Embed Size (px)
Citation preview

109
Using Agent Base Models to Optimize Large Scale Networkfor a Large System Inventories
Ramez Ahmed Shamseldin, Senior Design Engineer, Verizon Business and Shannon R Bowling,Assistant Professor, Old Dominion University
shamsrdinUv.hotmail.com and [email protected]
Abstract. The aim of this paper is to use Agent Base Models (ABM) to optimize large scale network handlingcapabilities for large system inventories and to implement strategies for the purpose of reducing capital expenses.The models used in this paper either use computational algorithms or procedure implementations de eloped byMatlab to simulate agent based models in a principal programming language and mathematical theory usingclusters, these clusters work as a high performance computational performance to run the program in parallelcomputational. In both cases, a model is defined as compilation of a set of structures and processes assumed tounderlie the behavior of a network system.
Introduction
The nature of digital networks. as described in [I] iscomprised of non-variable bandwidth channels thattransfer data. Furthermore. the growth of demand fortransmitted visual data has been abruptly increased tosatisfY customer needs, which resulted in thedevelopment of multi- ideo compression standards suchas MPEG-2 [2]. H.263 [3] and MPEG-4 [4].
In today's world. there are two kind of videotransmissions that have been established, one of themconsists of full transmission of stored packets of videofrom a server to the customer's premi es beforeplayback begins: the other is a concurrent transmissionwhich is under a certain restriction of quality of service(QoS) and serves as a real-time application.
The nodes in a network represent a video betweencustomers who requested the service to watch certainmovies. The selected video file is downloaded to thecustomer's computer site according to the systemrequested. It is also added to an inventory which can beallocated to several other sites in the future. Systemredundancy has been taken into account with regard tosystem needs for any overly excessive demands.
Agent-based models (ABM) are used in simulatingsocial life, not only to understand environmental changeand human role. but to be attractive to manypractitioners from a ariety of subject areas. Humanchanges can happen through space and on different timescales. Many ital opinions of ABM and simulations arethat numerous phenomena, even though system icomplexity, dynamically or both combined dynamicallycomplexity can be described as autonomous agents thatare relatively simple and follow certain rules forinteraction.
Computer models are used for interesting researchpractices and testing theories within certain disciplinestructures. The progression fundamentals of a real-worldstructure are difficult to be observed and collecting dataas well as controlling it under certain conditions isimpossible. Assumptions based on theories for thesestructures can be implemented in a computer model thatcan perform and compare to this practical data.
Mainly. models used in this conference either usecomputational algorithms or procedure implementationsdeveloped by agent based models in any principalprogramming language or mathematical theory tounderlie the behavior of a network system.
Literature Review
torage s stems occur in a variety of contexts, includingmanufacturing, warehousing, and the service sector.Most storage system do not deal with dynamiccomplexity because the are static and are usually in theform of physical warehouses. torage systems dealingwith materials can be either continuous or discretestorage. There are three major factors affecting storagesystems: depending on size of storage, storage methodsand layout of the storage system.
torage throughput has been used as a measurement todescribe the number of storage that can be retrieved pertime period storage/retrieval (SIR). From there the sizeof the storage system is powered by throughput and costparameters of transferring materials. Storage systemmission controls input/output (I/O) functionality that canbe determined by storage requirements is distributedcentrally over time.
The storage method contains specification of unit load.SIR and storage equipments; these methods can behandled by machine or by humans and can beautomatically launched by automatic guided ehicles.
The storage system layout. by using three dimensions height, length and width - can identifY the location ofstorage items. In this paper. the system layout controlother storage parameters throughput and storage methodwill be di cussed and five different storage systemlayouts will help to understand what the differences arebetween these physically traditional storage types andvirtual layouts for our case scenario.
Dedicated Storage Location
Every SKU (Stock Keeping Unit) is related to items in awarehouse and has a unique storage dedicated to it islocation. Dedicated storage is characterized by the
https://ntrs.nasa.gov/search.jsp?R=20100012883 2020-05-18T02:24:15+00:00Z

110
assignment of fixed storage locations for the itemsstored in the warehouse [5]. For items to be allocated asmeasured unites used in the warehouse, they areassigned the cube per order index (COl).
