhosentthemessage,howlongitis,whatkindofsoftwarewasused,andthesubject.Ablanklinefollowsandthenthemessagebodyfollowsasunformattedtext.
Downloadthe20news-bydate.tar.gzdatasetfromhttp://qwone.com/~jason/20Newsgroups/.ThefollowingstepsareusedtobuildtheNaïveBayesclassifierusingMahout:
1. Createa20newsdatadirectoryandunzipthedatahere:
mkdir/tmp/20newsdata
cd/tmp/20newsdata
tar–xzvf/tmp/20news-bydate.tar.gz
2. Youwillseetwofoldersunder20newsdata:20news-bydate-testand20news-bydate-train.Nowcreateanotherdirectorycalled20newsdataallandmergeboththetrainingandtestdataofthe20newsgroups.
3. Comeoutofthedirectoryandmovetothehomedirectoryandexecutethefollowing:
mkdir/tmp/20newsdataall
cp–R/20newsdata/*/*/tmp/20newsdataall
4. CreateadirectoryinHadoopandsavethisdatainHDFSformat:
hadoopfs–mkdir/user/hue/20newsdata
hadoopfs–put/tmp/20newsdataall/user/hue/20newsdata
5. Converttherawdataintoasequencefile.Theseqdirectorycommandwillgeneratesequencefilesfromadirectory.SequencefilesareusedinHadoop.Asequencefileisaflatfilethatconsistsofbinarykey/valuepairs.WeareconvertingthefilesintosequencefilessothatitcanbeprocessedinHadoop,whichcanbedoneusingthefollowingcommand:
bin/mahoutseqdirectory-i/user/hue/20newsdata/20newsdataall-o
/user/hue/20newsdataseq-out
Theoutputoftheprecedingcommandcanbeseeninthefollowingscreenshot:

6. Convertthesequencefileintoasparsevectorusingthefollowingcommand:
bin/mahoutseq2sparse-i/user/hue/20newsdataseq-out/part-m-00000-o
/user/hue/20newsdatavec-lnorm-nv-wttfidf
Thetermsusedintheprecedingcommandareasfollows:
lnorm:Thisisfortheoutputvectortobelognormalizednv:Thisreferstonamedvectorswt:Thisreferstothekindofweighttouse;here,weusetfidf
Theoutputoftheprecedingcommandontheconsoleisshowninthefollowingscreenshot:
7. Splitthesetofvectorstotrainandtestthemodel:
bin/mahoutsplit-i/user/hue/20newsdatavec/tfidf-vectors--
trainingOutput/user/hue/20newsdatatrain--testOutput

/user/hue/20newsdatatest--randomSelectionPct40--overwrite--
sequenceFiles-xmsequential
Thetermsusedintheprecedingcommandareasfollows:
randomSelectionPct:Thisdividesthepercentageofdataintotestingandtrainingdatasets.Here,60percentisfortestingand40percentfortraining.xm:Thisreferstotheexecutionmethodtouse:sequentialormapreduce.Thedefaultismapreduce.
8. Nowtrainthemodel:
bin/mahouttrainnb-i/user/hue/20newsdatatrain-el-o/user/hue/model
-li/user/hue/labelindex-ow-c
9. Testthemodelusingthefollowingcommand:
bin/mahouttestnb-i/user/hue/20newsdatatest-m/user/hue/model/-l
/user/hue/labelindex-ow-o/user/hue/results
Theoutputoftheprecedingcommandontheconsoleisshowninthefollowingscreenshot:

WegettheresultofourNaïveBayesclassifierforthe20newsgroups.


SummaryInthischapter,wediscussedtheNaïveBayesalgorithm.Thisalgorithmisasimplisticyethighlyregardedstatisticalmodelthatiswidelyusedinbothindustryandacademia,anditproducesgoodresultsonmanyoccasions.WeinitiallydiscussedconditionalprobabilityandtheBayesrule.WethensawanexampleoftheNaïveBayesalgorithm.Youlearnedabouttheapproachestoconverttextintoavectorformat,whichisaninputforclassifiers.Finally,weusedthe20newsgroupsdatasettobuildaclassifierusingtheNaïveBayesalgorithminMahout.Inthenextchapter,wewillcontinueourjourneyofexploringclassificationalgorithmsinMahoutwiththeHiddenMarkovmodelimplementation.


Chapter5.LearningtheHiddenMarkovModelUsingMahoutInthischapter,wewillcoveroneofthemostinterestingtopicsofclassificationtechniques:theHiddenMarkovModel(HMM).TounderstandtheHMM,wewillcoverthefollowingtopicsinthischapter:
DeterministicandnondeterministicpatternsTheMarkovprocessIntroducingtheHMMUsingMahoutfortheHMM

DeterministicandnondeterministicpatternsInadeterministicsystem,eachstateissolelydependentonthestateitwaspreviouslyin.Forexample,let’stakethecaseofasetoftrafficlights.Thesequenceoflightsisred→green→amber→red.So,hereweknowwhatstatewillfollowafterthecurrentstate.Oncethetransitionsareknown,deterministicsystemsareeasytounderstand.
Fornondeterministicpatterns,consideranexampleofapersonnamedBobwhohashissnacksat4:00P.M.everyday.Let’ssayhehasanyoneofthethreeitemsfromthemenu:icecream,juice,orcake.Wecannotsayforsurewhatitemhewillhavethenextday,evenifweknowwhathehadtoday.Thisisanexampleofanondeterministicpattern.


TheMarkovprocessIntheMarkovprocess,thenextstateisdependentonthepreviousstates.Ifweassumethatwehaveannstatesystem,thenthenextstateisdependentonthepreviousnstates.Thisprocessiscalledannmodelorder.IntheMarkovprocess,wemakethechoiceforthenextstateprobabilistically.So,consideringourpreviousexample,ifBobhadjuicetoday,hecanhavejuice,icecream,orcakethenextday.Inthesameway,wecanreachanystateinthesystemfromthepreviousstate.TheMarkovprocessisshowninthefollowingdiagram:
Ifwehavenstatesinaprocess,thenwecanreachanystatewithn2transitions.Wehaveaprobabilityofmovingtoanystate,andhence,wewillhaven2probabilitiesofdoingthis.ForaMarkovprocess,wewillhavethefollowingthreeitems:
States:Thisreferstothestatesinthesystem.Inourexample,let’ssaytherearethreestates:state1,state2,andstate3.Transitionmatrix:Thiswillhavetheprobabilitiesofmovingfromonestatetoanyotherstate.Anexampleofthetransitionmatrixisshowninthefollowingscreenshot:
Thismatrixshowsthatifthesystemwasinstate1yesterday,thentheprobabilityofittoremaininthesamestatetodaywillbe0.1.
Initialstatevector:Thisisthevectoroftheinitialstateofthesystem.(Anyoneofthestateswillhaveaprobabilityof1andtherestwillhaveaprobabilityof0inthisvector.)



IntroducingtheHiddenMarkovModelTheHiddenMarkovModel(HMM)isaclassificationtechniquetopredictthestatesofasystembyobservingtheoutcomeswithouthavingaccesstotheactualstatesthemselves.ItisaMarkovmodelinwhichthestatesarehidden.
Let’scontinuewithBob’ssnackexamplewesawearlier.Nowassumewehaveonemoresetofeventsinplacethatisdirectlyobservable.WeknowwhatBobhaseatenforlunchandhissnacksintakeisrelatedtohislunch.So,wehaveanobservationstate,whichisBob’slunch,andhiddenstates,whicharehissnacksintake.WewanttobuildanalgorithmthatcanforecastwhatwouldbeBob’schoiceofsnackbasedonhislunch.
InadditiontothetransitionprobabilitymatrixintheHiddenMarkovModel,wehaveonemorematrixthatiscalledanemissionmatrix.Thismatrixcontainstheprobabilityoftheobservablestate,provideditisassignedahiddenstate.Theemissionmatrixisasfollows:
P(observablestate|onestate)
So,aHiddenMarkovModelhasthefollowingproperties:
Statevector:ThiscontainstheprobabilityofthehiddenmodeltobeinaparticularstateatthestartTransitionmatrix:Thishastheprobabilitiesofahiddenstate,giventheprevioushiddenstateEmissionmatrix:Giventhatthehiddenmodelisinaparticularhiddenstate,thishastheprobabilitiesofobservingaparticularobservablestateHiddenstates:ThisreferstothestatesofthesystemthatcanbedefinedbytheHiddenMarkovModelObservablestate:Thestatesthatarevisibleintheprocess
UsingtheHiddenMarkovModel,threetypesofproblemscanbesolved.ThefirsttwoarerelatedtothepatternrecognitionproblemandthethirdtypeofproblemgeneratesaHiddenMarkovModel,givenasequenceofobservations.Let’slookatthesethreetypes

ofproblems:
Evaluation:Thisisfindingouttheprobabilityofanobservedsequence,givenanHMM.FromthenumberofdifferentHMMsthatdescribedifferentsystemsandasequenceofobservations,ourgoalwillbetofindoutwhichHMMwillmostprobablygeneratetherequiredsequence.WeusetheforwardalgorithmtocalculatetheprobabilityofanobservationsequencewhenaparticularHMMisgivenandfindoutthemostprobableHMM.Decoding:Thisisfindingthemostprobablesequenceofhiddenstatesfromsomeobservations.WeusetheViterbialgorithmtodeterminethemostprobablesequenceofhiddenstateswhenyouhaveasequenceofobservationsandanHMM.Learning:LearningisgeneratingtheHMMfromasequenceofobservations.So,ifwehavesuchasequence,wemaywonderwhichisthemostlikelymodeltogeneratethissequence.Theforward-backwardalgorithmsareusefulinsolvingthisproblem.
TheHiddenMarkovModelisusedindifferentapplicationssuchasspeechrecognition,handwrittenletterrecognition,genomeanalysis,partsofspeechtagging,customerbehaviormodeling,andsoon.


UsingMahoutfortheHiddenMarkovModelApacheMahouthastheimplementationoftheHiddenMarkovModel.Itisavailableintheorg.apache.mahout.classifier.sequencelearning.hmmpackage.
Theoverallimplementationisprovidedbyeightdifferentclasses:
HMMModel:ThisisthemainclassthatdefinestheHiddenMarkovModel.HmmTrainer:ThisclasshasalgorithmsthatareusedtotraintheHiddenMarkovModel.Themainalgorithmsaresupervisedlearning,unsupervisedlearning,andunsupervisedBaum-Welch.HmmEvaluator:ThisclassprovidesdifferentmethodstoevaluateanHMMmodel.Thefollowingusecasesarecoveredinthisclass:
Generatingasequenceofoutputstatesfromamodel(prediction)Computingthelikelihoodthatagivenmodelwillgeneratethegivensequenceofoutputstates(modellikelihood)Computingthemostlikelyhiddensequenceforagivenmodelandagivenobservedsequence(decoding)
HmmAlgorithms:ThisclasscontainsimplementationsofthethreemajorHMMalgorithms:forward,backward,andViterbi.HmmUtils:ThisisautilityclassandprovidesmethodstohandleHMMmodelobjects.RandomSequenceGenerator:Thisisacommand-linetooltogenerateasequencebythegivenHMM.BaumWelchTrainer:ThisistheclasstotrainHMMfromtheconsole.ViterbiEvaluator:Thisisalsoacommand-linetoolforViterbievaluation.
Now,let’sworkwithBob’sexample.
Thefollowingisthegivenmatrixandtheinitialprobabilityvector:
Icecream Cake Juice
0.36 0.51 0.13
Thefollowingwillbethestatetransitionmatrix:
Icecream Cake Juice
Icecream 0.365 0.500 0.135
Cake 0.250 0.125 0.625
Juice 0.365 0.265 0.370

Thefollowingwillbetheemissionmatrix:
Spicyfood Normalfood Nofood
Icecream 0.1 0.2 0.7
Cake 0.5 0.25 0.25
Juice 0.80 0.10 0.10
Nowwewillexecuteacommand-line-basedexampleofthisproblem.WehavethreehiddenstatesofwhatBob’seatenforsnacks:ice-cream,cake,orjuice.Then,wehavethreeobservablestatesofwhatheishavingatlunch:spicyfood,normalfood,ornofoodatall.Now,thefollowingarethestepstoexecutefromthecommandline:
1. Createadirectorywiththenamehmm:mkdir/tmp/hmm.Gotothisdirectoryandcreatethesampleinputfileoftheobservedstates.ThiswillincludeasequenceofBob’slunchhabit:spicyfood(state0),normalfood(state1),andnofood(state2).Executethefollowingcommand:
echo"012221100212111122200000022200000
011112222202120212110001010212121211
002202110">hmm-input
2. RuntheBaumWelchalgorithmtotrainthemodelusingthefollowingcommand:
mahoutbaumwelch-i/tmp/hmm/hmm-input-o/tmp/hmm/hmm-model-nh3-no
3-e.0001-m1000
Theparametersusedintheprecedingcommandareasfollows:
i:Thisistheinputfilelocationo:Thisistheoutputlocationforthemodelnh:Thisisthenumberofhiddenstates.Inourexample,itisthree(icecream,juice,orcake)no:Thisisthenumberofobservablestates.Inourexample,itisthree(spicy,normal,ornofood)e:Thisistheepsilonnumber.Thisistheconvergencethresholdvaluem:Thisisthemaximumiterationnumber
Thefollowingscreenshotshowstheoutputonexecutingthepreviouscommand:

