Embed Size (px)
Citation preview

Workbook 8String Processing Tools
Pace Center for Business and Technology
1

String Processing Tools
Key Concepts •When storing text, computers transform characters into a numeric representation. This process is referred to as encoding the text. •In order to accommodate the demands of a variety of languages, several different encoding techniques have been developed. These techniques are represented by a variety of character sets. •The oldest and most prevalent encoding technique is known as the ASCII character set, which still serves as a least common denominator among other techniques. •The wc command counts the number of characters, words, and lines in a file. When applied to structured data, the wc command can become a versatile counting tool. •The cat command has options that allow representation of nonprinting characters such as NEWLINE. •The head and tail commands have options that allow you to print only a certain number of lines or a certain number of bytes (one byte usually correlates to one character) from a file.
2

What are Files? • Linux, like most operating systems, stores information that needs to be
preserved outside of the context of any individual process in files. (In this context, and for most of this Workbook, the term file is meant in the sense of regular file). Linux (and Unix) files store information using a simple model: information is stored as a single, ordered array of bytes, starting from at first and ending at the last. The number of bytes in the array is the length of the file. [9]
• What type of information is stored in files? Here are but a few examples. • The characters that compose the book report you want to store until you
can come back and finish it tomorrow are stored in a file called (say) ~/bookreport.txt.
• The individual colors that make up the picture you took with your digital camera are stored in the file (say) /mnt/camera/dcim/100nikon/dscn1203.jpg.
• The characters which define the usernames of users on a Linux system (and their home directories, etc.) are stored in the file /etc/passwd.
• The specific instructions which tell an x86 compatible CPU how to use the Linux kernel to list the files in a given directory are stored in the file /bin/ls.
3

What is a Byte? At the lowest level, computers can only answer one type of question: is it on or off? What is it? When dealing with disks, it is a magnetic domain which is oriented up or down. When dealing with memory chips, it is a transistor which either has current or doesn't. Both of these are too difficult to mentally picture, so we will speak in terms of light switches that can either be on or off. To your computer, the contents of your file is reduced to what can be thought of as an array of (perhaps millions of) light switches. Each light switch can be used to store one bit of information (is it on, or is it off). Using a single light switch, you cannot store much information. To be more useful, an early convention was established: group the light switches into bunches of 8. Each series of 8 light switches (or magnetic domains, or transistors, ...) is a byte. More formally, a byte consists of 8 bits. Each permutation of ons and offs for a group of 8 switches can be assigned a number. All switches off, we'll assign 0. Only the first switch on, we'll assign 1; only the second switch on, 2; the first and second switch on, 3; and so on. How many numbers will it take to label each possible permutation for 8 light switches? A mathematician will quickly tell you the answer is 2^8, or 256. After grouping the light switches into groups of eight, your computer views the contents of your file as an array of bytes, each with a value ranging from 0 to 255. 4

Data EncodingIn order to store information as a series of bytes, the information must be somehow converted into a series of values ranging from 0 to 255. Converting information into such a format is called data encoding. What's the best way to do it? There is no single best way that works for all situations. Developing the right technique to encode data, which balances the goals of simplicity, efficiency (in terms of CPU performance and on disk storage), resilience to corruption, etc., is much of the art of computer science. As one example, consider the picture taken by a digital camera mentioned above. One encoding technique would divide the picture into pixels (dots), and for each pixel, record three bytes of information: the pixel's "redness", "greenness", and "blueness", each on a scale of 0 to 255. The first three bytes of the file would record the information for the first pixel, the second three bytes the second pixel, and so on. A picture format known as "PNM" does just this (plus some header information, such as how many pixels are in a row). Many other encoding techniques for images exist, some just as simple, many much more complex.
5

Text EncodingPerhaps the most common type of data which computers are asked to store is text. As computers have developed, a variety of techniques for encoding text have been developed, from the simple in concept (which could encode only the Latin alphabet used in Western languages) to complicated but powerful techniques that attempt to encode all forms of human written communication, even attempting to include historical languages such as Egyptian hieroglyphics. The following sections discuss many of the encoding techniques commonly used in Red Hat Enterprise Linux.
6
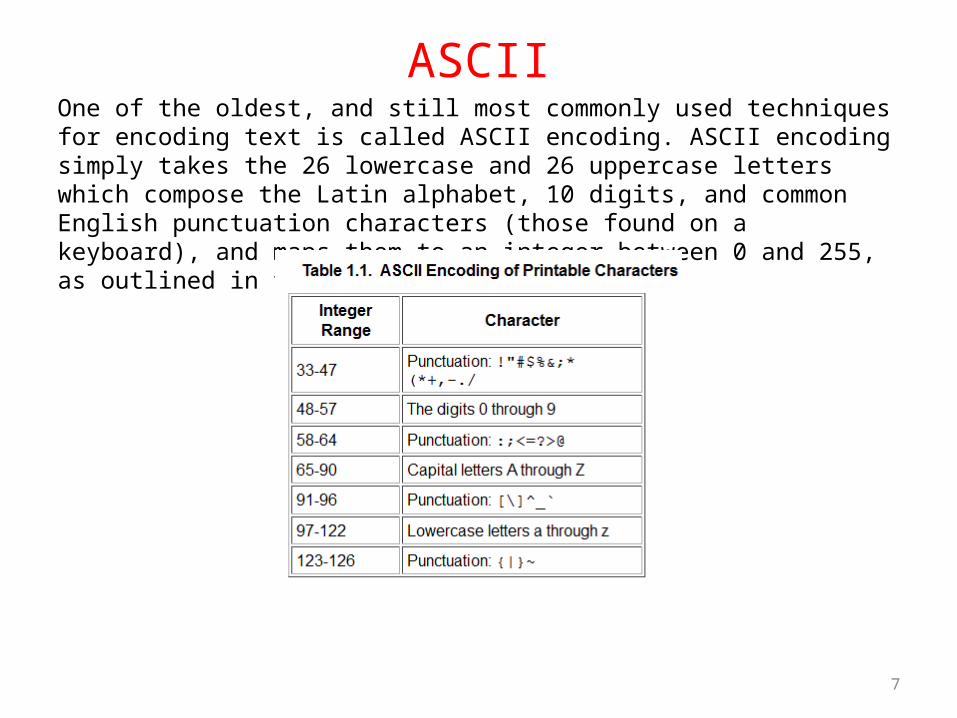
ASCIIOne of the oldest, and still most commonly used techniques for encoding text is called ASCII encoding. ASCII encoding simply takes the 26 lowercase and 26 uppercase letters which compose the Latin alphabet, 10 digits, and common English punctuation characters (those found on a keyboard), and maps them to an integer between 0 and 255, as outlined in the following table.
7
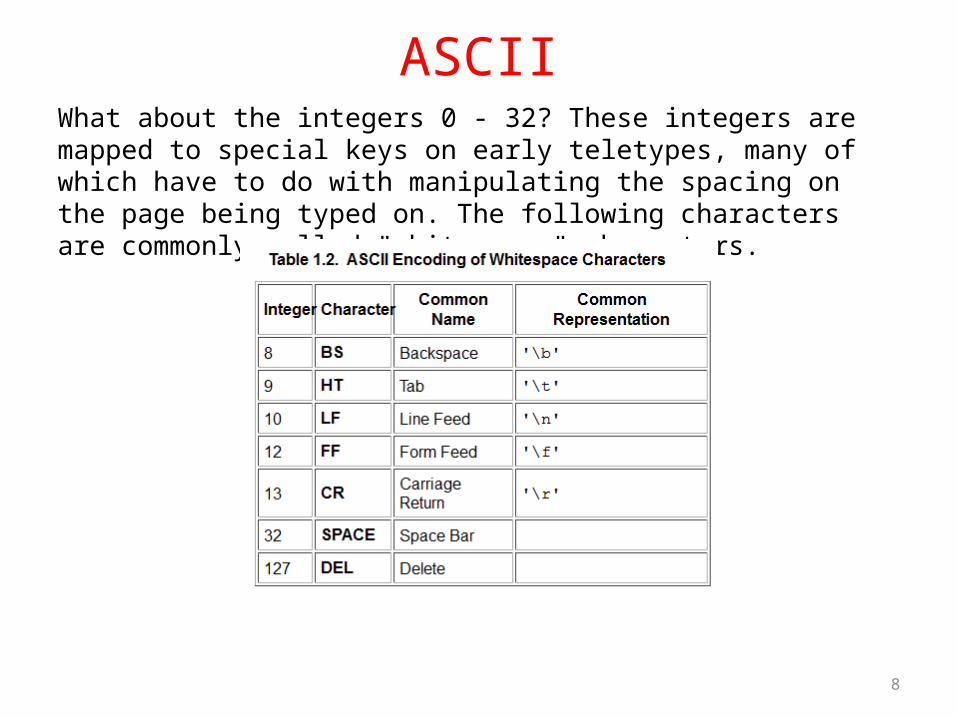
ASCIIWhat about the integers 0 - 32? These integers are mapped to special keys on early teletypes, many of which have to do with manipulating the spacing on the page being typed on. The following characters are commonly called "whitespace" characters.
8

Others of the first 32 integers are mapped to keys which did not directly influence the "printed page", but instead sent "out of band" control signals between two teletypes. Many of these control signals have special interpretations within Linux (and Unix).
ASCII
9

Generating Control Characters from the Keyboard
Control and whitespace characters can be generated from the terminal keyboard directly using the CTRL key. For example, an audible bell can be generated using CTRL+G, while a backspace can be sent using CTRL+H, and we have already mentioned that CTRL+D is used to generate an "End of File" (or "End of Transmission"). Can you determine how the whitespace and control characters are mapped to the various CTRL key combinations? For example, what CTRL key combination generates a tab? What does CTRL+J generate? As you explore various control sequences, remember that the reset command will restore your terminal to sane behavior, if necessary. A tab can be generated with CTRL+I, while CTRL+J will generate a line feed (akin to hitting the RETURN key). In general, CTRL+A will generate ASCII character 1, CTRL+B will generate ASCII character 2, and so on. What about the values 128-255? ASCII encoding does not use them. The ASCII standard only defines the first 128 values of a byte, leaving the remaining 128 values to be defined by other schemes.
10