In such cases, the more popular items have to be nearthe I/O point in the warehouse for reduction in traveltime and travel distance according to the SIR. As anexample, active items have to be placed in the mostconvenient and accessible place; this minimizes costeffectiveness and gets item to I/O points.
Randomized Storage Location
The items in the storage warehouse are stored randomlyin any available storage location. For an example, whenthe inbound load arrives for drop off, the item in theclosest available slot is designated. This is known asfirst-in and first-out.
This is common in the case of randomized storageresults when less storage space occurs. Having smallsized parts stored in a space designed for large size partswastes storage space, and for the same scenario, storinglarge parts to fit randomly can be impossible, soadjustable shelves may need to be used.
In randomized storage it is assumed each item of acertain product is equally likely to be recovered whenmUltiple storage locations exist for the product, and therecovery operation is achieved. In the case where thewarehouse is pretty full, the travel distances aresignificantly of the same "equal likelihood" [6].
Class-Based Dedicated Storage
Class based storage is defined as a grouped of SKUs inone class. These classes are assigned to a dedicatedstorage spot, at the same time; these SKUs within anindividual class are stored randomly and in a logicalsequence.
The products are distributed according to their demandrates, among the number of classes and have a reserveda region within the storage area for each class.Accordingly, an incoming load is stored at an arbitraryavailable location for the same class.
We must look to the randomized storage location as asingle class case of class-based storage policy wherededicated storage is counted as one class for each item.
In addition, the dedicated storage policy attempts toreduce travel times for SN (storage/retrieval) by sortingthe highest demand to the I/O point as well for classbased storage and calculate the product demand by COl[7].
Continuous Warehouse Storage
Increasing demand for continuous recording of hundredsof millions data daily, a necessary storage media shouldhave the capability to handle data volumes and dataflow rates.
These types of data could be called detailed records(CDRs) which are commonly used by thetelecommunication industry - at an individual basis for
each customer. Software applications have been used topose several challenges related to data volumes and dataflow rates to data warehouses and to online analyticalprocessing (OLAP).
Shared Storage
Shared storage is widely used within the computernetworking industry and addresses the needs ofcorporate computing environments for storage systemsthat propose scalability, availability and flexibility.
Storage systems are known as storage computer systems(hosts) and are connected to multiple individual hostswhile using the shared storage by these hosts and aremanaged independently and historically viewed (hostattached storage).
Shared storage systems enabled by networkingtechnology can provide high bandwidth. In turn, it offersseveral benefits for today's businesses, for example byimproving quality of service (QoS) and increasingoperational efficiency.
Moreover, as growing needs for shares (files, data, etc.)become necessary, it is necessary to prevent buyingmainframe computer complexes and computer clusterswhere a modest number of cooperating computersystems share a common set of storage devices.
As computing environments have grown in industry,computer storage systems have grown in storage sizeand in number as the cost of equipment becomes morereasonable in order to increase the computingenvironments.
The main disadvantage is that the known computerstorage systems processors have failed and replacementparts can be required to get the system back for fulloperation which wastes time and is followed by atypically propagation delay of the restoration of thedata.
Virtual Warehousing
As a physical location is not necessary to locate specificdata content, data can be located within many virtualstorage hosts. If a customer is looking for specific datato download, random locations can be used withoutspecification and taking into account how manylocations have been used.
The storage locations mentioned above, such asdedicated, randomized and class-based storage, can beused to benefit virtual storage warehouses with priority,size and rates of transferring data. On other hand,desired locations for data can be easily trackcd andassigned to scale from the highest to the least highactivities according to their demand.
At the same time, randomized storage results in areduction in space and will be significant with regard todata travel time much less so than those traveling from adedicated storage area.
Also, using other large-scale (shared) storagetechniques, such as Internet, without specifYing certainhosts is not problematic because data is already restored

111
within different hosts. Finally continuous warehouse storage techniques use network capability and add more data to different new hosts entering to networks as well using existing hosts.
Network and Complexity
The internet-wide system is viewed as a large scale structure with an underlying physical connectivity that deploys real experimental studies to evaluate system architectures, however this is not possible. Instead, a randomly generated network connectivity structure is used and has been accepted at the beginning as a node degree distribution technique. A generator - also known as a software based solution - is used to generate network nodes which represent network autonomous systems (AS), original power laws and connectivity to the Internet.
