October 14, 2015
On the Formation of Phoneme Categories in DNN Acoustic Models
Tasha Nagamine Department of Electrical Engineering, Columbia University
T. Nagamine October 14, 2015

Motivation
T. Nagamine October 14, 2015
• Large performance gap between humans and state-‐of-‐the-‐art ASR systems
• Computational principles of DNNs remain elusive; they are analytically intractable
• Improving these models requires a better understanding of their transformations
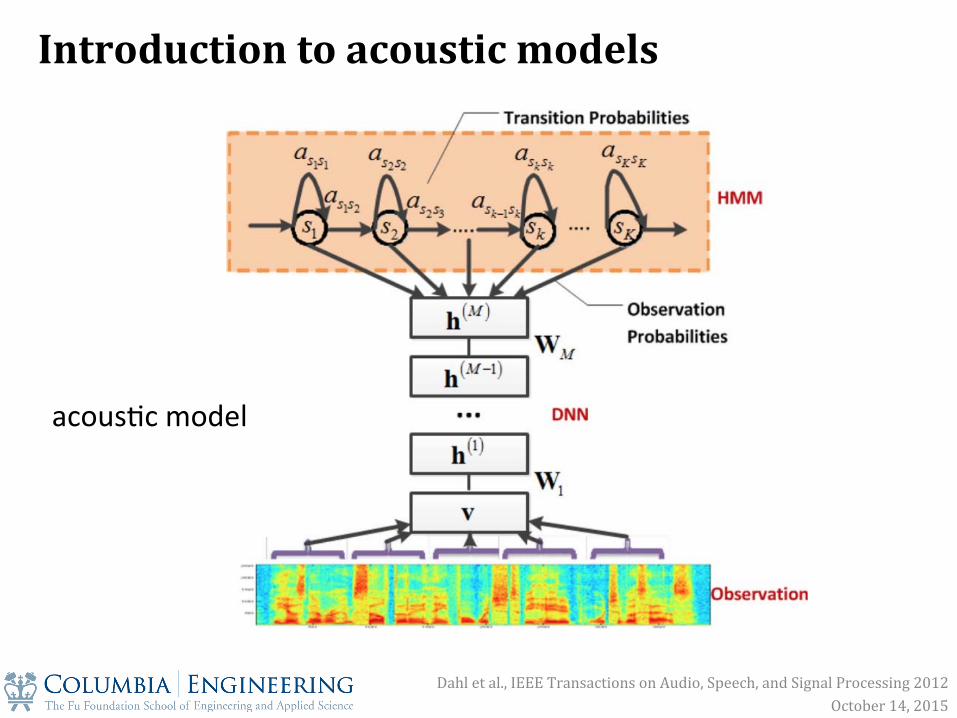
Dahl et al., IEEE Transactions on Audio, Speech, and Signal Processing 2012 October 14, 2015
acous&c model
Introduction to acoustic models
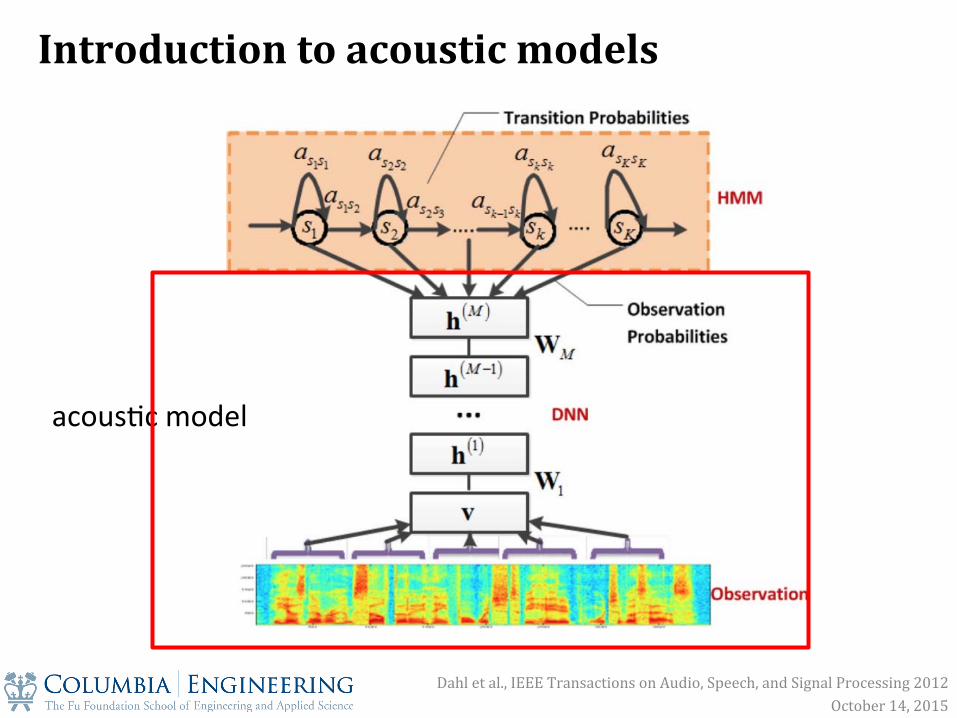
acous&c model
Dahl et al., IEEE Transactions on Audio, Speech, and Signal Processing 2012 October 14, 2015
Introduction to acoustic models
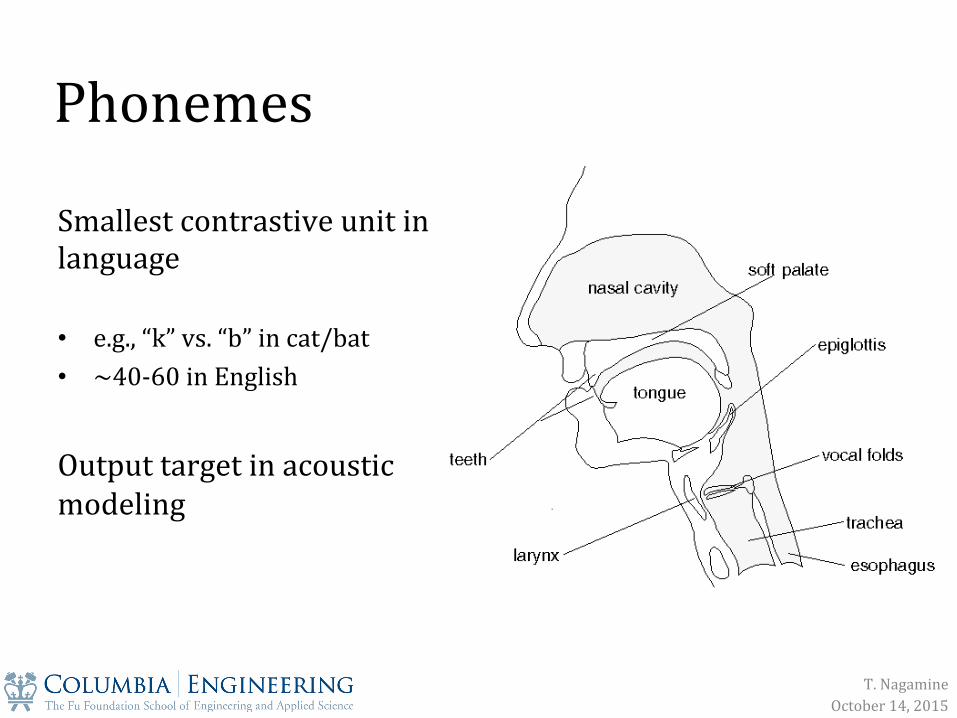
Phonemes
T. Nagamine October 14, 2015
Smallest contrastive unit in language • e.g., “k” vs. “b” in cat/bat • ~40-‐60 in English
Output target in acoustic modeling

Phonetic Features
T. Nagamine October 14, 2015
Manner of articulation Place of articulation Voicing
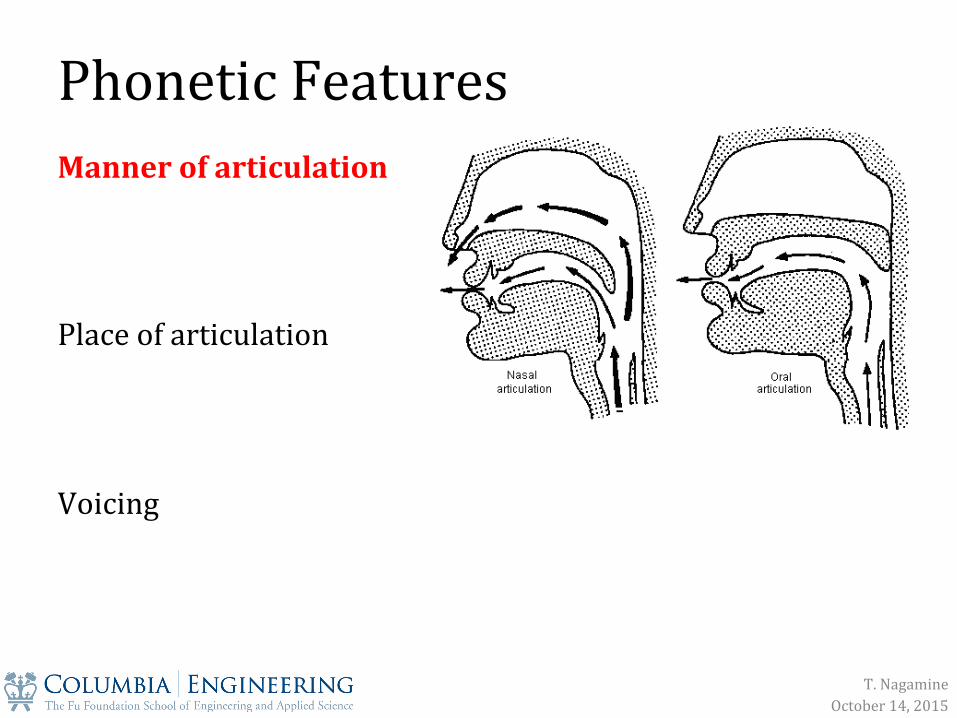
Phonetic Features
T. Nagamine October 14, 2015
Manner of articulation Place of articulation Voicing
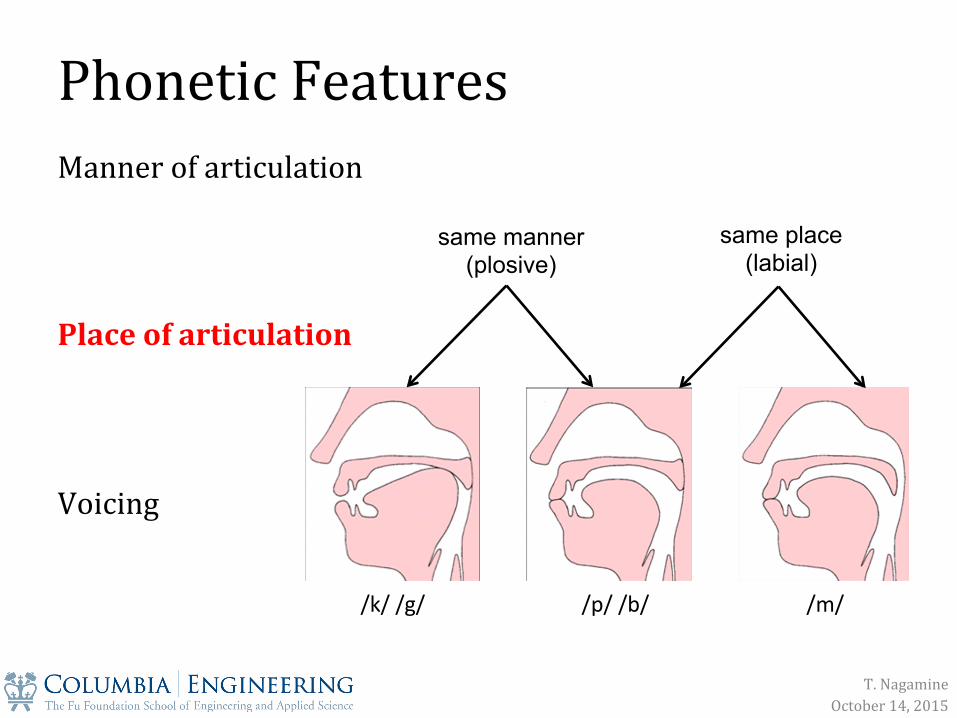
Phonetic Features
T. Nagamine October 14, 2015
Manner of articulation Place of articulation Voicing
/p/ /b/ /k/ /g/ /m/
same manner (plosive)
same place (labial)
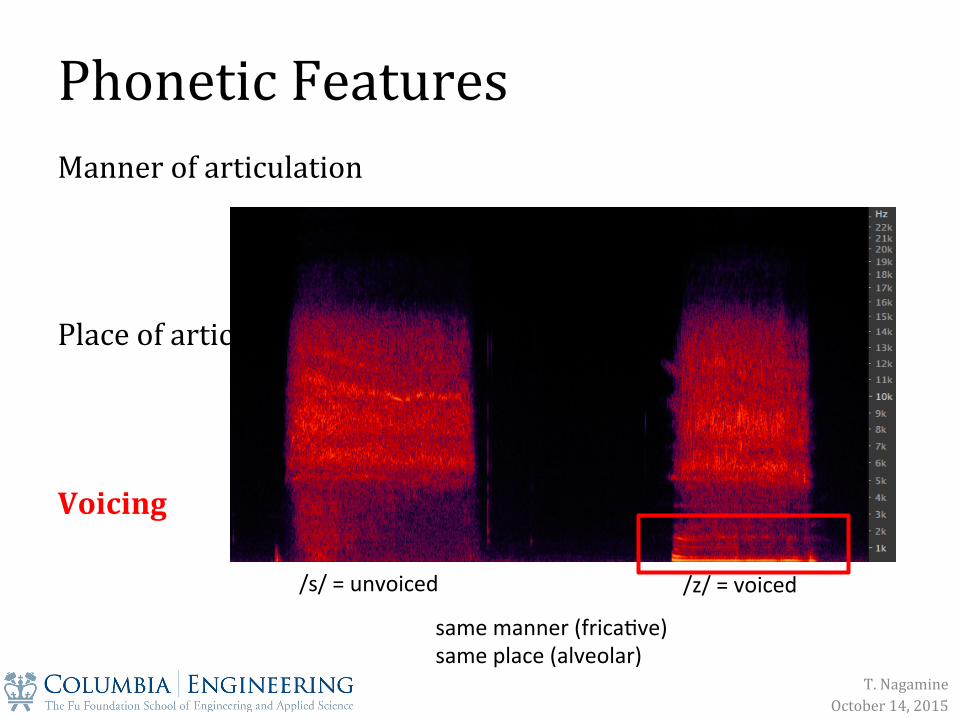
