Embed Size (px)
Citation preview

Uncertainty with Probabilities• There are several reasons to use a less formal
approach to uncertainty handling than the Bayesian probabilistic approach– the statistics used for the probabilities could be biased
• consider collecting data on patients with the flu, but only during the summer months
– we cannot assume independence of evidence and we cannot accumulate the statistics needed for 2|E| conditional probabilities • E being the set of evidence, so |E| is the number of elements in
that set– experts may feel more comfortable using a more
qualitative description of their beliefs– a chain of logic using probabilities results in very small
numbers because the probabilities are multiplied, but this is not reflective of how experts follow chains of logic

A Symbolic/Qualitative Approach• An expert will probably feel more comfortable
using terms like “likely”, “unlikely” and “ruled out” than using specific real values in [0, 1]
• A more symbolic vocabulary might be useful not only for the experts, but for the users– consider a 9 valued set of– confirmed, very likely, likely, somewhat likely,
neutral (don’t know), somewhat unlikely, unlikely, very unlikely, ruled out• these can be thought to correspond to values 1 (8/8), 7/8,
…, 1/8, 0 (0/8)
– since these terms are based on natural language, they are easy for anyone to apply

Feature Based Pattern Matching• Previously, we generated beliefs in our hypotheses
through– certainty factors which were provided to each rule– probabilities which were provided to every hypothesis and
combined using Bayes’ probability theory– fuzzy logic which were provided to every input and
propagated to conclusions using the fuzzy logic math derived by Zadeh
• In each case, the conditions of the rules represent features that we are seeking to justify the conclusion– a variant is to enumerate patterns of these conditions along
with the beliefs we might have if any single pattern matches– for instance, if we are seeking f1, f2, f3, f4, we might have
three patterns:• if T, T, T, T very likely (if all 4 features are present, conclude very
likely)• if T, ?, ?, T somewhat likely (? means don’t care)• if F, ?, ?, T neutral• else very unlikely

Deriving Patterns• For this to work, we first need to collect the “features of
interest” that help support a hypothesis– next, we need to enumerate the patterns by determining how
important each feature is– and whether it must absolutely be present or just helps add to the
conclusion– we may also include features that we expect not to be present to
help rule out our hypothesis– we can decrease the plausibility in our hypothesis if less critical
features are not present and provide a low plausibility if the critical features are absent• for instance, assume for hypothesis H1, the associated features are f1, f2
and f3 of which the first two are critical, and f4 which should not appear• If ?, ?, ?, T ruled out (if f4 is present, rule out H1)• If T, T, T, F confirmed• If T, T, ?, F very likely (f3 is not critical)• If T, ?, ?, ? neutral (one of two critical features is present gives us some
support but not enough)• If ?, T, ?, ? neutral (one of two critical features is present gives us some
support but not enough)

Hypothesis Matchers• Rather than building a knowledge-based system from
rules – as used in production systems, Bayesian probability systems
and Fuzzy Logic systems
• We collect the various hypotheses that are in the domain and for each one, we provide it a hypothesis matcher– a list of features to seek among the data, and a list of patterns– the hypothesis matcher, in seeking a feature, may ask the user,
may query a database, may ask another problem solver, or may call upon another hypothesis matcher
– based on the values returned, the hypothesis matcher generates a belief statement by working through the patterns until one matches
– we can provide a default response (an else clause) if no patterns match

