Embed Size (px)
Citation preview

XML Fundamentals
Transparency No. 1
XML Fundamentals
Cheng-Chia Chen
November 2004

XML Fundamentals
Transparency No. 2
Well-formed XML Document
An XML document is a sequence of characters: Each character is an atomic unit of text as specified by ISO
/IEC 10646 [unicode]. can be opened/edited with any program that knows how to
read/write a text file usually given a .xml extension file name MIME media type: application/xml or text/xml
Ex:
<?xml version=“1.0” encoding=“UTF-8”>
<student> 張得功 </student>
XML Fundamentals
Transparency No. 3
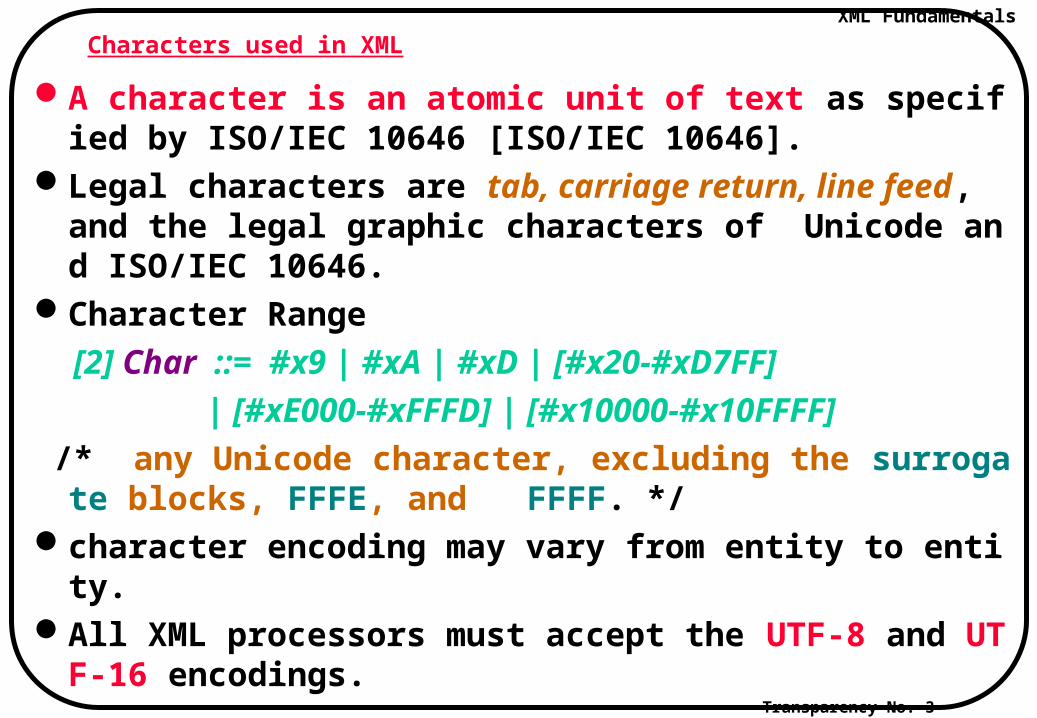
Characters used in XML
A character is an atomic unit of text as specified by ISO/IEC 10646 [ISO/IEC 10646].
Legal characters are tab, carriage return, line feed, and the legal graphic characters of Unicode and ISO/IEC 10646.
Character Range
[2] Char ::= #x9 | #xA | #xD | [#x20-#xD7FF]
| [#xE000-#xFFFD] | [#x10000-#x10FFFF]
/* any Unicode character, excluding the surrogate blocks, FFFE, and FFFF. */
character encoding may vary from entity to entity. All XML processors must accept the UTF-8 and UTF-16 e
ncodings.