3. NowwehaveanHMMmodelthatcanbeusedtobuildapredictedsequence.Wewillrunthemodeltopredictthenext15statesoftheobservablesequenceusingthefollowingcommand:
mahouthmmpredict-m/tmp/hmm/hmm-model-o/tmp/hmm/hmm-predictions-l
10
Theparametersusedintheprecedingcommandareasfollows:
m:ThisisthepathfortheHMMmodel
o:Thisistheoutputdirectorypath
l:Thisisthelengthofthegeneratedsequence
4. Toviewthepredictionforthenext10observablestates,usethefollowingcommand:
mahouthmmpredict-m/tmp/hmm/hmm-model-o/tmp/hmm/hmm-predictions-l
10
Theoutputofthepreviouscommandisshowninthefollowingscreenshot:
Fromtheoutput,wecansaythatthenextobservablestatesforBob’slunchwillbespicy,spicy,spicy,normal,normal,nofood,nofood,nofood,nofood,andnofood.
5. Now,wewilluseonemorealgorithmtopredictthehiddenstate.WewillusetheViterbialgorithmtopredictthehiddenstatesforagivenobservationalstate’ssequence.Wewillfirstcreatethesequenceoftheobservationalstateusingthefollowingcommand:
echo"012021100112">/tmp/hmm/hmm-viterbi-input
6. WewillusetheViterbicommand-lineoptiontogeneratetheoutputwiththelikelihoodofgeneratingthissequence:
mahoutviterbi--input/tmp/hmm/hmm-viterbi-input--outputtmp/hmm/hmm-
viterbi-output--model/tmp/hmm/hmm-model--likelihood

Theparametersusedintheprecedingcommandareasfollows:
input:Thisistheinputlocationofthefileoutput:ThisistheoutputlocationoftheViterbialgorithm’soutputmodel:ThisistheHMMmodellocationthatwecreatedearlierlikelihood:Thisisthecomputedlikelihoodoftheobservedsequence
Thefollowingscreenshotshowstheoutputonexecutingthepreviouscommand:
7. PredictionsfromtheViterbiaresavedintheoutputfileandcanbeseenusingthecatcommand:
cat/tmp/hmm/hmm-viterbi-output
Thefollowingoutputshowsthepredictionsforthehiddenstate:


SummaryInthischapter,wediscussedanotherclassificationtechnique:theHiddenMarkovModel.Youlearnedaboutdeterministicandnondeterministicpatterns.WealsotouchedupontheMarkovprocessandHiddenMarkovprocessingeneral.WecheckedtheclassesimplementedinsideMahouttosupporttheHiddenMarkovModel.WetookupanexampletocreatetheHMMmodelandfurtherusedthismodeltopredicttheobservationalstate’ssequence.WeusedtheViterbialgorithmimplementedinMahouttopredictthehiddenstatesinthesystem.
Now,inthenextchapter,wewillcoveronemoreinterestingalgorithmusedinclassificationarea:Randomforest.


Chapter6.LearningRandomForestUsingMahoutRandomforestisoneofthemostpopulartechniquesinclassification.Itstartswithamachinelearningtechniquecalleddecisiontree.Inthischapter,wewillexplorethefollowingtopics:
DecisiontreeRandomforestUsingMahoutforRandomforest

DecisiontreeAdecisiontreeisusedforclassificationandregressionproblems.Insimpleterms,itisapredictivemodelthatusesbinaryrulestocalculatethetargetvariable.Inadecisiontree,weuseaniterativeprocessofsplittingthedataintopartitions,thenwesplititfurtheronbranches.Asinotherclassificationmodelcreationprocesses,westartwiththetrainingdatasetinwhichtargetvariablesorclasslabelsaredefined.Thealgorithmtriestobreakalltherecordsintrainingdatasetsintotwopartsbasedononeoftheexplanatoryvariables.Thepartitioningisthenappliedtoeachnewpartition,andthisprocessiscontinueduntilnomorepartitioningcanbedone.Thecoreofthealgorithmistofindouttherulethatdeterminestheinitialsplit.Therearealgorithmstocreatedecisiontrees,suchasIterativeDichotomiser3(ID3),ClassificationandRegressionTree(CART),Chi-squaredAutomaticInteractionDetector(CHAID),andsoon.AgoodexplanationforID3canbefoundathttp://www.cse.unsw.edu.au/~billw/cs9414/notes/ml/06prop/id3/id3.html.
Formingtheexplanatoryvariablestochoosethebestsplitterinanode,thealgorithmconsiderseachvariableinturn.Everypossiblesplitisconsideredandtried,andthebestsplitistheonethatproducesthelargestdecreaseindiversityoftheclassificationlabelwithineachpartition.Thisisrepeatedforallvariables,andthewinnerischosenasthebestsplitterforthatnode.Theprocessiscontinuedinthenextnodeuntilwereachanodewherewecanmakethedecision.
Wecreateadecisiontreefromatrainingdatasetsoitcansufferfromtheoverfittingproblem.Thisbehaviorcreatesaproblemwithrealdatasets.Toimprovethissituation,aprocesscalledpruningisused.Inthisprocess,weremovethebranchesandleavesofthetreetoimprovetheperformance.Algorithmsusedtobuildthetreeworkbestatthestartingorrootnodesincealltheinformationisavailablethere.Lateron,witheachsplit,dataislessandtowardstheendofthetree,aparticularnodecanshowpatternsthatarerelatedtothesetofdatawhichisusedtosplit.Thesepatternscreateproblemswhenweusethemtopredicttherealdataset.Pruningmethodsletthetreegrowandremovethesmallerbranchesthatfailtogeneralize.Nowtakeanexampletounderstandthedecisiontree.
Considerwehaveairisflowerdataset.Thisdatasetishugelypopularinthemachinelearningfield.ItwasintroducedbySirRonaldFisher.Itcontains50samplesfromeachofthreespeciesofirisflower(Irissetosa,Irisvirginica,andIrisversicolor).Thefourexplanatoryvariablesarethelengthandwidthofthesepalsandpetalsincentimeters,andthetargetvariableistheclasstowhichtheflowerbelongs.

Asyoucanseeintheprecedingdiagram,allthegroupswereearlierconsideredasSentosaspeciesandthentheexplanatoryvariableandpetallengthwerefurtherusedtodividethegroups.Ateachstep,thecalculationformisclassifieditemswasalsodone,whichshowshowmanyitemswerewronglyclassified.Moreover,thepetalwidthvariablewastakenintoaccount.Usually,itemsatleafnodesarecorrectlyclassified.


RandomforestTheRandomforestalgorithmwasdevelopedbyLeoBreimanandAdeleCutler.Randomforestsgrowmanyclassificationtrees.Theyareanensemblelearningmethodforclassificationandregressionthatconstructsanumberofdecisiontreesattrainingtimeandalsooutputstheclassthatisthemodeoftheclassesoutputtedbyindividualtrees.
Singledecisiontreesshowthebias–variancetradeoff.Sotheyusuallyhavehighvarianceorhighbias.Thefollowingaretheparametersinthealgorithm:
Bias:ThisisanerrorcausedbyanerroneousassumptioninthelearningalgorithmVariance:Thisisanerrorthatrangesfromsensitivitytosmallfluctuationsinthetrainingset
Randomforestsattempttomitigatethisproblembyaveragingtofindanaturalbalancebetweentwoextremes.ARandomforestworksontheideaofbagging,whichistoaveragenoisyandunbiasedmodelstocreateamodelwithlowvariance.ARandomforestalgorithmworksasalargecollectionofdecorrelateddecisiontrees.TounderstandtheideaofaRandomforestalgorithm,let’sworkwithanexample.
Considerwehaveatrainingdatasetthathaslotsoffeatures(explanatoryvariables)andtargetvariablesorclasses:
Wecreateasamplesetfromthegivendataset:
Adifferentsetofrandomfeaturesweretakenintoaccounttocreatetherandomsub-dataset.Now,fromthesesub-datasets,differentdecisiontreeswillbecreated.Soactuallywehavecreatedaforestofthedifferentdecisiontrees.Usingthesedifferenttrees,wewillcreatearankingsystemforalltheclassifiers.Topredicttheclassofanewunknownitem,wewilluseallthedecisiontreesandseparatelyfindoutwhichclassthesetreesare

predicting.Seethefollowingdiagramforabetterunderstandingofthisconcept:
Differentdecisiontreestopredicttheclassofanunknownitem
Inthisparticularcase,wehavefourdifferentdecisiontrees.Wepredicttheclassofanunknowndatasetwitheachofthetrees.Aspertheprecedingfigure,thefirstdecisiontreeprovidesclass2asthepredictedclass,theseconddecisiontreepredictsclass5,thethirddecisiontreepredictsclass5,andthefourthdecisiontreepredictsclass3.Now,aRandomforestwillvoteforeachclass.Sowehaveonevoteeachforclass2andclass3andtwovotesforclass5.Therefore,ithasdecidedthatforthenewunknowndataset,thepredictedclassisclass5.Sotheclassthatgetsahighervoteisdecidedforthenewdataset.ARandomforesthasalotofbenefitsinclassificationandafewofthemarementionedinthefollowinglist:
CombinationoflearningmodelsincreasestheaccuracyoftheclassificationRunseffectivelyonlargedatasetsaswellThegeneratedforestcanbesavedandusedforotherdatasetsaswellCanhandlealargeamountofexplanatoryvariables
NowthatwehaveunderstoodtheRandomforesttheoretically,let’smoveontoMahoutandusetheRandomforestalgorithm,whichisavailableinApacheMahout.


UsingMahoutforRandomforestMahouthasimplementationfortheRandomforestalgorithm.Itisveryeasytounderstandanduse.Solet’sgetstarted.
Dataset
WewillusetheNSL-KDDdataset.Since1999,KDD‘99hasbeenthemostwidelyuseddatasetfortheevaluationofanomalydetectionmethods.ThisdatasetispreparedbyS.J.StolfoandisbuiltbasedonthedatacapturedintheDARPA‘98IDSevaluationprogram(R.P.Lippmann,D.J.Fried,I.Graf,J.W.Haines,K.R.Kendall,D.McClung,D.Weber,S.E.Webster,D.Wyschogrod,R.K.Cunningham,andM.A.Zissman,“Evaluatingintrusiondetectionsystems:The1998darpaoff-lineintrusiondetectionevaluation,”discex,vol.02,p.1012,2000).
DARPA‘98isabout4GBofcompressedraw(binary)tcpdumpdataof7weeksofnetworktraffic,whichcanbeprocessedintoabout5millionconnectionrecords,eachwithabout100bytes.Thetwoweeksoftestdatahavearound2millionconnectionrecords.TheKDDtrainingdatasetconsistsofapproximately4,900,000singleconnectionvectors,eachofwhichcontains41featuresandislabeledaseithernormaloranattack,withexactlyonespecificattacktype.
NSL-KDDisadatasetsuggestedtosolvesomeoftheinherentproblemsoftheKDD‘99dataset.Youcandownloadthisdatasetfromhttp://nsl.cs.unb.ca/NSL-KDD/.
WewilldownloadtheKDDTrain+_20Percent.ARFFandKDDTest+.ARFFdatasets.
NoteInKDDTrain+_20Percent.ARFFandKDDTest+.ARFF,removethefirst44lines(that

is,alllinesstartingwith@attribute).Ifthisisnotdone,wewillnotbeabletogenerateadescriptorfile.