Classification by Hypothesis Matching• One straight-forward implementation of a credit
assignment system is to– enumerate the domain in a taxonomic hierarchy where
each node represents a class/object in the domain– more specific classes/objects are children of more general
classes/objects• Use establish/refine– attempt to establish a given node as true (relevant) by
calling upon its hypothesis matcher– if the hypothesis matcher returns a high enough belief
value, accept that hypothesis as true and refine it by recursively attempting to establish each of its children
• This is like a rule based approach but the rules are captured inside of each hypothesis matcher and the structure of the hierarchy itself
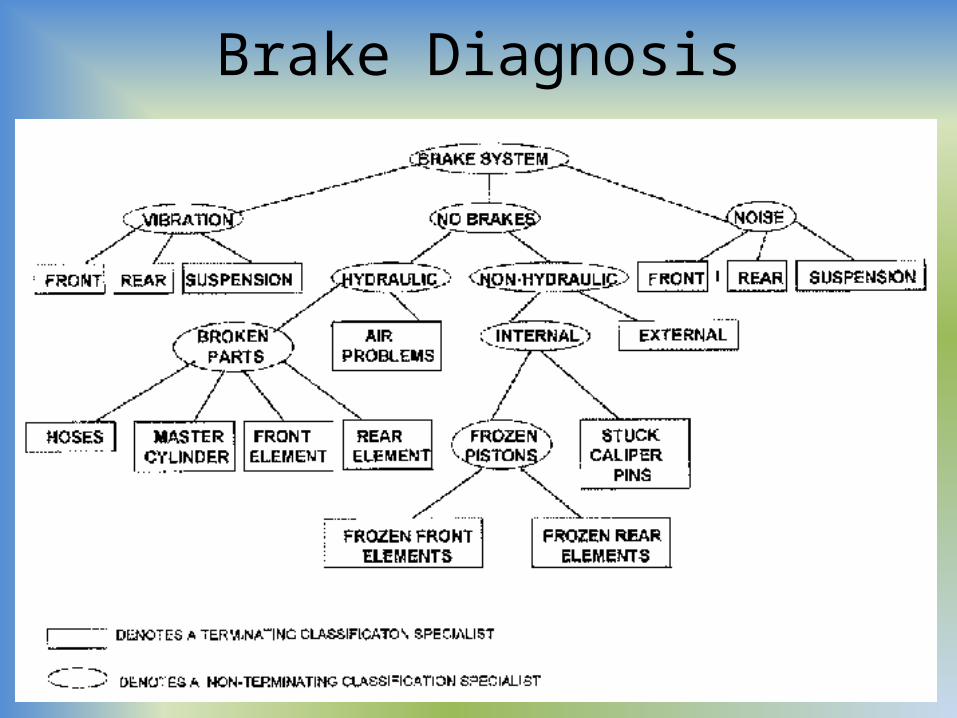
Brake Diagnosis

Syntactic Debugging by Classification• As an example, a syntactic debugging system can be developed using
classification– below is a partial hierarchy for the syntax errors generated in the
language Pascal– each error has a node high up in the hierarchy, whose children are
possible causes of the error, and each cause may itself be decomposed into more specific causes

Another Example• Here, we see the Unknown Identifier portion of the hierarchy elaborated
– the unknown identifier can be caused by • a misspelled reserved word or identifier• an identifier that was never declared• an identifier that was declared but is being used out of scope
• This is a trickier error to debug, what if we have – int x1, x2, x3;– … x1 = x2 * x4;– is x4 an undeclared identifier or a misspelled version of x3 (or x1 or x2)?