ISO 8859 and Other Character Sets Other standard encoding schemes have been developed, which map various glyphs (such as the symbol for the Yen and Euro), diacritical marks found in many European languages, and non Latin alphabets to the latter 128 values of a byte which the ASCII standard leaves undefined. The following table lists a few of these standard encoding schemes, which are referred to as character sets. The following table lists some character sets which are supported in Linux, including their informal name, formal name, and a brief description.
11

Notice a couple of implications about ISO 8859 encoding. 1.Each of the alternate encodings map a single glyph to a single byte, so that the number of letters encoded in a file equals the number of bytes which are required to encode them. 2.Choosing a particular character set extends the range of characters that can be encoded, but you cannot encode characters from different character sets simultaneously. For example, you could not encode both a Latin capital A with a grave and a Greek letter Delta simultaneously.
ISO 8859 and Other Character Sets
12

Unicode (UCS) In order to overcome the limitations of ASCII and ISO 8859 based encoding techniques, a Universal Character Set has been developed, commonly referred to as UCS, or Unicode. The Unicode standard acknowledges the fact that one byte of information, with its ability to encode 256 different values, is simply not enough to encode the variety of glyphs found in human communication. Instead, the Unicode standard uses 4 bytes to encode each character. Think of 4 bytes as 32 light switches. If we were to again label each permutation of on and off for 32 switches with integers, the mathematician would tell you that you would need 4,294,967,296 (over 4 billion) integers. Thus, Unicode can encode over 4 billion glyphs (nearly enough for every person on the earth to have their own unique glyph; the user prince would approve).
13

Unicode (UCS) What are some of the features and drawbacks of Unicode encoding? Scale The Unicode standard will easily be able to encode the variety of glyphs used in human communication for a long time to come. Simplicity The Unicode standard does have the simplicity of a sledgehammer. The number of bytes required to encode a set of characters is simply the number of characters multiplied by 4. Waste While The Unicode standard is simple in concept, it is also very wasteful. The ability to encode 4 billion glyphs is nice, but in reality, much of the communication that occurs today uses less than a few hundred glyphs. Of the 32 bits (light switches) used to encode each character, the first 20 or so would always be "off". ASCII Non-compatibilityFor better or for worse, a huge amount of existing data is already ASCII encoded. In order to convert fully to Unicode, that data, and the programs that expect to read it, would have to be converted.
14

Unicode Transformation Format (UTF-8) UTF-8 encoding attempts to balance the flexibility of Unicode, and the practicality and pervasiveness of ASCII, with a significant sacrifice: variable length encoding. With variable length encoding, each character is no longer encoded using simply 1 byte, or simply 4 bytes. Instead, the traditional 127 ASCII characters are encoded using 1 byte (and, in fact, are identical to the existing ASCII standard). The next most commonly used 2000 or so characters are encoded using two bytes. The next 63000 or so characters are encoded using three bytes, and the more esoteric characters may be encoded using from four to six bytes. Details of the encoding technique can be found in the utf-8(7) man page. With full backwards compatibility to ASCII, and the same functional range of pure Unicode, what is there to lose? ISO 8859 (and similar) character set compatibility. UTF-8 attempts to bridge the gap between ASCII, which can be viewed as the primitive days of text encoding, and Unicode, which can be viewed as the utopia to aspire toward. Unfortunately, the "intermediate" methods, the ISO 8859 and other alternate character sets, are as incompatible with UTF-8 as they are with each other. Additionally, the simple relationship between the number of characters that are being stored and the amount of space (measured in bytes) it takes to store them is lost. How much space will it take to store 879 printed characters? If they are pure ASCII, the answer is 879. If they are Greek or Cyrillic, the answer is closer to twice that much.
15

Text Encoding and the Open Source Community In the traditional development of operating systems, decisions such as what type of character encoding to use can be made centrally, with the possible disadvantage that the decision is wrong for some community of the operating system's users. In contrast, in the open source development model, these types of decisions are generally made by individuals and small groups of contributors. The advantages of the open source model are a flexible system which can accommodate a wide variety of encoding formats. The disadvantage is that users must often be educated and made aware of the issues involved with character encoding, because some parts of the assembled system use one technique while others parts use another. The library of man pages is an excellent example
16

When contributors to the open source community are faced with decisions involving potentially incompatible formats, they generally balance local needs with an appreciation for adhering to widely accepted standards where appropriate. The UTF-8 encoding format seems to be evolving as an accepted standard, and in recent releases has become the default for Red Hat Enterprise Linux. The following paragraph, extracted from the utf-8(7) man page, says it well:
Text Encoding and the Open Source Community
17

Internationalization (i18n) As this Workbook continues to discuss many tools and techniques for searching, sorting, and manipulating text, the topic of internationalization cannot be avoided. In the open source community, internationalization is often abbreviated as i18n, a shorthand for saying "i-n with 18 letters in between". Applications which have been internationalized take into account different languages. In the Linux (and Unix) community, most applications look for the LANG environment variable to determine which language to use. At the simplest, this implies that programs will emit messages in the user's native language. More subtly, the choice of a particular language has implications for sorting orders, numeric formats, text encoding, and other issues.
18

The LANG environment variable The LANG environment variable is used to define a user's language, and possibly the default encoding technique as well. The variable is expected to be set to a string using the following syntax:
The locale command can be used to examine your current configuration (as can echo $LANG), while locale -a will list all settings currently supported by your system. The extent of the support for any given language will vary.
19
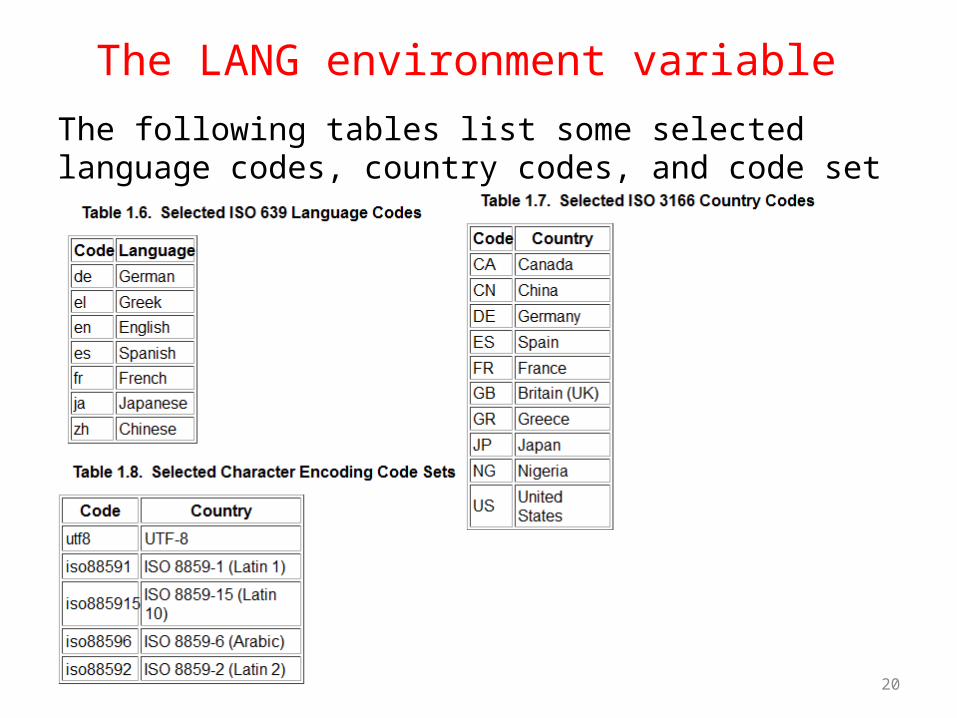
The following tables list some selected language codes, country codes, and code set specifications.
The LANG environment variable
20

Revisiting cat, head, and tail Revisiting cat We have been using the cat command to simply display the contents of files. Usually, the cat command generates a faithful copy of its input, without performing any edits or conversions. When called with one of the following command line switches, however, the cat command will indicate the presence tabs, line feeds, and other control sequences, using the following conventions. Using the -A command line switch, the whitespace structure of the file becomes evident, as tabs are replaced with ^I, and line feeds are decorated with $. E.g. cat -A /etc/hosts
21

Revisiting head and tail The head and tail commands have been used to display the first or last few lines of a file, respectively. But what makes a line? Imagine yourself working at a typewriter: click! clack! click! clack! clack! ziiing! Instead of the ziing! of the typewriter carriage at the end of each line, the line feed character (ASCII 10) is chosen to mark the end of lines. Unfortunately, a common convention for how to mark the end of a line is not shared among the dominant operating systems in use today. Linux (and Unix) uses the line feed character (ASCII 10, often represented \n), while Macintosh operating systems uses the carriage return character (ASCII 13, often represented \r or ^M), and Microsoft operating systems use a carriage return/line feed pair (ASCII 13, ASCII 10).
22

For example, the following file contains a list of four musicians.
Linux (and Unix) text files generally adhere to a convention that the last character of the file must be a line feed for the last line of text. Following the cat of the file musicians.mac, which does not contain any conventional Linux line feed characters, the bash prompt is not displayed in its usual location.
Revisiting head and tail
23

Revisiting head and tail
24

The wc (Word Count) Command
Counting Made Easy Have you ever tried to answer a “25 words or less” quiz? Did you ever have to write a 1500-word essay? With the wc you can easily verify that your contribution meets the criteria. The wc command counts the number of characters, words, and lines. It will take its input either from files named on its command line or from its standard input. Below is the command line form for the wc program:
25

When used without any command line switches, wc will report on the number of characters, lines, and words. Command line switches can be combined to return any combination of character count, line count or word count.
The wc (Word Count) Command
26

