Embed Size (px)
DESCRIPTION
Longest Common Subsequence Algorithm on ASC Processors using Coterie Network. Virdi Sabegh Singh (Advisor Dr. Robert A. Walker) Computer Science Department Kent State University. Presentation Outline. String matching and its variations Motivation of LCS - PowerPoint PPT Presentation
Citation preview

Virdi Sabegh Singh(Advisor Dr. Robert A. Walker)Computer Science Department
Kent State University
Longest Common Subsequence Algorithm on ASC Processors using Coterie Network

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome matching Overview of LCS Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

Presentation Outline Brief introduction on Coterie Network Longest Common Subsequence on Coterie
Network Exact match
Parallel SM algorithm and its Limitation Longest Common Subsequence on Coterie
Network Approximate match
Summary and Future work

String Matching String matching one of the most
fundamental operation in computing. May be two linear arrays of character can
be compared to determine their similarity One area where string matching gained
interest is in the area of bioinformatics, in particular in the area of searching genetic databases
The string involved are how ever enormous, efficient string processing is therefore a requirement

String MatchingVariations Is Exact match the only solution? What if the pattern does not occur in the
text? It still makes sense to find the longest
subsequence that occurs both in the pattern and in the text. This is the longest common subsequence problem
Longest Common Subsequence, Longest Common Substring, Sequence alignment, Edit distance Problem are all variation of SM problem

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome Matching Overview of LCS Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

Motivation of LCS
Molecular Biology File comparison Screen redisplay Cheater finder Plagiarism
detection Codes and Error
Control
Spell checking Human speech Gas
Chromatography Bird song analysis Data compression Speech recognition

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome matching Overview of lcs Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

Role of lcs in Molecular biology DNA sequences (genes) can be
represented as sequences of four letters ACGT, corresponding to the four submolecules forming DNA
When biologists find a new sequences, they typically want to know what other sequences it is most similar to
One way of computing how similar (homologous) two sequences are is to find the length of their longest common subsequence

Role of lcs in Molecular biology This is a simplification, since in the biological
situation one would typically take into account not only the length of the lcs, but also e.g. how gaps occur when the lcs is embedded in the two original sequences.
An obvious measure for the closeness of two strings is to find the maximum number of identical symbols (preserving symbol order)
This by definition, is the longest common subsequence of the strings

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome Matching Overview of lcs Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

Genome Matching Genome: A Genome is a string of DNA bases A,C,G,T In genetics application, the two string could
correspond to two strands of DNA, which could, for example, come from two individuals, who we will consider genetically related, if they have a long subsequence common to their respective DNA sequences
The concept of subsequences of a string is different from the one of substring of a string
The string involved are how ever enormous, efficient string processing is therefore a requirement

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome Matching Overview of LCS Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

Longest Common Subsequences
Formally, we compare two strings, X[1..m] and Y[1..n], which are elements of the set Σ*; here Σ denotes the input alphabet containing σ symbols
The lcs of strings X and Y, lcs(X,Y) is a common subsequences of maximal length
Special case of the edit distance problem The distance between X and Y is defined as the minimal
number of elementary operations needed to transform the source string X to the target string Y
In practical applications, operation are restricted to insertions, deletions and substitutions
For each operation, an application dependent cost is assigned

Longest Common Subsequences lcs can be reduced to other well known
problem lcs(X,Y) typically solved with the dynamic
programming technique and filling an mxn table
Table elements acts as a vertices in a graph, and the simple dependencies between the table values defines the edges
The task is to find the longest path between the vertices in the upper left and lower right corner of the table

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome Matching Overview of lcs Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