Example Hypothesis Matcher• From our previous excerpt of the hierarchy, we see that
the semicolon expected error can arise when a procedure call has the wrong number of parameters– below is the hypothesis matcher to determine how relevant
this hypothesis is
Feature 1: Is the error at the end of a procedure/function call?Feature 2: Does the function expect fewer parameters than supplied
in the procedure/function call?Feature 3: Does the procedure/function call have more than 1
parameter list?
Pattern 1: No ? ? Ruled OutPattern 2: Yes Yes ? Very LikelyPattern 3: Yes ? Yes Very LikelyNo match value Unlikely
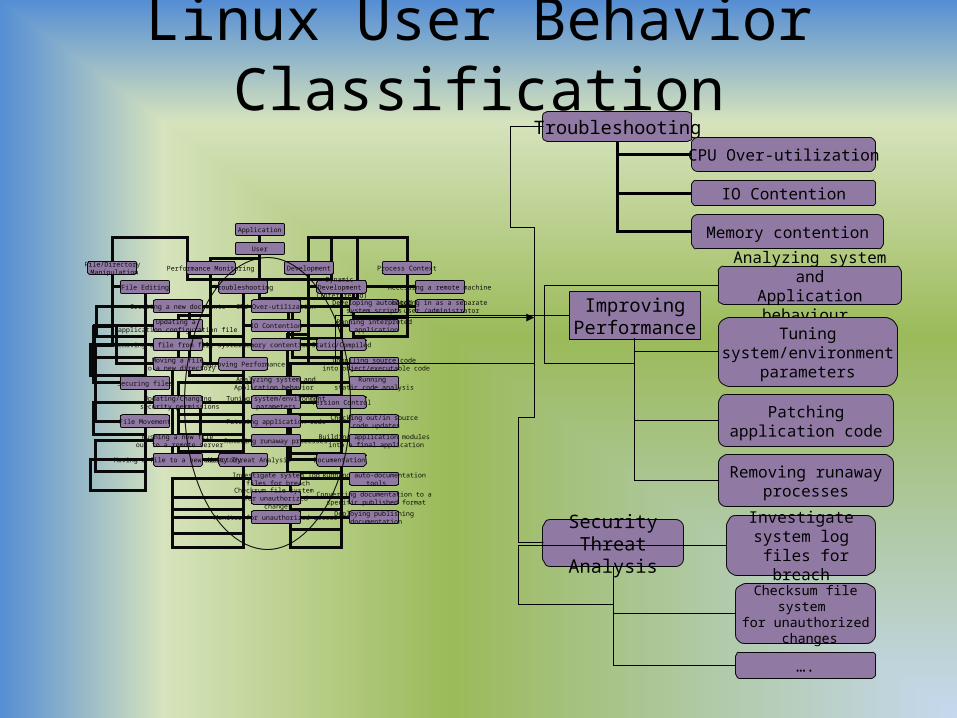
Linux User Behavior Classification
Application
User
File/Directory Manipulation Performance Monitoring
File Editing
Securing files
Troubleshooting
Improving Performance
Security Threat Analysis
Development Process Context
CPU Over-utilization
IO Contention
Memory contention
Dynamic Development (Interpreted)
Static/Compiled
Developing automated system scripts
Investigate system log files for breach
Checksum file system for unauthorized
changes
Version Control
Checking out/in source code updates
Compiling source code into object/executable code
Running interpreted application
Running static code analysis
Analyzing system andApplication behavior
Tuning system/environmentparameters
Patching application code
Documentation
Running auto-documentation tools
Converting documentation to a specific published format
Deploying publishing documentation
Creating a new documents
Updating/Changing security permissions
Updating a application configuration file
Removing a file from file system
Moving a file to a new directory
File Movement
Pushing a new file out to a remote server
Moving a file to a new directory
Monitor for unauthorized access
Building application modules into a final application
Accessing a remote machine
Logging in as a separate user /administrator
Removing runaway processes
TroubleshootingCPU Over-utilization
IO Contention
Memory contention
Improving Performance
Analyzing system andApplication behaviour
Patching application code
Tuning system/environment
parameters
Security Threat Analysis
Checksum file system for unauthorized
changes
Investigate system log
files for breach
Removing runaway processes
….

Variations• There are many variations to this form of problem solving– a feature may itself require problem solving to determine its
relevance • it may call upon other hypothesis matchers, use a neural network or
Bayesian probability module, or some other approach to determine its relevance
– a hierarchy may be tangled (a general tree in which a node has more than one parent)• to reach a node, we may require all parents to be established, or just a
single parent to be established
– which hypothesis do we use as our classification along the path from root to leaf?• obviously, if a node is established, its ancestors will have also been
established• which node(s) do we select? the most likely or the most specific?
– what if multiple nodes are established that are not related?• for instance, we determine that semicolon missing and semicolon in
comments are both relevant, which is true?

