Embed Size (px)
Citation preview

Un androïde doué de parole
A speech-gifted android
Institut de la
Communication ParléeLaplace

Robotic tools (theories, algorithms, paradigms) applied to a human cognitive
system (speech) instead of a human “artefact” (a “robot”)
The goal of the project
Or: study speech as a robotic system (a speaking android)

Speech: not an information processing system, but a sensori-motor system plugged on
language
This system deals with control, learning, inversion, adaptation, multisensoriality,
communication …
hence robotics!

" In studying human intelligence,
three common conceptual errors often occur: reliance on monolithic internal models,
on monolithic control, and on general purpose processing.
A modern understanding of cognitive science and neuroscience refutes these assumptions.
« Cog » at MIT (R. Brooks) http://www.ai.mit.edu/projects/cog/methodology.html

Our alternative methodology is based on evidence from cognitive science and neuroscience
which focus on four alternative attributes which we believe are critical attributes
of human intelligence:
embodiment and physical coupling, multimodal integration,
developmental organization, and social interaction.
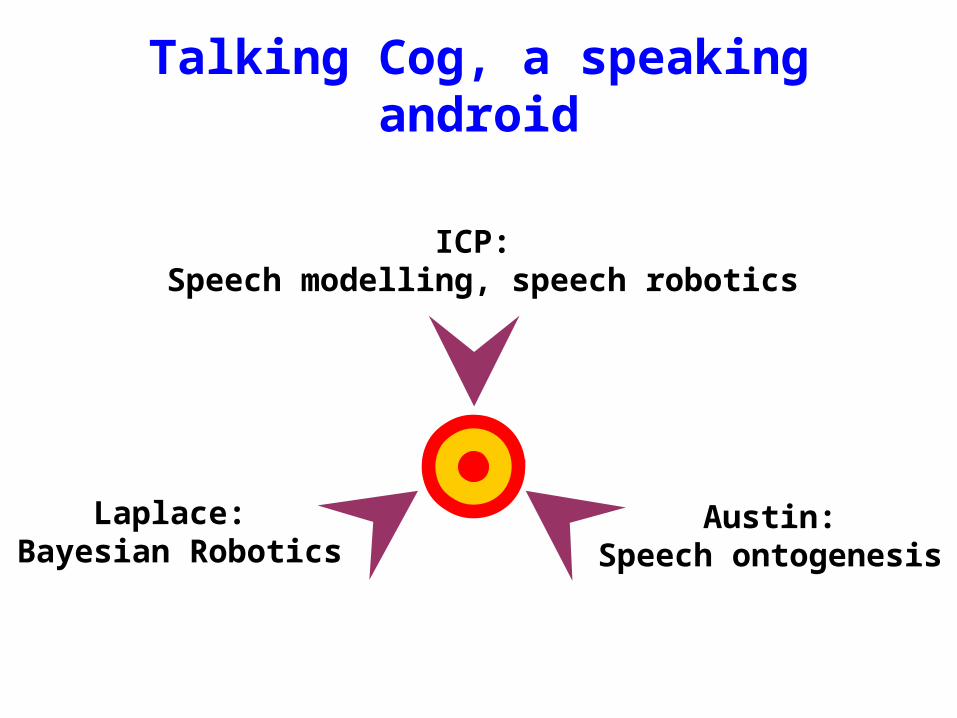
Talking Cog, a speaking android
ICP: Speech modelling, speech robotics
Laplace: Bayesian Robotics
Austin:Speech ontogenesis
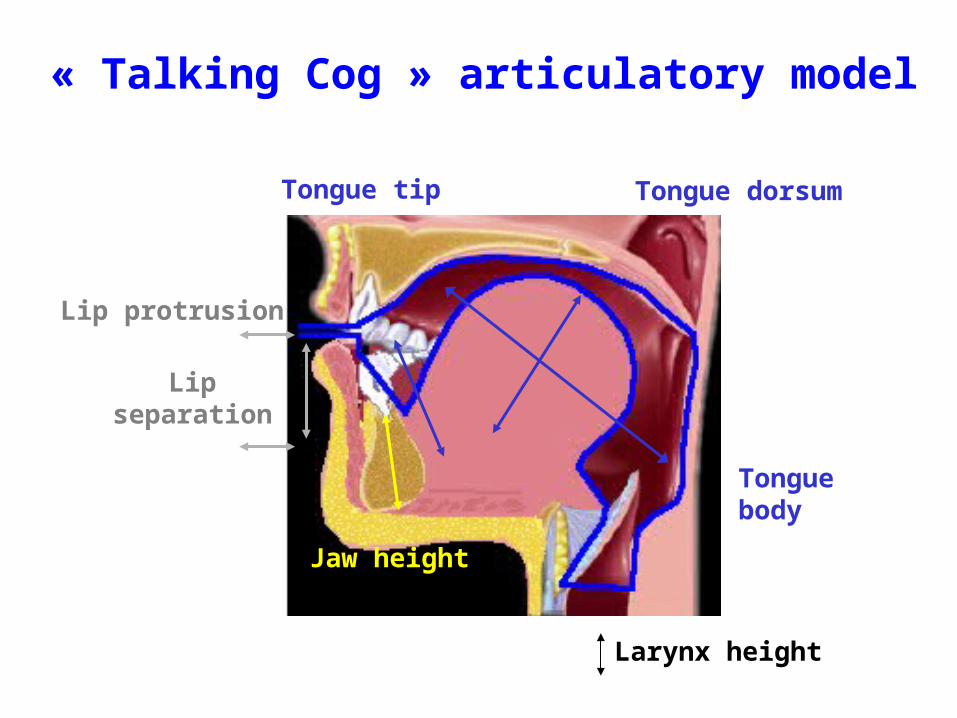
« Talking Cog » articulatory model
Jaw height
Lip protrusion
Larynx height
Tongue tip
Tongue body
Tongue dorsum
Lip separation
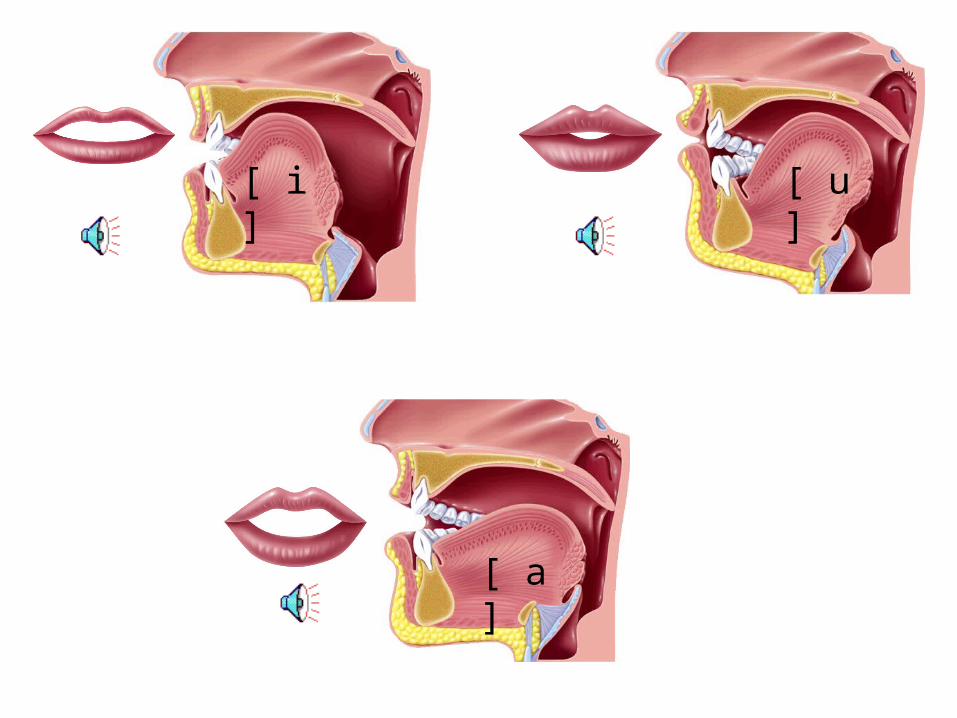
[ u ][ i ]
[ a ]
0 1000 2000 3000 4000 5000-50
0
50
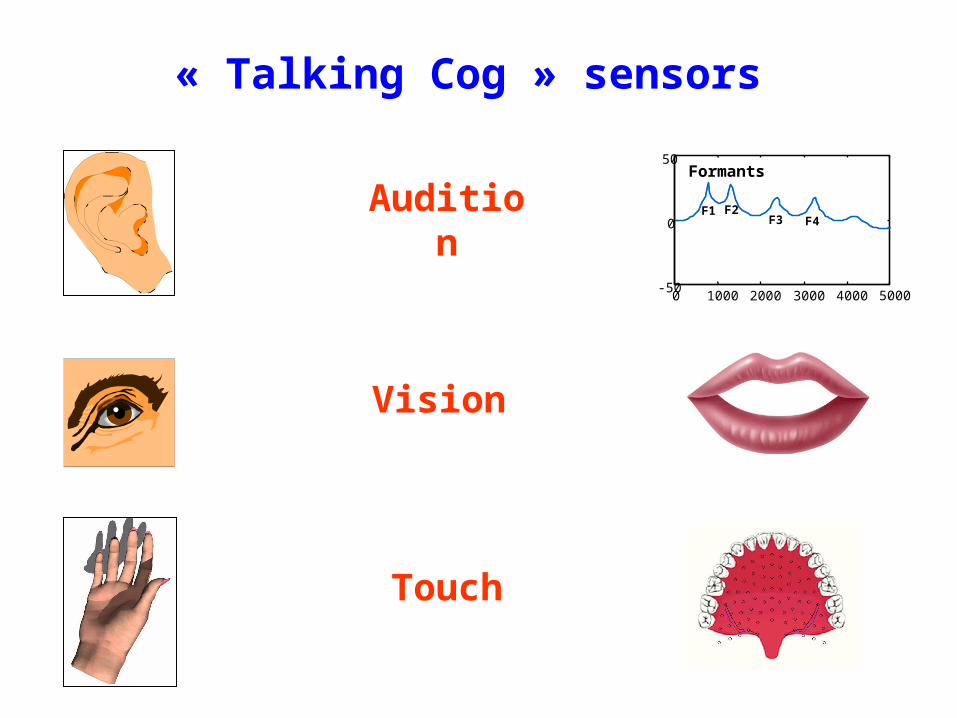