The studies were then used to randomly generate networked topologies and provide precise analyses that show network modeling include [8]:
• Regular topology, such as liner, rings, trees, and stars;
• Well recognized topology, such as ARPANET or the NSFNET backbone;
• Arbitrarily generated topologies.
According to [9] when any two nodes have a relation, one link will be added with a probability depending on the distance between them given by:
-d(u v) p(u, v) = fJ exp ,
La
Where d(u, v) is a distance from u to v; L is the
maximum distance between two nods, a > 0 and f3 ~ 1 . However, this method does not obligate a large
scale structure.
Albert et al [10] describe a system's components for a network as a complex system because of its functionality and attribute is largely to redundancy node connections. A large scale network consists of a complex communication network (CCN) along with groups of telecommunication carriers and ISPs (Internet Service Providers). It is almost impossible to analyze the infrastructure but this can be done within the limited boundaries of individual networks [11].
The redundancy of network connectivity, in other words scale-free network connections, represents an unpredicted degree of robustness for eaeh kind of system, such as the internet, social networks or cellular (metabolic) networks. Network nodes break when faced with an extremely broken down communication rate.
Agent Based Models (ABM)
Agent based model methodology has been applied to several studies, for example, social dynamics and communication and cooperation under ecological risk [12]; complexity in artificial life applications [13]; common dilemmas for ecological economics [14];
language evaluation [15]; armed forces contradictions [16]; and human social interaction interpolating with regeneration management [17].
Huigen [18] anticipates an ABM structure, called MameLuke, which will study human environment interaction. For like structures agents are categorized according to user definitions and determinations from the objective's study, meaning that individual agent sets can fit into multiple non-divergence categories. Potential option paths (POPs) are rule-based implementation through decision making, which depends on the agent's category.
ABM was significantly used in a spatial interest group within computational mathematical organization theory (CMOT). Today, on the other hand, simulations using ABM have expanded further than the original boundaries of use and have linked up with groups of people and cover work in a variety of different disciplines such as economics, biology, sociology, artificial intelligence, physics, computer science, archaeology and anthropology.
In the last few years, growth of ABM has bcen significant realized especially after releasing more helpful software toolkits. This was enough to attract many practitioners from different fields to simulate numerous subject areas. Some of the better known toolkits are Swarm, Repast, AnyLogic, MASON, Ascape and NetLogo.
Gilbert et al. [19] express an example of using ABM in the artificial intelligent field for developing cellular automata. At the time, Swarm, introduced in 1996, was the only agent based modeling simulation tool available [20].
The primary characteristic of an agent is the potential to make decisions on individual bases. On the other hand, agents, in a true case, are discrete events handled individually with a set of attributes and policies that influence its actions and decision making capability. In addition, an agent may have supplementary policies that modify its policies or attributes. An agent can be purposely independent in its atmosphere and in its interactions with other agents as well itself if not over an imperfect scope of posts. An agent has objectives to accomplish (not optimize) as goal bound within its actions. Furthermore, an agent is flexible and has the ability to learn and adapt its performance over time based on ongoing skills, in other word, some form of memory.
Network Description and Functionality
The network that will be handled in this dissertation has a total of 250 nodes which represent the total number of customers carried by this network. These nodes are virtually connected by the internet and each address is recorded and knows the location of each customer. Each node in the network follows these assumptions:
• Each node is connected to the network and works online all year long with no bad connections.

112
• All nodes share the same bandwidth speed (uploading or downloading), and uploading bandwidth is half the speed of downloading bandwidth.
• The bandwidth speeds that will be used are limited to 128kb, Sl2kb, 1000kb, 2000kb and SOOOkb per second.
• Uploading bandwidth and downloading bandwidth are two different streams and separated at each node.
• All nodes are spread all over the internet and connect to a separate network that can be located physically anywhere with no adverse affects on location or distance.
• All nodes can download simultaneously from the server with no affect on delay or connectivity.
• Each node can be used as virtual storage and upload any necessary file needed by another node upon request and can only to do this one node at a time.
• Each node can be downloaded from the server or from another node according to these guidelines:
o Each node can download, at the maximum, from two locations and can be the server, the server and a single node or two nodes simultaneously.
o Only one file can be downloaded at a time.
o If the file exists in two virtual locations in network, the server will be exempt.