Text files are composed using an alphabet of characters. Some characters are visible, such as numbers and letters. Some characters are used for horizontal distance, such as spaces and TAB characters. Some characters are used for vertical movement, such as carriage returns and line feeds. A line in a text file is a series of any character other than a NEWLINE (line feed) character and then a NEWLINE character. Additional lines in the file immediately follow the first line. While a computer represents characters as numbers, the exact value used for each symbol varies depending on which alphabet has been chosen. The most common alphabet for English speakers is ASCII, also called “Latin-1”. Different human languages are represented by different computer encoding rules, so the exact numeric value for a given character depends on the human language being recorded.
How To Recognize A Real Character
27

So, What Is A Word? A word is a group of printing characters, such as letters and digits, surrounded by white space, such as space characters or horizontal TAB characters. Notice that our definition of a word does not include any notion of “meaning”. Only the form of the word is important, not its semantics. As far as Linux is concerned, a line such as:
28

QuestionsChapter 1. Text Encoding and Word Counting
1 and 2
29

Chapter 2. Finding Text: grepKey Concepts •grep is a command that prints lines that match a specified text string or pattern. •grep is commonly used as a filter to reduce output to only desired items. •grep -r will recursively grep files underneath a given directory. •grep -v prints lines that do NOT match a specified text string or pattern. •Many other command line switches allow users to specify grep's output format.
30

Searching Text File Contents using grep In an earlier Lesson, we saw how the wc program can be used to count the characters, words and lines in text files. In this Lesson we introduce the grep program, a handy tool for searching text file contents for specific words or character sequences. The name grep stands for general regular expression parser. What, you may well ask, is a regular expression and why on earth should I want to parse one? We will provide a more formal definition of regular expressions in a later Lesson, but for now it is enough to know that a regular expression is simply a way of describing a pattern, or template, to match some sequence of characters. A simple regular expression would be “Hello”, which matches exactly five characters: “H”, “e”, two consecutive “l” characters, and a final “o”. More powerful search patterns are possible and we shall examine them in the next section. The figure below gives the general form of the grep command line:
31

There are actually three different names for the grep tool [10]: fgrep Does a fast search for simple patterns. Use this command to quickly locate patterns without any wildcard characters, useful when searching for an ordinary word. grep Pattern searches using ordinary regular expressions. egrep Pattern searches using more powerful extended regular expressions.
The pattern argument supplies the template characters for which grep is to search. The pattern is expected to be a single argument, so if pattern contains any spaces, or other characters special to the shell, you must enclose the pattern in quotes to prevent the shell from expanding or word splitting it.
Searching Text File Contents using grep
32

The following table summarizes some of grep's more commonly used command line switches. Consult the grep(1) man page (or invoke grep --help) for more.
Searching Text File Contents using grep
33

Show All Occurrences of a String in a File Under Linux, there are often several ways of accomplishing the same task. For example, to see if a file contains the word “even”, you could just visually scan the file:
Reading the file, we see that the file does indeed contain the letters “even”. Using this method on a large file suffers because we could easily miss one word in a file of several thousand, or even several hundred thousand, words. We can use the grep tool to search through the file for us in an automatic search:
Here we searched for a word using its exact spelling. Instead of just a literal string, the pattern argument can also be a general template for matching more complicated character sequences; we shall explore that in a later Lesson.
34

Searching in Several Files at Once An easy way to search several files is just to name them on the grep command line:
Perhaps we are more interested in just discovering which file mentions the word “nine” than actually seeing the line itself. Adding the -l switch to the grep line does just that:
35

Searching Directories RecursivelyGrep can also search all the files in a whole directory tree with a single command. This can be handy when working a large number of files. The easiest way to understand this is to see it in action. In the directory /etc/sysconfig are text files that contain much of the configuration information about a Linux system. The Linux name for the first Ethernet network device on a system is “eth0”, so you can find which file contains the configuration for eth0 by letting the grep -r command do the searching for you [11]:
36

Searching Directories RecursivelyEvery file in /etc/sysconfig that mentions eth0 is shown in the results. We can further limit the files listed to only those referring to an actual device by filtering the grep -r output through a grep DEVICE:
This shows a common use of grep as a filter to simplify the outputs of other commands. If only the names of the files were of interest, the output can be simplified with the -l command line switch.
37

Inverting grep By default, grep shows only the lines matching the search pattern. Usually, this is what you want, but sometimes you are interested in the lines that do not match the pattern. In these instances, the -v command line switch inverts grep's operation.
38

Getting Line NumbersOften you may be searching a large file that has many occurrences of the pattern. Grep will list each line containing one or more matches, but how is one to locate those lines in the original file? Using the grep -n command will also list the line number of each matching line. The file /usr/share/dict/words contains a list of common dictionary words. Identify which line contains the word “dictionary”:
You might also want to combine the -n switch with the -r switch when searching all the files below a directory:
39

Limiting Matching to Whole Words Remember the file containing our nursery rhyme earlier?
Suppose we wanted to retrieve all lines containing the word “at”. If we try the command:
Do you see what happened? We matched the “at” string, whether it was an isolated word or part of a larger word. The grep command provides the -w switch to imply that the specified pattern should only match entire words.
The -w switch considers a sequence of letters, numbers, and underscore characters, surrounded by anything else, to be a word.
40

Ignoring Case The string “Bob” has quite a meaning quite different from the string “bob”.
However, sometimes we want to find either one, regardless of whether the word is capitalized or not. The grep -i command solves just this problem.
41

ExamplesFinding Simple Character Strings
Verify that your computer has the system account “lp”, used for the line printer tools. Hint: the file /etc/passwd contains one line for each user account on the system.
42

QuestionsChapter 2. Finding Text: grep
1, 2 and 3
43

Chapter 3. Introduction to Regular Expressions
Key Concepts •Regular expressions are a standard Unix syntax for specifying text patterns. •Regular expressions are understood by many commands, including grep, sed, vi, and many scripting languages. •Within regular expressions, . and [] are used to match characters. •Within regular expressions, +, *, and ?specify a number of consecutive occurrences. •Within regular expressions, ^ and $ specify the beginning and end of a line. •Within regular expressions, (, ), and | specify alternative groups. •The regex(7) man page provides complete details.
44

Introducing Regular Expressions In the previous chapter you saw grep used to match either a whole word or part of a word. This by its self is very powerful, especially in conjunction with arguments like -i and -v, but it is not appropriate for all search scenarios. Here are some examples of searches that the grep usage you've learned so far would not be able to do: First, suppose you had a file that looked like this:
45

Introducing Regular Expressions What if you wanted to pull out just the names of the people in people_and_pets.txt? A command like grep -w Name: would match the 'Name:' line for each person, but also the 'Name:' line for each person's pet. How could we match only the 'Name:' lines for people? Well, notice that the lines for pets' names are all indented, meaning that those lines begin with whitespace characters instead of text. Thus, we could achieve our goal if we had a way to say "Show me all lines that begin with 'Name:'". Another example: Suppose you and a friend both witnessed a hit-and-run car accident. You both got a look at the fleeing car's license plate and yet each of you recalls a slightly different number. You read the license number as "4I35VBB" but your friend read it as "413SV88". It seems that what you read as an 'I' in the second character, your friend read as a '1'. Similar differences appear in your interpretations of other parts of the license like '5' vs 'S' and 'BB' vs '88'. The police, having taken both of your statements, now need to narrow down the suspects by querying their database of license plates for plates that might match what you saw.
46

Introducing Regular Expressions One solution might be to do separate queries for "4I35VBB" and "413SV88" but doing so assumes that one of you is exactly right. What if the perpetrator's license number was actually "4135VB8"? In other words, what if you were right about some of the characters in question but your friend was right about others? It would be more effective if the police could query for a pattern that effectively said: "Show me all license numbers that begin with a '4', followed by an 'I' or a '1', followed by a '3', followed by a '5' or an 'S', followed by a 'V', followed by two characters that are each either a 'B' or an '8'". Query scenarios like these can be solved using regular expressions. While computer scientists sometimes use the term "regular expression" (or "regex" for short) to describe any method of describing complex patterns, in Linux and many programming languages the term refers to a very specific set of special characters used for solving problems like the above. Regular expressions are supported by a large number of tools including grep, vi, find and sed.
47

Introducing Regular Expressions To introduce the usage of regular expressions, lets look at some solutions to two problems introduced earlier. Don't worry if these seem a bit complicated, the remainder of the unit will start from scratch and cover regular expressions in great detail. A regex that could solve the first problem, where we wanted to say "Show me all lines that begin with 'Name:'" might look like this:
...that's it! Regular expressions are all about the use of special characters, called metacharacters to represent advanced query parameters. The carat ("^"), as shown here, means "Lines that begin with...". Note, by the way, that the regular expression was put in single-quotes. This is a good habit to get into early on as it prevents bash from interpreting special characters that were meant for grep.
48

Ok, so what about the second problem? That one involved a much more complicated query: "Show me all license numbers that begin with a '4', followed by an 'I' or a '1', followed by a '3', followed by a '5' or an 'S', followed by a 'V', followed by two characters that are each either a 'B' or an '8'". This could be represented by a regular expression that looks like this:
Wow, that's pretty short considering how long it took to write out what we were looking for! There are only two types of regex metacharacters used here: square braces ('[]') and curly braces ('{}'). When two or more characters are shown within square braces it means "any one of these". So '[B8]' near the end of the expression means "'B' or '8'". When a number is shown within curly braces it means "this many of the preceding character". Thus, '[B8]{2}' means "two characters that are each either a 'B' or an '8'". Pretty powerful stuff! Now that you've gotten a taste of what regular expressions are and how they can be used, let's start from scratch and cover them in depth.
Introducing Regular Expressions
49

