Embed Size (px)
Citation preview

VizML: A Machine Learning Approach toVisualization Recommendation
Kevin HuMIT Media [email protected]
Michiel A. BakkerMIT Media [email protected]
Stephen LiMIT Media [email protected]
Tim KraskaMIT CSAIL
César HidalgoMIT Media [email protected]
2. Raw Corpus
Community FeedAPI Endpoints
3a. Features 4. Models1. Data Source
120K Datasets
Encoding-Level
120K x 841Dataset-level
3b. Design Choices
287K x 80Single-Column
Visualization-level
5. RecommendedChoicesPairwise-Column
287K x 18K { Scatter, Line, Bar }
{ True, False }
{ X, Y }
Mark Type
Is Shared Axis
Is on X- or Y-Axis
Visualization Type
Has Single Axis
Collection and Processing
AggregationFeature
Extraction
Design Choice Extraction
{ Scatter, Line, Bar }
{ True, False }
Concat
Training
Prediction
NN / BaselinesDataset-Visualization Pairs
120K Visualizations
NN / Baselines
NN / Baselines
NN / Baselines
NN / BaselinesCo
ncat
Training
Prediction
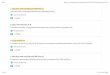
Figure 1: Diagram of data processing and analysis flow in VizML, starting from (1) the original Plotly Community Feed APIendpoints, proceeding to (2) the deduplicated dataset-visualization pairs, (3a) features describing each individual column, pairof columns, and dataset, (3b) design choices extracted from visualizations, (4) task-specific models trained on these features,and (5) potential recommended design choices.
ABSTRACTVisualization recommender systems aim to lower the barrierto exploring basic visualizations by automatically generatingresults for analysts to search and select, rather than manu-ally specify. Here, we demonstrate a novel machine learning-based approach to visualization recommendation that learnsvisualization design choices from a large corpus of datasetsand associated visualizations. First, we identify five key de-sign choices made by analysts while creating visualizations,such as selecting a visualization type and choosing to encodea column along the X- or Y-axis. We train models to predictthese design choices using one million dataset-visualizationpairs collected from a popular online visualization platform.Neural networks predict these design choices with high ac-curacy compared to baseline models. We report and interpretfeature importances from one of these baseline models. To
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copiesare not made or distributed for profit or commercial advantage and thatcopies bear this notice and the full citation on the first page. Copyrightsfor components of this work owned by others than the author(s) mustbe honored. Abstracting with credit is permitted. To copy otherwise, orrepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee. Request permissions from [email protected] 2019, May 4–9, 2019, Glasgow, Scotland UK© 2019 Copyright held by the owner/author(s). Publication rights licensedto ACM.ACM ISBN 978-1-4503-5970-2/19/05. . . $15.00https://doi.org/10.1145/3290605.3300358
evaluate the generalizability and uncertainty of our approach,we benchmark with a crowdsourced test set, and show thatthe performance of our model is comparable to human per-formance when predicting consensus visualization type, andexceeds that of other visualization recommender systems.
CCS CONCEPTS•Human-centered computing→ Visualization designand evaluationmethods;Visualization theory, conceptsandparadigms; •Computingmethodologies→Machinelearning.
KEYWORDSAutomated visualization, machine learning, crowdsourcing
ACM Reference Format:Kevin Hu, Michiel A. Bakker, Stephen Li, Tim Kraska, and CésarHidalgo. 2019. VizML: A Machine Learning Approach to Visual-ization Recommendation. In CHI Conference on Human Factors inComputing Systems Proceedings (CHI 2019), May 4–9, 2019, Glasgow,Scotland UK. ACM, New York, NY, USA, 18 pages. https://doi.org/10.1145/3290605.3300358
1 INTRODUCTIONKnowledge workers across domains – from business to jour-nalism to scientific research – increasingly use data visu-alization to generate insights, communicate findings, andmake decisions [9, 26, 58]. Yet, many visualization tools have

steep learning curves due to a reliance on manual specifica-tion through code [7, 68] or clicks [2, 62]. As a result, datavisualization is often inaccessible to the growing number ofdomain experts who lack the time or background to learnsophisticated tools.While required to create bespoke visualizations, manual
specification is unnecessary for many common use casessuch as preliminary data exploration and the creation ofbasic visualizations. To support these use cases in whichspeed and breadth of exploration are more important thancustomizability [63], systems can leverage the finding thatthe properties of a dataset influence how it can and shouldbe visualized. For example, prior research has shown thatthe accuracy with which visual channels (e.g. position andcolor) encode data depends on the type [5, 15, 67] and distri-bution [28] of data values.Most recommender systems encode these visualization
guidelines as collection of “if-then” statements, or rules [21],to automatically generate visualizations for analysts to searchand select, rather than manually specify [64]. For example,APT [35], BOZ [13], and SAGE [52] generate and rank vi-sualizations using rules informed by perceptual principles.Recent systems such as Voyager [72, 73], Show Me [34], andDIVE [23] extend these approaches with support for columnselection. While effective for certain use cases [72], theserule-based approaches face limitations such as costly rule cre-ation and the combinatorial explosion of possible results [1].
In contrast, machine learning (ML)-based systems directlylearn the relationship between data and visualizations bytraining models on analyst interaction. While recent sys-tems like DeepEye [33], Data2Vis [17], and Draco-Learn [37]are exciting, they do not learn to make visualization designchoices as an analyst would, which impacts interpretabil-ity and ease of integration into existing systems. Further-more, because these systems are trained with annotationson rule-generated visualizations in controlled settings, theyare limited by the quantity and quality of data.We introduce VizML, a ML-based approach to visualiza-
tion recommendation using a large corpus of datasets andassociated visualizations. To begin, we describe visualizationas a process of making design choices that maximize effec-tiveness, which depends on dataset, task, and context. Then,we formulate visualization recommendation as a problem ofdeveloping models that learn to make design choices.
We train and test machine learning models using one mil-lion unique dataset-visualization pairs from the Plotly Com-munity Feed [46]. We describe our process of collecting andcleaning this corpus, extracting features from each dataset,and extracting five key design choices from correspondingvisualizations. Our learning task is to optimize models thatuse features of datasets to predict these choices.
Neural networks trained on 60% of the corpus achieve∼ 70 − 95% accuracy at predicting design choices in a sep-arate 20% test set. This performance exceeds that of foursimpler baseline models, which themselves out-perform ran-dom chance. We report feature importances from one ofthese baseline models, interpret the contribution of featuresto a given task, and relate them to existing research.We evaluate the generalizability and uncertainty of our
model by benchmarking against a crowdsourced test set. Weconstruct this test set by randomly selecting datasets fromPlotly, visualizing each as a bar, line, and scatter plot, andmeasuring the consensus of Mechanical Turk workers. Usinga scoring metric that adjusts for the degree of consensus, wefind that VizML performs comparably to Plotly users andMechanical Turkers, and outperforms two rule-based andtwo ML-based visualization recommendation systems.
To conclude, we discuss interpretations, applications, andlimitations of our initial machine learning approach to visu-alization recommendation. We also suggest directions for fu-ture research, such as aggregating public training and bench-marking corpora, integrating separate recommender modelsinto an end-to-end system, and refining definitions of visual-ization effectiveness.
2 PROBLEM FORMULATIONData visualization communicates information by represent-ing data with visual elements. These representations arespecified using encodings that map from data to the retinalproperties (e.g. position, length, or color) of graphical marks(e.g. points, lines, or rectangles) [5, 12].
Concretely, consider a dataset that describes 406 automo-biles (rows) with eight attributes (columns) such as milesper gallon (MPG), horsepower (Hp), and weight in pounds(Wgt) [50]. To create a scatterplot showing the relationshipbetween MPG and Hp, an analyst encodes each pair of datapoints with the position of a circle on a 2D plane, while alsospecifying other retinal properties such as size and color:
mark:
circle
visual channel:
x-position
y-position
0 50 100 150 200Hp
0
10
20
30
40
50
MP
G
Retinal
Properties Position (x)
Circle
Position (y) 127.2px
Stroke Color OrangeFill Color White
Size (diameter) 2px
Mark
112.5px
To create bespoke visualizations, analysts may need toexhaustively specify encodings in detail using expressive