Phonetic Features
T. Nagamine October 14, 2015
Manner of articulation Place of articulation Voicing
/s/ = unvoiced /z/ = voiced
same manner (frica&ve) same place (alveolar)
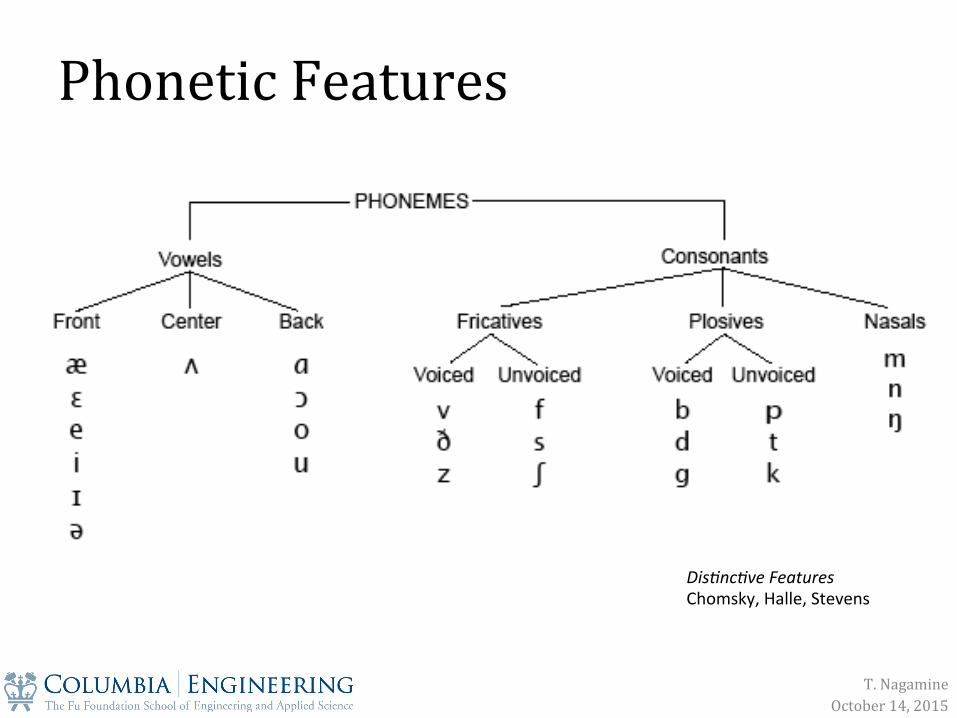
Phonetic Features
T. Nagamine October 14, 2015
Dis$nc$ve Features Chomsky, Halle, Stevens
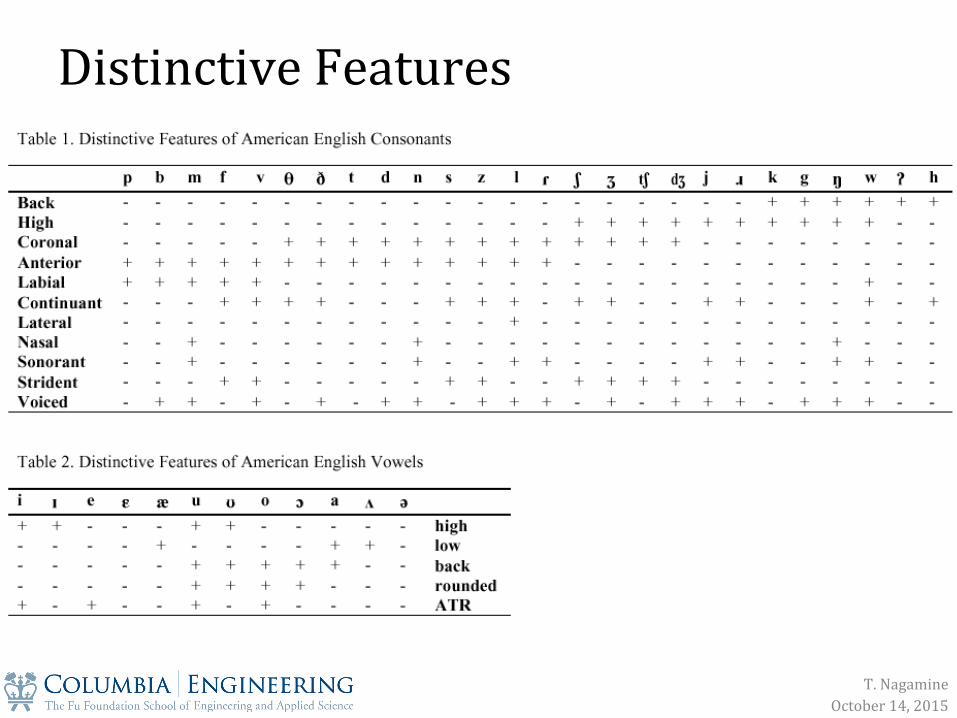
Distinctive Features
T. Nagamine October 14, 2015

Phonemes and phones
T. Nagamine October 14, 2015
Phoneme Smallest contrastive unit in language. Abstract idea.
Phone Instances of phonemes in actual utterances. Physical segments. Example: “pat” vs. “bat” 4 phonemes 6 phones

Nagamine et al. Interspeech 2015 October 14, 2015
. . .
. . .
. . . . . .. . .
. . .
log
Mel
filte
rban
kco
effic
ient
s
Input
ey sil aos ziht uw ah dh er k
1st t
empo
ral
deriv
ativ
e2n
d te
mpo
ral
deriv
ativ
e
Hidden Layers
t uw
Actual Labeley sil ao
Pred
icte
d La
bel
aaaeahaoawaxaybchddhehereyfghhihiyjhklmnngowoyprsshsiltthuhuwvwyzzh
Output
s zihah dh er k
Feed-‐forward series of nonlinear transforma&ons…
Nagamine et al. Interspeech 2015 October 14, 2015
. . .
. . .
. . . . . .. . .
. . .
log
Mel
filte
rban
kco
effic
ient
s
Input
ey sil aos ziht uw ah dh er k
1st t
empo
ral
deriv
ativ
e2n
d te
mpo
ral
deriv
ativ
e
Hidden Layers
t uw
Actual Labeley sil ao
Pred
icte
d La
bel
aaaeahaoawaxaybchddhehereyfghhihiyjhklmnngowoyprsshsiltthuhuwvwyzzh
Output
s zihah dh er k
? Nagamine et al. Interspeech 2015
October 14, 2015
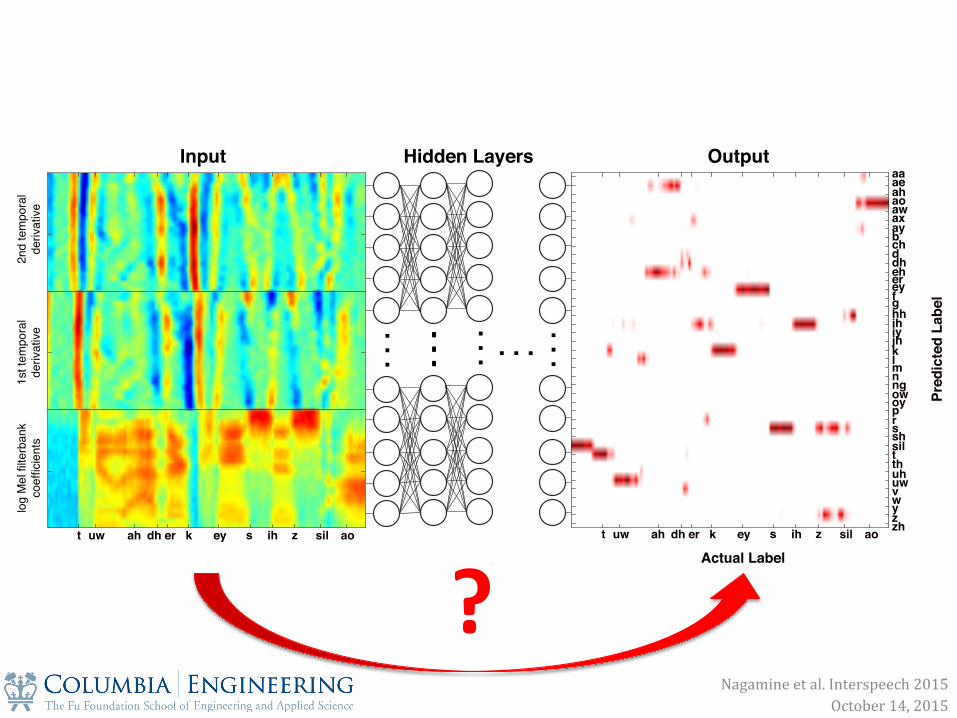
. . .