Audition
« Talking Cog » sensors
Vision
Touch
Formants
F1 F2F3 F4
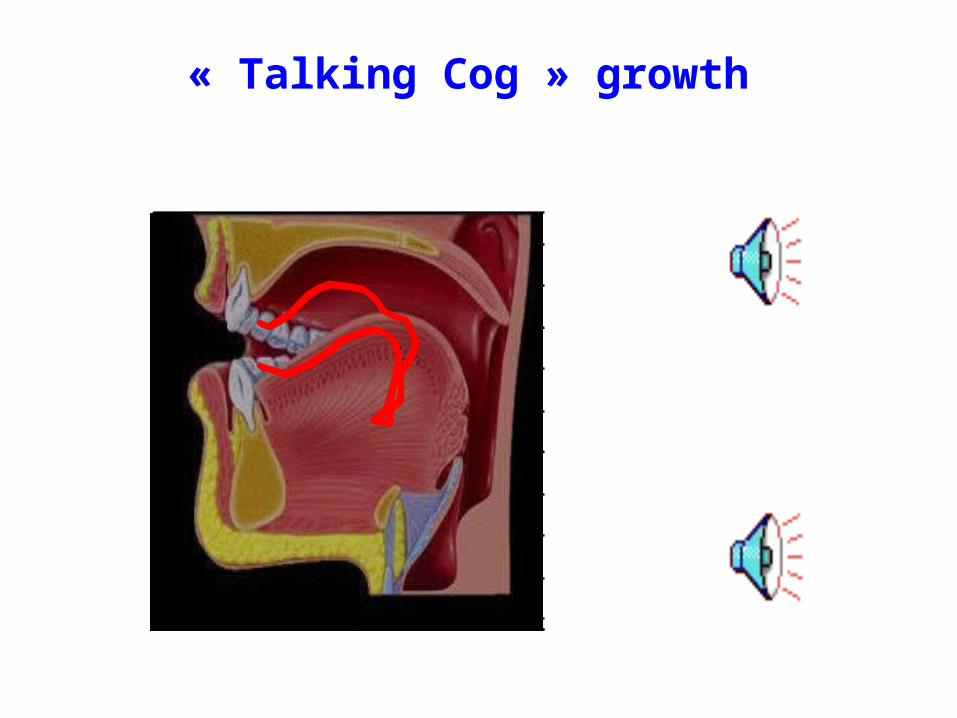
« Talking Cog » growth
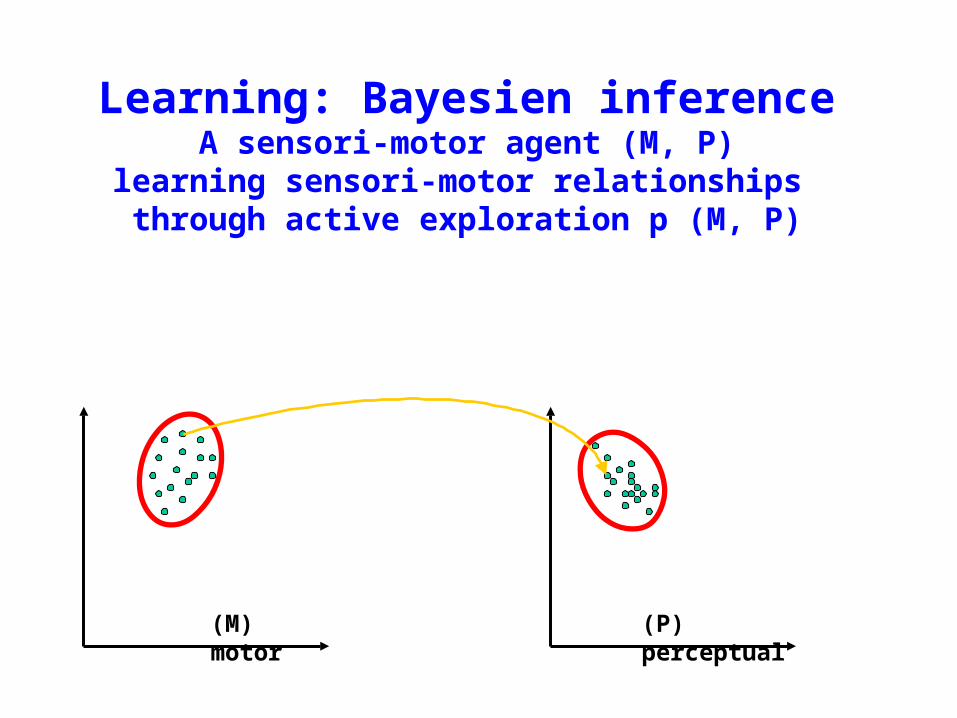
Learning: Bayesien inferenceA sensori-motor agent (M, P)
learning sensori-motor relationships through active exploration p (M, P)
(M) motor
(P) perceptual
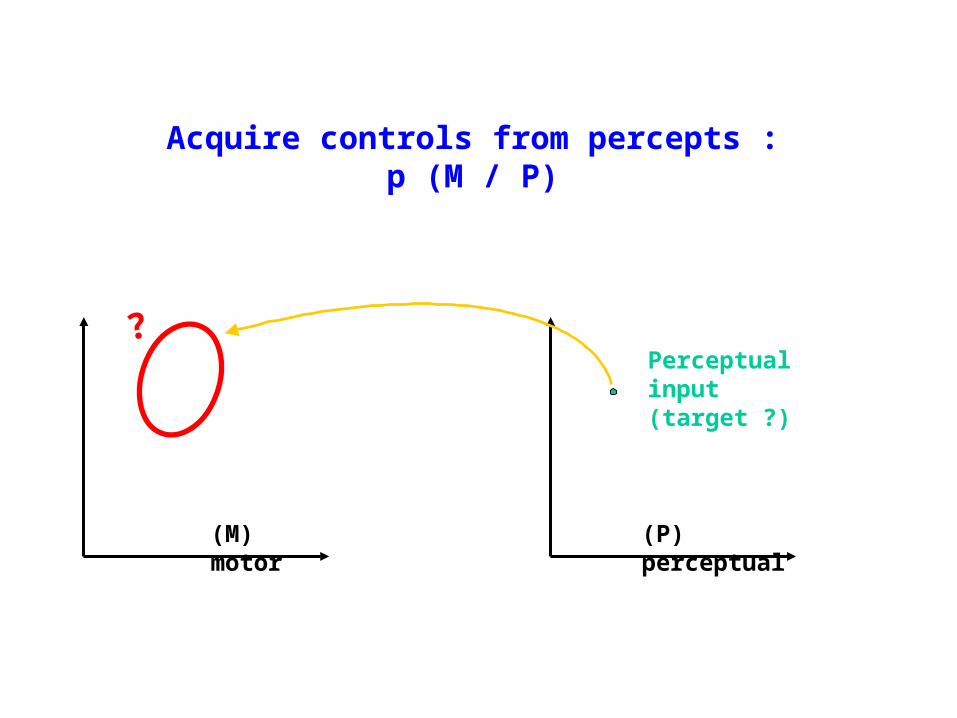
Acquire controls from percepts :p (M / P)
(M) motor
(P) perceptual
Perceptual input (target ?)
?
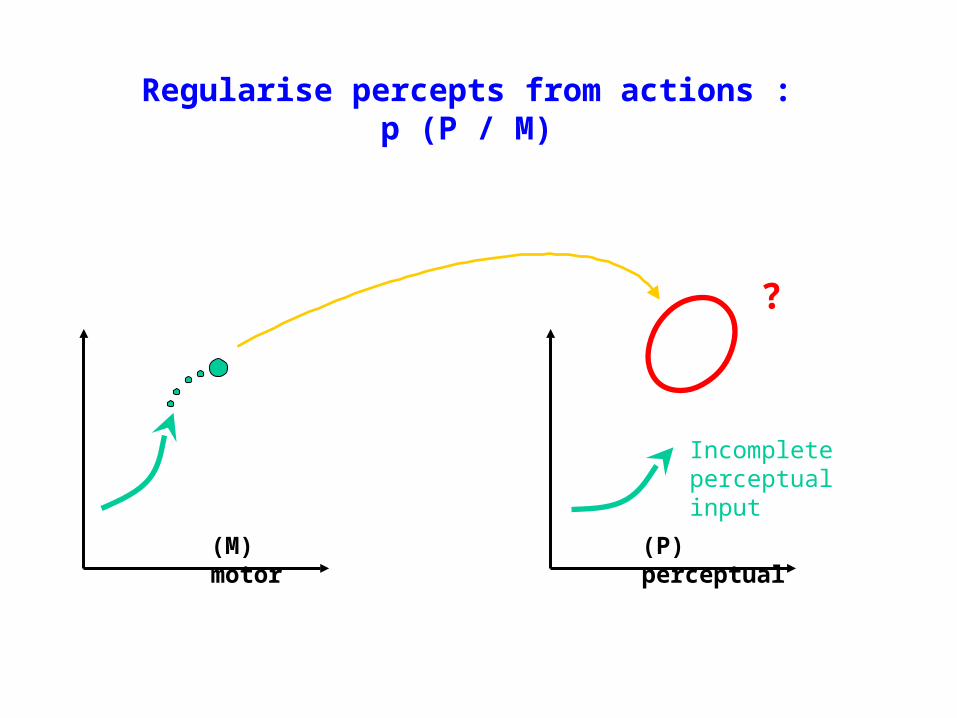
Regularise percepts from actions :p (P / M)
(M) motor
(P) perceptual
Incomplete perceptual input
?
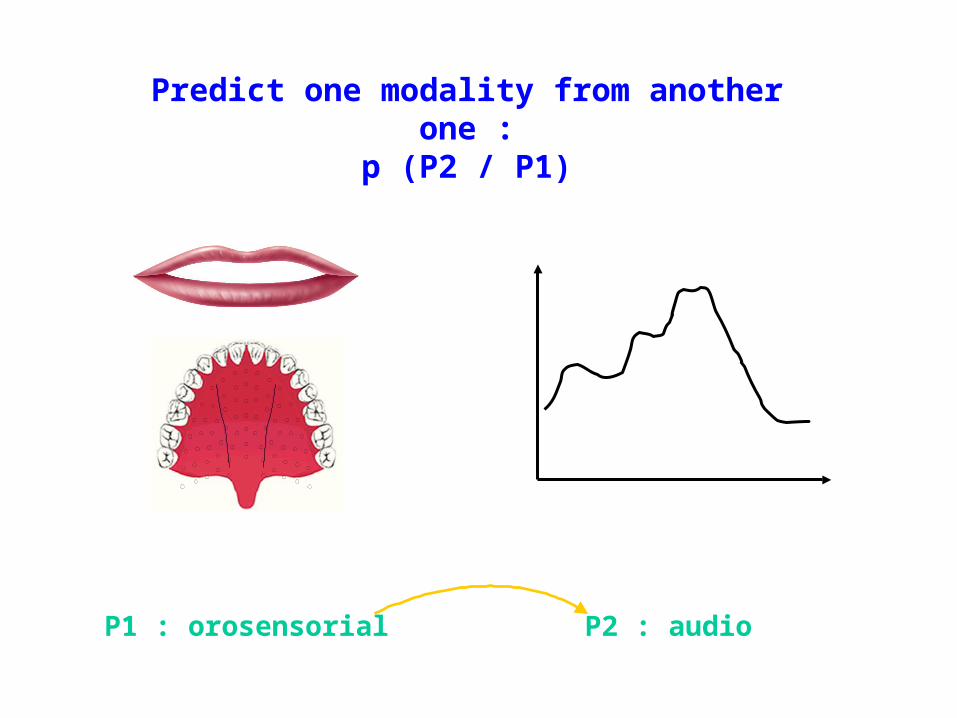
Predict one modality from another one :p (P2 / P1)
P1 : orosensorial P2 : audio
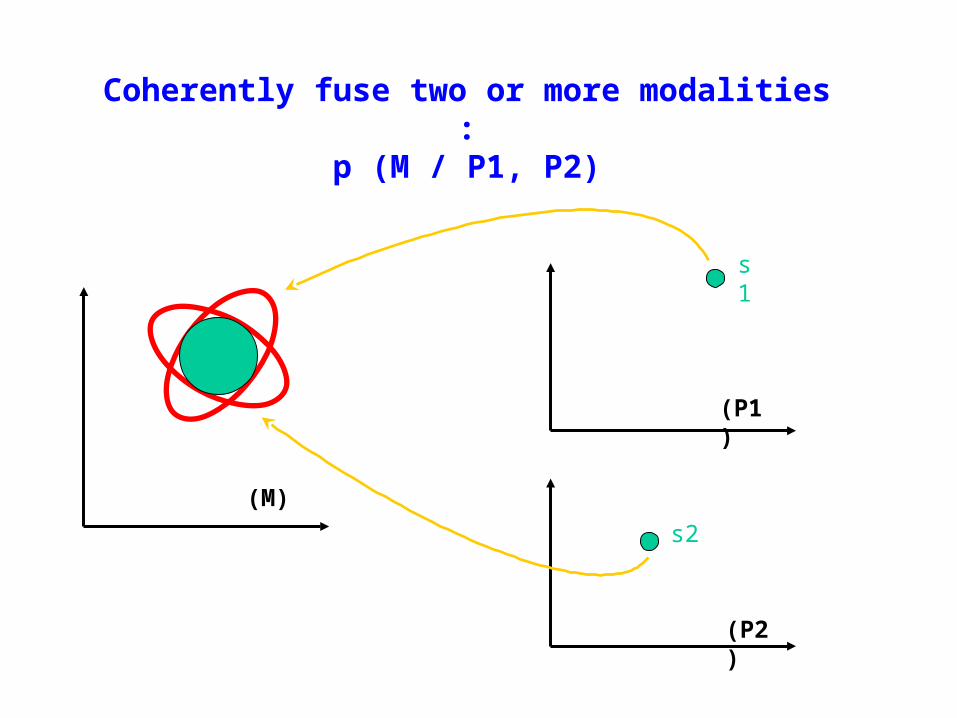
Coherently fuse two or more modalities :p (M / P1, P2)
(P2)
(P1)
s1
s2
(M)