StepstousetheRandomforestalgorithminMahoutThestepstoimplementtheRandomforestalgorithminApacheMahoutareasfollows:
1. Transferthetestandtrainingdatasetstohdfsusingthefollowingcommands:
hadoopfs-mkdir/user/hue/KDDTrain
hadoopfs-mkdir/user/hue/KDDTest
hadoopfs–put/tmp/KDDTrain+_20Percent.arff/user/hue/KDDTrain
hadoopfs–put/tmp/KDDTest+.arff/user/hue/KDDTest
2. Generatethedescriptorfile.BeforeyoubuildaRandomforestmodelbasedonthetrainingdatainKDDTrain+.arff,adescriptorfileisrequired.Thisisbecauseallinformationinthetrainingdatasetneedstobelabeled.Fromthelabeleddataset,thealgorithmcanunderstandwhichoneisnumericalandcategorical.Usethefollowingcommandtogeneratedescriptorfile:
hadoopjar$MAHOUT_HOME/core/target/mahout-core-xyz.job.jar
org.apache.mahout.classifier.df.tools.Describe
-p/user/hue/KDDTrain/KDDTrain+_20Percent.arff
-f/user/hue/KDDTrain/KDDTrain+.info
-dN3C2NC4NC8N2C19NL
Jar:Mahoutcorejar(xyzstandsforversion).IfyouhavedirectlyinstalledMahout,itcanbefoundunderthe/usr/lib/mahoutfolder.ThemainclassDescribeisusedhereandittakesthreeparameters:
Theppathforthedatatobedescribed.
Theflocationforthegenerateddescriptorfile.
distheinformationfortheattributeonthedata.N3C2NC4NC8N2C19NLdefinesthatthedatasetisstartingwithanumeric(N),followedbythreecategoricalattributes,andsoon.Inthelast,Ldefinesthelabel.
Theoutputofthepreviouscommandisshowninthefollowingscreenshot:
3. BuildtheRandomforestusingthefollowingcommand:
hadoopjar$MAHOUT_HOME/examples/target/mahout-examples-xyz-job.jar
org.apache.mahout.classifier.df.mapreduce.BuildForest
-Dmapred.max.split.size=1874231-d
/user/hue/KDDTrain/KDDTrain+_20Percent.arff
-ds/user/hue/KDDTrain/KDDTrain+.info
-sl5-p-t100–o/user/hue/nsl-forest
Jar:Mahoutexamplejar(xyzstandsforversion).IfyouhavedirectlyinstalledMahout,itcanbefoundunderthe/usr/lib/mahoutfolder.Themainclassbuild

forestisusedtobuildtheforestwithotherarguments,whichareshowninthefollowinglist:
Dmapred.max.split.sizeindicatestoHadoopthemaximumsizeofeachpartition.
dstandsforthedatapath.
dsstandsforthelocationofthedescriptorfile.
slisavariabletoselectrandomlyateachtreenode.Here,eachtreeisbuiltusingfiverandomlyselectedattributespernode.
pusespartialdataimplementation.
tstandsforthenumberoftreestogrow.Here,thecommandsbuild100treesusingpartialimplementation.
ostandsfortheoutputpaththatwillcontainthedecisionforest.
Intheend,theprocesswillshowthefollowingresult:
4. Usethismodeltoclassifythenewdataset:
hadoopjar$MAHOUT_HOME/examples/target/mahout-examples-xyz-job.jar
org.apache.mahout.classifier.df.mapreduce.TestForest
-i/user/hue/KDDTest/KDDTest+.arff
-ds/user/hue/KDDTrain/KDDTrain+.info-m/user/hue/nsl-forest-a–mr
-o/user/hue/predictions
Jar:Mahoutexamplejar(xyzstandsforversion).IfyouhavedirectlyinstalledMahout,itcanbefoundunderthe/usr/lib/mahoutfolder.Theclasstotesttheforesthasthefollowingparameters:
Iindicatesthepathforthetestdata
dsstandsforthelocationofthedescriptorfile
mstandsforthelocationofthegeneratedforestfromthepreviouscommand

ainformstoruntheanalyzertocomputetheconfusionmatrix
mrinformshadooptodistributetheclassification
ostandsforthelocationtostorethepredictionsin
Thejobprovidesthefollowingconfusionmatrix:
So,fromtheconfusionmatrix,itisclearthat9,396instanceswerecorrectlyclassifiedand315normalinstanceswereincorrectlyclassifiedasanomalies.Andtheaccuracypercentageis77.7635(correctlyclassifiedinstancesbythemodel/classifiedinstances).Theoutputfileinthepredictionfoldercontainsthelistwhere0and1.0definesthenormaldatasetand1definestheanomaly.


SummaryInthischapter,wediscussedtheRandomforestalgorithm.WestartedourdiscussionbyunderstandingthedecisiontreeandcontinuedwithanunderstandingoftheRandomforest.WetookuptheNSL-KDDdataset,whichisusedtobuildpredictivesystemsforcybersecurity.WeusedMahouttobuildtheRandomforesttree,anduseditwiththetestdatasetandgeneratedtheconfusionmatrixandotherstatisticsfortheoutput.
Inthenextchapter,wewilllookatthefinalclassificationalgorithmavailableinApacheMahout.Sostaytuned!


Chapter7.LearningMultilayerPerceptronUsingMahoutTounderstandaMultilayerPerceptron(MLP),wewillfirstexploreonemorepopularmachinelearningtechnique:neuralnetwork.Inthischapter,wewillexplorethefollowingtopics:
NeuralnetworkandneuronsMLPUsingMahoutforMLPimplementation

NeuralnetworkandneuronsNeuralnetworkisanoldalgorithm,anditwasdevelopedwithagoalinmind:toprovidethecomputerwithabrain.Neuralnetworkisinspiredbythebiologicalstructureofthehumanbrainwheremultipleneuronsareconnectedandformcolumnsandlayers.Aneuronisanelectricallyexcitablecellthatprocessesandtransmitsinformationthroughelectricalandchemicalsignals.Perceptualinputentersintotheneuralnetworkthroughoursensoryorgansandisthenfurtherprocessedintohigherlevels.Let’sunderstandhowneuronsworkinourbrain.
Neuronsarecomputationalunitsinthebrainthatcollecttheinputfrominputnerves,whicharecalleddendrites.Theyperformcomputationontheseinputmessagesandsendtheoutputusingoutputnerves,whicharecalledaxons.Seethefollowingfigure(http://vv.carleton.ca/~neil/neural/neuron-a.html):
Onthesamelines,wedevelopaneuralnetworkincomputers.Wecanrepresentaneuroninouralgorithmasshowninthefollowingfigure:
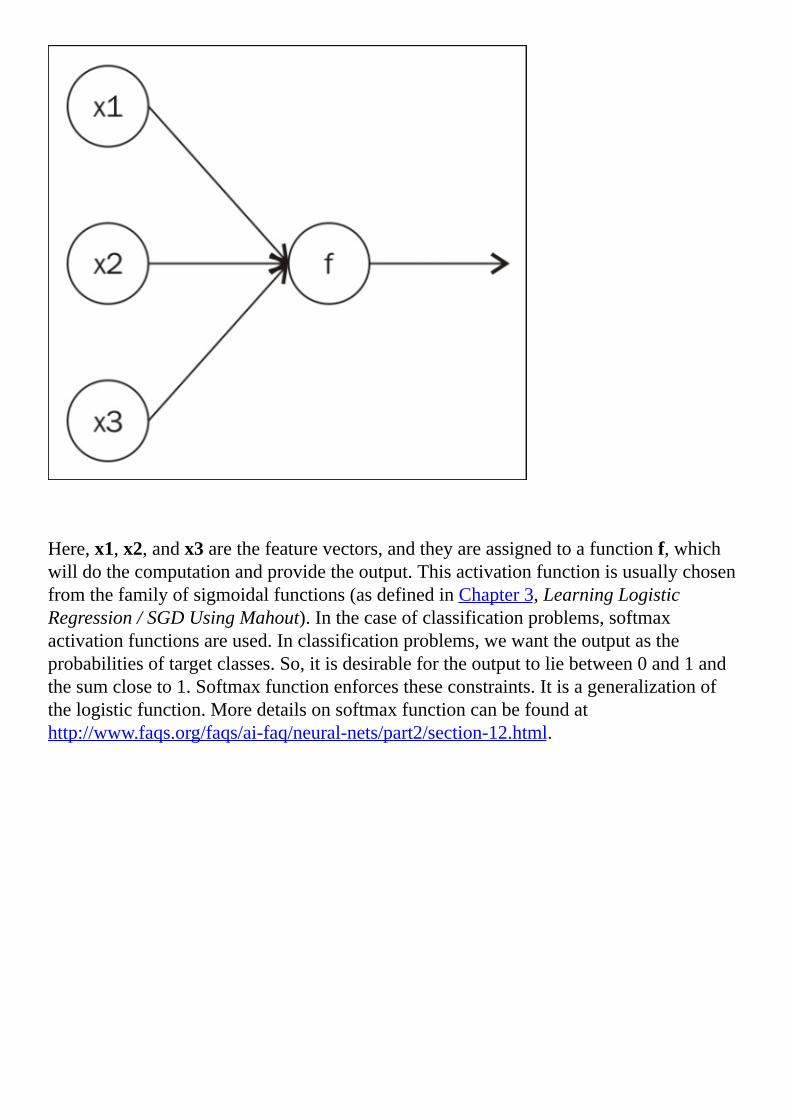
Here,x1,x2,andx3arethefeaturevectors,andtheyareassignedtoafunctionf,whichwilldothecomputationandprovidetheoutput.Thisactivationfunctionisusuallychosenfromthefamilyofsigmoidalfunctions(asdefinedinChapter3,LearningLogisticRegression/SGDUsingMahout).Inthecaseofclassificationproblems,softmaxactivationfunctionsareused.Inclassificationproblems,wewanttheoutputastheprobabilitiesoftargetclasses.So,itisdesirablefortheoutputtoliebetween0and1andthesumcloseto1.Softmaxfunctionenforcestheseconstraints.Itisageneralizationofthelogisticfunction.Moredetailsonsoftmaxfunctioncanbefoundathttp://www.faqs.org/faqs/ai-faq/neural-nets/part2/section-12.html.

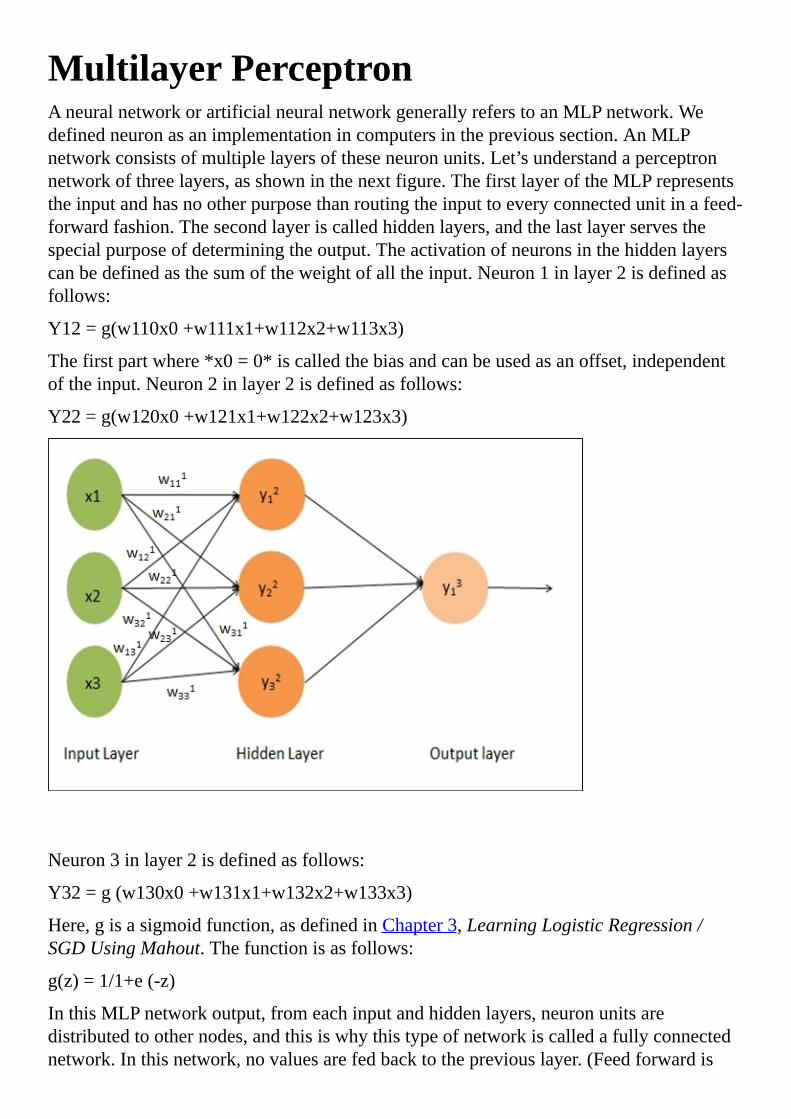
MultilayerPerceptronAneuralnetworkorartificialneuralnetworkgenerallyreferstoanMLPnetwork.Wedefinedneuronasanimplementationincomputersintheprevioussection.AnMLPnetworkconsistsofmultiplelayersoftheseneuronunits.Let’sunderstandaperceptronnetworkofthreelayers,asshowninthenextfigure.ThefirstlayeroftheMLPrepresentstheinputandhasnootherpurposethanroutingtheinputtoeveryconnectedunitinafeed-forwardfashion.Thesecondlayeriscalledhiddenlayers,andthelastlayerservesthespecialpurposeofdeterminingtheoutput.Theactivationofneuronsinthehiddenlayerscanbedefinedasthesumoftheweightofalltheinput.Neuron1inlayer2isdefinedasfollows:
Y12=g(w110x0+w111x1+w112x2+w113x3)
Thefirstpartwhere*x0=0*iscalledthebiasandcanbeusedasanoffset,independentoftheinput.Neuron2inlayer2isdefinedasfollows:
Y22=g(w120x0+w121x1+w122x2+w123x3)
Neuron3inlayer2isdefinedasfollows:
Y32=g(w130x0+w131x1+w132x2+w133x3)
Here,gisasigmoidfunction,asdefinedinChapter3,LearningLogisticRegression/SGDUsingMahout.Thefunctionisasfollows:
g(z)=1/1+e(-z)
InthisMLPnetworkoutput,fromeachinputandhiddenlayers,neuronunitsaredistributedtoothernodes,andthisiswhythistypeofnetworkiscalledafullyconnectednetwork.Inthisnetwork,novaluesarefedbacktothepreviouslayer.(Feedforwardis

