
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR
Analysis and Databases.
The Minnesota Supercomputing Institute for Advanced Computational Research
March 15th 2012
Pratik Jagtap
http://www.mass.msi.umn.edu/

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR Analysis
and Databases…
• Overview.
• Protein Grouping : Concept & Methods.
• Fdr Analysis : Concept & Methods.
• Peptide and Protein identification
• Databases
• Publication Guidelines
REFERENCES : „Reporting Protein Identifications from MS/MS Results‟ by Brian Searle
(ProteomeSoftware Inc.) and “Databases” by Akhilesh Pandey (John Hopkins University) at
the „BioInformatics for Protein Identification‟ workshop at Baltimore (2009).
© 2009 Regents of the University of Minnesota. All rights reserved.
Supercomputing Institute for Advanced Computational Research
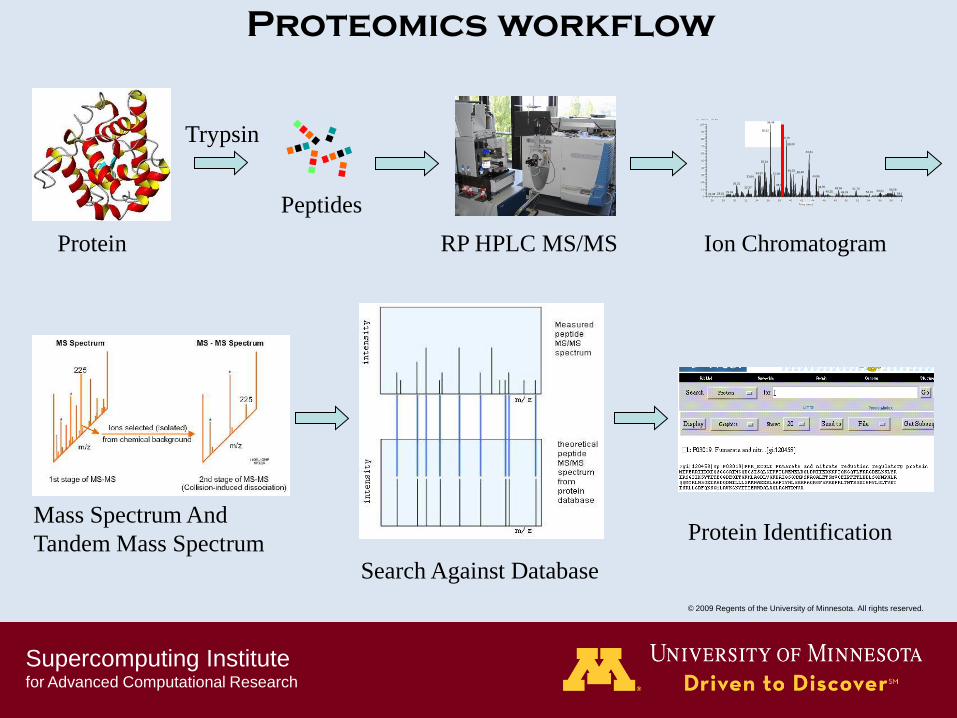
Proteomics workflow
Search Against Database
Protein
Peptides
Trypsin
Mass Spectrum And
Tandem Mass Spectrum
RP HPLC MS/MS
BSATEST2080708_080807191252 8/7/2008 7:12:52 PM
RT: 24.95 - 60.48
26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60
Time (min)
0
10
20
30
40
50
60
70
80
90
100
Re
lative
Ab
un
da
nce
36.46
36.37
39.19
39.29
43.31
35.34
40.0240.4834.52 37.08
44.5533.64
30.3138.03
44.9032.37 48.56 51.70 58.2956.0148.25 54.1029.08 49.2659.6728.5125.38
NL:
2.98E8
Base Peak
MS
BSATEST2
080708_08
080719125
2
RT: 24.95 - 60.48
26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60
Time (min)
0
10
20
30
40
50
60
70
80
90
100
Re
lative
Ab
un
da
nce
39.19
39.29
40.04 42.7843.3238.80 57.2245.53 58.2947.50 56.0736.8732.73 50.54 54.2951.5326.80 35.6527.74 29.89
NL:
2.34E8
Base Peak
m/z=
653.00-654.00
MS
BSATEST2080
708_0808071
91252Ion Chromatogram
Protein Identification
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
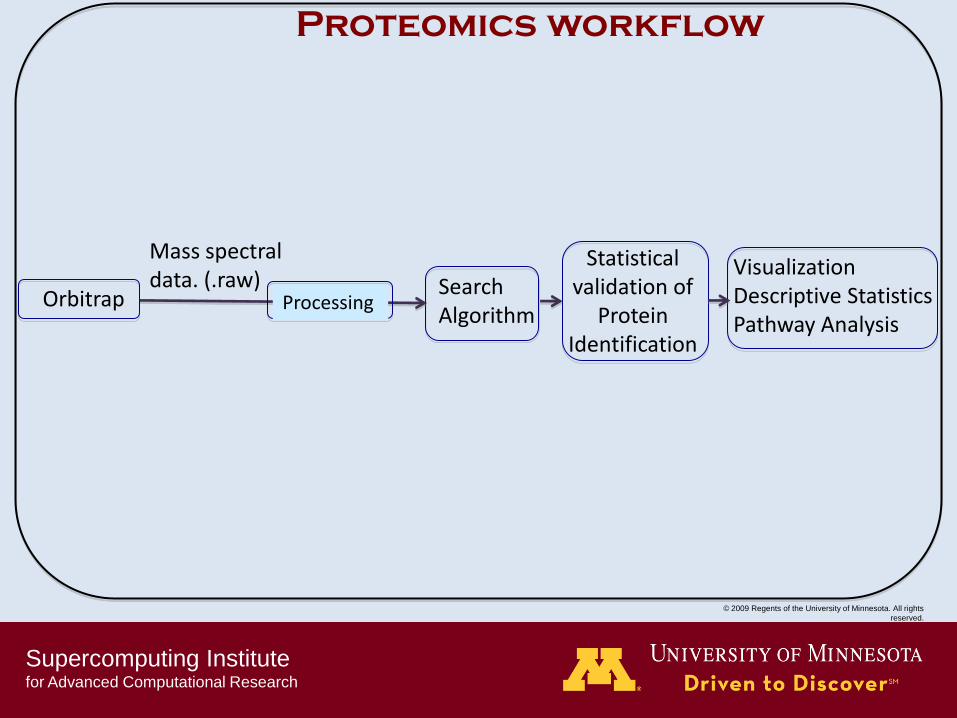
Proteomics workflow
Orbitrap
Mass spectral data. (.raw)
Search Algorithm
Statistical validation of
Protein Identification
Visualization Descriptive Statistics Pathway Analysis
Processing