The route towards adult speech: learning control
4 mth : vocalisation, imitation
7 mth : jaw cycles (babbling)
Later: control of carried articulators (lips, tongue) for vowels and consonants
0 mth : imitation of the three major speech gestures
Exploration & imitation

First experiment:
simulating explorationfrom 4 to 7 months
Phonetic data (sounds and formants) on 4- and 7-months babies ’
vocalisations
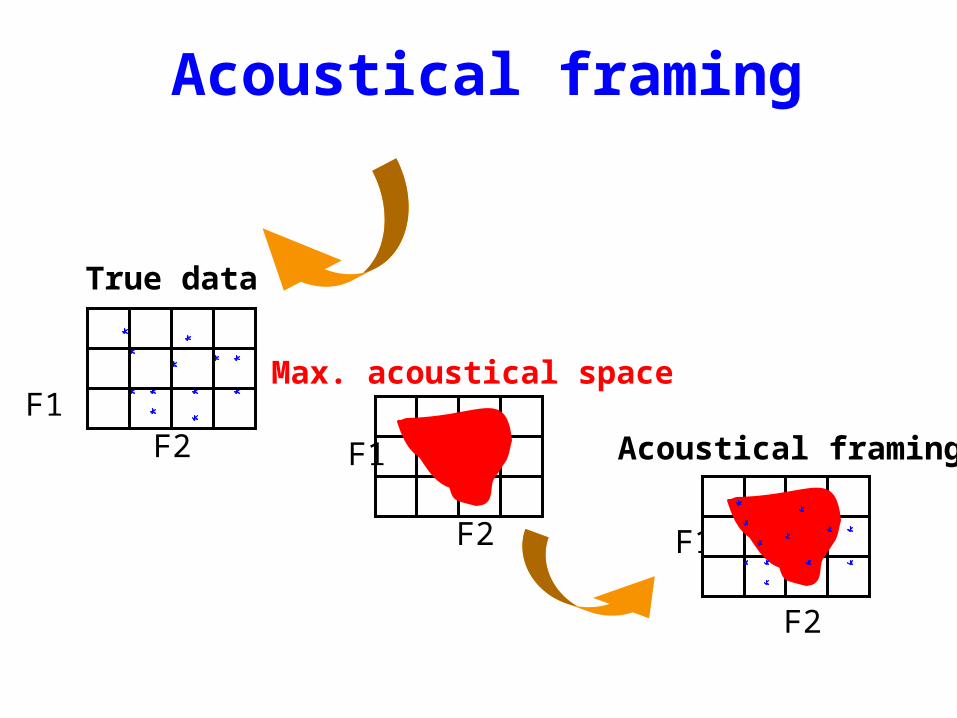
Acoustical framing
F2
F1
Acoustical framing
True data
F2
F1
F2
Max. acoustical space
F1
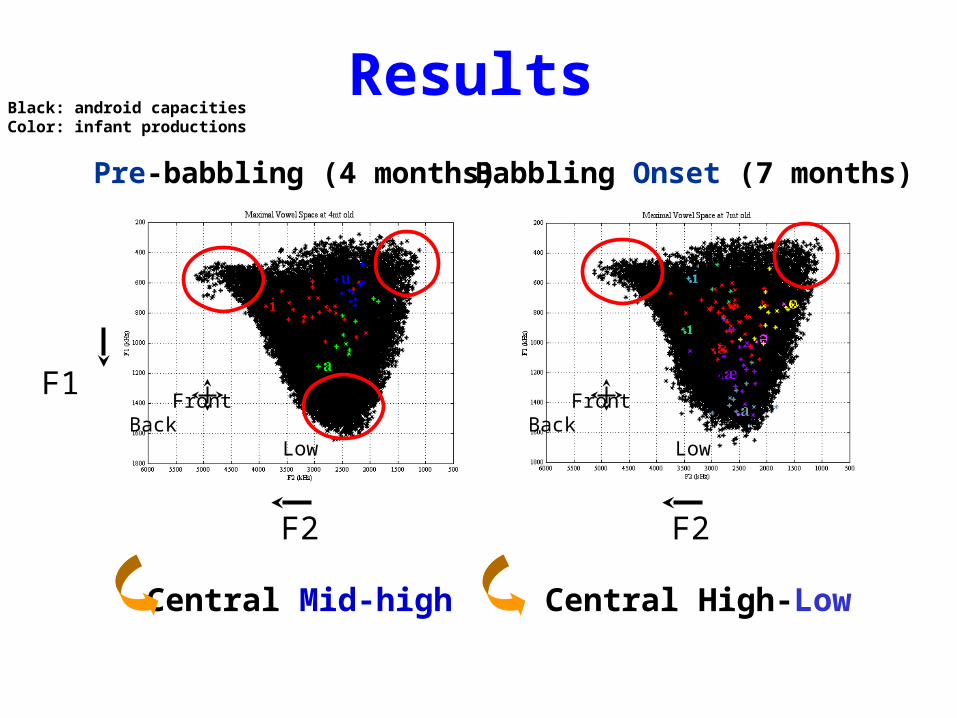
Results
High Front Back Low
F2
