Embed Size (px)
Citation preview

Using Term Statistics to Aide in ClusteringTwitter Posts
by
Andrew Bates
B.S., Colorado Technical University, Colorado Springs, 2005
A thesis submitted to the Graduate Faculty of the
University of Colorado at Colorado Springs
in partial fulfillment of the
requirements for the degree of
Master of Science
Department of Computer Science
2015

© Copyright Andrew Bates 2015All Rights Reserved

This thesis for Master of Science degree by
Andrew Bates
has been approved for the
Department of Computer Science
by
Dr. Jugal Kalita, Chair
Dr. Rory Lewis
Dr. Sudhanshu Semwal
Date

iii
Bates, Andrew (M.S., Computer Science)
Thesis directed by Dr. Jugal Kalita
Twitter is a massively popular social network website that allows users to send short
messages to the general public or a set of acquaintances. The topic of these messages range
from news items to notes of a more personal nature. Collecting tweets and extracting in-
formation from them could be very valuable in many areas including market analysis and
political research. In some cases, tweets have even been used to detect where earthquakes
have recently occurred. Extracting useful information from Twitter is a very challenging
endeavor. This research compares using traditional clustering techniques to a simpler sta-
tistical analysis in order to group common tweets for further analysis. The research shows
that the statistical approach finds a solution much quicker than a traditional clustering ap-
proach, and has similar cluster quality. At a minimum, the statistical based methods used
in this research could be used to determine the number of clusters used in a traditional
clustering solution.

Dedicated to my beautiful wife Mona, my son Tyler and my daughter
Eleanor

v
Acknowledgments
I would first like to recognize Dr. Kalita and his patience as I took far longer to complete
this thesis than I should have. Without his support I wouldn’t have been able to complete
the research.
I would also like to acknowledge the sacrifices my family made in order to allow me
to complete this work. I couldn’t have finished without their support and understanding.

TABLE OF CONTENTS
1 Introduction 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Organization of Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Related Work 8
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Document Summarization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Summarizing Blogs and Micro-Blogs . . . . . . . . . . . . . . . . . . . . . . 10
2.4 Document Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Twitter Data 17
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Format of Tweets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 Test Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4 Statistical Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4 Data Pre-Processing 27
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2 Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.3 MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.4 Normalization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.5 Language Categorization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Clustering Tweets 36
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.2 K-Means Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36

vii
5.3 Improving K-Means for Large Datasets . . . . . . . . . . . . . . . . . . . . . 37
5.4 Feature Vectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.5 Estimating the Number of Clusters . . . . . . . . . . . . . . . . . . . . . . . 40
5.6 Improving Performance by Reducing Dimension . . . . . . . . . . . . . . . . 49
5.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6 Results 53
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6.2 Alternate Approach to Clustering . . . . . . . . . . . . . . . . . . . . . . . . 53
6.3 Measuring Cluster Performance . . . . . . . . . . . . . . . . . . . . . . . . . 55
6.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.5 Comparison to Alternate Approach . . . . . . . . . . . . . . . . . . . . . . . 62
6.6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
7 Conclusions 66
7.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
References 68

TABLES
3.1 Common Status Attributes . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 Status Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3 Cyber Attack Tweets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4 Tweet Statistics (Uniform Sample) . . . . . . . . . . . . . . . . . . . . . . . 23
3.5 Tweet Statistics (Selected Topics) . . . . . . . . . . . . . . . . . . . . . . . . 24
3.6 Top Terms (Uniform Sample) . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.7 Top Terms (Selected Topics) . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1 Normalized Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.2 Normalized Top Terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.1 Estimated Number of Clusters . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2 Topics in the “Cyber Attack” Dataset . . . . . . . . . . . . . . . . . . . . . 47
6.1 Gap Statistic Results (All Terms) . . . . . . . . . . . . . . . . . . . . . . . . 57
6.2 Gap Statistics Results (Top 100 Terms) . . . . . . . . . . . . . . . . . . . . 58
6.3 Gap Statistic Results (Top 800 N-Grams) . . . . . . . . . . . . . . . . . . . 60
6.4 Gap Statistic Results (Top 100 N-Grams) . . . . . . . . . . . . . . . . . . . 60
6.5 Zipfian Clustering Results . . . . . . . . . . . . . . . . . . . . . . . . . . . 63

FIGURES
3.1 Twitter Collector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.1 Pre Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.1 Number of Dot Products Computed . . . . . . . . . . . . . . . . . . . . . . 39
5.2 Gap Statistic Results for “Cyber Attack” Dataset K=[2,20] . . . . . . . . . 42
5.3 Stability Measure for “Cyber Attack” Dataset K=[11,18] . . . . . . . . . . . 43
5.4 Stability Measure for “Cyber Attack” Dataset K=[2,10] . . . . . . . . . . . 43
5.5 Stability Measure for “Steve Jobs” Dataset K=[2,10] . . . . . . . . . . . . . 44
5.6 Stability Measure for “Steve Jobs” Dataset K=[11,18] . . . . . . . . . . . . 45
5.7 Gap Statistic for “Cyber Attack” Dataset . . . . . . . . . . . . . . . . . . . 46
5.8 Gap Statistic for “Steve Jobs” Dataset . . . . . . . . . . . . . . . . . . . . . 48
5.9 Zipf’s Law for “Cyber Attack” Dataset . . . . . . . . . . . . . . . . . . . . . 50
5.10 Zipf’s Law for “Steve Jobs” Dataset . . . . . . . . . . . . . . . . . . . . . . 50
5.11 Zipf’s Law for “Hurricane Sandy” Dataset . . . . . . . . . . . . . . . . . . . 51
6.1 N-Gram Frequency for “Steve Jobs” Dataset . . . . . . . . . . . . . . . . . 59
6.2 Dunn Index Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.3 Davies-Bouldin Index Results . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.4 Zipfian Clustering Results (Dunn Index) . . . . . . . . . . . . . . . . . . . . 63
6.5 Zipfian Clustering Results (Davies-Bouldin Index) . . . . . . . . . . . . . . 64

CHAPTER 1
INTRODUCTION
Internet enabled social networks have been around for nearly two decades. However,
the landscape of social networking has changed dramatically over the years. The Internet
has grown from a simple static information sharing network to a complex high speed network
designed to deliver data in real-time and on demand. The real-time nature of the Internet
has given social networking websites the ability to provide information exchange among
users as events are unfolding.
Exchanging information as events are unfolding is not a new concept on the Internet.
Much of the information exchanged on social networking sites is conversational in nature.
Conversational capabilities have been part of the Internet since its inception. The Simple
Mail Transfer Protocol (SMTP) [29] was created to allow electronic mail to be exchanged
over interconnected networks. The early Internet had other tools to exchange messages,
such as the Unix utilities “talk” and “write”. Gradually, new forms of information sharing
began to emerge. Near real-time instant messaging services, such as AOL Instant Mes-
senger1 and ICQ2 started gaining popularity in the mid to late 1990’s. As the ability to
have conversations and share information with people began to mature, social networking
websites started to include these capabilities.
As the Internet began to boom, so did social networking. Early sites, like class-
mates.com were built to simply allow people to connect with one another [22]. As social
networking became more popular, however, much more interactive sites like myspace.com
and facebook.com have been introduced. These websites include the ability to send instant
messages to friends and post statuses about oneself. Some sites allow posting journals or
logs. These web-logs, or blogs, allow followers to receive updates when new entries have
been created by the author. People blog opinions, news and even tutorials on a variety of
topics. Sometime in the mid 2000’s a new form of web-logging, known as micro-blogging,
1http://www.aim.com2http://www.icq.com

2
began to emerge. The term “microblog” was coined3 to refer to short sentences, links or
individual images that could be exchanged with followers of a blog.
In 2006 a new publicly available service was launched that allowed short messages to
be shared with a small group using text messaging services from cell phone providers [31].
This service, twitter.com, allowed users to exchange messages using the Short Message
Service4 (SMS) capability that was built into many cell phones. The original intent of
Twitter was to allow members to post their current status to a group of interested people.
Since its initial launch, Twitter has grown to exchange many millions of messages, or tweets,
every day.
Twitter is now exchanging an immense amount of data among people worldwide.
The information includes commentary of world events, opinion related to entertainment
news and typical conversational chatter. Twitter has recently proven useful to provide
information about rapidly changing current events5. Organized protests in the United
States have used Twitter as a means of communicating with protesters as well as a venue
to convey demands6. Even events surrounding classified military activities have even been
reported by Twitter users7. Evidence suggests that Twitter is a great source of information
about current events. However, the sheer volume of data produced by Twitter’s members
is di�cult to automatically parse and process in a reasonable amount of time. Countless
messages are produced about various topics every hour of the day. The current character
limit of Twitter messages, known as tweets, is 140 characters but the number of tweets
about a given topic could be in the hundreds or thousands. Recently, the Washington
Post reported that as many as 400 million tweets8 are posted each day. These tweets
include topics as disparate as what someone ate for a meal or something they saw while
riding the subway. Often, however, many tweets will be posted about a common topic.
Hundreds or thousands of tweets may be produced about common topics such as scandals
or celebrities. The information delivered by Twitter may prove to be an invaluable source
3http://en.wikipedia.org/wiki/Microblogging4http://www.3gpp.org/ftp/Specs/html-info/23040.htm5http://www.hu�ngtonpost.com/2011/02/21/middle-east-north-africa-protests n 826101.html6http://twitter.com/OccupyWallST7http://www.forbes.com/sites/parmyolson/2011/05/02/man-inadvertently-live-tweets-osama-bin-laden-
raid/8http://articles.washingtonpost.com/2013-03-21/business/37889387 1 tweets-jack-dorsey-twitter

3
of collective emotional state, current events or even terrorist activity. Summarizing tweets
about a common topic could prove useful for tracking world events, performing market
research or even determining public opinion. Text summarization itself is not a new topic
and much research has been completed in this area. However, the unique characteristics
of tweets introduce challenges to traditional summarization techniques. Clustering of data
is a common technique in the summarization process, and the focus of this thesis is on
improving performance of existing clustering techniques when applied to Twitter data.
1.1 Motivation
The ability to mine Twitter data and produce summaries of certain topics could
prove useful in many cases. According to Java et al. in [20] most tweets can be categorized
into the following: daily chatter, conversations, sharing information and reporting news.
Any number of useful metrics could be obtained from these categories if the data could
be e↵ectively mined. Recent research has used Twitter data to predict trends in the stock
market [5]. Bollen et al. study the collective mood of Twitter users and use that to enhance
stock market prediction methods. Their work uses simple text processing techniques to
determine changes in public mood. Bollen et al. are able to show correlation between the
mood data derived and the performance of the Dow Jones Industrial Average. Likewise,
Twitter can be monitored to e↵ectively alert on targeted world events. Recently, Twitter
data was used as a means to monitor for earthquakes. Sakaki et al. [32] used tweets with
certain keywords to rapidly (within 1 minute) detect the existence and location of earth-
quakes. The application possibilities are nearly endless. The entertainment industry could
mine the data to produce television program and movie ratings. Political analysis could
use Twitter to determine the public opinion of a candidate. A recent study of Twitter data
surrounding elections in Germany suggests this may already be happening [41]. Even the
intelligence community could use Twitter to monitor for terrorist threats9.
One of the key features of Twitter that makes it an attractive data source is the
ease of real-time data collection. Twitter allows collection of tweets using publicly available
9http://www.informationweek.com/news/201801990

4
and well documented Application Programming Interfaces (APIs). The Twitter Streaming
API allows keywords or phrases to be specified as a filter and then will provide a sampled
live feed of tweets containing the given keywords. This API provides a means to gather
specific data about any number of topics. For real-time information about a current event
or popular person one only needs to supply a keyword or phrase related to the topic. The
data could then be collected and mined to provide insight into many things. Being able
to mine this data in a reasonable amount of time is challenging given the volume of data
produced by Twitter. For instance, the keyword “Obama” was monitored by the author for
a period of about 1 hour in October of 2011. Twitter provided 4025 tweets for the keyword
“Obama”. This is about 67 tweets per minute. This value is relatively small, but still could
be time consuming to process depending on the data mining algorithm used. In contrast
to the small number of tweets produced by the topic “Obama” trending topics can produce
a much higher volume. In October of 2011 the trending topic ”#MyFavoriteSongsEver”
was collected for our research and produced over 730000 tweets in just over 6 hours. This
averages out to a rate of just over 32 tweets per second. Dramatic current events can also
cause high volume of tweets to be generated. During hurricane Sandy, in 2012, Twitter
was monitored for a period of about 8 days. In this period nearly 4 million tweets were
generated with the word “Sandy” in them. The average rate is only about 5 tweets per
second, but the overall data set is quite large. Given the potential volume of the data,
scalability of any approach must be taken into consideration.
In addition to providing access to streams of tweets, Twitter also tracks keywords and
reports the most frequently occurring phrases or topics. The top ten topics are reported
as being trending and the tweets for a given trend can be obtained programmatically using
the publicly available Twitter APIs. It would seem, empirically, that the findings of [20]
are correct in that the greatest category of tweets is daily chatter. Of all our trending data
collected, much of it was related to ongoing sporting and entertainment events. Very little
of the trending data obtained included current events. One exception to this surrounds the
death of Apple co-founder Steve Jobs on October 5, 2011. The phrase “Steve Jobs” was
marked as trending during a run of the collection software. This phrase was trending only
for about 15 minutes and produced about 1300 tweets at a rate of about 87 per minute.

