
October 9, 2016
Qiaoyong Zhong, Chao Li, Yingying Zhang, Haiming Sun
Shicai Yang, Di Xie, Shiliang Pu
{zhongqiaoyong, sunhaiming, yangshicai, xiedi}@hikvision.com
Hikvision Research Institute
Towards Good Practices for Recognition & Detection

Team Members
Scene Classification:
• Shicai Yang
Scene Parsing:
• Haiming Sun
• Di Xie
DET + LOC:
• Qiaoyong Zhong
• Chao Li
• Yingying Zhang
• Di Xie
2

Summary of Our Submissions
• Scene Classification
– 1st place, 0.0901 top5 error
• Scene Parsing
– 7th place, 0.53335 average mIoU & pixel accuracy
• Object Detection
– 2nd place, 0.653 mAP
• Object Localization
– 2nd place, 0.0874 localization error
3

Scene Classification
• Data Augmentation
– Color Augmentation (directly adopted from [1])
– PCA Jittering (from [2])
– Random Image Interpolation
– Crop Sampling • scale jittering (from [3][4])
• scale and aspect ratio augmentation (from [5])
– random area ratio (a = [0.08, 1])
– random aspect ratio (s = [3/4, 4/3])
– crop size: W’ = sqrt(W*H*a*s); H’ = sqrt(W*H*a/s)
– random offset to pick crop center, then crop and resize
• Supervised Data Augmentation
4
[1] https://github.com/facebook/fb.resnet.torch/
[2] A. Krizhevsky, et al. ImageNet Classification with Deep Convolutional Neural Networks. NIPS, 2012.
[3] K. Simonyan, et al. Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR, 2015.
[4] K. He, et al. Deep Residual Learning for Image Recognition. CVPR, 2016.
[5] C. Szegedy, et al. Going Deeper with Convolutions. CVPR, 2015.

Scene Classification
• Supervised Data Augmentation (SDA) – train a model from scratch (coarse model)
– use coarse model to generate ground truth class activation
– randomly select a location based on prob. of target class
– map this location to original image
– randomly select a crop center near that location in original image
– other steps are similar with the method in GoogLeNet paper
5
Inspired by: [6] B. Zhou, et al. Learning Deep Features for Discriminative Localization. CVPR, 2016.
image
(ground truth: wind_farm) ground truth class activation
1x1
conv classifier
…
pool
wind_farm

Scene Classification
• Supervised Data Augmentation (SDA) – train a model from scratch (coarse model)
– use coarse model to generate ground truth class activation
– randomly select a location based on prob. of target class
– map this location to original image
– randomly select a crop center near that location in original image
– other steps are similar with the method in GoogLeNet paper
6
Randomly Selected Crop:
Original (in red)
SDA (in green)
Inspired by: [6] B. Zhou, et al. Learning Deep Features for Discriminative Localization. CVPR, 2016.

Scene Classification
• Imbalanced Class Problem – Balanced Sampling via Label Shuffling
7
[7] L. Shen, et al. Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks. ECCV, 2016.
id name label
0 img000 0
1 img001 0
2 img002 0
0 img003 1
1 img004 1
0 img005 2
1 img006 2
2 img007 2
3 img008 2
4 img009 2
K1 = #C0 = 3
K2 = #C1 = 2
K3 = #C2 = 5
0
4
2
1
3
0 img000
1 img001
2 img002
1 img001
0 img000
2
1
4
0
3
0 img003
1 img004
0 img003
0 img003
1 img004
3
2
0
1
4
3 img008
2 img007
0 img005
1 img006
4 img009 1. sorting 2. counting
3. randperm
4. mod
5. selecting 6. concat & shuffling
img000 0
img004 1
img006 2
img001 0
img003 1
img002 0
img007 2
img004 1
img000 0
img009 2
img001 0
img005 2
img008 2
img003 1
img003 1