. . .
. . . . . .. . .
. . .
log
Mel
filte
rban
kco
effic
ient
s
Input
ey sil aos ziht uw ah dh er k
1st t
empo
ral
deriv
ativ
e2n
d te
mpo
ral
deriv
ativ
e
Hidden Layers
t uw
Actual Labeley sil ao
Pred
icte
d La
bel
aaaeahaoawaxaybchddhehereyfghhihiyjhklmnngowoyprsshsiltthuhuwvwyzzh
Output
s zihah dh er k
? Nagamine et al. Interspeech 2015
October 14, 2015
. . .
. . .
. . . . . .. . .
. . .
log
Mel
filte
rban
kco
effic
ient
s
Input
ey sil aos ziht uw ah dh er k
1st t
empo
ral
deriv
ativ
e2n
d te
mpo
ral
deriv
ativ
e
Hidden Layers
t uw
Actual Labeley sil ao
Pred
icte
d La
bel
aaaeahaoawaxaybchddhehereyfghhihiyjhklmnngowoyprsshsiltthuhuwvwyzzh
Output
s zihah dh er k
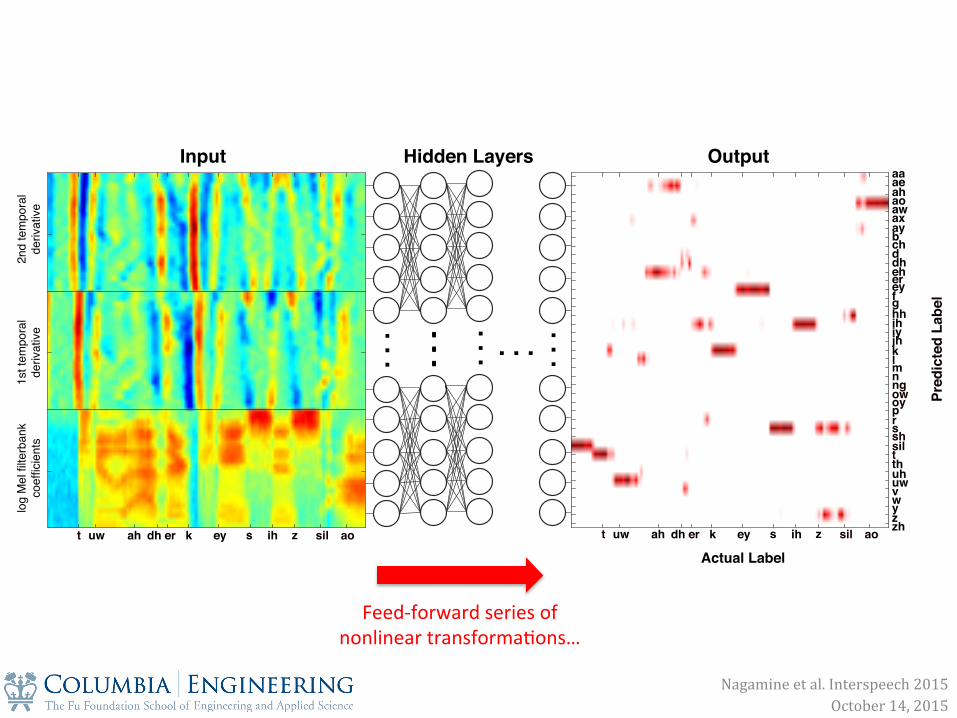
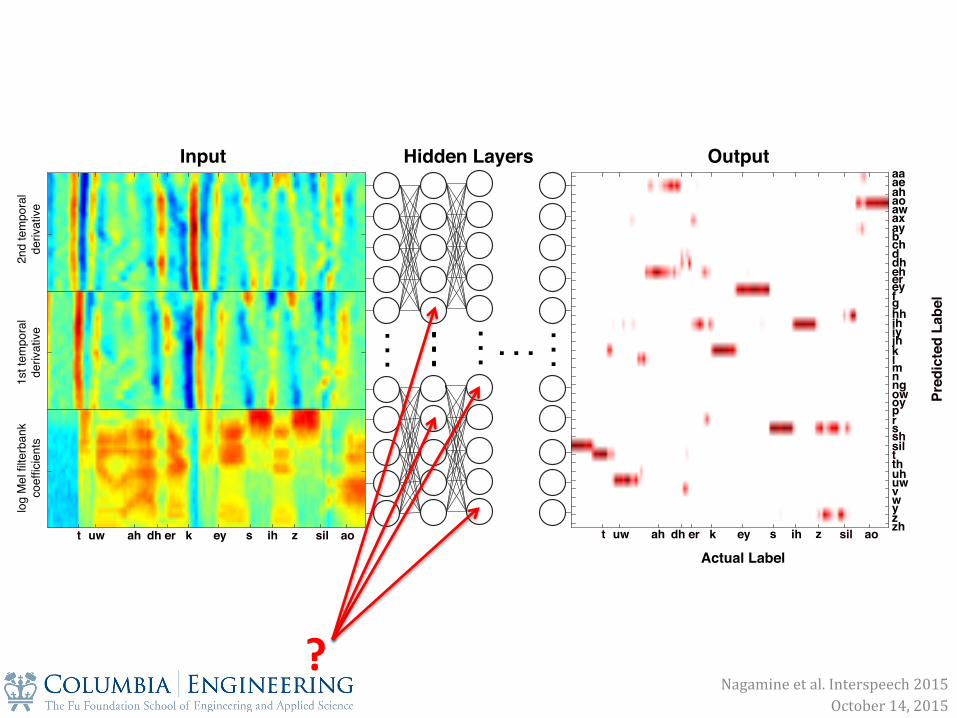
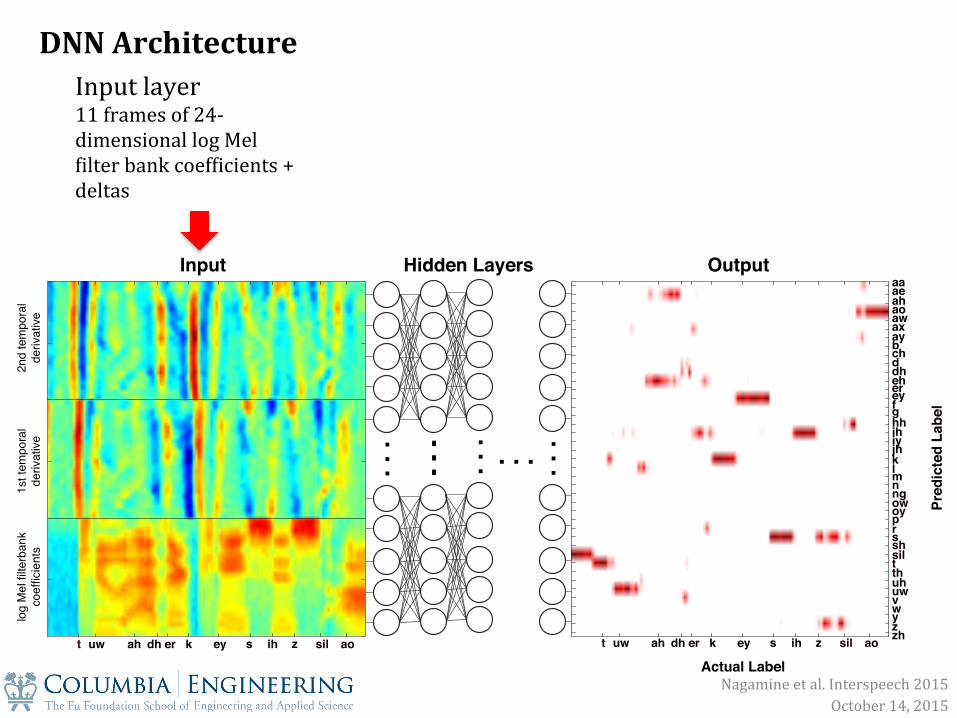
DNN Architecture Input layer 11 frames of 24-‐dimensional log Mel Xilter bank coefXicients + deltas
Nagamine et al. Interspeech 2015 October 14, 2015
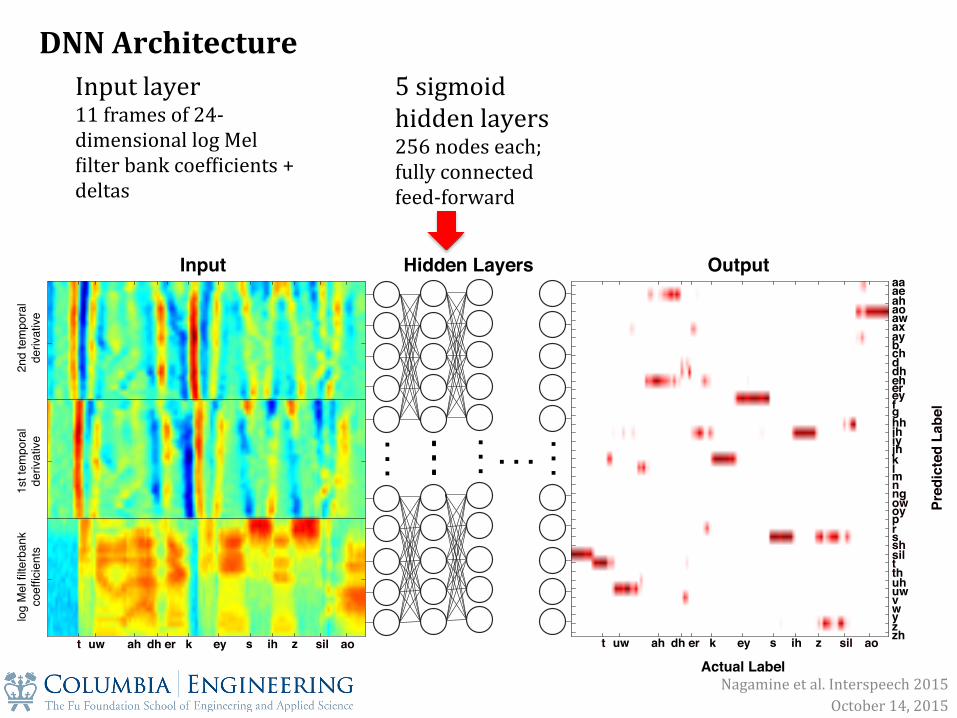
DNN Architecture 5 sigmoid hidden layers 256 nodes each; fully connected feed-‐forward
Nagamine et al. Interspeech 2015
. . .