Hypothesis Selection• What hierarchical classification does not do is
differentiate between established hypotheses– the hypothesis matcher has knowledge to recognize this
hypothesis, but not to determine if it is better than any other hypothesis
• Does the problem call for (or allow) multiple hypotheses?– is the problem one of multiple malfunctions, can one
malfunction lead to another?– are we looking for one hypothesis, a group of related
hypotheses, a group of unrelated hypotheses?• Abduction can serve us here by letting us form a
composite hypothesis out of the lesser/individual hypotheses– basically, we want to perform set covering on the data by
selecting among the relevant hypotheses those that best explain the data, but we want to do this tractably
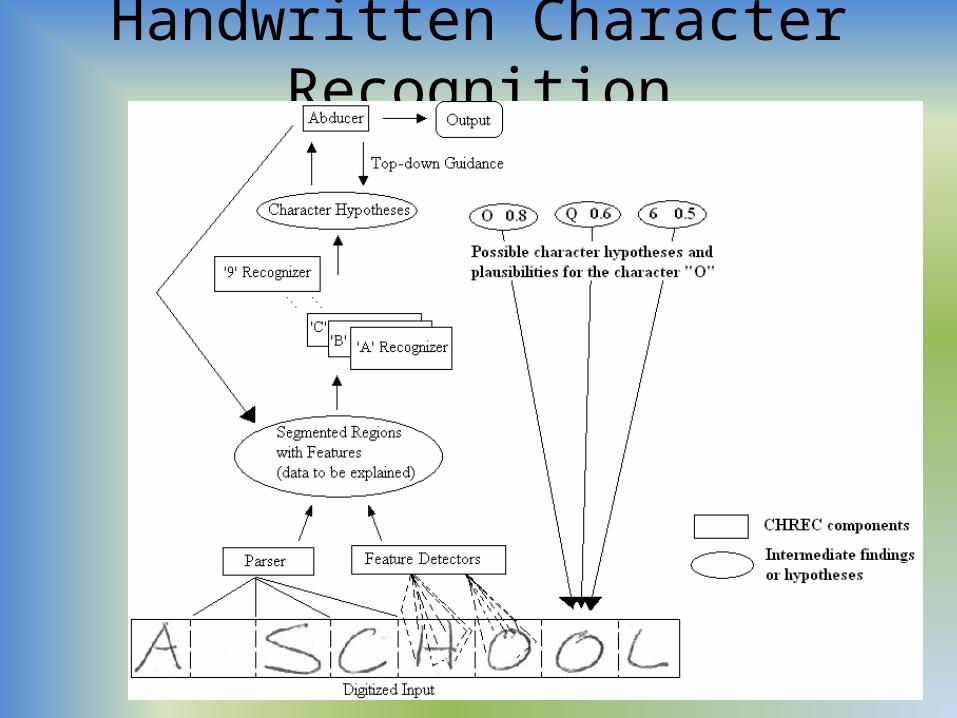
Handwritten Character Recognition
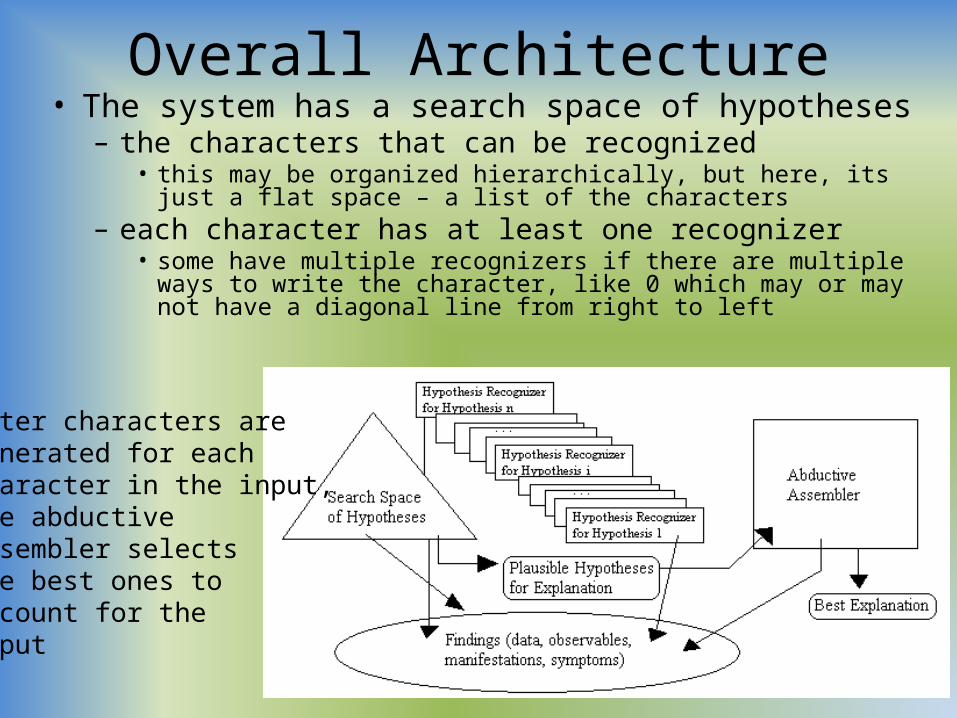
Overall Architecture• The system has a search space of hypotheses– the characters that can be recognized
• this may be organized hierarchically, but here, its just a flat space – a list of the characters
– each character has at least one recognizer• some have multiple recognizers if there are multiple ways to write the