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR Analysis
and Databases…
• Overview.
• Protein Grouping : Concept & Methods.
• Fdr Analysis : Concept & Methods.
• Peptide and Protein identification
• Databases
• Publication Guidelines
REFERENCES : „Reporting Protein Identifications from MS/MS Results‟ by Brian Searle
(ProteomeSoftware Inc.) and “Databases” by Akhilesh Pandey (John Hopkins University) at
the „BioInformatics for Protein Identification‟ workshop at Baltimore (2009).
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
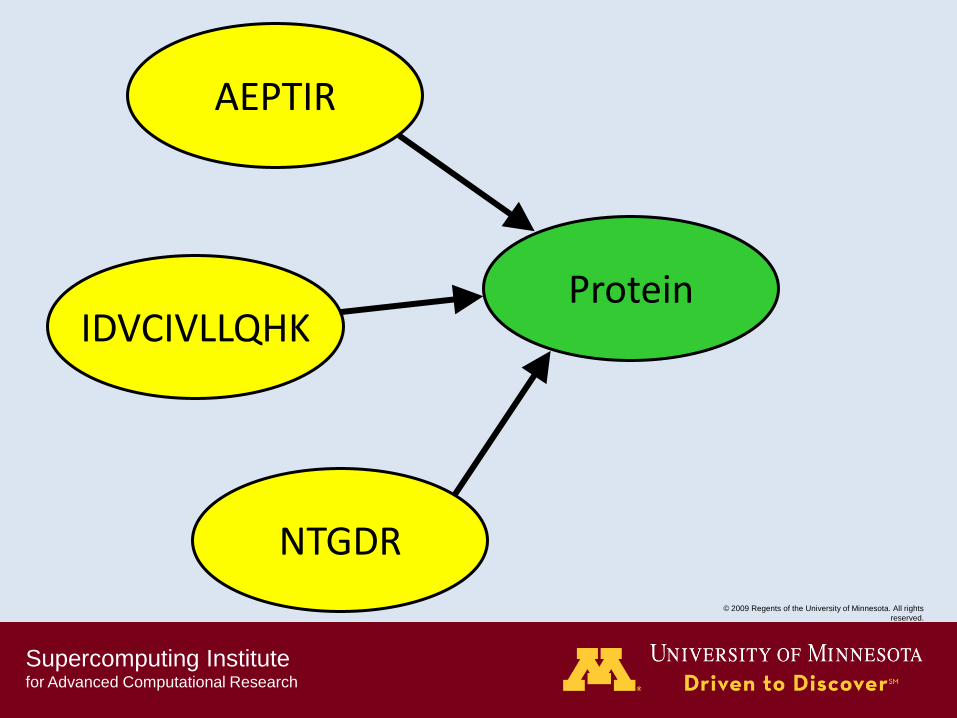
AEPTIR
IDVCIVLLQHK
NTGDR
Protein
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
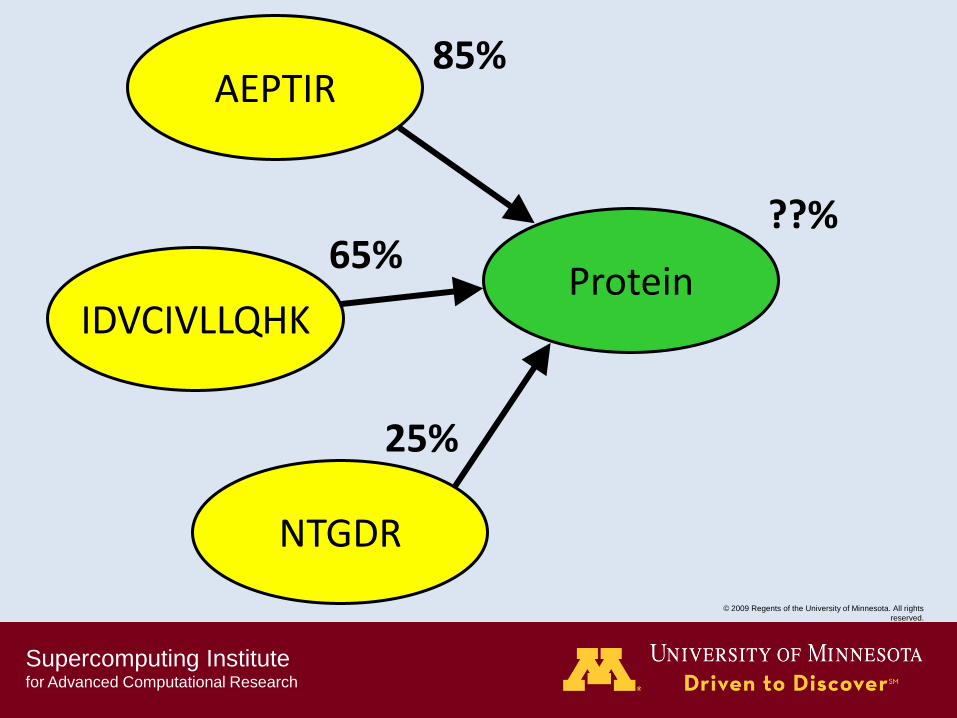
AEPTIR
IDVCIVLLQHK
NTGDR
Protein
85%
65%
25%
??%
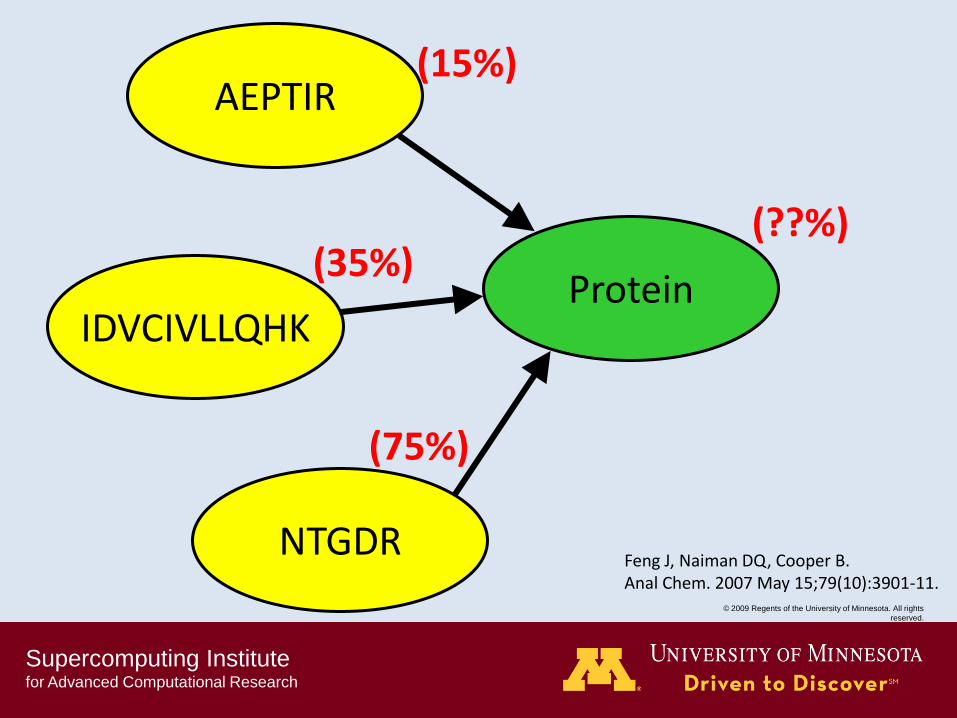
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
AEPTIR
IDVCIVLLQHK
NTGDR
Protein
(15%)
(35%)
(75%)
(??%)
Feng J, Naiman DQ, Cooper B. Anal Chem. 2007 May 15;79(10):3901-11.
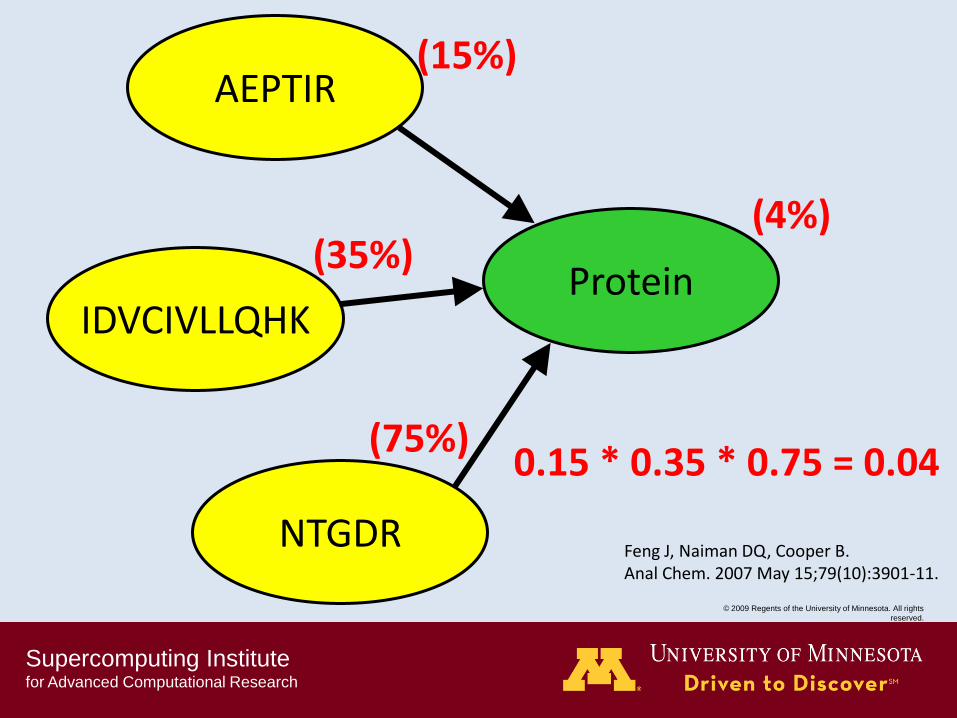
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
AEPTIR
IDVCIVLLQHK
NTGDR
Protein
(15%)
(35%)
(75%)
(4%)
0.15 * 0.35 * 0.75 = 0.04
Feng J, Naiman DQ, Cooper B. Anal Chem. 2007 May 15;79(10):3901-11.
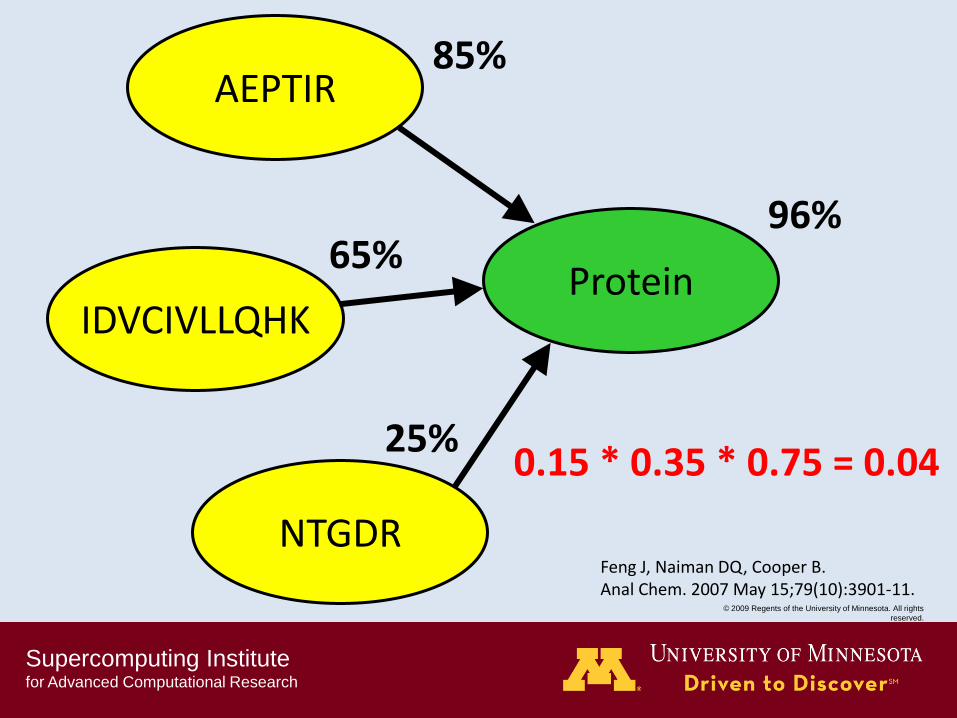
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
AEPTIR
IDVCIVLLQHK
NTGDR
Protein
85%
65%
25%
96%
0.15 * 0.35 * 0.75 = 0.04
Feng J, Naiman DQ, Cooper B. Anal Chem. 2007 May 15;79(10):3901-11.