. . .
. . . . . .. . .
. . .
log
Mel
filte
rban
kco
effic
ient
s
Input
ey sil aos ziht uw ah dh er k
1st t
empo
ral
deriv
ativ
e2n
d te
mpo
ral
deriv
ativ
e
Hidden Layers
t uw
Actual Labeley sil ao
Pred
icte
d La
bel
aaaeahaoawaxaybchddhehereyfghhihiyjhklmnngowoyprsshsiltthuhuwvwyzzh
Output
s zihah dh er k
Input layer 11 frames of 24-‐dimensional log Mel Xilter bank coefXicients + deltas
October 14, 2015
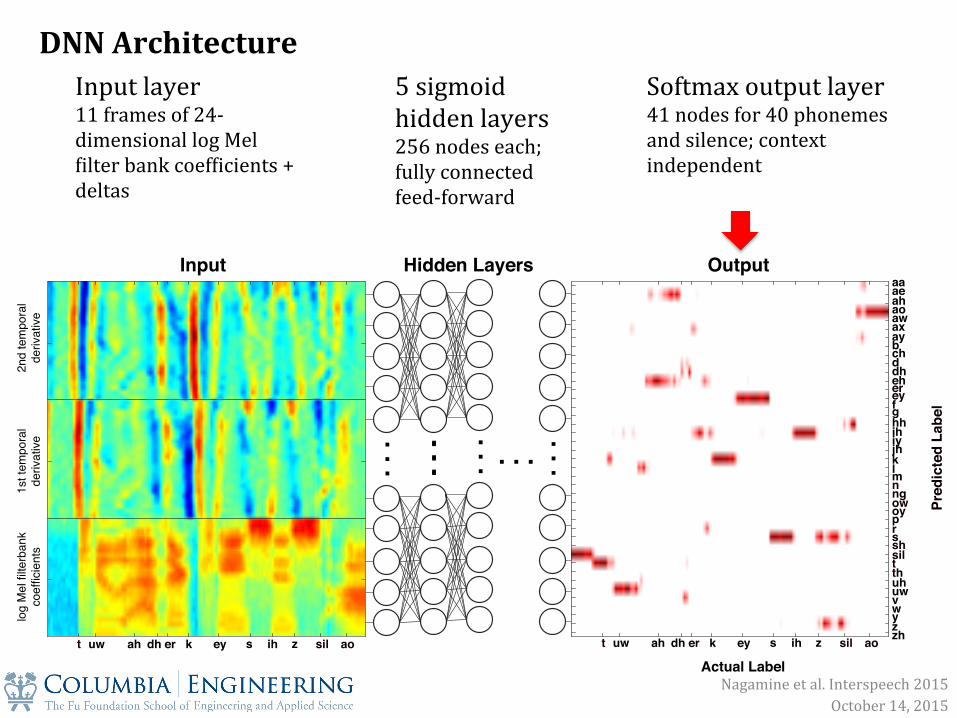
DNN Architecture 5 sigmoid hidden layers 256 nodes each; fully connected feed-‐forward
Softmax output layer 41 nodes for 40 phonemes and silence; context independent
Nagamine et al. Interspeech 2015
. . .
. . .
. . . . . .. . .
. . .
log
Mel
filte
rban
kco
effic
ient
s
Input
ey sil aos ziht uw ah dh er k
1st t
empo
ral
deriv
ativ
e2n
d te
mpo
ral
deriv
ativ
e
Hidden Layers
t uw
Actual Labeley sil ao
Pred
icte
d La
bel
aaaeahaoawaxaybchddhehereyfghhihiyjhklmnngowoyprsshsiltthuhuwvwyzzh
Output
s zihah dh er k
Input layer 11 frames of 24-‐dimensional log Mel Xilter bank coefXicients + deltas
October 14, 2015
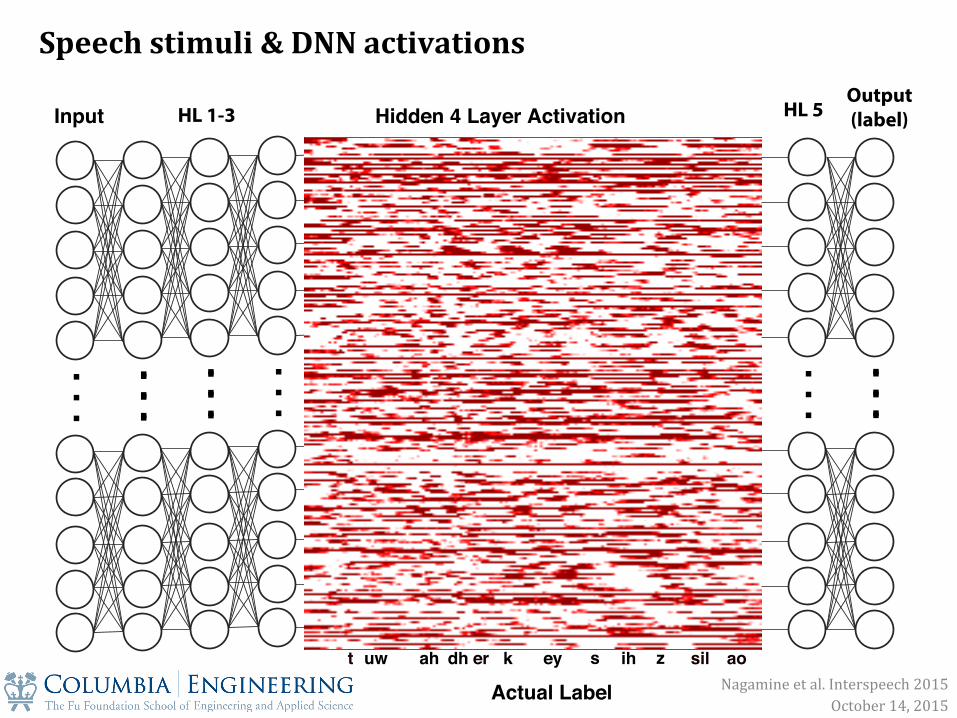
. .
.
. .
.
. .
..
. .
Input
t uw
Actual Label
ey sil ao
Hidden 4 Layer Activation
s zihah dh er k
. .
..
. .
. .
.
. .
..
. .
HL 1-3Output(label)HL 5
Speech stimuli & DNN activations
Nagamine et al. Interspeech 2015 October 14, 2015
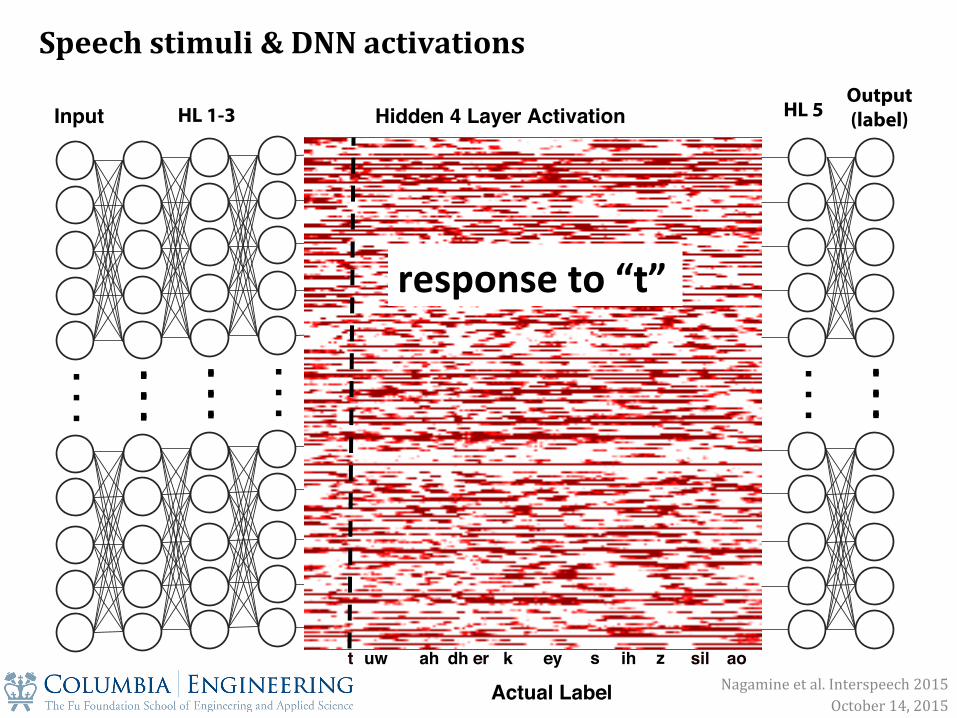
. .
.
. .
.
. .
..
. .
Input
t uw
Actual Label
ey sil ao
Hidden 4 Layer Activation
s zihah dh er k
. .
..
. .
. .
.
. .
..
. .
HL 1-3Output(label)HL 5
response to “t”
Nagamine et al. Interspeech 2015 October 14, 2015
Speech stimuli & DNN activations
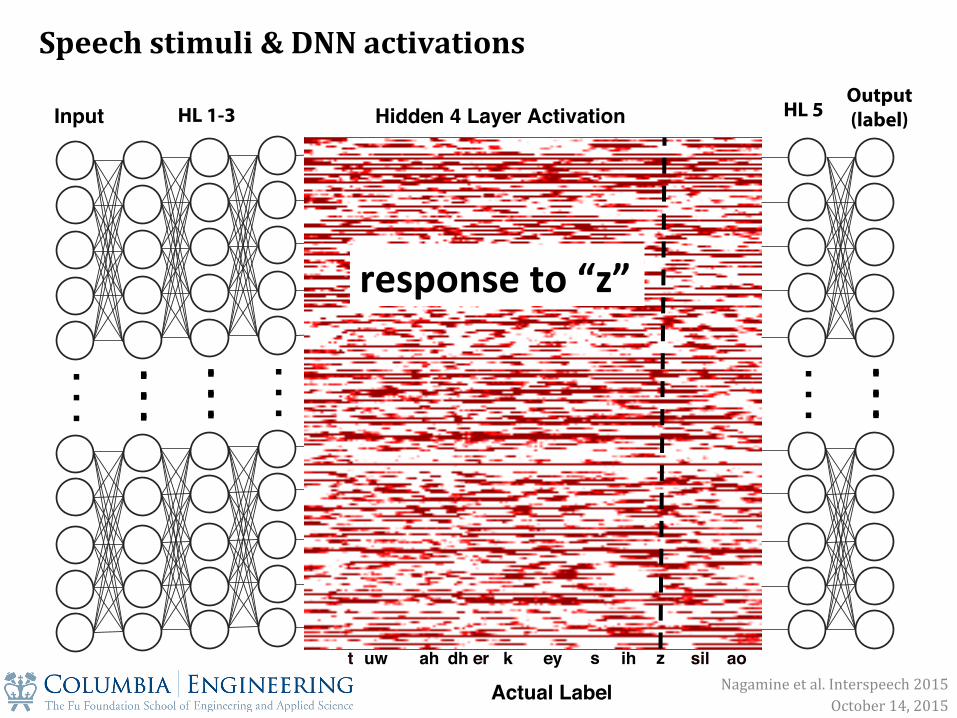
. .