Regular Expressions, Extended Regular Expressions, and the grep Command
As the Unix implementation of regular expression syntax has evolved, new metacharacters have been introduced. In order to preserve backward compatibility, commands usually choose to implement regular expressions, or extended regular expressions. In order to not become bogged down with the differences, this Lesson will introduce the extended syntax, summarizing differences at the end of the discussion. One of the most common uses for regular expressions is specifying search patterns for the grep command. As was mentioned in the previous Lesson, there are three versions of the grep command. Reiterating, the three differ in how they interpret regular expressions.
50

fgrep The fgrep command is designed to be a "fast" grep. The fgrep command does not support regular expressions, but instead interprets every character in the specified search pattern literally. grep The grep command interprets each patterns using the original, basic regular expression syntax. egrep The egrep command interprets each patterns using extended regular expression syntax. Because we are not yet making a distinction between the basic and extended regular expression syntax, the egrep command should be used whenever the search pattern contains regular expressions.
Regular Expressions, Extended Regular Expressions, and the grep Command
51

Anatomy of a Regular ExpressionIn our discussion of the grep program family, we were introduced to the idea of using a pattern to identify the file content of interest. Our examples were carefully constructed so that the pattern contained exactly the text for which we were searching. We were careful to use only literal characters in our regular expressions; a literal character matches only itself. So when we used “hello” as the regular expression, we were using a five-character regular expression composed only of literal characters. While this let us concentrate on learning how to operate the grep program, it didn't allow us to get a full appreciation of the power of regular expressions. Before we see regular expressions in use, we shall first see how they are constructed.
52

A regular expression is a sequence of: Literal Characters Literal characters match only themselves. Examples of literals are letters, digits and most special characters (see below for the exceptions). Wildcards Wildcard characters match any character. Within a regular expression, a period (“.”) matches any character, be it a space, a letter, a digit, punctuation, anything. Modifiers A modifier alters the meaning of the immediately preceding pattern character. For example, the expression “ab*c” matches the strings “ac”, “abc”, “abbc”, “abbbc”, and so on, because the asterisk (“*”) is a modifier that means “any number of (including zero)”. Thus, our pattern means to match any sequence of characters consisting of one “a”, a (possibly empty) series of “b” characters, and a final “c” character. Anchors Anchors establish the context for the pattern, such as "the beginning of a line", or "the end of a word". For example, the expression “cat” would match any occurrence of the three letters, while “^cat” would only match lines that begin “cat”.
Anatomy of a Regular Expression
53

Taking Literals Literally Literals are straightforward because each literal character in a regular expressions matches one, and only one, copy of itself in the searched text. Uppercase characters are distinct from lowercase characters, so that “A” does not match “a”. WildcardsThe "dot" wildcard The character “.” is used as a placeholder, to match one of any character. In the following example, the pattern matches any occurrence of the literal characters “x” and “s”, separated by exactly two other characters.
54

Bracket Expressions: Ranges of Literal Characters Normally a literal character in a regex pattern matches exactly one occurrence of itself in the searched text. Suppose we want to search for the string “hello” regardless of how it is capitalized: we want to match “Hello” and “HeLLo” as well. How might we do that? A regex feature called a bracket expression solves this problem neatly. A bracket expression is a range of literals enclosed in square brackets (“[” and “]”). For example, the regex pattern “[Hh]” is a character range that matches exactly one character: either an uppercase “H” or a lowercase “h” letter. Notice that it doesn't matter how large the set of characters within the range is, the set matches exactly one character, if it matches any at all. A bracket expression that matches the set of lowercase vowels could be written “[aeiou]” and would match exactly one vowel. In the following example, bracket expressions are used to find words from the file /usr/share/dict/words. In the first case, the first five words that contain three consecutive (lowercase) vowels are printed. In the second case, the first 5 words that contain lowercase letters in the pattern of vowel-consonant-vowel-consonant-vowel-consonant are printed.
55

If the first character of a bracket expression is a “^”, the interpretation is inverted, and the bracket expression will match any single occurrence of a character not included in the range. For example, the expression “[^aeiou]” would match any character that is not a vowel. The following example first lists words which contain three consecutive vowels, and secondly lists words which contain three consecutive consonant-vowel pairs.
Bracket Expressions: Ranges of Literal Characters
56

Range Expressions vs. Character Classes: Old School and New School
Another way to express a character range is by giving the start- and end-letters of the sequence this way: “[a-d]” would match any character from the set a, b, c or d. A typical usage of this form would be “[0-9]” to represent any single digit, or “[A-Z]” to represent all capital letters.
57

As an alternative to such quandaries, modern regular expression make use character classes. Character classes match any single character, using language specific conventions to decide if a given character is uppercase or lowercase, or if it should be considered part of the alphabet or punctuation. The following table lists some supported character classes, and the ASCII equivalent range expression, where appropriate.
Range Expressions vs. Character Classes: Old School and New School
58

Character classes avoid problems you may run into when using regular expressions on systems that use different character encoding schemes where letters are ordered differently. For example, suppose you were to run the command:
On a Red Hat Enterprise Linux system, this would match every word in the file, not just those that contain capital letters as one might assume. This is because in unicode (utf-8), the character encoding scheme that RHEL uses, characters are alphabetized case-insensitively, so that [A-Z] is equivalent to [AaBbCc...etc].
Range Expressions vs. Character Classes: Old School and New School
59

Range Expressions vs. Character Classes: Old School and New School
On older systems, though, a different character encoding scheme is used where alphabetization is done case-sensitively. On such systems [A-Z] would be equivalent to [ABC...etc]. Character classes avoid this pitfall. You can run:
on any system regardless of the encoding scheme being used and it will only match lines that contain capital letters. For more details about the predefined range expressions, consult the grep manual page. For more information on character encoding schemes under Linux, refer back to chapter 8.3. To learn about how character encoding schemes are used to support other languages in Red Hat Enterprise Linux, begin with the locale manual page.
60

Common Modifier Characters We saw a common usage of a regex modifier in our earlier example “ab*c” to match an a and c character with some number of b letters in between. The “*” character changed the interpretation of the literal b character from matching exactly one letter to matching any number of b's. Here are a list of some common modifier characters: b? The question mark (“?”) means “either one or none”: the literal character is considered to be optional in the searched text. For example, the regex pattern “ab?c” matches the strings “ac”, and “abc”, but not “abbc”. b* The asterisk (“*”) modifier means “any number of (including zero)” of the preceding literal character. The regex pattern “ab*c” matches the strings “ac”, “abc”, “abbc”, and so on.
61

b+ The plus (“+”) modifier means “one or more”, so the regex pattern “b+” matches a non-empty sequence of b's. The regex pattern “ab+c” matches the strings “abc” and “abbc”, but does not match “acb{m,n} The brace modifier is used to specify a range of between m and n occurrences of the preceding character. The regex pattern “b{2,4}” would match “abbc” and “abbbc”, and “abbbbc”, but not “abc” or “abbbbbc”. b{n} With only one integer, the brace modifier is used to specify exactly n occurrences for the preceding character.
Common Modifier Characters
62

Common Modifier Characters In the following example, egrep prints lines from /usr/share/dict/words that contain patterns which start with a (capital or lowercase) “a”, might or might not next have a (lowercase) “b”, but then definitely follow with a (lowercase) “a”.
The following example prints lines which contain patterns which start “al”, then use the “.” wildcard to specify 0 or more occurrences of any character, followed by the pattern “bra”.
63

Notice we found variations on the words algebra and calibrate. For the former, the .* expression matched “ge”, while for the latter, it matched the letter “i”. The expression “.*”, which is interpreted as "0 or more of any character", shows up often in regex patterns, acting as the "stretchable glue" between two patterns of significance. As a subtlety, we should note that the modifier characters are greedy: they always match the longest possible input string. For example, given the regex pattern:
Common Modifier Characters
64

Anchored Searches Four additional search modifier characters are available: ^foo A caret (“^”) matches the beginning of a line. Our example “^foo” matches the string “foo” only when it is at the beginning of a line foo$ A dollar sign (“$”) matches the end of a line. Our example “foo$” matches the string “foo” only at the end of a line, immediately before the newline character. \<foo\> By themselves, the less than sign (“<”) and the greater than sign (“>”) are literals. Using the backslash character to escape them transforms them into meaning “first of a word” and “end of a word”, respectively. Thus the pattern “\>cat\<” matches the word “cat” but not the word “catalog”. You will frequently see both ^ and $ used together. The regex pattern “^foo$” matches a whole line that contains only “foo” and would not match that line if it contained any spaces. The \< and \> are also usually used as pairs.
65

Anchored Searches In the following an example, the first search lists all lines that contain the letters “ion” anywhere on the line. The second search only lists lines which end in “ion”.
66

Coming to Terms with Regex Grouping The same way that you can use parenthesis to group terms within a mathematical expression, you also use parenthesis to collect regular expression pattern specifiers into groups. This lets the modifier characters “?”, “*” and “+” apply to groups of regex specifiers instead of only the immediately preceding specifier. Suppose we need a regular expression to match either “foo” or “foobar”. We could write the regex as “foo(bar)?” and get the desired results. This lets the “?” modifier apply to the whole string “bar” instead of only the preceding “r” character. Grouping regex specifiers using parenthesis becomes even more flexible when the pipe symbol (“|”) is used to separate alternative patterns. Using alternatives, we could rewrite our previous example as “(foo|foobar)”. Writing this as “foo|foobar” is simpler and works just as well, because just like mathematics, regex specifiers have precedence. While you are learning, always enclose your groups in parenthesis.
67

Coming to Terms with Regex Grouping In the following example, the first search prints all lines from the file /usr/share/dict/words which contain four consecutive vowels (compare the syntax to that used when first introducing range expressions, above). The second search finds words that contain a double “o” or a double “e”, followed (somewhere) by a double “e”.
68

Escaping Meta-CharactersSometimes you need to match a character that would ordinarily be interpreted as a regular expression wildcard or modifier character. To temporarily disable the special meaning of these characters, simply escape them using the backslash (“\”) character. For example, the regex pattern “cat.” would match the letters “cat” followed by any character: “cats” or “catchup”. To match only the letters “cat.” at the end of a sentence, use the regex pattern “cat\.” to disable interpreting the period as a wildcard character. Note one distracting exception to this rule. When the backslash character precedes a “<” or “>” character, it enables the special interpretation (anchoring the beginning or ending of a word) instead of disabling the special interpretation. Shudder. It even gets worse - see the footnote at the bottom of the following table.
69