tools. But a scatterplot is specified with the Vega-lite [55]grammar by selecting a mark type and fields to be encodedalong the x- and y-axes, and in Tableau [62] by placing thetwo columns onto the respective column and row shelves.
That is, to create basic visualizations in many grammars ortools, an analyst specifies higher-level design choices, whichwe define as statements that compactly and uniquely specifya bundle of lower-level encodings. Equivalently, each gram-mar or tool affords a design space of visualizations, which auser constrains by making choices.We formulate basic visualization of a dataset d as a set
of interrelated design choices C = {c}. However, not all de-sign choices result in valid visualizations – some choices areincompatible with each other. For instance, encoding a cate-gorical column with the Y position of a line mark is invalid.Therefore, the set of choices that result in valid visualizationsis a subset of the space of all possible choices.
The effectiveness of a visualization can be defined by infor-mational measures such as efficiency, accuracy, and memora-bility [6, 74], or emotive measures like engagement [19, 27].Prior research also shows that effectiveness is informed bylow-level perceptual principles [15, 22, 31, 51] and datasetproperties [28, 54], in addition to contextual factors such astask [3, 28, 53], aesthetics [14], domain [24], audience [60],and medium [36, 57]. In other words, an analyst makes de-sign choices Cmax that maximize visualization effectivenessgiven a dataset and contextual factors.
But making design choices can be expensive. A goal of vi-sualization recommendation is to reduce the cost of creatingvisualizations by automatically suggesting a subset of designchoices Cr ec ⊆ C that maximize effectiveness. Trained witha corpus of datasets {d} and corresponding design choices{C}, ML-based recommender systems treat recommendationas an optimization problem, such that predictedCr ec ∼ Cmax .A more detailed formulation of the learning task is includedin the Supplementary Material (SM) Section S1.
3 RELATEDWORKWe relate and compare our work to existing Rule-based Visu-alization Recommender Systems and ML-based VisualizationRecommender Systems.
Rule-based Visualization Recommender SystemsVisualization recommender systems either suggest data queries(selecting what data to visualize) or visual encodings (howto visualize selected data) [71]. Data query recommendersvary widely in their approaches [59, 69], with recent systemsoptimizing statistical “utility” functions [18, 65]. Thoughspecifying data queries is crucial to visualization, it is a dis-tinct task from design choice recommendation.Most visual encoding recommenders implement guide-
lines informed the seminal work of Bertin [5] and Cleveland
and McGill [15]. This approach is exemplified by Mackin-lay’s APT [35] – the ur-recommender system – which enu-merates, filters, and scores visualizations using expressive-ness and perceptual effectiveness criteria. The closely relatedSAGE [52], BOZ [13], and ShowMe [34] support more data,encoding, and task types. Recently, hybrid systems suchas Voyager [71–73], Explore in Google Sheets [20, 66],VizDeck [43], andDIVE [23] combine visual encoding ruleswith the recommendation of visualizations that include non-selected columns.
Though effective for many use cases, these systems sufferfrom three major limitations. First, visualization is a complexprocess that may require modelling non-linear relationshipsthat are difficult to capture with simple rules. Second, craft-ing rule sets is a costly process that relies on expert judgment.Lastly, as the dimension of input data increases, the com-binatorial nature of rules result in an explosion of possiblerecommendations.
ML-based Visualization Recommender SystemsThe guidelines encoded by rule-based systems often derivefrom experimental findings and expert experience. Therefore,an indirect manner, heuristics distill best practices learnedfrom another analyst’s experience of creating and consumingvisualizations. Instead of aggregating best practices learnedfrom data and representing them in a system with rules,ML-based systems propose to train models that learn di-rectly from data and can be embedded into systems as-is.A schematic comparison of ML-based visualization recom-mender systems can be found in the SM Section S2.
DeepEye [33] combines rule-based visualization gener-ation with models trained to 1) classify a visualization as“good” or “bad” and 2) rank lists of visualizations. The Deep-Eye corpus consists of 33,412 bivariate visualizations of columnsdrawn from 42 public datasets. 100 students annotated thesevisualizations as good/bad, and compared 285,236 pairs. Theseannotations, combined with 14 features for each column pair,train a decision tree for classification and a ranking neuralnetwork [10] for the “learning to rank” task.
Data2Vis [17] uses a neural machine translation approachto create a sequence-to-sequence model that maps JSON-encoded datasets to Vega-lite visualization specifications.The model is trained using 4,300 automatically generatedVega-Lite examples, consisting of 1-3 variables, generatedfrom 11 distinct datasets. Model predictions are qualitativelyvalidated by examining the visualizations generated from 24common datasets.
Draco-Learn [37] learns trade-offs between constraintsin Draco, a formal model that represents 1) visualizationsas logical facts and 2) design guidelines as hard and softconstraints. Constraint weights are learned using a ranking

support vector machine trained on ranked pairs of visualiza-tions harvested from graphical perception studies [28, 53].Draco then recommends visualizations that satisfy these con-straints by solving a combinatorial optimization problem.
VizML differs from these systems in three major respects.In terms of the learning task, DeepEye learns to classify andrank visualizations, Data2Vis learns an end-to-end genera-tion model, and Draco-Learn learns soft constraints weights.By learning to predict design choices, VizML models are eas-ier to quantitatively validate, provide interpretable measuresof feature importance, and can be more easily integrated intovisualization systems.
In terms of data quantity, the VizML training corpus is or-ders of magnitude larger than that of DeepEye and Data2Vis.The size of our corpus permits the use of 1) large feature setsthat capture many aspects of a dataset and 2) high-capacitymodels such as deep neural networks.The third major difference is one of data quality. In con-
trast to the few datasets used to train the three existing sys-tems, the datasets used to train VizML models are extremelydiverse in shape, structure, and distribution. Furthermore, thevisualizations used by otherML-based recommender systemsare generated by rule-based systems and evaluated undercontrolled settings. The corpus used by VizML is the resultof real visual analysis by analysts on their own datasets.
However, VizML faces two major limitations. First, thesethree ML-based systems recommend both data queries andvisual encodings, while VizML only recommends the latter.Second, in this paper, we do not create an application thatemploys our visualization model. Design considerations foruser-facing systems that productively and properly employML-based visualization recommendation are important, butbeyond the scope of this paper.
4 DATAWe describe our process for extracting features and designchoices from the processed Plotly data. These are steps 1,2 and 3 in Figure 1. In the SM Section S3, we describe ourprocess for collecting and cleaning the corpus of 2.3 milliondataset-visualization pairs from the Plotly Community Feed[44, 46] and provide a description of the data. This paper isthe first time the Plotly corpus, generated by 143,007 uniqueusers, is used to train visualization recommender systems.The corpus along with analysis scripts is publicly availableat https://vizml.media.mit.edu.
Feature ExtractionWe map each dataset to 841 features, mapped from 81 single-column features and 30 pairwise-column features using 16aggregation functions. Detail on each of the features is foundin Table S2 in the SM Section S4.
Da
tase
t
Pairwise-Column (30) Single-Column (81)
Fe
atu
res Dataset (841)
has decimal: true
# columns: 8
max corr: 0.951
type: decimal
median: 93.5
kurtosis: 0.672
Name Edit Dist.: 4
K-S Statistic: 1.0
Correlation: -0.805
Extract
Aggregate
Extract
Figure 2: Extracting features from the Automobile MPGdataset [50].
Mark Types:Is Shared Axis:Is on X Axis:Is on Y Axis:
Encoding-level Choices (3)
ScatterFalseFalseTrue
ScatterFalseFalseTrue
ScatterTrueTrueFalse
Visualization Type: ScatterHas Shared Axis: True
Visualization-level
Choices (1)
50 100 150 200
10
20
30
40
2000
3000
4000
5000
Wg
t
MP
G
Hp
MPGWgt
MPG Hp Wgt
Scatter Trace
Scatter Trace
De
sig
n C
ho
ice
sV
isu
aliza
tio
n
Shared X-Axis
No
n-s
hare
dY-A
xis
No
n-sh
are
dY-A
xis
Figure 3: Extracting design choices from a dual-axis scatter-plot visualizing three columns of the MPG dataset.
Each column is described by 81 single-column featuresacross four categories. The Dimensions (D) feature is thenumber of rows in a column. Types (T) features capturewhether a column is categorical, temporal, or quantitative.Values (V) features describe the statistical and structuralproperties of the valueswithin a column.Names (N) featuresdescribe the column name. We distinguish between thesefeature categories for three reasons. First, these categorieslet us organize how we create and interpret features. Second,we can observe the contribution of different types of features.Third, some categories of features may be less generalizablethan others. We order these categories (D → T → V → N)by how biased we expect those features to be towards thePlotly corpus.
We describe each pair of columnswith 30 pairwise-columnfeatures. These features fall into two categories:Values andNames. Note that many pairwise-column features depend

on the individual column types determined through single-column feature extraction. For instance, the Pearson corre-lation coefficient requires two numeric columns, and the“number of shared values” feature requires two categoricalcolumns.We create 841 dataset-level features by aggregating
these single- and pairwise-column features using the 16 ag-gregation functions shown in Table S2c in SM Section S4.These aggregation functions convert single-column features(across all columns) and pairwise-column features (acrossall pairs of columns) into scalar values. For example, given adataset, we can count the number of columns, describe thepercent of columns that are categorical, and compute themean correlation between all pairs of quantitative columns.Two other approaches to incorporating single-column fea-tures are to train separate models per number of columns, orto include column features with padding. Neither approachyielded a significant improvement over the results reportedin Section 6.
Design Choice ExtractionEach visualization in Plotly consists of traces that associatecollections of data with visual elements. Therefore, we ex-tract an analyst’s design choices by parsing these traces.Examples of encoding-level design choices include marktype, such as scatter, line, bar; and X or Y column encoding,which specifies which column is represented on which axis;and whether or not an X or Y column is the single columnrepresented along that axis. For example, the visualizationin Figure 3 consists of two scatter traces, both of which havethe same column encoded on the X axis (Hp), and two distinctcolumns encoded on the Y axis (MPG and Wgt).By aggregating these encoding-level design choices, we
can characterize visualization-level design choices of achart. Within our corpus, over 90% of the visualizations con-sist of homogeneous mark types. Therefore, we use visual-ization type to describe the type shared among all traces, andalso determined whether the visualization has a shared axis.The example in Figure 3 has a scatter visualization type anda single shared axis (X).
5 METHODSWe describe our feature processing pipeline, the machinelearning models we use, how we train those models, andhow we evaluate performance. These are steps 4 and 5 ofthe workflow in Figure 1.
Feature ProcessingWe converted raw features into a form suitable for modelingusing a five-stage pipeline. First, we apply one-hot encod-ing to categorical features. Second, we set numeric valuesabove the 99th percentile or below the 1st percentile to those
respective cut-offs. Third, we imputed missing categoricalvalues using the mode of non-missing values, and missingnumeric values with the mean of non-missing values. Fourth,we removed the mean of numeric fields and scaled to unitvariance.
Lastly, we randomly removed datasets that were exactdeduplicates of each other, resulting in unique 1, 066, 443datasets and 2, 884, 437 columns. However, many datasetsare slight modifications of each other, uploaded by the sameuser. Therefore, we removed all but one randomly selecteddataset per user, which also removed bias towards moreprolific Plotly users. This aggressive deduplication resultedin a final corpus of 119,815 datasets and 287,416 columns.Results from only exact deduplication result in significantlyhigher within-corpus test accuracies, while a soft threshold-based deduplication results in similar test accuracies.
Prediction TasksOur task is to train models that use the features describedin Section 4 to predict the design choices also described inSection 4. Two visualization-level prediction tasks usedataset-level features to predict visualization-level designchoices:
(1) Visualization Type [VT]: 2-, 3-, and 6-classGiven all traces are the same type, what type is it?Scatter Line Bar Box Histogram Pie44829 26209 16002 4981 4091 3144
(2) Has Shared Axis [HSA]: 2-classDo the traces all share one axis (either X or Y)?False True95723 24092
The three encoding-level prediction tasks use featuresabout individual columns to predict how they are visuallyencoded. These prediction tasks consider each column inde-pendently, instead of alongside other columns in the samedataset, which accounts for the effect of column order.
(1) Mark Type [MT]: 2-, 3-, and 6-classWhat mark type is used to represent this column?Scatter Line Bar Box Histo Heatmap68931 64726 30023 13125 5163 1032
(2) Is Shared X-axis or Y-axis [ISA]: 2-classIs this column the only column encoded on its axis?False True275886 11530
(3) Is on X-axis or Y-axis [XY]: 2-classIs this column encoded on the X-axis or the Y-axis?False True144364 142814