F1 High Front Back Low
F2
Pre-babbling (4 months)
Central Mid-high
Babbling Onset (7 months)
Central High-Low
Black: android capacitiesColor: infant productions
Articulatory framing
Which one is the best?
Various sub-models:
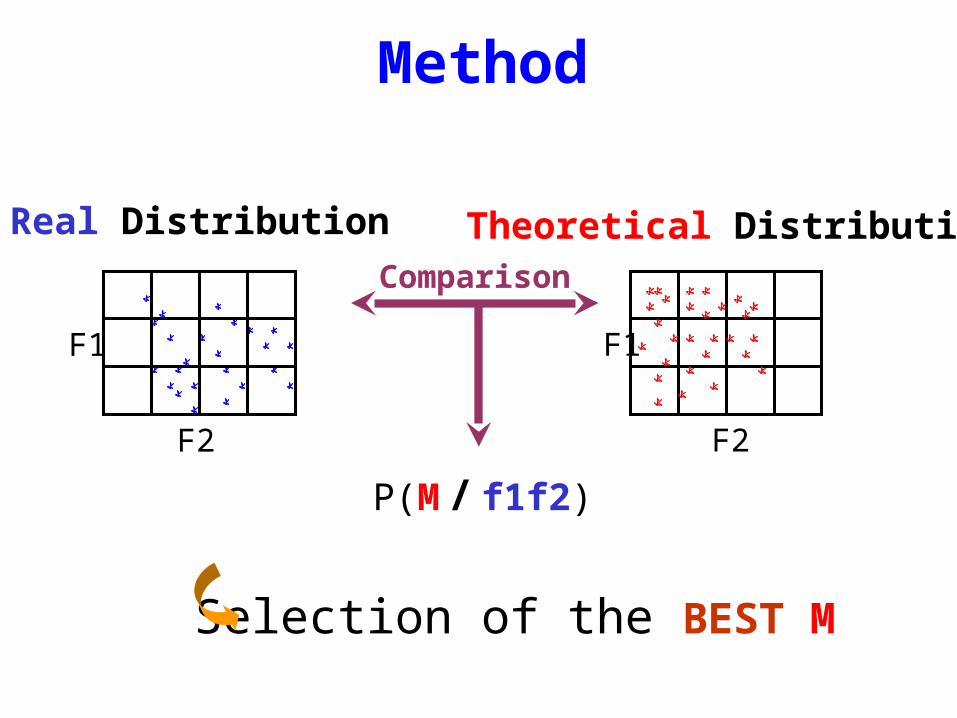
Method
Selection of the BEST M
P(M / f1f2)
Comparison
Theoretical Distribution
F2
F1
Real Distribution
F2
F1
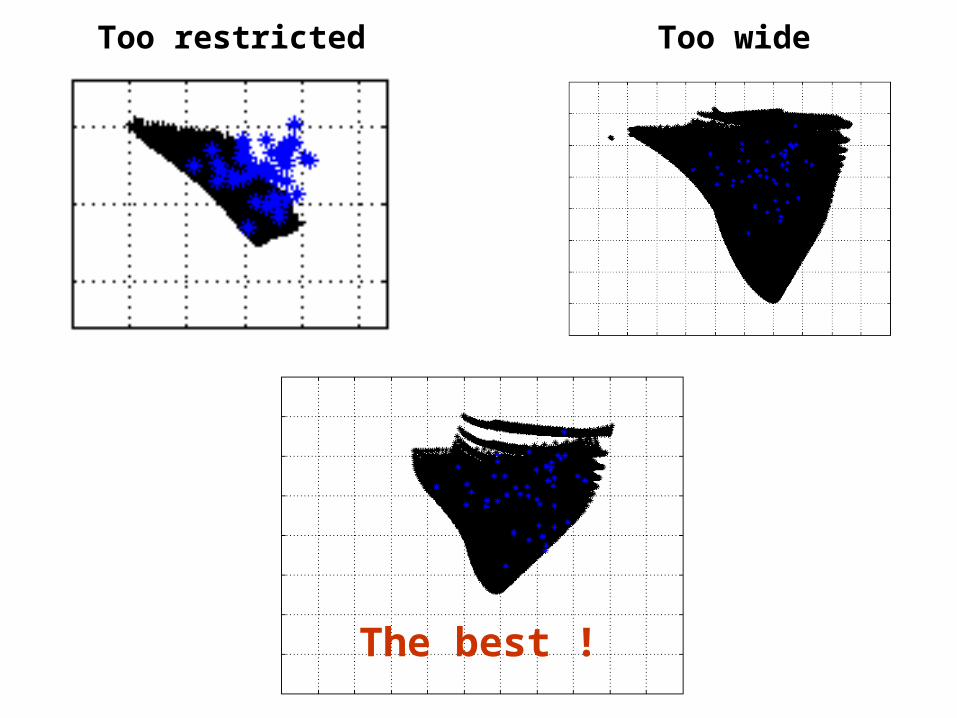
Too restricted Too wide
The best !
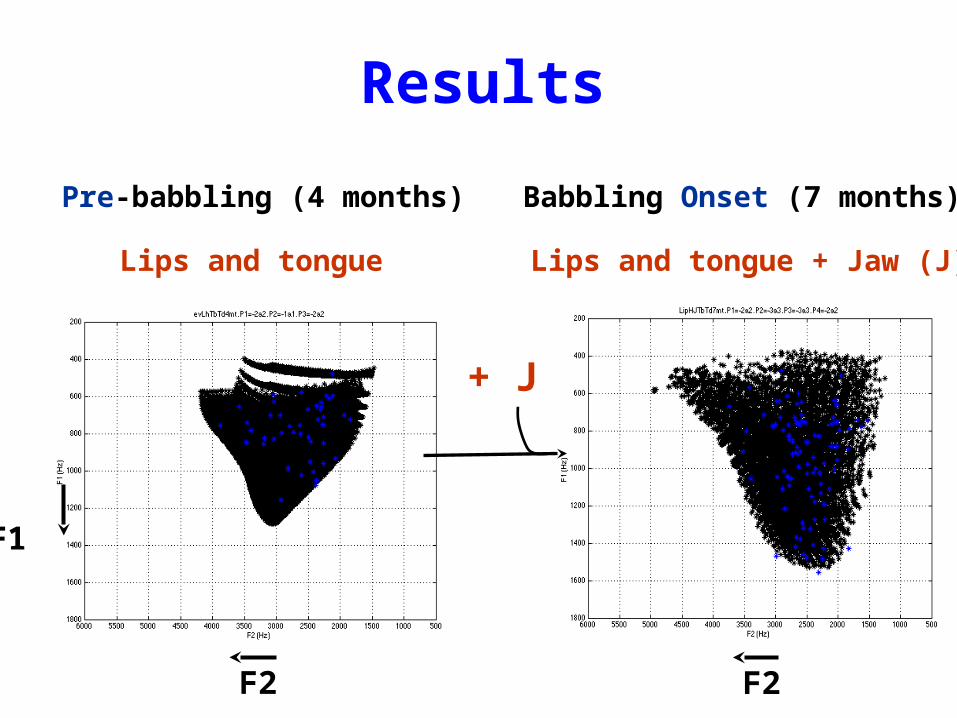
Results
F2
Lips and tongue
Pre-babbling (4 months)
Lips and tongue + Jaw (J)
Babbling Onset (7 months)
F1
F2
+ J