Summary of Linux Regular Expression Syntax The following table summarizes regular expression syntax, and identifies which components are found in basic regular expression syntax, and which are found only in the extended regular expression syntax.
70

Summary of Linux Regular Expression Syntax The following table summarizes regular expression syntax, and identifies which components are found in basic regular expression syntax, and which are found only in the extended regular expression syntax.
71

Regular Expressions are NOT File Globbing When first encountering regular expressions, students understandably confuse regular expressions with pathname expansion (file globbing). Both are used to match patterns in text. Both share similar metacharacters (“*”, “?”, “[...])”, etc.). However, they are distinctly different. The following table compares and contrasts regular expressions and file globbing.
72

Regular Expressions are NOT File Globbing In the following example, the first argument is a regular expression, specifying text which starts with an “l” and ends “.conf”, while the second argument is a file glob which specifies all files in the /etc directory whose filename starts with “l” and ends “.conf”.
Take a close look at the second line of output. Why was it matched by the specified regular expression? Why does the line containing the text “krb5.conf” match the expression? The “l” is found way back in the word “default”! In a similar vain, when specifying regular expressions on the bash command line, care must be taken to quote or escape the regex meta-characters, lest they be expanded away by the bash shell with unexpected results. In all of the examples found in this discussion, the first argument to the egrep command is protected with single quotes for just this reason.
73

Where to Find More Information About Regular Expressions
We have barely scratched the surface of the usefulness of regular expressions. The explanation we have provided will be adequate for your daily needs, but even so, regular expressions offer much more power, making even complicated text searches simple to perform. For more online information about regular expressions, you should check: The regex(7) manual page. The grep(1) manual page.
74

ExamplesRegular Expression Modifiers
75

Chapter 4. Everything Sorting: sort and uniq
Key Concepts •The sort command sorts data alphabetically. •sort -n sorts numerically. •sort -u sorts and removes duplicates. •sort -k and -t sorts on a specific field in patterned data.
76

The sort Command Sorting is the process of arranging records into a specified sequence. Examples of sorting would be arranging a list of usernames into alphabetical order, or a set of file sizes into numeric order. In its simplest form, the sort command will alphabetically sort lines (including any whitespace or control characters which are encountered). The sort command uses the local locale (language definition) to determine the order of the characters (referred to as the collating order). In the following example, madonna first displays the contents of the file /etc/sysconfig/mouse as is, and then sorts the contents of the file alphabetically.
77

Modifying the Sort Order By default, the sort command sorts lines alphabetically. The following table lists command line switches which can be used to modify this default sort order.
78

Examples of sortAs an example, madonna is examining the file sizes of all files that start with an m in the /var/log directory.
She next sorts the output with the sort command.
79

Examples of sortWithout being told otherwise, the sort command sorted the lines alphabetically (with 1952 coming before 20). Realizing this is not what she intended, madonna adds the -n command line switch.
80

Examples of sortBetter, but madonna would prefer to reverse the sort order, so that the largest files come first. She adds the -r command line switch
Why ls -1?Why was the -1 command line switch given to the ls command in the first example, but not the others? By default, when the ls command is using a terminal for standard out, it will group the filenames in multiple columns for easy readability. When the ls command is using a pipe or file for standard out, however, it will print the files one file per line. The -1 command line switch forces this behavior for for terminal output as well.
81

Specifying Sort Keys In the previous examples, the sort command performed its sort based on the first characters found on a line. Often, formatted data is not arranged so conveniently. Fortunately, the sort command allows users to specify which column of tabular data to use for determining the sort order, or, in more formally, which column should be used as the sort key. The following table of command line switches can be used to determine the sort key.
82

Sorting Output by a Particular ColumnAs an example, suppose madonna wanted to reexamine her log files, using the long format of the ls command. She tries simply sorting her output numerically.
Now that the sizes are no longer reported at the beginning of the line, she has difficulty. Instead, she repeats her sort using the -k command line switch to sort her output by the 5th column, producing the desired output.
83

Specifying Multiple Sort Keys Next, madonna is examining the file /etc/fdprm, which tables low level formatting parameters for floppy drives. She uses the grep command to extract the data from the file, stripping away comments and blank lines.
84

Specifying Multiple Sort Keys She next sorts the data numerically, using the 5th column as her key.
85

Specifying Multiple Sort Keys Her data is successfully sorted using the 5th column, with the formats specifying 40 tracks grouped at the top, and 80 tracks grouped at the bottom. Within these groups, however, she would like to sort the data by the 3rd column. She adds an additional -k command line switch to the sort command, specifying the third column as her secondary key.
Now the data has been sorted primarily by the fifth column. For rows with identical fifth columns, the third column has been used to determine the final order. An arbitrary number of keys can be specified by adding more -k command line switches.
86

Specifying the Field SeparatorThe above examples have demonstrated how to sort data using a specified field as the sort key. In all of the examples, fields were separated by whitespace (i.e., a series of spaces and/or tabs). Often in Linux (and Unix), some other method is used to separate fields. Consider, for example, the /etc/passwd file.
87

Specifying the Field SeparatorThe lines are structured into seven fields each, but the fields are separated using a “:” instead of whitespace. With the -t command line switch, the sort command can be instructed to use some specified character (such as a “:”) to separate fields. In the following, madonna uses the sort command with the -t command line switch to sort the first 10 lines of the /etc/passwd file by home directory (the 6th field).
The user bin, with a home directory of /bin, is now at the top, and the user mail, with a home directory of /var/spool/mail, is at the bottom.
88

SummaryIn summary, we have seen that the sort command can be used to sort structured data, using the -k command line switch to specify the sort field (perhaps more than once), and the -t command line switch to specify the field delimiter. The -k command line switch can receive more sophisticated arguments, which serve to specify character positions within a field, or customize sort options for individual fields. See the sort(1) man page for details.
89

The uniq Command The uniq program is used to identify, count, or remove duplicate records in sorted data. If given command line arguments, they are interpreted as filenames for files on which to operate. If no arguments are provided, the uniq command operates on standard in. Because the uniq command only works on already sorted data, it is almost always used in conjunction with the sort command. The uniq command uses the following command line switches to qualify its behavior.
90

The uniq Command In order to understand the uniq command's behavior, we need repetitive data on which to operate. The following python script simulates the rolling of three six sided dice, writing the sum of 100 roles once per line. The user madonna makes the script executable, and then records the output in a file called trial1.
91

Reducing Data to Unique Entries Now, madonna would like to analyze the data. She begins by sorting the data and piping the output through the uniq command.
Without any command line switches, the uniq command has removed duplicate entries, reducing the data from 100 lines to only 15. Easily, madonna sees that the data looks reasonable: the sum of every combination for three six sided die is represented, with the exception of 3. Because only one combination of the dice would yield a sum of 3 (all ones), she expects it to be a relatively rare occurrence. 92

Counting Instances of Data A particularly convenient command line switch for the uniq command is -c, or --count. This causes the uniq command to count the number of occurrences of a particular record, prepending the result to the record on output. In the following example, madonna uses the uniq command to reproduce its previous output, this time prepending the number of occurrences of each entry in the file.
93

Counting Instances of Data
As would be expected (by a statistician, at least), the largest and smallest numbers have relatively few occurrences, while the intermediate numbers occur more numerously. The first column can be summed to 100 to confirm that the uniq command identified every occurrence.
94

Identifying Unique or Repeated Data with uniq Sometimes, people are just interested in identifying unique or repeated data. The -d and -u command line switches allow the uniq command to do just that. In the first case, madonna identifies the dice combinations that occur only once. In the second case, she identifies combinations that are repeated at least once.
95

QuestionsChapter 4. Everything Sorting: sort and uniq
1 and 2
96

Chapter 5 Extracting and Assembling Text: cut and paste
Key Concepts •The cut command extracts texts from text files, based on columns specified by bytes, characters, or fields. •The paste command merges two text files line by line.
97

The cut Command Extracting Text with cut The cut command extracts columns of text from a text file or stream. Imagine taking a sheet of paper that lists rows of names, email addresses, and phone numbers. Rip the page vertically twice so that each column is on a separate piece. Hold onto the middle piece which contains email addresses, and throw the other two away. This is the mentality behind the cut command. The cut command interprets any command line arguments as filenames of files on which to operate, or operates on the standard in stream if none are provided. In order to specify which bytes, characters, or fields are to be cut, the cut command must be called with one of the following command line switches.
98

The cut Command The list arguments are actually a comma-separated list of ranges. Each range can take one of the following forms.
99

Extracting text by Character Position with cut -c With the -c command line switch, the list specifies a character's position in a line of text, where the first character is character number 1. As an example, the file /proc/interrupts lists device drivers, the interrupt request (IRQ) line to which they attach, and the number of interrupts which have occurred on that IRQ line. (Do not be concerned if you are not yet familiar with the concepts of a device driver or IRQ line. Focus instead on how cut is used to manipulate the data).
100

Extracting text by Character Position with cut -c Because the characters in the file are formatted into columns, the cut command can extract particular regions of interest. If just the IRQ line and the number of interrupts were of interest, the rest of the file could be cut away, as in the following example. (Note the use of the grep command to first reduce the file to just the lines pertaining to interrupt lines.)
101

Extracting text by Character Position with cut -c Alternately, if only the device drivers bound to particular IRQ lines were of interest, multiple ranges of characters could be specified.
If the character specifications were reversed, can the cut command be used to rearrange the ordering of the data?
The answer is no. Text will appear only once, in the same order it appears in the source, even if the range specifications are overlapping or rearranged.
102

Extracting Fields of Text with cut -f The cut command can also be used to extract text that is structured not by character position, but by some delimiter character, such as a TAB or “:”. The following command line switches can be used to further qualify what is meant by a field, or more selective select source lines.
103