anotherstrategyandisalsoknownasbackpropagation.Detailsonthiscanbefoundathttp://home.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html.)
AnMLPnetworkcanhavemorethanonehiddenlayer.TogetthevalueoftheweightssothatwecangetthepredictedvalueascloseaspossibletotheactualoneisatrainingprocessoftheMLP.Tobuildaneffectivenetwork,weconsideralotofitemssuchasthenumberofhiddenlayersandneuronunitsineachlayer,thecostfunctiontominimizetheerrorinpredictedandactualvalues,andsoon.
Nowlet’sdiscusstwomoreimportantandproblematicquestionsthatarisewhencreatinganMLPnetwork:
Howmanyhiddenlayersshouldoneuseforthenetwork?Howmanynumbersofhiddenunits(neuronunits)shouldoneuseinahiddenlayer?
Zerohiddenlayersarerequiredtoresolvelinearlyseparabledata.Assumingyourdatadoesrequireseparationbyanon-lineartechnique,alwaysstartwithonehiddenlayer.Almostcertainly,that’sallyouwillneed.IfyourdataisseparableusinganMLP,thenthisMLPprobablyonlyneedsasinglehiddenlayer.Inordertoselectthenumberofunitsindifferentlayers,thesearetheguidelines:
Inputlayer:Thisreferstothenumberofexplanatoryvariablesinthemodelplusoneforthebiasnode.Outputlayer:Inthecaseofclassification,thisreferstothenumberoftargetvariables,andinthecaseofregression,thisisobviouslyone.Hiddenlayer:Startyournetworkwithonehiddenlayerandusethenumberofneuronunitsequivalenttotheunitsintheinputlayer.Thebestwayistotrainseveralneuralnetworkswithdifferentnumbersofhiddenlayersandhiddenneuronsandmeasuretheperformanceofthesenetworksusingcross-validation.Youcanstickwiththenumberthatyieldsthebest-performingnetwork.Problemsthatrequiretwohiddenlayersarerarelyencountered.However,neuralnetworksthathavemorethanonehiddenlayercanrepresentfunctionswithanykindofshape.Thereiscurrentlynotheorytojustifytheuseofneuralnetworkswithmorethantwohiddenlayers.Infact,formanypracticalproblems,thereisnoreasontouseanymorethanonehiddenlayer.Anetworkwithnohiddenlayerisonlycapableofrepresentinglinearlyseparablefunctions.Networkswithonelayercanapproximateanyfunctionthatcontainsacontinuousmappingfromonefinitespacetoanother,andnetworkswithtwohiddenlayerscanrepresentanarbitrarydecisionboundarytoarbitraryaccuracywithrationalactivationfunctionsandcanapproximateanysmoothmappingtoanyaccuracy(Chapter5ofthebookIntroductiontoNeuralNetworksforJava).Numberofneuronsorhiddenunits:Usethenumberofneuronunitsequivalenttotheunitsintheinputlayer.Thenumberofhiddenunitsshouldbelessthantwicethenumberofunitsintheinputlayer.Anotherruletocalculatethisis(numberofinputunits+numberofoutputunits)*2/3.
Dothetestingforgeneralizationerrors,trainingerrors,bias,andvariance.Whenageneralizationerrordips,thenjustbeforeitbeginstoincreaseagain,thenumbersofnodesareusuallyfoundtobeperfectatthispoint.

Nowlet’smoveontothenextsectionandexplorehowwecanuseMahoutforanMLP.


MLPimplementationinMahoutTheMLPimplementationisbasedonamoregeneralneuralnetworkclass.ItisimplementedtorunonasinglemachineusingStochasticGradientDescent,wheretheweightsareupdatedusingonedatapointatatime.
Thenumberoflayersandunitsperlayercanbespecifiedmanuallyanddeterminesthewholetopologywitheachunitbeingfullyconnectedtothepreviouslayer.Abiasunitisautomaticallyaddedtotheinputofeverylayer.Abiasunitishelpfulforshiftingtheactivationfunctiontotheleftorright.Itislikeaddingacoefficienttothelinearfunction.
Currently,thelogisticsigmoidisusedasasquashingfunctionineveryhiddenandoutputlayer.
Thecommand-lineversiondoesnotperformiterationsthatleadtobadresultsonsmalldatasets.AnotherrestrictionisthattheCLIversionoftheMLPonlysupportsclassification,sincethelabelshavetobegivenexplicitlywhenexecutingtheimplementationinthecommandline.
Alearnedmodelcanbestoredandupdatedwithnewtraininginstancesusingthe`--update`flag.Theoutputoftheclassificationresultissavedasa.txtfileandonlyconsistsoftheassignedlabels.Apartfromthecommand-lineinterface,itispossibletoconstructandcompilemorespecializedneuralnetworksusingtheAPIandinterfacesinthemrlegacypackage.(Thecorepackageisrenamedasmrlegacy.)
Inthecommandline,weuseTrainMultilayerPerceptronandRunMultilayerPerceptronclassesthatareavailableinthemrlegacypackagewiththreeotherclasses:Neuralnetwork.java,NeuralNetworkFunctions.java,andMultilayerPerceptron.java.Forthisparticularimplementation,userscanfreelycontrolthetopologyoftheMLP,includingthefollowing:
ThesizeoftheinputlayerThenumberofhiddenlayersThesizeofeachhiddenlayerThesizeoftheoutputlayerThecostfunctionThesquashingfunction
Themodelistrainedinanonlinelearningapproach,wheretheweightsofneuronsintheMLPisupdatedandincrementedusingthebackPropagationalgorithmproposedbyRumelhart,D.E.,Hinton,G.E.,andWilliams,R.J.(1986),Learningrepresentationsbyback-propagatingerrors.Nature,323,533-536.


UsingMahoutforMLPMahouthasimplementationforanMLPnetwork.TheMLPimplementationiscurrentlylocatedintheMap-Reduce-Legacypackage.Aswithotherclassificationalgorithms,twoseparatedclassesareimplementedtotrainandusethisclassifier.Fortrainingtheclassifier,theorg.apache.mahout.classifier.mlp.TrainMultilayerPerceptronclass,andforrunningtheclassifier,theorg.apache.mahout.classifier.mlp.RunMultilayerPerceptronclassisused.Thereareanumberofparametersdefinedthatareusedwiththeseclasses,butwewilldiscusstheseparametersoncewerunourexampleonadataset.
Dataset
Inthischapter,wewilltrainanMLPtoclassifytheirisdataset.Theirisflowerdatasetcontainsdataofthreeflowerspecies,whereeachdatapointconsistsoffourfeatures.ThisdatasetwasintroducedbySirRonaldFisher.Itconsistsof50samplesfromeachofthreespeciesofiris.ThesespeciesareIrissetosa,Irisvirginica,andIrisversicolor.Fourfeaturesweremeasuredfromeachsample:
SepallengthSepalwidthPetallengthPetalwidth
Allmeasurementsareincentimeters.Youcandownloadthisdatasetfromhttps://archive.ics.uci.edu/ml/machine-learning-databases/iris/andsaveitasa.csvfile,asshowninthefollowingscreenshot:
Thisdatasetwilllooklikethethefollowingscreenshot:


StepstousetheMLPalgorithminMahoutThestepstousetheMLPalgorithminMahoutareasfollows:
1. CreatetheMLPmodel.
TocreatetheMLPmodel,wewillusetheTrainMultilayerPerceptronclass.Usethefollowingcommandtogeneratethemodel:
bin/mahoutorg.apache.mahout.classifier.mlp.TrainMultilayerPerceptron-
i/tmp/irisdata.csv-labelsIris-setosaIris-versicolorIris-virginica
-mo/tmp/model.model-ls483-l0.2-m0.35-r0.0001
Youcanalsorunusingthecorejar:Mahoutcorejar(xyzstandsfortheversion).IfyouhavedirectlyinstalledMahout,itcanbefoundunderthe/usr/lib/mahoutfolder.Executethefollowingcommand:
Java–cp/usr/lib/mahout/mahout-core-xyz-job.jar
org.apache.mahout.classifier.mlp.TrainMultilayerPerceptron-i
/tmp/irisdata.csv-labelsIris-setosaIris-versicolorIris-virginica-
mo/user/hue/mlp/model.model-ls483-l0.2-m0.35-r0.0001
TheTrainMultilayerPerceptronclassisusedhereandittakesdifferentparameters.Also,iisthepathfortheinputdataset.Here,wehaveputthedatasetunderthe/tmpfolder(localfilesystem).Additionally,labelsaredefinedinthedataset.Herewehavethefollowinglabels:
moistheoutputlocationforthecreatedmodel.lsisthenumberofunitsperlayer,includinginput,hidden,andoutputlayers.Thisparameterspecifiesthetopologyofthenetwork.Here,wehave4astheinputfeature,8forthehiddenlayer,and3fortheoutputclassnumber.listhelearningratethatisusedforweightupdates.Thedefaultis0.5.Toapproximategradientdescent,neuralnetworksaretrainedwithalgorithms.Learningispossibleeitherbybatchoronlinemethods.Inbatchtraining,weightchangesareaccumulatedoveranentirepresentationofthetrainingdata(anepoch)beforebeingapplied,whileonlinetrainingupdatesweighsafterthepresentationofeachtrainingexample(instance).Moredetailscanbefoundathttp://axon.cs.byu.edu/papers/Wilson.nn03.batch.pdf.misthemomentumweightthatisusedforgradientdescent.Thismustbeintherangebetween0–1.0.ristheregularizationvaluefortheweightvector.Thismustbeintherangebetween0–0.1.Itisusedtopreventoverfitting.

2. Totest/runtheMLPclassificationofthetrainedmodel,wecanusethefollowingcommand:
bin/mahoutorg.apache.mahout.classifier.mlp.RunMultilayerPerceptron-i
/tmp/irisdata.csv-cr03-mo/tmp/model.model-o/tmp/labelResult.txt
YoucanalsorunusingtheMahoutcorejar(xyzstandsforversion).IfyouhavedirectlyinstalledMahout,itcanbefoundunderthe/usr/lib/mahoutfolder.Executethefollowingcommand:
Java–cp/usr/lib/mahout/mahout-core-xyz-job.jar
org.apache.mahout.classifier.mlp.RunMultilayerPerceptron-i
/tmp/irisdata.csv-cr03-mo/tmp/model.model-o/tmp/labelResult.txt
TheRunMultilayerPerceptronclassisemployedheretousethemodel.Thisclassalsotakesdifferentparameters,whichareasfollows:
iindicatestheinputdatasetlocationcristherangeofcolumnstousefromtheinputfile,startingwith0(thatis,`-cr05`forincludingthefirstsixcolumnsonly)moisthelocationofthemodelbuiltearlieroisthepathtostorelabeledresultsfromrunningthemodel


SummaryInthischapter,wediscussedoneofthenewlyimplementedalgorithmsinMahout:MLP.WestartedourdiscussionbyunderstandingneuralnetworksandneuronunitsandcontinuedourdiscussionfurthertounderstandtheMLPnetworkalgorithm.Wediscussedhowtochoosedifferentlayerunits.WethenmovedtoMahoutandusedtheirisdatasettotestandrunanMLPalgorithmimplementedinMahout.Withthis,wehavefinishedourdiscussiononclassificationalgorithmsavailableinApacheMahout.
NowwemoveontothenextchapterofthisbookwherewewilldiscussthenewchangescomingupinthenewMahoutrelease.


Chapter8.MahoutChangesintheUpcomingReleaseMahoutisacommunity-drivenprojectanditscommunityisverystrong.Thiscommunitydecidedonsomeofthemajorchangesintheupcoming1.0release.Inthischapter,wewillexploretheupcomingchangesanddevelopmentsinApacheMahout.Wewilllookatthefollowingtopicsinbrief:
NewchangesdueinMahout1.0ApacheSparkH20-platform-relatedworkinApacheMahout

MahoutnewchangesMahoutwasusingthemapreduceprogrammingmodeltohandlelargedatasets.FromtheendofApril2014,thecommunitydecidedtostoptheimplementationofthenewmapreducealgorithm.Thisdecisionhasavalidreason.Mahout’scodebasewillbemovingtomoderndataprocessingsystemsthatofferaricherprogrammingmodelandmoreefficientexecutionthanHadoop’sMapReduce.
MahouthasstarteditsimplementationonthetopofDomainSpecificLanguage(DSL)forlinearalgebraicoperations.ProgramswritteninthisDSLareautomaticallyoptimizedandexecutedinparallelonApacheSpark.ScalaDSLandalgebraicoptimizerisScalaandSparkbindingforMahout.