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
If only it were so easy…
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
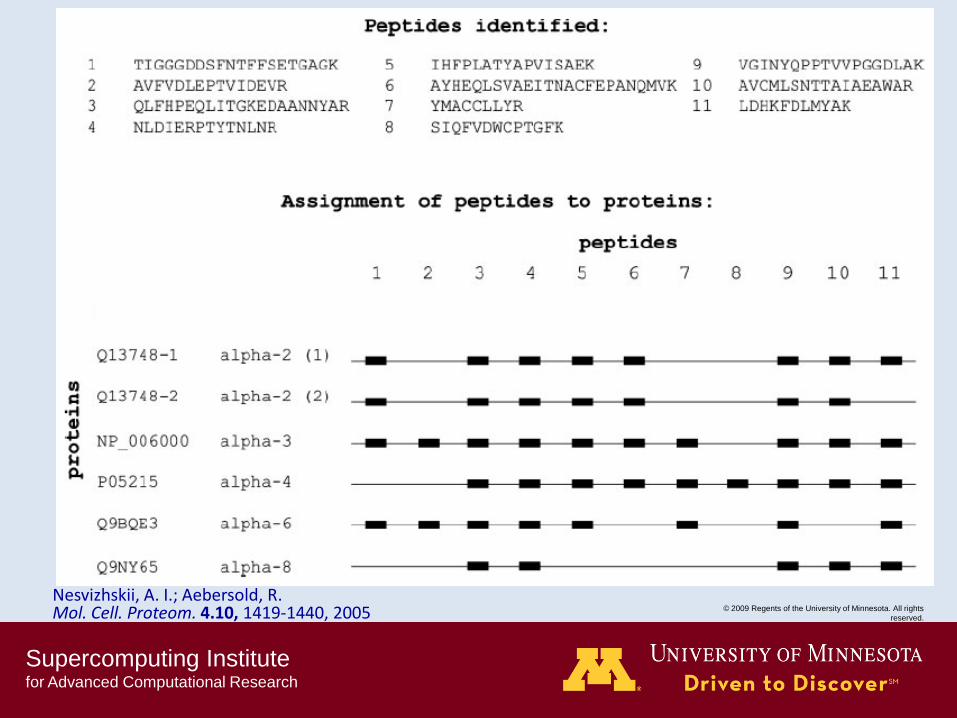
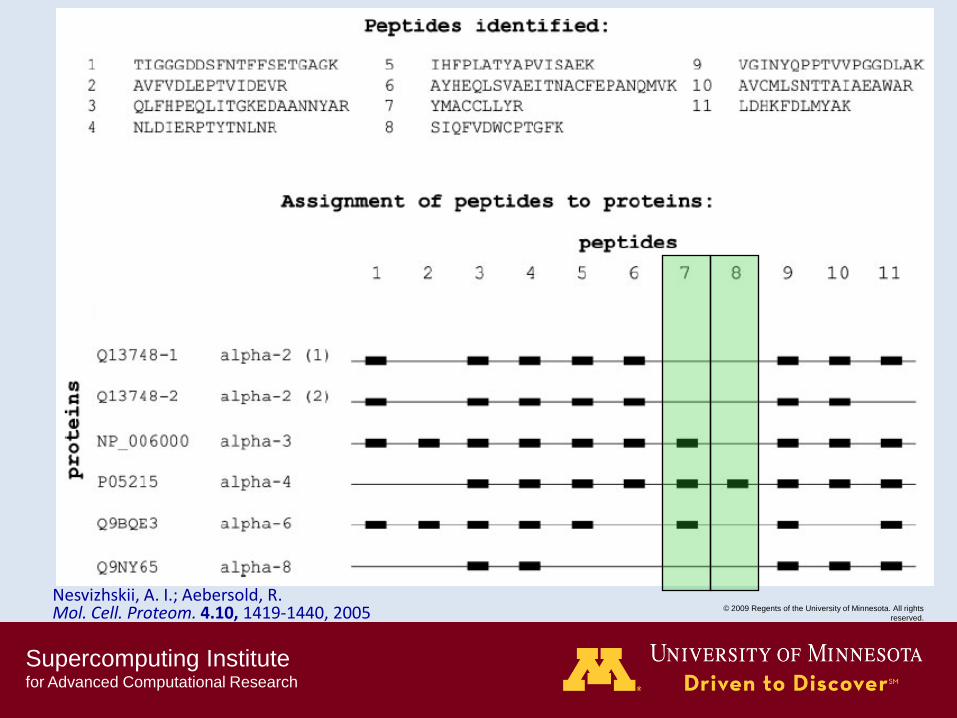
Nesvizhskii, A. I.; Aebersold, R. Mol. Cell. Proteom. 4.10, 1419-1440, 2005
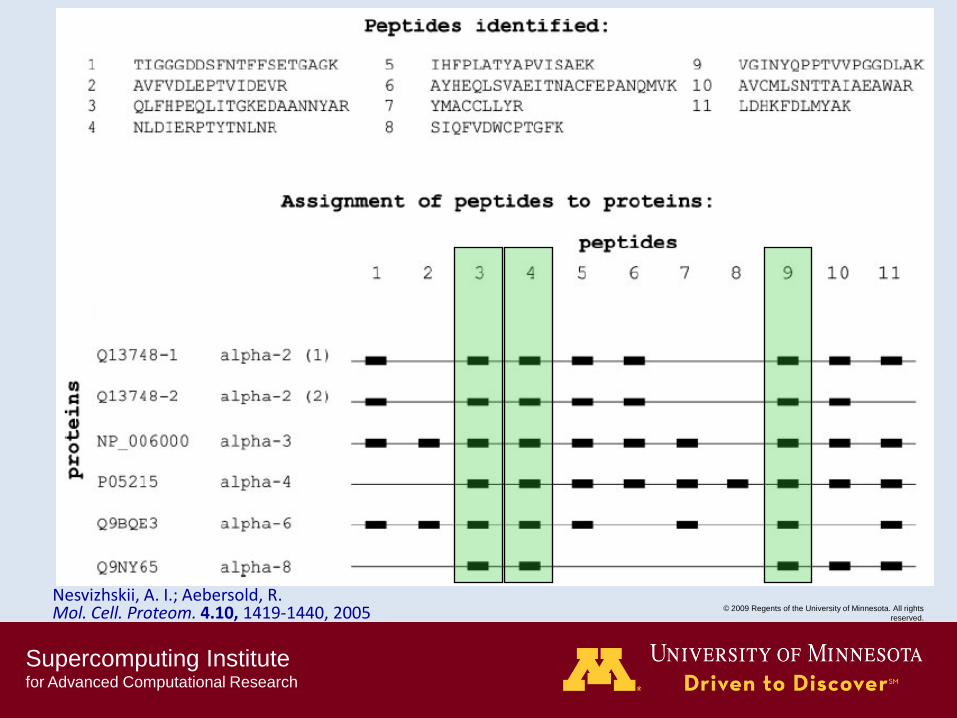
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Nesvizhskii, A. I.; Aebersold, R. Mol. Cell. Proteom. 4.10, 1419-1440, 2005
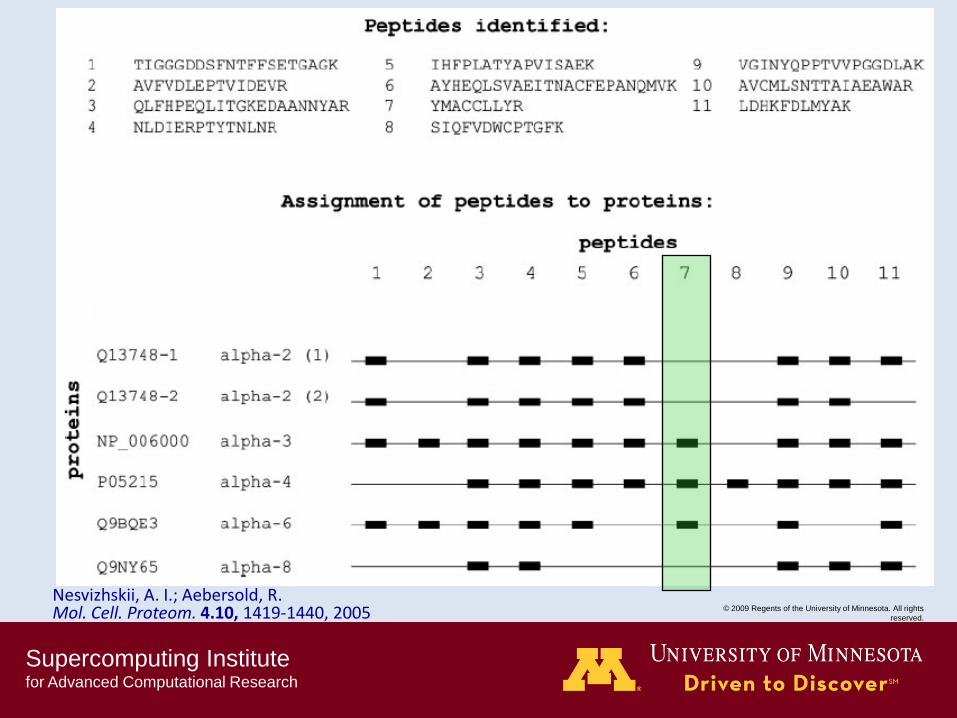
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Nesvizhskii, A. I.; Aebersold, R. Mol. Cell. Proteom. 4.10, 1419-1440, 2005
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
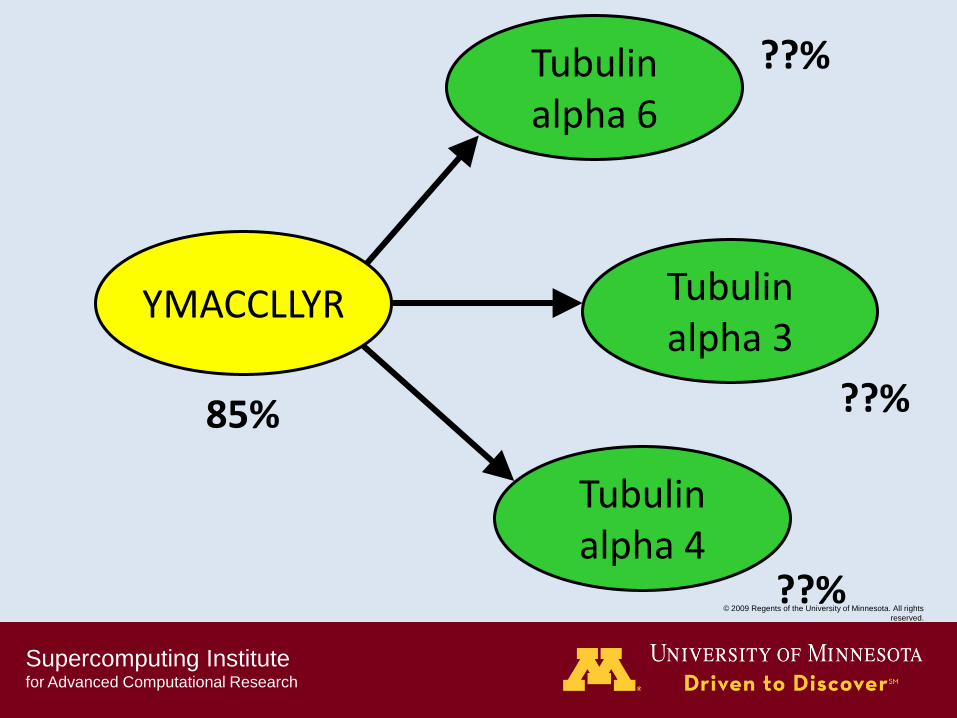
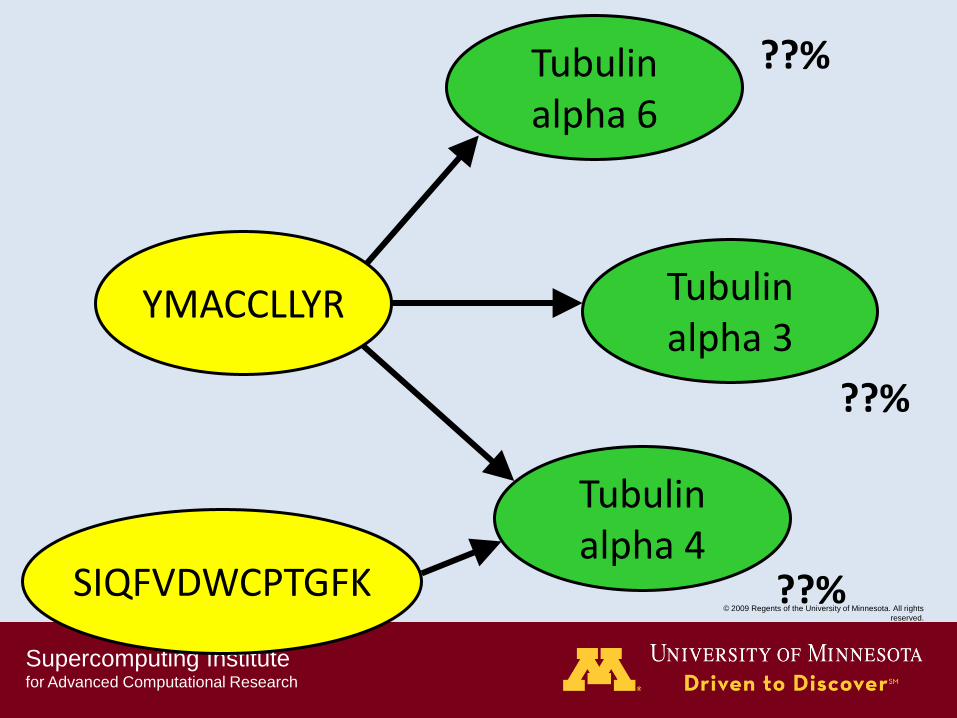
Tubulin alpha 6
Tubulin alpha 3
YMACCLLYR
Tubulin alpha 4
85%
??%
??%
??%
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
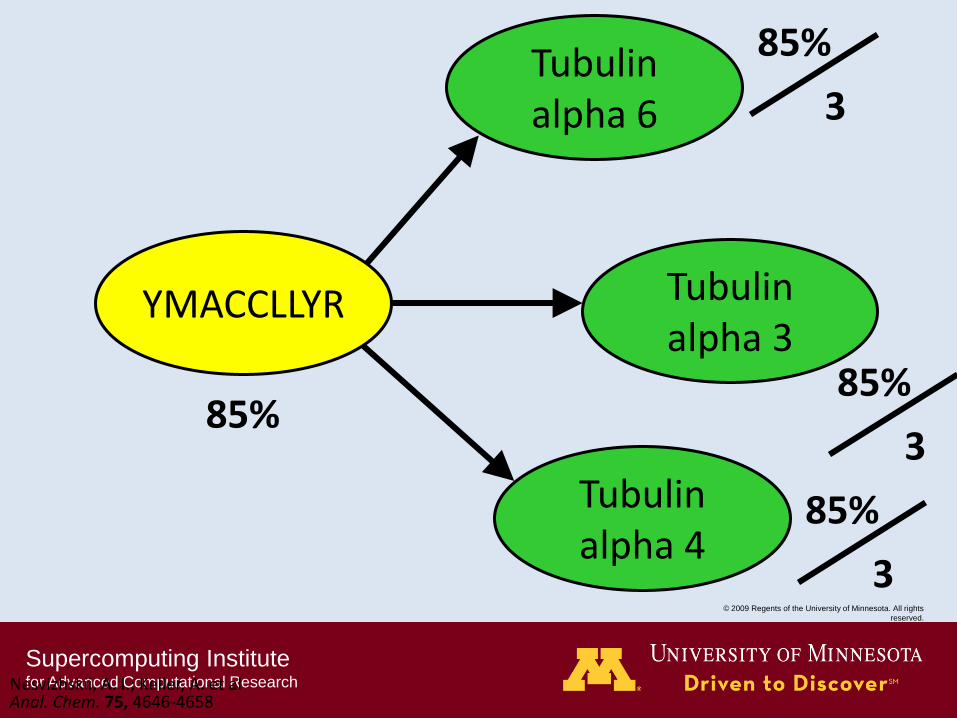
Tubulin alpha 6
Tubulin alpha 3
YMACCLLYR
Tubulin alpha 4
85%
85%
3
85%
3
85%
3
Nesvizhskii, A. I.; Keller, A. et al Anal. Chem. 75, 4646-4658
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Nesvizhskii, A. I.; Aebersold, R. Mol. Cell. Proteom. 4.10, 1419-1440, 2005
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
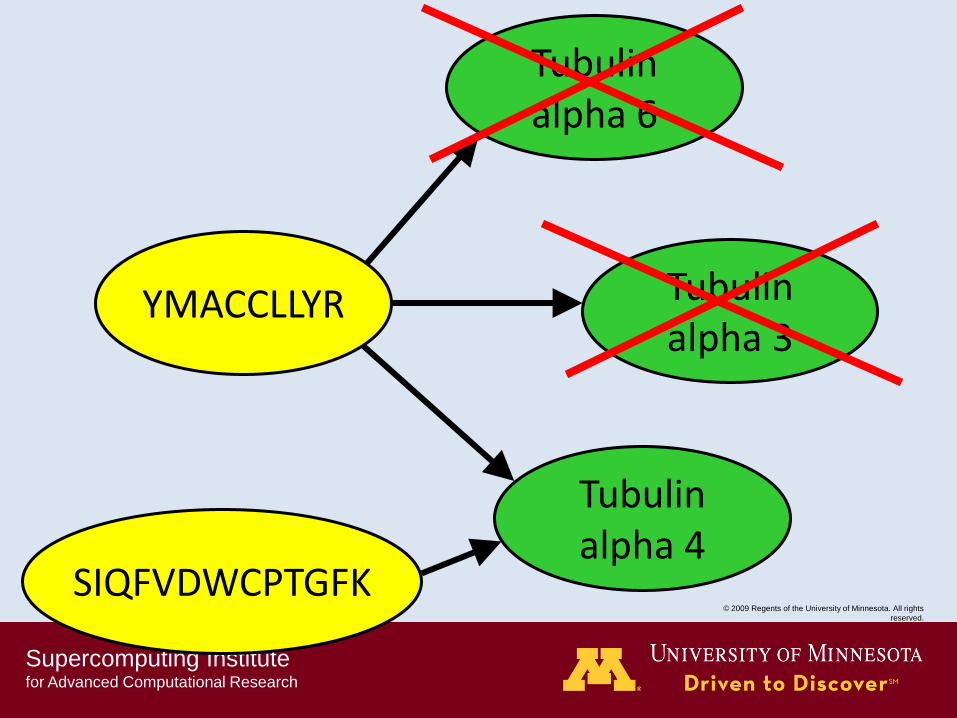
Tubulin alpha 6
Tubulin alpha 3
YMACCLLYR
SIQFVDWCPTGFK
Tubulin alpha 4
??%
??%
??%