5
On October 9, 2011 the topic “Tebow” (tweets about the popular Denver Broncos football
player) was trending for 10 minutes and produced almost 5000 tweets with a rate about
500 per minute. The actual number of tweets for these topics may have been higher given
that the Twitter Streaming API10 only provides a sample of the requested data. All the
trending topics were monitored for just over one day and produced nearly 2 million tweets.
The volume of data produced by Twitter is large enough that it is unreasonable to
think that an individual could monitor a topic and be successful in reading and summariz-
ing Twitter streams. It may be useful to systematically gather topical data from Twitter
and summarize it automatically, thus allowing a person to learn the general subject of
conversation from many tweets. However, summarizing this volume of data can be prob-
lematic. Work has been done to extract a single tweet as a representative summary for
a set of tweets [36–38]. However, the premise is that all tweets in the set are already re-
lated in some way (keyword or general topic). In order to produce sets of tweets around
common topics it would be helpful to be able to automatically cluster the data in some
way. Document clustering is not a new topic and recent research has been done to cluster
article titles [30] as well as other short texts [16]. While not the same as Twitter posts, the
research suggests that clustering short phrases across large data sets can be done.
There are many data analysis techniques that can be used with textual information,
and clustering is one of them. Clustering could be performed either real-time, as the tweets
are produced, or periodically with a set of previously obtained tweets. Clustering could be
done for a set of keywords in order to extract subtopics from the main cluster, or could
be performed across many topics to attempt to determine the main topics. Either of these
approaches presents an interesting computational problem. In some cases, for instance
K-means clustering [24], the clusters are assigned based on data points’ proximity to one
another. This proximity is usually determined by converting the data to a numeric vector
and calculating distance or similarity among all the vectors. For textual data a bag of words
is generally created that represents the words, or terms, across the entire document set.
Once this bag of words has been computed a count of each term from each document (term
frequency) is computed to create that document’s vector. Analysis of Twitter data suggests
10https://dev.twitter.com/docs/streaming-api/concepts#filter-limiting

6
that the dimension of these vectors could be huge while the actual non-zero values of each
vector would be exceedingly sparse. For instance, a sample of 25000 tweets, collected by the
author, from 57 di↵erent key phrases contains 38376 unique terms when using whitespace
as a delimiter. The average length of each tweet is only 10 terms making each document
vector over 99% sparse. Computing simple squared or Euclidean distance between even
two data points of this dimension would take tens of thousands of computations. Given
that very few values of each vector are non-zero the process can be optimized with creative
data structures and algorithms. Yet another approach to optimizing the problem is trying
to attempt to reduce the dimension of each vector [11]. Some simple text transformations
can greatly reduce the number of unique terms across a set of posts. A simple conversion
of each tweet to all lower case letters resulted in an average 15% decrease in dimension.
Many clustering algorithms themselves are already well known and commonly used for
text clustering. However, as noted, tweets introduce unique features that decrease cluster
quality when using these well known algorithms. This limitation is the basis of motivation
for this thesis. The focus of this research is to improve cluster quality for existing clustering
algorithms as well as attempting to determine the number of parititions to cluster into prior
to starting the clustering process. Cluster performance is improved by pre-processing the
data and number of paritions is determined based on statistical observations of the data.
1.2 Approach
Clustering data is not a new topic and a number of approaches to clustering textual
data have been developed over the years. In general there are only a few types of clustering
algorithms. Partitional clusterings assign every data point to a single cluster by way of
partitioning, or grouping, the data points by proximity. Each point in a partitional cluster
falls into exactly one partition and there are clear lines of separation between partitions.
Hierarchical clustering is similar, although the clusters are usually built in a tree
structure with the root of the tree being a cluster containing every point. Subsequent
portions of the tree are subdivided into other clusters. Therefore a single data point would
have an inheritance of clusters all the way to the root.

7
In contrast to assigning data points to individual clusters, fuzzy clustering will as-
sign every point to every cluster with a confidence measure. A confidence of zero means
absolutely not in the cluster while 1 means absolutely in the cluster.
Clusters can be complete (all data points assigned to a cluster) or partial (only some
data points assigned to a cluster). One of the most widely adopted clustering algorithms,
K-means, is a partitional clustering approach [24]. K-means has been used to cluster text
by way of bag of words vectors. These vectors are compared by any one of a number of
distance computations including Euclidean distance, squared distance and cosine similarity.
Various modified versions of K-means have also been used including bisecting K-means as
well as spherical K-means clustering. K-means, and its variants, are simple algorithms and
easy to implement. Therefore, the K-means algorithm is used as the reference clustering
algorithm in this thesis.
1.3 Organization of Thesis
A number of topics surrounding this research will be covered in the following chapters.
Previous work into document summarization and clustering will be the topic of Chapter
2. Chapter 3 will include a detailed description of how the data was collected and various
statistics about the data. Chapter 4 will cover data preprocessing including language clas-
sification, data reduction and parsing. Chapter 5 will outline our clustering algorithms and
implementation. Chapter 6 will review the results of our e↵orts and Chapter 7 will present
conclusions and suggestions for future work.

CHAPTER 2
RELATED WORK
2.1 Introduction
Clustering documents is a topic that has been well researched in the past. However,
a number of unique features of tweets make clustering di�cult. Twitter imposes a 140
character maximum limit on each post. This results in the average length of posts being
about 10 terms (separated by spaces). Due to this limit, people posting tweets tend to
abbreviate words and phrases (“lol” to indicate “laughing out loud” or “b↵” instead of
“best friend forever”). The short length of posts and colloquial nature tends to produce
very noisy datasets and creates a challenge in summarization and clustering.
This chapter is organized into several sections. The first section covers research into
summarizing well formed texts and documents. While not strictly related to document
clustering, the techniques used in automated summarization can aide such tasks as feature
selection for clustering. The second section examines research on summarizing web based
content of web-logs and microblogs. This section is followed by a section covering clustering
algorithms, especially focusing on clustering large high-dimensional data sets.
2.2 Document Summarization
The idea of summarizing documents is not a new one. In fact, research on automatic
generation of summaries has been ongoing since at least the 1950s. One of the first pub-
lished papers on the topic is by Luhn [23]. Luhn investigated the automatic creation of
abstracts for technical articles and documentation. His work introduced a means to pro-
duce summaries, or abstracts, for documentation based on word frequency. Luhn developed
software to consume documents in a machine readable format and produce a list of words in
the document. Certain common words (pronouns, prepositions and articles) were removed
from the list and similar words were combined. Word counts were calculated and any words
below a given threshold were removed from the list. This list represented the significant

9
words in the document. Sentences were then extracted from the document using a simple
scoring mechanism which examined proximity of significant words in phrases. High scoring
sentences thus became the basis for the abstract.
Expanding on this simple statistical analysis of documents, Edmundson argued that
additional factors should be accounted for [13]. Edmundson claimed that by using additional
features such as cue words, title and heading words as well as sentence location produced
better sentence extracts from documents. Numerical values for the three attributes were
calculated and summed to produce an overall score for each sentence. Values for cue words
were produced for the entire document based on word frequency, dispersion throughout the
document collection and ratio of words in selected sentences versus the entire collection.
Title and heading words were determined based on comparison between document headings
and document content. Finally, the location attribute was calculated based on proximity of
sentences to section headings and within paragraphs. In addition to these three criteria for
sentence weighting, Edumndson also used Luhn’s method of scoring high frequency words
and their proximity to each other.
These early techniques seem straight-forward and simple. However, research at the
time indicates even simple techniques could provide superior document analysis then manual
methods. Salton [34] compared performance between manual indexing of medical documents
and automated indexing using the SMART retrieval system. Salton’s work shows that
automated indexing is superior to more conventional, and manual, methods used at the
time. This work showed promise for the future of automated processing of text documents.
Work on automated summarization continued into the early 1980’s. In 1981, Paice [27]
introduced a new concept in weighting sentences for summarization that extended the more
primitive term frequency and structure based approaches. Paice proposed using indicator
phrases to determine key sentences in documents. These indicator phrases could be used as
locators for related sentences. Paice also proposed using more than one adjacent sentence
as part of the abstract so that a more natural flow could be achieved. Empirical analysis
of Paice’s results suggests using indicator phrases was a good start but much work still was
required.

10
While work continued to find more advanced phrase weighting systems simple ap-
proaches were still being researched. Although Luhn [23] had noted the correlation between
term frequency and document relevance, the notion of establishing cuto↵ values for high
and low frequency words could produce a loss in precision. In 1986, Salton and McGill [35]
reviewed and proposed a number of methods for text analysis and document indexing.
Among them was a simple term weighting method that has proven quite useful in more
recent research. The proposed weighting function computes the frequency of a term in a
document and combines that with the inverse document frequency of the given term across
all the documents in the collection. The Term Frequency-Inverse Document Frequency
(TF-IDF) function assigns a higher weight to high frequency terms occurring in only a few
documents than it does high frequency terms occurring in many documents. Although the
TF-IDF algorithm is quite simple to implement, it has not been well known as a leading
summarization algorithm.
Much of the early summarization and clustering work focused on using well formed
documents, such as news articles, professional journal entries and other well structured
forms of literature. New forms of literature have been introduced as documents have moved
from physical copies into digital representations of data. One of the early obstacles present
in much of the research was simply getting the data into a machine readable form. As
the Internet has gained popularity, more and more data is directly represented in digital
form. New forms of communication have also emerged. People write articles to web-logs
and social network sites as well as micro-blogs like Twitter. This data could prove to be a
valuable source of market data, security intelligence and public opinion. However, the data
from sources like Twitter is far from well formed. This is where previous research does not
solve the problem of clustering or summarizing text data.
2.3 Summarizing Blogs and Micro-Blogs
Even though early research focused on well-formed text documents, we should still
be able to derive useful techniques for clustering tweets. Much of the early work focused on
basic techniques such as term frequency, cue words, titles, headings and indicator phrases.

11
In many cases the research shows that automated abstracts and indices could be reliably
produced using these simple techniques. However, the research was focused on processing
complete documents and document collections. In the case of Edmundson [13] the goal
was to process documents of at least 40,000 words. A number of problems are presented
when attempting to use these methods with Twitter posts. Twitter posts are limited to 140
characters and have an average length of about 10 terms. These short phrases, however, can
number tens of thousands (or possibly millions) about many di↵erent topics. Likewise, the
posts themselves are generally “noisy” with much non-standard speech, abbreviation and
use of symbols. Research has also been conducted more recently on summarizing dynamic
web content from web-logs (blogs) and micro-blogs.
Zhou and Hovy [44] studied the problem of summarizing dynamic content from on-
line discussion boards as well as web-logs. Their summarization work clustered messages
hierarchically on topic and then extracted common segments across messages using Text-
Tiling [15]. Zhou and Hovy described web-logs and on-line discussions as having messages
with multiple subtopics. Responses and discussion could include the subtopics or introduce
new subtopics. Zhou and Hovy were able to compare the automated results with manually
generated summaries of technical discussion. Their results show good recall for the ap-
proach proposed. In addition to summarizing technical discussion boards, Zhou and Hovy
explored the possibility of summarizing web-log entries. Their assumption was that web-log
entries with URLs contained summaries and personal opinion of the linked content. Their
approach to summarizing the linked content was to delete sentences in the web-log entry
until any more deletions would reduce the similarity between the web-log entry and the
linked article.
Web-logs are similar to Twitter posts in the fact that they contain conversational
speech and colloquial syntax. However, web-logs and discussion boards contain much longer
posts. The short length of Twitter messages (a maximum of 140 characters) distinguishes
them from other dynamic web content. Research has been conducted on summarizing and
clustering Twitter posts, but this is a relatively new area of research.
Sharifi et al. developed the Phrase Reinforcement Algorithm which is a means to
summarize a set of Twitter posts about a common subject [36]. The method builds an

12
ordered acyclic graph. The root node of the graph is the particular phrase the given posts
have in common. The graph is built with node weights incrementing for each common term
placement in the collection of posts. The highest ranking phrase is then selected as the
summarization phrase. This approach builds a summarization phrase that is potentially
made up of parts of several posts. Sharifi et al. determined the phase reinforcement ap-
proach worked very well for sets of posts with a dominant phrase pattern. On the other
hand, if the set of posts does not contain a strong phrase (especially where the common
term may be a hashtag) then the performance of the phrase reinforcement algorithm isn’t
quite as good.
Sharifi et al. further expanded their research in Twitter summarization in [37] where
they describe a summarization approach that expands on the Term Frequency-Inverse Doc-
ument Frequency proposed by Salton [35]. The TF-IDF approach computes the relationship
of a term’s frequency in a single document with the number of documents that contain the
same word. Since Twitter posts usually only contain one or two sentences, it becomes di�-
cult to apply TF-IDF without a better definition of the document and collection. Sharifi et
al. propose a hybrid document where the term frequency is the ratio of the terms frequency
across all documents to the total number of terms in the collection. The inverse document
frequency component becomes the ratio of the number of sentences in all posts with the
number of sentences that contain the given term. This computation is then multiplied with
a normalization factor so that longer sentences are not weighted higher simply due to length.
Sharifi et al. were able to achieve good results when compared to manual summaries. The
results of the Hybrid TF-IDF were compared to manually generated summaries using the
ROUGE [26] performance measure. The ROUGE metric counts the number of overlapping
terms, n-grams or word pairs. The automatically generated summaries produced had a high
correlation with the manually generated summaries.
Sharifi et al. were able to produce a reasonable summary for a collection of posts by
choosing a single post with the highest score. In order to do this, however, an assumption
is made that the set of posts is already surrounding a given topic. If one were to simply
monitor the entire feed of Twitter posts it would become immediately apparent that the
posts are about a wide variety of topics. These posts need to be categorized by common topic

13
before summarization can occur. Even performing a simple categorization seems intuitively
inadequate. When considering the service Twitter provides it is almost natural to think that
a set of posts with a common topic will have some number of subtopic threads. Clustering
the data is one approach to finding subtopics and producing a representative summary.
Assuming the clusters are well formed with common members, each cluster might represent
a subtopic and the best post (as chosen by something like the hybrid TF-IDF) in the cluster
should be the best summary phrase for that subtopic. This set of summaries could then be
used to establish an abstract for a given topic, or even to produce the list of topics for a set
of random Twitter posts.
2.4 Document Clustering
Much of the work around automatically generated abstracts and document indexing
focuses on weighting phrases within a document and choosing the top performing phrases
to use as the summary. Clustering documents, however, takes a slightly di↵erent approach.
Phrases are compared using some discriminator function and appropriately similar phrases
are grouped together in a cluster. Since many of the well known clustering algorithms use
mathematical operations as their distance function, a mathematical model must be used to
compare documents.
In [33], G. Salton established a vector model for comparison. This model was a simple
vector of terms and their frequencies for a given document. Defining a document in this
way allows for mathematical comparison between two documents using many well known
algorithms. Common distance measures include cosine similarity and Euclidean distance.
Having the ability to measure a document in terms of a vector space allows for the use of
many well known clustering algorithms.
A major issue in clustering Twitter posts is that the vector space can be quite large
for even a moderate number of posts. In October of 2011 a sample of Twitter posts was
collected and in a collection of 1000 posts there were over 3401 unique terms. Attempting
to compute the similarity between two posts in that collection would result in thousands of
individual computations.