For the Visualization Type and Mark Type tasks, the 2-class task predicts line vs. bar, and the 3-class predicts scattervs. line vs. bar. Though Plotly supports over twenty marktypes, we limited prediction outcomes to the few types thatcomprise the majority of visualizations within our corpus.This heterogeneity of visualization types is consistent withthe findings of [4, 38].
Neural Network and Baseline ModelsOur primary model is a fully-connected feedforward neuralnetwork (NN) with 3 hidden layers, each consisting of 1, 000neurons with ReLU activation functions and implementedusing PyTorch [41]. For comparison, we chose four simplerbaseline models, all implemented using scikit-learn [42] withdefault parameters: naive Bayes (NB), K-nearest neighbors(KNN), logistic regression (LR) and random forest (RF). Ran-domized parameter search for each model did not result in asignificant performance increase over the reported results.For all models, we split the data into 60/20/20
train/validation/test sets and train and test each model fivetimes using 5-fold cross-validation. The reported results arethus test results averaged across the five test sets. We over-sample the train, validation, and test sets to the size of themajority class while ensuring no overlap between the threesets. We oversample because of the heterogeneous outcomes,naive classifiers guessing the base rates would have highaccuracies. Balanced classes also allow us to report standardaccuracies (fraction of correct predictions), ideal for inter-pretability and generalizing results to multi-class casesC > 2,in contrast to measures such as the F1 score.
The neural network was trained with the Adam optimizerand a mini-batch size of 200. The learning rate was initial-ized at 5 × 10−4, and followed a learning rate schedule thatreduces the learning rate by a factor of 10 upon encounteringa plateau, defined as 10 epochs during which validation accu-racy does not increase beyond a threshold of 10−3. Trainingended after the third decrease in the learning rate, or at 100epochs. Weight decay, dropout and batch normalization didnot significantly improve performances.
In terms of features, we constructed four different featuresets by incrementally adding the Dimensions (D), Types(T), Values (V), and Names (N) categories of features, inthat order. We refer to these feature sets as D, D+T, D+T+V,and D+T+V+N=All. The neural network was trained andtested using all four feature sets independently. The four base-line models only used the full feature set (D+T+V+N=All).
6 EVALUATING PERFORMANCEWe report performance of each model on the five predictiontasks in the barplot in Figure ?? and in Table 2 in the SM.The neural network consistently outperforms the baselinemodels and model performance generally progressed as NB
< KNN < LR ≈ RF < NN. That said, the performance of bothRF and LR is not significantly lower than that of the NN insome cases. Simpler classifiers may be desirable, dependingon the need for optimized accuracy, and the trade-off withother factors such as interpretability and training cost.
Because the four feature sets are a sequence of supersets (D⊂ D+T ⊂ D+T+V ⊂ D+T+V+N), we consider the accuracy ofeach feature set above and beyond the previous. For instance,the increase in accuracy of a model trained on D+T+V overa model trained on D+T is a measure of the contributionof value-based (V) features. These marginal accuracies arevisualized alongside baseline model accuracies in Figure ??in the SM.
We note that the value-based feature set (e.g. the statisticalproperties of a column) contribute more to performancethan the type-based feature set (e.g. whether a column iscategorical), potentially because there are many more value-based features than type-based features. Or, because manyvalue-based features are dependent on column type, theremay be overlapping information between value- and type-based features.
Interpreting Feature ImportancesFeature importances help relate our results to prior literatureand inform design guidelines for rule-based systems. Here,we determine feature importances for our top performingrandom forest models using the standard mean decreaseimpurity (MDI) measure [8, 32]. We choose this method forits interpretability and its stability across runs. The top tenfeatures for five different tasks are shown in Table 2a andfor all other tasks in the SM Table S3.
We first note the importance of dimensionality ( ), likethe length of columns (i.e. the number of rows) or the numberof columns. For example, the length of a column is the secondmost important feature for predicting whether that column isvisualized as a line or bar trace. The dependence of mark typeon number of visual elements is consistent with heuristicslike “keep the total number of bars under 12” for showingindividual differences in a bar chart [61], and not creating piecharts with more “more than five to seven” slices [30]. Thedependence on number of columns is related to the heuristicsdescribed by Bertin [5] and encoded in Show Me [34].Features related to column type ( ) are consistently
important for each prediction task. For example, whethera dataset contains a string type column is the fifth mostimportant feature for determining two-class visualizationtype. The dependence of visualization type choice on col-umn data type is consistent with the type-dependency ofthe perceptual properties of visual encodings described byMackinlay [35] and Cleveland and McGill [15].

(a) Prediction accuracies for two visualization-level tasks.
Visualization Type HSA
Model Features d C=2 C=3 C=6 C=2
NN D 15 66.3 50.4 51.3 84.1D+T 52 75.7 59.6 60.8 86.7D+T+V 717 84.5 77.2 87.7 95.4All 841 86.0 79.4 89.4 97.3
NB All 841 63.4 49.5 46.2 72.9KNN All 841 76.5 59.9 53.8 81.5LR All 841 81.8 64.9 69.0 90.2RF All 841 81.2 65.1 66.6 90.4
Nraw (in 1000s) 42.2 87.0 99.3 119
(b) Prediction accuracies for three encoding-level tasks.
Mark Type ISA XY
Model Features d C=2 C=3 C=6 C=2 C=2
NN D 1 65.2 44.3 30.5 52.1 49.9D+T 9 68.5 46.8 35.0 70.3 57.3D+T+V 66 79.4 59.4 76.0 95.5 67.4All 81 84.9 67.8 82.9 98.3 83.1
NB All 81 57.6 41.1 27.4 81.2 70.0KNN All 81 72.4 51.9 37.8 72.0 65.6LR All 81 73.6 52.6 43.7 84.8 79.1RF All 81 78.3 60.1 46.7 74.2 83.4
Nraw (in 1000s) 94.7 163 183 287 287Table 1: Design choice prediction accuracies for five models, averaged over 5-fold cross-validation. The standard error of themean was < 0.1% for all results. Results are reported for the neural network (NN) and four baseline models: naive Bayes(NB), K-nearest neighbors (KNN), logistic regression (LR), and random forest (RF). Features are separated into four categories:dimensions (D), types (T), values (V), and names (N). Nraw is the size of the training set before resampling, d is the number offeatures, and C is the number of outcome classes. HSA = Has Shared Axis, ISA = Is Shared X-axis or Y-Axis, and XY = Is onX-axis or Y-axis.
(a) Feature importances for two visualization-level tasks.
# Visualization Type (C=2) Has Shared Axis (C=2)
1 % Values are Mode std Number of Cols2 Min Value Length max Is Monotonic %3 Entropy var Field Name Length AAD4 Entropy std # Words In Name NR5 String Type has X In Name #6 Median Length max # Words In Name range7 Mean Value Length AAD Edit Distance mean8 Entropy mean Edit Distance max9 Entropy max Length std10 Min Value Length AAD Edit Distance NR
(b) Feature importances for three encoding-level tasks.
# Mark Type (C=2) Is Shared Axis (C=2) Is X or Y Axis (C=2)
1 Entropy # Words In Name Y In Name2 Length Unique Percent X In Name3 Sortedness Field Name Length Field Name Length4 % Outliers (1.5IQR) Is Sorted Sortedness5 Field Name Length Sortedness Length6 Lin Space Seq Coeff X In Name Entropy7 % Outliers (3IQR) Y In Name Lin Space Seq Coeff8 Norm. Mean Lin Space Seq Coeff Kurtosis9 Skewness Min # Uppercase Chars10 Norm. Range Length Skewness
Table 2: Top-10 feature importances determined bymean decrease impurity for the top performing random forestmodels. Thesecond column in the visualization-level importances table describes how each featurewas aggregated, using the abbreviationsin Table S2c. Colors represent different feature groupings: dimensions ( ), type ( ), statistical [Q] ( ), statistical [C] ( ),sequence ( ), scale of variation ( ), outlier ( ), unique ( ), name ( ), and pairwise-relationship ( ).
Statistical features (quantitative: , categorical: )such as Gini, entropy, skewness and kurtosis are impor-tant across the board. The presence of these higher ordermoments is striking because lower-order moments such asmean and variance are low in importance. The importance ofthese moments highlight the potential importance of captur-ing high-level characteristics of distributional shape. Theseobservations support the use of statistical properties in visu-alization recommendation, like in [59, 70], but also the useof higher-order properties such as skewness, kurtosis, andentropy in systems such as Foresight [16], VizDeck [43], andDraco [37].
Measures of orderedness ( ), specifically sortednessand monotonicity, are important for many tasks. Sortedness
is defined as the element-wise correlation between the sortedand unsorted values of a column, that is |corr(Xraw ,Xsor ted )|,which lies in the range [0, 1]. Monotonicity is determinedby strictly increasing or decreasing values in Xraw . The im-portance of these features could be due to pre-sorting of adataset by an analyst, which may reveal which column is con-sidered to be the independent or explanatory column, whichis typically visualized along the X-axis. While intuitive, wehave not seen orderedness factor into existing systems.We also note the importance of the linear or logarith-
mic space sequence coefficients, which are heuristic-basedfeatures that roughly capture the scale of variation ( ).Specifically, the linear space sequence coefficient is deter-mined by std(Y )/mean(Y ), where Y = {Xi − Xi−1} with