Scene Classification
• label smoothing (LS) via prior label distribution
8
[8] C. Szegedy, et al. Rethinking the Inception Architecture for Computer Vision. CVPR, 2016.
0 0 0 0 0 0 1 0 0 0 0 … 0
𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 1 − 𝜀 + 𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 𝜀/𝐾 … 𝜀/𝐾
𝜀/𝐾 𝜀/𝐾 𝜏/4 𝜀/𝐾 𝜏/4 𝜏/4 1 − 𝜏 − 𝜀 𝜀/𝐾 𝜏/4 𝜀/𝐾 𝜀/𝐾 … 𝜀/𝐾
Hard Label
Original LS
Proposed LS
labels of similar classes used for label smoothing
Co-label
Similarity
Top 4
Similar
Labels

Scene Classification
• Train and Test in Harmony – train in the same way as you test
• remove augmentation for the last several epochs (+0.3%)
– test in the same way as you train
• test 32 random crops from scale and ratio augmentation (+0.3%)
– multi-scale testing over multi-scale training
– use checkpoints from the middle of training to avoid overfitting (+0.3%)
9
299/
299
299/
336
331/
360
299/
299
363/
400
Single
Model
Ensemble
train
test
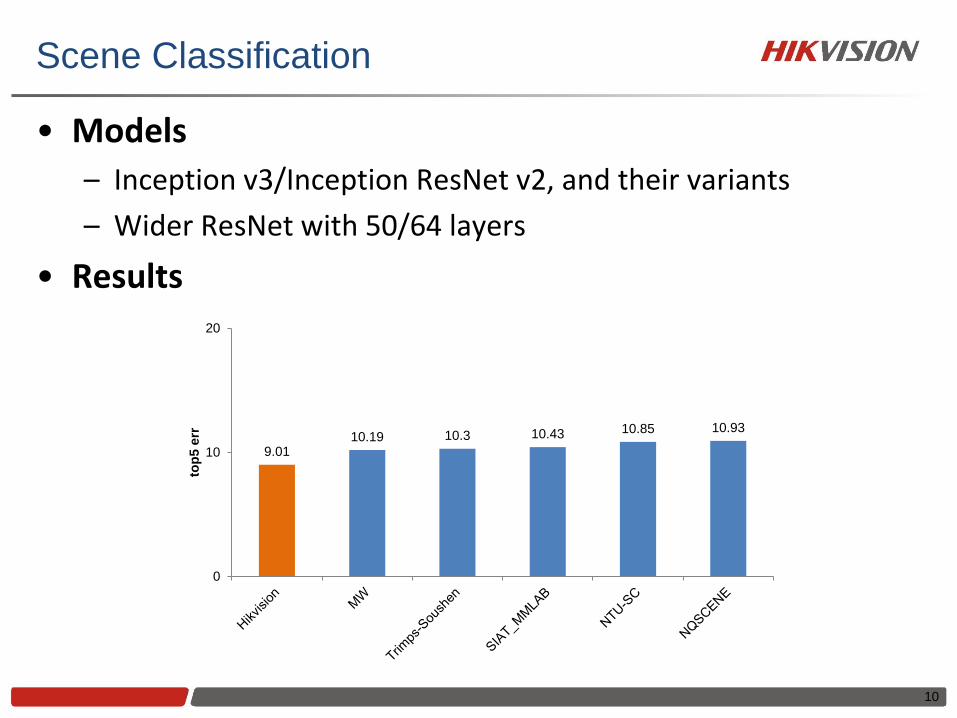
Scene Classification
• Models
– Inception v3/Inception ResNet v2, and their variants
– Wider ResNet with 50/64 layers
• Results
10
9.01 10.19 10.3 10.43 10.85 10.93
0
10
20
top
5 e
rr

Scene Parsing
11
1×1 conv
MCN block
MCN block
MCN block
MCN block
MCN block
upsample
Mixed Context Network
+
3×3 conv
3×3 dilated conv
concat
1×1 conv
1×1 conv
input
output
concat
1×1 conv
1×1 conv
1×1 conv
3×3 conv
3×3 convupsample
concat 1×1 conv
upsample
Message
Passing
Network
overall architecture for scene parsing