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Copyright ©2005 American Society for Biochemistry and Molecular Biology
Nesvizhskii, A. I. (2005) Mol. Cell. Proteomics 4: 1419-1440
Basic peptide grouping scenarios
Occam‟s Razor :
“When you have two
competing theories that
make exactly the same
predictions, the simpler one
is the better."
William of Ockham
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Tubulin alpha 6
Tubulin alpha 3
YMACCLLYR
SIQFVDWCPTGFK
Tubulin alpha 4

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Peptide 1 Peptide 2
Peptide 3 Peptide 4
Pro
tein
B
P
rote
in
A
Distinct Proteins
100% 100%
100% 100%
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
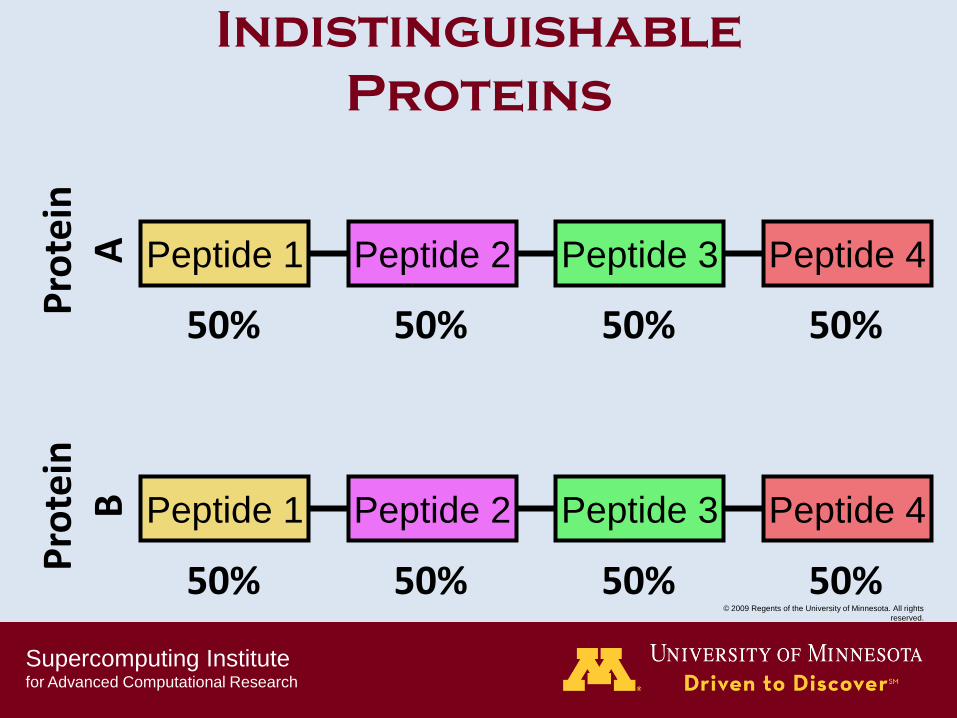
Peptide 1 Peptide 2 Peptide 3 Peptide 4
Peptide 1 Peptide 2 Peptide 3 Peptide 4
Pro
tein
B
P
rote
in
A
Indistinguishable
Proteins
50% 50% 50% 50%
50% 50% 50% 50%
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
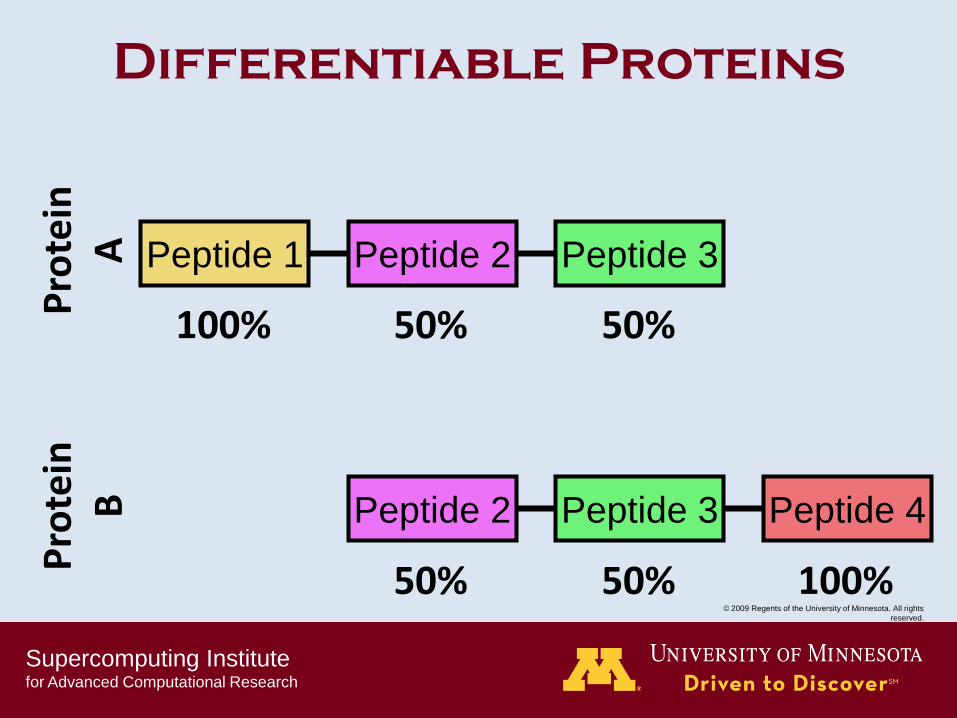
Peptide 1 Peptide 2 Peptide 3
Peptide 2 Peptide 3 Peptide 4
Pro
tein
B
P
rote
in
A
Differentiable Proteins
100% 50% 50%
50% 50% 100%
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
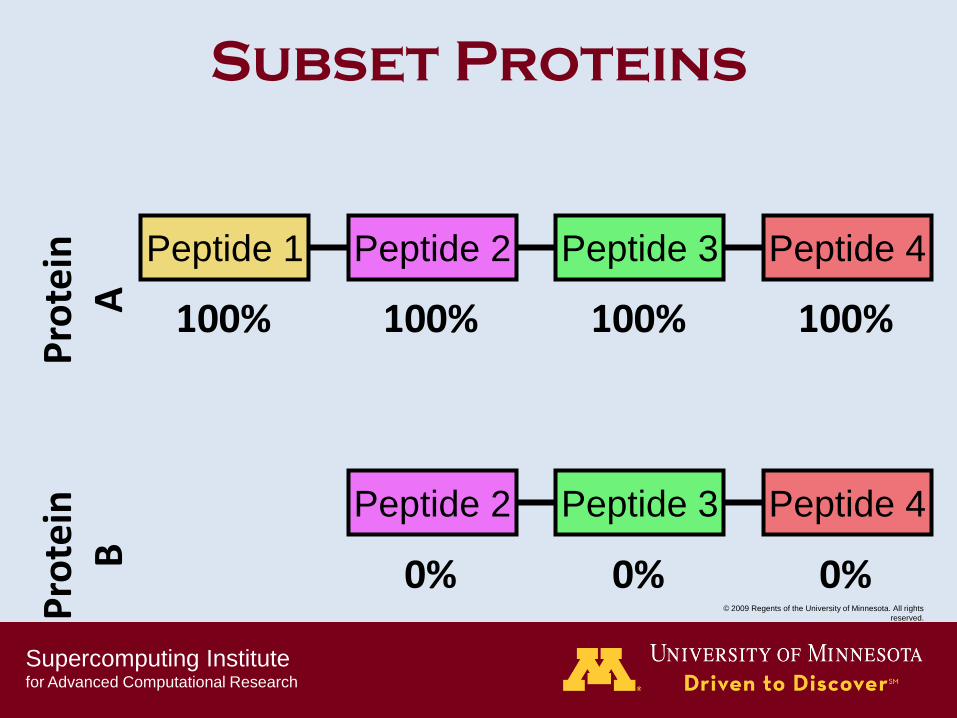
Peptide 1 Peptide 2 Peptide 3 Peptide 4
Peptide 2 Peptide 3 Peptide 4
Pro
tein
B
P
rote
in
A
Subset Proteins
100% 100% 100% 100%
0% 0% 0%
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
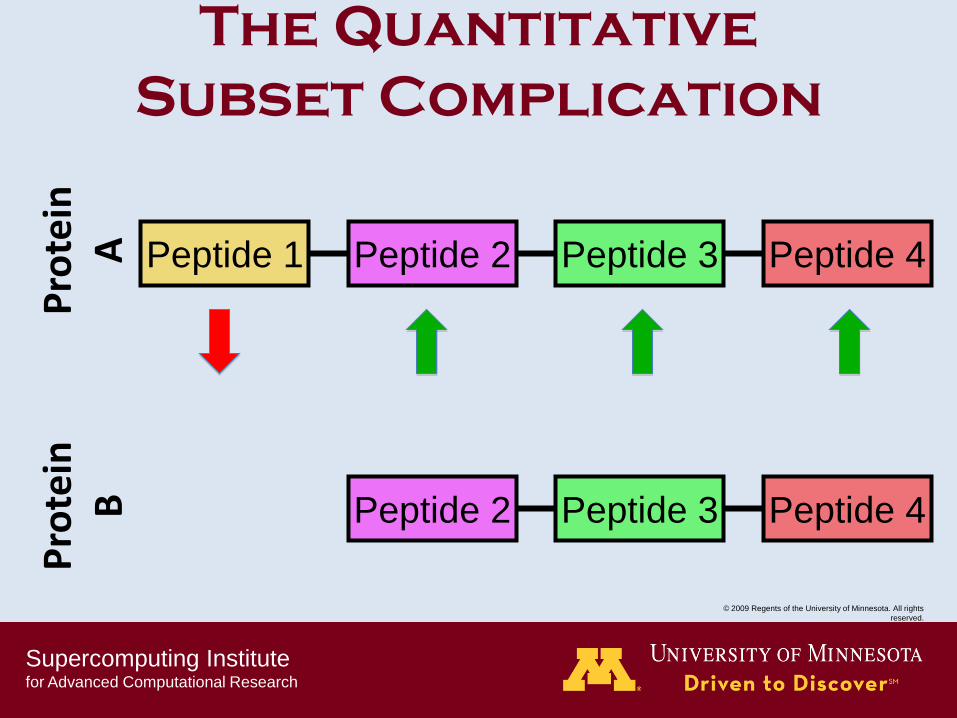
Peptide 1 Peptide 2 Peptide 3 Peptide 4
Peptide 2 Peptide 3 Peptide 4
Pro
tein
B
P
rote
in
A
The Quantitative
Subset Complication
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
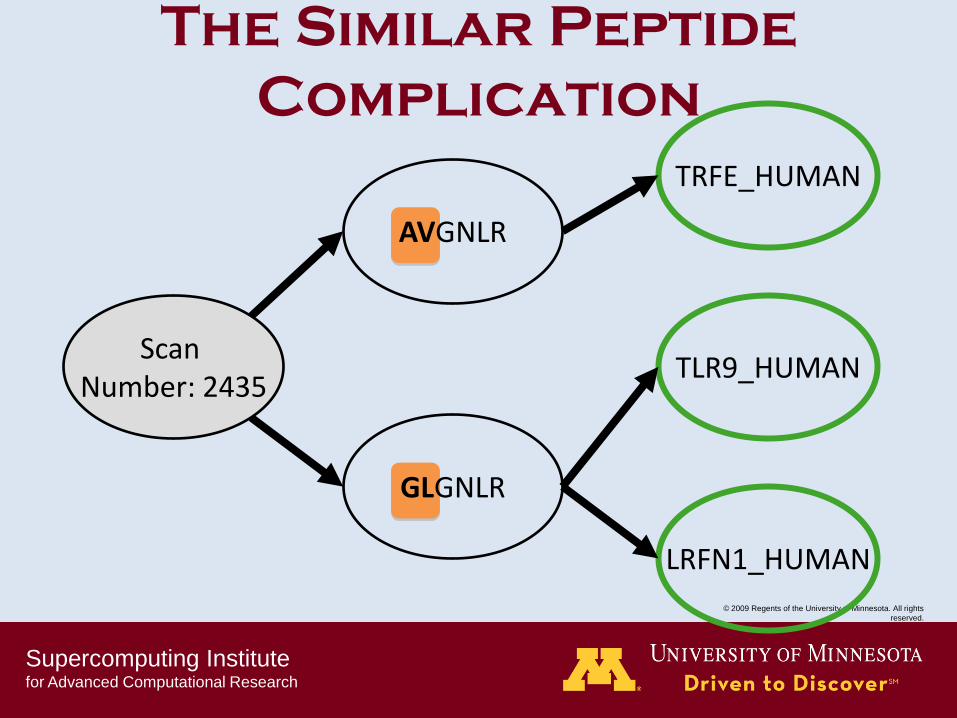
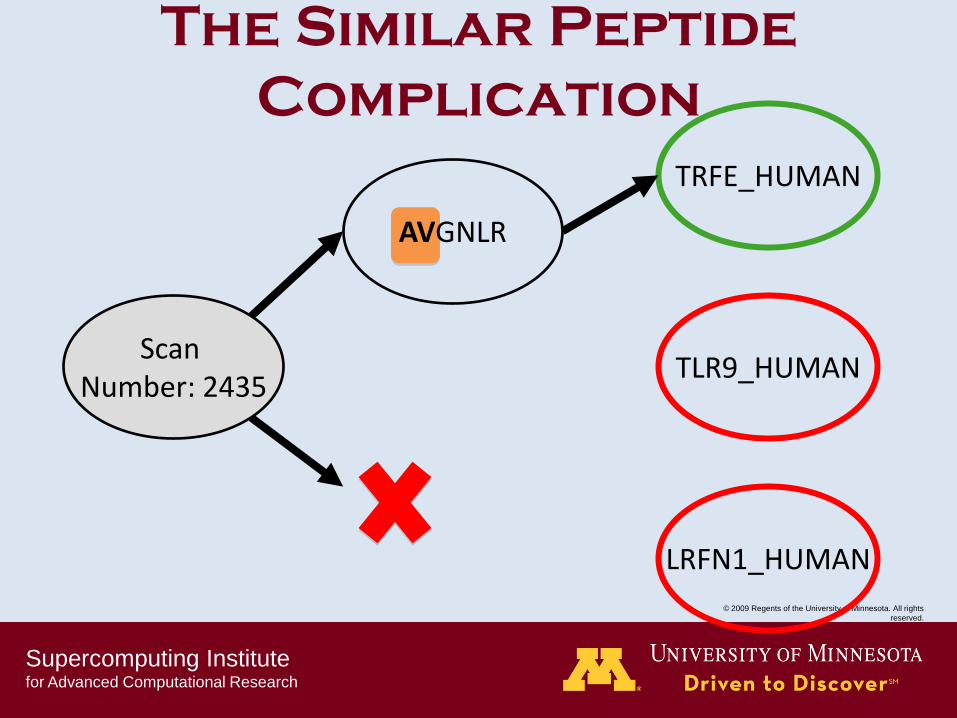
The Similar Peptide
Complication
AVGNLR
Scan Number: 2435
TLR9_HUMAN
GLGNLR
TRFE_HUMAN
LRFN1_HUMAN
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
The Similar Peptide
Complication
AVGNLR
Scan Number: 2435
TLR9_HUMAN
TRFE_HUMAN
LRFN1_HUMAN