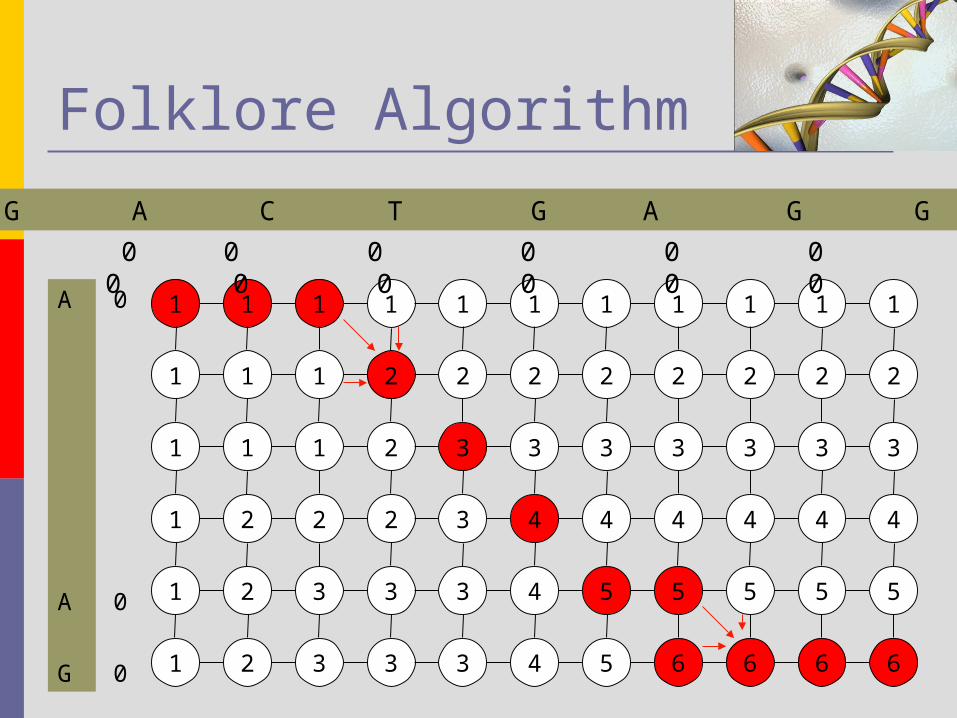
Folklore Algorithm Foundation of most of the LCS algorithm Given two strings, find the LCS common to both
strings. Example:
String 1: AGACTGAGGTA String 2: ACTGAG
AGACTGAGGTA - -ACTGAG - - - list of possible alignments - -ACTGA - G- - A- -CTGA - G- - A- -CTGAG - - -
The time complexity of this algorithm is clearly O(nm);

Folklore Algorithm Actually this time does not depend on the
sequences u and v themselves but only on their lengths
By choosing carefully the order of computing the d(i,j)'s one can execute the above algorithm in space O(n+m)
The bottleneck in efficient parallelization of LCS problem are the calculating the value of diagonal elements, as shown

As seen, the value of {i,j} depend upon the previous element {i-1,j-1}, when a match is found.
We may have more then one lcs for the same problem
In order to find the best LCS, we associate some parameter, to calculate the best possible alignment, which leads us to the Smith-Water Man Algorithm
The Smith-Waterman Algorithm uses the same concept that of Folklore algorithm, but gives us the optimal result (LCS)
Folklore Algorithm
Folklore Algorithm
1 1 1 1 1
11
2111
1 222222
111111
3
1
1
1
44443222
3333
43332
5
55
43332 6
5
4
3
2 2
666
5 5
4
3
0 0 0 0 0 0 0 0 0 0 0 0
A G A C T G A G G T A
0
0
0
0
0
0
A
C
T
G
A
G

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome Matching Overview of lcs Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor

Parallel Counterpart Most of the Serial LCS algorithm runs in O(nm) time,
where n is the length of the text string, and m is the length of pattern string
Efficient Parallel algorithm do exist to solve this computational extensive task Some algorithm runs in O(max{n,m}) using O(min{n,m}) processors O(logn) using O(mn/logn) processors There are constant time algorithm for this LCS
problem using the DP approach, using some assumptions

Computation Model Various Network Models have been used to solve
this lcs problem Some algorithm uses PRAM model, Suffix Tree,
2D-Mesh Network, Mesh with Reconfigurable buses, Mesh with Multiple buses etc
Algorithm which runs in constant time, assume that most of the operation are done in constant time
In parallel version, one of the important task is to distribute data efficiently and easy manner

Presentation Outline String matching and its variations Motivation of LCS Role of LCS in Molecular Biology Genome Matching Overview of lcs Overview of Folklore algorithm Parallel Algorithms for LCS Discussion on ASC processor Brief introduction on Coterie Network