.
. .
.
. .
..
. .
Input
t uw
Actual Label
ey sil ao
Hidden 4 Layer Activation
s zihah dh er k
. .
..
. .
. .
.
. .
..
. .
HL 1-3Output(label)HL 5
response to “z”
Nagamine et al. Interspeech 2015 October 14, 2015
Speech stimuli & DNN activations

Summary of Xindings
1. Nodes are selective to phonetic features at the individual and population level
Nagamine et al. Interspeech 2015 October 14, 2015
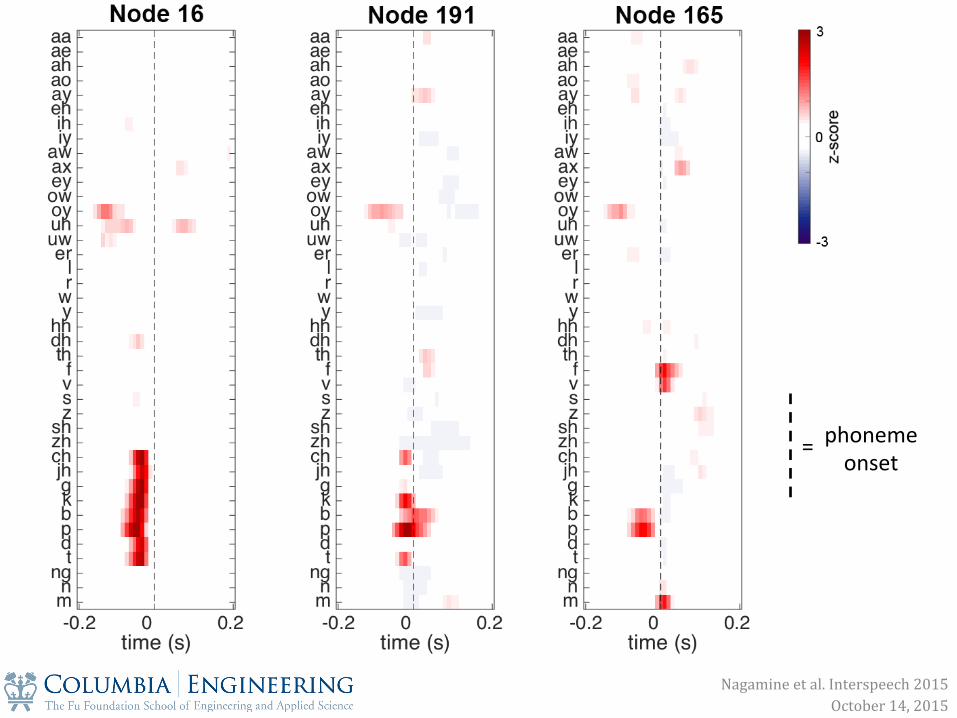
phoneme onset
=
Nagamine et al. Interspeech 2015 October 14, 2015
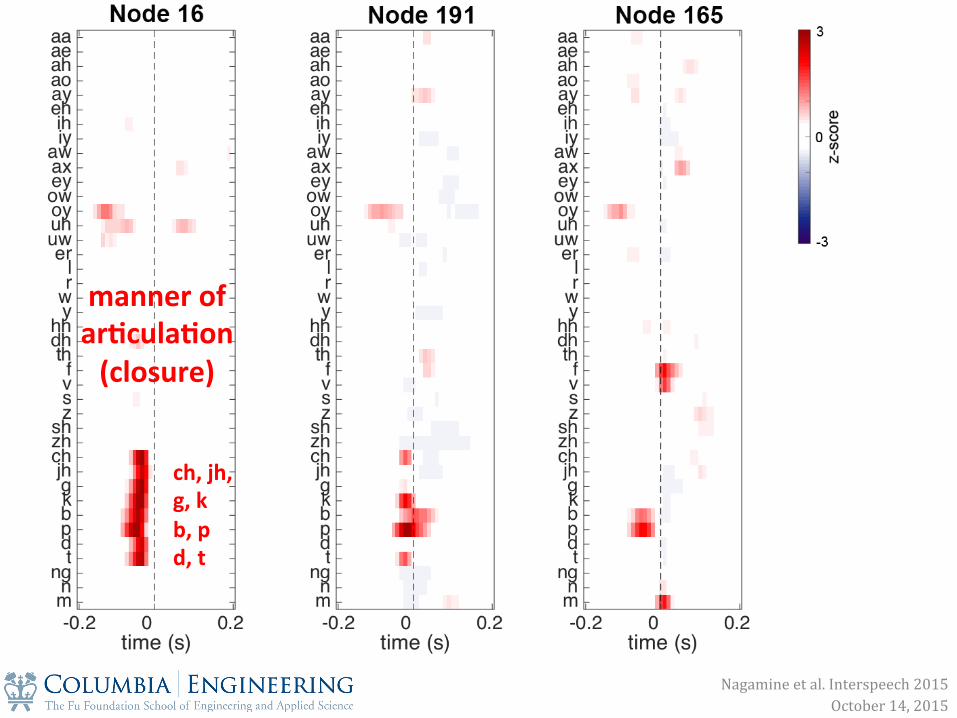
manner of ar0cula0on (closure)
ch, jh, g, k b, p d, t
Nagamine et al. Interspeech 2015 October 14, 2015
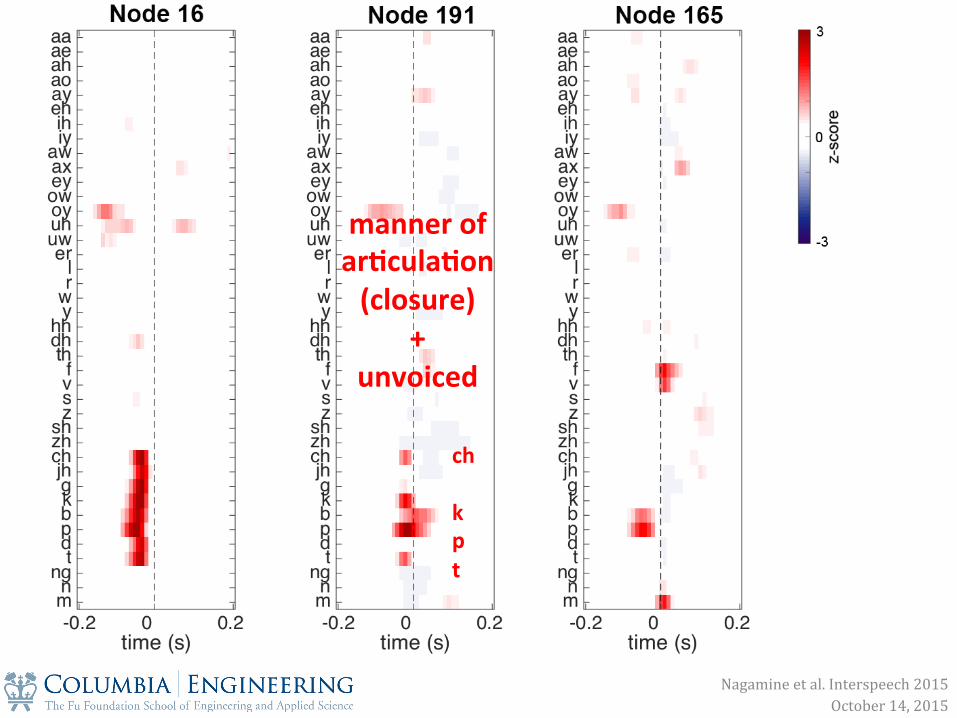
manner of ar0cula0on (closure)
+ unvoiced
ch k p t
Nagamine et al. Interspeech 2015 October 14, 2015
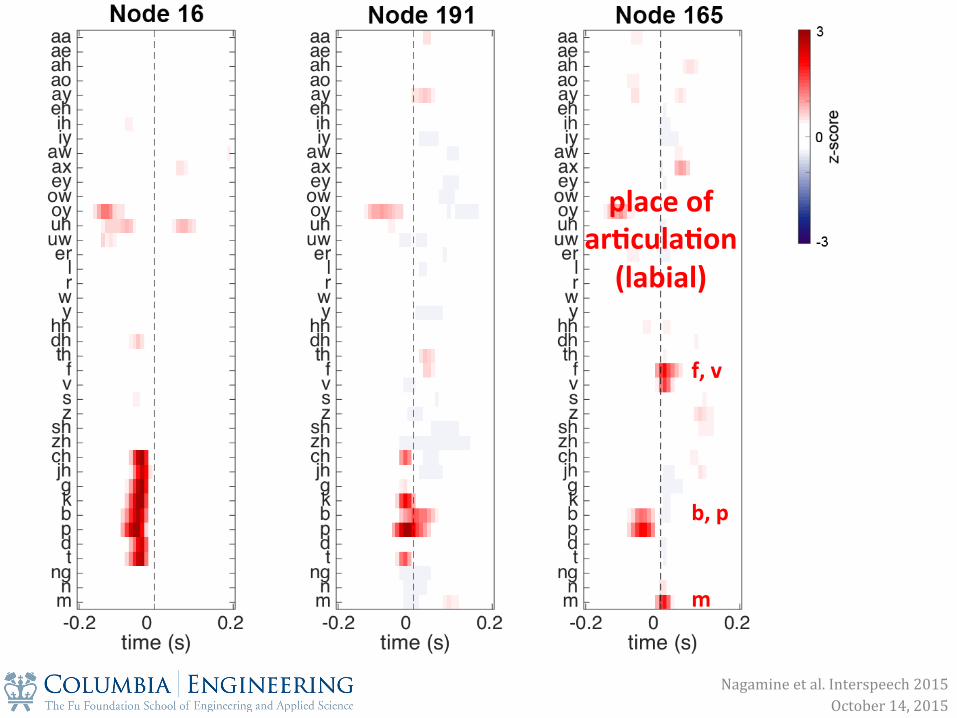
place of ar0cula0on (labial)
f, v b, p m
Nagamine et al. Interspeech 2015 October 14, 2015
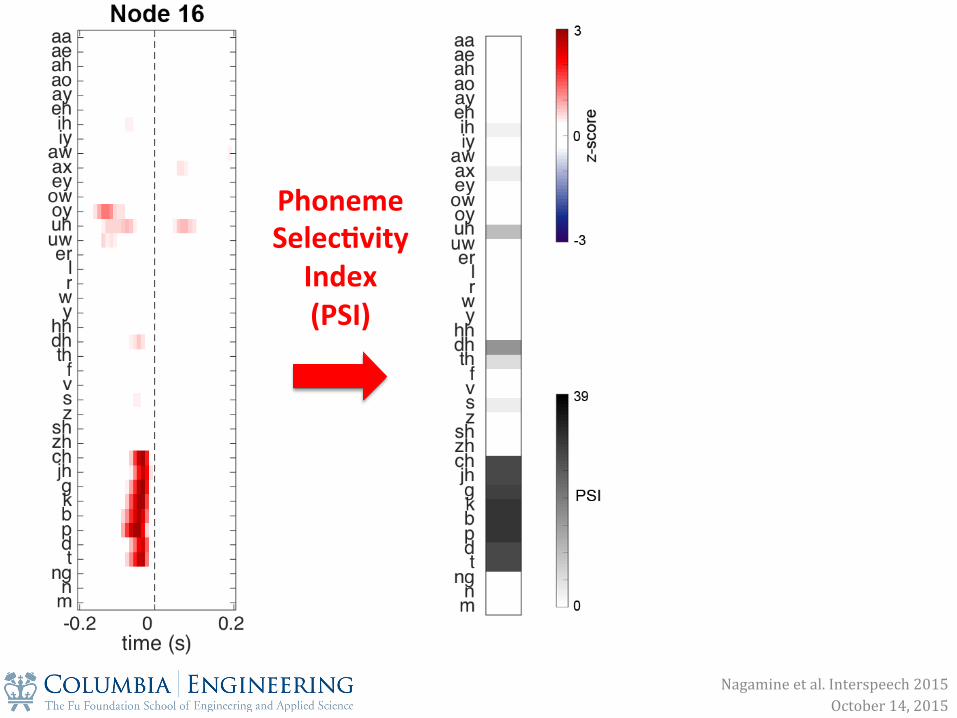
Phoneme Selec0vity Index (PSI)
Nagamine et al. Interspeech 2015 October 14, 2015