MahoutScalaandSparkbindingsWithMahoutScalabindingsandMahoutSparkbindingsforlinearalgebrasubroutines,developersinMahoutaretryingtobringsemanticexplicitnesstoMahout’sin-coreandout-of-corelinearalgebrasubroutines.TheyaredoingthiswhileaddingthebenefitsofthestrongprogrammingenvironmentofScalaandcapitalizingonscalabilitybenefitsofSparkandGraphX.ScalabindingisusedtoprovidesupportforScalaDSL,andthiswillmakewritingmachinelearningprogramseasier.
MahoutScalaandSparkbindingsarepackagesthataimtoprovideanR-likelookandfeeltoMahout’sin-coreandout-of-coreSpark-backedlinearalgebra.AnimportantpartofSparkbindingsistheexpressionoptimizer.Thisoptimizerlooksattheentireexpressionanddecidesonhowitcanbesimplifiedandwhichphysicaloperatorsshouldbepicked.Ahigh-leveldiagramofthebindingstackisshowninthefollowingfigure(https://issues.apache.org/jira/secure/attachment/12638098/BindingsStack.jpg):
TheSparkbindingshellhasalsobeenimplementedinMahout1.0.Let’sunderstandtheApacheSparkprojectfirstandthenwewillrevisittheSparkbindingshellinMahout.


ApacheSparkApacheSparkisanopensource,in-memory,general-purposecomputingsystem.Spark’sin-memorytechniqueprovidesperformancethatis100timesfaster.InsteadofHadoop-likedisk-basedcomputation,Sparkusesclustermemorytouploadallthedataintothememory,andthisdatacanbequeriedrepeatedly.
ApacheSparkprovideshigh-levelAPIsinJava,Python,andScalaandanoptimizedenginethatsupportsgeneralexecutiongraphs.Itprovidesthefollowinghigh-leveltools:
SparkSQL:ThisisforSQLandstructureddataprocessing.MLib:ThisisSpark’sscalablemachinelearninglibrarythatconsistsofcommonlearningalgorithmsandutilities,includingclassification,regression,clustering,collaborativefiltering,dimensionalityreduction,aswellastheunderlyingoptimizationprimitives.GraphX:ThisisthenewSparkAPIforgraphsandgraph-parallelcomputation.Sparkstreaming:Thiscancollectdatafrommanysourcesandafterprocessingthisdata,itusescomplexalgorithmsandcanpushthedatatofilesystems,databases,andlivedashboards.
AsSparkisgainingpopularityamongdatascientists,theMahoutcommunityisalsoquicklyworkingonmakingMahoutalgorithmsfunctiononSpark’sexecutionenginetospeedupitscalculation10to100timesfaster.MahoutprovidesseveralimportantbuildingblockstocreaterecommendationsusingSpark.Spark-itemsimilaritycanbeusedtocreateotherpeoplealsolikedthesethingskindofrecommendationsandwhenpairedwithasearchenginecanpersonalizerecommendationsforindividualusers.Spark-rowsimilaritycanprovidenon-personalizedcontentbasedonrecommendationsandwhenpairedwithasearchenginecanbeusedtopersonalizecontentbasedonrecommendations(http://comments.gmane.org/gmane.comp.apache.mahout.scm/6513).

UsingMahout’sSparkshellYoucanuseMahout’sSparkshellbyreferringtothefollowingsteps:
1. DownloadSparkfromhttp://spark.apache.org/downloads.html.2. Createanewfolderwiththenamesparkusingthefollowingcommandandmovethe
downloadedfilethere:
mkdir/tmp/spark
mv~/Downloads/spark-1.1.1.tgz/tmp/spark
3. Unpackthearchivedfileinafolderusingthefollowingcommand:
cd/tmp/spark
tarxzfspark-1.1.1.tgz
4. Thiswillunzipthefileunder/tmp/spark/spark-1.1.1.Now,movetothenewlycreatedfolderandrunthefollowingcommand:
cd/spark-1.1.1
sbt/sbtassembly
ThiswillbuildSparkonyoursystemasshowninthefollowingscreenshot:
5. NowcreateaMahoutdirectoryandmovethefiletoitusingthefollowingcommand:
mkdir/tmp/Mahout
6. CheckoutthemasterbranchofMahoutfromGitHubusingthefollowingcommand:
gitclonehttps://github.com/apache/mahoutmahout

Theoutputoftheprecedingcommandisshowninthefollowingscreenshot:
7. ChangeyourdirectorytothenewlycreatedMahoutdirectoryandbuildMahout:
cdmahout
mvn-DskipTestscleaninstall
Theoutputoftheprecedingcommandisshowninthefollowingscreenshot:
8. MovetothedirectorywhereyouunpackedSparkandtypethefollowingcommandtostartSparklocally:
cd/tmp/spark/spark-1.1.1
sbin/start-all-sh
Theoutputoftheprecedingcommandisshowninthefollowingscreenshot:
9. Openabrowser;pointittohttp://localhost:8080/tocheckwhetherSparkhas

successfullystarted.CopytheURLoftheSparkmasteratthetopofthepage(itstartswithspark://).
10. Definethefollowingenvironmentvariables:
exportMAHOUT_HOME=[directoryintowhichyoucheckedoutMahout]
exportSPARK_HOME=[directorywhereyouunpackedSpark]
exportMASTER=[urloftheSparkmaster]
11. Finally,changetothedirectorywhereyouunpackedMahoutandtypebin/mahoutspark-shell;youshouldseetheshellstartingandgetthemahout>prompt.
NowyourMahoutSparkshellisreadyandyoucanstartplayingwithdata.Formoreinformationonthistopic,seetheimplementationsectionathttps://mahout.apache.org/users/sparkbindings/play-with-shell.html.


H2OplatformintegrationAsdiscussedearlier,anexperimentalworktointegrateMahoutandtheH2Oplatformisalsoinprogress.TheintegrationprovidesanH2ObackendtotheMahoutalgebraDSL.
H2OmakesHadoopdomath!H2Oscalesstatistics,machinelearning,andmathoverbigdata.Itisextensibleanduserscanbuildblocksusingsimplemathlegosinthecore.H2OkeepsfamiliarinterfacessuchasR,Excel,andJSONsothatbigdataenthusiastsandexpertscanexplore,munge,model,andscoredatasetsusingarangeofsimple-to-advancedalgorithms.Datacollectioniseasy,whiledecisionmakingishard.H2Omakesitfastandeasytoderiveinsightsfromyourdatathroughfasterandbetterpredictivemodeling.Italsohasavisionofonlinescoringandmodelinginasingleplatform(http://0xdata.com/download/).
H2Oisfundamentallyapeer-to-peersystem.H2Onodesjointogethertoformacloudonwhichhigh-performancedistributedmathcanbeexecuted.Eachnodejoinsacloudofagivenname.Multiplecloudscanexistonthesamenetworkatthesametimeaslongastheirnamesaredifferent.Multiplenodescanexistonthesameserveraswell(theycanevenbelongtothesamecloud).
TheMahoutH2OintegrationisfitintothismodelbyhavingN-1workernodesandonedrivernode,allbelongingtothesamecloudname.Thedefaultcloudnameusedfortheintegrationismah2out.Cloudshavetobespunupaspertheirtask/job.
Moredetailscanbefoundathttps://issues.apache.org/jira/browse/MAHOUT-1500.


SummaryInthischapter,wediscussedtheupcomingreleaseofMahout1.0,andthechangesthatarecurrentlygoingon.WealsoglancedthroughSpark,Scalabinding,andApacheSpark.Wealsodiscussedahigh-leveloverviewofH2OMahoutintegration.
Nowlet’smoveontothefinalchapterofthisbookwherewewilldevelopaproduction-readyclassifier.


Chapter9.BuildinganE-mailClassificationSystemUsingApacheMahoutInthischapter,wewillcreateaclassifiersystemusingMahout.Inordertobuildthissystem,wewillcoverthefollowingtopics:
GettingthedatasetPreparationofthedatasetPreparingthemodelTrainingthemodel
Inthischapter,wewilltargetthecreationoftwodifferentclassifiers.Thefirstonewillbeaneasyonebecauseyoucanbothcreateandtestitonapseudo-distributedHadoopinstallation.Forthesecondclassifier,Iwillprovideyouwithallthedetails,soyoucanrunitusingyourfullydistributedHadoopinstallation.Iwillcountthesecondoneasahands-onexerciseforthereadersofthisbook.
Firstofall,let’sunderstandtheproblemstatementforthefirstusecase.Nowadays,inmostofthee-mailsystems,weseethate-mailsareclassifiedasspamornotspam.E-mailsthatarenotspamaredelivereddirectlyintoourinboxbutspame-mailsarestoredinafoldercalledSpam.Usually,basedonacertainpatternsuchasmessagesubject,sender’se-mailaddress,orcertainkeywordsinthemessagebody,wecategorizeanincominge-mailasspam.WewillcreateaclassifierusingMahout,whichwillclassifyane-mailintospamornotspam.WewilluseSpamAssassin,anApacheopensourceprojectdatasetforthistask.
Forthesecondusecase,wewillcreateaclassifier,whichcanpredictagroupofincominge-mails.Asanopensourceproject,therearelotsofprojectsundertheApachesoftwarefoundation,suchasApacheMahout,ApacheHadoop,ApacheSolr,andsoon.WewilltaketheApacheSoftwareFoundation(ASF)e-maildatasetandusingthis,wewillcreateandtrainourmodelsothatourmodelcanpredictanewincominge-mail.So,basedoncertainfeatures,wewillbeabletopredictwhichgroupanewincominge-mailbelongsto.
InMahout’sclassificationproblem,wewillhavetoidentifyapatterninthedatasettohelpuspredictthegroupofanewe-mail.Wealreadyhaveadataset,whichisseparatedbyprojectnames.WewillusetheASFpublice-mailarchivesdatasetforthisusecase.
Now,let’sconsiderourfirstusecase:spame-maildetectionclassifier.
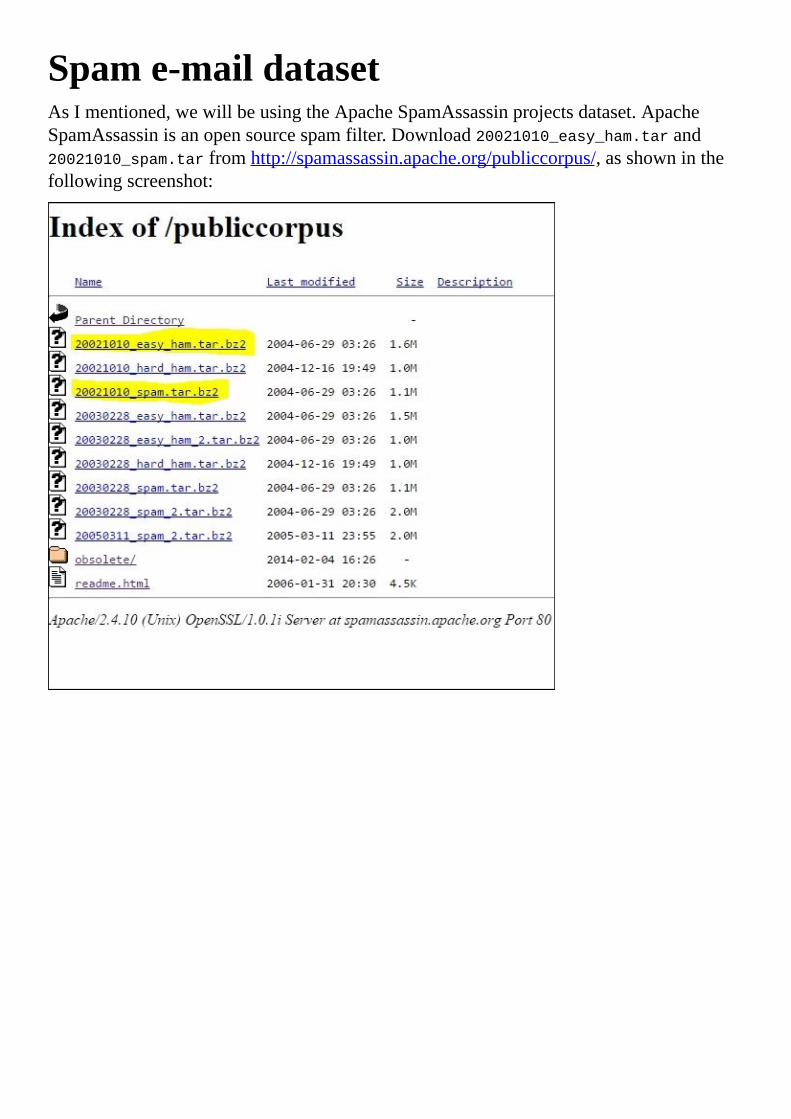
Spame-maildatasetAsImentioned,wewillbeusingtheApacheSpamAssassinprojectsdataset.ApacheSpamAssassinisanopensourcespamfilter.Download20021010_easy_ham.tarand20021010_spam.tarfromhttp://spamassassin.apache.org/publiccorpus/,asshowninthefollowingscreenshot:


CreatingthemodelusingtheAssassindatasetWecancreatethemodelwiththehelpofthefollowingsteps:
1. Createafolderundertmpwiththenamedataset,andthenclickonthefolderandunzipthedatasetsusingthefollowingcommand:
mkdir/tmp/assassin/dataset
tar–xvf/tmp/assassin/20021010_easy_ham.tar.bz2
tar–xvf/tmp/assassin/20021010_spam.tar.bz2
Thiswillcreatetwofoldersunderthedatasetfolder,easy_hamandspam,asshowninthefollowingscreenshot:
2. CreateafolderinHdfsandmovethisdatasetintoHadoop:
hadoopfs-mkdir/user/hue/assassin/
hadoopfs–put/tmp/assassin/dataset/user/hue/assassin
tar–xvf/tmp/assassin/20021010_spam.tar.bz2
Nowourdatapreparationisdone.Wehavedownloadedthedataandmovedthisdataintohdfs.Let’smoveontothenextstep.
3. ConvertthisdataintosequencefilessothatwecanprocessitusingHadoop:
bin/mahoutseqdirectory–i/user/hue/assassin/dataset–o
/user/hue/assassinseq-out

4. Convertthesequencefileintosparsevector(Mahoutalgorithmsacceptinputinvectorformat,whichiswhyweareconvertingthesequencefileintosparsevector)byusingthefollowingcommand:
bin/mahoutseq2sparse-i/user/hue/assassinseq-out/part-m-00000-o
/user/hue/assassinvec-lnorm-nv-wttfidf
Thecommandintheprecedingscreenshotisexplainedasfollows:
lnorm:Thiscommandisusedforoutputvectortobelognormalized.nv:Thiscommandisusedfornamedvector.wt:Thiscommandisusedtoidentifythekindofweighttouse.Hereweusetf-idf.
5. Splitthesetofvectorsfortrainingandtestingthemodel,asfollows:

bin/mahoutsplit-i/user/hue/assassinvec/tfidf-vectors--
trainingOutput/user/hue/assassindatatrain--testOutput
/user/hue/assassindatatest--randomSelectionPct20--overwrite--
sequenceFiles-xmsequential
Theprecedingcommandcanbeexplainedasfollows:
TherandomSelectionPctparameterdividesthepercentageofdataintotestandtrainingdatasets.Inthiscase,it’s80percentfortestand20percentfortraining.Thexmparameterspecifieswhatportionofthetf(tf-idf)vectorsistobeusedexpressedintimesthestandarddeviation.Thesigmasymbolspecifiesthedocumentfrequenciesofthesevectors.Itcanbeusedtoremovereallyhighfrequencyterms.Itisexpressedasadoublevalue.Agoodvaluetobespecifiedis3.0.Ifthevalueislessthan0,novectorswillbefilteredout.
6. Now,trainthemodelusingthefollowingcommand:
bin/mahouttrainnb-i/user/hue/assassindatatrain-el-o
/user/hue/prodmodel-li/user/hue/prodlabelindex-ow-c
7. Now,testthemodelusingthefollowingcommand:
bin/mahouttestnb-i/user/hue/assassindatatest-m/user/hue/prodmodel/
-l/user/hue/prodlabelindex-ow-o/user/hue/prodresults
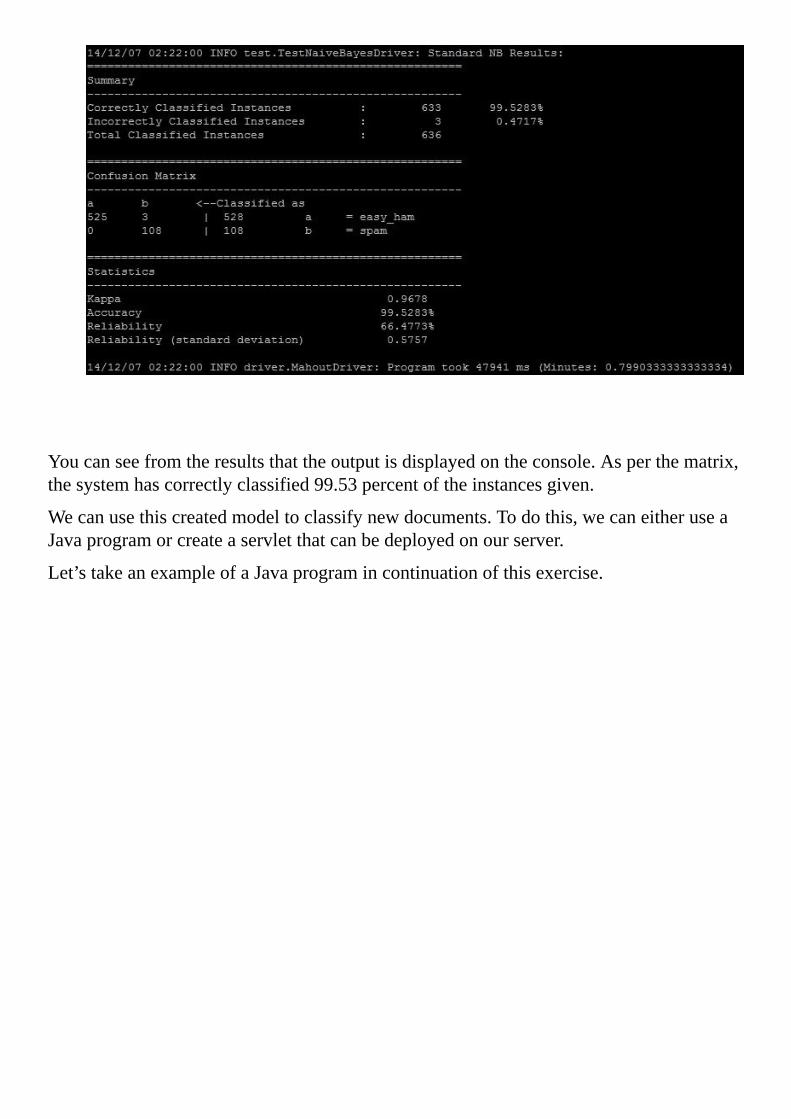
Youcanseefromtheresultsthattheoutputisdisplayedontheconsole.Asperthematrix,thesystemhascorrectlyclassified99.53percentoftheinstancesgiven.
Wecanusethiscreatedmodeltoclassifynewdocuments.Todothis,wecaneitheruseaJavaprogramorcreateaservletthatcanbedeployedonourserver.
Let’stakeanexampleofaJavaprogramincontinuationofthisexercise.


ProgramtouseaclassifiermodelWewillcreateaJavaprogramthatwilluseourmodeltoclassifynewe-mails.Thisprogramwilltakemodel,labelindex,dictionary-file,documentfrequency,andtextfileasinputandwillgenerateascoreforthecategories.Thecategorywillbedecidedbasedonthehigherscores.
Let’shavealookatthisprogramstepbystep:
The.jarfilesrequiredtomakeacompilationofthisprogramareasfollows:
Hadoop-core-x.y.x.jar
Mahout-core-xyz.jar
Mahout-integration-xyz.jar
Mahout-math-xyz.jar
Theimportstatementsarelistedasfollows.WearediscussingthisbecausetherearelotsofchangesintheMahoutreleasesandpeopleusuallyfinditdifficulttogetthecorrectclasses.
importjava.io.BufferedReader;
importjava.io.FileReader;
importjava.io.StringReader;
importjava.util.HashMap;
importjava.util.Map;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.lucene.analysis.Analyzer;
importorg.apache.lucene.analysis.TokenStream;
importorg.apache.lucene.analysis.standard.StandardAnalyzer;
import
org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
importorg.apache.lucene.util.Version;
importorg.apache.mahout.classifier.naivebayes.BayesUtils;
importorg.apache.mahout.classifier.naivebayes.NaiveBayesModel;
import
org.apache.mahout.classifier.naivebayes.StandardNaiveBayesClassifier;
importorg.apache.mahout.common.Pair;
import
org.apache.mahout.common.iterator.sequencefile.SequenceFileIterable;
importorg.apache.mahout.math.RandomAccessSparseVector;
importorg.apache.mahout.math.Vector;
importorg.apache.mahout.math.Vector.Element;
importorg.apache.mahout.vectorizer.TFIDF;
importorg.apache.hadoop.io.*;
importcom.google.common.collect.ConcurrentHashMultiset;
importcom.google.common.collect.Multiset;

Thesupportingmethodstoreadthedictionaryareasfollows:
publicstaticMap<String,Integer>readDictionary(Configurationconf,
PathdictionaryPath){
Map<String,Integer>dictionary=newHashMap<String,Integer>();
for(Pair<Text,IntWritable>pair:newSequenceFileIterable<Text,
IntWritable>(dictionaryPath,true,conf)){
dictionary.put(pair.getFirst().toString(),pair.getSecond().get());
}
returndictionary;
}
Thesupportingmethodstoreadthedocumentfrequencyareasfollows:
publicstaticMap<Integer,Long>readDocumentFrequency(Configuration
conf,PathdocumentFrequencyPath){
Map<Integer,Long>documentFrequency=newHashMap<Integer,Long>();
for(Pair<IntWritable,LongWritable>pair:new
SequenceFileIterable<IntWritable,LongWritable>(documentFrequencyPath,
true,conf)){
documentFrequency.put(pair.getFirst().get(),
pair.getSecond().get());
}
returndocumentFrequency;
}
Thefirstpartofthemainmethodisusedtoperformthefollowingactions:
GettingtheinputLoadingthemodelInitializingStandardNaiveBayesClassifierusingourcreatedmodelReadinglabelindex,documentfrequency,anddictionarycreatedwhilecreatingthevectorfromthedataset
Thefollowingcodecanbeusedfortheprecedingactions:
publicstaticvoidmain(String[]args)throwsException{
if(args.length<5){
System.out.println("Arguments:[model][labelindex]
[dictionary][documentfrequency][newfile]");
return;
}
StringmodelPath=args[0];
StringlabelIndexPath=args[1];
StringdictionaryPath=args[2];
StringdocumentFrequencyPath=args[3];
StringnewDataPath=args[4];
Configurationconfiguration=newConfiguration();//modelisa
matrix(wordId,labelId)=>probabilityscore
NaiveBayesModelmodel=NaiveBayesModel.materialize(new
Path(modelPath),configuration);
StandardNaiveBayesClassifierclassifier=new
StandardNaiveBayesClassifier(model);
//labelsisamaplabel=>classId
Map<Integer,String>labels=
BayesUtils.readLabelIndex(configuration,newPath(labelIndexPath));

Map<String,Integer>dictionary=readDictionary(configuration,
newPath(dictionaryPath));
Map<Integer,Long>documentFrequency=
readDocumentFrequency(configuration,new
Path(documentFrequencyPath));
Thesecondpartofthemainmethodisusedtoextractwordsfromthee-mail:
Analyzeranalyzer=newStandardAnalyzer(Version.LUCENE_CURRENT);
intlabelCount=labels.size();
intdocumentCount=documentFrequency.get(-1).intValue();
System.out.println("Numberoflabels:"+labelCount);
System.out.println("Numberofdocumentsintrainingset:"+
documentCount);
BufferedReaderreader=newBufferedReader(new
FileReader(newDataPath));
while(true){
Stringline=reader.readLine();
if(line==null){
break;
}
ConcurrentHashMultiset<Object>words=
ConcurrentHashMultiset.create();
//extractwordsfrommail
TokenStreamts=analyzer.tokenStream("text",new
StringReader(line));
CharTermAttributetermAtt=ts.addAttribute(CharTermAttribute.class);
ts.reset();
intwordCount=0;
while(ts.incrementToken()){
if(termAtt.length()>0){
Stringword=
ts.getAttribute(CharTermAttribute.class).toString();
IntegerwordId=dictionary.get(word);
//ifthewordisnotinthedictionary,skipit
if(wordId!=null){
words.add(word);
wordCount++;
}
}
}
ts.close();
Thethirdpartofthemainmethodisusedtocreatevectoroftheidwordandthetf-idfweights:
Vectorvector=newRandomAccessSparseVector(10000);
TFIDFtfidf=newTFIDF();
for(Multiset.Entryentry:words.entrySet()){
Stringword=(String)entry.getElement();
intcount=entry.getCount();
IntegerwordId=dictionary.get(word);
Longfreq=documentFrequency.get(wordId);

doubletfIdfValue=tfidf.calculate(count,freq.intValue(),
wordCount,documentCount);
vector.setQuick(wordId,tfIdfValue);
}
Inthefourthpartofthemainmethod,withclassifier,wegetthescoreforeachlabelandassignthee-mailtothehigherscoredlabel:
VectorresultVector=classifier.classifyFull(vector);
doublebestScore=-Double.MAX_VALUE;
intbestCategoryId=-1;
for(inti=0;i<resultVector.size();i++){
Elemente1=resultVector.getElement(i);
intcategoryId=e1.index();
doublescore=e1.get();
if(score>bestScore){
bestScore=score;
bestCategoryId=categoryId;
}
System.out.print(""+labels.get(categoryId)+":"+score);
}
System.out.println("=>"+labels.get(bestCategoryId));
}
}
Now,putallthesecodesunderoneclassandcreatethe.jarfileofthisclass.Wewillusethis.jarfiletotestournewe-mails.