14
Perhaps the most common clustering algorithm is the K-Means clustering [42] [3].
K-means clustering will assign every point to K cluster centers, recompute a new cluster
center for each cluster and repeat until cluster membership does not change. Assignment to
a cluster is based on nearest proximity to a cluster center using a distance function. K-means
is relatively fast depending on the data set. However, given the computation required for
very large vector models (such as those seen in samples of Twitter data), K-means clustering
becomes increasingly slow.
Research has been conducted on a means to reduce the size of the vector space as well
as improve performance by approximating distances rather then computing exact values.
Dhillon et al. [11] describe a series of optimizations that can be applied to many cluster-
ing algorithms, with a focus on improving the K-Means clustering. These optimizations
include simple dimension reduction by ignoring case, removing stop words and removing
non-content-bearing high-frequency and low-frequency words. These steps alone can re-
duce the dimension of the problem considerably. Dhillon et al. go on to study additional
performance improvements for clustering large sets of high-dimension data. The authors
propose that given the sparsity of the vector space model (99% sparse in most cases) us-
ing a hash table based vector model can significantly improve performance. Consider the
following: a document set containing 1000 unique words but the average sentence length is
only 10 words. This means that for each sentence a bag of words vector for any sentence
in the document would have a length of 1000 but 990 or more of the values would be zero.
By only tracking non-zero values and computing similarity between two document vectors
only using the union of vector keys, the computational and memory requirements can be
reduced by nearly 99%, in most cases. In addition to representing only non-zero value terms
in the vector model, Dhillon et al. also proposed using an approximation method during
clustering. They observed that as clustering progressed the clusters stabilize considerably
after only a few iterations of the algorithm. Dhillon et al. introduced a means to estimate
the distances between document vectors. Their work showed considerable improvement in
computational time for very large document sets.
The work described by Dhillon et al. focused on clustering abstracts to produce
lists of similar documents. Once again, this type of data is well formed and much longer

15
then Twitter posts. Research has been done to study clustering and summarizing Twitter
data itself. Inouye and Kalita [19] compare performance of many di↵erent summarization
algorithms, including two K-Means clustering derivatives (bisecting K-Means [43] and K-
Means++ [1]) as well as a clustering approach using the hybrid TF-IDF. Each clustering
method would choose k posts from a set to produce the summary. One of the problems noted
in the research was in choosing the correct value for k. The authors perform a simple survey
to determine how many clusters a given set of Twitter posts represents. The authors note
that research should be done into determining the optimal number of clusters automatically
rather then relying on this simple approach. Likewise, the authors note that simple word
frequency and redundancy reduction appear to be the best approach for clustering Twitter
posts. It is believed that the unique syntax and short nature of Twitter posts was the
reason the more complex algorithms had very little performance benefit.
2.5 Summary
Summarizing, indexing and clustering documents and document collections have been
an area of research for more then half a century. Early work, such as that completed by
Luhn [23] and Edmunson [13] used word frequencies and document proximity to weight
phrases for summarization. These techniques were shown to produce reasonable results for
digitized texts. However, at the time, the technology did not yet exist to examine large
document collections in a reasonable amount of time. Another issue with the research of
the time was the limited number of data sets in machine readable format. Nonetheless,
research continued in the field.
Later work in the field focused more on processing complete phrases rather than
individual words. Paice [27] developed a weighting system using indicator phrases. His ap-
proach assumed that phrases adjacent to highly weighted phrases would be good candidates
to include in the abstract. Meanwhile, new research by Salton and McGill [35] re-examined
basic term weighting methods. The TF-IDF weighting algorithm they proposed has been
recently used to summarize Twitter posts.

16
More recently, work has been done to summarize dynamic web-based content. Zhou
and Hovy [44] worked to summarize both web-base discussion boards of a technical nature
as well as political based web-logs. Throughout the research a key di↵erence exists between
the test data and what would be used in a Twitter based algorithm. Twitter posts are very
short and have non-standard syntax while almost all the data used in previous research was
much longer well-formed documents.
Sharifi et al. were able to develop a number of techniques that produced good single
post summaries from a collection of Twitter posts [36] [37]. In addition to this, Inouye and
Kalita [19] studied existing clustering techniques with respect to Twitter data. Their results
indicate simple word and term weighting approaches may be the best metric for clustering
Twitter data.

CHAPTER 3
TWITTER DATA
3.1 Introduction
One of the most attractive aspects of Twitter posts is that they are easily collected for
processing. This feature of Twitter means that conversations on widely discussed topics can
be collected and analyzed for use in many industries. Anyone can join Twitter and write
software to interact with the Twitter system1. Twitter provides the ability to download
chunks of posts or subscribe to a real-time stream. The standard streaming service will only
provide a sample of posts rather than the complete stream. However, the complete stream
is available on a request basis from Twitter. This chapter focuses on the various aspects of
tweets and our approach to collecting them. Section 3.2 describes what a tweet is as well as
the pre-processed attributes available from Twitter. Section 3.3 describes how some of our
test data sets were collected. Finally, section 3.4 reviews various statistics of data collected.
3.2 Format of Tweets
Twitter is a service that allows both human users as well as third party software to
create messages that are then broadcast to any number of accounts. These posts, called
tweets, can be sent publicly (viewable by anyone with a Twitter account) or privately to
a selected group of accounts. Twitter allows people to receive other’s tweets by means
of subscribing, or “following.” Followers will receive tweets posted by the user they are
following. These tweets are also referred to as status updates. According to Twitter2, there
are four distinct types of tweets: normal tweets, mentions, @Replies and Direct Messages
(DMs). Of the four types of tweets, only Direct Messages are between two individuals.
By default, all tweets are public and can be viewed by anyone with access to the Twitter
website. This setting can be changed so that a user’s tweets are protected and only viewable
1https://dev.twitter.com/start2http://support.twitter.com/groups/31-twitter-basics

18
by those who have been approved by the poster. Normal tweets are simply short messages
that will appear to any user following the poster’s tweets. Likewise, mentions and @Replies
are messages that use an @ sign to either mention another Twitter user or, if the @Reply
starts the message, to reply to another user.
Twitter imposes a 140 character limit for each message. This limit was originally
specified due to length restrictions by SMS messaging providers. Messages can be sent from
mobile phones, web browsers and even from other social networking websites and third party
software. The majority of tweets are conversational in nature with many reporting breaking
news and current events [20]. The conversational nature of tweets presents a challenge when
attempting to cluster or summarize conversation threads. The structure of conversations in
Twitter is similar to that of web based message boards. However, message boards generally
track posts within message threads. In [44] the authors are able to produce summaries of
online discussion boards, including subtopics discussed. However, the approach is based
on already having an existing thread. Twitter only tracks replies and who a message is in
response to, it does not maintain threads of conversation.
In addition to the conversational nature of tweets, the posts often contain abbreviated
text in order to adhere to the 140 character limit. The advent of text messaging has
introduced common abbreviations known as SMS language, or textese3. Since Twitter
started out as an e↵ort to allow SMS users to share updates with interested followers [31],
the SMS language was rapidly adopted by Twitter users. Common abbreviations include
“4u” instead of “for you” and “cul8r” instead of “see you later.” These abbreviations can
easily be understood by most people but present a significant challenge to the area of
automatic processing [21].
Twitter provides several basic techniques to refer to common topics as well as other
Twitter users. A common nomenclature in Twitter posts is the “@user” tag, which will
automatically link a tweet with another user. When the tag occurs within the text it is
known as a “mention” whereby the poster is mentioning another user. When the tag occurs
at the beginning of the text it indicates the message is a reply to the tagged user. This
3http://en.wikipedia.org/wiki/SMS language

19
simple tagging method introduces a basic community structure in which messages are linked
to groups of users.
In addition to the simple @ tag is another common tagging mechanism known as
the hashtag. Hashtags are simply keywords prepended with a hash (#) symbol. Hashtags
are preprocessed by Twitter and provided as a list in the tweet data structure. Hashtags
provide a basic mechanism to link messages to a common topic. Twitter will automatically
convert hashtags to URLs that link to lists containing all tweets with the given hashtag.
The use of hashtags was started by the Twitter community directly and not part of the
original intent. Web applications, such as http://hashtags.org/, have even been created to
track and search for posts containing hashtags.
All of this information is useless without easy access to the actual messages being
posted amoung users. In order allow third party software to send, receive and process
tweets, Twitter provides access to data via three APIs. The Search and REST APIs are
both REST (Representational State Transfer) based HTTP APIs. The streaming API is
also HTTP based but will continually send new matching tweets to the client. All tweets
collected using Twitter’s API contain the same attributes and are available in common
formats. The attributes associated with a given tweet are collected in an object known as
a status. The exact meaning of every attribute in a status object is not fully documented.
However, Table 3.1 displays some common attributes used in analyzing Twitter data. In
addition to the basic attributes available in a status object, a set of entities is also provided4.
These entities are pre-parsed from the tweet text and are included in the status object. A
listing of types of entities available in the entities relationship is given in Table 3.2.
4https://dev.twitter.com/docs/tweet-entities
Attribute Description
text The tweet text sent out to followersretweet count The number of times this tweet has been re-posted
user A data structure containing various attributes of the user that posted the statusentities An associative array of entities that appear in the text (hashtags, mentions, etc.)
Table 3.1: Common Status Attributes

20
Entity Type Description
media Array of information regarding any media included in a tweeturls Array of any URLs extracted from the tweet text
user mentions Array of Twitter screen names extracted from the tweet texthashtags Array of hashtags extracted from the tweet text
Table 3.2: Status Entities
At the time of this writing Twitter provides status objects in the following formats:
Extensible Markup Language (XML), JavaScript Object Notation (JSON), Resource De-
scription Framework Site Summary (RSS) and Atom. Most of the documentation and
examples illustrate concepts using JSON. Our work also utilizes the JSON format due to
its wide support across platforms and languages.
3.3 Test Data
Several test data sets exist for Twitter data including one from the National Institute
for Standards and Technology5. However, the Twitter terms of use agreement prohibit
distribution of tweets. Therefore, test sets that exist are simple lists of tweet IDs. This
allows a consumer of the test data to download tweets directly from Twitter using Twitter’s
standard API. Given rate limits imposed by Twitter it is virtually impossible to actually
retrieve the data sets in a timely manner. The current Twitter API imposes a limit of
15 requests per 15 minute period6. Given this rate limit it would take over 3 years to
completely download the NIST Twitter dataset. This limitation imposed an unreasonable
time restriction on our research, therefore we produced test data from the live Twitter
stream API. Over a period of time both trending topics and various selected topics were
gathered. Several newsworthy events were captured including tweets about hurricane Sandy
and the death of Steve Jobs. Another set of tweets captured involved posts about a cyber
attack against U.S. water treatment plants. This set of tweets was used for much of the
testing of our work due to its length (about 900 tweets) as well as its low number of di↵erent
5http://trec.nist.gov/data/tweets/6https://dev.twitter.com/docs/rate-limiting/1.1

21
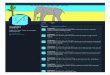
Figure 3.1: Twitter Collector
topics (about 6). The “Cyber Attack” data set is much larger than samples used in other
work (many research projects only use sets of 100 tweets) but it isn’t so large as to present
a computational challenge in research.
Figure 3.1 represents the process used to collect tweets for this project. The collector
process receives tweets in JSON format from the Twitter streaming API. Once a tweet has
been received it is dispatched to a keyword filter. The keyword filter organizes the tweets
by common keyword and writes them to common files. For instance, if the topic “Election
Day” is trending and we’re collecting tweets for “Election Day” any text with that phrase
will be written to a file containing all the other collected tweets containing the same phrase.
This process allows the Twitter collector to simultaneously collect tweets for many di↵erent
trending topics or keyword phrases.
It is interesting to note that trending topics are simply a single word or short phrase
that are occurring more frequently than other words or phrases. Twitter tracks word and
phrase occurrence over time and displays the top 10 as “trending topics.” Our Cyber Attack
data set happened to be a trending topic at the time of collection. The interesting aspect of

