
The message of today
• First: A summary• Second: Legal deposit in Norway• Third: Our digital library principles• Fourth: Harvesting, archiving and giving
access to the web• Fifth: The prototype, a demonstration

Part one: Summary
• Norwegian legislation on legal deposit: Includes digital information!
• The national library of Norway has a relatively advanced digital library activity
• Nordic cooperation on methods and technology for legal deposit of the web
• Nordic project on access to web archives

Part Two: Legal deposit in Norway
• Legislation revised in 1989• Includes all information carriers in the
”traditional domain”, like books, newspapers & more
• Also including music and broadcast programs
• And: Including the information living in the digital domain

The National Library of Norway
Bendik RugaasAdministrationIT & Innovation
NationalLibrarian
RanaDivision
OsloDivision
200 employeesAdministrationITTechnicalRepository Legal DepositMedia LabSound & Image
100 employeesAdministrationITPublicCollectionsBibliographicNorwegian Music
(Svein Arne)2

The challenge:
• Preserving the cultural heritage represented by the world-wide web– Including harvesting and archiving
• Giving access to historical web archives– …Nordic Web Archive access project

One strategy for most digital objects
• One large long-term digital repository• All storage, long-term preservation and
access based on this infrastructure

Our Digital Library reference model
-unix servers
- fault tolerant disk systems
-Tape libraries
-HSM
-Search Engines
-Personalization
-Specialized applications
-Collecting applications
-Metadata (DC)
-Identification (URN)
-Migration
-Quality and Formats
-IPR/Copyrights/Access control
- text, audio, still images, moving images, web pages & more
General storage facility
Digital objects
Repository functionality & organization
Digital Library application layer

Examples of current use
• Digital Radio Archive– Digitization & archiving of 50.000 hrs
• Galleri NOR– Still images in high quality
• Historical news-papers– Images of pages as well as OCR-
based text

Preserving the web: some focus areas
• Harvesting & collecting it all• Archiving
– Identification, versions, metadata, long-term preservation
• Access to archive

Harvesting
• Can it be possible?– Have a look at the search engines
• Available software– Public domain/OpenSource
• NEDLIB
– Commercial• several

Harvesting: Resolution in time
• Snapshots vs continous• Continous:
– Wanted for services considered interesting and with rapid updates
– Dependent on use of software agents placed at the publisher

Everything or bits & pieces
• Questions to be answered:– What is (technically) possible?– What do we want?– What level of metadata do we need?

Archiving
• Different models in the five countries (probably)
• The norwegian model based on use on the library’s general storage facilites
• Close integration to other digital objects• Online or near-line

Long-term preservation
• Migration – So far our choice
• Emulation– Technically complicated
• Museum– Hard to do over time

Nordic Web Archive
• A context for cooperation to find common technology and methods to harvest, archive and give access to the web
• Current focus on access to archives– Small, focused project

NWA: Members
• Denmark (Royal Library)• Finland (National Library)• Iceland (National Library)• Norway (National Library), project mgmt• Sweden (Royal Library)• Nordunet2

NWA: Current scope
• Focus on access to web archives• NOT harvesting• NOT archiving