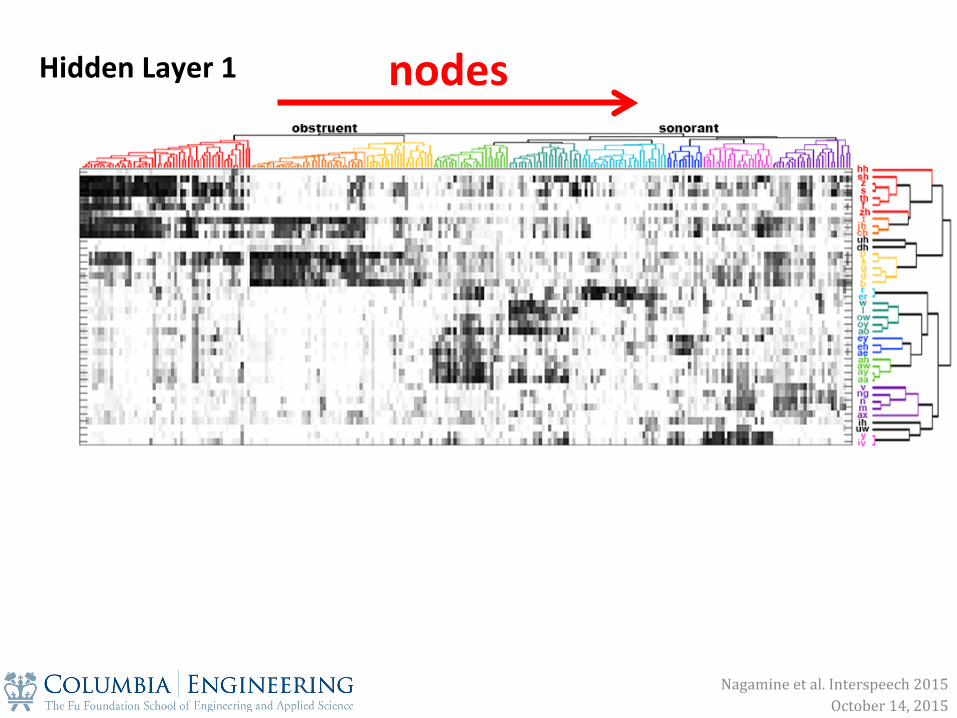
Hidden Layer 1 nodes
Nagamine et al. Interspeech 2015 October 14, 2015

Hidden Layer 1
phonemes
Nagamine et al. Interspeech 2015 October 14, 2015

Hidden Layer 1
Nagamine et al. Interspeech 2015 October 14, 2015
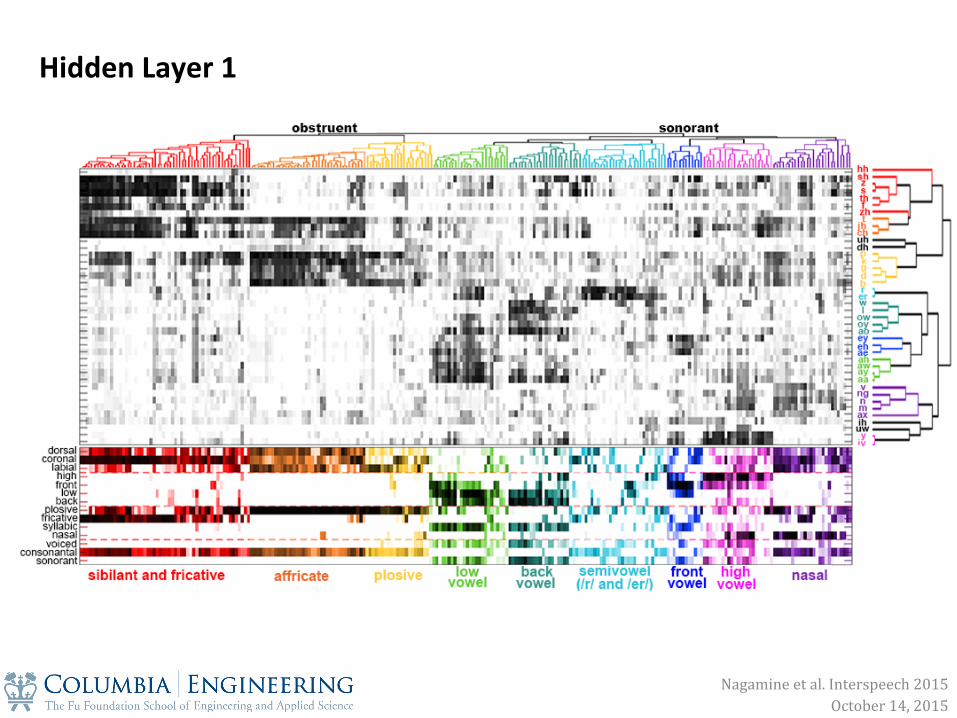
Hidden Layer 1
Nagamine et al. Interspeech 2015 October 14, 2015
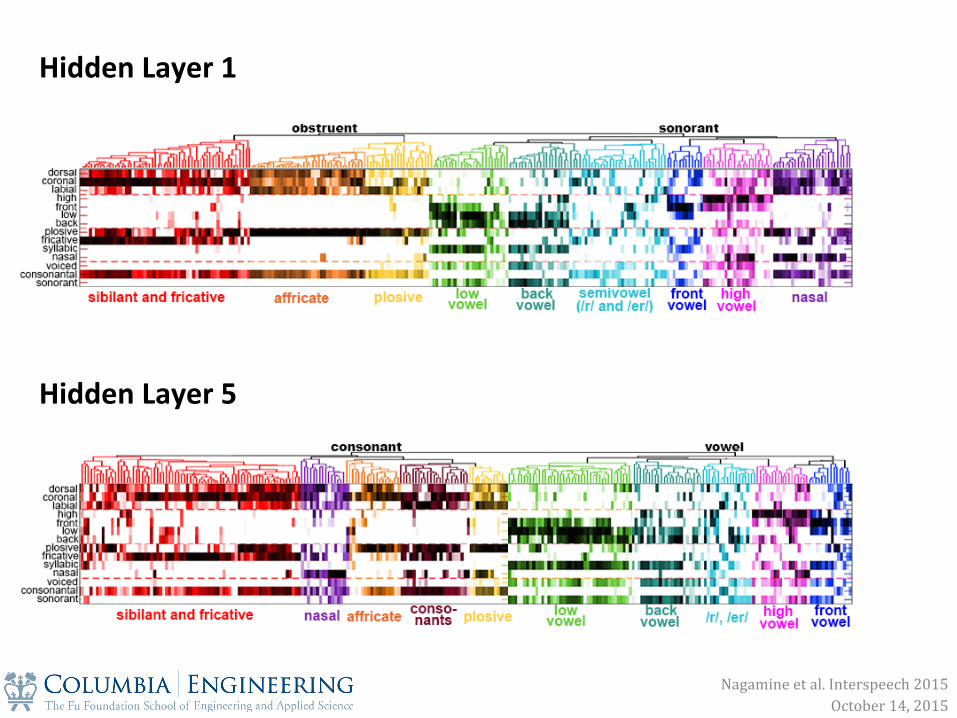
Hidden Layer 1
Hidden Layer 5
Nagamine et al. Interspeech 2015 October 14, 2015
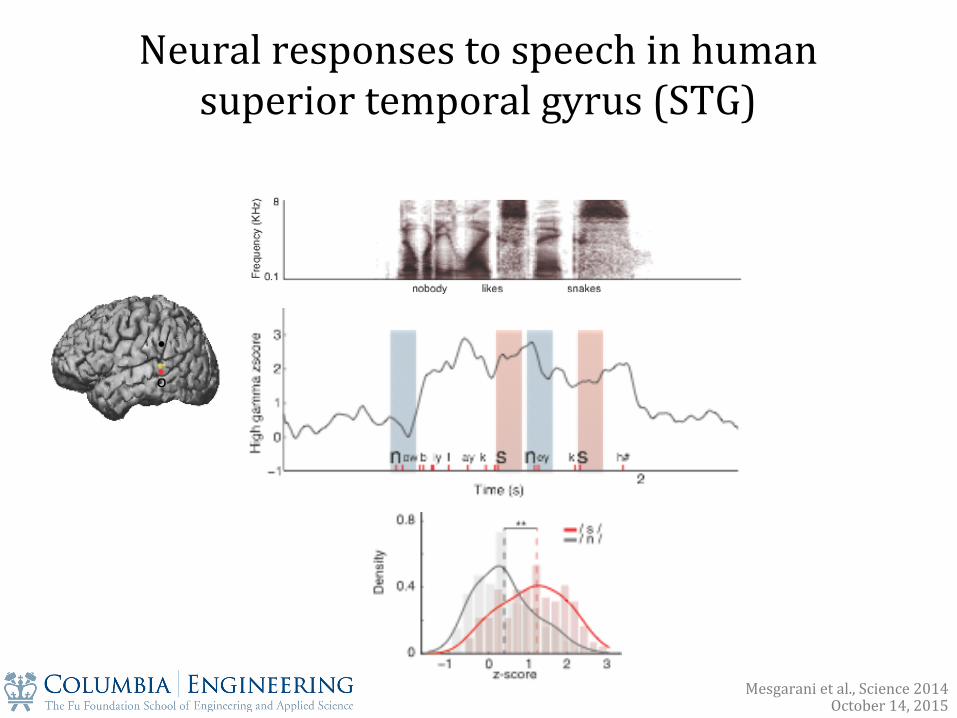
Neural responses to speech in human superior temporal gyrus (STG)
•
o
Mesgarani et al., Science 2014 October 14, 2015
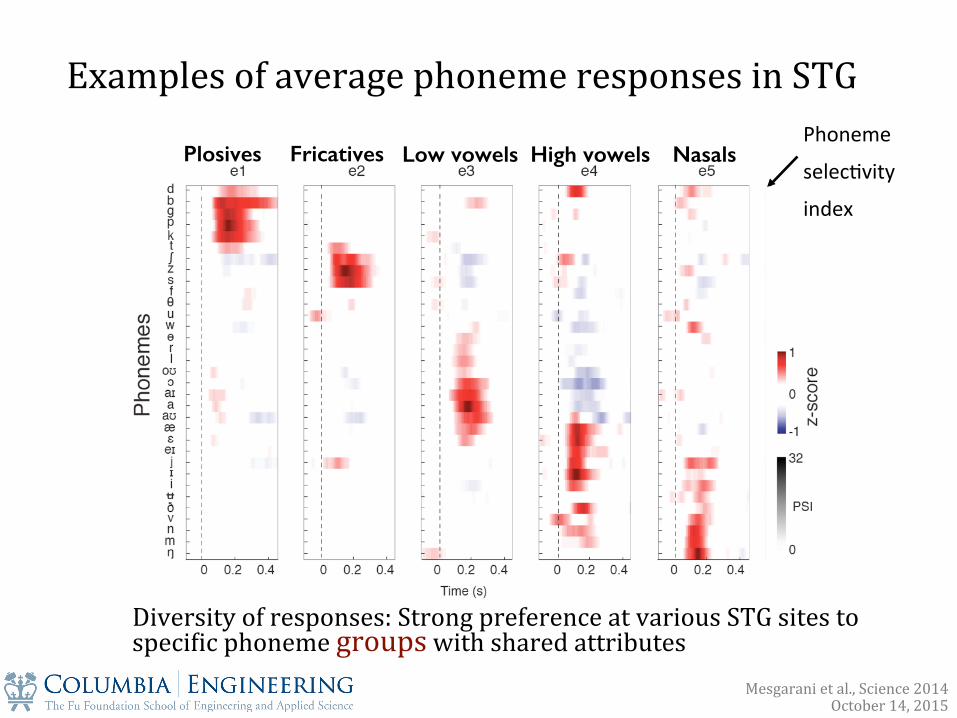
Examples of average phoneme responses in STG
Diversity of responses: Strong preference at various STG sites to speciXic phoneme groups with shared attributes
Plosives! Fricatives! Low vowels! High vowels! Nasals!Phoneme
selec&vity
index
Mesgarani et al., Science 2014 October 14, 2015

Clustering the PSI vectors
Local structures (single electrode)
Global structures
(population)