• All 2S0 nodes will be divided into five categories. Each category includes SO nodes selected randomly. These categories are Actions, Crime, Comedy, Drama and Romance.
• Each node has an internal storage device and is selected randomly from a set of sizes: SO, 100, ISO, 200, 2S0, 300, 3S0, 400, 4S0 or SOOGB.
Each node will be studied throughout the year and is equivalent to 8760 hours download time and is evaluated for how many files has been selected and downloaded as these files are selected according to each node's preferences.
Selected files will be chosen randomly and according to each node's preferences. These files have the following characteristics and assumptions:
• The network will handle files of different sizes having different time durations, and is limited to 10,000 files and all files can be downloaded from the server.
• The 10,000 files will be divided to five categories. Each category includes 2,000 files
ranked from the highest priority to the lowest according to the power law degree distribution $ P(k)\sim{k}"{y} $ with an exponent $ y $ range between 2 and 3. These categories are Actions, Crime, Comedy, Drama and Romance.
• The files can be downloaded from server, two nodes or a node and server at the same time by splitting the file's size to two batches - each batch contains half of the file.
• The file's batches will be downloaded either simultaneously by dividing the downstream bandwidth in half or downloading individually as the second batch will not start till the first one is completely downloaded.
• These files do not have expiration time but rather are replaceable inside the network's virtual storage which is located at the nodes. If the node's storage device reaches 7S\%, the files will be deleted according to the file's priority from low to high with the exception of the server. In this case, it will be remain stored as a reference for future requests.
All nodes will be able to download any files from a server at any time with no delay. All files are ranked according to its priority and stored in the server in the five different categories. Any node can search for any file across the entire network and download it in another in order to overcome network load and reach an optimum for the network.
Networks and Their Dynamic Complexity Purpose
Networks act as huge virtual storage warehouses that are dynamically changed over a period oftime. The address of the nodes will be constant, but a file's location will be changed from node to other node with time and determined priority.
The duration of this study is equivalent to 8760 hours over an entire year. This study will follow several procedures to highlight and identify the purposes of this research. In addition, it will also simulate the generated data not only to show the output results but to also understand how the network works with layers of dynamic changes as the files flow across the network.
A network's complexity is represented by nodes and a server that are interactively and laterally ordering files from the server, other neighbor nodes or both at the same time. Also, the simulation of each of these nodes requires further study. The criteria and procedure will follow:
• Gathering data of inter-arrival time which was observed for each node during the 8760 hours.
• Gathering information about what type of file category customers were interested in as well as how many files per node were accessed.