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR Analysis
and Databases…
• Overview.
• Protein Grouping : Concept & Methods.
• Fdr Analysis : Concept & Methods.
• Peptide and Protein identification
• Databases
• Publication Guidelines
REFERENCES : „Reporting Protein Identifications from MS/MS Results‟ by Brian Searle
(ProteomeSoftware Inc.) and “Databases” by Akhilesh Pandey (John Hopkins University) at
the „BioInformatics for Protein Identification‟ workshop at Baltimore (2009).
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
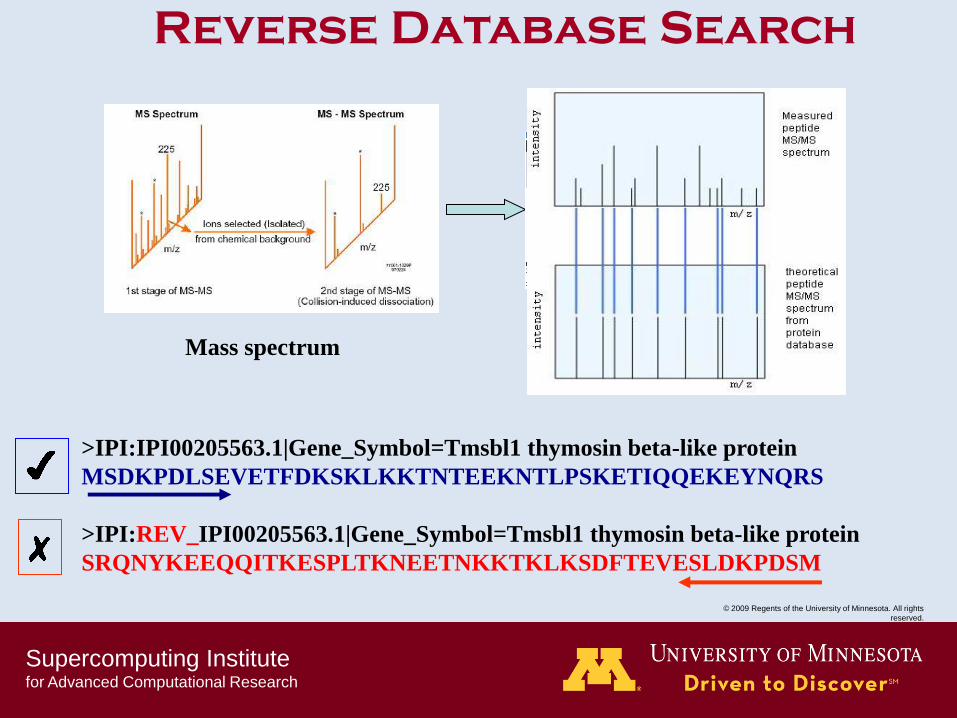
Search against database.
Mass spectrum
>IPI:IPI00205563.1|Gene_Symbol=Tmsbl1 thymosin beta-like protein
MSDKPDLSEVETFDKSKLKKTNTEEKNTLPSKETIQQEKEYNQRS
>IPI:REV_IPI00205563.1|Gene_Symbol=Tmsbl1 thymosin beta-like protein
SRQNYKEEQQITKESPLTKNEETNKKTKLKSDFTEVESLDKPDSM
Reverse Database Search
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
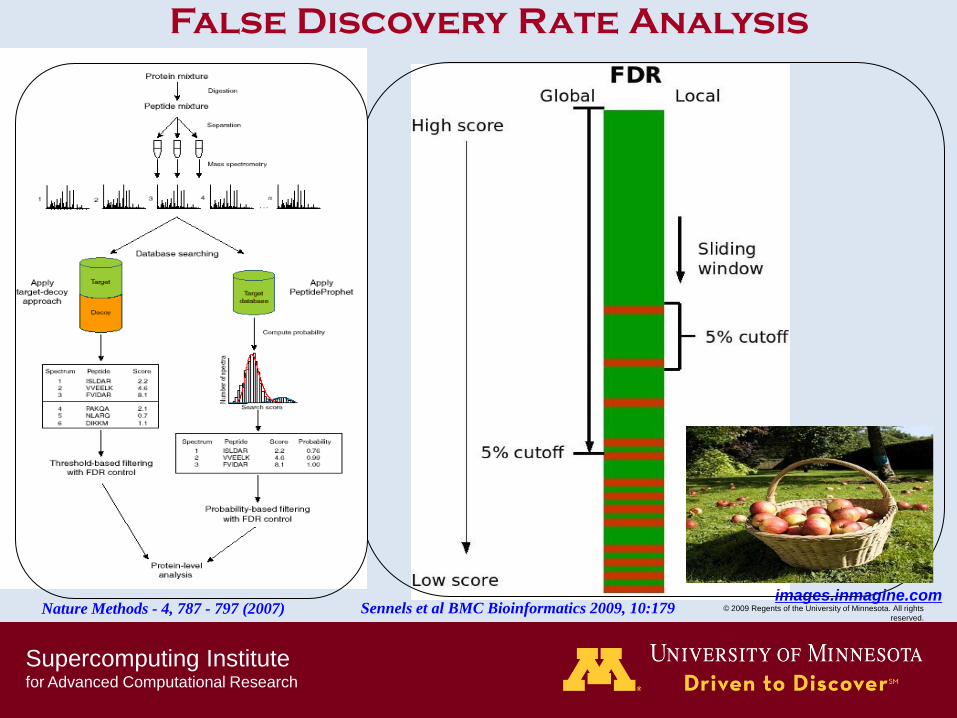
False Discovery Rate Analysis
Nature Methods - 4, 787 - 797 (2007) Sennels et al BMC Bioinformatics 2009, 10:179 images.inmagine.com
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
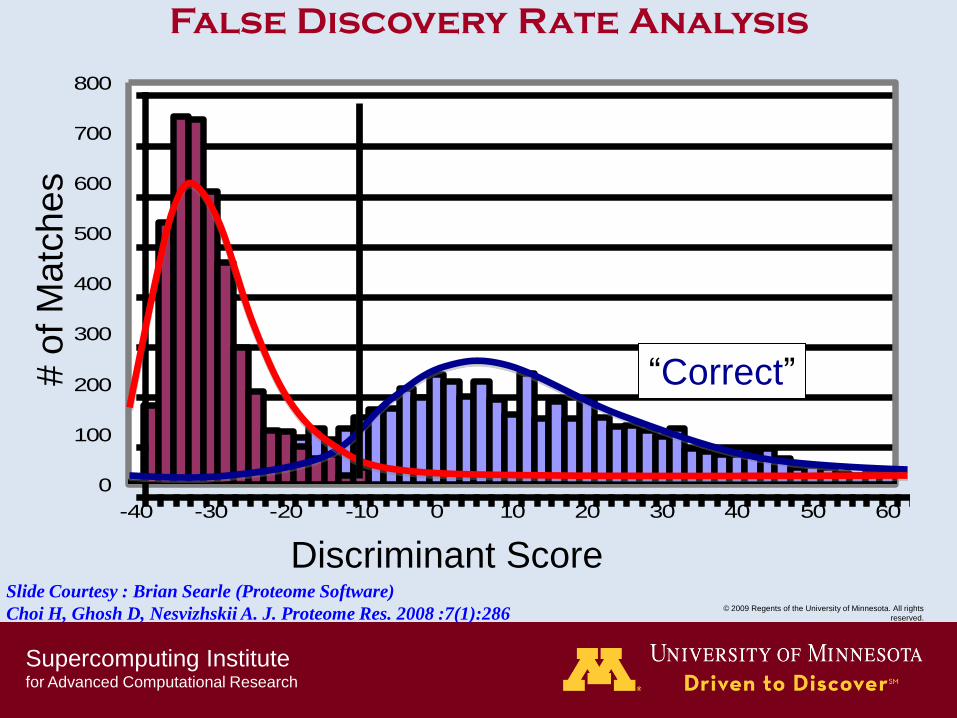
# o
f M
atc
hes
Discriminant Score
0
100
200
300
400
500
600
700
800
-40 -30 -20 -10 0 10 20 30 40 50 60
“Correct”
Slide Courtesy : Brian Searle (Proteome Software)
Choi H, Ghosh D, Nesvizhskii A. J. Proteome Res. 2008 :7(1):286
False Discovery Rate Analysis
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
# o
f M
atc
hes
Discriminant Score
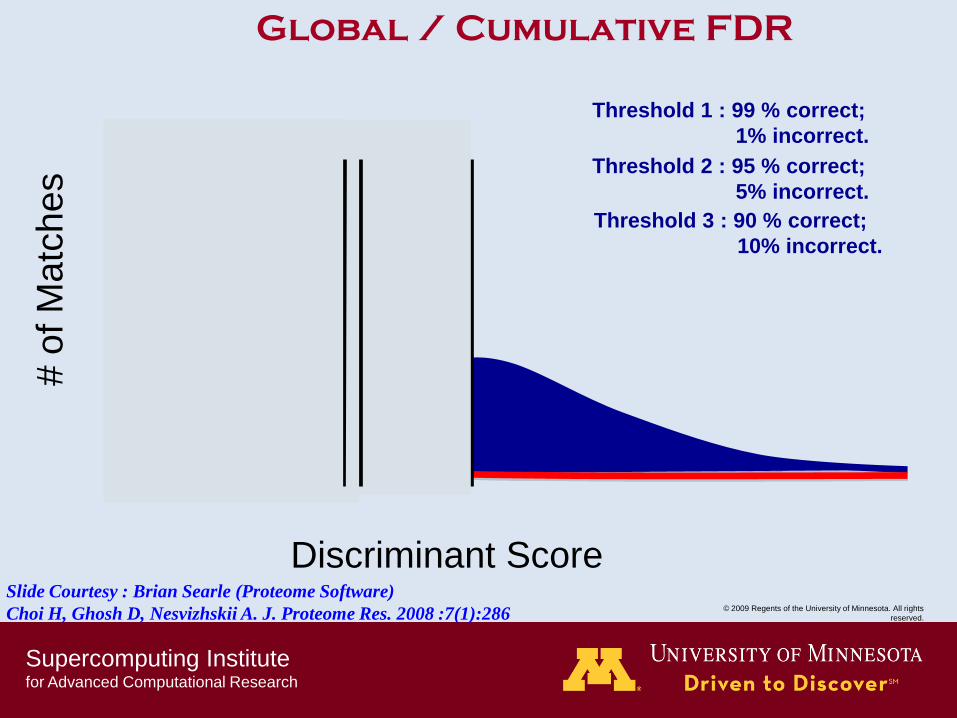
Global / Cumulative FDR
Slide Courtesy : Brian Searle (Proteome Software)
Choi H, Ghosh D, Nesvizhskii A. J. Proteome Res. 2008 :7(1):286
Threshold 1 : 99 % correct;
1% incorrect.
Threshold 2 : 95 % correct;
5% incorrect.
Threshold 3 : 90 % correct;
10% incorrect.
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
# o
f M
atc
hes
Discriminant Score
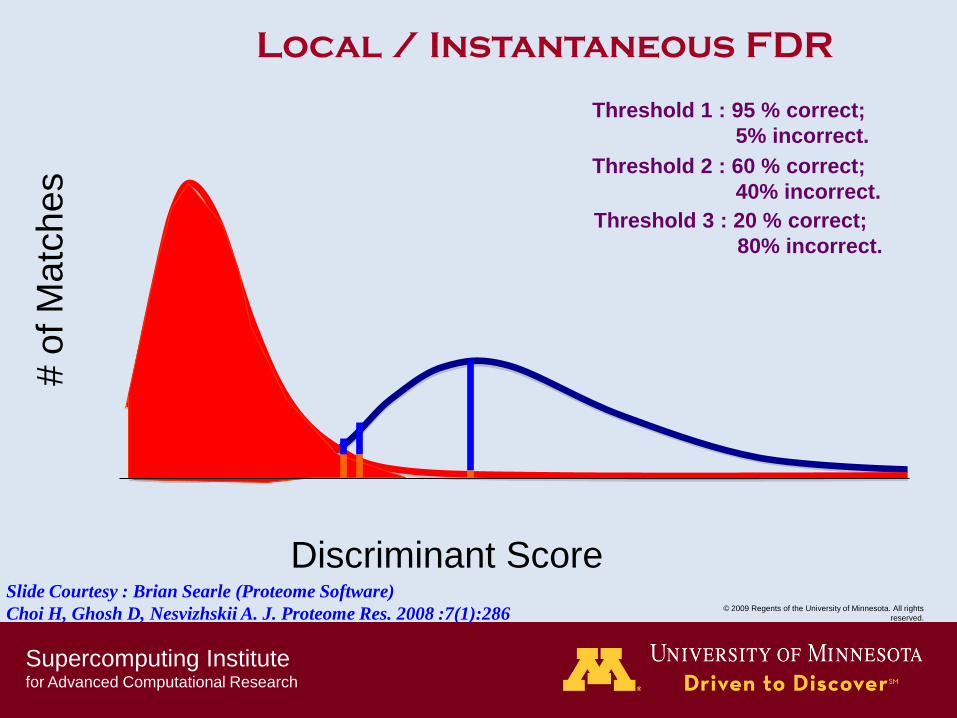
Local / Instantaneous FDR
Slide Courtesy : Brian Searle (Proteome Software)
Choi H, Ghosh D, Nesvizhskii A. J. Proteome Res. 2008 :7(1):286
Threshold 1 : 95 % correct;
5% incorrect.
Threshold 2 : 60 % correct;
40% incorrect.
Threshold 3 : 20 % correct;
80% incorrect.
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
# o
f M
atc
hes
Discriminant Score
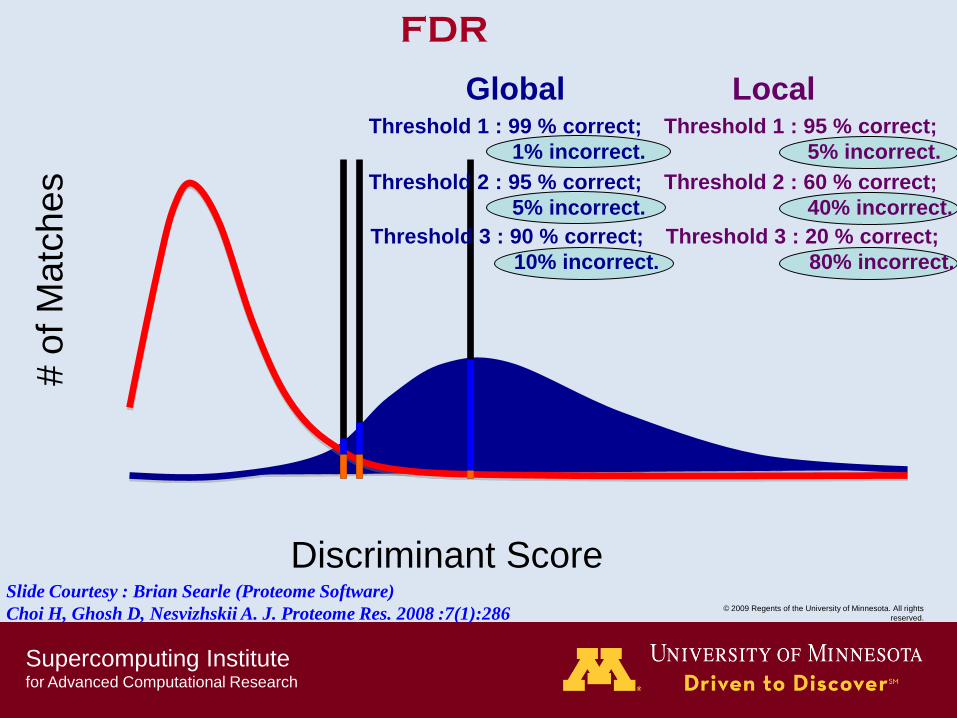
FDR
Slide Courtesy : Brian Searle (Proteome Software)
Choi H, Ghosh D, Nesvizhskii A. J. Proteome Res. 2008 :7(1):286
Threshold 1 : 99 % correct;
1% incorrect.
Threshold 2 : 95 % correct;
5% incorrect.
Threshold 3 : 90 % correct;
10% incorrect.
Threshold 1 : 95 % correct;
5% incorrect.
Threshold 2 : 60 % correct;
40% incorrect.
Threshold 3 : 20 % correct;
80% incorrect.
Global Local
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
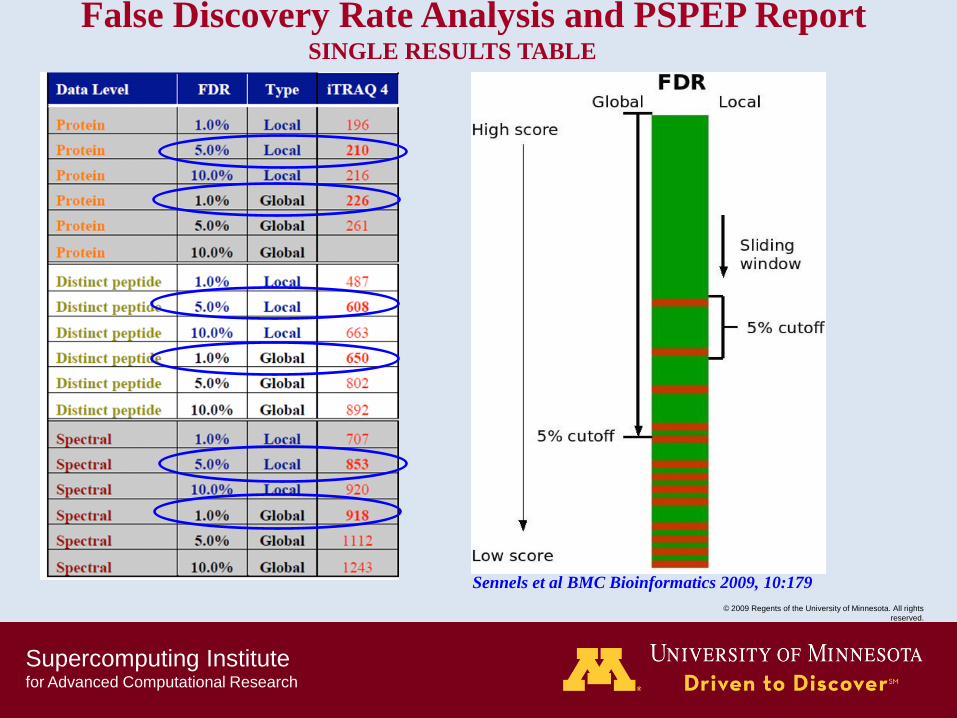
False Discovery Rate Analysis and PSPEP Report SINGLE RESULTS TABLE
Sennels et al BMC Bioinformatics 2009, 10:179