Manner
Place
Mesgarani et al., Science 2014 October 14, 2015

Summary of Xindings
1. Single nodes and populations of nodes in a layer are selective to phonetic features
2. Phonetic feature encoding becomes more explicit in deeper layers
Nagamine et al. Interspeech 2015 October 14, 2015
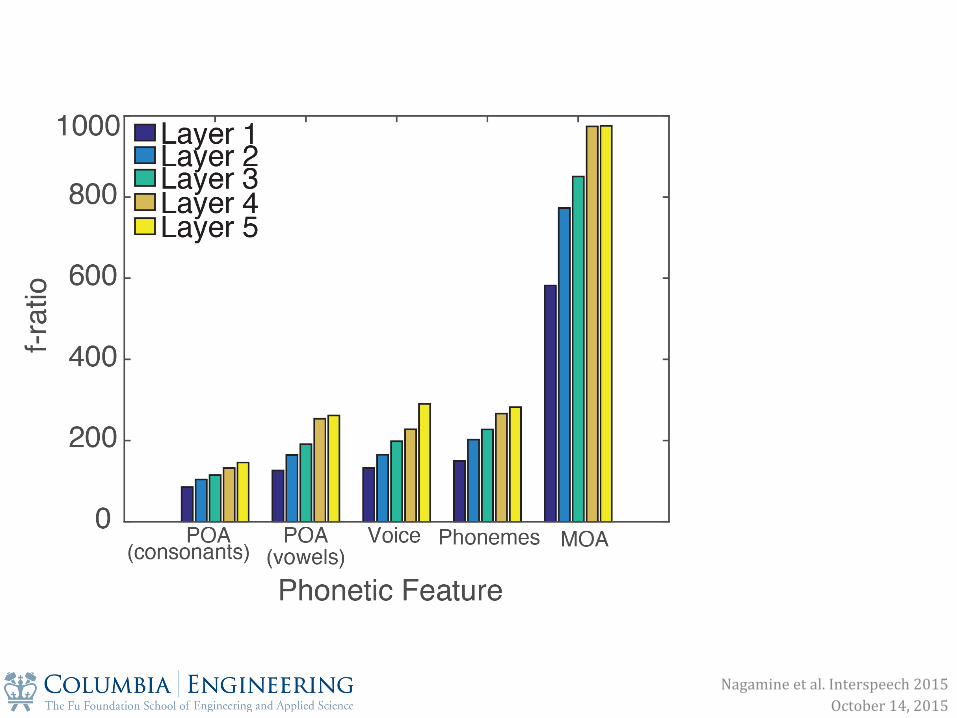
Nagamine et al. Interspeech 2015 October 14, 2015
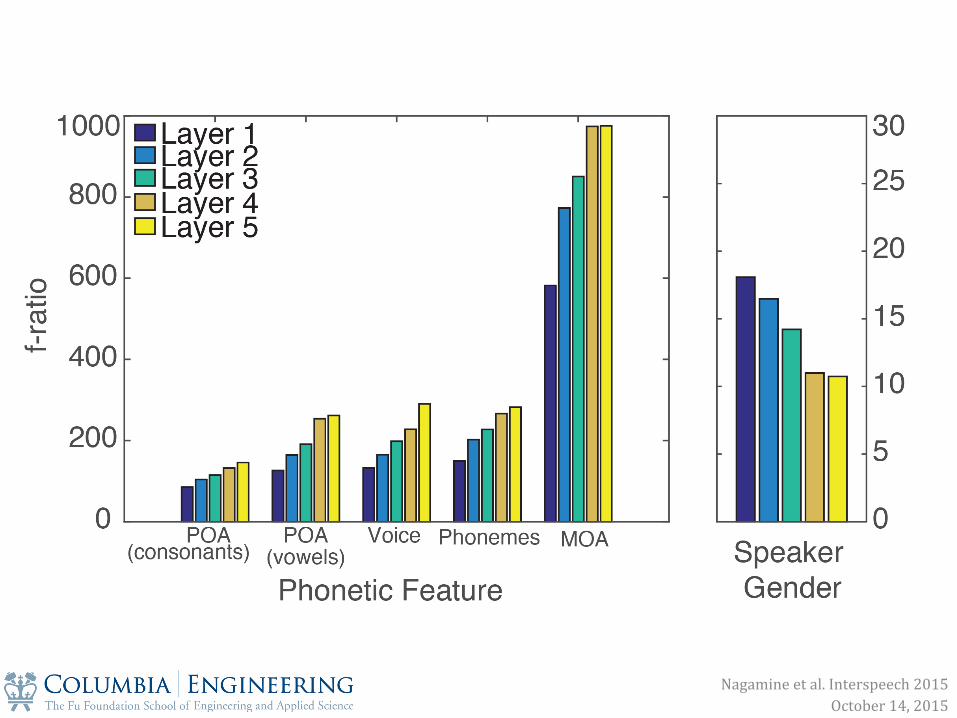
Nagamine et al. Interspeech 2015 October 14, 2015

Summary of Xindings
1. Single nodes and populations of nodes in a layer are selective to phonetic features
2. Node selectivity to phonetic features becomes more explicit in deeper layers
3. Network invariance is learned through explicit representation of sources of variability
Nagamine et al. Interspeech 2015 October 14, 2015

phoneme = “t” example selec0vity for three nodes (N1, N2, N3)
Nagamine et al. Interspeech 2015 October 14, 2015
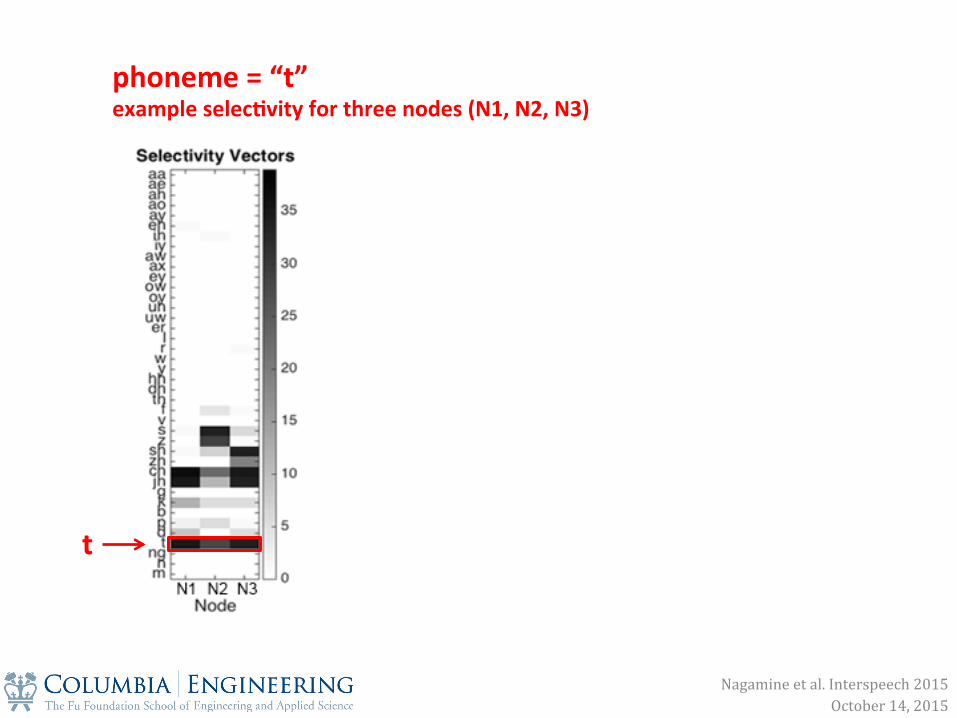
t
phoneme = “t” example selec0vity for three nodes (N1, N2, N3)
Nagamine et al. Interspeech 2015 October 14, 2015