XML Fundamentals
Transparency No. 4
Whitespace
White Space:
[3] S ::= (#x20 | #x9 | #xD | #xA)+S (white space) consists of one or more space (#x20) cha
racters, tabs, carriage returns or line feeds.Whitespace can used to separate otherwise indistinguis
hable parts of an XML Document. <student age=“15”>…</student> <studentage=“15”>…</student>

XML Fundamentals
Transparency No. 5
XML Declaration
<?xml version=“1.0” encoding=“Big5” standalone=“no” ?>
Besides using file extension name, an xml document may use an XML declaration to identify itself as an XML document.
If used, it should occur first (no proceding whitespace allowed) in the document.
Version of the
XML specification
1.0 or 1.1
character encoding of
the document, expressed
in Latin characters, e.g.,
UTF-8, UTF-16,
iso-8859-1,
no: parsing affected
by external
DTD subset
yes: not affected .

XML Fundamentals
Transparency No. 6
Elements, tags and character data
The previous example is composed of a single element named student Start-tag: <student> End-tag: </student>
Everything between start-tag and end-tag is called content Content encompasses real information Whitespace is part of the content, though many application
s will choose to ignore it<student> and </student> are markup張得功 and its surrounding whitespace are character dat
a

XML Fundamentals
Transparency No. 7
Structure of an element
Each XML document contains one or more elements, the boundaries of which are either delimited by start-tags and end-tags, or, for empty elements, by an empty-element tag.
Each element has a type, identified by name, and may have a set of attribute specifications. The name used in start-tag and end-tag must be identical. Note: xml is case sensitive, so <student> != <Student>
Each attribute specification has a name and a value. Element
[39] element ::= EmptyElemTag | STag content ETag

XML Fundamentals
Transparency No. 8
Element (cont’d)
The text between the start-tag and end-tag is called the element's content:
Content of Elements
[43] content ::= CharData? ((element | Reference | CDSect | PI | Comment) CharData?)*
If an element is empty, it must be represented either by a start-tag immediately followed by an end-tag or by an empty-element tag.
Tags for Empty Elements [44] EmptyElemTag ::= '<' Name (S Attribute)* S? '/>'
Empty element tags may be used for any element which has no content, whether or not it is declared using the keyword EMPTY.

XML Fundamentals
Transparency No. 9
Examples of empty elements
<IMG align="left” src="http://www.w3.org/Icons/WWW/w3c_home"
/>
<br></br>
<br/>
XML Fundamentals
Transparency No. 10
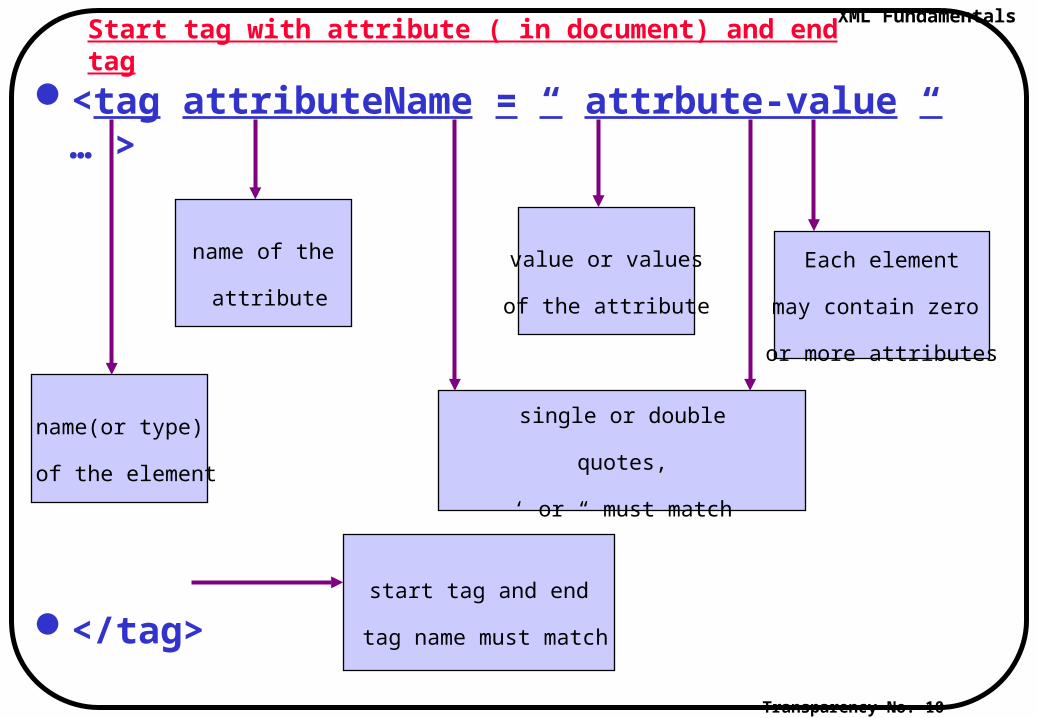
Start tag with attribute ( in document) and end tag
<tag attributeName = “ attrbute-value “ … >
</tag>
name of the
attribute
value or values
of the attribute
name(or type)
of the element
single or double
quotes,
‘ or “ must match
Each element
may contain zero
or more attributes
start tag and end
tag name must match