NWA: Main choises
• General and well-specified interface to archive
• Search (and navigation) through the use of a commercial search engine
• Access based on search and navigation/browsing
• Support for navigation in time and space
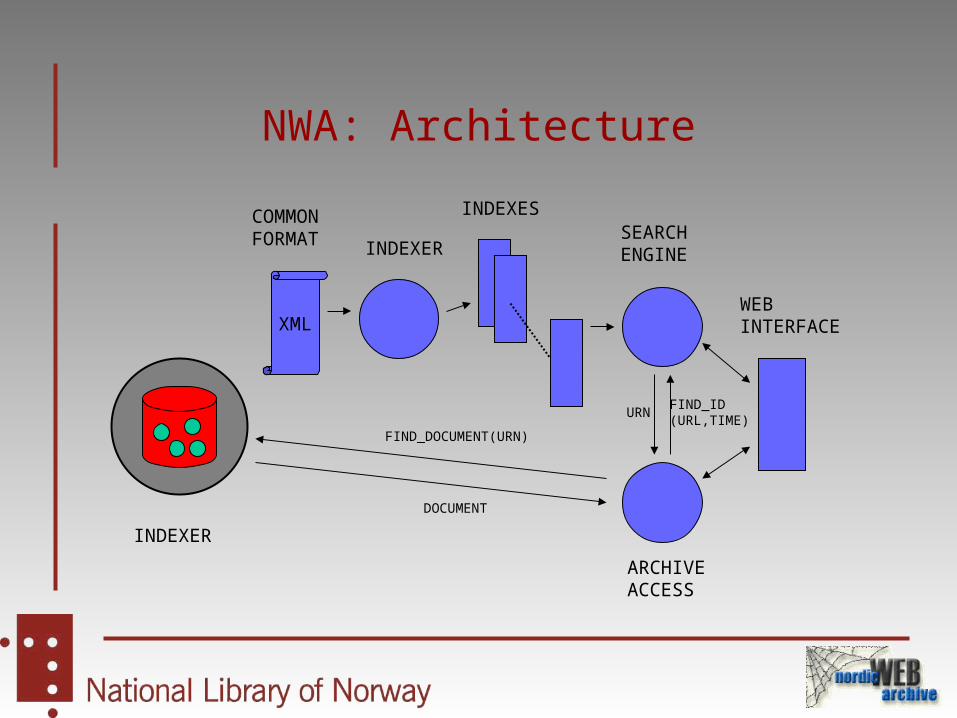
NWA: Architecture
XML
COMMONFORMAT
INDEXES
WEBINTERFACE
ARCHIVEACCESS
SEARCHENGINEINDEXER
INDEXER
FIND_DOCUMENT(URN)
DOCUMENT
FIND_ID(URL,TIME)
URN

NWA: The technology
• Based on commercial search engine from Fast Search & Transfer
• In-house development on Linux-platform– XML, PHP, Perl and Java– Probably OpenSource– General web user interface (no
additional plugins needed)

NWA: Search engine motivations
• Motivation– Support for search functionality on
text documents– Speed– Reduced complexity in
implementation

NWA: Search engine benefits
• (in addition to fullfilling the motivations)– Extreme scalability– Support for distributed searching– Easy integration with other indexes– Integrated language technologies
(limited)

NWA: Access methods
• Main principles:– The web seen in the archive should
look like it did on the net– It should be available through the use
of a ordinary web browser• Three main methods
– Search, navigation and browsing

NWA: Search
• Search based on search engine• Indexes based on exports from archives
– In general search on the original content is possible, but
– Some additional information available• Protocol metadata, timestamps and more
• Time limitations, phrase search and other funtionalities

NWA: Time navigation
• Given a location or service– The user should easily be able to go
to next/previous version• Using a JAVA-based time-line as time
navigation tool

NWA: Space navigation
• Given a point of time– The user should be able to go some
other service based on the url• In NWA prototype, the user can use
original url’s as reference to service within the archive

NWA: Metadata
• Few web recources contain user-produced metadata
• HTTP contains some metadata, like time of modification and more
• Tagging of documents (like <TITLE>) can be viewed as metadata, and is passed on to the indexer

NWA: Open Source?
• Many good reasons pro, few contra• Dependent on third-party software!
– Radical re-implementation to be independent

Further challenges
• ”The deep web”• Dynamic and user dependent services• Continuity• Description/metadata• Access rights to archive!
– This is the main obstacle

See also….
• http://www.openarchives.org• http://Sult.nb.no• http://Nwa.nb.no• http://www.dublincore.org• http://www.fast.no

That’s it!
• Thank you for listening (if you were ;-) )• Please contact me if there’s anything
– But on email only!• [email protected]
Recommended

