• Gathering information from where the files were downloaded by each node.
• Calculating the arrival time by each node.
113
IIlOIl
___._ --~ ~.
...~.....
.- ."I'm-J»JI1::a.rf'f'UIt
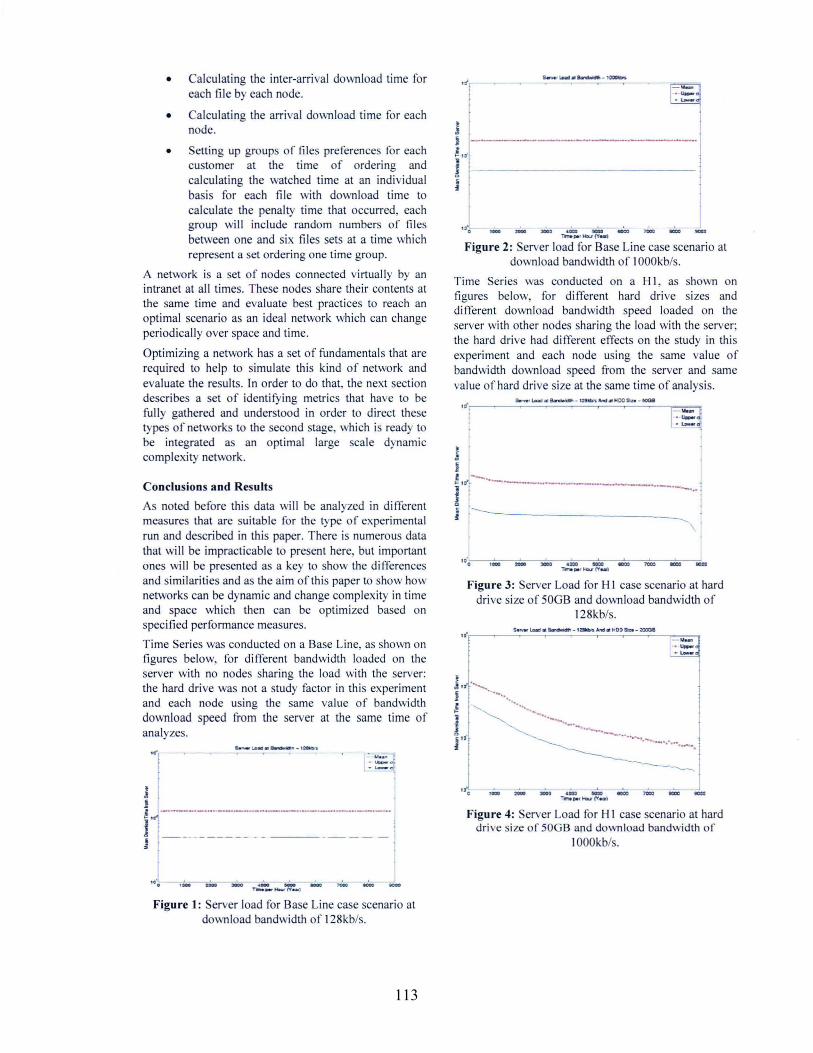
Figure 2: Server load for Ba e Line case scenario atdownload bandwidth of IOOOkb/s.
, 0
"•.~_~_.::;-:::..:::....~~.::....::...=-:;:-~'-=.:;:.....:.:~::.":::DD:,:-=..::..:-"""=.=.-'----"?'_'""'.......-...........
.t~__~_-=;::-='::""=;:'~'::"""-=;':':-"'::"'="''';,-·__---.-=o_~.-.<-'"
Figure 4: Ser er Load for H I case scenario at harddri e size of 50GB and download bandwidth of
IOOOkb/s.
Figure 3: Server Load for H I case scenario at harddrive size of 50GB and download bandwidth of
l28kb/s.
Time Series was conducted on a H I as shown onfigures below, for different hard drive sizes anddifferent download bandwidth speed loaded on theserver with other nodes sharing the load with the server;the hard drive had different effects on the study in thisexperiment and each node using the same value ofbandwidth download speed from the server and samevalue of hard drive size at the same time of analysis.
!!&l"r-.......··-·--_4.._ ..~ ...._. ..._.I i! :------------------" ~
iI ----.--..-.---.---.-.~ OIl'
I1
• Calculating the inter-arrival download time foreach file by each node.
• Calculating the arrival download time for eachnode.
• Setting up groups of files preferences for eachcustomer at the time of ordering andcalculating the watched time at an indi idualbasis for each file with download time tocalculate the penalty time that occurred, eachgroup will include random numbers of filesbetween one and six files sets at a time whichrepresent a set ordering one time group.
A network is a set of nodes connected virtually by anintranet at all times. These nodes share their contents atthe same time and evaluate best practices to reach anoptimal scenario as an ideal network which can changeperiodically over space and time.
Optimizing a network has a set of fundamentals that arerequired to help to simulate this kind of network andevaluate the results. In order to do that. the next sectiondescribes a set of identifying metrics that have to befully gathered and understood in order to direct thesetypes of networks to the second stage, which is ready tobe integrated as an optimal large scale dynamiccomplexity network.
Conclusions and Results
As noted before thi data will be analyzed in differentmeasures that are suitable for the type of experimentalrun and described in this paper. There is numerous datathat will be impracticable to present here, but importantones will be presented as a key to show the differencesand similarities and as the aim of this paper to how hownetworks can be dynamic and change complexity in timeand space which then can be optimized based onspecified performance measures.
Time Series was conducted on a Base Line. as shown onfigures below, for different bandwidth loaded on theserver with no nodes sharing the load with the server:the hard drive was not a study factor in this experimentand each node using the same value of bandwidthdownload speed from the server at the same time ofanalyzes.
"f"r--~__---:;-==""=.~::c"=-="''''-'----'.:'''''='-~---=~
,:=~1
i. -.-.- ..------.---.--!I -------1!
Figure 1; erver load for Base Line case scenario atdownload bandwidth of I28kb/s.