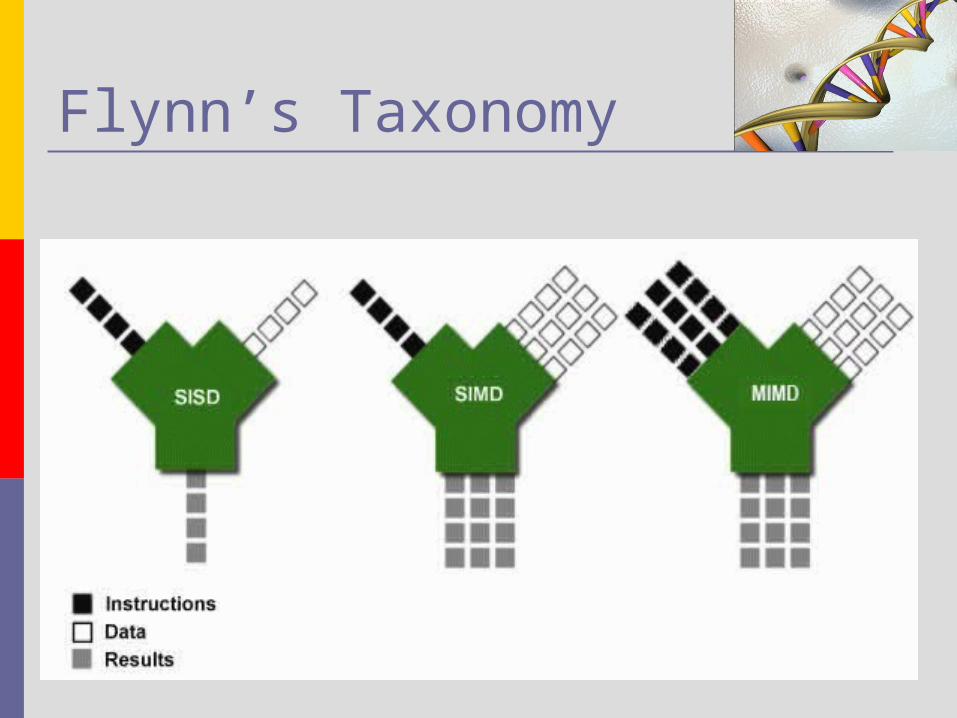
The ASC Processor A scalable design implemented on a
million gate Altera FPGA SIMD-like architecture Currently, 36 8-bit Processing Elements
(PE) available 8-bit Instruction Stream (IS) control unit
with 8-bit Instruction and Data addresses, 32-bit instructions
Flynn’s Taxonomy
m
em
ory
an
d s
up
po
rtin
g c
ircu
itry
PE and Memory
Netw
ork
PE and Memory
PE and Memory
PE and Memory
CommonRegisters
ResponderResolution
Unit
PE Array
ControlUnit
Instr
ucti
on
Bu
s
Data
Bu
s
From Control Unit
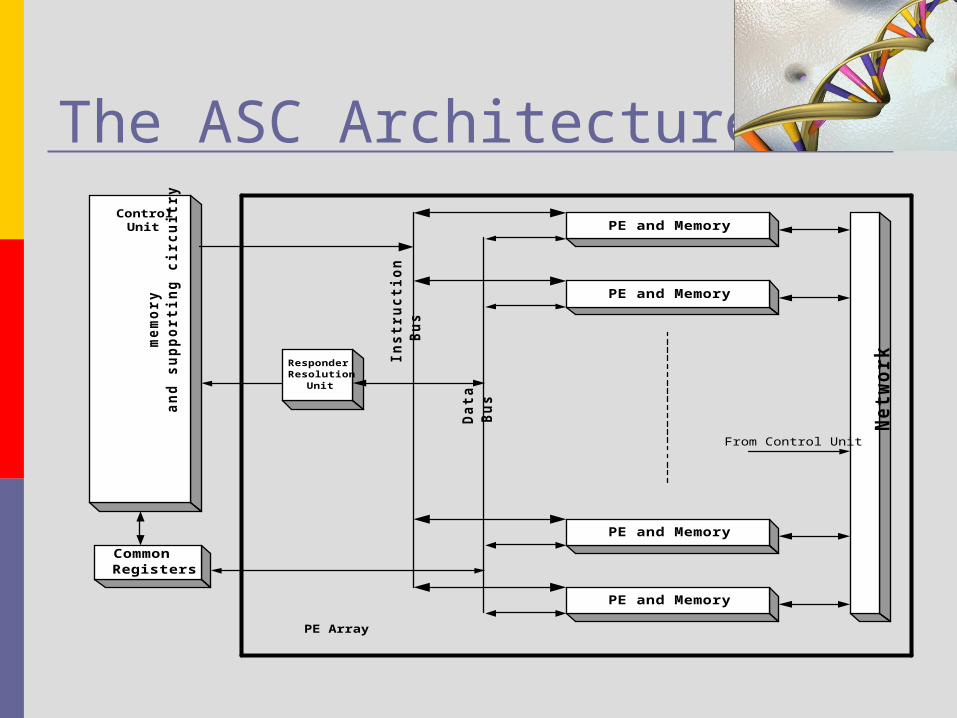
The ASC Architecture