Extracting Fields of Text with cut -f For example, the file /usr/share/hwdata/pcitable lists over 3000 vendor IDs and device IDs (which can be probed from PCI devices), and the kernel modules and text strings which should be associated with them, separated by tabs.
104
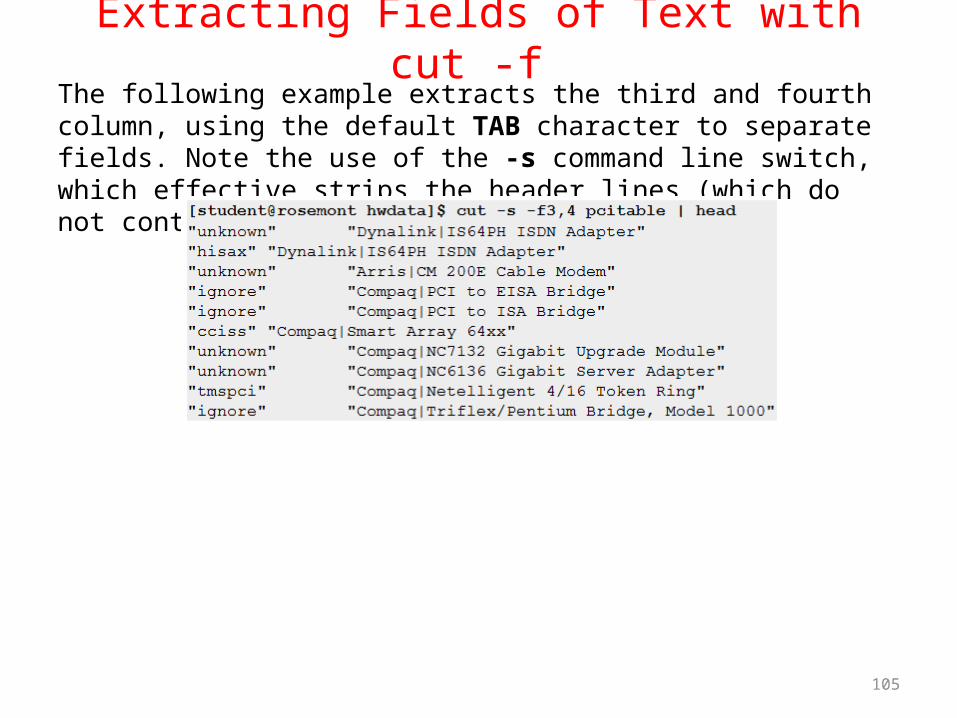
Extracting Fields of Text with cut -f The following example extracts the third and fourth column, using the default TAB character to separate fields. Note the use of the -s command line switch, which effective strips the header lines (which do not contain any TABs).
105

Extracting Fields of Text with cut -f As another example, suppose we wanted to obtain a list of the most commonly referenced kernel modules in the file. We could use a similar cut command, along with tricks learned in the last Lesson, to obtain a quick listing of the number of times each kernel module appears.
Many of the entries are obviously unknown, or intentionally ignored, but we do see that the aic7xxx SCSI driver, and the e100 Ethernet card driver, are commonly used.
106

Extracting Text by Byte Position with cut -b The -b command line switch is used to specify which text to extract by bytes. Extracting text using the -b command line switch is very similar in spirit as using -c. In fact, when dealing with text encoded using the ASCII or one of the ISO 8859 character sets (such as Latin-1), the two are identical. The -b switch differs from -c, however, when using character sets with variable length encoding, such as UTF-8 (a standard character set on which many people are converging, and the default in Red Hat Enterprise Linux). Usually, cut -c is the proper way to use the cut command, and cut -b will only be necessary for technical situations. NoteNotice the inconsistent nomenclature between with wc and cut. With wc -c, the wc command really returns the number of bytes contained in a string, while cut -c measures text in characters. Unfortunately, the wc command makes no equivalent distinction made between characters and bytes.
107

The paste Command The paste command is used to combine multiple files into a single output. Recall the fictional piece of paper which listed rows of names, email addresses, and phone numbers. After tearing the paper into three columns, what if we had glued the first back to the third, leaving a piece of paper listing only names and phone numbers? This is the concept behind the paste command. The paste command expects a series of filenames as arguments. The paste command will read the first line from each file, join the contents of each line inserting a TAB character in between, and write the resulting single line to standard out. It then continues with the second line from each file.
108

The paste Command Consider the following two files as an example.
If we had more than two files, the first line of each file would become the first line of the output. The second output line would contain the second lines of each input file, obtained in the order we gave them on the command line. As a convenience, the filename - can be supplied on the command line. For this "file", the paste command would read from standard in.
109

The paste Command
110

ExamplesChapter 5. Extracting and Assembling Text: cut and paste
Handling Free-Format Records In a free-format record layout, input record items are identified by their position on the line, not by their character position. Input fields are expected to be separated by exactly one TAB character, but any character that does not appear in the data items themselves may be used. Each occurrence of the delimiter separates a field. Our favorite example file /etc/passwd has fields separated by exactly one colon (“:”) character. Field 1 is the account name and field 7 gives the shell program used. Using the cut command, we could output a new file with just the account name and the shell name:
111

Chapter 6. Tracking differences: diff
Key Concepts •The diff command summarizes the differences between two files. •The diff command supports a wide variety of output formats, which can be chosen using various command line switches. The most commonly used of these is the unified format. •The diff command can be told to ignore certain types of differences, such as changes in white space or capitalization. •diff -r recursively summarizes the differences between two directories. •When comparing directories, the diff command can be told to ignore files whose filenames match specified patterns.
112

Chapter 6. Tracking differences: diff The diff Command The diff command is designed to compare two files that are similar, but not identical, and generate output that describes exactly how they differ. The diff command is commonly used to track changes to text files, such as reports, web pages, shell scripts, or C source code. Also, utilities coexist with the diff command, so that given a version of a file, and the output of the diff command comparing it to some other version, the file can be brought up to date automatically. Most notable of these commands is the patch command.
113

Chapter 6. Tracking differences: diff We first introduce the diff command by way of example. In the open source community, documentation generally sacrifices correctness of spelling or grammar for timeliness, as demonstrated in the following README.pam_ftp file.
Noticing that the words address and addresses are misspelled, blondie sets out to apply changes, first by correcting the misspelled words, and secondly by appending a line recording her revisions. She first makes a copy of the file, appending the .orig extension. She secondly makes her edits.
114

Chapter 6. Tracking differences: diff She now uses the diff command to compare the two revisions of the file.
Without yet going into detail about diff's syntax, we see that the command has identified the differences between the two files, exemplifying the essence of the diff command. The diff command is so commonly used, that its output is often referred to as a noun, as in "Here's the diff between those two files".
115

Output Formats for the diff Command
The diff command was conceived in the early days of the Unix community. Over time, improvements have been made in how diff annotates changes. To preserve backward compatibility, however, older formats are still available. The following lists commonly used diff formats. "Standard" diff Originally, the diff command was used to preserve bandwidth over slow network connections. Rather than transferring a new version of a file, a summary of the revisions would be transferred instead. This summary was in a format that was easily recognized by the ed command line editor, which is seldom used today. Examining the previous output, one can imagine the ed editor being asked to change lines 11 and 12, and append a line after line 18.
Soon, however, room for improvement was found. What if an administrator accidentally applied the changes twice? The ed editor would happily make the changes, corrupting the contents of the file. The solution is a context sensitive diff.
116

Output Formats for the diff Command Context diff (diff -c) The context sensitive diff is generated by specifying the -c or -C N command line switches. (The second form is used to specify that exactly N lines of context should be generated.) Consider the following example.
117

Output Formats for the diff Command
Obviously, the context diff includes several lines of surrounding context before identifying changes. Changes are annotated by using a “!” to mark lines that have changed, “+” to mark lines that have been added, and “-” to mark lines that have been removed. Using a content diff, utilities can automatically detect when an administrator accidentally tries to update a file twice. 118

Output Formats for the diff Command Unified diff (diff -u) The unified diff is generated by specifying the -u or -U N command line switches. (The second form is used to specify that exactly N lines of context should be generated.) Rather than duplicating lines of context, the unified diff attempts to record changes all in one stanza, creating a more compact, and arguably more readable, output.
Rather than identifying a line as "changed", the unified diff annotates that the original version should be deleted, and the new version added.
119

Output Formats for the diff Command Side by side diff (diff -y) The previous three formats were meant to be easy to read by some other utility, such as the ed editor or the patch utility. In contrast, the "side by side" format is intended to be read by humans. As the name implies, the two versions of the file are displayed side by side, with annotations in the middle that help identify changes. The following example requests a side by side diff using the -y command line switch, and further qualifies that the output should be formatted to 80 columns with -W80.
While the output would be more effective using a wide terminal, it does provide an intuitive feel for the differences between the two files. 120

Output Formats for the diff Command Quiet diff (diff -q) The quiet diff merely reports if two files differ, not the nature of the differences.
if-then-else Macro diff (diff -D tag)
This format generates differences using a syntax recognized by the cpp pre-processor. It allows either the original version or the new version to be included by defining the specified tag. While beyond the scope of this course, it is included for the benefit of those familiar with the cpp C preprocessor.
121

Output Formats for the diff Command Other, less commonly used output formats exist as well. Which format is the right one? The answer depends on the preferences of the generator of the "diff", or the expectations of whoever might be receiving the "diff". The diff command is often used in the open source community to communicate suggestions about exact changes to the source code of some program, in order to fix a bug or add a feature. In this context, the unified diff format is almost always preferred. The following table summarizes some of the various command line switches which can be used to specify output format for the diff command.
122

How diff Interprets ArgumentsThe diff command expects to be called with two arguments, a from-file and a to-file (or, in other words, an oldfile and a newfile). The output of the diff command describes what must be done to the from-file to create the to-file. If one of the filenames refers to a regular file, and the other a directory, the diff command will look for a file of the same name in the specified directory. If both are directories, the diff command will compare files in both directories, but will not recurse to subdirectories (unless the -r switch is specified, see below). Additionally, the special file name “-” will cause the diff command to read from standard in instead of a regular file.
123