XML Fundamentals
Transparency No. 11
Attributes
Attach additional information to elementsAn attribute is a name-value pair attached to an element’
s start-tag One element can have more than one attribute Name and value are separated by = and optional whitespac
e Attribute value is enclosed in double or single quotation m
arks <tel type=“office”>02-29381111</tel> Attribute order is not significant <student age=“20” gender=“male”> 趙得勝 </student>

XML Fundamentals
Transparency No. 12
Start Tag
Start-tag
[40] STag ::= '<' Name (S Attribute)* S? '>'
[ WFC: Unique Att Spec ]
[41] Attribute ::= Name Eq AttValue
Example:
<termdef id=“dt-dog” term=“dog”>End-tag
[42] ETag ::= '</' Name S? '>’
Example:
</termdef> </termdef > vs </ termdef> < /termdef>

XML Fundamentals
Transparency No. 13
Use attribute or element ?
Should one use child elements or attributes to hold information? Attributes are for metadata about the element, while eleme
nts are for the information itselfEach element may have no more than one attribute with
a given nameThe value of attribute is simply a text string – limited in s
tructureAn element-based structure is a lot more flexible and ext
ensibleIf you are designing your own XML vocabulary, it is up to
you to decide when to use which

XML Fundamentals
Transparency No. 14
XML Names
Rules for naming elements, attributes…Names and Tokens [4] NameChar ::= Letter | Digit | '.' | '-' | '_' | ':' | CombiningChar | Extender [5] Name ::= (Letter | '_' | ':') (NameChar)* [6] Names ::= Name ( #x20 Name)* [7] Nmtoken ::= (NameChar)+ [8] Nmtokens ::= Nmtoken (#x20 Nmtoken)*
Names beginning with (x|M)(m|M)(l|L) are reserved.Name is used for naming elements, attributes, entities et
c.Nmtoken (Nmtokens) is used for values of special attribu
tes(ID,IDREFS,NMTOKEN,NMTOKENS).