Conclusion I
1. Acoustical framing: cross-validation of the data and model
2. Articulatory framing:
articulatory abilities / exploration
4 months: Tongue dorsum / body + Lips
7 months : idem + Jaw
3. More on early sensori-motor maps

Second experiment:
simulating imitationat 4 months
From visuo-motor imitation at 0 months to audiovisuo-motor imitation at 4 months
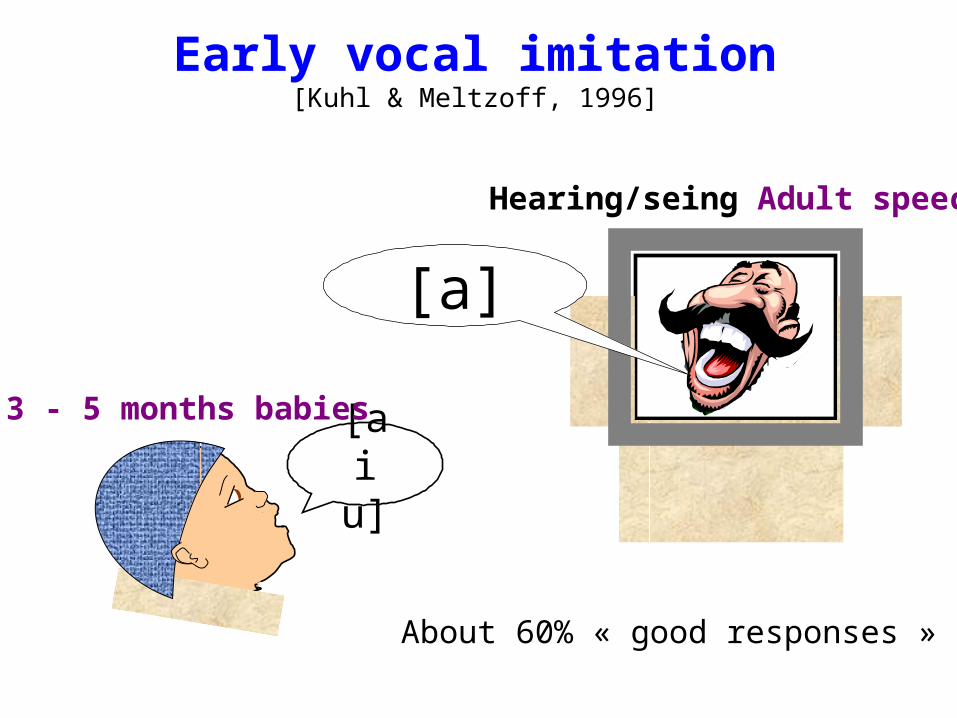
Early vocal imitation[Kuhl & Meltzoff, 1996]
Hearing/seing Adult speech
[a]
[a i u]
3 - 5 months babies
About 60% « good responses »

Questions
1. Is the imitation process visual, auditory, audio-visual?
2. How much exploration is necessary for imitation?
3. Is it possible to reproduce the experimental pattern of performances ?
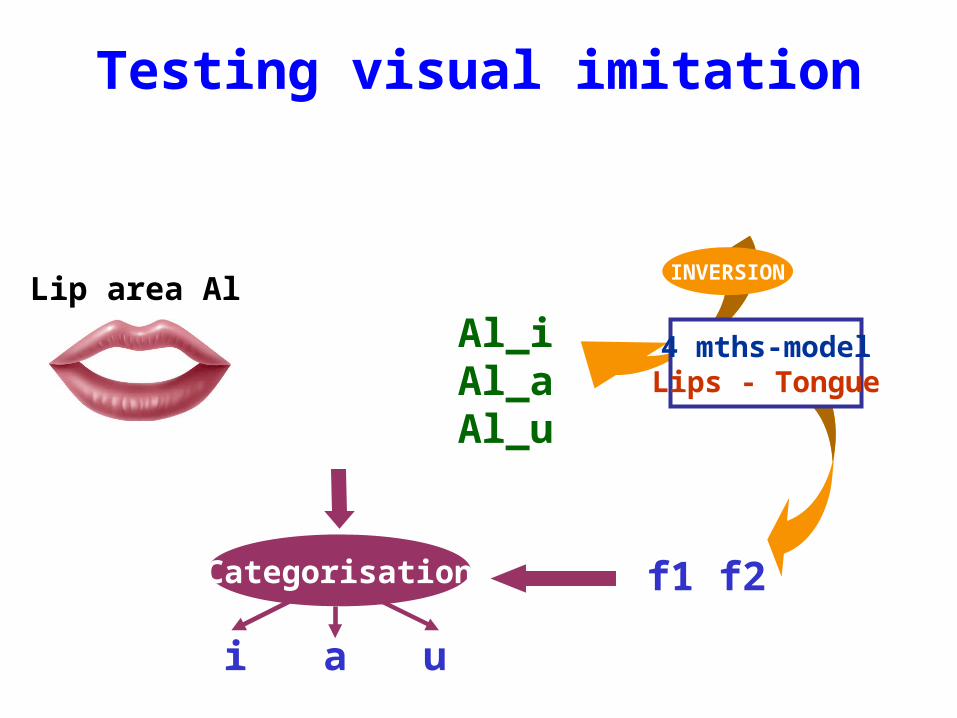
Testing visual imitation
f1 f2
INVERSION
4 mths-modelLips - Tongue
Categorisation
i a u
Al_iAl_aAl_u
Lip area Al

Visual imitation: simulation results
Experimental data
22 11 4 37
25 66 14 105
20 18 44 8267 95 62 224
i a u Som
i a uSom
Pro
duct
ion
s Total
Total
Simulation data
i a u Som
27,55 39,7 28,44 96,1639,45 55,3 0 87,4
0 0 33,56 40,4467 95 62 224
i a uSom
Alu i a
Total
Total
Experimental data do not concord with visual imitation response profiles