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR Analysis
and Databases…
• Overview.
• Protein Grouping : Concept & Methods.
• Fdr Analysis : Concept & Methods.
• Peptide and Protein identification
• Databases
• Publication Guidelines
REFERENCES : „Reporting Protein Identifications from MS/MS Results‟ by Brian Searle
(ProteomeSoftware Inc.) and “Databases” by Akhilesh Pandey (John Hopkins University) at
the „BioInformatics for Protein Identification‟ workshop at Baltimore (2009).
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
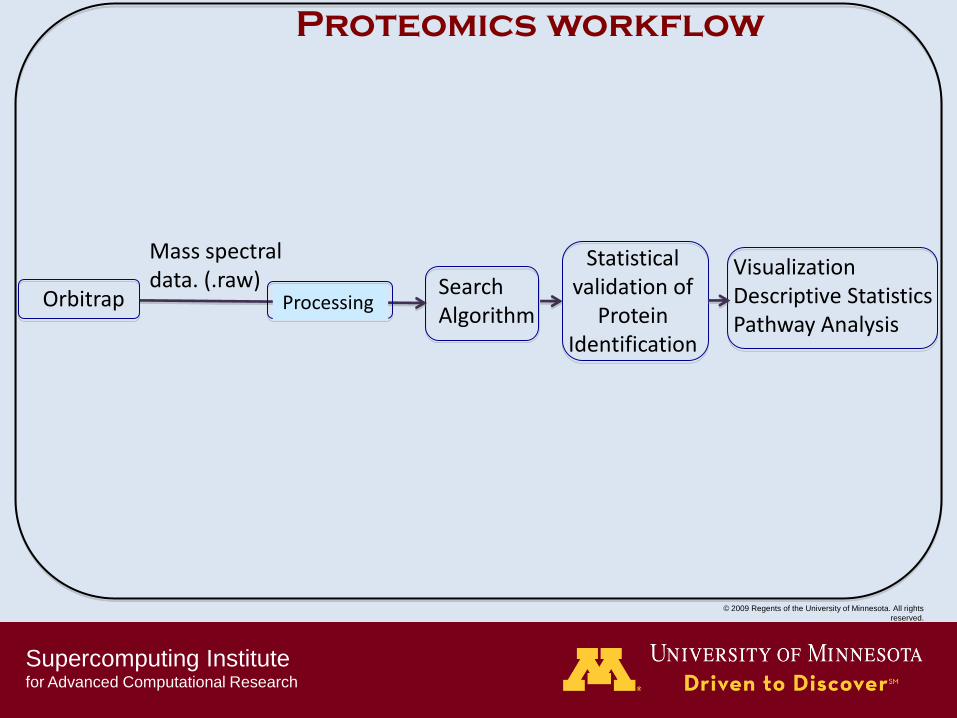
Proteomics workflow
Orbitrap
Mass spectral data. (.raw)
Search Algorithm
Statistical validation of
Protein Identification
Visualization Descriptive Statistics Pathway Analysis
Processing
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
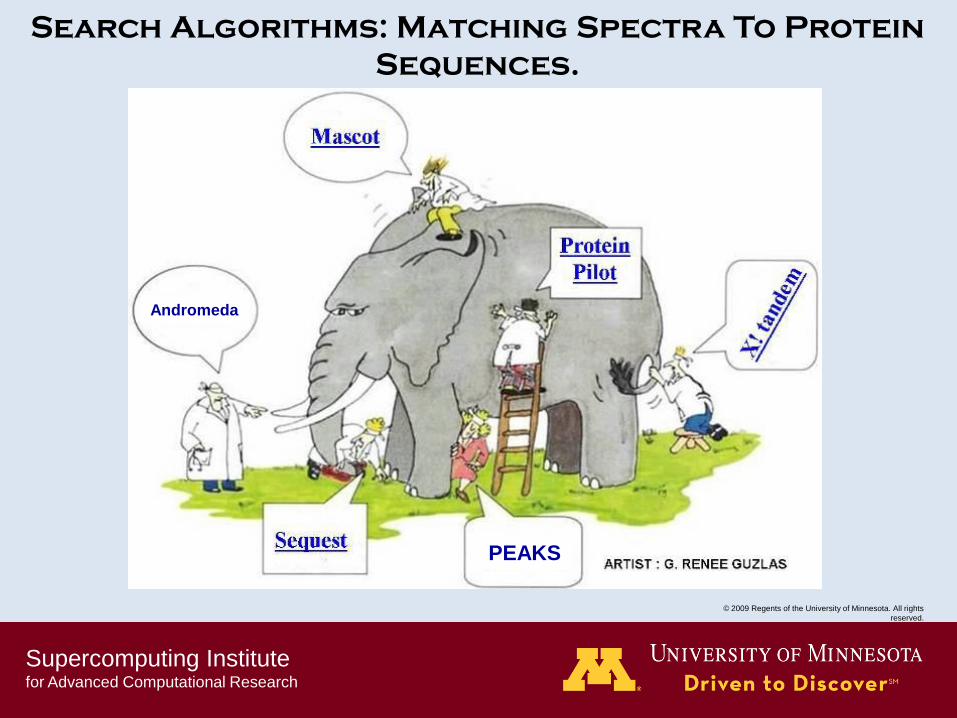
Search Algorithms: Matching Spectra To Protein
Sequences.
Andromeda
PEAKS
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
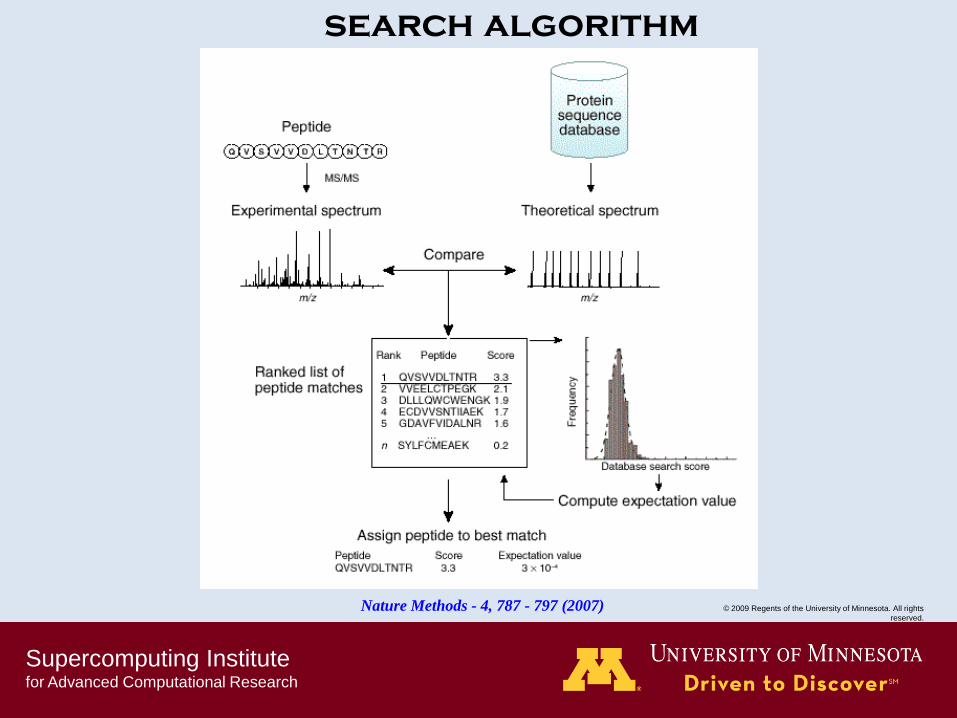
search algorithm
Nature Methods - 4, 787 - 797 (2007)
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protip / TINT
https://tropix.msi.umn.edu/
John Chilton Mark Nelson
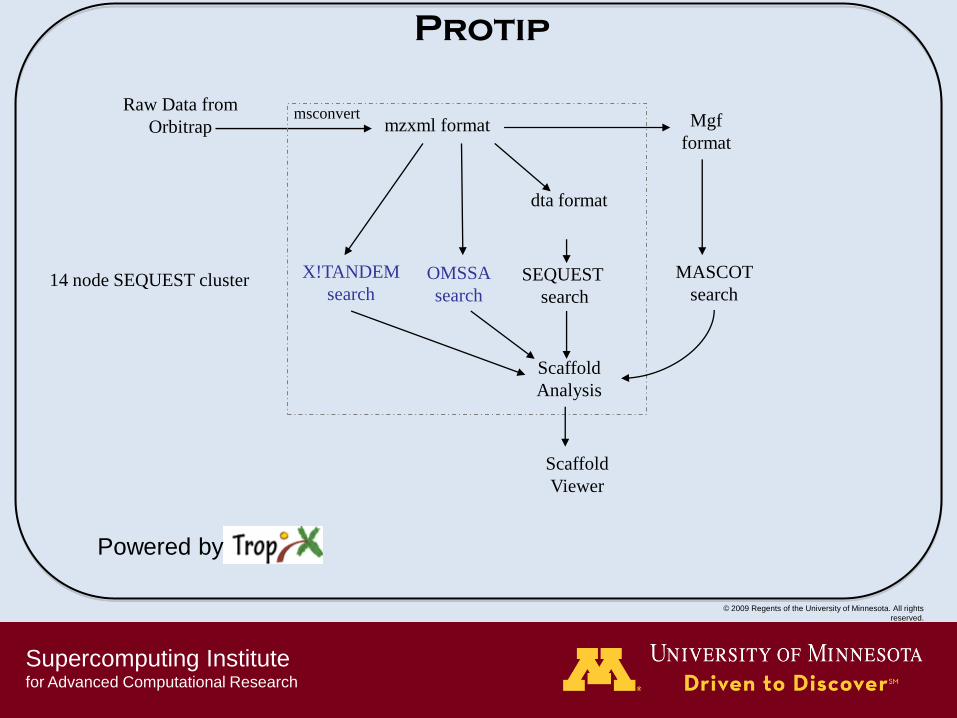
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protip
Raw Data from
Orbitrap mzxml format
dta format
X!TANDEM
search
Scaffold
Analysis
Scaffold
Viewer
MASCOT
search SEQUEST
search
Mgf
format
OMSSA
search
Powered by
14 node SEQUEST cluster
msconvert
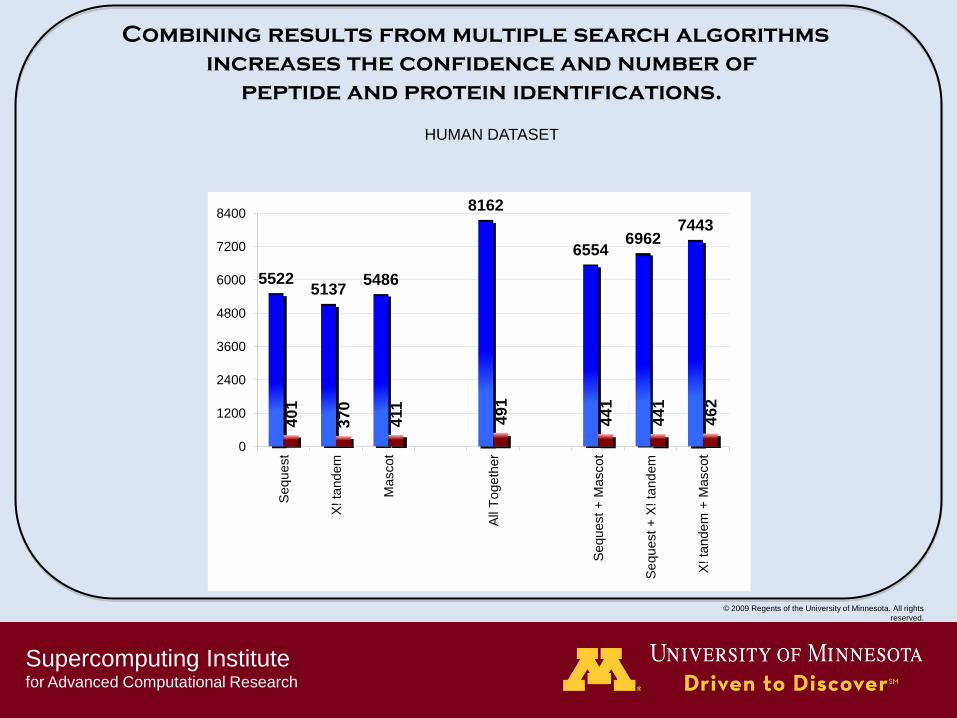
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Combining results from multiple search algorithms
increases the confidence and number of
peptide and protein identifications.
5522 5137
5486
8162
6554 6962
7443
40
1
37
0
411
49
1
44
1
44
1
46
2
0
1200
2400
3600
4800
6000
7200
8400
Sequest
X! ta
ndem
Mascot
All
Togeth
er
Sequest
+ M
ascot
Sequest
+ X
! ta
ndem
X! ta
ndem
+ M
ascot
HUMAN DATASET