XML Fundamentals
Transparency No. 15
AttValues (attribute value literal)
are those that can occur as an attribute value.
[10] AttValue ::= '"' ([^<&"] | Reference)* '"'
| "'" ([^<&'] | Reference)* "'"
Enclosed by double or single quotes.Can contain entity/char references or any char data but <
and &.
XML Fundamentals
Transparency No. 16
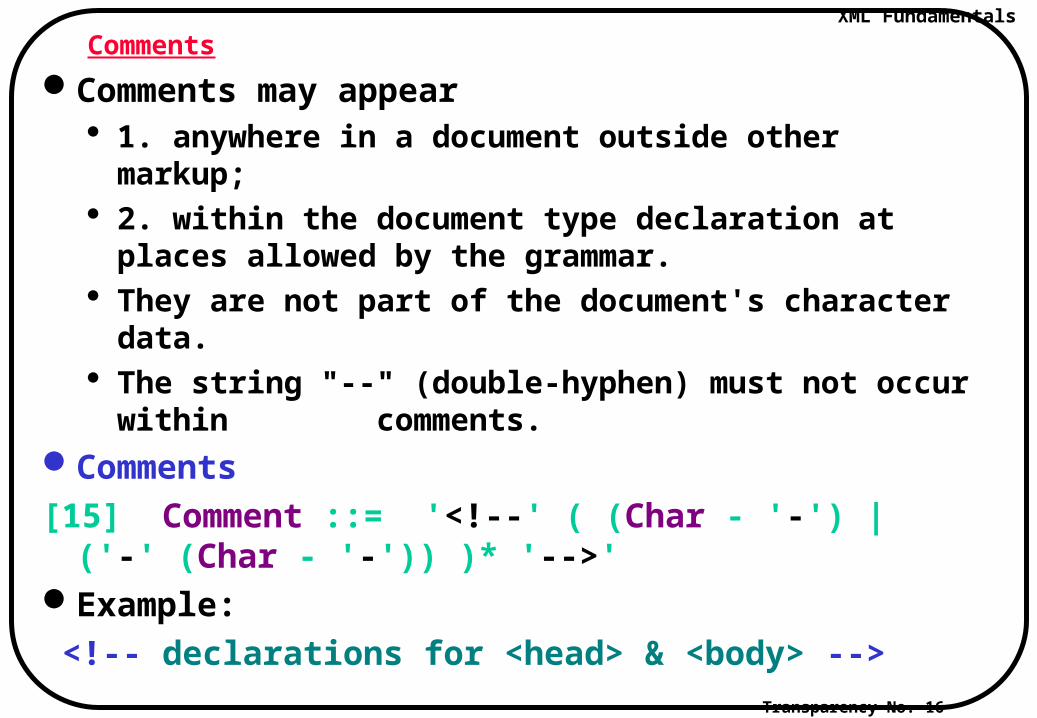
Comments
Comments may appear 1. anywhere in a document outside other markup; 2. within the document type declaration at places
allowed by the grammar. They are not part of the document's character data. The string "--" (double-hyphen) must not occur within
comments. Comments
[15] Comment ::= '<!--' ( (Char - '-') | ('-' (Char - '-')) )* '-->'Example:
<!-- declarations for <head> & <body> -->

XML Fundamentals
Transparency No. 17
Processing Instructions (PIs)
Processing instructions (PIs) allow documents to contain instructions for applications.
Processing Instructions:
[16] PI ::= '<?' PITarget (S (Char* - (Char* '?>' Char*)))? '?>'
[17] PITarget ::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l'))
The PI begins with a target (PITarget) used to identify the application.
The target names "XML", "xml", and so on are reserved for standardization.
Ex: <?xml-stylesheet type=“text/css” href=“style.css” ?>

XML Fundamentals
Transparency No. 18
Processing Instruction and comment
<?PItarget ***other staff*** ?>
<!-- 這是說明或註解 -->
may contain any characters
except the string “--”