Vocal tract
Xh, Yh
Al
Lh Tb TdArticulatory inputs
Xh Yh AlIntermediary
control variables
F1 F2Auditory outputs
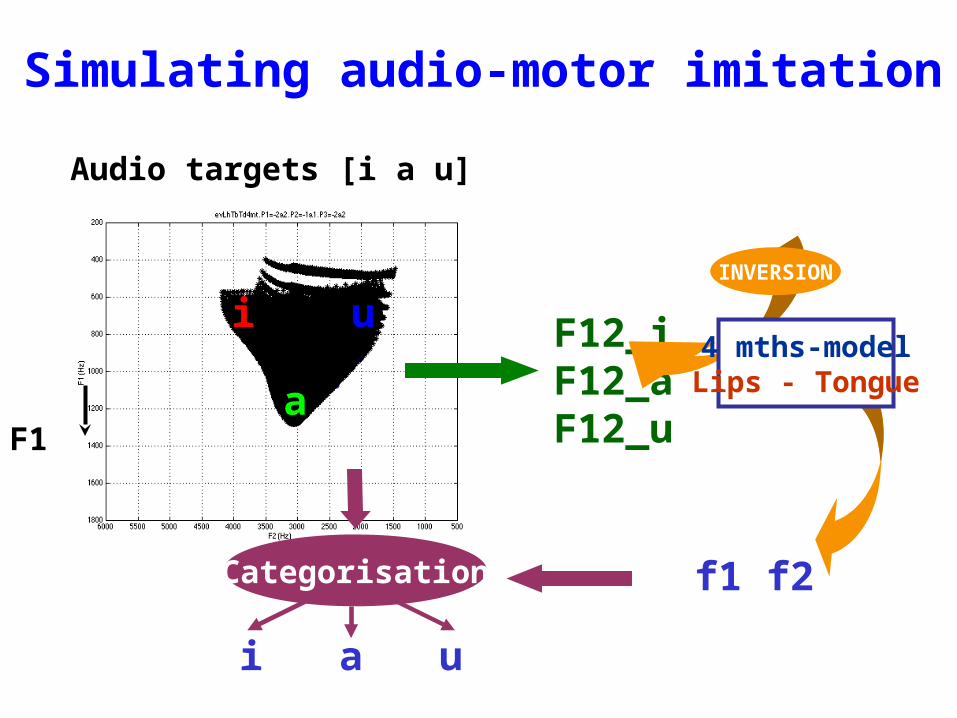
Testing audio imitation
The three intermediary control variables correspond to crucial parameters for control, connected to orosensorial channels, and able to
simplify the control
for the 7-parameters articulatory model

Articulatory variables : Lh, Tb & Td -> Gaussian Control variables : Xh, Yh & Al -> Laplace Auditory variables : F1 & F2 -> Gaussian
Parametrisation and decomposition
P (Xh Yh Al ) = P (Xh) * P (Yh) * P(Al)
P (Lh Tb Td F1 F2 / Xh Yh Al)= P (Lh Tb Td / Xh Yh Al)* P (F1 F2/ Xh Yh Al) P (Lh / Xh Yh Al) = P (Lh / Al)
P (Tb Td / Xh Yh Al) = P (Tb Td / Xh Yh)
P ( Lh Tb Td Xh Yh Al F1 F2 )
Joint probability :

Dependance Structure
= P (Xh) * P (Yh) * P(Al) * P (Lh / Al)* P(Tb / Xh Yh)*P(Td / Xh Yh Tb) * P (F1 / Xh Yh Al) * P (F2 / Xh Yh Al)
P ( Lh Tb Td Xh Yh Al F1 F2 )
Learning
Description of the sensori-motor behaviour