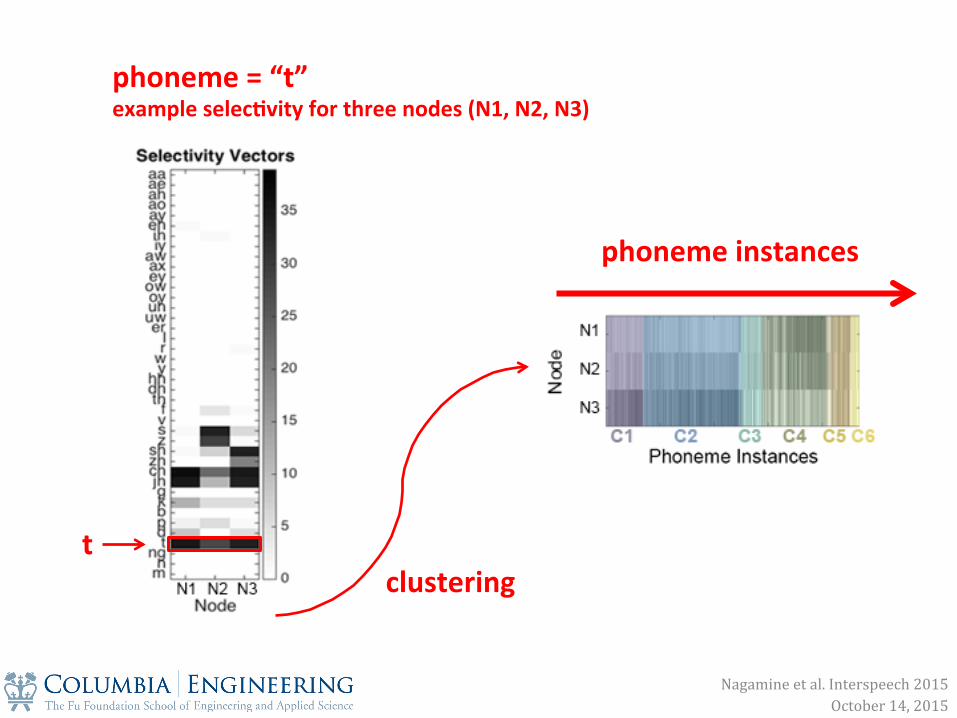
phoneme = “t” example selec0vity for three nodes (N1, N2, N3)
clustering t
phoneme instances
Nagamine et al. Interspeech 2015 October 14, 2015
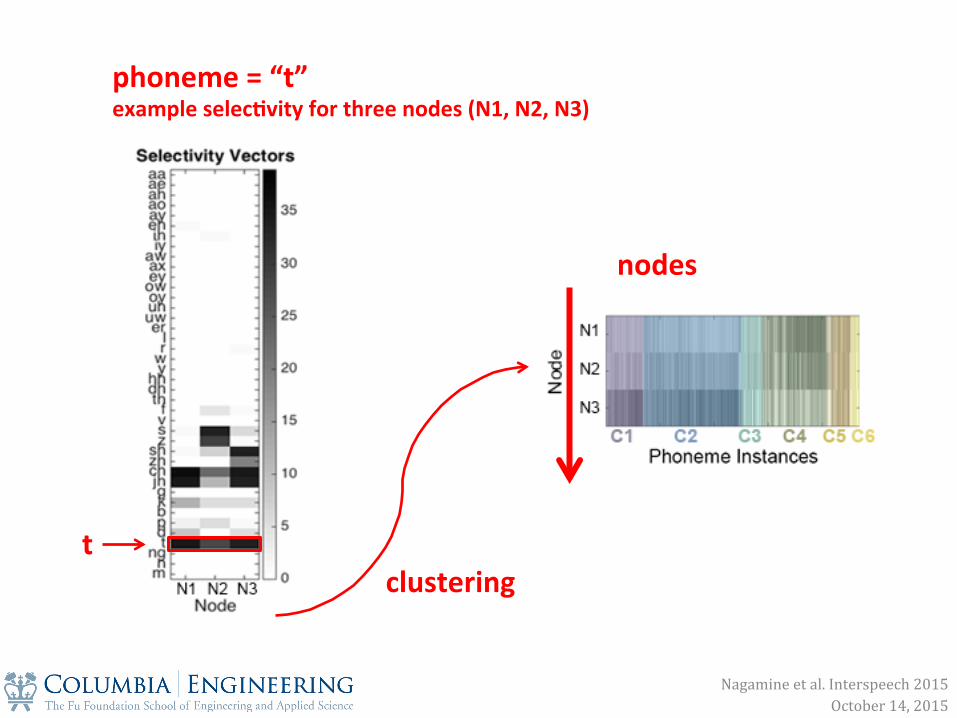
phoneme = “t” example selec0vity for three nodes (N1, N2, N3)
clustering t
nodes
Nagamine et al. Interspeech 2015 October 14, 2015
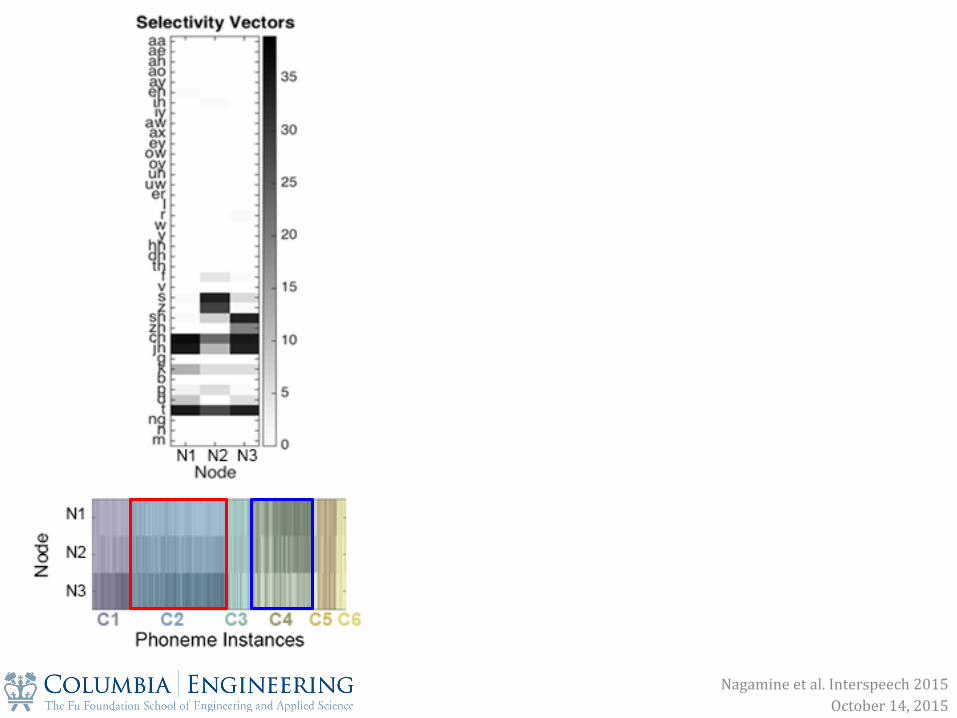
Nagamine et al. Interspeech 2015 October 14, 2015
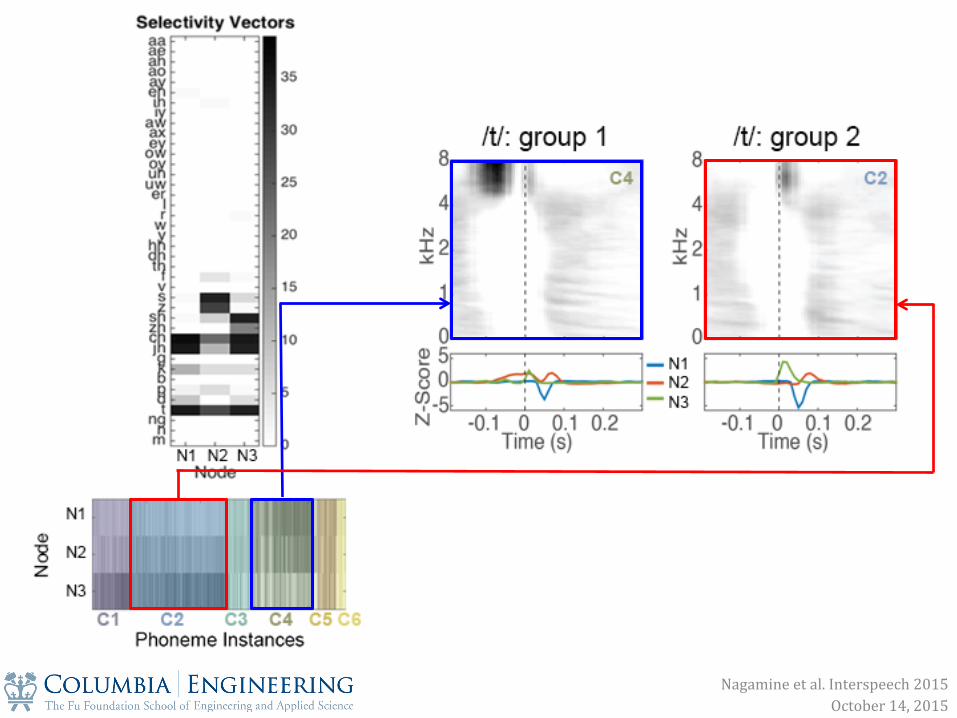
Nagamine et al. Interspeech 2015 October 14, 2015
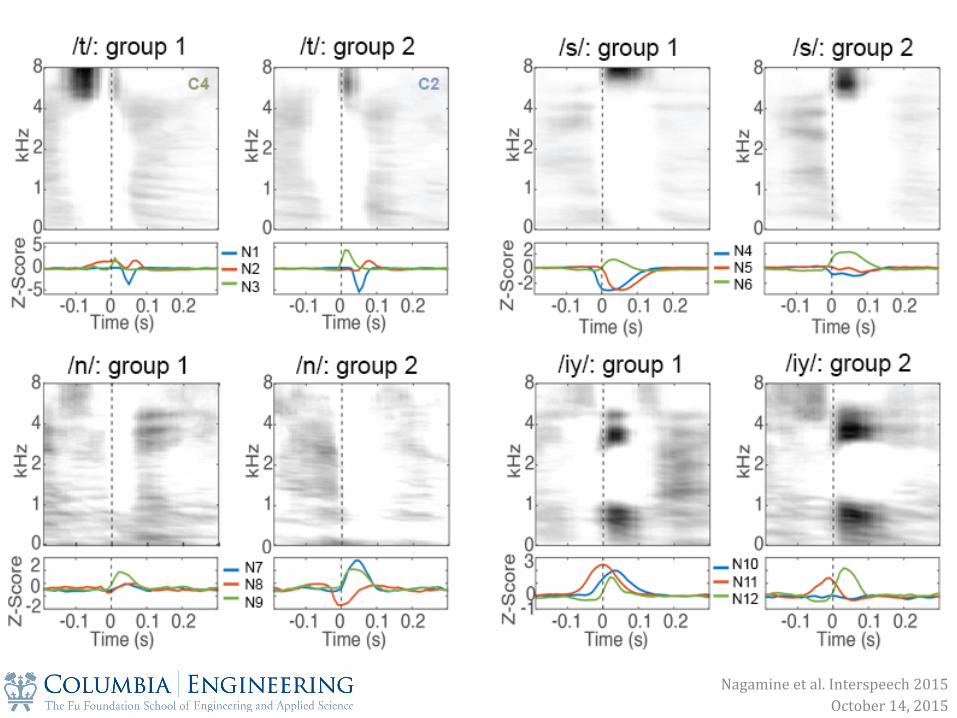
Nagamine et al. Interspeech 2015 October 14, 2015

Summary of Xindings
1. Single nodes and populations of nodes in a layer are selective to phonetic features
2. Node selectivity to phonetic features becomes more explicit in deeper layers
3. Network invariance is learned through explicit representation of sources of variability
Nagamine et al. Interspeech 2015 October 14, 2015

Questions?
Nagamine et al. Interspeech 2015 October 14, 2015
Recommended