XML Fundamentals
Transparency No. 19
XML Document
[1]document ::= prolog element Misc*
elemet is called the root or document element of the document
[22] prolog ::= XMLDecl? Misc* (doctypedecl Misc*)?
[23] XMLDecl ::= '<?xml' VersionInfo EncodingDecl?
SDDecl? S? '?>'
[27] Misc ::= Comment | PI | S
XML Fundamentals
Transparency No. 20
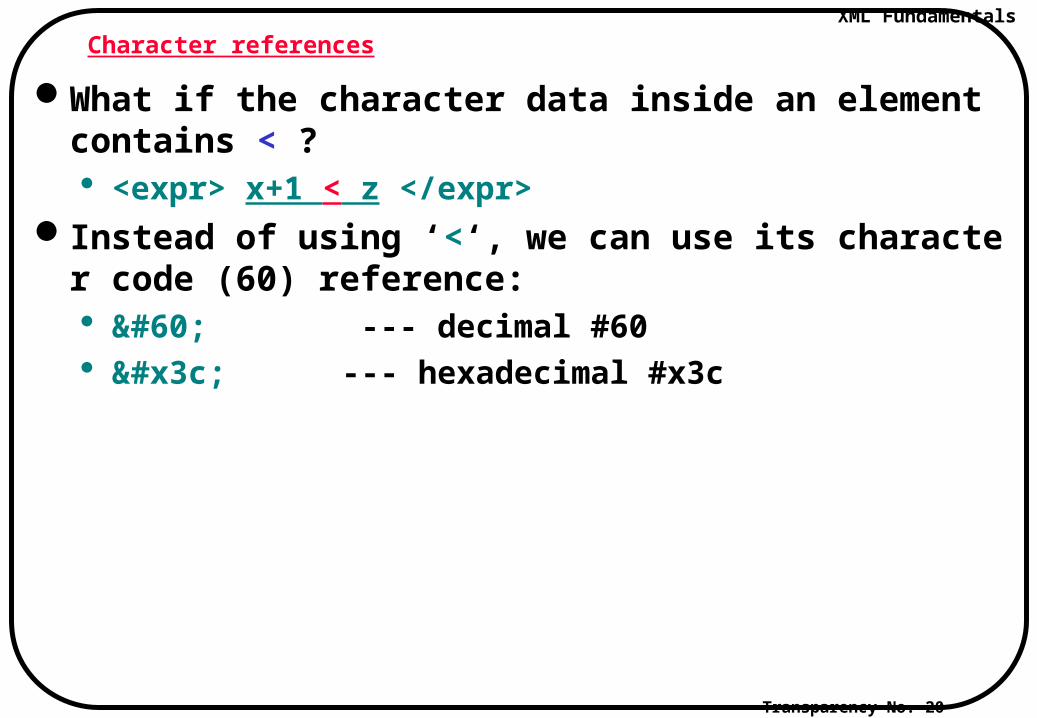
Character references
What if the character data inside an element contains < ? <expr> x+1 < z </expr>
Instead of using ‘<‘, we can use its character code (60) reference: < --- decimal #60 < --- hexadecimal #x3c

XML Fundamentals
Transparency No. 21
Entity reference
Numeric code is hard to remember. Can use a name to denote a char or a sequence of chars Such name is called entity.
Entity reference – If xxx is an entity => &xxx; is it entity reference when parsing an XML document, xml processor replaces t
he entity reference with the actual characters to which the entity reference refers
XML predefines 5 entity references – you can define more < – the less-than sign (<) & – the ampersand (&) > – the greater-than sign(>) " – the straight, double quotation marks (") ' – the straight single quote (')

XML Fundamentals
Transparency No. 22
CDATA Section
What if my element content has a lot of special characters ? Ex: <expr> x < y && z < 1 </expr>
Solution 1: <expr> x < y &s;&s; z < 1 </expr> Hard to read
Solution 2: <expr><![CDATA[ x < y && z < 1 ]]></expr>
XML Fundamentals
Transparency No. 23
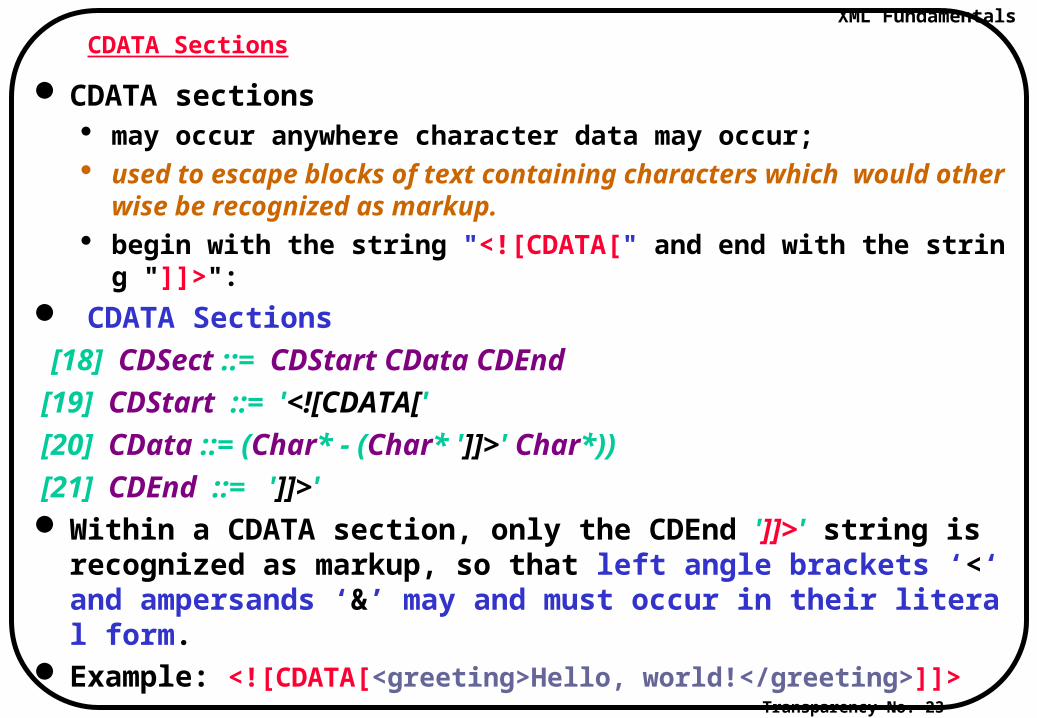
CDATA Sections
CDATA sections may occur anywhere character data may occur; used to escape blocks of text containing characters which would othe
rwise be recognized as markup. begin with the string "<![CDATA[" and end with the string "]]>":
CDATA Sections
[18] CDSect ::= CDStart CData CDEnd
[19] CDStart ::= '<![CDATA['
[20] CData ::= (Char* - (Char* ']]>' Char*))
[21] CDEnd ::= ']]>' Within a CDATA section, only the CDEnd ']]>' string is recognized a
s markup, so that left angle brackets ‘<‘ and ampersands ‘&’ may and must occur in their literal form.
Example: <![CDATA[<greeting>Hello, world!</greeting>]]>