Scene Parsing
12
score map S(0)
score map S(i)
permutohedral conv
score map S(i+1)
permutohedral conv
Concat
1×1 conv
softmax
eltwise
score map S(0)
score map S(i)
permutohedral conv
score map S(i+1)
1×1 conv
Concat
3×3 conv
eltwise
CRF as RNN Message Passing Network

Parsing Results
13
images ground truths our results

Object Detection Elements
Identity Mapping
ResNet-101 Variants
Cascade RPN
Constrained Neg/Pos
Anchor Ratio
RPN Proposal
Testing Tricks
Multi-Scale Testing
HFlip Box Voting
Training Tricks
Multi-Scale Training
OHEMBalanced Sampling
Pretrained Global
Context
Pretraining
Pretrain on LOC
14
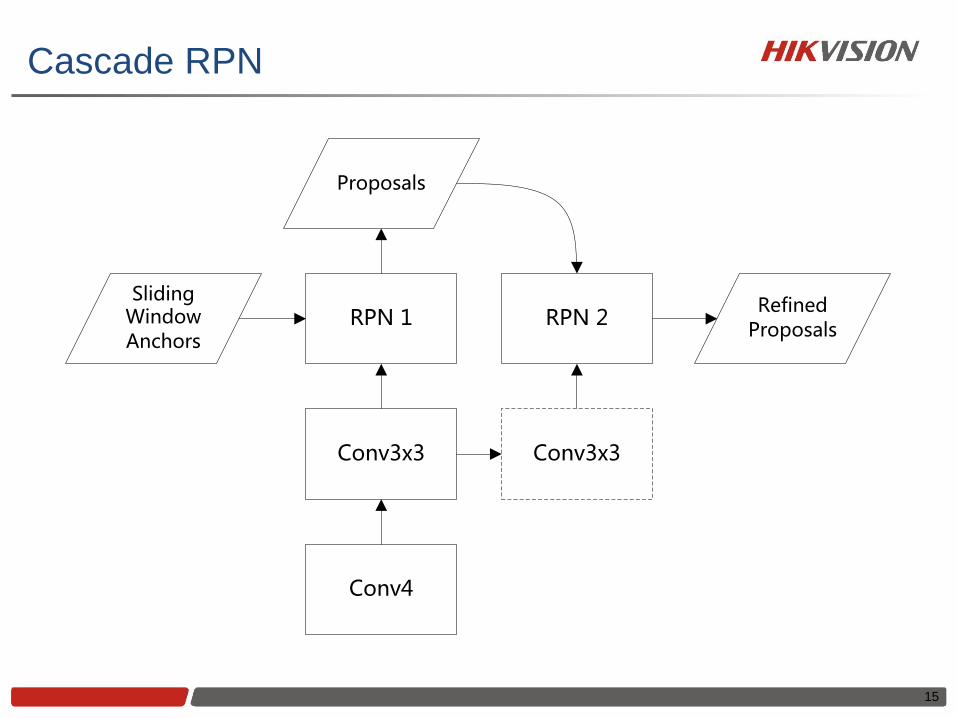
Cascade RPN
Conv4
Conv3x3
RPN 2RPN 1Sliding
Window Anchors
Proposals
Conv3x3
Refined Proposals
15