The ASC Architecture Each PE listens to the IS through the
broadcast and reduction network PEs can communicate amongst
themselves using the PE Network PE may either execute or ignore the
microcode instruction broadcast by IS under the control of the Mask Stack

The ASC Features Associative Search
Each PE can search its local memory for a key under the control of IS
Responder Resolution A special circuit signals if ‘at least one’ record
was found Masked Operation
Local Mask Stacks can turn on or off the execution of instruction from IS

Communication between PE’s In 2D mesh network,
Communication between P.E’s themselves take place in two different ways
By using the nearest neighbors mesh interconnection network
Powerful variation on the nearest-neighbor mesh called the “Coterie network”, developed in response to the requirement for nonlocal communication
This network has properties that are significantly different from the usual mesh
Because the processors in a group share common properties and purpose, we call the group a coterie, and hence the name coterie network

Presentation Outline Brief introduction on Coterie Network Longest Common Subsequence on Coterie
Network Exact match
Parallel SM algorithm and its Limitation Longest Common Subsequence on Coterie
Network Approximate match
Summary and Future work

Coteries[ Weems & Herbordt ]“A small often selected group of persons who
associate with one another frequently” Features:
Related to other Reconfigurable broadcast network Describable using hypergraphs And they are dynamic in nature
Advantages: Propagation of information quickly over long
distances at electrical speed Support of one-to-many communication within
coterie, reconfigurability of the coterie

Coterie Network Provides method of performing operations on
regions of an image in parallel Used extensively for Matrix Arithmetic, FFT,
Convex Hull Computation, Simulating a pyramid processors, General Permutation Routing and Parallel Prefix
Note that the coterie network is separate from the nearest-neighbor mesh, which we refer to as the SEWN network
Coterie network results in a new mode of parallelism that falls between SIMD and MIMD

Coterie Network There is still a single instruction stream,
broadcasting of data values and collection of summary information are no longer restricted to a central entity, a capability that has previously been restricted to MIMD architecture
We refer this mode of parallelism as multiassociative, because the Coteries act as independent associative processors that share an instruction stream
Connection Machine-5 has such capabilities, but it was not purely SIMD system
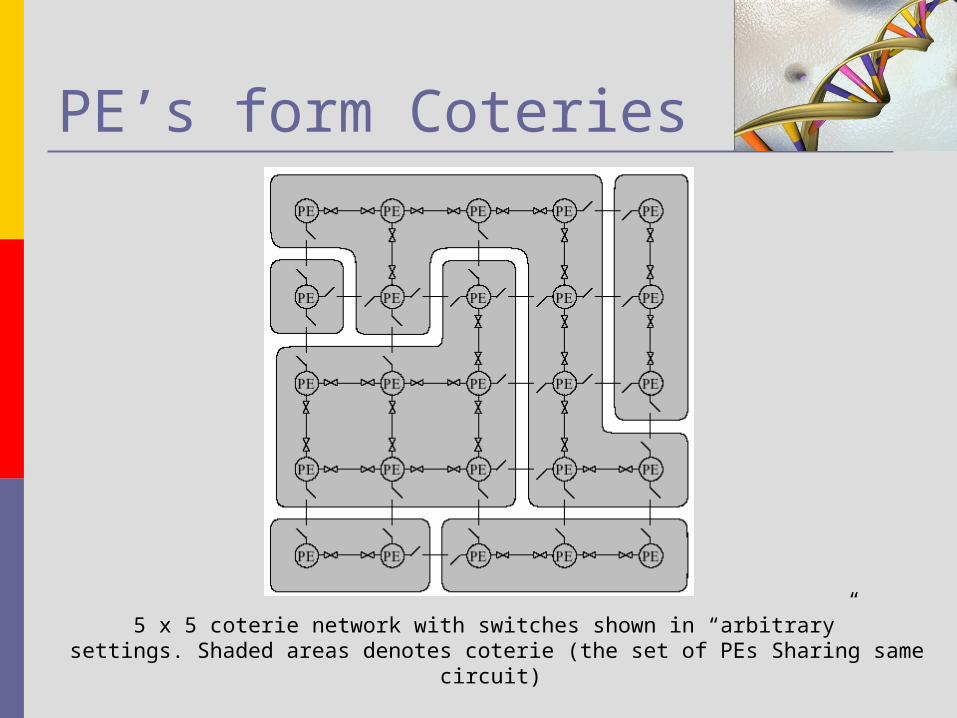
PE’s form Coteries
5 x 5 coterie network with switches shown in “arbitrary” settings. Shaded areas denotes coterie (the set of PEs Sharing same circuit)