22
Tweet Text
Feds investigating Illinois ’pump failure’ as possible cyber attack: Federal o�cials confirmedthey are investigating Friday whethe...
Norweigian Oil And Defense Industries Are Hit By A Major Cyber Attack:http://t.co/irEBDlao
Canada says cyber-attack serious, won’t harm budget — Reuters http://t.co/JPN1PVck— Finance Department and Treasury ...
UK to test banks with simulated cyber attack http://t.co/fpcGewgS
Feds investigate possible cyber attack http://t.co/2wHzKcSx
Banks to be tested with simulated cyber attack http://t.co/wIUuWiDN
THE CIA/ISRAELIS ARE DESPERATE TO CYBER-ATTACK ME BECAUSE I KEEPDEFEATING/HUMILIATING THEM & WON’T STOP!!!
Table 3.3: Cyber Attack Tweets
the Cyber Attack data set is that, although every tweet includes the phrase “Cyber Attack”,
there are several distinct topics being discussed. Table 3.3 displays several of the tweet texts
included in the Cyber Attack data set. Although the predominant topic involves an attack
on a water treatment plant, other topics include simulated attacks in the United Kingdom,
attacks against Norwegian industry, attacks in Canada as well as completely unrelated
rhetoric. This observation helps to emphasize the need to do statistical pre-processing of
data prior to clustering.
3.4 Statistical Analysis
Understanding various statistical aspects of text data can provide insight into im-
proving performance of clustering algorithms. Two well known measures include Heap’s
Law [14] and Zipf’s Law [45]. Heap’s Law establishes that as the size of the document
collection increases the growth in the size of the vocabulary will decrease. Likewise, Zipf’s
Law suggests that in a given corpus, the frequency of a given term is inversely proportional
to its rank. Thus the most common term will occur twice as often as the second most
common term and so on. Both Heap’s Law and Zipf’s Law are used throughout natural

23
Size Vocabulary Average Tweet Length % Singletons
1000 3401 9.628 535000 11831 10.0264 5010000 19517 10.0114 4925000 38376 10.04136 4950000 63700 10.03848 48100000 105328 10.05548 471000000 519862 10.03894 43
Table 3.4: Tweet Statistics (Uniform Sample)
language processing and document clustering as metrics and in document feature selection.
Therefore, it is reasonable to assume that clustering performance would be better when the
corpus conforms to these laws. In [17], the authors found that the growth in vocabulary
of Twitter posts (with respect to number of posts) is higher than in collections of longer
documents. Likewise, the authors noted that when plotting word frequencies based on the
Zipf-Mandlebrot distribution [25], the slope for Twitter posts was less than that of longer
documents. The explanation for this is that collections of shorter documents contain fewer
repeated words.
Over 5 million tweets were collected during several collection periods in 2011 and
2012. For analysis purposes the tweets collected were grouped by common topic (either
trending topic or specified topic). For some of the statistical analysis performed, uniform
samples of data were retrieved from the grouped sets and mixed together into 1000, 5000,
10000, 25000, 50000, 100000 and 1000000 sized collections of tweets.
A major source of noise in the tweets we’ve collected is in the large number of single-
tons occurring in the dataset. A singleton is simply a term (string of characters) that occurs
exactly once in the given dataset. Some examples of singletons in table 3.3 include, “pump”,
“failure” and “serious”. These terms are complete English words that are spelled correctly.
Many times in the twitter datasets the singletons are not words at all. Most noteworthy of
these terms are the URLs (e.g. “http://t.co/jpn1pvck”) from table 3.3. The singletons add
no value to the clustering computation and can singificantly increase computation time if
they are not filtered out.

24
Collection Size Vocabulary Average Tweet Length % Singletons
Cyber Attack 841 2602 11.7088 76Steve Jobs 1314 6769 16.6735 76Hurricane Sandy 3958962 6904272 17.975 87
Table 3.5: Tweet Statistics (Selected Topics)
Table 3.4 shows several statistics for samples of data we collected. Not surprisingly
it is largely consistent with the statistics from [17]. However, the percentage of singletons
(single occurrence of a term in a collection) in our data set is notably lower than those
calculated in [17]. It is also noteworthy to point out that as the sample size increases the
percentage of singletons appears to decrease.
Tweets appear to be relatively consistent with respect to average number of terms per
tweet. Table 3.4 shows the vocabulary size as well as average number of terms for several
sample sizes of tweets collected in the fall of 2011. The data set used for this analysis is a
uniform sampling of tweets from followed trending topics over a period of several days and
terms were retrieved by splitting each post on whitespace and then indexed. The vocabulary
size of each set of posts (the unique number of terms in the text of the status) is quite large.
Given the size of the vocabulary and the average length of each tweet the term vector for
each post will always be 99% sparse (99% of the values in the vector will be zero).
Table 3.5 shows the same statistical analysis for 3 selected topics. Several noteworthy
aspects are immediately evident. The selected topics appear to have far more single occur-
ring terms than the uniform samples. Also, the average tweet length is considerably longer.
Finally, the Hurricane Sandy data set appears to have a vocabulary of nearly 7 million
words. The English language contains significantly less than 1 million words7. Therefore,
this suggests a great deal of non-standard terminology is in use, especially in the Hurricane
Sandy data set.
Table 3.6 shows the top 10 terms in each of the 7 samples. Not surprisingly, the top-
ics with the greatest number of posts (#MyFavoriteSongsEver and #ThingsPeopleShould-
NotDo) are in the top 10 for all sample sizes. The rest of the top terms are mostly common
7http://www.oxforddictionaries.com/us/words/how-many-words-are-there-in-the-english-language

25
Collection Size Top 10 Terms
1000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, you, is, Happy
5000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, and, you, I
10000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, you, and, is
25000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, and, you, is
50000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, you, and, I
100000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, you, and, is
1000000 #MyFavoriteSongsEver, RT, -, #ThingsPeopleShouldNotDo, the, a,to, you, and, is
Table 3.6: Top Terms (Uniform Sample)
Collection Size Top 10 Terms
Cyber Attack 841 cyber, attack, water, U.S., on, in, RT, -, Feds, investigates
Steve Jobs 1314 jobs, rt, and, the, no, -, jobs, we, a
HurricaneSandy
3958962 sandy, to, the, hurricane, #sandy, of, .., a, in
Table 3.7: Top Terms (Selected Topics)
stop words. In contrast to this observation, Table 3.7 shows the top 10 terms for three
selected topics. These terms appear to be much more indicative of the subject of the posts
as there are fewer common stop words. Note: the term “RT” generally means the tweet
is a “retweet,” e↵ectively someone forwarding a tweet they received. However, this term is
added by the user, so the actual content of the tweet may be modified from the original.
Analysis of both the uniform sample as well as statistically grouped samples indicate that
a number of pre-processing steps could yield better terms for clustering. Removal of stop

26
words and grouping by term frequency appear to be steps that would yield a much better
data set for clustering.
3.5 Summary
In this chapter we have reviewed a number of details about Twitter and tweets (sta-
tuses). Twitter provides a simple to use API for programmatic access to live streams or
previously posted tweets. The data returned by the API includes various features in addi-
tion to the text of the tweet. In an e↵ort to produce test data we have collected selected
topics as well as trending topics over several di↵erent time periods. The data collected ap-
pears to align statistically with other research in the field. Finally, simple techniques (like
grouping based on term frequency) appear to produce data sets with more representative
terms for the contained tweets.

CHAPTER 4
DATA PRE-PROCESSING
4.1 Introduction
The previous chapter illustrated the need for pre-processing the tweets in order to
produce more representative clusters. Grouping by high frequency terms and eliminating
stop words are two steps that can be taken to reduce the vocabulary size in a data set, but
there are several other pre-processing steps that can be taken to improve data set quality.
In addition to improving the quality of the text itself, other pre-processing must take place
in order to cluster the tweets.
The clustering algorithms used in this research require mathematical distance func-
tions to determine a given document’s relationship to the current clusters. Therefore, before
any document clustering can take place the tweets themselves must be converted to a form
compatible with the clustering algorithms.
This chapter covers several pre-processing steps that were performed on the data to
attempt to produce good usable numeric vectors for clustering. The chapter is divided into
several sections including challenges in pre-processing, parallel processing using MapReduce,
normalizing the tweets and labeling the language of the tweets.
The sequence of steps used in pre-processing is listed in Figure 4.1. The output of
the Twitter Collector (described in section 3.3) is fed into the pre-processing system. Each
tweet is dispatched, in parallel, to a chain of tasks for pre-processing. The current system
normalizes the data, identifies the language and tokenizes the document for clustering. This
modular approach to pre-processing allows additional steps to be added later by simply
adding them to the end of the processing chain. This is a similar concept to piping output
from a Unix command into another Unix command for subsequent processing.

28
Figure 4.1: Pre Processing
4.2 Challenges
There are a number of challenges in pre-processing tweets to produce usable doc-
ument vectors. These challenges are related both to simple computation as well as the
expected challenges inherent to natural language processing. The sheer volume of data
itself presents many computational problems, while the structure and atypical syntax used
in tweets present problems with language computation.
It is common practice [11,18,19,36,37] to convert tweets into vectors by counting the
terms in a collection of tweets and building vectors of term frequency relationships. These
vectors can then be used to compute relationships among the other vectors. Counting terms
seems to be a trivial task. However, with very large document collections it can take quite
a bit of time to perform even the simple task counting terms. One of the approaches to
document vectorization used in this research was to use n-gram frequencies as well as simple
term frequencies. An n-gram frequency is simply the frequency of an observed sequence of
characters or terms rather than a single term. The justification for using n-gram frequencies
is that single terms can be exceedingly ambiguous in large datasets, but n-grams are far
less ambiguous.

29
An example where grouping terms (as opposed to characters) produces a better match
can be observed in the “Cyber Attack” and “Hurricane Sandy” datasets. In theses datasets
the word “water” is found throughout. However, taken out of context it might indicate a
relationship between the two datasets that really doesn’t exist. If we were to only cluster
around the word “water” (across all the collected datasets) then at least one cluster would
include the tweet “I was sitting here watching everything I’ve worked for, everything I’ve
fought for, go under water.” That tweet is found in the Hurricane Sandy data set and is
clearly not related to a cyber attack. If we were to expand the single term “water” to “water
plant” or “water system” we would have reduced the similarity between the two tweets and
would have a better feature for clustering. Computing and counting sequences of terms
in this manner increases computational requirements and requires even greater amount of
time to complete than just working with single terms.
In addition to the computational problems, the data itself must be parsed in such a
way as to produce good features for clustering. A simple look at some of our larger data
sets reveals that they include more individual terms (not including emoticons or URLs)
than there are in the English language. Many of these terms are named entities, hash tags,
mentions and many other non-word type characters and sequences. Care must be taken
when using these terms as features in the cluster vectors.
4.3 MapReduce
Tasks, such as language classification and clustering, are tasks that can take much
time if done in a sequential fashion. Most of the pre-processing required for clustering
tweets can be done on individual tweets with no interdependency among the tweets. This
lack of dependency allows for massive parallel processing. This won’t necessarily reduce
computational requirements (in fact, it can actually increase computing requirements), but
processing time is remarkably inexpensive so reduced time can be achieved at little ad-
ditional financial cost. The ability to process the data in parallel is leveraged using the
common MapReduce concept.

30
There are many ways to achieve parallel processing of data. In fact, parallel processing
systems have been around for many years. To this day many single processor operating
systems have been adapted to allow parallel processing on multi-core and multi-processor
systems [39]. As cloud computing services become more popular it is becoming increasingly
inexpensive to deploy many parallel systems for simultaneous processing. Additionally,
there are more and more open source frameworks for parallel processing. As a result of this
trend in computing, several standard parallel processing frameworks have emerged including
one known as MapReduce.
MapReduce is a fairly new concept first published in 2008 [9]. The concept is to
distribute data across a cluster of inexpensive systems. The name “MapReduce” is a com-
bination of the two processes in a given parallel job. A Map task will take a series of input
key/value pairs and map them to an intermediate set of output key/value pairs. Once the
map task has completed a reduce task combines all the values with a common key thus
reducing the data set.
A concrete example where MapReduce can be used is in term counting. An input
of many phrases is split among some number of processing nodes. The input key (in this
case) is not as important. In the case of counting terms in Twitter data the key is usually
the tweet ID. Once the data has been split among the nodes of the cluster, each node will
examine the set of phrases provided to it and produce a count of individual terms in the
phrases. The intermediate output produced by this step is a set of key/value pairs where
the keys are the terms and the values are their counts in a given phrase. It is worthy to
note that any given term may, and probably will, occur more than once. This duplication
is accounted for in the reduce step.
Once the map task is complete, the reduce tasks proceed. In this case, a reduce
task will take some output from the map task and combine all the keys. The result of the
combination is the sum of values for like keys. The final data set is a list of key/value pairs
with the key being a given term and the value being the total number of occurrences in the
document. The keys will all be unique with no duplicates in the set.
An alternative to counting terms in this way would be to somehow load the tweets
into a Relational Database Management System (RDBMS) and then use SQL operations on