Constrained NEG/POS Anchor Ratio
• Naïve RPN
• Batch size: 256
• Expected N/P ratio: 1
• Real N/P ratio: usually > 10
• Our RPN
• Min batch size: 32
• Max N/P ratio: 1.5
Ablation Study
Cascade RPN
Constrained N/P
[email protected] 91.0 91.2 92.0 91.9
[email protected] 70.2 77.9 74.0 79.7
Average Recall 52.5 57.2 54.6 57.9
5.4 AR gain 9.5 [email protected] gain
16
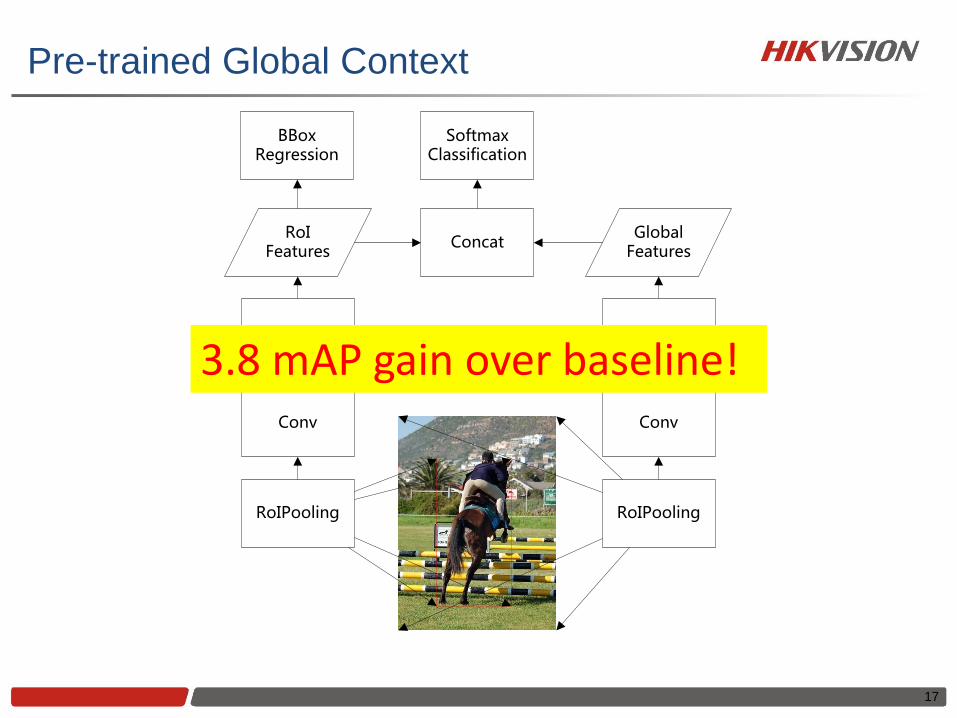
Pre-trained Global Context
Conv
RoI Features
...
RoIPooling
Global Features
RoIPooling
Conv
...
Concat
Softmax Classification
BBox Regression
3.8 mAP gain over baseline!
17

Pre-training on LOC
0.5 mAP gain over baseline!
18

Dog
Person
Class list
...
Person list
…
Dog list
…
Balanced Sampling
• Adapted from Shen et al. [7] for detection task
0.7 mAP gain on VOC2007
[7] L. Shen, et al. Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks. ECCV, 2016.
19

Performance
• ImageNet DET
• ImageNet CLS-LOC
• PASCAL VOC2012
Team mAP Rank
Hikvision 87.9 1
ResNet Baseline 83.8 2
Team mAP Rank
Single Model Hikvision 63.40 1
CUImage 63.36 2
Ensemble CUImage 66.3 1
Hikvision 65.3 2
CLS LOC Rank
LOC (Ensemble) 3.7 8.7 2
20

Take Home Message
• Scene Classification – better utilize your data and model (SDA) – label smoothing via soft label – balanced sampling via label shuffling – train and test in harmony
• Scene Parsing – Mixed Context Net & Message Passing Net
• Object Detection – use identity mapping – cascade RPN – constrained NEG/POS anchor ratio – pre-trained global context – balanced sampling
• Object Localization – LOC = CLS + DET
21

Acknowledgments
• We would like to thank our HPC team:
– Peng Wang
– Jianfeng Peng
– Xing Zheng
– Zhiqiang Zhou
– etc…
22

23
Thank you!
Recommended

