i = (1 + 1)..N for the linear space sequence coefficient, andY = {Xi/Xi−1} with i = (1 + 1)..N for the logarithmic spacesequence coefficient. A column “is” linear or logarithmic ifits coefficient ≤ 10−3. Both coefficients are important in allfour selected encoding-level prediction tasks. We have notseen similar measures of scale used in prior systems.In sum, the diversity of the features in Table 2a and Ta-
ble S3 in the SM suggest that rule-based recommender sys-tems should include more features than the current typebased features most systems rely on (e.g. [34, 73]). Further-more, the task-specific ranking of features, as well as thenon-linear dependencies in the models, make it even harderfor rule-based systems to perform well across tasks and do-mains and thus further emphasize the need for ML-basedrecommender systems
7 BENCHMARKINGWITH CROWDSOURCEDEFFECTIVENESS
We expand our definition of effectiveness from a binary to acontinuous function that can be determined through crowd-sourced consensus. Then, we describe our experimental pro-cedure for gathering visualization type evaluations fromMechanical Turk workers. We compare different models atpredicting these evaluations using a consensus-based effec-tiveness score.
Modeling and Measuring EffectivenessAs discussed in Section 2, we model data visualization asa process of making a set of design choices C = {c} thatmaximize an effectiveness criteria Eff that depends on datasetd , task, and context. In Section 6, we predict these designchoices by training a machine learning model on a corpus ofdataset-design choice pairs [(d, cd )]. But because each datasetwas visualized only once by each user, we consider the userchoices cd to be effective, and each other choice as ineffective.That is, we consider effectiveness to be binary.
But prior research suggests that effectiveness is contin-uous. For example, Saket et al. use time and accuracy pref-erence to measure task performance [53], Borkin et al. usea normalized memorability score [6], and Cleveland andMcGill use absolute error rates to measure performance onelementary perceptual tasks [15]. Discussions by visualiza-tion experts [25, 29] also suggest that multiple visualizationscan be equally effective at displaying the same data.
Our effectiveness metric should be continuous and reflectthe ambiguous nature of data visualization, which leads tomultiple choices receiving a non-zero or even maximal scorefor the same dataset. This is in agreement with measures ofperformance for other machine learning tasks such as theBLEU score in language translation [40] and the ROUGEmetric in text summarization [11], where multiple resultscan be (partly) correct.
To estimate this effectiveness function, we need to observea dataset d visualized by multiple potential users. Assumethat a design choice c can take on multiple discrete values{v}. For instance, we consider c the choice of VisualizationType, which can take on the values {bar, line, scatter}. Usingnv to denote the number of timesv was chosen, we computethe probability of making choice v as Pc (v) = nv/N , anduse {Pc } to denote the collection of probabilities across all v .We normalize the probability of choice v by the maximumprobability to define an effectiveness score ˆEffc (v) = Pc (v) /
max ({Pc }). Now, if all N users make the same choicev , onlyc = v will get themaximimum score while every other choicec , v will receive a zero score. However, if two choices arechosen with an equal probability and are thus both equallyeffective, the normalization will ensure that both receive amaximum score.Developing this crowdsourced score that reflects the am-
biguous nature of making data visualization choices servesthree main purposes. First, it lets us establish uncertaintyaround our models – in this case, by bootstrap. Second, itlets us test whether models trained on the Plotly corpus cangeneralize and if Plotly users are actually making optimalchoices. Lastly, it lets us benchmark against performance ofthe Plotly users as well as other predictors.To generate the crowdsourced evaluation data, we re-
cruited and successfully pre-screened 300 participants throughAmazon Mechanical Turk. The data preparation and crowd-sourced evaluation procedures is described in more detail inSM Section S6.
Benchmarking ProcedureWe use four types of predictors in our benchmark: human,rule-based model, ML-based model, and baseline. The twohuman predictors are the Plotly predictor, which is the visu-alization type of the original plot created by the Plotly user,and the MTurk predictor is the choice of a single randomMechanical Turk participant. When evaluating the perfor-mance of individual Mechanical Turkers, that individual’svote was excluded from the set of votes used in the modeestimation.The two rule-based predictors include one commercial
system and another research system. The first, Tableau’sShowMe feature [34], is based on the expressiveness and ef-fectiveness criteria of Mackinlay’s APT [35]. The second, theCompassQL recommender engine [71], powers the Voyagerand Voyager 2 systems [72, 73].
The two learning-based predictors areDeepEye andData2Vis.In all cases, we tried to make choices that maximize predic-tion performance, within reason. We uploaded datasets toShow Me, DeepEye, and CompassQL as comma-separatedvalues (CSV) files, and to Data2Vis as JSON objects. Unlike

VizML and Data2Vis, DeepEye supports pie, bar, and scattervisualization types. We marked both pie and bar recommen-dations were both bar predictions, and scatter recommenda-tions as line predictions in the two-type case.
For all tools, we modified the data within reason to maxi-mize the number of valid results. For the remaining errors (4for Data2Vis, 14 for DeepEye), and cases without returnedresults (12 for DeepEye and 33 for CompassQL) we assigneda random chart prediction.Predictor performance is evaluated as the total sum of
normalized effectiveness scores. This Consensus-AdjustedRecommendation Score (CARS) of a predictor is defined as:
CARSpredictor =1|D |
∑d ∈D
Pc(cpredictor, d
)max ({Pc })
× 100 (1)
where |D | is the number of datasets (66 for two-class and99 for three-class), cpredictor, d is the predicted visualizationtype for dataset d , and Pc returns the fraction of MechanicalTurker votes for a given visualization type. Note that theminimum CARS > 0%. We establish 95% confidence intervalsaround these scores by comparing against 105 bootstrapsamples of the votes, which can be thought of as syntheticvotes drawn from the observed probability distribution.
Benchmarking ResultsWe first measure the degree of consensus using the Ginicoefficient, the distribution of which is shown in Figure 4. Ifa strong consensus was reached for all visualizations, thenthe Gini distributions would be strongly skewed towards themaximum, which is 1/2 for the two-class case, and 2/3 for thethree-class case. Conversely, a lower Gini implies a weakerconsensus, indicating an ambiguous ideal visualization type.TheGini distributions are not skewed towards either extreme,which supports the use of a soft scoring metric such as CARSover a hard measure like accuracy.
The Consensus-Adjusted Recommendation Scores for eachmodel and task are visualized as a bar chart in Figure 5.We first compare the CARS of VizML (88.96 ± 1.66) againstthat of Mechanical Turkers (86.66 ± 5.38) and Plotly users(90.35± 1.85) for the two-class case, as shown in Figure 5a. Itis surprising that VizML performs comparably to the originalPlotly users, who possess domain knowledge and investedtime into visualizing their own data. VizML significantlyout-performs Data2Vis (75.61 ± 2.44) and DeepEye (79.12 ±4.33). Show Me achieves a CARS of (81.70 ± 2.05), which issimilar to that of CompassQL (80.98 ± 4.32). While the otherrecommenders were not trained to perform visualizationtype prediction, all perform slightly better than the random
Gini Coefficient
Two-Type
Fre
quen
cy
Three-Type
Low Consensus (Gini=0.07) High Consensus (Gini=0.41)
Figure 4: Distribution of Gini coefficients
classifier (74.30 ± 7.09). For this task, the absolute minimumscore was (48.61 ± 2.95).The same results hold for the three-class case shown in
Figure 5b, in which the CARS of VizML (81.18 ± 2.39) isslightly higher, but within error bars, than that of MechanicalTurkers (79.28±4.66), and Plotly users (79.58±2.44). Data2Vis(64.75 ± 3.13) and DeepEye (68.09 ± 4.11) outperform theRandom (60.37 ± 6.98) with a larger margin, but still withinerror. CompassQL (68.95 ± 4.48) slightly surpasses Show Me(65.37 ± 2.98), also within error. The minimum score was(26.93 ± 3.46).
8 DISCUSSIONIn this paper, we introduce VizML, a machine learning ap-proach to visualization recommendation using a large corpusof datasets and corresponding visualizations.We identify fivekey prediction tasks and show that neural network classifiersattain high test accuracies on these tasks, relative to bothrandom guessing and simpler classifiers. We also benchmarkwith a test set established through crowdsourced consen-sus, and show that the performance of neural networks iscomparable that of individual humans.Visualization system developers have multiple paths to-
wards incorporatingML-based recommenders such as VizMLinto authoringworkflows. Partial specification recommenderson top of existing manual specification tools, such as theShow Me [34] feature in Tableau [62], rely on design choicesuggestions that could be provided by a learned model. Code-based authoring environments such as the Draco [37] and