31
the schema to count the terms. There are mixed opinions on the performance of MapReduce
when compared to other solutions, such as an RDBMS [10, 28], but our use of the system
has shown dramatic improvement in time when compared to attempting a similar operation
using a traditional RDBMS.
Given the observed benefit of MapReduce in this project, MapReduce was used for
parsing the tweets, determining the language of the tweet, normalizing the data, producing
n-grams and producing the document vectors to be clustered.
There are several implementations of MapReduce that are free to use. However the
Apache Hadoop1 project is one of the more popular and was chosen for this research. The
Hadoop framework is easy to deploy and can even be used with services such as Amazon
Web Services (AWS)2. For this research much of the processing was done on a 10 node
Hadoop cluster hosted in the AWS cloud using the c1.medium instance type and 64 bit
Ubuntu 12.04 server. The c1.medium instance type has 5 virtual compute units and 1.7 GB
of memory. Performance was compared with single 6 core system with 16 GB of memory
running 64 bit Ubuntu 12.04 executing sequential tasks. One of the most simple processing
steps was to produce n-grams and their counts across a collection of about 4 million tweets.
The 10 node AWS hosted cluster was able to complete this task in about 6 minutes compared
to the single node system taking about 2 hours.
4.4 Normalization
Very basic pre-processing steps can be taken on tweets in order to reduce the volume
of data as well as make the data itself more usable. A popular action on Twitter is to
take someone else’s tweet and “re-tweet” it. This simply means to send a tweet back out
to anyone following your tweets. The tweet itself is usually exactly the same text as the
original, but (in some cases) can be modified by the re-tweeter. Since this data adds very
little information to a given collection, any re-tweets are discarded at the beginning. A
few simple heuristics were used to determine if a tweet is a re-tweet in addition to the
re-tweet indicator in the original tweet data structure from the Twitter API feed. Tweets
1http://hadoop.apache.org/2http://aws.amazon.com

32
are marked as a re-tweet and discarded if either the Twitter API indicates a re-tweet or if
the text itself begins with “RT”. Upon observing the data, it was noted that retweets are
often not indicated as such in the Twitter API, especially if the retweet begins with one or
more mentions followed by the term “RT” and then the original tweet. The heuristic used
in this case is to continuously shift the tweet left term by term until it no longer begins
with mention tags. If the tweet then begins with an “RT” then it is marked as such and
discarded. In the data we collected (about 5.7 million tweets) discarding re-tweets reduced
the data by about 40%.
Another common practice is to use “mentions” (an @ sign in front of a follower’s
username) to direct a tweet to the follower. These mentions are frequently found at the
beginning of a tweet and can be a single username or a list of usernames. As with the
previous heuristic, these mentions are shifted as the salient portion of the tweet almost
always follows the mentions.
The movitation for discarding the tweets and removing the leading mentions is the
assumption that little salient information is lost by discarding these features. It is possible
that removing duplicate tweets could a↵ect the cluster centers when using K-Means clus-
tering (discussed in the following chapter), but further research must be done to determine
if the impact is significant.
Another simple normalization step is to convert the entire text to lower case charac-
ters. Use of upper and lower case characters is generally for formatting only and doesn’t
change the intent of a phrase. Therefore all text is converted to lower case so that words
with the same spelling will always be programmatically equivalent. The final pre-processing
step taken is to remove non-standard symbols (emoticons, non-letter characters, etc) as well
as URLs and single character terms. None of these character strings are useful in conveying
information useful in our clustering system.
The results of pre-processing three selected datasets are shown in tables 4.1 and 4.2.
The top terms are much more representative of the topics and the data has been reduced
significantly. The number of tweets is reduced by 17% for the Cyber Attack data set, 58%
for the Hurricane Sandy set and by 69% for the Steve Jobs data set. Removing duplicate
tweets (in this case by ignoring retweets) has reduced our data sets significantly without

33
Collection Size Vocabulary Average Tweet Length % Singletons
Cyber Attack 618 1229 10.67 76Steve Jobs 408 1931 11.4975 74Hurricane Sandy 1672882 2101296 10.7880 92
Table 4.1: Normalized Statistics
Collection Size Top 10 Terms
Cyber Attack 618 attack, water, pump, system, failure, investigating, feds, in-vestigates, banks
Steve Jobs 408 steve, hope, apple, cash, now, dies, rt, tartan, via
HurricaneSandy
1672882 hurricane, #sandy, new, my, help, victims, out, via, york
Table 4.2: Normalized Top Terms
actually removing any salient information. Surprisingly, the data suggests that over 90%
of the terms in the Hurricane Sandy data set are singletons. Singletons are terms that
occur only once throughout the entire data set. This is very important information since
singletons provide no information that can be used to distinguish topics. If we remove the
singletons from the dataset we are left with about 168,000 terms in the vocabulary. This
is well within the estimated number of words in the English language and would seem to
correct the inconsistency we illustrated in the previous chapter.
4.5 Language Categorization
This research focuses only on clustering tweets in the English language. Therefore,
each tweet collected must be classified by language. Language categorization can be done
in many ways. One approach, called Text Categorization, or TextCat, uses n-gram based
frequency detection to determine how likely a string of terms is written in a given language
[7]. This approach builds upon Zipf’s law that the frequency of a word in a language is
inversely proportional to its rank in the language [45]. In [7], Canvar, proposes that when
comparing documents of the same language they should both have similar n-gram frequency

34
distributions. The work goes further to establish a system where n-gram frequency profiles
are computed for document collections where the language is known. A frequency profile
calculated for a document where the language is not known and then compared to the
known profiles. The relationship with the lowest distance (using an ”out of place” measure)
is deemed the winning classification.
In other work, the TextCat framework is extended to categorize the language of
tweets. Given the short nature of tweets, research shows that the TextCat algorithm may not
perform as well as it would with more formal document collections. The work in [6] attempts
to overcome the observed performance deficiency of the traditional TextCat algorithm when
applied to tweet texts. In [6] information related to the tweets (links, mentions, other posts
by the same user, etc.) are used to improve the language categorization. The research
shows that even without the additional information (using n-gram frequency distribution
only) the algorithm correctly identifies Dutch, English, French, German and Spanish 90%
of the time or more. While the modifications to TextCat that [6] present would improve this
performance, a great deal of additional information must be collected including additional
detail about the author of the post. Most of the data collected in our research was only
the text of the tweets and did not include any additional information about the author or
historical posts by authors. Therefore the basic n-gram statistics approach was used for
language identification. Random samples of the labeled data indicate about a 90% success
in correctly identifying the language.
4.6 Summary
This chapter describes the challenges of working with Twitter data as well as steps
taken to prepare the data for clustering. One of the major challenges is simply the time it
takes to process the voluminous amount of data produced by Twitter. This challenge is ad-
dressed by processing Twitter data in parallel across an Apache Hadoop cluster. Steps taken
to pre-process the data include normalizing the text by removing re-tweets, mentions, stop
words, non-standard symbols, URLs and single character words. The final pre-processing
step involves converting the text to lower case characters in order to improve term match-

35
ing performance. The pre-processing steps prove to reduce the dimension of data to within
expected limits and suggest improved clustering performance.

CHAPTER 5
CLUSTERING TWEETS
5.1 Introduction
Clustering tweets seems to be a task similar to clustering any other document col-
lection. However, tweets di↵er significantly from more standard documents. As mentioned
previously, even the non-standard terminology creates a challenge in clustering. One might
argue that the most profound di↵erence in tweet clustering is the document length. Most
documents used in clustering are much longer than tweets. A single tweet is at most 140
characters and, as shown previously, only around 10 words. However, that single tweet
could represent a report for an entire event, a segment of a longer conversation or activity,
or even a nonsensical collection of symbols representing an emotion. One major question
in clustering tweets is how to di↵erentiate “documents” from tweets. If a single tweet is
treated as a document then the collection of documents could number in the millions. How-
ever [18, 19, 37] use a hybrid approach where single tweets at times are used as complete
documents and other times are used as contributors to a single document containing all the
tweets in the collection.
Clustering tweets requires several steps. This chapter covers each step taken to cluster
both the raw tweets as well as the pre-processed tweets (outlined in Chapter 4). The
clustering algorithm used will be covered first followed by discussion of some performance
improvements made to the basic clustering algorithm. The next section covers the steps in
clustering including producing numeric feature vectors, estimating the number of clusters
and performing the clustering step. These sections are followed by some results of the
clustering and a summary.
5.2 K-Means Clustering
One of the most commonly used clustering algorithms is known as the “K-Means”
clustering algorithm. This approach to clustering dates back to the late 1960s [24] as a way

37
to partition data into K sets within a given population. The algorithm assigns K random
points from the popluation as cluster centers. Once the centers have been chosen, every
point in the dataset is assigned to the closest center in order to form a cluster. Once all
points have been assigned to a cluster, the mean point of every cluster is chosen as the new
cluster center. The process repeats by re-assigning every point to the nearest center (which,
presumably, has changed iteration to iteration) until convergence or some other threshold
(number of epochs for instance) has been reached. This procedure will generally converge
quickly with only a small number of iterations.
The K-Means clustering technique generally performs well. However, some research
has shown that improved performance can be achieved by carefully selecting the initial
cluster centers. Arthur and Vassilvitskii [1] assert that centers with the greatest distance
from each other will have a greater probability of producing correct clustering partitions
than simple random sampling of the points for initial centers. This process begins by
randomly choosing a single cluster center and then choosing the remainingK clusters using a
cumulative probability distribution to determine the next center with the highest probability
of good performance. Once the initial centers are chosen, the algorithm proceeds as normal.
Using this “K-Means++” approach has shown to have lower convergence time and more
accurate classifying of datasets with outliers.
The K-Means algorithm has been used in much of the previous research in this area.
Chapter 2 covers clustering of texts and microblogs and much of that recent research has
used K-Means as the gold standard in clustering. For this reason, the K-Means algorithm,
specifically K-Means++ was used in all experiments.
5.3 Improving K-Means for Large Datasets
In the classic K-Means clustering solution each iteration of the algorithm must calcu-
late the distance from each input vector to each of the current centers. The distance can be
computed in any number of ways including Euclidean distance, squared Euclidean distance
or cosine similarity. In each of these distance algorithms there is a dot product that must be
computed between the two vectors. This dot product consumes the most computing time

38
during the course of a single iteration of the K-Means algorithm. In our case, computing
the distances between about 8000 cluster centers and the 1.5M pre-processed input tweets
for the “Hurricane Sandy” dataset requires calculating more than 1.5 billion dot products.
In our reference implementation (single thread, no parallelization) each epoch for the “Hur-
ricane Sandy” dataset requires over 8 hours to complete and over 15 iterations to reach
convergence.
Since the gap statistic and stability approach both require starting at a low value
for K and increasing it until some stopping criteria is met, the classic K-Means algorithm
proves too slow for very large datasets. Research has been done in reducing the time a
given K-Means iteration requires. A similarity estimation is used in [11] which progressively
reduces the number of dot products required in each iteration of K-Means. This approach
stores upper bound information for each cluster in a table of d ⇥ k dimension where d
is the number of input documents (input vectors) and k is the number of clusters. This
approach works well with a relatively small number of clusters. However, the memory
demands for the upper bound matrix exceed realistic requirements for large datasets with
a very high number of clusters. For instance, the pre-processed “Hurricane Sandy” dataset
contains about 1.5M tweets. Emperical evidence suggests there are thousands of distinct
topics discussed in this dataset. If we set K = 5000 then our upper bound matrix would
require 1500000 ⇥ 5000 elements. If each element is 4 bytes (the width of the double type
on a 64 bit architecture) then more than 28GB of memory would be required to store the
upper bound matrix. Current high end workstations and typical servers would be able to
accomodate this requirement, but given that the dataset itself is only about 130MB these
memory requirements are excessive. In fact, our Java reference design was not even able
to allocate the memory required for the “Hurricane Sandy” upper bound matrix. While
the algorithm could be modified to support swapping the upper bound matrix in and out
of disk, the act of swapping to and from disk is expensive, do to IO limits, and would be
required almost constantly due to the nature of the algorithm.
Although the upper bound matrix and approach used in [11] prove too resource in-
tensive for our experiments, one observation the authors made is very useful. Dhillon et
al. [11] note that as clustering continues the number of points and centers in the solution

39
Figure 5.1: Number of Dot Products Computed
progressively decrease. Although the estimation approach of the paper was not used in
our research we were able to use this observation to make a performance improvement.
Rather than computing the distance between each input vector and each of K centers on
each iteration of the algorithm, we only compute the distances between the cluster centers
that changed the previous iteration. Figure 5.1 displays the number of dot products com-
puted per iteration for the “Hurricane Sandy” dataset clustering into 9636 clusters. The
figure compares dot products when computing for all centers versus only those centers that
changed in the previous iteration. The results show that there is a dramatic drop o↵ in
computations required as the solution approaches convergence. Using this approach, the
reference implementation was updated and the iteration completion time was improved by
an average of 3 hours (for the “Hurricane Sandy” dataset).
5.4 Feature Vectors
Many clustering algorithms, including the K-Means algorithm used in this research,
perform clustering using numeric similarity measures. Common similarity measures include

40
Euclidean distance, squared Euclidean distance, cosine similarity and Manhattan distance.
In document clustering the dimension label is typically a word or term observed one or more
times throughout a given document collection and the magnitude is the number of times
that word is observed within a single document.
Two approaches are taken when generating feature vectors for this research. The
first simply counts terms and records their counts as vectors. Each tweet represents a
single vector and that vector would contain the word/term counts for the associated tweet.
These vectors rarely have values other than “0” or “1” as very few tweets repeat terms.
Additionally, the vectors are extremely sparse with 99% of the values having zero length.
The second approach to producing vectors is to take the simple vectors from the first
approach and apply the hybrid TF-IDF weighting algorithm to the values. The hybrid TF-
IDF algorithm is described in [18, 19, 37]. The hybrid TF-IDF vectors are also extremely
sparse, but their non-zero values are distributed between zero and 1.
Each of the two approaches to creating document feature vectors utilize sparse data
structures where only non-zero values are stored. Subsequently, geometric computations,
such as Euclidean distance, can be performed faster as only a computation on the union of
the sets of labels between two feature vectors is required for each distance.
5.5 Estimating the Number of Clusters
Once feature vectors have been computed, a suitable value for the number of clusters
must be chosen. This step can be very error prone and di�cult since the goal is to cluster
into common clusters without any knowledge of the structure of the tweet corpora. One
approach to choosing the value for K is to simply guess an appropriate number. In some
cases, datasets for a specific area of study may frequently be structured into similar numbers
of clusters. Inouye and Kalita [19] assert that observation indicates that their small Twitter
datasets (collected by keyword) fall into 4 clusters. However, the authors note that future
research should include dynamically chosen a good value for K.
Much research has been done on automatically determining the optimal number of
clusters in some dataset. In [40] intra cluster dispersion is computed for increasing values