TestingtheprogramTotesttheprogram,performthefollowingsteps:
1. Createafoldernamedassassinmodeltestinthelocaldirectory,asfollows:
mkdir/tmp/assassinmodeltest
2. Tousethismodel,getthefollowingfilesfromhdfsto/tmp/assassinmodeltest:
Fortheearliercreatedmodel,usethefollowingcommand:
hadoopfs–get/user/hue/prodmodel/tmp/assassinmodeltest
Forlabelindex,usethefollowingcommand:
hadoopfs–get/user/hue/prodlabelindex/tmp/assassinmodeltest
Fordf-countsfromtheassassinvecfolder(changethenameofthepart-00000filetodf-count),usethefollowingcommands:
hadoopfs–get/user/hue/assassinvec/df-count
/tmp/assassinmodeltest
dictionary.file-0fromthesameassassinvecfolder
hadoopfs–get/user/hue/assassinvec/dictionary.file-0
/tmp/assassinmodeltest
3. Under/tmp/assassinmodeltest,createafilewiththemessageshowninthefollowingscreenshot:
4. Now,runtheprogramusingthefollowingcommand:
Java–cp/tmp/assassinmodeltest/spamclassifier.jar:/usr/lib/mahout/*
com.packt.spamfilter.TestClassifier/tmp/assassinmodeltest
/tmp/assassinmodeltest/prodlabelindex
/tmp/assassinmodeltest/dictionary.file-0/tmp/assassinmodeltest/df-
count/tmp/assassinmodeltest/testemail
5. Now,updatetheteste-mailfilewiththemessageshowninthefollowingscreenshot:

6. Runtheprogramagainusingthesamecommandasgiveninstep4andviewtheresultasfollows:
Now,wehaveaprogramreadythatcanuseourclassifiermodelandpredicttheunknownitems.Let’smoveontooursecondusecase.


SecondusecaseasanexerciseAsdiscussedatthestartofthischapter,wewillnowworkonasecondusecase,wherewewillpredictthecategoryofanewe-mail.
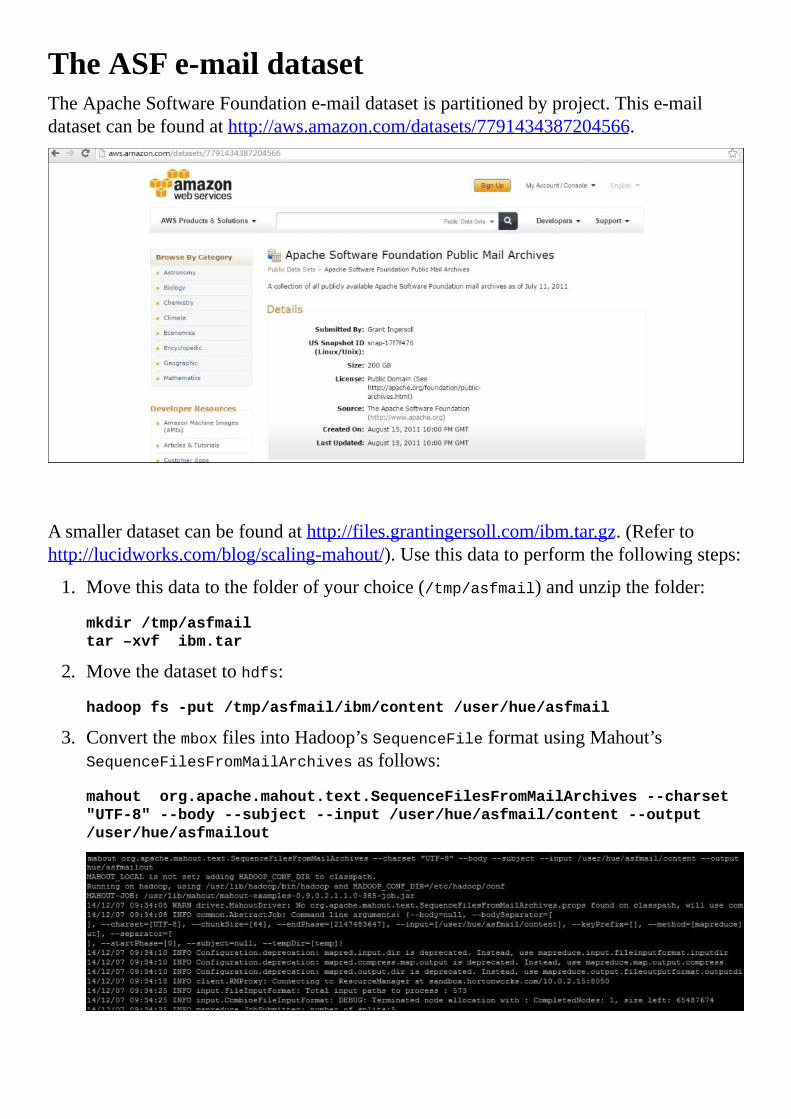
TheASFe-maildatasetTheApacheSoftwareFoundatione-maildatasetispartitionedbyproject.Thise-maildatasetcanbefoundathttp://aws.amazon.com/datasets/7791434387204566.
Asmallerdatasetcanbefoundathttp://files.grantingersoll.com/ibm.tar.gz.(Refertohttp://lucidworks.com/blog/scaling-mahout/).Usethisdatatoperformthefollowingsteps:
1. Movethisdatatothefolderofyourchoice(/tmp/asfmail)andunzipthefolder:
mkdir/tmp/asfmail
tar–xvfibm.tar
2. Movethedatasettohdfs:
hadoopfs-put/tmp/asfmail/ibm/content/user/hue/asfmail
3. ConvertthemboxfilesintoHadoop’sSequenceFileformatusingMahout’sSequenceFilesFromMailArchivesasfollows:
mahoutorg.apache.mahout.text.SequenceFilesFromMailArchives--charset
"UTF-8"--body--subject--input/user/hue/asfmail/content--output
/user/hue/asfmailout

4. Convertthesequencefileintosparsevector:
mahoutseq2sparse--input/user/hue/asfmailout--output
/user/hue/asfmailseqsp--norm2--weightTFIDF--namedVector--
maxDFPercent90--minSupport2--analyzerName
org.apache.mahout.text.MailArchivesClusteringAnalyzer
5. Modifythelabels:
mahoutorg.apache.mahout.classifier.email.PrepEmailDriver--input
/user/hue/asfmailseqsp--output/user/hue/asfmailseqsplabel--
maxItemsPerLabel1000
Now,thenextthreestepsaresimilartotheonesweperformedearlier:
1. Splitthedatasetintotrainingandtestdatasetsusingthefollowingcommand:
mahoutsplit--input/user/hue/asfmailseqsplabel--trainingOutput
/user/hue/asfmailtrain--testOutput/user/hue/asfmailtest--
randomSelectionPct20--overwrite--sequenceFiles
2. Trainthemodelusingthetrainingdatasetasfollows:
mahouttrainnb-i/user/hue/asfmailtrain-o/user/hue/asfmailmodel-
extractLabels--labelIndex/user/hue/asfmaillabels
3. Testthemodelusingthetestdataset:
mahouttestnb-i/user/hue/asfmailtest-m/user/hue/asfmailmodel--
labelIndex/user/hue/asfmaillabels
Asyoumayhavenoticed,allthestepsareexactlyidenticaltotheonesweperformedearlier.Hereby,Ileavethistopicasanexerciseforyoutocreateyourownclassifiersystemusingthismodel.Youcanusehintsasprovidedforthespamfilterclassifier.Wenowmoveourdiscussiontotuningourclassifier.Let’stakeabriefoverviewofthebestpracticesinthisarea.


ClassifierstuningWealreadydiscussedclassifiers’evaluationtechniquesinChapter1,ClassificationinDataAnalysis.Justasareminder,weevaluateourmodelusingtechniquessuchasconfusionmatrix,entropymatrix,areaundercurve,andsoon.
Fromtheexplanatoryvariables,wecreatethefeaturevector.Tocheckhowaparticularmodelisworking,thesefeaturevectorsneedtobeinvestigated.InMahout,thereisaclassavailableforthis,ModelDissector.Ittakesthefollowingthreeinputs:
Features:Thisclasstakesafeaturevectortouse(destructively)TraceDictionary:ThisclasstakesatracedictionarycontainingvariablesandthelocationsinthefeaturevectorthatareaffectedbythemLearner:Thisclasstakesthemodelthatweareprobingtofindweightsonfeatures
ModelDissectortweaksthefeaturevectorandobserveshowthemodeloutputchanges.Bytakinganaverageofthenumberofexamples,wecandeterminetheeffectofdifferentexplanatoryvariables.
ModelDissectorhasasummarymethod,whichreturnsthemostimportantfeatureswiththeirweights,mostimportantcategory,andthetopfewcategoriesthattheyaffect.
TheoutputofModelDissectorishelpfulintroubleshootingproblemsinawronglycreatedmodel.
Moredetailsforthecodecanbefoundathttps://github.com/apache/mahout/blob/master/mrlegacy/src/main/java/org/apache/mahout/classifier/sgd/ModelDissector.java
Whileimprovingtheoutputoftheclassifier,oneshouldtakecarewithtwocommonlyoccurringproblems:targetleak,andbrokenfeatureextraction.
Ifthemodelisshowingresultsthataretoogoodtobetrueoranoutputbeyondexpectations,wecouldhaveaproblemwithtargetleak.Thiserrorcomesonceinformationfromthetargetvariableisincludedintheexplanatoryvariables,whichareusedtotraintheclassifier.Inthisinstance,theclassifierwillworktoowellforthetestdataset.
Ontheotherhand,brokenfeatureextractionoccurswhenfeatureextractionisbroken.Thistypeofclassifiershowstheoppositeresultfromthetargetleakclassifiers.Here,themodelprovidesresultspoorerthanexpected.
Totunetheclassifier,wecanusenewexplanatoryvariables,transformationsofexplanatoryvariables,andcanalsoeliminatesomeofthevariables.Weshouldalsotrydifferentlearningalgorithmstocreatethemodelandchooseanalgorithm,whichisgoodinperformance,trainingtime,andspeed.
MoredetailsontuningcanbefoundinChapter16,DeployingaclassifierinthebookMahoutinAction.


SummaryInthischapter,wediscussedcreatingourownproductionreadyclassifiermodel.Wetookuptwousecaseshere,oneforane-mailspamfilterandtheotherforclassifyingthee-mailaspertheprojects.WeuseddatasetsforApacheSpamAssassinforthee-mailfilterandASFforthee-mailclassifier.
Wealsosawhowtoincreasetheperformanceofyourmodel.
SoyouarenowreadytoimplementclassifiersusingApacheMahoutforyourownrealworldusecases.Happylearning!