Pred
icto
r
Consensus-Adjusted Recommendation Score
VizML
Plotly
MTurk
CompassQL
DeepEye
Show Me
Data2Vis
Random
0 10 20 30 40 50 60 70 80 90 100
90.4
89.0
86.7
81.7
81.0
79.1
75.6
74.3
(a) Two-type (bar/line) visualization type CARS.
Pred
icto
r
Consensus-Adjusted Recommendation Score
Predictor Type
VizML
Plotly
MTurk
CompassQL
DeepEye
Show Me
Data2Vis
Random
0 10 20 30 40 50 60 70 80 90 100
ML-basedBaseline Rule-based Human
80.2
79.6
79.3
69.0
68.1
65.4
64.8
60.4
(b) Three-type (bar/line/scatter) visualization type CARS.
Figure 5: Consensus-Adjusted Recommendation Score ofthree ML-based, two rule-based, and two human predictorswhen predicting consensus visualization type. Error barsshow 95% bootstrapped confidence intervals, with 105 boot-straps. The mean minimum achievable score is the lowerdashed line, while the highest achieved CARS is the upperdotted line.
Vega-Lite [55] editors, could use partial specification rec-ommenders to power visualization “autocomplete” features,which suggest design choices in response to user interaction,in real time. Mixed-initiative systems such as Voyager [73]and DIVE [23] could leverage Top-N recommendations topresent a gallery of visualizations for users to search anddrill-down. Designing interactions with ML-based recom-menders is an important area of future work.
In order to develop ML-based recommenders for their ownsystems, developers could begin by identifying user designchoices and extracting simple features from data. Given suffi-cient volume, those features and design choices can be usedto train models as we have demonstrated in this paper. Al-ternatively, developers can overcome the cold-start problemby using pre-trained models such as VizML. With modelsin hand, developers can progress further by collecting theusage analytics (e.g. measures of engagement such as clicksand shares) to establish customized measures of visualizationeffectiveness.
We acknowledge the limitations of the Plotly corpus andour approach. First, despite aggressive deduplication, ourmodel is certainly biased towards the Plotly dataset. As aweb-based platform, Plotly could draw a certain cohort ofanalysts, encourage certain types of plots by interface designor defaults, or be more appropriate for specific types andsizes of data. Second, neither the Plotly user nor the Mechan-ical Turker is an expert in data visualization. Thirdly, weacknowledge that this paper was only focused on a subsetof the tasks usually considered in a visualization recommen-dation pipeline.Promising avenues for future work lie in both data col-
lection and modelling directions. On the data side, there isa need for more diverse training data from other tools (e.g.Many Eyes and Tableau) and pertaining to adjacent data sci-ence tasks such as feature selection and data transformation.Richer training data allows researchers to investigate the pre-vious bias concerns, optimize visualization recommenderswith a task-based (or generally multi-objective) effectivenessmetric, recommend multiple views of a dataset, study com-plementary approaches to feature engineering, and integratedistinct design choice recommendations using a probabilisticgraphical model.
Underlying each ML-based recommender model is a mea-sure of visualization effectiveness. Determining the param-eters that inform effectiveness is an open question for thevisualization community. Machine learning tasks such asimage annotation or medical diagnosis are often objective,in that there exists a clear human-annotated ground truth.Other tasks are subjective, such as language translation ortext summarization tasks, and are benchmarked against hu-man evaluation or against human-generated results.
Questions of objective visualization quality point towardsthe role of experts in visualization assessment. Visualizationexperts provide evaluations that are informed by experienceand knowledge of perceptual studies. But if laypeople are thetarget audience of visualizations, the consensus opinion ofcrowdsourced agents may be a good measure of visualizationquality. By providing a large training corpus, initial machinelearning models, and a crowdsourced benchmark, VizML isa step forward in addressing these questions.

REFERENCES[1] C. C. Aggarwal. Recommender Systems: The Textbook. Springer Pub-
lishing Company, Incorporated, 1st edition, 2016.[2] C. Ahlberg. Spotfire: An Information Exploration Environment. SIG-
MOD Rec., 25(4):25–29, Dec. 1996.[3] R. Amar, J. Eagan, and J. Stasko. Low-Level Components of Analytic
Activity in Information Visualization. In Proceedings of the Proceedingsof the 2005 IEEE Symposium on Information Visualization, INFOVIS ’05,pages 15–, Washington, DC, USA, 2005. IEEE Computer Society.
[4] L. Battle, P. Duan, Z. Miranda, D. Mukusheva, R. Chang, and M. Stone-braker. Beagle: Automated Extraction and Interpretation of Visual-izations from the Web. In Proceedings of the 2018 CHI Conference onHuman Factors in Computing Systems, CHI ’18, pages 594:1–594:8, NewYork, NY, USA, 2018. ACM.
[5] J. Bertin. Semiology of Graphics. University of Wisconsin Press, 1983.[6] M. A. Borkin, A. A. Vo, Z. Bylinskii, P. Isola, S. Sunkavalli, A. Oliva, and
H. Pfister. What Makes a Visualization Memorable? IEEE Transactionson Visualization and Computer Graphics, 19(12):2306–2315, Dec 2013.
[7] M. Bostock, V. Ogievetsky, and J. Heer. D3 Data-Driven Documents.IEEE Transactions on Visualization and Computer Graphics, 17(12):2301–2309, Dec. 2011.
[8] L. Breiman, J. Friedman, R. A. Olshen, and C. J. Stone. Classificationand Regression Trees. Chapman and Hall/CRC, 1984.
[9] E. Brynjolfsson and K. McElheran. The Rapid Adoption of Data-DrivenDecision-Making. American Economic Review, 106(5):133–39, May2016.
[10] C. Burges, T. Shaked, E. Renshaw, A. Lazier, M. Deeds, N. Hamilton,and G. Hullender. Learning to Rank Using Gradient Descent. InProceedings of the 22nd International Conference on Machine Learning,ICML ’05, pages 89–96, New York, NY, USA, 2005. ACM.
[11] C. Lin. ROUGE: a package for automatic evaluation of summaries.pages 25–26, 2004.
[12] S. K. Card, J. D. Mackinlay, and B. Shneiderman, editors. Readings inInformation Visualization: Using Vision to Think. Morgan KaufmannPublishers Inc., San Francisco, CA, USA, 1999.
[13] S. M. Casner. Task-analytic Approach to the Automated Design ofGraphic Presentations. ACM Trans. Graph., 10(2):111–151, Apr. 1991.
[14] N. Cawthon and A. V. Moere. The Effect of Aesthetic on the Usabilityof Data Visualization. In Information Visualization, 2007. IV ’07. 11thInternational Conference, pages 637–648, July 2007.
[15] W. S. Cleveland and R. McGill. Graphical Perception: Theory, Experi-mentation, and Application to the Development of Graphical Methods.Journal of the American Statistical Association, 79(387):531–554, 1984.
[16] Ç. Demiralp, P. J. Haas, S. Parthasarathy, and T. Pedapati. Foresight:Rapid Data Exploration Through Guideposts. CoRR, abs/1709.10513,2017.
[17] V. Dibia and Ç. Demiralp. Data2Vis: Automatic Generation of Data Vi-sualizations Using Sequence to Sequence Recurrent Neural Networks.CoRR, abs/1804.03126, 2018.
[18] H. Ehsan, M. A. Sharaf, and P. K. Chrysanthis. MuVE: Efficient Multi-Objective View Recommendation for Visual Data Exploration. 2016IEEE 32nd International Conference on Data Engineering (ICDE), pages731–742, 2016.
[19] S. Few. Data Visualization Effectiveness Profile. https://www.perceptualedge.com/articles/visual_business_intelligence/data_visualization_effectiveness_profile.pdf, 2017.
[20] Google. Explore in Google Sheets. https://www.youtube.com/watch?v=9TiXR5wwqPs, 2015.
[21] F. Hayes-Roth. Rule-based Systems. Commun. ACM, 28(9):921–932,Sept. 1985.
[22] J. Heer, N. Kong, and M. Agrawala. Sizing the Horizon: The Effects ofChart Size and Layering on the Graphical Perception of Time Series
Visualizations. In Proceedings of the SIGCHI Conference on HumanFactors in Computing Systems, CHI ’09, pages 1303–1312, New York,NY, USA, 2009. ACM.
[23] K. Hu, D. Orghian, and C. Hidalgo. DIVE: A Mixed-Initiative SystemSupporting Integrated Data Exploration Workflows. In ACM SIGMODWorkshop on Human-in-the-Loop Data Analytics (HILDA). ACM, 2018.
[24] E. M. Jonathan Meddes. Improving visualization by capturing domainknowledge. volume 3960, pages 3960 – 3960 – 10, 2000.
[25] B. Jones. Data Dialogues: To Optimize or to Satisfice WhenVisualizing Data? https://www.tableau.com/about/blog/2016/1/data-dialogues-optimize-or-satisfice-data-visualization-48685, 2016.
[26] S. Kandel, A. Paepcke, J. M. Hellerstein, and J. Heer. Enterprise DataAnalysis and Visualization: An Interview Study. IEEE Transactions onVisualization and Computer Graphics, 18(12):2917–2926, Dec. 2012.
[27] H. Kennedy, R. L. Hill, W. Allen, , and A. Kirk. In Engaging with (big)data visualizations: Factors that affect engagement and resulting newdefinitions of effectiveness, volume 21, USA, 2016. First Monday.
[28] Y. Kim and J. Heer. Assessing Effects of Task and Data Distributionon the Effectiveness of Visual Encodings. Computer Graphics Forum(Proc. EuroVis), 2018.
[29] C. N. Knaflic. Is there a single right answer?http://www.storytellingwithdata.com/blog/2016/1/12/is-there-a-single-right-answer, 2016.
[30] R. Kosara. Understanding Pie Charts. https://eagereyes.org/techniques/pie-charts, 2010.
[31] Y. Liu and J. Heer. Somewhere Over the Rainbow: An EmpiricalAssessment of Quantitative Colormaps. In Proceedings of the 2018 CHIConference on Human Factors in Computing Systems, CHI ’18, pages598:1–598:12, New York, NY, USA, 2018. ACM.
[32] G. Louppe, L. Wehenkel, A. Sutera, and P. Geurts. Understanding Vari-able Importances in Forests of Randomized Trees. In Proceedings of the26th International Conference on Neural Information Processing Systems- Volume 1, NIPS’13, pages 431–439, USA, 2013. Curran Associates Inc.
[33] Y. Luo, X. Qin, N. Tang, and G. Li. DeepEye: Towards AutomaticData Visualization. The 34th IEEE International Conference on DataEngineering (ICDE), 2018.
[34] J. Mackinlay, P. Hanrahan, and C. Stolte. Show Me: Automatic Pre-sentation for Visual Analysis. IEEE Transactions on Visualization andComputer Graphics, 13(6):1137–1144, Nov. 2007.
[35] J. D. Mackinlay. Automating the Design of Graphical Presentations ofRelational Information. ACM Trans. Graphics, 5(2):110–141, 1986.
[36] P. Millais, S. L. Jones, and R. Kelly. Exploring Data in Virtual Reality:Comparisons with 2D Data Visualizations. In Extended Abstracts ofthe 2018 CHI Conference on Human Factors in Computing Systems, CHIEA ’18, pages LBW007:1–LBW007:6, New York, NY, USA, 2018. ACM.
[37] D. Moritz, C. Wang, G. L. Nelson, H. Lin, A. M. Smith, B. Howe, andJ. Heer. Formalizing Visualization Design Knowledge as Constraints:Actionable and Extensible Models in Draco. IEEE Trans. Visualization& Comp. Graphics (Proc. InfoVis), 2018.
[38] K. Morton, M. Balazinska, D. Grossman, R. Kosara, and J. Mackinlay.Public data and visualizations: How are many eyes and tableau publicused for collaborative analytics? SIGMOD Record, 43(2):17–22, 6 2014.
[39] N. Natarajan, I. S. Dhillon, P. Ravikumar, and A. Tewari. Learningwith Noisy Labels. In Proceedings of the 26th International Conferenceon Neural Information Processing Systems - Volume 1, NIPS’13, pages1196–1204, USA, 2013. Curran Associates Inc.
[40] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. BLEU: A Methodfor Automatic Evaluation of Machine Translation. In Proceedings ofthe 40th Annual Meeting on Association for Computational Linguistics,ACL ’02, pages 311–318, Stroudsburg, PA, USA, 2002. Association forComputational Linguistics.