41
of k. This “gap statistic” will fall once the optimal number of clusters is reached. Once the
optimal number of clusters has been surpassed the gap statistic falls o↵ notably. The process
for computing the gap statistic for a given clustering of k clusters is by first computing
the pooled within-cluster sum of squares for all clusters (equations 5.1 and 5.2) and then
computing the same metric for a set of computed reference data sets. The gap statistic is
then computed (equation 5.3) from the di↵erence of the logs of both values. The average
using all reference datasets is used as the final metric. As K slowly increments from a
starting value of 2, the gap statistic will generally go up until the optimal number of clusters
is reached. Once the gap statistic drops below the previous gap (considering the standard
deviation of the result set) then the optimal number of clusters has been found.
Dr =X
i,i02Cr
dii0 (5.1)
Let Dr be the sum of all pairwise distances in cluster r
Wk =kX
r=1
1
2nrDr (5.2)
Wk is the pooled within-cluster sum of squares where nr is the size of cluster r
Gap(k) =1
B
X
b
log(W ⇤kb)� log(Wk) (5.3)
Where W
⇤kb is the within-cluster sum of squares for reference set b.
The gap statistic was tested for this research and appears to perform well. However,
the gap statistic’s requirement for random datasets requires significant computation and
thus can take a long time to find a solution. The gap statistic uses a randomly generated
null dataset that requires significant computation time for the extremely large cardinality of
the tweet vectors. Repeated experimentation has shown that the gap statistic will produce
similar results on random datasets produced from a subset of the input. Figure 5.2 displays
the results of varying the reference dataset size at 10% intervals of the input dataset size.
Each reference size was clustered 100 times using the gap statistic method. These results
were then graphed into the histograms in Figure 5.2. The overwhelming result is K =

42
Figure 5.2: Gap Statistic Results for “Cyber Attack” Dataset K=[2,20]
5 is picked the marjority of the time regardless of the size of the reference distribution.
Therefore, in most cases the our gap statistic experiments used a null dataset smaller than
the input data set. For the smaller “Cyber Attack” and “Steve Jobs” datasets we chose a
reference size 20% smaller than the input dataset.
A stability measurement was was used to estimate the number of clusters in [2]. The
stability approach compares clusterings from many subsets of the dataset. Stability of the
clusterings is determined by comparing the number of similarities between clusters in two
clusterings. The best value for k is reached when the stability of the clusterings falls.
The stability based approach to finding K is a relatively straightforward procedure.
The algorithm involves repeatedly sampling the input dataset into pairs of subsets. The
subsets are then clustered over a range of values for K. After each iteration completes,

43
Figure 5.3: Stability Measure for “Cyber Attack” Dataset K=[11,18]
Figure 5.4: Stability Measure for “Cyber Attack” Dataset K=[2,10]

44
Figure 5.5: Stability Measure for “Steve Jobs” Dataset K=[2,10]
a similarity measurement is computed between the common subset pairs. The value of
K which has the most subsets with the highest similarity is chosen as the best K. The
similarity between clusterings can be computed in many ways. For example, the Jaccard
Coe�cient?? computes a similarity measurement between two sample sets. In order to
compute this similarity measurement, two samples of the input data must be extracted.
Each sample is paritioned using normal K-Means clustering. These partitions (or labelings)
are referred to as L1 and L2. Equation 5.4 computes a matrix for each labeling representing
the number of points in common clusters. Once these matrices are computed, the Jaccard
coe�cient can be computed using Equations 5.5 and 5.6.
Ci,j =
8>><
>>:
1 if xi and xj belong to the same cluster and i 6= j,
0 if xi and xj belong to di↵erent clusters
(5.4)
Let Ci,j be a matrix with values of 1.0 where two points are in the same cluser and 0.0
where they are in di↵erent clusters.

45
Figure 5.6: Stability Measure for “Steve Jobs” Dataset K=[11,18]
hL1, L2i =X
i,j
C
(1)i,j C
(2)i,j (5.5)
Let hL1, L2i be the dot product where L1 and L2 represent the common points (intersection)
between the paritioning of two samples of the input data.
J(L1, L2) =hC(1)
, C
(2)ihC(1)
, C
(1)i+ hC(2), C
(2)i � hC(1), C
(2)i(5.6)
Figures 5.4 and 5.3 display the similarity measurements for clusterings of the “Cyber
Attack” dataset. In [2], Ben-Hur suggests that as the most stable value of K is approached
incrementally, then the similarity of all subset clusterings will approach 1.0. Once the best
K is reached, then the similarities will fall o↵. Figures 5.4 and 5.3 don’t show the behavior
expected from the previous research. This is due to the high level of noise in the input data
causing very high dimensions and extremely sparse vectors.
Another example of the performance of the stability approach is shown in Figures 5.5
and 5.6. These results are for the dataset obtained shortly after the death of Steve Jobs.

46
Figure 5.7: Gap Statistic for “Cyber Attack” Dataset
Approach Cyber Attack Steve Jobs Hurricane Sandy
Dataset Size 568 364 1,503,287Gap Statistic 5 3 3Stability Based 2 2 N/A
Table 5.1: Estimated Number of Clusters
The algorithm chose K = 2 as the best number of clusters for the final solution. However,
as with the “Cyber Attack” dataset, the “Steve Jobs” dataset is also noisy and the stability
method doesn’t appear to be able to find structure. Both the “Steve Jobs” and “Cyber
Attack” datasets were used with only minimal processing. This included removing retweets
and stop words. However, the entire dictionary of terms in the datasets were used to create
the input vectors.
Table 5.1 displays the output of the gap statistic as well as the Stability algorithm for
3 of our collected datasets. The first two datasets (“Cyber Attack” and “Steve Jobs”) are
relatively small while the “Hurricane Sandy” dataset is significantly larger. Executing the

47
Topic Summary
1 Recent Cyber attack at Illinois water treatment plant2 Cyber attack simulation at U.K. banks3 Investigation of cyber attack against NASDAQ4 Cyber attack against Illinois water treatment plant is revenge for Stuxnet
Table 5.2: Topics in the “Cyber Attack” Dataset
algorithms on the smaller datasets completed in a very short period of time and appeared
to produce a reasonble value for the number of clusters. The “Hurricane Sandy” datasets,
however, took days to complete single executions of the Gap Statistic and produced highly
variable values forK. The number of clusters suggested by the Gap Statistic for the “Sandy”
dataset varied evenly between 2 and 10. Our expectation was that the number of clusters
in this dataset would be much larger due to the length of the dataset. Close examination
of the results indicate that the null sets cluster almost as well as the actual dataset. This
could be do to the very noisy (thus random looking) nature of the tweets.
The gap statistic was also tested against the minimally processed input tweets using
the complete dictionary of terms. Like the stability based approach, the gap statistic
algorithm completed in a reasonable amount of time for the two smaller datasets but was
not able to complete at all using the much larger dataset. Figure 5.7 displays the relevant
data for the gap statistic execution on the “Cyber Attack” dataset. As expected, the
cluster dispersion for the random null set decreases as the value of K increases. Likewise,
the dispersion for the input dataset has several sharp increases, the first being at K = 5.
Using the method outlined in [40] the best K is at K = 5.
Observation of the underlying “Cyber Attack” dataset would indicate that K = 5 is a
reasonable value for K as there appear to be at least 4 distinct topics in the “Cyber Attack”
dataset. These topics are listed in Table 5.2. The vast majority of the tweets surround the
first topic. Since the description of the event is widely varying, it is presumed that several
of the clusters would be regarding the same main topic. In addition to K = 5 the dispersion
data suggests that good values for K coule be at K = 6, K = 10 or K = 13.

48
Figure 5.8: Gap Statistic for “Steve Jobs” Dataset
Figure 5.8 shows the results of the gap statistic algorithm on the “Steve Jobs” dataset.
There are also several noted increases in cluster dispersion, the chosen being at K = 6.
While the algorithm chose K = 6, the dispersion data would seem to indicate the best K
being at K = 9. An observation of the tweets, such as that done for the “Cyber Attack”
data reveals that almost all the tweets are about the main topic (the death of Apple founder
Steve Jobs) but that each tweet is very distinct from the others. Most are tributes with
links to articles and pictures while others are comments about other recent notable deaths.
Given the vast array of comments it is much more di�cult to come up with short summaries
of the main topics. This may be an indicator for the two sharp changes in dispersion over
K.
Both the gap statistic and the stability approach appear to be viable solutions to
finding the clustering structure in sets of tweets. However, in the small problems the gap
statistic appears to supply much more accurate estimates compared to the observed struc-
ture of the data. Also, both approaches to finding K appear to produce sub-optimal results
for the “Hurricane Sandy” dataset. The next section will outline methods for reducing

49
the dimension of the clustering problem in order to increase the ability to find K for large
datasets.
5.6 Improving Performance by Reducing Dimension
One of the main di�culties in clustering tweets is the size of the input vectors produced
from the dataset. As discussed previously, the “Hurricane Sandy” dataset contains over 2
million distinct terms. If the entire set of terms was used to build bag-of-words vectors then
that would mean the geometric space for this problem would be over 2 million dimensions.
Clearly that would produce less than optimal results. The previous section outlined some
information on the gap statistic and stability approach for three Twitter datasets. The
results of those experiments was based on using the entire dataset dictionary to produce
vectors from the tweets.
Using every term in a corpus is clearly not feasible to produce good clustering results.
Therefore, the number of terms must be decreased to an acceptable level. Zipf’s law [45]
states that a term’s frequency in a text is inversly related to its rank in the same text. For
instance, the second most common word in a text would occur half as many times as the
first, the third would occur one third as many times as the second and so on. Further, Zipf’s
law utilizes a constant value to compute the probability distribution for a terms frequency
versus rank. Best fit algorithms can be used to tune the constant and should produce
similar constants for di↵erent samples of common datasets. For tweet data collected in this
research, the best fit line for plotted term frequencies generates a constant near 0.77. Zipf’s
law holds true for many document collections and can be used to determine the set of terms
that will most likely produce a good clustering.
Figures 5.9, 5.10 and 5.11 show term counts ordered by term rank as well as the
corresponding plot of Zipf’s law. Clearly, in every dataset, the importance of terms drops
significantly by rank. In fact, the Sandy dataset shows that after about the first 20 terms
the frequency drops below about 50,000. Since the dataset itself is nearly 4,000,000 this
shows that it would be possible to divide the dataset into subsets by removing the highest
ranking terms and then grouping the tweets by the remaining terms. Since the tweets

50
Figure 5.9: Zipf’s Law for “Cyber Attack” Dataset
Figure 5.10: Zipf’s Law for “Steve Jobs” Dataset

51
Figure 5.11: Zipf’s Law for “Hurricane Sandy” Dataset
themselves appear to be topics based around single operative terms, the highest ranking
term, typically, cannot discriminate tweets. In all of our collected datasets, the highest
frequency term appears in every tweet while the next highest term only appears in half
the tweets. This observation indicates that not the highest ranking term, but the second
highest ranking term is the discriminator for initial division of tweets into clusters.
These observations are clearly seen in the “Cyber Attack”, “Steve Jobs” and “Sandy”
datasets where the top ranking terms or phrases are “Cyber Attack”, “Steve Jobs” and
“Sandy,” respectively. Each of tweets in the datasets contains, at a minimum, the highest
ranking term. Since our goal is to cluster into sub-topics, we can no longer rely on the
terms “Cyber Attack”, “Steve Jobs” and “Sandy” in their respective datasets.
5.7 Summary
In this chapter the approach to actually clustering the tweets has been reviewed.
The K-Means clustering algorithm is considered the gold standard in clustering algorithms.
The algorithm generally converges in a relatively low number of iterations and is easy to

52
implement and distribute across map reduce frameworks. This lends itself well to clustering
large datasets due to the ability to increase computational capability by simply adding
cheap commodity hardware. The K-Means algorithm will simply remap input vectors to
centers and then recompute the centers by finding the mean of the cluster. This continues
until the solution converges or some other threshold (minimal computed distance change,
etc.) is reached.
The K-Means algorithm uses geometric input vectors and this produces a challenge
with respect to document clustering. Numeric vectors mush be derived from the bag of
words that represent each tweet. In our case, the numeric vectors are simply the term
counts for each term in each tweet. Therefore a tweet of 10 distinct terms will produce a
vector with 10 slots having a value of 1.0 and the remaining slots (for whatever dimension
the document set is) will be 0. Since the vectors are so sparse they are represented as
hashes containing only the non-zero values. This conserves space (memory or disk) as well
as reduces the computational time during the distance measurement since only the non-zero
values need to be examined.
Now that feature vectors and performance measurements have been established, the
best number for K must be chosen. In many cases of clustering the value for K is guessed
based on some fore-knowledge of the data. However, in the case of our tweets, we have
no idea how many subtopics, or clusters, are contained in these datasets. Therefore, an
automated way of checking for the best K is performed. Both the gap statstic and the sta-
bility approach are used to determine the best value for K. The results of these algorithms
produces similar values, but not exactly the same. It is noted that for the large “Sandy”
dataset that neither approach ever converged even though the algorithms were allowed to
run for a significant period of time.
The results so far indicate that the clusterings are not necessarily ideal. Especially
given the fact that the large “Sandy” dataset clustering never converges. Zipf’s law indicates
that term frequency diminishes inversely based on rank of the term. Using this observation
as well as the evidence supporting this in the tweets themselves, we determine that for
the large “Sandy” dataset the tweets can be subdivided by simply removing the very high
frequency, yet low importance terms.