IndexA
algorithms,classificationLogisticregression/ClassificationalgorithmsStochasticGradientDescent(SGD)/ClassificationalgorithmsNaïveBayesclassification/ClassificationalgorithmsHiddenMarkovModel(HMM)/Classificationalgorithmsrandomforest/ClassificationalgorithmsMulti-layerperceptron(MLP)/Classificationalgorithms
ApacheSpamAssassinproject/Spame-maildatasetApacheSpark
about/ApacheSparkSparkSQL/ApacheSparkMLib/ApacheSparkGraphX/ApacheSparkSparkstreaming/ApacheSpark
ASFe-maildatasetabout/TheASFe-maildatasetURL/TheASFe-maildataset
Assassindatasetused,forcreatingmodel/CreatingthemodelusingtheAssassindataset
AUC(areaundertheROCcurve)/AreaundertheROCcurveaxons/Neuralnetworkandneurons

Bbackpropagation/MultilayerPerceptronBagofwords/UnderstandingthetermsusedintextclassificationBaumWelchTrainerclass/UsingMahoutfortheHiddenMarkovModelBayesrule
about/IntroducingconditionalprobabilityandtheBayesrulebindingstack
URL/MahoutScalaandSparkbindings

CChi-squaredAutomaticInteractionDetector(CHAID)/Decisiontreeclassification
about/Introducingtheclassification,IntroducingApacheMahoutapplication/Applicationoftheclassificationsystemsystem,working/Workingoftheclassificationsystemalgorithms/Classificationalgorithms
ClassificationandRegressionTree(CART)/Decisiontreeclassifier
trainingdataset/Workingoftheclassificationsystemtestdataset/Workingoftheclassificationsystemmodel/Workingoftheclassificationsystembuilding/Workingoftheclassificationsystem
classifiermodelusing,programfor/Programtouseaclassifiermodel
classifierstuning/Classifierstuning
clusteringabout/IntroducingApacheMahout
conditionalprobabilityabout/IntroducingconditionalprobabilityandtheBayesrule
confusionmatrixabout/TheconfusionmatrixAccuracy/TheconfusionmatrixPrecisionorpositivepredictivevalue/TheconfusionmatrixNegativepredictivevalue/TheconfusionmatrixSensitivity/truepositiverate/recall/TheconfusionmatrixSpecificity/TheconfusionmatrixF1score/Theconfusionmatrix
costfunction,linearregressionabout/Costfunction

DDARPA‘98/UsingMahoutforRandomforestdataanalysis
classification/Introducingtheclassificationdecisiontree
about/Decisiontreedendrites/Neuralnetworkandneuronsdependentvariable/Logisticregressiondeterministicpatterns/Deterministicandnondeterministicpatternsdevelopmentenvironment
settingup,Eclipseused/SettingupadevelopmentenvironmentusingEclipsedimensionalreduction
about/IntroducingApacheMahoutDomainSpecificLanguage(DSL)/Mahoutnewchanges

EEclipse
used,forbuildingdevelopmentenvironment/SettingupadevelopmentenvironmentusingEclipse
emissionmatrix,HMM/IntroducingtheHiddenMarkovModelEntropymatrix
about/Theentropymatrixexplanatoryvariable/Logisticregressionexplanatoryvariables
about/Workingoftheclassificationsystem
Ggradientdescent
about/Gradientdescentsigmoidfunction/Logisticregressionlogisticfunction/Logisticregression
GraphX/ApacheSpark

HH2Oplatform
integration/H2OplatformintegrationURL/H2Oplatformintegration
HadoopURL/IntroducingApacheMahout,InstallingMahout
hiddenlayer,MLPnetwork/MultilayerPerceptronhiddenlayers,MLPnetwork/MultilayerPerceptronHiddenMarkovModel(HMM)/Classificationalgorithmshiddenstates,HMM/IntroducingtheHiddenMarkovModelHMM
about/IntroducingtheHiddenMarkovModelproperties/IntroducingtheHiddenMarkovModelstatevector/IntroducingtheHiddenMarkovModeltransitionmatrix/IntroducingtheHiddenMarkovModelemissionmatrix/IntroducingtheHiddenMarkovModelhiddenstates/IntroducingtheHiddenMarkovModelobservablestate/IntroducingtheHiddenMarkovModelMahoutused/UsingMahoutfortheHiddenMarkovModelModelclass/UsingMahoutfortheHiddenMarkovModelHmmTrainerclass/UsingMahoutfortheHiddenMarkovModelHmmEvaluatorclass/UsingMahoutfortheHiddenMarkovModelHmmAlgorithmsclass/UsingMahoutfortheHiddenMarkovModelHmmUtilsclass/UsingMahoutfortheHiddenMarkovModelRandomSequencerGenerator/UsingMahoutfortheHiddenMarkovModelBaumWelchTrainerclass/UsingMahoutfortheHiddenMarkovModelViterbiEvaluatorclass/UsingMahoutfortheHiddenMarkovModelinputcommand/UsingMahoutfortheHiddenMarkovModeloutputcommand/UsingMahoutfortheHiddenMarkovModelmodelcommand/UsingMahoutfortheHiddenMarkovModellikelihoodcommand/UsingMahoutfortheHiddenMarkovModel
HMM,issuesevaluation/IntroducingtheHiddenMarkovModeldecoding/IntroducingtheHiddenMarkovModellearning/IntroducingtheHiddenMarkovModel
HmmAlgorithmsclass/UsingMahoutfortheHiddenMarkovModelHmmEvaluatorclass/UsingMahoutfortheHiddenMarkovModelHMMModelclass/UsingMahoutfortheHiddenMarkovModelHmmTrainerclass/UsingMahoutfortheHiddenMarkovModelHmmUtilsclass/UsingMahoutfortheHiddenMarkovModelHortonworksSandbox
URL/SettingupMahoutforaWindowsuser

IiInitialstatevector,Markovprocess/TheMarkovprocessindependentvariable/Logisticregressioninputlayer,MLPnetwork/MultilayerPerceptronirisdataset
URL/UsingMahoutforMLPIterativeDichotomiser3(ID3)
URL/Decisiontree

JJava
URL/InstallingMahout

Llabels
about/WorkingoftheclassificationsystemLatentDirichletAllocation(LDA)/IntroducingApacheMahoutlinearregression
about/Understandinglinearregressioncostfunction/Costfunctiongradientdescent/Gradientdescent
logisticfunction/Logisticregressionlogisticregression/Classificationalgorithms
about/LogisticregressionMahout,usingfor/UsingMahoutforlogisticregressiondataset/UsingMahoutforlogisticregressiontrainingandtestdata,preparing/UsingMahoutforlogisticregressionmodel,training/UsingMahoutforlogisticregressiontrainlogistic/UsingMahoutforlogisticregressioninput/UsingMahoutforlogisticregressionoutput/UsingMahoutforlogisticregressiontarget/UsingMahoutforlogisticregressioncategories/UsingMahoutforlogisticregressionpredictors/UsingMahoutforlogisticregressiontypes/UsingMahoutforlogisticregressionfeatures/UsingMahoutforlogisticregressionpasses/UsingMahoutforlogisticregressionrate/UsingMahoutforlogisticregressionrunlogistic/UsingMahoutforlogisticregressionmodel/UsingMahoutforlogisticregressionauc/UsingMahoutforlogisticregressionconfusion/UsingMahoutforlogisticregression

MM2Eclipse
URL/InstallingMavenMahout
about/IntroducingApacheMahoutusecases/IntroducingApacheMahoutfeatures/ReasonsforMahoutbeingagoodchoiceforclassificationinstalling/InstallingMahoutprerequisites/InstallingMahoutbuildingfromsource,Mavenused/BuildingMahoutfromsourceusingMavenMaven,installing/InstallingMavencode,building/BuildingMahoutcodedistributionfile,URL/BuildingMahoutcode,SettingupadevelopmentenvironmentusingEclipsesettingup,forWindowsuser/SettingupMahoutforaWindowsuserused,forlogisticregression/UsingMahoutforlogisticregressionNaïveBayesalgorithm/UsingtheNaïveBayesalgorithminApacheMahoutusing,forHMM/UsingMahoutfortheHiddenMarkovModelusing,forRandomforestalgorithm/UsingMahoutforRandomforestRandomforestalgorithm,implementing/StepstousetheRandomforestalgorithminMahoutMLP,implementing/MLPimplementationinMahoutusing,forMLP/UsingMahoutforMLPMLPalgorithm,using/StepstousetheMLPalgorithminMahoutupdations/MahoutnewchangesScalabindings/MahoutScalaandSparkbindingsSparkbindings/MahoutScalaandSparkbindingsSparkshell,using/UsingMahout’sSparkshellH2Oplatform,integration/H2Oplatformintegration
Mahout,algorithmsabout/AlgorithmssupportedinMahoutsequentialalgorithms/AlgorithmssupportedinMahoutparallelalgorithms/AlgorithmssupportedinMahout
Mahout,usecasesrecommendation/IntroducingApacheMahoutclassification/IntroducingApacheMahoutclustering/IntroducingApacheMahoutdimensionalreduction/IntroducingApacheMahouttopicmodeling/IntroducingApacheMahout
MahoutScalabindingsabout/MahoutScalaandSparkbindings
MahoutSparkbindingsabout/MahoutScalaandSparkbindings

Markovprocessabout/TheMarkovprocessstates/TheMarkovprocesstransitionmatrix/TheMarkovprocessTransitionmatrix/TheMarkovprocessInitialstatevector/TheMarkovprocess
Mavenused,forbuildingMahoutfromsource/BuildingMahoutfromsourceusingMaveninstalling/InstallingMavenURL/InstallingMaven
MLib/ApacheSparkMLP
implementing,inMahout/MLPimplementationinMahoutMahoutused/UsingMahoutforMLPirisdataset/UsingMahoutforMLP
MLPalgorithmusing,inMahout/StepstousetheMLPalgorithminMahout
MLPnetworkabout/MultilayerPerceptronhiddenlayers/MultilayerPerceptronbackpropagation/MultilayerPerceptronzerohiddenlayers/MultilayerPerceptroninputlayer/MultilayerPerceptronoutputlayer/MultilayerPerceptronhiddenlayer/MultilayerPerceptronnumberofneuronsorhiddenunits/MultilayerPerceptron
modelcreating,Assassindatasetused/CreatingthemodelusingtheAssassindatasetclassifiermodel,programforusing/Programtouseaclassifiermodel
model,evaluationconfusionmatrix/TheconfusionmatrixReceiverOperatingCharacteristics(ROC)graph/TheReceiverOperatingCharacteristics(ROC)graphareaundertheROCcurve(AUC)/AreaundertheROCcurveEntropymatrix/Theentropymatrix
model,issuesoverfitting/Workingoftheclassificationsystemunderfitting/Workingoftheclassificationsystem
ModelDissectorFeaturesclass/ClassifierstuningTraceDictionaryclass/ClassifierstuningLearnerclass/Classifierstuningabout/Classifierstuning

Multi-layerperceptron(MLP)/Classificationalgorithms

NNaïveBayesalgorithm
about/UnderstandingtheNaïveBayesalgorithminApacheMahout/UsingtheNaïveBayesalgorithminApacheMahout
NaïveBayesclassification/Classificationalgorithmsneuralnetwork
about/Neuralnetworkandneuronsneurons
about/NeuralnetworkandneuronsURL/Neuralnetworkandneurons
nondeterministicpatterns/DeterministicandnondeterministicpatternsNSL-KDDdataset
URL/UsingMahoutforRandomforest

Oobservablestate,HMM/IntroducingtheHiddenMarkovModeloutlierdetection
about/Workingoftheclassificationsystemoutputlayer,MLPnetwork/MultilayerPerceptronoverfitting,model
issues/Workingoftheclassificationsystem
Pparallelalgorithms/AlgorithmssupportedinMahoutprogram
testing/Testingtheprogrampruning/Decisiontree

Rrandomforest/ClassificationalgorithmsRandomforestalgorithm
about/RandomforestBiasparameter/RandomforestVarianceparameter/RandomforestMahoutused/UsingMahoutforRandomforestNSL-KDDdataset/UsingMahoutforRandomforestdataset/UsingMahoutforRandomforestimplementing,inMahout/StepstousetheRandomforestalgorithminMahout
RandomSequencerGenerator/UsingMahoutfortheHiddenMarkovModelReceiverOperatingCharacteristics(ROC)graph
about/TheReceiverOperatingCharacteristics(ROC)graphregression
about/Introducingregressionlinearregression/Understandinglinearregression
regressionintercept/Logisticregression

Ssequentialalgorithms/AlgorithmssupportedinMahoutsigmoidfunction/Logisticregressionsoftmaxfunction
URL/Neuralnetworkandneuronsspame-maildatasetclassifier
about/Spame-maildatasetSpark
URL/UsingMahout’sSparkshellbinding,URL/UsingMahout’sSparkshell
Spark-item/ApacheSparkSpark-row/ApacheSparkSparkshell
using/UsingMahout’sSparkshellSparkSQL/ApacheSparkSparkstreaming/ApacheSparkstates,Markovprocess/TheMarkovprocessstatevector,HMM/IntroducingtheHiddenMarkovModelStochasticGradientDescent(SGD)/Classificationalgorithms
about/StochasticGradientDescent

Ttargetvariables
about/WorkingoftheclassificationsystemTermfrequency/Understandingthetermsusedintextclassificationtermfrequency
Stemmingofwords/UnderstandingthetermsusedintextclassificationCasenormalization/UnderstandingthetermsusedintextclassificationStopwordremoval/UnderstandingthetermsusedintextclassificationInversedocumentfrequency/UnderstandingthetermsusedintextclassificationTermfrequencyandinversetermfrequency/Understandingthetermsusedintextclassification
textclassificationabout/Understandingthetermsusedintextclassification
topicmodelingabout/IntroducingApacheMahout
transitionmatrix,HMM/IntroducingtheHiddenMarkovModeltransitionmatrix,Markovprocess/TheMarkovprocess

Uunderfitting,model
issues/Workingoftheclassificationsystem

Vvectors
about/UnderstandingthetermsusedintextclassificationViterbiEvaluatorclass/UsingMahoutfortheHiddenMarkovModel
WWindows
user,Mahoutsettingupfor/SettingupMahoutforaWindowsuserWisconsinDiagnosticBreastCancer(WDBC)dataset
URL/UsingMahoutforlogisticregression





