[41] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin,A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation inPyTorch. 2017.
[42] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion,O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vander-plas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duches-nay. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res.,12:2825–2830, Nov. 2011.
[43] D. B. Perry, B. Howe, A. M. Key, and C. Aragon. VizDeck: Streamliningexploratory visual analytics of scientific data. In iConference, 2013.
[44] Plotly. Plotly. https://plot.ly, 2018.[45] Plotly. Plot.ly Chart Studio. https://plot.ly/online-chart-maker/, 2018.[46] Plotly. Plotly Community Feed. https://plot.ly/feed, 2018.[47] Plotly. Plotly for Python. https://plot.ly/
d3-js-for-python-and-pandas-charts/, 2018.[48] Plotly. Plotly REST API. https://api.plot.ly/v2, 2018.[49] Plotly. Plotly.js Open-Source Announcement. https://plot.ly/javascript/
open-source-announcement, 2018.[50] E. Ramos and D. Donoho. ASA Data Exposition Dataset. http://
stat-computing.org/dataexpo/1983.html, 1983.[51] K. Reda, P. Nalawade, and K. Ansah-Koi. Graphical Perception of
Continuous Quantitative Maps: The Effects of Spatial Frequency andColormap Design. In Proceedings of the 2018 CHI Conference on HumanFactors in Computing Systems, CHI ’18, pages 272:1–272:12, New York,NY, USA, 2018. ACM.
[52] S. F. Roth, J. Kolojejchick, J. Mattis, and J. Goldstein. Interactive GraphicDesign Using Automatic Presentation Knowledge. In Proceedings ofthe SIGCHI Conference on Human Factors in Computing Systems, CHI’94, pages 112–117, New York, NY, USA, 1994. ACM.
[53] B. Saket, A. Endert, and C. Demiralp. Task-Based Effectiveness ofBasic Visualizations. IEEE Transactions on Visualization and ComputerGraphics, 2018.
[54] B. Santos. Evaluating visualization techniques and tools: What are themain issues. In The AVI Workshop on Beyond Time and Errors: NovelEvaluation Methods For information Visualization (BELIV ’08), 2008.
[55] A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer. Vega-Lite: A Grammar of Interactive Graphics. IEEE Transactions on Visual-ization and Computer Graphics, 23(1):341–350, Jan. 2017.
[56] A. Satyanarayan, K. Wongsuphasawat, and J. Heer. Declarative Inter-action Design for Data Visualization. In ACM User Interface Software& Technology (UIST), 2014.
[57] M. M. Sebrechts, J. V. Cugini, S. J. Laskowski, J. Vasilakis, and M. S.Miller. Visualization of Search Results: A Comparative Evaluationof Text, 2D, and 3D Interfaces. In Proceedings of the 22Nd AnnualInternational ACM SIGIR Conference on Research and Development inInformation Retrieval, SIGIR ’99, pages 3–10, New York, NY, USA, 1999.ACM.
[58] E. Segel and J. Heer. Narrative Visualization: Telling Stories with Data.IEEE Transactions on Visualization and Computer Graphics, 16(6):1139–1148, Nov. 2010.
[59] J. Seo and B. Shneiderman. A Rank-by-Feature Framework for Inter-active Exploration of Multidimensional Data. 4:96–113, 2005.
[60] S. Silva, B. S. Santos, and J. Madeira. Using color in visualization: Asurvey. Computers & Graphics, 35(2):320 – 333, 2011. Virtual Reality inBrazil Visual Computing in Biology and Medicine Semantic 3D mediaand content Cultural Heritage.
[61] D. Skau. Best Practices: Maximum Elements ForDifferent Visualization Types. https://visual.ly/blog/maximum-elements-for-visualization-types/, 2012.
[62] C. Stolte, D. Tang, and P. Hanrahan. Polaris: a system for query,analysis, and visualization of multidimensional databases. Commun.ACM, 51(11):75–84, 2008.
[63] J. Tukey. Exploratory Data Analysis. Addison-Wesley series in behav-ioral science. Addison-Wesley Publishing Company, 1977.
[64] M. Vartak, S. Huang, T. Siddiqui, S. Madden, and A. Parameswaran. To-wards Visualization Recommendation Systems. SIGMOD Rec., 45(4):34–39, May 2017.
[65] M. Vartak, S. Madden, A. Parameswaran, and N. Polyzotis. SeeDB:Automatically Generating Query Visualizations. Proceedings of theVLDB Endowment, 7(13):1581–1584, 2014.
[66] F. Viégas, M. Wattenberg, D. Smilkov, J. Wexler, and D. Gundrum.Generating charts from data in a data table. US 20180088753 A1., 2018.
[67] C. Ware. Information Visualization: Perception for Design. MorganKaufmann Publishers Inc., San Francisco, CA, USA, 2004.
[68] H. Wickham. ggplot2: Elegant Graphics for Data Analysis. SpringerPublishing Company, Incorporated, 2nd edition, 2009.
[69] L. Wilkinson, A. Anand, and R. Grossman. Graph-Theoretic Scagnos-tics. In Proceedings of the Proceedings of the 2005 IEEE Symposium onInformation Visualization, INFOVIS ’05, Washington, DC, USA, 2005.IEEE Computer Society.
[70] G. Wills and L. Wilkinson. AutoVis: Automatic Visualization. Infor-mation Visualization, 9:47–6927, 2010.
[71] K. Wongsuphasawat, D. Moritz, A. Anand, J. Mackinlay, B. Howe, andJ. Heer. Towards A General-Purpose Query Language for VisualizationRecommendation. In ACM SIGMOD Workshop on Human-in-the-LoopData Analytics (HILDA), 2016.
[72] K. Wongsuphasawat, D. Moritz, A. Anand, J. Mackinlay, B. Howe,and J. Heer. Voyager: Exploratory Analysis via Faceted Browsing ofVisualization Recommendations. IEEE Trans. Visualization & Comp.Graphics (Proc. InfoVis), 2016.
[73] K. Wongsuphasawat, Z. Qu, D. Moritz, R. Chang, F. Ouk, A. Anand,J. Mackinlay, B. Howe, and J. Heer. Voyager 2: Augmenting VisualAnalysis with Partial View Specifications. In ACM Human Factors inComputing Systems (CHI), 2017.
[74] Y. Zhu. Measuring Effective Data Visualization . In G. Bebis, R. Boyle,B. Parvin, D. Koracin, N. Paragios, S.-M. Tanveer, T. Ju, Z. Liu, S. Co-quillart, C. Cruz-Neira, T. Müller, and T. Malzbender, editors, Advancesin Visual Computing, pages 652–661, Berlin, Heidelberg, 2007. SpringerBerlin Heidelberg.