XML Fundamentals
Transparency No. 24
Character Data and Markup
XML Document consists of intermingled character data and markup. Markup takes the form of start-tags, end-tags, empty-element tags, entity references, character references, comments, CDATA section delimiters, document type declarations, processing instructions, XML declarations, text declarations and white space outside root element
All text that is not markup constitutes the character data of the document. I.e., it may occur in the content of an element or In the content of an CDATA Section.

XML Fundamentals
Transparency No. 25
Character Data and Markup (cont’d)
In the content of elements, character data is any string of characters which does not contain the start-delimiter of any markup.
In a CDATA section, character data is any string of characters not including the CDATA-section-close delimiter, "]]>".
To allow attribute values to contain both single and double quotes, the apostrophe or single-quote character (') may be represented as "'", and the double-quote character (") as """.
Character Data :
[14] CharData ::= [^<&]* - ([^<&]* ']]>' [^<&]*) i.e., Any string containing none of <, & and ]]>.

XML Fundamentals
Transparency No. 26
Possible contents of an element content
Element
[39] element ::= EmptyElemTag | STag content ETag
Content of Elements
[43] content ::= CharData? ((element | Reference | CDSect | PI | Comment) CharData?)*
In addition to char data and child elements, an element may contain as children also references, PIs, comments or CDATA sections.

XML Fundamentals
Transparency No. 27
Rules for well-formed XML Documents
1: balance start and end tags The set of tags is unlimited but all start tags must have mat
ching end tags
Example of legal XML <student>
<name> DeTsi Wang</name><email> [email protected]</email><age> 20 </age></student>
2: There must be exactly one root element

XML Fundamentals
Transparency No. 28
Rules for well-formed XML Documents
Rule 3: Proper element nesting All tags must be nested correctly. Like HTML, XML can inte
rmix tags and text, but tags may not overlap each other. Legal XML
<student><name> DeTsi Wang</name><email> [email protected]</email><age> 20 </age>
</student> Illegal XML
<b><i>This text is bold and italic</b> and italic</i>

XML Fundamentals
Transparency No. 29
Rules for well-formed XML Documents
Rule 4: Attribute values must be single or double quoted Legal
<tag attribute=“value”><tag attribute=‘value’>
Illegal<font size=6> <font size=“60’>
Rule 5: An element may not have two attributes with the same name <font size=“6” size = “10”/>
Rule 6: Comments and processing instructions may not appear inside tags <font <!– error comment --> size = “6” />
Rule 7: No unescaped < or & signs may occur in the character data of an element or attributes <font zise=“<20”> 20&3 </font>





