Customizing diff to be Less Picky If not told otherwise, the diff command will diligently track all differences between two files. Several command line switches can be used to cause the diff command to have a more relaxed behavior. The following table summarizes the relevant command line switches.
124

Customizing diff to be Less Picky As an example, consider the following two files.
125

Customizing diff to be Less Picky The file cal_edited.txt differs in two respects. First, a four line header was added to the top. Secondly, an extra (empty) line was added to the bottom. An "ordinary" diff recognizes all of these changes.
126

Recursive diff's The diff command can act recursively, descending two similar directory trees and annotating any differences. The following table lists command line switches relevant to diff's recursive behavior.
As an example, blondie is examining two versions of a project called vreader. The project involves Python scripts which convert calendering information from the vcal format to an XML format. She has downloaded two versions of the project, vreader-1.2.tar.gz and vreader-1.3.tar.gz, and expanded each of the archives into her local directory.
127

Recursive diff's The directories vreader-1.2 and vreader-1.3 have the following structure.
128

Recursive diff's In order to summarize the differences between the two versions. She runs a recursive diff on the two directories.
The diff command recurses through the two directories, and notes the following differences.
1.The two binary files vreader-1.2/conv_db.pyc and vreader-1.3/conv_db.pyc differ. Because they are not text files, however, the diff command does not try to annotate the differences. 2.The complementary file to vreader-1.3/datebook.out.xml is not found in the vreader-1.2 directory. 3.The files vreader-1.2/templates/datebook.xml and vreader-1.3/templates/datebook.xml differ, and diff annotates the changes. 4.The files vreader-1.2/vreader.py and vreader-1.3/vreader.py differ, and diff annotates the changes.
129

Recursive diff's Often, when comparing more complicated directory trees, there are files that are expected to change, and files that are not. For example, the file conv_db.pyc is compiled Python code automatically generated from the text Python script file conv_db.py. Because blondie is not interested in differences between the compiled versions of the file, she uses the -x command line switch to exclude the file form her comparisons. Likewise, she is not interested in the files ending .xml, so she specifies them with an additional -x command line switch.
Now the output of the diff command is limited to only the file vreader-1.2/vreader.py and its complement in vreader-1.3. As an alternative to listing file patterns to exclude on the command line, they may be collected in a simple text file which is specified instead, using the -X command line switch. In the following, blondie has created and uses such a file.
Because blondie included *.py in her list of file patterns to exclude, the diff command is left with nothing to say.
130

Online Exercises Chapter 6. Tracking differences: diff
Specification 1.Use the diff command to annotate the differences between the files /usr/share/doc/pinfo-0*/COPYING and /usr/share/doc/mtools-3*/COPYING, using the context sensitive format. Record the output in the newly created file ~/COPYING.diff. When specifying the filenames on the command line, list the pinfo file first, and use an absolute reference for both. 2.Create a local copy of the directory /usr/share/gedit-2, using the following command (in your home directory).
[student@station student]$ cp -a /usr/share/gedit-2 . To your local copy of the gedit-2 directory, make the following changes.
A. Remove any two files. B. Create an arbitrarily named file somewhere underneath the gedit-2 directory, with
arbitrary content. C. Using a text editor, delete three lines from any file in the gedit-2/taglist directory.
Once you have finished, generate a recursive "diff" between /usr/share/gedit-2 and your copy, gedit-2. Record the output in the newly created file ~/gedit.diff. When specifying the directories on the command line, specify the original copy first, and use an absolute reference for both. Do not modify the contents of your gedit-2 unless you also reconstruct your file ~/gedit.diff.
131

Chapter 7 Translating Text: tr
Key Concepts •The tr command performs translations on data read from standard in. •In its most basic form, the tr command performs byte for byte substitutions. •Using the -d command line switch, the tr command will delete specified characters from a stream. •Using the -s command line switch, the tr command will squeeze a series of repeated characters in a stream into a single instance of the character.
132

The tr Command The tr command is a versatile utility that performs character translations on streams. Translating can mean replacing one character for another, deleting characters, or "squeezing" characters (collapsing repeated sequences of a character into one). Each of these uses will be examined in the following sections. Unlike all of the previous commands in this section, the tr command does not expect filenames as arguments. Instead, the tr command operates exclusively on the standard in stream, reserving command line arguments to specify transformations. The following table specifies the various ways of invoking the tr command.
133

Character Specification
134
The table is not meant to be a complete list. Consult the tr(1) man page, or tr --help, for more information.

Using tr to Translate Characters Unless instructed otherwise (using command line switches), the tr command expects to be called with two arguments, each of which specify a range of characters. For each of the characters specified in the first set, the tr will substitute the character found in the same position in the second set. Consider the following trivial example.
Notice that in the output, the character “d” is replaced with the character “z”, “e” is replaced with the character “y”, and “f” is replaced with the character “x”. The ordering of the sets is important. The third letter from the first set is replaced with the third letter from the second set. What happens if the lengths of the two sets have unequal lengths? the second set is extended to the length of the first set by copying the last character.
135

Using tr to Translate Characters A classic example of the tr command is to translate text into all upper case or all lower case letters. The "old school" syntax for such a translation would use character ranges.
136

Using tr to Translate Characters As mentioned in the Lesson on regular expressions, however, range specifications can produce odd results when various character sets are considered. The "new school" approach is to use character classes.
Recalling that the ordering of the character ranges is important to the tr command, the character classes would need to generate consistently ordered ranges. Only the [:lower:] and [:upper:] character classes are guaranteed to do so, implying that they are the only classes appropriate for use when using tr for character translation.
137

Using tr to Delete Characters When invoked with the -d command line switch, the tr command adopts a radically different behavior. The tr command now expects a single argument (as opposed to two, above), which is again a set of characters. The tr command will now filter the standard in stream, deleting each of the specified characters writing it to standard out. Consider the following couple of examples.
In the first case, the specified literal characters “d”, “e”, and “f” were deleted. In the second case, all characters that belonged to either the [:punct:] or [:upper:] character classes were deleted.
138

Using tr to Squeeze Characters By using the -s command line switch, the tr command can be used to squeeze a continues series of characters into a single character. If called with one argument, the tr command will simply squeeze the specified set of characters, as in the following example.
139

Complementing Sets Other than -s and -d, there are only two command line switches which modify tr's behavior, tabled below.
As a quick example of the -c command line switch, the following deletes every character that is not a vowel or a white space character from standard in.
140

One Final Caution: Avoid File Globbing! One final note before we leave our “a”s and “e”s and head for more practical examples. In some of the previous examples, madonna was careful to protect expressions such as [:punct:] with single quotes, and sometimes she was not. When she didn't, she got lucky. Consider the following sequence.
Why did madonna get two very different results from the same command line? If you don't know the answer, and even if you do, you should protect arguments to the tr command with quotes. The problem is that the [...] syntax is also used by the bash shell to implement file globbing. In the first case, no files that matched the expression [...] existed, so bash (as a "favor") preserved the glob. In the second case, the file n did exist, so bash expanded the glob, effectively running the command tr -d n.
141

Online Exercises Chapter 7. Translating Text: tr
Specification
1.The /etc/passwd file uses colons as a field delimiter. Create the file ~/passwd.tsv, which is a copy of the /etc/passwd file converted to use tabs as field delimiters (i.e., every “:” is converted to a tab). 2.Create the file ~/webalizer.converted, which is a copy of the file /etc/webalizer.conf, with the following transformations.
– Convert double quotes (") to single quotes ('). (Do not use backticks (`).) 3.Create a file called ~/openssl.converted, which is a copy of the file /etc/pki/tls/openssl.cnf, with the following transformations.
– All comments lines (lines whose first non-whitespace character is a #) are removed.
– All empty lines are removed. – All upper case letters are folded into lower case letters. – All digits are replaced with the underscore character (“_”).
142

Chapter 8. Spell Checking: aspell
Key Concepts •The aspell -c command performs interactive spell checks on files. •The aspell -l command performs a non-interactive spell check on the standard in stream. •The aspell dump command can be used to view the system's master or a user's personal dictionary. •The command aspell create personal and aspell merge personal can be used to create or append to a user's personal dictionary from a word list.
143

Chapter 8. Spell Checking: aspell In the Red Hat Enterprise Linux distribution, the aspell utility is the primary utility for checking the spelling of text files. In this Lesson, we learn how to use aspell to interactively spell check a file and customize the spell checker with a personal dictionary. When running aspell, the first argument (other than possible command line switches) is interpreted as a command, telling aspell what to do. The following commands are supported by aspell.
144

Chapter 8. Spell Checking: aspell The following table lists some of the more common command line switches that are used with the aspell command.
145

Performing an Interactive Spell Check The user prince has composed the following message, which he plans to email to the user elvis.
Before sending the message, prince uses aspell -c to perform an interactive spell check.
146

Performing an Interactive Spell Check Upon execution, the aspell command open an interactive session, highlighting the first recognized misspelled word.
147

Performing an Interactive Spell Check At this point, prince has a "live" keyboard, meaning that single key presses will take effect without him needing to use the return key. He may choose from the following options. Use Suggested Replacement The aspell command will do its best to suggest replacements for the misspelled word from its library. If it has found a correct suggestion (as in this case, it has), that suggestion can be replaced by simply hitting the numeric key associated with it. Ignore the Word By pressing i, aspell will simply ignore the word this instance and move on. Pressing capital I will cause aspell to ignore all instances of the word in the current file. Replace the Word If aspell was not able to generate an appropriate suggestion, prince may use r to manually replace the word. When finished, aspell will pick up again, first rechecking the specified replacement. By using capital R, aspell will remember the replacement and automatically replace other instances of the misspelled word.
148