CHAPTER 6
RESULTS
6.1 Introduction
The previous chapters have covered all aspects taken to capture tweets, process them,
convert them to clusterable entities, attempt to find the number of clusters in the data as
well as producing the final clusters of tweets. This chapter will attempt to objectively
examine the performance of the process described as well as compare the performance to an
alternate approach of grouping common tweets. The alternate approach is not a clustering
algorithm. However, the results of both K-Means clustering as well as the altnerate approach
will be compared with two common performance measurements.
This chapter will outline the statistical approach used to group tweets, followed by
a description of the Dunn index and the Davies Bouldin index used to compare the re-
sults between K-Means clustering and the statistical approach. Finally the results of our
experiments will be compared using both methods.
6.2 Alternate Approach to Clustering
An alternate approach to clustering was used as a comparison for cluster performance.
Previous observations indicate that terms rarely repeat in a single tweet. Using Zipf’s law,
it would seem that the second most common term in a Twitter dataset would only occur
in half the tweets in the set. The alternate approach uses this observation and will group
tweets by having the second most common term or not having the second most common
term. The subsets created from this step are then fed back into the algorithm and split
again using the same logic. The step by step process established in this research follows:

54
Algorithm 1 The Zipfian Clustering Algorithm
1: clusters ()2: function process(tweets terms minTweets)3: oldTerms ()4: while |terms| > 0 and terms 6= oldTerms do5: retainedTweets tweets having terms[0]6: discardedTweets tweets not having terms[0]7: if |retainedTweets| > minTweets then8: if |discardedTweets| = 0 then9: terms ShiftLeft(terms, 1)
10: end if11: process(retainedTweets terms)12: else13: clusters[k] discardedTweets
14: k k + 115: end if16: if discardedTweets > minTweets and retainedTweets > minTweets then17: terms discardedTerms
18: else19: clusters[k] discardedTweets
20: k k + 121: terms ()22: end if23: end while24: end function
The basic function of algorithm 1 is to take a set of tweets and divide them into two
new distinct sets. Line 2 defines a function that takes a set of tweets to be divided, a set of
terms in the tweets (ordered by descending number of occurances) and a stopping threshold
that defines the minimum number of terms allowed to continue processing. Lines 5 through
22 will divide the tweets into two sets: the first set having the most common term and
the second set not having the most common term. If the set having the most common
term is larger than the stopping point, then the list of terms is shifted (poppping o↵ the
most common term) and the retained tweets are processed into two new groups using the
second most common term as the discriminator. The same process is used to divide the
“discarded” (those tweets not having the most common term). This process of dividing
groups of tweets by most common term continues until the stopping point is achieved. The
stopping point is the only tunable parameter in the process. For very large dataset a good

55
value for this parameter can be rather high. For this researc a valu of 100 was used for the
large datasets. For smaller datasets, a value near 40 or 50 appears to work best.
6.3 Measuring Cluster Performance
In order for us to test the results of our experiements, we must have an objective means
to measure the performance of the clusterings. Many performance measures have been used
to calculate the e↵ectiveness of a clustering including the Davies Bouldin Index [8] and the
Dunn Index [12]. Other work in the area of clustering tweets [4] has used the Dunn Index to
measure clustering performance. The Dunn Index is a simple algorithm that computes the
relationship between inter and intra cluster distances. Higher values indicate better cluster
separation and generally denser clusters. Lower values indicate lower cluster separation and
more sparse clusters.
The Dunn index is calculated by dividing the inter-cluster distance (equation 6.1
by the intra cluster distance 6.2) for all clusters and then choosing the minimum as the
metric (6.3). Many di↵erent approaches can be taken to compute both the inter and intra
cluster distances. Our approach finds the minimum inter-cluster distance by finding the
minimum distance between any two cluster centers. The intra cluster distance is computed
by iterating each point in each cluster and finding the greatest distance separating points
in the same cluster. In all instances, the squared euclidean distance measurement was used
for both clustering the data as well as measuring the Dunn index.
Dij =q|Ai �Aj |2 (6.1)
The Euclidean distance between cluster centers for cluster i and j
D
0ij =
p|Xij �Ai|2 (6.2)
This is the Euclidean distance between a vector Xij in cluster i and the center Ai of cluster
i.

56
min
✓D
0ij
maxDij
◆(6.3)
For all clusters where i 6= j
We will also compare results using the Davies Bouldin index. The Davies Bouldin
index [8] produces lower values for better clusterings. The index is an average of the
relationship between cluster dispersion (equation 6.4) and inter-cluster distance (equation
6.5). The cluster dispersion is calculated as the standard deviation of a given cluster’s points
from its center while the inter cluster distance is simply the Euclidean distance between a
given cluster’s center and any other given cluster’s center (equation 6.5). The index is then
computed as the average of the maximum values of these relationships (equations 6.6 and
6.7).
Si =
⇢1
Ti
TiX
j=1
|Xj �Ai|2� 1
2
(6.4)
Where Ti is the size of cluster i, Xj is a vector in cluster i and Ai is the center of cluster i.
Mij = ||ai � aj ||2 (6.5)
Where ai is the center of cluster i and aj is the center of cluster j and i 6= j.
Rij =Si + Sj
Mij(6.6)
R =1
N
NX
i=1
maxRi (6.7)
For our alternate approach, we simply allow the algorithm to complete, then convert
the computed clustered points to vectors (decribed in earlier chapters) and then calculate
the Dunn and Davies Bouldin indices.

57
Dataset Number of Clusters Dunn Index Davies-Bouldin Index
Hurricane Sandy 3 1.80958 0
Cyber Attack 5 0.9422 1.6969
Steve Jobs 4 1.3188 2.2441
Lucy 4 1.0749 1.8220
Silver Line 6 0.8706 1.9737
Sharifi 2 1.6180 2.1563
Table 6.1: Gap Statistic Results (All Terms)
6.4 Results
Our underlying hypothesis in this research is that K-Means clustering will not produce
good clusters for tweets due to the short length of the texts as well as the very noisy nature.
For control datasets we followed two keywords for a short period of time and sanitized the
results. The first, “Lucy” was followed on the day of a new movie release of the same name.
The second control dataset followed the key phrase “Silver Line” where most tweets were
about the opening of the new Metrorail Silver Line in the Washington D.C. area. Each
of these control datasets were hand sanitized to remove abbreviations, emoticons and to
normalize the grammar. The “Lucy” dataset contains 114 tweets while the “Silver Line”
dataset contains 87 tweets. Removing the noise from the datasets (symbols, non-standard
grammar, abbreviations, URLs, etc) mitigates part of the problem stated in our hypothesis
leaving only the short length of the tweets as contributing to the poor performance of K-
Means. In addition to the three test datasets and two control datasets we also used the
dataset from [36, 37] which includes about 3000 tweets across 50 topics This dataset is
referred to as simply the “Sharifi” dataset.
Several surprising results were uncovered during this research. Tables 6.1 through
6.4 display the results of the various experiments. The gap statistic appeared to produce a
reasonable number of clusters for the smaller datasets. However, it did not compute values
near our expectation for the “Sandy” dataset. It also required an extensive amount of time

58
Dataset Number of Clusters Dunn Index Davies-Bouldin Index
Hurricane Sandy 5 1.7406 2.0710
Cyber Attack 4 0.9251 1.5367
Steve Jobs 3 1.3977 1.8218
Lucy 5 1.0329 1.9094
Silver Line 7 0.8751 1.9105
Sharifi 5 0.7179 1.8796
Table 6.2: Gap Statistics Results (Top 100 Terms)
to find a solution for the “Sandy” dataset, sometimes taking over a day to complete a single
solution.
In each of the experiments, the results of the Gap Statistic were used to cluster the
data 100 times. The Gap Statistic algorithm was allowed to run 100 times for each dataset
and the average value for K was used as the optimal number of clusters. Once K was
chosen, 100 executions of K-Means was executed for each dataset and the values for the
Dunn and Davies-Bouldin indices were averaged and displayed in the tables.
Table 6.1 displays the results of performing the Gap Statistic on the datasets using
every term in each dataset. One very interesting result is that the Gap Statistic overwhelm-
ingly chose K = 2 for the Sharifi dataset. Since that dataset was manual processed into 50
topical groupings, it was expected that the Gap Statistic would choose a much higher value
for K.
Table 6.2 displays the Gap Statistic approach on the same datasets only limiting the
number of terms used to build the vectors. The number of terms were limited to only
the top 100 terms. The previous chapter analyzed the vocabularies from the three focus
datasets. When examining the term frequency by rank, and comparing to a Zipf’s law plot,
the plot is nearly flat around term rank 100 in each of the three cases. This suggests that
the discrimanting power beyond those terms is negligible.
In some cases the vector model used in document clustering is composed of document
n-grams rather than document terms. The Zipf’s law curve shown in Figure ?? demonstrates

59
Figure 6.1: N-Gram Frequency for “Steve Jobs” Dataset
that the n-grams in our datasets appear to have much better discriminating power. When
using the raw terms, their frequency was near zero around the 100th term. The n-grams,
however, remain much higher frequency for term ranks between 800 and 1000. Other n-gram
frequency plots were very similar to the “Steve Job” dataset.
The n-gram frequencies were used to build document vectors and were re-clustered
to compare performance with raw terms. The top 800 n-grams were used in the first set of
clusters. As in the previous experiment, the clusterings were computed 100 times and the
average Dunn and Davies-Bouldin Indices were computed across all solutions. The results
are displayed in Table 6.3. Additionally, the documents were clustered using only the top
100 n-grams and those results are listed in Table 6.4.
Figures 6.2 and 6.3 display the results of the experiments side by side. The Dunn
index results seem to indicate that using the top 100 n-grams performs slightly better in
most cases. However, the Davies-Bouldin index for the same clusters indicates almost no
di↵erence in performance regardless of number of terms or n-grams used in clustering. Of
specific interest is performance of the top 100 n-grams for the “Cyber Attack” and “Lucy”

60
Dataset Number of Clusters Dunn Index Davies-Bouldin Index
Hurricane Sandy N/A N/A N/A
Cyber Attack 4 0.9627 1.5350
Steve Jobs 3 1.2538 2.1043
Lucy 8 0.7603 1.8418
Silver Line 5 1.2102 2.1760
Sharifi 3 1.3205 2.0303
Table 6.3: Gap Statistic Results (Top 800 N-Grams)
Dataset Number of Clusters Dunn Index Davies-Bouldin Index
Hurricane Sandy 0 0 0
Cyber Attack 4 0.6529 1.4948
Steve Jobs 3 2.0323 2.2670
Lucy 8 0.7481 1.8654
Silver Line 6 1.0976 2.0905
Sharifi 6 1.7629 2.2615
Table 6.4: Gap Statistic Results (Top 100 N-Grams)
datasets. Both of these datasets clustering performance was more than 30% worse with
the top 100 n-grams. Since the “Lucy” dataset was sanitized, that could explain why the
term performance was better than n-gram performance, but that doesn’t account for the
di↵erence in performance of the “Cyber Attack” dataset. Closer examination of the “Cyber
Attack” dictionary reveals that the top 14 n-grams are all bigrams. The “Steve Jobs” and
“Silver Line” datasets both have fewer bigrams in the top 10. This intuitively indicates
that the longer the n-gram the more discriminating it is in identifying clusters.

61
Figure 6.2: Dunn Index Results
Figure 6.3: Davies-Bouldin Index Results

62
6.5 Comparison to Alternate Approach
The previous section demonstrates that traditional mechanisms for finding the best
K appear to perform poorly with the Twitter data collected in this research. The alternate
approach uses a basic statistical analysis to count terms and split the datasets into binary
groups using a principle demonstrated in Zipf’s law. The Zipfian clustering algorithm
produced some number of grouped tweets for each dataset. This number was used to select
K for a K-Means clustering. Upon completion of the clustering, the Dunn and Davies-
Bouldin indices were computed for the K-Means results as well as the Zipfian clustering
results. Table 6.5 compares the results from the deterministic Zipfian clustering algorithm
as well as the results from K-Means clustering the tweets into the same number of clusters
as the Zipfian clustering. Figures 6.4 and 6.5 show the results visually.
The results are somewhat mixed. Using the Dunn index as a measure would seem to
indicate similar or better performance in all cases except in the “Steve Jobs” dataset. In
that case, the reference K-Means clustering performed 15% better than the Zipfian cluster-
ing algorithm. Examining the results using the Davies-Bouldin index also indicates mixed
performance. The “Cyber Attack” and “Steve Jobs” datasets show a slightly better perfor-
mance from the Zipfian clustering algorithm while the other three tests show a decidedly
better performance from the reference K-Means clustering. Regardless of the mixed results,
the computing time required for the Zipfian clustering is much better. The smaller datasets
were computed in less than a second using the Zipfian clutering algorithm, while taking sev-
eral seconds for clustering. The “Hurricane Sandy” reduction took only about 30 minutes
to complete where clustering the “Hurricane Sandy” dataset took several hours.
One interesting note is the value for K chosen by the Zipfian clustering algorithm.
Specifically in the “Sharifi” case, the dataset is composed of 50 distinct topics [36, 37] and
the Zipfian clustering algorithm chose 49 clusters. The computed value for K is very close
to the actual number of topics and performs much better, in that respect, than either the
Gap Statistic or Stability approach.