Supplemental Materials for VizML: A MachineLearning Approach to Visualization
Recommendation (CHI 2019)
S1 DETAILED PROBLEM FORMULATIONWe formulate basic visualization of a datasetd as a set of inter-related design choicesC = {c}, each of which is selected froma possibility space c ∼ C. However, not all design choicesresult in valid visualizations – some choices are incompatiblewith each other. For instance, encoding a categorical columnwith the Y position of a line mark is invalid. Therefore, theset of choices that result in valid visualizations is a subset ofthe space of all possible choices C1 × C2 × . . . × C |C | .
Design Choice Possibility Space Set of Real Design Choices
Valid Design
Choices
Invalid Design
Choices
VisualExploration
Visualization
EffectivenessDataset
ContextAesthetics, Task, Medium, Domain,
Audience
Figure S1: Creating visualizations is a process of making de-sign choices, which can be recommended by a system orspecified by an analyst.
The effectiveness of a visualization can be defined by infor-mational measures such as efficiency, accuracy, and memora-bility [6, 74], or emotive measures like engagement [19, 27].Prior research also shows that effectiveness is informed bylow-level perceptual principles [15, 22, 31, 51] and datasetproperties [28, 54], in addition to contextual factors such astask [3, 28, 53], aesthetics [14], domain [24], audience [60],and medium [36, 57]. In other words, an analyst makes de-sign choices Cmax that maximize visualization effectivenessEff given a dataset d and contextual factors T :
Cmax = argmaxC
Eff (C | d,T ) (1)
But making design choices can be expensive. A goal of vi-sualization recommendation is to reduce the cost of creatingvisualizations by automatically suggesting a subset of designchoices Cr ec ⊆ C .
Modeling Design Choice RecommendationConsider a single design choice c ∈ C . Let C ′ = C \ {c}denote the set of all other design choices excluding c . Given
C ′, a dataset d , and contextT , there is an ideal design choicerecommendation function Fc that outputs the design choicecmax ∈ Cmax from Eqn. 1 that maximizes visualization effec-tiveness:
Fc (d | C ′,T ) = cmax (2)Our goal is to approximate Fc with a function Gc ≈ Fc .
Assume now a corpus of datasets D = {d} and correspond-ing visualizations V = {Vd }, each of which can be describedby design choices Cd = {cd }. Machine learning-based rec-ommender systems consider Gc as a model with a set ofparameters Θc that can be trained on this corpus by a learn-ing algorithm that maximizes an objective function Obj:
Θf it = argmaxΘc
∑d ∈D
Obj (cd ,Gc (d | Θc ,C′,T )) (3)
Without loss of generality, say the objective function max-imizes the likelihood of observing the training output {Cd }.Even if an analyst makes sub-optimal design choices, collec-tively optimizing the likelihood of all observed design choicescan still be optimal [39]. This is precisely the case with ourobserved design choices cd = Fc (d | C ′,T ) + noise + bias.Therefore, given an unseen dataset d∗, maximizing this ob-jective function can plausibly lead to a recommendation thatmaximizes effectiveness of a visualization.
Gc(d∗ | Θf it ,C
′,T)≈ Fc (d
∗ | C ′, ) = cmax (4)In this paper, our model Gc is a neural network and Θc
are connection weights. We simplify the recommendationproblem by optimizing each Gc independently, and withoutcontextual factors:Gc (d | Θ) = Gc (d | Θ,C ′,T ). We note thatindependent recommendations may not be compatible, nordo they necessarily maximize overall effectiveness. Gener-ating a complete visualization output will require modelingdependencies between Gc for each c .
S2 COMPARISONWITH ML-BASEDVISUALIZATION RECOMMENDER SYSTEMS
A tabular comparison of the ML-based visualization rec-ommendation systems VizML (this work), DeepEye [33],Data2Vis [17] and Draco-Learn [37] is shown in Table S1.
S3 PLOTLY DATA DESCRIPTION AND ANALYSISCollection and CleaningPlotly [44] is a software company that creates tools andsoftware libraries for data visualization and analysis. For ex-ample, Plotly Chart Studio [45] is a web application that letsusers upload datasets and manually create interactive D3.jsand WebGL visualizations of over 20 visualization types.

System Source Ndata Generation Learning Task Training Data Features Model
VizML Public(Plotly) 106 Human Design Choice
RecommendationDataset-Visualization Pairs
Single + Pairwise +Aggregated Neural Network
DeepEye Crowd 1) 33.4K2) 285K
Rules →Annotation
1) Good-Bad Classif.2) Ranking
1) Good-Bad Labels2) Pairwise Comparisons Column Pair 1) Decision Tree
2) RankNet
Data2Vis Tool(Voyager) 4,300 Rules →
ValidationEnd-to-EndViz. Generation
Dataset Subset-Visualization Pairs Raw Seq2Seq NN
Draco-Learn Crowd 1,100 +10
Rules →Annotation
Soft ConstraintWeights Pairwise Comparisons Soft Constraint
Violation Counts RankSVM
Table S1: Comparison of machine learning-based visualization recommendation systems. The major differences are that ofLearning Task definition, and the quantity (Ndata) and quality (Generation and Training Data) of training data.
Users familiar with Python can use the Plotly Python li-brary [47] to create those same visualizations with code.Visualizations in Plotly are specified with a declarative
schema. In this schema, each visualization is specified withtwo data structures. The first is a list of traces that specifyhow a collection of data is visualized. The second is a dictio-nary that specifies aesthetic aspects of a visualization untiedfrom the data, such as axis labels and annotations. For exam-ple, the scatterplot from Section 2 is specified with a single“scatter” trace with Hp as the x parameter and MPG as the yparameter:
Plotly Chart Builder Plotly Schema
Plotly Python Library......
Traces
Layout
The Plotly schema is similar to that of MATLAB and ofthe matplotlib Python library. The popular Vega [56] andVega-lite [55] schemas are more opinionated, which “allowsfor complicated chart display with a concise JSON descrip-tion, but leaves less control to the user" [49]. Despite thesedifferences, it is straightforward to convert Plotly schemasinto other schemas, and vice versa.Plotly also supports sharing and collaboration. Starting
in 2015, users could publish charts to the Plotly Commu-nity Feed [46], which provides an interface for searching,sorting, and filtering millions of visualizations, as shown inFigure S2. The underlying /plots endpoint from the PlotlyREST API [48] associates each visualization with three ob-jects: data contains the source data, specification con-tains the traces, and layout defines display configuration.
Data DescriptionUsing the Plotly API, we collected approximately 2.5 years ofpublic visualizations from the feed, starting from 2015-07-17and ending at 2018-01-06. We gathered 2,359,175 visualiza-tions in total, 2,102,121 of which contained all three configu-ration objects, and 1,989,068 of which were parsed withouterror. To avoid confusion between user-uploaded datasetsand our dataset of datasets, we refer to this collection ofdataset-visualization pairs as the Plotly corpus.
The Plotly corpus contains visualizations created by 143, 007unique users, who vary widely in their usage. The distribu-tion of visualizations per user is shown in Figure S3. Ex-cluding the top 0.1% of users with the most visualizations,many of whom are bots that programmatically generate vi-sualizations, users created a mean of 6.86 and a median of 2visualizations each.
Datasets also vary widely in number of columns and rows.Though some datasets contain upwards of 100 columns,94.97% contain less than or equal to 25 columns. Exclud-ing datasets with more than 25 columns, the average dataset
Figure S2: Screenshot of the Plotly Community Feed [46].

has 4.75 columns, and the median dataset has 3 columns.The distribution of columns per visualization is shown inFigure S4a. The distribution of rows per dataset is shown in
Figure S3: Distribution of plots per user, visualized on a log-linear scale.
(a) Distribution of columns per dataset, after removing the5.03% of datasets with more than 25 columns, visualized ona log-linear scale.
(b) Distribution of rows per dataset, visualized on a log-logscale.
Figure S4: Distribution of dataset dimensions in the Plotlycorpus.
Figure S4b, and has a mean of 3105.97, median of 30, andmaximum of 10 × 106. These heavy-tailed distributions areconsistent with those of IBM ManyEyes and Tableau Publicas reported by [38].Though Plotly lets users generate visualizations using
multiple datasets, 98.32% of visualizations used only onesource dataset. Therefore, we are only concerned with vi-sualizations using a single dataset. Furthermore, over 90%of visualizations used all columns in the source dataset, sowe are not able to address data query selection. Lastly, outof 13, 321, 598 traces, only 0.16% of have transformations oraggregations. Given this extreme class imbalance, we arenot able to address column transformation or aggregationas learning tasks.
S4 FEATURES AND AGGREGATIONSDetails on the 81 single-column features, 30 pairwise-columnfeatures and 16 aggregation functions can be found in Ta-ble S2. Single-column features in Table S2a fall into fourcategories: Dimensions (D) (number of rows in a column),Types (T) (categorical, temporal, or quantitative), Values(V) (the statistical and structural properties) and Names(N) (related to column name). Pairwise-column features inTable S2b fall into two categories” Values and Names. Fi-nally, 841 dataset-level features are created by aggregatingthese features using the 16 aggregation functions shownin Table S2c.
S5 PERFORMANCE EVALUATIONA stacked bar chart describing baseline model predictionperformance and the marginal contribution by feature setfor the neural network is shown in Figure ??
S6 CROWDSOURCED EVALUATION PROCEDUREFor the crowdsourced evaluation, we recruited participantsthrough Amazon Mechanical Turk. To participate in the ex-periment, workers had to hold a U.S. bachelor degree and beat least 18 years of age, and be completing the survey on aphone. Workers also had to successfully answer three pre-screen questions: 1) Have you ever seen a data visualization?[Yes or No], 2) Does the x-axis of a two-dimensional plot runhorizontally or vertically? [Horizontally, Vertically, Both,Neither], 3) Which of the following visualizations is a barchart? [Picture of Bar Chart, Picture of Line Chart, Pictureof Scatter]. 150 workers successfully completed the two-classexperiment, while 150 separate workers completed the three-class experiment.After successfully completing the pre-screen, workers
evaluated the visualization type of 30 randomly selecteddatasets from our test set. Each evaluation had two stages.First, the user was presented the first 10 rows of the dataset,and told to "Please take a moment to examine the following