character, like 0 which may or may not have a diagonal line from right to left
After characters aregenerated for eachcharacter in the input,the abductive assembler selects the best ones to account for theinput
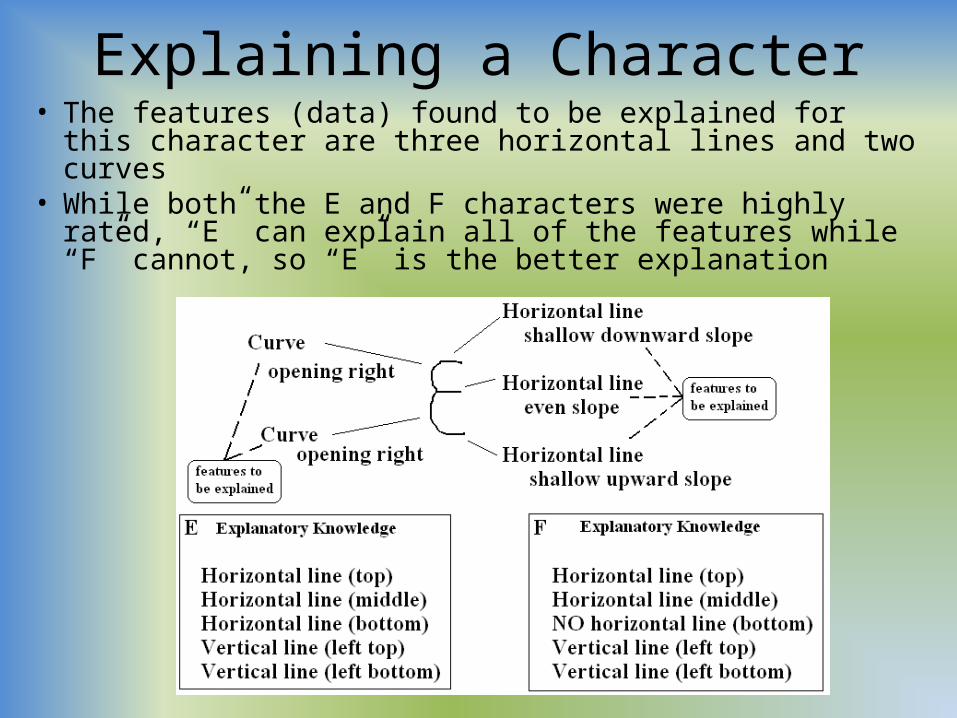
Explaining a Character• The features (data) found to be explained for this character
are three horizontal lines and two curves• While both the E and F characters were highly rated, “E”
can explain all of the features while “F” cannot, so “E” is the better explanation

Top-down Guidance• One benefit of this approach is that, by using
domain dependent knowledge– the abductive assembler can increase or decrease
individual character hypothesis beliefs based on partially formed explanations
– for instance, in the postal mail domain, if the assembler detects that it is working on the zip code (because it already found the city and state on one line), then it can rule out any letters that it thinks it found• since we know we are looking at Saint James, NY, the
following five characters must be numbers, so “I” (for one of the 1’s, “B” for the 8, and “O” for the 0 can all be ruled out (or at least scored less highly)

Full Example in a Natural Language Domain





