63
Dataset K D Dk DB DBk
Hurricane Sandy 10215 1.0000 N/A 2.0290 N/A
Cyber Attack 12 0.8515 1.5340 0.8928 1.6306
Steve Jobs 4 1.1215 2.1797 1.3214 2.5596
Lucy 2 2.4056 2.4374 2.0309 2.0930
Silver Line 2 2.9882 2.6868 1.5841 1.5470
Sharifi 49 0.9861 2.1578 0.7884 1.7827
K computed from the Zipfian clustering algorithmD Dunn IndexDk Dunn Index for K-Means clusteringDB Davies-Bouldin IndexDBk Davies-Bouldin Index for K-Means clustering
Table 6.5: Zipfian Clustering Results
Figure 6.4: Zipfian Clustering Results (Dunn Index)

64
Figure 6.5: Zipfian Clustering Results (Davies-Bouldin Index)
6.6 Conclusions
Traditional document clustering techniques appear to struggle with finding good solu-
tions with the tweet datasets used in this research. This is evident both in the performance
of the clusterings (using the Dunn index and Davies-Bouldin index as measurements) as
well as in the amount of processing time required for the algorithms to find a solution.
Additionally, the estimated values for K do not appear to accurately model the number of
topics or groups of similar tweets in the datasets.
The Zipfian clustering algorithm (a statistical based approach) requires significantly
less processing time and appears to produce equal or higher quality clusters and the results
seem to more accurately represent the number of topics in the datasets. The Dunn index
results support this assertion while the Davies-Bouldin results are mixed. In cases where no
solution could be found using traditional techniques, e.g. Gap Statistic on the “Hurricane
Sandy” dataset, the Zipfian clustering algorithm produced useable results in a reasonable

65
amount of time. Clearly, statistical approaches appear to work better than traditional
clustering for analyising tweets.

CHAPTER 7
CONCLUSIONS
7.1 Conclusions
Clustering tweets has proven to be a major challenge. Both the dimension of the
term vectors as well as their sparsity lead to high processing time as well as poor cluster
performance. These problems are improved only marginally when reducing datasets by
removing duplicate data as well as isolating by language. Clustering using K-Means requires
knowledge of the structure of the data a priori and this itself presents a challenge with very
large datasets. While some methods exist to automatically determine the best value for “K”,
these methods appear to fall short when applied to the short tweet texts. The statistical
based Zipfian clustering algorithm appears to quickly identify appropriate values for “K”,
but the grouped tweets aren’t necessarily in clusters that have better performance when
compared to “K-Means” using the same value for “K”. Through this research some topics
have emerged as possible improvements in solving the problem of clustering tweets. The
following section summarizes some of the areas of possible future research.
7.2 Future Work
One of the observations made throughout this research is that many tweets follow a
loose hierarchy. For instance, an initial tweet will be sent out. This tweet may gain notori-
ety due to various factors, but when it becomes popular many people begin to retweet the
original text. Each retweet is essentially a child of the original with some optional infor-
mation included (comments about the original tweet). The retweets can be subsuquently
retweeted and a simple hierarchy begins. Due to this basic structure, a hierarchical clus-
tering approach may work better than the aggolmerative K-Means approach taken here. In
some ways, this is the way the Zipfian clustering algorithm works. The root cluster contains
all tweets. Child clusters are then chosen using a binary selector based on presence of the

67
most occuring term. While the hierarchy isn’t based on retweets, it is arguably based on
topics.
Another approach that could improve clustering performance is one that adds ad-
ditional features to the tweets. Any tweets containing links to other pages could include
the content of those pages as part of the document vectors. Additionally, tools such as
Wikipedia1 or Wordnet2 could be used to provide additional document features. These
approaches should reduce the document vector sparsity as well as reduce the noise level.
Intuition also suggests that clusters of tweets occur in a common timer period as
well as a common geographic location. Including the date and time as well as originating
location in the document vectors could improve clustering performance. It seems that these
features would be more discriminating that simple terms, so a weighting mechanism should
be chosen in order to appropriately represent this importance.
Another area that might yield results is in using phrases rather than terms when
building the document vectors. In some cases, for instance “Hurrican Sandy”, the topic
of interest is more than one successive term. It may be useful to create document vectors
of phrases rather than terms, much in the same way as creating document vectors of n-
grams. This would slightly decrease the sparsity of the document vectors as well as provide
highly discriminating values in the document vectors. If the document vectors were further
processed using a technique similar to the hybrid TF-IDF [37] then the phrases could become
even more discriminating.
1http://http://www.wikipedia.org/2http://wordnet.princeton.edu/

REFERENCES
[1] David Arthur and Sergei Vassilvitskii. k-means++: the advantages of careful seeding.In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms,SODA ’07, pages 1027–1035, Philadelphia, PA, USA, 2007. Society for Industrial andApplied Mathematics.
[2] Asa Ben-Hur, Andre Elissee↵, and Isabelle Guyon. A stability based method for dis-covering structure in clustered data. Pacific Symposium on Biocomputing. PacificSymposium on Biocomputing, pages 6–17, 2002.
[3] Pavel Berkhin. Survey of clustering data mining techniques. Technical report, AccrueSoftware, Inc., 2002.
[4] Gary Beverungen and Jugal K. Kalita. Coherent summarization of twitter posts. FinalReport NSF REU, University of Colorado, Colorado Springs, 2011.
[5] Johan Bollen, Huina Mao, and Xiaojun Zeng. Twitter mood predicts the stock market.Journal of Computational Science, 2(1):1 – 8, 2011.
[6] Simon Carter, Wouter Weerkamp, and Manos Tsagkias. Microblog language identi-fication: overcoming the limitations of short, unedited and idiomatic text. LanguageResources and Evaluation, pages 1–21, 2012.
[7] William B. Cavnar and John M. Trenkle. N-gram-based text categorization. Ann ArborMI, 48113(2):161–175, 1994.
[8] David L. Davies and Donald W. Bouldin. A cluster separation measure. PatternAnalysis and Machine Intelligence, IEEE Transactions on, pages 224–227, 1979.
[9] Je↵rey Dean and Sanjay Ghemawat. Mapreduce: simplified data processing on largeclusters. Communications of the ACM, 51(1):107–113, 2008.
[10] Je↵rey Dean and Sanjay Ghemawat. Mapreduce: a flexible data processing tool. Com-mun. ACM, 53(1):72–77, jan 2010.
[11] Inderjit S. Dhillon, James Fan, and Yuqiang Guan. Data Mining for Scientific andEngineering Applications, chapter E�cient Clustering Of Very Large Document Col-lections, pages 357–381. Kluwer Academic Publishers, 2001.
[12] Joseph C. Dunn. A fuzzy relative of the isodata process and its use in detecting compactwell-separated clusters. Journal of Cybernetics, 1973.
[13] H. P. Edmundson. New methods in automatic extracting. J. ACM, 16:264–285, apr1969.
[14] H.S. Heaps. Information Retrieval: Computational and Theoretical Aspects. AcademicPress, Inc., Orlando, FL, USA, 1978.
[15] Marti A. Hearst. Multi-paragraph segmentation of expository text. In Proceedings ofthe 32nd annual meeting on Association for Computational Linguistics, ACL ’94, pages9–16, Stroudsburg, PA, USA, 1994. Association for Computational Linguistics.

69
[16] Xia Hu, Nan Sun, Chao Zhang, and Tat-Seng Chua. Exploiting internal and externalsemantics for the clustering of short texts using world knowledge. In Proceedings of the18th ACM conference on Information and knowledge management, CIKM ’09, pages919–928, New York, NY, USA, 2009. ACM.
[17] Giacomo Inches, Mark Carman, and Fabio Crestani. Statistics of online user-generatedshort documents. In Cathal Gurrin, Yulan He, Gabriella Kazai, Udo Kruschwitz,Suzanne Little, Thomas Roelleke, Stefan Ruger, and Keith van Rijsbergen, editors,Advances in Information Retrieval, volume 5993 of Lecture Notes in Computer Science,pages 649–652. Springer Berlin / Heidelberg, 2010.
[18] David Inouye. Multiple post microblog summarization. Research Final Report, jul2010.
[19] David Inouye and Jugal K. Kalita. Comparing twitter summarization algorithms formultiple post summaries. In IEEE International Conference on Social Computing,pages 298–306, oct 2011.
[20] Akshay Java, Xiaodan Song, Tim Finin, and Belle Tseng. Why we twitter: un-derstanding microblogging usage and communities. In Proceedings of the 9th We-bKDD and 1st SNA-KDD 2007 workshop on Web mining and social network analysis,WebKDD/SNA-KDD ’07, pages 56–65, New York, NY, USA, 2007. ACM.
[21] Max Kaufmann and Jugal K. Kalita. Syntactic normalization of Twitter messages. InProceedings of the 8th International Conference on Natural Language Processing (ICON2010), Chennai, India, 2010. Macmillan India.
[22] Rebecca Leung. http://www.cbsnews.com/stories/2003/05/05/60II/main552363.shtml.may 2003.
[23] Hans Peter Luhn. The automatic creation of literature abstracts. IBM Journal ofResearch and Development, 2(2):159 –165, Apr 1958.
[24] J. MacQueen. Some methods for classification and analysis of multivariate observa-tions. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics andProbability, Volume 2, pages 281–297. University of California Press, 1967.
[25] B. Mandelbrot. Information theory and psycholinguistics: A theory of word frequencies.In Readings in mathematical social sciences, pages 350–368. MIT Press, MA, USA,1966.
[26] Marie-Francine Moens and Stan Szpakowicz, editors. ROUGE: A Package for Auto-matic Evaluation of Summaries, Barcelona, Spain, jul 2004. Association for Computa-tional Linguistics.
[27] C.D. Paice. The automatic generation of literature abstracts: an approach based onthe identification of self-indicating phrases. In Proceedings of the 3rd annual ACMconference on Research and development in information retrieval, SIGIR ’80, pages172–191, Kent, UK, UK, 1981. Butterworth & Co.

70
[28] Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel J. Abadi, David J. DeWitt,Samuel Madden, and Michael Stonebraker. A comparison of approaches to large-scale data analysis. In Proceedings of the 35th SIGMOD international conference onManagement of data, pages 165–178. ACM, 2009.
[29] Jonathan B. Postel. Simple Mail Transfer Protocol. RFC 821 (Standard), Aug 1982.Obsoleted by RFC 2821 Apr 2001.
[30] Vahed Qazvinian and Dragomir R. Radev. Exploiting phase transition in latent net-works for clustering. In Proceedings of the Twenty-Fifth AAAI Conference on ArtificialIntelligence, pages 908–913, 2011.
[31] Don Sagolla. How twitter was born. http://www.140characters.com/2009/01/30/how-twitter-was-born/. jan 2009.
[32] Takeshi Sakaki, Makoto Okazaki, and Yutaka Matsuo. Earthquake shakes twitter users:real-time event detection by social sensors. In Proceedings of the 19th internationalconference on World wide web, WWW ’10, pages 851–860, New York, NY, USA, 2010.ACM.
[33] Gerard Salton. Automatic Information Organization and Retrieval. McGraw Hill, 1968.
[34] Gerard Salton. Recent studies in automatic text analysis and document retrieval. J.ACM, 20:258–278, Apr 1973.
[35] Gerard Salton and Michael J. McGill. Introduction to Modern Information Retrieval.McGraw-Hill, Inc., New York, NY, USA, 1986.
[36] Beaux Sharifi, Mark-Anthony Hutton, and Jugal K. Kalita. Automatic summarizationof twitter topics. In National Workshop on Design and Analysis of Algorithms 2010,pages 121–128, 2010.
[37] Beaux Sharifi, Mark-Anthony Hutton, and Jugal K. Kalita. Experiments in microblogsummarization. In Social Computing (SocialCom), 2010 IEEE Second InternationalConference on, pages 49 –56, Aug 2010.
[38] Beaux Sharifi, Mark-Anthony Hutton, and Jugal K. Kalita. Summarizing microblogsautomatically. In Human Language Technologies: The 2010 Annual Conference of theNorth American Chapter of the Association for Computational Linguistics, HLT ’10,pages 685–688, Stroudsburg, PA, USA, 2010. Association for Computational Linguis-tics.
[39] Andrew S. Tanenbaum. Modern operating systems, volume 2. prentice Hall New Jersey,1992.
[40] Robert Tibshirani, Guenther Walther, and Trevor Hastie. Estimating the number ofclusters in a dataset via the gap statistic. Journal of the Royal Statistical Society,Series B, 63:411–423, 2000.
[41] Andranik Tumasjan, Timm O. Sprenger, Philipp G. Sandne, and Isabell M. Welpe.Predicting elections with twitter: What 140 characters reveal about political sentiment.In Proceedings of the Fourth International AAAI Conference on Weblogs and SocialMedia, pages 178–185, May 2010.

71
[42] Ian H. Witten and Eibe Frank. Data Mining - Practical Machine Learning Tools andTechniques. Elsevier, 2005.
[43] Ying Zhao and George Karypis. Criterion functions for document clustering: Ex-periments and analysis. Technical report, University of Minnesota, Department ofComputer Science / Army HPC Research Center, 2002.
[44] Liang Zhou and Eduard Hovy. On the summarization of dynamically introduced in-formation: Online discussions and blogs. In AAAI Symposium on Computational Ap-proaches to Analysing Weblogs (AAAI-CAAW), pages 237–242, 2006.
[45] George K. Zipf. Human Behavior and the principle of least e↵ort. Addison-WesleyPress., Oxford, England, 1949.