Coterie’s Physical Structure In the physical
implementation, each PE controls set of switches Four of these switches
control access in the different directions (N,S,E,W)
Two switches H and V are used to emulated horizontal and vertical buses
The last two switches NE and NW are used to creation of eight way connected region
Coteries Structure
NWNE
WSES
V
H E
S
W
: Switch
N

Coterie Network The isolated group of processors called
coterie’s, have access only to the multicast within a coterie
When the switches are set, connected processors form a Coterie
The coterie network switches are set by loading the corresponding bits of the mesh control register in each P.E

Basic Coterie structure algorithm The complexity is assumed to be O(1)
unless otherwise stated Transfer of data between two adjacent coteries Symmetry breaking between a pair of nodes in
a coterie Two nodes within a coterie exchange
information

Presentation Outline Brief introduction on Coterie Network Longest Common Subsequence on
Coterie Network Exact match
Parallel SM algorithm and its Limitation Longest Common Subsequence on Coterie
Network Approximate match
Summary and Future work

Steps of LCS on Coterie Network
We assume, initially all the internal switch of the PEs are open
Let the Text string T=T(1)T(2)…T(n) been fed into row 1 of the coterie network
PE(0,j) stores T(j), where 0<=j<=n, as shown
This steps take unit time.

LCS Algorithm on Coterie Network
A G A C T G A G G T A

PE’s form Coterie PE’s with index value j as a constant forms
m coteries as shown Within each coteries operation Multicast is
performed simultaneously, a constant time operation
The following slides shown the content of each PE after above operation

LCS Algorithm on Coterie Network
A G A C T G A G G T A

LCS Algorithm on Coterie Network
A G A C T G A G G T A
A G A C T G A G G T A
A G A C T G A G G T A
A G A C T G A G G T A
A G A C T G A G G T A
A G A C T G A G G T A
Content of each PE’s after MULTICAST operation

LCS Algorithm on Coterie Network Let the Pattern string P=P(1)P(2)…P(m)
been fed into column 1 of the coterie network
PE(i,0) stores P(j), where 0<=i<=m, as shown
This steps take unit time

LCS Algorithm on Coterie Network
A
C
T
G
A
G

PE’s form Coteries PE’s with index value i as a constant forms
n coteries as shown Within each coteries operation Multicast is
performed simultaneously, a constant time operation
The following slides show the content of each PE after above operation

LCS Algorithm on Coterie Network
A
C
T
G
A
G

LCS Algorithm on Coterie Network
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
A
C
T
G
A
G
Content of each PE’s after MULTICAST operation

LCS Algorithm on Coterie Network After this step each PE’s with index [i,j]
have P[i] T[j]. Now each PE’s compares the content held
in his internal Register. It set the value 1 if they are equal else 0 in
its Control register R. This step takes unit time. Next figure shows the value after this
operation

LCS Algorithm on Coterie Network
1 0 1 0 0
00
0000
0 000001
100010
1
0
0
1
11010001
0000
00010
0
01
10001 1
0
0
1
0 0
001
0 1
0
0
A G A C T G A G G T A
A
C
T
G
A
G