114
"I ,.-__~S_~::-~.="::"="':::,,:-I:::-=:;:'''-''':':.:':":::';:'SIn=-:.::''''''''=----,'*'''7.~
,.. ,.-__-=-=-=.:.:..=-=::.-:..:'''"''''=:.:.•;=....:.:..:.:''=DO:;.:.=U.~-:::.'''''''''=__;~_"'':'......i:'::''''!.....
Zegura, E.W. and Calvert, K.L. and Donahoo, MJ.(1997) "A Quantitative Comparison of Graph-BasedModels for {Internet} Topology," IEEElslash ACMTransactions on Networking, vol. 5, no. 6, pp. 770782 .
Bernard M. Waxman (1991) "Routing of multipointconnections," Broadband switching: architectures,protocols, design, and analysis, IEEE ComputerSociety Press, ISB = "0-8186-8926-9", LosAlamitos, CA, USA, pp. 347-352.
Albert, R. and Jeong, H. and Baraba i, A.L. (2000)"Error and attack tolerance of complex networks,"
ature, vol. 409, pp. 371-384.
Claffy, K. and Monk, T.E. and McROBB, D. (1999)"Internet Tomography, Nature:Http://www.narure.com/nature/webmaners/tomog/tomog.htrnl.
Andras, P. and Roberts, G. and Lazarus, J. (2003)"Environmental Risk, Cooperation, andCommunication Complexity, Adaptive Agents andMulti-Agent Systems, vol. 2636, pp. 49-65.
Menczer, F. and Belew, R. K. (1996) "From ComplexEnvironments to Complex Behavior ," AdaptiveBehavior, vol. 4, pp. 3-4.
II.
10.
12.
13.
9.
8.
.__._--~_ .._._-.......
..~...~~----- ....._---'.--..._~-.-......--.-... .............
---------
,·~'o!-----;;=-----;;=------.;;t;;;------:.;;; ;;;----.;_:..-......~---;;"""';;;;----.;;;;;-~nto. Htvf"l...
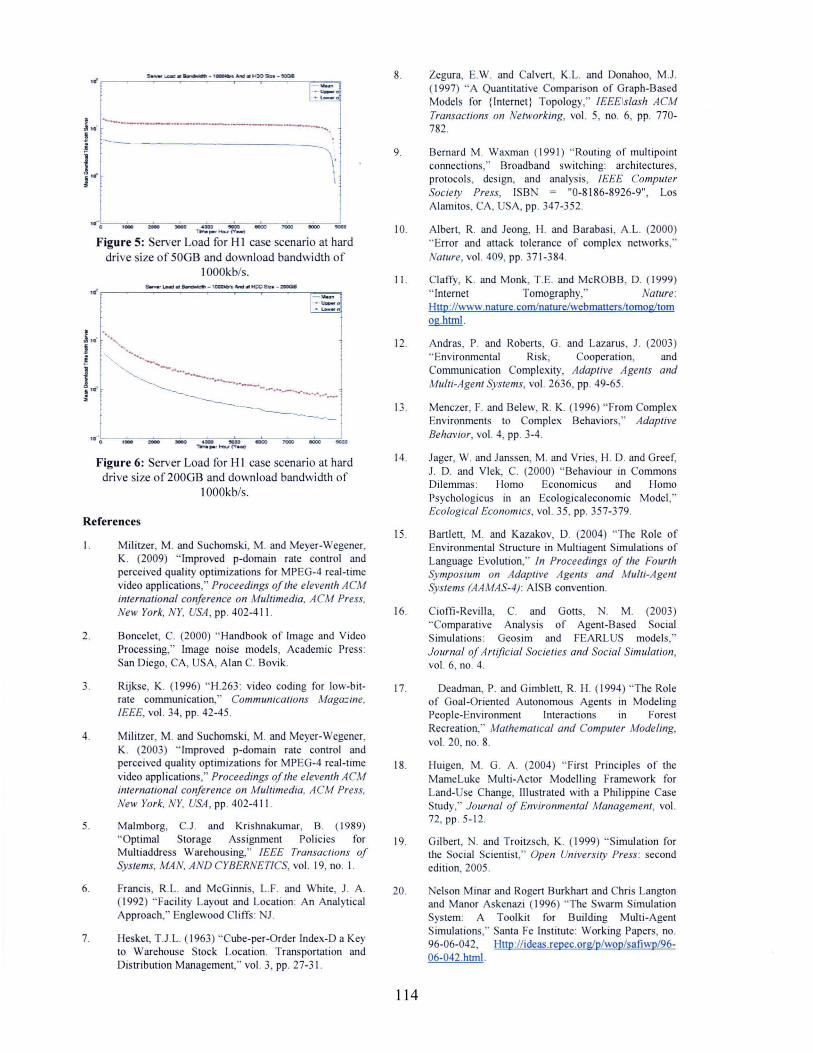
Figure 5: Server Load for H I case scenario at hard
drive size of 50GB and download bandwidth of1000kb/s.