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
One hit wonders
Option 1 : Throw Out One-Hit-Wonders Advantages: Easy, works!
Disadvantages: Loss of sensitivity!
Option 2 : Use Multiple Filters
Filter 1 - Protein Mode
• ≥2 peptides/protein • moderate spectrum threshold
Filter 2 - Peptide Mode
• 1 peptide/protein • high spectrum threshold
Advantages: More sensitive!
Disadvantages: Pretty arbitrary!
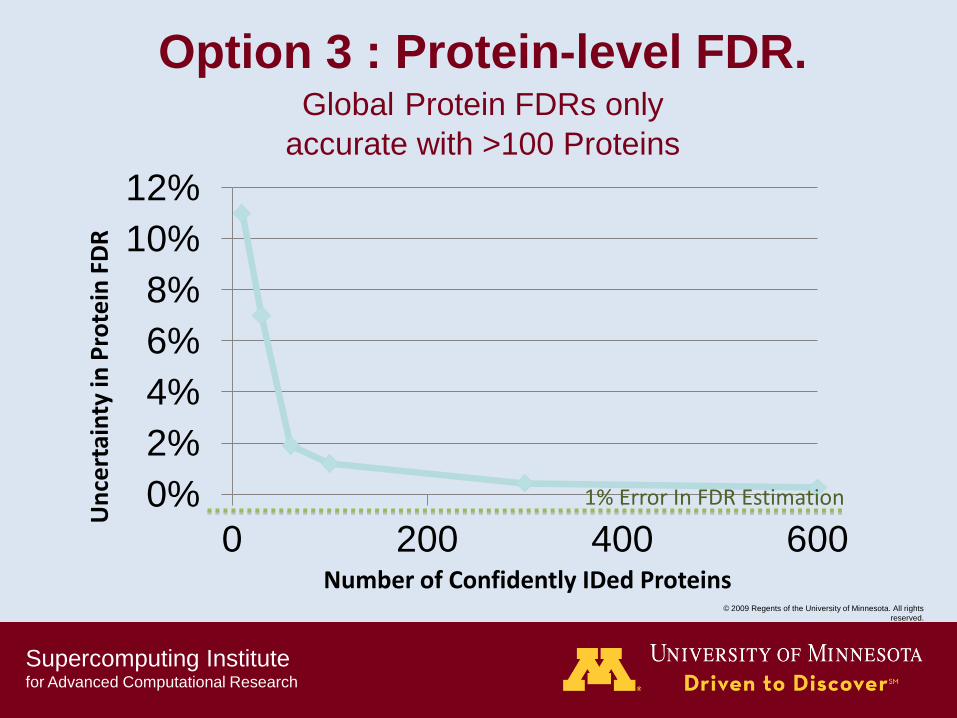
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Option 3 : Protein-level FDR. Global Protein FDRs only
accurate with >100 Proteins
0%
2%
4%
6%
8%
10%
12%
0 200 400 600 Number of Confidently IDed Proteins
Un
cert
ain
ty in
Pro
tein
FD
R
1% Error In FDR Estimation