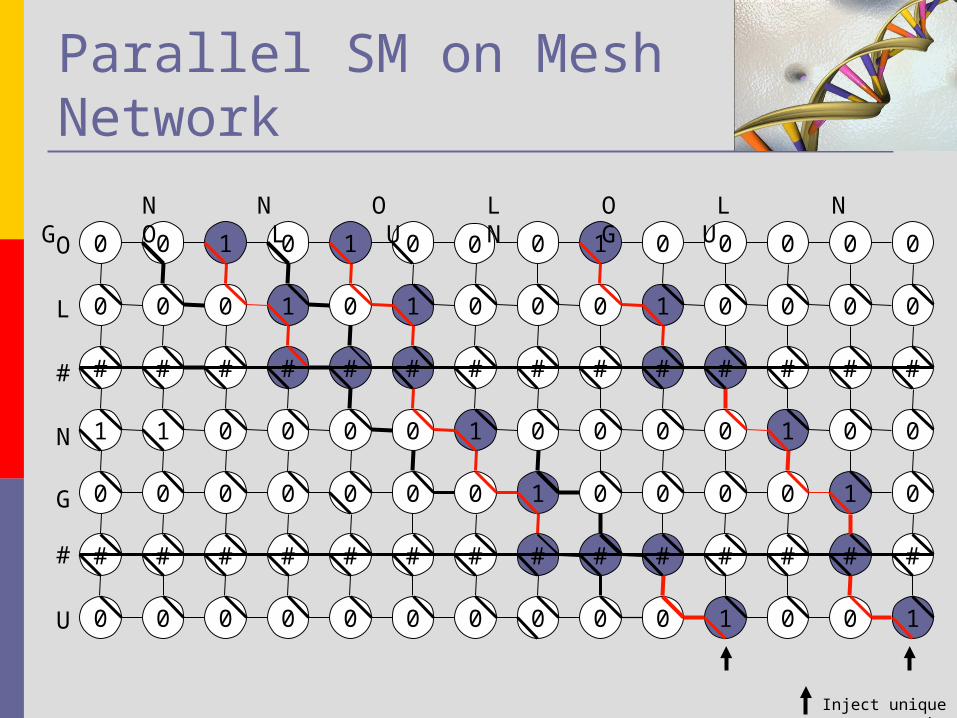
Parallel SM on Mesh Network A Parallel SM algorithm With VLDC proposed by
K.L. Chung in 1995 Uses the Mesh-Connected Computer with
reconfigurable buses system. Runs in O(1) time Pattern of size m , Text of size n uses, O(nm)
PE’s. Works only for particular cases, as seen from the
example. Text : NNOLONGOLUNGU Pattern : OL#NG#U
Parallel SM on Mesh Network
0
##
0000
# ######
1
0
0
#
00010000
0000
#####
0
##
00000 0
#
0
1
# #
001
# #
1
0
##
11
0
0
#
0
#
0
#
1
#
0
0
10 0 010001 0 000 0
1 0 1 0 0000100 0 0
N N O L O L N G O L U N G U
O
#
N
G
#
U
L
Inject unique token

LCS Algorithm on Coterie Network PE’s having value 1 in its Control register R, form
Coterie 1 while PE’s having value 0 form Coteries 0
This step takes unit time Now expect the PE’s with index[0,j], where
0<=j<=n in both the coteries, each PE with value 0 in its special register closes the N-E switch.
PE’s with value 1 in its Control Register R closes the W-S switch as shown
Both the steps takes unit time

LCS Algorithm on Coterie Network
1 0 1 0 0
00
0000
0 000001
100010
1
0
0
1
11010001
0000
00010
0
01
10001 1
0
0
1
0 0
001
0 1
0
0
A G A C T G A G G T A
A
C
T
G
A
G
Inject unique token