(a) 81 single-column features describing the dimensions,types, values, and names of individual columns.
Dimensions (1)Length (1) Number of values
Types (8)General (3) Categorical (C), quantitative (Q), temporal (T)Specific (5) String, boolean, integer, decimal, datetime
Values (58)Statistical [Q, T](16)
Mean, median, range × (Raw/normalized by max),variance, standard deviation, coefficient of variance,minimum, maximum, (25th/75th) percentile,median absolute deviation, average absolutedeviation, quantitative coefficient of dispersion
Distribution [Q](14)
Entropy, Gini, skewness, kurtosis, moments(5-10), normality (statistic, p-value),is normal at (p < 0.05, p < 0.01).
Outliers (8) (Has/%) outliers at (1.5 × IQR, 3 × IQR, 99%ile, 3σ )Statistical [C] (7) Entropy, (mean/median) value length, (min, std,
max) length of values, % of modeSequence (7) Is sorted, is monotonic, sortedness, (linear/log)
space sequence coefficient, is (linear/space) spaceUnique (3) (Is/#/%) uniqueMissing (3) (Has/#/%) missing values
Names (14)Properties (4) Name length, # words, # uppercase characters,
starts with uppercase letterValue (10) (“x", “y", “id", “time", digit, whitespace, “$",
“€", “£", “Y") in name
(b) 30 pairwise-column features describing the relationshipbetween values and names of pairs of columns.
Values (25)[Q-Q] (8) Correlation (value, p, p < 0.05),
Kolmogorov-Smirnov (value, p, p < 0.05),(has, %) overlapping range
[C-C] (6) χ2 (value, p, p < 0.05),nestedness (value, = 1, > 0.95%)
[C-Q] (3) One-Way ANOVA (value, p, p < 0.05)Shared values (8) is identical, (has/#/%) shared values, unique values
are identical, (has/#/%) shared unique valuesNames (5)
Character (2) Edit distance (raw/normalized)Word (3) (Has, #, %) shared words
(c) 16 Aggregation functions used to aggregate single- andpairwise-column features into 841 dataset-level features.
Categorical (5) Number (#), percent (%), has, only one (#=1), allQuantitative (10) Mean, variance, standard deviation, coefficient
of variance (CV), min, max, range, normalizedrange (NR), average absolute deviation (AAD)median absolute deviation (MAD)
Special (1) Entropy of data typesTable S2: Features and aggregation functions.
dataset. (Showing first 10 out of X rows)." Then, after five sec-onds, the "next" button appeared. At the next stage, the userwas asked "Which visualization best represents this dataset?(Showing first 10 out of X rows)." On this stage, the user wasshown both the dataset and the corresponding bar, line, andscatter charts representing that dataset. A user could submitthis question after a minimum of ten seconds. The evalua-tions were split into two groups of 15 by an attention checkquestion. Therefore, each of the 66 datasets were evaluated68.18 times on average, while each of the 99 ground truthdatasets was evaluated 30 times on average.
Data PreparationTo select the datasets in our benchmarking test set, we firstrandomly surfaced a set of candidate datasets that werevisualized as either a bar, line, or scatter chart. Then, weremoved obviously incomplete visualizations (e.g. blank vi-sualizations). Finally, we removed datasets that could notbe visually encoded in all three visualization types withoutlosing information. From the remaining set of candidates,we randomly selected 33 bar charts, 33 line charts, and 33scatter charts.
Aswe cleaned the data, we adhered to four principles: mod-ify the user’s selections as little as possible, apply changesconsistently to every dataset, rely on Plotly defaults, anddon’t make any change that is not obvious. For each ofthese datasets, we modified the raw column names to removePlotly-specific biases (e.g. removing “,x" or “,y" that wasautomatically append to column names). We also wanted tomake the user evaluation experience as close to the originalchart creation experience as possible. Therefore, we changedcolumn names from machine-generated types if they areobvious from the user visualization axis labels or legend(e.g. the first column is unlabeled but visualized as SepalWidth on the X-axis). Because of these modifications, boththe Plotly users and the Mechanical Turkers accessed moreinformation than our model.
We visualized each of these 99 datasets as a bar, line, andscatter chart. We created these visualizations by forking theoriginal Plotly visualization then modifying Mark Typesusing Plotly Chart Studio. We ensured that color choices andaxis ranges were consistent between all visualization types.The rest of the layout was held constant to the user’s originalspecification, or the defaults provided by Plotly.

Bar
(B)
Da
tase
ts
Dataset 1 Dataset DDataset 1UTC Time latency (in ms)
2015-08-24 18:41:56 1.25
2015-08-24 18:31:56 1.28
2015-08-24 18:21:56 1.43
2.28
...
1.63
...
2015-08-24 18:11:56
2015-08-23 17:21:58
Label Penicillin
Aerobacter aerogenes 0.001149425287
Brucella abortus 1
Brucella anthracis 1000
Diplococcus pneumoniae 200
...
Streptococcus viridans 200
Streptomycin
1
0.5
100
0.09090909091
...
0.1
Neomycin
0.625
50
142.8571429
0.1
...
0.025
...
...
Lin
e (L
)S
catt
er
(S)
Vis
ua
liza
tio
ns (
Tw
o o
r T
hre
e T
yp
e)
Votes
EmpiricalProbabilities
[L, B, L, L, ..., L] [S, S, L, B, ..., S]...
SimulatedVotes
Bootstrap
[[L, B, L, L, ..., L], ...,[L, L, L, L, ..., B]]
[[L, S, S, B, ..., S], ...,[S, S, S, L, ..., B]]
SimulatedProbabilities
...
Original
OriginalGenerated
Generated
Generated
Generated
Crowdsourced Evaluation
Figure S6: Experiment flow. The original user-generated vi-sualizations are highlighted in blue, while we generated thevisualizations of the remaining types. After crowdsourcedevaluation, we have a set of votes for the best visualizationtype of that dataset. We calculate confidence intervals formodel scores through bootstrapping.

(a) Feature importances for two visualization-level prediction tasks. The second column describes how each feature was ag-gregated, using the abbreviations in Table S2c.
# Visualization Type (C=2) Visualization Type (C=3) Visualization Type (C=6) Has Shared Axis (C=2)
1 % of Values are Mode std Entropy std Is Monotonic % Number of Columns2 Min Value Length max Entropy var Number of Columns Is Monotonic %3 Entropy var String Type % Sortedness max Field Name Length AAD4 Entropy std Mean Value Length var Y In Name # # Words In Name NR5 String Type has Min Value Length var Y In Name % X In Name #6 Median Value Length max String Type has # Shared Unique Vals std # Words In Name range7 Mean Value Length AAD Percentage Of Mode std # Shared Values MAD Edit Distance mean8 Entropy mean Median Value Length max Entropy std Edit Distance max9 Entropy max Entropy mean Entropy range Length std10 Min Value Length AAD Length mean % of Values are Mode std Edit Distance NR
(b) Feature importances for four encoding-level prediction tasks.
# Mark Type (C=2) Mark Type (C=3) Mark Type (C=6) Is Shared Axis (C=2) Is X or Y Axis (C=2)
1 Entropy Length Length # Words In Name Y In Name2 Length Entropy Field Name Length Unique Percent X In Name3 Sortedness Field Name Length Entropy Field Name Length Field Name Length4 % Outliers (1.5IQR) Sortedness Sortedness Is Sorted Sortedness5 Field Name Length Lin Space Seq Coeff Lin Space Seq Coeff Sortedness Length6 Lin Space Seq Coeff % Outliers (1.5IQR) Kurtosis X In Name Entropy7 % Outliers (3IQR) Gini Gini Y In Name Lin Space Seq Coeff8 Norm. Mean Skewness Normality Statistic Lin Space Seq Coeff Kurtosis9 Skewness Norm. Range Norm Range Min # Uppercase Chars10 Norm. Range Norm. Mean Skewness Length Skewness
Table S3: Top-10 feature importances for visualization- and encoding-level prediction tasks. Feature importance is determinedbymean decrease impurity for the top performing random forestmodels. Colors represent different feature groupings: dimen-sions ( ), type ( ), statistical [Q] ( ), statistical [C] ( ), sequence ( ), scale of variation ( ), outlier ( ), unique ( ),name ( ), and pairwise-relationship ( ).