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Local Protein FDRs…
• Estimate the likelihood that a single
protein of interest is present
• Are trouble at best due to stochastic
sampling
• Shouldn’t be used with <500 likely
proteins
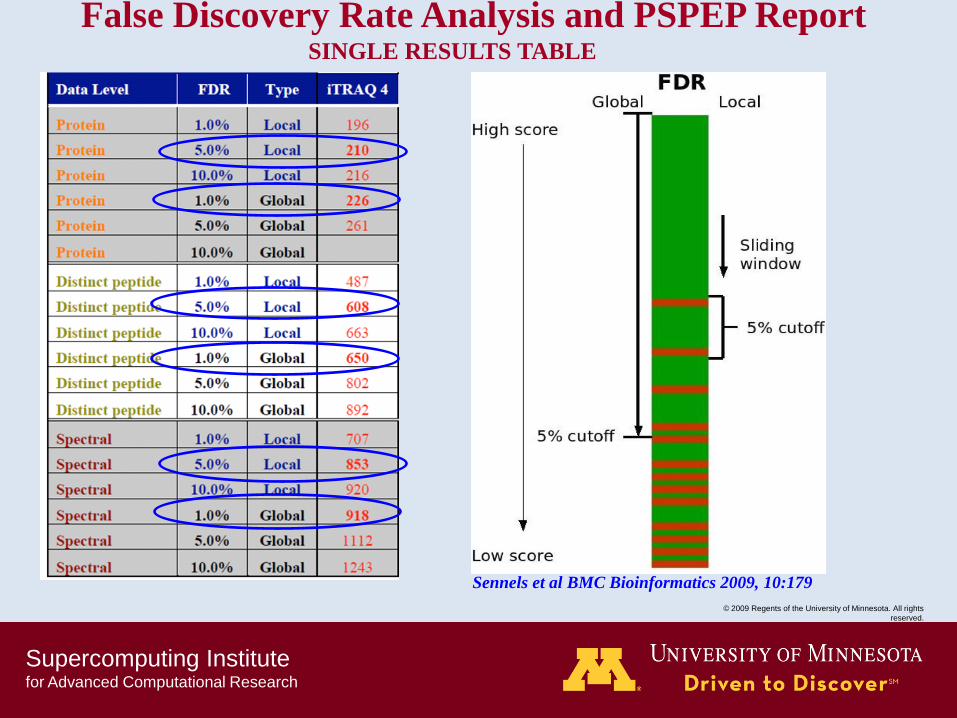
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
False Discovery Rate Analysis and PSPEP Report SINGLE RESULTS TABLE
Sennels et al BMC Bioinformatics 2009, 10:179

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR Analysis
and Databases…
• Overview.
• Protein Grouping : Concept & Methods.
• Fdr Analysis : Concept & Methods.
• Peptide and Protein identification
• Databases
• Publication Guidelines
REFERENCES : „Reporting Protein Identifications from MS/MS Results‟ by Brian Searle
(ProteomeSoftware Inc.) and “Databases” by Akhilesh Pandey (John Hopkins University) at
the „BioInformatics for Protein Identification‟ workshop at Baltimore (2009).
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
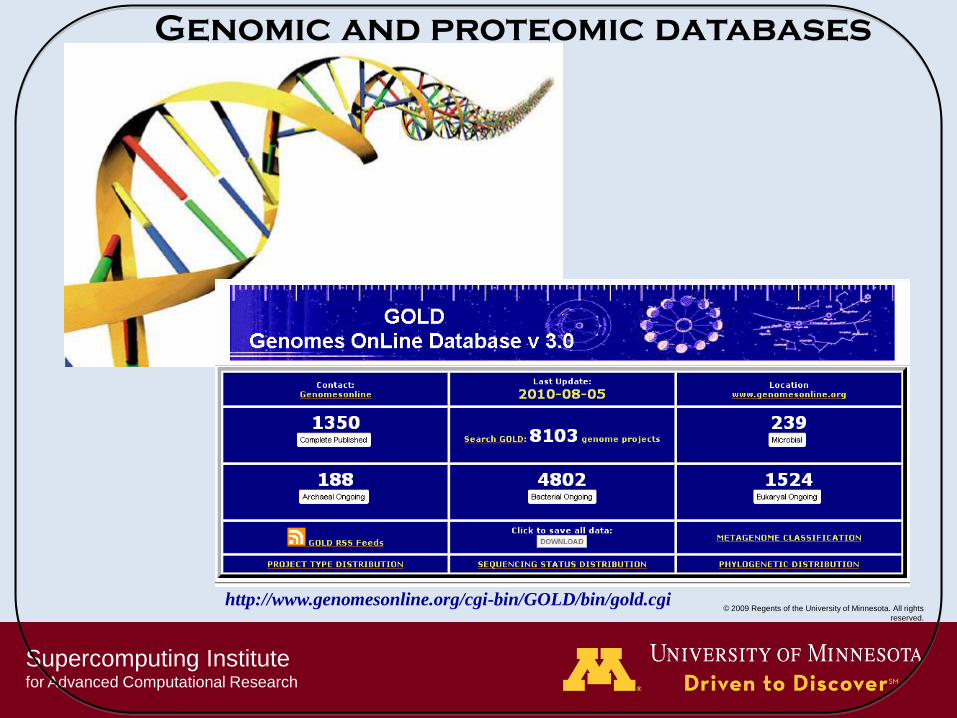
Genomic and proteomic databases
http://www.genomesonline.org/cgi-bin/GOLD/bin/gold.cgi
Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
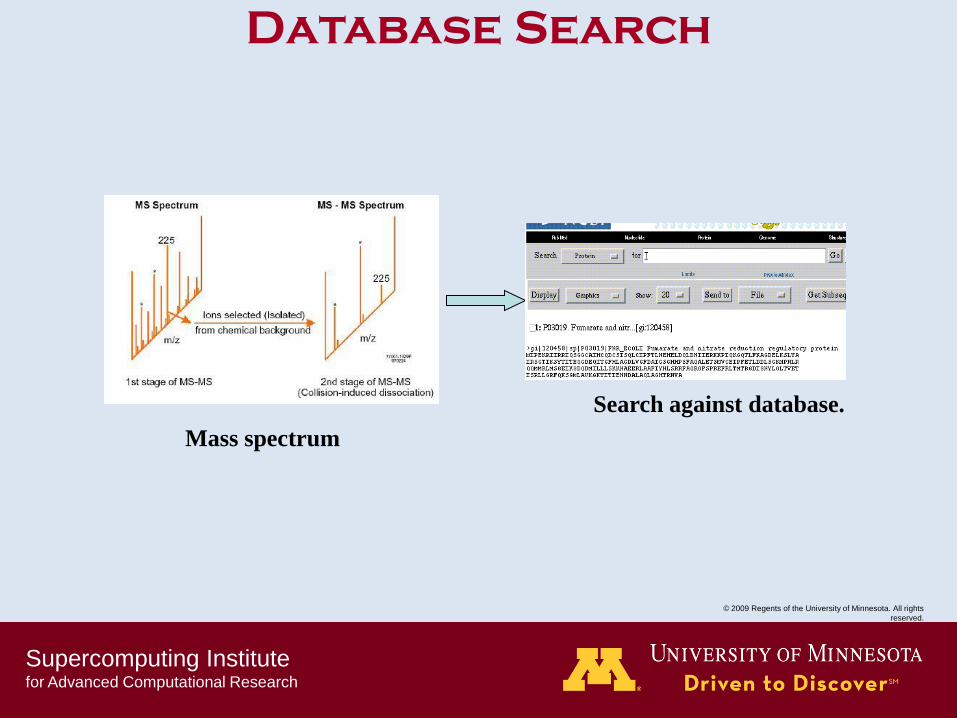
Search against database.
Mass spectrum
Database Search

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Choose your database according to your experimental setup • GenBank allows you to submit DNA databases and not protein
databases. Databases are not always correct. Sequence errors can be
altered only by the submitter.
• Acclimatize yourself with details about your database (eg UniProt /IPI /
RefSeq).
• Transatlantic Divide : GenBank / EMBL
NCBI / EBI
Tranche / PRIDE
NCBInr / TreMBL
• Searching with different databases and search algorithms and their
effect on IDs. Effect of search algorithm on Protein grouping.
• Database size affects ranking of proteins, scoring threshold, etc.
Using combined databases / Contaminant sequences.
proteomic databases

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Protein Grouping, FDR Analysis
and Databases…
• Overview.
• Protein Grouping : Concept & Methods.
• Fdr Analysis : Concept & Methods.
• Peptide and Protein identification
• Databases
• Publication Guidelines
REFERENCES : „Reporting Protein Identifications from MS/MS Results‟ by Brian Searle
(ProteomeSoftware Inc.) and “Databases” by Akhilesh Pandey (John Hopkins University) at
the „BioInformatics for Protein Identification‟ workshop at Baltimore (2009).

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Publication Standards
• In 2006 MCP published guidelines for
reporting peptide and protein
identifications
• Other proteomics journals have adopted
similar standards
• Revised “Paris 2” guidelines (1/1/2010).

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Guidelines remind you to…
• To present a complete methods/results section I. Search Parameters and Acceptance Criteria
VI. Raw Data Submission
• Follow smart criteria for choosing results to
publish II. Protein and Peptide Identification
IV. Protein Inference from Peptide Assignments
V. Quantification
• To not over-report your results III. Post-Translational Modifications

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Software Can Make
Guideline Fulfillment Easier

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Where are the Guidelines?
Molecular & Cellular Proteomics: Bradshaw, R. A.,
Burlingame, A. L., Carr, S., Aebersold, R., Reporting
Protein Identification Data: The next Generation of
Guidelines. Mol. Cell. Proteomics, 5:787-788, 2006.
Journal of Proteome Research: Beavis, R., Editorial: The
Paris Consensus. J. Proteome Res., 2005, 4 (5), p 1475
Proteomics: Wilkins, M. R., Appel, R. D., Van Eyk, J. E.,
Maxey, C. M., et al., Guidelines for the next 10 years of
proteomics. Proteomics. 2006, 6, 1, 4-8.
http://www.mcponline.org/site/misc/MSDataResources.xhtml

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
• We identify Proteins (not Peptides)!
– Can’t stop at Peptide FDRs and Probabilities
• One-Hit-Wonders can be wrong and need to be
seriously investigated (manually or mathematically)
• You can compute Protein level FDRs
– But take them with a grain of salt!
• Occam’s Razor can simplify Shared Peptides
• Publication Standards exist to help you
A few take home points…

Supercomputing Institute for Advanced Computational Research
© 2009 Regents of the University of Minnesota. All rights
reserved.
Questions ?
http://sitemaker.umich.edu/iwsmoi
Recommended

