J -._••• •••jUt'I __
~~
t~
I ..· ....I!
I~ .cf;
Figure 6: Server Load for HI case scenario at harddrive size of 200GB and download bandwidth of
IOOOkb/s.
References
14. Jager, W. and Janssen, M. and Vries, H. D. and Greef,J. D. and Vlek, C. (2000) "Behaviour in CommonsDilemmas: Homo Economicus and HomoPsychologicus in an Ecologicaleconomic Model,"Ecological Economics, vol. 35, pp. 357-379.
I.
2.
3.
4.
5.
6.
7.
Militzer, M. and Suchomski, M. and Meyer-Wegener,K. (2009) "Improved p-domain rate control andperceived quality optimizations for MPEG-4 real-timevideo applications, , Proceedings ofthe eleventh ACMinternational conference on Multimedia, ACM Press.New York, NY. USA, pp. 402-411.
Boncelet, C. (2000) "Handbook of Image and VideoProcessing," Image noise models, Academic Press:San Diego, CA, USA, Alan C. Bovik.
Rijkse, K. (1996) "H.263: video coding for low-bitrate communication," Communications Maga::ine.IEEE, vol. 34, pp. 42-45.
Militzer, M. and uchomski, M. and Meyer-Wegener,K. (2003) "Improved p-domain rate control andperceived quality optimizations for MPEG-4 real-timevideo applications," Proceedings ofthe eleventh ACMinternational conference on Multimedia. ACM Press,New York, NY. USA, pp. 402-411.
Malmborg, C.J. and Krishnakumar, B. (1989)"Optimal Storage Assignment Policies forMultiaddress Warehou ing," IEEE Transactions ofSystems, MAN, A D CYBERNETICS, vol. 19, no. I.
Francis, R.L. and McGinnis, L.F. and White, J. A.(1992) "Facility Layout and Location: An AnalyticalApproach," Englewood Cliffs: J.
Hesket, TJ.L. (1963) "Cube-per-Order I.ndex-D a Keyto Warehouse Stock Location. Transportation andDistribution Management," vol. 3, pp. 27-31.
15.
16.
17.
18.
19.
20
Bartlett, M. and Kazakov, D (2004) "The Role ofEnvironmental Structure in Multiagent imulations ofLanguage Evolution," In Proceedings of the FourthSymposium on Adaptive Agents and Multi-AgentSystems (AAMAS-4): AI B convention.
Cioffi-Revilla, C. and Gotts, M. (2003)"Comparative Analysis of Agent-Based SocialSimulations: Geosim and FEARLUS models,"Journal of ArtifiCial Societies and Social Simulation,vol. 6, no. 4.
Deadman, P. and Gimblett, R. H. (1994) "The Roleof Goal-Oriented Autonomous Agents in ModelingPeople-Environment I.nteractions in ForestRecreation," Mathematical and Compll/er Modeling,vol. 20, no. 8.
Huigen. M. G. A. (2004) "First Principles of theMameLuke Multi-Actor Modelling Framework forLand-Use Change, Illustrated with a Philippine CaseStudy," Journal of Environmental Management, vol.72, pp. 5-12.
Gilbert, . and Troitzsch, K. (1999) "Simulation forthe ocial Scientist," Open University Press: secondedition, 2005.
el on Minar and Rogert Burkhart and Chris Langtonand Manor Askenazi (1996) "The Swarm SimulationSystem: A Toolkit for Building Multi-AgentSimulations," Santa Fe Institute: Working Papers, no.96-06-042, Http://ideas.repec.org/p/wop/safiwp/9606-042.html.