The challenge
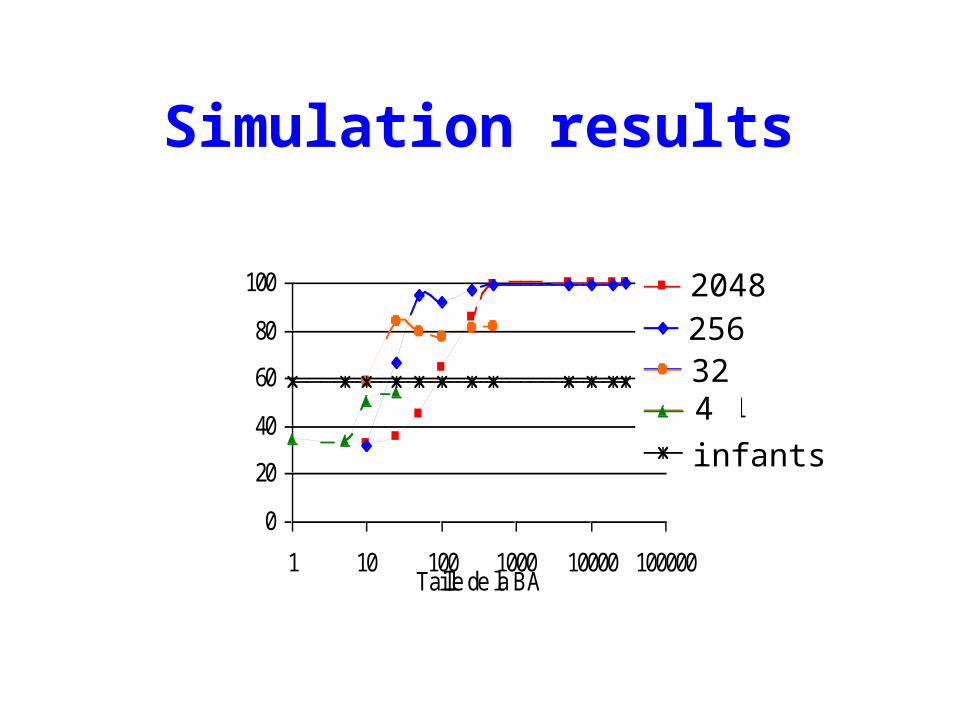
From the exploration defined by Exp. 1, what is the amount of data (self-vocalisations) necessary for learning enough to produce 60% correct responses in Exp. 2?
The idea
If your amount of learning data is small, the discretisation of your control space should be rough
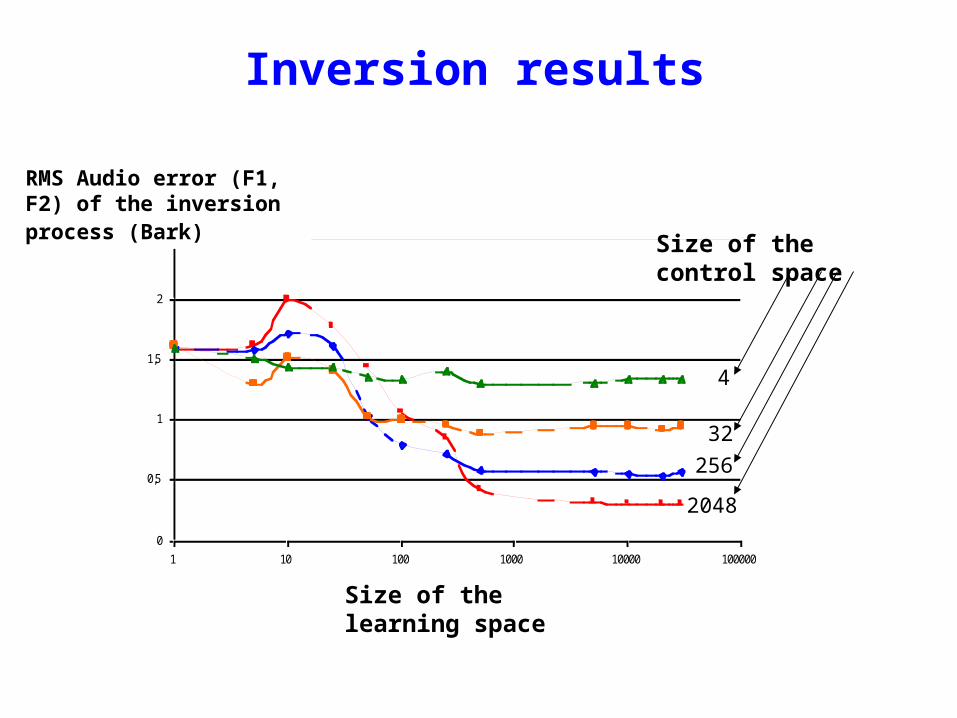
Inversion results
4
32
256
2048
0
0,5
1
1,5
2
2,5
1 10 100 1000 10000 100000
Taille de la Base d' Apprentissage
Moy des erreurs quadratiques moy sur F1 et F2
16_16_8
8_8_4
4_4_2
2_2_1
Size of the control space
Size of the learning space
RMS Audio error (F1, F2) of the inversion process (Bark)
4
32
256
2048
1
10
100
1000
10000
1 10 100 1000 10000
Nombre de cases géométriques
Taille de BA à 10 % de l'erreur max
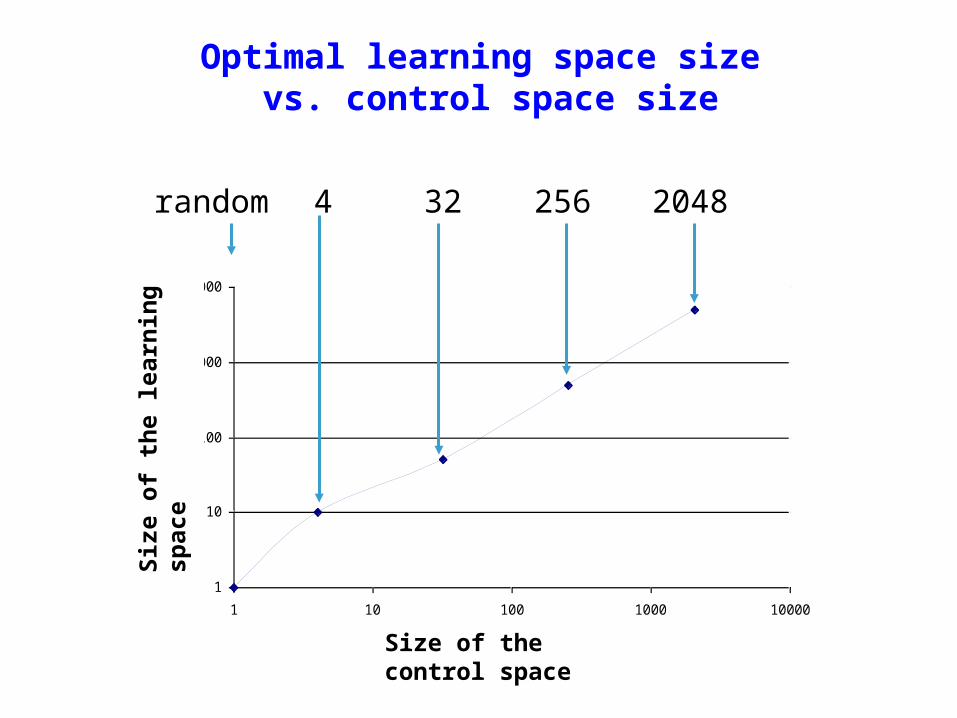
204832 2564random
Optimal learning space size vs. control space size
Size of the control space
Size
of
the
lear
nin
g sp
ace
Simulating audio-motor imitation
F1
F2
a
ui
Audio targets [i a u]
F12_iF12_aF12_u
f1 f2
INVERSION
4 mths-modelLips - Tongue
Categorisation
i a u
Simulation results
0
20
40
60
80
100
1 10 100 1000 10000 100000Taille de la BA
% Bonne Réponses
16_16_8
8_8_4
4_4_2
2_2_1
Kuhl
4322562048
infants
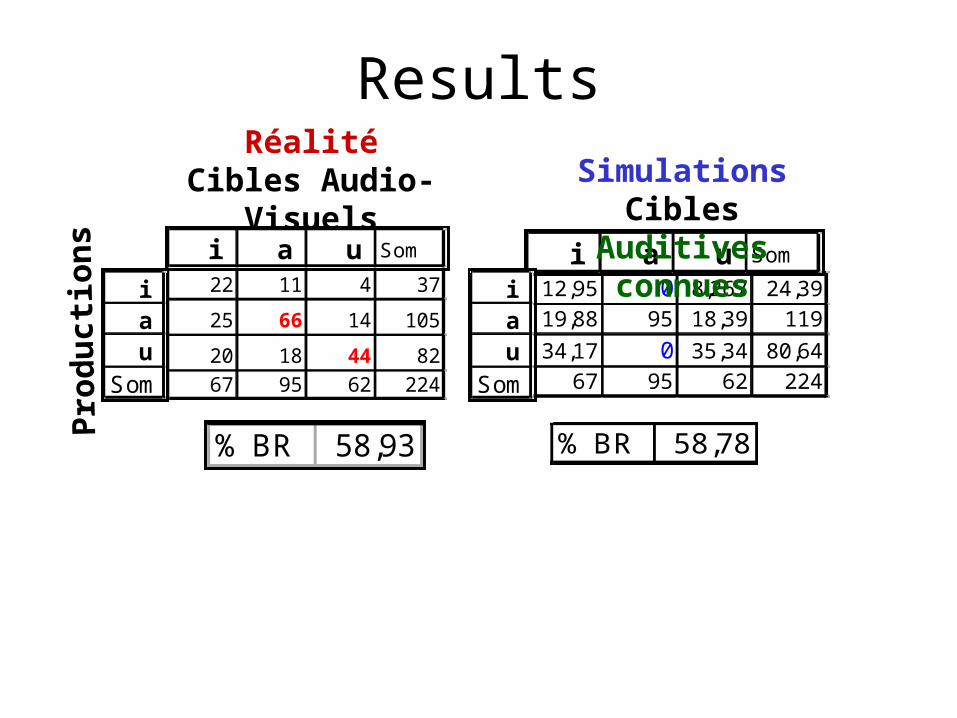
ResultsRéalité
Cibles Audio-Visuels
22 11 4 37
25 66 14 105
20 18 44 8267 95 62 224
i a u Som
i a uSom
Pro
duct
ion
s
12,95 0 8,267 24,3919,88 95 18,39 119
34,17 0 35,34 80,6467 95 62 224
i a u Som
i a uSom
Simulations Cibles Auditives connues
% BR 58,78% BR 58,93

Conclusion II
1. 10 to 30 vocalisations are enough for an infant to learn to produce 60% good vocalisations in the audio-imitation paradigm!
2. Three major factors intervene in the baby android performances : learning size, control size, and variance distribution in the learning set (not shown here)

Final conclusions and perspectives
1. Some of the exploration and imitation of human babies reproduced by their android cousins (Feasibility / Understanding)
2. The developmental path must be further explored, and the baby android must be questioned about what it really learned, and what it can do at the output of the learning process





