Performing an Interactive Spell Check Add the Word to the Personal Dictionary If prince would like aspell to learn a new word, so that it will not be flagged when checking future files, he may press a to add the word to his personal dictionary. Exit aspell By pressing x, prince can immediately exit the interactive aspell section. Any spelling corrections already implemented will be saved. As prince proceeds through the interactive session, aspell flags procesing, prety, and IIRC as misspelled. For the first two, prince accepts aspell's suggestions for the correct spelling. The last "word" is an abbreviations that prince commonly uses in his emails, so he adds them to his personal dictionary. Unfortunately, because its is a legitimate word, aspell does not report prince's misuse of it. When finished, prince now has two files, the corrected version of toelvis, and an automatically generated backup of the original, toelvis.bak.
149

Add the Word to the Personal Dictionary If prince would like aspell to learn a new word, so that it will not be flagged when checking future files, he may press a to add the word to his personal dictionary. Exit aspell By pressing x, prince can immediately exit the interactive aspell section. Any spelling corrections already implemented will be saved. As prince proceeds through the interactive session, aspell flags procesing, prety, and IIRC as misspelled. For the first two, prince accepts aspell's suggestions for the correct spelling. The last "word" is an abbreviations that prince commonly uses in his emails, so he adds them to his personal dictionary. Unfortunately, because its is a legitimate word, aspell does not report prince's misuse of it. When finished, prince now has two files, the corrected version of toelvis, and an automatically generated backup of the original, toelvis.bak.
150

Performing a Non-interactive Spell Check Using the list subcommand, the aspell command can be used to perform spell checks in a non-interactive batch mode. Used this way, aspell simple reads standard in, and writes to standard out every word it would flag as misspelled. In the following, suppose prince performed a non-interactive spell check before he had run the aspell session interactively.
The aspell utility lists the three words it would flag as misspelled. After the interactive spell check, prince performs a non-interactive spell check on his backup of the original file.
Because the word IIRC was added to prince's personal dictionary, it is no longer flagged as misspelled.
151

Managing the Personal Dictionary By default, the aspell command uses two dictionaries when performing spell checks: the system wide master dictionary, and a user's personal dictionary. When prince chooses to add a word, the word gets stored in his personal dictionary. He uses aspell's ability to dump to view his personal dictionary.
Likewise, he could dump the system's master dictionary as well.
152

Managing the Personal Dictionary The aspell command can also automatically create a personal dictionary (if it doesn't already exist), or merge into it (if it does) using words read from standard in. Suppose prince has a previous email message, in which he used many of his commonly used abbreviations. He would like to add all of the abbreviations found in that email to his personal dictionary. He first uses aspell -l to extract the words from the original message.
After observing the results, he decides to add all of these words to his personal dictionary, using aspell merge personal. When he finishes, he again dumps his (expanded) personal dictionary.
153

Questions Chapter 8. Spell Checking: aspell
1 and 2
154

Chapter 9. Formatting Text (fmt) and Splitting Files (split)
Key Concepts•The fmt command can reformat text to differing widths. •Using the -p command line switch, the fmt command will only reformat text that begins with the specified prefix, preserving the prefix. •The split command can be used to split a single file into multiple files based on either a number of lines or a number of bytes.
155

The fmt Command
One side effect of the variety of text editors in Linux, and in particular the coexistence of text editors and word processors, is the inconsistencies with which word wrapping is handled. To a word processor, and many HTML based text entry forms, new line characters are usually considered not worthy of the concern of users. A user begins typing text, without ever using the RETURN key, and the application decides when to wrap a line and where to insert a new line character. While this is not a problem, and perhaps even desirable, for writing a letter to a friend, it can cause significant problems when editing a line based configuration file (such as the /etc/passwd file, the /etc/hosts file, the /etc/fstab file, etc..., etc...). As an example of the inconsistencies of various text editors, the user elvis tries a simple experiment. He types the first sentence from the previous paragraph using four different applications: the nano text editor, the vim text editor, the gedit text editor, and the OpenOffice word processor. In each case, he types the sentence without ever hitting the RETURN key, and saves the document as side_effect.extension using the default settings. The only exception is the OpenOffice word processor, whose default format uses binary encoding. For this applications, elvis saved the file twice. Once, using the "default" settings (the OpenOffice format), and once choosing the simplest "save as text" setting possible.
156

The fmt Command
157

The fmt Command
158

The fmt Command
What result does wc show? The four different applications used four different conventions for displaying and saving the simple text sentence (five, if you include the binary OpenOffice format).
159

The fmt Command
The nano text editor was the only application that implemented word wrapping by default. Although elvis never hit the return key, three ASCII new line characters were inserted. The gedit and gvim applications were consistent with Linux (and Unix) convention: they did not insert new line characters in the middle of the text, but they would not let a text file end without a terminating new line character. Although consistent with each other in terms of how the file was stored, they differed in how the text was presented to the user: gedit wrapped the text at word boundaries, while gvim wrapped the text only when it could fit no more on a line. Like gedit, the OpenOffice application wrapped the text while displaying it, but did not add the conventional Linux new line to the end of the file while saving it to disk. We can't even begin to discuss why the OpenOffice standard format took nearly 5000 bytes of binary data to store about 200 characters. All of this is to say that how an application handles the word wrapping issues is not obvious to the casual user, and often, when reading text with one utility that was written by another, word wrapping issues cause problems.
160

Rewrapping Text with the fmt Command
The fmt command is used to rewrap text, inserting newlines at word boundaries to create lines of a specified length (75 character) by default. As a quick example, consider how the fmt command reformats the file side_effect.gedit.
The cat command, true to its nature, performed no formatting on the file when it displayed it. The fact that the lines wrapped at 80 characters is a side effect of the terminal that was displaying it. The fmt command, on the other hand, wrapped the text at word boundaries so that no line was over 75 characters in length.
161

fmt Command Syntax
Like most of the text processing commands encountered in this Workbook, the fmt command interprets arguments as filenames on which to operate, or operates on standard in if none are provided. Its output is written to standard out. The following table list command lines switches that can be used to modify fmt's behavior.
162

Formatting to a Specific Width
The maximum width of the resulting text can be specified with the -w N command line switch, or more simply just -N, where N is the maximum line width measured in characters. In the following example, elvis reapplies the format command to the file side_effect.gvim, formatting it first to a width of 60 characters, and then to a width of 40 characters.
163

Formatting Text with a Prefix
Often, text is found with some sort of decoration or prefix. Particularly when commenting source code or scripts, all of the text of the comment needs to be marked with the appropriate comment character. The following snippet of text is found in the /usr/include/db_cxx.h header file for the C++ programming language.
Suppose a programmer edited the comment, adding the following few words on the second line.
164

Formatting Text with a Prefix
Because each line of the text begins with a “//”, and ends with an ASCII new line character, readjusting the line to fit back into 80 characters would involve pushing some words to the next line, which would then also need to be reformatted, and so on. Fortunately, the fmt command with the -p command line switch makes life much easier.
The fmt command did all of the hard work, and preserved the prefix characters.
165

The split Command
Dividing files with the split Command Suppose someone has a file that is too large to handle as a single piece. For that, or for some other reason, the split command will divide the file into smaller file, each a specified number of lines or bytes. As an example, elvis generate the following pointless 1066 line file.
166
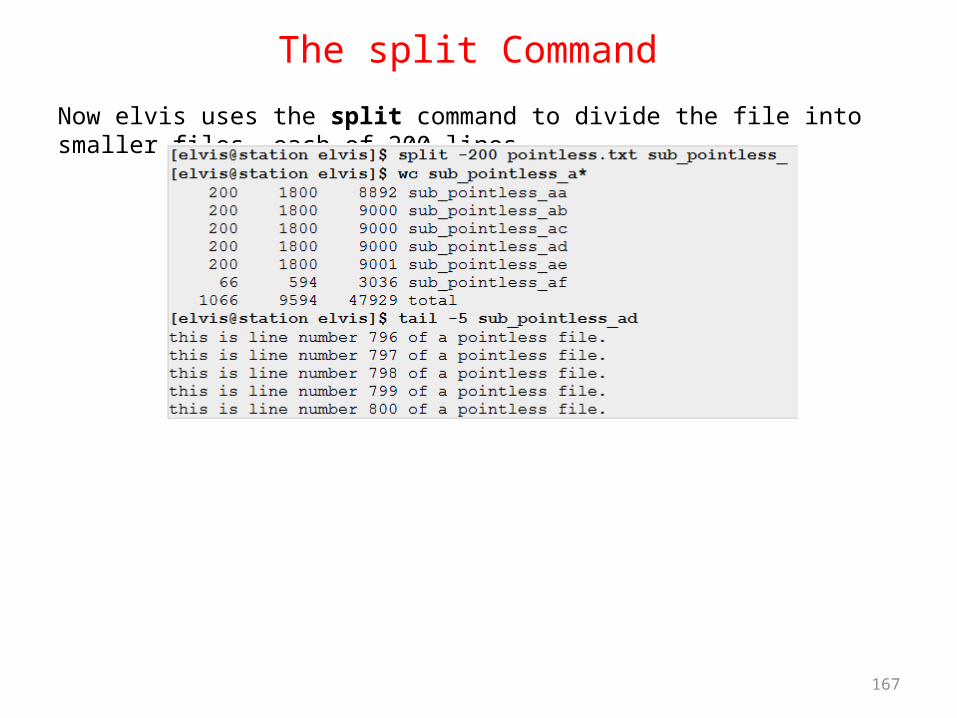
The split Command
Now elvis uses the split command to divide the file into smaller files, each of 200 lines.
167

split Command Syntax
In addition to any command lines switches, the split command expects either zero, one or two arguments. split [SWITCHES] [FILENAME [PREFIX] ]If called with one or two arguments, the first argument is the name of the file to split. If called with two arguments, the second argument is used as a prefix for the newly created files. If called with no arguments, or if the first argument is the special filename “-”, the split command will operate on standard in. The action of the split command is to split FILENAME into smaller files titled PREFIXaa, PREFIXab, etc.
168

Splitting Standard In
In the previous Lesson, we saw that aspell's master dictionary can be dumped using the following command.
169




