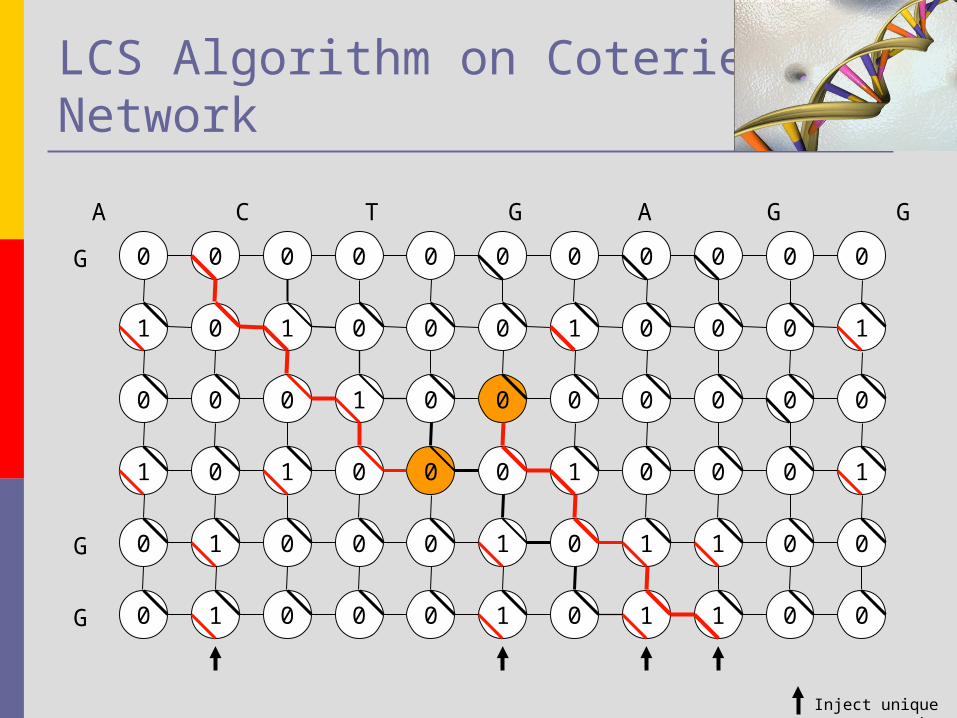
LCS Algorithm on Coterie Network We try to refine the previous Parallel SM
with VLDC algorithm to support approximate matching
We make use of tokens to demonstrate how we can get lcs
The next example demonstrate this problem For the string:
Text :AGACTGAGGTA Pattern : ACTAAG

Presentation Outline Brief introduction on Coterie Network Longest Common Subsequence on Coterie
Network Exact match
Parallel SM algorithm and its Limitation Longest Common Subsequence on Coterie
Network Approximate match
Summary and Future work

LCS Algorithm on Coterie Network
1 0 1 0 0
00
0000
0 000001
100010
1
1
0
1
00100010
0000
00010
0
01
10001 1
0
0
1
0 0
001
0 1
1
0
A G A C T G A G G T A
A
C
T
A
A
G
Inject unique token
LCS Algorithm on Coterie Network
0 0 0 0 0
01
1000
1 001000
000000
0
1
0
0
00100010
0000
10001
0
10
10001 1
1
0
0
0 1
001
0 0
1
0
A G A C T G A G G T A
G
A
C
A
G
G
Inject unique token

Trial and Error method In this method, we explicitly close the W-S
switch based on some condition We inject unique token symbols as shown
in the next slide Where this two symbol intersect within a
PE’s, we close the W-S switch as shown, Thus we get a path from first row to the
last row as shown

LCS Algorithm on Coterie Network
1 0 1 0 0
00
0000
0 000001
100010
1
1
0
1
00100010
0000
00010
0
01
10001 1
0
0
1
0 0
001
0 1
1
0
A G A C T G A G G T A
A
C
T
A
A
G
Inject unique token

LCS Algorithm on Coterie Network
0 1 0 0 0
01
1000
1 001000
001101
0
1
0
0
00100010
0000
10001
0
10
10001 1
1
0
0
0 1
001
0 0
1
0
A G A C T G A G G T A
G
A
C
A
G
G
Inject unique token

Presentation Outline Brief introduction on Coterie Network Longest Common Subsequence on Coterie
Network Exact match
Parallel SM algorithm and its Limitation Longest Common Subsequence on Coterie
Network Approximate match
Summary and Future work

Summary and Future work
Summary:
In this thesis we have presented two variation of the lcs algorithm
We have used a new network for this problem Constant time algorithm for exact match Approximate algorithm depends upon the
diameter of the network

Summary and Future work Future Work:
Optimize the algorithm for Approximate match Implementing the algorithm on FPGA’s model Incorporating the Don’t Care Symbol Extend the idea to support sequence alignment Conserve memory by using encoding scheme
Use two bits to represent four bases of DNA Using this idea, we save 75% of space/memory
We can use Virtual simulation of PEs, in case we ran out of PEs

Acknowledgements Professor Walker Professor Baker Committee members for their time Kevin Schaffer, Hong Wang, Shannon
Steinfadt

THANK YOU

Questions….





























